15. Оценка дисперсии случайной ошибки модели регрессии
При проведении регрессионного анализа основная трудность заключается в том, что генеральная дисперсия случайной ошибки является неизвестной величиной, что вызывает необходимость в расчёте её несмещённой выборочной оценки.
Несмещённой оценкой дисперсии (или исправленной дисперсией) случайной ошибки линейной модели парной регрессии называется величина, рассчитываемая по формуле:
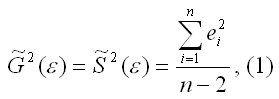
где n – это объём выборочной совокупности;
еi– остатки регрессионной модели:
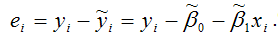
Для линейной модели множественной регрессии несмещённая оценка дисперсии случайной ошибки рассчитывается по формуле:
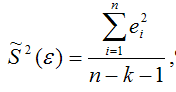
где k – число оцениваемых параметров модели регрессии.
Оценка матрицы ковариаций случайных ошибок Cov(?) будет являться оценочная матрица ковариаций:
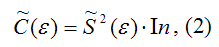
где In – единичная матрица.
Оценка дисперсии случайной ошибки модели регрессии распределена по ?2(хи-квадрат) закону распределения с (n-k-1) степенями свободы.
Для доказательства несмещённости оценки дисперсии случайной ошибки модели регрессии необходимо доказать справедливость равенства
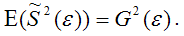
Доказательство. Примем без доказательства справедливость следующих равенств:
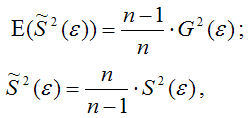
где G2(?) – генеральная дисперсия случайной ошибки;
S2(?) – выборочная дисперсия случайной ошибки;
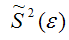
– выборочная оценка дисперсии случайной ошибки.
Тогда:
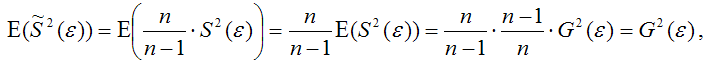
т. е.
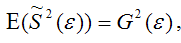
что и требовалось доказать.
Следовательно, выборочная оценка дисперсии случайной ошибки
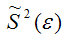
является несмещённой оценкой генеральной дисперсии случайной ошибки модели регрессии G2(?).
При условии извлечения из генеральной совокупности нескольких выборок одинакового объёма n и при одинаковых значениях объясняющих переменных х, наблюдаемые значения зависимой переменной у будут случайным образом колебаться за счёт случайного характера случайной компоненты ?. Отсюда можно сделать вывод, что будут варьироваться и зависеть от значений переменной у значения оценок коэффициентов регрессии и оценка дисперсии случайной ошибки модели регрессии.
Для иллюстрации данного утверждения докажем зависимость значения МНК-оценки
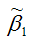
от величины случайной ошибки ?.
МНК-оценка коэффициента ?1 модели регрессии определяется по формуле:
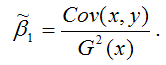
В связи с тем, что переменная у зависит от случайной компоненты ? (yi=?0+?1xi+?i), то ковариация между зависимой переменной у и независимой переменной х может быть представлена следующим образом:
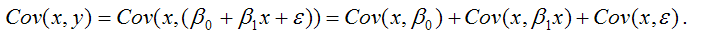
Для дальнейших преобразования используются свойства ковариации:
1) ковариация между переменной х и константой С равна нулю: Cov(x,C)=0, C=const;
2) ковариация переменной х с самой собой равна дисперсии этой переменной: Cov(x,x)=G2(x).
Исходя из указанных свойств ковариации, справедливы следующие равенства:
Cov(x,?0)=0 (?0=const);
Cov(x, ?1x)= ?1*Cov(x,x)= ?1*G2(x).
Следовательно, ковариация между зависимой и независимой переменными Cov(x,y) может быть записана как:
Cov(x,y)= ?1G2(x)+Cov(x,?).
В результате МНК-оценка коэффициента ?1 модели регрессии примет вид:
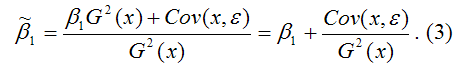
Таким образом, МНК-оценка
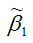
может быть представлена как сумма двух компонент:
1) константы ?1, т. е. истинного значения коэффициента;
2) случайной ошибки Cov(x,?), вызывающей вариацию коэффициента модели регрессии.
Однако на практике подобное разложение МНК-оценки невозможно, потому что истинные значения коэффициентов модели регрессии и значения случайной ошибки являются неизвестными. Теоретически данное разложение можно использовать при изучении статистических свойств МНК-оценок.
Аналогично доказывается, что МНК-оценка
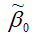
коэффициента модели регрессии и несмещённая оценка дисперсии случайной ошибки
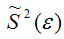
могут быть представлены как сумма постоянной составляющей (константы) и случайной компоненты, зависящей от ошибки модели регрессии ?.
Данный текст является ознакомительным фрагментом.
Читайте также
11. Критерии оценки неизвестных коэффициентов модели регрессии
11. Критерии оценки неизвестных коэффициентов модели регрессии
В ходе регрессионного анализа была подобрана форма связи, которая наилучшим образом отражает зависимость результативной переменной у от факторной переменной х:y=f(x).Необходимо оценить неизвестные
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
14. Оценка коэффициентов модели парной регрессии с помощью выборочного коэффициента регрессии
Помимо метода наименьших квадратов, с помощью которого в большинстве случаев определяются неизвестные параметры модели регрессии, в случае линейной модели парной регрессии
18. Характеристика качества модели регрессии
18. Характеристика качества модели регрессии
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным.Для оценки качества модели регрессии используются специальные показатели.Качество линейной модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
22. Проверка гипотезы о значимости коэффициентов модели парной регрессии
Проверкой статистической гипотезы о значимости отдельных параметров модели называется проверка предположения о том, что данные параметры значимо отличаются от нуля.Необходимость проверки
25. Точечный и интервальный прогнозы для модели парной регрессии
25. Точечный и интервальный прогнозы для модели парной регрессии
Одна из задач эконометрического моделирования заключается в прогнозировании поведения исследуемого явления или процесса в будущем. В большинстве случаев данная задача решается на основе регрессионных
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
32. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии и коэффициент множественной детерминации
Помимо рекуррентных формул, которые используются для построения частных коэффициентов корреляции для
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
35. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Проверка значимости коэффициентов регрессии означает проверку основной гипотезы об их значимом отличии от нуля.Основная гипотеза состоит в предположении о незначимости
39. Модели регрессии, нелинейные по факторным переменным
39. Модели регрессии, нелинейные по факторным переменным
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
40. Модели регрессии, нелинейные по оцениваемым коэффициентам
Нелинейными по оцениваемым параметрам моделями регрессииназываются модели, в которых результативная переменная yi нелинейно зависит от коэффициентов модели ?0…?n.К моделям регрессии, нелинейными по
41. Модели регрессии с точками разрыва
41. Модели регрессии с точками разрыва
Определение. Моделями регрессии с точками разрыва называются модели, которые нельзя привести к линейной форме, т. е. внутренне нелинейные модели регрессии.Модели регрессии делятся на два класса:1) кусочно-линейные модели регрессии;2)
44. Методы нелинейного оценивания коэффициентов модели регрессии
44. Методы нелинейного оценивания коэффициентов модели регрессии
Функцией потерь или ошибок называется функционал вида
Также в качестве функции потерь может быть использована сумма модулей отклонений наблюдаемых значений результативного признака у от теоретических
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
46. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все
57. Гетероскедастичность остатков модели регрессии
57. Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:?i=yi–?0–?1x1i–…–?mxmiВ связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается
60. Устранение гетероскедастичности остатков модели регрессии
60. Устранение гетероскедастичности остатков модели регрессии
Существует множество методов устранения гетероскедастичности остатков модели регрессии. Рассмотрим некоторые из них.Наиболее простым методом устранения гетероскедастичности остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
63. Устранение автокорреляции остатков модели регрессии
В связи с тем, что наличие в модели регрессии автокорреляции между остатками модели может привести к негативным результатам всего процесса оценивания неизвестных коэффициентов модели, автокорреляция остатков
67. Модели регрессии с переменной структурой. Фиктивные переменные
67. Модели регрессии с переменной структурой. Фиктивные переменные
При построении модели регрессии может возникнуть ситуация, когда в неё необходимо включить не только количественные, но и качественные переменные (например, возраст, образование, пол, расовую
Гомоскедастичность (Homoscedasticity)

Гомоскедастичность – допущение линейной регрессии об «одинаковости» Дисперсии (Variance). Иными словами, разность между реальным Ypred и предсказанным Yactual значениями, скажем, Линейной регрессии (Linear Regresion) остается в определенном известном диапазоне, что позволяет в принципе использовать такую Модель (Model). В случае такого единообразия ошибок Наблюдения (Observation) с большими значениями будут иметь то же влияние на предсказывающий Алгоритм (Algorithm), что и наблюдения с меньшими значениями:

Линейная регрессия базируется на предположении, что для всех случаев ошибки будут одинаковыми и с очень малой дисперсией.
Пример. У нас есть две переменные – высота дерева навскидку и реальный его рост. Естественно, по мере увеличения оценочной высоты реальные тоже растут. Итак, мы подбираем модель линейной регрессии и видим, что ошибки имеют одинаковую дисперсию:

Прогнозы почти совпадают с линейной регрессией и имеют одинаковую известную дисперсию повсюду. Кроме того, если мы нанесем эти остатки на ось X, мы увидим их вдоль прямой линии, параллельной оси X. Это явный признак гомоскедастичности.

Когда это условие нарушается, в модели присутствует Гетероскедастичность (Heteroscedasticity). Предположим, что для деревьев с меньшей приблизительной высотой разность между прогнозируемым и реальным значением меньше, чем для высоких представителей флоры. По мере увеличения высоты дисперсия в прогнозах увеличивается, что приводит к увеличению значения ошибки или Остатка (Residual). Когда мы снова построим график остатков, то увидим типичную коническую кривую, которая четко указывает на наличие гетероскедастичности в модели:

Гетероскедастичность – это систематическое увеличение или уменьшение дисперсии остатков в диапазоне независимых переменных. Это проблема, потому нарушается базовое предположение о линейной регрессии: все ошибки должны иметь одинаковую дисперсию.
Как узнать, присутствует ли гетероскедастичность?
Проще говоря, самый простой способ узнать, присутствует ли гетероскедастичность, – построить график остатков. Если вы видите какую-либо закономерность, значит, есть гетероскедастичность. Обычно значения увеличиваются, образуя конусообразную кривую.
Причины гетероскедастичности
- Есть большая разница в переменной. Другими словами, когда наименьшее и наибольшее значения переменной слишком экстремальны. Это также могут быть Выбросы (Outlier).
- Мы выбираем неправильную модель. Если вы подгоните модель линейной регрессии к нелинейным данным, это приведет к гетероскедастичности.
- Когда масштаб значений в переменной некорректен (например, стоит рассматривать данные по сезонам, а не по дням).
- Когда для регрессии используется неправильное преобразование данных.
- Когда в данных присутствует Скошенность (Skewness).
Чистая и нечистая гетероскедастичности
Когда мы подбираем правильную модель (линейную или нелинейную) и все же есть видимый образец в остатках, это называется чистой гетероскедастичностью.
Однако, если мы подбираем неправильную модель, а затем наблюдаем закономерность в остатках, то это случай нечистой гетероскедастичности. В зависимости от типа гетероскедастичности необходимо принять меры для ее преодоления. Это зависит и от сферы, в которой мы работаем.
Эффекты гетероскедастичности в Машинном обучении
Как мы обсуждали ранее, модель линейной регрессии делает предположение о наличии гомоскедастичности в данных. Если это предположение неверно, мы не сможем доверять полученным результатам.
Наличие гетероскедастичности делает коэффициенты менее точными, и, следовательно, правильные находятся дальше от значения Генеральной совокупности (Population).
Как лечить гетероскедастичность?
Если мы обнаружили гетероскедастичность, есть несколько способов справиться с ней. Во-первых, давайте рассмотрим пример, в котором у нас есть две переменные: население города и количество заражений COVID-19.
В этом примере будет огромная разница в количестве заражений в крупных мегаполисах по сравнению с небольшими городами. Переменная «Количество инфекций» будет Целевой переменной (Target Variable), а «Население города» – Предиктором (Predictor Variable). Мы знаем, что в модели присутствует гетероскедастичность, и ее необходимо исправить.
В нашем случае, источник проблемы – это переменная с большой дисперсией (Население). Есть несколько способов справиться с подобным неоднообразием остатков, мы же рассмотрим три таких метода.
Управление переменными
Мы можем внести некоторые изменения в имеющиеся переменные, чтобы уменьшить влияние этой большой дисперсии на прогнозы модели. Один из способов сделать это – осуществить Нормализацию (Normalization), то есть привести значения Признака (Feature) к диапазону от 0 до 1. Это заставит признаки передавать немного другую информацию. От проблемы и данных будет зависеть, можно ли реализовать такой подход.
Этот метод требует минимальных модификаций и часто помогает решить проблему, а в некоторых случаях даже повысить производительность модели.
В нашем случае, мы изменим параметр «Количество инфекций» на «Скорость заражения». Это поможет уменьшить дисперсию, поскольку совершенно очевидно, что число инфекций в городах с большой численностью населения будет большим.
Взвешенная регрессия
Взвешенная регрессия – это модификация нормальной регрессии, при которой точкам данных присваиваются определенные Веса (Weights) в соответствии с их дисперсией. Те, у которых есть бо́льшая дисперсия, получают небольшой вес, а те, у которых меньшая дисперсия, получают бо́льший вес.
Таким образом, когда веса возведены в квадрат, это позволяет снизить влияние остатков с большой дисперсией.
Когда используются правильные веса, гетероскедастичность заменяется гомоскедастичностью. Но как найти правильный вес? Один из быстрых способов – использовать инверсию этой переменной в качестве веса (население города превратится в дробь 1/n, где n – число жителей).
Трансформация
Преобразование данных – последнее средство, поскольку при этом вы теряете интерпретируемость функции. Это означает, что вы больше не сможете легко объяснить, что показывает признак. Один из способов – взятие логарифма. Воспринять новые значения высоты дерева (например, 16 метров превратятся в ≈2.772) будет сложнее.
Контрольная работа: Контрольная работа по эконометрике вариант №8
Тема: Контрольная работа по эконометрике вариант №8
Тип: Контрольная работа | Размер: 29.98K | Скачано: 176 | Добавлен 07.04.16 в 21:06 | Рейтинг: 0 | Еще Контрольные работы
Вуз: Финансовый университет
Год и город: Владимир 2015
Вариант 8
По 14 страховым компаниям имеются данные, характеризующие зависимость объема чистой годовой прибыли от годовых объемов собственных средств, страховых резервов, страховых премий и страховых выплат, тыс. руб.:
1. Постройте линейную регрессионную модель объема чистой годовой прибыли страховой компании, не содержащую коллинеарных факторов. Оцените параметры модели.
2. Являются ли уравнение регрессии и его коэффициенты статистически значимыми?
3. Имеют ли остатки регрессии одинаковую дисперсию?
4. Приемлема ли точность регрессионной модели?
5. Дайте экономическую интерпретацию коэффициентов уравнения регрессии.
6. Изменение какого фактора сильнее всего влияет на изменение объема годовой прибыли?
7. Используя результаты регрессионного анализа, ранжируйте компании по степени эффективности деятельности.
Чтобы полностью ознакомиться с контрольной, скачайте файл!
Если вам нужна помощь в написании работы, то рекомендуем обратиться к профессионалам. Более 70 000 авторов готовы помочь вам прямо сейчас. Бесплатные корректировки и доработки. Узнайте стоимость своей работы
Понравилось? Нажмите на кнопочку ниже. Вам не сложно, а нам приятно).
Чтобы скачать бесплатно Контрольные работы на максимальной скорости, зарегистрируйтесь или авторизуйтесь на сайте.
Важно! Все представленные Контрольные работы для бесплатного скачивания предназначены для составления плана или основы собственных научных трудов.
Друзья! У вас есть уникальная возможность помочь таким же студентам как и вы! Если наш сайт помог вам найти нужную работу, то вы, безусловно, понимаете как добавленная вами работа может облегчить труд другим.
Если Контрольная работа, по Вашему мнению, плохого качества, или эту работу Вы уже встречали, сообщите об этом нам.
Добавление отзыва к работе
Добавить отзыв могут только зарегистрированные пользователи.
Ответы на тесты по эконометрике
Q=………..min соответствует методу наименьших квадратов
Автокорреляция — это корреляционная зависимость уровней ряда от предыдущих значений.
Автокорреляция имеется когда каждое следующее значение остатков
Аддитивная модель временного ряда имеет вид: Y=T+S+E
Атрибутивная переменная может употребляться, когда: независимая переменная качественна;
В каких пределах изменяется коэффициент детерминанта: от 0 до 1.
В каком случае модель считается адекватной Fрасч>Fтабл
В каком случае рекомендуется применять для моделирования показателей с увелич. ростом параболу если относительная величина…неограниченно
В результате автокорреляции имеем неэффективные оценки параметров
В хорошо подобранной модели остатки должны иметь нормальный закон
В эконометрическом анализе Xj рассматриваются как случайные величины
Величина доверительного интервала позволяет установить предположение о том, что: интервал содержит оценку параметра неизвестного.
Величина рассчитанная по формуле r=…является оценкой парного коэф. Корреляции
Внутренне нелинейная регрессия — это истинно нелинейная регрессия, которая не может быть приведена к линейной регрессии преобразованием переменных и введением новых переменных.
Временной ряд — это последовательность значений признака (результативного переменного), принимаемых в течение последовательных моментов времени или периодов.
Выберете авторегрессионную модель Уt=a+b0x1+Ɣyt-1+ƹt
Выберете модель с лагами Уt= a+b0x1…….(самая длинная формула)
Выборочное значение Rxy не > 1, |R|
Выборочный коэффициент корреляции r по абсолютной величине не превосходит единицы
Гетероскедастичность — нарушение постоянства дисперсии для всех наблюдений.
Гетероскедастичность присутствует когда: дисперсия случайных остатков не постоянна
Гетероскидастичность – это когда дисперсия остатков различна
Гипотеза об отсутствии автокорреляции остатков доказана, если Dтабл2…
Гомоскедастичность — постоянство дисперсии для всех наблюдений, или одинаковость дисперсии каждого отклонения (остатка) для всех значений факторных переменных.
Гомоскидастичность – это когда дисперсия остатков постоянна и одинакова для всех … наблюдений.
Дисперсия — показатель вариации.
Для определения параметров неиденцифицированной модели применяется.: не один из сущ. методов применить нельзя
Для определения параметров сверх иденцифицированной модели примен.: применяется. 2-х шаговый МНК
Для определения параметров структурную форму модели необходимо преобразовать в приведенную форму модели
Для определения параметров точно идентифицируемой модели: применяется косвенный МНК;
Для оценки … изменения y от x вводится: коэффициент эластичности:
Для парной регрессии ơ²b равно ….(xi-x¯)²)
Для проверки значимости отдельных параметров регрессии используется: t-тест.
Для регрессии y=a+bx из n наблюдений интервал доверия (1-а)% для коэф. b составит b±t…….·ơb
Для регрессии из n наблюдений и m независимых переменных существует такая связь между R² и F..=[(n-m-1)/m]( R²/(1- R²)]
Доверительная вероятность – это вероятность того, что истинное значение результативного показателя попадёт в расчётный прогнозный интервал.
Допустим что для описания одного экономического процесса пригодны 2 модели. Обе адекватны по f критерию фишера. какой предоставить преимущество, у той у кот.: большее значения F критерия
Допустим, что зависимость расходов от дохода описывается функцией y=a+bx среднее значение у=2…равняется 9
Если Rxy положителен, то с ростом x увеличивается y.
Если в уравнении регрессии имеется несущественная переменная, то она обнаруживает себя по низкому значению T статистки
Если качественный фактор имеет 3 градации, то необходимое число фиктивных переменных 2
Если коэффициент корреляции положителен, то в линейной модели с ростом х увеличивается у
Если мы заинтересованы в использовании атрибутивных переменных для отображения эффекта разных месяцев мы должны использовать 11 атрибутивных методов
Если регрессионная модель имеет показательную зависимость, то метод МНК применим после приведения к линейному виду.
Зависимость между коэффициентом множественной детерминации (D) и корреляции (R) описывается следующим методом R=√D
Значимость уравнения регрессии — действительное наличие исследуемой зависимости, а не просто случайное совпадение факторов, имитирующее зависимость, которая фактически не существует.
Значимость уравнения регрессии в целом оценивают: -F-критерий Фишера
Значимость частных и парных коэф. корреляции поверен. с помощью: -t-критерия Стьюдента
Интеркорреляция и связанная с ней мультиколлинеарность — это приближающаяся к полной линейной зависимости тесная связь между факторами.
Какая статистическая характеристика выражается формулой R²=…коэффициент детерминации
Какая статистическая хар-ка выражена формулой : rxy=Ca(x;y) разделить на корень Var(x)*Var(y): коэффициент. корреляции
Какая функция используется при моделировании моделей с постоянным ростом степенная
Какие точки исключаются из временного ряда процедурой сглаживания и в начале, и в конце.
Какое из уравнений регрессии является степенным y=a˳aͯ¹a
Классический метод к оцениванию параметров регрессии основан на: – метод наименьших квадратов (МНК)
Количество степеней свободы для t статистики при проверки значимости параметров регрессии из 35 наблюдений и 3 независимых переменных 31;
Количество степеней свободы знаменателя F-статистики в регрессии из 50 наблюдений и 4 независимых переменных: 45
Компоненты вектора Ei имеют нормальный закон
Корреляция — стохастическая зависимость, являющаяся обобщением строго детерминированной функциональной зависимости посредством включения вероятностной (случайной) компоненты.
Коэффициент автокорреляции: характеризует тесноту линейной связи текущего и предстоящего уровней ряда
Коэффициент детерминации — показатель тесноты стохастической связи в общем случае нелинейной регрессии
Коэффициент детерминации – это величина, которая характеризует связь между зависимыми и независимыми переменными.
Коэффициент детерминации – это квадрат множественного коэффициента корреляции
Коэффициент детерминации – это: величина, которая характеризует связь между независимой и зависимой (зависящей) переменными;
Коэффициент детерминации R показывает долю вариаций зависимой переменной y, объяснимую влиянием факторов, включаемых в модель.
Коэффициент детерминации изменяется в пределах: – от 0 до 1
Коэффициент доверия — это коэффициент, который связывает линейной зависимостью предельную и среднюю ошибки, выясняет смысл предельной ошибки, характеризующей точность оценки, и является аргументом распределения (чаще всего, интеграла вероятностей). Именно эта вероятность и есть степень надежности оценки.
Коэффициент доверия (нормированное отклонение) — результат деления отклонения от среднего на стандартное отклонение, содержательно характеризует степень надежности (уверенности) полученной оценки.
Коэффициент корелляции Rxy используется для определения полноты связи X и Y.
Коэффициент корелляции меняется в пределах : от -1 до 1
Коэффициент корелляции равный 0 означает, что: –отсутствует линейная связь.
Коэффициент корелляции равный 1 означает, что: -существует функциональная зависимость.
Коэффициент корреляции используется для: определения тесноты связи между случайными величинами X и Y;
Коэффициент корреляции рассчитывается для измерения степени линейной взаимосвязи между двумя случайными переменными.
Коэффициент линейной корреляции — показатель тесноты стохастической связи между фактором и результатом в случае линейной регрессии.
Коэффициент регрессии — коэффициент при факторной переменной в модели линейной регрессии.
Коэффициент регрессии b показывает: на сколько единиц увеличивается y, если x увеличивается на 1.
Коэффициент регрессии изменяется в пределах: применяется любое значение ; от 0 до 1; от -1 до 1;
Коэффициент эластичности измеряется в: неизмеримая величина.
Критерий Дарвина-Чотсона применяется для: – отбора факторов в модель; или – определения автокорреляции в остатках
Критерий Стьюдента — проверка значимости отдельных коэффициентов регрессии и значимости коэффициента корреляции.
Критерий Фишера показывает статистическую значимость модели в целом на основе совокупной достоверности всех ее коэффициентов;
Лаговые переменные : – это переменные, относящиеся к предыдущим моментам времени; или -это значения зависим. перемен. за предшествующий период времени.
Лаговые переменные это значение зависимых переменных за предшествующий период времени
Модель в целом статистически значима, если Fрасч > Fтабл.
Модель идентифицирована, если: – число параметров структурной модели равно числу параметров приведён. формы модели.
Модель неидентифицирована, если: – число приведён. коэф . больше числа структурных коэф.
Модель сверхидентифицирована, если: число приведён. коэф. меньше числа структурных коэф
Мультиколлениарность возникает, когда: ошибочное включение в уравнение 2х или более линейно зависимых переменных; 2. две или более объясняющие переменные, в нормальной ситуации слабо коррелированные, становятся в конкретных условиях выборки сильно коррелированными; . в модель включается переменная, сильно коррелирующая с зависимой переменной.
Мультипликативная модель временного ряда имеет вид: – Y=T*S*E
Мультипликативная модель временного ряда строится, если: амплитуда сезонных колебаний возрастает или уменьшается
На основе поквартальных данных…значения 7-1 квартал, 9-2квартал и 11-3квартал …-5
Неправильный выбор функциональной формы или объясняющих переменных называется ошибками спецификации
Несмещённость оценки параметра регрессии, полученной по МНК, означает: – что она характеризуется наименьшей дисперсией.
Одной из проблем которая может возникнуть в многофакторной регрессии и никогда не бывает в парной регрессии, является корреляция между независимыми переменными
От чего зависит количество точек, исключаемых из временного ряда в результате сглаживания: от применяемого метода сглаживания.
Отметьте основные виды ошибок спецификации: отбрасывание значимой переменной; добавление незначимой переменной;
Оценки коэффициентов парной регрессии является несмещённым, если: математические ожидания остатков =0.
Оценки параметров парной линейной регрессии находятся по формуле b= Cov(x;y)/Var(x);a=y¯ bx¯
Оценки параметров регрессии являются несмещенными, если Математическое ожидание остатков равно 0
Оценки параметров регрессии являются состоятельными, если: -увеличивается точность оценки при n, т. е. при увеличении n вероятность оценки от истинного значения параметра стремится к 0.
Оценки парной регрессии явл. эффективными, если: оценка обладают наименьшей дисперсией по сравнению с другими оценками
При наличии гетероскедастичности следует применять: – обобщённый МНК
При проверке значимости одновременно всех параметров используется: -F-тест.
При проверке значимости одновременно всех параметров регрессии используется: F-тест.
Применим ли метод наименьших квадратов для расчетов параметров показательной зависимости применим после ее приведения
Применим ли метод наименьших квадратов(МНК) для расчёта параметров нелинейных моделей? применим после её специального приведения к линейному виду
С помощью какого критерия оценивается значимость коэффициента регрессии T стьюдента
С увеличением числа объясняющих переменных скоррестированный коэффициент детерминации: – увеличивается.
Связь между индексом множественной детерминации R² и скорректированным индексом множественной детерминации Ȓ² есть
Скорректиров. коэф. детерминации: – больше обычного коэф. детерминации
Стандартизованный коэффициент уравнения регрессии Ƀk показывает на сколько % изменится результирующий показатель у при изменении хi на 1%при неизмененном среднем уровне других факторов
Стандартный коэффициент уравнения регрессии: показывает на сколько 1 изменится y при изменении фактора xk на 1 при сохранении др.
Суть коэф. детерминации r 2 xy состоит в следующем: – характеризует долю дисперсии результативного признака y объясняем. регресс., в общей дисперсии результативного признака.
Табличное значение критерия Стьюдента зависит от уровня доверительной вероятности и от числа включённых факторов и от длины исходного ряда.(от принятого уровня значимости и от числа степеней свободы ( n – m -1))
Табличные значения Фишера (F) зависят от доверительной вероятности и от числа включённых факторов и от длины исходного ряда (от доверительной вероятности p и числа степеней свободы дисперсий f1 и f2)..
Уравнение в котором H число эндогенных переменных, D число отсутствующих экзогенных переменных, идентифицируемо если D+1=H
Уравнение в котором H число эндогенных переменных, D число отсутствующих экзогенных переменных, НЕидентифицируемо если D+1 H
Уравнение идентифицировано, если: – D+1=H
Уравнение неидентифицировано, если: – D+1 H
Фиктивные переменные – это: атрибутивные признаки (например, как профессия, пол, образование), которым придали цифровые метки;
Формула t= rxy….используется для проверки существенности коэффициента корреляции
Частный F-критерий: – оценивает значимость уравнения регрессии в целом
Число степеней свободы для факторной суммы квадратов в линейной модели множественной регрессии равно: m;
Что показывает коэффициент наклона – на сколько единиц изменится у, если х изменился на единицу,
Что показывает коэффициент. абсолютного роста на сколько единиц изменится у, если х изменился на единицу
Экзогенная переменная – это независимая переменная или фактор-Х.
Экзогенные переменные — это переменные, которые определяются вне системы и являются независимыми
Экзогенные переменные – это предопределенные переменные, влияющие на зависимые переменные (Эндогенные переменные), но не зависящие от них, обозначаются через х
Эластичность измеряется единица измерения фактора…показателя
Эластичность показывает на сколько % изменится редуктивный показатель y при изменении на 1% фактора xk .
Эндогенные переменные – это: зависимые переменные, число которых равно числу уравнений в системе и которые обозначаются через у
Определения
T-отношение (t-критерий) — отношение оценки коэффициента, полученной с помощью МНК, к величине стандартной ошибки оцениваемой величины.
Аддитивная модель временного ряда – это модель, в которой временной ряд представлен как сумма перечисленных компонент.
Критерий Фишера — способ статистической проверки значимости уравнения регрессии, при котором расчетное (фактическое) значение F-отношения сравнивается с его критическим (теоретическим) значением.
Линейная регрессия — это связь (регрессия), которая представлена уравнением прямой линии и выражает простейшую линейную зависимость.
Метод инструментальных переменных — это разновидность МНК. Используется для оценки параметров моделей, описываемых несколькими уравнениями. Главное свойство — частичная замена непригодной объясняющей переменной на такую переменную, которая некоррелированна со случайным членом. Эта замещающая переменная называется инструментальной и приводит к получению состоятельных оценок параметров.
Метод наименьших квадратов (МНК) — способ приближенного нахождения (оценивания) неизвестных коэффициентов (параметров) регрессии. Этот метод основан на требовании минимизации суммы квадратов отклонений значений результата, рассчитанных по уравнению регрессии, и истинных (наблюденных) значений результата.
Множественная линейная регрессия — это множественная регрессия, представляющая линейную связь по каждому фактору.
Множественная регрессия — регрессия с двумя и более факторными переменными.
Модель идентифицируемая — модель, в которой все структурные коэффициенты однозначно определяются по коэффициентам приведенной формы модели.
Модель рекурсивных уравнений — модель, которая содержит зависимые переменные (результативные) одних уравнений в роли фактора, оказываясь в правой части других уравнений.
Мультипликативная модель – модель, в которой временной ряд представлен как произведение перечисленных компонент.
Несмещенная оценка — оценка, среднее которой равно самой оцениваемой величине.
Нулевая гипотеза — предположение о том, что результат не зависит от фактора (коэффициент регрессии равен нулю).
Обобщенный метод наименьших квадратов (ОМНК) — метод, который не требует постоянства дисперсии (гомоскедастичности) остатков, но предполагает пропорциональность остатков общему множителю (дисперсии). Таким образом, это взвешенный МНК.
Объясненная дисперсия — показатель вариации результата, обусловленной регрессией.
Объясняемая (результативная) переменная — переменная, которая статистически зависит от факторной переменной, или объясняющей (регрессора).
Остаточная дисперсия — необъясненная дисперсия, которая показывает вариацию результата под влиянием всех прочих факторов, неучтенных регрессией.
Предопределенные переменные — это экзогенные переменные системы и лаговые эндогенные переменные системы.
Приведенная форма системы — форма, которая, в отличие от структурной, уже содержит одни только линейно зависящие от экзогенных переменных эндогенные переменные. Внешне ничем не отличается от системы независимых уравнений.
Расчетное значение F-отношения — значение, которое получают делением объясненной дисперсии на 1 степень свободы на остаточную дисперсию на 1 степень свободы.
Регрессия (зависимость) — это усредненная (сглаженная), т.е. свободная от случайных мелкомасштабных колебаний (флуктуаций), квазидетерминированная связь между объясняемой переменной (переменными) и объясняющей переменной (переменными). Эта связь выражается формулами, которые характеризуют функциональную зависимость и не содержат явно стохастических (случайных) переменных, которые свое влияние теперь оказывают как результирующее воздействие, принимающее вид чисто функциональной зависимости.
Регрессор (объясняющая переменная, факторная переменная) — это независимая переменная, статистически связанная с результирующей переменной. Характер этой связи и влияние изменения (вариации) регрессора на результат исследуются в эконометрике.
Система взаимосвязанных уравнений — это система одновременных или взаимозависимых уравнений. В ней одни и те же переменные выступают одновременно как зависимые в одних уравнениях и в то же время независимые в других. Это структурная форма системы уравнений. К ней неприменим МНК.
Система внешне не связанных между собой уравнений — система, которая характеризуется наличием одних только корреляций между остатками (ошибками) в разных уравнениях системы.
Случайный остаток (отклонение) — это чисто случайный процесс в виде мелкомасштабных колебаний, не содержащий уже детерминированной компоненты, которая имеется в регрессии.
Состоятельные оценки — оценки, которые позволяют эффективно применять доверительные интервалы, когда вероятность получения оценки на заданном расстоянии от истинного значения параметра становится близка к 1, а точность самих оценок увеличивается с ростом объема выборки.
Спецификация модели — определение существенных факторов и выявление мультиколлинеарности.
Стандартная ошибка — среднеквадратичное (стандартное) отклонение. Оно связано со средней ошибкой и коэффициентом доверия.
Степени свободы — это величины, характеризующие число независимых параметров и необходимые для нахождения по таблицам распределений их критических значений.
Тренд — основная тенденция развития, плавная устойчивая закономерность изменения уровней ряда.
Уровень значимости — величина, показывающая, какова вероятность ошибочного вывода при проверке статистической гипотезы по статистическому критерию.
Фиктивные переменные — это переменные, которые отражают сезонные компоненты ряда для какого-либо одного периода.
Эконометрическая модель — это уравнение или система уравнений, особым образом представляющие зависимость (зависимости) между результатом и факторами. В основе эконометрической модели лежит разбиение сложной и малопонятной зависимости между результатом и факторами на сумму двух следующих компонентов: регрессию (регрессионная компонента) и случайный (флуктуационный) остаток. Другой класс эконометрических моделей образует временные ряды.
Эффективность оценки — это свойство оценки обладать наименьшей дисперсией из всех возможных.
источники:
http://studrb.ru/works/entry29502WbDxMY
http://damirock.com/exam/math/otvetyi-na-testyi-po-ekonometrike/

