Уровень сложности
Средний
Время на прочтение
5 мин
Количество просмотров 6.9K

1. Недостаточное покрытие
Иногда из-за нашей лени, невнимательности или чего-либо ещё получается неполный охват тестами всех важных сценариев, крайних случаев и потенциальных ошибок. Представим, что у нас есть очень простой класс Calculator, который умеет делать сложение:
public int Add(int a, int b)
{
return a + b;
}Порой, когда на работе заставляют чтобы код сопровождался юнит-тестами, может получиться класс, содержащий всего один тест:
[Test]
public void Add_WhenCalled_ReturnsSum()
{
// Arrange
var a = 40;
var b = 2;
var calculator = new Calculator();
// Act
var result = calculator.Add(a,b);
// Assert
Assert.AreEqual(42, result);
}Тестирует ли код выше метод Add? Да, тестирует и даже гарантирует правильность сложения чисел 40 и 2. Однако, ни отрицательные числа, ни большие числа, сумма которых выходит за пределы размера int, ни сложение с нулем здесь не проверены.
Как сделать правильно?
Ещё до написания кода желательно вместе с аналитиком/тестировщиком/другими разработчиками обсудить все возможные корнер-кейсы (крайние случаи) и то, как код должен реагировать при встрече с ними.
2. Переизбыток тестов
В противоположность к первому пункту можно увлечься и насоздавать много излишних тестов для тривиального или простого кода, что приведет к увеличению нагрузки на поддержку и замедлению выполнения тестов.
[Test]
public void Add_WithFortyAndTwo_ReturnsFortyTwo()
{
// ...
}
[Test]
public void Add_WithOneAndOne_ReturnsTwo()
{
// ...
}
[Test]
public void Add_WithTenAndTen_ReturnsTwenty()
{
// ...
}
[Test]
public void Add_WithZeroFirst_ReturnsSum()
{
// ...
}
[Test]
public void Add_WithZeroSecond_ReturnsSum()
{
// ...
}Как сделать правильно?
Совет по составлению списка проверок с другими людьми здесь так же актуален. Плюс, порой можно воспользоваться передачей параметров в тестовый метод, что сокращает размер файла с тестами и их чтение. Еще более продвинутый вариант — использовать генераторы данных, например, Bogus. Ну и самый хардкорный вариант — использование pairwise testing.
3. Нетестируемый код
После работы в Лаборатории Касперского, где код обкладывался кучами разных тестов, я наиболее явно ощутил весь смысл слова «тестопригодность», когда встретил код, который мне пришлось несколько дней рефакторить, чтобы добавить для него юнит-тесты. Один из примеров как сделать код нетестопригодным — использовать другие классы напрямую.
public class Calculator
{
private readonly ILogger _logger;
public Calculator()
{
_logger = new Logger();
}
public int Add(int a, int b)
{
_logger.Log("Add method called.");
return a + b;
}
}Ну и соответственно, чтобы сделать его тестопригодным, надо сделать инверсию зависимости, а если по-русски, то заменить зависимость от класса на зависимость от интерфейса:
public class Calculator
{
private readonly ILogger _logger;
public Calculator(ILogger logger)
{
_logger = logger;
}
public int Add(int a, int b)
{
_logger.Log("Add method called.");
return a + b;
}
}Как сделать правильно?
Не завязываться на конкретные реализации и как можно скорее убирать такие связи, если они есть — станет легче не только писать тесты, но и просто поддерживать код.
4. Игнорирование или пропуск тестов
Если бы сам не столкнулся с подобным в нескольких компаниях, то мне бы и в голову не пришло, что тесты можно (а порой даже нужно) игнорировать.
Как сделать правильно?
Назначить ответственного человека, либо самому следить за тем, чтобы игнорированием тестов не злоупотребляли, а использовали только когда необходимо. Например, когда идет крупномасштабное внедрение изменений — обновление кодстайла, сторонней или своей библиотеки.
5. Тестирование реализации
Довольно стандартная ловушка для новичков в юнит-тестировании — написать сначала нужный код и потом на основе этого кода писать тесты. Причем тесты пишутся так, чтобы покрыть логику этого написанного кода. Проблема такого подхода — то, что не было написано, не будет и протестировано. Например, если при добавлении в класс Calculator метода Divide мы не учтем в коде проверку деления на ноль, то и при написании тестов по уже существующему коду вероятность написать тест деления на ноль исчезающе мала.
Как сделать правильно?
Вспоминаем совет к первым двум пунктам — составлять тест-кейсы ДО написания кода и опираться в них на требуемую бизнес-логику, а не на уже реализованную функциональность. Хотя, сразу оговорюсь, что для написания тестов к уже существующему коду, по которому никаких зафиксированных бизнес-требований нет и никто их не знает/не помнит, подход на основе реализации вполне подходит. Но только для целей регрессионного тестирования.
6. Хрупкие тесты
Предположим, что мы написали класс А, который реализует необходимую нам бизнес-логику. Затем, в процессе рефакторинга, мы вынесли из класса А два вспомогательных класса — В и С. Нужно ли писать тесты на все три класса? Конечно, это зависит от логики, которая была вынесена во вспомогательные классы и того, будет ли она использоваться где-то ещё помимо класса А, однако, в 99% случаев писать тесты на классы В и С не нужно.
Как сделать правильно?
Рискуя набить оскомину, повторюсь, надо тестировать не написанный код, а бизнес-логику, которая реализуется этим кодом.
7. Отсутствие организации тестов
Видел я и такие проекты, гды пытались внедрить юнит-тесты, однако, все они лежали в корне тестового проекта и было тяжело разобраться есть ли уже нужные тебе тесты или нет. И вместо того, чтобы разбираться в этом бардаке и искать нужный класс, люди просто создавали ещё один, куда писали свои тесты. Хаос в таком случае только увеличивался.
Как сделать правильно?
Надо договориться о том, как будут организованы тесты в вашей компании/команде. Один из наиболее простых и распостраненных подходов — полностью копировать структуру основного проекта, добавляя постфикс «Tests». То есть, если был проект CalculationSolution и в нем был путь Calculations/Calculators/, по которому лежал файл Calculator.cs, для которого мы хотим добавить юнит-тесты, то юнит-тесты должны быть в проекте CalculationSolution.Tests по пути Calculations/Calculators/CalculatorTests.cs.
8. Божественные тесты
Как в процессе программирования может появиться god object — класс, который делает все и вся, так и при написании тестов могут получаться тесты, в которых проверяется не что-то одно, а сразу штук 10 разных аспектов. Да, такая «денормализация» тестов порой имеет место быть в end-to-end, UI или интеграционных тестах в целях экономии ресурсов (в т.ч. времени выполнения), однако, юнит-тесты должны проходить очень быстро и нет смысла усложнять себе разбор упавших тестов ради экономии пары миллисекунд.
Как сделать правильно?
Следить за тем, чтобы один тест тестировал только один аспект бизнес-логики.
9. Недостаточная обработка ошибок
Соблазн протестировать happy path и, возможно, парочку самых простых в тестировании ошибок может привести к тому, что непойманные на этапе автоматизированного тестирования ошибки приведут к проблемам в продакшн среде и цена этой ошибки будет намного выше. Отличие этого пункта от первого в том, что, если в первом пункте было наглядно видно маленькое количество тестов, их практически не было, то здесь тесты уже есть и их даже может быть много, однако, они могут быть направлены на количество, а не на качество.
Как сделать правильно?
Опять же, составлять список тестов заранее, плюс, можно добавить в чеклист ревьюера пункт о том, что все тест-кейсы должны быть реализованы.
10. Смешивание юнит-тестов с другими видами тестов
Как я писал выше, юнит-тесты обычно проходят очень быстро, так как не требуют сложной подготовки, подтягивания зависимостей и прочего. Остальные виды тестов уже несколько более продвинутые и более ресурсоемкие. Поэтому смешивание всех тестов в одну кучу является не очень хорошим вариантом.
Как сделать правильно?
Правильным будет разделять мух от котлет. Сделать это можно, например, разнеся тесты по разным проектам или используя идентифицирующие атрибуты. Далее с помощью этих атрибутов можно настроить так, чтобы ни один коммит не попадал ни в одну ветку до тех пор, пока все юнит-тесты, связанные с этим кодом, не пройдут успешно. Также, можно выделить под разные виды тестов разные виртуальные машины и/или стратегии запуска этих тестов.
Статья подготовлена в рамках набора на специализацию C# Developer. Узнать подробнее о специализации.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.

Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa

Автор: Артём Ваулин
Если вы действительно радеете за результат, то обязательно постарайтесь привлечь к тестированию требований и ваших разработчиков, если самостоятельно они этого не делают, ошибочно полагая, что всем связанным с тестирование должны заниматься вы (т.е. тестировщики), а всем, связанным с требованиями, — консультанты и аналитики. Проанализировав требования с точки зрения внутренний архитектуры системы (программы) и кода, разработчики могут дать множество ценных советов и замечаний относительно того, что в требованиях написано не так или чего там не хватает.
Странное название?
Обычно TOP-ы круглочисленные (Fortuna 500, Русская 10-ка и т.д.)?
Почему именно 13? Не потому ли, что по общепринятому мнению (программисты часто считают свое мнение — общепринятым) тестировщики приносят одни несчастья?
Думаю, что примерно такие вопросы за долю секунды промелькнут в ваших головах, когда вы увидели название этого эссе.
Все намного проще…
Именно столько пометок (13 штук) я сделал в своем блокноте во время подготовки к совещанию с группой тестирования, на котором я хотел выступить с вопросом о том, какие недочеты и промахи в своей работе допускают тестировщики и какие проблемы имеются в организации нашего процесса тестирования.
Сразу же хочу оговориться, что данные рекомендации выработаны на основе одного конкретного процесса тестирования, которого придерживается созданная мной группа тестирования. Но я также не исключаю, что любой практикующий тестировщик, руководитель тестировщиков и т.д. сможет вынести нечто полезное из нашего опыта.
Для лучшего восприятия и наибольшей запоминаемости, я постарался сгруппировать свои 13 рекомендаций в несколько обобщенных категорий и расставить их по приоритету, начиная, по моему мнению, с самого важного. Получилось следующее:
- Требования
- Тест-кейсы
- Управление ошибками
- Документирование
- Взаимодействие
Внутри каждой категории я обозначу и постараюсь объяснить каждую пометку из тех, которые я набросал в своем блокноте во время подготовки.
Требования
1. Требования необходимо тестировать
Речь здесь идет о тестировании требований всех уровней и видов: бизнес-требования, пользовательские требования, системные требования, функциональные требования, нефункциональные требования, требований производительности, требования удобства использования и т.д.
Мало того, что их надо тестировать. Тестировать требования необходимо на самых ранних этапах и/или стадиях процесса разработки (думаю, что Америки я не открыл). Начинать тестировать требования надо сразу, как только у вас появилась уникальная возможность получить к ним доступ, несмотря на то, где и в каком виде они находятся — в электронном виде, размещенные на общедоступном ресурсе, высланные вам по электронной почте или только что сформировавшиеся в голове консультанта/аналитика и еще не получившие формального отражения.
Если вы действительно радеете за результат, то обязательно постарайтесь привлечь к тестированию требований и ваших разработчиков, если самостоятельно они этого не делают, ошибочно полагая, что всем связанным с тестирование должны заниматься вы (т.е. тестировщики), а всем, связанным с требованиями, — консультанты и аналитики. Проанализировав требования с точки зрения внутренний архитектуры системы (программы) и кода, разработчики могут дать множество ценных советов и замечаний относительно того, что в требованиях написано не так или чего там не хватает.
Последствиями либо отсутствия тестирования требований вообще, либо откладывания тестирования требований до лучших времен или тезиса «все их недостатки выявятся в процессе разработки и тестирования» являются:
- выявление серьезных ошибок проектирования непосредственно перед выпуском релиза, что приводит к необходимости серьезных доработок, как требований, так и кода (я уже не говорю о доработке тест-кейсов, тестовых данных и повторном тестировании). Естественно, все это приводит к срыву сроков, авральной работе (по ночам и/или выходным) и прочим негативным вещам, которых можно было бы избежать своевременным тестированием требований;
- перекладывание всей ответственности и вины за случившееся на создателей требований, что по меньшей мере, не оздоровляет отношения между участниками разработки. Наверное, многие сталкивались с позицией программистов, аналогичной этим: «Не было написано, поэтому и не сделал», «Как написано, так и сделал», «Писать надо лучше» и т.п.
Несмотря на важность тестирования требований программистами, речь здесь идет прежде всего о тестировщиках, которые громко кричат, что консультант Пупкин здесь не написал то, здесь недодумал это, тут не понятно, а в следующем абзаце вообще чушь полную написал, которая никак не состыкуется с тем, что было написано и сделано до этого. Честь бы и хвала была такому тестировщику, если бы кричал он об этом не за день до выкладки релиза, а в первый день работы над данной функциональностью.
В заключении заметки о тестировании требований еще раз осмелюсь повторить критерии качества требований к программному обеспечению:
- Корректность
- Недвусмысленность (однозначность)
- Полнота
- Непротиворечивость (совместимость)
- Упорядоченность (ранжированность по важности и стабильности)
- Проверяемость (тестируемость или тестопригодность)
- Модифицируемость
- Трассируемость (прослеживаемость)
- Понятность
Тест- кейсы
Для лучшего понимания раздела, посвященного тест-кейсам, приведу здесь определение этих самых тест-кейсов, которое предлагает энциклопедия Wikipedia (прошу прощения за мой вольный перевод).
Тест-кейс (тестовый случай, test case) — это набор условий и/или переменных, с помощью которых тестировщик будет определять насколько полно тестируемое приложение удовлетворяет предъявляемому к нему требованию. Для того, чтобы убедиться, что требование полностью удовлетворяется, может понадобиться несколько тест-кейсов. Для полного тестирования всех требований, предъявляемых к приложению, должен быть создан/выполнен по меньшей мере один тест-кейс для каждого требования. Если требование имеет дочерние требования, то для каждого такого дочернего требования должен быть создан/выполнен также по крайней мере один тест-кейс. Некоторые методологии (например, RUP) рекомендуют создавать по меньшей мере два тест-кейса для каждого требования. Один из них должен выполнять позитивное тестирование, другой — негативное.
Если приложение создается без формальных требований, то тест-кейсы пишутся основываясь на обычном поведении программ схожего класса (на так называемых оракулах — но это уже совсем другая история).
Что формально характеризует написанный тест-кейс? Наличие известного ввода (входные данные) и ожидаемого результата, который достигается после выполнения теста. Входные данные называются предусловиями теста, а ожидаемый результат — постусловиями теста.
Написанные тест-кейсы часто объединяются в тестовые наборы (test suite).
Комбинации тест-кейсов наиболее часто используются в приемочном тестировании. Приемочное тестирование выполняется группой конечных пользователей, клиентов (или как в нашем случае, группой разработчиков — об этом позже), чтобы убедиться, что разработанная система удовлетворяет их требованиям. Приемочное тестирования обычно характеризуется включением в него позитивных тест-кейсов, которые определяют удачный путь выполнения приложения.
2. Тест-кейсы необходимо писать по требованиям
Начну здесь, пожалуй, с того, что же такое тестирование и какой программный продукт (систему) мы можем назвать качественным. Надеюсь, что дальше станет понятно, почему я начинаю с определения очевидных вещей.
Одним из определений качественного продукта (не обязательного программного) является то, на сколько данный продукт удовлетворяет предъявляемым к нему требованиям. Исходя из такого подхода к качественному продукту, можно дать следующее определение тестированию. Тестирование — это процесс проверки соответствия продукта предъявляемым к нему требованиям. Т.е. в процессе тестирования программного продукта мы определяем соответствует ли то, что написали программисты, тому, что написали консультанты и аналитики (формализовав требования и пожелания Заказчика).
Данное определение ни в коем случае не претендует на полноту и описывает процесс тестирования только с одной стороны. С той стороны, которая повернута к требованиям. Именно поэтому не стоит расценивать все, что будет написано дальше, как исчерпывающую инструкцию по написанию тест-кейсов.
Отталкиваясь от приведенного мной выше определения через призму рассматриваемой проблемы с тест-кейсами, можно заключить, что тест-кейсы, по своей сути направленные на проверку требований, должны писаться исходя из предъявляемых к продукту требований и никак иначе.
Что же делают наиболее изобретательные тестировщики? При написании тест-кейсов они пытаются заручиться поддержкой программистов, а если еще точнее, то они пытаются как можно быстрей получить готовую реализацию продукта и писать все тест-кейсы, опираясь на реализованный продукт, т.к. это по их мнению объективно проще и понятней. Это крайне неправильно!
В этом случае получается, что в процессе тестирования проверяется соответствие разработанного продукта разработанному продукту (вот такой каламбурчик). Сами можете представить себе, что из этого получается.
Поэтому, резюмирую все описанное выше — базисом для подготовки тест-кейсов должны быть требования (в том или ином виде), а ни в коем случае не готовый продукт.
3. Тест-кейсы должны не повторять требования, а проверять их
Лень… Она является как источником великих прорывов и открытий, так и причиной, которая делает бессмысленной проделанную работу, проведенного впустую времени. Осмысленность любому начинанию, любой работе придает результат (желательно, конечно, положительный), ради которого эта работа задумывалась и выполнялась.
Тоже самое можно сказать и о тест-кейсах. Смыслом написания/выполнения тест-кейсов является проверка того, насколько тестируемое приложение удовлетворяет предъявляемому к нему требованию. Результатом выполнения тест-кейса должны стать его прохождение или провал, что подтвердит соответствие реализации требованию или нет (кстати, для тестировщика любой исход является положительным, правда, в случае провала тест-кейса — более приятным :)).
Что я имею в виду, когда пишу, что тесты должны не повторять требования, а проверять их?
Поясню на простых (естественно, выдуманных, чтобы читатели не краснели, при виде своих собственных творений) примерах.
Есть одно из функциональных требований к системе, для которого необходимо написать тест-кейсы: Значение в поле «Сумма» должно рассчитываться как сумма значений из полей «A» и «B».
Тест-кейс, написанный ленивым тестировщиком:
…
Действия:
Ввести значения в поля «A» и «B».
Ожидаемый результат:
Значение в поле «Сумма» должно рассчитываться как сумма значений из полей «А» и «B». (Иногда еще также в графе с ожидаемым результатом встречаются такие «шедевры» как: См. в ТЗ, в соответствии с ТЗ, наблюдаем ожидаемые значения и т.п.).
…
Тест-кейс, написанный неленивым тестировщиком:
…
Действия:
1. В поле «А» ввести значение 2
2. В поле «B» ввести значение 3
3. Нажать на кнопку «Рассчитать»
Ожидаемый результат:
В поле «Сумма» отобразилось значение 5
…
Чем второй тест-кейс лучше первого?
Первый тест-кейс является всего лишь повторением написанного требования. Во-первых, он не направлен на проверку этого требования, а во-вторых, зачем еще раз дублировать то, что уже написано, — тратить время впустую.
Далее, если речь идет о приемочных тест-кейсах, которые должны обязательно выполнить разработчики перед тем, чтобы передать версию на тестирование, то здесь в случае с первым тест-кейсом вообще все плохо. Т.е. реакция разработчика на такой тест-кейс такова (сужу по своему собственному опыту): «Я же и так все делал по требованиям, поэтому должно все работать, как я и сделал. Тем более я когда-то проверял, что 2 + 2 = 4». И разработчик со спокойной совестью ставит Pass и переходит к следующему тест-кейсу (который наверняка будет таким же неоднозначным :)).
Приведенный пример с суммированием, конечно же, очень примитивен для простоты понимания, но на практике часто приходится сталкиваться с тем, что менее очевидные вещи, чем A + B, описываются в тест-кейсах аналогичным образом и не приносят ожидаемого результата, т.е. проверки какого — либо требования. И в силу этого, после выкладки тестовой версии кажущиеся на первый взгляд очевидными (позитивные) тесты проваливаются.
Здесь суть еще заключается в том, что кроме того, что тест-кейсы должны проверять требования, а не повторять их, очень важным является следующий момент: тест-кейсы должны быть однозначными, т.е. должны быть составлены и сформулированы таким образом, чтобы они не допускали двусмысленного толкования, а однозначно понимались всеми участниками.
4. Написание приемочных тест-кейсов (по определенным правилам)
В предыдущих заметках я уже упоминал о приемочных тестах, которые подготавливают тестировщики для принятия на тестирование очередной тестовой версии приложения.
Проясню немного ситуацию. На проекте сложилась классическая ситуация, описанная еще когда-то господином Канером, когда с появлением выделенного тестирования разработчики расслабляются и абсолютно перестают тестировать свои бесценные творения. Доходит даже до того, что написав что-то (или исправив очередную ошибку в коде) они даже не удосуживаются посмотреть, что же в результате их писательства получилось, а с легкой руки передают на тестирование. Спасибо, что хоть привычка компилировать еще сохранилась!
Для пресечения такой ситуации было перепробовано множество различных способов и методов, начиная с дружеского разъяснения, проведения обучающих семинаров, написания чек-листов и памяток для разработчиков и заканчивая различными степенями наказания (насколько позволяет корпоративная культура), но ничего не помогало. Поэтому было решено подготавливать некоторые наборы приемочных тест-кейсов для разработчиков, которые они в обязательном порядке должны прогонять на системе для разработке перед выкладкой тестовой версии. Обязательным условием выкладки тестовой версии является 100% Pass приемочных тест-кейсов. После выкладки тестовой версии тестировщики начинают свою работу с повторного прогона того же самого приемочного набора для проверки того, что разработчики действительно выполнили все тест-кейсы (а не просто проставили отметки). Я здесь не вдаюсь в технические детали всей этой процедуры. По результатам такой проверки тестировщиками происходит разбор полетов, после которого кто-то получает прянички, а кто-то кнуты.
Результат улучшился — разработчики стали в некоторой степени контролировать свои деяния, но сами понимаете, появились другие проблемы, о которых я и хотел здесь написать, — как написать приемочные тест-кейсы, чтобы они были понятны разработчикам, и чтобы они смогли прогнать их на своей системе для разработки, данные на которой, как правило сильно отличаются от тестовых.
Парочку таких правил я уже написал в предыдущем пункте: тест-кейсы (в том числе и приемочные) должны проверять требования, а не повторять их и тест-кейсы должны быть однозначными, т.е. максимально одинаково пониматься как тестировщиками, так и разработчиками. Здесь о другом.
1. Первое и, на мой взгляд, самое главное — при написании тест-кейсов (а особенно приемочных) тестировщик должен осознать, что данные тест-кейсы предназначены не для него самого, а для другого человека. И писать их, соответственно, необходимо максимально подробно и максимально понятно даже не для посвященного в бизнес-логику приложения человека.
2. Существует два варианта подготовки приемочных тест-кейсов: первый — после подготовки набора тест-кейсов для полного тестирования выбрать из него тест-кейсы для приемочного тестирования, которые покрывают основной (положительный) путь работы приложения; второй — специально подготовить набор только приемочных тест-кейсов.
Однозначно сказать, какой вариант предпочтительней, не возможно. Все очень сильно зависит от ситуации и от тестируемой функциональности. Одно могу сказать совершенно точно (это и есть следующее правило) — тест-кейсы должны быть составлены таким образом, чтобы они не зависели от тех данных, от тех ситуаций, объектов и т.п., которыми тестировщик оперирует на тестовой системе. Т.е. все необходимые данные, объекты и т.д., необходимые для прогона приемочного тест-кейса, должны быть подготовлены самими разработчиками. Как этого добиться? Написать вспомогательные тест-кейсы (либо же написать вспомогательные действия в том же самом приемочном тест-кейсе), которые позволят сделать все предварительные приготовления для основного тест-кейса. В приемочных тестах для разработчиков нельзя ссылаться на какие-то объекты с тестовой системы. Сами понимаете, разработчик просто может не найти их и, в лучшем случае, постарается разобраться в ситуации, а в худшем — напишет комментарий к этому тест-кейсу и поставит Blocked.
3. Еще один очень важный момент, который приводит в замешательство разработчиков, которые прогоняют приемочные тест-кейсы, и не способствует их качественному выполнению. Кстати, этот пунктик относится не только к приемочным тест-кейсам, а к правилам написания тест-кейсов вообще.
Сокращенно звучит он так — один тест-кейс — одна проверка.
Как реагировать на следующий тест-кейс?
…
Steps
1. Действие 1
2. Действие 2
3. Действие 3
4. Действие 4
Expected Results
1. Результат 1
2. Результат 2
3. Результат 3
4. Результат 4
…
Каждому номеру действия необходимо сопоставлять соответствующий номер ожидаемого результата? Или же после выполнения полностью всех действий мы получим результат, состоящий из четырех пунктов? А может быть как — то еще?
Здесь же встает еще и другой вопрос — какой статус выставлять для тест-кейса, если либо часть действий выполнилась, а часть нет, либо в результате успешного выполнения всех действий часть ожидаемых результатов появилась, а часть нет?
И это не голая теория, а реальные вопросы, которые мне задают разработчики, которые выполняют таким образом составленные тест-кейсы.
Поэтому, чтобы избежать таких ситуаций, необходимо писать тест-кейсы таким образом, чтобы они содержали только одну проверку. Не путать с требованиями. Т.к. чтобы проверить одно требование, может понадобиться несколько проверок, а, следовательно, несколько тест-кейсов.
5. Своевременность отметок о прохождении/сбое тест-кейсов
Если все (или почти все) мировое сообщество тестировщиков использует в своих тест-кейсах отметку о прохождении/сбое этих самых тест-кейсов, то, как минимум, необходимо задуматься о том, что они проставляются не просто так, а с какой-то определенной целью (цель, естественно, у каждого своя).
В нашем случае цель проста — в любой момент времени отслеживать текущую ситуацию по процессу выполнения тест-кейсов:
- процент выполнения от общего запланированного количества;
- количество успешно пройденных тест-кейсов;
- количество проваленных тест-кейсов;
- и другие производные от них метрики.
Чтобы получать объективную информацию, необходимо, чтобы в каждый момент времени данные о выполнении тест-кейсов были актуальными. Для этого необходимо, чтобы сразу же после прогона тест-кейса тестировщик проставлял соответствующую отметку.
Чаще всего тестировщики не проставляют отметки сразу же, откладывая на потом, когда полностью закончат тестирование. Какие я вижу минусы в этом подходе:
Нет оперативной информации о том, на каком этапе в данный момент находится тестирование и, следовательно, совершенно не понятно укладывается тестирование в отведенные сроки или необходимы корректирующие действия.
Выполнив 125 тест-кейсов тестировщик вряд ли точно вспомнит, какие тест-кейсы прошли успешно, а какие нет.
Тестировщику придется потратить дополнительное время для того, чтобы восстановить в памяти, что было некоторое время назад и, самое главное, чтобы проставить все эти статусы (а если тест-кейсов будет несколько тысяч, а процесс тестирования будет занимать несколько месяцев, сколько же времени понадобиться на приведение статусов к актуальному виду?). И даже если тестировщику это удастся, то данная информация к тому времени утратит свою ценность.
Поэтому давайте делать все в свое время! Как говорится: «Дорога ложка к обеду».
В таком случае, как менеджер тестов, что вы будете делать?
А) Согласиться с командой тестирования, что это дефект
Б) Менеджер теста берет на себя роль судьи, чтобы решить, является ли проблема дефектом или нет
В) договориться с командой разработчиков, что не является дефектом
Для разрешения конфликта, вы (менеджер проекта) берете на себя роль судьи, который решает, является ли проблема продукта дефектом или нет.
Категории ошибок
Классификация дефектов помогает разработчикам программного обеспечения определять приоритеты своих задач и в первую очередь устранить те дефекты, которые больше прочих угрожают работоспособности продукта.
Критический – дефект должен быть устранены немедленно, иначе это может привести к большим потерям для продукта
Например: функция входа на сайт не работает должным образом.
Вход в систему является одной из основных функций банковского сайта, если эта функция не работает, это серьезные ошибки.
Высокий – дефект негативно влияет на основные функции продукта
Например: производительность сайта слишком низкая.
Средний – дефект вносит минимальные отклонения от требований к к продукту
Например: не корректно отображается интерфейс на мобильных устройствах.
Низкий – минимальное не функциональное влияние на продукт
Например: некоторые ссылки не работают.
Решение
После того, как дефекты приняты и классифицированы, вы можете выполнить следующие шаги, чтобы исправить их.
- Назначение: проблемы отправлены разработчику или другому техническому специалисту для исправления и изменило статус на отвечающий.
- График устранения: сторона разработчика берет на себя ответственность на этом этапе, они создадут график для устранения этих дефектов в зависимости от их приоритета.
- Исправление: пока группа разработчиков устраняет дефекты, диспетчер тестов отслеживает процесс устранения проблем, исходя из графика.
- Сообщить о решении: получите отчет об устранении бага от разработчиков, когда дефекты устранены.
Верификация
После того, как команда разработчиков исправила дефект и сообщила об этом, команда тестирования проверяет, действительно ли устранены все заявленные дефекты.
Закрытие
После устранения и проверки дефекта его статус меняется на закрытый. Если он не устранен, вы отправляете уведомление в отдел разработки, чтобы они проверили дефект еще раз.
Составление отчетов
Далее вы должны сообщить правлению текущую ситуацию с дефектами, чтобы получить от них обратную связь. Они должно видеть и понимать процесс управления дефектами, чтобы поддержать вас в случае необходимости.
Как измерить и оценить качество выполнения теста?
Это вопрос, который хочет знать каждый менеджер в тестировании. Есть 2 параметра, которые вы можете рассмотреть следующим образом…
В приведенном выше сценарии можно рассчитать коэффициент отклонения брака (DRR), равный 20/84 = 0,238 (23,8%).
Другой пример: предположительно, в продукте всего 64 дефекта, но ваша группа по тестированию обнаружила только 44 дефекта, т.е. они пропустили 20 дефектов. Следовательно, можно рассчитать коэффициент утечки дефектов (DLR), равный 20/64 = 0,312 (31,2%).
Вывод, качество выполнения теста оценивается по следующим двум параметрам.
Defect reject ratio (DRR) – 23,8%
Defect leakage ratio (DLR) – 31,2%
Чем меньше значение DRR и DLR, тем, соответственно, лучше качество тестирования. Какой диапазон коэффициентов является приемлемым? Этот диапазон может быть определен и принят за основу в проекте исходя из целей, или вы можете ссылаться на показатели аналогичных проектов.
В рассматриваемом нами проекте рекомендуемое значение показателей качества тестирования должно составлять 5 ~ 10%. Это означает, что качество выполнения теста низкое.
Чтобы уменьшить эти коэффициенты:
- Улучшите навыки тестирования участников проекта.
- Тратьте больше времени на выполнение тестов и на просмотр результатов.
22 июля 2021, 09:47
778 просмотров
Если вы работаете в области финансов и банкинга, то наверняка много внимания уделяете безопасности и стабильности программных продуктов. Всестороннее тестирование ПО в этой сфере ― неотъемлемый элемент на всех этапах жизненного цикла разработки, который помогает заботиться о клиентах и их конфиденциальных данных.
По данным Мирового отчёта по качеству (World Quality Report, WQR) 2020-2021, около 66% банков покрывают тестами всю функциональность цифрового решения, ведь QA позволяет занять лидирующие позиции на рынке. Но главное ― удержать их. Предлагаем детально рассмотреть 3 ключевых правила и 3 типичные ошибки при тестировании ПО в финансовой области.
3 ОШИБКИ, КОТОРЫЕ СНИЖАЮТ ЭФФЕКТИВНОСТЬ QA
Добиться абсолютного качества программного продукта невозможно, а вот максимально приблизиться к нему ― реально. Фундаментом результативной QA-стратегии станет определение типовых ошибок и избавление от них.
Ошибка 1. Сокращение тестового покрытия для ускорения QA-процессов
Чтобы быстрее выйти на рынок, компании часто сокращают затраты на разработку, тестирование или вовсе отказываются от QA. Как показывает практика, подобный подход приносит краткосрочные преимущества и негативно влияет на качество кода.
Чтобы убедиться в стабильной и надёжной работе ПО, стоит проверять все функциональности финтех-продукта, их взаимосвязи и различные интеграции со сторонними системами. При обратном сценарии незамеченными остаются критические дефекты, блокирующие работу приложения после релиза.
Помимо тестирования производительности, в последнее время важное место занимает безопасность, ведь используемое в банках и страховых компаниях ПО наиболее уязвимо перед атаками киберпреступников.
Возросшее из-за пандемии число онлайн-транзакций дало хакерам больше возможностей для незаконного получения конфиденциальных данных пользователей и организаций. Некоторые банки отметили увеличение кибератак в 4,5 раза по сравнению с 2019 годом. А утечка информации вследствие преступной активности стала второй по актуальности угрозой для представителей финансового сектора. Это отметили 71% опрошенных по результатам исследования 2021 года «Защита от DDoS-атак в банках», поэтому не стоит отказываться от тестирования безопасности.
Ошибка 2. Ложная оптимизация при автоматизации тестирования
Внедрение автотестов служит проверенным методом сокращения предрелизного периода. Но без необходимого опыта и точной стратегии для QA-команды автоматизация тестирования может стать импровизацией.
К примеру, изменения в функциональности могут замедлить QA-процессы даже при максимальном объёме автотестов, ведь алгоритмы проверок нужно постоянно пересматривать, как и код автотестов. В свою очередь, недостаток автоматизации тоже не сэкономит время, ведь эффективность мануального тестирования при сохранении численности команды останется на прежнем уровне или снизится.
Ошибка 3. Недостаточное внимание к UX
Хотя портативные устройства стали неотъемлемой частью жизни пользователей, некоторые компании пренебрегают мобильным тестированием и оценивают качество только веб-версий. Представьте, что генеральный директор крупной сети магазинов зайдёт в приложение, чтобы отправить денежный перевод, но неинтуитивный интерфейс замедлит проведение данной операции. Это послужит причиной снижения его лояльности как клиента.
Частой ошибкой мобильных проверок является использование исключительно эмуляторов и симуляторов вместо реальных устройств. Подобная имитация не позволит выявить все критические дефекты ПО.
Давайте же разберёмся, как можно избежать подобных ошибок и улучшить QA-процесс.
3 ПРАВИЛА ПРОДУКТИВНОГО ТЕСТИРОВАНИЯ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ В ФИНТЕХ
Для существенного ускорения при выходе на рынок в долгосрочной перспективе стоит включить новые подходы и технологии в стратегию по обеспечению качества.
Правило 1. Внедряйте автоматизацию тестирования с умом
Оптимальным решением является сбалансированный подход к внедрению автоматизированного тестирования для тех функциональностей, которые регулярно проверяются тестировщиками, но не меняются кардинально в течение нескольких недель.
Это ускоряет QA-процессы и помогает выявлять ошибки быстрее, чем при ручном тестировании. Чтобы получить максимум пользы, компании внедряют искусственный интеллект, машинное обучение и прочие инновации в процессы автоматизации тестирования. На старте это потребует дополнительных усилий, но подобное сочетание выглядит многообещающе с точки зрения результатов для бизнеса. На изображении ниже вы можете оценить три основных аспекта переосмысления решения по автоматизации тестирования.

