Ошибки регистрации
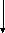

Систематические ошибки
Случайные ошибки– ошибки регистрации, которые могут
быть допущены как опрашиваемыми в их
ответах, так и регистраторами при
заполнении бланков.

Преднамеренные
ошибкиполучаются в результате
того, что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные.
Непреднамеренные
ошибкивызываются различными
случайными причинами (небрежность,
невнимание регистратора; неисправность
измерительных приборов).



Рис.
2.1. Виды ошибок регистрации.
Для
выявления и устранения допущенных при
регистрации ошибок может применяться
счетный и логический контроль собранного
материала.
Счетный
контроль
заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путем их
логического осмысления или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Примером
логического сравнения могут служить
листы переписи населения: в переписном
листе двухлетний ребенок имеет высшее
образование, а девятилетний мальчик
женат. Ясно, что полученные ответы на
вопросы не верны и требуют уточнения и
исправления допущенных ошибок.
Так же примером
логического контроля может являться
сопоставление сведений о фонде заработной
платы, содержащихся в отчете по труду
и в отчете по издержкам обращения.
Контрольные вопросы и задания к теме 2:
-
Что такое
статистическая информация. Особенности
ее формирования. -
Организация
государственной и международной
статистики. -
Виды и формы
статистического наблюдения. Основные
требования, предъявляемые к его
организации и проведению. -
Сущность и
содержание программно-методологических
вопросов статистического наблюдения. -
Приведите пример
объекта и единицы статистического
наблюдения. -
Виды и содержание
статистических формуляров. -
Какими методами
проверяют достоверность отчетных
данных.
Тема 3. Сводка и группировка статистических данных.
-
Понятие о
статистической сводке. -
Статистическая
группировка как основной метод обобщения
информации. -
Ряды распределения.
-
Статистические
таблицы. -
Графическое
изображение статистических показателей.
-
Понятие о
статистической сводке.
В результате статистического
наблюдения получают материала, которые
содержат данные о каждой единице
совокупности. Дальнейшая задача
заключается в том, чтобы привести эти
материалы в определенный порядок,
систематизировать их и не этой основе
дать сводную характеристику всей
совокупности фактов при помощи обобщающих
статистических показателей. Этого
достигают при помощи статистической
сводки.
Статистическая
сводка
– это научная обработка первичных
материалов статистического наблюдения
для характеристики совокупности
обобщающими показателями.
Это вторая стадия статистического
исследования.
Основная
цель и
содержание
статистической сводки состоит в том,
чтобы, обобщив материл, дать полную и
объективную характеристику всей
совокупности фактов, вскрыть закономерности
массовых процессов, которые в нем
содержатся и которые проявляются в
обобщающих показателях.
Статистические
сводки различаются по ряду признаков:
сложности построения, месту проведения
и способу разработки материалов
статистического наблюдения.
По
сложности
построения
сводка может, прежде всего, представлять
общие итоги по изучаемой совокупности
в целом без какой-либо предварительной
систематизации собранного материала.
Она определяет общий размер изучаемого
явления по заданным показателям. Это
так называемая простая сводка. Она может
быть вспомогательной, если содержащаяся
в ней информация используется в дальнейшем
для углубленного изучения статистической
совокупности.
Примером могут выступать результата
переписи населения в декабре 2001 года,
в соответствие с которыми численность
населения в Донецкой области составила
4,8 млн. чел. Данные о численности населения
в Украине могут быть более детально
рассмотрены по различным направлениям:
пол, возраст, семейное положение, место
жительства, образования и т.д.
Статистическая
сводка в широком ее понимании предполагает
систематизацию и группировку цифровых
данных, характеристику образованных
групп системой показателей, подсчет
соответствующих итогов и представление
результатов сводки в виде таблиц,
графиков.
Выделение однородных
в социально-экономическом отношении
групп является основой статистической
сводки исходной информации, непременным
условием ее научной разработки и
практического использования в коммерческой
деятельности.
Последовательность
работ по
статистической сводке исходной информации
подразделяется на следующие этапы:
-
формулировка
задач сводки на основе цели статистического
исследования; -
формирование
групп и подгрупп, определение
группировочных признаков, числа групп
и величины интервала. Решение вопросов,
связанных с осуществлением группировки,
включая выделение существенных
признаков, установление специализированных
интервалов, построение комбинированных
группировок; -
осуществление
технической стороны сводки, то есть
проверка полноты и качества собранного
материала, подсчет различных итогов и
исчисление необходимых показателей
для характеристики всей совокупности
и ее частей.
Статистическую
сводку производят по определенной
программе, составленной в соответствии
с задачами статистического исследования,
и с учетом принятой формы организации
сводки и техники разработки. Программа
содержит перечень групп, на которые
должна быть расчленена совокупность
по отдельным признакам, а так же перечень
показателей, которые следует подсчитать
для характеристики каждой группы. В ней
так же предусматривают территориальные
границы, в которых надо произвести
разработку материала, степень детализации
материала.
По результатам
переписи в Донецкой области проживает
90% городского населения и 10% сельского;
женщин 54%, а мужчин соответственно –
46%.
Способ
разработки
статистической сводки может быть
централизованным и децентрализованным.
При централизованной
сводке
все данные сосредотачиваются в одном
месте и сводятся по разработанной
методике. При децентрализованной
сводке
обобщение материала осуществляется
снизу вверх по иерархической лестнице
управления, подвергаясь на каждом из
них соответствующей обработке.
Положив начало
научной систематизации и обработке
исходной информации, сводка и группировка
статистических данных служат тем самым
базой для осуществления всестороннего
анализа и прогнозирования коммерческой
деятельности.
П
-
Статистическая
группировка как основной метод обобщения
информации.
ри сводке статистических материалов
не ограничиваются простым подсчетом
общей численности учтенных единиц и
объема зарегистрированных признаков.
Как правило, в процессе сводки
статистические материалы упорядочиваются,
систематизируются, делятся на группы
по существенным признакам. Это достигается
с помощью группировки.
Группировка
– это процесс образования однородных
групп на основе расчленения статистической
совокупности на части или объединение
изучаемых единиц в частные совокупности
по существенным для них признакам.
Иначе говоря, группировка – выделение
единиц, однородных в заданном смысле.
Группировка всегда отвечает поставленным
задачам,
а именно:
-
Выделение
социально-экономических типов явлений. -
Изучение структуры
изучаемого явления. -
Выявление
взаимосвязи между изучаемыми признаками.
Для решения этих
задач соответственно применяют различные
виды группировок:
-
Типологические
группировки.
Важнейшим их содержанием является
выделение из множества признаков,
характеризующих изучаемые явления,
основных типов в качественно однородные.
Особое значение имеет правильный выбор
группировочного признака. При атрибутивном
признаке с незначительным разнообразием
его значений число групп определяется
свойствами изучаемого явления
(группировка
населения по половому признаку).
Выделение типов на основе количественно
признака состоит в определении групп
с учетом значений изучаемых признаков.
При этом очень важно правильно установить
интервал группировки, на основе которого
количественно различаются одни группы
от других, намечаются границы выделения
их нового качества. -
Структурные
группировки.
Представляет собой группировку изучаемых
единиц в пределах одного типа явления
или однокачественной совокупности.
Такие группировки имеют задачей либо
изучение состава (структуры) совокупности
по какому-либо варьирующему признаку,
либо изучение в пределах этой совокупности
взаимосвязей варьирующих признаков
(состав
населения по полу, возрасту, образованию). -
Аналитические
группировки.
Дают возможность исследовать взаимосвязь
между изменяющихся признаков в пределах
однородной совокупности. Взаимосвязанные
признаки делятся на факторные, те
которые оказывают влияние, и результативные,
те которые изменяются под воздействием
фактора. Группировка позволяет выявить
и изучить формы зависимости между
варьирующими признаками, отражающими
различные свойства совокупности
(зависимость
товарооборота от производительности
труда). -
Комбинированные
группировки.
Происходит образование групп по двум
и более признакам, взятым в определенном
сочетании (зависимость
товарооборота от производительности
труда и средней заработной платы).
Признаки
единиц совокупности, положенные в
основание группировки статистического
материала, называются группировочными
признаками.
Следует различать признаки, имеющие
количественное выражение, которые
называются количественными, и признаки,
не имеющие количественного выражения
– атрибутивные.
Разновидностью
атрибутивные признаков являются признаки
альтернативные, которые может иметь
данная единица совокупности, а может и
не иметь (студент может быть отличником,
а может и не быть).
Важнейшим
вопросом теории группировки является
выбор группировочных признаков. От
правильного выбора группировочного
признака зависят выводы, которые получают
в результате статистической разработки.
Выбор
группировочного признака
необходимо проводить с учетом следующих
основополагающих моментов:
-
Руководствуясь
знанием сущности данного явления,
законов его развития, в основание
группировки необходимо положить
наиболее существенные признаки,
отвечающие задачам исследования. -
Следует исходить
из тех конкретных исторических и
территориальных условий, в которых
протекает процесс развития изучаемого
явления, так как с изменением конкретных
условий могут меняться и группировочные
признаки. -
При изучении
явлений, на которые воздействует
несколько различных закономерностей,
необходимо в основание группировки
класть не один, а несколько признаков,
взятых в комбинации.
