Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
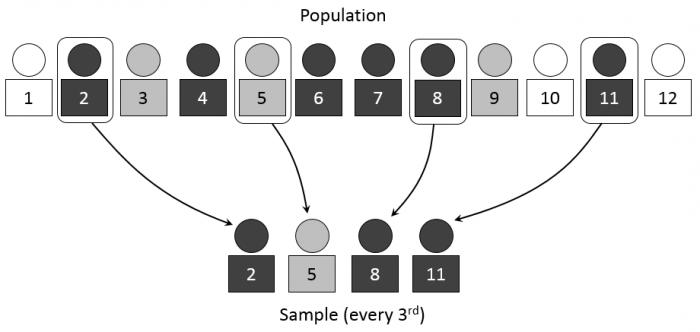
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.

Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.

Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.

Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
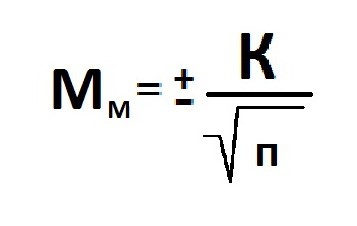
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
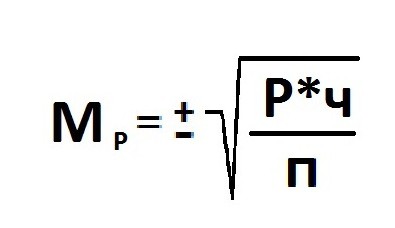
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
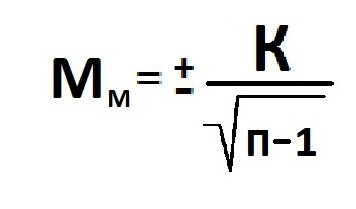
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
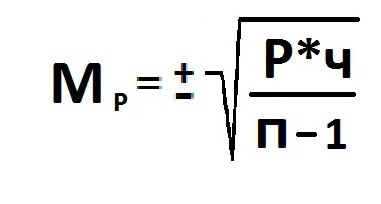
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.

Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.
Пример об ошибке репрезентативности
Лекция 4.1 Выборочный метод
К настоящему времени Вы заработали баллов: 0 из 0 возможных.
ГЕНЕРАЛЬНАЯ И ВЫБОРОЧНАЯ СОВОКУПНОСТЬ
Генеральная совокупность — вся подлежащая изучению совокупность объектов (наблюдений).
Генеральная совокупность носит гипотетический характер. Она представляет собой совокупность всех мыслимых наблюдений, которые могли бы быть произведены при данных условиях. Даже если бы у нас была возможность провести сплошное исследование всей совокупности признака, все равно в нее не попали бы объекты, которое по какой то причине отсутствуют на текущий момент, но должны были существовать при данных условиях.

Та часть объектов, которая отобрана для непосредственного изучения, называется выборочной совокупностьюили выборкой
Сущность выборочного метода
Сущность выборочного метода состоит в том, чтобы по некоторой части генеральной совокупности выносить суждение о её свойствах в целом

Чтобы по данным выборки иметь возможность судить о генеральной совокупности, она должна быть репрезентативной(представительной).

Репрезентативная выборка сохраняет и повторяет структуру генеральной совокупности.
Если две выборки взяты из одной генеральной совокупности, то разница в получаемых оценках (например, средних) будет носить случайный характер, как следствие ошибки репрезентативности

Ошибка репрезентативности возникает по причине того, что мы исследуем не всю совокупность, а только её части (выборки). Мы получаем случайную комбинацию элементов из генеральной совокупности.
Для того, чтобы минимизировать различия однородных (взятых из одной генеральной совокупности) выборок необходимо правильным образом их формировать.
Наилучшим способом формирования репрезентативной выборки является случайный отбор элементов из генеральной совокупности без расчленения на части или группы (случайная выборка).
Пример об ошибке репрезентативности
Рассмотрим следующий пример.
Исследователь задался вопросом: «существуют ли различия в эмпатических способностях между психологами и педагогами?». Для того чтобы это прояснить он набрал две группы испытуемых в соответствии с их профессиональной деятельностью и предложил им заполнить опросник на эмпатические способности. Далее, он рассчитал среднее значение в каждой группе.
В группе психологов среднее составило 23,4 балла, а в группе педагогов 21,1. Таким образом, разница в средних между группами составила2,3 балла (23,4 — 21,1 = 2,3).
Если бы представители этих профессий не отличались по изучаемому признаку, тогда разница в средних равнялась бы нулю.
Однако, можно ли считать эту разницу в 2,3 балла достаточной, чтобы судить о реальных различиях между группами? Может сложится так, что психологи и педагоги по эмпатии в реальности не отличаются (выборки однородны), а разница в 2,3 балла, полученная исследователем носит случайный характер, как ошибка репрезентативности.
Таким образом, мы можем сформулировать две гипотезы:

Гипотезы являются альтернативами по отношению к друг другу. Принятие одной из них как верной влечет за собой исключение «истинности» другой.
СТАТИСТИЧЕСКАЯ ГИПОТЕЗА
Статистическая гипотеза – это любое предположение о виде или параметрах неизвестного закона распределения (закона распределения генеральной совокупности)
В статистике принято формулировать пару гипотез. Первая гипотеза называется нулевой, а вторая – альтернативной.
| Нулевая гипотеза Н | Альтернативная гипотеза Н1 |
| 1. 1. Является проверяемой 2. Обычно гипотеза об отсутствии явления (например, различий или зависимости) | Является логическим отрицанием нулевой |
| Поскольку нулевая гипотеза является проверяемой, то её можно отвергать и принимать | Альтернативную гипотезу принимают как следствие отрицания нулевой гипотезы |

пример:
· Н (нулевая): Женщины не отличаются от мужчин по среднему уровню развития эмпатических способностей (средние значения равны)
· Н1 (альтернативная): Средний уровень эмпатических способностей выше у женщин по сравнению с мужчинами
пример:
· Н (нулевая): Линейная корреляция между самооценкой и тревожностью равна 0
· Н1 (альтернативная): Самооценка отрицательно связана с тревожностью (линейная корреляция меньше нуля / чем выше самооценка, тем ниже тревожность и наоборот)
Вопрос:Какая из двух формулировок соответствует нулевой гипотезе Н?
· А) между психологами и педагогами нет различий по среднему уровню выраженности эмпатии
· Б) между психологами и педагогами есть различия по среднему уровню выраженности эмпатии
Статистический критерий
Правило, по которому нулевая гипотеза отвергается или принимается, называется статистическим критерием.
Статистика – это специально составленная выборочная характеристика (распределение), у которой есть критическое значение такое, что если верна нулевая гипотеза, то вероятность (α) того, что случайная величина превысит это критическое значение, мала (Кремер Н.Ш., 2004).

Критическое значение делит распределение «нулевой гипотезы» на две области: область допустимых значений и область критических значений

Таким образом, критические значения позволяют исследователю либо принять, либо отвергнуть нулевую гипотезу.
В математической статистике можно подбирать критические значение для разных альфа-уровней (уровней значимости). Чаще всего:
1. Критическое значение, которое выделяет критическую область с вероятностью α
Источник
Ошибки статистического наблюдения и основные приёмы их устранения