В этой серии мы внимательно рассмотрим алгоритм машинного обучения и изучим плюсы и минусы каждого алгоритма. Мы рассмотрим алгоритмы вместе с математикой, лежащей в основе алгоритма.
Во-первых, давайте проясним некоторые основные термины, используемые в машинном обучении.
- Контролируемый алгоритм ML: Те алгоритмы, которые используют помеченные данные, известны как контролируемые алгоритмы ml. Контролируемые алгоритмы ml широко используются для двух задач: классификации и регрессии.
- Классификация: Когда задача состоит в том, чтобы классифицировать объекты выборки по определенным категориям (целевая переменная), тогда это называется классификацией. Например, определение того, является ли электронное письмо спамом или нет.
- Регрессия: когда задача состоит в том, чтобы предсказать непрерывную переменную (целевую переменную), тогда это называется регрессией. Например, прогнозирование цен на жилье.
- Неконтролируемый алгоритм ML: те алгоритмы, которые используют немаркированные данные, известны как неконтролируемые алгоритмы ml. Для кластеризации используется неконтролируемый алгоритм.
- Кластеризация: задача поиска групп в заданных немаркированных данных известна как кластеризация.
- Ошибка: разница между фактическим и прогнозируемым значением.
- Градиентный спуск: механизм обновления параметров модели таким образом, чтобы генерировать минимальное значение функции ошибки.
Что такое линейная регрессия в машинном обучении?
Линейная регрессия — это тип контролируемого алгоритма машинного обучения, который используется для прогнозирования непрерывной числовой переменной, известной как цель. Это один из самых простых алгоритмов машинного обучения. Он называется «линейным», потому что алгоритм предполагает, что взаимосвязь между входными характеристиками (также известными как независимые переменные) и выходной переменной (также известной как зависимая или целевая переменная) является линейной. Другими словами, алгоритм пытается найти прямую линию (или гиперплоскость в случае нескольких входных объектов), которая наилучшим образом соответствует данным.
Типы линейной регрессии:
Простая линейная регрессия:
Линейная регрессия известна как простая линейная регрессия, когда прогнозирование выходного значения выполняется с использованием одной входной функции. Мы можем провести линию между зависимыми и независимыми переменными в 2D-пространстве, когда задан один входной признак. здесь b0 — точка пересечения, b1 — коэффициент, x1, x2,…, xn — входные признаки, а y — выходная переменная.
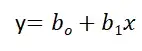
Множественная линейная регрессия:
Линейная регрессия известна как множественная линейная регрессия, когда прогнозирование выходной переменной выполняется с использованием нескольких входных признаков. Мы можем нарисовать плоскость между зависимой и независимой переменными в 3D-пространстве, когда заданы только два входных объекта. В более высоких измерениях визуализация становится затруднительной, но интуиция заключается в том, чтобы найти гиперплоскость в более высоких измерениях. здесь b0 — это перехват, а b1, b2, b3, ......., bn-1, bn известны как коэффициенты, а x1, x2,..., xn известны как входные характеристики, а y — переменная результата.
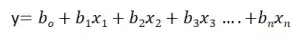
К этому моменту мы поняли, что линейная регрессия пытается построить линейную границу, но как она это делает?
Как он найдет идеальную линию, которая разделяет данные два класса?
Как указано в уравнении, b0 известен как перехват, а b1, b2,...., bn известны как коэффициенты линейной регрессии, и теперь цель состоит в том, чтобы найти ту линейную границу, которая минимизирует функцию ошибки. Функция ошибки представляет собой квадрат суммы разностей между прогнозируемыми и фактическими значениями целевой переменной. Если мы не сведем ошибку в квадрат, то положительные и отрицательные моменты будут компенсировать друг друга.
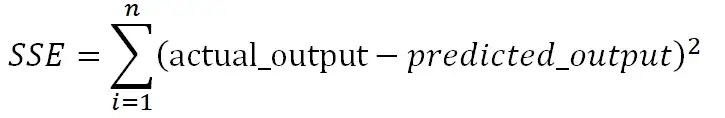
Нам нужно найти коэффициенты и перехваты для линейной регрессии таким образом, чтобы сумма квадратов ошибок (SSE) была минимизирована. Градиентный спуск — один из самых популярных методов, который используется для нахождения оптимальных коэффициентов для ml и алгоритмов глубокого обучения.
В приведенном ниже разделе мы обучим модель на базе данных страхования, где мы должны спрогнозировать расходы с учетом входных данных: возраст, пол, ИМТ, расходы на больницу, количество прошлых консультаций и т.д.
Реализация на Python:
Вы можете использовать библиотеку sklearn на python для обучения и тестирования модели линейной регрессии. Мы будем использовать набор данных insurance.csv для обучения модели линейной регрессии. Некоторые этапы предварительной обработки выполняются для описания данных, обработки пропущенных значений и проверки допущений линейной регрессии.
Шаг 1: Загрузите все необходимые библиотеки и наборы данных, используя библиотеку pandas.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from statsmodels.stats.outliers_influence import variance_inflation_factor as VIF
from sklearn.metrics import classification_report
insurance=pd.read_csv('new_insurance_data.csv')
insurance.head()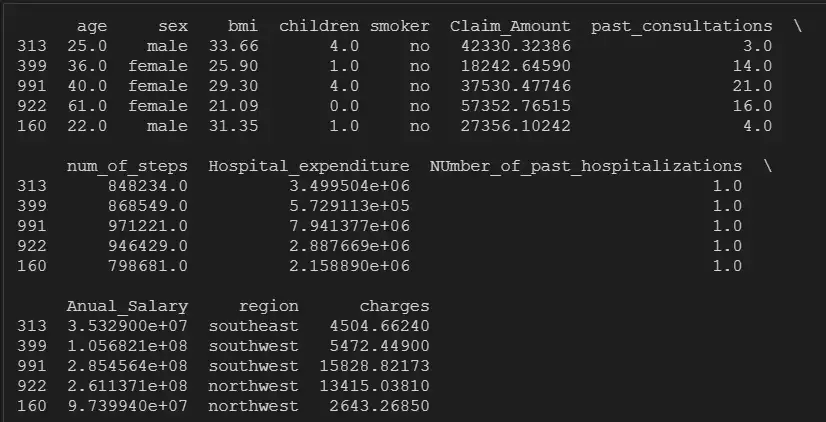
Шаг 2: Проверьте нулевые значения, форму и тип данных переменных:
# checks for non-null entries, size and datatype
insurance.info()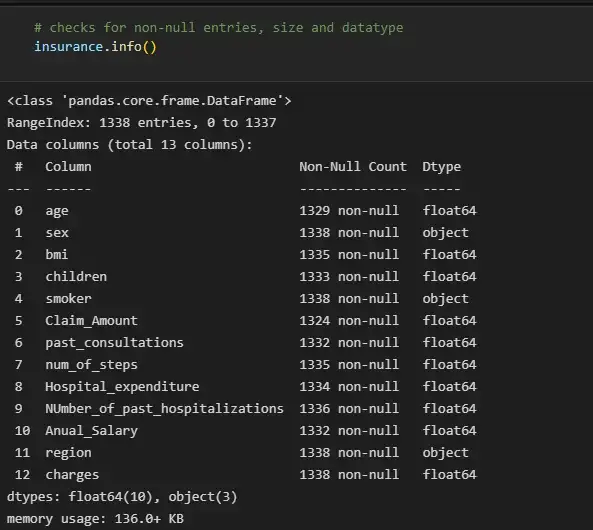
Мы можем отдельно проверить количество нулей для каждой функции, используя df.isna().sum():
insurance.isnull().sum()
# helps me to check for null values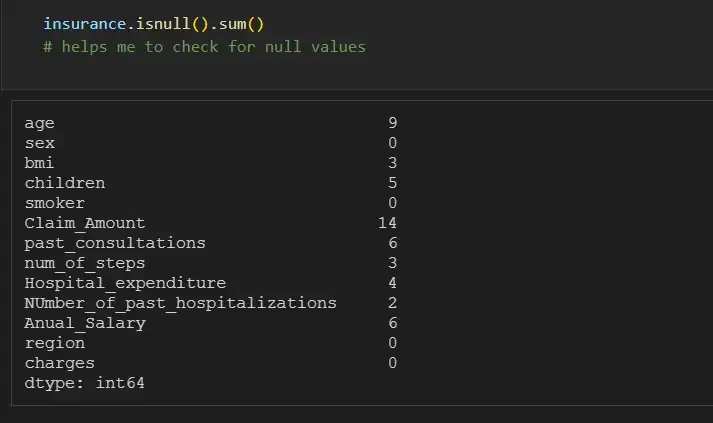
Шаг 3. Заполните пропущенные значения
Мы можем заполнить недостающие значения объектов объектного типа, используя режим, а объектов целочисленного типа — среднее значение или медиану.
# calculating mode for object data type features which will be used to fill missing values.
# We have 3 features which are of object type
print(f"mode of sex feature: {insurance['sex'].mode()[0]}")
print(f"mode of region feature: {insurance['region'].mode()[0]}")
print(f"mode of smoker feature: {insurance['smoker'].mode()[0]}")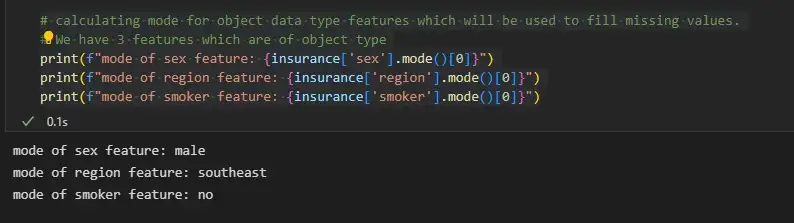
# describe() function will give the descriptive statistics for all numerical features
insurance.describe().transpose()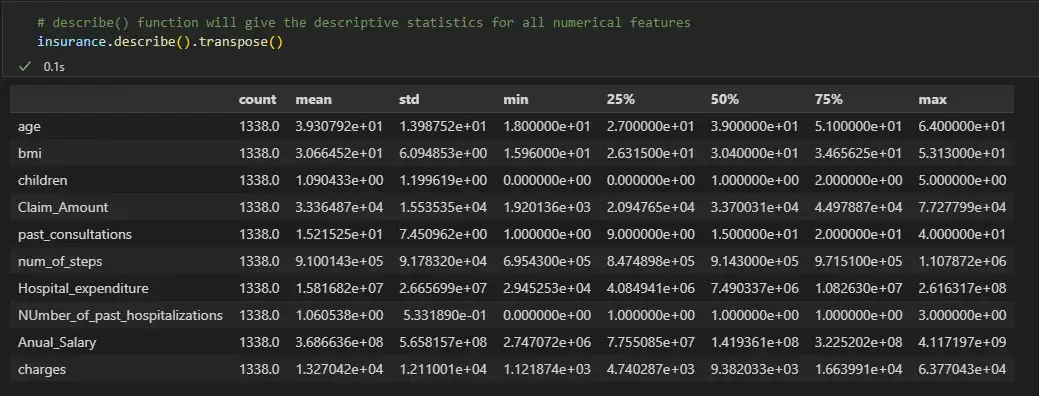
Мы видим, что для числовых признаков среднее и медиана почти одинаковы. Поэтому теперь мы заменим нулевые значения числовых признаков их медианой, а нулевые значения категориальных переменных — их режимом.
for col_name in list(insurance.columns):
if insurance[col_name].dtypes=='object':
# filling null values with mode for object type features
insurance[col_name] = insurance[col_name].fillna(insurance[col_name].mode()[0])
else:
# filling null values with mean for numeric type features
insurance[col_name] = insurance[col_name].fillna(insurance[col_name].median())
# Now the null count for each feature is zero
print("After filling null values:")
print(insurance.isna().sum())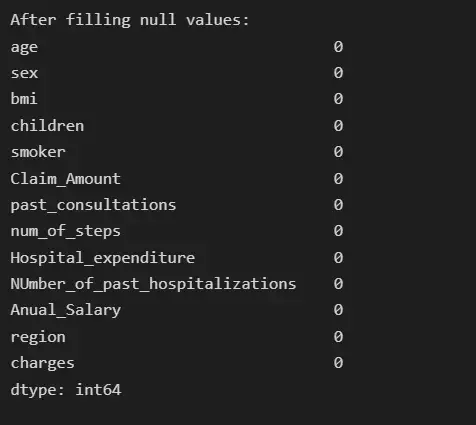
Шаг 4: Анализ выбросов
Мы построим прямоугольную диаграмму для всех числовых характеристик, кроме целевых переменных зарядов.
i = 1
plt.figure(figsize=(16,15))
for col_name in list(insurance.columns):
# total 9 box plots will be plotted, therefore 3*3 grid is taken
if((insurance[col_name].dtypes=='int64' or insurance[col_name].dtypes=='float64') and col_name != 'charges'):
plt.subplot(3,3, i)
plt.boxplot(insurance[col_name])
plt.xlabel(col_name)
plt.ylabel('count')
plt.title(f"Box plot for {col_name}")
i += 1
plt.show()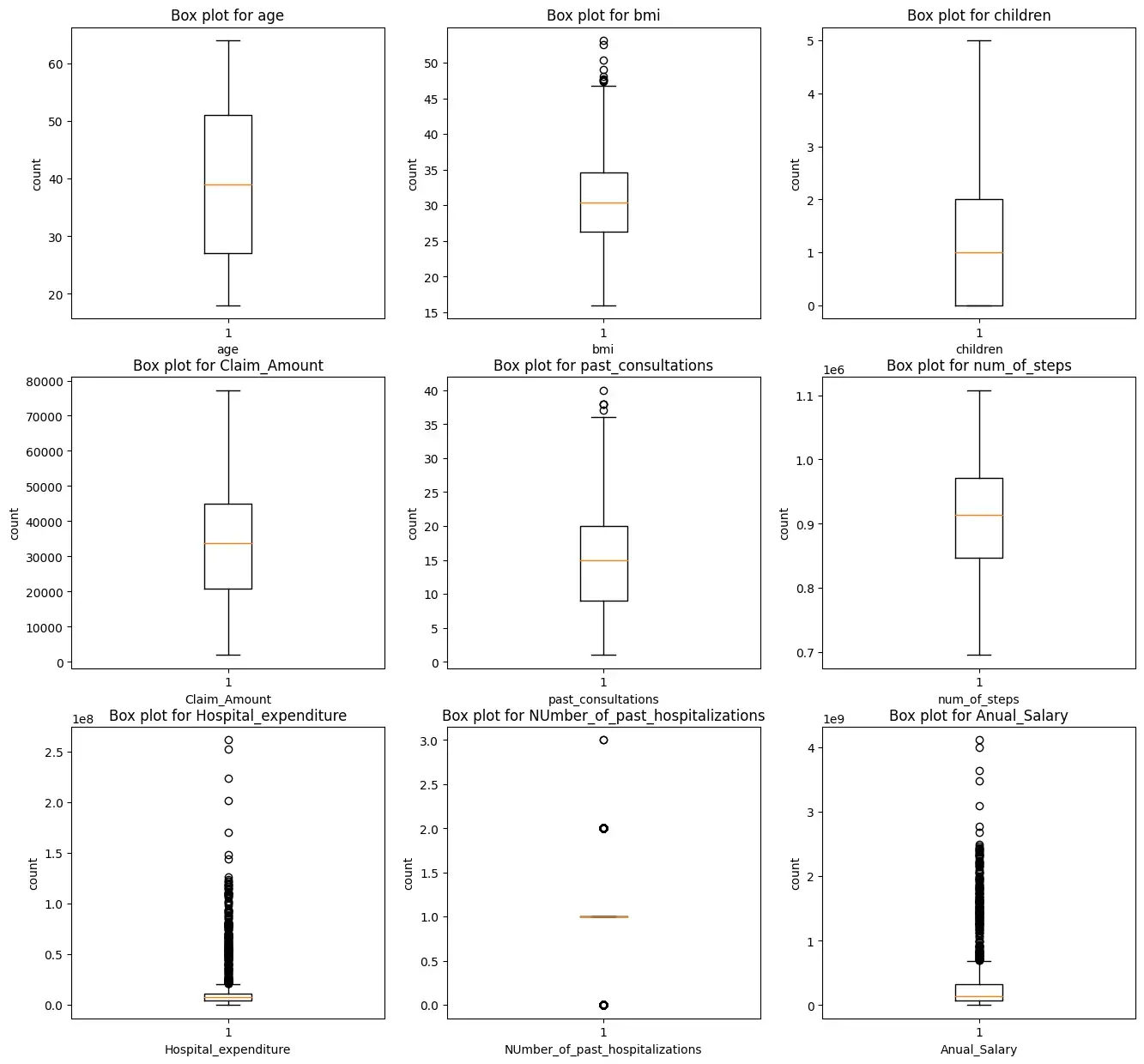
Мы видим, что характеристики ‘bmi’, ‘Hospital_expenditure’ и ‘Number_of_past_hospitalizations’ имеют выбросы. Мы удалим эти выбросы:
outliers_features = ['bmi', 'Hospital_expenditure', 'Anual_Salary', 'past_consultations']
for col_name in outliers_features:
Q3 = insurance[col_name].quantile(0.75)
Q1 = insurance[col_name].quantile(0.25)
IQR = Q3 - Q1
upper_limit = Q3 + 1.5*IQR
lower_limit = Q1 - 1.5*IQR
prev_size = len(insurance)
insurance = insurance[(insurance[col_name] >= lower_limit) & (insurance[col_name] <= upper_limit)]
cur_size = len(insurance)
print(f"dropped {prev_size - cur_size} rows for {col_name} due to presence of outliers")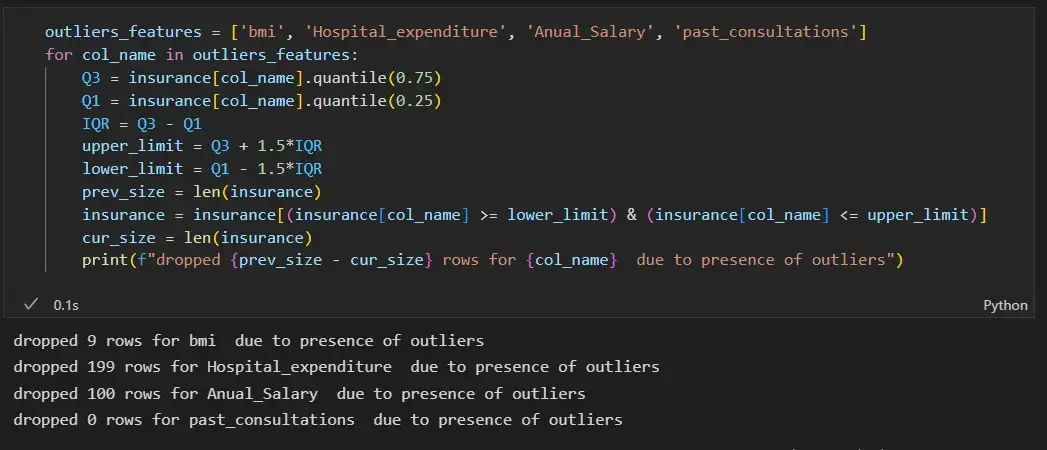
Шаг 5: Проверьте корреляцию:
Существует корреляция между age & charges, age & Anual_salary и т. д., поскольку их корреляция больше 0,5.
import seaborn as sns
sns.heatmap(insurance.corr(),cmap='gist_rainbow',annot=True)
plt.show()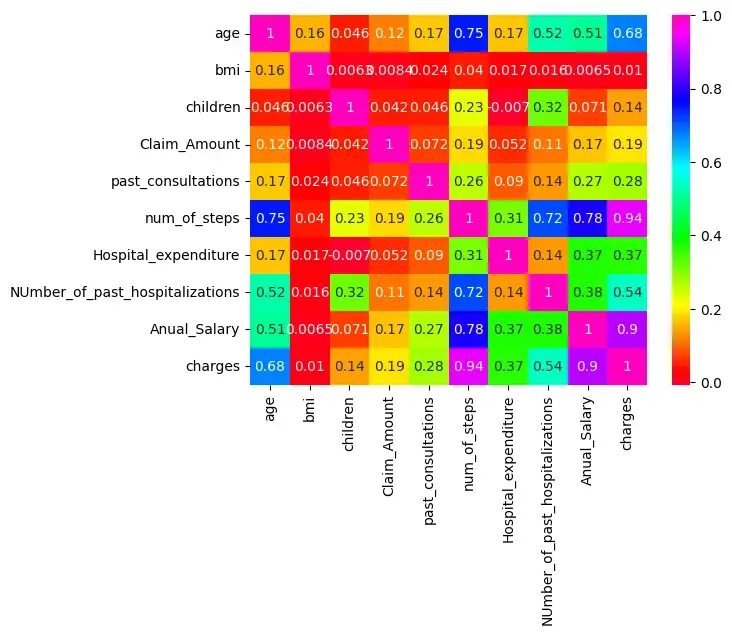
Мы проверим наличие мультиколлинеарности среди признаков:
from statsmodels.stats.outliers_influence import variance_inflation_factor
col_list = []
for col in insurance.columns:
if ((insurance[col].dtype != 'object') & (col != 'charges') ):#only num cols except for the charges column
col_list.append(col)
X = insurance[col_list]
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))]
print(vif_data)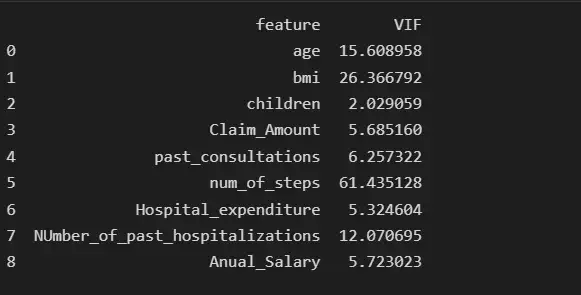
Мы видим, что функция num_of_steps имеет самую высокую коллинеарность, равную 61,43, поэтому мы удалим функцию num_of_steps и снова проверим оценку VIF.
# deleting num_of_steps feature
insurance.drop('num_of_steps', axis = 1, inplace= True)
from statsmodels.stats.outliers_influence import variance_inflation_factor
col_list = []
for col in insurance.columns:
if ((insurance[col].dtype != 'object') & (col != 'charges') ):#only num cols except for the charges column
col_list.append(col)
X = insurance[col_list]
X = insurance[col_list]
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))]
print(vif_data)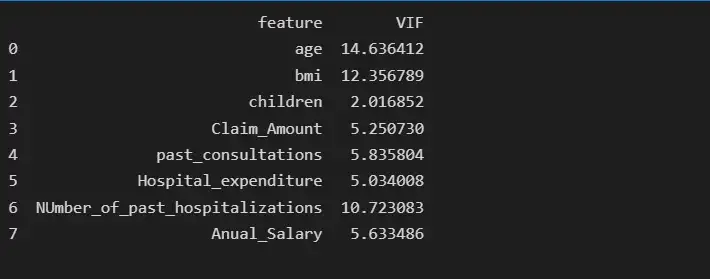
После удаления функции num_of_steps age имеет самую высокую коллинеарность, равную 14,63, поэтому мы удалим функцию age и снова проверим оценку VIF.
# deleting age feature
insurance.drop('age', axis = 1, inplace= True)
from statsmodels.stats.outliers_influence import variance_inflation_factor
col_list = []
for col in insurance.columns:
if ((insurance[col].dtype != 'object') & (col != 'charges') ):#only num cols except for the charges column
col_list.append(col)
X = insurance[col_list]
X = insurance[col_list]
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))]
print(vif_data)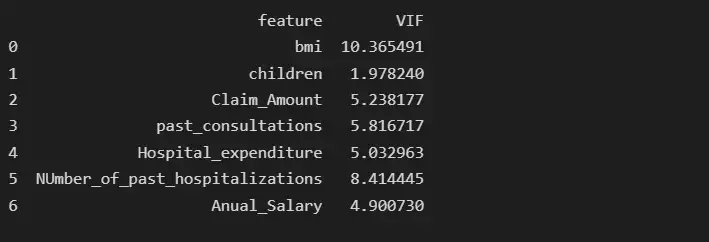
После удаления функции возраста BMI имеет самую высокую коллинеарность, равную 10,36, поэтому мы удалим BMI и снова проверим показатель VIF.
# deleting bmi feature
insurance.drop('bmi', axis = 1, inplace= True)
from statsmodels.stats.outliers_influence import variance_inflation_factor
col_list = []
for col in insurance.columns:
if ((insurance[col].dtype != 'object') & (col != 'charges') ):#only num cols except for the charges column
col_list.append(col)
X = insurance[col_list]
X = insurance[col_list]
vif_data = pd.DataFrame()
vif_data["feature"] = X.columns
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(len(X.columns))]
print(vif_data)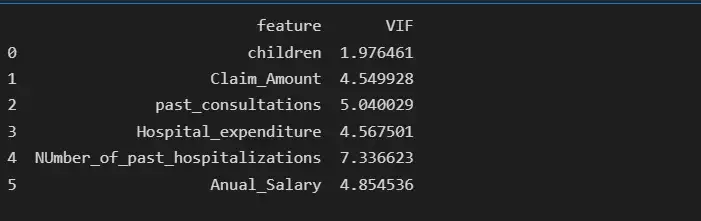
Шаг 6: Разделение входных функций и целевой переменной:
x=insurance.loc[:,['children','Claim_Amount','past_consultations','Hospital_expenditure','NUmber_of_past_hospitalizations','Anual_Salary']]
y=insurance.loc[:,'charges']
x_train, x_test, y_train, y_test=train_test_split(x,y,train_size=0.8, random_state=0)
print("length of train dataset: ",len(x_train) )
print("length of test dataset: ",len(x_test) )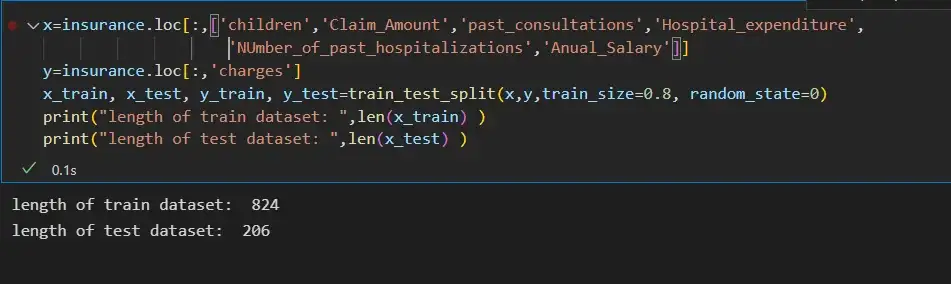
Шаг 7: Обучение модели линейной регрессии на наборе поездов и ее оценка на тестовом наборе данных:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import classification_report, recall_score, r2_score, f1_score, accuracy_score
model = LinearRegression()
# train the model
model.fit(x_train, y_train)
print("trained model coefficients:", model.coef_, " and intercept is: ", model.intercept_)
# model.intercept_ is b0 term in linear boundary equation, and model.coef_ is
# the array of weights assigned to ['children','Claim_Amount','past_consultations','Hospital_expenditure',
# 'NUmber_of_past_hospitalizations','Anual_Salary'] respectively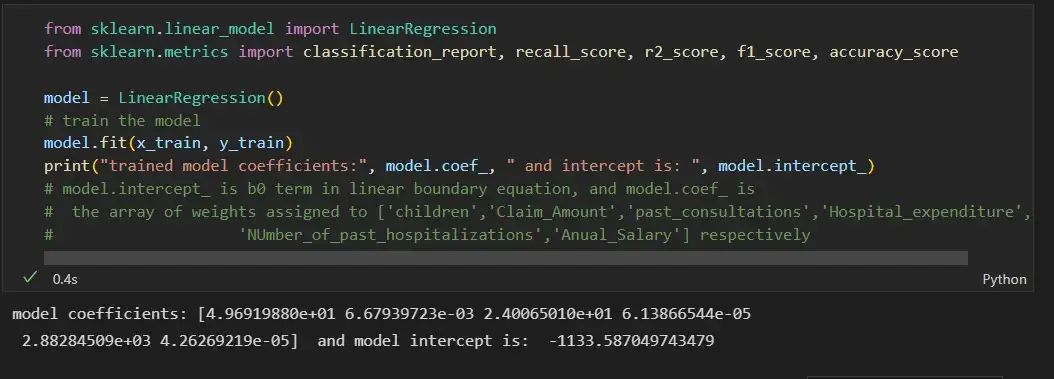
y_pred = model.predict(x_test)
error_pred=pd.DataFrame(columns={'Actual_data','Prediction_data'})
error_pred['Prediction_data'] = y_pred
error_pred['Actual_data'] = y_test
error_pred["error"] = y_test - y_pred
sns.distplot(error_pred['error'])
plt.show()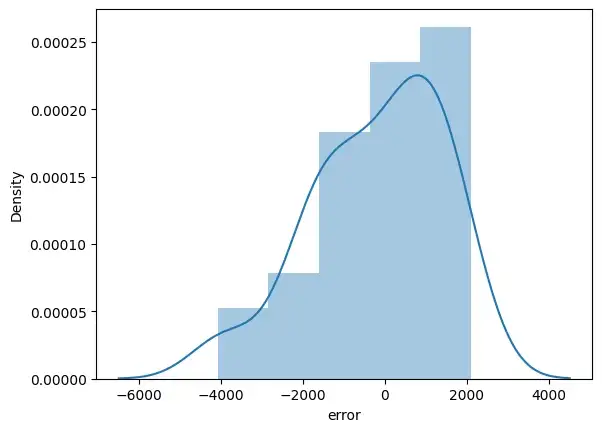
Мы можем построить остаточные графики между фактической целью и остатками или ошибками:
sns.scatterplot(x = y_test,y = (y_test - y_pred), c = 'g', s = 40)
plt.hlines(y = 0, xmin = 0, xmax=20000)
plt.title("residual plot")
plt.xlabel("actural target")
plt.ylabel("residula error")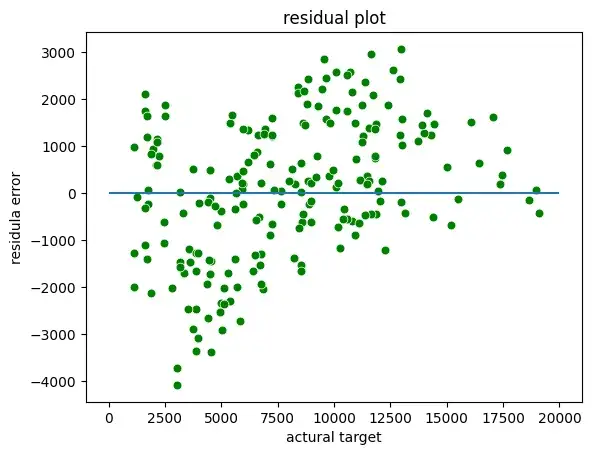
Оценка R-квадрата:
R-квадрат известен как коэффициент детерминации. R Squared — это статистическая мера, которая представляет долю дисперсии зависимой переменной, объясненную независимыми переменными в регрессии. Это значение находится в диапазоне от 0 до 1. Значение «1» указывает, что предиктор полностью учитывает все изменения в Y. Значение «0» указывает, что предиктор «x» не учитывает никаких изменений в «y». Значение R-Squared содержит три термина SSE, SSR и SST.
SSE — это сумма квадратов ошибок. Его также называют остаточной суммой квадратов (RSS).
SSR — это сумма квадратов регрессии.
SST (Сумма в квадрате) — это квадрат разницы между наблюдаемой зависимой переменной и ее средним значением.