Источник: Мировой отчёт по качеству 2020-2021
Читайте продолжение статьи по ссылке: https://www.a1qa.ru/blog/dos-and-donts-in-bfsi-testing/
Подписывайтесь на наши новостные
рассылки,
а также на каналы
Telegram
,
Vkontakte
,
Яндекс.Дзен
чтобы первым быть в курсе главных новостей Retail.ru.
Добавьте «Retail.ru» в свои источники в
Яндекс.Новости
-
Классификация ошибок
Задача любого
тестировщика заключается в нахождении
наибольшего количества ошибок, поэтому
он должен хорошо знать наиболее часто
допускаемые ошибки и уметь находить их
за минимально короткий период времени.
Остальные ошибки, которые не являются
типовыми, обнаруживаются только тщательно
созданными наборами тестов. Однако из
этого не следует, что для типовых ошибок
не нужно составлять тесты.
Для классификации
ошибок мы должны определить термин
«ошибка».
Ошибка – это
расхождение между вычисленным, наблюдаемым
и истинным, заданным или теоретически
правильным значением.
Итак, по времени
появления ошибки можно разделить на
три вида:
– структурные ошибки
набора;
– ошибки компиляции;
– ошибки периода
выполнения.
Структурные
ошибки
возникают непосредственно при наборе
программы. К данному типу ошибок относятся
такие как: несоответствие числа
открывающих скобок числу закрывающих,
отсутствие парного оператора (например,
try
без catch).
Ошибки
компиляции
возникают из-за ошибок в тексте кода.
Они включают ошибки в синтаксисе,
неверное использование конструкции
языка (оператор else
в операторе for
и т. п.), использование несуществующих
объектов или свойств, методов у объектов,
употребление синтаксических знаков и
т. п.
Ошибки
периода выполнения
возникают, когда программа выполняется
и компилятор (или операционная система,
виртуальная машина) обнаруживает, что
оператор делает попытку выполнить
недопустимое или невозможное действие.
Например, деление на ноль.
Если проанализировать
все типы ошибок согласно первой
классификации, то можно прийти к
заключению, что при тестировании
приходится иметь дело с ошибками периода
выполнения, так как первые два типа
ошибок определяются на этапе кодирования.
В теоретической
информатике программные ошибки
классифицируют по степени нарушения
логики на:
– синтаксические;
–семантические;
– прагматические.
Синтаксические
ошибки
заключаются в нарушении правописания
или пунктуации в записи выражений,
операторов и т. п., т. е. в нарушении
грамматических правил языка. В качестве
примеров синтаксических ошибок можно
назвать:
– пропуск необходимого
знака пунктуации;
– несогласованность
скобок;
– пропуск нужных
скобок;
– неверное написание
зарезервированных слов;
– отсутствие описания
массива.
Все ошибки данного
типа обнаруживаются компилятором.
Семантические
ошибки
заключаются в нарушении порядка
операторов, параметров функций и
употреблении выражений. Например,
параметры у функции add
(на языке Java)
в следующем выражении указаны в
неправильном порядке:
GregorianCalendar.add(1,
Calendar.MONTH).
Параметр, указывающий
изменяемое поле (в примере – месяц),
должен идти первым. Семантические ошибки
также обнаруживаются компилятором.
Надо отметить, что некоторые исследователи
относят семантические ошибки к следующей
группе ошибок.
Прагматические
ошибки (или
логические) заключаются в неправильной
логике алгоритма, нарушении смысла
вычислений и т. п. Они являются самыми
сложными и крайне трудно обнаруживаются.
Компилятор может выявить только следствие
прагматической ошибки.
Таким образом, после
рассмотрения двух классификаций ошибок
можно прийти к выводу, что на этапе
тестирования ищутся прагматические
ошибки периода выполнения, так как
остальные выявляются в процессе
программирования.
На этом можно было
бы закончить рассмотрение классификаций,
но с течением времени накапливался опыт
обнаружения ошибок и сами ошибки,
некоторые из которых образуют характерные
группы, которые могут тоже служить
характерной классификацией.
Ошибка
адресации
– ошибка, состоящая в неправильной
адресации данных (например, выход за
пределы участка памяти).
Ошибка
ввода-вывода
– ошибка, возникающая в процессе обмена
данными между устройствами памяти,
внешними устройствами.
Ошибка
вычисления
– ошибка, возникающая при выполнении
арифметических операций (например,
разнотипные данные, деление на нуль и
др.).
Ошибка
интерфейса
– программная ошибка, вызванная
несовпадением характеристик фактических
и формальных параметров (как правило,
семантическая ошибка периода компиляции,
но может быть и логической ошибкой
периода выполнения).
Ошибка
обращения к данным
– ошибка, возникающая при обращении
программы к данным (например, выход
индекса за пределы массива, не
инициализированные значения переменных
и др.).
Ошибка
описания данных
– ошибка, допущенная в ходе описания
данных.[2]
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Kevin J. Clancy
Peter C. Krieg
На удивление большое количество новых продуктов и услуг терпят провал, в основном потому, что они не были должным образом протестированы перед запуском. Знание того, как избежать некоторых наиболее распространенных ошибок в тестировании концепций и маркетинговых планов, поможет компаниям обеспечить своим продуктам долгую и счастливую жизнь на рынке.
При просмотре в понедельник отчета об игре, прошедшей в воскресенье, любой фанат может указать на ошибки квотербека, и что тот мог сделать лучше, чтобы использовать ошибки другой команды. Точно так же, после того как новый продукт провалился, любой хоть немного разбирающийся в предмете маркетолог обычно может указать на ошибки компании.
Посмотрим на Cottonelle Fresh Rollwipes, «первый и единственный в Америке рулон увлажненной туалетной бумаги». Компания Kimberly-Clark объявила об этом «прорыве» в январе 2001 года. Согласно пресс-релизу, «это самая революционная инновация в данной категории с тех пор, как туалетная бумага впервые появилась в виде рулона в 1890 году».
Корпорация была уверена, что рынок для продукта существует. Ее маркетинговое исследование показало, что 63% американцев экспериментировали с мокрым «методом очистки», а каждый четвертый ежедневно использует влажные салфетки. Большинство используют детские салфетки, но те не могут использовать антисептические препараты. Kimberly-Clark продавала коробки с листами увлаженной туалетной бумаги много лет, и рост продаж этого товара убедил компанию инвестировать в более удобный механизм доставки.
Она разработала многоразовый пластиковый контейнер, который можно повесить на обычный держатель туалетной бумаги, к которому одновременно крепятся и обычный рулон сухой бумаги и влажный Fresh Rollwipes. Контейнер с четырьмя рулонами стоил $8.99; четыре новых рулона –$3.99. Kimberly-Clark, которая уверяет, что потратила $100 миллионов на проект, защитила продукт и контейнер при помощи 30 патентов.
В январе 2001 года корпорация заявила, что американский рынок туалетной бумаги – $4.8 миллиарда в год. В Kimberly-Clark ожидали, что в первый же год продажи Fresh Rollwipes достигнут, по меньшей мере, $150 миллионов и еще $500 миллионов – в последующие шесть лет. Более того, эти продажи расширят весь рынок туалетной бумаги, потому что влажная бумага скорее дополняет сухую, а не заменяет ее.
Но к октябрю, спустя 10 месяцев, Kimberly-Clark в плохих продажах начала винить слабую экономику. Согласно данным Information Resources Inc., продажи Cottonelle Fresh Rollwipes вышли на уровень примерно трети от запланированных $150 миллионов. Однако по нашему опыту, если потребители заинтересовались продуктом, слабая экономика не может столь сильно сказаться на продажах. Что-то не так было с маркетингом Kimberly-Clark, и в апреле 2002 года The Wall Street Journal сообщила о некоторых из ошибок компании.
Преждевременное объявление о начале. Хотя Kimberly-Clark начала рекламную и PR кампании в январе, она была не готова поставлять продукт в магазины до июля. Это как топить дом летом в надежде, что он сохранит тепло зимой. Поздняя поставка производственного оборудования стала причиной «большей части» задержки, но к июлю большинство покупателей уже забыли о товаре. «Я знаю, что что-то об этом слышал, но не помню то ли это была реклама, то ли какой-то комик шутил по этому поводу», — говорит Роб Алмонд, который закупает бумажные товары для Richfield Nursing Center, Вирджиния.
Неэффективная реклама. Учитывая то, что Kimberly-Clark пыталась продвигать преимущества продукта, о котором лишь немногие люди могут говорить без смущения, компания в своей рекламе так внятно и не объяснила, что именно делает продукт. Реклама, которая стоила $35 миллионов, содержала слоган «иногда лучше, когда мокро» и показывала со спины людей, плескающихся в воде. Печатная реклама крупным планом демонстрировала сзади борца сумо. Аналитики критиковали рекламу за то, что она внятно не описывает продукт и не создает спрос. Плюс к этому Kimberly-Clark запустила общенациональную кампанию при том, что (a) продукта еще не было в продаже и (б) когда он, наконец, появился, его продавали только в некоторых южных штатах.
Если когда-то и был продукт идеально подходящий для раздачи образцов, это был именно тот случай. Но Rollwipes не производили в небольших упаковках, что означает отсутствие бесплатных образцов. Вместо этого Kimberly-Clark запланировала передвижной туалетный тур с остановками в людных местах, где все желающие могли его попробовать. Тур был запланирован на середину сентября 2001 года, и был отложен после событий 11 сентября.
Еще одна проблема была с дизайном продукта. В отличие от бумаги в обычных коробках, которую излишне скромные потребители могут спрятать под раковиной, пластиковый бежевый контейнер Rollwipes был виден сразу же. Он крепился к обычному держателю туалетной бумаги, но размером был с два рулона, поставленных друг на друга. Не в каждой ванной есть столько места, и не каждый потребитель хочет постоянно иметь перед глазами бежевый пластик.
Через полтора года после того, как Kimberly-Clark объявила о запуске, Fresh Rollwipes присутствовали только на одном региональном рынке, а продажи шли так плохо, что финансовой отдачи почти не наблюдалось.
Стоимость провала
Хотя маркетологи могут получить пользу от понедельничного разбора игры квотербека, это не повышает чьи-то шансы произвести успешный запуск нового продукта или услуги или предотвратить бесполезные траты миллионов или даже миллиардов долларов.
Представители отрасли обычно заявляют, что успешными являются от 80% до 90% новых продуктов, однако недавнее исследование Nielsen BASES и Ernst & Young показало, что в США терпят неудачу до 95% новых потребительских продуктов, а в Европе – до 90%. По данным исследований, которые мы проводим в Copernicus, успеха добиваются не более 10% всех новых продуктов и услуг. Под успешными понимаются те, которые присутствуют на рынке через три года и являются прибыльными. Это происходит и с потребительскими товарами, и с финансовыми услугами, и товарами длительного спроса, и телекоммуникационными услугами, и лекарствами.
А неудачи обходятся компаниям в огромные суммы денег. Точно их можно подсчитать, взяв среднюю стоимость разработки нового продукта и умножив ее на количество неудач.
Эдвард Огиба, президент Group EFO Limited, консалтинговой компании, пишет, что вывод нового общенационального брэнда обычно обходится в более чем $20 миллионов.
Редактор New Product News пишет: «общенациональный запуск действительного нового безалкогольного напитка стоит примерно $100 миллионов, а запуск нового вкуса мороженого только в Миннеаполисе обходится в $10,000. Бесполезные «средние» затраты на запуск нового продукта лежат где-то в середине». Он добавляет, что при помощи медиа экспертов журналы создали «идеальный» маркетинговый план для серьезного нового продукта, включающий общенациональную рекламу, продвижение среди потребителей и торговое продвижение. Общие расходы на него составляют примерно $54 миллиона и не включают разработку самого продукта, упаковки, обучение продавцов или затраты на управление брэндом.
Менеджер по маркетинговым исследованиям из Best Foods Division компании CPC International недавно рассказал нам, что по самым консервативным оценкам каждый год производители тратят на маркетинг провалившихся новых продуктов от $9 до $14 миллиардов, а по нашему мнению, так и много больше.
А теперь сравните эти оценки затрат на разработку и запуск с удивительным анализом, проведенным несколько лет назад SAMI/Burke, который показал, что менее 200 продуктов из нескольких тысяч, запущенных в течение последних 10 лет, достигли уровня продаж в $15 миллионов, и продажи лишь нескольких из них превысили $100 миллионов. Очень немногие новые продукты и услуги могут похвастаться положительным возвратом на инвестиции.
Но не обязательно, чтобы всегда было именно так. Повысить шансы на успех, можно избегая главных маркетинговых ошибок. Для этого требуется новый способ формирования идей для новых продуктов, тестирования концепций, тестирования продукта и услуги с точки зрения готовности потребителей ее принять, тестирования рекламы и продвижения, и наконец проверки всего маркетингового плана. В этой статье мы остановимся на двух возможных причинах неудачи: проверке концепции и сбоях в маркетинговых планах.
Тестирование концепции, которая не достигает цели
Новые идеи для продуктов и услуг появляются отовсюду. Они приходят в голову посреди ночи. Или у компании появляется возможность купить лицензию или права на что-то из другой страны (например, Hаagen-Daz добился потрясающего успеха с мороженым dulce de leche, появившимся в Южной Америке; или Red Bull – с энергетическим напитком из Таиланда). Или в фирме действительно возникли идеи новых продуктов в результате интервью, фокус-групп или наблюдений за потребителями, за которыми последовал мозговой штурм.
В какой-то момент идея превращается в концепцию, часто описываемую одним – двумя параграфами, иногда сопровождаемую названием и ценой. И если маркетолог умен, эта концепция проверяется на потенциальных покупателях в данной категории. В конце концов, зачем тратить ценные время и доллары на разработку продукта, который потребители не хотят покупать?
Проверка концепции, как она сегодня чаще всего проводится, сопряжена однако с множеством проблем. Почти каждый маркетолог проводил хотя бы одну (если не сто), и все же такие проверки поднимают больше вопросов, чем они дают ответов. Мы слышим, как маркетинговые руководители задают вопросы, такие как, «а 14% в верхней ячейке («почти наверняка купят») – это хорошо?» Или они говорят «Мы проанализировали три варианта цены. Как каждый из них может получить 10% в верхней ячейке? Может нам придумать четвертый вариант?» Или «Если мы поменяем цену, насколько повысится доля тех, кто попробует продукт? До 30% дойти может?» Традиционные виды тестирования концепций сопровождаются проблемами, которые мы перечислили ниже:
Ограничения по выборке . Маркетологи заключают контракты с исследовательскими компаниями, которые обычно используют небольшие (75 – 150 человек) нерепрезентативные опросы мужчин и женщин, прогуливающихся в магазинах и готовых ответить на вопросы. Более того, они часто используют не более трех первых попавшихся торговых центра для каждого исследования.
Сбор данных . Проверка концепций по телефону или через интернет также имеет недостатки. По телефону интервьюер читает описание концепции. Поскольку люди забывают первое предложение, прежде чем дослушали до конца второе, исследователи максимально сокращают концепции, иногда умещая их в одно предложение. Упрощенная концепция затем дополняется шкалой с небольшим количеством вариантов ответов (чтобы уменьшить разброс), которая затем будет использована в личных интервью или интернет опросах. По телефону же респондент должен запомнить все варианты ответов и выдать номер.
Интернет предоставляет больше визуальных возможностей, но может быть столь же опасен, как и телефон. Многие маркетологи не понимают, что есть два основных метода сбора данных через сеть: базы данных и панели. По мнению Грега МакМаона, старшего вице-президента международной исследовательской фирмы Synovate, важно провести четкую границу между двумя методами: «Только исследовательские фирмы, имеющие настоящие интернет панели, поддерживают подробную демографическую (и другую) информацию об их членах и сверяют ее с данными переписи населения. Без этого баланса существует очень высокий риск, что результаты исследования не измерят то, что должны были измерить, и что им будет не доставать последовательности». Средний отклик на интернет опросы менее 1%, что делает из него не очень достоверный источник информации о потенциале новых продуктов.
Альтернативные возможности . Немногие маркетологи способны эффективно задать вопрос «что если?», касающийся различных характеристик и выгод концепции. Например, страховая компания, рассматривающая концепцию нового продукта автострахования, может задаться вопросом «Что если мы предоставим льготный доступ в авторемонт? Что если за небольшую плату возьмем на себя весь процесс регистрации? А бесплатно?»
Незнание издержек . Согласно нашему опыту, менеджеры по маркетингу редко знают постоянные и переменные «производственные» и маркетинговые издержки нового продукта или услуги. И уж точно они никогда не передают такую информацию людям, проводящим исследование. Но, не зная издержек, менеджер не может оценить прибыльность.
Ограниченные модели. Наконец, лишь некоторые исследовательские компании могут предложить действенную модель маркетингового микса, в которую они могут закладывать результаты концепций, чтобы предсказать продажи и прибыльность. Исследователи представляют результаты концепций маркетологам, как будто те являются самодостаточными частями информации сами по себе: «Эта получила 33% в двух верхних ячейках, обойдя контрольную концепцию почти два к одному». Это мило, но будет ли она продаваться? А если будет, станет ли приносить прибыль? В ответ пустой взгляд исследователя.
Быстрая починка
Хорошая новость заключается в том, что компании могут справиться с большинством этих проблем при помощи традиционного тестирования, но с некоторыми модификациями:
Укрупните выборку . Проинструктируйте исследователей, чтобы они использовали более крупную и репрезентативную выборку потенциальных покупателей (от 300 до 500) в большем числе торговых точек. Это должны быть серьезные респонденты, набранные через случайный выбор телефонных номеров, а затем приглашенные в специальное место, а не первые встречные в торговом центре, согласные остановиться на минутку.
Правильно сочетайте телефон и интернет . Отправьте описание концепции и шкалу оценки респонденту до телефонного звонка. Проведите несколько индивидуальных интервью, чтобы скорректировать результаты интернет опроса. Удостоверьтесь, что исследовательская компания использует интернет панель.
Полные описания . Представьте опрашиваемым полное описание концепции, вместе с названием, позиционированием, упаковкой, характеристиками и ценой (мы не перестаем удивляться, как часто исследователи игнорируют цену). Представьте концепцию в контексте конкуренции, т.е. какие конкурирующие продукты продаются на рынке и по каким ценам. Чем более точно тестирование отражает реальность, тем более точным будет прогноз. Большинство проверок концепций игнорируют конкурентное окружение.
Измеряйте прибыльность . Пусть потребители оценят концепцию с точки зрения прибыльности. Мы выяснили в ходе множества экспериментов, что шкала с 11 оценками наиболее полно предсказывает реальное поведение, особенно для сложных продуктов.
Но даже эта шкала завышает реальные покупки. Люди ведут себя не так, как говорят. Во-первых, исследование предполагает 100% осведомленность и 100% дистрибуцию, другими словами, все знают о продукте и могут легко его найти, чего никогда не происходит в реальности. И даже учитывая это, проблемы с завышенными ожиданиями остаются.
Мы плотно изучили соотношение между ответами людей по шкале с 11 градациями и реальным покупательским поведением (среди людей, осведомленных о продукте или услуге, и имеющих возможность совершить покупку) для множества компаний в потребительских и В2В категориях. Обычно не более 75% людей, заявивших, что обязательно купят продукт, действительно его покупают. Цифра снижается по мере снижения намерения купить, но соотношение сохраняется. Это ведет к необходимости ряда поправок для каждого уровня вовлеченности и конвертирует рейтинги опросника в оценку вероятного поведения.
Поправки зависят от уровня «вовлеченности» потребителей (или корпоративных покупателей) в категорию. Чем выше вовлеченность, тем больше мы верим в то, что люди говорят, и тем ниже потребность в поправке на преувеличение. Можно не говорить, что учитывая вероятность покупки и вовлеченность, возможно дать довольно точную оценку реального уровня продаж (процента потребителей, которые совершат хотя бы одну покупку).
Хотя традиционные методы тестирования остаются наиболее распространенным способом тестирования концепций новых продуктов, традиционные методы не означают ipso facto наилучшего подхода. Цель традиционного теста – найти концепцию продукта, обладающую наивысшим уровнем привлекательности для покупателей, но они часто не соответствуют тому, что действительно нужно компании.
Доводка нового продукта/услуги при помощи компьютера – альтернатива традиционным методам. Она начинается с модифицированного множественного анализа с целью выбора компромиссного решения, при котором используется или конжойнт – анализ, или методология моделирования выбора. Эти подходы предлагают несколько продвинутых характеристик: они прогнозируют реальное поведение и продажи для нескольких альтернативных концепций; используют алгоритм нелинейной оптимизации, чтобы выделить наиболее прибыльные концепции; позволяют маркетологам проигрывать «что если» сценарии; и предлагают руководство по таргетированию и позиционированию.
Проблемы с тестовыми рынками
После того, как концепция выбрана, отточена и готова к запуску, следующий шаг для большинства маркетологов – тестовый рынок. Но, как и в случае с традиционными методами тестирования концепций, традиционные тестовые рынки также ведут к проблемам. Часто компания выбирает тестовый рынок, потому что им легко управлять, или потому что ритейлер на этом рынке готов к сотрудничеству. Не выбираются рынки, которые наиболее точно соответствуют целям, которые компания хотела бы достичь.
У работы с традиционными тестовыми рынками есть четыре основных недостатка. Во-первых, они дорого стоят. Они могут обойтись «всего» в $3 миллиона, но обычно больше. Затраты включают исследования, СМИ и усилия организации по контролю и проверке тестирования. Во-вторых, они занимают много времени. Ждать год, полтора или два, чтобы получить результаты, в сегодняшнем конкурентном окружении не представляется возможным.
Третья проблема заключается в том, что конкуренты могут саботировать результаты. Даже небольшие усилия с их стороны могут значительно затруднить возможности компании по оценке результатов. В то же время конкуренты могут разработать схожий продукт или услугу.
Наконец традиционные тестовые рынки обычно не сообщают маркетологам то, что тем требуется знать. И хотя провал продукта на тестовом рынке это не то же самое, что провал на национальном уровне, часто трудно определить причины этого провала. Что-то не так с воплощением идеи или с самой идеей? С маркетинговой программой или реакцией конкурентов? Какая часть маркетинговой программы не сработала? Может ли компания сделать что-то, чтобы превратить небольшой провал в большой успех? И наоборот, если тест был успешным, может ли произойти что-то, что снизит его прибыльность в будущем?
Симуляция тестового рынка (STM) – одновременно и альтернатива, и дополнение к традиционным методам. Существующие системы STM улавливают все важные компоненты маркетингового микса и оценивают эффект любого маркетингового плана на осведомленность о продукте, первые и последующие покупки, долю рынка, прибыльность и многое другое. Эти STM проверяют любой план, даже разработанный конкурентами. Маркетолог вносит подробности плана в компьютерную программу, а модель прогнозирует, что случится в реальном мире на каждом этапе, месяц за месяцем.
Сделайте что-нибудь новое
Если вы делаете только то, что уже делали, то и получите вы то, что уже получали. Большинству компаний мало что удавалось сделать для обеспечения успеха новых продуктов или услуг в последние пару десятков лет. Компаниям требуется что-то новое.
Все больше компаний увлекаются идеями гарвардских профессоров по экономике Джона МакАртура и Джеффри Сакса, которые заявили: «Инновация – это не просто нашлепка тщеславия на экономическом двигателе страны. По вкладу в рост, она превосходит и накопление капитала и распределение ресурсов».
Сегодня самое время для компаний использовать компьютерные технологии и симуляции тестовых рынков, чтобы повысить эффективность маркетинговых программ для новых продуктов и услуг. Технологии помогут маркетологам найти наилучшие концепции продуктов и услуг и разработать маркетинговый план, который приведет к росту спроса и увеличению прибыли.
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.
В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
7.3.2. Классификация ошибок и тестов
Каждая организация, разрабатывающая ПО общесистемного назначения, сталкивается с проблемами нахождения ошибок. Поэтому приходится классифицировать типы обнаруживаемых ошибок и определять свое отношение к устранению этих ошибок.
На основе многолетней деятельности в области создания ПО разные фирмы создали свою классификацию ошибок, основанную на выявлении причин их появления в процессе разработки, в функциях и в области функциональной деятельности ПО.
Известно много различных подходов к классификации ошибок, рассмотрим некоторые из них.
Фирма IВМ разработала подход к классификации ошибок, называемый ортогональной классификацией дефектов [7.4]. Подход предусматривает разбиение ошибок по категориям с соответствующей ответственностью разработчиков за них.
Схема классификации не зависит от продукта, организации разработки и может применяться ко всем стадиям разработки ПО разного назначения. табл. 7.1 дает список ошибок согласно данной классификации. Используя эту таблицу, разработчик имеет возможность идентифицировать не только типы ошибок, но и места, где пропущены или совершены ошибки. Предусмотрены ситуации, когда найдена неинициализированная переменная или инициализированной переменной присвоено неправильное значение.
Ортогональность схемы классификации заключается в том, что любой ее термин принадлежит только одной категории.
Таблица
7.1.
Ортогональная классификация дефектов IBM
| Контекст ошибки | Классификация дефектов |
|---|---|
| Функция | Ошибки интерфейсов конечных пользователей ПО, вызванные аппаратурой или связаны с глобальными структурами данных |
| Интерфейс | Ошибки во взаимодействии с другими компонентами, в вызовах, макросах, управляющих блоках или в списке параметров |
| Логика | Ошибки в программной логике, неохваченной валидацией, а также в использовании значений переменных |
| Присваивание | Ошибки в структуре данных или в инициализации переменных отдельных частей программы |
| Зацикливание | Ошибки, вызванные ресурсом времени, реальным временем или разделением времени |
| Среда | Ошибки в репозитории, в управлении изменениями или в контролируемых версиях проекта |
| Алгоритм | Ошибки, связанные с обеспечением эффективности, корректности алгоритмов или структур данных системы |
| Документация | Ошибки в записях документов сопровождения или в публикациях |
Другими словами, прослеживаемая ошибка в системе должна находиться в одном из классов, что дает возможность разным разработчикам классифицировать ошибки одинаковым способом.
Фирма Hewlett-Packard использовала классификацию Буча, установив процентное соотношение ошибок, обнаруживаемых в ПО на разных стадиях разработки (рис. 7.2) [7.12].
Это соотношение — типичное для многих фирм, производящих ПО, имеет некоторые отклонения.
Исследования фирм IBM показали, чем позже обнаруживается ошибка в программе, тем дороже обходится ее исправление, эта зависимость близка к экспоненциальной. Так военновоздушные силы США оценили стоимость разработки одной инструкции в 75 долларов, а ее стоимость сопровождения составляет около 4000 долларов.