![]()
![]()
Всякое статистическое наблюдение должно быть полным и достоверным. Однако по ряду причин степень точности данных может быть различной.
Все ошибки наблюдения подразделяются на два вида:
Ошибки регистрации возникают вследствие неправильного установления фактов в процессе наблюдения или неправильной их записи.
Ошибки регистрации могут возникать как при сплошном наблюдении, так и при несплошном и имеют следующие виды:
Случайные ошибки – это ошибки, которые возникают в результате небрежной описки или невнимательного отношения регистратора при заполнении формуляра (ошибки в подсчёте).
Систематические ошибки – это ошибки, которые искажают сведения по каждой отдельной единице наблюдения в одном и том же направлении.
Систематические ошибки делятся на:
Преднамеренные ошибки (сознательные, тенденциозные ошибки), возникающие в результате сознательного искажения статистической информации. К ним относятся: приписки, неправильные сведения об объёме выпущенной продукции, об остатках сырья и материалов и т. д.
Непреднамеренные ошибки – это ошибки, которые возникают в результате случайных причин, т.е. неумышленно (неисправность измерительных приборов, невнимательность регистратора и т.д.).
Ошибки репрезентативности свойственны несплошному наблюдению. Они возникают в результате выборочного наблюдения, когда отобранная часть единиц совокупности недостаточно полно отражает состав всей изучаемой совокупности.
Ошибки репрезентативности (так же, как и ошибки регистрации) могут быть случайными и систематическими.
Случайные ошибки оцениваются с помощью математических методов.
Систематические ошибки – это отклонения, которые возникают в результате случайного отбора единиц изучаемой совокупности. Их размеры не поддаются количественной оценке.
Для выявления и устранения допущенных при регистрации ошибок применяются следующие методы:
а) внешний контроль;
б) логический контроль;
в) счётный контроль.
При внешнем контроле проверяется: правильность оформления документов; наличие всех необходимых записей, которые предусмотрены инструкцией и т.д.
Логический контроль заключается в проверке ответов на вопросы программы наблюдения путём сопоставления полученных данных с другими источниками.
Сущность счётного (арифметического) контроля заключается в счётной проверке всех итоговых показателей, которые содержатся в отчётности или формуляре исследования. Задачей такого контроля является исправление итогов и отдельных числовых показателей.
В ряде случаев, при счётном контроле данных статистического наблюдения применяется метод балансовой увязки показателей (наличие на начало отчётного периода плюс поступления минус расход должно быть равно наличию на конец отчётного периода). Такой метод применяют: при проверках поголовья скота, при учёте поступления и расхода сырья и материалов и т.д.
Указанные методы проверки достоверности статистического наблюдения позволяют сократить до минимального значения допуск ошибок.
Источник
Репрезентативность — что это за процесс? Ошибка репрезентативности
Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.
Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.
Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.
Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.
Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.
Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.
Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.
Источник
Ошибки статистического наблюдения
Информация,
полученная в ходе статистического
наблюдения может не отвечать
действительности, а расчетные значения
показателей не соответствовать
фактическим значениям.
Расхождение
между расчетным значением и фактическим
называется ошибкой
наблюдения.
В
зависимости от причин возникновения
различают ошибки
регистрации и ошибки репрезентативности.
Ошибки регистрации характерны как для
сплошного, так и для несплошного
наблюдения, а ошибки репрезентативности
— только для несплошного наблюдения.
Ошибки регистрации, как и ошибки
репрезентативности, могут быть случайными
и систематическими.
Ошибки
регистрации —
представляют собой отклонения между
значением показателя, полученного в
ходе статистического наблюдения, и его
фактическим значением. Ошибки регистрации
бывают случайными (результат действий
случайных факторов — перепутаны строки
например) и систематическими (проявляются
постоянно).
Ошибки
репрезентативности —
возникают, когда отобранная совокупность
недостаточно точно воспроизводит
исходную совокупность. Характерны для
несплошного наблюдения и заключаются
в отклонении величины показателя
исследуемой части совокупности от его
величины в генеральной совокупности.
Случайные
ошибки —
являются результатом действия случайных
факторов.
Систематические
ошибки —
всегда имеют одинаковую направленность
к увеличению или уменьшению показателя
по каждой единице наблюдения, вследствие
чего значение показателя по совокупности
в целом будет включать накопленную
ошибку.
Способы
контроля:
-
Счетный
(арифметический) — проверка правильности
арифметического расчета. -
Логический
— основан на смысловой взаимосвязи
между признаками.
Сводка статистических данных
Статистическая
сводка является следующим
после статистического
наблюдения этапом
статистической работы. Её задача
заключается в том, чтобы привести
собранную информацию и материалы в
определенный порядок, систематизировать
и на этой основе дать сводную характеристику
всей изучаемой совокупности.
Статистическая
сводка —
комплекс последовательных операций по
