A great many users receive the end-to-end error when using certain hard drives. What does the end-to-end error mean? How to fix it? If you are also confused about these questions, then you come to the right place. In this post, MiniTool will explore them together with you.
According to user reports, this end-to-end error often appears while copying data or transferring an application on Windows. Here’s a true example on the tom’s hardware forum.
Hello, Crystal Disk info shows the end-to-end error in my 1TB HDD…Values are like this 88 , 88 ,99 I don’t know what does the error means, but I’m experience slowness during copying and sometimes the copying stuck. I just did a clean OS install but the error still exists…Is my HDD no longer good? https://forums.tomshardware.com/threads/hard-disk-end-to-end-error.1905221/
What Does End-to-End Error Mean
The first thing you need to figure out is the meaning of the end-to-end error. In fact, this error is usually detected by Hewlett-Packard’s SMART technology or other vendors’ hard drive I/O error detection technologies.
That is to say, the end-to-end error only appears on hard drives supported by the SMART attribute or other similar technologies. According to a survey, these hard drives come from Samsung, Seagate, IBM (Hitachi), Western Digital, Hewlett-Packard (HP), and Maxtor.
The SMART technology can detect an amount of parity data errors while transferring data via the hard drive’s cache RAM. If you receive the end-to-end error, it indicates that the parity data between your host and the hard drive cannot match.
Bear in mind that the end-to-end error is a critical parameter that means an imminent hard drive failure. So, it is highly recommended that you make a full backup of your hard drive in order to avoid any unnecessary loss.
What Causes the SMART End-to-End Error
What causes the HP SMART hard disk error? After analyzing lots of user reports and references, we conclude some possible causes for the error. The most common reason is that your hard drive gets faulty due to bad sectors. In addition, the end to end error can be caused by overheating disk temperature, bit rot, and disk fragmentation.
Now, let’s see how to fix the HP SMART hard disk error.
How to Fix the SMART End-to-End Error
There are five main solutions for the SMART end to end error. Here we recommend you try the following methods one by one until the error message disappears.
Fix 1. Check Hard Drive for Bad Sectors
If you receive the SMART Hewlett-Packard hard drive failure error message, the first and simplest solution is to check if there are any bad sectors on your hard drive. To fully check hard drive errors, we highly recommend you use the professional utility – MiniTool Partition Wizard.
It is a reliable partition management tool that boasts many powerful features like converting MBR to GPT, convert FAT to NTFS, format hard drive, perform disk benchmark, align partitions, etc. With this powerful software, you can not only check file system errors but bad sectors. For that:
Free Download Buy Now
Step 1. In the main interface of this program, select the hard disk that you receive the end to end error and click on the Surface Test from the left pane.
Step 2. Click on the Start now button in the pop-up window. After that, this tool will scan the whole disk immediately and show you the test result.
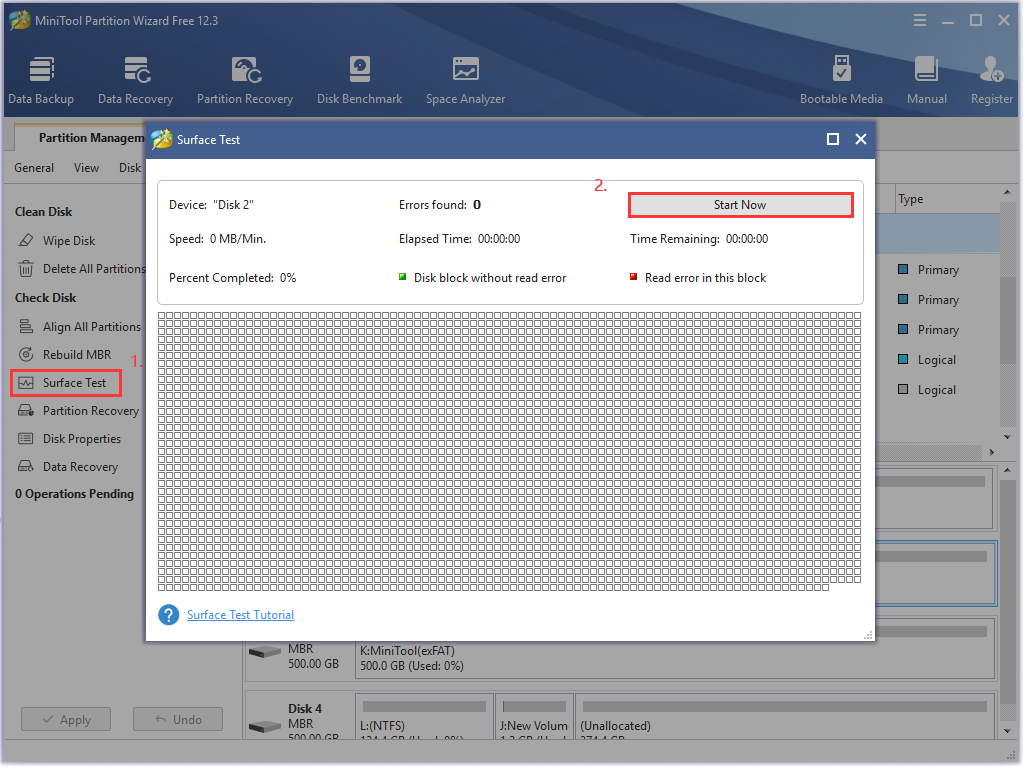
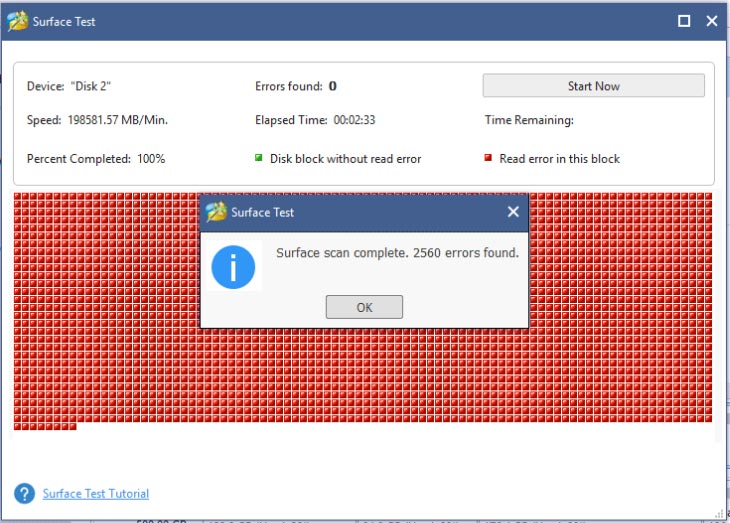
If there are any blocks marked with red color like the following picture, it indicates that your hard drive is getting failing.
For bad sectors, you can use a special utility to mark them as unusable. CHKDSK is a Windows built-in tool that can help you shield the bad sectors. Now, please keep reading the following part.
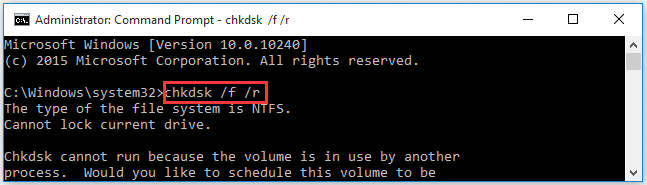
Step 1. Type cmd in the search box, and then right-click the Command Prompt app and select Run as administrator.
Step 2. In the elevated command prompt, type chkdsk /f /r command and hit Enter. Then type Y to continue this operation. After that, this command will start scanning the hard drive and mark the bad sectors as unavailable.
Fix 2. Run Hard Drive Defragmentation
Disk Defragmenter is a widely used Microsoft utility that can help you optimize your hard disk or handle disk fragmentation. As mentioned above, the SMART hard disk error HP can be caused by defragmentation. To fix the problem, you can perform hard disk defragmentation.
Tip: If you encounter the Windows 10 defragmentation not working issue, you can read this post.
Step 1. Press Win + E keys to open the File Explorer, and then click on This PC from the left pane.
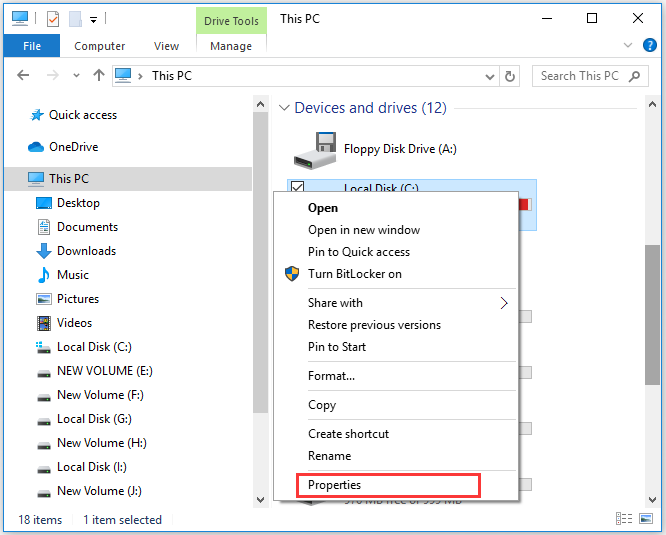
Step 2. Scroll down to the Devices and drives section, and then right-click the drive that experiences the end-to-end error and select Properties.
Step 3. Navigate to the Tools tab, and then click on the Optimise button under the Optimise and defragment drive section.
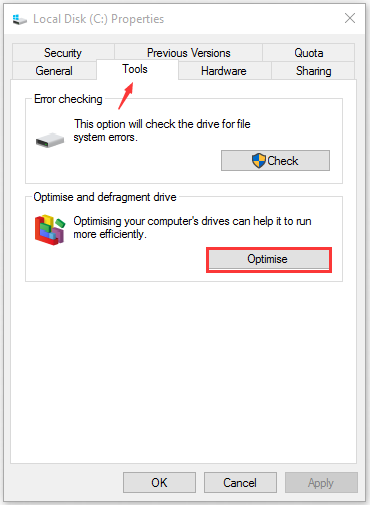
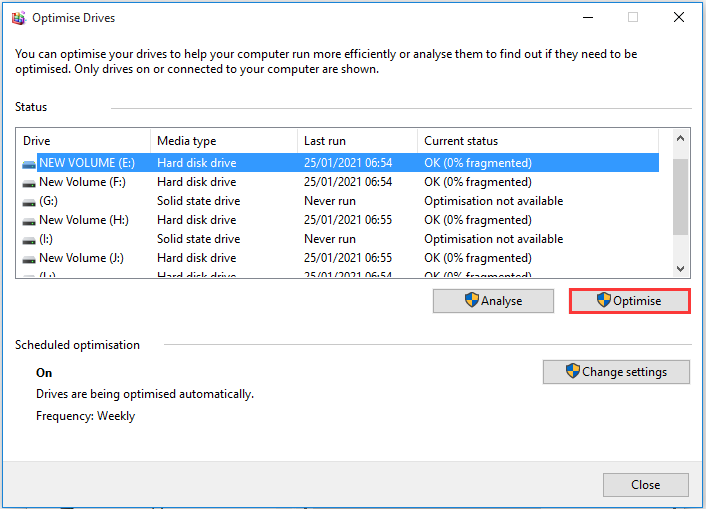
Step 4. In the pop-up window, select the problematic drive from the list and click on Optimise button. Then you may wait for some time until the optimization completes.
Top recommendation: [Resolved] Disk Defragmenter Was Scheduled Using Another Program.
Fix 3. Provide Insufficient Ventilation for Hard Drive
In some cases, the SMART HP hard disk error message can pop up when your hard disk exceeds the maximum temperature. To avoid this situation, you should make sure your hard drive has sufficient ventilation and all coolers on the computer are working properly.
How to improve the ventilation for your hard drive? The simplest method is to clean the dust on your computer fan and air vents. To do so, follow the steps below carefully.
Step 1. Please make sure that you turn off your computer entirely and disconnect any power supply.
Step 2. Flip it to the backside and remove its battery.
Step 3. Find the air vents on the outer edge and use a screwdriver to open that panel. Then you should see the fan underneath it.
Step 4. Now, get rid of the dust accumulation carefully using a soft brush. After that, put everything back together.
Tip: Alternatively, you can take some other measures like upgrading your CPU fan or adding a case fan.
Fix 4. Reset the SMART Self-Test in BIOS
If the Hewlett-Packard hard drive failure message still persists on the SMART attribute, you may consider resetting the SMART self-test in BIOS. Here is a simple guide for you.
Note: To avoid any unexpected situation, we highly recommend you make a backup for all important data beforehand.
Step 1. Restart your computer and press the F2 or Delete key to enter BIOS when the manufacturer’s loading screen appears. Since the BIOS hotkeys vary on different PC brands, you should check your manufacturer’s manual to enter BIOS.
Step 2. In the BIOS Setup Utility window, navigate to the Advanced tab and then select SAMRT settings.
Step 3. Select SMART self-test and set its status as Disabled. Then press the F10 or Enter key to save the change.
After that, you can restart your computer and check if the HP hard disk error has been resolved.
Fix 5. Upgrade to a New Hard Drive/SSD
As pointed out above, the SMART end-to-end error often indicates physical damage on your hard drive. If so, it is impossible to completely get rid of the error message. We highly recommend you replace the faulty hard drive with a new one.
Then here comes to a new question. How to upgrade to a hard drive/SSD without reinstalling OS? Here MiniTool Partition Wizard is highly recommended. It can help you copy the whole disk to a new hard drive/SSD.
Buy Now
Step 1. Connect your new hard drive/SSD to your computer and launch the program to enter its main interface.
Step 2. Click on the Copy Disk Wizard feature on the left pane and click on the Next button.
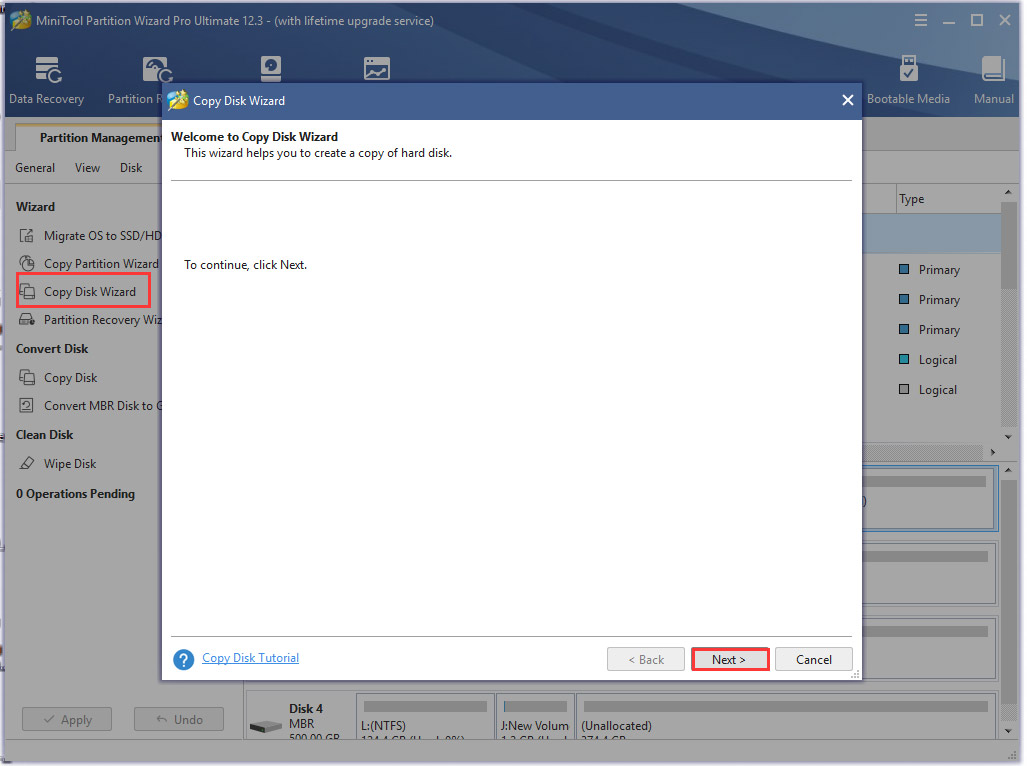
Step 3. Select the original hard drive and click on Next to go on.
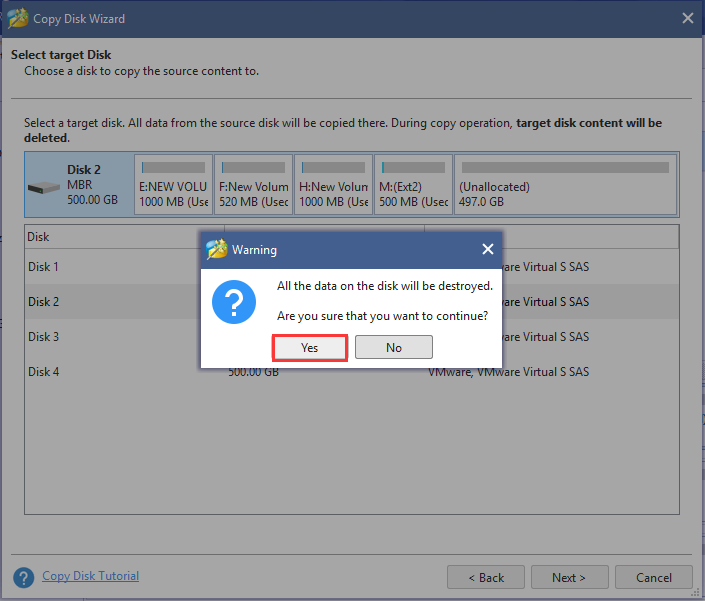
Step 4. Select the new hard disk that you just installed and click on Next to continue. Then you will be prompted with all data on the disk will be destroyed. If you have ensured this operation, click on the Yes button.
Step 5. Select a copy option based on your needs and click Next. Then click on the Finish button in the pop-up window.
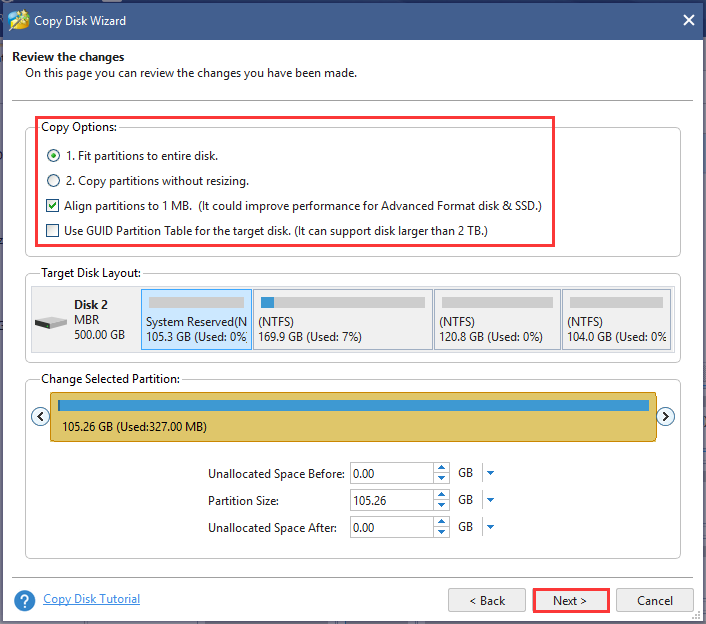
Step 6. Finally, click Apply button to execute this operation.
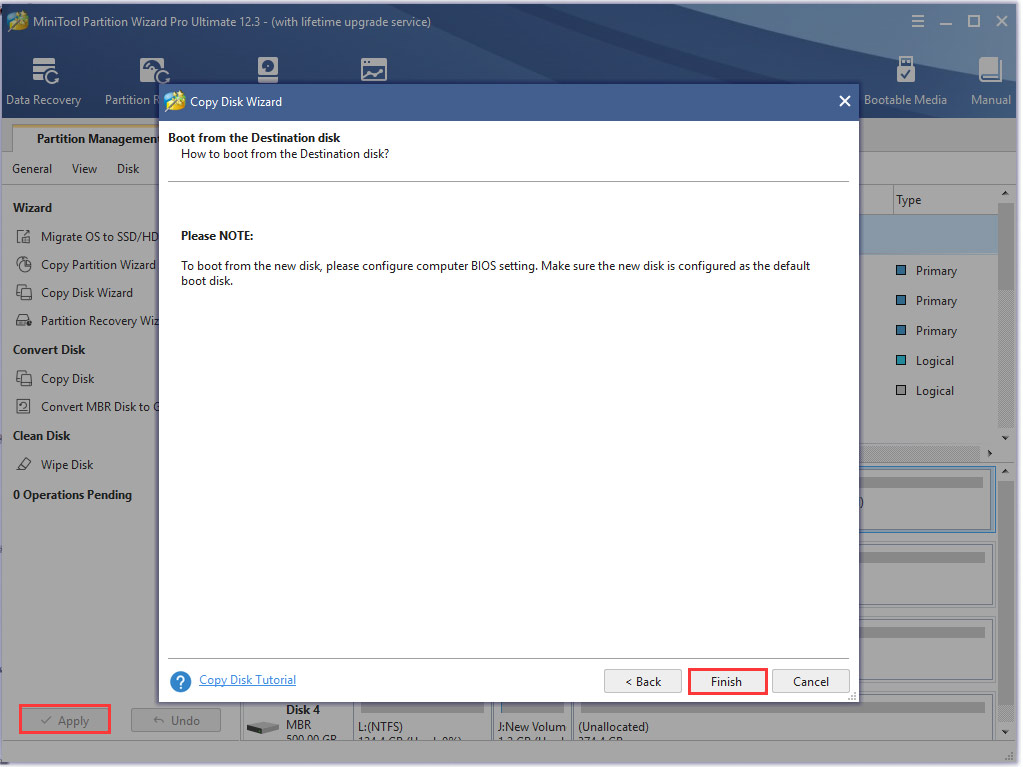
Once you have finished all the above steps, your previous hard drive should be copied into the new one.
Recently, the SMART test always gives me an error message on the Seagate hard drive: “end-to-end error, the disk is abnormal, change immediately it”. What does the error mean? Is my hard drive going bad? Fortunately! This post provides a free tool that helped me check hard drive errors.Click to Tweet
What’s Your Opinion
Now, here comes the end of this post. What does the end-to-end error mean? How to fix the SMART hard disk error? Now, I believe that you already have known the answers. In addition, you can utilize the MiniTool Partition Wizard to upgrade your hard drive without reinstalling OS.
If you have any better ideas or opinions, please share them in the comment area. Also, you can send us an email via [email protected] if you have any suggestions about the MiniTool software.
End-to-End Error FAQ
How to fix a hard drive error for HP?
Usually, the HP hard drive error can be caused by bad sectors. You can use the CHKDSK utility to scan the hard drive and shield the bad sectors. Here’s how:
- Press Win + R keys to open the Run dialog box, and then type cmd in it and press Ctrl + Shift + Enter keys to open the elevated command prompt.
- Type chkdsk /f /r in the pop-up window and hit Enter.
- Restart your computer and see if the error has been resolved.
What causes the SMART hard drive failure?
According to a survey, the main reason for SMART hard disk error is bad sectors. In addition, other factors like director errors and lost clusters can trigger the error. To fix the issue, you can try running CHKDSK command.
How to bypass the SMART hard disk error?
To do so, you need to enter BIOS and change the boot priority order. For that:
- Power off your HP laptop and then power on it. Immediately press the F10 or Delete key once you see the loading screen.
- Go to the Advanced tab by pressing the left or right arrow key.
- Use the up or down arrow key to change the Boot Order.
- Press F10 key to save the change and exit BIOS.
What are common symptoms when hard drive fails?
There are several common signs if a hard drive fails. Here we list them as follows:
- Frequently computer crashing and freezing like blue screen of death.
- Files always fail to open.
