-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
1. Причины и типы ошибок
ПРИЧИНЫ И ТИПЫ ОШИБОК
2. Классификация ошибок по причине возникновения
• синтаксические ошибки;
• семантические ошибки;
• логические ошибки.
3. Синтаксические ошибки
это ошибки, возникающие в связи с
нарушением синтаксических правил
написания предложений используемого
языка программирования (к таким ошибкам
относятся пропущенные точки с запятой,
ссылки на неописанные переменные,
присваивание переменной значений
неверного типа и т. д.).
4. Семантические ошибки
• Причина возникновения ошибок данного
типа связана с нарушением семантических
правил написания программ (примером
являются ситуации попытки открыть
несуществующий файл или выполнить
деление на нуль).
5. Логические ошибки
• связаны с неправильным применением тех
или иных алгоритмических конструкций.
• Эти ошибки при выполнении программы могут
проявиться явно (выдано сообщение об
ошибке, нет результата или выдан неверный
результат, программа «зацикливается»), но
чаще они проявляют себя только при
определенных сочетаниях параметров или
вообще не вызывают нарушения работы
программы, которая в этом случае выдает
правдоподобные, но неверные результаты.
6. Классификация ошибок по этапу обработки программы
Ошибки, которые могут быть в программе,
принято делить на три группы:
• ошибки компиляции;
• ошибки компоновки;
• ошибки выполнения.
7.
Ошибки компиляции
Ошибки компиляции (Compile-time error) – ошибки,
фиксируемые компилятором (транслятором, интерпретатором)
при выполнении синтаксического и частично семантического
анализа программы;
Наиболее легко устранимы.
Их обнаруживает компилятор, а программисту остается только
внести изменения в текст программы и выполнить повторную
компиляцию.
Компилятор просматривает программу от начала. Если
обнаруживается
ошибка,
то
процесс
компиляции
приостанавливается и в окне редактора кода выделяется строка,
которая, по мнению компилятора, содержит ошибочную
конструкцию.
8.
Ошибки компиляции
В нижнюю часть окна редактора кода компилятор выводит сообщения об
ошибках. Первая ошибка – это первая от начала текста программы
синтаксическая ошибка, обнаруженная компилятором. Наличие в тексте даже
одной синтаксической ошибки приводит к возникновению второй, фатальной
ошибки (Fatal Error) – невозможности генерации исполняемой программы.
9. Наиболее типичные ошибки компиляции
Сообщения компилятора
Undeclared identifier
(Необъявленный
идентификатор)
Вероятная причина
Используется переменная, не объявленная в
разделе var программы;
Ошибка при написании имени переменной;
Ошибка при написании имени инструкции
(оператора).
Unterminated string
При записи строковой константы не
(Незавершенная строка)
поставлена завершающая кавычка.
Incompaible types … and В операторе присваивания тип выражения
…
не соответствует или не может быть
(Несовместимые типы)
приведен к типу переменной, получающей
значение выражения.
Missing operator or
Не поставлена точка с запятой после
semicolon
инструкции программы.
(Отсутствует оператор или точка
с запятой)
10. Ошибки компоновки
Ошибки компоновки – ошибки, обнаруженные
компоновщиком (редактором связей) при объединении
модулей программы.
Эти ошибки связаны с проблемами, обнаруженными при
разрешении внешних ссылок. Например, предусмотрено
обращение к подпрограмме другого модуля, а при
объединении модулей данная подпрограмма не найдена
или не стыкуются списки параметров.
В большинстве случаев ошибки такого рода также
удается быстро локализовать и устранить.
11. Ошибки выполнения
Ошибки выполнения – ошибки, обнаруженные
операционной системой, аппаратными средствами или
пользователем при выполнении программы.
Могут иметь разную природу, и соответственно поразному проявляться.
Часть ошибок обнаруживается и документируется
операционной системой.
12. Ошибки выполнения
Выделяют четыре способа проявления таких ошибок:
появление сообщения об ошибке, зафиксированной схемами
контроля выполнения машинных команд, например,
переполнении разрядной сетки, нарушении адресации и
т.п.;
появление
сообщения
об
ошибке,
обнаруженной
операционной системой, например, нарушении защиты
памяти, попытке записи на устройства, защищенные от
записи, отсутствии файла с заданным именем и т.п.;
«зависание» компьютера, как простое, когда удается
завершить программу без перезагрузки операционной
системы, так и «тяжелое», когда для продолжения работы
необходима перезагрузка;
несовпадение полученных результатов с ожидаемыми.
13. Причины ошибок выполнения
Все возможные причины ошибок можно разделить на
следующие группы:
• неверное определение исходных данных,
• логические ошибки,
• накопление погрешностей результатов вычислений.
14. Причины ошибок выполнения
15. Предотвращение и обработка исключений
• При
разработке
проекта
программист
должен
предусмотреть все возможные варианты некорректных
действий пользователя, которые могут привести к
возникновению ошибок времени выполнения, и
обеспечить способы защиты от них.
16. Предотвращение и обработка исключений
Инструкция обработки исключения в общем виде:
try // инструкции, выполнение которых может вызвать
исключение
except // начало секции обработки исключений
on ТипИсключения1 do Обработка1;
on ТипИсключения2 do Обработка2;
…;
else // инструкции обработки остальных исключений
end;
17. Предотвращение и обработка исключений
где:
• try — ключевое слово, обозначающее, что далее следуют
инструкции, при выполнении которых возможно
возникновение исключений, и что обработку этих
исключений берет на себя программа;
• except — ключевое слово, обозначающее начало секции
обработки исключений. Инструкции этой секции будут
выполнены, если в программе возникнет ошибка;
• on — ключевое слово, за которым следует тип
исключения, обработку которого выполняет инструкция,
следующая за do;
• else — ключевое слово, за которым следуют инструкции,
обеспечивающие обработку исключений, тип которых не
указаны в секции except.
18. Типичные исключения
Тип
исключения
Возникает
EZeroDivide
При выполнении операции деления, если
делитель равен нулю
EConvertError
При выполнении преобразования, если
преобразуемая величина не может быть
приведена к требуемому виду. Наиболее часто
возникает при преобразовании строки символов в
число
EFilerError
При обращении к файлу. Наиболее частой
причиной является отсутствие требуемого файла
или, в случае использования сменного диска,
отсутствие диска в накопителе
19. Пример: Обработка исключения типа EZeroDivide
procedure TForm1.Button1Click(Sender: TObject);
Var u, r, i: real; // напряжение , сопротивление, ток
begin
Labels.Caption := ‘ ‘;
try // инструкции, которые могут вызвать исключение (ошибку)
u := StrToFloat(Edit1.Text);
r := StrToFloat(Edit2.Text);
i := u/r;
except // секция обработки исключений
onEZeroDivide do // деление на ноль
begin
ShowMessage(‘Сопротивление не может быть равно нулю!’);
exit;
end;
on EConvertError do // ошибка преобразования строки в число
begin
ShowMessage(‘Напряжение и сопротивление должны быть заданы числом. ‘ );
exit;
end; end;
20. Отладка и тестирование
ОТЛАДКА И ТЕСТИРОВАНИЕ
21.
Немного истории
Долгое время было принято считать, что целью тестирования
является доказательство отсутствия ошибок в программе.
Но полный
перебор
всех
возможных
вариантов
выполнения
программы
находится
за
пределами
вычислительных возможностей даже для очень небольших
программ.
«Тестирование – это процесс выполнения программ с
целью обнаружения ошибок».
Гленфорд Майерс
Майерс, Г. Искусство тестирования программ, 1982
22.
Немного истории
До начала 80-х годов процесс тестирования программного
обеспечения (ПО) был разделен с процессом разработки: вначале
программисты реализовывали заданную функциональность, а
затем тестировщики приступали к проверке качества созданных
программ.
Проблемы:
• разработка программ может оказаться достаточно длительной –
чем в это время должны заниматься тестировщики?
• Плохая предсказуемости результатов такого процесса разработки.
Ключевой вопрос: сколько времени потребуется на завершение
продукта, в котором существует 500 известных ошибок?
23.
Немного истории
Статистика:
Даже
однострочное
изменение
в
программе
с
вероятностью 55 % либо не исправляет старую ошибку,
либо вносит новую. Если же учитывать изменения любого
объема, то в среднем менее 20 % изменений корректны с
первого раза.
24.
Немного истории
В 90-х годах появилась другая методика разработки
(zero-defect mindset), основная идея которой заключается в
том, что качество программ проверяется постоянно в
процессе разработки.
Тестирование становится центральной частью любого
процесса разработки программ
Данная методика предъявляет существенно более высокие требования к
квалификации инженера тестирования: в сферу его ответственности
попадает не только функциональное тестирование, но и организация
процесса разработки (процесс ежедневной сборки, участие в инспекциях,
сквозных просмотрах и обычное чтение исходных текстов тестируемых
программ). Поэтому идеальной кандидатурой на позицию тестировщика
становится наиболее опытный программист в команде.
25. Зависимость вероятности правильного исправления ошибок и стоимости исправления ошибок от этапа разработки
Многократно проводимые исследования показали, что чем
раньше обнаруживаются те или иные несоответствия или
ошибки, тем больше вероятность их правильного
исправления (рис. а) и ниже его стоимость (рис. б).
26.
Основные понятия, связанные с
тестированием и отладкой
Отладка программного средства – это деятельность,
направленная на обнаружение и исправление ошибок в ПС с
использованием процессов выполнения его программ.
Тестирование программного средства — процесс выполнения
программ на некотором наборе данных, для которого заранее
известен результат применения или известны правила поведения
этих программ.
Отладка = Тестирование + Поиск ошибок + Редактирование
27.
Основные понятия, связанные с
тестированием и отладкой
Процесс отладки включает:
• действия, направленные на выявление ошибок
(тестирование);
• диагностику и локализацию ошибок (определение
характера ошибок и их местонахождение);
• внесение исправлений в программу с целью устранения
ошибок (редактирование).
Отладка = Тестирование + Поиск ошибок + Редактирование
Самым трудоемким и дорогим является тестирование,
затраты на которое приближаются к 45% общих затрат на
разработку ПС и от 30 до 60% общей трудоемкости создания
программного продукта.
28.
Две задачи тестирования
Первая задача тестирования – подготовить набор тестов и
применить к ним ПС, чтобы обнаружить в нём по возможности
большее число несоответсвий.
Вторая задача тестирования — определить момент окончания
отладки ПС (или отдельной его компоненты).
29.
Для повышения качества тестирования рекомендуется
соблюдать следующие основные принципы:
• предполагаемые результаты должны быть известны до
тестирования;
• следует избегать тестирования программы автором;
• необходимо досконально изучать результаты каждого
теста;
• необходимо проверять действия программы на неверных
данных;
• необходимо проверять программу на неожиданные
побочные эффекты на неверных данных.
30. Требования к программному продукту и тестирование
Разработка любого программного продукта начинается с
выявления требований к этому продукту.
Спецификация (англ. Software Requirements Specification, SRS) документ, в котором отражены все требования к продукту описываются, как функциональные (что должна делать
программа, варианты взаимодействия между пользователями
и программным обеспечением), так и нефункциональные
(например, на каком оборудовании должна работать
программа,
производительность, стандарты качества)
требования.
31. Рекомендуемая стандартом IEEE 830 структура SRS
Введение
– Цели
– Соглашения о терминах
– Предполагаемая аудитория и последовательность восприятия
– Масштаб проекта
– Ссылки на источники
Общее описание
– Видение продукта
– Функциональность продукта
– Классы и характеристики пользователей
– Среда функционирования продукта (операционная среда)
– Рамки, ограничения, правила и стандарты
– Документация для пользователей
– Допущения и зависимости
Функциональность системы
– Функциональный блок X (таких блоков может быть несколько)
• Описание и приоритет
• Причинно-следственные связи, алгоритмы
• Функциональные требования
32. Рекомендуемая стандартом IEEE 830 структура SRS (продолжение)
Требования к внешним интерфейсам
– Интерфейсы пользователя (UX)
– Программные интерфейсы
– Интерфейсы оборудования
– Интерфейсы связи и коммуникации
Нефункциональные требования
– Требования к производительности
– Требования к сохранности (данных)
– Критерии качества программного обеспечения
– Требования к безопасности системы
Прочие требования
– Приложение А: Глоссарий
– Приложение Б: Модели процессов и предметной области и другие
диаграммы
– Приложение В: Список ключевых задач
33.
Подходы к выработке стратегии
проектирования тестов
1. Тестирование по отношению к спецификациям функциональный подход
2. Тестирование по отношению к текстам программ структурный подход
34. Стратегия проектирования тестов
В тестирование ПС входят
• постановка задачи для теста,
• проектирование,
• написание тестов,
• выполнение тестов,
• изучение результатов тестирования.
35.
По объекту тестирования
Функциональное тестирование
Тестирование производительности
Нагрузочное тестирование
Стресс-тестирование
Тестирование стабильности
Конфигурационное тестирование
Юзабилити-тестирование
Тестирование интерфейса пользователя
Тестирование безопасности
Тестирование локализации
Тестирование совместимости
По знанию системы
Тестирование чёрного ящика
Тестирование белого ящика
Тестирование серого ящика
По степени автоматизации –
Ручное тестирование
Автоматизированное тестирование
Полуавтоматизированное тестирование
По степени изолированности компонентов
Модульное тестирование
Интеграционное тестирование
Системное тестирование
По времени проведения тестирования
Альфа-тестирование
Дымовое тестирование
Тестирование новой функции
Подтверждающее тестирование
Регрессионное тестирование
Приёмочное тестирование
Бета-тестирование
По признаку позитивности сценариев
Позитивное тестирование
Негативное тестирование
По степени подготовленности к
тестированию
Тестирование по документации
(формальное тестирование)
Интуитивное тестирование (англ. ad hoc
testing)
36.
Подходы к выработке стратегии
проектирования тестов
Функциональный подход основывается на том, что
структура программного обеспечения не известна (программа
рассматривается как «черный ящик»). В этом случае тесты
проектируют, исследуя внешние спецификации или
спецификации сопряжения программы или модуля, которые
он тестирует.
Логика проектировщика тестов такова: «Меня не
интересует, как выглядит эта программа, и выполнил ли я все
команды. Я удовлетворен, если программа будет вести себя
так, как указано в спецификациях».
В идеале — проверить все возможные комбинации
и значения на входе.
37.
Подходы к выработке стратегии
проектирования тестов
Структурный подход базируется на том, что известна
структура тестируемого программного обеспечения, в том
числе его алгоритмы («стеклянный ящик»). В этом случае
тесты строят так, чтобы проверить правильность реализации
заданной логики в коде программы.
Проектировщики
тестов
стремятся
подготовить
достаточное число тестов, чтобы каждая команда была
выполнена, хотя бы, один раз. Чтобы каждая команда
условного перехода выполнялась в каждом направлении
хотя бы раз.
В идеале — проверить каждый путь, каждую ветвь
алгоритма.
38.
Подходы к выработке стратегии
проектирования тестов
Тестирование
по отношению
к спецификациям
Тестирование
по отношению
к текстам программ
Оптимальная
стратегия
Оптимальная
стратегия
проектирования
тестов
расположена внутри интервала между этими крайними
подходами, но ближе к левому краю
Наборы тестов, полученные в соответствии с методами
этих
подходов,
обычно
объединяют,
обеспечивая
всестороннее тестирование программного обеспечения.
39.
Критерии полноты тестирования
40.
Критерии полноты тестирования
Только на основании выбранного критерия можно определить
тот момент времени, когда конечное множество тестов
окажется достаточным для проверки программы с некоторой
полнотой (степень полноты, определяется экспериментально).
Используется два вида критериев: критерии черного и белого
ящика.
Соответственно тесты делятся на функциональные и
структурные.
• функциональные тесты составляются исходя
из спецификации программы;
• структурные тесты составляются исходя из
текста программы.
41. Критерии полноты тестирования
• Функциональные критерии:
• Структурные критерии:
1)
2)
3)
4)
5)
Покрытие операторов
Покрытие условий
Покрытие путей
Покрытие функций
Покрытие вход/выход
42. Критерии полноты тестирования
Критерий тестирования функций
43. Критерии полноты тестирования
Критерии тестирования входных и
выходных данных
44. Критерий тестирования функций
Критерии тестирования входных и
выходных данных
• Пример. Программа для учета кадров предприятия
45. Критерии тестирования входных и выходных данных
Тестирование области допустимых значений
Процесс тестирования области допустимых значений
можно разделить на три этапа:
1. Проверка в нормальных условиях.
2. Проверка в экстремальных условиях.
3. Проверка в исключительных ситуациях.
Проверка в нормальных условиях
Проверка в нормальных условиях предполагает тестирование на основе
данных, которые характерны для реальных условий функционирования
программы. Проверка в нормальных условиях должна показать, что
программа выдает правильные результаты для характерных
совокупностей данных.
46. Критерии тестирования входных и выходных данных
• Проверка в экстремальных условиях
Тестовые данные этого этапа включают граничные значения области
изменения входных переменных, которые должны восприниматься
программой как правильные данные.
Для нецифровых данных необходимо использовать подобные
типичные символы, охватывающие все возможные ситуации.
Для цифровых данных в качестве экстремальных условий следует
брать начальное и конечное значения допустимой области
изменения переменной при одновременном изменении длины
соответствующего поля от минимальной до максимальной.
Типичными примерами таких экстремальных значений являются
очень большие числа, очень малые числа и отсутствие
информации.
Каждая
программа
характеризуется
своими
собственными экстремальными данными, которые должны
подбираться программистом.
47. Критерии тестирования входных и выходных данных
Проверка в экстремальных условиях (продолжение)
Особый интерес представляют так называемые нулевые примеры.