Рис.
7.2.
Процентное соотношение ошибок при разработке ПО
Согласно данным [7.6, 7.11] стоимость анализа и формирования требований, внесения в них изменений составляет примерно 10%, аналогично оценивается стоимость спецификации продукта. Стоимость кодирования оценивается более чем 20%, а стоимость тестирования продукта составляет более 45% от его общей стоимости. Значительную часть стоимости составляет сопровождение готового продукта и исправление обнаруженных в нем ошибок.
Определение теста.Для проверки правильности программ специально разрабатываются тесты и тестовые данные. Под тестом понимается некоторая программа, предназначенная для проверки работоспособности другой программы и обнаружения в ней ошибочных ситуаций. Тестовую проверку можно провести также путем введения в проверяемую программу отладочных операторов, которые будут сигнализировать о ходе ее выполнения и получения результатов.
Тестовые данные служат для проверки работы системы и составляются разными способами: генератором тестовых данных, проектной группой на основе внемашинных документов или имеющихся файлов, пользователем по спецификациям требований и др. Очень часто разрабатываются специальные формы входных документов, в которых отображается процесс выполнения программы с помощью тестовых данных [7.11].
Создаются тесты, проверяющие:
- полноту функций;
- согласованность интерфейсов;
- корректность выполнения функций и правильность функционирования системы в заданных условиях;- надежность выполнения системы;
- защиту от сбоев аппаратуры и не выявленных ошибок и др.
Тестовые данные готовятся как для проверки отдельных программных элементов, так и для групп программ или комплексов на разных стадиях процесса разработки. На рис. 7.3. приведена классификация тестов проверки по объектам тестирования на основных этапах разработки.
Многие типы тестов готовятся заказчиком для проверки работы программной системы. Структура и содержание тестов зависят от вида тестируемого элемента, которым может быть модуль, компонент, группа компонентов, подсистема или система. Некоторые тесты зависят от цели и необходимости знать: работает ли система в соответствии с ее проектом, удовлетворены ли требования и участвует ли заказчик в проверке работы тестов и т.п.
В зависимости от задач, которые ставятся перед тестированием программ, составляются тесты проверки промежуточных результатов проектирования элементов на этапах ЖЦ, а также создаются тесты испытаний окончательного кода системы.
Тесты интегрированной системы.Тесты для проверки отдельных элементов системы и тесты интегрированной системы имеют общие и отличительные черты. Так, на рис. 7.4 в качестве примера приведена схема интеграции готовых оттестированных элементов. В ней заданы связи между разными уровнями тестирования интегрируемой ПС.
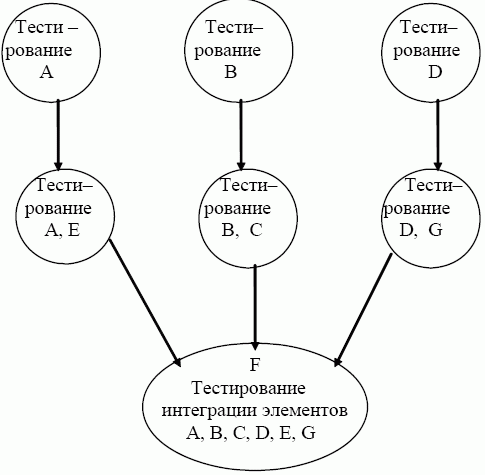
Рис.
7.4.
Интегрированное тестирование компонент
Рассмотрим этот процесс более подробно. Каждый компонент этой схемы тестируется отдельно от других компонентов с помощью тестов, включающих наборы данных и сценарии, составленные в соответствии с их типами и функциями, специфицированные в проекте системы. Тестирование проводится в контрольной операционной среде на предопределенном множестве тестовых данных и операциях, производимых над ними.
Тесты обеспечивают проверку внутренней структуры, логики и граничных условий выполнения для каждого компонента.
Согласно приведенной схеме сначала тестируются компоненты А, В, D независимо друг от друга и каждый с отдельным тестом. После их проверки выполняется проверка интерфейсов для последующей их интеграции, суть которой заключается в анализе выполнения операторов вызова А -> E, B -> C, D -> G, на нижних уровнях графа: компоненты Е, С, G. При этом предполагается, что указанные вызываемые компоненты, так же должны быть отлажены отдельно. Аналогично проверяются все обращения к компоненту F, являющемуся связывающим звеном с вышележащими элементами.
При этом могут возникать ошибки, в случае неправильного задания параметров в операторах вызова или при вычислениях процедур или функций. Возникающие ошибки в связях устраняются, а затем повторно проверяется связь с компонентом F в виде троек: компонентинтерфейскомпонент.Следующим шагом тестирования комплексной системы является проверка функционирования системы с помощью тестов проверки функций и требований к ним. После проверки системы на функциональных тестах происходит проверка на исполнительных и испытательных тестах, подготовленных согласно требованиям к ПО, аппаратуре и выполняемым функциям. Испытательному тесту предшествует верификация и валидация ПО.
Тест испытаний системы в соответствии с требованиями заказчика проверяется в реальной среде, в которой система будет в дальнейшем функционировать.
-
Классификация ошибок
Задача любого
тестировщика заключается в нахождении
наибольшего количества ошибок, поэтому
он должен хорошо знать наиболее часто
допускаемые ошибки и уметь находить их
за минимально короткий период времени.
Остальные ошибки, которые не являются
типовыми, обнаруживаются только тщательно
созданными наборами тестов. Однако из
этого не следует, что для типовых ошибок
не нужно составлять тесты.
Для классификации
ошибок мы должны определить термин
«ошибка».
Ошибка – это
расхождение между вычисленным, наблюдаемым
и истинным, заданным или теоретически
правильным значением.
Итак, по времени
появления ошибки можно разделить на
три вида:
– структурные ошибки
набора;
– ошибки компиляции;
– ошибки периода
выполнения.
Структурные
ошибки
возникают непосредственно при наборе
программы. К данному типу ошибок относятся
такие как: несоответствие числа
открывающих скобок числу закрывающих,
отсутствие парного оператора (например,
try
без catch).
Ошибки
компиляции
возникают из-за ошибок в тексте кода.
Они включают ошибки в синтаксисе,
неверное использование конструкции
языка (оператор else
в операторе for
и т. п.), использование несуществующих
объектов или свойств, методов у объектов,
употребление синтаксических знаков и
т. п.
Ошибки
периода выполнения
возникают, когда программа выполняется
и компилятор (или операционная система,
виртуальная машина) обнаруживает, что
оператор делает попытку выполнить
недопустимое или невозможное действие.
Например, деление на ноль.
Если проанализировать
все типы ошибок согласно первой
классификации, то можно прийти к
заключению, что при тестировании
приходится иметь дело с ошибками периода
выполнения, так как первые два типа
ошибок определяются на этапе кодирования.
В теоретической
информатике программные ошибки
классифицируют по степени нарушения
логики на:
– синтаксические;
–семантические;
– прагматические.
Синтаксические
ошибки
заключаются в нарушении правописания
или пунктуации в записи выражений,
операторов и т. п., т. е. в нарушении
грамматических правил языка. В качестве
примеров синтаксических ошибок можно
назвать:
– пропуск необходимого
знака пунктуации;
– несогласованность
скобок;
– пропуск нужных
скобок;
– неверное написание
зарезервированных слов;
– отсутствие описания
массива.
Все ошибки данного
типа обнаруживаются компилятором.
Семантические
ошибки
заключаются в нарушении порядка
операторов, параметров функций и
употреблении выражений. Например,
параметры у функции add
(на языке Java)
в следующем выражении указаны в
неправильном порядке:
GregorianCalendar.add(1,
Calendar.MONTH).
Параметр, указывающий
изменяемое поле (в примере – месяц),
должен идти первым. Семантические ошибки
также обнаруживаются компилятором.
Надо отметить, что некоторые исследователи
относят семантические ошибки к следующей
группе ошибок.
Прагматические
ошибки (или
логические) заключаются в неправильной
логике алгоритма, нарушении смысла
вычислений и т. п. Они являются самыми
сложными и крайне трудно обнаруживаются.
Компилятор может выявить только следствие
прагматической ошибки.
Таким образом, после
рассмотрения двух классификаций ошибок
можно прийти к выводу, что на этапе
тестирования ищутся прагматические
ошибки периода выполнения, так как
остальные выявляются в процессе
программирования.
На этом можно было
бы закончить рассмотрение классификаций,
но с течением времени накапливался опыт
обнаружения ошибок и сами ошибки,
некоторые из которых образуют характерные
группы, которые могут тоже служить
характерной классификацией.
Ошибка
адресации
– ошибка, состоящая в неправильной
адресации данных (например, выход за
пределы участка памяти).
Ошибка
ввода-вывода
– ошибка, возникающая в процессе обмена
данными между устройствами памяти,
внешними устройствами.
Ошибка
вычисления
– ошибка, возникающая при выполнении
арифметических операций (например,
разнотипные данные, деление на нуль и
др.).
Ошибка
интерфейса
– программная ошибка, вызванная
несовпадением характеристик фактических
и формальных параметров (как правило,
семантическая ошибка периода компиляции,
но может быть и логической ошибкой
периода выполнения).
Ошибка
обращения к данным
– ошибка, возникающая при обращении
программы к данным (например, выход
индекса за пределы массива, не
инициализированные значения переменных
и др.).
Ошибка
описания данных
– ошибка, допущенная в ходе описания
данных.[2]
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.
В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Обработка исключительных ситуаций. Методы и способы идентификации сбоев и ошибок.
Конструкция try..catch..finally
Иногда при выполнении программы возникают ошибки, которые трудно предусмотреть или предвидеть, а иногда и вовсе невозможно. Например, при передачи файла по сети может неожиданно оборваться сетевое подключение. такие ситуации называются исключениями. Язык C# предоставляет разработчикам возможности для обработки таких ситуаций. Для этого в C# предназначена конструкция try…catch…finally.
try { } catch { } finally { }
При использовании блока try…catch..finally вначале пытаются выполниться инструкции в блоке try. Если в этом блоке не возникло исключений, то после его выполнения начинает выполняться блок finally. И затем конструкция try..catch..finally завершает свою работу.
Если же в блоке try вдруг возникает исключение, то обычный порядок выполнения останавливается, и среда CLR (Common Language Runtime) начинает искать блок catch, который может обработать данное исключение. Если нужный блок catch найден, то он выполняется, и после его завершения выполняется блок finally.
Если нужный блок catch не найден, то при возникновении исключения программа аварийно завершает свое выполнение.
Рассмотрим следующий пример:
class Program { static void Main(string[] args) { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае происходит деление числа на 0, что приведет к генерации исключения. И при запуске приложения в режиме отладки мы увидим в Visual Studio окошко, которое информирует об исключении:

В этом окошке мы видим, что возникло исключение, которое представляет тип System.DivideByZeroException, то есть попытка деления на ноль. С помощью пункта View Details можно посмотреть более детальную информацию об исключении.
И в этом случае единственное, что нам остается, это завершить выполнение программы.
Чтобы избежать подобного аварийного завершения программы, следует использовать для обработки исключений конструкцию try…catch…finally. Так, перепишем пример следующим образом:
class Program { static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); } finally { Console.WriteLine("Блок finally"); } Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае у нас опять же возникнет исключение в блоке try, так как мы пытаемся разделить на ноль. И дойдя до строки
выполнение программы остановится. CLR найдет блок catch и передаст управление этому блоку.
После блока catch будет выполняться блок finally.
Возникло исключение!
Блок finally
Конец программы
Таким образом, программа по-прежнему не будет выполнять деление на ноль и соответственно не будет выводить результат этого деления, но теперь она не будет аварийно завершаться, а исключение будет обрабатываться в блоке catch.
Следует отметить, что в этой конструкции обязателен блок try. При наличии блока catch мы можем опустить блок finally:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); }
И, наоборот, при наличии блока finally мы можем опустить блок catch и не обрабатывать исключение:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } finally { Console.WriteLine("Блок finally"); }
Однако, хотя с точки зрения синтаксиса C# такая конструкция вполне корректна, тем не менее, поскольку CLR не сможет найти нужный блок catch, то исключение не будет обработано, и программа аварийно завершится.
Обработка исключений и условные конструкции
Ряд исключительных ситуаций может быть предвиден разработчиком. Например, пусть программа предусматривает ввод числа и вывод его квадрата:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x = Int32.Parse(Console.ReadLine()); x *= x; Console.WriteLine("Квадрат числа: " + x); Console.Read(); }
Если пользователь введет не число, а строку, какие-то другие символы, то программа выпадет в ошибку. С одной стороны, здесь как раз та ситуация, когда можно применить блок try..catch, чтобы обработать возможную ошибку. Однако гораздо оптимальнее было бы проверить допустимость преобразования:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x; string input = Console.ReadLine(); if (Int32.TryParse(input, out x)) { x *= x; Console.WriteLine("Квадрат числа: " + x); } else { Console.WriteLine("Некорректный ввод"); } Console.Read(); }
Метод Int32.TryParse() возвращает true, если преобразование можно осуществить, и false — если нельзя. При допустимости преобразования переменная x будет содержать введенное число. Так, не используя try…catch можно обработать возможную исключительную ситуацию.
С точки зрения производительности использование блоков try..catch более накладно, чем применение условных конструкций. Поэтому по возможности вместо try..catch лучше использовать условные конструкции на проверку исключительных ситуаций.
Блок catch и фильтры исключений
Определение блока catch
За обработку исключения отвечает блок catch, который может иметь следующие формы:
-
Обрабатывает любое исключение, которое возникло в блоке try. Выше уже был продемонстрирован пример подобного блока.
catch { // выполняемые инструкции }
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch.
catch (тип_исключения) { // выполняемые инструкции }
Например, обработаем только исключения типа DivideByZeroException:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); }
Однако если в блоке try возникнут исключения каких-то других типов, отличных от DivideByZeroException, то они не будут обработаны.
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch. А вся информация об исключении помещается в переменную данного типа.
catch (тип_исключения имя_переменной) { // выполняемые инструкции }
Например:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException ex) { Console.WriteLine($"Возникло исключение {ex.Message}"); }
Фактически этот случай аналогичен предыдущему за тем исключением, что здесь используется переменная. В данном случае в переменную ex, которая представляет тип DivideByZeroException, помещается информация о возникшем исключени. И с помощью свойства Message мы можем получить сообщение об ошибке.
Если нам не нужна информация об исключении, то переменную можно не использовать как в предыдущем случае.
Фильтры исключений
Фильтры исключений позволяют обрабатывать исключения в зависимости от определенных условий. Для их применения после выражения catch идет выражение when, после которого в скобках указывается условие:
В этом случае обработка исключения в блоке catch производится только в том случае, если условие в выражении when истинно. Например:
int x = 1; int y = 0; try { int result = x / y; } catch(DivideByZeroException) when (y==0 && x == 0) { Console.WriteLine("y не должен быть равен 0"); } catch(DivideByZeroException ex) { Console.WriteLine(ex.Message); }
В данном случае будет выброшено исключение, так как y=0. Здесь два блока catch, и оба они обрабатывают исключения типа DivideByZeroException, то есть по сути все исключения, генерируемые при делении на ноль. Но поскольку для первого блока указано условие y == 0 && x == 0, то оно не будет обрабатывать исключение — условие, указанное после оператора when возвращает false. Поэтому CLR будет дальше искать соответствующие блоки catch далее и для обработки исключения выберет второй блок catch. В итоге если мы уберем второй блок catch, то исключение вобще не будет обрабатываться.
Типы исключений. Класс Exception
Базовым для всех типов исключений является тип Exception. Этот тип определяет ряд свойств, с помощью которых можно получить информацию об исключении.
-
InnerException: хранит информацию об исключении, которое послужило причиной текущего исключения
-
Message: хранит сообщение об исключении, текст ошибки
-
Source: хранит имя объекта или сборки, которое вызвало исключение
-
StackTrace: возвращает строковое представление стека вызывов, которые привели к возникновению исключения
-
TargetSite: возвращает метод, в котором и было вызвано исключение
Например, обработаем исключения типа Exception:
static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); Console.WriteLine($"Метод: {ex.TargetSite}"); Console.WriteLine($"Трассировка стека: {ex.StackTrace}"); } Console.Read(); }

Однако так как тип Exception является базовым типом для всех исключений, то выражение catch (Exception ex) будет обрабатывать все исключения, которые могут возникнуть.
Но также есть более специализированные типы исключений, которые предназначены для обработки каких-то определенных видов исключений. Их довольно много, я приведу лишь некоторые:
-
DivideByZeroException: представляет исключение, которое генерируется при делении на ноль
-
ArgumentOutOfRangeException: генерируется, если значение аргумента находится вне диапазона допустимых значений
-
ArgumentException: генерируется, если в метод для параметра передается некорректное значение
-
IndexOutOfRangeException: генерируется, если индекс элемента массива или коллекции находится вне диапазона допустимых значений
-
InvalidCastException: генерируется при попытке произвести недопустимые преобразования типов
-
NullReferenceException: генерируется при попытке обращения к объекту, который равен null (то есть по сути неопределен)
И при необходимости мы можем разграничить обработку различных типов исключений, включив дополнительные блоки catch:
static void Main(string[] args) { try { int[] numbers = new int[4]; numbers[7] = 9; // IndexOutOfRangeException int x = 5; int y = x / 0; // DivideByZeroException Console.WriteLine($"Результат: {y}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException ex) { Console.WriteLine(ex.Message); } Console.Read(); }
В данном случае блоки catch обрабатывают исключения типов IndexOutOfRangeException, DivideByZeroException и Exception. Когда в блоке try возникнет исключение, то CLR будет искать нужный блок catch для обработки исключения. Так, в данном случае на строке
происходит обращение к 7-му элементу массива. Однако поскольку в массиве только 4 элемента, то мы получим исключение типа IndexOutOfRangeException. CLR найдет блок catch, который обрабатывает данное исключение, и передаст ему управление.
Следует отметить, что в данном случае в блоке try есть ситуация для генерации второго исключения — деление на ноль. Однако поскольку после генерации IndexOutOfRangeException управление переходит в соответствующий блок catch, то деление на ноль int y = x / 0 в принципе не будет выполняться, поэтому исключение типа DivideByZeroException никогда не будет сгенерировано.
Однако рассмотрим другую ситуацию:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } Console.Read(); }
В данном случае в блоке try генерируется исключение типа InvalidCastException, однако соответствующего блока catch для обработки данного исключения нет. Поэтому программа аварийно завершит свое выполнение.
Мы также можем определить для InvalidCastException свой блок catch, однако суть в том, что теоретически в коде могут быть сгенерированы сами различные типы исключений. А определять для всех типов исключений блоки catch, если обработка исключений однотипна, не имеет смысла. И в этом случае мы можем определить блок catch для базового типа Exception:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); } Console.Read(); }
И в данном случае блок catch (Exception ex){} будет обрабатывать все исключения кроме DivideByZeroException и IndexOutOfRangeException. При этом блоки catch для более общих, более базовых исключений следует помещать в конце — после блоков catch для более конкретный, специализированных типов. Так как CLR выбирает для обработки исключения первый блок catch, который соответствует типу сгенерированного исключения. Поэтому в данном случае сначала обрабатывается исключение DivideByZeroException и IndexOutOfRangeException, и только потом Exception (так как DivideByZeroException и IndexOutOfRangeException наследуется от класса Exception).
Создание классов исключений
Если нас не устраивают встроенные типы исключений, то мы можем создать свои типы. Базовым классом для всех исключений является класс Exception, соответственно для создания своих типов мы можем унаследовать данный класс.
Допустим, у нас в программе будет ограничение по возрасту:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (Exception ex) { Console.WriteLine($"Ошибка: {ex.Message}"); } Console.Read(); } } class Person { private int age; public string Name { get; set; } public int Age { get { return age; } set { if (value < 18) { throw new Exception("Лицам до 18 регистрация запрещена"); } else { age = value; } } } }
В классе Person при установке возраста происходит проверка, и если возраст меньше 18, то выбрасывается исключение. Класс Exception принимает в конструкторе в качестве параметра строку, которое затем передается в его свойство Message.
Но иногда удобнее использовать свои классы исключений. Например, в какой-то ситуации мы хотим обработать определенным образом только те исключения, которые относятся к классу Person. Для этих целей мы можем сделать специальный класс PersonException:
class PersonException : Exception { public PersonException(string message) : base(message) { } }
По сути класс кроме пустого конструктора ничего не имеет, и то в конструкторе мы просто обращаемся к конструктору базового класса Exception, передавая в него строку message. Но теперь мы можем изменить класс Person, чтобы он выбрасывал исключение именно этого типа и соответственно в основной программе обрабатывать это исключение:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (PersonException ex) { Console.WriteLine("Ошибка: " + ex.Message); } Console.Read(); } } class Person { private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена"); else age = value; } } }
Однако необязательно наследовать свой класс исключений именно от типа Exception, можно взять какой-нибудь другой производный тип. Например, в данном случае мы можем взять тип ArgumentException, который представляет исключение, генерируемое в результате передачи аргументу метода некорректного значения:
class PersonException : ArgumentException { public PersonException(string message) : base(message) { } }
Каждый тип исключений может определять какие-то свои свойства. Например, в данном случае мы можем определить в классе свойство для хранения устанавливаемого значения:
class PersonException : ArgumentException { public int Value { get;} public PersonException(string message, int val) : base(message) { Value = val; } }
В конструкторе класса мы устанавливаем это свойство и при обработке исключения мы его можем получить:
class Person { public string Name { get; set; } private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена", value); else age = value; } } } class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 13 }; } catch (PersonException ex) { Console.WriteLine($"Ошибка: {ex.Message}"); Console.WriteLine($"Некорректное значение: {ex.Value}"); } Console.Read(); } }
Поиск блока catch при обработке исключений
Если код, который вызывает исключение, не размещен в блоке try или помещен в конструкцию try..catch, которая не содержит соответствующего блока catch для обработки возникшего исключения, то система производит поиск соответствующего обработчика исключения в стеке вызовов.
Например, рассмотрим следующую программу:
using System; namespace HelloApp { class Program { static void Main(string[] args) { try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); } Console.WriteLine("Конец метода Main"); Console.Read(); } } class TestClass { public static void Method1() { try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); } Console.WriteLine("Конец метода Method1"); } static void Method2() { try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); } Console.WriteLine("Конец метода Method2"); } } }
В данном случае стек вызовов выглядит следующим образом: метод Main вызывает метод Method1, который, в свою очередь, вызывает метод Method2. И в методе Method2 генерируется исключение DivideByZeroException. Визуально стек вызовов можно представить следующим образом:

Внизу стека метод Main, с которого началось выполнение, и на самом верху метод Method2.
Что будет происходить в данном случае при генерации исключения?
-
Метод Main вызывает метод Method1, а тот вызывает метод Method2, в котором генерируется исключение DivideByZeroException.
-
Система видит, что код, который вызывал исключение, помещен в конструкцию try..catch
try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); }
Система ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако такого блока catch нет.
-
Система опускается в стеке вызовов в метод Method1, который вызывал Method2. Здесь вызов Method2 помещен в конструкцию try..catch
try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); }
Система также ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако здесь также подобный блок catch отсутствует.
-
Система далее опускается в стеке вызовов в метод Main, который вызывал Method1. Здесь вызов Method1 помещен в конструкцию try..catch
try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
Система снова ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. И в данном случае ткой блок найден.
-
Система наконец нашла нужный блок catch в методе Main, для обработки исключения, которое возникло в методе Method2 — то есть к начальному методу, где непосредственно возникло исключение. Но пока данный блок catch НЕ выполняется. Система поднимается обратно по стеку вызовов в самый верх в метод Method2 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method2"); }
-
Далее система возвращается по стеку вызовов вниз в метод Method1 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method1"); }
-
Затем система переходит по стеку вызовов вниз в метод Main и выполняет в нем найденный блок catch и последующий блок finally:
catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
-
Далее выполняется код, который идет в методе Main после конструкции try..catch:
Console.WriteLine("Конец метода Main");
Стоит отметить, что код, который идет после конструкции try…catch в методах Method1 и Method2, не выполняется, потому что обработчик исключения найден именно в методе Main.
Консольный вывод программы:
Блок finally в Method2
Блок finally в Method1
Catch в Main: Попытка деления на нуль.
Блок finally в Main
Конец метода Main
Генерация исключения и оператор throw
Обычно система сама генерирует исключения при определенных ситуациях, например, при делении числа на ноль. Но язык C# также позволяет генерировать исключения вручную с помощью оператора throw. То есть с помощью этого оператора мы сами можем создать исключение и вызвать его в процессе выполнения.
Например, в нашей программе происходит ввод строки, и мы хотим, чтобы, если длина строки будет больше 6 символов, возникало исключение:
static void Main(string[] args) { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch (Exception e) { Console.WriteLine($"Ошибка: {e.Message}"); } Console.Read(); }
После оператора throw указывается объект исключения, через конструктор которого мы можем передать сообщение об ошибке. Естественно вместо типа Exception мы можем использовать объект любого другого типа исключений.
Затем в блоке catch сгенерированное нами исключение будет обработано.
Подобным образом мы можем генерировать исключения в любом месте программы. Но существует также и другая форма использования оператора throw, когда после данного оператора не указывается объект исключения. В подобном виде оператор throw может использоваться только в блоке catch:
try { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch { Console.WriteLine("Возникло исключение"); throw; } } catch (Exception ex) { Console.WriteLine(ex.Message); }
В данном случае при вводе строки с длиной больше 6 символов возникнет исключение, которое будет обработано внутренним блоком catch. Однако поскольку в этом блоке используется оператор throw, то исключение будет передано дальше внешнему блоку catch.
Методы поиска ошибок в программах
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования [7.6, 7.11]. Отказ может быть результатом следующих причин:
- ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
- спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
- проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
- программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
- непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
- спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
- организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
- неадекватность спецификации требований конечным пользователям;
- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
- несоответствие требований заказчика к отдельным и общим свойствам ПО;
- некорректность описания функциональных характеристик;
- необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
- с определением интерфейса пользователя со средой;
- с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
- с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
- с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
- с некорректным описанием алгоритмов модулей;
- с определением условий возникновения возможных ошибок в программе;
- с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
- бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
- неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
- нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
- использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;
- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
- логические и функциональные ошибки;
- ошибки вычислений и времени выполнения;
- ошибки вводавывода и манипулирования данными;
- ошибки интерфейсов;
- ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с необеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибкаотказ» выполняются следующие действия:
- идентификация изъянов в технологиях проектирования и программирования;
- взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
- классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;
- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
- проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
- сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
- разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка-отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
- аппаратный, при котором общесистемное ПО не работоспособно;
- информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
- эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
- программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
Фундаментальная теория тестирования
В тестировании нет четких определений, как в физике, математике, которые при перефразировании становятся абсолютно неверными. Поэтому важно понимать процессы и подходы. В данной статье разберем основные определения теории тестирования.