- Consuming excessive time to access folders and files.
- Strange noises.
- Overheating.
- A rising number of bad sectors.
A great many users receive the end-to-end error when using certain hard drives. What does the end-to-end error mean? How to fix it? If you are also confused about these questions, then you come to the right place. In this post, MiniTool will explore them together with you.
According to user reports, this end-to-end error often appears while copying data or transferring an application on Windows. Here’s a true example on the tom’s hardware forum.
Hello, Crystal Disk info shows the end-to-end error in my 1TB HDD…Values are like this 88 , 88 ,99 I don’t know what does the error means, but I’m experience slowness during copying and sometimes the copying stuck. I just did a clean OS install but the error still exists…Is my HDD no longer good? https://forums.tomshardware.com/threads/hard-disk-end-to-end-error.1905221/
What Does End-to-End Error Mean
The first thing you need to figure out is the meaning of the end-to-end error. In fact, this error is usually detected by Hewlett-Packard’s SMART technology or other vendors’ hard drive I/O error detection technologies.
That is to say, the end-to-end error only appears on hard drives supported by the SMART attribute or other similar technologies. According to a survey, these hard drives come from Samsung, Seagate, IBM (Hitachi), Western Digital, Hewlett-Packard (HP), and Maxtor.
The SMART technology can detect an amount of parity data errors while transferring data via the hard drive’s cache RAM. If you receive the end-to-end error, it indicates that the parity data between your host and the hard drive cannot match.
Bear in mind that the end-to-end error is a critical parameter that means an imminent hard drive failure. So, it is highly recommended that you make a full backup of your hard drive in order to avoid any unnecessary loss.
What Causes the SMART End-to-End Error
What causes the HP SMART hard disk error? After analyzing lots of user reports and references, we conclude some possible causes for the error. The most common reason is that your hard drive gets faulty due to bad sectors. In addition, the end to end error can be caused by overheating disk temperature, bit rot, and disk fragmentation.
Now, let’s see how to fix the HP SMART hard disk error.
How to Fix the SMART End-to-End Error
There are five main solutions for the SMART end to end error. Here we recommend you try the following methods one by one until the error message disappears.
Fix 1. Check Hard Drive for Bad Sectors
If you receive the SMART Hewlett-Packard hard drive failure error message, the first and simplest solution is to check if there are any bad sectors on your hard drive. To fully check hard drive errors, we highly recommend you use the professional utility – MiniTool Partition Wizard.
It is a reliable partition management tool that boasts many powerful features like converting MBR to GPT, convert FAT to NTFS, format hard drive, perform disk benchmark, align partitions, etc. With this powerful software, you can not only check file system errors but bad sectors. For that:
Free Download Buy Now
Step 1. In the main interface of this program, select the hard disk that you receive the end to end error and click on the Surface Test from the left pane.
Step 2. Click on the Start now button in the pop-up window. After that, this tool will scan the whole disk immediately and show you the test result.
If there are any blocks marked with red color like the following picture, it indicates that your hard drive is getting failing.
For bad sectors, you can use a special utility to mark them as unusable. CHKDSK is a Windows built-in tool that can help you shield the bad sectors. Now, please keep reading the following part.
Step 1. Type cmd in the search box, and then right-click the Command Prompt app and select Run as administrator.
Step 2. In the elevated command prompt, type chkdsk /f /r command and hit Enter. Then type Y to continue this operation. After that, this command will start scanning the hard drive and mark the bad sectors as unavailable.
Fix 2. Run Hard Drive Defragmentation
Disk Defragmenter is a widely used Microsoft utility that can help you optimize your hard disk or handle disk fragmentation. As mentioned above, the SMART hard disk error HP can be caused by defragmentation. To fix the problem, you can perform hard disk defragmentation.
Tip: If you encounter the Windows 10 defragmentation not working issue, you can read this post.
Step 1. Press Win + E keys to open the File Explorer, and then click on This PC from the left pane.
Step 2. Scroll down to the Devices and drives section, and then right-click the drive that experiences the end-to-end error and select Properties.
Step 3. Navigate to the Tools tab, and then click on the Optimise button under the Optimise and defragment drive section.
Step 4. In the pop-up window, select the problematic drive from the list and click on Optimise button. Then you may wait for some time until the optimization completes.
Top recommendation: [Resolved] Disk Defragmenter Was Scheduled Using Another Program.
Fix 3. Provide Insufficient Ventilation for Hard Drive
In some cases, the SMART HP hard disk error message can pop up when your hard disk exceeds the maximum temperature. To avoid this situation, you should make sure your hard drive has sufficient ventilation and all coolers on the computer are working properly.
How to improve the ventilation for your hard drive? The simplest method is to clean the dust on your computer fan and air vents. To do so, follow the steps below carefully.
Step 1. Please make sure that you turn off your computer entirely and disconnect any power supply.
Step 2. Flip it to the backside and remove its battery.
Step 3. Find the air vents on the outer edge and use a screwdriver to open that panel. Then you should see the fan underneath it.
Step 4. Now, get rid of the dust accumulation carefully using a soft brush. After that, put everything back together.
Tip: Alternatively, you can take some other measures like upgrading your CPU fan or adding a case fan.
Fix 4. Reset the SMART Self-Test in BIOS
If the Hewlett-Packard hard drive failure message still persists on the SMART attribute, you may consider resetting the SMART self-test in BIOS. Here is a simple guide for you.
Note: To avoid any unexpected situation, we highly recommend you make a backup for all important data beforehand.
Step 1. Restart your computer and press the F2 or Delete key to enter BIOS when the manufacturer’s loading screen appears. Since the BIOS hotkeys vary on different PC brands, you should check your manufacturer’s manual to enter BIOS.
Step 2. In the BIOS Setup Utility window, navigate to the Advanced tab and then select SAMRT settings.
Step 3. Select SMART self-test and set its status as Disabled. Then press the F10 or Enter key to save the change.
After that, you can restart your computer and check if the HP hard disk error has been resolved.
Fix 5. Upgrade to a New Hard Drive/SSD
As pointed out above, the SMART end-to-end error often indicates physical damage on your hard drive. If so, it is impossible to completely get rid of the error message. We highly recommend you replace the faulty hard drive with a new one.
Then here comes to a new question. How to upgrade to a hard drive/SSD without reinstalling OS? Here MiniTool Partition Wizard is highly recommended. It can help you copy the whole disk to a new hard drive/SSD.
Buy Now
Step 1. Connect your new hard drive/SSD to your computer and launch the program to enter its main interface.
Step 2. Click on the Copy Disk Wizard feature on the left pane and click on the Next button.
Step 3. Select the original hard drive and click on Next to go on.
Step 4. Select the new hard disk that you just installed and click on Next to continue. Then you will be prompted with all data on the disk will be destroyed. If you have ensured this operation, click on the Yes button.
Step 5. Select a copy option based on your needs and click Next. Then click on the Finish button in the pop-up window.
Step 6. Finally, click Apply button to execute this operation.
Once you have finished all the above steps, your previous hard drive should be copied into the new one.
Recently, the SMART test always gives me an error message on the Seagate hard drive: “end-to-end error, the disk is abnormal, change immediately it”. What does the error mean? Is my hard drive going bad? Fortunately! This post provides a free tool that helped me check hard drive errors.Click to Tweet
What’s Your Opinion
Now, here comes the end of this post. What does the end-to-end error mean? How to fix the SMART hard disk error? Now, I believe that you already have known the answers. In addition, you can utilize the MiniTool Partition Wizard to upgrade your hard drive without reinstalling OS.
If you have any better ideas or opinions, please share them in the comment area. Also, you can send us an email via [email protected] if you have any suggestions about the MiniTool software.
End-to-End Error FAQ
How to fix a hard drive error for HP?
Usually, the HP hard drive error can be caused by bad sectors. You can use the CHKDSK utility to scan the hard drive and shield the bad sectors. Here’s how:
- Press Win + R keys to open the Run dialog box, and then type cmd in it and press Ctrl + Shift + Enter keys to open the elevated command prompt.
- Type chkdsk /f /r in the pop-up window and hit Enter.
- Restart your computer and see if the error has been resolved.
What causes the SMART hard drive failure?
According to a survey, the main reason for SMART hard disk error is bad sectors. In addition, other factors like director errors and lost clusters can trigger the error. To fix the issue, you can try running CHKDSK command.
How to bypass the SMART hard disk error?
To do so, you need to enter BIOS and change the boot priority order. For that:
- Power off your HP laptop and then power on it. Immediately press the F10 or Delete key once you see the loading screen.
- Go to the Advanced tab by pressing the left or right arrow key.
- Use the up or down arrow key to change the Boot Order.
- Press F10 key to save the change and exit BIOS.
What are common symptoms when hard drive fails?
There are several common signs if a hard drive fails. Here we list them as follows:
- Frequently computer crashing and freezing like blue screen of death.
- Files always fail to open.
- Consuming excessive time to access folders and files.
- Strange noises.
- Overheating.
- A rising number of bad sectors.
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
1 |
|
|
02.08.2019, 09:26. Показов 3713. Ответов 22
Доброго времени суток.
__________________ 0 |