Для цифрового ввода — это обычно нулевые значения вводимых
данных; для последовательностей символов — это цепочка пробелов
или нулей.
Нулевые примеры представляют собой один из лучших тестов,
поскольку они имитируют состояние данных, которое время от
времени имеет место в реальных условиях эксплуатации программы.
Если подобное тестирование не выполняется, то впоследствии часто
приходится сталкиваться с непонятным поведением программы.
48. Критерии тестирования входных и выходных данных
• Проверка в исключительных ситуациях.
проводится с использованием данных, значения которых
лежат за пределами допустимой области изменения.
Например:
• Что произойдет, если программе, не рассчитанной на обработку
отрицательных или нулевых значений переменных, в результате
какой-либо ошибки придется иметь дело как раз с такими данными?
• Как будет вести себя программа, работающая с массивами, если
количество их элементов превысит величину, указанную в описании?
• Что случится, если цепочки символов окажутся длиннее или короче,
чем это предусмотрено?
49. Критерии тестирования входных и выходных данных
Структурные критерии
Структурные критерии — критерии покрытия кода.
Покрытие кода — мера, используемая при тестировании
программного обеспечения. Она показывает процент, насколько
исходный код программы был протестирован.
• Покрытие операторов — каждая ли строка исходного кода была
выполнена и протестирована?
• Покрытие условий — каждая ли точка решения (вычисления
истинно ли или ложно выражение) была выполнена и
протестирована?
• Покрытие путей — все ли возможные пути через заданную
часть кода были выполнены и протестированы?
• Покрытие функций — каждая ли функция программы была
выполнена
• Покрытие вход/выход — все ли вызовы функций и возвраты из
них были выполнены
50. Критерии тестирования входных и выходных данных
Пример. Показывает отличие количества тестов при различных выбранных
структурных критериях.
В случае выбора критерия «Покрытие операторов» достаточен 1 тест
(рис.а)
В случае выбора критерия «Покрытие условий» достаточно двух тестов,
покрывающих пути 1, 4 или 2, 3 (рис.б)
В случае выбора критерия «Покрытие путей необходимо четыре теста
для всех четырех путей (рис.б)
51. Структурные критерии
Покрытие операторов
Пример 1
If ((A>1) and (B =0))
then X := X/A;
If ((A=2) or (X>1))
then X:=X+1;
Можно выполнить каждый оператор,
записав один-единственный тест,
который реализовал бы путь асе.
Иными словами, если бы в точке а были
установлены значения А = 2, В = 0 и Х =
3, каждый оператор выполнялся бы
один раз (в действительности Х может
принимать любое значение)
52.
Покрытие операторов
Пример 2
53. Покрытие операторов
Покрытие условий
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
Покрытие условий может быть выполнено двумя тестами,
покрывающими либо пути асе и abd, либо пути acd и abe.
Если мы выбираем последнее альтернативное покрытие, то входами двух тестов являются A = 3, В = 0, Х = 1 и A = 2, В = 1, Х = 1.
54. Покрытие операторов
Покрытие условий
Пример 2
a:=7;
while a>x do a:=a-1;
b:=1/a;
a:=7
a>x
—
b:=1/a
+
a:=a-1
Для того чтобы удовлетворить критерию покрытия ветвей в данном
случае достаточно одного теста. Например такого, чтобы х был равен
6 или 5. Все ветви будут пройдены. Но ошибка в программе
обнаружена так и не будет. Она проявится в единственном случае,
когда х=0. Но такого теста от нас критерий покрытия ветвей не
требует.
55. Покрытие условий
Покрытие путей
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
Покрытие путей (все возможные пути
через заданную часть кода должны быть
выполнены и протестированы) может быть
выполнено четырьмя тестами:
a,c,e – A=2, B=0, X=3
a,b,e – A=2, B=1, X=1
a,b,d – A=3, B=1, X=1
a,c,d – A=3, B=0, X=1
56. Покрытие условий
Покрытие путей
a
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
c
b
е
d
57. Покрытие путей
Критерий комбинаторного покрытия условий
Пример 2
If (a=0) or (b=0) or (c=0)
Then d:=1/(a+b)
Else d:=1;
Ошибка будет выявлена только при a=0 и b=0.
Критерий покрытия путей не гарантирует
проверки такой ситуации.
Для решения этой проблемы был предложен критерий комбинаторного
покрытия условий, который требует подобрать такой набор тестов, чтобы
хотя бы один раз выполнялась любая комбинация простых условий.
Критерий значительно более надежен, чем покрытие путей, но обладает
двумя существенными недостатками.
• Во-первых, он может потребовать очень большого числа тестов.
Количество тестов, необходимых для проверки комбинаций n простых
условий, равно 2n.
• Во-вторых, даже комбинаторное покрытие условий не гарантирует
надежную проверку циклов.
58. Покрытие путей
Уровни тестирования
• Модульное тестирование (автономное тестирование,
юнит-тестирование) — тестируется минимально
возможный для тестирования компонент, например,
отдельный класс или функция. Часто модульное
тестирование осуществляется разработчиками ПО.
• Интеграционное тестирование — тестируются
интерфейсы между компонентами, подсистемами. При
наличии резерва времени на данной стадии тестирование
ведётся итерационно, с постепенным подключением
последующих подсистем.
• Системное тестирование — тестируется интегрированная
система на её соответствие требованиям.
59.
Основные этапы разработки
сценария автономного тестирования
1. На основании спецификации отлаживаемого модуля
подготовить тесты для
– каждой логической возможности ситуации;
– каждой границы областей возможных значений всех
входных данных;
– каждой области недопустимых значений;
– каждого недопустимого условия.
2. Проверить текст модуля, чтобы убедиться, что каждое
направление любого разветвления будет пройдено хотя
бы один раз. Добавить недостающие тесты.
60. Два основных вида тестирования
Основные этапы разработки
сценария автономного тестирования
3. Проверить текст модуля, чтобы убедиться, что для
каждого цикла существуют тесты, обеспечивающие, по
крайней мере, три следующие ситуации
– тело цикла не выполняется ни разу;
– тело цикла выполняется один раз;
– тело цикла выполняется максимальное число раз;
4. Проверить текст модуля, чтобы убедиться, что существуют
тесты, проверяющие чувствительность к отдельным
особым значениям входных данных. Добавить
недостающие тесты.
61. Уровни тестирования
Основная особенность практики
тестирования ПС
По мере роста числа обнаруженных и исправленных
ошибок в ПС растёт также относительная вероятность
существования в нём необнаруженных ошибок.
Это подтверждает важность предупреждения ошибок на
всех стадиях разработки ПС.
62. Основные этапы разработки сценария автономного тестирования
Творческая работа
1. Разделиться на группы
2. Получить тему (практические работы по Delphi №№ 3, 5, 7,
9, 10)
3. Составить спецификацию
4. Разработать программу тестирования:
4.1. Определить виды тестирования
4.2. Определить объекты тестирования
4.3. Определить субъекты тестирования
4.4. Определить классы входных данных
4.5. Написать тест-кейсы для тестирования функций и ожидаемые
результаты
4.6. Написать тест-кейсы для структурного тестирования и
ожидаемые результаты
Составить чек-листы для проведения всех видов тестирования
5. Провести тестирование
6. Сделать выводы
63. Основные этапы разработки сценария автономного тестирования
Содержание ПЗ к проекту
Титульный лист
Бриф
Спецификация
ТЗ
Пользователи
Интерфейсы
Информационно-логическая схема
Схема БД
Алгоритм одной процедуры
Программа тестирования
Результаты тестирования
- D.1.Сообщения об ошибках компилятора.
- D.1.1. Сообщения о фатальных ошибках.
- D.1.2. Сообщения об ошибках компилятора.
- D.1.3. Предупреждающие сообщения.
- D.1.4. Ограничения компилятора.
- D.2.Сообщения об ошибках в командной строке.
- D.2.1. Неисправимые ошибки командной строки.
- D.2.2. Сообщения об ошибках командной строки.
- D.2.3. Предупреждающие сообщения командной строки.
- D.3. Сообщения об ошибках периода выполнения.
- D.3.1. Исключительные ситуации операций с плавающей точкой.
- D.3.1. Сообщения об ошибках периода выполнения.
- D.3.3. Ограничения периода выполнения.
- D.4. Сообщения об ошибках компановщика.
- D.5.Сообщения об ошибках утилиты LIB.
- D.6. Сообщения об ошибках утилиты MAKE.
В данном Приложении приводится список сообщений об ошибках, на которые вы можете натолкнуться в процессе разработки программ, и, кроме того, дает краткое описание действий, которые вам следует предпринять для исправления ошибок. Следующий список покащывает вам, где искать ошибочные сообщения различных компонентов компилятора Microsoft Quick-C:
Компонент Раздел
Компилятор Microsoft Quick-C Раздел D.1, "Сообщения об ошибках
компилятора.
Командная строка, используемая Раздел D.2, "Сообщение об ошибках
для вызова компилятора Quick-C командной строки".
Библиотеки исполняющей системы Раздел D.3, "Сообщения об ошибках
Microsoft C и другие ситуации периода выполнения".
периода выполнения.
Оверлейный компановщик Microsoft, Раздел D.4, "Сообщения об ошибках
утилита LINK. компановщика".
Диспетчер библиотек фирмы Раздел D.5, "Сообщения об ошибках
Microsoft-утилита LIB утилиты LIB".
Утилита поддержки разработки Раздел D.6, "Сообщения об ошибках
программ MAKE утилиты MAKE".
Обратите внимание, что все ошибочные сообщения компилятора, командной строки, периода выполнения приведены в данном приложении в алфавитном порядке.
В Разделе D.1.4 вы найдете информацию об ограничениях компилятора, а в Разделе D.3.3-ограничения периода выполнения.
D.1.Сообщения об ошибках компилятора.
Сообщения об ошибках, Полученные при сбоях СИ-компилятора, делятся на три категории:
1.Сообщения о фатальных ошибках.
2.Сообщения об ошибках компиляции.
3.Предупреждающие сообщения.
Сообщения каждой категории даны ниже в пронумерованном порядке, с кратким объяснением каждой ошибки. Чтобы найти требуемое сообщение, сначала определите категорию сообщения, затем найдите соответствующий номер ошибки. Каждое сообщение, сгенерированное в среде Quick-C, появляется в окне ошибок; курсор устанавливается на строке, вызвавшей ошибку (подробности в Разделе 7.3.4). Каждое сообщение об ошибке, сгенерированное во время компиляции с помощью команды QCL, содержит имя файла и номер строки, вызвавшей ошибку.
Сообщения о фатальных ошибках.
Сообщение о фатальной ошибке обозначает некоторую проблему, которая запрещает компилятору дальнейшее выполнение. Данный тип сообщения имеет следующий формат:
имя файла(строка): fatal error C1xxx: текст сообщения После того, как компилятор высветит сообщение о фатальной ошибке, он завершит выполнения без создания объектного файла и какой-либо проверки на последующие ошибки.
Сообщения об ошибках компилятора.
Сообщения об ошибках компилятора индицируют реальные программные ошибки. Данные сообщения выводятся в следующем формате:
имя файла(строка):error C2xxx:текст сообщения
Компилятор в данном случае не создает объектный файл для исходного файла, в котором компилятор обнаружил ошибки. Если компилятор встречает такие ошибки, он делает попытку их исправить. Если это возможно, он продолжает обработку исходного файла и выдает ошибочные сообщения. Если ошибок слишком много или они слишком серьезны, компилятор прекращает работу.
Предупреждающие сообщения.
Предупреждающие сообщения носят только информативный характер; они не прерывают процесс компиляции или компановки. Данные сообщения появляются в следующем формате:
имя файла(строка): warning C4xxx: текст сообщения
Вы можете использовать опцию /W для управления уровнем сообщений, генерируемых компилятором. Данная опция описана в Разделе 9.3.1.
D.1.1. Сообщения о фатальных ошибках.
Следующие сообщения идентифицируют фатальные ошибки. Компилятор не может исправить фатальную ошибку; он прекращает работу после распечатки сообщения об ошибке.
Номер Сообщение о фатальной ошибке C1000 "Неизвестная фатальная ошибка, Свяжитесь с Техническим сервисом фирмы Microsoft". Компилятор обнаружил неизвестную ошибку. Пожалуйста, сообщите фирме Microsoft Corporation условия возникновения данной ошиб- ки посредством специальной формы "Product Assistan Request", на обложке данного руководства. C1001 "Внутренняя ошибка компилятора, свяжитесь с Техническим серви- сом фирмы Microsoft". Компилятор обнаружил внутреннее несоответствие. Пожалуйста, со- общите условия возникновения данной ошибке с помощью бланка "Product Assistance Request" на обложке данного руководства. Пожалуйста, включите в ваше сообщение имя файла и номер стро- ки, вызвавшей ошибку; обратите внимание, что "имя файла" отно- носится к внутреннему файлу компилятора, а не к вашему исход- ному файлу. C1002 "Выход за пределы динамической области". Компилятор вышел за пределы динамическогй области памяти. Дан- ная ситуация обычно означает, что ваша программа имеет слишком много символических имен и/или комплексных выражений. Чтобы из- бавиться от данной проблемы, разделите файл на несколько мень- ших исходных файлов, либо разбейте выражения на меньшие подвы- ражения. C1003 "Счетчик ошибок превысил n; компиляция остановлена". Ошибок в программе слишком много, либо они слишком серьезны, чтобы возможно было восстановление, компилятор должен прервать выполнение. C1004 "Неожиданный конец файла (EOF). Данное сообщение появляется, если у вас не достаточно памяти на стандартном дисковом устройстве, чтобы компилятор создал требу- емые временные файлы. Требуемое пространство примерно в 2 раза больше размера исходного файла. Данное сообщение может быть также сгенерировано, если комментарий не имеет закрывающего ограничителя (*/), либо если директиве #if не хватает закры- вающей директивы #endif. C1005 "Строка слишком велика для буфера". Строка в промежуточном файле компилятора переполняет буфер. C1006 "Ошибка записи в промежуточный файл компилятора". Компилятор не может создать промежуточные файлы, используемые в процессе компиляции. К данной ошибке обычно приводят следую- щие ситуации: 1.Слишком мало файлов в строке files = number файла CONFIG.SYS (компилятор требует чтобы число number было не меньше 15). 2.Не хватает памяти на устройстве, содержащем промежуточные файлы компилятора. C1007 "Нераспознанный флаг 'string' в 'option'" string-в опции командной строки option не является корректной опцией. C1009 "Ограничения компилятора, возможно рекурсивно определенное мак- роопределение". Расширение макрокоманды превышает размеры доступной памяти. Проверьте, не было ли рекурсивно-определенных макрокоманд, либо не слишком велик расширяемый текст. C1010 "Ограничения компилятора: макро-расширение слишком большое". Расширение макрокоманды превышает доступную память. C1012 "Неверное вложение скобок-пропущенный 'character' (символ)". Несоответствие скобок в директиве препроцессора; 'character'- -это либо левая, либо правая скобка. C1013 "Невозможно открыть исходный файл 'filename'". Данный файл 'filename' либо не существует, либо не может быть открыт, либо не найден. Удостоверьтесь, что параметры установ- ки среды корректны, и что для файла задано корректное имя марш- рута. C1014 "Слишком много включаемых файлов". Вложение директив #include превышает 10-уровневый предел. C1015 "Невозможно открыть включаемый файл 'filename'". Данный файл либо не существует, либо не может быть открыт, либо не найден. Удостоверьтесь, что параметры неазначений среды за- даны корректно, и что вы определили корректное имя маршрута для данного файла. C1016 "Директиве #if [n]def требуется идертификатор". С директивами #ifdef и #ifndef вы обязательно должны употреб- лять идентификатор. C1017 "Неверное выражение целой константы". Выражение в директиве #if должно вычисляться в константу. C1018 "Неожиданная директива '#elif'". Появление директивы #elif разрешено только внутри директив #if, #ifdef, или #ifdef. C1019 "Неожиданная директива '#else'". Появление директивы #else возможно только внутри директив #if, #ifdef, или #ifndef. C1020 "Неожиданная директива '#endif'" Директива #endif появилась без соответствующей директивы #if, #ifdif, или #ifndef. C1021 "Неверная команда препроцессора 'string'" Символы, следующие за знаком (#) формируют неверную директиву препроцессора. C1022 "Ожидается директива '#endif'". Директива #if, #ifdef или #ifndef не заканчивается директивой #endif. C1026 "Переполнение стэка, пожалуйста, упростите вашу программу." Ваша программа не может быть далее обработана, поскольку па- мять, требуемая для "разбора" программы переполняет стэк ком- пилятора. Чтобы разрешить данную проблему, упростите вашу программу. C1027 "Ограничения компилятора: вложение структур/смесей". Определения структур и смесей вложены более 10 раз. C1028 "Сегмент segment занимает более 64К" В данном сегменте размещены более 64 "дальних" данных. Один мо- дуль может иметь не более 64К "дальних" данных. Чтобы разрешить данную проблему, либо разбейте объяснения на отдельные модули, сократите общий объем используемых данных, либо откомпилируйте вашу программу с помощью Оптимизирующего компилятора Microsoft-C. C1032 "Невозможно открыть файл, содержащий объектный листинг 'filename'". Имеет силу одно из следующих утверждений, касающихся имени фай- ла или имени маршрута: 1.Данное имя не верно. 2.Файл с данным именем не может быть открыт из-за нехватки памяти. 3.