Перейдем к основным понятиям
Тестирование программного обеспечения (Software Testing) — проверка соответствия реальных и ожидаемых результатов поведения программы, проводимая на конечном наборе тестов, выбранном определённым образом.
Цель тестирования — проверка соответствия ПО предъявляемым требованиям, обеспечение уверенности в качестве ПО, поиск очевидных ошибок в программном обеспечении, которые должны быть выявлены до того, как их обнаружат пользователи программы.
Для чего проводится тестирование ПО?
- Для проверки соответствия требованиям.
- Для обнаружение проблем на более ранних этапах разработки и предотвращение повышения стоимости продукта.
- Обнаружение вариантов использования, которые не были предусмотрены при разработке. А также взгляд на продукт со стороны пользователя.
- Повышение лояльности к компании и продукту, т.к. любой обнаруженный дефект негативно влияет на доверие пользователей.
Принципы тестирования
- Принцип 1 — Тестирование демонстрирует наличие дефектов (Testing shows presence of defects).
Тестирование только снижает вероятность наличия дефектов, которые находятся в программном обеспечении, но не гарантирует их отсутствия. - Принцип 2 — Исчерпывающее тестирование невозможно (Exhaustive testing is impossible).
Полное тестирование с использованием всех входных комбинаций данных, результатов и предусловий физически невыполнимо (исключение — тривиальные случаи). - Принцип 3 — Раннее тестирование (Early testing).
Следует начинать тестирование на ранних стадиях жизненного цикла разработки ПО, чтобы найти дефекты как можно раньше. - Принцип 4 — Скопление дефектов (Defects clustering).
Большая часть дефектов находится в ограниченном количестве модулей. - Принцип 5 — Парадокс пестицида (Pesticide paradox).
Если повторять те же тестовые сценарии снова и снова, в какой-то момент этот набор тестов перестанет выявлять новые дефекты. - Принцип 6 — Тестирование зависит от контекста (Testing is context depending). Тестирование проводится по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем новостной портал.
- Принцип 7 — Заблуждение об отсутствии ошибок (Absence-of-errors fallacy). Отсутствие найденных дефектов при тестировании не всегда означает готовность продукта к релизу. Система должна быть удобна пользователю в использовании и удовлетворять его ожиданиям и потребностям.
Обеспечение качества (QA — Quality Assurance) и контроль качества (QC — Quality Control) — эти термины похожи на взаимозаменяемые, но разница между обеспечением качества и контролем качества все-таки есть, хоть на практике процессы и имеют некоторую схожесть.
QC (Quality Control) — Контроль качества продукта — анализ результатов тестирования и качества новых версий выпускаемого продукта.
К задачам контроля качества относятся:
- проверка готовности ПО к релизу;
- проверка соответствия требований и качества данного проекта.
QA (Quality Assurance) — Обеспечение качества продукта — изучение возможностей по изменению и улучшению процесса разработки, улучшению коммуникаций в команде, где тестирование является только одним из аспектов обеспечения качества.
К задачам обеспечения качества относятся:
- проверка технических характеристик и требований к ПО;
- оценка рисков;
- планирование задач для улучшения качества продукции;
- подготовка документации, тестового окружения и данных;
- тестирование;
- анализ результатов тестирования, а также составление отчетов и других документов.

Верификация и валидация — два понятия тесно связаны с процессами тестирования и обеспечения качества. К сожалению, их часто путают, хотя отличия между ними достаточно существенны.
Верификация (verification) — это процесс оценки системы, чтобы понять, удовлетворяют ли результаты текущего этапа разработки условиям, которые были сформулированы в его начале.
Валидация (validation) — это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, его требованиям к системе.
Пример: когда разрабатывали аэробус А310, то надо было сделать так, чтобы закрылки вставали в положение «торможение», когда шасси коснулись земли. Запрограммировали так, что когда шасси начинают крутиться, то закрылки ставим в положение «торможение». Но вот во время испытаний в Варшаве самолет выкатился за пределы полосы, так как была мокрая поверхность. Он проскользил, только потом был крутящий момент и они, закрылки, открылись. С точки зрения «верификации» — программа сработала, с точки зрения «валидации» — нет. Поэтому код изменили так, чтобы в момент изменения давления в шинах открывались закрылки.
Документацию, которая используется на проектах по разработке ПО, можно условно разделить на две группы:
- Проектная документация — включает в себя всё, что относится к проекту в целом.
- Продуктовая документация — часть проектной документации, выделяемая отдельно, которая относится непосредственно к разрабатываемому приложению или системе.
Этапы тестирования:
- Анализ продукта
- Работа с требованиями
- Разработка стратегии тестирования и планирование процедур контроля качества
- Создание тестовой документации
- Тестирование прототипа
- Основное тестирование
- Стабилизация
- Эксплуатация
Стадии разработки ПО — этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широкого круга пользователей.
Программный продукт проходит следующие стадии:
- анализ требований к проекту;
- проектирование;
- реализация;
- тестирование продукта;
- внедрение и поддержка.
Требования
Требования — это спецификация (описание) того, что должно быть реализовано.
Требования описывают то, что необходимо реализовать, без детализации технической стороны решения.
Атрибуты требований:
- Корректность — точное описание разрабатываемого функционала.
- Проверяемость — формулировка требований таким образом, чтобы можно было выставить однозначный вердикт, выполнено все в соответствии с требованиями или нет.
- Полнота — в требовании должна содержаться вся необходимая для реализации функциональности информация.
- Недвусмысленность — требование должно содержать однозначные формулировки.
- Непротиворечивость — требование не должно содержать внутренних противоречий и противоречий другим требованиям и документам.
- Приоритетность — у каждого требования должен быть приоритет(количественная оценка степени значимости требования). Этот атрибут позволит грамотно управлять ресурсами на проекте.
- Атомарность — требование нельзя разбить на отдельные части без потери деталей.
- Модифицируемость — в каждое требование можно внести изменение.
- Прослеживаемость — каждое требование должно иметь уникальный идентификатор, по которому на него можно сослаться.
Дефект (bug) — отклонение фактического результата от ожидаемого.
Отчёт о дефекте (bug report) — документ, который содержит отчет о любом недостатке в компоненте или системе, который потенциально может привести компонент или систему к невозможности выполнить требуемую функцию.
Атрибуты отчета о дефекте:
- Уникальный идентификатор (ID) — присваивается автоматически системой при создании баг-репорта.
- Тема (краткое описание, Summary) — кратко сформулированный смысл дефекта, отвечающий на вопросы: Что? Где? Когда(при каких условиях)?
- Подробное описание (Description) — более широкое описание дефекта (указывается опционально).
- Шаги для воспроизведения (Steps To Reproduce) — описание четкой последовательности действий, которая привела к выявлению дефекта. В шагах воспроизведения должен быть описан каждый шаг, вплоть до конкретных вводимых значений, если они играют роль в воспроизведении дефекта.
- Фактический результат (Actual result) — описывается поведение системы на момент обнаружения дефекта в ней. чаще всего, содержит краткое описание некорректного поведения(может совпадать с темой отчета о дефекте).
- Ожидаемый результат (Expected result) — описание того, как именно должна работать система в соответствии с документацией.
- Вложения (Attachments) — скриншоты, видео или лог-файлы.
- Серьёзность дефекта (важность, Severity) — характеризует влияние дефекта на работоспособность приложения.
- Приоритет дефекта (срочность, Priority) — указывает на очерёдность выполнения задачи или устранения дефекта.
- Статус (Status) — определяет текущее состояние дефекта. Статусы дефектов могут быть разными в разных баг-трекинговых системах.
- Окружение (Environment) – окружение, на котором воспроизвелся баг.
Жизненный цикл бага

Severity vs Priority
Серьёзность (severity) показывает степень ущерба, который наносится проекту существованием дефекта. Severity выставляется тестировщиком.
Градация Серьезности дефекта (Severity):
- Блокирующий (S1 – Blocker)
тестирование значительной части функциональности вообще недоступно. Блокирующая ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна. - Критический (S2 – Critical)
критическая ошибка, неправильно работающая ключевая бизнес-логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, то есть не работает важная часть одной какой-либо функции либо не работает значительная часть, но имеется workaround (обходной путь/другие входные точки), позволяющий продолжить тестирование. - Значительный (S3 – Major)
не работает важная часть одной какой-либо функции/бизнес-логики, но при выполнении специфических условий, либо есть workaround, позволяющий продолжить ее тестирование либо не работает не очень значительная часть какой-либо функции. Также относится к дефектам с высокими visibility – обычно не сильно влияющие на функциональность дефекты дизайна, которые, однако, сразу бросаются в глаза. - Незначительный (S4 – Minor)
часто ошибки GUI, которые не влияют на функциональность, но портят юзабилити или внешний вид. Также незначительные функциональные дефекты, либо которые воспроизводятся на определенном устройстве. - Тривиальный (S5 – Trivial)
почти всегда дефекты на GUI — опечатки в тексте, несоответствие шрифта и оттенка и т.п., либо плохо воспроизводимая ошибка, не касающаяся бизнес-логики, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Срочность (priority) показывает, как быстро дефект должен быть устранён. Priority выставляется менеджером, тимлидом или заказчиком
Градация Приоритета дефекта (Priority):
- P1 Высокий (High)
Критическая для проекта ошибка. Должна быть исправлена как можно быстрее. - P2 Средний (Medium)
Не критичная для проекта ошибка, однако требует обязательного решения. - P3 Низкий (Low)
Наличие данной ошибки не является критичным и не требует срочного решения. Может быть исправлена, когда у команды появится время на ее устранение.
Существует шесть базовых типов задач:
- Эпик (epic) — большая задача, на решение которой команде нужно несколько спринтов.
- Требование (requirement ) — задача, содержащая в себе описание реализации той или иной фичи.
- История (story) — часть большой задачи (эпика), которую команда может решить за 1 спринт.
- Задача (task) — техническая задача, которую делает один из членов команды.
- Под-задача (sub-task) — часть истории / задачи, которая описывает минимальный объем работы члена команды.
- Баг (bug) — задача, которая описывает ошибку в системе.
Тестовые среды
- Среда разработки (Development Env) – за данную среду отвечают разработчики, в ней они пишут код, проводят отладку, исправляют ошибки
- Среда тестирования (Test Env) – среда, в которой работают тестировщики (проверяют функционал, проводят smoke и регрессионные тесты, воспроизводят.
- Интеграционная среда (Integration Env) – среда, в которой проводят тестирование взаимодействующих друг с другом модулей, систем, продуктов.
- Предпрод (Preprod Env) – среда, которая максимально приближена к продакшену. Здесь проводится заключительное тестирование функционала.
- Продакшн среда (Production Env) – среда, в которой работают пользователи.
Основные фазы тестирования
- Pre-Alpha: прототип, в котором всё ещё присутствует много ошибок и наверняка неполный функционал. Необходим для ознакомления с будущими возможностями программ.
- Alpha: является ранней версией программного продукта, тестирование которой проводится внутри фирмы-разработчика.
- Beta: практически готовый продукт, который разработан в первую очередь для тестирования конечными пользователями.
- Release Candidate (RC): возможные ошибки в каждой из фичей уже устранены и разработчики выпускают версию на которой проводится регрессионное тестирование.
- Release: финальная версия программы, которая готова к использованию.
Основные виды тестирования ПО
Вид тестирования — это совокупность активностей, направленных на тестирование заданных характеристик системы или её части, основанная на конкретных целях.

- Классификация по запуску кода на исполнение:
- Статическое тестирование — процесс тестирования, который проводится для верификации практически любого артефакта разработки: программного кода компонент, требований, системных спецификаций, функциональных спецификаций, документов проектирования и архитектуры программных систем и их компонентов.
- Динамическое тестирование — тестирование проводится на работающей системе, не может быть осуществлено без запуска программного кода приложения.
- Классификация по доступу к коду и архитектуре:
- Тестирование белого ящика — метод тестирования ПО, который предполагает полный доступ к коду проекта.
- Тестирование серого ящика — метод тестирования ПО, который предполагает частичный доступ к коду проекта (комбинация White Box и Black Box методов).
- Тестирование чёрного ящика — метод тестирования ПО, который не предполагает доступа (полного или частичного) к системе. Основывается на работе исключительно с внешним интерфейсом тестируемой системы.
- Классификация по уровню детализации приложения:
- Модульное тестирование — проводится для тестирования какого-либо одного логически выделенного и изолированного элемента (модуля) системы в коде. Проводится самими разработчиками, так как предполагает полный доступ к коду.
- Интеграционное тестирование — тестирование, направленное на проверку корректности взаимодействия нескольких модулей, объединенных в единое целое.
- Системное тестирование — процесс тестирования системы, на котором проводится не только функциональное тестирование, но и оценка характеристик качества системы — ее устойчивости, надежности, безопасности и производительности.
- Приёмочное тестирование — проверяет соответствие системы потребностям, требованиям и бизнес-процессам пользователя.
- Классификация по степени автоматизации:
- Ручное тестирование.
- Автоматизированное тестирование.
- Классификация по принципам работы с приложением
- Позитивное тестирование — тестирование, при котором используются только корректные данные.
- Негативное тестирование — тестирование приложения, при котором используются некорректные данные и выполняются некорректные операции.
- Классификация по уровню функционального тестирования:
- Дымовое тестирование (smoke test) — тестирование, выполняемое на новой сборке, с целью подтверждения того, что программное обеспечение стартует и выполняет основные для бизнеса функции.
- Тестирование критического пути (critical path) — направлено для проверки функциональности, используемой обычными пользователями во время их повседневной деятельности.
- Расширенное тестирование (extended) — направлено на исследование всей заявленной в требованиях функциональности.
- Классификация в зависимости от исполнителей:
- Альфа-тестирование — является ранней версией программного продукта. Может выполняться внутри организации-разработчика с возможным частичным привлечением конечных пользователей.
- Бета-тестирование — программное обеспечение, выпускаемое для ограниченного количества пользователей. Главная цель — получить отзывы клиентов о продукте и внести соответствующие изменения.
- Классификация в зависимости от целей тестирования:
- Функциональное тестирование (functional testing) — направлено на проверку корректности работы функциональности приложения.
- Нефункциональное тестирование (non-functional testing) — тестирование атрибутов компонента или системы, не относящихся к функциональности.
- Тестирование производительности (performance testing) — определение стабильности и потребления ресурсов в условиях различных сценариев использования и нагрузок.
- Нагрузочное тестирование (load testing) — определение или сбор показателей производительности и времени отклика программно-технической системы или устройства в ответ на внешний запрос с целью установления соответствия требованиям, предъявляемым к данной системе (устройству).
- Тестирование масштабируемости (scalability testing) — тестирование, которое измеряет производительность сети или системы, когда количество пользовательских запросов увеличивается или уменьшается.
- Объёмное тестирование (volume testing) — это тип тестирования программного обеспечения, которое проводится для тестирования программного приложения с определенным объемом данных.
- Стрессовое тестирование (stress testing) — тип тестирования направленный для проверки, как система обращается с нарастающей нагрузкой (количеством одновременных пользователей).
- Инсталляционное тестирование (installation testing) — тестирование, направленное на проверку успешной установки и настройки, обновления или удаления приложения.
- Тестирование интерфейса (GUI/UI testing) — проверка требований к пользовательскому интерфейсу.
- Тестирование удобства использования (usability testing) — это метод тестирования, направленный на установление степени удобства использования, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий.
- Тестирование локализации (localization testing) — проверка адаптации программного обеспечения для определенной аудитории в соответствии с ее культурными особенностями.
- Тестирование безопасности (security testing) — это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
- Тестирование надёжности (reliability testing) — один из видов нефункционального тестирования ПО, целью которого является проверка работоспособности приложения при длительном тестировании с ожидаемым уровнем нагрузки.
- Регрессионное тестирование (regression testing) — тестирование уже проверенной ранее функциональности после внесения изменений в код приложения, для уверенности в том, что эти изменения не внесли ошибки в областях, которые не подверглись изменениям.
- Повторное/подтверждающее тестирование (re-testing/confirmation testing) — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
Тест-дизайн — это этап тестирования ПО, на котором проектируются и создаются тестовые случаи (тест-кейсы).
Техники тест-дизайна
Автор книги «A Practitioner’s Guide to Software Test Design», Lee Copeland, выделяет следующие техники тест-дизайна:
- Тестирование на основе классов эквивалентности (equivalence partitioning) — это техника, основанная на методе чёрного ящика, при которой мы разделяем функционал (часто диапазон возможных вводимых значений) на группы эквивалентных по своему влиянию на систему значений.
- Техника анализа граничных значений (boundary value testing) — это техника проверки поведения продукта на крайних (граничных) значениях входных данных.
- Попарное тестирование (pairwise testing) — это техника формирования наборов тестовых данных из полного набора входных данных в системе, которая позволяет существенно сократить количество тест-кейсов.
- Тестирование на основе состояний и переходов (State-Transition Testing) — применяется для фиксирования требований и описания дизайна приложения.
- Таблицы принятия решений (Decision Table Testing) — техника тестирования, основанная на методе чёрного ящика, которая применяется для систем со сложной логикой.
- Доменный анализ (Domain Analysis Testing) — это техника основана на разбиении диапазона возможных значений переменной на поддиапазоны, с последующим выбором одного или нескольких значений из каждого домена для тестирования.
- Сценарий использования (Use Case Testing) — Use Case описывает сценарий взаимодействия двух и более участников (как правило — пользователя и системы).
Методы тестирования

Тестирование белого ящика — метод тестирования ПО, который предполагает, что внутренняя структура/устройство/реализация системы известны тестировщику.
Согласно ISTQB, тестирование белого ящика — это:
- тестирование, основанное на анализе внутренней структуры компонента или системы;
- тест-дизайн, основанный на технике белого ящика — процедура написания или выбора тест-кейсов на основе анализа внутреннего устройства системы или компонента.
- Почему «белый ящик»? Тестируемая программа для тестировщика — прозрачный ящик, содержимое которого он прекрасно видит.
Тестирование серого ящика — метод тестирования ПО, который предполагает комбинацию White Box и Black Box подходов. То есть, внутреннее устройство программы нам известно лишь частично.
Тестирование чёрного ящика — также известное как тестирование, основанное на спецификации или тестирование поведения — техника тестирования, основанная на работе исключительно с внешними интерфейсами тестируемой системы.
Согласно ISTQB, тестирование черного ящика — это:
- тестирование, как функциональное, так и нефункциональное, не предполагающее знания внутреннего устройства компонента или системы;
- тест-дизайн, основанный на технике черного ящика — процедура написания или выбора тест-кейсов на основе анализа функциональной или нефункциональной спецификации компонента или системы без знания ее внутреннего устройства.
Тестовая документация
Тест план (Test Plan) — это документ, который описывает весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков.
Тест план должен отвечать на следующие вопросы:
- Что необходимо протестировать?
- Как будет проводиться тестирование?
- Когда будет проводиться тестирование?
- Критерии начала тестирования.
- Критерии окончания тестирования.
Основные пункты тест плана:
- Идентификатор тест плана (Test plan identifier);
- Введение (Introduction);
- Объект тестирования (Test items);
- Функции, которые будут протестированы (Features to be tested;)
- Функции, которые не будут протестированы (Features not to be tested);
- Тестовые подходы (Approach);
- Критерии прохождения тестирования (Item pass/fail criteria);
- Критерии приостановления и возобновления тестирования (Suspension criteria and resumption requirements);
- Результаты тестирования (Test deliverables);
- Задачи тестирования (Testing tasks);
- Ресурсы системы (Environmental needs);
- Обязанности (Responsibilities);
- Роли и ответственность (Staffing and training needs);
- Расписание (Schedule);
- Оценка рисков (Risks and contingencies);
- Согласования (Approvals).
Чек-лист (check list) — это документ, который описывает что должно быть протестировано. Чек-лист может быть абсолютно разного уровня детализации.
Чаще всего чек-лист содержит только действия, без ожидаемого результата. Чек-лист менее формализован.
Тестовый сценарий (test case) — это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Атрибуты тест кейса:
- Предусловия (PreConditions) — список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
- Шаги (Steps) — список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям.
- Ожидаемый результат (Expected result) — что по факту должны получить.
Резюме
Старайтесь понять определения, а не зазубривать. Если хотите узнать больше про тестирование, то можете почитать Библию QA. А если возникнет вопрос, всегда можете задать его нам в телеграм-канале @qa_chillout.
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.
В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
При разработке программного обеспечения значительная часть производственного процесса опирается на тестирование программ. Что это такое и как осуществляется подобная деятельность обсудим в данной статье.
Что называют тестированием?