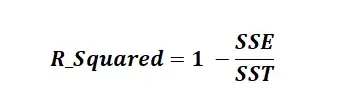
# check for model performance
print(f'r2 score of trained model: {r2_score(y_pred=y_pred, y_true= y_test)}')
Предположения линейной регрессии
- Линейная связь: линейная регрессия предполагает линейную связь между прогнозируемой переменной и независимой переменной. Вы можете использовать точечную диаграмму, чтобы визуализировать взаимосвязь между независимой переменной и зависимой переменной в 2D-пространстве.
- Небольшая мультиколлинеарность или отсутствие мультиколлинеарности между функциями: линейная регрессия предполагает, что функции должны быть независимыми друг от друга, т. Е. Никакой корреляции между функциями. Вы можете использовать функцию VIF, чтобы найти значение мультиколлинеарности признаков. Общее предположение гласит, что если значение признака VIF больше 5, то признаки сильно коррелированы.
- Однородность: линейная регрессия предполагает, что члены ошибок имеют постоянную дисперсию, т. е. разброс членов ошибок должен быть постоянным. Это предположение можно проверить, построив остаточную диаграмму. Если предположение нарушается, то точки образуют форму воронки, в противном случае они будут постоянными.
- Нормальность: линейная регрессия предполагает, что каждая функция данного набора данных следует нормальному распределению. Вы можете строить гистограммы и графики KDE для каждой функции, чтобы проверить, нормально ли они распределены или нет.
- Ошибка: линейная регрессия предполагает, что условия ошибки также должны быть нормально распределены. Вы можете строить гистограммы, а KDE строит графики ошибок, чтобы проверить, нормально ли они распределены или нет.
Вот ссылка GitHub для кода и набора данных.
Содержание:
Регрессионный анализ:
Регрессионным анализом называется раздел математической статистики, объединяющий практические методы исследования корреляционной зависимости между случайными величинами по результатам наблюдений над ними. Сюда включаются методы выбора модели изучаемой зависимости и оценки ее параметров, методы проверки статистических гипотез о зависимости.
Пусть между случайными величинами X и Y существует линейная корреляционная зависимость. Это означает, что математическое ожидание Y линейно зависит от значений случайной величины X. График этой зависимости (линия регрессии Y на X) имеет уравнение 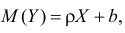
Линейная модель пригодна в качестве первого приближения и в случае нелинейной корреляции, если рассматривать небольшие интервалы возможных значений случайных величин.
Пусть параметры линии регрессии 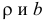 неизвестны, неизвестна и величина коэффициента корреляции
неизвестны, неизвестна и величина коэффициента корреляции 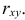 Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений:
Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений: 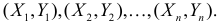 Эти результаты могут служить источником информации о неизвестных значениях
Эти результаты могут служить источником информации о неизвестных значениях 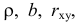 надо только уметь эту информацию извлечь оттуда.
надо только уметь эту информацию извлечь оттуда.
Неизвестная нам линия регрессии 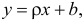 как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция
как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция 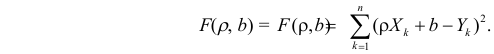
Такие значения , согласно необходимым условиям экстремума, находятся из системы уравнений:
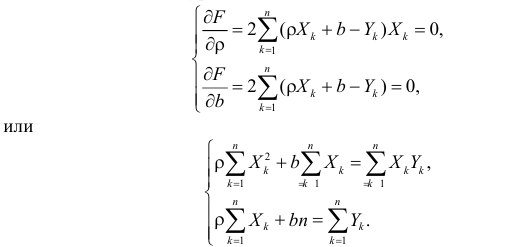
Решения этой системы уравнений дают оценки называемые оценками по методу наименьших квадратов.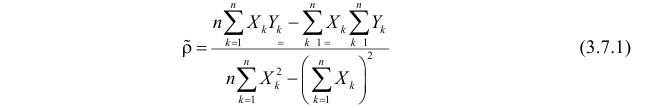
и
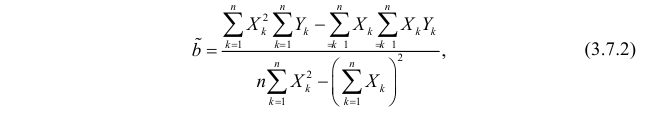
Известно, что оценки по методу наименьших квадратов являются несмещенными и, более того, среди всех несмещенных оценок обладают наименьшей дисперсией. Для оценки коэффициента корреляции можно воспользоваться тем, что 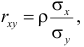 где
где  средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через
средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через  оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку
оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку 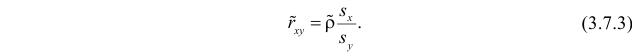
По методу наименьших квадратов можно находить оценки параметров линии регрессии и при нелинейной корреляции. Например, для линии регрессии вида 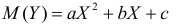 оценки параметров
оценки параметров 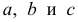 находятся из условия минимума функции
находятся из условия минимума функции
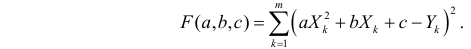
Пример:
По данным наблюдений двух случайных величин найти коэффициент корреляции и уравнение линии регрессии Y на X 
Решение. Вычислим величины, необходимые для использования формул (3.7.1)–(3.7.3):
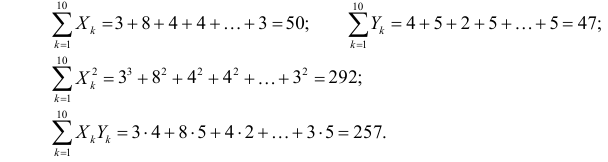
По формулам (3.7.1) и (3.7.2) получим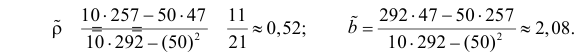
Итак, оценка линии регрессии имеет вид 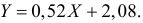 Так как
Так как 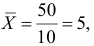 то по формуле (3.1.3)
то по формуле (3.1.3)
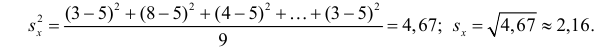
Аналогично, 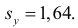 Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину
Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину 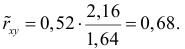
Ответ. 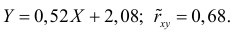
Пример:
Получена выборка значений величин X и Y
Для представления зависимости между величинами предполагается использовать модель 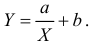 Найти оценки параметров
Найти оценки параметров 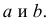
Решение. Рассмотрим сначала задачу оценки параметров этой модели в общем виде. Линия 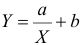 играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)
играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)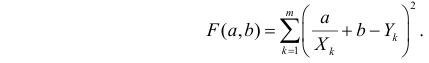
Необходимые условия экстремума приводят к системе из двух уравнений: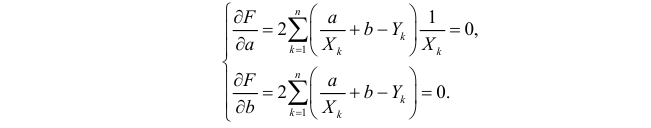
Откуда
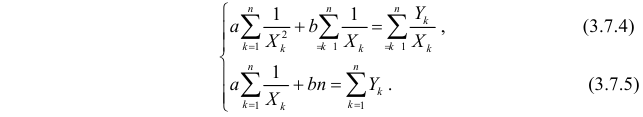
Решения системы уравнений (3.7.4) и (3.7.5) и будут оценками по методу наименьших квадратов для параметров 
На основе опытных данных вычисляем: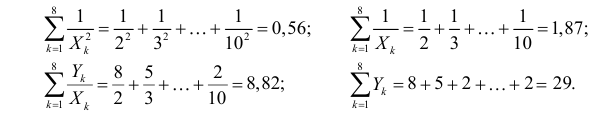
В итоге получаем систему уравнений (?????) и (?????) в виде 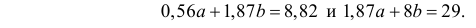
Эта система имеет решения 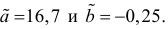
Ответ. 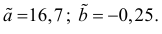
Если наблюдений много, то результаты их обычно группируют и представляют в виде корреляционной таблицы.
В этой таблице 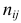 равно числу наблюдений, для которых X находится в интервале
равно числу наблюдений, для которых X находится в интервале 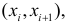 а Y – в интервале
а Y – в интервале 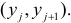 Через
Через 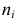 обозначено число наблюдений, при которых
обозначено число наблюдений, при которых 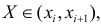 а Y произвольно. Число наблюдений, при которых
а Y произвольно. Число наблюдений, при которых 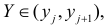 а X произвольно, обозначено через
а X произвольно, обозначено через 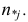
Если величины дискретны, то вместо интервалов указывают отдельные значения этих величин. Для непрерывных случайных величин представителем каждого интервала считают его середину и полагают, что 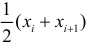 и
и 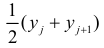 наблюдались
наблюдались 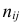 раз.
раз.
При больших значениях X и Y можно для упрощения вычислений перенести начало координат и изменить масштаб по каждой из осей, а после завершения вычислений вернуться к старому масштабу.
Пример:
Проделано 80 наблюдений случайных величин X и Y. Результаты наблюдений представлены в виде таблицы. Найти линию регрессии Y на X. Оценить коэффициент корреляции.