|
1377 / 764 / 202 Регистрация: 10.02.2018 Сообщений: 3,157 |
|
|
02.08.2019, 14:05 |
2 |
|
По смартам: P.S. http://https://www.cyberforum…. 42311.html 0 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
02.08.2019, 15:04 [ТС] |
3 |
|
Забыл добавить по поводу пыли — все почищено, на обоих hdd были сняты платы и на всякий случай протерты, хотя необходимости в этом не было (контакты оказались чистые, никаких окислений и пыли). 0 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
02.08.2019, 16:49 |
4 |
|
Да, камрады, я предвижу вопрос об электропитании. Скрины прилагаются ниже, и сразу уточню, что такая картина была годами, ничего не изменилось, сколько лет помню уже. Линия 12 V показывает 9.302V. — Оно не то что годами, а вообще работать не должно. А атрибут ID=184 — это ошибки электроники харда… 1 |

|
Модератор
20479 / 12372 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
02.08.2019, 20:21 |
5 |
|
Xtrail, какой у вас блок питания? Нет ли другого для теста? 0 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
05.08.2019, 09:19 [ТС] |
6 |
|
kumehtar, БП MaxSilent, 410 Ватт. Другого для проверки нету, увы. Линия 12 V показывает 9.302V. — Оно не то что годами, а вообще работать не должно. Вот именно((( И как теперь верить всем этим прогам. Тем более, вчера решил проверить еще и КристалДискИнфо — в результате оказалось, что у меня с хдд вообще все норм, цирк: А ведь я знаю, что с дисками не все гуд, о чем говорит и регулярное системное сообщение: А атрибут ID=184 — это ошибки электроники харда… М-да.. А везде ж пишут, что шлейф шлейф. Век живи — век учись, как говорится… 0 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
05.08.2019, 10:34 |
7 |
|
Замеров вольтметрами выходных напряжений не проводил. Плохо, что даже необходимую элементарную проверку не сделали… На Самсунгах этот атрибут ввели как фичу. Если дальше ВСЁ будет нормально, то часов через 100-200 этот атрибут после self-тестов сам сбросится… 1 |
|
Модератор
20479 / 12372 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
05.08.2019, 13:54 |
8 |
|
И как теперь верить всем этим прогам. А вы мультиметром проверьте. 0 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
12.08.2019, 10:48 [ТС] |
9 |
|
Проверил мультиметром — показатели отличные, ни по 12В, ни по 5В отклонение не превышает 5% ! 0 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
12.08.2019, 12:15 |
10 |
|
почему вдруг 2 разных жестких диска (753 куплен 4 года назад) начали показывать одни и те же две ошибки смарта, причем с интервалом в пару дней, ведь в эти дни никаких экстраординарных событий не было. Природа компьютера такова, что он постоянно делает аппаратные ошибки (миллионы…). Большинство этих ошибок он аппаратно успешно исправляет и даже нигде не их показывает. В частности, харды Самсунг порою регистрируют ошибку паритета SMART ID B8… А производители других хардов считают это дело избыточным… Если эта ошибка мешает Вам жить — сбросьте её при помощи ESwin SAMSUNG S.M.A.R.T UTILITY. Только подходящую версию ESwin подберите. И посмотрите тему двухгодичной давности HDD — end-to-end error 1 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
12.08.2019, 16:44 [ТС] |
11 |
|
Tau_0, да, спасибо, видел раньше этот топик, где у чела была якобы несовместимость материнки и hdd, но тоже сомневаюсь, что после 100500 часов практически безупречной работы вдруг возникла какая-то техническая несовместимость. А повторные попытки перезапуска приводят лишь к такому: После переключения hdd на другой сата-порт материнки запуск, как правило, удается, но через время история повторяется уже на новом порту. 0 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
12.08.2019, 22:08 |
13 |
|
А повторные попытки перезапуска приводят лишь к такому: Если синий экран с STOP: 0x0000007A — это ошибка Windows. Пусть будет из-за невозможности чтения страницы из своп-файла. А своп на харде… И в ошибке «Reboot and Select proper Boot device or Insert Boot Media in selected Boot device and press a key» может и совсем не в харде дело. — Нельзя его делать крайним… Вы SMART при помощи ESwin на самсунге /самсунгах сбрасывали…???… Если нет, то сбросьте… Ещё раз по поводу ошибки паритета end-to-end error. Как (на какое число бит в блоке) идёт контроль по паритету я не знаю. Но, по идее, бит не должно быть много… И в случае паритетного контроля виноватым может быть любой элемент в цепочке. Хотя у каждого элемента есть свой контроль… У Вас двое наиболее вероятных виновных — хард и хост контроллер. — Не дружат они. А может есть и третья сторона. — Например, разгон, нестабильное питание… ЗЫ Самые тяжёлые ошибки — это плавающие ошибки. — Уж пусть лучше сразу оно конкретно сломается… 1 |
|
Модератор
15123 / 7716 / 721 Регистрация: 03.01.2012 Сообщений: 31,759 |
|
|
13.08.2019, 11:05 |
14 |
|
0x0000007A: KERNEL_DATA_INPAGE_ERROR 0 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
13.08.2019, 11:38 [ТС] |
15 |
|
Tau_0, да, для начала, наверно, попробую поработать с ESwin. Но, если у вас есть подходящая версия, скиньте плизз. А то по ссылке с софтпедии.ком скачалась версия, явно не та, которая надо мне: Нифига не видит вообще, че т не то( Помогите с этой прогой, а то боюсь скачать какую-нить гадость, типа скрытого майнера. 0 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
13.08.2019, 14:46 |
16 |
|
Помогите с этой прогой, а то боюсь скачать какую-нить гадость, типа скрытого майнера. ESwin SAMSUNG S.M.A.R.T UTILITY ver. J ESwin SAMSUNG S.M.A.R.T UTILITY — программа для теста чтения и стирания жестких дисков Samsung, а так же некоторых Seagate. Версия J отличается от G тем, что поддерживает не только внешние жесткие диски, но и SATA ЗЫ Наверное надо, чтобы host-контроллер в BIOS был в режиме PATA/IDE…???… А может и нет… Миниатюры
2 |
|
X-Factor
3173 / 2104 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
13.08.2019, 14:57 |
17 |
|
Ошибка вызвана плохим А цепочка достаточно длинная — неясно где слабое звено…???… 1 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
13.08.2019, 21:47 [ТС] |
18 |
|
ESwin SAMSUNG S.M.A.R.T UTILITY ver. J Помогло буквально на 1 запуск винды. Хотя второй диск — 750 — остался только с желтой 199-й ошибкой, а красная 184-я исчезла: То есть, вылеты и зависания остались. 1 |
|
Модератор
20479 / 12372 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
13.08.2019, 23:08 |
19 |
|
ни по 12В, ни по 5В отклонение не превышает 5% ! а поточнее — что намерили? 0 |
|
7 / 7 / 0 Регистрация: 06.07.2015 Сообщений: 25 |
|
|
14.08.2019, 10:36 [ТС] |
20 |
|
а поточнее — что намерили? По 12 было около 12.3.., чет такое. Ну и по 5 — тоже в пределах. 0 |
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
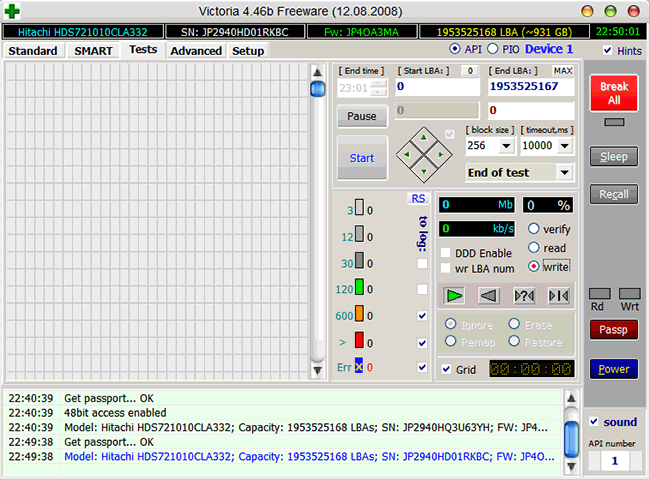
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
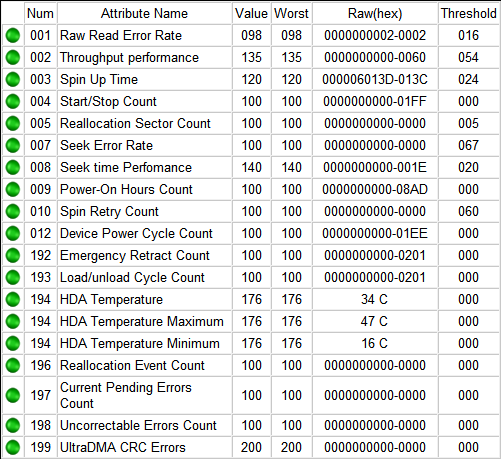
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
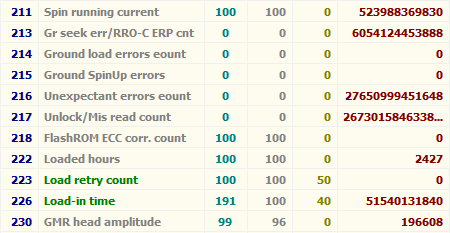
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
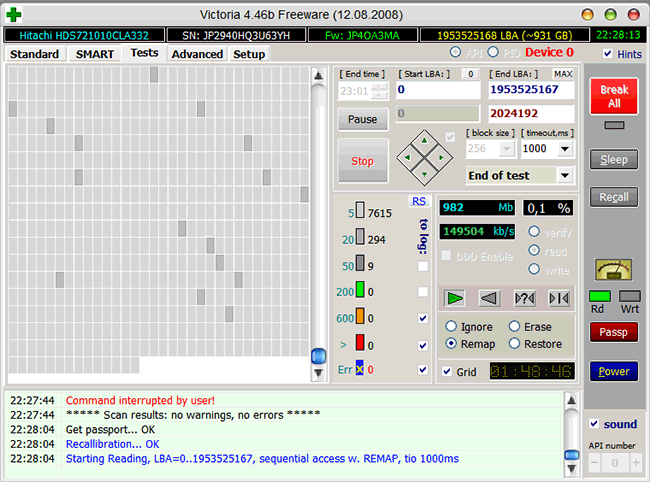
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Технология S.M.A.R.T. позволяет считывать сохраняемые в служебной области жесткого диска сведения, необходимые для оценки его состояния. Расшифровка термина такова: Self – сам, Monitoring – контроль, Analysis – анализ, Reporting Technology – технология отчетов. Как и для чего использовать S.M.A.R.T., детально рассмотрено в данной статье. Проверить звук микрофона онлайн.

Содержание
- Для чего нужна эта технология
- Программы для просмотра S.M.A.R.T.
- CrystalDiskInfo
- AIDA64
- Victoria
- HDDScan
- Speccy
- Сложности при сканировании
- Значение атрибутов S.M.A.R.T.
- 01 Raw Read Error Rate
- 02 Throughput Performance
- 03 Spin-Up Time
- 04 Number of Spin-Up Times (Start/Stop Count)
- 05 Reallocated Sector Count
- 07 Seek Error Rate
- 08 Seek Time Performance
- 09 Power On Hours Count (Power-on Time)
- 10 (0A) Spin Retry Count
- 11 (0B) Calibration Retry Count (Recalibration Retries)
- 12 (0C) Power Cycle Count
- 183 (B7) SATA Downshift Error Count
- 184 (B8) End-to-End Error
- 187 (BB) Reported Uncorrected Sector Count (UNC Error)
- 188 (BC) Command Timeout
- 189 (BD) High Fly Writes
- 190 (BE) Airflow Temperature
- 191 (BF) G-Sensor Shock Count (Mechanical Shock)
- 192 (C0) Power Off Retract Count (Emergency Retry Count)
- 193 (C1) Load/Unload Cycle Count
- 194 (C2) Temperature (HDA Temperature, HDD Temperature)
- 195 (C3) Hardware ECC Recovered
- 196 (C4) Reallocated Event Count
- 197 (C5) Current Pending Sector Count
- 198 (C6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
- 199 (C7) UltraDMA CRC Error Count
- 200 (C8) Write Error Rate (MultiZone Error Rate)
- 201 (C9) Soft Read Error Rate
- 202 (CA) Data Address Mark Error
- 203 (CB) Run Out Cancel
- 220 (DC) Disk Shift
- 240 (F0) Head Flying Hours
- 254 (FE) Free Fall Event Count
- Предсказание поломки диска в командной строке
- Определение статуса диска
- Прогнозируемый сбой
- Предсказание в Windows PowerShell
- Анализ в приложении Системный монитор
- Что делать с ошибками S.M.A.R.T.
- Прекратите использование сбойного HDD
- Восстановите удаленные данные диска
- Просканируйте диск на наличие битых секторов
- Снизьте температуру диска
- Произведите дефрагментацию жесткого диска
- Приобретите новый жесткий диск
- Как сбросить S.M.A.R.T ошибку и стоит ли это делать?
Для чего нужна эта технология
Все современные жесткие диски оснащены S.M.A.R.T.-блоком, ответственным за отслеживание и сохранение информации об их основных параметрах: нагревание винчестера в процессе работы, скорость вращения, время позиционирования магнитных головок, предназначенных для записи и считывания данных. Также отслеживаются сбои, возникающие при эксплуатации накопителя. Инструкция как сделать тест веб камеры.
В случае обнаружения на дисковой поверхности битых секторов производится их замещение резервными блоками. Использование данной технологии позволяет своевременно предвидеть выход из строя винчестера и заранее позаботиться об его замене на исправное дисковое устройство. Пользователь может, не дожидаясь окончательной поломки жесткого диска, создать резервную копию всех хранящихся на нем файлов. В таком случае потери информации можно больше не опасаться.
Программы для просмотра S.M.A.R.T.
Ряд производителей HDD выпускают также утилиты собственной разработки, предназначенные для получения информации от S.M.A.R.T. Они максимально адаптированы для работы с носителями определенных моделей. Но такой софт разработан не для всех винчестеров, да и его возможностей иногда оказывается недостаточно для всесторонней оценки состояния накопителя.
В качестве альтернативы можно использовать один из многочисленных программных продуктов, созданных сторонними разработчиками. Далее мы рассмотрим несколько хорошо зарекомендовавших себя приложений, предоставляющих доступ к S.M.A.R.T.
CrystalDiskInfo

CrystalDiskInfo – бесплатное приложение для просмотра параметров S.M.A.R.T. и оценки тенденции их изменений. Интерфейс утилиты полностью русифицирован (язык можно переключить с помощью меню). Температура винчестера или твердотельного накопителя показывается в системном трее (внизу экрана справа). Программа позволяет построить график, на котором будут наглядно отображены изменения, произошедшие за последний месяц с носителем информации. В случае необходимости приложение может быть запущено с задержкой. С помощью CrystalDiskInfo пользователю удобно изменить режим работы жесткого диска: установить максимально возможную скорость либо включить режим экономии электроэнергии (при этом также уменьшится издаваемый HDD шум). Помимо этого, разработчиками реализована поддержка внешних HDD и карманов, а также RAID-массивов Intel.
AIDA64