Под этим понимают процесс, во время которого выполняется программное обеспечение с целью обнаружения мест некорректного функционирования кода. Для достижения наилучшего результата намеренно конструируются трудные наборы входных данных. Главная цель проверяющего заключается в том, чтобы создать оптимальные возможности для отказа программного продукта. Хотя иногда тестирование разработанной программы может быть упрощено до обычной проверки работоспособности и выполнения функций. Это позволяет сэкономить время, но часто сопровождается ненадежностью программного обеспечения, недовольством пользователей и так далее.
Эффективность
То, насколько хорошо и быстро находятся ошибки, существенным образом влияет на стоимость и длительность разработки программного обеспечения необходимого качества. Так, несмотря на то, что тестеры получают заработную плату в несколько раз меньшую, чем программисты, стоимость их услуг обычно достигает 30 – 40 % от стоимости всего проекта. Это происходит из-за численности личного состава, поскольку искать ошибку – это необычный и довольно трудный процесс. Но даже если программное обеспечение прошло солидное количество тестов, то нет 100 % гарантии, что ошибок не будет. Просто неизвестно, когда они проявятся. Чтобы стимулировать тестеров выбирать типы проверки, которые с большей вероятностью найдут ошибку, применяются различные средства мотивации: как моральные, так и материальные.
Подход к работе

Оптимальной является ситуация, когда реализовываются различные механизмы, направленные на то, чтобы ошибок в программном обеспечении не было с самого начала. Для этого необходимо позаботится о грамотном проектировании архитектуры, четком техническом задании, а также важно не вносить коррективы в связи, когда работа над проектом уже начата. В таком случае перед тестером стоит задача нахождения и определения небольшого количества ошибок, которые остаются в конечном результате. Это сэкономит и время, и деньги.
Что такое тест?
Это немаловажный аспект деятельности проверяющего, который необходим для успешного выявления недочетов программного кода. Они необходимы для того, чтобы контролировать правильность приложения. Что входит в тест? Он состоит их начальных данных и значений, которые должны получиться как результирующие (или промежуточные). Для того чтобы успешнее выявлять проблемы и несоответствия, тесты необходимо составлять после того, как был разработан алгоритм, но не началось программирование. Причем желательно использовать несколько подходов при расчете необходимых данных. В таком случае растёт вероятность обнаружения ошибки благодаря тому, что можно исследовать код с другой точки зрения. Комплексно тесты должны обеспечивать проверку внешних эффектов готового программного изделия, а также его алгоритмов работы. Особенный интерес предоставляют предельные и вырожденные случаи. Так, в практике деятельности с ошибками часто можно выявить, что цикл работает на один раз меньше или больше, чем было запланировано. Также важным является тестирование компьютера, благодаря которому можно проверить соответствие желаемому результату на различных машинах. Это необходимо для того, чтобы удостовериться, что программное обеспечение сможет работать на всех ЭВМ. Кроме того, тестирование компьютера, на котором будет выполняться разработка, является важным при создании мультиплатформенных разработок.
Искусство поиска ошибок

Программы часто нацелены на работу с огромным массивом данных. Неужели его необходимо создавать полностью? Нет. Широкое распространение приобрела практика «миниатюризации» программы. В данном случае происходит разумное сокращение объема данных по сравнению с тем, что должно использоваться. Давайте рассмотрим такой пример: есть программа, в которой создаётся матрица размером 50×50. Иными словами – необходимо вручную ввести 2500 тысячи значений. Это, конечно, возможно, но займёт очень много времени. Но чтобы проверить работоспособность, программный продукт получает матрицу, размерность которой составляет 5×5. Для этого нужно будет ввести уже 25 значений. Если в данном случае наблюдается нормальная, безошибочная работа, то это значит, что всё в порядке. Хотя и здесь существуют подводные камни, которые заключаются в том, что при миниатюризации происходит ситуация, в результате которой изменения становятся неявными и временно исчезают. Также очень редко, но всё же случается и такое, что появляются новые ошибки.
Преследуемые цели
Тестирование ПО не является легким делом из-за того, что данный процесс не поддаётся формализации в полном объеме. Большие программы почти никогда не обладают необходимым точным эталоном. Поэтому в качестве ориентира используют ряд косвенных данных, которые, правда, не могут полностью отражать характеристики и функции программных разработок, что отлаживаются. Причем они должны быть подобраны таким образом, чтобы правильный результат вычислялся ещё до того, как программный продукт будет тестирован. Если этого не сделать заранее, то возникает соблазн считать всё приблизительно, и если машинный результат попадёт в предполагаемый диапазон, то будет принято ошибочное решение, что всё правильно.
Проверка в различных условиях

Как правило, тестирование программ происходит в объемах, которые необходимы для минимальной проверки функциональности в ограниченных пределах. Деятельность ведётся с изменением параметров, а также условий их работы. Процесс тестирования можно поделить на три этапа:
- Проверка в обычных условиях. В данном случае тестируется основной функционал разработанного программного обеспечения. Полученный результат должен соответствовать ожидаемому.
- Проверка в чрезвычайных условиях. В этих случаях подразумевается получение граничных данных, которые могут негативно повлиять на работоспособность созданного программного обеспечения. В качестве примера можно привести работу с чрезвычайно большими или малыми числами, или вообще, полное отсутствие получаемой информации.
- Проверка при исключительных ситуациях. Она предполагает использование данных, которые лежат за гранью обработки. В таких ситуациях очень плохо, когда программное обеспечение воспринимает их как пригодные к расчету и выдаёт правдоподобный результат. Необходимо позаботиться, чтобы в подобных случаях происходило отвержение любых данных, которые не могут быть корректно обработаны. Также необходимо предусмотреть информирование об этом пользователя
Тестирование ПО: виды

Создавать программное обеспечение без ошибок весьма трудно. Это требует значительного количества времени. Чтобы получить хороший продукт часто применяются два вида тестирования: «Альфа» и «Бета». Что они собой представляют? Когда говорят об альфа-тестировании, то под ним подразумевают проверку, которую проводит сам штат разработчиков в «лабораторных» условиях. Это последний этап проверки перед тем, как программа будет передана конечным пользователям. Поэтому разработчики стараются развернуться по максимуму. Для легкости работы данные могут протоколироваться, чтобы создавать хронологию проблем и их устранения. Под бета-тестированием понимают поставку программного обеспечения ограниченному кругу пользователей, чтобы они смогли поэксплуатировать программу и выявить пропущенные ошибки. Особенностью в данном случае является то, что часто ПО используется не по своему целевому назначению. Благодаря этому неисправности будут выявляться там, где ранее ничего не было замечено. Это вполне нормально и переживать по этому поводу не нужно.
Завершение тестирования
Если предыдущие этапы были успешно завершены, то остаётся провести приемочный тест. Он в данном случае становиться простой формальностью. Во время данной проверки происходит подтверждение, что никаких дополнительных проблем не найдено и программное обеспечение можно выпускать на рынок. Чем большую важность будет иметь конечный результат, тем внимательней должна проводиться проверка. Необходимо следить за тем, чтобы все этапы были пройдены успешно. Вот так выглядит процесс тестирования в целом. А теперь давайте углубимся в технические детали и поговорим о таких полезных инструментах, как тестовые программы. Что они собой представляют и в каких случаях используются?
Автоматизированное тестирование

Ранее считалось, что динамический анализ разработанного ПО – это слишком тяжелый подход, который неэффективно использовать для обнаружения дефектов. Но из-за увеличения сложности и объема программ появился противоположный взгляд. Автоматическое тестирование применяется там, где самыми важными приоритетами является работоспособность и безопасность. И они должны быть при любых входных данных. В качестве примера программ, для которых целесообразным является такое тестирование, можно привести следующие: сетевые протоколы, веб-сервер, sandboxing. Мы далее рассмотрим несколько образцов, которые можно использовать для такой деятельности. Если интересуют бесплатные программы тестирования, то среди них качественные найти довольно сложно. Но существуют взломанные «пиратские» версии хорошо зарекомендовавших себя проектов, поэтому можно обратиться к их услугам.
Avalanche
Этот инструмент помогает обнаружить дефекты, проходя тестирование программ в режиме динамического анализа. Он собирает данные и анализирует трассу выполнения разработанного объекта. Тестеру же предоставляется набор входных данных, которые вызывают ошибку или обходят набор имеющихся ограничений. Благодаря наличию хорошего алгоритма проверки разрабатывается большое количество возможных ситуаций. Программа получает различные наборы входных данных, которые позволяют смоделировать значительное число ситуаций и создать такие условия, когда наиболее вероятным является возникновение сбоя. Важным преимуществом программы считается применение эвристической метрики. Если есть проблема, то ошибка приложения находится с высокой вероятностью. Но эта программа имеет ограничения вроде проверки только одного помеченного входного сокета или файла. При проведении такой операции, как тестирование программ, будет содержаться детальная информация о наличие проблем с нулевыми указателями, бесконечными циклами, некорректными адресами или неисправностями из-за использования библиотек. Конечно, это не полный список обнаруживаемых ошибок, а только их распространённые примеры. Исправлять недочеты, увы, придётся разработчикам – автоматические средства для этих целей не подходят.
KLEE

Это хорошая программа для тестирования памяти. Она может перехватывать примерно 50 системных вызовов и большое количество виртуальных процессов, таким образом, выполняется параллельно и отдельно. Но в целом программа не ищет отдельные подозрительные места, а обрабатывает максимально возможное количество кода и проводит анализ используемых путей передачи данных. Из-за этого время тестирования программы зависит от размера объекта. При проверке ставка сделана на символические процессы. Они являются одним из возможных путей выполнения задач в программе, которая проверяется. Благодаря параллельной работе можно анализировать большое количество вариантов работы исследуемого приложения. Для каждого пути после окончания его тестирования сохраняются наборы входных данных, с которых начиналась проверка. Следует отметить, что тестирование программ с помощью KLEE помогает выявлять большое количество отклонений, которых не должно быть. Она может найти проблемы даже в приложениях, которые разрабатываются десятилетиями.
Типичными ошибками являются следующие:
1. Несоответствие оценки готовой продукции методу оценки, установленному учетной политикой организации.
Организации могут вести учет выпуска продукции двумя способами:
· без использования счета 40 «Выпуск продукции (работ, услуг)»;
· с использованием счета 40.
Если организация не использует счет 40 «Выпуск готовой продукции (работ, услуг)», тогда на счете 43 «Готовая продукция» продукция отражается по фактической себестоимости.
Если организация использует счет 40 «Выпуск готовой продукции (работ, услуг)», то на счете 43 «Готовая продукция» продукция отражается по нормативной или плановой производственной себестоимости, а отклонение ее от фактической производственной себестоимости списывается со счета 40 «Выпуск готовой продукции (работ, услуг)» в дебет счета 90 «Продажи».
Необходимым условием применения счета 40 является применение на предприятии показателей нормативной или плановой себестоимости, что достигается обычно при использовании нормативного метода учета затрат на производство и калькулирования себестоимости продукции.
Учет выхода готовой продукции с использованием счета 40 не целесообразен, если отклонения фактической себестоимости продукции от нормативной или плановой оказываются значительными, а продукция реализуется неритмично. Задержки с реализацией продукции могут привести к убыточности организации, поскольку отклонения со счета 40 сразу списываются на счет 90-2. Если такие факты подтверждаются, аудитору следует указать руководству предприятия на неэффективность применяемого учетного решения.
Готовая продукция списывается в порядке реализации со счета 43 «Готовая продукция» в дебет счета 90 «Продажи», только если она отгружена или сдана покупателю на месте и расчетные документы за нее предъявлены этим покупателям (заказчикам).
2. Несоответствие оценки отгруженной продукции методу оценки, установленному учетной политикой организации.
Отгруженные товары учитываются на счете 45 «Товары отгруженные» по фактической производственной или нормативной (плановой) себестоимости. Записи по дебету счета 45 «Товары отгруженные» в корреспонденции со счетами 43 «Готовая продукция», 41 «Товары» могут производиться только в соответствии с оформленными документами (накладными, приемо-сдаточными актами и др.) по отгрузке готовых изделий (товаров) или передаче их для реализации на комиссионных и иных подобных началах.
Суммы списываются с кредита счета 45 «Товары отгруженные» в дебет счета 90 «Продажи» только при предъявлении покупателям (заказчикам) расчетных документов за отгруженную продукцию либо поступлении извещения комиссионера о реализации переданных ему изделий.
Если предприятие отражает реализацию продукции (товаров, работ, услуг) по мере оплаты покупателем (заказчиком) расчетных документов, то счет 45 «Товары отгруженные» используется для обобщения информации о наличии и движении всей отгруженной продукции (товаров), выполненных и сданных работ (услуг). При этом принятые на учет по счету 45 «Товары отгруженные» суммы списываются в дебет счета 90 «Продажи» при оплате расчетных документов покупателем (заказчиком).
3. Неправильный расчет и отражениев учете отклонений фактической производственной себестоимости готовой продукции от стоимости ее по учетным ценам (при учете готовой продукции по учетным ценам).
При учете готовой продукции на синтетическом счете 43 «Готовая продукция» по фактической производственной себестоимости в аналитическом учете движение ее отдельных наименований, возможно, отражать по учетным ценам с выделением отклонений фактической производственной себестоимости изделий от их стоимости по учетным ценам. Такие отклонения учитываются по однородным группам готовой продукции, которые формируются предприятием исходя из уровня отклонений фактической производственной себестоимости от стоимости по учетным ценам отдельных изделий.
При списании готовой продукции со счета 43 относящаяся к этой продукции сумма отклонений фактической производственной себестоимости от стоимости по ценам, принятым в аналитическом учете, определяется по проценту, исчисленному исходя из отношения отклонений на остаток готовой продукции на начало отчетного периода и отклонений по продукции, поступившей на склад в течение отчетного месяца, к стоимости этой продукции по учетным ценам. Сумма отклонений фактической производственной себестоимости готовой продукции от ее стоимости по учетным ценам, относящаяся к отгруженной и реализованной продукции, отражается по кредиту счета 43 и дебиту соответствующих счетов дополнительной или сторнировочной записью в зависимости от того, представляют они перерасход или экономию.