Уже существует файл с данным именем и атрибутом "только-чте- ние". C1033 "Невозможно открыть выходной файл на языке ассемблер 'filename'". Одно из условий, рассмотренных в описании ошибки с кодом C1032, привело к невозможности открыть данный файл. C1034 "Невозможно открыть исходный файл 'filename'". Одно из условий, рассмотренных в описании ошибки с кодом C1032, привело к невозможности открыть данный файл. C1035 "Выражение является слишком сложным, пожалуйста упростите". Компилятор не смог сгенерировать код для сложного выражения. Чтобы разрешить данную проблему, разбейте выражение на более простые подвыражения и повторите компиляцию. C1036 "Невозможно открыть файл, содержащий исходный листинг 'filename'". Одно из условий, рассмотренных в описании ошибки с кодом C1032, привело к невозможности открыть данный файл. C1037 "Невозможно открыть объектный файл 'filename'". Одно из условий, рассмотренных в описании ошибки с кодом C1032, привело к невозможности открыть данный файл. C1039 "Невосстанавливаемое переполнение динамической области в треть- ем проходе компилятора": В третьем оптимизирующем проходе компилятор переполнил динами- ческую область и прекратил работу. Попытайтесь повторить компиляцию с включенной опцией Optimiza- tions (в среде программирования Quick-C), либо с опцией /Od (в командной строке QCL), либо попытайтесь отделить функцию, со- держащую строку, вызвавшую ошибку. C1040 "Неожиданный EOF в исходном файле 'filename'". В процессе создания листинга исходного файла, либо исходного/ объектного файла компилятор обнаружил неожиданный конец файла. Данная ошибка произошла, вероятно, если исходный файл был отре- дактирован в процессе компиляции. C1041 "Невозможно открыть промежуточный файл компилятора-больше нет". Компилятор не может создать промежуточный файл, используемый в процессе компиляции, поскольку больше нет логических номеров файлов. Данная ошибка может быть исправлена путем изменения строки files=number в файле CONFIG.SYS, чтобы задать большее число од- новременно открытых файлов (рекомендуется назначить число 20). C1042 "Невозможно открыть промежуточный файл компилятора-нет такого файла или каталога". Компилятор не может создать промежуточные файлы, используемые в процессе компиляции, поскольку в переменной операционный среды TMP задан неправильный каталог, или маршрут. C1043 "Невозможно открыть промежуточный файл компилятора". Компилятор не может создать промежуточные файлы, используемые в процессе компиляции. Точная причина неизвестна. C1044 "Нехватка дисковой памяти для промежуточного файла компилятора" Из-за недостатка памяти компилятор не может создать промежуточ- ный файл, используемый в процессе компиляции. Для исправления данной ситуации освободите место на диске и повторите компиля- цию. C1045 "Переполнение при операции с плавающей точкой". Компилятор получил ошибку при присваивании арифметических конс- тант элементам с плавающей точкой, как в следующем примере: float fp val = 1.0e100; В данном примере константа двойной точности 1.0е100 превышает максимально-допустимое значение для данных с плавющей точкой. C1047 "Слишком много появлений опции 'string'". Данная опция упоминается слишком много раз. Строка 'string' со- держит опцию, вызвавшую ошибку. C1048 "Неизвестная опция 'character' в 'optionstring'". Символ является некорректной буквой для опции 'optionstring'. C1049 "Неверный числовой аргумент 'string'". Вместо string ожидался числовой аргумент. C1050 "Сегмент кода 'segmentname' слишком большой". В процессе компиляции сегмент кода вырос за пределы 36 байтов от 64К. В данном случае используется 36-байтовый заполнитель, поскольку сбой на некоторых платах микропроцессоров 80286 могут вызвать непредсказуемое поведение программ, если среди прочих условий размер кодового сегмента находится в пределах 36 байтов от 64К. C1052 "Слишком много директив #if/#ifdef's". В программе превышено максимальное число уровней вложения ди- #if/#ifdef. C1053 "Размещение данных DGROUP превышает 64К". В стандартном сегменте данных были размещены более 64К перемен- ных. Для программ компактной, средней и большой модели памяти выпол- няйте компиляцию с помощью команды QCL, используя опцию /GT для размещения элементов данных в отдельных сегментах. C1054 "Ограничения компилятора: слишком глубокая вложенность инициа- заторов". Были превышены ограничения компилятора на вложенность инициали- заторов. Предел - от 10 до 15 уровней, в зависимости от комби- нации инициализируемых типов. Чтобы решить данную проблему, для сокращения уровней вложен- ности упростите тип инициализируемых данных, либо после опи- санияия присваивайте первоначальное значение в отдельных опе- раторах. C1056 "Ограничения компилятора: переполнение в процессе макро-расши- рения". Компилятор переполнил внутренний буфер при расширения макрокоманды. C1057 "Неожиданный EOF в макро-расширении; (пропущено ')'?)". Компилятор обнаружил конец исходного файла в процессе сборки аргументов макро-вызова. Обычно, это является результатом опу- щенной закрывающей правой скобки) в макро-вызове, как и в сле- дующем примере: #define print(a) printf(string is(,#a)) main() { print(the quick brown fox; } C1059 "Превышены пределы "ближней" динамической области". При размещении элементов данных в "ближней" динамической обла- сти (стандартный сегмент данных), компилятор вышел за допусти- мые пределы. C1060 "Превышены пределы "дальней" динамической области". При размещении элементов данных в "дальней" динамической облас- ти компилятор вышел за допустимые пределы памяти. Обычно дан- ная ошибка происходит во встроенных в память программах, по причине того, что таблица имен содержит слишком много имен. Чтобы исправить данную ситуацию, попробуйте выполнить компиля- цию с выключенной опцией Debug, либо попытайтесь подключить меньше включаемых файлов. Если такой способ не спасает ситу- ацию, выполните компиляцию программы посредством команды QCL. C1061 "Ограничения компилятора: слишком глубокое вложение блоков". Вложенность блоков в данной прогамме превышает возможности ком- пилятора. Для исправления данной ситуации перепишите программу так, чтобы вложенность блоков была меньшей. C1063 "Ограничения компилятора-переполнение стека компилятора". Ваша программа слишком сложна, поскольку привела к переполнению стека. Упростите вашу программу и повторите компиляцию.
D.1.2. Сообщения об ошибках компилятора.
Сообщения, перечисленные ниже, означают, что ваша программа имеет ошибки. Когда компилятор встречает одну из ошибок, перечисленных в данном разделе, программа продолжает рассматриваться (если возможно), причем продолжают выводиться оставшиеся сообщения об ошибках. Однако, объектный файл не строится.
Номер Сообщения об ошибках компилятора C2000 "Нераспознанная ошибка. Обратитесь в Технический сервис фирмы Microsoft". Компилятор не может определить тип обнаруженной ошибки. Пожа- луйста, сообщите условие возникновения данной ошибки в фирму Microsoft, воспользовавшись специальным бланком "Product Assis- tance Reguest", находящимся на обложке данного руководства. C2001 "В константе обнаружен символ перехода на новую строку (newline)". Символ перехода на новую строку в символьной или строковой константе употребляется не в корректной форме управляющей последовательности (/n). C2002 "Фактические параметры макрокоманды превышают допустимые пре- делы памяти". Аргументы макро-препроцессора превышабт 256 байтов. C2003 "Требуется идентификатор". Идентификатор для проверки условия в #if не найден. C2004 "Требуется идентификатор". Директива #if вызвала синтаксическую ошибку. C2005 "В директиве #line требуется номер строки". В директиве #line не хватает заданного номера строки. C2006 "Директиве #include требуется имя файла". В директиве #include не хватает спецификации имени файла. C2007 "Синтаксическая ошибка директивы #define". В директиве #define была обнаружена синтаксическая ошибка. C2008 "'character': невозможен в макроопределении". Данный символ был использован в макроопределении некорректно. C2009 "Повторное использование формального параметра 'identifier' макроопределения". Данный идентификатор был дважды использован в списке формальных параметров макроопределения. C2010 "'character': невозможен в формальном списке". Данный символ был некорректно использован в списке формальных параметров макроопределения. C2011 "'identifier': определения слишком велико". Данное макроопределение превышает 256 байтов. C2012 "Пропущено имя, следующее за '<'". В директиве #include не хватает требуемой спецификации имени файла. C2013 "Не хватает знака '>'". В директиве #include пропущена закрывающая угловая скобка (>) C2014 "Команда препроцессора должна начинаться с первого значащего (не пробельного) символа". В директиве препроцессора на той же самой строке появились не пробельные символы перед знаком #. C2015 "Слишком много символов в константе". Символьная константа содержит более одного символа, либо была использована управляющая последовательность. C2016 "Отсутствует закрывающая одинарная кавычка". Символьная константа не была заключена в одинарные кавычки. C2017 "Некорректная управляющая последовательность". Символ или символы, следующие за знаком () не имеют корректной формы для управляющей последовательности. C2018 "Неизвестный символ 'Oxcharacter'". Данное шестнадцатеричное число не соответствует символу. C2019 "Требуется команда препроцессора, обнаружен символ 'character'" Данный символ следует за знаком (#), но не является первой бук- вой директивы препроцессора. C2020 "Неверное восьмеричное число 'character'". Данный символ не является корректной восьмеричной цифрой. C2021 "Число 'number'слишком велико для символа". Число 'number' слишком велико, чтобы представлять символ. C2023 "Деление на нуль". Второй операнд операции деления (/) при вычислении дает нуль. что может привести к непредсказуемым результатам. C2024 "По модулю 0". Второй операнд в остатке операции (%) при вычислении дает нуль, что может привести к непредсказуемым результатам. C2025 "'identifier': переопределение типа enum/struct/union". Данный идентификатор уже был использован в перечислении, струк- туре или тэге смеси. C2026 "'identifier': переопределение числа перечисления ". Данный идентификатор уже был использован в константе перечисле- ния, либо в том же самом типе перечисления, либо в другом типе перечисления в том же самом виде. C2028 "Член структуры/смеси должен находиться внутри структуры/смеси" Члены структуры или смеси должны быть описаны внутри структу- ры или смеси. Данная ошибка может быть вызвана описанием пе- речисления, содержащим описание члена структуры, как в следу- ющем примере: enum a { january, february, int march; /* описание структуры : ** некорректно */ }; C2029 "'identifier': битовые поля разрешены только в структурах". Только структуры могут содержать битовые поля. C2030 "'identifier': переопределение члена структуры/смеси". Данный идентификатор был более одного раза использован в качес- тве члена одной и той же структуры/смеси. C2031 "'identifier': функция не может быть членом структуры или сме- си". Данная функция была описана в качестве члена структуры или смеси. Для исправления данной ошибки воспользуйтесь указателем на функцию. C2032 "'identifier': базовый тип с ключевыми словами near/far/huge не разрешен". Данный член структуры или смеси был описан с ключевыми слова- ми far и near. C2033 "'identifier': к битовым полям нельзя применять оператор кос- венного обращения (*)". Данное битовое поле было описано как указатель (*), что не разрешено. C2034 "'identifier': битовое поле слишком мало для данного количества разрядов". Количество разрядов, заданное в описаний битового поля превы- ша%т количест-о разрядов в данеод базовом т(пе. C2040 "'.'требует имя структуры или смеси". Выражение перед оператором выбора структуры или смеси (.) явля- ется указателем на структуру или смесь, а не структурой или смесью, как требуется. C2041 "Ключевое слово 'enum' некорректно". В описании структуры или смеси появилось ключевое слово 'enum', либо определение типа 'enum' было сформировано некор- ректно. C2042 "ключевые слова signed/unsigned является взаимо-исключающими". Оба ключевых слова signed и unsigned были одновременно исполь- зованы в одном описании, как в следующем примере: unsigned signed int i; C2043 "Некорректный оператор break". Оператор break разрешен только внутри операторов do, for, while или switch. C2044 "Некорректный оператор continue". Оператор continue разрешен только внутри операторо do, for, или while. C2045 "'identifier': повторное определение метки". Данная метка появилась перед более, чем одним оператором в од- ной и той же функции. C2046 "Некорректное ключевое слово case". Ключевое слово case может находиться только внутри оператора switch. C2047 "Некорректное ключевое слово default". Ключевое слово default может находиться только внутри оператора switch. C2048 "Более одного default". Оператор switch содержит более одной метки default. C2050 "Не целое выражение switch". Выражение switch не является целым. C2051 "Выражение case не константное". Выражения case должны быть целыми константами. C2052 "Выражение case не является целым". Выражения case должны быть целыми константами. C2054 "Значение case 'number' уже было использовано". Данное значение case уже было использовано в операторе switch. C2054 "Требуется знак '(' после идентификатора 'identifier'". По контексту требуются скобки после функции 'identifier'. C2055 "Требуется список формальных параметров, а не тип list". В определении функции вместо списка формальных параметров поя- вился тип аргумента list. C2056 "Некорректное выражение". Из-за предыдущей ошибки выражение является некорректным (Пре- дыдущая ошибка могла не вызвать ошибочного сообщения). C2057 "Требуется константное выражение". По контексту требуется константное выражение. C2058 "Константное выражение не является целым". По контексту требуется целое константное выражение. C2059 "Синтаксическая ошибка: 'token'". Данная лексема вызвала синтаксическую ошибку. C2060 "Синтаксическая ошибка: EOF". Был обнаружен неожиданный конец файла, что вызвало синтак- сическую ошибку. Данная ошибка может быть вызвана опущенной зак рывающей скобкой '}' в конце вашей программы. C2061 "Синтаксическая ошибка: идентификатор 'identifier'". Данный идентификатор вызвал синтаксическую ошибку. C2062 "Тип 'type' не требуется". Данный тип был некорректно употреблен. C2063 "'identifier': не является функцией". Данный идентификатор не объявлен как функция, но сделана попы- тка использовать его в качестве функции. C2064 "Данный терм не вычисляется в функцию". Сделана попытка вызова функции с помощью выражения, которое при вычислении не дает указатель функции. C2065 "'identifier': не определен". Данный идентификатор не определен. C2066 "Преобразование к функции некорректно". Объект был преобразован к типу функции. C2067 "Преобразование к типу массива некорректно". Объект был преобразован к типу массива. C2068 "Некорректное приведение типов". Тип, используемый в приведении типов, не является корректным. C2069 "Приведение типа void к типу, не являющемуся void". Тип void был приведен к другому типу. C2070 "Некорректный операнд sizeof". Операнд выражения sizeof не является идентификатором, либо наи- менованием типа. C2071 "'class': неверный класс памяти". Данный класс памяти не может быть использован в таком контекс- те. C2072 "'identifier': инициализация функции". Была сделана попытка инициализации функции. C2073 "'identifier': невозможно инициализировать массив в функции". Была сделана попытка проинициализировать данный массив внутри функции. Массив можно поринициализировать только на внешнем уровне. C2074 "В функции запрещено инициализировать структуру или смесь". Была сделана попытка проинициализировать данную структуру или смесь внутри функции. Структуры и функции могут быть проинициа- лизированы только на внешнем уровне. C2075 "'identifier': инициализация массива требует только фигурных скобок". При инициализации массива были пропущены фигурные скобки {}. C2076 "'identifier': инициализация структуры или смеси требует только фигурных скобок". При инициализации структуры или смеси были пропущены фигурные скобки {}. C2077 "Нецелый инициализатор поля 'identifier'". Была сделана попытка инициализации члена структуры-битового по- ля нецелым значением. C2078 "Слишком много инициализаторов". Количество инициализаторов превышает количество инициализируе- мых объектов. C2079 "'identifier'-неопределенная структура или смесь". Данный идентификатор был описан, как структура или смесь, тип которой не определен. C2082 "Повторное определение формального параметра 'identifier'". Формальный параметр функции был повторно описан в теле функции. C2083 "Массив 'identifier' уже имеет размер". Размерность для данного массива уже была описана. C2084 "Функция 'identifier' уже имеет тело". Данная функция уже была определена. C2085 "'identifier': не в списке формальных параметров". Данный параметр был объявлен в определении функции для несущес- твующего формального параметра. C2086 "'identifier': переопределение". Данный идентификатор был определен более одного раза. C2087 "'identifier': пропущенный описатель". В определении массива с несколькими описателями было опущено значение описателя для размерности, отличной от первой, как в следующем примере: int func(a) char a[10][]; /* некорректно */ { . . . } int func(a) char a[][5]; /* корректно */ { . . . } C2088 "Использование неопределенного идентификатора 'identifier' пе- речисления/структуры/смеси". Данный идентификатор обращается к структуре или смеси, тип ко- торой не определен. C2089 "typedef определяет функцию near/far". Использование ключевых слов near или far в объявлении typedef не согласуется с использованием ключевых слов near или far для объявленного элемента, как в следующем примере. typedef int far FARFUNC(); FARFUNC near *fp; C2090 "Функция возвращает массив". Функция не может возвращать массив (она может возвращать только указатель на массив). C2091 "Функция возвращает функцию". Функция не может возвращать функцию (она может возвращать толь- ко указатель на функцию). C2092 "Элемент массива не может быть функцией". Массивы функций не разрешаются; однако, можно использовать мас- сивы указателй на функции. C2093 "Невозможно инициализировать статические данные или структуры адресами автоматических переменных". C2098 "Не-адресное выражение". Была сделана попытка инициализации элемента данных, не являю- щегося адресным выражением. C2099 "Неконстантное смещение". Инициализатор использовал неконстантное смещение. C2100 "Некорректное использование оператора (*)". Оператор (*) был применен к неуказателю. C2101 "'&' в константе". Оператор (&) не имеет адресного значения в качестве операнда. C2102 "'&' требуется адресное значение". Оператор адресации (&) должен применяться к адресному значению. C2103 "'&' в регистровой переменной". Была сделана попытка взять адрес регистровой переменной. C2104 "'&' в битовом поле". Была сделана попытка взять адрес битового поля. C2105 "'operator' требует адресного значения". Данный оператор не имеет адресного операнда. C2106 "'operator': левый операнд должен быть адресным". Левый операнд данного оператора не является адресным. C2107 "Некорректный индекс, косвенное наименование (*) не разрешено". Описатель был применен к выражению, которое не вычисляется в указатель. C2108 "Не-целый индекс". В качестве описателя массива было использовано не-целое выраже- ние. C2109 "Описатель в не-массиве". Описатель был использован в переменной, которая не является массивом. C2110 "'+': 2 указателя". Была сделана попытка сложить один указатель с другим. C2111 "Указатель + не-целое значение". Была сделана попытка сложить не-целое