
Опираясь на статистику легко лгать,
но без статистики очень трудно выяснить истину.
В любом научном исследовании главное — это полученные результаты. Однако, для того чтобы из них можно было сделать выводы, требуется статистическая обработка полученных данных.
Для тех, кто хорошо разбирается в математике, статистика не вызывает серьезных затруднений. Тем не менее разнообразные исследования показывают, что значительная доля научных публикаций содержит те или иные статистические ошибки. Об ошибках при переводе научных работ читайте в статье.
В. Джонсон из Техасского университета считает, что плохая статистика является одной из главных причин недостаточной воспроизводимости результатов в психологических исследованиях.
В этой статье мы расскажем о часто встречающихся ошибках статистического анализа и о том, как их избежать. С полезными сервисами для авторов можно ознакомиться здесь.
Содержание статьи
- 1. Сколько вешать в граммах?
- 2. Разбивка непрерывных данных на группы.
- 3. Среднее и сигмальное отклонение, медиана и доверительный интервал.
- 4. p-критерий.
- 5. Адекватность модели.
- 6. Понятие нормы.
- 7. Учет сомнительных и неопределенных результатов.
- 8. Понятие объекта исследования.
- 9. Статистическая значимость полученных результатов.
- 10. Влияние факторов риска.
- Заключение
1. Сколько вешать в граммах?
Любой ученый дорожит полученными результатами. Каждая цифра представляется нам достаточно значимой, чтобы представить ее в том виде, в котором она была получена. Получили вес 60,245 кг — так и запишем. Часто кажется, что, округляя данные, мы обесцениваем собственный труд.
Однако, с точки зрения читателя излишняя точность скорее мешает. Цифры с длинными хвостами трудно воспринимать и оценивать. Если их можно округлить без ущерба для точности выводов, нужно это сделать. Например, ни для каких целей нет смысла указывать вес взрослого человека с точностью до грамма.
Учитывайте при округлении точность приборов. Если весы дают погрешность более 100 граммов, указывать десятые доли килограмма не стоит.
При округлении процентов в научных статьях рекомендуется использовать следующие правила: если выборка больше 1 000, результат округляется до сотых; от 100 до 1 000 – до десятых; от 20 до 100 – до целых значений процентов. Для выборки менее 20, лучше дать абсолютные значения. В маленьких группах проценты скорее запутывают читателя и часто выглядят курьезно: в результате лечения 33, 333% животных выздоровели; 33, 333% погибли; третья мышь убежала.
Количество знаков после запятой должно быть одинаковым во всей статье. Если все результаты округляются до сотых, а какой-то из них имеет вид целого числа, то его нужно записать так же, как все остальные цифры, например 24,00.
2. Разбивка непрерывных данных на группы.
Такие данные, как рост, вес или возраст часто делят на категории. Разбивка упрощает статистический анализ, но в любом случае необходимо обосновать принципы, по которым это сделано.
Деление на категории может приводить к некорректным выводам. Например, если выборку разделили на пациентов с нормальной массой тела, дефицитом и избытком массы, то различия между людьми с весом 80 и 150 килограммов могут быть больше, чем между людьми с весом 70 и 80 килограммов, хотя в первом случае они входят в одну группу (с избытком массы), а во втором — в разные.
3. Среднее и сигмальное отклонение, медиана и доверительный интервал.
Представление в статье только средних групповых значений без учета индивидуальных различий может приводить к неверным выводам. Пресловутая средняя температура по больнице не дает представления не только обо всех пациентах, но даже о большинстве из них.
Средняя величина и среднее квадратическое отклонение или сигмальное отклонение δ (standard deviation — sd) описывают вариабельность выборки.
Среднее квадратическое отклонение применяется только в случае нормального распределения данных, то есть когда 68% показателей находятся в пределах ±1δ, 95% в пределах ±2δ, и 99% в пределах ±3δ.
При асимметричном распределении данных среднее квадратическое отклонение не дает правильного представления о выборке. В этом случае используется медиана median и межквартильный диапазон interquartile range (IQR) (как правило, от 25 до 75 центиля).
Точечные данные характеризуют такие показатели, как стандартная ошибка среднего и доверительный интервал.
Стандартная ошибка среднего standard error of the mean (m) показывает отличие фактических данных от значений, полученных на модели. Она позволяет оценить точность модели.
Доверительный интервал confidence interval (CI) демонстрирует, насколько выборка отражает свойства генеральной совокупности. В медицинских исследованиях обычно указывают 95% доверительный интервал.
Средняя величина, указанная без доверительного интервала, не дает полного и правильного представления о полученном эффекте. Например, если среднее снижение артериального давления 20 мм. рт. ст., эффект может показаться клинически значимым. Однако при 95% доверительном интервале от 5 до 30 мм. рт. ст. целесообразность применяемой схемы лечения уже представляется сомнительной, так как снижение показателя на 5 мм. рт. ст. клинически несущественно. Окончательный вывод о целесообразности изучаемой схемы лечения из этих результатов сделать нельзя.
Важно: в медицинских исследованиях результаты, подчиняющиеся нормальному распределению, встречаются довольно редко. Кроме того, средняя величина и среднее квадратическое отклонение плохо работают на малых выборках.
4. p-критерий.
Критерий р недостаточно информативен в медицинских и биологических исследованиях.
Дело в том, что статистическая значимость не равна клиническому значению и целесообразности использования тех или иных выводов на практике. Решение о рациональности использования препарата не может опираться только на статистическую значимость полученного клинического эффекта. Например, статистически значимое снижение артериального давления на 10 мм. рт. ст. клинически можно расценивать как отсутствие эффекта.
р-критерий не может равняться нулю. Это значило бы, что между группами есть действительно достоверное различие. Однако, такое различие невозможно установить методами статистики. Обычно эта ошибка связана с тем, что программы для статистической обработки данных приводят очень малые значения как р=0,00000. На самом деле это означает p<0,000001, что и должно быть указано в статье.
р-критерий не применяется к генеральной совокупности. Он показывает, что имеющиеся различия не являются случайностью и такой же результат может быть получен на другой выборке. В случае генеральной совокупности этот показатель не имеет смысла, так как речь о случайности различий не идет.
Если в исследовании участвует несколько групп, определение нескольких p-критериев повышает вероятность принять случайное совпадение фактов за причинно-следственную связь. Существует несколько методов решения проблемы множественных сравнений, их использование должно быть обосновано и описано.
В рандомизированных клинических исследованиях р-критерий указывать необязательно, так как исходные различия между группами всегда имеют место в силу случайности выбора.
5. Адекватность модели.
Регрессионные модели не работают, если зависимость между переменными не имеет линейного характера.
Чтобы подтвердить или опровергнуть линейный характер связи между величинами, нужно изучить остатки residuals, то есть отклонение реальных данных от линии регрессии, построенной на основании модели.
Регрессионная модель хорошо объясняет реальное положение дел, если остатки:
- независимы
- подчиняются нормальному распределению
- имеют нулевое среднее
- в их величинах нет тренда
Дисперсия остатков variance of the residuals показывает те изменения полученных данных, которые не объясняются моделью. Чем меньше дисперсия, тем лучше работает модель.
6. Понятие нормы.
Отсутствие четкого понимания, что следует принять за норму является серьезным недостатком клинических исследований.
Для определения нормы существует несколько подходов:
- результат говорит о наличии или отсутствии заболевания
- является показанием к назначению лечения
- указывает на риск развития болезни
- встречается у здоровых лиц
- укладывается в определенный диапазон значений
Далеко не во всех случаях норма клинически значима. Например, несовпадение индивидуальных сроков прорезывания зубов с нормальными, как правило, ни о чем не говорит.
Причины, по которым тот или иной показатель принят за норму, должны быть обоснованы.
7. Учет сомнительных и неопределенных результатов.
В медицинских и клинических исследованиях не всегда ясно, как учитываются сомнительные результаты при определении чувствительности и специфичности тестов. При наличии значительного процента сомнительных результатов практическая значимость выводов снижается.
Результат нельзя однозначно оценить как отрицательный или положительный если:
- получены пограничные значения показателя;
- интенсивность окрашивания препарата недостаточная;
- ответы на вопросы психологических тестов неоднозначные;
- нарушены стандарты при проведении исследования.
Если в статистический анализ включены не все результаты и не все участники исследования, возникают вопросы:
- Данные пропустили по ошибке или сознательно исключили из анализа, поскольку они противоречат первоначальной гипотезе и выводам?
- Не приведет ли исключение некоторых данных к тому, что результаты не будут воспроизводиться на другой выборке или при повторном исследовании?
- Если данные не были представлены полностью, то можно ли доверять другим фактам, содержащимся в статье?
Все это не украшает автора и снижает ценность его работы в глазах читателя и редактора журнала. Поэтому в статье нужно указать наличие и количество сомнительных и неопределенных результатов; пояснить, включались ли они в статистический анализ и как были интерпретированы.
8. Понятие объекта исследования.
Неверное определение объекта исследования может приводить к ошибкам и неточностям.
В клинических исследованиях объектом принято считать пациента. Когда в работе о методах лечения переломов единицей учета является не пациент, а сломанная кость, возникает вопрос, сколько больных участвовали в исследовании. Тем более непонятно, что означает 50% эффективность.
Если объектом исследования является язвенная болезнь, то размер выборки будет соответствовать количеству выявленных случаев заболевания, а не количеству обследованных пациентов.
В работах, основанных на заключениях специалистов, может быть необходимым исследовать выборку специалистов, а не общий массив заключений.
9. Статистическая значимость полученных результатов.
Статистическая значимость Statistical significance не равна клиническому значению.
При сравнении больших выборок статистически значимыми могут оказаться различия, не имеющие никакой реальной важности. Например, при среднем сроке службы приборов 5 лет различия на 1-2 недели клинического значения не имеют.
Наоборот, в малых выборках статистически незначимые различия могут быть важными клинически. Например, если в группе из нескольких больных в терминальном состоянии выжил хотя бы один, это безусловно клинически значимо.
10. Влияние факторов риска.
Истинное влияние фактора риска показывает относительный риск relative risk (RR) — отношение риска наступления исхода у подвергавшихся воздействию фактора к риску в контрольной группе. Этот показатель можно рассчитать, если группы набираются по принципу наличия и отсутствия фактора риска.
Если же группы набираются по принципу наличия или отсутствия исхода, то влияние можно оценить только приблизительно, используя показатель отношения шансов odds ratio (OR), описывающий силу связи между факторами.
Заключение
Главный вывод из сказанного: методы статистического анализа должны соответствовать характеру данных. Выбор тех или иных методов анализа нужно обосновать. Во избежание ошибок учтите:
- Характер распределения данных. Нормальное и асимметричное распределение требует разных подходов к анализу.
- Для анализа независимых выборок и парных данных (относящихся к одному и тому же участнику исследования) используются разные методы.
- Характер связи между переменными. Линейный характер связи позволяет использовать регрессионные модели. Чтобы подтвердить или опровергнуть линейную зависимость, нужно проанализировать остатки.
- В медицинских исследованиях клиническая значимость имеет приоритет над статистической.
- Норма должна быть клинически значимой; а выбор значения, принимаемого за норму, нужно обосновать.
- При наличии сомнительных или неопределенных результатов следует объяснить, как они учитываются в статистическом анализе.
- Объектом исследования следует считать человека или животное, а не болезнь и не клинический случай, так как два и более клинических случая могут иметь отношение к одному пациенту.
Статистические показатели в любом случае можно улучшить увеличением числа участников. По мнению В. Джонсона, принимая эталонное значение р-критерия в медицинских и биологических исследованиях на уровне <0.0005, можно существенно повысить качество статистики.
Часто ошибки статистического анализа вытекают из того, что эксперимент или исследование было изначально неправильно спланировано. В сомнительных случаях стоит обратиться к специалистам по статистике, однако делать это нужно на этапе подготовки, а не тогда, когда все работы уже завершены и возник вопрос, что же теперь делать с этими цифрами.
Современные программы для статистической обработки данных сильно облегчают вычисления, однако они не решают проблему выбора адекватных методов анализа и соответствия их характеру полученных данных. Поэтому залог успеха — тщательная подготовка исследования. Убедитесь, что материалы и методы, статистический анализ результатов и выводы соответствуют цели исследования.
Присоединяйтесь, чтобы моментально узнавать о новых статьях в нашем научном блоге, акциях и получать только полезные материалы!