С помощью данного приложения можно получить информацию обо всех аппаратных компонентах системы и их технических характеристиках, а также выполнить их тестирование. Для просмотра информации о жестком диске следует перейти к разделу «Меню» в левой части окна и щелчком по треугольнику слева открыть подменю «Хранение данных». В его нижней части присутствует пункт «SMART», именно его и нужно выбрать. В правой секции окна вверху появится список всех установленных в системе жестких дисков. Остается выбрать только нужный накопитель и щелкнуть мышью по соответствующей строке. Сведения о выбранном диске будут отображены в секции ниже.
AIDA64 – условно-бесплатное приложение, период безвозмездного пользования которым ограничен 30 днями. Чтобы иметь возможность работать с ним и дальше, необходимо купить лицензию.
Victoria

Victoria – одна из лучших утилит для диагностики и восстановления неисправностей жестких дисков. Существует 2 версии программы: для запуска с загрузочного носителя и для работы непосредственно в среде Windows. В последнем случае для корректной работы приложения его следует запускать от имени администратора (соответствующую команду можно выбрать из его контекстного меню посредством щелчка по значку правой кнопкой мыши). Для загрузки с внешнего носителя потребуется предварительно создать загрузочный USB-диск или CD (DVD) и записать на него образ приложения.
После того, как Victoria запустится, на вкладке «Standard» в правой половине окна вверху выбираем тестируемый HDD и жмем на кнопку «Passport» для обновления сведений о нем. В самом низу окна отобразится информация о модели винчестера, его вместимости в дорожках и серийном номере. Затем можно переходить на вкладку “SMART”. Для считывания данных нажимаем на кнопку «Get SMART» в правой секции окна вверху.
При всех своих прочих достоинствах программа бесплатна. Также следует отметить, что ее новейшие версии поддерживают работу со S.M.A.R.T.-данными SSD-накопителей.
HDDScan
Отличительной особенностью утилиты является предельная простота в использовании. Достаточно выбрать из списка «Select Drive» жесткий диск и нажать на кнопку «S.M.A.R.T.», как на экране появится новое окно с подобной информацией о жестком диске. Разработчиками предусмотрена возможность менять некоторые из этих параметров (AAM, APM и др.). И за все это платить ничего не надо.
Speccy

С помощью бесплатного приложения Speccy с поддержкой русского языка можно получить сведения об установленных в компьютере комплектующих и их технических характеристиках. Предусмотрена возможность сохранения этой информации в виде подробного отчета.
Из меню в левой части экрана выбираем «Хранение данных», и в правой части окна приложения появятся сведения сразу обо всех установленных на машине пользователя жестких дисках. Если информация сразу не будет выведена на экран, надо подождать несколько секунд до завершения ее считывания.
Сложности при сканировании
Как правило, при проверке жестких дисков никаких проблем не возникают. Сканирование невозможно только для старых моделей винчестеров, не поддерживающих S.M.A.R.T.-технологию, или самотестирование которых отключено. Но тут уж ничего не поделать.
Определенные проблемы возникнут и в случае подключения винчестера в AHCI-режиме, поскольку данные S.M.A.R.T. в такой ситуации прочесть нельзя. Об этом выводится соответствующее сообщение на экран (например, может отображаться надпись «Non ATA». Чтобы обойти данное ограничение, необходимо загрузить BIOS и перейти на вкладку «Config > Serial ATA (SATA) > SATA Controller Mode Option». Вместо AHCI нужно выбрать Compatibility и сохранить изменения. Когда тестирование закончено, следует вернуться к прежней настройке.
Значение атрибутов S.M.A.R.T.
Для каждого из атрибутов программа тестирования отобразит следующие сведения (в зависимости от приложения они могут несколько отличаться от приведенного здесь списка):
- наименование;
- номер;
- пороговое значение;
- текущее значение;
- графический индикатор состояния на момент тестирования;
- динамика зарегистрированных изменений;
- приблизительная дата окончательной поломки накопителя.
Здесь следует обратить внимание на цвета индикаторов атрибутов. Зеленый цвет говорит о том, что соответствующий ему показатель в норме. Если же какие-то атрибуты попали в желтую зону, ситуацию следует расценивать как тревожную. В случае же окраски индикатора в красный цвет состояние винчестера критическое, и полностью сломаться он может в любой момент.
Рассмотрим каждый из S.M.A.R.T.-атрибутов жесткого диска.
01 Raw Read Error Rate
Этот показатель используется для определения числа ошибок, возникающих при считывании данных с винчестера. Его значения могут интерпретироваться по-разному в зависимости от модели устройства. Для одних производителей идеалом считается нулевое значение, для других же – чем больше, тем лучше.
02 Throughput Performance
Отображает среднее значение производительности накопителя. Строгих норм для него не существует. Для диагностики HDD практически бесполезен.
03 Spin-Up Time
Позволяет установить время, необходимое винчестеру для раскрутки. Сам по себе данный параметр мало что значит. Его следует оценивать только с учетом заявленных технических характеристик конкретного жесткого диска.
04 Number of Spin-Up Times (Start/Stop Count)
Показывает, сколько раз производилось включение жесткого диска за весь период его эксплуатации. Может использоваться для получения косвенной оценки длительности и интенсивности использования устройства.
05 Reallocated Sector Count
Один из важнейших атрибутов, позволяющий определить физическое состояние винчестера. Показывает количество сбойных секторов, замененных на исправные из резервной области. Такая замена называется ремапом. Ремап производится автоматически в случае, если чтение информации с какого-либо участка диска сильно затруднено или невозможно. При этом поврежденный сектор помечается как неисправный, чтобы операционная система больше не пыталась его использовать.
Надо понимать, что резервная область не безгранична, и когда возможности резервирования будут исчерпаны, начнется необратимое разрушение жесткого диска. Число резервных секторов у разных моделей винчестеров различно. Но максимальное их количество не превышает нескольких тысяч (чаще всего не больше тысячи).
07 Seek Error Rate
Отображает данные, с помощью которых можно определить частоту появления сбоев в ходе позиционирования блока магнитных головок. Во многом схож с атрибутом Raw Read Error Rate. Отличие состоит в том, что для дисков Hitachi нормальным считается только нулевое значение. На дисках Seagate, Samsung SpinPoint F1 и более новых его моделей, а также Fujitsu 2.5’’ этот показатель вообще не стоит учитывать.
08 Seek Time Performance
Показывает среднее значение производительности операций позиционирования дисковых головок. Никаких предельных значений для него не предусмотрено.
09 Power On Hours Count (Power-on Time)
С помощью этого параметра мы можем узнать, сколько часов отработал жесткий диск с начала его использования.
10 (0A) Spin Retry Count
Позволяет определить, сколько раз производились повторные запуски шпинделя с момента первой неудачной попытки его старта. Однако рост данного показателя не всегда означает физическую неисправность винчестера. В большинстве случаев проблема связана с плохим контактом HDD с блоком питания или недостаточным количеством получаемой устройством электроэнергии. Если значение атрибута не превышает 2, то все в порядке. В противном случае следует проверить блок питания и его контакт с жестким диском.
11 (0B) Calibration Retry Count (Recalibration Retries)
Здесь отображается число повторных попыток произвести сброс носителя информации (в результате такой процедуры магнитные головки устанавливаются на нулевую дорожку) после того, как была зарегистрирована первая неудачная попытка. Если значение атрибута нулевое, проблемы отсутствуют, если нет – устройство, скорее всего, неисправно.
12 (0C) Power Cycle Count
Отмечается общее число циклов «включение-отключение» винчестера.
183 (B7) SATA Downshift Error Count
В этом параметре хранится информация о том, сколько попыток понижения режима SATA завершилось неудачей. Дело в том, что при выявлении определенных ошибок HDD может попытаться переключиться на работу в режиме с меньшей скоростью. Такое переключение завершится неудачей, если контроллер по каким-либо причинам откажется выполнять поступившую команду. Но в любом случае к здоровью накопителя это отношения не имеет.
184 (B8) End-to-End Error
Дает возможность оценить, сколько всего ошибок возникло в процессе передачи информации через кэш жесткого диска за все время его использования. О проблеме с устройством может свидетельствовать любое ненулевое значение.
187 (BB) Reported Uncorrected Sector Count (UNC Error)
Означает число секторов, которые в скором времени подлежат переназначению. Иногда сектор повторно может определяться как кандидат на переназначение, что также приводит к увеличению значения атрибута. Если в этой строке не ноль (особенно когда атрибут 197 тоже не равен нулю), с винчестером начали происходить деструктивные изменения.
188 (BC) Command Timeout
Сохраняет данные о том, сколько операций пришлось прервать в связи с превышением предельно допустимого периода ожидания. Любое значение больше нуля свидетельствует о наличии таких сбоев. Но не всегда это связано с неисправностью жесткого диска. Проблема может возникнуть также при использовании некачественных кабелей, плохих переходников, поврежденных контактов, несовместимости с контроллером SATA/PATA на системной плате. В Windows такая ошибка может проявляться появлением «синего экрана смерти».
189 (BD) High Fly Writes
Показывает, сколько было зарегистрировано процессов записи на носитель, когда скорость головки превышала рассчитанную величину. Основной причиной этого явления является внешнее влияние (толчки, удары, вибрация). Однако каких-либо стандартов по данному пункту нет.
190 (BE) Airflow Temperature
Выводит на экран температуру жесткого диска в момент тестирования. Нагревание выше +55 – +60ºC негативно отражается на работе устройства. В таком случае полезно будет установить дополнительное охлаждение.
191 (BF) G-Sensor Shock Count (Mechanical Shock)
По этому параметру можно определить число критических ускорений головки HDD. Причинами их появления могут стать падания накопителя либо удары по его корпусу. Но даже если такие ускорения были зарегистрированы датчиками устройства, это еще не значит, что он был поврежден. Состояние HDD нужно оценивать с учетом значений других атрибутов. Также следует отметить, что у жестких дисков Samsung данный параметр можно не смотреть, поскольку его датчики могут реагировать едва ли не на движение воздуха.
192 (C0) Power Off Retract Count (Emergency Retry Count)
Отображаемая в соответствующей строке информация зависит от модели устройства. Здесь может выводиться или общее количество операций парковок магнитных головок, производящихся при появлении аварийных ситуаций, или число циклов включения/выключения устройства за все время его работы.
193 (C1) Load/Unload Cycle Count
Показывает суммарное количество циклов парковки и распарковки магнитных головок накопителя. С помощью этого параметра мы можем узнать, активирована ли автоматическая парковка HDD. Если значение атрибута 192 превышает значение атрибута 09, это означает, что автоматическая парковка включена и используется.
194 (C2) Temperature (HDA Temperature, HDD Temperature)
Выводит температуру винчестера в момент считывания информации из S.M.A.R.T. Также может содержать сведения о минимальной и максимальной температурах устройства, зарегистрированных за период его эксплуатации. Нужно убедиться, что жесткий диск не перегревается (предельно допустимая температура составляет +55ºC).
195 (C3) Hardware ECC Recovered
Позволяет определить общее количество ошибок, обработанных аппаратными средствами ECC HDD. Является аналогом атрибутов 01 и 07.
196 (C4) Reallocated Event Count
Один из наиболее значимых атрибутов для определения реального состояния винчестера. Чем выше его значение, тем хуже обстоят дела. Но для того, чтобы дать объективную оценку состояния устройства, следует учитывать значения и остальных параметров.
Данный показатель находится в тесной связи с атрибутом 05. Если один из них начал ухудшаться, негативные перемены обычно начинают происходить и с другим. Если же перемены затрагивают только атрибут 196, это означает, что в ходе выполнения ремапа оказалось, что проблемы с сектором обусловлены нарушением логической структуры, а не физической неисправностью, и были устранены средствами жесткого диска.
Иногда возникает ситуация, когда значение атрибута 05 больше аналогичного показателя у атрибута 196. В таком случае был выполнен ремап нескольких секторов одновременно.
197 (C5) Current Pending Sector Count
Выводит информацию о количестве секторов, подлежащих перераспределению. Но не всегда они имеют физическую неисправность. Перераспределяются только кандидаты, получившие статус bad, а сектора со статусом soft (логическая ошибка) после их исправления снова становятся пригодными для использования.
198 (C6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
Во многом схож с атрибутом 197. Основное отличие заключается в том, что атрибут 198 показывает зафиксированное число кандидатов на ремап, выявленных в процессе оффлайн-тестирования (оно запускается во время простоя).
199 (C7) UltraDMA CRC Error Count
Этот показатель позволяет определить, сколько ошибок произошло в ходе выполнения операций передачи информации по интерфейсному кабелю, осуществляемых в режиме UltraDMA. Если наблюдается тенденция к росту параметра, это может свидетельствовать о некачественном или поврежденном шлейфе передачи данных, работе шин PCI/PCI-E в режиме разгона или плохом подключении кабеля SATA к соответствующему разъему на материнской плате или винчестере.
При появлении таких ошибок HDD может быть автоматически переключен в режим PIO, следствием чего станет ощутимое снижение его производительности. В большинстве случаев проблема решается переподключением интерфейсного кабеля или заменой его на новый.
200 (C8) Write Error Rate (MultiZone Error Rate)
Данный параметр отвечает за количество ошибок, зарегистрированных при выполнении записи на информационный носитель. Если их число неуклонно возрастает, жесткий диск уже нельзя считать надежным устройствам. В первую очередь это относится к накопителям WD. Для них высокие значения атрибута 200 могут означать скорый выход из строя пишущей головки.
201 (C9) Soft Read Error Rate
Показывает, сколько ошибок возникает в ходе считывания информации.
202 (CA) Data Address Mark Error
Высокие значения этого показателя свидетельствуют о проблемах, возникающих при работе винчестера.
203 (CB) Run Out Cancel
Здесь фиксируется количество ошибок ECC.
220 (DC) Disk Shift
Позволяет узнать значение сдвига пластин по отношению к оси шпинделя накопителя.
240 (F0) Head Flying Hours
Атрибут можно использовать для оценки времени, которое требуется для позиционирования головки. Позволяет отслеживать состояние блока магнитных головок.
254 (FE) Free Fall Event Count
Регистрирует факты падения жесткого диска и предоставляет возможность определить их количество. Если здесь не нулевое значение, это повод для беспокойства, поскольку в таком случае нельзя исключать физическое повреждение HDD.
Предсказание поломки диска в командной строке
Проверить винчестер на наличие неисправностей с использованием командной строки можно двумя способами. Это определение статуса диска и получение информации о его прогнозируемом сбое.
Определение статуса диска
Для того, чтобы проверить S.M.A.R.T. жесткого диска с помощью командной строки, следует придерживаться такой последовательности действий:
- Запустить системное приложение «Командная строка» с административными правами. Найти ярлык командной строки можно в меню «Пуск». Для того, выполнить запуск приложения с привилегированными правами доступа в Windows 10, нужно кликнуть по его ярлыку правой кнопкой мыши, перейти в меню «Дополнительно» и активировать команду «Запуск от имени администратора».
- После того, как окно консоли появится на экране, ввести в него команду wmic diskdrive get status.
- Подтвердить выполнение команды нажатием клавиши «Enter».
- Подождать пару секунд окончания выполнения команды. Результаты проверки отобразятся в столбце «Status». Если с установленными в компьютере дисками все нормально, везде будет стоять «OK». При выявлении ошибок статус может иметь значения «bad», «unknown» или «caution».
Прогнозируемый сбой
Чтобы заранее предсказать вероятную поломку винчестера, пользователю следует придерживаться такого алгоритма:
- Выполнить запуск командной строки в режиме администратора (как это делается, описано в предыдущем разделе).
- Ввести в консоль команду wmic /namespace:rootwmi path MSStorageDriver_FailurePredictStatus.
- Подтвердить выполнение операции нажатием на «Enter».
- Дождаться вывода результата на экран. Нужная нам информация будет находиться в столбце «PredictFailure». Если результат тестирования – «FALSE», накопитель функционирует нормально. Значение «TRUE» свидетельствует о серьезных проблемах с HDD, в такой ситуации можно ожидать его скорую поломку. Также следует обратить внимание на столбец «Reason», особенно если в нем отображается число больше нуля. Значение выводимого здесь числового кода у разных производителей винчестеров может расшифровываться по-разному.
Предсказание в Windows PowerShell
Windows PowerShell – встроенный расширяемый инструмент автоматизации, предоставляемый компанией «Microsoft». Чтобы предсказать с его помощью возможные неполадки, нужно выполнить следующие шаги:
- Произвести запуск приложения «Windows PowerShell». В Windows 10 проще всего это сделать с помощью меню «Опытного пользователя». Процедура запуска такова: после щелчка правой кнопкой мыши по кнопке «Пуск» откройте это самое меню и выберите в нем команду «Windows PowerShell (администратор)».
- Введите в консоль команду Get-WmiObject -namespace rootwmi –class SStorageDriver_FailurePredictStatus.
- Нажмите «Enter».
- После того, как команда будет выполнена, на экране отобразится отчет в виде таблицы. В ней будет присутствовать информация обо всех установленных в компьютере дисках. Нас прежде всего интересует значение строки «PredictFailure». Если здесь стоит «FALSE», за судьбу жесткого диска можно пока не переживать. «TRUE» свидетельствует о серьезных проблемах с устройством и предсказывает ему скорую утрату работоспособности. О неисправностях может говорить и ненулевое значение строки «Reason» (что означает то или иное число, можно уточнить, обратившись в службу поддержки производителя HDD).
Анализ в приложении Системный монитор
В отличие от рассмотренных ранее предустановленных в систему приложений, «Системный монитор» работает не в консольном, а в графическом режиме. Для оценки состояния винчестера пользователю потребуется:
- Запустить программу «Системный монитор». Для этого нужно щелкнуть на кнопку «Пуск и открыть панель поиска, в которую ввести запрос «Системный монитор». Искомое приложение будет показано в разделе «Лучшее соответствие». Останется только произвести по нему щелчок левой кнопкой мыши.
- В левой секции появившегося окна щелчком по стрелке слева открыть раздел группы «Сборщиков данных». Ниже будут показаны вложенные в него элементы.
- Открыть подраздел «Системные».
- Перейти на вкладку «System Diagnostics (Диагностика системы)». Вызвать ее контекстное меню щелчком правой кнопки мыши. Выбрать в нем строку «Пуск».
- Еще раз развернуть вложенные элементы и открыть раздел «Отчеты».
- Найти подраздел «Системные» и раскрыть его.
- Развернуть содержимое подраздела «System Diagnostics» и изучить его содержимое.
- Кликнуть мышью по диагностическому отчету, наименование которого соответствует кодовому имени компьютера.
- Через некоторое время детальный отчет будет выведен в правой части окна. В нем следует открыть раздел «Предупреждения», а затем в таблице «Базовые системные проверки» в графе «Тесты» щелкнуть по кнопке с плюсом (она располагается около пункта «Проверка диска»).
- Ознакомиться с содержанием строки «Проверка SMART – предсказания сбоя». Если в колонке «Отказ» стоит нулевое значение, а в колонке «Описание» отображается надпись «Выполнена», то проблем с жестким диском не выявлено.
Что делать с ошибками S.M.A.R.T.
Ответ на этот вопрос зависит от характера проблем с винчестером и степени его неисправности.
Прекратите использование сбойного HDD
Если на жестком диске уже появились битые сектора, это говорит о его значительном износе. Фактически он уже начал рассыпаться, и остановить этот процесс невозможно. Дальнейшее использование такого HDD чревато потерей данных. Поскольку причина этого – физическая неисправность устройства, восстановить их скорее всего не получится.
Восстановите удаленные данные диска
Информация с носителя может исчезать и вследствие логических ошибок (они могут возникать при повреждении файловой системы. В таком случае пропавшие в результате сбоя данные подлежат восстановлению (если они не были перезаписаны другими данными), поскольку физические повреждения на жестком диске отсутствуют. Их можно восстановить, например, с помощью программы R-Studio, которая позволяет спасти информацию даже с удаленных или отформатированных разделов.
Просканируйте диск на наличие битых секторов
Проверить HDD на битые сектора можно с помощью стандартных средств Windows. Для этого необходимо перейти к нужному диску (или разделу), вызвать его контекстное меню и открыть пункт «Свойства». Затем на вкладке «Сервис» кликнуть по кнопке «Выполнить проверку» и в открывшемся окне поставить галочки «Автоматически исправлять системные ошибки» и «Проверять и восстанавливать поврежденные сектора». Возможно, потребуется перезагрузка компьютера после нажатия кнопки «Запуск». Проверка очень объемных винчестеров может длиться до нескольких часов. После завершения процедуры логические ошибки будут исправлены, а bad-сектора подвергнуты ремапу (если их резерв еще не исчерпан).