Специфический
характер образования групп зависит от
признаков, на которых основывается
группировка, и от задач группировки.
При группировке по количественным
признакам возникает вопрос о количестве
групп и величине интервала. Количество
групп во многом зависит от того, какой
признак служит основанием группировки.
Интервалы групп устанавливаются только
при значительной колеблемости дискретного
признака и тем более при непрерывно
изменяющемся количественном признаке.
Под
величиной
интервала
обычно понимают разность между
максимальными и минимальными значениями
признака в каждой группе. Для определения
величины интервала (i)
при выделении равновеликих групп разница
между максимальным (xmax)
и минимальным значениями (xmin)
изучаемого признака делится на число
выделяемых групп (n):
i
=
![]()
Намечаемые
при группировке интервалы бывают
открытые
(у них указана одно граница – верхняя
или нижняя) и закрытые
(имеют и верхнюю и нижнюю границы). При
дальнейшем исследовании изучаемой
совокупности открытые интервалы
закрывают путем определения границ
интервала на основе его величины.
Для определения
нижней границы интервала: из верхней
границы вычитают величину интервала.
Для закрытия верхней границы наоборот:
к нижней границе прибавляют величину
интервала.
Если с помощью
группировки исследуют структуру той
или иной совокупности, то показателями
такой группировки обычно бывают единицы
совокупности – их число и процент к
итогу. Когда группировка преследует
аналитические цели выявления и измерения
зависимостей в каждой группе, то кроме
числа единиц совокупности, обязательно
приводят среднее значение того признака,
изменение которого изучают в зависимости
от изменения группировочного признака.
Р
-
Ряды распределения.
езультаты сводки и группировки
материалов статистического наблюдения
оформляются в виде статистических рядов
распределения и таблиц.
Статистические
ряды распределения представляют собой
упорядоченное расположение единиц
изучаемой совокупности на группы по
группировочному признаку.
Они характеризуют состав изучаемого
явления, позволяют судить об однородности
совокупности, границах ее изменения,
закономерностях развития наблюдаемого
объекта.
Распределение
может быть по признакам, не имеющим
количественной меры (атрибутивным),
и по признакам, в которых изменяется их
количественная
мера.
Атрибутивные
ряды
распределения показывают состав
совокупности по тем или иным существенным
признакам. В изменении состава выявляются
важные черты закономерности изучаемого
явления.
Ряды
распределения единиц совокупности по
количественным признакам, называю
вариационными
рядами.
Вариационные ряды дают возможность
установить характер распределения
единиц совокупности по тому или иному
количественному признаку.
Однодневный
товарооборот продовольственных товаров
по предприятиям розничной торговли
Ворошиловского района составил:
-
до 1000 грн. –10
магазинов; -
от 1000 до 2000 грн.
– 17магазинов; -
от 2000 до 3000 грн.
– 6 магазинов; -
более 3000 грн.- 2
магазина.
В
вариационном ряду различают два элемента:
варианты и частоты. Вариантами
называются отдельные значения
группировочного признака, которые он
принимает в вариационном ряду. Числа,
которые показывают как часто встречаются
те или иные варианты в ряду распределения,
называют частотами.
Частоты, выраженные в долях единицы или
процентах к итогу, называются частностями.
Сумма частот составляет объем ряда
распределения.
Вариационные
ряды, как и сами вариации, бывают
интервальными и дискретными. Интервальные
вариационные ряды
– это такие ряды, где значения варианты
даны в виде интервалов. Дискретные
вариационные ряды
основаны на прерывной вариации признака,
то есть отдельные варианты имеют
определенные значения.
Примером
дискретного вариационного ряда могут
являться средние цены на продовольственные
товары. Средняя цена на сахар по Донецкой
области составляла:
-
1995 год – 1,28 грн.;
-
1998 год – 1,27 грн.;
-
2001 год – 2,62 грн.
В
дискретных рядах распределение
изображается как ряд перпендикулярных
линий к соответствующим значениям
вариант, при этом высота этих линий
определяется частотой данной варианты.
Если концы этих линий соединить прямыми,
то график будет называться полигоном
распределения.
Интервальные
ряды распределения изображаются
графически в виде гистограммы. При
ее построении на оси абсцисс откладывают
интервалы ряда, высота которых равна
частотам, отложенным на оси ординат.
Над осью абсцисс строятся прямоугольники,
площадь которых соответствует величинам
произведений интервалов и их частоты.
На
основании ранжированных рядов, то есть
рядов, расположенных в порядке убывания
или возрастания могут строится кумуляты
накопленных частот.
Накопленные частоты определяются путем
последовательного прибывления к частотам
первой группы этих показателей последующих
групп ряда распределения. Накопленные
частоты наносятся на график в виде
перпендикуляров к оси х,
в точках, отмечающих полусуммы интервалов.
Длина перпендикуляра равна сумме
накопленных частот в данном интервале.
Перпендикуляры затем соединяем прямыми,
в результате чего получаем ломанную
линию, которая начиная от нуля, все время
возрастает до тех пор, пока не достигнет
высоты, равной общей сумме частот.
Р
-
Статистические
таблицы.
езультаты сводки и группировки
материалов наблюдения, как правило,
представляются в виде статистических
таблиц. Значение статистических таблиц
состоит в том, что они позволяют охватить
материалы статистической сводки в
целом. Статистическая таблица, по
существу, является системой мыслей об
исследуемом объекте, излагаемых цифрами
на основе определенного порядка в
расположении систематизированной
информации.
Статистические
таблицы
– это форма систематизированного
рационального и наглядного изложения
цифрового материала характеризующего
изучаемые явления и процессы.
По внешнему виду
статистическая таблица представляет
собой ряд пересекающихся горизонтальных
(строк) и вертикальных линий (граф,
столбцов, колонок). Составленную, но не
заполненную таблицу принято называть
макетом таблицы. В таблице имеются два
основных элемента:
-
подлежащее
– то, о чем говориться в таблице, объект
изучения. Может быть представлен в виде
групп и подгрупп, которые характеризуются
рядом показателей; -
сказуемое
– перечень числовых показателей,
которыми характеризуется объект
изучения.
Подлежащее обычно
располагается в левой части таблиц;
сказуемое – в верхней части таблицы в
виде названий граф.
Вид
статистической таблицы зависит от
построения подлежащего – рисунок 3.1.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
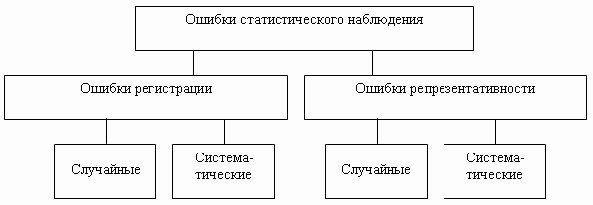
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Ошибки в наблюдении и способы их преодоления.
Вероятность статистических данных — закон государственной статистики Обеспечивается она должным составлением программы и плана наблюдения, научной организацией сбора, обработки и анализа информации Как к тщательно не было организованное статистическое наблюдение, собранные материалы могут иметь разные по характеру и возникновением неточности: неполный охват единиц наблюдения, подлежащих рег ее; пропуски отдельных записей; ошибки отдельных записей и т.п. Если полноту охвата единиц наблюдения и пропуски отдельных показателей установить нетрудно, то найти допущенные погрешности единичных запись ей, так называемые ошибки наблюдения, дело не из легкиких.
Ошибки в процессе наблюдения приводят к снижению его точности
Точностью статистического наблюдения называют степень соответствия величины какого-либо показателя (признака), установленной с помощью наблюдения, действительной величине Она измеряется разницей или соотнонням этих величинын.
Разница между величиной какого-либо показателя, установленного путем наблюдения и настоящим его размером называютошибками статистического наблюдения Ошибки наблюдения разделяют на два вида: ошибки регистрации и ошибки репрезентативности
Ошибки регистрации возникают вследствие неправильного установления фактов или неправильного их записи в формуляр
Ошибки репрезентативности имеют место лишь при выборочном обследовании и возникают вследствие того, что выборочная совокупность недостаточно полно воспроизводит всю изучаемую совокупность Подробнее ошибки репрезентативности описаны в § 11.4.
Ошибки репрезентативности могут быть как при сплошном, так и при сплошные наблюдении Они могут быть преднамеренными и непреднамереннымиУмышленные ошибки являются следствием сознательного искажения действительности в сторону увеличения или уменьшения истинных размеров исследуемого признака
Непреднамеренные ошибки возникают независимо от желания лиц, сообщающих или регистрируют данные
Непреднамеренные ошибки регистрации могут иметь случайный или систематический характер
Случайные непреднамеренные ошибки регистрации — это ошибки, возникающие вследствие различных случайных причин: описка, оговорка и т др. Они приводят к отклонениям данных наблюдения от фактических размеров признаки с одинаковой вероятностью ю как в сторону увеличения, так и в сторону уменьшения данных При достаточно большом количестве единиц наблюдений случайные ошибки могут взаимно погашаться и не производить существенного влияния на результаты видеонаблюдениЭннння.