значение с указателем. C2112 "Некорректное вычитание указателей". Была сделана попытка вычесть указатели, не указывающие на один и тот же тип. C2113"'-': правый операнд-указатель". Правый операнд в операции вычитания (-) является указателем, а левый операнд-нет. C2114 "'operator': указатель слева; требуется целое справа". Левый операнд в данном операторе является указателем; правый операнд должен быть целым значением. C2115 "'identifier': несовместимые типы". Выражение содержит несовместимые типы. C2116 "'operator': неправильный левый (или правый) операнд". Заданный операнд данного оператора не соответствует данному оператору. C2117 "'operator': Некорректно для структуры или смеси". Значение структуры и смеси не разрешено с данным оператором. C2118 "Отрицательный описатель". Значение, определяющее размер массива, -отрицательно. C2119 "'typedefs' оба определяют косвенное наименование (*)". Были использованы одновременно два типа typedef для объявления элемента данных и оба типа typedef имеют косвенное наимено- вание. Например, объявление p в следующем примере-некорректно: typedef int *P INT; typedef short *P SHORT; /* данное объявление некорректно */ P SHORT P INT P; C2120 "'void'-некорректно со всеми типами". Тип void был использован в объявлении с другим типом. C2121 "typedef определяет другое перечисление". Была попытка использовать тип, объявленный в операторе typedef для задания, как типа перечисления, так и другого типа. C2122 "typedef определяет другую структуру". Была сделана попытка использовать тип, объявленный в операторе typedef, для задания как типа структуры, так и другого типа. C2123 "typedef определяет другую смесь". Была сделана попытка использовать тип, объявленный в операторе typedef, для задания как типа смеси, так и другого типа. C2125 "'idetifier': память, занятая данными, превышает 64К": Данный элемент данных превышает предельный размер 64К. C2126 "'identifier': данные типа automatic превышают размер 32К". Память, занятая локальными переменными функции, превышает зада- нный предел. C2127 "Память, занятая параметрами, превышает 32К". Память, требуемая для парметров функции превышает предел 32К. C2129 "Статическая функция 'identifier' не найдена". Была сделана ссылка на статическую функцию, которая никогда не была определена. C2130 "#line требуется строка, содержащая имя файла". В директиве #line было опущено имя файла. C2131 "Атрибуты near/far/huge заданы более одного раза". Ключевые слова near и far были применены к элементу данных бо- лее одного раза, как в следующем примере: typedef int near NINT; NINT far a; /* некорректно */ C2132 "Синтаксическая ошибка: неожиданный идентификатор". Идентификатор появлился в синтаксически некорректном формате. C2133 "Массив 'identifier': неизвестный размер" Была сделана попытка описать массив с неназначенным размером, как в следующем примере: int mat add(array1) int array1[]; /* корректно */ { int array2[]; /* некорректно */ . . . } C2134 "'identifier': структура или смесь слишком велики". Размер структуры или смеси превышает предел, установленный ком- пилятором (232 байтов). C2135 "Пропущен знак ')' в макро-расширении". В обращении к макрокоманде с аргументами была опущена закрыва- ющая скобка. C2137 "Пустая символьная константа". Была использована некорректная пустая символьная константа (' '). C2138 "Несоответствие закрывающей границы комментария '/*'". Компилятор обнаружил открывающий ограничитель комментария (/*) без соответствующего закрывающего ограничителя (*/). Данная ошибка может возникнуть из-за попытки использования не- корректных вложенных коментариев. C2139 "Тип, за которым следует 'type', некорректен". Некорректная комбинация типов, как в следующем примере: long char a; C2140 "Тип аргумента не может быть функцией, возвращающей ...". Функция была объявлена, как формальный параметр другой функ- ции, как в следующем примере: int funcl (a) int a(); /* некорректно */ C2141 "Для константы перечисления значение превышает допустимые пре- делы". Константа перечисления имеет значение, превышающее допустимые пределы для типа int. C2142 "Для многоточия требуется три точки". Компилятор обнаружил лексему, содержащую две точки (..) и пред- C2143 "Синтаксическая ошибка: недостает лексемы 'token1' перед лексе- мой 'token2'". Компилятор ожидает появления перед token2-token1. Данное сооб- щение может появиться, если пропущена требуемая закрывающая фи- гурная скобка (}), правая скобка ()) либо точка с запятой (;). C2144 "Синтаксическая ошибка: недостает лексемы 'token' перед типом 'type'". Компилятор требует наличия данной лексемы перед данным типом. Данное сообщение может появиться пре пропущенной закрывающей фигурной скобке (}), правой скобке ()), или точке с запятой (;). C2145 "Синтаксическая ошибка: перед идентификатором не хватает лексе- мы 'token'". Компилятор требует наличия перед идентификатором данной лексе- мы. Данное сообщение может появиться при пропущенной точке с запятой (;) в последнем объявлении блока. C2146 "Синтаксическая ошибка: перед идентификатором 'identifier' не хватает лексемы 'token'". Компилятор требует наличия данной лексемы перед данным иденти- фикатором. C2147 "Массив: неизвестный размер". Сделана попытка увеличить индекс, либо указатель на массив, ба- зовый тип которого еще не объявлен. C2148 "Слишком большой массив". Массив превышает максимально-допустимый размер (232 байта). C2149 "'identifier': данное битовое поле не может иметь нулевую шири- ну". Битовое поле с данным именем имеет нулевую ширину. Нулевой раз- мер разрешается иметь только неименованным битовым полям. C2150"'identifier': битовое поле должно иметь тип int, signed int или unsigned int. Стандарт ANSI C требует, чтобы битовые поля имели типы int, signed int или unsigned int. Данное сообщение может появиться только при компиляции с опцией /Za. C2151 "Задано более одного атрибута cdecl/fortran/pascal". Было задано более одного ключевого слова, определяющего согла- щения о вызове функций. C2152 "'identifier': указатели на функции с различными атрибутами". Была сделана попытка присвоить указатель на функцию, объявлен- ную с одними соглашениями о связях (cdecl, fortran или pascal)- -указателю на функцию, объявленную с другими соглашениями о связях. C2153 "Шестнадцатеричные константы должны иметь по крайней мере одну шестнадцатеричную цифру". Ox или OX-являются некорректными шестнадцатеричными константа- ми. За "x" или "X" должна следовать хотя бы одна шестнадца- теричная цифра. C2154 "'name': не относится к сегменту". Имя функции name было первым идентификатором, заданным в аргу- ментном списке прагмы alloc_text, и уже определено как какое- -либо имя, отличное от имени сегмента. C2155 "Имя 'name': уже имеется в сегменте". Имя функции name появляется более, чем в одной прагме alloc_ text. C2156 "Прагма должна быть на внешнем уровне". Некоторые прагмы должны быть определены на глобальном уровне, вне тела функции, а одна из таких прагм оказалась внутри фун- кции. C2157 "'name': перед использованием в списке прагмы данное имя долж- но быть описано". Данное имя функции из списка функций прагмы alloc_text не было описано перед включением в список. C2158 "'name': является функцией". Имя name было задано в списке переменных прагмы same_seg, но ранее было объявлено, как функция. C2159 "Определено более одного класса памяти". В описании было задано более одного класса памяти, как в сле- дующем примере: extern static int i; C2160 "## не может встретиться в начале макро-определения". Макро-определение начинается с оператора подстановки лексем, как в следующем примере: #define mac(a,b) ##a... C2161 "## не может находиться в конце макро-определения". Макро-определение заканчивается оператором подстановки лексем (##). C2162 "Требуется формальный параметр макрокоманды". Лексема, следующая за оператором (#), не является именем фор- мального параметра, как в следующем примере: #Define print(a) printf(#b) C2163"'string': отсутствует, как intrinsic". Функция, определенная в списке функций для прагмы intrinsic или function, не является одной из имеющихся в форме intrinsic фун- кций. C2165 "'keyword': невозможно изменить указатели на данные". Были некорректно использованы ключевые слова fortran, pascal или cdecl для модификации указателя на данные, как в следующем примере: char pascal *p; C2166 "Значение определяет объект, относящийся к классу памяти 'const'". Была сделана попытка присвоить значение элементу данных, объяв- ленному с классом памяти const. C2167 "'name': слишком много фактических параметров для intrinsic. Ссылка на имя intrinsic function содержит слишком много факти- ческих параметров. C2168 "'name': слишком мало фактических параметров для intrinsic". Ссылка на имя содержит слишком мало фактических параметров. C2169 "'name': является intrinsic оно не может быть определено ". Была сделана попытка задать определение для функции, уже описа- нной, как intrinsic. C2171 "'operator': неверный операнд". Данный унарный оператор был использован с операндом некоррект- ного типа, как в следующем примере: int (*fp)(); double d, d1; . . . fp++; d=~d1 C2172 "'function': фактически не указатель, параметр номер'number'. Была сделана попытка передать аргумент, не являющийся указате- лем, функции, требующей указатель. Данный номер указывает, ка- кой аргумент ошибочен. C2173 "'function': фактически не указатель, параметр 'number': спи- сок параметров 'number'". Была сделана попытка передать аргумент, не являющийся указате- лем, функции, требующей указатель. Данная ошибка может произой- ти в вызовах, возвращающих указатель на функцию. Первый номер указывает, какой аргумент вызвал ошибку; второй номер показы- вает, какой список аргументов содержит неверный аргумент. C2174 "'function': фактически имеет тип void: параметр 'number', спи- сок параметров 'number'". Была сделана попытка передать аргумент типа void функции. Фор- мальные параметры и аргументы функции не могут иметь тип void; однако, они могут иметь тип void* (указатель на void). Данная ошибка происходит в вызовах, возвращающих указатель на функцию. Первый номер показывает, какой аргумент вызвал ошибку; второй номер показывает, какой список аргументов содержит неправильный аргумент. C2175 "'function': неразрешенная внешняя ссылка". Данная функция неопределена в исходном файле, либо встроена в среду программирования QUICK-C, либо находится в библиотеке QUICK, если она загружена. Данная ошибка возникает только в одно-модульных, встроенных в среду Quick-C программах. Чтобы разрешить данную проблему, либо определите функцию в исходном файле, либо загрузите библиотеку QUICK,содержащую данную функцию, либо (если функция содержится в стандартной библиотеке СИ-функций), создайте для программы программный список. C2177 "Константа слишком велика". Информация была потеряна, поскольку константа слишком велика, чтобы заменить тип, которому она присваевается. (1)
D.1.3. Предупреждающие сообщения.
Сообщения, перечисленные в данном разделе, вскрывают некоторые возможные проблемы, но не мешают компиляции и компановке. Номер в скобках в конце сообщения об ошибке означает минимальный уровень предупреждения, установленный для данного сообщения.
Номер Предупреждающее сообщение C4000 "Нераспознанное предупреждение, свяжитесь с техническим сер- висом фирмы Microsoft". Компилятор обнаружил неизвестную ошибку. Пожалуйста, сообщите условия возникновения данной ошибке фирме Microsoft Corpora- tion, воспользовавшись бланком "Product Assistant Request", находящимся в конце данного руководства. C4001 "Макрокоманда 'identifier'требует параметров". Данный идентификатор был определен, как макрокоманда, имеющая один или более аргументов, но используется в программе без ар- гументов. (1). C4002 "Слишком много фактических параметров для макрокоманды 'identi- fier'". Число фактических аргументов, употребляемых с данным идентифи- катором, больше, чем число формальных параметров, заданных в макроопределении данного идентификатора. (1). C4003 "Не достаточно фактических параметров для макрокоманды 'identifier'". Число фактических аргументов, употребляемых с данным идентифи- катором, меньше, чем число формальных параметров, заданных в макроопределении данного идентификатора. (1). C4004 "Не хватает закрывающей скобки после 'defined'". После фразы #if defined пропущена закрывающая скобка. (1). C4005 "'identifier': повторное определение". Данный идентификатор был повторно определен. (1). C4006 "Директиве #indef требуется идентификатор". В директиве #indef задан идентификатор, определение которого отсутствет. (1). C4009 "Строка слишком велика, хвостовые символы отсекаются". Размер строки превышает предел, установленный компилятором. Для исправления данной ситуации разбейте строку на две или бо- лее подстроки. (1). C4011 "Идентификатор усечен до 'identifier'". Принимаются только первые 31 символ идентификатора. (1). C4014 "'identifier': битовое поле должно иметь тип unsigned. Данное битовое поле не было описано с типом unsigned. Битовые поля должны быть описаны, как целые без знака. Компилятор со- ответственно конвертирует данное битовое поле. (1). C4014 "'identifier': битовое поле должно иметь целый тип". Данное битовое поле было описано, не как целое. Битовые поля должны быть описаны, как целые без знака. Было применено пре- образование. (1). C4016 "'identifier': нет типа, возвращаемого функцией". Данная функция еще не была описана либо определена, поэтому тип возвращаемого значения неизвестен. Подразумевается стандартный тип (int). (2). C4017 "Приведение целого выражения к 'дальнему' указателю". Дальние указатели содержат полные адреса сегментов. На процес- соре 8086/8088 приведение целого (int) значения к "дальнему" указателю может создать адрес с бессмысленным значением сегмен- та. (1). C4020 "Слишком много фактических параметров". Число аргументов, определенных в вызове функции, больше числа формальных аргументов, заданных в списке аргументов определения функции. (1). C4021 "Слишком мало фактических параметров". Число аргументов, заданных в вызове функции, меньше числа фор- мальных параметров, определенных в списке аргументов определе- ния функции. (1). C4022 "Несоответствие указателей: параметр n". Тип указателя данного параметра отличен от типа указателя, за- данного в списке аргументов определения функции. (1). C4024 "Различные типы: параметр n". Тип данного параметра функции не согласуется с типом, заданным в списке аргументов определения функции. (1). C4025 "Описание функции задает переменный список аргументов". Список типов аргументов определения функции заканчивается запя- той, за которой следует многоточие, что означает, что функция может принимать переменное число аргументов, но для функции не были описаны формальные параметры. (1). C4026 "Функция была описана со списком формальных параметров". Функция была описана, как принимающая аргументы, но в определе- нии функции не задано формальных параметров. (1). C4027 "Функция была описана без списка формальных параметров". Функция была описана, как не принимающая аргументов (список типов аргументов состоит из слова void), но в определении функ- ции заданы формальные параметры, либо в вызове функции заданы фактические параметры. (1). C4028 "Отличается описание параметра n". Тип данного параметра не согласуется с соответствующим типом в списке типов аргументов, либо с соответствующим формальным па- раметром. (1). C4029 "Описание списка параметров отлично от определения": Список типов аргументов, заданный в описании функции, не со- гласуется с типами формальных параметров, заданных в опреде- лении функции. (1). C4030 "Первый список параметров длиннее второго". Функция была описана более одного раза, причем с различными списками типов аргументов. (1). C4031 "Второй список параметров длиннее, чем первый". Функция была описана более одного раза, причем с различными списками типов аргументов. (1). C4032 "Неименованная структура/смесь в качестве параметра". Тип структуры или смеси был передан как неименованный аргумент, то есть описание формального параметра не может использовать имя и должно описать тип. (1). C4033 "Функция должна возвращать значение". Если функция не описана, как void, она должна возвращать зна- чение. (2). C4034 "Оператор sizeof возвратил 0". Оператор sizeof был применен к операнду, причем в результате был получен 0. (1). C4035 "'identifier': нет возвращаемого значения". Функция описана, как возвращающая значение, но не делает этого. (2). C4036 "Не ожидаемый список формальных параметров". Список формальных параметров был задан в описании функции. Список формальных параметров игнорируется. (1). C4037 "'identifier': формальные параметры игнорируются". В описании функции не найдено перед описанием формальных параметров ни класса памяти, ни наименование типа, как в сле- дующем примере: int * f(a,b,c); Формальные параметры игнорируются. (1). C4038 "'identifier':формальный параметр имеет некорректный класс па- мяти". Данный формальный параметр был описан с классом памяти, от- личным от auto или register. (1). C4039 "'identifier': функция используется в качестве аргумента" Формальный параметр функции был описан, как функция, что не- корректно.Формальный параметр будет преобразован в указатель функции (1). C4040 "Ключевое слово near/far/ в идентификаторе 'identifier' игнори- руется". Ключевые слова near или far не оказывают никакого действия на данный идентификатор и потому игнорируются.(1). C4041 "Формальный параметр 'identifier' переопределен". Данный формальный параметр был в теле функции определен повтор- но, сделав соответствующий фактический параметр для функции не- доступным. (1). C4042 "'identifier' имеет не корректный класс памяти". Заданный класс памяти не может быть использован в данном конте- ксте (например, параметрам функции не может быть присвоен класс extern). Для данного контекста использован вместо некорректного стандартный класс памяти. (1). C4043 "'identifier': тип void изменен на int". Элемент данных, отличный от функции, был описан с типом void. (1). C4045 "'identifier': массив переполнен". Для данного массива было задано слишком много инициализаторов. Лишние инициализаторы будут игнорированы. (1). C4046 "Знак '&' в функции/массиве игнорируется". Была сделана попытка применить оператор адресации (&) к иден- тификатору, обозначающему функцию или массив. (1). C4047 "'operator': различные уровни косвенного наименования". Данную ситуацию иллюстрирует следующий пример: char **p; char *q; . . . p=q; C4048 "Массив описан с помощью различных описателей". Массив был описан дважды с различными размерами. Используется большой размер. (1). C4049"'operator': косвенное наименование применяется к различным ти- пам". Оператор косвенного наименования (*) был использован в выраже- нии для доступа к значениям различных типов. (1). C4051 "Преобразование данных". В выражении два элемента данных имеют различные типы, что при- ведет к преобразованию данных к одному типу. (2). C4052 "Различные типы enum". В выражении были использованы два различных типа enum. (1). C4053 "По крайней мере один операнд void" Выражение с типом void было использовано в качестве операнда. (1). C4056 "Переполнение в константной арифметике". Результат операции превышает 0x7FFFFFFF. (1). C4057 "Переполнение при перемножении констант". Результат операции превышает 0x7FFFFFFF. (1). C4058 "Взят адрес переменной фрейма, DS!