первичной обработке данных с целью
выявления типичных черт и закономерностей,
присущих изучаемому явлению. Это
научно-организованная обработка
материалов наблюдения,
включающая подсчет групповых и общих
итогов, систематизацию, группировку
данных и составление таблиц.
Виды
сводки
Различают
простую и сложную сводку:
-
При простой
сводке производится
подсчет общих итогов по изучаемой совокупности. -
При сложной
сводке производится
группировка единиц наблюдения, подсчет
итогов по каждой группе и по всей
совокупности, и представление результатов
группировки в виде статистических
таблиц.
Сводка
называется децентрализованной если
единое руководство работой осуществляется
из центра, а непосредственная работа
проводится на местах (обычно используется
при обработке статистической
отчетности).
Если же сбор и обработка
данных проводится в одном месте, то
сводка называется централизованной.
Централизованная сводка обычно
используется для обработки материалов
единовременных статистических
обследований.
Проведению
статистической сводки и группировки
предшествует разработка программы
статистического наблюдения, состоящая
из нескольких этапов: выбор группировочного
признака, разработка системы статистических
показателей.
Статистическая
сводка должна проводиться по определенной
программе и плану.
Сводка
состоит из следующих этапов:
-
Выбор
группировочного признака; -
Определение
порядка формирования групп; -
Разработка
системы статистических показателей
для характеристики отдельных групп и
совокупности в целом; -
Разработка
макетов статистических таблиц для
представления результатов сводки.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка — репрезентативность
Cтраница 1
Ошибки репрезентативности делятся на случайные и систематические. Случайные ошибки возникают вследствие того, что выборочная совокупность недостаточно точно воспроизводит всю совокупность вследствие несплошного характера наблюдения. Случайные ошибки могут быть доведены до незначительных размеров, как это показано далее, а главное, размеры и пределы их можно определить с достаточной точностью на основании закона больших чисел. На этом законе базируется теория выборочного метода.
[1]
Ошибки репрезентативности, т.е. расхождения между данными выборочного наблюдения и данными всей совокупности, могут быть получены только при несплошном наблюдении, они про-изводны от самой сути выборочного наблюдения. При этом существуют и, соответственно, аудиторы должны различать две разные группы ошибок репрезентативности: случайные и систематические.
[2]
Ошибки репрезентативности также бывают случайными и систематическими. Случайные ошибки репрезентативности возникают, если отобранная совокупность неполно воспроизводит совокупность в целом. Величина этих ошибок может быть оценена.
[3]
Ошибка Д является ошибкой репрезентативности ( представительства) выборки. Она возникает только вследствие того, что исследуется не вся совокупность, а лишь часть ее ( выборка), отобранная случайно. Эту ошибку часто называют случайной ошибкой репрезентативности. Ее не следует путать с систематической ошибкой репрезентативности, появляющейся в результате нарушения принципа случайности при отборе элементов в выборку.
[4]
При прочих равных условиях ошибка репрезентативности возрастает по мере увеличения вариабельности объектов изучаемой совокупности и уменьшается при увеличении объема выборки.
[5]
В отличие от ошибок регистрации ошибки репрезентативности характерны только для несплошного наблюдения. Они возникают потому, что отобранная и обследованная совокупность недостаточно точно воспроизводит генеральную совокупность в целом.
[6]
Разность между результатами выборочного и сплошного наблюдения называется ошибками репрезентативности.
[7]
После проведения выборки рассчитывают возможные ошибки выборочных показателей ( ошибки репрезентативности), которые используются для оценки результатов выборки и для получения характеристик генеральной совокупности.
[8]
Очень часто малоопытный социолог не улавливает разницы между проблемой ошибки репрезентативности выборки и ошибки вывода из данного конкретного распределения в рамках выборочной совокупности.
[9]
Если разность между ошибками регистрации этих видов обследования превысит ошибку репрезентативности, то общая ошибка при несплошном наблюдении может оказаться меньше, чем ошибка регистрации сплошного наблюдения. Особенно вероятен такой результат при выборочном наблюдении.
[10]
Ошибки наблюдения подразделяются на два вида: ошибки регистрации и ошибки репрезентативности.
[11]
Ошибки статистического наблюдения могут быть разбиты на две группы: ошибки репрезентативности и ошибки регистрации.
[12]
Оценку генерального параметра получают на основе выборочного показателя с учетом ошибки репрезентативности. В другом случае в отношении свойств генеральной совокупности выдвигается некоторая гипотеза о величине средней, дисперсии, характере распределения, форме и тесноте связи между переменными. Если расхождение между сравниваемыми величинами не выходит за пределы случайных ошибок, гипотезу принимают. При этом не делается никаких заключений о правильности самой гипотезы, речь идет лишь о согласованности сравниваемых данных. Основой проверки статистических гипотез являются данные случайных выборок. При этом безразлично, оцениваются ли гипотезы в отношении реальной или гипотетической генеральной совокупности. Последнее открывает путь применения этого метода за пределами собственно выборки: при анализе результатов эксперимента, данных сплошного наблюдения, но малой численности. В этом случае рекомендуется проверить, не вызвана ли установленная закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится изучаемая совокупность.