Решение. Представителем каждого интервала будем считать его середину. Перенесем начало координат и изменим масштаб по каждой оси так, чтобы значения X и Y были удобны для вычислений. Для этого перейдем к новым переменным 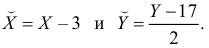 Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Чтобы иметь представление о виде линии регрессии, вычислим средние значения 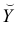 при фиксированных значениях
при фиксированных значениях 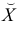 :
:
Нанесем эти значения на координатную плоскость, соединив для наглядности их отрезками прямой (рис. 3.7.1).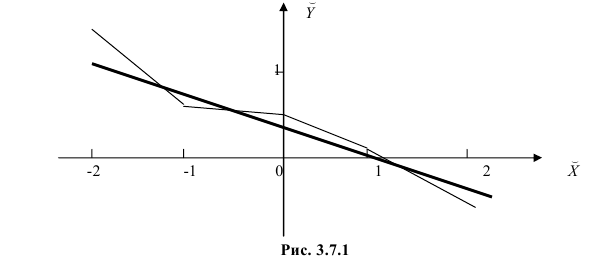
По виду полученной ломанной линии можно предположить, что линия регрессии Y на X является прямой. Оценим ее параметры. Для этого сначала вычислим с учетом группировки данных в таблице все величины, необходимые для использования формул (3.31–3.33): 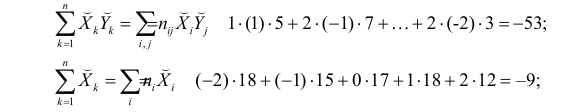
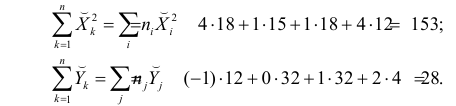
Тогда
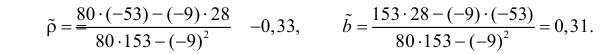
В новом масштабе оценка линии регрессии имеет вид 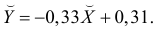 График этой прямой линии изображен на рис. 3.7.1.
График этой прямой линии изображен на рис. 3.7.1.
Для оценки 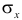 по корреляционной таблице можно воспользоваться формулой (3.1.3):
по корреляционной таблице можно воспользоваться формулой (3.1.3):
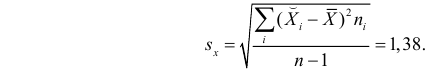
Подобным же образом можно оценить 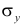 величиной
величиной 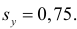 Тогда оценкой коэффициента корреляции может служить величина
Тогда оценкой коэффициента корреляции может служить величина 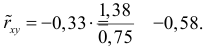
Вернемся к старому масштабу:
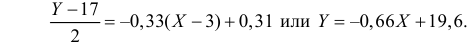
Коэффициент корреляции пересчитывать не нужно, так как это величина безразмерная и от масштаба не зависит.
Ответ. 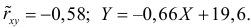
Пусть некоторые физические величины X и Y связаны неизвестной нам функциональной зависимостью 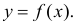 Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то
Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то 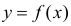 играет роль линии регрессии и все свойства линии регрессии приложимы к
играет роль линии регрессии и все свойства линии регрессии приложимы к 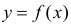 . В частности,
. В частности, 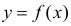 обычно находят по методу наименьших квадратов.
обычно находят по методу наименьших квадратов.
Регрессионный анализ
Основные положения регрессионного анализа:
Основная задача регрессионного анализа — изучение зависимости между результативным признаком Y и наблюдавшимся признаком X, оценка функции регрессий.
Предпосылки регрессионного анализа:
- Y — независимые случайные величины, имеющие постоянную дисперсию;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание
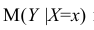 можно представить в виде
можно представить в виде 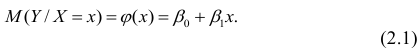
Выражение (2.1), как уже упоминалось в п. 1.2, называется функцией регрессии (или модельным уравнением регрессии) Y на X. Оценке в этом выражении подлежат параметры 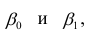 называемые коэффициентами регрессии, а также
называемые коэффициентами регрессии, а также 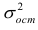 — остаточная дисперсия.
— остаточная дисперсия.
Остаточной дисперсией называется та часть рассеивания результативного признака, которую нельзя объяснить действием наблюдаемого признака; Остаточная дисперсия может служить для оценки точности подбора вида функции регрессии (модельного уравнения регрессии), полноты набора признаков, включенных в анализ. Оценки параметров функции регрессии находят, используя метод наименьших квадратов.
В данном вопросе рассмотрен линейный регрессионный анализ. Линейным он называется потому, что изучаем лишь те виды зависимостей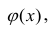 которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости
которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости 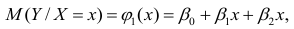
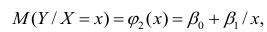
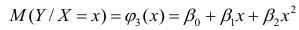 линейны относительно параметров
линейны относительно параметров 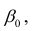
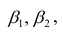 хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости
хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости 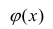 выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
Важное место в линейном регрессионном анализе занимает так называемая «нормальная регрессия». Она имеет место, если сделать предположения относительно закона распределения случайной величины Y. Предпосылки «нормальной регрессии»:
- Y — независимые случайные величины, имеющие постоянную дисперсию и распределенные по нормальному закону;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание
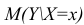 можно представить в виде (2.1).
можно представить в виде (2.1).
В этом случае оценки коэффициентов регрессии — несмещённые с минимальной дисперсией и нормальным законом распределения. Из этого положения следует что при «нормальной регрессии» имеется возможность оценить значимость оценок коэффициентов регрессии, а также построить доверительный интервал для коэффициентов регрессии и условного математического ожидания M(YX=x).
Линейная регрессия
Рассмотрим простейший случай регрессионного анализа — модель вида (2.1), когда зависимость 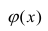 линейна и по оцениваемым параметрам, и
линейна и по оцениваемым параметрам, и
по переменным. Оценки параметров модели (2.1) 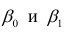 обозначил
обозначил 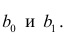 Оценку остаточной дисперсии
Оценку остаточной дисперсии 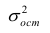 обозначим
обозначим 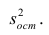 Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии
Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии 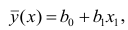 коэффициенты которого
коэффициенты которого 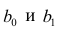 находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака
находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака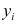 от вычисленных по уравнению регрессии
от вычисленных по уравнению регрессии 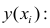
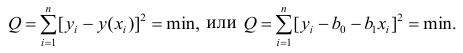
Составим систему нормальных уравнений: первое уравнение
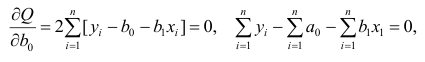
откуда 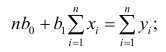
второе уравнение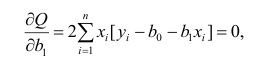
откуда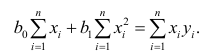
Итак,
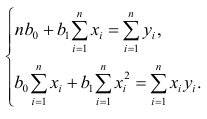
Оценки, полученные по способу наименьших квадратов, обладают минимальной дисперсией в классе линейных оценок. Решая систему (2.2) относительно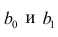 найдём оценки параметров
найдём оценки параметров 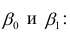
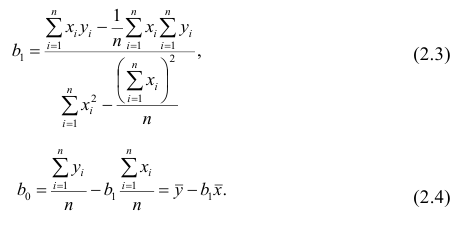
Остаётся получить оценку параметра 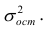 . Имеем
. Имеем
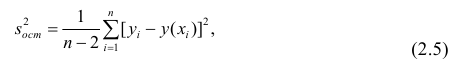
где т — количество наблюдений.
Еслит велико, то для упрощения расчётов наблюдавшиеся данные принята группировать, т.е. строить корреляционную таблицу. Пример построения такой таблицы приведен в п. 1.5. Формулы для нахождения коэффициентов регрессии по сгруппированным данным те же, что и для расчёта по несгруппированным данным, но суммы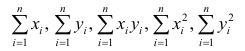 заменяют на
заменяют на
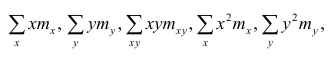
где 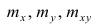 — частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
— частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
Нелинейная регрессия
Рассмотрим случай, когда зависимость нелинейна по переменным х, например модель вида
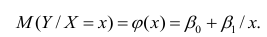
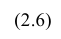
На рис. 2.1 изображено поле корреляции. Очевидно, что зависимость между Y и X нелинейная и её графическим изображением является не прямая, а кривая. Оценкой выражения (2.6) является уравнение регрессии
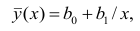
где 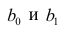 —оценки коэффициентов регрессии
—оценки коэффициентов регрессии 
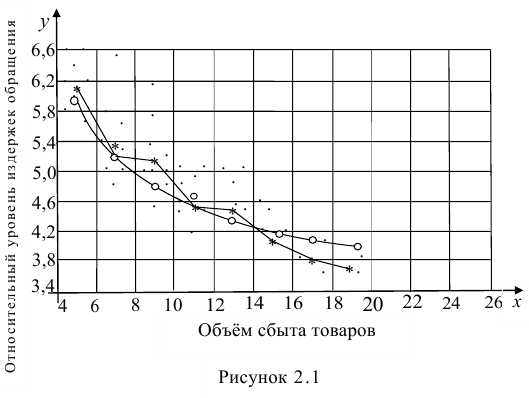
Принцип нахождения коэффициентов тот же — метод наименьших квадратов, т.е.
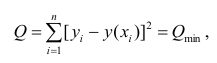
или
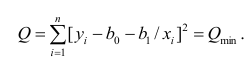
Дифференцируя последнее равенство по 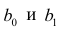 и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
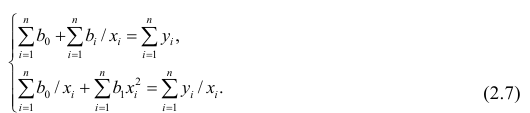
В общем случае нелинейной зависимости между переменными Y и X связь может выражаться многочленом k-й степени от x:
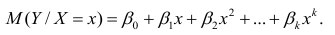
Коэффициенты регрессии определяют по принципу наименьших квадратов. Система нормальных уравнений имеет вид
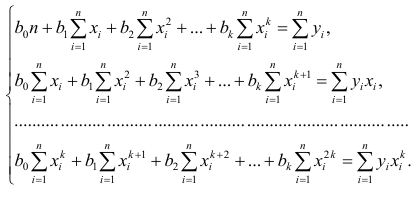
Вычислив коэффициенты системы, её можно решить любым известным способом.
Оценка значимости коэффициентов регрессии. Интервальная оценка коэффициентов регрессии
Проверить значимость оценок коэффициентов регрессии — значит установить, достаточна ли величина оценки для статистически обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Для этого проверяют гипотезу о равенстве нулю коэффициента регрессии, соблюдая предпосылки «нормальной регрессии». В этом случае вычисляемая для проверки нулевой гипотезы 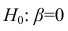 статистика
статистика

имеет распределение Стьюдента с к= n-2 степенями свободы (b — оценка коэффициента регрессии, 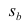 — оценка среднеквадратического отклонения
— оценка среднеквадратического отклонения
коэффициента регрессии, иначе стандартная ошибка оценки). По уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (см. табл. 1 приложений) критическое значение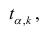 удовлетворяющее условию
удовлетворяющее условию 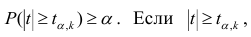 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При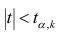 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
Оценки среднеквадратического отклонения коэффициентов регрессии вычисляют по следующим формулам:
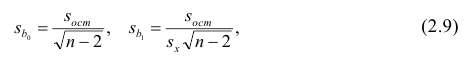
где 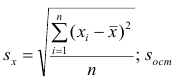 — оценка остаточной дисперсии, вычисляемая по
— оценка остаточной дисперсии, вычисляемая по
формуле (2.5).
Доверительный интервал для значимых параметров строят по обычной схеме. Из условия
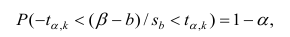
где а — уровень значимости, находим

Интервальная оценка для условного математического ожидания
Линия регрессии характеризует изменение условного математического ожидания результативного признака от вариации остальных признаков.
Точечной оценкой условного математического ожидания 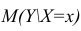 является условное среднее
является условное среднее 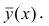 Кроме точечной оценки для
Кроме точечной оценки для 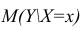 можно
можно
построить доверительный интервал в точке 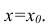
Известно, что 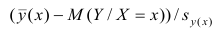 имеет распределение
имеет распределение
Стьюдента с k=n—2 степенями свободы. Найдя оценку среднеквадратического отклонения для условного среднего, можно построить доверительный интервал для условного математического ожидания 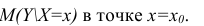
Оценку дисперсии условного среднего вычисляют по формуле
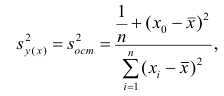
или для интервального ряда
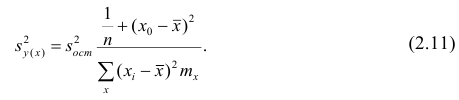
Доверительный интервал находят из условия
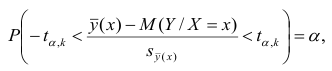
где а — уровень значимости. Отсюда
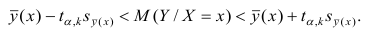
Доверительный интервал для условного математического ожидания можно изобразить графически (рис, 2.2).
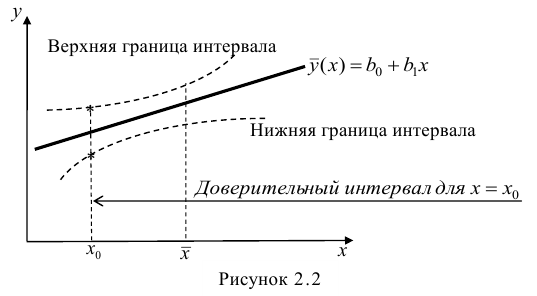
Из рис. 2.2 видно, что в точке 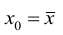 границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
Проверка значимости уравнения регрессии
Оценить значимость уравнения регрессии — значит установить, соответствует ли математическая, модель, выражающая зависимость между Y и X, экспериментальным данным. Для оценки значимости в предпосылках «нормальной регрессии» проверяют гипотезу 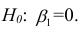 Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением
Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением 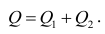 — Общая сумма квадратов отклонений результативного признака
— Общая сумма квадратов отклонений результативного признака
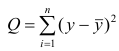 разлагается на
разлагается на 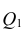 (сумму, характеризующую влияние признака
(сумму, характеризующую влияние признака
X) и 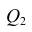 (остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
(остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
Для проверки нулевой гипотезы вычисляют статистику 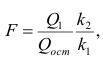 которая имеет распределение Фишера-Снедекора с А
которая имеет распределение Фишера-Снедекора с А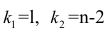 степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы
степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы 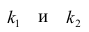 находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение
находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение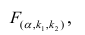 удовлетворяющее условию
удовлетворяющее условию 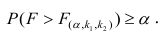 . Если
. Если 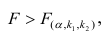 нулевую гипотезу отвергают, уравнение считают значимым. Если
нулевую гипотезу отвергают, уравнение считают значимым. Если 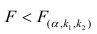 то нет оснований отвергать нулевую гипотезу.
то нет оснований отвергать нулевую гипотезу.
Многомерный регрессионный анализ
В случае, если изменения результативного признака определяются действием совокупности других признаков, имеет место многомерный регрессионный анализ. Пусть результативный признак У, а независимые признаки 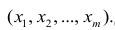 Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним
Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним 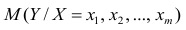 и постоянной дисперсией
и постоянной дисперсией 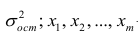 — линейно независимые векторы
— линейно независимые векторы 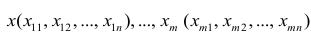 . Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
. Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
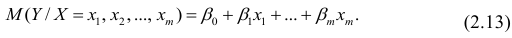
Оценке подлежат параметры 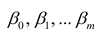 и остаточная дисперсия.
и остаточная дисперсия.
Заменив параметры их оценками, запишем уравнение регрессии
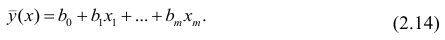
Коэффициенты в этом выражении находят методом наименьших квадратов.
Исходными данными для вычисления коэффициентов 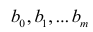 является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:
является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:

Как и в двумерном случае, составляют систему нормальных уравнений
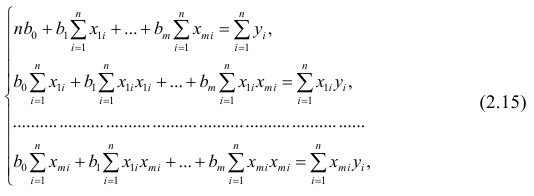
которую можно решить любым способом, известным из линейной алгебры. Рассмотрим один из них — способ обратной матрицы. Предварительно преобразуем систему уравнений. Выразим из первого уравнения значение 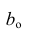 через остальные параметры:
через остальные параметры:
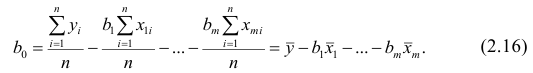
Подставим в остальные уравнения системы вместо 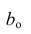 полученное выражение:
полученное выражение:
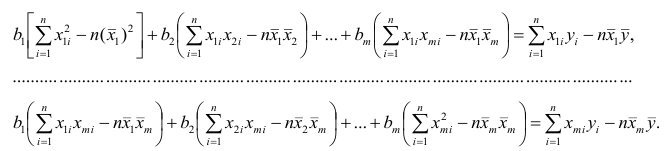
Пусть С — матрица коэффициентов при неизвестных параметрах 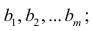
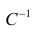 — матрица, обратная матрице С;
— матрица, обратная матрице С; 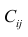 — элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы
— элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы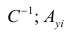 — выражение
— выражение
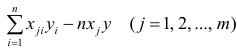 . Тогда, используя формулы линейной алгебры,
. Тогда, используя формулы линейной алгебры,
запишем окончательные выражения для параметров:
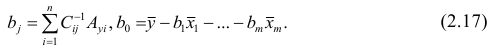
Оценкой остаточной дисперсии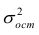 является
является
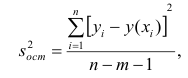
где 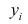 — измеренное значение результативного признака;
— измеренное значение результативного признака;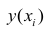 значение результативного признака, вычисленное по уравнению регрессий.
значение результативного признака, вычисленное по уравнению регрессий.
Если выборка получена из нормально распределенной генеральной совокупности, то, аналогично изложенному в п. 2.4, можно проверить значимость оценок коэффициентов регрессии, только в данном случае статистику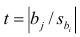 вычисляют для каждого j-го коэффициента регрессии
вычисляют для каждого j-го коэффициента регрессии
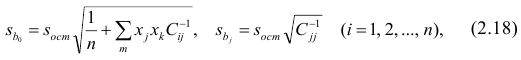
где 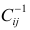 —элемент обратной матрицы, стоящий на пересечении i-й строки и j-
—элемент обратной матрицы, стоящий на пересечении i-й строки и j-
го столбца;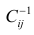 —диагональный элемент обратной матрицы.
—диагональный элемент обратной матрицы.
При заданном уровне значимости а и числе степеней свободы к=n— m—1 по табл. 1 приложений находят критическое значение 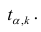 Если
Если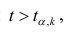 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если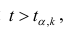 то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
Для значимых коэффициентов регрессии целесообразно построить доверительные интервалы по формуле (2.10). Для оценки значимости уравнения регрессии следует проверить нулевую гипотезу о том, что все коэффициенты регрессии (кроме свободного члена) равны нулю: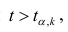
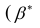 — вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики
— вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики 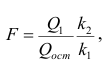 , где
, где 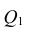 — сумма квадратов, характеризующая влияние признаков X;
— сумма квадратов, характеризующая влияние признаков X; 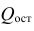 — остаточная сумма квадратов, характеризующая влияние неучтённых факторов;
— остаточная сумма квадратов, характеризующая влияние неучтённых факторов; 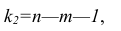
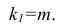 Для уровня значимости а и числа степеней свободы
Для уровня значимости а и числа степеней свободы 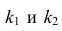 по табл. 3 приложений находят критическое значение
по табл. 3 приложений находят критическое значение 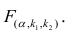 Если
Если 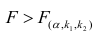 то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При
то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При 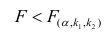 нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
Факторный анализ
Основные положения. В последнее время всё более широкое распространение находит один из новых разделов многомерного статистического анализа — факторный анализ. Первоначально этот метод
разрабатывался для объяснения многообразия корреляций между исходными параметрами. Действительно, результатом корреляционного анализа является матрица коэффициентов корреляций. При малом числе параметров можно произвести визуальный анализ этой матрицы. С ростом числа параметра (10 и более) визуальный анализ не даёт положительных результатов. Оказалось, что всё многообразие корреляционных связей можно объяснить действием нескольких обобщённых факторов, являющихся функциями исследуемых параметров, причём сами обобщённые факторы при этом могут быть и неизвестны, однако их можно выразить через исследуемые параметры.
Один из основоположников факторного анализа Л. Терстоун приводит такой пример: несколько сотен мальчиков выполняют 20 разнообразных гимнастических упражнений. Каждое упражнение оценивают баллами. Можно рассчитать матрицу корреляций между 20 упражнениями. Это большая матрица размером 20><20. Изучая такую матрицу, трудно уловить закономерность связей между упражнениями. Нельзя ли объяснить скрытую в таблице закономерность действием каких-либо обобщённых факторов, которые в результате эксперимента непосредственно, не оценивались? Оказалось, что обо всех коэффициентах корреляции можно судить по трём обобщённым факторам, которые и определяют успех выполнения всех 20 гимнастических упражнений: чувство равновесия, усилие правого плеча, быстрота движения тела.
Дальнейшие разработки факторного анализа доказали, что этот метод может быть с успехом применён в задачах группировки и классификации объектов. Факторный анализ позволяет группировать объекты со сходными сочетаниями признаков и группировать признаки с общим характером изменения от объекта к объекту. Действительно, выделенные обобщённые факторы можно использовать как критерии при классификации мальчиков по способностям к отдельным группам гимнастических упражнений.
Методы факторного анализа находят применение в психологии и экономике, социологии и экономической географии. Факторы, выраженные через исходные параметры, как правило, легко интерпретировать как некоторые существенные внутренние характеристики объектов.
Факторный анализ может быть использован и как самостоятельный метод исследования, и вместе с другими методами многомерного анализа, например в сочетании с регрессионным анализом. В этом случае для набора зависимых переменных наводят обобщённые факторы, которые потом входят в регрессионный анализ в качестве переменных. Такой подход позволяет сократить число переменных в регрессионном анализе, устранить коррелированность переменных, уменьшить влияние ошибок и в случае ортогональности выделенных факторов значительно упростить оценку значимости переменных.
Представление, информации в факторном анализе
Для проведения факторного анализа информация должна быть представлена в виде двумерной таблицы чисел размерностью 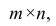 аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений
аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений 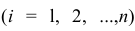 столбцы — признакам
столбцы — признакам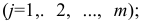 таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных
таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных 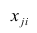 переходят к переменным
переходят к переменным 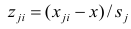 В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
Основная модель факторного анализа. Основная модель факторного анализа имеет вид
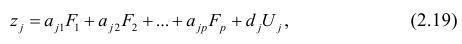
где 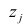 -j-й признак (величина случайная);
-j-й признак (величина случайная); 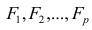 — общие факторы (величины случайные, имеющие нормальный закон распределения);
— общие факторы (величины случайные, имеющие нормальный закон распределения); 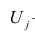 — характерный фактор;
— характерный фактор; 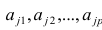 — факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);
— факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);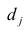 — нагрузка характерного фактора.
— нагрузка характерного фактора.
Модель предполагает, что каждый из j признаков, входящих в исследуемый набор и заданных в стандартной форме, может быть представлен в виде линейной комбинации небольшого числа общих факторов 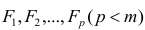 и характерного фактора
и характерного фактора 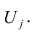
Термин «общий фактор» подчёркивает, что каждый такой фактор имеет существенное значение для анализа всех признаков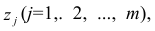 , т.е.
, т.е.
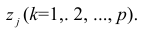
Термин «характерный фактор» показывает, что он относится только к данному j-му признаку. Это специфика признака, которая не может быть, выражена через факторы 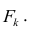
Факторные нагрузки 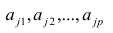 . характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
. характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
Для j-го признака и i-го объекта модель (2.19) можно записать в. виде
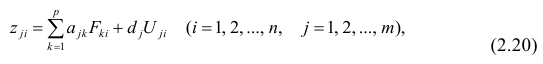
где 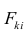 значение k-го фактора для i-го объекта.
значение k-го фактора для i-го объекта.
Дисперсию признака 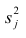 можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность
можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность 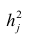 и часть, обусловленную действием j-го характера фактора, характерность
и часть, обусловленную действием j-го характера фактора, характерность 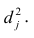 Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака
Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака 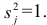 Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Если общие и характерные факторы не коррелируют между собой, то дисперсию j-го признака можно представить в виде
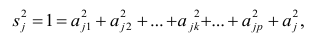
где 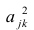 —доля дисперсии признака
—доля дисперсии признака 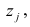 приходящаяся на k-й фактор.
приходящаяся на k-й фактор.
Полный вклад k-го фактора в суммарную дисперсию признаков
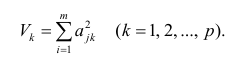
Вклад общих факторов в суммарную дисперсию 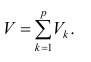
Факторное отображение
Используя модель (2.19), запишем выражения для каждого из параметров:
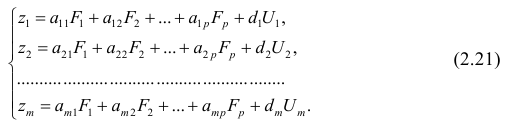
Коэффициенты системы (2,21) — факторные нагрузки — можно представить в виде матрицы, каждая строка которой соответствует параметру, а столбец — фактору.
Факторный анализ позволяет получить не только матрицу отображений, но и коэффициенты корреляции между параметрами и
факторами, что является важной характеристикой качества факторной модели. Таблица таких коэффициентов корреляции называется факторной структурой или просто структурой.
Коэффициенты отображения можно выразить через выборочные парные коэффициенты корреляции. На этом основаны методы вычисления факторного отображения.
Рассмотрим связь между элементами структуры и коэффициентами отображения. Для этого, учитывая выражение (2.19) и определение выборочного коэффициента корреляции, умножим уравнения системы (2.21) на соответствующие факторы, произведём суммирование по всем n наблюдениям и, разделив на n, получим следующую систему уравнений:
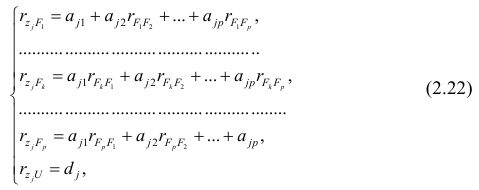
где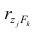 — выборочный коэффициент корреляции между j-м параметром и к-
— выборочный коэффициент корреляции между j-м параметром и к-
м фактором;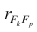 — коэффициент корреляции между к-м и р-м факторами.
— коэффициент корреляции между к-м и р-м факторами.
Если предположить, что общие факторы между собой, не коррелированы, то уравнения (2.22) можно записать в виде
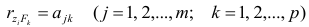 , т.е. коэффициенты отображения равны
, т.е. коэффициенты отображения равны
элементам структуры.
Введём понятие, остаточного коэффициента корреляции и остаточной корреляционной матрицы. Исходной информацией для построения факторной модели (2.19) служит матрица выборочных парных коэффициентов корреляции. Используя построенную факторную модель, можно снова вычислить коэффициенты корреляции между признаками и сравнись их с исходными Коэффициентами корреляции. Разница между ними и есть остаточный коэффициент корреляции.
В случае независимости факторов имеют место совсем простые выражения для вычисляемых коэффициентов корреляции между параметрами: для их вычисления достаточно взять сумму произведений коэффициентов отображения, соответствующих наблюдавшимся признакам: 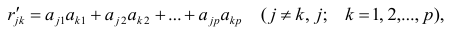
где 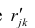 —вычисленный по отображению коэффициент корреляции между j-м
—вычисленный по отображению коэффициент корреляции между j-м
и к-м признаком. Остаточный коэффициент корреляции
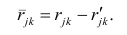
Матрица остаточных коэффициентов корреляции называется остаточной матрицей или матрицей остатков
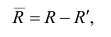
где 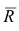 — матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
— матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
Результаты факторного анализа удобно представить в виде табл. 2.10.