При работе с big data ошибок не избежать. Вам нужно докопаться до сути данных, расставить приоритеты, оптимизировать, визуализировать данные, извлечь правильные идеи. По результатам опросов, 85 % компаний стремятся к управлению данными, но только 37% сообщают об успехах в этой области. На практике изучать негативный опыт сложно, поскольку о провалах никто не любит говорить. Аналитики с удовольствием расскажут об успехах, но как только речь зайдет об ошибках, будьте готовы услышать про «накопление шума», «ложную корреляцию» и «случайную эндогенность», и без всякой конкретики. Действительно ли проблемы с big data существуют по большей части лишь на уровне теории?
Сегодня мы изучим опыт реальных ошибок, которые ощутимо повлияли на пользователей и аналитиков.
Ошибки выборки

В статье «Big data: A big mistake?» вспомнили об интересной истории со стартапом Street Bump. Компания предложила жителям Бостона следить за состоянием дорожного покрытия с помощью мобильного приложения. Софт фиксировал положение смартфона и аномальные отклонения от нормы: ямы, кочки, выбоины и т.д. Полученные данные в режиме реального времени отправлялись нужному адресату в муниципальные службы.
Однако в какой-то момент в мэрии заметили, что из богатых районов жалоб поступает гораздо больше, чем из бедных. Анализ ситуации показал, что обеспеченные жители имели телефоны с постоянным подключением к интернету, чаще ездили на машинах и были активными пользователями разных приложений, включая Street Bump.
В результате основным объектом исследования стало событие в приложении, но статистически значимой единицей интереса должен был оказаться человек, использующий мобильное устройство. Учитывая демографию пользователей смартфонов (на тот момент это в основном белые американцы со средним и высоким уровнем дохода), стало понятно, насколько ненадежными оказались данные.
Проблема неумышленной предвзятости десятилетиями кочует из одного исследования в другое: всегда будут люди, активнее других пользующиеся соцсетями, приложениями или хештегами. Самих по себе данных оказывается недостаточно — первостепенное значение имеет их качество. Подобно тому, как вопросники влияют на результаты опросов, электронные платформы, используемые для сбора данных, искажают результаты исследования за счет воздействия на поведение людей при работе с этими платформами.
По словам авторов исследования «Обзор методов обработки селективности в источниках больших данных», существует множество источников big data, не предназначенных для точного статистического анализа — опросы в интернете, просмотры страниц в Твиттере и Википедии, Google Trends, анализ частотности хештегов и др.
Одной из самых ярких ошибок такого рода является прогнозирование победы Хилари Клинтон на президентских выборах в США в 2016 году. По данным опроса Reuters/Ipsos, опубликованным за несколько часов до начала голосования, вероятность победы Клинтон составляла 90%. Исследователи предполагают, что методологически сам опрос мог быть проведен безупречно, а вот база, состоящая из 15 тыс. человек в 50 штатах, повела себя иррационально — вероятно, многие просто не признавались, что хотят проголосовать за Трампа.
Ошибки корреляций
Непонятная корреляция и запутанная причинно-следственная связь часто ставят в тупик начинающих дата-сайнтистов. В результате появляются модели, безупречные с точки зрения математики и совершенно не жизнеспособные в реальности.