4. Неполное отражение в учете выпущенной продукции.
По строке «Готовая продукция» в бухгалтерской отчетности показывается фактическая производственная себестоимость остатка законченных производством изделий, прошедших испытания и приемку, укомплектованных всеми частями согласно условиям договоров с заказчиками и соответствующим техническим условиям и стандартам. Продукция, не отвечающая указанным требованиям, и несданные работы считаются незаконченными и показываются в составе незавершенного производства.
Если продукция предприятия отвечает всем вышеуказанным требованиям, то она должна быть, и отражена в учете как готовая продукция. Для выявления фактов учета фактически готовой продукции в составе незавершенного производства, как правило, знаний аудитора бывает недостаточно. В таких случаях требуется привлечение эксперта.
При использовании для учета затрат на производство счета 40 «Выпуск продукции (работ, услуг)» готовая продукция отражается по данной статье по нормативной (плановой) себестоимости.
5. Отражение в учете как собственной готовой продукции, выработанной из давальческого сырья.
Материально-производственные запасы, не принадлежащие организации, но находящиеся в ее пользовании или распоряжении в соответствии с условиями договора, принимаются к бухгалтерскому учете на забалансовые счета в оценке, предусмотренной в договоре.
Под давальческим сырьем законодательство подразумевает сырье, материалы, принимаемые без оплаты их стоимости и подлежащие переработке по договору с давальцами.
Учет затрат по переработке или доработке сырья и материалов ведется на счетах учета затрат на производство, отражающих связанные с этим затраты (за исключением стоимости сырья и материалов заказчика).
Таким образом, отдавая сырье в переработку, право собственности на него сохраняет владелец (ст.220 ГК РФ), также как и право дальнейшей реализации изготовленной из него продукции, если договором не предусмотрено иное. Следовательно, затраты по изготовлению продукции предприятия-изготовителя представляют собой услуги, оказанные стороннему потребителю, и отражаются на счетах учета затрат с последующим списанием их на себестоимость реализованных услуг без отражения по счету 43 «Готовая продукция».
6. Несвоевременное и неполное отражение в учете отгруженной и реализованной продукции.
При отражении в учете отгруженной и реализованной продукции возможны два варианта ошибки:
· отражение в учете продукции как реализованной, в то время как в соответствии с договором она еще не может быть признана реализованной, а должна быть отражена в учете и отчетности как отгруженная;
· отражение в учете продукции как отгруженной, в то время как в соответствии с договором она уже реализована, т.е. момент перехода права собственности от продавца к покупателю уже состоялся.
7. Отсутствие налаженного аналитического учета готовой продукции по местам хранения и отдельным видам готовой продукции.
Для хранения готовой продукции на предприятии должны быть организованы отдельные складские помещения. Хранить готовую продукцию в тех же помещениях, что и материальные ценности, используемые для ее производства, нельзя.
Если на предприятии имеется несколько складов готовой продукции, на первичных документах и документах аналитического учета должно быть указано место хранения, например, номер или код склада.
Согласно отраслевыми требованиями продукция должна быть идентифицирована по артикулам, сортам, размерам, типам и т.д. Аналитический учет должен быть организован так, чтобы позволял в любой момент времени иметь точные данные о том, какая продукция, какого типа, сорта, размера имеется на предприятии, а также где она храниться.
8. Ошибки в проведении инвентаризации готовой продукции.
При инвентаризации готовая продукция заносится в описи по каждому отдельному наименованию с указанием вида, группы, количества и других необходимых данных (артикула, сорта и др.)
Инвентаризация готовой продукции должна, как правило, проводиться в порядке расположения ценностей в данном помещении. При хранении готовой продукции в разных изолированных помещениях у одного материально-ответственного лица инвентаризация проводится последовательно по местам хранения. После проверки ценностей вход в помещение не допускается (например, опломбировывается) и комиссия переходит для работы в следующее помещение.
В присутствии заведующего складом и других материально ответственных лиц комиссия проверяет фактическое наличие готовой продукции путем обязательного ее пересчета, перевешивания, перемеривания. Не допускается вносить в описи данные об остатках готовой продукции со слов материально-ответственных лиц или по данным учета без проверки их фактического наличия.
Готовая продукция, поступающая во время проведения инвентаризации, принимается материально-ответственными лицами в присутствии членов инвентаризационной комиссии и приходуется по реестру или товарному отчету после инвентаризации. Эта готовая продукция заносится в отдельную опись под наименованием «Готовая продукция, поступившая во время инвентаризации». В описи указывается дата поступления, дата и номер приходного документа, наименование продукции, количество, цена и сумма. Одновременно на приходном документе за подписью председателя инвентаризационной комиссии (или по его поручению председателя инвентаризационной комиссии (или по его поручению члена комиссии) делается отметка «после инвентаризации» со ссылкой на дату описи, в которую записаны эти ценностей.
9. Неправильное отражение в учете морально устаревшей, испорченной при хранении готовой продукции.
Согласно п. 12 ПБУ 5/01 фактическая себестоимость материально-производственных запасов, в которой они приняты к бухгалтерскому учету, не подлежит изменению (кроме случаев, установленных законодательно). Материально-производственные запасы (кроме оборудования к установке), на которые цена в течение года снизилась либо которые морально устарели или частично потеряли свое первоначальное качество, отражаются в бухгалтерском балансе на конец отчетного года по цене возможной реализации, если она ниже первоначальной стоимости заготовления (приобретения), с отнесением разницы в ценах на финансовые результаты организации путем создания резерва под снижение стоимости материальных ценностей – оформляется бухгалтерской записью (Дт 91 Кт 14 – сумма резерва).
10. Неверное представление как торговой деятельности, связанной с изготовлением продукции из давальческого сырья у давальца-заказчика.
Деятельность предприятия (в том числе торговой организации) по приобретению сырья и материалов и продаже готовых изделий, произведенных из этого сырья и материалов сторонней организацией, относится к производственной.
При приобретении предприятием продукции для ее дальнейшей переработки эту продукцию следует учитывать на счет 10 «Материалы», субсчет «Материалы, переданные в переработку на сторону». Отражать такие операции на счет 41 «Товары» неправомерно. В этом случае организации, занимающиеся торговой деятельностью, должны вести учет в порядке, аналогичном применяемому предприятиями, занимающимися промышленно-производственной деятельностью.
В то же время деятельность торговой организации по передаче принадлежащих ей товаров другим предприятием (организациям) для их упаковки, переупаковки, дробления партий или иной предпродажной подготовки к производственной не относится.
11. Неверное отражение в бухгалтерском учете различных товарно-материальных ценностей.
Некоторые предприятия неправильно используют бухгалтерский счет 43 «Готовая продукция». Неверно, в частности, использование этого счета предприятиями, оказывающими услуги, выполняющими работы; отражение как готовой продукции товаров, приобретенных для продажи (их следует отражать на счете 41 «Товары»); отражение в учете готовой продукции собственного производства, реализуемой в розницу, как товара.
На счетах бухгалтерского учете хозяйственной операции, связанные с передачей готовой продукции со склада готовой продукции в подразделение организации, осуществляющее торговую деятельность, могут быть отражены, например, следующим образом. Организация может открыть к счету 43 «Готовая продукция» субсчет 43-1 «Готовая продукция на складе» и 43-2 «Готовая продукция в торговом павильоне» и отражать передачу готовой продукции со склада в структурное подразделение, осуществляющее торговлю, проводкой: Дт43-2 Кт 43-1.
Следует иметь в виду, что согласно инструкции по применению плана счетов бухгалтерского учета финансово-хозяйственной деятельности предприятия счет 41 «Товары» применяется для отражения информации о наличии и движении товарно-материальных ценностей, приобретенных организацией в качестве товаров для перепродажи, а не изготовленных своими силами. Стоимость проданных торгующим подразделением организации произведенных другим подразделением изделий отражается по дебету счета 90 «Продажи», в корреспонденции с кредитом счета 43 «Готовая продукция».
Приведите тесты для задачи:
Ввести элементы двумерного массива MAS(2,2) и, если выше главной диагонали хотя бы один элемент >10, просчитать количество всех элементов матрицы, в противном случае вывести сообщение «Условие не выполнено».
Тестирование — процесс выполнения программы с целью обнаружения ошибок.
2. Типы ошибок.
Все ошибки в разработке программ делятся на следующие
Ошибка (error) – состояние программы, при котором выдается неправильные результаты, причиной которых являются изъяны в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, а следовательно и к неверному решению.
Дефект (fault) в программе является следствием ошибок разработчика на любом из этапов разработки и может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. Дефект обнаруживается в процессе выполнения программы.
Отказ (failure) – это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями и рассматривается как событие, способствующее переходу программы в неработоспособное состояние из–за ошибок, скрытых в ней дефектов или сбоев в среде функционирования.
Все ошибки, которые возникают в программах, принято подразделять на следу-ющие классы:
– логические и функциональные ошибки — являются причиной нарушения логи-ки алгоритма, внутренней несогласованности переменных и операторов, а также пра-вил программирования;
– ошибки вычислений и времени выполнения — возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов;
– ошибки ввода–вывода и манипулирования данными — являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базах данных или при выборке из нее;
– ошибки интерфейсов — относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования;
– ошибки объема данных и др. — относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют объемам информации системы или интенсивности ее обработки
3. Этапы тестирования ПО.
• модульное тестирование – тестируется минимально возможный для тестиро-вания компонент, например, отдельный класс или функция;
• интегрированное тестирование – проверяется, есть ли какие-либо проблемы в интерфейсах и взаимодействии между интегрируемыми компонентами, например, не передается информация, передается некорректная информация;
• системное тестирование – тестируется интегрированная система на соответствие исходным требованиям:
o альфа-тестирование – имитация реальной работы с системой разработчи-ками либо реальная работа с системой потенциальными пользователями-заказчиками на стороне разработчика.
o бета-тестирование – в некоторых случаях выполняется распространение версии с ограничениями ( по функциональности или времени работы) для некоторой группы лиц с тем, чтобы убедиться, что продукт содержит доста-точно мало ошибок.
Дать понятие класса.
Описать классы, использующиеся для моделирования ПО.
Разработать графическое представление изображения классов для моделирования программного обеспечения:
а) управляющий класс;
б) класс-сущность;
В) граничный класс.
Структура и поведение одинаковых объектов описывается в общем для них классе.
· управляющий класс отвечает за координацию действий других классов и контролирует последовательность выполнения действий варианта использования для данного ПО. На каждой диаграмме классов должен быть хотя бы один управляющий класс (рис. 1, а).
· класс-сущность – пассивный класс, информация о котором должна храниться постоянно. Как правило, этот класс соответствует отдельной таблице БД. В этом случае его атрибуты являются полями этой таблицы, а операции — присоединенными или хранимыми процедурами (рис. 1, б).
· граничный класс располагается на границе системы с внешней средой. К этому типу относят как классы, реализующие пользовательские интерфейсы, так и классы, обеспечивающие интерфейс с аппаратными средствами или программными системами (рис. 1, в).

…
Читайте также:
©2015-2022 poisk-ru.ru
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-02-12
Нарушение авторских прав и Нарушение персональных данных
Поиск по сайту:

Мы поможем в написании ваших работ!
Типичными
ошибками
и нарушениями в учете готовой продукции
и ее реализации являются следующие:
• нарушения,
допущенные при оформлении первичных
документов;
• отсутствие
графиков документооборота;
• нарушения
сроков хранения документации в архиве;
• отсутствие
инвентаризации готовой продукции;
• несоответствие
применяемого предприятием способа
оценки готовой продукции, отражаемой
в бухгалтерском балансе, способу,
утвержденному учетной политикой;
• несоответствие
способа списания общехозяйственных и
коммерческих расходов способу,
закрепленному в учетной политике для
целей бухгалтерского учета;
• счетные
(арифметические) ошибки при расчете
отклонений фактической производственной
себестоимости выпущенной продукции от
нормативной (плановой) производственной
себестоимости продукции;
• несоответствие
данных аналитического и синтетического
учета готовой продукции;
• отсутствие
аналитического учета в разрезе видов
произведенной и отгруженной продукции;
• несоответствие
данных складского учета данным
бухгалтерского учета в части отгруженной
продукции и хранящейся на складе;
• несвоевременное
отражение выручки от продажи продукции;
• исправления
по выявленным ошибкам прошлых лет в
отчетном периоде путем увеличения
выручки от продажи продукции ткущего
периода;
• нарушение
методологии учета (неверно составленные
корреспонденции счетов).
Обобщение
результатов проверки. Рабочие документы
аудитора
Аудитор
обязан составлять рабочие документы о
проведенных аудиторских процедурах в
отношении выпуска, отгрузки и продажи
продукции в достаточно полной и подробной
форме, необходимой для обеспечения
общего понимания аудита. В рабочих
документах должно содержаться обоснование
разить профессиональное суждение,
вместе с выводами аудитора по ним. В тех
случаях, когда аудитор проводил
рассмотрение сложных принципиальных
вопросов или высказывал по каким-либо
важным для аудита вопросам профессиональное
суждение, в рабочие документы следует
включать факты, которые были известны
аудитору на момент формулирования
выводов, и необходимую аргументацию.
В целях
повышения эффективности подготовки и
проверки рабочих документов аудитор
может использовать типовые формы
документации:
• стандартную
структуру аудиторского файла (папки)
рабочих документов;
• бланки;
• вопросники;
• типовые
письма;
• обращения
и т. п.
Для
повышения эффективности аудита аудитор
вправе использовать в ходе проверки
расчетов графики, аналитическую и иную
документацию, подготовленные аудируемым
лицом.
Такой
документацией могут быть аналитические
данные о количестве, видах отгруженной
и проданной продукции конкретным
покупателям, о динамике изменения
операций по выпуску, отгрузке
и продаже
продукции, финансовых результатах от
продажи продукции по сравнению с
предшествующими периодами. В этих
случаях аудитор обязан убедиться в том,
что такие материалы подготовлены
надлежащим образом. Подготовленная
аудируемым лицом документация является
частью рабочих документов аудитора.
В состав
рабочей документации при проверке
операций по вы-
пуску,
отгрузке и продаже продукции обычно
включают:
• информацию,
отражающую процесс планирования, включая
программы аудита и любые изменения к
ним;
• доказательства
понимания аудитором систем бухгалтерского
учета и внутреннего контроля;
• доказательства,
подтверждающие оценку неотъемлемого
и иных видов риска, и любые корректировки
этих оценок;
• доказательства,
подтверждающие факт анализа аудитором
работы аудируемого лица по внутреннему
аудиту и сделанные аудитором выводы;
• анализ
хозяйственных операций по выпуску,
отгрузке и продаже продукции и остатков
по счетам бухгалтерского учета «Выпуск
продукции (работ, услуг)», «Готовая
продукция», «Товары отгруженные»,
«Продажи», «Прибыли и убытки»;
• сверку
расчетов между предприятием и покупателями
за отгруженную и проданную продукцию;
• анализ
показателей финансового результата от
продажи продукции и тенденций деятельности
предприятия;
• сведения
о характере, временных рамках, объеме
аудиторских процедур и результатах их
выполнения;
• сведения
о том, кто выполнял аудиторские процедуры,
с указанием времени их выполнения;
• копии
сообщений, направленных другим аудиторам,
экспертам и третьим лицам (покупателям),
и полученных от них ответов;
• копии
писем и телеграмм по вопросам аудита,
направленных руководству аудируемого
лица или обсуждавшийся с ним, включая
выявленные существенные недостатки
системы внутреннего контроля;
• письменные
заявления, полученные от аудируемого
лица;
• выводы,
сделанные аудитором по наиболее важным
вопросам проверки выпуска, отгрузки и
продажи продукции, включая ошибки и
необычные обстоятельства, которые были
выявлены аудитором в ходе проверки и
сведения о действиях, предпринятых в
связи с этим аудитором;
• копии
финансовой (бухгалтерской) отчетности
и аудиторского заключения.
Рабочая
документация может создаваться аудитором
на бумажных, машинных или иных носителях,
обеспечивающих сохранность сведений,
содержащихся в ней, в течение времени,
установленного для хранения рабочей
документации в архиве.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Цель этой задачи:
- Исследовать Протокол тестирования и проанализировать неполадки, возникшие в процессе реализации и выполнения теста
- Устранить неполадки, которые возникли из-за ошибок в процедуре тестирования
- Записать важные полученные данные соответствующим образом
Исследовать протоколы тестирования
| Цель: | Рассмотреть и понять выходные данные проведенных тестов. |
Начните со сбора данных в Протоколах тестирования, внесенных в них в процессе реализации и выполнения тестов. Источники
подходящих протоколов могут быть разными: они могут быть собраны используемыми вами средствами (как выполнения тестов,
так и диагностических средств), собраны пользовательскими процедурами, разработанными в вашем коллективе, получены из
самих Целевых элементов теста, или записаны вручную тестировщиком. Соберите все доступные источники Тестовых протоколов
и проверьте их содержимое. Проверьте, все ли запланированные тесты полностью выполнены, и все ли необходимые тесты
запланированы.
Собрать нетривиальные данные инцидента
| Цель: | Записать появление всех отклонений, нетривиальных событий для последующего исследования. |
Важно собрать все случаи отклонений, даже если вы пока не можете их воспроизвести и объяснить, последующие инциденты с
похожими симптомами со временем предоставят достаточно информации для обнаружения ошибки, которая их вызвала.
Внесите в протокол как можно больше подробностей, но укажите, что инцидент пока еще не решен.
Определить процедурные ошибки в тесте
| Цель: | Устранить человеческие, процедурные и другие рабочие ошибки процесса тестирования, обнаруженные в протоколе. |
Довольно часто количество неполадок зависит от ошибок, внесенных в процессе реализации теста или при управлении
тестовой средой. Определите и исправьте эти ошибки.
При неправильном завершении теста, до выполнения других тестов необходимо исправить ошибку, а затем продолжить
выполнение тестов.
Найти в выделить неполадки
| Цель: | Определить, где произошла неполадка, устранив те Целевые элементы теста из анализа неполадки, которые не вызвали ошибок. |
Чем больше признаков неполадки вы найдете, тем вероятнее ее определить и понять.
Попытайтесь выделить неполадку, устранив Целевые элементы теста, которые скорей всего не связаны с ней, а затем найти
тенденции и характеристики в оставшихся элементах, состояние системы и т.д.
Произведите анализ неполадки, воспроизведя ее в управляемых условиях, если ее нельзя достаточно исследовать без
воспроизведения. Там, где это полезно, примените средства диагностики и отладки.
Определить признаки и характеристики неполадки
| Цель: | Зафиксировать полезные данные анализа неполадки, чтобы облегчить ее определение и устранение. |
Попытайтесь поставить диагноз основной ошибки, используя свой опыт подобных инцидентов, которые происходили ранее.
Если это требуется и возможно, заручитесь поддержкой разработчиков, используя их знание программного обеспечения, чтобы
улучшить анализ неполадки.
Определить возможные решения
Внести в документацию полученные данные подходящим образом
Оценка и проверка результатов
| Цель: | Убедиться в том, что задача правильно выполнена, и что получены приемлемые рабочие продукты. |
Теперь, когда работа выполнена, стоит проверить, имела ли она достаточную пользу, или вы просто потратили кучу бумаги.
Вы должны оценить, имела ли ваша работа подходящее качество, достаточно ли она завершена для того, чтобы быть полезной
тем членам коллектива, которые впоследствии будут использовать ее в своей работе. Там, где это возможно, применяйте
справочные таблицы, предоставленные в RUP для проверки качества и полноты работы.
Позвольте тем, кто будет впоследствии использовать вашу работу, участвовать в просмотре промежуточных вариантов.
Делайте это, пока еще есть достаточно времени для удовлетворения их пожеланий. Необходимо также оценить свою работу по
отношению к ключевым входным рабочим продуктам, чтобы убедиться в том, что они точно и в достаточной мере представлены.
Может быть полезным, чтобы автор входного рабочего продукта просмотрел вашу работу.
Помните, что RUP — это итерационный процесс и во многих случаях рабочие продукты развиваются с течением времени.
Поэтому, не всегда необходимо (а часто даже приводит к обратным результатам) полностью формировать рабочий продукт,
который будет использоваться только частично или не будет использоваться совсем в работе, которая непосредственно
следует за этой. Причина этого состоит в том, что существует высокая вероятность изменения ситуации вокруг рабочего
продукта до его использования, что приводит к потерянным напрасно усилиям и дорогостоящей переработке. Также избегайте
ошибки тратить слишком много времени на представление в ущерб содержимому. В средах тех проектов, в которых
представление имеет важность и экономическое значение при их сдаче, можно использовать административный ресурс для
выполнения задач представления.