Сканирование может быть выполнено и рядом сторонних приложений. Для этого отлично подходит программа Victoria. Чтобы полностью проверить весь винчестер на битые сектора, следует на вкладке «Standard» выбрать HDD, а затем перейти на вкладку «Tests» и нажать там кнопку «Start». Количество найденных сбойных секторов будет отображаться в процессе сканирования справа от синего прямоугольника, обозначенного «Err». Цифры рядом с красным и оранжевым прямоугольниками – это еще рабочие сектора, но скорость доступа к ним очень низкая (небольшое их количество может находиться даже на новом винчестере). Полная проверка может продолжаться несколько часов.
Снизьте температуру диска
Перегрев жесткого диска может оказывать негативное влияние на работу его механических компонентов и электроники. Поэтому при подъеме его температуры до 55ºC и выше ему требуется дополнительное охлаждение. Для снижения температуры устройства можно установить в корпус компьютера еще один вентилятор. Также существуют специальные вентиляторы, предназначенные для охлаждения винчестеров. Наконец, температуру накопителя можно немного понизить, если отключить установленные в корпус ПК устройства, выделяющие тепло, без которых можно некоторое время обойтись (например, второй HDD или видеокарта в случае наличия в системной плате интегрированной видеокарты).
Произведите дефрагментацию жесткого диска
Замедление скорости чтения и записи на диск зачастую обусловлено высокой степенью фрагментации хранящихся на нем файлов. Сильная фрагментация файловой системы может способствовать ускоренному износу блока магнитных головок. Это приведет к дополнительным проблемам, связанным с ухудшением показателей их позиционирования, а также с ростом температуры накопителя (поскольку файлы разбиваются на фрагменты, зачастую расположенные друг от друга на значительном удалении, магнитным головкам приходится выполнять дополнительные перемещения, что увеличивает выделение тепла).
SSD-диски дефрагментировать не нужно, т.к. в них нет движущихся пластин и головок, в отличии от HDD.
Для предотвращения этих проблем следует выполнить дефрагментацию диска. Для этого нужно зайти в его свойства (путем вызова контекстного меню), перейти на вкладку «Сервис» и нажать на кнопку «Оптимизировать» (в Windows 10). Затем установить курсор на нужный диск или раздел и уже в этом окне кликнуть по кнопке «Оптимизировать». Обычно процедура оптимизации продолжается несколько минут.
Приобретите новый жесткий диск
Если количество сбойных секторов превышает резерв для их переназначения, приближается к этому показателю или неуклонно возрастает, следует позаботиться о покупке нового винчестера. После покупки надо как можно быстрее установить на него операционную систему и скопировать всю информацию, пока ее считывание еще возможно.
Как сбросить S.M.A.R.T ошибку и стоит ли это делать?
Информацию, записанную в S.M.A.R.T. HDD, в принципе можно удалить. После того, как все данные о накопителе будут сброшены, его S.M.A.R.T. станет выглядеть как у совершенно нового диска, котором еще не начали пользоваться. Конечно же, физические проблемы от этого никуда не исчезнут. Но такой возможностью иногда полезно воспользоваться (и не только недобросовестным продавцам бывших в употреблении винчестеров), если, например, сектора, обозначенные как кандидаты на ремап, оказались физически исправными, а такой статус они получили в результате логических проблем с файловой системой.
Данную операцию можно выполнить при помощи специальных приложений. Одной из таких программ является DRevitalize (с некоторыми моделями винчестеров она не работает). После запуска этой утилиты следует выбрать подлежащий обнулению HDD и нажать на кнопку «Start». Далее выбираем пункт «Features menu and firmware data», после чего жмем по строке «Clear defect reassign list» и подтверждаем выполнение операции. Через несколько секунд можно будет перейти на «SMART Reset Attribute Values» и нажать «ОК». Если после проведения этих манипуляций обновление S.M.A.R.T. не произойдет, следует выполнить перезапуск компьютера.

Восстановить жесткий диск, используя специальные программы. Они позволяют протестировать винчестер, а также исправить незначительные неисправности. Зачастую, этого вполне достаточно для продолжения плодотворной работы. Из статьи вы узнаете об одной из них под названием Victoria.
Проверка жесткого диска программой Victoria полностью бесплатна. Также программа обладает множеством функций и рассчитана не только на профессионалов, но также и на неопытных пользователей. Итак, сейчас вы узнаете, как проверить жесткий диск программой Victoria.
Технология S.M.A.R.T.
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков.
В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем — SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute — имя атрибута
- ID — идентификатор атрибута
- Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое низкое значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type (необязательно) — тип атрибута — характеризует производительность (PR — Performance-related), характеризует сбои (ER — Error rate), счетчик событий (EC — Events count), определено производителем или не используется (SP — Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково. Например, атрибут с идентификатором 5 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского.
На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности — для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows.
Назначение, основные возможности и порядок использования программы найдете на сайте автора
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки — уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN). Пользователь имеет возможность задать.
область тестирования
Start LBA :0 — начало области (по умолчанию — 0)
End LBA :14680064 — конец области (по умолчанию — номер последнего блока диска)
Режим тестирования
Линейное чтение — последовательное чтение от начального блока до конечного
Случайное чтение — номер считываемого блока формируется случайным образом.
BUTTERFLY чтение — выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования.
Изменение режима выполняется по нажатию клавиши «пробел»
Режим обработки ошибок
Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей «пробел». Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
Ignore Bad Blocks — программа не будет выполнять никаких действий при обнаружении ошибки.
BB = RESTORE DATA — программа попытается восстановить данные из поврежденных секторов.
BB = Classic REMAP — выполняется запись в поврежденный сектор для вызова процедуры переназначения.
BB = Advanced REMAP — улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап — если есть ошибка, выполняется переназначение, если нет ошибки — блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
BB = Fujitsu Remap — выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
BB = Erase 256 sect — при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.

В процессе работы с программой можно вызвать контекстную справку клавишей F1
Расшифровка кодов ошибок в Victoria:
BBK (Bad Block Detected) — Найден бэд-блок.
UNCR (Uncorrectable Error) — Неисправимая ошибка. Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных (софтовый Bad Block), так и неисправностью HDD;
IDNF (ID Not Found) — Не найден идентификатор сектора. Обычно говорит о разрушении микрокода или формата низкого (физического уровня) HDD . У исправных HDD такая ошибка выдается при попытке обратиться к несуществующему адресу физического сектора;
ABRT (Aborted Command) — HDD отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель и т.д.)
T0NF (Track 0 Not Found) — не найдена нулевая дорожку, невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
AMNF (Address Mark Not Found) — адресный маркер не найден, невозможно прочитать сектор, обычно в результате неисправности тракта чтения или дефекта поверхности.
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка , однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте ее по ссылке на странице загрузки сайта автора.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню «Запуск от имени администратора».
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows — включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки — нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком. В информационном окне будет отображен паспорт накопителя — модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку «Get SMART». Результат будет отображен в информационном окне программы.