Здесь суммы квадратов нагрузок по строкам — общности параметров, а суммы квадратов нагрузок по столбцам — вклады факторов в суммарную дисперсию параметров. Имеет место соотношение
Определение факторных нагрузок
Матрицу факторных нагрузок можно получить различными способами. В настоящее время наибольшее распространение получил метод главных факторов. Этот метод основан на принципе последовательных приближений и позволяет достичь любой точности. Метод главных факторов предполагает использование ЭВМ. Существуют хорошие алгоритмы и программы, реализующие все вычислительные процедуры.
Введём понятие редуцированной корреляционной матрицы или просто редуцированной матрицы. Редуцированной называется матрица выборочных коэффициентов корреляции у которой на главной диагонали стоят значения общностей
у которой на главной диагонали стоят значения общностей 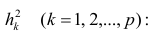 :
: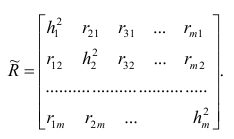
Редуцированная и полная матрицы связаны соотношением

где D — матрица характерностей.
Общности, как правило, неизвестны, и нахождение их в факторном анализе представляет серьезную проблему. Вначале определяют (хотя бы приближённо) число общих факторов, совокупность, которых может с достаточной точностью аппроксимировать все взаимосвязи выборочной корреляционной матрицы. Доказано, что число общих факторов (общностей) равно рангу редуцированной матрицы, а при известном ранге можно по выборочной корреляционной матрице найти оценки общностей. Числа общих факторов можно определить априори, исходя из физической природы эксперимента. Затем рассчитывают матрицу факторных нагрузок. Такая матрица, рассчитанная методом главных факторов, обладает одним интересным свойством: сумма произведений каждой пары её столбцов равна нулю, т.е. факторы попарно ортогональны.
Сама процедура нахождения факторных нагрузок, т.е. матрицы А, состоит из нескольких шагов и заключается в следующем: на первом шаге ищут коэффициенты факторных нагрузок при первом факторе так, чтобы сумма вкладов данного фактора в суммарную общность была максимальной:
Максимум  должен быть найден при условии
должен быть найден при условии
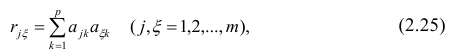
где 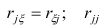 —общность
—общность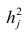 параметра
параметра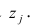
Затем рассчитывают матрицу коэффициентов корреляции с учётом только первого фактора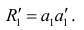 Имея эту матрицу, получают первую матрицу остатков:
Имея эту матрицу, получают первую матрицу остатков: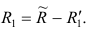
На втором шаге определяют коэффициенты нагрузок при втором факторе так, чтобы сумма вкладов второго фактора в остаточную общность (т.е. полную общность без учёта той части, которая приходится на долю первого фактора) была максимальной. Сумма квадратов нагрузок при втором факторе
Максимум  находят из условия
находят из условия
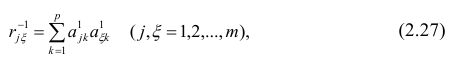
где 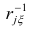 — коэффициент корреляции из первой матрицы остатков;
— коэффициент корреляции из первой матрицы остатков; 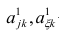 — факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков:
— факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков: 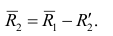
Факторный анализ учитывает суммарную общность. Исходная суммарная общность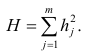 Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на
Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на  — наперёд заданное малое число).
— наперёд заданное малое число).
Адекватность факторной модели оценивается по матрице остатков (если величины её коэффициентов малы, то модель считают адекватной).
Такова последовательность шагов для нахождения факторных нагрузок. Для нахождения максимума функции (2.24) при условии (2.25) используют метод множителей Лагранжа, который приводит к системе т уравнений относительно m неизвестных 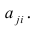
Метод главных компонент
Разновидностью метода главных факторов является метод главных компонент или компонентный анализ, который реализует модель вида
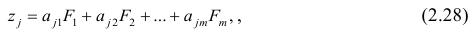
где m — количество параметров (признаков).
Каждый из наблюдаемых, параметров линейно зависит от m не коррелированных между собой новых компонент (факторов) 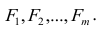 По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
Если для дальнейшего анализа оставить все найденные т компонент, то тем самым будет использована вся информация, заложенная в корреляционной матрице. Однако это неудобно и нецелесообразно. На практике обычно оставляют небольшое число компонент, причём количество их определяется долей суммарной дисперсии, учитываемой этими компонентами. Существуют различные критерии для оценки числа оставляемых компонент; чаще всего используют следующий простой критерий: оставляют столько компонент, чтобы суммарная дисперсия, учитываемая ими, составляла заранее установленное число процентов. Первая из компонент должна учитывать максимум суммарной дисперсии параметров; вторая — не коррелировать с первой и учитывать максимум оставшейся дисперсии и так до тех пор, пока вся дисперсия не будет учтена. Сумма учтённых всеми компонентами дисперсий равна сумме дисперсий исходных параметров. Математический аппарат компонентного анализа полностью совпадает с аппаратом метода главных факторов. Отличие только в исходной матрице корреляций.
Компонента (или фактор) через исходные переменные выражается следующим образом:
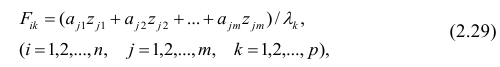
где 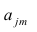 — элементы факторного решения:
— элементы факторного решения: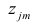 — исходные переменные;
— исходные переменные; 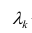 .— k-е собственное значение; р — количество оставленных главных
.— k-е собственное значение; р — количество оставленных главных
компонент.
Для иллюстрации возможностей факторного анализа покажем, как, используя метод главных компонент, можно сократить размерность пространства независимых переменных, перейдя от взаимно коррелированных параметров к независимым факторам, число которых р
Следует особо остановиться на интерпретации результатов, т.е. на смысловой стороне факторного анализа. Собственно факторный анализ состоит из двух важных этапов; аппроксимации корреляционной матрицы и интерпретации результатов. Аппроксимировать корреляционную матрицу, т.е. объяснить корреляцию между параметрами действием каких-либо общих для них факторов, и выделить сильно коррелирующие группы параметров достаточно просто: из корреляционной матрицы одним из методов
факторного анализа непосредственно получают матрицу нагрузок — факторное решение, которое называют прямым факторным решением. Однако часто это решение не удовлетворяет исследователей. Они хотят интерпретировать фактор как скрытый, но существенный параметр, поведение которого определяет поведение некоторой своей группы наблюдаемых параметров, в то время как, поведение других параметров определяется поведением других факторов. Для этого у каждого параметра должна быть наибольшая по модулю факторная нагрузка с одним общим фактором. Прямое решение следует преобразовать, что равносильно повороту осей общих факторов. Такие преобразования называют вращениями, в итоге получают косвенное факторное решение, которое и является результатом факторного анализа.
Приложения
Значение t — распределения Стьюдента 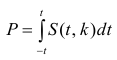
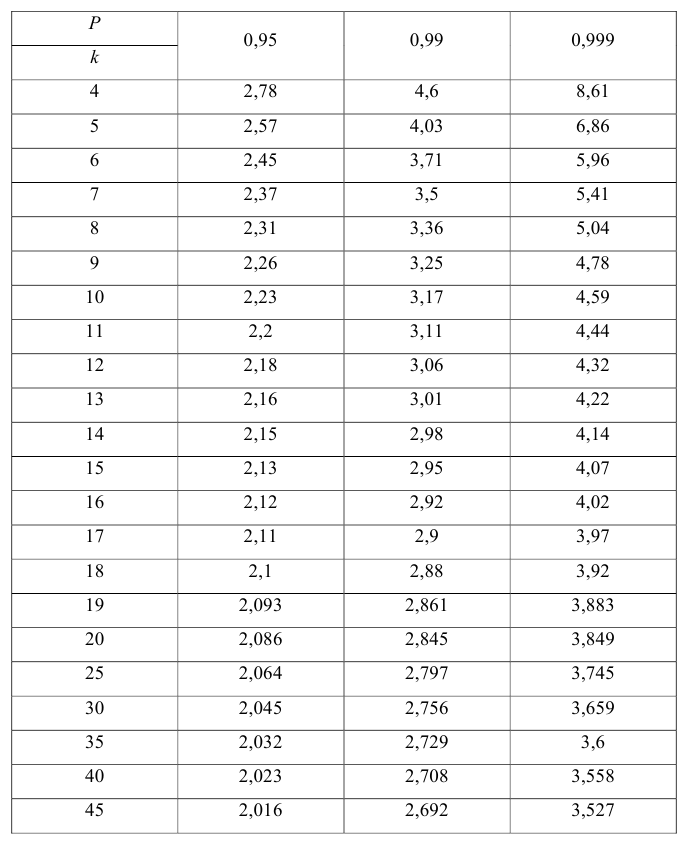
Понятие о регрессионном анализе. Линейная выборочная регрессия. Метод наименьших квадратов (МНК)
Основные задачи регрессионного анализа:
- Вычисление выборочных коэффициентов регрессии
- Проверка значимости коэффициентов регрессии
- Проверка адекватности модели
- Выбор лучшей регрессии
- Вычисление стандартных ошибок, анализ остатков
Построение простой регрессии по экспериментальным данным.
Предположим, что случайные величины 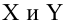 связаны линейной корреляционной зависимостью
связаны линейной корреляционной зависимостью 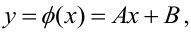 для отыскания которой проведено
для отыскания которой проведено  независимых измерений
независимых измерений 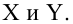
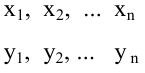
Диаграмма рассеяния (разброса, рассеивания)
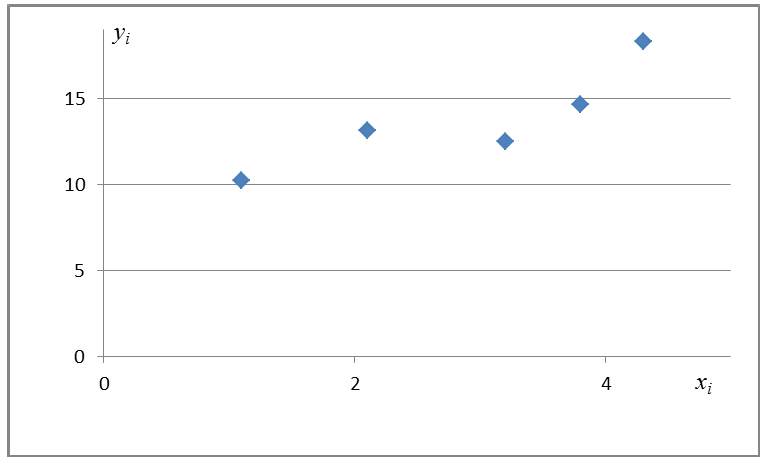
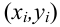 — координаты экспериментальных точек.
— координаты экспериментальных точек.
Выборочное уравнение прямой линии регрессии 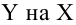 имеет вид
имеет вид
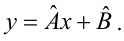
Задача: подобрать  таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой
таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой 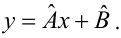
Для того, что бы провести прямую 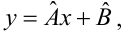 воспользуемся МНК. Потребуем,
воспользуемся МНК. Потребуем,
чтобы 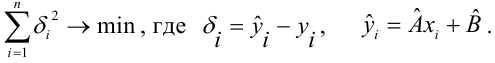
Постулаты регрессионного анализа, которые должны выполняться при использовании МНК.
 подчинены нормальному закону распределения.
подчинены нормальному закону распределения.- Дисперсия
 постоянна и не зависит от номера измерения.
постоянна и не зависит от номера измерения. - Результаты наблюдений
 в разных точках независимы.
в разных точках независимы. - Входные переменные
 независимы, неслучайны и измеряются без ошибок.
независимы, неслучайны и измеряются без ошибок.
Введем функцию ошибок 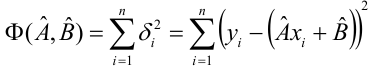 и найдём её минимальное значение
и найдём её минимальное значение
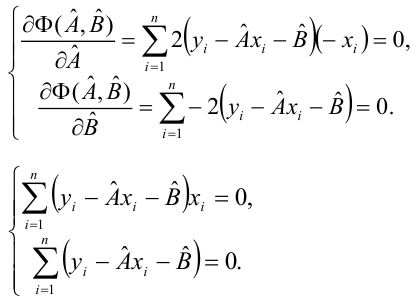
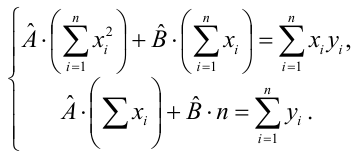
Решив систему, получим искомые значения 
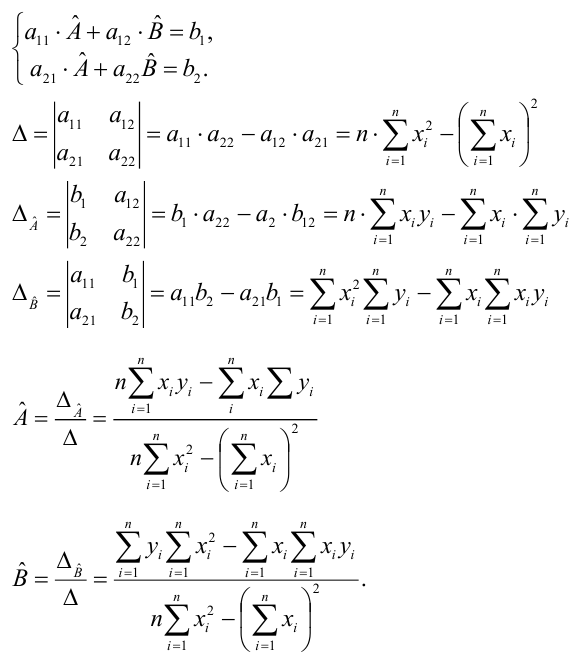
 является несмещенными оценками истинных значений коэффициентов
является несмещенными оценками истинных значений коэффициентов 
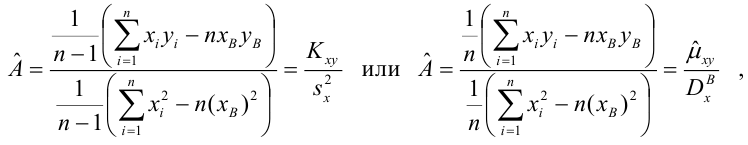 где
где
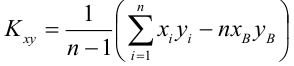 несмещенная оценка корреляционного момента (ковариации),
несмещенная оценка корреляционного момента (ковариации),
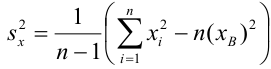 несмещенная оценка дисперсии
несмещенная оценка дисперсии 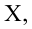
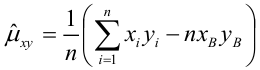 выборочная ковариация,
выборочная ковариация,
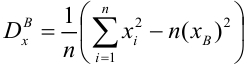 выборочная дисперсия
выборочная дисперсия 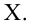
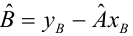
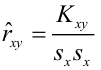 — выборочный коэффициент корреляции
— выборочный коэффициент корреляции
Коэффициент детерминации
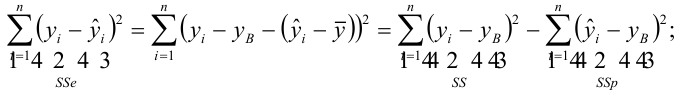
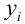 — наблюдаемое экспериментальное значение
— наблюдаемое экспериментальное значение  при
при 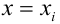
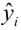 — предсказанное значение
— предсказанное значение  удовлетворяющее уравнению регрессии
удовлетворяющее уравнению регрессии
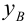 — средневыборочное значение
— средневыборочное значение 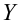
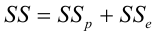
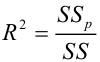 — коэффициент детерминации, доля изменчивости
— коэффициент детерминации, доля изменчивости 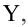 объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии
объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии 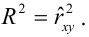
Коэффициент детерминации принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это используется для доказательства адекватности модели (качества регрессии). Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 0,5 (в этом случае коэффициент множественной корреляции превышает по модулю 0,7). Модели с коэффициентом детерминации выше 0,8 можно признать достаточно хорошими (коэффициент корреляции превышает 0,9). Подтверждение адекватности модели проводится на основе дисперсионного анализа путем проверки гипотезы о значимости коэффициента детерминации.
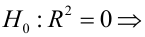 регрессия незначима
регрессия незначима
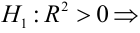 регрессия значима
регрессия значима
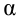 — уровень значимости
— уровень значимости
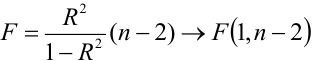 — статистический критерий
— статистический критерий
Критическая область — правосторонняя; 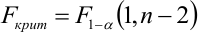
Если 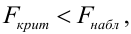 то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
Мощность статистического критерия. Функция мощности
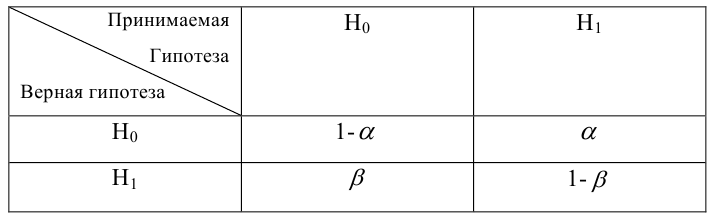
Определение. Мощностью критерия  называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
Задача: построить критическую область таким образом, чтобы мощность критерия была максимальной.
Определение. Наилучшей критической областью (НКО) называют критическую область, которая обеспечивает минимальную ошибку второго рода 
Пример:
По паспортным данным автомобиля расход топлива на 100 километров составляет 10 литров. В результате измерения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки были проведены испытания 25 автомобилей с модернизированным двигателем; выборочная средняя расхода топлива по результатам испытаний составила 9,3 литра. Предполагая, что выборка получена из нормально распределенной генеральной совокупности с математическим ожиданием  и дисперсией
и дисперсией 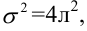 проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
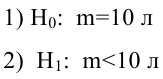
3) Уровень значимости 
4) Статистический критерий
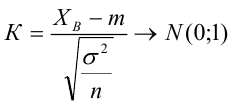
5) Критическая область — левосторонняя
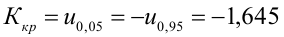
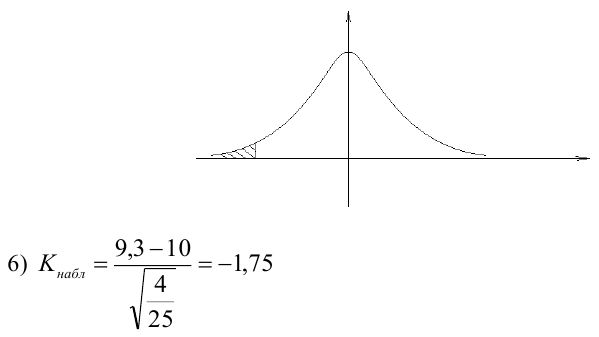
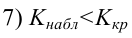 следовательно
следовательно 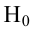 отвергается на уровне значимости
отвергается на уровне значимости 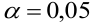
Пример:
В условиях примера 1 предположим, что наряду с 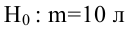 рассматривается конкурирующая гипотеза
рассматривается конкурирующая гипотеза 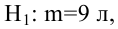 а критическая область задана неравенством
а критическая область задана неравенством 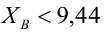 Найти вероятность ошибок I рода и II рода.
Найти вероятность ошибок I рода и II рода.
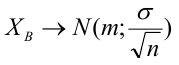
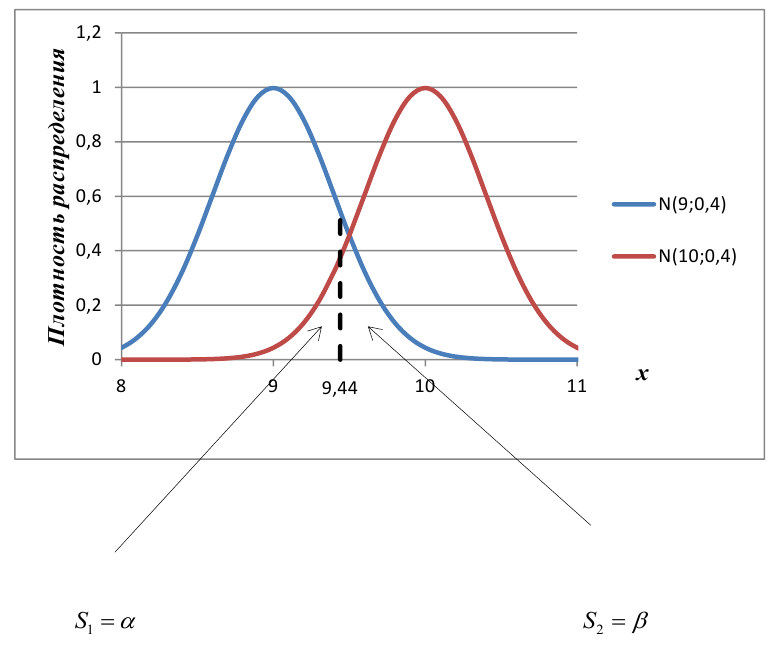
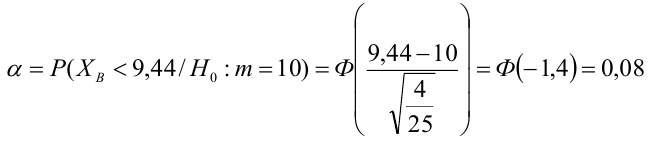
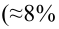 автомобилей имеют меньший расход топлива)
автомобилей имеют меньший расход топлива)
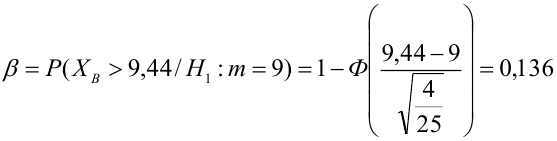
 автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
Определение. Пусть проверяется  — критическая область критерия с заданным уровнем значимости
— критическая область критерия с заданным уровнем значимости  Функцией мощности критерия
Функцией мощности критерия 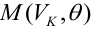 называется вероятность отклонения
называется вероятность отклонения  как функция параметра
как функция параметра  т.е.
т.е.
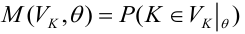
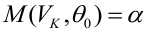 — ошибка 1-ого рода
— ошибка 1-ого рода
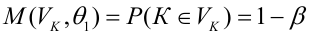 — мощность критерия
— мощность критерия
Пример:
Построить график функции мощности из примера 2 для 
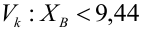 попадает в критическую область.
попадает в критическую область.
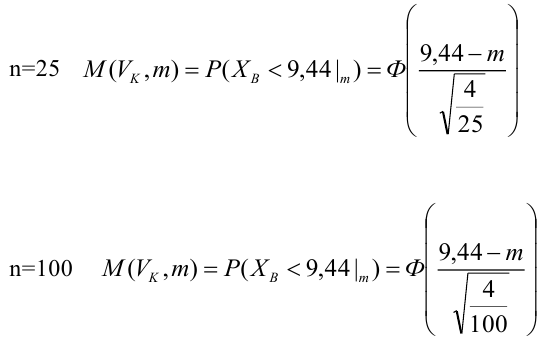
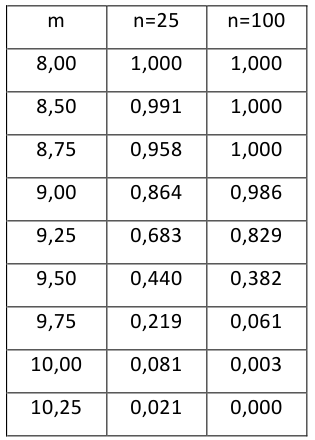
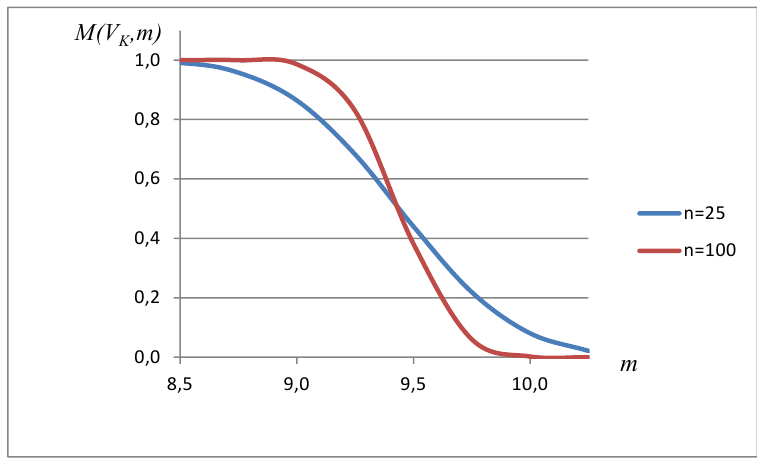
Пример:
Какой минимальный объем выборки следует взять в условии примера 2 для того, чтобы обеспечить 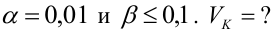
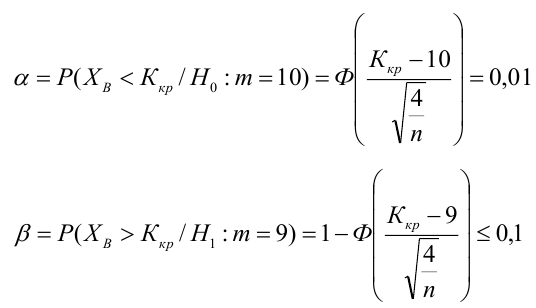
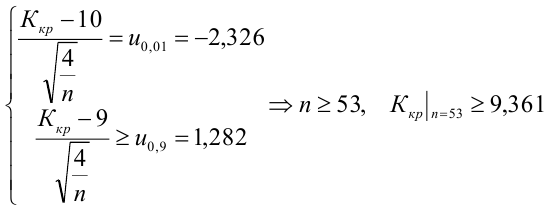
Лемма Неймана-Пирсона.
При проверке простой гипотезы 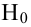 против простой альтернативной гипотезы
против простой альтернативной гипотезы 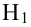 наилучшая критическая область (НКО) критерия заданного уровня значимости
наилучшая критическая область (НКО) критерия заданного уровня значимости  состоит из точек выборочного пространства (выборок объема
состоит из точек выборочного пространства (выборок объема  для которых справедливо неравенство:
для которых справедливо неравенство:
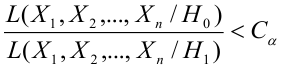
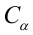 — константа, зависящая от
— константа, зависящая от 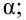
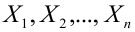 — элементы выборки;
— элементы выборки;
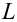 — функция правдоподобия при условии, что соответствующая гипотеза верна.
— функция правдоподобия при условии, что соответствующая гипотеза верна.
Пример:
Случайная величина 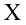 имеет нормальное распределение с параметрами
имеет нормальное распределение с параметрами 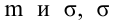 известно. Найти НКО для проверки
известно. Найти НКО для проверки 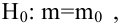 против
против 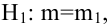 причем
причем 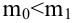
Решение:
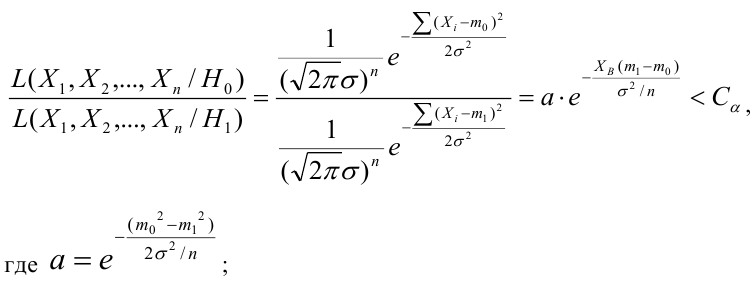
Ошибка первого рода: 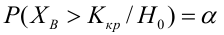
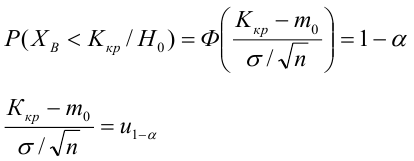
НКО: 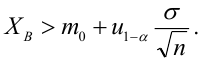
Пример:
Для зависимости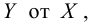 заданной корреляционной табл. 13, найти оценки параметров
заданной корреляционной табл. 13, найти оценки параметров 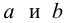 уравнения линейной регрессии
уравнения линейной регрессии 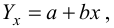 остаточную дисперсию; выяснить значимость уравнения регрессии при
остаточную дисперсию; выяснить значимость уравнения регрессии при 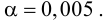
Решение. Воспользуемся предыдущими результатами
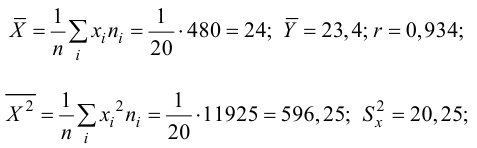
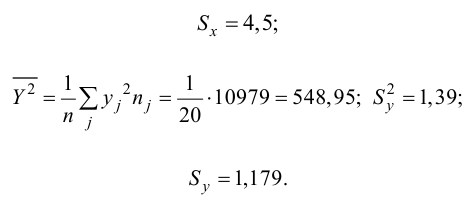
Согласно формуле (24), уравнение регрессии будет иметь вид 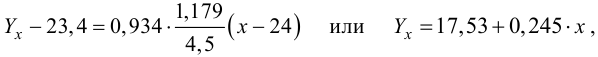 тогда
тогда 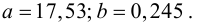
Для выяснения значимости уравнения регрессии вычислим суммы 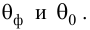 Составим расчетную таблицу:
Составим расчетную таблицу:
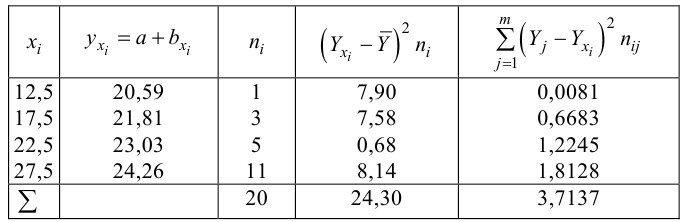
Из (27) и (28) по данным таблицы получим 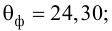
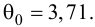
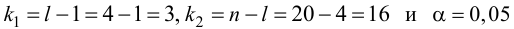 по табл. П7 находим
по табл. П7 находим 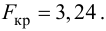
Вычислим статистику
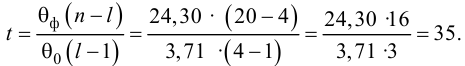
Так как 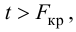 то уравнение регрессии значимо. Остаточная дисперсия равна
то уравнение регрессии значимо. Остаточная дисперсия равна 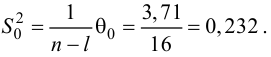
- Корреляционный анализ
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
Содержание:
Регрессионный анализ:
Регрессионным анализом называется раздел математической статистики, объединяющий практические методы исследования корреляционной зависимости между случайными величинами по результатам наблюдений над ними. Сюда включаются методы выбора модели изучаемой зависимости и оценки ее параметров, методы проверки статистических гипотез о зависимости.
Пусть между случайными величинами X и Y существует линейная корреляционная зависимость. Это означает, что математическое ожидание Y линейно зависит от значений случайной величины X. График этой зависимости (линия регрессии Y на X) имеет уравнение
Линейная модель пригодна в качестве первого приближения и в случае нелинейной корреляции, если рассматривать небольшие интервалы возможных значений случайных величин.
Пусть параметры линии регрессии неизвестны, неизвестна и величина коэффициента корреляции Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений: Эти результаты могут служить источником информации о неизвестных значениях надо только уметь эту информацию извлечь оттуда.
Неизвестная нам линия регрессии как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция
Такие значения , согласно необходимым условиям экстремума, находятся из системы уравнений:
Решения этой системы уравнений дают оценки называемые оценками по методу наименьших квадратов.
и
Известно, что оценки по методу наименьших квадратов являются несмещенными и, более того, среди всех несмещенных оценок обладают наименьшей дисперсией. Для оценки коэффициента корреляции можно воспользоваться тем, что где средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку
По методу наименьших квадратов можно находить оценки параметров линии регрессии и при нелинейной корреляции. Например, для линии регрессии вида оценки параметров находятся из условия минимума функции
Пример:
По данным наблюдений двух случайных величин найти коэффициент корреляции и уравнение линии регрессии Y на X
Решение. Вычислим величины, необходимые для использования формул (3.7.1)–(3.7.3):
По формулам (3.7.1) и (3.7.2) получим
Итак, оценка линии регрессии имеет вид Так как то по формуле (3.1.3)
Аналогично, Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину
Ответ.
Пример:
Получена выборка значений величин X и Y
Для представления зависимости между величинами предполагается использовать модель Найти оценки параметров
Решение. Рассмотрим сначала задачу оценки параметров этой модели в общем виде. Линия играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)
Необходимые условия экстремума приводят к системе из двух уравнений:
Откуда
Решения системы уравнений (3.7.4) и (3.7.5) и будут оценками по методу наименьших квадратов для параметров
На основе опытных данных вычисляем:
В итоге получаем систему уравнений (?????) и (?????) в виде
Эта система имеет решения
Ответ.
Если наблюдений много, то результаты их обычно группируют и представляют в виде корреляционной таблицы.
В этой таблице равно числу наблюдений, для которых X находится в интервале а Y – в интервале Через обозначено число наблюдений, при которых а Y произвольно. Число наблюдений, при которых а X произвольно, обозначено через
Если величины дискретны, то вместо интервалов указывают отдельные значения этих величин. Для непрерывных случайных величин представителем каждого интервала считают его середину и полагают, что и наблюдались раз.
При больших значениях X и Y можно для упрощения вычислений перенести начало координат и изменить масштаб по каждой из осей, а после завершения вычислений вернуться к старому масштабу.
Пример:
Проделано 80 наблюдений случайных величин X и Y. Результаты наблюдений представлены в виде таблицы. Найти линию регрессии Y на X. Оценить коэффициент корреляции.
Решение. Представителем каждого интервала будем считать его середину. Перенесем начало координат и изменим масштаб по каждой оси так, чтобы значения X и Y были удобны для вычислений. Для этого перейдем к новым переменным Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Чтобы иметь представление о виде линии регрессии, вычислим средние значения при фиксированных значениях :
Нанесем эти значения на координатную плоскость, соединив для наглядности их отрезками прямой (рис. 3.7.1).
По виду полученной ломанной линии можно предположить, что линия регрессии Y на X является прямой. Оценим ее параметры. Для этого сначала вычислим с учетом группировки данных в таблице все величины, необходимые для использования формул (3.31–3.33):
Тогда
В новом масштабе оценка линии регрессии имеет вид График этой прямой линии изображен на рис. 3.7.1.
Для оценки по корреляционной таблице можно воспользоваться формулой (3.1.3):
Подобным же образом можно оценить величиной Тогда оценкой коэффициента корреляции может служить величина
Вернемся к старому масштабу:
Коэффициент корреляции пересчитывать не нужно, так как это величина безразмерная и от масштаба не зависит.
Ответ.
Пусть некоторые физические величины X и Y связаны неизвестной нам функциональной зависимостью Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то играет роль линии регрессии и все свойства линии регрессии приложимы к . В частности, обычно находят по методу наименьших квадратов.
Регрессионный анализ
Основные положения регрессионного анализа:
Основная задача регрессионного анализа — изучение зависимости между результативным признаком Y и наблюдавшимся признаком X, оценка функции регрессий.
Предпосылки регрессионного анализа:
- Y — независимые случайные величины, имеющие постоянную дисперсию;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание можно представить в виде
Выражение (2.1), как уже упоминалось в п. 1.2, называется функцией регрессии (или модельным уравнением регрессии) Y на X. Оценке в этом выражении подлежат параметры называемые коэффициентами регрессии, а также — остаточная дисперсия.
Остаточной дисперсией называется та часть рассеивания результативного признака, которую нельзя объяснить действием наблюдаемого признака; Остаточная дисперсия может служить для оценки точности подбора вида функции регрессии (модельного уравнения регрессии), полноты набора признаков, включенных в анализ. Оценки параметров функции регрессии находят, используя метод наименьших квадратов.
В данном вопросе рассмотрен линейный регрессионный анализ. Линейным он называется потому, что изучаем лишь те виды зависимостей которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости
линейны относительно параметров хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
Важное место в линейном регрессионном анализе занимает так называемая «нормальная регрессия». Она имеет место, если сделать предположения относительно закона распределения случайной величины Y. Предпосылки «нормальной регрессии»:
- Y — независимые случайные величины, имеющие постоянную дисперсию и распределенные по нормальному закону;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание можно представить в виде (2.1).
В этом случае оценки коэффициентов регрессии — несмещённые с минимальной дисперсией и нормальным законом распределения. Из этого положения следует что при «нормальной регрессии» имеется возможность оценить значимость оценок коэффициентов регрессии, а также построить доверительный интервал для коэффициентов регрессии и условного математического ожидания M(YX=x).
Линейная регрессия
Рассмотрим простейший случай регрессионного анализа — модель вида (2.1), когда зависимость линейна и по оцениваемым параметрам, и
по переменным. Оценки параметров модели (2.1) обозначил Оценку остаточной дисперсии обозначим Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии коэффициенты которого находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака от вычисленных по уравнению регрессии
Составим систему нормальных уравнений: первое уравнение
откуда
второе уравнение
откуда
Итак,