На диаграмме выше показано общее количество наблюдений НЛО с 1963 года. Число зарегистрированных случаев из базы данных Национального центра отчетности по НЛО в течение многих лет оставалось примерно на одном уровне, однако в 1993 году произошел резкий скачок.
Таким образом, можно сделать совершенно логичный вывод, что 27 лет назад пришельцы всерьез взялись за изучение землян. Реальная же причина заключалась в том, что в сентябре 1993 года вышел первый эпизод «Секретных материалов» (на пике его посмотрели более 25 млн человек в США).
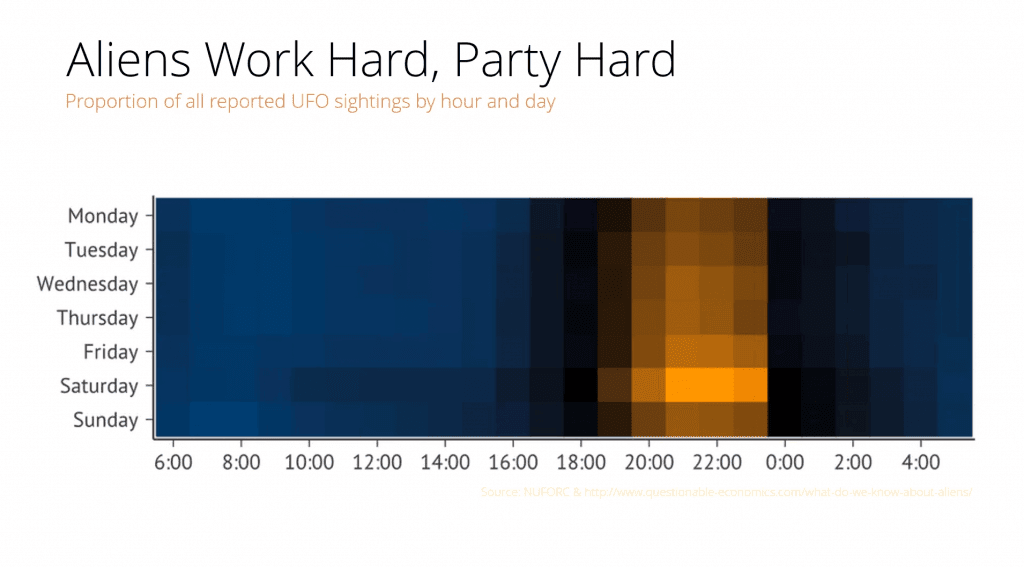
Теперь взгляните на данные, которые показывают частоту наблюдений НЛО в зависимости от времени суток и дня недели: желто-оранжевым окрашена наибольшая частота случаев наблюдения. Очевидно, что пришельцы чаще высаживаются на Землю в выходные, потому что в остальное время они ходят на работу. Значит, исследование людей для них — хобби?
Эти веселые корреляции имеют далеко идущие последствия. Так, например, исследование «Доступ к печати в сообществах с низким уровнем дохода» показало, что школьники, имеющие доступ к большему количеству книг, получают лучшие оценки. Руководствуясь данными научной работы, власти Филадельфии (США) занялись реорганизацией системы образования.
Пятилетний проект предусматривал преобразование 32 библиотек, что обеспечило бы равные возможности для всех детей и семей в Филадельфии. На первый взгляд, план выглядел великолепно, но, к сожалению, в исследовании не учитывалось, действительно ли дети читали книги — в нем лишь рассматривался вопрос, доступны книги или нет.
В итоге значимых результатов добиться не удалось. Дети, не читавшие книги до исследования, не полюбили вдруг чтение. Город потерял миллионы долларов, оценки у школьников из неблагополучных районов не улучшились, а дети, воспитанные на любви к книгам, продолжили учиться так же, как учились.
Потеря данных

(с)
Иногда выборка может быть верной, но авторы просто теряют необходимые для анализа данные. Так произошло в работе, широко разошедшейся по миру под названием «Фрикономика». В книге, общий тираж которой превысил 4 млн экземпляров, исследовался феномен возникновения неочевидных причинно-следственных связей. Например, среди громких идей книги звучит мысль, что причиной спада подростковой преступности в США стал не рост экономики и культуры, а легализация абортов.
Авторы «Фрикономики», профессор экономики Чикагского университета Стивен Левитт и журналист Стивен Дабнер, через несколько лет признались, что в итоговое исследование абортов попали не все собранные цифры, поскольку данные просто исчезли. Левитт объяснил методологический просчет тем, что в тот момент «они очень устали», и сослался на статистическую незначимость этих данных для общего вывода исследования.
Действительно ли аборты снижают количество будущих преступлений или нет — вопрос все еще дискуссионный. Однако у авторов подметили множество других ошибок, и часть из них удивительно напоминает ситуацию с популярностью уфологии в 1990-х годах.
Ошибки анализа