Систематические непреднамеренные ошибки регистрации возникают из определенных неслучайных причин и приводят к отклонениям данных наблюдения от фактических размеров признаки в сторону увеличения или уменьшения Причиной таких ошибок может быть несправнисво измерительных приборов, нечеткая формулировка вопросов, несовершенство статистического инструментария, склонность людей к округлению цифр и т иін.
Умышленные ошибки регистрации всегда имеют систематический характер
Логично завершается статистическое наблюдение приемом материалов исследования Когда материал статистического наблюдения получены полностью от всех единиц, подлежащих наблюдению, проверяют полноту (качество) заполнения бланков Если при приеме материала наблюдения выявлено незаполненные (или частично заполненные) бланки, значит при статистическом наблюдении пропущена единица сп выговор Поэтому ответственное лицо, принимая статистические формуляры (бланки) в первую очередь проверяет полноту их заполнения и в случае необходимости принимает меры для их исправленияня. .
Наряду с проверкой полноты заполнения бланков осуществляется контроль за достоверностью и правильностью ответов При приеме материалов наблюдения главное внимание уделяется правильности заполнения соответствующих бланков и проверке достоверности (точности) показательв.
Контроля за достоверностью статистических данных статистические органы уделяют особое внимание Такие функции (обязанности) государственная статистика выполняет в тесном контакте с органами контроля, прокуратуры и гром венных организациями.
С целью выявления и устранения допущенных при регистрации ошибок статистические органы осуществляют арифметический и логический контроль собранного материала
Арифметический контроль заключается в проверке точности арифметических подсчетов и расчетов: проверка итоговых показателей в документах, проверка правильности подсчетов процентов, средних величин и т др.
Логический контроль заключался в сопоставлении ответов на вопросы и выяснения их логической согласованности В процессе логического контроля могут быть установлены нереальные или малоправдоподибни ответа
Рассмотрим общие приемы логического контроля
1 Сопоставление ответов на различные взаимосвязанные вопросы в формулярах Например, запись в формуляре о том, что ребенок дошкольного возраста имеет среднее образование, является ошибочным
2 Сравнение записей в документе, проверяемого с аналогичными записями в других документах
3 Сопоставление отчетных показателей за смежные периоды
4 Применение метода балансовой согласованности показателей
часто используют такую ??балансовую равенство: наличие на начало периода плюс поступления минус выбытия равна наличии на конец отчетного периода
5 Проведение напрямую переписями контрольных проверок — сплошных или выборочных
Указанные приемы проверки статистических данных путем арифметического и логического контроля используют как при проверке материалов специально организованных статистических наблюдений, так и отчетности Можно утверждать, что арифметический контроль четко устанавливает наличие ошибки, а логический — в большинстве случаев лишь выявляет возможность ошибки При этом, если проведение арифметического контроля вы МАГАТЭ от статистика элементарной грамотности, то логический — может осуществляться только высококвалифицированными специалистамми.
Значительная вероятность статистических данных обусловлено действующей системой мер, направленных на уменьшение и избежание ошибок Среди них следует назвать следующие: качественный первичный учет, разработка научных рекомендаций ендаций по вопросам проверки достоверности данных; подбор квалифицированных кадров-статистиков, автоматизация статистических работ и т д.
Источник
Ошибки наблюдения и способы их устранения
Способы наблюдения (получения информации) (слайд 1.2.8)
В т.ч. по способам организации опроса
Непосредственноенаблюдение – это регистрация величин признаков на основе непосредственного осмотра единиц совокупностей путем замеров и подсчетов.
Документальныйспособ – способ регистрации признаков на основе документов первичного или бухгалтерского учета, а также по данным каких- либо публикаций.
На практике это по существу вторичное наблюдение , так как исследование ведется по уже опубликованным материалам исследования по территориям, административным подразделениям, отраслям, выступающим в исследовании единицам совокупности. Это наименее трудоемкий способ формирования баз данных для изучения явлений и процессов.
Опрос- это получение сведений о регистрируемых признаках от опрашиваемых лиц.
При экспедиционном способе опросы ведут специальные счетчики или интервьюеры. (например, при переписях населения)
При корреспондентском способе опрос проводят добровольцы по заранее установленному кругу вопросов.
При саморегистрации опрашиваемые сами заполняют опросные листы или другие документы с вопросами программы наблюдения.
Полученные в результате статистического наблюдения базы данных необходимо оценить на полноту ( отсутствие пропусков) и достоверность величин, то есть установить наличие возможных ошибок. Все ошибки можно классифицировать в зависимости от причин возникновения на следующие группы (слайд
Виды ошибок наблюдения: (слайд 1.2.9)
I. Ошибки регистрации
II. Ошибки репрезентативности
Ошибки регистрации возникают в процессе записи значений признаков в формуляры. Если произошло искажение фактических уровней признака случайно, с силу описок, ошибки следует признать случайными. Их разнотипные отклонения (в большую и меньшую сторону) от реальных данных, как правило, при большом числе наблюдений «взаимопогашаются», и они не вызывают существенные искажения свойств совокупности. Напротив, систематические ошибки приводят к существенному искажению информации об объекте исследования, так как представляют собой однотипные отклонения ( в одну сторону) от реальных данных. Причинами для непреднамеренных систематических ошибок могут быть неисправность приборов, низкий уровень квалификации субъекта наблюдения. Преднамеренное искажение исходных данных, как правило, связано с личной заинтересованностью субъекта в фальсификации данных, что приводит к преднамеренной систематической ошибке регистрации. Ошибки регистрации могут возникнуть как при сплошном, так и несплошном наблюдении.
Ошибки репрезентативности — это ошибки несплошного наблюдения, возникающие в силу того, что не все единицы совокупности подвергаются наблюдению, а только часть их. Наиболее полно изучены ошибки при выборочном наблюдении. Если нарушаются принципы отбора единиц из генеральной совокупности в выборку, возникают систематические ошибки. Случайные ошибки выборки присутствуют в базе данных как результат неполного обследования единиц совокупности.
Результатом контроля за ошибками должно быть полное устранение систематических ошибок любого рода и учет возможных случайных ошибок выборки.
Для устранения ошибок применяют
1) Логический контроль
2) Арифметический контроль
При логическом контроле проверяется соответствие ответа поставленному вопросу и заранее установленным правилам и соотношениям, согласованность ответов между собой, непротиворечивость их друг другу. Не может, например, ребенок 5 лет работать на предприятии и иметь среднее образование, а хронически убыточное предприятие платить налоги на прибыль.
Арифметически проверяют, чтобы сумма частных показателей не превышала общего итога или равнялась ему, чтобы часть не была больше целого, а относительные показатели были рассчитаны правильно как соотношение приведенных в программе наблюдения значений абсолютных величин.
В последние годы широко стало применяться автоматическое редактирование собранных первичных, особенно выборочных, данных наблюдения, когда, с использованием приемов математической статистики оценивается принадлежность признака к данной совокупности и выделяются артефакты. Разрабатываются также расчетные формулы, с помощью которых на основе достоверных данных определяются сомнительные значения признаков. Но в области общественных явлений необходимо быть очень осторожным в исправлении расчетным путем полученных признаков наблюдения и ни в коем случае не изменять по субъективным соображениям их значение без проверки достоверности, поскольку общественные явления очень подвижны и динамичны.
Резюме по модульной единице 2:статистическое наблюдение –первый этап статистического исследования, обеспечивающий получение полной, достоверной, объективной, своевременной информации по изучаемому объекту, реализуется посредством разработки плана и программы наблюдения, непосредственного сбора признаков по единицам статистической совокупности и контроля их с целью выявления ошибок.
Контрольные вопросы:
1.Статистическое наблюдение –это…?
2.С какой целью проводится наблюдение?
3.Какие этапы статистического наблюдения необходимо реализовать при его проведении?
4.Какие вопросы включает план наблюдения ?
5. Программа наблюдения – это…?
6. Какие виды наблюдения Вы знаете?
7. Какое наблюдение называется наблюдением основного массива?
8. Какие способы проведения наблюдения Вы знаете ?
9. Какие формы могут иметь место при организации наблюдения ?
10. Какие ошибки наблюдения называются случайными и систематическими ошибками выборки? Какие методы борьбы с ними?
Тесты для контроля знаний:
1. Статистическое наблюдение-это…
1. Получение показателей по социально-экономическому явлению или процессу.

2.Научно организованный сбор признаков по единицам статистической совокупности.