Оценки, полученные по способу наименьших квадратов, обладают минимальной дисперсией в классе линейных оценок. Решая систему (2.2) относительно найдём оценки параметров
Остаётся получить оценку параметра . Имеем
где т — количество наблюдений.
Еслит велико, то для упрощения расчётов наблюдавшиеся данные принята группировать, т.е. строить корреляционную таблицу. Пример построения такой таблицы приведен в п. 1.5. Формулы для нахождения коэффициентов регрессии по сгруппированным данным те же, что и для расчёта по несгруппированным данным, но суммызаменяют на
где — частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
Нелинейная регрессия
Рассмотрим случай, когда зависимость нелинейна по переменным х, например модель вида
На рис. 2.1 изображено поле корреляции. Очевидно, что зависимость между Y и X нелинейная и её графическим изображением является не прямая, а кривая. Оценкой выражения (2.6) является уравнение регрессии
где —оценки коэффициентов регрессии
Принцип нахождения коэффициентов тот же — метод наименьших квадратов, т.е.
или
Дифференцируя последнее равенство по и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
В общем случае нелинейной зависимости между переменными Y и X связь может выражаться многочленом k-й степени от x:
Коэффициенты регрессии определяют по принципу наименьших квадратов. Система нормальных уравнений имеет вид
Вычислив коэффициенты системы, её можно решить любым известным способом.
Оценка значимости коэффициентов регрессии. Интервальная оценка коэффициентов регрессии
Проверить значимость оценок коэффициентов регрессии — значит установить, достаточна ли величина оценки для статистически обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Для этого проверяют гипотезу о равенстве нулю коэффициента регрессии, соблюдая предпосылки «нормальной регрессии». В этом случае вычисляемая для проверки нулевой гипотезы статистика
имеет распределение Стьюдента с к= n-2 степенями свободы (b — оценка коэффициента регрессии, — оценка среднеквадратического отклонения
коэффициента регрессии, иначе стандартная ошибка оценки). По уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (см. табл. 1 приложений) критическое значение удовлетворяющее условию то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. Принет оснований отвергать нулевую гипотезу.
Оценки среднеквадратического отклонения коэффициентов регрессии вычисляют по следующим формулам:
где — оценка остаточной дисперсии, вычисляемая по
формуле (2.5).
Доверительный интервал для значимых параметров строят по обычной схеме. Из условия
где а — уровень значимости, находим
Интервальная оценка для условного математического ожидания
Линия регрессии характеризует изменение условного математического ожидания результативного признака от вариации остальных признаков.
Точечной оценкой условного математического ожидания является условное среднее Кроме точечной оценки для можно
построить доверительный интервал в точке
Известно, что имеет распределение
Стьюдента с k=n—2 степенями свободы. Найдя оценку среднеквадратического отклонения для условного среднего, можно построить доверительный интервал для условного математического ожидания
Оценку дисперсии условного среднего вычисляют по формуле
или для интервального ряда
Доверительный интервал находят из условия
где а — уровень значимости. Отсюда
Доверительный интервал для условного математического ожидания можно изобразить графически (рис, 2.2).
Из рис. 2.2 видно, что в точке границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
Проверка значимости уравнения регрессии
Оценить значимость уравнения регрессии — значит установить, соответствует ли математическая, модель, выражающая зависимость между Y и X, экспериментальным данным. Для оценки значимости в предпосылках «нормальной регрессии» проверяют гипотезу Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением — Общая сумма квадратов отклонений результативного признака
разлагается на (сумму, характеризующую влияние признака
X) и (остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
Для проверки нулевой гипотезы вычисляют статистику которая имеет распределение Фишера-Снедекора с А степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение удовлетворяющее условию . Если нулевую гипотезу отвергают, уравнение считают значимым. Если то нет оснований отвергать нулевую гипотезу.
Многомерный регрессионный анализ
В случае, если изменения результативного признака определяются действием совокупности других признаков, имеет место многомерный регрессионный анализ. Пусть результативный признак У, а независимые признаки Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним и постоянной дисперсией — линейно независимые векторы . Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
Оценке подлежат параметры и остаточная дисперсия.
Заменив параметры их оценками, запишем уравнение регрессии
Коэффициенты в этом выражении находят методом наименьших квадратов.
Исходными данными для вычисления коэффициентов является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:
Как и в двумерном случае, составляют систему нормальных уравнений
которую можно решить любым способом, известным из линейной алгебры. Рассмотрим один из них — способ обратной матрицы. Предварительно преобразуем систему уравнений. Выразим из первого уравнения значение через остальные параметры:
Подставим в остальные уравнения системы вместо полученное выражение:
Пусть С — матрица коэффициентов при неизвестных параметрах — матрица, обратная матрице С; — элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы — выражение
. Тогда, используя формулы линейной алгебры,
запишем окончательные выражения для параметров:
Оценкой остаточной дисперсии является
где — измеренное значение результативного признака; значение результативного признака, вычисленное по уравнению регрессий.
Если выборка получена из нормально распределенной генеральной совокупности, то, аналогично изложенному в п. 2.4, можно проверить значимость оценок коэффициентов регрессии, только в данном случае статистику вычисляют для каждого j-го коэффициента регрессии
где —элемент обратной матрицы, стоящий на пересечении i-й строки и j-
го столбца; —диагональный элемент обратной матрицы.
При заданном уровне значимости а и числе степеней свободы к=n— m—1 по табл. 1 приложений находят критическое значение Если то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
Для значимых коэффициентов регрессии целесообразно построить доверительные интервалы по формуле (2.10). Для оценки значимости уравнения регрессии следует проверить нулевую гипотезу о том, что все коэффициенты регрессии (кроме свободного члена) равны нулю: — вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики , где — сумма квадратов, характеризующая влияние признаков X; — остаточная сумма квадратов, характеризующая влияние неучтённых факторов; Для уровня значимости а и числа степеней свободы по табл. 3 приложений находят критическое значение Если то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
Факторный анализ
Основные положения. В последнее время всё более широкое распространение находит один из новых разделов многомерного статистического анализа — факторный анализ. Первоначально этот метод
разрабатывался для объяснения многообразия корреляций между исходными параметрами. Действительно, результатом корреляционного анализа является матрица коэффициентов корреляций. При малом числе параметров можно произвести визуальный анализ этой матрицы. С ростом числа параметра (10 и более) визуальный анализ не даёт положительных результатов. Оказалось, что всё многообразие корреляционных связей можно объяснить действием нескольких обобщённых факторов, являющихся функциями исследуемых параметров, причём сами обобщённые факторы при этом могут быть и неизвестны, однако их можно выразить через исследуемые параметры.
Один из основоположников факторного анализа Л. Терстоун приводит такой пример: несколько сотен мальчиков выполняют 20 разнообразных гимнастических упражнений. Каждое упражнение оценивают баллами. Можно рассчитать матрицу корреляций между 20 упражнениями. Это большая матрица размером 20><20. Изучая такую матрицу, трудно уловить закономерность связей между упражнениями. Нельзя ли объяснить скрытую в таблице закономерность действием каких-либо обобщённых факторов, которые в результате эксперимента непосредственно, не оценивались? Оказалось, что обо всех коэффициентах корреляции можно судить по трём обобщённым факторам, которые и определяют успех выполнения всех 20 гимнастических упражнений: чувство равновесия, усилие правого плеча, быстрота движения тела.
Дальнейшие разработки факторного анализа доказали, что этот метод может быть с успехом применён в задачах группировки и классификации объектов. Факторный анализ позволяет группировать объекты со сходными сочетаниями признаков и группировать признаки с общим характером изменения от объекта к объекту. Действительно, выделенные обобщённые факторы можно использовать как критерии при классификации мальчиков по способностям к отдельным группам гимнастических упражнений.
Методы факторного анализа находят применение в психологии и экономике, социологии и экономической географии. Факторы, выраженные через исходные параметры, как правило, легко интерпретировать как некоторые существенные внутренние характеристики объектов.
Факторный анализ может быть использован и как самостоятельный метод исследования, и вместе с другими методами многомерного анализа, например в сочетании с регрессионным анализом. В этом случае для набора зависимых переменных наводят обобщённые факторы, которые потом входят в регрессионный анализ в качестве переменных. Такой подход позволяет сократить число переменных в регрессионном анализе, устранить коррелированность переменных, уменьшить влияние ошибок и в случае ортогональности выделенных факторов значительно упростить оценку значимости переменных.
Представление, информации в факторном анализе
Для проведения факторного анализа информация должна быть представлена в виде двумерной таблицы чисел размерностью аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений столбцы — признакамтаким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных переходят к переменным В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
Основная модель факторного анализа. Основная модель факторного анализа имеет вид
где -j-й признак (величина случайная); — общие факторы (величины случайные, имеющие нормальный закон распределения); — характерный фактор; — факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению); — нагрузка характерного фактора.
Модель предполагает, что каждый из j признаков, входящих в исследуемый набор и заданных в стандартной форме, может быть представлен в виде линейной комбинации небольшого числа общих факторов и характерного фактора
Термин «общий фактор» подчёркивает, что каждый такой фактор имеет существенное значение для анализа всех признаков, т.е.
Термин «характерный фактор» показывает, что он относится только к данному j-му признаку. Это специфика признака, которая не может быть, выражена через факторы
Факторные нагрузки . характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
Для j-го признака и i-го объекта модель (2.19) можно записать в. виде
где значение k-го фактора для i-го объекта.
Дисперсию признака можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность и часть, обусловленную действием j-го характера фактора, характерность Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Если общие и характерные факторы не коррелируют между собой, то дисперсию j-го признака можно представить в виде
где —доля дисперсии признака приходящаяся на k-й фактор.
Полный вклад k-го фактора в суммарную дисперсию признаков
Вклад общих факторов в суммарную дисперсию
Факторное отображение
Используя модель (2.19), запишем выражения для каждого из параметров:
Коэффициенты системы (2,21) — факторные нагрузки — можно представить в виде матрицы, каждая строка которой соответствует параметру, а столбец — фактору.
Факторный анализ позволяет получить не только матрицу отображений, но и коэффициенты корреляции между параметрами и
факторами, что является важной характеристикой качества факторной модели. Таблица таких коэффициентов корреляции называется факторной структурой или просто структурой.
Коэффициенты отображения можно выразить через выборочные парные коэффициенты корреляции. На этом основаны методы вычисления факторного отображения.
Рассмотрим связь между элементами структуры и коэффициентами отображения. Для этого, учитывая выражение (2.19) и определение выборочного коэффициента корреляции, умножим уравнения системы (2.21) на соответствующие факторы, произведём суммирование по всем n наблюдениям и, разделив на n, получим следующую систему уравнений:
где — выборочный коэффициент корреляции между j-м параметром и к-
м фактором; — коэффициент корреляции между к-м и р-м факторами.
Если предположить, что общие факторы между собой, не коррелированы, то уравнения (2.22) можно записать в виде
, т.е. коэффициенты отображения равны
элементам структуры.
Введём понятие, остаточного коэффициента корреляции и остаточной корреляционной матрицы. Исходной информацией для построения факторной модели (2.19) служит матрица выборочных парных коэффициентов корреляции. Используя построенную факторную модель, можно снова вычислить коэффициенты корреляции между признаками и сравнись их с исходными Коэффициентами корреляции. Разница между ними и есть остаточный коэффициент корреляции.
В случае независимости факторов имеют место совсем простые выражения для вычисляемых коэффициентов корреляции между параметрами: для их вычисления достаточно взять сумму произведений коэффициентов отображения, соответствующих наблюдавшимся признакам:
где —вычисленный по отображению коэффициент корреляции между j-м
и к-м признаком. Остаточный коэффициент корреляции
Матрица остаточных коэффициентов корреляции называется остаточной матрицей или матрицей остатков
где — матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
Результаты факторного анализа удобно представить в виде табл. 2.10.
Здесь суммы квадратов нагрузок по строкам — общности параметров, а суммы квадратов нагрузок по столбцам — вклады факторов в суммарную дисперсию параметров. Имеет место соотношение
Определение факторных нагрузок
Матрицу факторных нагрузок можно получить различными способами. В настоящее время наибольшее распространение получил метод главных факторов. Этот метод основан на принципе последовательных приближений и позволяет достичь любой точности. Метод главных факторов предполагает использование ЭВМ. Существуют хорошие алгоритмы и программы, реализующие все вычислительные процедуры.
Введём понятие редуцированной корреляционной матрицы или просто редуцированной матрицы. Редуцированной называется матрица выборочных коэффициентов корреляции у которой на главной диагонали стоят значения общностей :
Редуцированная и полная матрицы связаны соотношением
где D — матрица характерностей.
Общности, как правило, неизвестны, и нахождение их в факторном анализе представляет серьезную проблему. Вначале определяют (хотя бы приближённо) число общих факторов, совокупность, которых может с достаточной точностью аппроксимировать все взаимосвязи выборочной корреляционной матрицы. Доказано, что число общих факторов (общностей) равно рангу редуцированной матрицы, а при известном ранге можно по выборочной корреляционной матрице найти оценки общностей. Числа общих факторов можно определить априори, исходя из физической природы эксперимента. Затем рассчитывают матрицу факторных нагрузок. Такая матрица, рассчитанная методом главных факторов, обладает одним интересным свойством: сумма произведений каждой пары её столбцов равна нулю, т.е. факторы попарно ортогональны.
Сама процедура нахождения факторных нагрузок, т.е. матрицы А, состоит из нескольких шагов и заключается в следующем: на первом шаге ищут коэффициенты факторных нагрузок при первом факторе так, чтобы сумма вкладов данного фактора в суммарную общность была максимальной:
Максимум должен быть найден при условии
где —общностьпараметра
Затем рассчитывают матрицу коэффициентов корреляции с учётом только первого фактора Имея эту матрицу, получают первую матрицу остатков:
На втором шаге определяют коэффициенты нагрузок при втором факторе так, чтобы сумма вкладов второго фактора в остаточную общность (т.е. полную общность без учёта той части, которая приходится на долю первого фактора) была максимальной. Сумма квадратов нагрузок при втором факторе
Максимум находят из условия
где — коэффициент корреляции из первой матрицы остатков; — факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков:
Факторный анализ учитывает суммарную общность. Исходная суммарная общность Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на — наперёд заданное малое число).
Адекватность факторной модели оценивается по матрице остатков (если величины её коэффициентов малы, то модель считают адекватной).
Такова последовательность шагов для нахождения факторных нагрузок. Для нахождения максимума функции (2.24) при условии (2.25) используют метод множителей Лагранжа, который приводит к системе т уравнений относительно m неизвестных
Метод главных компонент
Разновидностью метода главных факторов является метод главных компонент или компонентный анализ, который реализует модель вида
где m — количество параметров (признаков).
Каждый из наблюдаемых, параметров линейно зависит от m не коррелированных между собой новых компонент (факторов) По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
Если для дальнейшего анализа оставить все найденные т компонент, то тем самым будет использована вся информация, заложенная в корреляционной матрице. Однако это неудобно и нецелесообразно. На практике обычно оставляют небольшое число компонент, причём количество их определяется долей суммарной дисперсии, учитываемой этими компонентами. Существуют различные критерии для оценки числа оставляемых компонент; чаще всего используют следующий простой критерий: оставляют столько компонент, чтобы суммарная дисперсия, учитываемая ими, составляла заранее установленное число процентов. Первая из компонент должна учитывать максимум суммарной дисперсии параметров; вторая — не коррелировать с первой и учитывать максимум оставшейся дисперсии и так до тех пор, пока вся дисперсия не будет учтена. Сумма учтённых всеми компонентами дисперсий равна сумме дисперсий исходных параметров. Математический аппарат компонентного анализа полностью совпадает с аппаратом метода главных факторов. Отличие только в исходной матрице корреляций.
Компонента (или фактор) через исходные переменные выражается следующим образом:
где — элементы факторного решения:— исходные переменные; .— k-е собственное значение; р — количество оставленных главных
компонент.
Для иллюстрации возможностей факторного анализа покажем, как, используя метод главных компонент, можно сократить размерность пространства независимых переменных, перейдя от взаимно коррелированных параметров к независимым факторам, число которых р
Следует особо остановиться на интерпретации результатов, т.е. на смысловой стороне факторного анализа. Собственно факторный анализ состоит из двух важных этапов; аппроксимации корреляционной матрицы и интерпретации результатов. Аппроксимировать корреляционную матрицу, т.е. объяснить корреляцию между параметрами действием каких-либо общих для них факторов, и выделить сильно коррелирующие группы параметров достаточно просто: из корреляционной матрицы одним из методов
факторного анализа непосредственно получают матрицу нагрузок — факторное решение, которое называют прямым факторным решением. Однако часто это решение не удовлетворяет исследователей. Они хотят интерпретировать фактор как скрытый, но существенный параметр, поведение которого определяет поведение некоторой своей группы наблюдаемых параметров, в то время как, поведение других параметров определяется поведением других факторов. Для этого у каждого параметра должна быть наибольшая по модулю факторная нагрузка с одним общим фактором. Прямое решение следует преобразовать, что равносильно повороту осей общих факторов. Такие преобразования называют вращениями, в итоге получают косвенное факторное решение, которое и является результатом факторного анализа.
Приложения
Значение t — распределения Стьюдента
Понятие о регрессионном анализе. Линейная выборочная регрессия. Метод наименьших квадратов (МНК)
Основные задачи регрессионного анализа:
- Вычисление выборочных коэффициентов регрессии
- Проверка значимости коэффициентов регрессии
- Проверка адекватности модели
- Выбор лучшей регрессии
- Вычисление стандартных ошибок, анализ остатков
Построение простой регрессии по экспериментальным данным.
Предположим, что случайные величины связаны линейной корреляционной зависимостью для отыскания которой проведено независимых измерений
Диаграмма рассеяния (разброса, рассеивания)
— координаты экспериментальных точек.
Выборочное уравнение прямой линии регрессии имеет вид
Задача: подобрать таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой
Для того, что бы провести прямую воспользуемся МНК. Потребуем,
чтобы
Постулаты регрессионного анализа, которые должны выполняться при использовании МНК.
- подчинены нормальному закону распределения.
- Дисперсия постоянна и не зависит от номера измерения.
- Результаты наблюдений в разных точках независимы.
- Входные переменные независимы, неслучайны и измеряются без ошибок.
Введем функцию ошибок и найдём её минимальное значение
Решив систему, получим искомые значения
является несмещенными оценками истинных значений коэффициентов
где
несмещенная оценка корреляционного момента (ковариации),
несмещенная оценка дисперсии
выборочная ковариация,
выборочная дисперсия
— выборочный коэффициент корреляции
Коэффициент детерминации
— наблюдаемое экспериментальное значение при
— предсказанное значение удовлетворяющее уравнению регрессии
— средневыборочное значение
— коэффициент детерминации, доля изменчивости объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии
Коэффициент детерминации принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это используется для доказательства адекватности модели (качества регрессии). Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 0,5 (в этом случае коэффициент множественной корреляции превышает по модулю 0,7). Модели с коэффициентом детерминации выше 0,8 можно признать достаточно хорошими (коэффициент корреляции превышает 0,9). Подтверждение адекватности модели проводится на основе дисперсионного анализа путем проверки гипотезы о значимости коэффициента детерминации.
регрессия незначима
регрессия значима
— уровень значимости
— статистический критерий
Критическая область — правосторонняя;
Если то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
Мощность статистического критерия. Функция мощности
Определение. Мощностью критерия называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
Задача: построить критическую область таким образом, чтобы мощность критерия была максимальной.
Определение. Наилучшей критической областью (НКО) называют критическую область, которая обеспечивает минимальную ошибку второго рода
Пример:
По паспортным данным автомобиля расход топлива на 100 километров составляет 10 литров. В результате измерения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки были проведены испытания 25 автомобилей с модернизированным двигателем; выборочная средняя расхода топлива по результатам испытаний составила 9,3 литра. Предполагая, что выборка получена из нормально распределенной генеральной совокупности с математическим ожиданием и дисперсией проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
3) Уровень значимости
4) Статистический критерий
5) Критическая область — левосторонняя
следовательно отвергается на уровне значимости
Пример:
В условиях примера 1 предположим, что наряду с рассматривается конкурирующая гипотеза а критическая область задана неравенством Найти вероятность ошибок I рода и II рода.
автомобилей имеют меньший расход топлива)
автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
Определение. Пусть проверяется — критическая область критерия с заданным уровнем значимости Функцией мощности критерия называется вероятность отклонения как функция параметра т.е.
— ошибка 1-ого рода
— мощность критерия
Пример:
Построить график функции мощности из примера 2 для
попадает в критическую область.
Пример:
Какой минимальный объем выборки следует взять в условии примера 2 для того, чтобы обеспечить
Лемма Неймана-Пирсона.
При проверке простой гипотезы против простой альтернативной гипотезы наилучшая критическая область (НКО) критерия заданного уровня значимости состоит из точек выборочного пространства (выборок объема для которых справедливо неравенство:
— константа, зависящая от
— элементы выборки;
— функция правдоподобия при условии, что соответствующая гипотеза верна.
Пример:
Случайная величина имеет нормальное распределение с параметрами известно. Найти НКО для проверки против причем
Решение:
Ошибка первого рода:
НКО:
Пример:
Для зависимости заданной корреляционной табл. 13, найти оценки параметров уравнения линейной регрессии остаточную дисперсию; выяснить значимость уравнения регрессии при
Решение. Воспользуемся предыдущими результатами
Согласно формуле (24), уравнение регрессии будет иметь вид тогда
Для выяснения значимости уравнения регрессии вычислим суммы Составим расчетную таблицу:
Из (27) и (28) по данным таблицы получим
по табл. П7 находим
Вычислим статистику
Так как то уравнение регрессии значимо. Остаточная дисперсия равна
- Корреляционный анализ
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
Предположение о постоянной дисперсии: определение и пример
17 авг. 2022 г.
читать 2 мин
Линейная регрессия — это метод, который мы используем для количественной оценки взаимосвязи между одной или несколькими переменными-предикторами и переменной- откликом .
Одно из ключевых предположений линейной регрессии состоит в том, что остатки имеют постоянную дисперсию на каждом уровне предиктора (переменных).
Если это предположение не выполняется, говорят, что остатки страдают гетероскедастичностью.Когда это происходит, оценки коэффициентов модели становятся ненадежными.
Как оценить постоянную дисперсию
Наиболее распространенный способ определить, имеют ли остаточные значения регрессионной модели постоянную дисперсию, — это построить график сопоставления подходящих значений с остаточными значениями .
Это тип графика, который отображает подогнанные значения регрессионной модели по оси x и остатки этих подогнанных значений по оси y.
Если разброс остатков примерно одинаков на каждом уровне подобранных значений, мы говорим, что выполняется предположение о постоянной дисперсии.
В противном случае, если разброс остатков систематически увеличивается или уменьшается, это предположение, вероятно, нарушается.
Примечание.Этот тип графика можно создать только после подбора регрессионной модели к набору данных.
На следующем графике показан пример графика сопоставленных значений и остатка, который отображает постоянную дисперсию :