(с)
Биотех стал для технологических предпринимателей новым рок-н-роллом. Его также называют «новым IT-рынком» и даже «новым криптомиром», имея ввиду взрывную популярность у инвесторов компаний, занимающихся обработкой биомедицинской информации.
Являются ли данные по биомаркерам и клеточным культурам «новой нефтью» или нет — вопрос второстепенный. Интерес вызывают последствия накачки индустрии быстрыми деньгами. В конце концов, биотех может представлять угрозу не только для кошельков венчурных фондов, но и напрямую влиять на здоровье людей.
Например, как указывает генетик Стивен Липкин, для генома есть возможность делать высококлассные анализы, но информация о контроле качества часто закрыта для врачей и пациентов. Иногда до заказа теста вы не можете заранее узнать, насколько велика глубина покрытия при секвенировании. Когда ген прочитывают недостаточное число раз для адекватного покрытия, программное обеспечение находит мутацию там, где ее нет. Зачастую мы не знаем, какой именно алгоритм используется для классификации аллелей генов на полезные и вредные.
Тревогу вызывает большое количество научных работ в области генетики, в которых содержатся ошибки. Команда австралийских исследователей проанализировала около 3,6 тыс. генетических работ, опубликованных в ряде ведущих научных журналов. В результате обнаружилось, что примерно одна из пяти работ включала в свои списки генов ошибки.
Поражает источник этих ошибок: вместо использования специальных языков для статистической обработки данных ученые сводили все данные в Excel-таблице. Excel автоматически преобразовывал названия генов в календарные даты или случайные числа. А вручную перепроверить тысячи и тысячи строк просто невозможно.
В научной литературе гены часто обозначаются символами: например, ген Септин-2 сокращают до SEPT2, а Membrane Associated Ring Finger (C3HC4) 1 — до MARCH1. Excel, опираясь на настройки по умолчанию, заменял эти строки датами. Исследователи отметили, что не стали первооткрывателями проблемы — на нее указывали более десятилетия назад.
В другом случае Excel нанес крупный удар по экономической науке. Знаменитые экономисты Гарвардского университета Кармен Рейнхарт и Кеннет Рогофф в исследовательской работе проанализировали 3,7 тыс. различных случаев увеличения госдолга и его влияние на рост экономики 42 стран в течение 200 лет.
Работа «Рост за время долга» однозначно указывала, что при уровне госдолга ниже 90 % ВВП он практически не влияет на рост экономики. Если же госдолг превышает 90 % ВВП, медианные темпы роста падают на 1 %.
Исследование оказало огромное влияние на то, как мир боролся с последним экономическим кризисом. Работа широко цитировалась для оправдания сокращения бюджета в США и Европе.
Однако несколько лет спустя Томас Херндорн, Майкл Эш и Роберт Поллин из Университета Массачусетса, разобрав по пунктам работу Рогоффа и Рейнхарта, выявили банальные неточности при работе с Excel. Статистика, на самом деле, не показывает никакой зависимости между темпами роста ВВП и госдолгом.
Заключение: исправление ошибок как источник ошибок
(с)
Учитывая огромное количество информации для анализа, некоторые ошибочные ассоциации возникают просто потому, что такова природа вещей. Если ошибки редки и близки к случайным, выводы итогового анализа могут не пострадать. В некоторых случаях бороться с ними бессмысленно, так как борьба с ошибками при сборе данных может привести к возникновению новых ошибок.
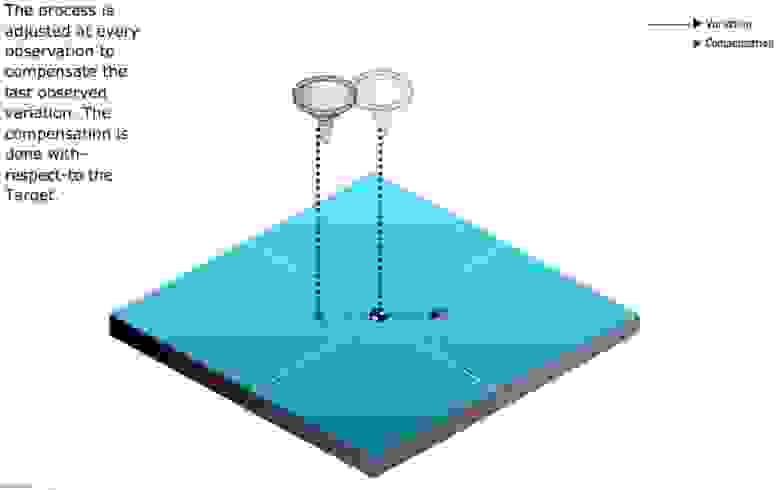
Знаменитый статистик Эдвард Деминг сформулировал описание этого парадокса следующим образом: настройка стабильного процесса для компенсации небольших имеющихся отклонений с целью достижения наиболее высоких результатов может привести к худшему результату, чем если бы не происходило вмешательства в процесс.
В качестве иллюстрации проблем с чрезмерным исправлением данных используется моделирование корректировок в процессе случайного падения шариков через воронку. Корректировать процесс можно с помощью нескольких правил, основная цель которых — предоставить возможность попасть как можно ближе к центру воронки. Однако чем больше вы будете следовать правилам, тем более разочаровывающими будут результаты.
Проще всего эксперимент с воронкой провести онлайн, для чего создали симулятор. Пишите в комментариях, каких результатов вам удалось достичь.
Правильно анализировать большие данные мы можем научить в Академии MADE — бесплатном образовательном проекте от Mail.ru Group. Заявки на обучение принимаем до 1 августа включительно.

Проведение любого исследования и написание курсовой, дипломной или научной работы немыслимо без проведения анализа данных. Данная операция основывается не просто на сравнении, сопоставлении фактов, изучении тенденций, но и грамотном обосновании авторской позиции, проверке гипотезы и развитии заявленной темы. Сегодня мы расскажем о распространенных ошибках, которые студенты допускают при выполнении аналитического раздела или применении аналитических методов, приемов.
Ошибка №1. Использование недостоверной информационной базы.
Аналитическая деятельность предполагает изучение информации по заявленной теме и использование ее для констатации конкретных фактов, тенденций, обоснования авторской позиции или проверки гипотезы. Притом именно в ходе сравнительно-сопоставительных операций автор удостоверится в точности и надежности материалов.
Если исследователь полагается на непроверенные, сомнительные сведения, то результат исследования не может быть безупречно чистым и достоверным. То есть полученные итоги научной мысли или иной деятельности невозможно будет использовать для развития темы, так как они будут сомнительными, неточными.

Конечно, бывают ситуации, когда для раскрытия темы проекта невозможно обойтись без ненадежных и непроверенных фактов. О правилах их применения при выполнении курсовой, дипломной или научной работы мы писали ранее. Но в любом случае выход один: для проведения анализа данных и успешного решения проблемы важно полагаться только на достоверные, точные сведения.
Использование непроверенной информации приведет к некорректным результатам и не позволит автору обрести достойную репутацию. Более того, дальнейшее использование итогов подобного исследования может привести к серьезным погрешностям и роковым ошибкам в урегулировании проблемы и развитии прогресса.
Ошибка №2. Неточные или некорректные расчеты.
Аналитические операции могут затрагивать как текстовую информацию (оценка явлений, процессов), так и исследование различных показателей: экономических, статистических, психологических, математических и пр. В любом случае в данном деле не обойтись без перевода качественной информации в количественный вид, а также наоборот.
Студентам при написании курсовых, дипломных, научно-исследовательских работ для проведения анализа данных приходится заниматься расчетной деятельностью. В этом деле возникают недочеты при проведении расчетных итераций – неправильное округление данных, проблемы с математическими операциями и получение неправильного результата, искажение фактов и пр.

Самой грубой ошибкой считается неправильное исчисление (автор сбился со счета, реализовал неправильную математическую операцию или банально ошибся в расчетах, использовал не те сведения (перепутал данные), полагался не на те формулы и пр.).
Малейшая ошибка при расчете даже одного показателя приведет к ошибочным расчетам и результатам всего исследования. Вследствие этого конечные результаты проекта будут неверными, ненадежными и не смогут в перспективе привести к логичному и обоснованному решению проблемы.
Более того, на фоне некорректных расчетов при исследовании темы могут возникнуть явные противоречия в анализе данных. Научное обоснование показателей может подчеркивать иные тенденции или вовсе не соответствовать реальному положению дел объекта. В этом случае потребуется перепроверка материалов и результатов, повторное проведение исследования темы и пр.
Ошибка №3. Некорректная интерпретация фактов и данных.
Данная ошибка связана с неправильной интерпретаций фактов и выявленных изменений, явлений, процессов и пр. Чаще всего огреха проявляется в виде неверного истолкования фактов на фоне неправильного восприятия сведений или некорректного понимания научных канонов, терминов, правил и пр.
Также некачественное описание показателей или сведений может иметь логические противоречия и нестыковки. Чаще всего результаты расчетов, сравнений противоречат научным канонам и классическим правилам, отражают разные по своей сути и характеру тенденции, которые не могут укладываться в единую картину, явно противоречат друг другу, не позволяют оценить или отразить реальное положение дел объекта.
В данном случае исследователю предстоит разбираться в теме с ноля: заново проводить необходимые расчеты, внимательно изучать тему и соответствующие правила, а затем заново оценить, анализировать информацию и делать соответствующие выводы.
Ошибка №4. Неинформативная или некорректная группировка, преобразование данных.
Для проведения аналитических операций при выполнении курсовых, дипломных или научных работ студент должен уметь правильно находить и распределять информацию, оценивать ее на предмет необходимости, качества, логичности и пр. Притом для емкого отражения важных тенденций, изменений, фактов важно грамотно комбинировать сведения.
Автор должен не просто корректно сочетать различные материалы, но и красиво и корректно их преподносить: объединять различные показатели по смыслу или сути, явлению, классифицировать данные с учетом принципа совместимости и логичности, достаточности и пр.