[13]
Поэтому при несплошном обследовании общая ошибка наблюдения является суммой ошибки регистрации и ошибки репрезентативности. Однако это отнюдь не означает, что при любом несплошном наблюдении ошибка будет больше, чем при сплошном.
[14]
Отклонение значения показателя обследованной совокупности от его величины в генеральной совокупности называется ошибкой репрезентативности.
[15]
Страницы:
1
2
Подборка по базе: Зуев К.А. Практическое задание..docx, Практическое занятие 3.rtf, Зуев К.А. Практическое задание. (2).docx, Общий Психологический Практикум Практическое задание.docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание. (1).docx, Пожидаева К.М. Практическое задание 3.doc, 3 Практическое задание № 3 английский2.docx
Практическое занятие №3. Ошибки выборки
3.1 Ошибки регистрации и ошибки репрезентативности
В результате статистической обработки данных могут возникнуть ошибки наблюдения, получаемые вследствие расхождения между величиной какого-либо показателя, найденного при статистическом наблюдении данных и действительными его размерами. Их еще называют выбросами. Это данные среди исходных результатов измерений (или данные, занесенные в таблицу и полученные из результатов измерений), которые настолько отклоняются от сопоставимых данных, внесенных в ту же самую таблицу, что признаются несовместимыми.
В зависимости от причин возникновения различаю ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации возникают в результате неправильного установления фактов или ошибочной записи в процессе наблюдения. Они бывают случайными и систематическими. Случайные ошибки регистрации могут быть допущены как в опрашиваемыми в их ответах, так и регистраторами. Систематические ошибки могут быть и преднамеренными, и непреднамеренными. Преднамеренные ошибки – сознательные, тенденциозные искажения действительного положения дел. Непреднамеренные ошибки могут быть вызваны различными случайными причинами (небрежность, невнимательность).
Ошибки репрезентативности (представительности) возникают в результате неполного обследования и в случае, если обследуемая совокупность недостаточно полно воспроизводит генеральную совокупность. Они могут быть случайными и систематическими.
Ошибки репрезентативности присущи выборочному наблюдению и возникают в связи с тем, что выборочная совокупность не полностью воспроизводит генеральную.
Выборка является репрезентативной (или представительной), если она достаточно полно представлять изучаемые признаки генеральной совокупности. Условием обеспечения репрезентативности выборки является, согласно закону больших чисел, соблюдение случайности отбора, т.е. все объекты генеральной совокупности должны иметь равные вероятности попасть в выборку.
Анализ репрезентативности выборки особенно важен на начальном этапе исследований, когда численность генеральной совокупности неизвестна, но известны некоторые параметры опыта, позволяющие оценить репрезентативность.
Ошибки выборки – разность между характеристиками выборочной и генеральной совокупностей. Для среднего значения определяют предельную ошибку выборки по формуле
 (3.1)
(3.1)
где
 (3.2)
(3.2)
N– объем выборки.
Грубые ошибки и промахи обнаруживают и исключают из расчетов следующим образом:
- находят среднее арифметическое
 результата n—кратного измерения величины хi;
результата n—кратного измерения величины хi; - определяют среднее квадратическое отклонение S; Если базовый элемент ijсодержит лишь два результата измерений, то внутриэлементное расхождение (аналог стандартного отклонения) равно
 (3.3)
(3.3)
Таким образом, если во всех базовых элементах содержится по два результата измерений, для простоты вместо стандартных отклонений могут быть использованы абсолютные расхождения;
- вычисляют вспомогательную величину t(S) (табл. 3.1).
Таблица 3.1 – Значения вспомогательной величины t(S) в зависимости от числа nповторных измерений (степень достоверности 0,95)
| n | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| t(S) | 15,56 | 4,97 | 3,56 | 3,04 | 2,78 | 2,62 | 2,51 | 2,43 | 2,37 |
При |хi — |>t(S) результат измерения хiявляется грубой ошибкой, поэтому его исключают из расчетов и среднее значение вычисляют заново для оставшихся достоверных результатов измерения.
Ошибки (промахи) могут быть исключены из генеральной совокупности с помощью следующего правила:
Если k больше допустимого значения, то делается вывод о том, что xi не принадлежит к генеральной совокупности.
Значения допустимых k дано в таблице 3.2.
Таблица 3.2 – Значения допустимых kв зависимости от числа измерений
| Число измерений | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 25 |
| Значение k | 1,49 | 1,94 | 2,22 | 2,41 | 2,55 | 2,66 | 2,75 | 2,82 | 2,88 | 3,01 |
В литературе известны также критерии 3s, Граббса (Смирнова) [ГОСТ Р ИСО 5725-2-2002 Точность (правильность и прецизионность) методов и результатов измерений. Часть 2. Основной метод определения повторяемости и воспроизводимости стандартного метода измерений], Шарлье, Шовенэ, Диксона и др., которые позволяют исключить грубые промахи.
3.2 Критерий Романовского
Используя критерий Романовского можно определить грубую погрешность в зависимости от числа измерений и уровня значимости α. Для этого необходимо вычислить расчетное значение Vрасч сомнительного результата по формулам:

 (3.4)
(3.4)
где Vнб, Vнм – соответственно расчетные значения соответствующие наибольшему (хнб) и наименьшему (хнм) значениям сомнительного результата.
Для принятых значений числа измерений n и уровня значимости α определяется максимально допустимое значение Vдоп по таблице 3.3, которое сравнивается с расчетным. Если Vдоп<Vрасч, то сомнительные значения (хнб, хнм) являются грубыми погрешностями и должны быть исключены из дальнейших рассмотрений.
Если Vдоп>Vрасч, то хнб и хнм необходимо оставить в данном ряду измерений и учитывать при обработке результатов измерений.
Таблица 3.3 – Значение критерия Романовского Vдоп в зависимости от числа измерений и уровня значимости
| Число измерений n | Уровень значимости | |||
| 0,1 | 0,05 | 0,025 | 0,01 | |
| 3 | 1,41 | 1,41 | 1,41 | 1,41 |
| 4 | 1,65 | 1,69 | 1,71 | 1,72 |
| 5 | 1,79 | 1,87 | 1,92 | 1,96 |
| 6 | 1,89 | 2,00 | 2,07 | 2,13 |
| 7 | 1,97 | 2,09 | 2,18 | 2,27 |
| 8 | 2,04 | 2,17 | 2,27 | 2,37 |
| 9 | 2,10 | 2,24 | 2,35 | 2,46 |
| 10 | 2,15 | 2,29 | 2,41 | 2,54 |
| 11 | 2,19 | 2,34 | 2,47 | 2,61 |
| 12 | 2,23 | 2,39 | 2,52 | 2,66 |
| 13 | 2,26 | 2,43 | 2,56 | 2,71 |
| 14 | 2,30 | 2,46 | 2,60 | 2,76 |
| 15 | 2,33 | 2,49 | 2,64 | 2,8 |
| 16 | 2,35 | 2,52 | 2,67 | 2,84 |
| 17 | 2,38 | 2,55 | 2,70 | 2,87 |
| 18 | 2,40 | 2,58 | 2,73 | 2,90 |
| 19 | 2,43 | 2,60 | 2,75 | 2,93 |
| 20 | 2,45 | 2,62 | 2,78 | 2,96 |
| 21 | 2,47 | 2,64 | 2,8.’ | 2,98 |
| 22 | 2,49 | 2,66 | 2,82 | 3,01 |
| 23 | 2,50 | 2,68 | 2,84 | 3,03 |
| 24 | 2,52 | 2,7 | 2,86 | 3,05 |
| 25 | 2,54 | 2,72 | 2,88 | 3,07 |
Пример 3.1. Проверить результат хнб = 17,15 на соответствие грубой погрешности при =0,05. Выполнено измерений п = 12; разброс значений составил = 0,03, 
Решение. Рассчитаем критерий Романовского по формуле (3.4):
Vрасч = (17,15 – 17,00)/0,03 = 5.
Для заданных = 0,05 и п = 12 найти по таблице 3 допустимое значение критерия Романовского Vдоп = 2,39. Сравнивая табличное значение с расчетным, получаем 2,39<5, т.е. Vдоп<Vрасч, следовательно, хнб является грубой погрешностью и должно быть исключено из дальнейших рассмотрений.
3.3 Статистическая обработка экспериментальных данных. Собственно-случайная выборка (простая случайная)
Выборочное наблюдение относится к разновидности несплошного наблюдения, цель которого – по отобранной части единиц дать характеристику всей совокупности единиц. Необходимо, чтобы отобранная часть была репрезентативна (т.е. представляла всю совокупность единиц).
Используя теорему Чебышева П.Л. можно вычислить величину  , выражающую среднее квадратическое отклонение выборочной средней от математического ожидания:
, выражающую среднее квадратическое отклонение выборочной средней от математического ожидания:
 , (3.5)
, (3.5)
которую называют средней ошибкой выборки.
С учетом выбранного уровня вероятности и соответствующего ему значения t (выбирается по табл. 2.5) предельная ошибка выборки составит:
 , (3.6)
, (3.6)
где tα(N-1) – квантиль распределения Стьюдента для вероятности α и числа степеней свободы f = (N-1).
С учётом (3.5) и (3.6) можно утверждать, что при заданной вероятности генеральная средняя  будет находиться в следующих границах:
будет находиться в следующих границах:
 (3.7)
(3.7)
Пример 3.2. Предположим, в результате выборочного обследования жилищных условий жителей города, осуществленного на основе собственно-случайной повторной выборки, получен следующий ряд распределения (табл. 3.4).
Таблица 3.4 – Результаты выборочного обследования жилищных условий жителей города
| Общая площадь жилищ, приходящаяся на 1 чел., кв. м. | До 5,0 | 5,0…10,0 | 10,0…15,0 | 15,0…20,0 | 20,0…25,0 | 25,0…30,0 | 30,0 и более |
| Число жителей | 8 | 95 | 204 | 207 | 210 | 130 | 83 |
Рассмотрим определение границ генеральной средней, в данном случае – средней площади жилищ в расчёте на 1 чел. в целом по городу, опираясь только на результаты выборочного обследования. Для определения средней ошибки выборки нам необходимо, прежде всего, рассчитать выборочную среднюю величину и дисперсию изучаемого признака (табл. 3.5).
В случае, когда данные сгруппированы по интервалам, т. е. представлены в виде интервальных рядов распределения, при расчёте средней арифметической в качестве значения признака принимают середину интервала, исходя из предположения о равномерном распределении единиц совокупности на данном интервале.
Таблица 3.5 – Расчёт средней (полезной) площади жилищ, приходящейся на 1 чел., и дисперсии
| Общая (полезная) площадь жилищ,
приходящаяся на 1 чел., м2 |
Число
жителей mi |
Середина
интервала xi |
xi·mi |  |
| До 5,0
5,0 … 10,0 10,0 … 15,0 15,0 … 20,0 20,0 … 25,0 25,0 … 30,0 30,0 и более |
8
95 204 270 210 130 83 |
2,5
7,5 12,5 17,5 22,5 27,5 32,5 |
20,0
712,5 2550,0 4725,0 4725,0 3575,0 2697,5 |
50,0
5343,75 31875,0 82687,5 106312,5 98312,5 87668,75 |
| Итого: | 1000 | – | 19005,0 | 412250,0 |
Расчёт ведется по формулам:
 (3.8)
(3.8)
где xi – середина интервала.
В нашем примере:

Дисперсию определим по формуле:
 (3.9)
(3.9)
Тогда получаем:

Откуда получаем значение выборочного среднего квадратичного отклонения:
S = 7,16м2.
Средняя ошибка выборки составит:

Определим предельную ошибку выборки с вероятностью 0,954 (t=2):
 .
.
Установим границы генеральной средней:
 или
или  .
.
Таким образом, на основании проведенного выборочного обследования с вероятностью 0,954 можно заключить, что средний размер общей площади, приходящейся на 1 чел., в целом по городу лежит в пределах от 18,5 до 19,5 м2.
При расчёте средней ошибки собственно-случайной бесповторной выборки необходимо учитывать поправку на бесповторность отбора:
 , (3.10)
, (3.10)
где Nx – генеральная совокупность. Если предположить, что представленные в таблице 6 данные являются результатом 5%-го бесповторного отбора (следовательно, генеральная совокупность включает 20 000 ед.), т.е. средняя ошибка выборки согласно (3.10) будет несколько меньше:
 .
.
Соответственно уменьшится и предельная ошибка выборки, что вызовет сужение границ генеральной средней. Особенно ощутимо влияние поправки на бесповторность отбора при относительно большом проценте выборки.
Варианты заданий к практическому занятию №3
| Вариант | в | хср | хнб | сигма | n |
| 1 | 0,1 | 24 | 24,48 | 0,12 | 3 |
| 2 | 0,05 | 24 | 26,16 | 0,12 | 4 |
| 3 | 0,025 | 18 | 19,26 | 0,09 | 5 |
| 4 | 0,01 | 5 | 5,3 | 0,09 | 6 |
| 5 | 0,1 | 25 | 26,75 | 0,11 | 7 |
| 6 | 0,05 | 10 | 10,8 | 0,1 | 8 |
| 7 | 0,025 | 18 | 19,62 | 0,11 | 9 |
| 8 | 0,01 | 8 | 8,48 | 0,09 | 10 |
| 9 | 0,1 | 18 | 18,18 | 0,13 | 11 |
| 10 | 0,05 | 18 | 18,36 | 0,1 | 20 |
| 11 | 0,025 | 18 | 19,08 | 0,1 | 21 |
| 12 | 0,01 | 14 | 15,4 | 0,09 | 22 |
| 13 | 0,1 | 16 | 17,6 | 0,09 | 23 |
| 14 | 0,05 | 9 | 9,18 | 0,11 | 24 |
| 15 | 0,025 | 7 | 7,63 | 0,12 | 25 |
| 16 | 0,01 | 23 | 23,23 | 0,09 | 3 |
| 17 | 0,1 | 17 | 18,36 | 0,11 | 4 |
| 18 | 0,05 | 21 | 21,63 | 0,1 | 5 |
| 19 | 0,025 | 6 | 6,18 | 0,11 | 6 |
| 20 | 0,01 | 10 | 10,5 | 0,12 | 7 |
| 21 | 0,1 | 6 | 6,66 | 0,11 | 8 |
| 22 | 0,05 | 12 | 12,6 | 0,09 | 9 |