Обратите внимание, как остатки случайным образом разбросаны вокруг нуля без какой-либо конкретной закономерности с примерно постоянной дисперсией на каждом уровне подобранных значений.
На следующем графике показан пример графика сопоставления подобранных значений и остатка, который отображает непостоянную дисперсию :

Обратите внимание, что разброс остатков становится все больше и больше по мере увеличения подогнанных значений. Это типичный признак непостоянной дисперсии.
Это говорит нам о том, что наша регрессионная модель страдает непостоянной дисперсией остатков, и поэтому оценки коэффициентов модели ненадежны.
Как исправить нарушение постоянной дисперсии
Если предположение о постоянной дисперсии нарушается, наиболее распространенный способ справиться с этим — преобразовать переменную отклика с помощью одного из трех преобразований:
1. Преобразование журнала: преобразование переменной ответа из y в log(y)
2. Преобразование квадратного корня: преобразование переменной отклика из y в √ y
3. Преобразование кубического корня: преобразование переменной ответа из y в y 1/3
Выполняя эти преобразования, проблема непостоянной дисперсии обычно исчезает.
Дополнительные ресурсы
В следующих руководствах представлена дополнительная информация о линейной регрессии и анализе невязок:
Введение в простую линейную регрессию
Введение в множественную линейную регрессию
Четыре допущения линейной регрессии
Что такое остатки в статистике?
| layout | use_math |
|---|---|
|
default |
true |
Previous: Chapter 2 — Statistical Learning
Chapter 3 — Linear Regression
Simple Linear Regression
Simple linear regression predicts a
quantitative response $$ Y $$ on the basis of a single predictor variable $$ X .
$$ It assumes an approximately linear relationship between $$ X $$ and $$ Y . $$
Formally,
$$ normalsize Y approx beta_{0} + beta_{1}X $$
where $$ beta_{0} $$ represents the intercept or the
value of $$ Y $$ when $$ X $$ is equal to $$ 0 $$ and $$ beta_{1} $$ represents
the slope of the line or the average amount of change in $$ Y
$$ for each one-unit increase in $$ X . $$
Together, $$ beta_{0} $$ and $$ beta_{1} $$ are known as the model
coefficients or parameters.
Estimating Model Coefficients
Since $$ beta_{0} $$ and $$ beta_{1} $$ are typically unknown, it is first
necessary to estimate the coefficients before making predictions. To estimate
the coefficients, it is desirable to choose values for $$ beta_{0} $$ and $$
beta_{1} $$ such that the resulting line is as close as possible to the
observed data points.
There are many ways of measuring closeness. The most common method strives to
minimizes the sum of the residual square differences
between the $$ i text{th} $$ observed value and the $$ i text{th} $$ predicted
value.
Assuming the $$ i text{th} $$ prediction of $$ Y $$ is described as
$$ normalsize hat{y_{i}} = hat{beta_{0}} + hat{beta_{1}}x_{i} $$
then the $$ i text{th} $$ residual can be represented as
$$ normalsize e_{i} = y_{i} — hat{y_{i}} = y_{i} — hat{beta_{0}} —
hat{beta_{1}}x_{i} . $$
The residual sum of squares can then be
described as
$$ normalsize RSS = e_{1}^2 + e_{2}^2 + ldots + e_{n}^2 $$
or
$$ normalsize RSS = (y_{1} — hat{beta_{0}} — hat{beta_{1}}x_{1})^2 + (y_{2}
- hat{beta_{0}} — hat{beta_{1}}x_{2})^2 + ldots + (y_{n} — hat{beta_{0}}
- hat{beta_{1}}x_{n})^2 .$$
Assuming sample means of
$$ normalsize bar{y} = frac{1}{n} sum_{i=1}^{n} y_{i} $$
and
$$ normalsize bar{x} = frac{1}{n} sum_{i=1}^{n} x_{i} , $$
calculus can be applied to estimate the least squares coefficient estimates for
linear regression to minimize the residual sum of squares like so
$$ normalsize beta_{1} = frac{sum_{i=1}^{n}(x_{i} — bar{x})(y_{i} —
bar{y})}{sum_{i=1}^{n}(x_{i} — bar{x})^2} $$
$$ normalsize beta_{0} = bar{y} — hat{beta_{1}}bar{x} $$
Assessing Coefficient Estimate Accuracy
Simple linear regression represents the relationship between $$ Y $$ and $$ X $$
as
$$ normalsize Y = beta_{0} + beta_{1}X + epsilon $$
where $$ beta_{0} $$ is the intercept term, or the value of $$ Y $$ when $$ X =
0 $$; $$ beta_{1} $$ is the slope, or average increase in $$ Y $$ associated
with a one-unit increase in $$ X $$; and $$ epsilon $$ is the error term which
acts as a catchall for what is missed by the simple model given that the true
relationship likely isn’t linear, there may be other variables that affect $$ Y
$$, and/or there may be error in the observed measurements. The error term is
typically assumed to be independent of $$ X . $$
The model used by simple linear regression defines the population
regression line, which describes the best
linear approximation to the true relationship between $$ X $$ and $$ Y $$ for
the population.
The coefficient estimates yielded by least squares regression characterize the
least squares line,
$$ normalsize hat{y_{i}} = hat{beta_{0}} + hat{beta_{1}}x_{i} . $$
The difference between the population regression line and the least squares
line is similar to the difference that emerges when using a sample to estimate
the characteristics of a large population.
In linear regression, the unknown coefficients, $$ beta_{0} $$ and $$ beta_{1}
$$ define the population regression line, whereas the estimates of those
coefficients, $$ hat{beta_{0}} $$ and $$ hat{beta_{1}} $$ define the least
squares line.
Though the parameter estimates for a given sample may overestimate or
underestimate the value of a particular parameter, an unbiased
estimator does not systemically overestimate or
underestimate the true parameter.
This means that using an unbiased estimator and a large number of data sets, the
values of the coefficients $$ beta_{0} $$ and $$ beta_{1} $$ could be
determined by averaging the coefficient estimates from each of those data sets.
To estimate the accuracy of a single estimated value, such as an average, it can
be helpful to calculate the standard error of the
estimated value $$ hat{mu} $$, which can be accomplished like so
$$ normalsize mathrm{Var}(hat{mu}) = mathrm{SE}(hat{mu})^2 =
frac{sigma^{2}}{n} $$
where $$ sigma $$ is the standard deviation of each $$ y_{i} . $$
Roughly, the standard error describes the average amount that the estimate $$
hat{mu} $$ differs from $$ mu . $$
The more observations, the larger $$ n $$, the smaller the standard error.
To compute the standard errors associated with $$ beta_{0} $$ and $$ beta_{1}
$$, the following formulas can be used:
$$ normalsize mathrm{SE}(beta_{0})^{2} = sigma^{2}bigg[frac{1}{n} +
frac{bar{x}^{2}}{sum_{i=1}^{n}(x_{i} — bar{x})^2}bigg] $$
and
$$ normalsize mathrm{SE}(beta_{1})^{2} =
frac{sigma^{2}}{sum_{i=1}^{n}(x_{i} — bar{x})^2} $$
where $$ sigma^{2} = mathrm{Var}(epsilon) $$ and $$ epsilon_{i} $$ is not
correlated with $$ sigma^{2} . $$
$$ sigma^{2} $$ generally isn’t known, but can be estimated from the data. The
estimate of $$ sigma $$ is known as the residual standard
error and can be calculated with the
following formula
$$ normalsize mathrm{RSE} = sqrt{frac{mathrm{RSS}}{(n — 2)}} $$
where $$ mathrm{RSS} $$ is the residual sum of squares.
Standard errors can be used to compute confidence intervals and prediction
intervals.
A confidence interval is defined as a range of
values such that there’s a certain likelihood that the range will contain the
true unknown value of the parameter.
For simple linear regression the 95% confidence interval for $$ beta_{1} $$ can be
approximated by
$$ normalsize hat{beta_{1}} pm 2 times mathrm{SE}(hat{beta_{1}}) . $$
Similarly, a confidence interval for $$ beta_{0} $$ can be approximated as
$$ normalsize hat{beta_{0}} pm 2 times mathrm{SE}(hat{beta_{0}}) . $$
The accuracy of an estimated prediction depends on whether we wish to predict an
individual response, $$ y = f(x) + epsilon $$, or the average response, $$ f(x)
. $$
When predicting an individual response, $$ y = f(x) + epsilon $$, a prediction
interval is used.
When predicting an average response, $$ f(x) $$, a confidence interval is used.
Prediction intervals will always be wider than confidence intervals because they
take into account the uncertainty associated with $$ epsilon $$, the
irreducible error.
The standard error can also be used to perform hypothesis
testing on the estimated coefficients.
The most common hypothesis test involves testing the null
hypothesis that states
$$ H_{0} $$: There is no relationship between $$ X $$ and $$ Y $$
versus the alternative hypothesis
$$ H_{1} $$: Thee is some relationship between $$ X $$ and $$ Y . $$
In mathematical terms, the null hypothesis corresponds to testing if $$
beta_{1} = 0 $$, which reduces to
$$ normalsize Y = beta_{0} + epsilon $$
which evidences that $$ X $$ is not related to $$ Y . $$
To test the null hypothesis, it is necessary to determine whether the estimate
of $$ beta_{1} $$, $$ hat{beta_{1}} $$, is sufficiently far from zero to provide
confidence that $$ beta_{1} $$ is non-zero.
How close is close enough depends on $$ mathrm{SE}(hat{beta_{1}}) . $$ When
$$ mathrm{SE}(hat{beta_{1}}) $$ is small, then small values of $$
hat{beta_{1}} $$ may provide strong evidence that $$ beta_{1} $$ is not zero.
Conversely, if $$ mathrm{SE}(hat{beta_{1}}) $$ is large, then $$
hat{beta_{1}} $$ will need to be large in order to reject the null hypothesis.
In practice, computing a T-statistic, which measures the
number of standard deviations that $$ hat{beta_{1}} $$, is away from $$ 0 $$,
is useful for determining if an estimate is sufficiently significant to reject
the null hypothesis.
A T-statistic can be computed as follows
$$ normalsize t = frac{hat{beta}{1} — 0}{mathrm{SE}(hat{beta{1}})} $$
If there is no relationship between $$ X $$ and $$ Y $$, it is expected that a
t-distribution with $$ n — 2 $$ degrees of freedom
should be yielded.
With such a distribution, it is possible to calculate the probability of
observing a value of $$ |t| $$ or larger assuming that $$ hat{beta_{1}} = 0 .
$$ This probability, called the p-value, can indicate an
association between the predictor and the response if sufficiently small.
Assessing Model Accuracy
Once the null hypothesis has been rejected, it may be desirable to quantify to
what extent the model fits the data. The quality of a linear regression model is
typically assessed using residual standard
error (RSE) and the $$ R^{2} $$
statistic statistic.
The residual standard error is an estimate of the standard deviation of $$
epsilon $$, the irreducible error.
In rough terms, the residual standard error is the average amount by which the
response will deviate from the true regression line.
For linear regression, the residual standard error can be computed as
$$ normalsize mathrm{RSE} = sqrt{frac{1}{n-2}mathrm{RSS}} =
sqrt{frac{1}{n-2}sum_{i=1}^{n}(y_{i} — hat{y}_{i})^{2}} $$
The residual standard error is a measure of the lack of fit of the model to the
data. When the values of $$ y_{i} approx hat{y}{i} $$, the RSE will be small
and the model will fit the data well. Conversely, if $$ y{i} ne hat{y_{i}} $$
for some values, the RSE may be large, indicating that the model doesn’t fit the
data well.
The RSE provides an absolute measure of the lack of fit of the model in the
units of $$ Y . $$ This can make it difficult to know what constitutes a good
RSE value.
The $$ R^{2} $$ statistic is an alternative
measure of fit that takes the form of a proportion. The $$ R^{2} $$ statistic
captures the proportion of variance explained as a value between $$ 0 $$ and $$
1 $$, independent of the unit of $$ Y . $$
To calculate the $$ R^2 $$ statistic, the following formula may be used
$$ normalsize R^{2} = frac{mathrm{TSS}-mathrm{RSS}}{mathrm{TSS}} = 1 —
frac{mathrm{RSS}}{mathrm{TSS}} $$
where
$$ normalsize mathrm{RSS} = sum_{i=1}^{n}(y_{i} — hat{y}_{i})^{2} $$
and
$$ normalsize mathrm{TSS} = sum_{i=1}^{n}(y_{i} — bar{y}_{i})^{2} . $$
The total sum of squares, TSS, measures the
total variance in the response $$ Y . $$ The TSS can be thought of as the total
variability in the response before applying linear regression. Conversely, the
residual sum of squares, RSS, measures the amount of variability left after
performing the regression.
Ergo, $$ TSS — RSS $$ measures the amount of variability in the response that is
explained by the model. $$ R^{2} $$ measures the proportion of variability in $$
Y $$ that can be explained by $$ X . $$ An $$ R^{2} $$ statistic close to $$ 1 $$
indicates that a large portion of the variability in the response is explained
by the model. An $$ R^{2} $$ value near $$ 0 $$ indicates that the model
accounted for very little of the variability of the model.
An $$ R^{2} $$ value near $$ 0 $$ may occur because the linear model is wrong
and/or because the inherent $$ sigma^{2} $$ is high.
$$ R^{2} $$ has an advantage over RSE since it will always yield a value between
$$ 0 $$ and $$ 1 $$, but it can still be tough to know what a good $$ R^{2} $$
value is. Frequently, what constitutes a good $$ R^{2} $$ value depends on the
application and what is known about the problem.
The $$ R^{2} $$ statistic is a measure of the linear relationship between $$ X
$$ and $$ Y . $$
Correlation is another measure of the linear
relationship between $$ X $$ and $$ Y . $$ Correlation of can be calculated as
$$ normalsize mathrm{Cor}(X,Y) = frac{sum_{i=1}^{n}(x_{i} — bar{x})(y_{i} —
bar{y})}{sqrt{sum_{i=1}^{n}(x_{i} —
bar{x})^{2}}sqrt{sum_{i=1}^{n}(y_{i}-bar{y})^{2}}} $$
This suggests that $$ r = mathrm{Cor}(X,Y) $$ could be used instead of $$ R^{2}
$$ to assess the fit of the linear model, however for simple linear regression
it can be shown that $$ R^{2} = r^{2} . $$ More concisely, for simple linear
regression, the squared correlation and the $$ R^{2} $$ statistic are
equivalent. Though this is the case for simple linear regression, correlation
does not extend to multiple linear regression since correlation quantifies the
association between a single pair of variables. The $$ R^{2} $$ statistic can,
however, be applied to multiple regression.
Multiple Regression
The multiple linear regression model
takes the form of
$$ normalsize Y = beta_{0} + beta_{1}X_{1} + beta_{2}X_{2} + ldots +
beta_{p}X_{p} + epsilon . $$
Multiple linear regression extends simple linear regression to accommodate
multiple predictors.
$$ X_{j} $$ represents the $$ j text{th} $$ predictor and $$ beta_{j} $$ represents
the average effect of a one-unit increase in $$ X_{j} $$ on $$ Y $$, holding all
other predictors fixed.
Estimating Multiple Regression Coefficients
Because the coefficients $$ beta_{0}, beta_{1}, ldots, beta_{p} $$ are
unknown, it is necessary to estimate their values. Given estimates of $$
hat{beta_{0}}, hat{beta_{1}}, ldots, hat{beta_{p}} $$, estimates can be
made using the formula below
$$ normalsize hat{y} = hat{beta_{0}} + hat{beta_{1}}x_{1} + hat{beta_{2}}x_{2} +
ldots + hat{beta_{p}}x_{p} $$
The parameters $$ hat{beta_{0}}, hat{beta_{1}}, ldots, hat{beta_{p}} $$
can be estimated using the same least squares strategy as was employed for
simple linear regression. Values are chosen for the parameters $$
hat{beta_{0}}, hat{beta_{1}}, ldots, hat{beta_{p}} $$ such that the
residual sum of squares is minimized
$$ normalsize RSS = sum_{i=1}^{n}(y_{i} — hat{y}{i})^{2} =
sum{i=1}^{n}(y_{i} — hat{beta_{0}} — hat{beta_{1}}x_{1} —
hat{beta_{2}}x_{2} — ldots — hat{beta_{p}}x_{p})^{2} $$
Estimating the values of these parameters is best achieved with matrix algebra.
Assessing Multiple Regression Coefficient Accuracy
Once estimates have been derived, it is next appropriate to test the null
hypothesis
$$ normalsize H_{0}: beta_{1} = beta_{2} = ldots = beta_{p} = 0 $$
versus the alternative hypothesis
$$ H_{a}: at least one of B_{j} ne 0 . $$
The F-statistic can be used to determine which
hypothesis holds true.
The F-statistic can be computed as
$$ normalsize mathrm{F} = frac{(mathrm{TSS} —
mathrm{RSS})/p}{mathrm{RSS}/(n — p — 1)} = frac{frac{mathrm{TSS} —
mathrm{RSS}}{p}}{frac{mathrm{RSS}}{n — p
- 1}} $$
where, again,
$$ normalsize mathrm{TSS} = sum_{i=1}^{n}(y_{i} — bar{y}_{i})^{2} $$
and
$$ normalsize mathrm{RSS} = sum_{i=1}^{n}(y_{i} — hat{y}_{i})^2 $$
If the assumptions of the linear model, represented by the alternative
hypothesis, are true it can be shown that
$$ normalsize mathrm{E}{frac{mathrm{RSS}}{n — p — 1}} = sigma^{2} $$
Conversely, if the null hypothesis is true, it can be shown that
$$ normalsize mathrm{E}{frac{mathrm{TSS} — mathrm{RSS}}{p}} = sigma^{2} $$
This means that when there is no relationship between the response and the
predictors the F-statisitic takes on a value close to $$ 1 . $$
Conversely, if the alternative hypothesis is true, then the F-statistic will
take on a value greater than $$ 1 . $$
When $$ n $$ is large, an F-statistic only slightly greater than $$ 1 $$ may
provide evidence against the null hypothesis. If $$ n $$ is small, a large
F-statistic is needed to reject the null hypothesis.
When the null hypothesis is true and the errors $$ epsilon_{i} $$ have a normal
distribution, the F-statistic follows and
F-distribution. Using the F-distribution, it is
possible to figure out a p-value for the given $$ n $$, $$ p $$, and
F-statistic. Based on the obtained p-value, the validity of the null hypothesis
can be determined.
It is sometimes desirable to test that a particular subset of $$ q $$
coefficients are $$ 0 . $$ This equates to a null hypothesis of
$$ normalsize H_{0}: beta_{p — q + 1} = beta_{p — q + 2} = ldots = beta_{p}
= 0 . $$
Supposing that the residual sum of squares for such a model is $$
mathrm{RSS}_{0} $$ then the F-statistic could be calculated as
$$ normalsize mathrm{F} = frac{(mathrm{RSS}{0} —
mathrm{RSS})/q}{mathrm{RSS}/(n — p — 1)} = frac{frac{mathrm{RSS}{0} —
mathrm{RSS}}{q}}{frac{mathrm{RSS}}{n — p
- 1}} . $$
Even in the presence of p-values for each individual variable, it is still
important to consider the overall F-statistic because there is a reasonably high
likelihood that a variable with a small p-value will occur just by chance, even
in the absence of any true association between the predictors and the response.
In contrast, the F-statistic does not suffer from this problem because it
adjusts for the number of predictors. The F-statistic is not infallible and when
the null hypothesis is true the F-statistic can still result in p-values below
$$ 0.05 $$ about 5% of the time regardless of the number of predictors or the
number of observations.
The F-statistic works best when $$ p $$ is relatively small or when $$ p $$ is
relatively small compared to $$ n . $$
When $$ p $$ is greater than $$ n $$, multiple linear regression using least
squares will not work, and similarly, the F-statistic cannot be used either.
Selecting Important Variables
Once it has been established that at least one of the predictors is associated
with the response, the question remains, which of the predictors is related to
the response? The process of removing extraneous predictors that don’t relate to
the response is called variable selection.
Ideally, the process of variable selection would involve testing many different
models, each with a different subset of the predictors, then selecting the best
model of the bunch, with the meaning of «best» being derived from various
statistical methods.
Regrettably, there are a total of $$ 2^{p} $$ models that contain subsets of $$
p $$ predictors. Because of this, an efficient and automated means of choosing a
smaller subset of models is needed. There are a number of statistical approaches
to limiting the range of possible models.
Forward selection begins with a null
model, a model that has an intercept but no predictors,
and attempts $$ p $$ simple linear regressions, keeping whichever predictor
results in the lowest residual sum of squares. In this fashion, the predictor
yielding the lowest RSS is added to the model one-by-one until some halting
condition is met. Forward selection is a greedy process and it may include
extraneous variables.
Backward selection begins with a model that
includes all the predictors and proceeds by removing the variable with the
highest p-value each iteration until some stopping condition is met. Backwards
selection cannot be used when $$ p > n . $$
Mixed selection begins with a null model, like
forward selection, repeatedly adding whichever predictor yields the best fit. As
more predictors are added, the p-values become larger. When this happens, if the
p-value for one of the variables exceeds a certain threshold, that variable is