3.Запись значений признаков в статистические формуляры
4.Опрос с целью получения информации по единице наблюдения
2. План статистического наблюдения — это…
1.формуляр с перечнем признаков, подлежащих наблюдению
2. документ с изложением методологии и организации сбора данных
3.Сбор сведений по формам статистического наблюдения
4.возможные статистические показатели, получаемые в результате обработки информации
3. Составной элемент объекта, являющийся носителем признаков, подлежащих регистрации, называется…
1) единицей наблюдения
2) единицей регистрации
3) статистическим формуляром
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Источник
5. Ошибки статистического наблюдения
В процессе исследования явлений может возникать отклонение исчисленных показателей от их действительной величины, то есть могут возникать ошибки статистического наблюдения.
По источникам происхождения ошибки наблюдения можно подразделить на следующие:
непреднамеренные, которые в свою очередь делятся на:
Преднамеренные(сознательные, злостные) получаются в результате того, что сознательно сообщаются неправильные данные. Например, сокрытие фирмами прибыли от налогообложения, искажение сведений об объеме выпускаемой продукции, приписки и т. д.
Законом предусматривается применение экономических и административных мер к предприятиям и лицам за злостные ошибки (иногда и уголовная ответственность).
Непреднамеренные случайныеошибки чаще связаны с невнимательностью регистратора, небрежностью в заполнении документов, неточностью измерительных приборов, ошибками в ответах опрашиваемых.
Непреднамеренные систематическиеошибки возникают при округлении признака в большую или меньшую сторону, при использовании ЭВМ.
Ошибки репрезентативности(представительности) свойственны несплошному наблюдению, они возникают вследствие неправильного выбора единиц для обследования, нарушен принцип случайного отбора, и выборочная совокупность не полно характеризует генеральную.
Б) Способы предотвращения ошибок статистического наблюдения
Чтобы предупредить возникновение ошибок или уменьшить их размеры необходимо:
обеспечивать правильный подбор и подготовку кадров;
вести широкую разъяснительную работу, применять меры взыскания за искажение фактов;
проводить систематический контроль.
Контроль может быть: счетным и логическим.
Счетный контроль заключается в проверке точности арифметических расчетов.
Логический контроль проводится путем сопоставления полученных данных с известными признаками, логическое осмысление, сопоставление с данными за прошлый период.
Например, о заработной плате работников предприятия можно судить по отчету, по труду и по отчету о себестоимости продукции. Сведения о заработной плате должны быть одинаковыми, сопоставимыми (приведите примеры).
Источник
Ошибки регистрации
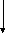

Систематические ошибки
Случайные
ошибки– ошибки регистрации, которые
могут быть допущены как опрашиваемыми
в их ответах, так и регистраторами при
заполнении бланков.

Преднамеренные
ошибкиполучаются в результате
того, что опрашиваемый, зная действительное
положение дела, сознательно сообщает
неправильные данные.
Непреднамеренные
ошибкивызываются различными
случайными причинами (небрежность,
невнимание регистратора; неисправность
измерительных приборов).



Рис.
2.1. Виды ошибок регистрации.
Для выявления и
устранения допущенных при регистрации
ошибок может применяться счетный и
логический контроль собранного материала.
Счетный
контроль
заключается в проверке точности
арифметических расчетов, применявшихся
при составлении отчетности или заполнении
формуляров обследования.
Логический
контроль
заключается в проверке ответов на
вопросы программы наблюдения путем их
логического осмысления или путем
сравнения полученных данных с другими
источниками по этому же вопросу.
Примером
логического сравнения могут служить
листы переписи населения: в переписном
листе двухлетний ребенок имеет высшее
образование, а девятилетний мальчик
женат. Ясно, что полученные ответы на
вопросы не верны и требуют уточнения и
исправления допущенных ошибок.
Так
же примером логического контроля может
являться сопоставление сведений о фонде
заработной платы, содержащихся в отчете
по труду и в отчете по издержкам обращения.
Контрольные вопросы и задания к теме 2:
-
Что
такое статистическая информация.
Особенности ее формирования. -
Организация
государственной и международной
статистики. -
Виды
и формы статистического наблюдения.
Основные требования, предъявляемые к
его организации и проведению. -
Сущность
и содержание программно-методологических
вопросов статистического наблюдения. -
Приведите
пример объекта и единицы статистического
наблюдения. -
Виды
и содержание статистических формуляров. -
Какими
методами проверяют достоверность
отчетных данных.
Тема 3. Обобщение статистических данных.
-
Понятие
о статистической сводке. -
Статистическая
группировка как основной метод обобщения
информации. -
Ряды
распределения. -
Статистические
таблицы. -
Графическое
изображение статистических показателей.
-
Понятие
о статистической сводке.
В результате статистического
наблюдения получают материала, которые
содержат данные о каждой единице
совокупности. Дальнейшая задача
заключается в том, чтобы привести эти
материалы в определенный порядок,
систематизировать их и не этой основе
дать сводную характеристику всей
совокупности фактов при помощи обобщающих
статистических показателей. Этого
достигают при помощи статистической
сводки.
Статистическая
сводка
– это научная обработка первичных
материалов статистического наблюдения
для характеристики совокупности
обобщающими показателями.
Это вторая стадия статистического
исследования.
Основная
цель и
содержание
статистической сводки состоит в том,
чтобы, обобщив материл, дать полную и
объективную характеристику всей
совокупности фактов, вскрыть закономерности
массовых процессов, которые в нем
содержатся и которые проявляются в
обобщающих показателях.
Статистические
сводки различаются по ряду признаков:
сложности построения, месту проведения
и способу разработки материалов
статистического наблюдения.
По
сложности
построения
сводка может, прежде всего, представлять
общие итоги по изучаемой совокупности
в целом без какой-либо предварительной
систематизации собранного материала.
Она определяет общий размер изучаемого
явления по заданным показателям. Это
так называемая простая сводка. Она может
быть вспомогательной, если содержащаяся
в ней информация используется в дальнейшем
для углубленного изучения статистической
совокупности.
Примером могут
выступать результата переписи населения
в декабре 2001 года, в соответствие с
которыми численность населения в
Донецкой области составила 4,8 млн. чел.
Данные о численности населения в Украине
могут быть более детально рассмотрены
по различным направлениям: пол, возраст,
семейное положение, место жительства,
образования и т.д.
Статистическая
сводка в широком ее понимании предполагает
систематизацию и группировку цифровых
данных, характеристику образованных
групп системой показателей, подсчет
соответствующих итогов и представление
результатов сводки в виде таблиц,
графиков.
Выделение
однородных в социально-экономическом
отношении групп является основой
статистической сводки исходной
информации, непременным условием ее
научной разработки и практического
использования в коммерческой деятельности.
Последовательность
работ по
статистической сводке исходной информации
подразделяется на следующие этапы:
-
формулировка
задач сводки на основе цели статистического
исследования; -
формирование
групп и подгрупп, определение
группировочных признаков, числа групп
и величины интервала. Решение вопросов,
связанных с осуществлением группировки,
включая выделение существенных
признаков, установление специализированных
интервалов, построение комбинированных
группировок; -
осуществление
технической стороны сводки, то есть
проверка полноты и качества собранного
материала, подсчет различных итогов и
исчисление необходимых показателей
для характеристики всей совокупности
и ее частей.
Статистическую
сводку производят по определенной
программе, составленной в соответствии
с задачами статистического исследования,
и с учетом принятой формы организации
сводки и техники разработки. Программа
содержит перечень групп, на которые
должна быть расчленена совокупность
по отдельным признакам, а так же перечень
показателей, которые следует подсчитать
для характеристики каждой группы. В ней
так же предусматривают территориальные
границы, в которых надо произвести
разработку материала, степень детализации
материала.
По результатам
переписи в Донецкой области проживает
90% городского населения и 10% сельского;
женщин 54%, а мужчин соответственно –
46%.
Способ
разработки
статистической сводки может быть
централизованным и децентрализованным.
При централизованной
сводке
все данные сосредотачиваются в одном
месте и сводятся по разработанной
методике. При децентрализованной
сводке
обобщение материала осуществляется
снизу вверх по иерархической лестнице
управления, подвергаясь на каждом из
них соответствующей обработке.
Положив
начало научной систематизации и обработке
исходной информации, сводка и группировка
статистических данных служат тем самым
базой для осуществления всестороннего
анализа и прогнозирования коммерческой
деятельности.
П
-
Статистическая
группировка как основной метод обобщения
информации.
ри сводке статистических материалов
не ограничиваются простым подсчетом
общей численности учтенных единиц и
объема зарегистрированных признаков.
Как правило, в процессе сводки
статистические материалы упорядочиваются,
систематизируются, делятся на группы
по существенным признакам. Это достигается
с помощью группировки.
Группировка
– это процесс образования однородных
групп на основе расчленения статистической
совокупности на части или объединение
изучаемых единиц в частные совокупности
по существенным для них признакам.
Иначе говоря, группировка – выделение
единиц, однородных в заданном смысле.
Группировка всегда отвечает поставленным
задачам,
а именно:
-
Выделение
социально-экономических типов явлений. -
Изучение
структуры изучаемого явления. -
Выявление
взаимосвязи между изучаемыми признаками.