=SS". Программа была скомпилирована со стандартным сегментом данных (DS), не равным стэковому сегменту (SS), программа пытается об- ратиться к переменной фрейма посредством ближнего указателя.(1) C4059 "В результате преобразования адрес сегмента потерян". Преобразование "дальнего" указателя (полного адреса сегмента) к "ближнему" указателю (смещение) привело к потере адреса сегмен- та. (1). C4060 "Преобразование 'длинного' адреса в 'короткий' адрес". Преобразование длинного адреса (32-разрядного указателя) в ко- роткий адрес (16-разрядного указателя) привело к потере адреса сегмента. (1). C4061 "long/short несоответствие в аргументе: применено преобразо- вание". Базовые типы действительных и формальных параметров функции различны. Фактический параметр преобразовывается к типу фор- мального параметра. (1) C4063 "'identifier': функция слишком велика для шага оптимизации". Данная функция не была оптимизирована, поскольку для этого недостаточно памяти. Чтобы исправить данную ситуацию, сократи- те размер функции путем разделения ее на две или более меньших функций. (0). C4066 "Таблица локальных имен переполнена-некоторые локальные имена могут быть пропущены в списке". Генератор листинга вышел за пределы динамической области, отве- денной под локальные переменные, поэтому исходный листинг может не включать в себя полную таблицу имен для всех локальных пере- менных C4067 "За директивой 'directive' следуют непонятные символы-требует- ся символ перехода на следующю строку". За директивой препроцессора следуют лишние символы, как в следующем примере: #endif NO_EXT_KEYS Это принимается в некоторых версиях компилятора Microsoft C, исключая версию 1.0 Microsoft Quick C. (1). C4068 "Неизвестная прагма". Компилятор не смог распознать прагму и игнорировал ее. (1). C4069 "Преобразование ближнего указателя к длинному целому". Ближний указатель был преобразован к длинному целому, что за- полнило старшие разряды текущим значением сегмента данных, не равным нулю. (1). C4071 "'identifier': прототип функции не задан". Данная функция была вызвана компилятором перед тем, как компи- лятор обработал соответствующий прототип функции. (3). C4072 "Недостаточно памяти для обработки отладочной информации". Вы скомпилировали программу с опцией /Zi, но для создания со- ответствующей отладочной информации недостаточно памяти. (1). C4073 "Вложенность слишком глубока, дальнейшая вложенность во время отладки игнорируется". Описания появились на уровне вложенности, большем 13. В ре- зультате, все описания будут восприниматься как бы на одном уровне. (1). C4074 "Было использовано нестандартное расширение-'extension'". Было использовано данное нестандартное расширение в то время, как опция Language Extension в диалоговой рамке Compile была выключена, либо опция /Ze не действовала. Данные расширения да- ны в Разделе 8.1.4.6. "Использование расширений языка СИ фирмы Microsoft: Опция Language Extension". (если включена опция /Za, данная ситуация дает ошибку). (3). C4075 "Размер выражения в операторе switch или константа в операторе case имеют слишком большой размер-преобразуются к типу int". Значение, появляющееся в операторах switch или case, больше ти- па int. Компилятор преобразует данное некорректное значение в тип int. (1). C4076 "'type': может быть использовано только с целыми типами". Модификатор типа signed или unsigned был применен к не целому типу, как в следующем примере: unsigned double b; C4077 "Неизвестная опция прагмы check_stack". Со старой формой прагмы check_stack была задана неизвестная опция, как в следующем примере: #pragma check_stack yes В старой форме прагмы check_stack аргумент прагмы должен быть пустым + или -. C4079 "Неожиданный символ 'character'". В аргументном списке прагмы был найден неожиданный разделитель 'character'". C4080 "Пропущено имя сегмента". В первом аргументе аргументного списка прагмы alloc_text про- пущено имя сегмента. Это случается, если первая лексема в ар- гументном списке не является идентификатором. C4082 "Требуется идентификатор". В списке аргументов прагмы пропущен идентификатор. C4083 "Пропущено'('". В аргументном списке прагмы пропущена открывающая левая скобка, как в следующем примере: #pragma check_pointer on) C4084 "Требуется ключевое слово pragma". Лексема, следующая за ключевым словом pragma, не является иден- тификатором, как в следующем примере: #pragma (on) C4085 "Требуется [on/off] Для новой формы прагмы check_stack был задан некорректный аргу- мент, как в следующем примере: #pragma check_stack (yes) C4087 "'name': описана с пустым списком параметров". Данная функция была описана, как не принимающая параметров, в то время как вызов функции определяет фактические параметры, как в следующем примере: int fl(void); . . . fl(10); C4090 "Различные атрибуты 'const'". Указатель на элемент данных, описанный, как const, был пере- дан функции, соответствующий формальный параметр которой явля- ется указателем на элемент данных, не являющийся const. Это значит, что данный элемент данных может быть незаметно изме- нен, как в следующем примере: const char *p = "ascde"; int str(char *s); . . . str(p); C4091 "Не описано никаких имен". Компилятор обнаружил пустое описание, как в следующем примере (2): int; C4092 "Описание перечисления/структуры/смеси не имеет имени". Компилятор обнаружил пустое описание, использующее не имеющую соответствующего тэга структуру, смесь или перечисление, как в следующем примере: struct { . . . }; C4093 "Некорректный символ перехода на новую строку в символьной кон- танте в не действующем коде". Константное выражение в директиве препроцессора #if, #ifdef или #ifndef вычисляется в 0, что делает соответствующий код неактив ным, причем символ перехода на новую строку появляется в данном не активном коде между соответствующими одиночными или двойными кавычками. C4095 "Слишком много аргументов для прагмы". В прагме, имеющей только один аргумент, появляется более одного аргумента. C4096 "Элемент типа huge трактуется, как far". Поскольку компилятор Microsoft Quick-C не поддерживает ключевое слово huge, элемент данных трактуется, как описанный с ключе- вым словом far. Если элемент данных или функция должны все же иметь тип huge, перекомпилируйте программу с помощью Оптимизиру ющего компилятора Microsoft C. C4097 "В строке встретился символ 'hex-character', не относящийся к коду ASCII". Данный не ASCII-символ был использован в данной символьной строке.
D.1.4. Ограничения компилятора.
Для работы с компилятором Microsoft Quick-C вам нужно иметь достаточное количество памяти для обработки временных файлов, используемых для обработки. Требуется память приблизительно в два раза большая, чем размер исходного файла.
В таблице D.1 приводятся ограничения,накладываемые СИ-компиля- тором. Если ваша программа превышает один из заданных пределов, вас информирует об этом сообщение об ошибке.
Таблица D.1. Ограничения СИ-компилятора. Элемент программы Описание Ограничения Строковые литералы Максимальная длина строки, 512 байтов включающая нулевое оконча- ние (). Константы Максимальный размер констан- ты зависит от ее типа; смот- рите "Справочное руководство по языку СИ". Идентификаторы Максимальная длина идентифи- 31 байт (дополни- катора тельные символы не воспринимают- ся). Описания Максимальный уровень вло- 10 уровней женности для определений структуры или смеси. Директивы препроцес- Максимальный размер макро- 512 байтов. сора определения. Максимальное количество 8 аргументов фактических параметров в макроопределении. Максимальная длина реально- 256 байтов го аргумента препроцессора. Максимальный уровень вложен- 32 уровня ности директив #if, #ifdef, #ifndef. Максимальный уровень вложен- 10 уровней ности для подключаемых фай- лов.
Компилятор не устанавливает явные ограничения на число и сложность описаний, определений и операторов в отдельных функциях или в программе. Если компилятор встречает функцию или программу слишком большую или слишком сложную для обработки, он выводит сообщение об ошибке.
D.2.Сообщения об ошибках в командной строке.
Сообщения, указывающие на ошибки в командной строке, используемой для вызова компилятора, имеют один из следующих форматов:
command line fatal error D1xxx: messagetext Fatal error (Фатальная ошибка командной строки D1xxx: текст сообщения Фатальная ошибка) command line error D2xxx: messagetext Error (Ошибка командной строки D2xxx: текст сообщения Ошибка) command line warning D4xxx: messagetext Warning (Предупреждение командной строки D4xxx: текст сообщения Предупреждение).
Если возможно, компилятор продолжает работу, распечатывая предупреждающее сообщение. В некоторых случаях ошибки командной строки являются неисправимыми и компилятор прекращает работу. Сообщения, приведенные в разделах D.2.1-D.2.3 описывают ошибки командной строки.
D.2.1. Неисправимые ошибки командной строки.
Следующие сообщения описывают фатальные ошибки. Драйвер компилятора не может восстановить работу после фатальной ошибки; он прекращает работу после распечатки сообщения.
Номер Сообщение о фатальной ошибке в командной строке D1000 Неизвестная фтатальная ошибка командной строки. Свяжитесь с тех нической службой фирмы Microsoft. Компилятор обнаружил нераспоз нанную неисправимую ошибку. Пожалуйста, сообщите условия возникновения данной ошибки в фир- му Microsoft Corporation с помощью формы Product Assistance Request, находящейся в конце данного руководства. D1001 "Невозможно выполнить 'filename'". Компилятор не может найти данный файл в текущем рабочем катало- ге, либо в других каталогах, определяемых посредством перемен- ной PATH. D1002 "Слишком много открытых файлов, невозможно переадресовать 'filename'". Больше нет файлов, чтобы переадресовать вывод опции /P в файл. Попробуйте изменить ваш файл CONFIG.SYS и увеличьте значение num в строке files=num (если num меньше 20).
D.2.2. Сообщения об ошибках командной строки.
Как только драйвер компилятора встречает одну из ошибок, перечисленных в данном разделе, он (если возможно) продолжает компиляцию программы и выводит дополнительные сообщения об ошибках. Однако, объектный файл не строится.
Номер Сообщение об ошибках командной строки D2000 "Нераспознанная ошибка командной строки, обратитесь в техничес- кий сервис фирмы Microsoft". Компилятор обнаружил неизвестную ошибку. Пожалуйста, сообщите условия возникновения данной ошибки фирме Microsoft Corporati- on, используя бланк "Product assistance Request", находяцийся в конце данного руководства. D2001 "Слишком много имен определены с -D". Слишком много символических констант были определены с помощью опции /D командной строки. Обычный предел определений на командной строке 16; если вы ис- пользуете опции /U или /u-предел увеличивается до 20. D2002 "Предварительно определенная модель была отменена". Были определены две различные модели памяти; используется мо- дель, заданная на командной строке позже. D2003 "Пропущено имя исходного файла". Вы не задали имя компилируемого исходного файла. D2007 "Неверно задана опция, следует заменить 'string1' на 'string2'". Данная опция была задана более одного раза с конфликтующими ар- гументами string1 и string2. D2008 "Слишком много флажков опции 'string'". С заданной опцией было определено слишком много букв (например, с опцией /O). D2009 "Неизвестный символ опции 'option string'". Одна из букв данной опции нераспознана. D2010 "Неизвестная опция плавающей точки". Данная опция плавающей точки ( опция /FP) не является коррект- ной. D2011 "Разрешена только одна опция плавающей точки". На командной строке вы задали более одной опции плавающей точ- ки (/FP). D2012 "На командной строке слишком много опций компановщика". Вы сделали попытку задать на командной строке более 128 отдель- ных опций и объектных файлов для компановщика. D2015 "Ассемблерные файлы не обрабатываются". Вы задали на командной строке имя файла с расширением .ASM. Поскольку компилятор не может автоматически вызывать Макроас- семблер (MASM), он не может ассемлировать данные файлы. D2018 "Невозможно открыть файл компановщика cmd". Файл соответствий, передающий компановщику имена объектных фай- лов и опции, не может быть открыт. Данная ошибка может произойти, если какой-либо файл с атрибутом "только-чтение" имеет то же самое имя, что файл соответствий компановщика. D2019 "Невозможно перезаписать исходный файл 'name'". Вы задали исходный файл в качестве выводного. Компилятор не позволяет исходному файлу быть перезаписанным одним из выход- ных файлов компилятора. D2020 "Опция -Gc требует возможности разрешения расширенных ключевых слов (-Ze)". Опция /Gc и опция /Za были заданы на одной командной строке. Опция /Gc требует возможности задания расширенного ключевого слова cdecl, если осуществляется доступ к библиотечным функ- циям. D2021 "Неверный числовой аргумент 'string'". Нечисловая строка была задана за опцией, требующей числового аргумента. D2022 "Невозможно открыть файл помощи cl.hlp". Была задана опция /HELP, но файл содержащий вспомогательные сообщения не был найден в текущем каталоге, либо в каталогах, заданных с помощью переменной PATH.
D.2.3. Предупреждающие сообщения командной строки.
Сообщения, перечисленные в данном разделе, описывают возможные проблемы, но не прерывают компиляцию и компановку.
Номер Предупреждающие сообщения D4000 "Неизвестное предупреждение командной строки, свяжитесь с тех- нической службой фирмы Microsoft". Компилятором была обнаружена неизвестная ситуация. Пожалуйста, сообщите условия возникновения данной ситуации фир- ме Microsoft Corporation, используя бланк "Product Assistance Request", находящийся в конце данного руководства. D4002 "Неизвестная опция 'string' игнорируется". Одна из опций, заданных на командной строке, была нераспоз- нана и потому проигнорирована. D4003 "Для генерации кода выбран 80186/286, а не 8086". Были заданы обе опции: /G0 и /G2; преимущество дано опции /G2. D4004 "Оптимизация по времени, а не по размеру". Данное сообщение подтвердило использование для оптимизации оп- ции /Ot. D4005 "Невозможно выполнить 'filename'; пожалуйста, вставьте дискету и нажмите любой ключ". Команда QCL не может найти заданный выполняемый файл по задан- ному маршруту. D4006 "Разрешена только одна из опций -P/-E/-EP, выбрана -P". Было задано более одной выводной опции препроцессора. D4007 "Опция -C игнорируется (нужно задать также -P или -E, либо -EP)". Опция /C должна использоваться вместе с одной из выводных опций препроцессора (/E, /EP, /P). D4009 "Порог только для данных far/huge, игнорируется". Опция /Gt была использована в модели памяти, имеющей ближние указатели на данные. Она может применяться только для ком- пактной и большой моделей. D4010 "Опция -Gp не применяется, игнорируется". Версия операционной системы DOS Microsoft C не поддерживает профайлинг. D4013 "Комбинированный листинг имеет преимущество над объектным листингом" Если опция /Fc задана вместе с одной из опций /Fl или /Fa, соз- дается комбинированный листинг (/Fc). D4014 "Неверное значение number для строки 'string'. Используете ста- ндартное значение number". В контексте, требующем определенное числовое значение, было за- дано некорректное значение. D4017 "Конфликтующие опции проверки стэка-проверка стека отменяется". Вы задали на командной строке CL обе опции /Ge и /Gs. Опция Gs имеет преимущество, поэтому в данной программе стэковый конт- роль отменяется.
D.3. Сообщения об ошибках периода выполнения.
Ошибки периода выполнения подразделяются на четыре категории: 1.Исключительные ситуации при выполнении операций с плавающей точкой математическим сопроцессором 8087/80287 или эмулятором. Данные ситуации описаны в Разделе D.3.1.
2. Сообщения об ошибках, сгенерированные библиотекой периода выполнения, информирующие вас о серьезных ошибках. Данные сообщения перечислены и описаны в Разделе D.3.2.
3. Сообщения об ошибках, сгенерированные во время обращения к процедурам обработки ошибок библиотеки периода выполнения — abort, assert, perror-как только программа вызовет процедуру. Данная процедура направляет сообщения в стандартный вывод. Описание данных процедур и соответствующих сообщений об ошибках смотрите в документе: «Справочное руководство по библиотеке процедур Microsoft-C».
4. Сообщения об ошибках, сгенерированные вызовами математических процедур из библиотеки СИ периода выполнения. В случае ошибки математические процедуры возвращают ошибочное значение, а некоторые выводят сообщение на стандартной вывод. Описание математических процедур и соответствующие сообщения об ошибках смотрите в документе «Справочное руководство по библиотеке проц Microsoft-C».
D.3.1. Исключительные ситуации операций с плавающей точкой.
Сообщения об ошибках, перечисленные ниже, генерируются математическим сопроцессором 8087/80287. Описание сбоев оборудования смотрите в документации по процессорам семейства Intel. Данные ошибки могут быть также выявлены эмулятором операций с плавающей точкой, встроенным в стандартную библиотеку Quick-C.
С помощью назначений управляющего слова сопроцессора 8087/80287, следующие исключительные ситуации маскируются и потому не происходят Исключительная Стандартное маскирующее действие
ситуация
Слишком малое число Ситуация маскируется Потеря значимости Результат приводится к нулю Потеря точности Ситуация маскируется
Информацию о том, как изменить управляющее слово операций с плавающей точкой, смотрите в справочных страницах, посвященных _control87, в документе «Справочное руководство по библиотеке процедур Microsoft C».