Краткое описание атрибутов
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 ( 3 ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 ( 4 ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого — либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment», он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 ( 7 ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 ( 8 ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 ( 9 ) Power-On Hours — Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF — Mean Time Between Failures).
- 010 ( 0A ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства ( например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи — увеличивается счетчик повторов и повторяется попытка старта.
- 011 ( 0B ) Recalibration Retries — количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0C ) Device Power Cycle Count — Количество циклов включения/выключения диска.
- 184 ( B8 ) End-to-End error — Данный атрибут — часть технологии HP SMART IV — означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 ( BB ) Reported Uncorrectable Error — Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 ( BC ) Command Timeout Количество прерванных операций в связи с отсутствием ответа от накопителя. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, возможными причинами могут быть проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 ( BD ) High Fly Writes — Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BE ) Airflow Temperature — температура окружающей среды блока магнитных головок. Для различных моделей HDD данный атрибут отсутствует и используются атрибуты 194 или 231.
- 191 (BF ) Mechanical Shock — количество механических ударов. Вместо данного атрибута может использоваться атрибут 221.
- 192 ( C0 ) Power-off retract count — количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 ( C1 ) Load/Unload Cycle — количество циклов перемещения блока магнитных головок в зону парковки.
- 194 ( C2 ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CD ) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры. В некоторых моделях накопителей вместо атрибута 194 может использоваться атрибут 231.
- 195 ( C3 ) Hardware ECC recovered — характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле Raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле Raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8 ) Write Error Rate ( Multi-Zone Error Rate ) — Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 201 ( C9 ) Soft Read Error Rate — количество некорректируемых ошибок чтения, обнаруженных программным обеспечением.
- 202 ( CA ) Data Address Mark Errors — количество некорректируемых ошибок при чтении собственного адреса сектора.
- 203 ( CB ) Run Out Cancel — количество ошибок, зафиксированных при выполнении коррекции данных.
- 204 ( CC ) Soft ECC Correction — количество ошибок, исправленных внутренней микропрограммой накопителя.
- 205 ( CD ) Thermal Asperity Rate — общее количество проблем, вызванных повышенной температурой.
- 206 ( CE ) Flying Height — высота полета головок над поверхностью диска.
- 207 ( CF ) Spin High Current — ток, необходимый для раскручивания двигателя.
- 208 ( D0 ) Spin Buzz — количество повторных попыток запуска двигателя из-за пониженного тока.
- 209 ( D1 ) Offline Seek Performance — производительность, определенная при выполнении внутренних тестов накопителя.
- 210 ( D2 ) Vibration During Write — вибрации, зафиксированные при выполнении операций записи.
- 211 ( D3 ) Shock During Write — удары, зафиксированные при выполнении операций записи.
- 220 ( DC ) Disk Shift — смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 221 ( DD ) G-Sense Error Rate— количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 222 ( DE ) Loaded Hours — количество часов, отработанных накопителем.
- 223 ( DF ) Load/Unload Retry Count — количество операций ввода/вывода головок в зону данных.
- 226 ( E0 ) Load-in Time — общее время нахождения головок в зоне данных.
- 228 ( E4 ) Power-Off Retract Cycle — Количество автоматических парковок магнитных головок при пропадании питания.
- 230 ( E6 ) GMR Head Amplitude — Амплитуда перемещения головок между операциями.
- 231 ( E7 ) Hard Disk Temperature — температура, зафиксированная внутренними датчиками накопителя.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T ( self-test ), статистика ошибок, номера сбойных блоков LBA и т.п.
Ремап (Remap) и проверка поверхности жесткого диска
Удивительно, как долго могут существовать ошибочные представления о жестких дисках и их правильной эксплуатации. В частности, даже неплохие специалисты в области компьютерной техники, бывает, рекомендуют выполнять в среде ОС Windows полное форматирование поверхности вместо быстрого, или даже низкоуровневое форматирование. Что касается последнего, свою лепту в путаницу с форматированием вносят и некоторые производители программного обеспечения, выпускающие программы для «низкоуровневого форматирования», которые ничего не форматируют. Низкоуровневое форматирование (Low Level Format) — это разметка поверхности диска специальной служебной информацией, в соответствии с геометрией накопителя, выполняемой специальной командой посылаемой накопителю. В стандарте ST506/412, который предшествовал современному стандарту ATA (AT attachment) имелась команда 50h (Format Track), при выполнении которой производилась разметка дорожки адресными маркерами, в соответствии с геометрией диска, т.е. в соответствии с номером цилиндра, номером головки и количеством секторов на дорожке. В дальнейшем, при записи данных, эта часть информации никогда не изменялась. При выполнении команды записи данных в сектор, накопитель никогда и ничего не записывает в ту область дорожки, которая является служебной и была создана при низкоуровневом форматировании дорожек поверхности специально для этого предназначенной командой 50h.
В современных накопителях стандарта ATA команды низкоуровневого форматирования вообще отсутствуют, а рекламируемые некоторыми производителями программы для выполнения данной операции являются простыми «стиралками» данных, выполняющими запись в область данных секторов. Нет, и не может быть, никаких программ для выполнения настоящего низкоуровневого форматирования в среде любой операционной системы. Любое подобное «низкоуровневое» форматирование — это высокоуровневое форматирование логической структуры пользовательских данных.
Что же касается полного форматирования в среде Windows, то по сравнению с быстрым, сразу создающим пустое оглавление, оно просто добавляет проверку поверхности диска перед тем, как выполнить то же самое, что делает быстрое форматирование. Что также не имеет смысла, поскольку проверка и отбраковка нестабильных секторов выполняется средствами аппаратной реализации технологии S.M.A.R.T накопителя, которая с данной задачей справляется гораздо эффективнее автоматически и в непрерывном режиме. Полное форматирование имело смысл на старых дисках, которые не могли выполнять замену нестабильных секторов на сектора из резервной зоны, и такие сектора сразу становились дефектными блоками ( Bad Block ), которые исключались из файловой структуры при форматировании с проверкой поверхности. Существует также утверждение, что при полном форматировании выполняется стирание всей поверхности диска. Это тоже не соответствует действительности, что легко проверяется любыми программами мониторинга обращений к диску , например, утилитой Disk Monitor из пакета Sysinternals Suite. Программа показывает, что при полном форматировании выполняется чтение поверхности, и небольшое количество операций записи, выполняемой после проверки поверхности при формировании пустого оглавления, в самом конце работы. И даже из того факта, что существую программы для восстановления данных после форматирования ( любого, в том числе и полного ) вполне логично следует вывод – никакого стирания данных не происходит.
При записи жесткий диск не проверяет, что и как было записано в область данных сектора, кроме случаев, когда предварительная диагностика, которой накопитель занимается все «свободное время», не пометила в соответствующих журналах эти сектора, как проблемные, или кандидаты на переназначение, что отражается в атрибуте 197 SMART (Current Pending Sectors).
Кандидат — это сектор (или группа секторов), который не был считан за стандартное время и с установленным числом повторов. В режиме простоя, запустится программа самотестирования, которая попытается считать данные с применением дополнительных режимов. Если сектор будет успешно считан — программа самодиагностики попытается записать данные обратно, и если запись выполнится успешно, то из кандидатов такой сектор удалится. Если же записанная на то же место информация не будет нормально считываться, то выполнится переназначение сектора (Remap), данные запишутся в сектор из специально для этого предназначенной резервной области (spare area). В дальнейшем, всегда вместо этого сбойного сектора будут считываться данные из резервной области. А сектор-кандидат на переназначение, не исправленный программой самотестирования, увеличит значение атрибута 198 (Offline Scan UNC Sectors). Убрать такой «бед» можно только перезаписью. Но если резервная область закончилась, то все последующие кандидаты на переназначение превратятся в реальные «плохие секторы» (Bad Blocks). В этом случае программы полного форматирования и проверки поверхности могут исключить сбойный сектор из логической структуры диска, однако, использовать накопитель с закончившейся резервной областью — это очень рискованная идея, которая обязательно закончится потерей данных. Использовать такой диск можно разве что для опасных экспериментов, хранения некритичных данных, или выбросить его на помойку.
При возникновении плохих блоков (Bad Block) нередко возникает необходимость проверки принадлежности сбойного участка конкретному файлу. Для этих целей можно воспользоваться консольной утилитой NFI.EXE (NTFS File Sector Information Utility) из состава пакета Support Tools от Microsoft. Скачать 10кб
Формат командной строки
nfi.exe Диск Номер логического сектора
Подсказку по использованию NFI.EXE можно получить по команде nfi.exe /?
Букву логического диска можно задавать без двоеточия. Номер логического сектора — это номер сектора относительно начала логического диска. Обратите внимание на тот факт, что программы сканирования работают со всей поверхностью физического диска и используют нумерацию секторов, не привязанную к его логической структуре. А номер сектора, задаваемый в качестве параметра утилиты NFI.EXE — это номер сектора логического диска (раздела), и он отличается величиной смещения начального сектора раздела от начала диска. Значение номеров начальных секторов логических дисков можно получить нажав кнопку View part data вкладки «Advanced» программы Victoria For Windows.
nfi.exe C: 655234 — выдать имя файла, которому принадлежит сектор 655234
nfi.exe C: 0xBF5E34 — то же самое, но номер сектора задан в шестнадцатеричной системе счисления
В результате выполнения команды будет выдано сообщение
***Logical sector 12541492 (0xbf5e34) on drive C is in file number 49502.
WINDOWS system32 D3DCompiler_38.dll
Т.е. интересующий нас сбойный сектор принадлежит файлу D3DCompiler_38.dll в каталоге Windowssystem32. В случае, когда сбойные блоки принадлежат системным файлам Windows, возможно появление синих экранов смерти или зависаний системы с перезагрузкой. В большинстве случаев, информация о наличии сбоев дисковой подсистемы, будет отображаться в системном журнале Windows.
Для выполнения тестирования поверхности накопителя с принудительным переназначением (ремапом) сбойных секторов можно воспользоваться программами тестирования HDD, алгоритм работы которых специально разработан таким образом, чтобы «заставить» внутреннюю микропрограмму накопителя выполнить переназначение нестабильного участка.
Так, например, подобные алгоритмы будут использоваться, в упоминаемой выше программе Victoria, если выбран режим тестирования поверхности с выполнением операций восстановления или переназначения (Classic Remap, Advanced Remap :). Изначально режим выполнения теста установлен в Ignore Bad Blocks

Нажатие пробела изменяет режим обработки сбоев. При выполнении такого вида тестирования накопителя, пользовательские данные остаются в сохранности.
Добавлю, что режим Advanced Remap, хотя и является наиболее эффективным, на практике может приводить к «зависанию» микропрограммы на некоторых моделях HDD, выйти из которого можно только с использованием принудительного сброса (режим Reset, клавиша F3). После чего можно продолжить тестирование. Если в режиме Advanced Remap таймауты происходят слишком часто, имеет смысл перейти к использованию классического ремапа.
Для программы Victoria For Windows переназначение сбойных секторов включается установками режима выполнения теста в правой части основного окна. По умолчанию установлен режим Ignore — ничего не делать при обнаружении сбоя, а нужно установить режим Remap

|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
1 |
|
|
16.12.2017, 14:40. Показов 51541. Ответов 38
Здравствуйте! Миниатюры
0 |

|
Модератор
23042 / 12879 / 2251 Регистрация: 23.11.2016 Сообщений: 64,542 Записей в блоге: 26 |
|
|
19.12.2017, 10:10 |
2 |
|
Ни один смарт не видно полностью.
0 |
|
3139 / 1907 / 323 Регистрация: 25.10.2011 Сообщений: 5,541 |
|
|
19.12.2017, 10:20 |
3 |
|
В графе end-to-end error проблема не в этом параметре а в 199.
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
20.12.2017, 12:49 [ТС] |
4 |
|
проверил еще двумя прогами (см. скрины). CristalDiskInfo вроде никаких проблем не находит на обоих дисках и считает их состояние хорошим.
0 |
|
Модератор
23042 / 12879 / 2251 Регистрация: 23.11.2016 Сообщений: 64,542 Записей в блоге: 26 |
|
|
20.12.2017, 13:42 |
5 |
|
из прочитанных замены шлейфа не помогла. Это накапливающий параметр. Нолём он не станет, не ждите. Важно чтобы он не рос
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
20.12.2017, 13:47 [ТС] |
6 |
|
Это накапливающий параметр. Нолём он не станет, не ждите. Важно чтобы он не рос ну так на первом диске он не 200, но 199. и почему-то прога не ругается.
0 |
|
Модератор
23042 / 12879 / 2251 Регистрация: 23.11.2016 Сообщений: 64,542 Записей в блоге: 26 |
|
|
20.12.2017, 13:53 |
7 |
|
aldo, Смотрите на столбик Raw. На одном диске он ноль, а на другом — здоровенное число. Добавлено через 22 секунды Добавлено через 1 минуту И потом следить чтобы он не рос.
0 |
|
X-Factor
3175 / 2106 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
20.12.2017, 17:01 |
8 |
|
на бОльшем диске таки имеются проблемы: опять же, в области end-to-end error и в части UltraDMA CRS Error. Ага, на харде ST31000524AS Нормализованное значение атрибута упало ниже плинтуса/порога равного 99. 001 это слишком низко… End-to-End error S.M.A.R.T. Сквозная ошибка передачи даннных. Единственное решение этой серьёзной проблемы проблемы, которое я видел в сети — попытаться подружить хард с другим хостом…
2 |
|
Модератор
23042 / 12879 / 2251 Регистрация: 23.11.2016 Сообщений: 64,542 Записей в блоге: 26 |
|
|
20.12.2017, 17:15 |
9 |
|
По сравнению с этим интерфейсные ошибки мелочи… Как по мне — так одно следствие другого.Может у него там контакты в грязи, вот контроллер и глючит.
2 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
20.12.2017, 19:54 [ТС] |
10 |
|
попытаться подружить хард с другим хостом… это как? Может у него там контакты в грязи, вот контроллер и глючит. надо будет разобрать посмотреть
0 |
|
3139 / 1907 / 323 Регистрация: 25.10.2011 Сообщений: 5,541 |
|
|
20.12.2017, 20:25 |
11 |
|
Это плохой кэш на SSD HDD. Но это ошибка электроники… но это может быть вызвано плохим кабелем, и если после чиски, замены кабеля и порта ошибок не будет — значит что то из этого было причиной. Иначе диск в утиль.
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
20.12.2017, 20:27 [ТС] |
12 |
|
но это может быть вызвано плохим кабелем, и если после чиски, замены кабеля и порта ошибок не будет — значит что то из этого было причиной. Иначе диск в утиль. мммм…а форматирование ему не поможет?
0 |
|
Модератор
23042 / 12879 / 2251 Регистрация: 23.11.2016 Сообщений: 64,542 Записей в блоге: 26 |
|
|
20.12.2017, 21:21 |
13 |
|
мммм…а форматирование ему не поможет? Не сейчас.
На этом диске нужно сменить сата-кабель, и протереть ластиком и спиртом контакты контроллера на платке с жесткого диска. только акуртано..
0 |
|
X-Factor
3175 / 2106 / 183 Регистрация: 16.11.2011 Сообщений: 5,840 |
|
|
20.12.2017, 23:08 |
14 |
|
мммм…а форматирование ему не поможет? Ещё раз…
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
21.12.2017, 12:24 [ТС] |
15 |
|
вобщем, посмотрел я, что там происходит внутри компа. все, конечно, пыльновато. высунул и снова всунул шлейфы (см. фото). по ощущениям комп стал шустрее работать, меньше подлагивать . но картинка, которую показала программа HD Tune pro осталась без изменений: также end to end и interface CRC error (см. скрин). интересно, если ошибки были вызваны тем. что шлейф немного отходил, то эти ошибки же никуда потом не пропадут и останутся на харде, даже когда шлейф встанет на место? End-to-End error — это ошибка несовместимости харда и хоста материнской платы… материнка старая, может, там реально не было предусмотрена поддержка дисков объемом от 1 Тб? а драйвера тут никакие не помогут?
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
21.12.2017, 12:31 [ТС] |
16 |
|
УПД: у меня второй диск на 1 Тб от фирмы baracuda Seagate. и по скринам вроде с ним проблемы. поэтому навряд ли к нему прога от Самсунга подойдет (это у меня первый диск от него). но попробую.
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
21.12.2017, 13:01 [ТС] |
17 |
|
установил ESWIN — не хочет видеть диски. остается единственная прога от производителя — SeaTools. Но результаты ее SMART теста я уже выкладывал в начале темы — там все ок. Миниатюры
0 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
21.12.2017, 13:07 [ТС] |
18 |
|
также запустил короткий тест самопроверки и короткий универсальный. результат — пройдены на оба диска Миниатюры
0 |
|
1687 / 975 / 96 Регистрация: 23.01.2017 Сообщений: 3,758 |
|
|
30.12.2017, 00:54 |
19 |
|
aldo, Рядом параллельная тема HGST 84 End-to-End Error сброс ошибки Как выше сказали: «попытаться подружить хард с другим хостом». А как в работе сказывается, тормоза ST31000524AS есть?
2 |
|
14 / 14 / 2 Регистрация: 11.02.2013 Сообщений: 634 |
|
|
09.01.2018, 18:22 [ТС] |
20 |
|
в указанной теме, насколько я понял, грешат на контакты материнки и/или харда. в принципе, у меня тоже там разъемах пыли особо взятся неоткуда было — все таки они были закрыты заглушками кабеля. Изображения
0 |
|
# |
|
|
Темы: 7 Сообщения: 1044 Участник с: 28 мая 2012 |
Уважаемые Гуру , сделал проверку своих хардов —
и вот это — зто предупреждение , обнаружилось на одном из HDD , на форуме по этому случаю подобного не нашел , однако большей гугль показал — для этого диска есть новая версия firmware и нужно обновить , подскажите (может кто проводил такие операции)какие могут быть последствия после такого обновления , также в моем ПК установлен еще один HDD и один USB SSD , так вот нужно ли эти диски отключать перед обновлением ? |

|
lampslave |
# |
|
Темы: 32 Сообщения: 4800 Участник с: 05 июля 2011 |
Я что-то немного сомневаюсь, что винт сможет обновить прошивку, если вы с него загрузитесь. К тому же, диск диагностирует у себя если не смерть, то болезнь. См. параметр 184. http://forum.ixbt.com/post.cgi?id=annc:11:36706 |
|
teplovoz |
# |
|
Темы: 7 Сообщения: 1044 Участник с: 28 мая 2012 |
Да уж… , вот и оно —
, и что , невозможно уже вылечить ? |
|
User6260 |
# |
|
Темы: 1 Сообщения: 53 Участник с: 08 мая 2013 |
А почему и нет. Я в свое время обновлял прошивку у своего диска (давно правда это было). |