Для
решения этих задач соответственно
применяют различные виды группировок:
-
Типологические
группировки.
Важнейшим их содержанием является
выделение из множества признаков,
характеризующих изучаемые явления,
основных типов в качественно однородные.
Особое значение имеет правильный выбор
группировочного признака. При атрибутивном
признаке с незначительным разнообразием
его значений число групп определяется
свойствами изучаемого явления
(группировка
населения по половому признаку).
Выделение типов на основе количественно
признака состоит в определении групп
с учетом значений изучаемых признаков.
При этом очень важно правильно установить
интервал группировки, на основе которого
количественно различаются одни группы
от других, намечаются границы выделения
их нового качества. -
Структурные
группировки.
Представляет собой группировку изучаемых
единиц в пределах одного типа явления
или однокачественной совокупности.
Такие группировки имеют задачей либо
изучение состава (структуры) совокупности
по какому-либо варьирующему признаку,
либо изучение в пределах этой совокупности
взаимосвязей варьирующих признаков
(состав
населения по полу, возрасту, образованию). -
Аналитические
группировки.
Дают возможность исследовать взаимосвязь
между изменяющихся признаков в пределах
однородной совокупности. Взаимосвязанные
признаки делятся на факторные, те
которые оказывают влияние, и результативные,
те которые изменяются под воздействием
фактора. Группировка позволяет выявить
и изучить формы зависимости между
варьирующими признаками, отражающими
различные свойства совокупности
(зависимость
товарооборота от производительности
труда). -
Комбинированные
группировки.
Происходит образование групп по двум
и более признакам, взятым в определенном
сочетании (зависимость
товарооборота от производительности
труда и средней заработной платы).
Признаки
единиц совокупности, положенные в
основание группировки статистического
материала, называются группировочными
признаками.
Следует различать признаки, имеющие
количественное выражение, которые
называются количественными, и признаки,
не имеющие количественного выражения
– атрибутивные.
Разновидностью
атрибутивные признаков являются признаки
альтернативные, которые может иметь
данная единица совокупности, а может и
не иметь (студент может быть отличником,
а может и не быть).
Важнейшим
вопросом теории группировки является
выбор группировочных признаков. От
правильного выбора группировочного
признака зависят выводы, которые получают
в результате статистической разработки.
Выбор
группировочного признака
необходимо проводить с учетом следующих
основополагающих моментов:
-
Руководствуясь
знанием сущности данного явления,
законов его развития, в основание
группировки необходимо положить
наиболее существенные признаки,
отвечающие задачам исследования. -
Следует
исходить из тех конкретных исторических
и территориальных условий, в которых
протекает процесс развития изучаемого
явления, так как с изменением конкретных
условий могут меняться и группировочные
признаки. -
При
изучении явлений, на которые воздействует
несколько различных закономерностей,
необходимо в основание группировки
класть не один, а несколько признаков,
взятых в комбинации.
Специфический
характер образования групп зависит от
признаков, на которых основывается
группировка, и от задач группировки.
При группировке по количественным
признакам возникает вопрос о количестве
групп и величине интервала. Количество
групп во многом зависит от того, какой
признак служит основанием группировки.
Интервалы групп устанавливаются только
при значительной колеблемости дискретного
признака и тем более при непрерывно
изменяющемся количественном признаке.
Под
величиной
интервала
обычно понимают разность между
максимальными и минимальными значениями
признака в каждой группе. Для определения
величины интервала (i)
при выделении равновеликих групп разница
между максимальным (xmax)
и минимальным значениями (xmin)
изучаемого признака делится на число
выделяемых групп (n):
i
=
![]()
Намечаемые
при группировке интервалы бывают
открытые
(у них указана одно граница – верхняя
или нижняя) и закрытые
(имеют и верхнюю и нижнюю границы). При
дальнейшем исследовании изучаемой
совокупности открытые интервалы
закрывают путем определения границ
интервала на основе его величины.
Для определения
нижней границы интервала: из верхней
границы вычитают величину интервала.
Для закрытия верхней границы наоборот:
к нижней границе прибавляют величину
интервала.
Если
с помощью группировки исследуют структуру
той или иной совокупности, то показателями
такой группировки обычно бывают единицы
совокупности – их число и процент к
итогу. Когда группировка преследует
аналитические цели выявления и измерения
зависимостей в каждой группе, то кроме
числа единиц совокупности, обязательно
приводят среднее значение того признака,
изменение которого изучают в зависимости
от изменения группировочного признака.
Р
-
Ряды
распределения.
езультаты сводки и группировки
материалов статистического наблюдения
оформляются в виде статистических рядов
распределения и таблиц.
Статистические
ряды распределения представляют собой
упорядоченное расположение единиц
изучаемой совокупности на группы по
группировочному признаку.
Они характеризуют состав изучаемого
явления, позволяют судить об однородности
совокупности, границах ее изменения,
закономерностях развития наблюдаемого
объекта.
Распределение
может быть по признакам, не имеющим
количественной меры (атрибутивным),
и по признакам, в которых изменяется их
количественная
мера.
Атрибутивные
ряды
распределения показывают состав
совокупности по тем или иным существенным
признакам. В изменении состава выявляются
важные черты закономерности изучаемого
явления.
Ряды
распределения единиц совокупности по
количественным признакам, называю
вариационными
рядами.
Вариационные ряды дают возможность
установить характер распределения
единиц совокупности по тому или иному
количественному признаку.
Однодневный
товарооборот продовольственных товаров
по предприятиям розничной торговли
Ворошиловского района составил:
-
до
1000 грн. –10 магазинов; -
от
1000 до 2000 грн. – 17магазинов; -
от
2000 до 3000 грн. – 6 магазинов; -
более
3000 грн.- 2 магазина.
В
вариационном ряду различают два элемента:
варианты и частоты. Вариантами
называются отдельные значения
группировочного признака, которые он
принимает в вариационном ряду. Числа,
которые показывают как часто встречаются
те или иные варианты в ряду распределения,
называют частотами.
Частоты, выраженные в долях единицы или
процентах к итогу, называются частностями.
Сумма частот составляет объем ряда
распределения.
Вариационные
ряды, как и сами вариации, бывают
интервальными и дискретными. Интервальные
вариационные ряды
– это такие ряды, где значения варианты
даны в виде интервалов. Дискретные
вариационные ряды
основаны на прерывной вариации признака,
то есть отдельные варианты имеют
определенные значения.
Примером
дискретного вариационного ряда могут
являться средние цены на продовольственные
товары. Средняя цена на сахар по Донецкой
области составляла:
-
1995
год – 1,28 грн.; -
1998
год – 1,27 грн.; -
2001
год – 2,62 грн.
В
дискретных рядах распределение
изображается как ряд перпендикулярных
линий к соответствующим значениям
вариант, при этом высота этих линий
определяется частотой данной варианты.
Если концы этих линий соединить прямыми,
то график будет называться полигоном
распределения.
Интервальные ряды
распределения изображаются графически
в виде гистограммы. При ее построении
на оси абсцисс откладывают интервалы
ряда, высота которых равна частотам,
отложенным на оси ординат. Над осью
абсцисс строятся прямоугольники, площадь
которых соответствует величинам
произведений интервалов и их частоты.
На
основании ранжированных рядов, то есть
рядов, расположенных в порядке убывания
или возрастания могут строится кумуляты
накопленных частот.
Накопленные частоты определяются путем
последовательного прибывления к частотам
первой группы этих показателей последующих
групп ряда распределения. Накопленные
частоты наносятся на график в виде
перпендикуляров к оси х,
в точках, отмечающих полусуммы интервалов.
Длина перпендикуляра равна сумме
накопленных частот в данном интервале.
Перпендикуляры затем соединяем прямыми,
в результате чего получаем ломанную
линию, которая начиная от нуля, все время
возрастает до тех пор, пока не достигнет
высоты, равной общей сумме частот.
Р
-
Статистические
таблицы.
езультаты сводки и группировки
материалов наблюдения, как правило,
представляются в виде статистических
таблиц. Значение статистических таблиц
состоит в том, что они позволяют охватить
материалы статистической сводки в
целом. Статистическая таблица, по
существу, является системой мыслей об
исследуемом объекте, излагаемых цифрами
на основе определенного порядка в
расположении систематизированной
информации.
Статистические
таблицы
– это форма систематизированного
рационального и наглядного изложения
цифрового материала характеризующего
изучаемые явления и процессы.
По
внешнему виду статистическая таблица
представляет собой ряд пересекающихся
горизонтальных (строк) и вертикальных
линий (граф, столбцов, колонок).
Составленную, но не заполненную таблицу
принято называть макетом таблицы. В
таблице имеются два основных элемента:
-
подлежащее
– то, о чем говориться в таблице, объект
изучения. Может быть представлен в виде
групп и подгрупп, которые характеризуются
рядом показателей; -
сказуемое
– перечень числовых показателей,
которыми характеризуется объект
изучения.