Кроме того, следующие ошибки не возникают в коде, сгенерированном с помощью компилятора Microsoft Quick-C или полученном посредством стандартной СИ-библиотеки:
Квадратный корень Выход за нижнюю границу стэка Неэмулируется
Исключительные ситуации при операциях с плавающей точкой имеют следующий формат:
run-time error M61nn: MATH - floating-point error: messagetext
Номер Исключительные ситуации при операциях с плавающей точкой
М6101 "Неверно". Произошла некорректная операция. Обычно это происходит при дей- ствиях с с неопределенностями. Данная ошибка приводит к останову программы с кодом завершения 129. Номер Исключительные ситуации при операциях с плавающей точкой М6102 "Слишком малое число". Было сгенерировано слишком малое число с плавающей точкой, даль нейшее его использование приведет к потере значимости. Такие ситуации обычно маскируются, они отлавливаются и обрабатывают- ся. Программа заканчивается с кодом завершения 130. М6103 "Деление на нуль". Была сделана попытка деления на нуль. Программа заканчивается с кодом 131. М6104 "Переполнение". При выполнении операции с плавающей точкой произошло переполне- ние. Программа заканчивается с кодом 132. М6105 "Потеря значимости". Во времы операции с плавающей точкой произошла потеря значимос- ти. Такие ситуации обычно маскируются; слишком малое значение заменяется нулем. Программа заканчивается с кодом завершения 133. М6106 "Потеря точности". Во время операции с плавающей точкой произошла потеря точности. Данная ситуация обычно проходит незамеченной, поскольку почти все операции с плавающей точкой могут привести к потере точнос- ти. Программа заканчивается с кодом 134. М6107 "Невозможна эмуляция" Была сделана попытка выполнить инструкцию сопроцессора 8087/ /80287, являющуюся некорректной и не поддерживаемую эмулятором. Программа завершается с кодом 135. М6108 "Квадратный корень". Операнд операции извлечения квадратного корня отрицателен. Про- грамма завершается с кодом 136. (обратите внимание, функция sqrt из библиотеки процедур языка СИ проверяет аргумент перед выполнением и возвращает ошибку, если аргумент отрицателен; описание функции sqrt смотрите в документе: "Справочное руко- водствопо библиотеке процедур Microsoft-C": М6110 "Переполнение стэка". Выражение с плавающей точкой привело к переполнению стэка на сопроцессоре 8087/80287 или эмуляторе. (ситуации переполнения стэка отлавливаются до предела 7 уровней в дополнение к восьми уровням, обычно поддерживаемым сопроцессором 8087/80287). Прог- рамма завершается с кодом 138. М6111 "Выход за нижнюю границу стэка". Выполнение операции с плавающей точкой на сопроцессоре 8087/80287 или эмуляторе вызвало выход за нижнюю границу стэка. Программа завершается с кодом 139. М6112 "Явно сгенерирована ошибка". Сигнал, означающий ошибку при выполнении операции с плавающей точкой, был послан с помощью вызова raise (SIGFPE). Программа завершается с кодом 140.
D.3.1. Сообщения об ошибках периода выполнения.
Следующие сообщения описывают ошибки, сгенерированные в процессе выполнения программы. Номера ошибок периода выполнения лежит в пределах от R6000 до R6999.
Сообщения об ошибках периода выполнения имеют следующую основную форму:
run-time error R6nnn - messagetext (ошибка периода выполнения R6nnn) (- текст сообщения)
Номер Сообщение об ошибке периода выполнения
R6000 "Переполнение стэка". Ваша программа переполнила пространство, отведенное под стэк. Это может произойти, если ваша программа использует большое количество локальных данных или является рекурсивной. Программа завершается с кодом 255. Чтобы исправить данную ситуацию, перекомпилируйте программу с помощью команды QCL с опцией /F и перекомпануйте программу, ис- пользуя опцию компановщика /STACK для размещения большого стэка R6001 "Присваивание нулевого указателя". В процессе выполнения программы было изменено содержимое сег- мента NULL. Сегмент NULL-это специальное место, расположенное по младшим адресам памяти, которое обычно не используется. Ес- ли содержимое сегмента NULL изменилось в процессе выполнения программы, это означает, что программа была записана на эту об- ласть, обычно, из-за примененного по небрежности нулевого ука- зателя. Заметим, что ваша программа может содержать нулевые указатели, но данное сообщение не будет генерироваться; данное сообщение появляется только в случае обращения к области памяти с помощью нулевого указателя Данная ошибка не будет вызывать останов программы; за сообщени- ем об ошибке следует нормальное завершение программы. Ошибка возвращает ненулевой код завершения. Данное сообщение отражает возможность серьезных ошибок в программе. Хотя программа, в ко- торой возникла такая ошибка, может работать правильно, она ве- роятно дает ошибки в будущем, и может дать сбой при работе в другой операционной среде. R6002 "Библиотека процедур операций с плавающей точкой не загружена". Ваша программа требует библиотеку с плавающей точкой, но данная библиотека не загружена. Программа завершается по ошибке с ко- дом 255. Такая ошибка может произойти в следующих двух ситуа- циях: 1.Программа была скомпилирована или скомпанована с такой опци- ей, как /FPi87, требующей сопроцессор 8087 или 80287, но прог- рамма выполняется на машине, не имеющей такого. Для исправления ошибки либо перекомпилируйте программу с опцией /FPi, либо ус- тановите сопроцессор. (В разделе 9.3.5 данного руководства вы найдете более подробную информацию о данных опциях и билиоте- ках. 2.Строка формата для одной из процедур семейства printf или scanf содержит спецификацию для формата с плавающей точкой, в то время, как значений или переменных с плавающей точкой в про- грамме нет. Компилятор Quick-C делает попытку минимизировать размер программы посредством загрузки библиотеки поддержки пла- вающей точки только в случае крайней необходимости. Поскольку в форматных строках не обнаружено спецификаций плавающей точки, необходимые процедуры для работы с плавающей точкой не были за- гружены. Для исправления данной ошибки используйте какой-либо аргумент с плавающей точкой для соответствия заданной специфи- кации формата. Это приведет к тому, что библиотека поддержки плавающей точки будет загружена. R6003 "Целое, деленное на нуль". Была сделана попытка разделить целое число на нуль, что дало неопределенный результат. Программа завершается с кодом 255. R6004 "Требуется версия DOS 2.0 или выше". Компилятор Quick-C не может работать на версиях операционной системы DOS младше 2.0. R6005 "Не хватает памяти для exec". Ошибки с R6005 по R6007 происходят при сбое в процедурах, вызы- ваемых одной из библиотечных, когда операционная система DOS не может вернуть управление в родительский процесс. Данная ошибка показывает, что для загрузки вызываемой программы не хватает памяти. R6006 "Неверный формат для exec". Файл, выполняемый одной из функций exec, не имеет формата, тре- буемого для выполняемого файла. R6007 "Некорректная среда для exec". Во время вызова одной из функций exec, операционная система DOS обнаружила некорректность среды для детского процесса. R6008 "Не хватает памяти для аргументов". R6009 "Не хватает памяти для программной среды". Ошибки R6008 и R6009 могут произойти при старте программы, если для загрузки программы хватает памяти, но недостаточно места для вектора argv, либо вектора envp, либо для обоих. Чтобы избежать данной проблемы перепишите процедуры _setargv или _setenvp R6012 "Некорректное обращение к ближнему указателю". В программе был использован нулевой ближний указатель. Данная ошибка может произойти только при включенном контроле на указатели (то есть, если программа была скомпилирована с опцией Pointer Check в диалоговой рамке Compile, опцией /Zr на команд- ной строке, либо при действующей прагме pointer_check). R6015 "Неожидаемое прерывание". Программа не может выполняться, поскольку она содержит неожида- емые прерывания. Когда прерывания создаются в программе из программного списка, работающей в программной среде, Quick-C автоматически создает объектные файлы и передает компановщику. Объектные файлы, пере- данные компановщику, содержат прерывания , требуемые для про- граммной среды Quick-C. Однако, вы не сможете запускать програ- мму, полученную из данных объектных файлов, вне программной среды Quick-C.
D.3.3. Ограничения периода выполнения.
В таблице D.2 приведены ограничения, накладываемые на программы в период выполнения. Если ваша программа нарушает одно из данных ограничений, система выдает соответствующее сообщение об ошибке.
Таблица D.2. Программные ограничения периода выполнения. Элемент данных Описание Ограничения Файлы Максимальный размер файла 232-1 байт (4 гигабайта) Максимальное число одновременно от- 20 крытых файлов (потоков). Командная строка Максимальное количество символов 128 (включая имя программы). Таблица операци- Максимальный размер. 32К онной среды.
Примечание:
Пять стандартных потоков открываются автоматически (stdin, stdout, stderr, stdaux, stdprn), оставляя еще 15 потоков для нужд программы.
D.4. Сообщения об ошибках компановщика.
Данный раздел описывает сообщения об ошибках, генерируемые компановщиком LINK (Оверлейный компановщик фирмы Microsoft). При возникновении фатальной ошибки компановщик прерывает выполнение. Сообщения о фатальных ошибках имеют следующий формат:
место возникновения: fatal error L1xxx: текст сообщения Нефатальные ошибки выявляют проблемы в выполняемом файле. Компановщик LINK строит выполняемый файл. Нефатальные ошибки имеют следующий формат:
место возникновения: error L2xxx: текст сообщения
Предупреждения также обозначают возможные проблемы в выполняемом файле. Компановщик LINK строит выполняемый файл. Предупреждения имеют следующий формат:
место возникновения: warning L4xxx: текст сообщения
В данных сообщениях-место возникновения-это входной файл, в котором обнаружена ошибка, либо программа LINK, если входного файла нет. Если входной файл-это файл .OBJ или .LIB и известно имя модуля, имя модуля заключается в скобки, как показано в следующем примере:
SLIBC.LIB( file) MAIN.OBJ(main.c) TEXT.OBJ
Ошибки компановщика могут возникнуть, как при неявном его вызове с помощью команды QCL, так и при явном вызове с помощью команды LINK. Они могут также произойти и при компиляции программы, имеющей программный список, либо когда вы создаете на диске выполняемый файл в среде Quick-C. Если ошибка компановщика возникает в программной среде Quick-C, Quick-C высвечивает сообщение:
Error during link phase No .EXE file produced (Ошибка в процессе компановки Выполняемого файла не создается).
Для просмотра ошибок компановщика нажмите ENTER, либо отметьте «мышью» командную кнопку OK. Ошибки последнего прохода компановщика хранятся в файле с именем LINK.ERR. В следующем списке приведены ошибки, возникающие во время компановки объектных файлов с помощью Microsoft Overlay Linker, LINK.
Номер Сообщение об ошибке компановщика L1001 "'option': имя опции неясно". После индикатора опции (/) не появилось уникального имени оп- ции. Например, команда Link /N main; сгенерирует ошибку, поскольку программа LINK не может опреде- лить, какая из опций, начинающихся на букву "N" имеется в виду. L1002 "'option': нераспознанное имя опции". За индикатором опции (/) появился нераспознанный символ, как в следующем примере: LINK /ABCDEF main; L1004 "'option': неверное числовое значение". Для одной из опций было задано некорректное числовое значение. Например, для опции, требующей числовое значение, задана сим- вольная строка. L1006 "'option': размер стэка превышает 65535 байтов". Размер, определенный для стэка, превышает 65535 байтов. l1007 "'option': номер прерывания превышает 255". В качестве значения опции /OVERLAYINTERRUPT задано число, более 255. l1008 "'option': слишком большое предельное число сегментов". Было установлено предельное число сегментов, большее 3072 ( с помощью опции /SEGMENTS). L1009 "'option': CPARMAXALLOC: некорректное значение". Число, определенное в опции /CPARMAXALLOC не лежит в пределах 1-65535. L1020 "Не заданы объектные модули". Для компановщика не заданы имена объектных файлов. L1021 "Файлы соответствий вкладывать невозможно". Один файл соответствий оказался внутри другого файла соответст- вий. L1022 "Файл соответствий слишком длинный". Строка в файле соответствий длиннее 127 символов. L1023 "Выполнение прекращено пользователем". Вы нажали CONTROL+C. L1024 "Вложение правых скобок". В командной строке содержимое оверлея было написано некоррекн- но. L1025 "Вложение левых скобок". В командной строке содержимое оверлея было написано некоррекн- но. L1026 "Несоответствие правых скобок". В командной строке в спецификации содержимого оверлея пропуще- на правая скобка. L1027 "Несоответствие левых скобок". В командной строке в спецификации содержимого оверлея пропуще- на левая скобка. L1043 "Таблица распределения памяти переполнена". В программе задано более 32768 длинных вызовов, длинных перехо- дов, либо других длинных указателей. Попытайтесь заменить длинные ссылки короткими, если возможно, и перестроить объектный модуль L1045 "Слишком много записей TYPDEF. Объектный модуль содержит более 255 записей TYPDEF. Данные за- писи описывают общие переменные. Такая ошибка может возникнуть только в программах, созданных компилятором Microsoft Quick-C или другими компиляторами, поддерживающими общие переменные. (TYPDEF-это термин операционной системы DOS. Он разъясняется в документе "Справочное руководство программиста по операционной системе MS-DOS фирмы Microsoft" или других справочных книг по DOS.) L1046 "Слишком много внешних имен в одном модуле". В объектном модуле определено более 1023 внешних имен. Разбейте модуль на меньшие части. L1047 "Слишком много имен групп, сегментов, классов в одном модуле". Программа содержит слишком много имен групп, сегментов, клас- сов. Сократите число групп, сегментов или классов и перестройте объектный файл. L1048 "Слишком много сегментов в одном модуле". Объектный модуль имеет более 255 сегментов. Расщепите модуль или объедините сегменты. L1049 "Слишком много сегментов". Программа имеет более, чем максимально разрешенное число сег- ментов. (опция /SEGMENTS определяет максимально разрешенное число; стандартно 128). Повторите компановку с опцией /SEGMENTS с соответствующим чис- лом сегментов. L1050 "Слишком много групп в одном модуле". Программа LINK обнаружила более 21 определения групп (GRPDEF) в одном модуле. Сократите число определений групп или расщепите модуль. (Опре- деления групп разъясняются в документе "Справочное руководство программиста по MS-DOS" и в других справочных книгах по DOS. L1051 "Слишком много групп". В программе определено более 20 групп, не считая DGROUP. Сократите количество групп. L1052 "Слишком много библиотек". Была сделана попытка скомпановать более 32 библиотек. Объедините библиотеки, либо используйте модули, требующие мень- шего количества библиотек. L1053 "Переполнение таблицы имен". Компановщик не имеет достаточно места для размещения таблицы имен программы (таких, как глобальные, внешние, имена сегмен- тов, групп, классов, файлов). Объедините модули или сегменты и перестройте объектные файлы. Исключите столько глобальных имен, сколько возможно. L1054 "Требуемое количество сегментов слишком велико". Компановщик не имеет достаточно памяти для размещения таблицы, описывающей количество требуемых сегментов (стандартное число 128 или значение, определенное в опции /SEGMENTS). Повторите компановку снова, используя опцию /SEGMENTS для задания меньше- го количества сегментов (например, 64, если ранее было исполь- зовано стандартное значение), либо освободите некоторое коли- чество памяти путем удаления резидентных программ или паралле- льных задач. L1056 "Слишком много оверлеев". В программе определно более 63 оверлеев. L1057 "Запись данных слишком велика". Запись LIDATA (в объектном модуле) содержит более 1024 байтов данных. Это ошибка транслятора. (LIDATA-это термин операционной системы DOS, его объяснение можно найти в документе "Справочное руководство программиста по MS-DOS фирмы Microsoft" или в дру- гих справочных книгах по DOS. Обратите внимание, какой транслятор (компилятор или ассемблер) построил некорректный объектный модуль и при каких обстоятель- ствах. Пожалуйста, сообщите о данной ошибке, используя форму Product Assistance Request, находящуюся в конце данного руко- водства. L1070 "'name': размер сегмента превышает 64К". Заданный сегмент содержит более 64К кода или данных. Повторите компиляцию и компановку в большой модели памяти. L1071 "Сегмент _TEXT больше 65520 байтов". Данная ошибка вероятнее всего может случиться только в СИ-прог- раммах малой модели памяти, однако она может произойти и, если любая программа с сегментом, названным _TEXT, компануется пос- редством команды LINK с опцией /DOSSEG. Программы на языке СИ малой модели памяти должны резервировать адреса кода 0 и 1; для целей выравнивания этот предел увеличивается до 16. L1072 "Общая область больше 65536 байтов". Программа имеет более 64 общих переменных. Данная ошибка не мо- жет возникнуть в объектных файлах, сгенерированных с помощью Макроассемблера MASM (Microsoft Macro Assembler). Она возникает только в программах, полученных с помощью компилятороа, поддер- живающих общие переменные. L1080 "Невозможно открыть файл-листинг". Диск или корневой каталог переполнены. Удалите или переместите файлы, чтобы освободить место. L1081 "Переполнение при записи выполняемого файла". Диск, на который записывается выполняемый файл .EXE, переполнен Освободите место на диске и повторите компановку. L1083 "Невозможно открыть выполняемый файл". Диск или корневой каталог переполнены. Удалите или переместите файлы, чтобы освободить место. L1084 "Невозможно создать временный файл". Диск или корневой каталог переполнены. Освободите место на диске и повторите компановку. L1085 "Невозможно открыть временный файл". Диск или корневой каталог переполнены. Удалите или переместите файлы, чтобы освободить место. L1086 "Не хватает временного файла". Заметьте обстоятельства возникновения данной ситуации и свяжи- тесь с фирмой Microsoft Corporation, воспользовавшись формой "Product Assitance Request", находящейся в конце данного руко- водства. L1087 "Неожиданный конец временного файла". Диск с временным выходным файлом компановщика удален. L1088 "Переполнение при записи файла-листинга". При записи на диск файла-листинга диск переполнился. Освободите место на диске и повторите компановку. L1089 "'filename': невозможно открыть файл соответствий". Программа LINK не может найти заданный файл соответствий. Обыч- но, это опечатка при задании имени файла. L1090 "Повторно открыть файл-листинг невозможно" По запросу оригинальный диск не был заменен. Повторите компа- новку. L1091 "Неожиданный конец файла в библиотеке". Диск, содержащий библиотеку, был вероятно, удален. Установите диск, содержащий библиотеку и повторите компановку. L1093 "'filename':объектный файл не найден". Компановщик не может найти заданного объектного файла. Задайте правильное имя объектного файла и повторите компановку. L1101 "Некорректный объектный модуль". Один из объектных модулей является некорректным. Если данная ошибка произошла после перекомпиляции, пожалуйста, свяжитесь с фирмой Microsoft Corporation, воспользовавшись формой "Product Assitance Request", приложенной в конце данного руководства. L1102 "Неожиданный конец файла". Для библиотеки был обнаружен некорректный формат. L1103 "Попытка обращения к данным, лежащим за границами сегмента". Заданная запись в объектном модуле продолжена за границы сег- мента. Это ошибка транслятора. Заметьте, какой транслятор (ком- пилятор или ассемблер) создал некорректный объектный модуль, и обстоятельства, в которых он был создан. Пожалуйста, сообщите о данной ситуации в фирму Microsoft Corporation, воспользовав- шись формой "Product Assistance Request", находящейся в конце данного руководства. L1104 "'filename': некорректная библиотека". Заданный файл не является корректным библиотечным файлом. Дан- ная ошибка прекращает работу программы LINK. L1113 "Неразрешенная COMDEF; системная ошибка". Заметьте обстоятельства возникновения данного сбоя и свяжитесь с фирмой Microsoft Corporation, воспользовавшись формой Product Assistance Request, находящейся в конце данного руководства. L1114 "Файл не подходит для /EXEPACK; повторите компановку без опции /EXEPACK". В компануемой программе размер упакованного загружаемого обра- за плюс заголовок больше, чем неупакованный загружаемый образ. Повторите компановку с помощью опции /EXEPACK. L2001 "Запись fixup без данных". Запись FIXUPP не имеет непосредственно предшествующей записи данных. Вероятно, это ошибка компилятора. (Подробности о FIXUPP смотрите в документе "Справочное руководство программис- та по MS-DOS фирмы Microsoft"). L2002 "Переполнение записи fixup при "ближнем" вызове 'number' frame seg 'segname' target seg 'segname' target offset 'number'" Данную ошибку могут вызвать следующие условия: -Программа компилируется в малой модели памяти с опцией /NT. -Группа больше 64К. -Программа содержит междусегментные короткие переходы или меж- дусегментные короткие вызовы. -Имя элемента данных в программе не соответствует процедуре из библиотеки процедур, подключенной к компановке. -Объявление EXTRN в исходном файле на яхыке ассемблер появилось в теле сегмента, как в следующем примере: code SEGMENT public 'CODE' EXTRN main:far start PROC far call main ret start ENDP code ENDS Предпочтительна следующая конструкция: EXTRN main:far code SEGMENT public 'CODE' start PROC far call main start ENDP code ENDS Перепишите исходный файл и перестройте объектный файл. (Подроб- ную информация о frame segment и target segment вы найдете в документе "Справочное руководство программиста по MS-DOS фирмы Microsoft".) L2003 "Дальний вызов на данные собственного сегмента". Дальние вызовы на данные собственного сегмента не разрешаются. L2005 "Тип fixup не поддерживается". Оказалось, что тип fixup не поддерживается компановщиком фирмы Microsoft. Вероятно, это ошибка компилятора. Обратите внимание на обстоятельства данной ошибки и сообщите их в фирму Microsoft Corporation, воспользовавшись формой "Product Assistance Request", находящейся в конце данного руководства. L2012 "'name': несоответствие размера элемента массива". "Дальний" общий массив был описан с двумя или более различны- ми размерами элементов массива (например, первый раз массив был описан, как массив символов, а второй раз, как массив дейст- вительных чисел). L2013 "Запись LIDATA слишком велика". Запись LIDATA в объектном модуле имеет размер более 512 байтов, максимально разрешенного размера. Это ошибка компилятора. По- жалуйста, сообщите об условиях возникновения данной ошибки в фирму Microsoft, воспользовавшись формой "Product Assistance Request" в конце данного руководства. L2024 "'name': имя уже определено". Одно из специальных оверлейных имен, требуемое для поддержки оверлеев, было определено в объектном файле. L2025 "'name': имя определено более одного раза". Удалите из объектного файла лишние определения имен. L2029 "Неразрешенные внешние ссылки". В одном или более модулей одно или более имен описаны, как внешние, но они не были определены, как публичные ни в одном из модулей или библиотек. После сообщения появляется список нераз- решенных внешних ссылок, как показано в следующем примере: EXIT in file(s): MAIN.OBJ (main.for) OPEN in file(s): MAIN.OBJ (main.for) Имя, которое идет перед 'in file(s)'-это неразрешенное внешнее имя. На следующей строке-список объектных модулей, имеющих ссы- лки на данное имя. Это сообщение и список записываются также в файл карты распределения памяти, если он существует. L2041 "Стэк плюс данные превышает 64К". Общий размер стэкового сегмента программы плюс DGROUP превышает 64К; в результате, программа загружается неверно. L2043 "Стартовый адрес__ aulstart не найден". Если вы строите библиотеку Quick с использованием опции /Q, компановщик требует имя __aulstart, определенное, как стар- товый адрес. L4003 "Неразрешенный вызов: смещение offset". Данная ошибка может быть вызвана компиляцией программы в малой модели памяти с опцией /NT. L4012 "Опция /HIGH отменяет /EXEPACK". Опции /HIGH и /EXEPACK не могут быть использованы одновременно. L4015 "Опция /CODEVIEW отменяет /DSALLOCATE". Опции /CODEVIEW и /DSALLOCATE не могут быть использованы одно- временно. L4016 "Опция /CODEVIEW отменяет /EXEPACK". Опции /CODEVIEW и /EXEPACK не могут быть использованы одно- временно. L4020 "'name': размер сегмента кода превышает 65500". Сегмент кода размером 65501-65536 байтов в длину может на про- цессоре Intel 80286 быть обработан некорректно. L4021 "Нет стэкового сегмента". Программа не имеет стэкового сегмента, определенного с типом STACK. Данное сообщение не возникнет при обработке модулей, скомпилированных с помощью компилятора Microsoft Quick-C, но не с помощью Макроассемблера. Обычно, каждая программа должна иметь стэковый сегмент с типом объединения STACK. Если у вас есть особые причины не определять стэк или определить его без типа объединения STACK, вы можете проигнорировать данное сообщение. Данное сообщение может быть получено и при компановке с помощью LINK версий 2.40 и младше, поскольку данные компановщики просматривают библиотеки только один раз. L4031 "'name': сегмент описан более, чем в одной группе". Сегмент был описан, как член двух различных групп. Исправьте исходный файл и перестройте объектные файлы. L4034 "Более 239 оверлейных сегментов; лишние помещены в корень". В оверлеях не может быть объявлено более 239 кодовых сегментов. Все сегменты свыше данного предела помещаются в корень. L4045 "Имя выходного файла 'name'". Компановщик высветил в запросе "Run file" стандартное выходное имя файла, но поскольку была использована опция /Q, имя выход- ного файла было изменено. L4050 "Слишком много глобальных имен". Для получения отсортированного списка глобальных имен в файле распределения памяти была использована опция /MAP, но задано для сортировки слишком много имен (более 2048 имен по умолча- нию). Повторите компановку с опцией /MAP:number. Компановщик выдает неотсортированный список глобальных имен. L4051 "'filename': невозможно найти библиотеку". Компановщик не может найти заданный файл. Введите новое имя, новую спецификацию маршрута, или и то, и другое. L4053 "VM.TMP: некорректное имя файла; игнорируется". Имя VM.TMP появилось, как объектное имя файла. Переименуйте файл и повторите компановку. L4054 "'filename': невозможно найти файл". Компановщик не может найти заданный файл. Введите новое имя файла, новую спецификацию маршрута, либо и то, и другое.
D.5.Сообщения об ошибках утилиты LIB.
Сообщения об ошибках, сгенерированные администратором библиотек, программой LIB, имеет один из следующих форматов:
{filename|LIB}: fatal error U1xxx: текст сообщения {filename|LIB}: error U2xxx: текст сообщения {filename|LIB}: warning U4xxx: текст сообщения
Сообщение начинается именем входного файла (filename), если он существует, либо именем утилиты. Если возможно, программа LIB распечатывает предупреждение и продолжает работу. В некоторых случаях ошибки неисправимы и утилита LIB прекращает работу. Утилита LIB может высветить следующие сообщения:
Номер Сообщения об ошибках утилиты LIB U1150 "Размер страницы слишком мал". Размер страницы входной библиотеки слишком мал, что означает некорректный входной файл .LIB. U1151 "Синтаксическая ошибка: неверная спецификация файла". Командный оператор, такой как знак минус(-) был задан без соот- ветствующего имени модуля. U1152 "Синтаксическая ошибка: наименование опции опущено". Знак опции слэш (/) был задан без следующей за ним опции. U1153 "Синтаксическая ошибка: значение опции пропущено". Опция /PAGESIZE была задана без соответствующего значения. U1154 "Неизвестная опция". Была задана неизвествная опция. В данный момент программа LIB распознает только опции /PAGESIZE. U1155 "Синтаксическая ошибка: некорректный ввод". Данная команда не следует правильному синтаксису утилиты LIB, описанному в Главе 10, "Создание библиотек Quick и автономных библиотек". U1156 "Синтаксическая ошибка". Данная команда не следует правильному синтаксису утилиты LIB, описанному в Главе 10, "Создание библиотек Quick и автономных библиотек". U1157 "Пропущена запятая или символ перехода на новую строку". В командной строке ожидалась запятая или возврат каретки, кото- рые не появились. Это может означать нечаянно поставленную запятую, как в следующей строке: LIB math.lib, -mod1+mod2; Эта строка должна иметь следующий вид: LIB math.lib -mod1+mod2; U1158 "Пропущен возврат каретки". Либо ответ на запрос "Output library", либо последняя строка в файле соответствий, используемого для запуска программы LIB, не заканчивается возвратом каретки. U1161 "Невозможно переименовать старую библиотеку". Программа LIB не может переименовать старую библиотеку с рас- ширением .BAK, поскольку версия .BAK уже существует с защитой "только-чтение". Измените защиту старой версии .BAK. U1162 "Невозможно повторно открыть библиотеку". Старая библиотека не может быть повторно открыта после того, как она была переименована с расширением .BAK. U1163 "Ошибка при записи файла перекрестных ссылок". Диск или корневая директория переполнены. Удалите или переком- пилируйте файлы, чтобы освободить место. U1170 "Слишком много имен". В библиотечном файле появилось более 4609 имен. U1171 "Не хватает памяти". Программе LIB не хватает памяти для работы. Удалите параллель- ные и резидентные программы и повторите попытку, либо увеличьте память. U1172 "Не хватает виртуальной памяти". Заметьте обстоятельства данного сбоя и уведомите фирму Microsoft Corporation, воспользовавшись формой "Product Assistance Request", находящейся в конце данного руководства. U1173 "Системный сбой". Обратите внимание на обстоятельства данного сбоя и уведомите фирму Microsoft Corporation, воспользовавшись формой "Product Assistance Request", находящейся в конце данного руководства. U1174 "mark: не размещено". Заметьте обстоятельства данного сбоя и уведомите фирму Microsoft Corporation, воспользовавшись формой "Product Assistance Request", находящейся в конце данного руководства. U1175 "free: не размещено". Заметьте обстоятельства данного сбоя и известите фирму Microsoft Corporation, воспользовавшись формой "Product Assistance Request", находящейся в конце данного руководства. U1180 "Запись извлекаемого файла потерпела неудачу". Диск или корневой каталог переполнены. Удалите или перемес- тите файлы, чтобы освободить место. U1181 "Запись в библиотечный файл потерпела неудачу". Диск или корневой каталог переполнены. Удалите или перемес- тите файлы, чтобы освободить место. U1182 "'filename': невозможно создать извлекаемый файл". Диск или корневой каталог переполнены, либо заданный извлекае- мый файл уже существует с защитой "только-чтение". Освободите место на диске, либо измените вид защиты файла. U1183 "Невозможно открыть файл соответствий". Данный файл соответствий не найден. U1184 "Неожиданный конец файла при вводе команды". В ответе на запрос был обнаружен символ конца файла. U1185 "Невозможно создать новую библиотеку". Диск или корневой каталог переполнены, либо библиотечный файл уже существует с защитой "только-чтение". Освободите место на диске или измените атрибуты защиты библиотечного файла. U1186 "Ошибка при записи новой библиотеки". Диск или корневой каталог переполнены. Удалите или переместите файлы для освобождения места. U1187 "Невозможно открыть VM.TMP". Диск или корневой каталог переполнены. U1188 "Невозможно записать в VM". Отметьте обстоятельства возникновения данного сбоя и сообщите в фирму Microsoft Corporation, воспользовавшись бланком "Product Assistance Request", находящейся в конце данного руко- водства. U1189 "Невозможно прочесть из VM". Обратите внимание на обстоятельства возникновения данной ошибки и сообщите в фирму Microsoft Corporation, воспользовавшись бланком "Product Assistance Request", находящейся в конце данного руководства. U1190 "Прервано пользователем". Вы прервали работу программы LIB до завершения работы. U1200 "'name': некорректный заголовок библиотеки". Входной библиотечный файл имеет неправильный формат. Он либо не является библиотечным файлом, либо разрушен. U1203 "'name': некорректный объектный модуль по ближнему адресу". Модуль, заданный по имени 'name', является некорректным объект- ным модулем. U2152 "'filename': невозможно создать листинг". Диск или каталог переполнены, либо файл перекрестных ссылок уже существует с защитой "только-чтение". Освободите место на диске, либо измените атрибуты файла. U2155 "'modulename': модуль не найден в библиотеке; игнорируется". Заданный модуль не найден во входной библиотеке U2157 "'filename': невозможно получить доступ к файлу". Программа LIB не могла открыть заданный файл. U2158 "'libraryname': неверный заголовок библиотеки; файл игнориру- ется". Входная библиотека имеет некорректный формат. U2159 "'filename': неверный формат 'hexnumber'; файл игнорируется". Опознавательный байт слова 'hexnumber' данного файла не имеет одного из следующих распознаваемых типов: библиотека Microsoft, библиотека Intel, объектный файл Micro- soft, архив XENIX. U4150 "'modulname': переопределение модуля игнорируется". Модуль был определен для добавления в библиотеку, но модуль с тем де именем уже есть в библиотеке. Либо, модуль с одним и тем же именем помещен в библиотеку дважды. U4151 "'symbol (modulename): переопределение имени игнорируется". Заданное имя определено более, чем в одном модуле. U4153 "'number': размер страницы слишком мал; игнорируется". Значение, определенное в опции /PAGESIZE меньше 16. U4156 "'libraryname': спецификация выходной библиотеки игнорируется". В дополнение к новому библиотечному имена была задана выходная библиотека. Например, задав: LIB new.lib+one.obj, new.lst,new.lib где new.lib еще не существует-вы получите ошибку.
D.6. Сообщения об ошибках утилиты MAKE.
Ошибки, высвечиваемые в процессе работы утилиты поддержки программ Microsoft (MAKE) имеют один из следующих форматов:
{filename|MAKE}: fatal error U1xxx: текст сообщения {filename|MAKE}: warning U4xxx: текст сообщения
Сообщения начинаются с имени входного файла (filename), если он существует, либо с имени утилиты. Если возможно, утилита MAKE печатает предупреждение и продолжает работу. В некоторых случаях ошибки являются неисправимыми и утилита MAKE прекращает работу. Сообщения, генерируемые утилитой MAKE, перечислены в данном разделе.