|
Perfect_Gentleman |
# |
|
Темы: 55 Сообщения: 1039 Участник с: 29 октября 2012 |
у меня такая же фигня. говорят, что это глюк некторых моделей Seagate, типа что-то с буфером. SeaTools’ами сделал полную проверку, ошибок не обнаружилось; полный тест Smart тоже ошибок не нашёл. |
|
vasek |
# |
|
Темы: 47 Сообщения: 11613 Участник с: 17 февраля 2013 |
teplovoz, попробую тебя успокоить. 184 — End-to-End Error, считается некритичной ошибкой, но следует взять на контроль и периодически анализировать. А Smartctl выдает варнинг потому, что значение THRESH больше, чем VALUE. Если VALUE меньше или равно THRESH, атрибут считается failed и отображается в столбце WHEN_FAILED — и судя по показаниям это превышение у тебя было уже 4 раза. Конечно, много……..на практике такого не встречал. UPD….. Все относятся к этому по-разному — лично я на это не очень обращаю внимание, просто чаще присматриваюсь к динамике изменения. А также встречал в инете следующее — хоть и пишут, что это показывает ошибки кэша винта, но обычно появляется при несовместимости винта и хоста материнки + существует также мнение, что этот атрибут учитывает и интерфейсные ошибки. Так что верить, не верить — решать тебе — но опыта на этом набраться советую, а в итоге и нас просветишь — как долго проживет винт с этой ошибкой. Ошибки не исчезают с опытом — они просто умнеют |
|
vasek |
# |
|
Темы: 47 Сообщения: 11613 Участник с: 17 февраля 2013 |
В дополнение — только сейчас заметил большое количество ошибок атрибута 199 UDMA_ CRC_ Error_Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера (вот тебе и выход на прошивку). Для интереса почитай PS………..есть вероятность, что это может также вносить вклад в ошибку атрибута 184 End-to-End Error Ошибки не исчезают с опытом — они просто умнеют |
|
User6260 |
# |
|
Темы: 1 Сообщения: 53 Участник с: 08 мая 2013 |
Я тоже поддерживаю мнение участника форума vasek. Параметр Reallocated_Sector_Ct равен 0, значит плохих секторов нет. Значение параметра 1 Raw_Read_Error_Rate равно значению параметра 195 Hardware_ECC_Recovered. Это говорит о том, что диск исправил все ошибки на лету. Меня смущает значение параметра Seek_Error_Rate. У Вас диск случайно не на боку установлен? Сколько дисков установлено. Возможно надо поставить прокладку, которая будет гасить вибрации. Попытаться найти информацию по изменениям в новой прошивке и решить надо обновляться или нет. |
|
Perfect_Gentleman |
# |
|
Темы: 55 Сообщения: 1039 Участник с: 29 октября 2012 |
User6260, вот показания моего проверенного диска
|
|
teplovoz |
# |
|
Темы: 7 Сообщения: 1044 Участник с: 28 мая 2012 |
Спасибо за наставления и внимание к моей проблеме , хотя я особо не растраиваюсь достался он мне почти даром , однако новым , друг привез из Москвы , решил — буду эсперементировать , сделал тестирование на битые блоки вот что выдало —
теперь попробую обновить … |
SMART — технология самоконтроля, анализа и отчетности, которая поддерживается большинством современных жестких дисков. С ее помощью можно отслеживать различные внутренние и внешние проблемы end to end error 1, например, количество неисправных блоков, увеличение количества ошибок, циклов пуска/остановки, повышение температуры внутренней среды и своевременно сообщать о проблемах пользователям. Таким образом, это может быть любая предупредительная информация о состоянии дисков, способном привести к поломке системника с потерей данных. Есть также другие параметры информации, включающие уведомления о будущих потенциальных проблемах, не требующих немедленных действий.
SMART: контрольный режим

SMART — это технология, которая встроена в жесткие диски, позволяет прогнозировать все их сбои и постоянно контролирует состояние винчестера. Используя определенные атрибуты, она предоставляет администраторам информацию о текущей температуре, общем количестве часов, ошибках чтения, проблемах, состоянии здоровья и других функциях, связанных с системными блоками.
Что такое RSS-лента и зачем она нужна? Является ли технология пережитком прошлого или она все еще…
СМАРТ был изначально разработан для ошибок end to end error и определен комитетом SFF в середине 90-х годов прошлого века. У системы было несколько эволюций, которые обозначают, как SMART I, II и III. С годами комитет T13 взял на себя ответственность за стандарт, и теперь он жестко нормирован в спецификации ATA. WD рассматривает следующие определения:
- SMART I: определено в спецификации SFF-8035i v1.0 (май 1995 г.), рассчитывается на основе активности в режиме онлайн, означающий, что хост-система запросила диск для выполнения действия, такого как чтение или запись.
- SMART II: определено в спецификации SFF-8035i v2.0 (апрель 1996 г.), рассчитывается на основе оперативной и автономной активности привода. В периоды простоя может выполняться автономное сканирование на предмет end to end error для всего носителя.
- SMART III: не определено ни одной отраслевой стандартной спецификацией. Автономное сканирование расширено, чтобы включить восстановление сектора.
Ключевые преимущества инструментов СМАРТ:
Delphi был чрезвычайно продвинутым языком с момента своего создания — конца 1990-х. Ко времени,…
- Отслеживает состояние здоровья жестких дисков.
- Предсказывает сбои диска.
- Проверяет наличие проблем с системником.
- Дает подробные отчеты о состоянии.
- Обеспечивает резервное копирование до отказа винчестера.
- Предупреждает по электронной почте или на рабочем столе.
Сквозная ошибка жесткого диска

Параметры СМАРТ описывают конкретные аспекты состояния системника — повреждения поверхности, ошибки чтения/записи, проблемы с электромеханическими компонентами и другие сбои. Когда критический параметр уменьшается, то вероятность отказа диска увеличивается до 30 раз. Это означает, что сбой может произойти в любую минуту, и требуется срочная замена оборудования, чтобы избежать потери важных данных.
В разработке программного обеспечения, процесс наследования дает возможность создавать класс на…
Каждый производитель оборудования поддерживает свой собственный набор параметров SMART, которые различаются в зависимости от модели диска.
Значимые данные SMART:
- Исходные данные имеют формат, указанный поставщиком.
- Необработанные значения некоторых режимов используются Acronis Drive Monitor для расчета работоспособности диска.
- Нормализованное значение преобразуется производителем и составляет от 1 до 253 и уменьшается в течение срока службы диска.
- Порог — это самое низкое допустимое значение SMART, установленное производителем, например, end to end error 99. Для некоторых режимов оно не устанавливается. Когда параметр становится ниже порогового значения, это указывает на то, что винчестер находится в критическом состоянии, и требуется защита данных.
Таблица атрибутов
Существуют распространенные сообщения об ошибках, связанных со СМАРТ жесткого диска. Если информация появляется во время запуска системы, сообщение отображается как предсказанный сбой на винчестере, а дополнительное сообщение предупреждает о немедленном резервном копировании данных с него. Ниже представлена таблица атрибутов SMART поддерживаемых твердотельными накопителями Intel.
|
Код ошибки |
Размер |
Контрольная функция |
|
4 |
4 |
Start / Stop Count |
|
5 |
5 |
Перераспределенный счетчик секторов |
|
9 |
9 |
Количество часов при включении |
|
0C |
12 |
Подсчет циклов питания |
|
А.А. |
170 |
Доступное зарезервированное пространство |
|
AB |
171 |
Количество сбоев программы |
|
Переменный ток |
172 |
Стереть счетчик ошибок |
|
B7 |
183 |
SATA Счетчик пониженной передачи |
|
B8 |
184 |
b8 end to end error — счетчик сквозных обнаружений ошибок |
|
BB |
187 |
Некорректируемое количество ошибок |
|
C0 |
192 |
Счетчик небезопасного выключения (счетчик отключения питания) |
|
С2 |
194 |
Температура — внутреннее устройство |
|
C7 |
199 |
Счетчик ошибок CRC |
|
E1 |
225 |
Ведущая информация |
|
E2 |
226 |
Временная нагрузка, износ носителей |
|
E3 |
227 |
Временная рабочая нагрузка, коэффициент чтения / записи хоста |
|
E4 |
228 |
Таймер рабочей нагрузки |
|
E8 |
232 |
Доступное зарезервированное пространство |
|
E9 |
233 |
Индикатор износа СМИ |
|
F1 |
241 |
Всего написано LBA |
|
F2 |
242 |
Всего прочитанных LBA |
Сброс счетчика B8
Система оповещения ошибок SMART – важная функция работы ПК, которая подсказывает пользователю, что он должен делать дальше. Она является краткосрочным прогнозом отказа диска. Диагностические тесты имеют статус PASS.
Система сообщит о сбое при достижении порога b8 end to end error. Привод контролирует несколько видов областей производительности. Некоторые из этих областей включают повторные попытки чтения, что означает, что данные не были прочитаны правильно в первый раз.
Погрешность чтения может быть вызвана медленным ускорением, высокой температурой и наличием проблемного сектора. Особенности этих порогов не являются общедоступными и могут различаться в зависимости от производителя. У разных производителей приводов будут разные спецификации и пороги SMART.

Системная ошибка SMART B8 «Счетчик сквозных обнаружений ошибок» — это внутренняя функция винчестера, позволяющая отслеживать его работоспособность и производительность и быстро оценивать возможные сбои на диске. Эти значения доступны только для чтения и записываются самой микропрограммой привода. Получив такую информацию, пользователь должен как можно скорее сделать резервную копию всех данных.
Ошибка: 196 (С4) Event
Данный сбой демонстрирует этапы переназначения. Ее размер подтверждает уровень работоспособности диска с прямо пропорциональной зависимостью, чем больше, тем более нестабильна работа винчестера. Только по параметру smart end to end error без учета иных атрибутов нереально оценить производительность системного блока.

В классификации этот сбой имеет значение 196 (C4) Reallocated Event Count и напрямую связан с параметром 05 Reallocated Sector Count. При повышении кода 196 также увеличивается параметр 05. Если режим 05 не увеличивается, то при вторичной корреляции плохие дефектные блоки исправляются, сектор считается исправным и не требующим переназначения.
В разработке программного обеспечения, процесс наследования дает возможность создавать класс на…
Для ситуации, когда error end event определяется выражением «196 < 05», фиксируется перенос на 1 шаг определенных операций переназначения для поврежденных секторов. Вариант «196 > 05» демонстрирует, что в результате определенной операции с переназначением обнаруженная ошибка была устранена.
Атрибут: 197 (C5) Count
Код ошибки охватывает участки, являющиеся кандидатами для направления в зону резервирования. Диск, попадая в мертвую зону, фиксирует ее для переназначения, помещает в перечень, расширяя аргумент «197». Атрибут обозначается в системе стандартизации: 197 (C5) Current Pending Sector Count.

Перед секторальной записью диск тестирует наличие участка в списке. В случае его отсутствия процесс идет непрерывно. Когда сектор тестируется стандартным образом, предполагается, что он в хорошем состоянии. Если во время записи отключается питание ПК, прекращается запись и сектор диска остается неполным, в процессе тестирования выявляется несоответствие между этими данными в виде end to end error count. Тогда диск выполняет регистрацию и удаляет битый сектор из списка. Если параметр atri booth 197 уменьшается, то размер «196» будет увеличен.
В ситуации, когда тесты не пройдены, диск выполнит переназначение операции, снижая «197», увеличивая размеры «196/05» и отмечая изменения в перечне G. В этом случае любое ненулевое значение свидетельствует о сбое. Если значение отличается от нуля, необходимо приступить к считыванию поверхности с перспективой перераспределения в ПО Victoria или MHDD. Затем при тестировании диск попадет в сектор с недостатками и попытается записать его. Так Victoria 3.5 с расширенным аргументом переназначения попытается это сделать 10 раз. Следовательно, ПО инициирует «лечение» сектора, в результате чего он будет исправлен или переназначен.
Автоматическое исправление Error
Можно исправить смарт-ошибку end to end error на винчестере автоматически с помощью бесплатного программного обеспечения.
Алгоритм восстановления жесткого диска Windows 7/10 утилитой Windows Free:
- В Windows 7 нажимают «Пуск» -> «Компьютер», в Win 10 — «Просмотр файлов».
- Нажимают мышью любой раздел с ошибкой SMART.
- Выбирают «Свойства» -> «Инструменты» и нажимают «Проверить сейчас» в разделе «Проверка ошибок».
- Включают параметры «Автоматически исправлять ошибки файловой системы», «Сканировать и пытаться восстановить поврежденные сектора».
- Нажимают «Пуск», чтобы начать процесс автоматического исправления умных ошибок утилитой Windows Free.
Мастер EaseUS Partition
Бесплатный менеджер разделов EaseUS работает по аналогии со встроенной утилитой Windows для восстановления ручной загрузкой.
Скачивают портативное программное обеспечение небольшого размера на ПК, оно поддерживается Windows 7810.
Алгоритм установки:
- Открывают EaseUS Partition Master на компьютере. Затем находят диск, нажимают правой кнопкой мыши проверяемый раздел и выбирают режим «Проверить файловую систему».
- В окне «Проверка файловой системы» оставляют выбранным параметр «Попытаться исправить ошибки» и нажимают «Пуск».
- Программное обеспечение начнет проверку файловой системы раздела на диске.
- По завершении нажимают «Готово».
- Помимо проверки функции раздела, выполняют другую функцию, называемую разделом формата в EaseUS Partition Master, которую используют для удаления умной ошибки, особенно когда она возникает из-за повреждения винчестера.
Ремонт диска

Если пользователь получает ошибку SMART на жестком диске SATA, можно запустить утилиту Check Disk в Windows для исправления сбоев.
Алгоритм исправления ошибок винчестера:
- Перед тем как исправить end to end error, нажимают кнопку «Пуск» в Windows, а затем значок «Компьютер» в меню «Пуск».
- Нажимают мышью на опции для диска для отображения контекстного меню.
- Нажимают окно «Свойства».
- Переходят на «Инструменты» и «Проверить сейчас».
- Откроется дисковая утилита.
- Устанавливают отметку рядом с опцией «Автоматически исправлять ошибки».
- Устанавливают отметку рядом с параметром «Сканировать и попытаться восстановить поврежденные сектора».
- Нажимают кнопку «Пуск». Утилита Check Disk проверяет жесткий диск SATA на наличие ошибок и пытается исправить ошибки.
- Перезагружают компьютер после завершения работы утилиты. SMART ошибка должна быть устранена.
Исправление update process

Системная ошибка update process ended with error 1 относится к ошибкам ОС Android. О ней часто сообщают пользователи, которые скачивают пакет обновлений OTA и пытаются загрузить его на свое устройство. Она также может появиться при установке ПЗУ через пользовательское восстановление, например, ClockworkMod, PhilZ или TWRP. Эта ошибка означает, что системный раздел был изменен, и в результате программа обновления прерывает установку.
Лучший способ устранить любые возможные причины ошибки — восстановить стоковую версию устройства, перепрошив устройство. Обновление восстановления CWM до последней версии срабатывает во многих случаях. В этом случае пользователю рекомендуется скачать последнюю версию восстановления CWM / PhilZ / TWRP для модели устройства и прошить его с помощью ADB или кастомного рекавери.
Также можно попробовать переключиться на другое восстановление (TWRP / PhilZ), и ошибка должна быть исправлена. Во многих случаях она появляется, когда файл сценария обновления ПЗУ проверяет, совместима ли модель устройства с ПЗУ. Удалив условие подтверждения из сценария, можно сделать так, чтобы оно обошло проверку, которая приводит к ошибке состояния. На самом деле, это функция безопасности, но иногда разработчик ПЗУ вносит изменения в скрипт для конкретной модели устройства.
Рекомендации по выбору инструментов