Подлежащее
обычно располагается в левой части
таблиц; сказуемое – в верхней части
таблицы в виде названий граф.
Вид
статистической таблицы зависит от
построения подлежащего – рисунок 3.1.
2.4. Точность статистического наблюдения
Под точностью статистического наблюдения понимают степень соответствия значения наблюдаемого показателя, вычисленного по материалам обследования, его действительной величине. Расхождение, или разница, между ними называется ошибкой статистического наблюдения.
Различают две группы ошибок:
- ошибки регистрации;
- ошибки репрезентативности.
Ошибки регистрации присущи любому статистическому наблюдению, как сплошному, так и несплошному. Они делятся на случайные ошибки регистрации и систематические ошибки регистрации.
Случайными ошибками регистрации называют ошибки, возникающие вследствие действия случайных факторов. К ним можно отнести различного рода непреднамеренные описки: например, вместо возраста человека «15 лет» указано «5 лет», у Ивановой Марии Петровны в графе пол отмечен «Мужской» и т. п. Такие ошибки легко выявляются методом логического анализа, например, если человеку 8 лет, но имеется высшее образование, а в графе «Семейное положение» указано «Состоит в браке», то, естественно, следует исправить возраст. Если объем исследуемой совокупности велик или велика доля отбора при выборочном наблюдении, случайные ошибки регистрации имеют тенденцию взаимопогашаться вследствие действия закона больших чисел, поскольку ошибки, как правило, разнонаправлены и искажают статистический показатель как в большую, так и в меньшую сторону. При небольшом объеме наблюдения требуется тщательная выверка его результатов — логический анализ данных.
Систематические ошибки регистрации чаще всего имеют однонаправленные искажения: они либо увеличивают, либо уменьшают статистический показатель, и, что характерно, подобная ситуация повторяется от обследования к обследованию. Так, по результатам переписей (практически всех!) число замужних женщин превышает число женатых мужчин — мужчинам приятнее ощущать себя неженатыми, а для женщины как бы «стыдно» быть не замужем. Другой пример, когда человек округляет свой возраст — вместо 32 лет говорит 30, вместо 79-80 и т. п. (это явление широко известно и даже получило свое название — «аккумуляция возрастов»). Систематические ошибки регистрации могут возникать и из-за неточностей измерительных приборов, если сбор информации проводят путем непосредственного наблюдения.
Ошибки репрезентативности присущи только несплошному обследованию. Они также делятся на случайные и систематические ошибки.
Случайные ошибки репрезентативности возникают из-за того, что обследованию подвергается не вся совокупность в целом, а только ее часть, и, следовательно, при несплошном наблюдении они присутствуют всегда. В теории статистики разработаны специальные методы для оценки величин таких ошибок, на их основе для наблюдаемых показателей строят доверительные интервалы, т.д. эти ошибки вычисляются и находятся как бы «под контролем».
Хуже обстоит дело, если наряду со случайными ошибками имеются и ошибки систематические.
Систематические ошибки репрезентативности возникают, если при несплошном наблюдении кардинально нарушаются технологии отбора единиц из генеральной совокупности объектов, но чаще — если в ходе обследования не удается получить информацию обо всех отобранных для наблюдения единицах, например, вследствие отказа отвечать на вопросы анкеты, или если человека не удалось застать дома и т. п.
Ошибки статистического наблюдения для наглядности можно изобразить в виде схемы (рис. 2.1).
Рис.
2.1.
Виды ошибок статистического наблюдения
Для повышения точности наблюдения необходимо:
- правильно разработать формуляр статистического наблюдения: вопросы должны быть четкими, однозначными, не допускающими двойного толкования;
- иметь хорошо обученный персонал для проведения обследования;
- строго придерживаться выбранной технологии обследования (если проводится несплошное наблюдение) и помнить, что если не удается опросить какую-то конкретную единицу, отобранную для наблюдения, замена ее на другую единицу может привести к возникновению систематической ошибки репрезентативности;
- провести логический анализ данных, основанный на логических взаимосвязях показателей, после сбора всей совокупности анкет или формуляров;
- целесообразно провести и арифметический контроль данных, т.д. заново пересчитать расчетные величины, если какие-либо показатели получаются в результате определенных арифметических действий;
- предпринять определенные меры по восстановлению данных при наличии незаполненных анкет или формуляров либо при получении результатов обследования сделать поправку на неответы респондентов.
Подборка по базе: Зуев К.А. Практическое задание..docx, Практическое занятие 3.rtf, Зуев К.А. Практическое задание. (2).docx, Общий Психологический Практикум Практическое задание.docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание..docx, Зуев К.А. Практическое задание. (1).docx, Пожидаева К.М. Практическое задание 3.doc, 3 Практическое задание № 3 английский2.docx
Практическое занятие №3. Ошибки выборки
3.1 Ошибки регистрации и ошибки репрезентативности
В результате статистической обработки данных могут возникнуть ошибки наблюдения, получаемые вследствие расхождения между величиной какого-либо показателя, найденного при статистическом наблюдении данных и действительными его размерами. Их еще называют выбросами. Это данные среди исходных результатов измерений (или данные, занесенные в таблицу и полученные из результатов измерений), которые настолько отклоняются от сопоставимых данных, внесенных в ту же самую таблицу, что признаются несовместимыми.
В зависимости от причин возникновения различаю ошибки регистрации и ошибки репрезентативности.
Ошибки регистрации возникают в результате неправильного установления фактов или ошибочной записи в процессе наблюдения. Они бывают случайными и систематическими. Случайные ошибки регистрации могут быть допущены как в опрашиваемыми в их ответах, так и регистраторами. Систематические ошибки могут быть и преднамеренными, и непреднамеренными. Преднамеренные ошибки – сознательные, тенденциозные искажения действительного положения дел. Непреднамеренные ошибки могут быть вызваны различными случайными причинами (небрежность, невнимательность).
Ошибки репрезентативности (представительности) возникают в результате неполного обследования и в случае, если обследуемая совокупность недостаточно полно воспроизводит генеральную совокупность. Они могут быть случайными и систематическими.
Ошибки репрезентативности присущи выборочному наблюдению и возникают в связи с тем, что выборочная совокупность не полностью воспроизводит генеральную.
Выборка является репрезентативной (или представительной), если она достаточно полно представлять изучаемые признаки генеральной совокупности. Условием обеспечения репрезентативности выборки является, согласно закону больших чисел, соблюдение случайности отбора, т.е. все объекты генеральной совокупности должны иметь равные вероятности попасть в выборку.
Анализ репрезентативности выборки особенно важен на начальном этапе исследований, когда численность генеральной совокупности неизвестна, но известны некоторые параметры опыта, позволяющие оценить репрезентативность.
Ошибки выборки – разность между характеристиками выборочной и генеральной совокупностей. Для среднего значения определяют предельную ошибку выборки по формуле
 (3.1)
(3.1)
где
 (3.2)
(3.2)
N– объем выборки.
Грубые ошибки и промахи обнаруживают и исключают из расчетов следующим образом:
- находят среднее арифметическое
 результата n—кратного измерения величины хi;
результата n—кратного измерения величины хi; - определяют среднее квадратическое отклонение S; Если базовый элемент ijсодержит лишь два результата измерений, то внутриэлементное расхождение (аналог стандартного отклонения) равно
 (3.3)
(3.3)
Таким образом, если во всех базовых элементах содержится по два результата измерений, для простоты вместо стандартных отклонений могут быть использованы абсолютные расхождения;
- вычисляют вспомогательную величину t(S) (табл. 3.1).
Таблица 3.1 – Значения вспомогательной величины t(S) в зависимости от числа nповторных измерений (степень достоверности 0,95)
| n | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| t(S) | 15,56 | 4,97 | 3,56 | 3,04 | 2,78 | 2,62 | 2,51 | 2,43 | 2,37 |
При |хi — |>t(S) результат измерения хiявляется грубой ошибкой, поэтому его исключают из расчетов и среднее значение вычисляют заново для оставшихся достоверных результатов измерения.
Ошибки (промахи) могут быть исключены из генеральной совокупности с помощью следующего правила:
Если k больше допустимого значения, то делается вывод о том, что xi не принадлежит к генеральной совокупности.
Значения допустимых k дано в таблице 3.2.
Таблица 3.2 – Значения допустимых kв зависимости от числа измерений
| Число измерений | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 25 |
| Значение k | 1,49 | 1,94 | 2,22 | 2,41 | 2,55 | 2,66 | 2,75 | 2,82 | 2,88 | 3,01 |
В литературе известны также критерии 3s, Граббса (Смирнова) [ГОСТ Р ИСО 5725-2-2002 Точность (правильность и прецизионность) методов и результатов измерений. Часть 2. Основной метод определения повторяемости и воспроизводимости стандартного метода измерений], Шарлье, Шовенэ, Диксона и др., которые позволяют исключить грубые промахи.