Самой грубой ошибкой данного плана выступает сочетание несочетаемого, отсутствие явной связи между показателями или сведениями, отражаемыми в одном блоке, разделе или таблице как следствие на фоне чрезмерного изобилия фактов, сведений невозможно получить целостную картину по происходящим явлениям, показать конкретную единую тенденцию или обосновать авторскую позицию.
Неграмотная или неинформативная выборка данных не позволит в полной мере раскрыть заявленную тему и подчеркнуть проблематику ил подобрать достойное, оптимальное и эффективное решение. В данном выходом из ситуации станет поиск причинно-следственных связей и взаимосвязанных показателей, материалов, аргументов, объединение информации по сочетаемости, взаимозаменяемости и взаимодополняемости, логичности и пр.
Ошибка №5. Необоснованные выводы, результаты анализа без конкретики и фактов.
Анализ данных предполагает не просто сравнение и сопоставление материалов, выявление закономерностей, тенденций, но и наличие определенных логических завершений на каждом этапе. Оценка любой системы показателей или данных сопровождается подготовкой промежуточных выводов.
В любой научно-исследовательском труде все выводы должны быть четко аргументированными. Анализ каждого весомого аргумента призван подчеркнуть авторскую позицию, проблематику и перспективы развития темы, решение и пр.

Отсутствие конкретных фактов и мнения автора в выводах превращает исследовательскую работу в банальный реферат, а все гипотезы, умозаключения становятся голословными обвинениями, рассуждениями без каких-либо подкрепляющих моментов. Такие промежуточные итоги не способны привести к серьезному и оправданному результату, а сама аналитическая работа идет насмарку, ведь полученные аргументы нигде не фигурируют и не подчеркивают эффективность гипотезы, не обосновывают авторскую позицию.
Для устранения текущей огрехи необходимо пересмотреть формулировку промежуточных и итоговых выводов. Важно выделить 1-3 серьезных аргумента и на их основе показать соответствующие тенденции, авторскую позицию, определить и отмерить перспективы дальнейшего развития.
Ошибка №6. Структурные нарушения.
В данном случае возникает нестыковка названия раздела или параграфа с его содержанием. Самым ярким проявлением рассматриваемой огрехи является некорректное заглавие разделов или отклонение от заявленного плана и использование дополнительного материала, который не имеет явной связи с выбранным этапом исследования, отклоняется от заданного курса и захватывает смежные пути, не имеет ценности при раскрытии обозначенной темы.
Структурные нарушения встречаются не только при выполнении аналитического раздела или аналитических операций. Они могут в целом затрагивать весь проект. Как правило, каждый раздел тщательно планируется с учетом логики, последовательности и связности показателей, данных и тенденций. Отклонение от плана чревато появлением логических и структурных нарушений.
Структурные нарушения в анализе данных проявляются в том, что автор скачет по несвязным показателям и фактам, пытаясь всесторонне изучить и описать тенденцию, показать проблему и состоятельность идеи, обосновать собственное мнение или выдвигаемое решение.
Исправить недочеты можно только приведя в соответствие содержимое разделов с заголовками, планом исследования и темой. Важно, чтобы каждый шаг и раздел был связан с темой, проблемой и целью проекта, не отклонялись от общей траектории исследования и подчеркивали конкретное направление (проблематику, позицию, перспективы решения и пр.).
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

Ошибка №7. Отклонения от научного стиля и научности.
Проведение анализа потребует от автора не только выдержки и знания темы, правил, но и умения корректно выражать собственные мысли по определенным изменениям, динамике, фактам. Написание курсовых, дипломных и научных работ всегда придерживается правил научного стиля и научной обоснованности. Этот канон затрагивает все разделы исследования, в том числе и проведение анализа.

Самыми частыми ошибками в данном плане является отклонение от академического письма, использование повседневной профессиональной лексики при описании тенденции, отказ от научных парадигм и терминов в пользу более простого, обыденного изложения фактов, то есть банальное реферирование, обзор или пересказ моментов.
Исправить ошибку поможет только строгая приверженность научного стиля и использование соответствующих терминов в умеренном количестве с учётом правил целесообразности и уместности.
Ошибка №8. Отсутствие взаимосвязи между этапами и результатами исследования.
Аналитические операции призваны не просто диагностировать проблему по теме исследования, но и показать возможности по ее решению, подобрать наиболее эффективные способы воздействия и пр. Притом реализация каждой последующей итерации должна быть обоснованной и оправданной, логическим верной и связной с предшествующим этапом.
Отсутствие связности между результатами порождает нарушение в логике исследования и проведении аналитических операций. Более того, подобные схемы могут породить реализацию бесполезных и неважных действий, неоправданно раздуть исследование и привести к иным результатам, отклонить от изначально заданной темы и пр.
Чтобы избежать рассматриваемого замечания, важно тщательно планировать программу исследования и не отклоняться от утверждённого плана без согласования с научным руководителем и пр.
Ошибка №9. Применение неэффективной или неоправданной методики.
При выполнении курсовой, дипломной или научной работы автор старается использовать посильную и понятную для них методику исследования, подирая соответствующие инструменты с учетом уровня их подготовки.
Банальная лень разбираться в современных подходах и приемах, новейших агрегатах и инструментах усложняет процесс решения проблемы. Автор полагается на старые и менее эффективные методики, а недостающие факты и материалы старается заменить или найти с помощью дополнительных действий. На фоне этого объем исследования неоправданно растет и может превышать действующие нормы и требования.