Для достоверности результатов обычно выполняют несколько разных тестов на жестком диске. Например, есть «быстрая проверка SMART», которая запрашивает наиболее важные индикаторы во встроенном программном обеспечении жесткого диска согласно определению производителя. Эти индикаторы включают поврежденные и переназначенные сектора, количество запусков вращения шпинделя до полной скорости, счетчик повторных попыток вращения и многие другие.
Наиболее важные тесты — это «Самотестирование диска (DST)», «Короткий тест» или «Длинный тест», где читается каждый сектор жесткого диска. Этот процесс может занять очень много времени. Различные тесты предоставляют разные типы информации в своих отчетах, что позволяет составить представление об общем состоянии диска.
Многие производители винчестеров встраивают свои собственные диагностические инструменты, которые представляют большое количество важной информации и делают ее доступной для пользователя. Кроме того, некоторые из них могут изменять настройки жесткого диска, при этом производители не несут никакой ответственности за потерю данных в результате использования таких инструментов, поэтому пользователю приходится быть особенно осторожным.
Информация, предоставляемая инструментами, зависит от конкретного производителя. Они обычно перечисляют дефекты и дают возможность исправить проблемные участки.
Вот наиболее популярные бесплатные диагностические инструменты: Seagate, Western Digital, Hitachi и Fujitsu. Всеобъемлющими бесплатными инструментами для личного использования являются CrystalDiskInfo, DiskCheckup, HD Tune или HDDScan. Все четыре инструмента просты в использовании и очень быстро информируют пользователя о состоянии тестируемого жесткого диска. HDDScan — единственный из них, который тестирует тома RAID и выполняет поверхностный тест. С этими функциями он также подходит в качестве быстрого диагностического инструмента для небольших компаний.
Кроме того, существует множество коммерческих инструментов, которые сильно различаются по объему и предлагают различную информацию, что делает их интересными, поскольку они объединяют различные диагностические исследования в одном решении. В дополнение к диагностическим проверкам SMART, они выполняют контрольные и файловые проверки, мониторинг диска и сканирование ошибок, а также проверки энергопотребления и температуры.
Подводя итог, можно констатировать, что сквозная ошибка SMART end to end error является частью технологии проверки жесткого диска, подверженного риску отказа. Статистически SMART может прогнозировать более половины дисковых отказов, что делает эту технологию надежным источником информации о его текущем состоянии.
Некоторые накопители, такие как твердотельные накопители (SSD), содержат дополнительные поля SMART, которые некоторые BIOS не могут правильно интерпретировать. Это можно исправить, перейдя на сайт производителя материнской платы, чтобы установить наличие обновлений для BIOS компьютера. Если это не помогает, можно обратиться к ним за инструкциями по отключению SMART-тестов в BIOS. Статистика пользователей говорит о том, что самые распространенные сбои фиксируются по следующим атрибутам.
|
Атрибут SMART |
Описание |
|
5 |
Количество перераспределенных секторов |
|
187 |
Сообщения о неисправимых ошибках |
|
188 |
Тайм-аут команды |
|
197 |
Текущий счетчик ожидающих секторов |
|
198 |
Неправильный счетчик секторов |
Когда значение RAW для одного из этих пяти атрибутов больше нуля, у пользователя есть причина для пристального внимания к диску.
Восстановить жесткий диск, используя специальные программы. Они позволяют протестировать винчестер, а также исправить незначительные неисправности. Зачастую, этого вполне достаточно для продолжения плодотворной работы. Из статьи вы узнаете об одной из них под названием Victoria.
Проверка жесткого диска программой Victoria полностью бесплатна. Также программа обладает множеством функций и рассчитана не только на профессионалов, но также и на неопытных пользователей. Итак, сейчас вы узнаете, как проверить жесткий диск программой Victoria.
Технология S.M.A.R.T.
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков.
В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем — SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute — имя атрибута
- ID — идентификатор атрибута
- Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое низкое значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type (необязательно) — тип атрибута — характеризует производительность (PR — Performance-related), характеризует сбои (ER — Error rate), счетчик событий (EC — Events count), определено производителем или не используется (SP — Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково. Например, атрибут с идентификатором 5 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского.
На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности — для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows.
Назначение, основные возможности и порядок использования программы найдете на сайте автора
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки — уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN). Пользователь имеет возможность задать.
область тестирования
Start LBA :0 — начало области (по умолчанию — 0)
End LBA :14680064 — конец области (по умолчанию — номер последнего блока диска)
Режим тестирования
Линейное чтение — последовательное чтение от начального блока до конечного
Случайное чтение — номер считываемого блока формируется случайным образом.
BUTTERFLY чтение — выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования.
Изменение режима выполняется по нажатию клавиши «пробел»
Режим обработки ошибок
Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей «пробел». Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
Ignore Bad Blocks — программа не будет выполнять никаких действий при обнаружении ошибки.
BB = RESTORE DATA — программа попытается восстановить данные из поврежденных секторов.
BB = Classic REMAP — выполняется запись в поврежденный сектор для вызова процедуры переназначения.
BB = Advanced REMAP — улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап — если есть ошибка, выполняется переназначение, если нет ошибки — блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
BB = Fujitsu Remap — выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
BB = Erase 256 sect — при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.
В процессе работы с программой можно вызвать контекстную справку клавишей F1
Расшифровка кодов ошибок в Victoria:
BBK (Bad Block Detected) — Найден бэд-блок.
UNCR (Uncorrectable Error) — Неисправимая ошибка. Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных (софтовый Bad Block), так и неисправностью HDD;
IDNF (ID Not Found) — Не найден идентификатор сектора. Обычно говорит о разрушении микрокода или формата низкого (физического уровня) HDD . У исправных HDD такая ошибка выдается при попытке обратиться к несуществующему адресу физического сектора;
ABRT (Aborted Command) — HDD отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель и т.д.)
T0NF (Track 0 Not Found) — не найдена нулевая дорожку, невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
AMNF (Address Mark Not Found) — адресный маркер не найден, невозможно прочитать сектор, обычно в результате неисправности тракта чтения или дефекта поверхности.
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка , однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте ее по ссылке на странице загрузки сайта автора.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню «Запуск от имени администратора».
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows — включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки — нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком. В информационном окне будет отображен паспорт накопителя — модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку «Get SMART». Результат будет отображен в информационном окне программы.
Краткое описание атрибутов
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 ( 3 ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 ( 4 ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого — либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment», он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 ( 7 ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 ( 8 ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 ( 9 ) Power-On Hours — Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF — Mean Time Between Failures).
- 010 ( 0A ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства ( например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи — увеличивается счетчик повторов и повторяется попытка старта.
- 011 ( 0B ) Recalibration Retries — количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0C ) Device Power Cycle Count — Количество циклов включения/выключения диска.
- 184 ( B8 ) End-to-End error — Данный атрибут — часть технологии HP SMART IV — означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 ( BB ) Reported Uncorrectable Error — Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 ( BC ) Command Timeout Количество прерванных операций в связи с отсутствием ответа от накопителя. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, возможными причинами могут быть проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 ( BD ) High Fly Writes — Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BE ) Airflow Temperature — температура окружающей среды блока магнитных головок. Для различных моделей HDD данный атрибут отсутствует и используются атрибуты 194 или 231.
- 191 (BF ) Mechanical Shock — количество механических ударов. Вместо данного атрибута может использоваться атрибут 221.
- 192 ( C0 ) Power-off retract count — количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 ( C1 ) Load/Unload Cycle — количество циклов перемещения блока магнитных головок в зону парковки.
- 194 ( C2 ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CD ) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры. В некоторых моделях накопителей вместо атрибута 194 может использоваться атрибут 231.
- 195 ( C3 ) Hardware ECC recovered — характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле Raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле Raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8 ) Write Error Rate ( Multi-Zone Error Rate ) — Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 201 ( C9 ) Soft Read Error Rate — количество некорректируемых ошибок чтения, обнаруженных программным обеспечением.
- 202 ( CA ) Data Address Mark Errors — количество некорректируемых ошибок при чтении собственного адреса сектора.
- 203 ( CB ) Run Out Cancel — количество ошибок, зафиксированных при выполнении коррекции данных.
- 204 ( CC ) Soft ECC Correction — количество ошибок, исправленных внутренней микропрограммой накопителя.
- 205 ( CD ) Thermal Asperity Rate — общее количество проблем, вызванных повышенной температурой.
- 206 ( CE ) Flying Height — высота полета головок над поверхностью диска.
- 207 ( CF ) Spin High Current — ток, необходимый для раскручивания двигателя.
- 208 ( D0 ) Spin Buzz — количество повторных попыток запуска двигателя из-за пониженного тока.
- 209 ( D1 ) Offline Seek Performance — производительность, определенная при выполнении внутренних тестов накопителя.
- 210 ( D2 ) Vibration During Write — вибрации, зафиксированные при выполнении операций записи.
- 211 ( D3 ) Shock During Write — удары, зафиксированные при выполнении операций записи.
- 220 ( DC ) Disk Shift — смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 221 ( DD ) G-Sense Error Rate— количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 222 ( DE ) Loaded Hours — количество часов, отработанных накопителем.
- 223 ( DF ) Load/Unload Retry Count — количество операций ввода/вывода головок в зону данных.
- 226 ( E0 ) Load-in Time — общее время нахождения головок в зоне данных.
- 228 ( E4 ) Power-Off Retract Cycle — Количество автоматических парковок магнитных головок при пропадании питания.
- 230 ( E6 ) GMR Head Amplitude — Амплитуда перемещения головок между операциями.
- 231 ( E7 ) Hard Disk Temperature — температура, зафиксированная внутренними датчиками накопителя.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T ( self-test ), статистика ошибок, номера сбойных блоков LBA и т.п.
Ремап (Remap) и проверка поверхности жесткого диска
Удивительно, как долго могут существовать ошибочные представления о жестких дисках и их правильной эксплуатации. В частности, даже неплохие специалисты в области компьютерной техники, бывает, рекомендуют выполнять в среде ОС Windows полное форматирование поверхности вместо быстрого, или даже низкоуровневое форматирование. Что касается последнего, свою лепту в путаницу с форматированием вносят и некоторые производители программного обеспечения, выпускающие программы для «низкоуровневого форматирования», которые ничего не форматируют. Низкоуровневое форматирование (Low Level Format) — это разметка поверхности диска специальной служебной информацией, в соответствии с геометрией накопителя, выполняемой специальной командой посылаемой накопителю. В стандарте ST506/412, который предшествовал современному стандарту ATA (AT attachment) имелась команда 50h (Format Track), при выполнении которой производилась разметка дорожки адресными маркерами, в соответствии с геометрией диска, т.е. в соответствии с номером цилиндра, номером головки и количеством секторов на дорожке. В дальнейшем, при записи данных, эта часть информации никогда не изменялась. При выполнении команды записи данных в сектор, накопитель никогда и ничего не записывает в ту область дорожки, которая является служебной и была создана при низкоуровневом форматировании дорожек поверхности специально для этого предназначенной командой 50h.
В современных накопителях стандарта ATA команды низкоуровневого форматирования вообще отсутствуют, а рекламируемые некоторыми производителями программы для выполнения данной операции являются простыми «стиралками» данных, выполняющими запись в область данных секторов. Нет, и не может быть, никаких программ для выполнения настоящего низкоуровневого форматирования в среде любой операционной системы. Любое подобное «низкоуровневое» форматирование — это высокоуровневое форматирование логической структуры пользовательских данных.
Что же касается полного форматирования в среде Windows, то по сравнению с быстрым, сразу создающим пустое оглавление, оно просто добавляет проверку поверхности диска перед тем, как выполнить то же самое, что делает быстрое форматирование. Что также не имеет смысла, поскольку проверка и отбраковка нестабильных секторов выполняется средствами аппаратной реализации технологии S.M.A.R.T накопителя, которая с данной задачей справляется гораздо эффективнее автоматически и в непрерывном режиме. Полное форматирование имело смысл на старых дисках, которые не могли выполнять замену нестабильных секторов на сектора из резервной зоны, и такие сектора сразу становились дефектными блоками ( Bad Block ), которые исключались из файловой структуры при форматировании с проверкой поверхности. Существует также утверждение, что при полном форматировании выполняется стирание всей поверхности диска. Это тоже не соответствует действительности, что легко проверяется любыми программами мониторинга обращений к диску , например, утилитой Disk Monitor из пакета Sysinternals Suite. Программа показывает, что при полном форматировании выполняется чтение поверхности, и небольшое количество операций записи, выполняемой после проверки поверхности при формировании пустого оглавления, в самом конце работы. И даже из того факта, что существую программы для восстановления данных после форматирования ( любого, в том числе и полного ) вполне логично следует вывод – никакого стирания данных не происходит.
При записи жесткий диск не проверяет, что и как было записано в область данных сектора, кроме случаев, когда предварительная диагностика, которой накопитель занимается все «свободное время», не пометила в соответствующих журналах эти сектора, как проблемные, или кандидаты на переназначение, что отражается в атрибуте 197 SMART (Current Pending Sectors).
Кандидат — это сектор (или группа секторов), который не был считан за стандартное время и с установленным числом повторов. В режиме простоя, запустится программа самотестирования, которая попытается считать данные с применением дополнительных режимов. Если сектор будет успешно считан — программа самодиагностики попытается записать данные обратно, и если запись выполнится успешно, то из кандидатов такой сектор удалится. Если же записанная на то же место информация не будет нормально считываться, то выполнится переназначение сектора (Remap), данные запишутся в сектор из специально для этого предназначенной резервной области (spare area). В дальнейшем, всегда вместо этого сбойного сектора будут считываться данные из резервной области. А сектор-кандидат на переназначение, не исправленный программой самотестирования, увеличит значение атрибута 198 (Offline Scan UNC Sectors). Убрать такой «бед» можно только перезаписью. Но если резервная область закончилась, то все последующие кандидаты на переназначение превратятся в реальные «плохие секторы» (Bad Blocks). В этом случае программы полного форматирования и проверки поверхности могут исключить сбойный сектор из логической структуры диска, однако, использовать накопитель с закончившейся резервной областью — это очень рискованная идея, которая обязательно закончится потерей данных. Использовать такой диск можно разве что для опасных экспериментов, хранения некритичных данных, или выбросить его на помойку.
При возникновении плохих блоков (Bad Block) нередко возникает необходимость проверки принадлежности сбойного участка конкретному файлу. Для этих целей можно воспользоваться консольной утилитой NFI.EXE (NTFS File Sector Information Utility) из состава пакета Support Tools от Microsoft. Скачать 10кб
Формат командной строки
nfi.exe Диск Номер логического сектора
Подсказку по использованию NFI.EXE можно получить по команде nfi.exe /?
Букву логического диска можно задавать без двоеточия. Номер логического сектора — это номер сектора относительно начала логического диска. Обратите внимание на тот факт, что программы сканирования работают со всей поверхностью физического диска и используют нумерацию секторов, не привязанную к его логической структуре. А номер сектора, задаваемый в качестве параметра утилиты NFI.EXE — это номер сектора логического диска (раздела), и он отличается величиной смещения начального сектора раздела от начала диска. Значение номеров начальных секторов логических дисков можно получить нажав кнопку View part data вкладки «Advanced» программы Victoria For Windows.
nfi.exe C: 655234 — выдать имя файла, которому принадлежит сектор 655234
nfi.exe C: 0xBF5E34 — то же самое, но номер сектора задан в шестнадцатеричной системе счисления
В результате выполнения команды будет выдано сообщение
***Logical sector 12541492 (0xbf5e34) on drive C is in file number 49502.
WINDOWS system32 D3DCompiler_38.dll
Т.е. интересующий нас сбойный сектор принадлежит файлу D3DCompiler_38.dll в каталоге Windowssystem32. В случае, когда сбойные блоки принадлежат системным файлам Windows, возможно появление синих экранов смерти или зависаний системы с перезагрузкой. В большинстве случаев, информация о наличии сбоев дисковой подсистемы, будет отображаться в системном журнале Windows.
Для выполнения тестирования поверхности накопителя с принудительным переназначением (ремапом) сбойных секторов можно воспользоваться программами тестирования HDD, алгоритм работы которых специально разработан таким образом, чтобы «заставить» внутреннюю микропрограмму накопителя выполнить переназначение нестабильного участка.
Так, например, подобные алгоритмы будут использоваться, в упоминаемой выше программе Victoria, если выбран режим тестирования поверхности с выполнением операций восстановления или переназначения (Classic Remap, Advanced Remap :). Изначально режим выполнения теста установлен в Ignore Bad Blocks
Нажатие пробела изменяет режим обработки сбоев. При выполнении такого вида тестирования накопителя, пользовательские данные остаются в сохранности.
Добавлю, что режим Advanced Remap, хотя и является наиболее эффективным, на практике может приводить к «зависанию» микропрограммы на некоторых моделях HDD, выйти из которого можно только с использованием принудительного сброса (режим Reset, клавиша F3). После чего можно продолжить тестирование. Если в режиме Advanced Remap таймауты происходят слишком часто, имеет смысл перейти к использованию классического ремапа.
Для программы Victoria For Windows переназначение сбойных секторов включается установками режима выполнения теста в правой части основного окна. По умолчанию установлен режим Ignore — ничего не делать при обнаружении сбоя, а нужно установить режим Remap