3.2 Критерий Романовского
Используя критерий Романовского можно определить грубую погрешность в зависимости от числа измерений и уровня значимости α. Для этого необходимо вычислить расчетное значение Vрасч сомнительного результата по формулам:

 (3.4)
(3.4)
где Vнб, Vнм – соответственно расчетные значения соответствующие наибольшему (хнб) и наименьшему (хнм) значениям сомнительного результата.
Для принятых значений числа измерений n и уровня значимости α определяется максимально допустимое значение Vдоп по таблице 3.3, которое сравнивается с расчетным. Если Vдоп<Vрасч, то сомнительные значения (хнб, хнм) являются грубыми погрешностями и должны быть исключены из дальнейших рассмотрений.
Если Vдоп>Vрасч, то хнб и хнм необходимо оставить в данном ряду измерений и учитывать при обработке результатов измерений.
Таблица 3.3 – Значение критерия Романовского Vдоп в зависимости от числа измерений и уровня значимости
| Число измерений n | Уровень значимости | |||
| 0,1 | 0,05 | 0,025 | 0,01 | |
| 3 | 1,41 | 1,41 | 1,41 | 1,41 |
| 4 | 1,65 | 1,69 | 1,71 | 1,72 |
| 5 | 1,79 | 1,87 | 1,92 | 1,96 |
| 6 | 1,89 | 2,00 | 2,07 | 2,13 |
| 7 | 1,97 | 2,09 | 2,18 | 2,27 |
| 8 | 2,04 | 2,17 | 2,27 | 2,37 |
| 9 | 2,10 | 2,24 | 2,35 | 2,46 |
| 10 | 2,15 | 2,29 | 2,41 | 2,54 |
| 11 | 2,19 | 2,34 | 2,47 | 2,61 |
| 12 | 2,23 | 2,39 | 2,52 | 2,66 |
| 13 | 2,26 | 2,43 | 2,56 | 2,71 |
| 14 | 2,30 | 2,46 | 2,60 | 2,76 |
| 15 | 2,33 | 2,49 | 2,64 | 2,8 |
| 16 | 2,35 | 2,52 | 2,67 | 2,84 |
| 17 | 2,38 | 2,55 | 2,70 | 2,87 |
| 18 | 2,40 | 2,58 | 2,73 | 2,90 |
| 19 | 2,43 | 2,60 | 2,75 | 2,93 |
| 20 | 2,45 | 2,62 | 2,78 | 2,96 |
| 21 | 2,47 | 2,64 | 2,8.’ | 2,98 |
| 22 | 2,49 | 2,66 | 2,82 | 3,01 |
| 23 | 2,50 | 2,68 | 2,84 | 3,03 |
| 24 | 2,52 | 2,7 | 2,86 | 3,05 |
| 25 | 2,54 | 2,72 | 2,88 | 3,07 |
Пример 3.1. Проверить результат хнб = 17,15 на соответствие грубой погрешности при =0,05. Выполнено измерений п = 12; разброс значений составил = 0,03, 
Решение. Рассчитаем критерий Романовского по формуле (3.4):
Vрасч = (17,15 – 17,00)/0,03 = 5.
Для заданных = 0,05 и п = 12 найти по таблице 3 допустимое значение критерия Романовского Vдоп = 2,39. Сравнивая табличное значение с расчетным, получаем 2,39<5, т.е. Vдоп<Vрасч, следовательно, хнб является грубой погрешностью и должно быть исключено из дальнейших рассмотрений.
3.3 Статистическая обработка экспериментальных данных. Собственно-случайная выборка (простая случайная)
Выборочное наблюдение относится к разновидности несплошного наблюдения, цель которого – по отобранной части единиц дать характеристику всей совокупности единиц. Необходимо, чтобы отобранная часть была репрезентативна (т.е. представляла всю совокупность единиц).
Используя теорему Чебышева П.Л. можно вычислить величину  , выражающую среднее квадратическое отклонение выборочной средней от математического ожидания:
, выражающую среднее квадратическое отклонение выборочной средней от математического ожидания:
 , (3.5)
, (3.5)
которую называют средней ошибкой выборки.
С учетом выбранного уровня вероятности и соответствующего ему значения t (выбирается по табл. 2.5) предельная ошибка выборки составит:
 , (3.6)
, (3.6)
где tα(N-1) – квантиль распределения Стьюдента для вероятности α и числа степеней свободы f = (N-1).
С учётом (3.5) и (3.6) можно утверждать, что при заданной вероятности генеральная средняя  будет находиться в следующих границах:
будет находиться в следующих границах:
 (3.7)
(3.7)
Пример 3.2. Предположим, в результате выборочного обследования жилищных условий жителей города, осуществленного на основе собственно-случайной повторной выборки, получен следующий ряд распределения (табл. 3.4).
Таблица 3.4 – Результаты выборочного обследования жилищных условий жителей города
| Общая площадь жилищ, приходящаяся на 1 чел., кв. м. | До 5,0 | 5,0…10,0 | 10,0…15,0 | 15,0…20,0 | 20,0…25,0 | 25,0…30,0 | 30,0 и более |
| Число жителей | 8 | 95 | 204 | 207 | 210 | 130 | 83 |
Рассмотрим определение границ генеральной средней, в данном случае – средней площади жилищ в расчёте на 1 чел. в целом по городу, опираясь только на результаты выборочного обследования. Для определения средней ошибки выборки нам необходимо, прежде всего, рассчитать выборочную среднюю величину и дисперсию изучаемого признака (табл. 3.5).
В случае, когда данные сгруппированы по интервалам, т. е. представлены в виде интервальных рядов распределения, при расчёте средней арифметической в качестве значения признака принимают середину интервала, исходя из предположения о равномерном распределении единиц совокупности на данном интервале.
Таблица 3.5 – Расчёт средней (полезной) площади жилищ, приходящейся на 1 чел., и дисперсии
| Общая (полезная) площадь жилищ,
приходящаяся на 1 чел., м2 |
Число
жителей mi |
Середина
интервала xi |
xi·mi |  |
| До 5,0
5,0 … 10,0 10,0 … 15,0 15,0 … 20,0 20,0 … 25,0 25,0 … 30,0 30,0 и более |
8
95 204 270 210 130 83 |
2,5
7,5 12,5 17,5 22,5 27,5 32,5 |
20,0
712,5 2550,0 4725,0 4725,0 3575,0 2697,5 |
50,0
5343,75 31875,0 82687,5 106312,5 98312,5 87668,75 |
| Итого: | 1000 | – | 19005,0 | 412250,0 |
Расчёт ведется по формулам:
 (3.8)
(3.8)
где xi – середина интервала.
В нашем примере:

Дисперсию определим по формуле:
 (3.9)
(3.9)
Тогда получаем:

Откуда получаем значение выборочного среднего квадратичного отклонения:
S = 7,16м2.
Средняя ошибка выборки составит:

Определим предельную ошибку выборки с вероятностью 0,954 (t=2):
 .
.
Установим границы генеральной средней:
 или
или  .
.
Таким образом, на основании проведенного выборочного обследования с вероятностью 0,954 можно заключить, что средний размер общей площади, приходящейся на 1 чел., в целом по городу лежит в пределах от 18,5 до 19,5 м2.
При расчёте средней ошибки собственно-случайной бесповторной выборки необходимо учитывать поправку на бесповторность отбора:
 , (3.10)
, (3.10)
где Nx – генеральная совокупность. Если предположить, что представленные в таблице 6 данные являются результатом 5%-го бесповторного отбора (следовательно, генеральная совокупность включает 20 000 ед.), т.е. средняя ошибка выборки согласно (3.10) будет несколько меньше:
 .
.
Соответственно уменьшится и предельная ошибка выборки, что вызовет сужение границ генеральной средней. Особенно ощутимо влияние поправки на бесповторность отбора при относительно большом проценте выборки.