Во избежание данной огрехи следует грамотно подбирать программу исследования акцентируя внимание на располагаемых данных и грамотно ими оперируя. По возможности нужно стараться сократить искомую траекторию, чтобы получить результат быстрее, точнее, без лишних усилий и пр.
Ошибка №10. Нарушение принципа соразмерности разделов НИР.
Анализ данных в тексте студенческой или научной работы всегда отнимет немало места. Каждый график, таблица, диаграмма подвергается анализу. Главное в данном деле – кратко, емко описать факты и тенденции, сделать общий вывод и подвести целевую аудиторию к следующему шагу.
Если анализ данных подробный, а главы и параграфы загромождены табличными и графическими материалами неравномерно, то нарушается принцип соразмерности текста.
В данном случае важно оптимально распределить данные, преобразовать их в новый вид, объединить или сократить аналитические описания и пр.
Обратите внимание, что любые ошибки, допущенные в рамках анализа данных или при выполнении сравнительно-сопоставительных операций способны исказить результаты и сбить автора с логики, привести к некорректному завершению и вовсе привести к недопуску исследования к защите. Поэтому важно ответственно и обоснованно подходить к подбору инструментария и данных, умело оперировать ими и тщательно перепроверять полученные итоги.
Главные ошибки при анализе данных
https://t.me/ai_machinelearning_big_data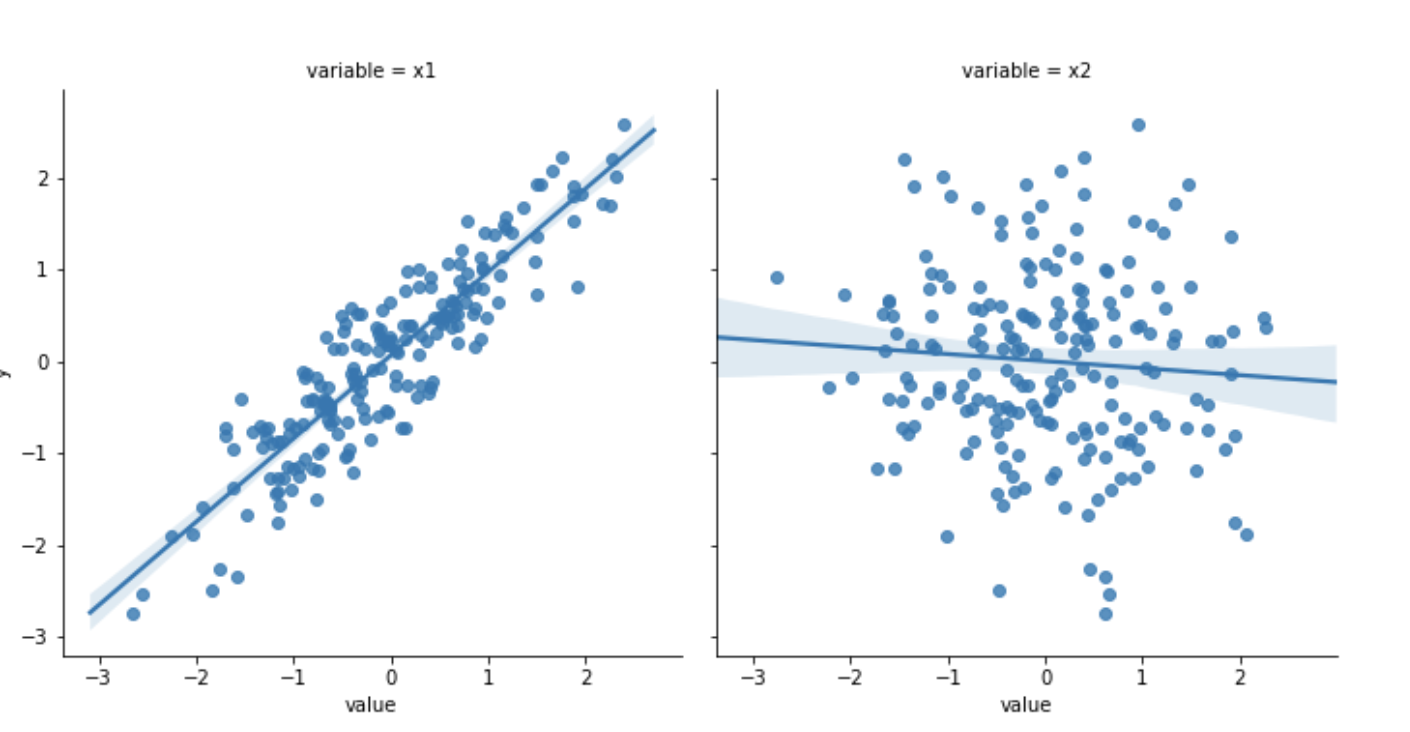
- 1. Неполное понимание целевой функции
- 2. Это работает, но почему?
- 3. Вы не смотрите на данные до интерпретации
- 4. У вас нет простейшей базовой модели
- 5. Неправильное тестирование вне выборки
- 6. Предварительная обработка всего набора
- 7. Перекрёстная проверка и панельный анализ
- 8. Какие данные доступны при принятии решения?
- 9. Переобучение
- 10. Нужно больше данных?
Аналитик данных — лучший в статистике среди программистов и лучший программист среди статистиков. В этом топе обсудим, как программисту стать лучше в статистике.
Примеры, код и детальный вывод доступны на github и в Jupyter Notebook. В коде библиотека d6tflowуправляет рабочим процессом, а d6tpipe обеспечивает публичное хранение данных.
1. Неполное понимание целевой функции
Аналитики хотят создать «лучшую» модель. Но красота в глазах смотрящего. Если вы не знаете, в чем заключается основная задача и целевая функция, не знаете, как модель себя ведёт, то вряд ли построите «лучшую» модель. Кроме того, задача может заключаться в улучшении бизнес-метрики, а не в построении математической функции.
Решение: убольшинства победителей Kaggle уходит много времени на понимание целевой функции и того, как с ней связаны модель и данные. Если вы оптимизируете бизнес-метрику, сопоставьте её с соответствующей целевой функцией.
Пример: для оценки моделей классификации используется F-мера. Однажды мы построили модель классификации, успех которой зависел от того, в каком проценте случаев она была правильной. Как выяснилось, F-мера вводит в заблуждение, потому что показывает, что модель была правильной примерно 60% времени, а на самом деле — только 40%.
f1 0.571 accuracy 0.4
2. Это работает, но почему?
Аналитики хотят строить «модели». Они слышали, что xgboost и алгоритм “случайный лес” работают лучше всего и просто используют их. Они читают о глубоком обучении и думают, что, возможно, оно улучшит результат. Они бросают модели в проблему, не глядя на данные и не выдвигая гипотезы, какая модель лучше всего отражает особенности данных. Это сильно усложняет объяснение вашей работы хотя бы потому, что вы сами её не понимаете.
Решение: смотрите на данные! Поймите их характеристики и сформулируйте гипотезы о том, какие модели лучше всего их отражают.
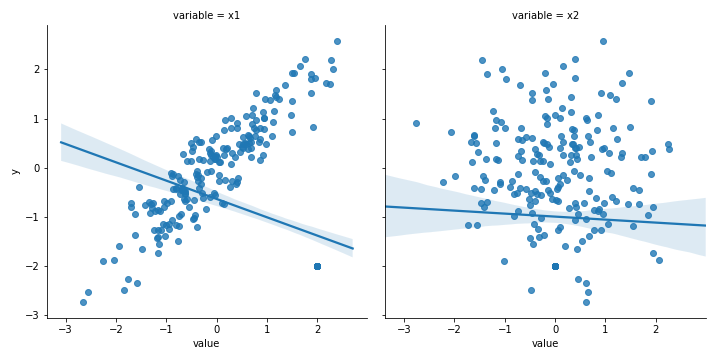
Пример: посмотрев на данные на графике даже без запуска модели, вы увидите: x1 линейно связан с y, а x2 не имеет с ним сильно выраженной связи.
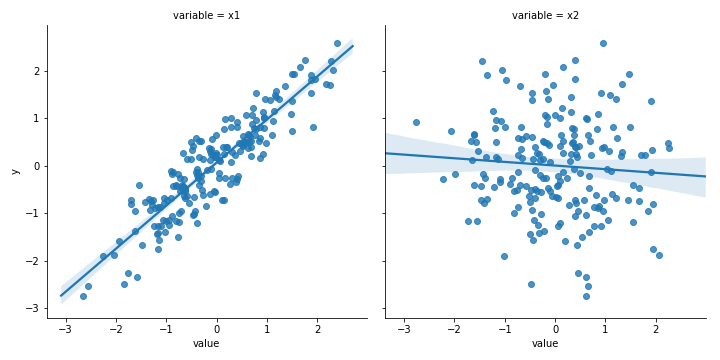
3. Вы не смотрите на данные до интерпретации
Ещё одна подобная проблема: ваши результаты могут быть обусловлены выбросами и другими артефактами. Это особенно актуально для моделей, минимизирующих суммы квадратов. Даже без выбросов возникают проблемы с балансом, отброшенными или отсутствующими значениями и другими аномалиями реальных данных, которые вы не разбирали в университете.
Решение: повторяю, смотрите на данные — это очень важно! Поймите, как их природа влияет на результат.
Пример: с выбросами наклон x1 изменился с 0,906 до -0,375!
4. У вас нет простейшей базовой модели
Современные библиотеки ML упрощают задачу. Почти. Просто измените одну строчку кода и запускайте модель. И другую. И ещё одну. Метрики ошибок уменьшаются, ещё настройка. Великолепно — они снижаются ещё… При всей изощрённости модели вы можете забыть о глупом способе прогнозирования. Без этого примитивного теста у вас нет абсолютного показателя качества моделей, а они могут быть плохими в абсолютном выражении.
Решение: какой простейший способ, предсказывающий значения? Создайте модель, используя последнее известное значение, (скользящее) среднее или постоянную вроде 0. Сравните производительность с прогнозом какой-нибудь обезьяны!
Пример: с этим набором временных рядов первая модель должна быть лучше второй: среднеквадратичная ошибка (далее — СКО) 0,21 и 0,45. Но подождите! Принимая во внимание только последнее известное значение, СКО падает до 0,003!
ols CV mse 0.215rf CV mse 0.428last out-sample mse 0.003
5. Неправильное тестирование вне выборки
Это может разрушить карьеру! Модель выглядела великолепно в исследованиях и разработках, но ужасно проявила себя на реальных данных. Такая модель приводит к очень плохим результатам, она может стоить компании миллионов. Это самая грубая ошибка из всех!
Решение: убедитесь, что работаете с моделью в реалистичных условиях и понимаете, когда она будет работать, а когда — нет.
Пример: внутри выборки случайный лес работает намного лучше линейной регрессии: СКО 0,048 в сравнении с 0,183, но вне выборки случайный лес намного хуже: 0,259 против 0,187. Случайный лес переобучен и провалится в реальных условиях!
in-samplerf mse 0.04 ols mse 0.183out-samplerf mse 0.261 ols mse 0.187
6. Предварительная обработка всего набора
Вы уже знаете, что мощная модель может переобучиться. Это означает, что она хорошо работает в выборке, но плохо вне выборки. То есть нужно знать об утечках обучающих данных в тестовые. Если не будете внимательны, то каждый раз, когда выполняете проектирование или перекрёстную проверку, тренировочные данные могут проникать в тестовые, снижая производительность.
Решение: убедитесь, что у вас есть настоящий тестовый набор без примесей тренировочного. Особенно остерегайтесь любых зависящих от времени отношений, возникающих в реальных условиях.
Пример: это случается часто. Предварительная обработка применяется ко всему набору данных до разделения на обучающие и тестовые данные, то есть у вас не будет пригодного для теста набора. Предварительная обработка должна применяться после разделения и отдельно к каждому набору, чтобы у вас был настоящий тестовый набор.