| 23 | 0,025 | 15 | 15,6 | 0,09 | 10 |
| 24 | 0,01 | 12 | 12,36 | 0,12 | 11 |
| 25 | 0,1 | 22 | 23,54 | 0,11 | 20 |
| 26 | 0,05 | 15 | 16,35 | 0,13 | 21 |
| 27 | 0,025 | 5 | 5,35 | 0,08 | 22 |
| 28 | 0,01 | 18 | 19,62 | 0,11 | 23 |
| 29 | 0,1 | 10 | 10,9 | 0,11 | 24 |
| 30 | 0,05 | 15 | 16,5 | 0,1 | 25 |
| Вариант | Общая площадь на 1 чел, кв. м. | до 5 | 5-10 | 10-15 | 15-20 | 20-25 | 25-30 | больше 30 | P |
| 1 | Число жителей | 100 | 98 | 121 | 61 | 12 | 180 | 72 | 0,953 |
| 2 | 71 | 61 | 90 | 184 | 87 | 60 | 102 | 0,939 | |
| 3 | 67 | 105 | 63 | 165 | 123 | 105 | 51 | 0,931 | |
| 4 | 57 | 41 | 188 | 124 | 127 | 85 | 30 | 0,937 | |
| 5 | 199 | 146 | 146 | 72 | 101 | 7 | 156 | 0,971 | |
| 6 | 178 | 55 | 85 | 102 | 182 | 60 | 85 | 0,974 | |
| 7 | 45 | 136 | 136 | 37 | 62 | 31 | 33 | 0,926 | |
| 8 | 152 | 13 | 80 | 67 | 144 | 73 | 23 | 0,953 | |
| 9 | 199 | 111 | 75 | 61 | 197 | 198 | 78 | 0,962 | |
| 10 | 66 | 6 | 12 | 61 | 171 | 123 | 178 | 0,955 | |
| 11 | 169 | 36 | 177 | 35 | 132 | 147 | 101 | 0,975 | |
| 12 | 40 | 120 | 17 | 42 | 53 | 116 | 140 | 0,967 | |
| 13 | 38 | 158 | 107 | 194 | 26 | 204 | 166 | 0,923 | |
| 14 | 83 | 201 | 110 | 23 | 161 | 93 | 46 | 0,942 | |
| 15 | 64 | 151 | 84 | 162 | 188 | 96 | 49 | 0,958 | |
| 16 | 115 | 20 | 183 | 198 | 84 | 190 | 109 | 0,922 | |
| 17 | 189 | 106 | 89 | 138 | 148 | 132 | 38 | 0,977 | |
| 18 | 144 | 9 | 156 | 81 | 204 | 148 | 11 | 0,979 | |
| 19 | 31 | 150 | 202 | 125 | 182 | 62 | 119 | 0,947 | |
| 20 | 16 | 78 | 148 | 35 | 30 | 147 | 132 | 0,971 | |
| 21 | 6 | 136 | 123 | 132 | 163 | 29 | 64 | 0,97 | |
| 22 | 99 | 160 | 159 | 165 | 29 | 64 | 196 | 0,969 | |
| 23 | 89 | 198 | 56 | 71 | 152 | 15 | 198 | 0,967 | |
| 24 | 153 | 54 | 150 | 36 | 134 | 40 | 189 | 0,95 | |
| 25 | 112 | 161 | 66 | 65 | 182 | 28 | 146 | 0,923 | |
| 26 | 37 | 90 | 88 | 136 | 25 | 20 | 149 | 0,943 | |
| 27 | 187 | 59 | 13 | 7 | 148 | 156 | 194 | 0,922 | |
| 28 | 84 | 118 | 159 | 200 | 62 | 127 | 7 | 0,961 | |
| 29 | 66 | 86 | 11 | 24 | 54 | 155 | 202 | 0,956 | |
| 30 | 50 | 144 | 179 | 104 | 86 | 10 | 49 | 0,968 |