Варианты заданий к практическому занятию №3
| Вариант | в | хср | хнб | сигма | n |
| 1 | 0,1 | 24 | 24,48 | 0,12 | 3 |
| 2 | 0,05 | 24 | 26,16 | 0,12 | 4 |
| 3 | 0,025 | 18 | 19,26 | 0,09 | 5 |
| 4 | 0,01 | 5 | 5,3 | 0,09 | 6 |
| 5 | 0,1 | 25 | 26,75 | 0,11 | 7 |
| 6 | 0,05 | 10 | 10,8 | 0,1 | 8 |
| 7 | 0,025 | 18 | 19,62 | 0,11 | 9 |
| 8 | 0,01 | 8 | 8,48 | 0,09 | 10 |
| 9 | 0,1 | 18 | 18,18 | 0,13 | 11 |
| 10 | 0,05 | 18 | 18,36 | 0,1 | 20 |
| 11 | 0,025 | 18 | 19,08 | 0,1 | 21 |
| 12 | 0,01 | 14 | 15,4 | 0,09 | 22 |
| 13 | 0,1 | 16 | 17,6 | 0,09 | 23 |
| 14 | 0,05 | 9 | 9,18 | 0,11 | 24 |
| 15 | 0,025 | 7 | 7,63 | 0,12 | 25 |
| 16 | 0,01 | 23 | 23,23 | 0,09 | 3 |
| 17 | 0,1 | 17 | 18,36 | 0,11 | 4 |
| 18 | 0,05 | 21 | 21,63 | 0,1 | 5 |
| 19 | 0,025 | 6 | 6,18 | 0,11 | 6 |
| 20 | 0,01 | 10 | 10,5 | 0,12 | 7 |
| 21 | 0,1 | 6 | 6,66 | 0,11 | 8 |
| 22 | 0,05 | 12 | 12,6 | 0,09 | 9 |
| 23 | 0,025 | 15 | 15,6 | 0,09 | 10 |
| 24 | 0,01 | 12 | 12,36 | 0,12 | 11 |
| 25 | 0,1 | 22 | 23,54 | 0,11 | 20 |
| 26 | 0,05 | 15 | 16,35 | 0,13 | 21 |
| 27 | 0,025 | 5 | 5,35 | 0,08 | 22 |
| 28 | 0,01 | 18 | 19,62 | 0,11 | 23 |
| 29 | 0,1 | 10 | 10,9 | 0,11 | 24 |
| 30 | 0,05 | 15 | 16,5 | 0,1 | 25 |
| Вариант | Общая площадь на 1 чел, кв. м. | до 5 | 5-10 | 10-15 | 15-20 | 20-25 | 25-30 | больше 30 | P |
| 1 | Число жителей | 100 | 98 | 121 | 61 | 12 | 180 | 72 | 0,953 |
| 2 | 71 | 61 | 90 | 184 | 87 | 60 | 102 | 0,939 | |
| 3 | 67 | 105 | 63 | 165 | 123 | 105 | 51 | 0,931 | |
| 4 | 57 | 41 | 188 | 124 | 127 | 85 | 30 | 0,937 | |
| 5 | 199 | 146 | 146 | 72 | 101 | 7 | 156 | 0,971 | |
| 6 | 178 | 55 | 85 | 102 | 182 | 60 | 85 | 0,974 | |
| 7 | 45 | 136 | 136 | 37 | 62 | 31 | 33 | 0,926 | |
| 8 | 152 | 13 | 80 | 67 | 144 | 73 | 23 | 0,953 | |
| 9 | 199 | 111 | 75 | 61 | 197 | 198 | 78 | 0,962 | |
| 10 | 66 | 6 | 12 | 61 | 171 | 123 | 178 | 0,955 | |
| 11 | 169 | 36 | 177 | 35 | 132 | 147 | 101 | 0,975 | |
| 12 | 40 | 120 | 17 | 42 | 53 | 116 | 140 | 0,967 | |
| 13 | 38 | 158 | 107 | 194 | 26 | 204 | 166 | 0,923 | |
| 14 | 83 | 201 | 110 | 23 | 161 | 93 | 46 | 0,942 | |
| 15 | 64 | 151 | 84 | 162 | 188 | 96 | 49 | 0,958 | |
| 16 | 115 | 20 | 183 | 198 | 84 | 190 | 109 | 0,922 | |
| 17 | 189 | 106 | 89 | 138 | 148 | 132 | 38 | 0,977 | |
| 18 | 144 | 9 | 156 | 81 | 204 | 148 | 11 | 0,979 | |
| 19 | 31 | 150 | 202 | 125 | 182 | 62 | 119 | 0,947 | |
| 20 | 16 | 78 | 148 | 35 | 30 | 147 | 132 | 0,971 | |
| 21 | 6 | 136 | 123 | 132 | 163 | 29 | 64 | 0,97 | |
| 22 | 99 | 160 | 159 | 165 | 29 | 64 | 196 | 0,969 | |
| 23 | 89 | 198 | 56 | 71 | 152 | 15 | 198 | 0,967 | |
| 24 | 153 | 54 | 150 | 36 | 134 | 40 | 189 | 0,95 | |
| 25 | 112 | 161 | 66 | 65 | 182 | 28 | 146 | 0,923 | |
| 26 | 37 | 90 | 88 | 136 | 25 | 20 | 149 | 0,943 | |
| 27 | 187 | 59 | 13 | 7 | 148 | 156 | 194 | 0,922 | |
| 28 | 84 | 118 | 159 | 200 | 62 | 127 | 7 | 0,961 | |
| 29 | 66 | 86 | 11 | 24 | 54 | 155 | 202 | 0,956 | |
| 30 | 50 | 144 | 179 | 104 | 86 | 10 | 49 | 0,968 |
6. Достоверность статистических данных и
ошибки статистического наблюдения
Важнейшим требованием
предъявляемым к статистическим данным является их достоверность. Под достоверностью
данных наблюдения понимается степень приближения, соответствия
данных тому, что есть на самом деле. Расхождение межу фактическим значением и
результатом наблюдения называют погрешностью (ошибкой) наблюдения.
Ошибки наблюдения
разнообразны по происхождению и своему содержанию. В зависимости от
причин возникновения различают следующие виды ошибок:
• методические ошибки;
• ошибки регистрации;
• ошибки
репрезентативности (представительности).
Методические ошибки возникают
в результате использования несовершенных методик, неправильных теоретических
концепций, лежащих в основе исследования.
Ошибки регистрации возникают при
получении данных об отдельных единицах совокупности вследствие неправильного
установления фактов в процессе наблюдения или неправильной их записи. Они
подразделяются на:
-объективные (непреднамеренные)
причиной появления которых является неправильное восприятие наблюдаемых фактов,
неисправность измерительных приборов и неправильная регистрация. Такие ошибки
являются результатом добросовестного заблуждения регистратора;
— субъективные (преднамеренные)
ошибки, возникающие по причине сознательного искажения фактов. К ним относятся
всевозможные преднамеренные ошибки и приписки, при которых опрашиваемый
преднамеренно сообщает неправильные сведения; регистратор преднамеренно
воздействует на респондента с целью получения нужного ответа; регистратор
преднамеренно искажает в формулярах результаты наблюдения.
Ошибки репрезентативности
(представительности) характерны только для несплошного наблюдения.
Они возникают в результате того, что состав отобранной для обследования части
единиц совокупности (выборки) не полностью отражает состав и свойства всей
изучаемой совокупности, несмотря на то, что регистрация сведений по каждой
отобранной единице была проведена точно.
По форме проявления (по
влиянию на результат) ошибки делятся на:
• систематически;
• случайные.
Систематические ошибки возникают
по какой-то определенной причине и вызывают одностороннее искажение значений
признака у наблюдаемых единиц (увеличение или уменьшение). Они очень опасны,
так как величина показателя, рассчитанная в целом по всей совокупности будет
включать накопленную ошибку.
Случайные ошибки являются
результатом действия различных случайных факторов. Они не имеют какой-либо
направленности. В больших совокупностях в результате действия закона больших
чисел эти ошибки взаимно погашаются и не оказывают существенного влияния на
точность наблюдения.
Оба вида ошибок в любом
исследовании выступают совместно и составляют совокупную ошибку наблюдения Δ:
Δ=σ+ε;
где σ — систематическая
ошибка наблюдения,
ε — случайная ошибка
наблюдения.
Для выявления и
исправления ошибок, данные наблюдения необходимо тщательно контролировать.
Процедура контроля сводится к следующему:
• Проверка материалов
наблюдения на полноту и правильность оформления. Проверяется полнота охвата
статистических единиц наблюдения, правильность заполнения каждого формуляра.
• Арифметический
(счетный) контроль. Этот вид контроля основан на использовании
количественных связей между показателями, которые могут быть проверены
арифметическими действиями. Такие связи обычно отражаются в заголовках граф или
строк формуляров. Например, графа x = графа y — графа z и т.д. Арифметический
контроль используется для проверки итоговых данных, с его помощью устанавливается
наличие ошибки.
• Логический контроль основан
на использовании логической взаимосвязи показателей, установлении логического
соответствия между ними. Он не выявляет ошибки наблюдения, а лишь ставит под
сомнение правильность полученных данных. Логический контроль заключается в
проверке ответов на вопросы программы наблюдения путем их логического
осмысления или сравнения полученных данных с другими источниками по данному
вопросу. Классическим примером логического контроля является соответствие данных
при переписи населения о возрасте, образовании и семейном положении. Для
проверки данных наблюдения обычно составляется схема контроля, в которую
включаются различные виды контроля. При обнаружении ошибок нельзя
самостоятельно их исправлять. Для этого необходимо получить дополнительную
информацию путем повторного наблюдения. Данные наблюдения считаются принятыми,
если они прошли контроль, и в них внесены все необходимые исправления.
Проверкой собранных данных заканчивается начальная стадия статистического
исследования. После этого можно переходить ко второй стадии исследования
обработке данных наблюдения. Обработка заключается в классификации и
систематизации полученного статистического материала, осуществляемых через
сводку и группировку.
О сводке и группировке мы
поговорим с Вами в следующей лекции.