СКО между двумя выборками (0,187 смешанной выборки против 0,181 истинной) не сильно отличается: свойства распределения у наборов тоже не так уж различны, но это дело случая.
mixed out-sample CV mse 0.187 true out-sample CV mse 0.181
7. Перекрёстная проверка и панельный анализ
Вас учили, что перекрёстная проверка — всё, что нужно. Sklearn даже предоставляет несколько удобных функций для неё, поэтому вы думаете, что сделали всё. Но большинство методов перекрёстной проверки используют случайную выборку, а значит, можно получить смешение наборов с завышением производительности.
Решение: создавайте данные, точно отражающие те, на которых можно делать предсказания в реальном использовании. Особенно с временными рядами и панельными данными. В этом случае, вероятно, для перекрёстной проверки придётся генерировать пользовательские данные или делать пошаговую оптимизацию.
Пример: есть панельные данные для двух разных объектов (например, компаний) и они сильно пересечены друг с другом. Если разделение случайно, то вы делаете точные прогнозы, используя данные, что на самом деле не были доступны во время тестирования. Это приводит к завышению производительности. Вы думаете, что избежали ошибки #5 с перекрёстной проверкой и видите, что случайный лес работает намного лучше линейной регрессии. Но после пошагового тестирования, предотвращающего утечку будущих данных в тестовый набор, случайный лес снова работает хуже! (СКО от 0,047 до 0,211. Выше, чем у линейной регрессии!)
normal CV ols 0.203 rf 0.051 true out-sample error ols 0.166 rf 0.229
8. Какие данные доступны при принятии решения?
Когда вы запускаете модель в реальных условиях, она получает доступные именно в этот момент данные. Они могут отличаться от тех, что предполагалось использовать в обучении. Например, они опубликованы с задержкой, поэтому к моменту запуска другие входные данные изменились. Значит, вы делаете прогнозы с неверными данными или ваша истинная переменная y теперь ложна.
Решение: проведите пошаговое тестирование вне выборки. Если бы модель испытывалась в реальных условиях, то как бы выглядел обучающий набор? Какие данные имеются для прогнозирования? Кроме того, подумайте вот о чём: если бы вы действовали на основании прогноза, то какой результат был бы в момент принятия решения?
9. Переобучение
Чем больше времени вы тратите на набор данных, тем вероятнее переобучение. Вы работали с функциями, оптимизировали параметры, использовали перекрёстную проверку, поэтому всё должно быть хорошо.
Решение: закончив построение модели, попробуйте найти другую версию наборов данных. Она может быть суррогатом для настоящего набора вне выборки. Если вы менеджер, сознательно скрывайте данные, чтобы они не использовались для обучения.
Пример: применение моделей, обученных на первом наборе данных ко второму набору, показывает: СКО более чем удвоилось. Это приемлемо? Решение за вами, но результаты #4 могут помочь.
первый наборrf mse 0.261 ols mse 0.187новый наборrf mse 0.681 ols mse 0.495
10. Нужно больше данных?
Интуитивно это покажется странным, но зачастую лучший способ начать анализ — работать с репрезентативной выборкой. Это позволяет ознакомиться с данными и построить конвейер, не дожидаясь их обработки и обучения модели. Но аналитикам, похоже, это не нравится: лучше больше данных.
Решение: начните работу с небольшой репрезентативной выборкой и посмотрите, сможете ли вы получить из нее что-то полезное. Верните выборку конечным пользователям. Они могут её использовать? Это решает реальную проблему? Если нет, то проблема скорее всего не в количестве данных, а в подходе.
Дополнительно посмотрите вывод и код для каждого примера
Другие ошибки анализа
Биотех стал для технологических предпринимателей новым рок-н-роллом. Его также называют «новым IT-рынком» и даже «новым криптомиром», имея ввиду взрывную популярность у инвесторов компаний, занимающихся обработкой биомедицинской информации.
Являются ли данные по биомаркерам и клеточным культурам «новой нефтью» или нет — вопрос второстепенный. Интерес вызывают последствия накачки индустрии быстрыми деньгами. В конце концов, биотех может представлять угрозу не только для кошельков венчурных фондов, но и напрямую влиять на здоровье людей.
Например, как указывает генетик Стивен Липкин, для генома есть возможность делать высококлассные анализы, но информация о контроле качества часто закрыта для врачей и пациентов. Иногда до заказа теста вы не можете заранее узнать, насколько велика глубина покрытия при секвенировании. Когда ген прочитывают недостаточное число раз для адекватного покрытия, программное обеспечение находит мутацию там, где ее нет. Зачастую мы не знаем, какой именно алгоритм используется для классификации аллелей генов на полезные и вредные.
Тревогу вызывает большое количество научных работ в области генетики, в которых содержатся ошибки. Команда австралийских исследователей проанализировала около 3,6 тыс. генетических работ, опубликованных в ряде ведущих научных журналов. В результате обнаружилось, что примерно одна из пяти работ включала в свои списки генов ошибки.
Поражает источник этих ошибок: вместо использования специальных языков для статистической обработки данных ученые сводили все данные в Excel-таблице. Excel автоматически преобразовывал названия генов в календарные даты или случайные числа. А вручную перепроверить тысячи и тысячи строк просто невозможно.
В научной литературе гены часто обозначаются символами: например, ген Септин-2 сокращают до SEPT2, а Membrane Associated Ring Finger (C3HC4) 1 — до MARCH1. Excel, опираясь на настройки по умолчанию, заменял эти строки датами. Исследователи отметили, что не стали первооткрывателями проблемы — на нее указывали более десятилетия назад.
В другом случае Excel нанес крупный удар по экономической науке. Знаменитые экономисты Гарвардского университета Кармен Рейнхарт и Кеннет Рогофф в исследовательской работе проанализировали 3,7 тыс. различных случаев увеличения госдолга и его влияние на рост экономики 42 стран в течение 200 лет.
Работа «Рост за время долга» однозначно указывала, что при уровне госдолга ниже 90 % ВВП он практически не влияет на рост экономики. Если же госдолг превышает 90 % ВВП, медианные темпы роста падают на 1 %.
Исследование оказало огромное влияние на то, как мир боролся с последним экономическим кризисом. Работа широко цитировалась для оправдания сокращения бюджета в США и Европе.
Однако несколько лет спустя Томас Херндорн, Майкл Эш и Роберт Поллин из Университета Массачусетса, разобрав по пунктам работу Рогоффа и Рейнхарта, выявили банальные неточности при работе с Excel. Статистика, на самом деле, не показывает никакой зависимости между темпами роста ВВП и госдолгом.
Заключение: исправление ошибок как источник ошибок