Номер Сообщения об ошибках утилиты MAKE U1001 "Макроопределение больше, чем number". Было определено макро, имеющее значение строки, длинее установ- ленного числа, разрешающего максимальную длину. Попытайтесь пе- реписать файл описанний утилиты MAKE и расщепить макро на два меньших. U1002 "Бесконечно рекурсивное макро". Был определен циклический вызов макрокоманд, как в следующем примере: A=$(B) B=$(C) C=$(A) U1003 "Выход за пределы памяти". Во время обработки файла описаний утилита MAKE вышла за пределы памяти. Попытайтесь сократить размер файла описаний утилиты MAKE путем его реорганизации или расщепления на меньшие. U1004 "Синтаксическая ошибка: пропущено имя макрокоманды". Файл описаний утилиты MAKE содержит макроопределение без левой части (то есть строки, начинающейся с =). U1005 "Синтаксическая ошибка: пропущено двоеточие". В строке, которая должна содержать выходной файл/входной файл, не хватает двоеточия, разделяющего выходной файл и входной файл. Утилита MAKE требует любую строку, за которой следует пустая строка, чтобы считать ее строкой выходного/входного фай- ла. U1006 "'targetname': макрорасширение больше числа 'number'". Макрорасширение плюс длина любой строки, с которой оно может быть объединено, длинее установленного числа. Попытайтесь пере- записать файл описаний утилиты MAKE, расшепив макро на два ме- ньших. U1007 "Много источников". Правило вывода были определено более одного раза. U1008 "'name': невозможно найти файл или каталог". Заданные файл или каталог не могут быть найдены. U1009 "'command': список аргументов слишком длинный". Командная строка в файле описаний утилиты MAKE длиннее 128 бай- тов, что максимально разрешено в DOS. Перепишите команды, чтобы сделать список аргументов короче. U1010 "'filename': отказ доступа". Файл, определенный, как 'filename'-имеет атрибут "только-чте- ние. U1011 "'filename': не хватает памяти". Для выполнения программы утилите MAKE не хватает памяти. U1012 "'filename': неизвестная ошибка". Заметьте обстоятельства возникновения данной ошибки и сообщите о них фирме Microsoft Corporation, воспользовавшись бланком "Product Assistance Request", данным в конце данного руко- водства. U1013"'command': ошибка errcode". Одна из программ или команд, вызванная в файле описаний утилиты MAKE, завершилась с ненулевым кодом завершения. U1015 "'file': целевой файл не существует". Обычно, это не означает ошибку. Данное сообщение предупреждает пользователя о том, что целевой файл не существует. Утилита MAKE выполняет любые команды, заданные в блоке описаний, поско- льку в большинстве случаев выходной файл создается последней командой файла описаний утилиты MAKE. U4000 "'filename': не существует". Обычно, это сообщение не свидетельствует об ошибке. Оно пре- дупреждает пользователя о том, что указанный файл не существует MAKE выполняет все команды, заданные в блоке, так как в боль- шистве случаев отсутствующий файл будет создан последующими командами файла MAKE. U4001 "Зависимый файл 'filename' не существует; целевой файл 'filena me' не строится". Утилита MAKE не может продолжать, поскольку требуемый входной файл не существует. Удостоверьтесь, что все имена файлов при- сутствуют и что все они корректно описываются в файле описаний утилиты MAKE. U4013 "'command': ошибка errcode (игнорируется)". Одна из программ или команд, вызванных в файле описаний утилиты MAKE, возвратила ненулевой код ошибки, в то время, как утилита MAKE работала с опцией /I. Ошибки игнорируются и утилита про- должает работу. U4014 "Синтаксис: make options [name-value...] file options=[/n] [/d][/i][/s][/x file] Утилита MAKE была неправильно вызвана. Стартуйте утилиту зано- во, воспользовавшись синтаксисом, представленным в сообщении: make опции[имя-значение...] file опции=[/n][/d][/i][/s] [/x file].
Классификация ошибок
Отладка – это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
В целом сложность отладки обусловлена следующими причинами:
- требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
- психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
- возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
- отсутствуют четко сформулированные методики отладки.
В соответствии с этапом обработки, на котором проявляются ошибки, различают:
- синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы;
- логические ошибки — …;
- ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
- ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых.
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами, обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
- появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
- появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
- «зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
- несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
- неверное определение исходных данных,
- логические ошибки,
- накопление погрешностей результатов вычислений.

Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
- ручного тестирования;
- индукции;
- дедукции;
- обратного прослеживания.
Метод ручного тестирования
Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которыми была обнаружена ошибка. Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций. Данный метод часто используют как составную часть других методов отладки.
Метод индукции
Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рисунке в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о её проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов. В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции
По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину.
Метод обратного прослеживания
Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Методы и средства получения дополнительной информации
Для получения дополнительной информации об ошибке можно выполнить добавочные тесты или использовать специальные методы и средства:
- отладочный вывод;
- интегрированные средства отладки;
- независимые отладчики.
Отладочный вывод. Метод требует включения в программу дополнительного отладочного вывода в узловых точках. Узловыми считают точки алгоритма, в которых основные переменные программы меняют свои значения. Например, отладочный вывод следует предусмотреть до и после завершения цикла изменения некоторого массива значений. (Если отладочный вывод предусмотреть в цикле, то будет выведено слишком много значений, в которых, как правило, сложно разбираться.) При этом предполагается, что, выполнив анализ выведенных значений, программист уточнит момент, когда были получены неправильные значения, и сможет сделать вывод о причине ошибки.
Данный метод не очень эффективен и в настоящее время практически не используется, так как в сложных случаях в процессе отладки может потребоваться вывод большого количества — «трассы» значений многих переменных, которые выводятся при каждом изменении. Кроме того, внесение в программы дополнительных операторов может привести к изменению проявления ошибки, что нежелательно, хотя и позволяет сделать определенный вывод о ее природе.
Примечание. Ошибки, исчезающие при включении в программу или удалению из нее каких-либо «безобидных» операторов, как правило, связаны с «затиранием» памяти. В результате добавления или удаления операторов область затирания может сместиться в другое место и ошибка либо перестанет проявляться, либо будет проявляться по-другому.
Интегрированные средства отладки. Большинство современных сред программирования (Delphi, Builder C++, Visual Studio и т. д.) включают средства отладки, которые обеспечивают максимально эффективную отладку. Они позволяют:
- выполнять программу по шагам, причем как с заходом в подпрограммы, так и выполняя их целиком;
- предусматривать точки останова;
- выполнять программу до оператора, указанного курсором;
- отображать содержимое любых переменных при пошаговом выполнении;
- отслеживать поток сообщений и т. п.
Отладка с использованием независимых отладчиков.
При отладке программ иногда используют специальные программы — отладчики, которые позволяют выполнить любой фрагмент программы в пошаговом режиме и проверить содержимое интересующих программиста переменных. Как правило такие отладчики позволяют отлаживать программу только в машинных командах, представленных в 16-ричном коде.
Общая методика отладки программного обеспечения
Суммируя все сказанное выше, можно предложить следующую методику отладки программного обеспечения:
1 этап — изучение проявления ошибки — если выдано какое-либо сообщение или выданы неправильные или неполные результаты, то необходимо их изучить и попытаться понять, какая ошибка могла так проявиться. При этом используют индуктивные и дедуктивные методы отладки. В результате выдвигают версии о характере ошибки, которые необходимо проверить. Для этого можно применить методы и средства получения дополнительной информации об ошибке. Если ошибка не найдена или система просто «зависла», переходят ко второму этапу.
2 этап — локализация ошибки — определение конкретного фрагмента, при выполнении которого произошло отклонение от предполагаемого вычислительного процесса. Локализация может выполняться:
- путем отсечения частей программы, причем, если при отсечении некоторой части программы ошибка пропадает, то это может означать как то, что ошибка связана с этой частью, так и то, что внесенное изменение изменило проявление ошибки;
- с использованием отладочных средств, позволяющих выполнить интересующих нас фрагмент программы в пошаговом режиме и получить дополнительную информацию о месте проявления и характере ошибки, например, уточнить содержимое указанных переменных.
При этом если были получены неправильные результаты, то в пошаговом режиме проверяют ключевые точки процесса формирования данного результата. Как подчеркивалось выше, ошибка не обязательно допущена в том месте, где она проявилась. Если в конкретном случае это так, то переходят к следующему этапу.
3 этап — определение причины ошибки — изучение результатов второго этапа и формирование версий возможных причин ошибки. Эти версии необходимо проверить, возможно, используя отладочные средства для просмотра последовательности операторов или значений переменных.
4 этап — исправление ошибки — внесение соответствующих изменений во все операторы, совместное выполнение которых привело к ошибке.
5 этап — повторное тестирование — повторение всех тестов с начала, так как при исправлении обнаруженных ошибок часто вносят в программу новые.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию:
- программу наращивать «сверху-вниз», от интерфейса к обрабатывающим подпрограммам, тестируя ее по ходу добавления подпрограмм;
- выводить пользователю вводимые им данные для контроля и проверять их на допустимость сразу после ввода;
- предусматривать вывод основных данных во всех узловых точках алгоритма (ветвлениях, вызовах подпрограмм).
Кроме того, следует более тщательно проверять фрагменты программного обеспечения, где уже были обнаружены ошибки, так как вероятность ошибок в этих местах по статистике выше. Это вызвано следующими причинами. Во-первых, ошибки чаще допускают в сложных местах или в тех случаях, если спецификации на реализуемые операции недостаточно проработаны. Во-вторых, ошибки могут быть результатом того, что программист устал, отвлекся или плохо себя чувствует. В-третьих, как уже упоминалось выше, ошибки часто появляются в результате исправления уже найденных ошибок.
Источник:
-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
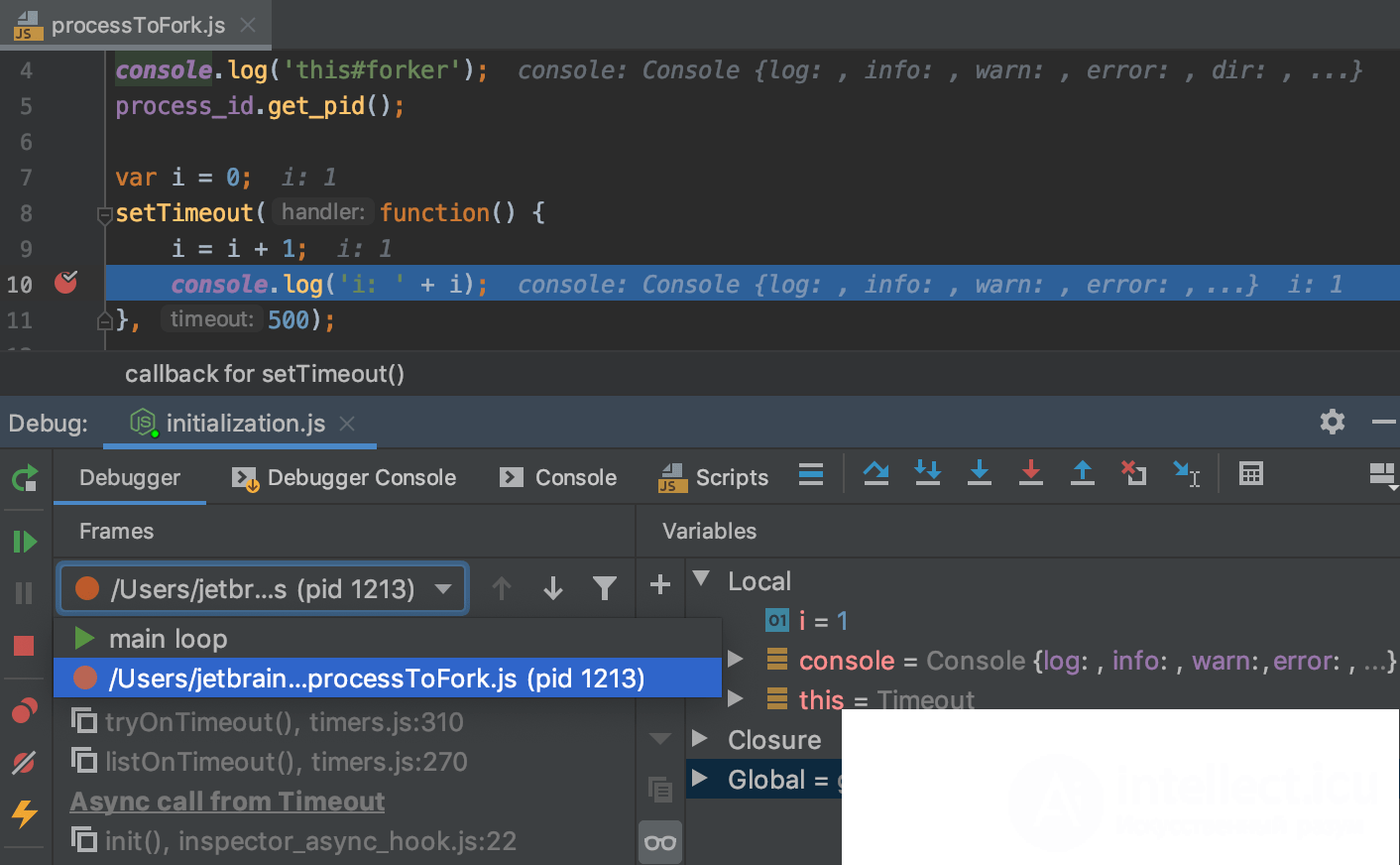 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
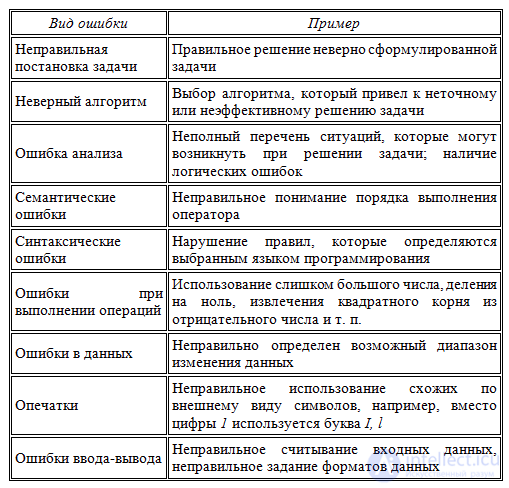
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
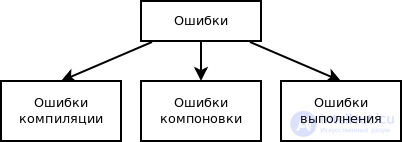
Классификация ошибок по этапу обработки программы
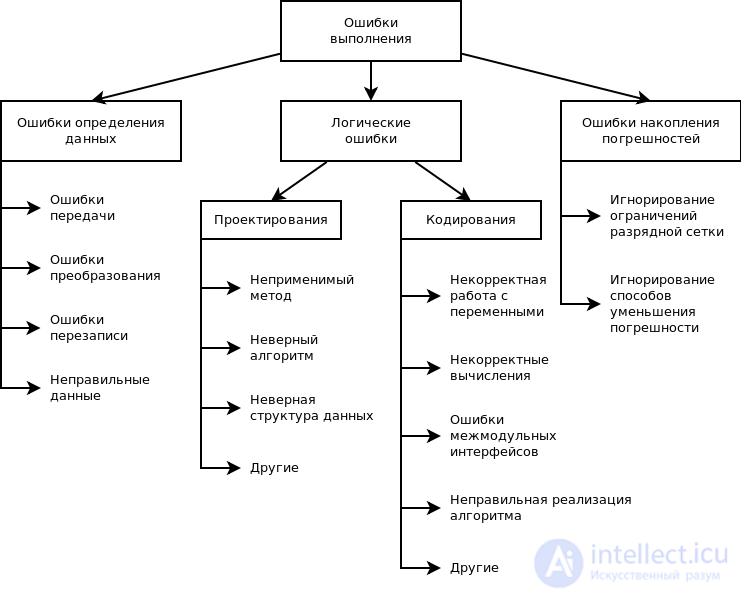
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
From Wikipedia, the free encyclopedia
Compilation error refers to a state when a compiler fails to compile a piece of computer program source code, either due to errors in the code, or, more unusually, due to errors in the compiler itself. A compilation error message often helps programmers debugging the source code. Although the definitions of compilation and interpretation can be vague, generally compilation errors only refer to static compilation and not dynamic compilation. However, dynamic compilation can still technically have compilation errors,[citation needed] although many programmers and sources may identify them as run-time errors. Most just-in-time compilers, such as the Javascript V8 engine, ambiguously refer to compilation errors as syntax errors since they check for them at run time.[1][2]
Examples[edit]
Common C++ compilation errors[edit]
- Undeclared identifier, e.g.:
doy.cpp: In function `int main()':[3]
doy.cpp:25: `DayOfYear' undeclared (first use this function)
This means that the variable «DayOfYear» is trying to be used before being declared.
- Common function undeclared, e.g.:
xyz.cpp: In function `int main()': xyz.cpp:6: `cout' undeclared (first use this function)[3]
This means that the programmer most likely forgot to include iostream.
- Parse error, e.g.:
somefile.cpp:24: parse error before `something'[4]
This could mean that a semi-colon is missing at the end of the previous statement.
Internal Compiler Errors[edit]
An internal compiler error (commonly abbreviated as ICE) is an error that occurs not due to erroneous source code, but rather due to a bug in the compiler itself. They can sometimes be worked around by making small, insignificant changes to the source code around the line indicated by the error (if such a line is indicated at all),[5][better source needed] but sometimes larger changes must be made, such as refactoring the code, to avoid certain constructs. Using a different compiler or different version of the compiler may solve the issue and be an acceptable solution in some cases. When an internal compiler error is reached many compilers do not output a standard error, but instead output a shortened version, with additional files attached, which are only provided for internal compiler errors. This is in order to insure that the program doesn’t crash when logging the error, which would make solving the error nigh impossible. The additional files attached for internal compiler errors usually have special formats that they save as, such as .dump for Java. These formats are generally more difficult to analyze than regular files, but can still have very helpful information for solving the bug causing the crash.[6]
Example of an internal compiler error:
somefile.c:1001: internal compiler error: Segmentation fault Please submit a full bug report, with preprocessed source if appropriate. See <http://bugs.gentoo.org/> for instructions.
References[edit]
- ^ «Errors | Node.js v7.9.0 Documentation». nodejs.org. Retrieved 2017-04-14.
- ^ «SyntaxError». Mozilla Developer Network. Retrieved 2017-04-14.
- ^ a b «Common C++ Compiler and Linker Errors». Archived from the original on 2008-02-16. Retrieved 2008-02-12.
- ^ «Compiler, Linker and Run-Time Errors».
- ^ Cunningham, Ward (2010-03-18). «Compiler Bug». WikiWikiWeb. Retrieved 2017-04-14.
- ^ జగదేశ్. «Analyzing a JVM Crash». Retrieved 2017-04-15.