(с)
Учитывая огромное количество информации для анализа, некоторые ошибочные ассоциации возникают просто потому, что такова природа вещей. Если ошибки редки и близки к случайным, выводы итогового анализа могут не пострадать. В некоторых случаях бороться с ними бессмысленно, так как борьба с ошибками при сборе данных может привести к возникновению новых ошибок.
Знаменитый статистик Эдвард Деминг сформулировал описание этого парадокса следующим образом: настройка стабильного процесса для компенсации небольших имеющихся отклонений с целью достижения наиболее высоких результатов может привести к худшему результату, чем если бы не происходило вмешательства в процесс.
В качестве иллюстрации проблем с чрезмерным исправлением данных используется моделирование корректировок в процессе случайного падения шариков через воронку. Корректировать процесс можно с помощью нескольких правил, основная цель которых — предоставить возможность попасть как можно ближе к центру воронки. Однако чем больше вы будете следовать правилам, тем более разочаровывающими будут результаты.
Проще всего эксперимент с воронкой провести онлайн, для чего создали симулятор. Пишите в комментариях, каких результатов вам удалось достичь.
на github и Jupyter Notebook.
https://t.me/itchannels_telegram — полезнные ресурсы для анализ даннных
Источник

Существует много распространенных ошибок при анализе данных. В предыдущей статье мы описали множество ошибок анализа данных. Благодаря введению этих ошибок мы видим, что игнорирование этих ошибок приведет к очень серьезным последствиям. В этой статье мы расскажем вам больше о распространенных ошибках при анализе данных. Надеюсь, эта статья поможет вам лучше понять анализ данных.
Во-первых, это ошибка измерения. Когда программное или аппаратное обеспечение, с помощью которого мы собираем данные, допускает ошибки, не может захватить доступные данные или генерирует ложные данные, возникнут ошибки измерения. Например, если журнал использования не синхронизирован с сервером, информация о поведении пользователя в мобильном приложении может быть потеряна. Точно так же, если мы используем аппаратные датчики, такие как микрофоны, наши записи могут захватывать фоновый шум или помехи от других электрических сигналов.
Тогда есть ошибка обработки. У многих компаний есть данные десятилетия назад, а команд, которые могли бы объяснить решения, связанные с данными, больше нет. Многие из их предположений и вопросов, вероятно, не задокументированы. Это будет зависеть от наших выводов, которые могут оказаться сложной задачей. Наша команда может делать различные предположения, отличные от исходного процесса сбора данных, и получать очень разные результаты. Распространенные ошибки включают пропуск определенного фильтра, использование разных стандартов бухгалтерского учета и просто методологические ошибки.
Конечно, к распространенным ошибкам при анализе данных относятся ошибки покрытия. Так что же такое ошибка охвата? Эта ошибка относится к ситуации, когда целевые респонденты не имеют достаточно возможностей для участия в опросе данных. Например, если мы собираем данные о пожилых людях, но проводим только опросы на веб-сайтах, мы можем пропустить многих респондентов.
Затем возникает ошибка выборки. Когда мы анализируем небольшую выборку, возникает ошибка выборки. Когда данные существуют только в определенной группе, это неизбежно. Напрашивается вывод, что наша репрезентативная выборка не может применяться ко всему.
Ошибка рассуждения заключается в том, что когда статистические модели и модели машинного обучения делают неточные суждения на основе существующих данных, их последующие результаты вывода также могут быть неверными. Если у нас есть очень чистая база данных «наземной истины», то мы можем использовать ее для проверки правильности выводов, полученных из модели данных, но на самом деле большинство баз данных полны шума, поэтому обычно трудно определить выводы ИИ. Где ошибка?
Неизвестные ошибки также являются одной из ошибок, которую нельзя игнорировать. Реальность неуловима, и мы не всегда можем легко установить факты. Во многих случаях, например при использовании цифровых продуктов, мы можем фиксировать данные о поведении большого количества пользователей на платформе, а не их мотивацию к такому поведению. В дополнение ко многим типам известных ошибок, существуют некоторые неизвестные, которые оставляют разрыв между реальностью, представленной данными, и самой реальностью.
Вообще говоря, менеджеры, не имеющие опыта в области науки о данных или машинного обучения, обычно совершают эти девять больших ошибок, поэтому друзьям из отрасли анализа данных или искусственного интеллекта следует уделять больше внимания.Только после изучения этих знаний мы можем приступить к работе. Лучше стоять и стоять твердо, чтобы другие тебя не обнаружили и не утаскивала собственная небрежность.