removed from the model. The selection process continues in this forward and
backward manner until all the variables in the model have sufficiently low
p-values and all the predictors excluded from the model would result in a high
p-value if added to the model.
Assessing Multiple Regression Model Fit
While in simple linear regression the $$ mathrm{R}^{2} $$, the fraction of
variance explained, is equal to $$ mathrm{Cor}(X, Y) , $$ in multiple linear
regression, $$ mathrm{R}^{2} $$ is equal to $$ mathrm{Cor}(Y, hat{Y})^{2} .
$$ In other words, $$ mathrm{R}^{2} $$ is equal to the square of the
correlation between the response and the fitted linear model. In fact, the
fitted linear model maximizes this correlation among all possible linear models.
An $$ mathrm{R}^{2} $$ close to $$ 1 $$ indicates that the model explains a
large portion of the variance in the response variable. However, it should be
noted that $$ mathrm{R}^{2} $$ will always increase when more variables are
added to the model, even when those variables are only weakly related to the
response. This happens because adding another variable to the least squares
equation will always yield a closer fit to the training data, though it won’t
necessarily yield a closer fit to the test data.
Residual standard error, RSE, can also be
used to assess the fit of a multiple linear regression model. In general, RSE
can be calculated as
$$ normalsize RSE = sqrt{frac{mathrm{RSS}}{n — p — 1}} $$
which simplifies to the following for simple linear regression
$$ normalsize RSE = sqrt{frac{mathrm{RSS}}{n — 2}} . $$
Given the definition of RSE for multiple linear regression, it can be seen that
models with more variables can have a higher RSE if the decrease in RSS is small
relative to the increase in $$ p . $$
In addition to $$ mathrm{R}^{2} $$ and RSE, it can also be useful to plot the
data to verify the model.
Once coefficients have been estimated, making predictions is a simple as
plugging the coefficients and predictor values into the multiple linear model
$$ normalsize hat{y} = hat{beta_{0}} + hat{beta_{1}}x_{1} +
hat{beta_{2}}x_{2} + ldots + hat{beta_{p}}x_{p} . $$
However, it should be noted that these predictions will be subject to three
types of uncertainty.
-
The coefficient estimates, $$ hat{beta}{0}, hat{beta}{1}, ldots,
hat{beta}{p}, $$ are only estimates of the actual coefficients $$ beta{0},
beta_{1}, ldots, beta_{p}. $$ That is to say, the least squares plane is only
an estimate of the true population regression plane. The error introduced by
this inaccuracy is reducible error and a confidence interval can be computed to
determine how close $$ hat{y} $$ is to $$ f(X) . $$ -
Assuming a linear model for $$ f(X) $$ is almost always an approximation of
reality, which means additional reducible error is introduced due to model bias.
A linear model often models the best linear approximation of the true,
non-linear surface. -
Even in the case where $$ f(X) $$ and the true values of the
coefficients, $$ beta_{0}, ldots,, beta_{p} $$ are known, the response value
cannot be predicted exactly because of the random, irreducible error $$ epsilon
$$, in the model. How much $$ hat{Y} $$ will tend to vary from $$ Y $$ can be
determined using prediction intervals.
Prediction intervals will always be wider than confidence intervals because they
incorporate both the error in the estimate of $$ f(X) $$, the reducible error,
and the variation in how each point differs from the population regression
plane, the irreducible error.
Qualitative predictors
Linear regression can also accommodate qualitative variables.
When a qualitative predictor or factor has only two possible values or levels,
it can be incorporated into the model my introducing an indicator
variable or
dummy variable that takes on only two numerical
values.
For example, using a coding like
$$ normalsize X_{i} = left{ begin{array}{cc}
1&mathrm{if p_{i} = class A}\
0&mathrm{if p_{i} = class B}
end{array} right. $$
yields a regression equation like
$$ normalsize y_{i} = beta_{0} + beta_{1}X_{1} + epsilon_{i} =
left{ begin{array}{cc}
beta_{0} + beta_{1} + epsilon_{i}&mathrm{if p_{i} = class A}\
beta_{0} + epsilon_{i}&mathrm{if p_{i} = class B}
end{array} right. $$
Given such a coding, $$ beta_{1} $$ represents the average difference in $$
X_{1} $$ between classes A and B.
Alternatively, a dummy variable like the following could be used
$$ normalsize X_{i} = left{ begin{array}{cc}
1&mathrm{if p_{i} = class A}\
-1&mathrm{if p_{i} = class B}
end{array} right. $$
which results in a regression model like
$$ normalsize y_{i} = beta_{0} + beta_{1}X_{1} + epsilon_{i} =
left{ begin{array}{cc}
beta_{0} + beta_{1} + epsilon_{i}&mathrm{if p_{i} = class A}\
beta_{0} — beta_{1} + epsilon_{i}&mathrm{if p_{i} = class B}
end{array} right. . $$
In which case, $$ beta_{0} $$ represents the overall average and $$ beta_{1}
$$ is the amount class A is above the average and class B below the average.
Regardless of the coding scheme, the predictions will be equivalent. The only
difference is the way the coefficients are interpreted.
When a qualitative predictor takes on more than two values, a single dummy
variable cannot represent all possible values. Instead, multiple dummy variables
can be used. The number of variables required will always be one less than the
number of values that the predictor can take on.
For example, with a predictor that can take on three values, the following
coding could be used
$$ normalsize X_{i1} = left{ begin{array}{cc}
1&mathrm{if p_{i} = class A}\
0&mathrm{if p_{i} ne class A}
end{array} right. $$
$$ normalsize X_{i2} = left{ begin{array}{cc}
1&mathrm{if p_{i} = class B}\
0&mathrm{if p_{i} ne class B}
end{array} right. $$
$$ normalsize y_{i} = beta_{0} + beta_{1}X_{1} + beta_{2}X_{2} +
epsilon_{i} = left{ begin{array}{cc}
beta_{0} + beta_{1} + epsilon_{i}&mathrm{if p_{i} = class A}\
beta_{0} + beta_{2} + epsilon_{i}&mathrm{if p_{i} = class B}\
beta_{0} + epsilon_{i}&mathrm{if p_{i} = class C}
end{array} right. . $$
With such a coding, $$ beta_{0} $$ can be interpreted as the average response
for class C. $$ beta_{1} $$ can be interpreted as the average difference in
response between classes A and C. Finally, $$ beta_{2} $$ can be interpreted as
the average difference in response between classes B and C.
The case where $$ beta_{1} $$ and $$ beta_{2} $$ are both zero, the level with
no dummy variable, is known as the baseline.
Using dummy variables allows for easily mixing quantitative and qualitative
predictors.
There are many ways to encode dummy variables. Each approach yields equivalent
model fits, but results in different coefficients and different interpretations
that highlight different contrasts.
Extending the Linear Model
Though linear regression provides interpretable results, it makes several highly
restrictive assumptions that are often violated in practice. One assumption is
that the relationship between the predictors and the response is additive.
Another assumption is that the relationship between the predictors and the
response is linear.
The additive assumption implies that the effect of changes in a predictor $$
X_{j} $$ on the response $$ Y $$ is independent of the values of the other
predictors.
The linear assumption implies that the change in the response $$ Y $$ due to a
one-unit change in $$ X_{j} $$ is constant regardless of the value of $$ X_{j}
. $$
The additive assumption ignores the possibility of an interaction between
predictors. One way to account for an interaction effect is to include an
additional predictor, called an interaction term,
that computes the product of the associated predictors.
Modeling Predictor Interaction
A simple linear regression model account for interaction between the predictors
would look like
$$ normalsize mathrm{Y} = beta_{0} + beta_{1}X_{1} + beta_{2}X_{2} +
beta_{3}X_{1}X_{2} + epsilon $$
$$ beta_{3} $$ can be interpreted as the increase in effectiveness of $$
beta_{1} $$ given a one-unit increase in $$ beta_{2} $$ and vice-versa.
It is sometimes possible for an interaction term to have a very small p-value
while the associated main effects, $$ X_{1}, X_{2}, etc. $$, do not. Even in
such a scenario the main effects should still be included in the model due to
the hierarchical principle.
The hierarchical principle states that, when an interaction term is included in
the model, the main effects should also be included, even if the p-values
associated with their coefficients are not significant. The reason for this is
that $$ X_{1}X_{2} $$ is often correlated with $$ X_{1} $$ and $$ X_{2} $$ and
removing them tends to change the meaning of the interaction.
If $$ X_{1}X_{2} $$ is related to the response, then whether or not the
coefficient estimates of $$ X_{1} $$ or $$ X_{2} $$ are exactly zero is of
limited interest.
Interaction terms can also model a relationship between a quantitative predictor
and a qualitative predictor.
In the case of simple linear regression with a qualitative variable and without
an interaction term, the model takes the form
$$ normalsize y_{i} = beta_{0} + beta_{1}X_{1} +
left{ begin{array}{cc}
beta_{2}&mathrm{if p_{i} = class A}\
0&mathrm{if p_{i} ne class A}
end{array} right. $$
with the addition of an interaction term, the model takes the form
$$ normalsize y_{i} = beta_{0} + beta_{1}X_{1} +
left{ begin{array}{cc}
beta_{2} + beta_{3}X_{1}&mathrm{if p_{i} = class A}\
0&mathrm{if p_{i} ne class A}
end{array} right.
$$
which is equivalent to
$$ normalsize y_{i} = left{ begin{array}{cc}
(beta_{0} + beta_{2}) + (beta_{1} + beta_{3})X_{1}&mathrm{if p_{i} =
class A} beta_{0} + beta_{1}X_{1}&mathrm{if p_{i} ne class A}
end{array} right.
$$
Modeling Non-Linear Relationships
To mitigate the effects of the linear assumption it is possible to accommodate
non-linear relationships by incorporating polynomial functions of the predictors
in the regression model.
For example, in a scenario where a quadratic relationship seems likely, the
following model could be used
$$ normalsize Y_{i} = beta_{0} + beta_{1}X_{1} + beta_{2}X_{1}^{2} +
epsilon $$
This extension of the linear model to accommodate non-linear relationships is
called polynomial regression.
Common Problems with Linear Regression
- Non-linearity of the response-predictor relationship
- Correlation of error terms
- Non-constant variance of error terms
- Outliers
- High-leverage points
- Collinearity
1. Non-linearity of the response-predictor relationship
If the true relationship between the response and predictors is far from linear,
then virtually all conclusions that can be drawn from the model are suspect and
prediction accuracy can be significantly reduced.
Residual plots are a useful graphical tool for
identifying non-linearity. For simple linear regression this consists of
graphing the residuals, $$ e_{i} = y_{i} — hat{y}{i} $$ versus the predicted
or fitted values of $$ hat{y}{i} . $$
If a residual plot indicates non-linearity in the model, then a simple approach
is to use non-linear transformations of the predictors, such as $$ log{x} $$,
$$ sqrt{x} $$, or $$ x^{2} $$, in the regression model.

The example residual plots above suggest that a quadratic fit may be more
appropriate for the model under scrutiny.
2. Correlation of error terms
An important assumption of linear regression is that the error terms, $$
epsilon_{1}, epsilon_{2}, ldots, epsilon_{n} $$, are uncorrelated. Because
the estimated regression coefficients are calculated based on the assumption
that the error terms are uncorrelated, if the error terms are correlated it will
result in incorrect standard error values that will tend to underestimate the
true standard error. This will result in prediction intervals and confidence
intervals that are narrower than they should be. In addition, p-values
associated with the model will be lower than they should be. In other words,
correlated error terms can make a model appear to be stronger than it really is.
Correlations in error terms can be the result of time series data, unexpected
observation relationships, and other environmental factors. Observations that
are obtained at adjacent time points will often have positively correlated
errors. Good experiment design is also a crucial factor in limiting correlated
error terms.
3. Non-constant variance of error terms
Linear regression also assumes that the error terms have a constant variance,
$$ normalsize mathrm{Var}(epsilon_{i}) = sigma^{2} . $$
Standard errors, confidence intervals, and hypothesis testing all depend on this
assumption.
Residual plots can help identify non-constant variances in the error, or
heteroscedasticity, if a funnel shape is present.

One way to address this problem is to transform the response $$ Y $$ using a
concave function such as $$ log{Y} $$ or $$ sqrt{Y} . $$ This results in a
greater amount of shrinkage of the larger responses, leading to a reduction in
heteroscedasticity.
4. Outliers
An outlier is a point for which $$ y_{i} $$ is far from the
value predicted by the model.
Excluding outliers can result in improved residual standard error and improved
$$ mathrm{R}^{2} $$ values, usually with negligible impact to the least squares
fit.
Residual plots can help identify outliers, though it can be difficult to know
how big a residual needs to be before considering a point an outlier. To address
this, it can be useful to plot the studentized
residuals instead of the normal residuals.
Studentized residuals are computed by dividing each residual, $$ e_{i} $$, by
its estimated standard error. Observations whose studentized residual is greater
than $$ |3| $$ are possible outliers.
Outliers should only be removed when confident that the outliers are due to a
recording or data collection error since outliers may otherwise indicate a
missing predictor or other deficiency in the model.
5. High-Leverage Points
While outliers relate to observations for which the response $$ y_{i} $$ is
unusual given the predictor $$ x_{i} $$, in contrast, observations with high
leverage are those that have an unusual value for the
predictor $$ x_{i} $$ for the given response $$ y_{i} . $$
High leverage observations tend to have a sizable impact on the estimated
regression line and as a result, removing them can yield improvements in model
fit.
For simple linear regression, high leverage observations can be identified as
those for which the predictor value is outside the normal range. With multiple
regression, it is possible to have an observation for which each individual
predictor’s values are well within the expected range, but that is unusual in
terms of the combination of the full set of predictors.
To qualify an observation’s leverage, the leverage statistic can be computed.
A large leverage statistic indicates an observation with high leverage.
For simple linear regression, the leverage statistic can be computed as
$$ normalsize h_{i} = frac{1}{n} + frac{(x_{i} —
bar{x})^{2}}{sum_{j=1}^{n}(x_{j} — bar{x})^{2}} . $$
The leverage statistic always falls between $$ frac{1}{n} $$ and $$ 1 $$ and
the average leverage is always equal to $$ frac{p + 1}{n} . $$ So, if an
observation has a leverage statistic greatly exceeds $$ frac{p + 1}{n} $$ then
it may be evidence that the corresponding point has high leverage.
6. Collinearity
Collinearity refers to the situation in which two or
more predictor variables are closely related to one another.
Collinearity can pose problems for linear regression because it can make it hard
to determine the individual impact of collinear predictors on the response.
Collinearity reduces the accuracy of the regression coefficient estimates, which
in turn causes the standard error of $$ beta_{j} $$ to grow. Since the
T-statistic for each predictor is calculated by dividing $$ beta_{j} $$ by its
standard error, collinearity results in a decline in the true T-statistic. This
may cause it to appear that $$ beta_{j} $$ and $$ x_{j} $$ are related to the
response when they are not. As such, collinearity reduces the effectiveness of
the null hypothesis. Because of all this, it is important to address possible
collinearity problems when fitting the model.
One way to detect collinearity is to generate a correlation matrix of the
predictors. Any element in the matrix with a large absolute value indicates
highly correlated predictors. This is not always sufficient though, as it is
possible for collinearity to exist between three or more variables even if no
pair of variables have high correlation. This scenario is known as
multicollinearity.
Multicollinearity can be detected by computing the
variance inflation factor. The variance
inflation factor is the ratio of the variance of $$ hat{beta}{j} $$ when
fitting the full model divided by the variance of $$ hat{beta}{j} $$ if fit
on its own. The smallest possible VIF value is $$ 1.0 $$, which indicates no
collinearity whatsoever. In practice, there is typically a small amount of
collinearity among predictors. As a general rule of thumb, VIF values that
exceed 5 or 10 indicate a problematic amount of collinearity.
The variance inflation factor for each variable can be computed using the
formula
$$ normalsize mathrm{VIF}(hat{beta_{j}}) = frac{1}{1 —
mathrm{R}{x{j}|x_{-j}}^{2}} $$
where $$ mathrm{R}{x{j}|x_{-j}} $$ is the $$ mathrm{R}^{2} $$ from a
regression of $$ X_{j} $$ onto all of the other predictors. If $$
mathrm{R}{x{j}|x_{-j}} $$ is close to one, the VIF will be large and
collinearity is present.
One way to handle collinearity is to drop one of the problematic variables. This
usually doesn’t compromise the fit of the regression as the collinearity implies
that the information that the predictor provides about the response is abundant.
A second means of handling collinearity is to combine the collinear predictors
together into a single predictor by some kind of transformation such as an
average.
Parametric Methods Versus Non-Parametric Methods
A non-parametric method akin to linear regression is k-nearest neighbors
regression which is closely related to
the k-nearest neighbors classifier.
Given a value for $$ K $$ and a prediction point $$ x_{0} $$, k-nearest
neighbors regression first identifies the $$ K $$ observations that are closest
to $$ x_{0} $$, represented by $$ N_{0} . $$ $$ f(x_{0}) $$ is then estimated
using the average of $$ N_{0i} $$ like so
$$ normalsize hat{f}(x_{0}) = frac{1}{k}sum_{x_{i} in N_{0}}y_{i} $$
A parametric approach will outperform a non-parametric approach if the
parametric form is close to the true form of $$ f(X) . $$
The choice of a parametric approach versus a non-parametric approach will depend
largely on the bias-variance trade-off and the shape of the function $$ f(X) .
$$
When the true relationship is linear, it is difficult for a non-parametric
approach to compete with linear regression because the non-parametric approach
incurs a cost in variance that is not offset by a reduction in bias.
Additionally, in higher dimensions, K-nearest neighbors regression often
performs worse than linear regression. This is often due to combining too small
an $$ n $$ with too large a $$ p $$, resulting in a given observation having no
nearby neighbors. This is often called the curse of
dimensionality. In other words, the $$ K $$
observations nearest to an observation may be far away from $$ x_{0} $$ in a $$
p $$-dimensional space when $$ p $$ is large, leading to a poor prediction of $$
f(x_{0}) $$ and a poor K-nearest neighbors regression fit.
As a general rule, parametric models will tend to outperform non-parametric
models when there are only a small number of observations per predictor.
Next: Chapter 4 — Classification

Добавил:
Upload
Опубликованный материал нарушает ваши авторские права? Сообщите нам.
Вуз:
Предмет:
Файл:
Бардасов — Эконометрика.pdf
Скачиваний:
323
Добавлен:
06.03.2016
Размер:
2.47 Mб
Скачать
![]()
Знание дисперсий и стандартных ошибок позволяет анализировать точность оценок, строить доверительные интервалы для теоретических коэффициентов, проверять соответствующие гипотезы. Выборочные дисперсии эмпирических коэффициентов регрессии имеют вид:
где z jj
n
∑ei2
|
2 |
i=1 |
2 |
|
|
S b j = |
z jj =S e z jj , |
||
|
n−m−1 |
(3.12) |
||
|
— j-ый диагональный элемент матрицы |
|||
|
Z =(X T X )−1, |
j =0,1, 2, …, m. |
Отметим, что здесь в матрицах X T X и (X T X )−1 первая строка
истолбец обозначены цифрой 0.
Впримере 3.1
z00 =7,310816; z11 =0,001593; z22 =0,043213 .
|
Как и в случае парной регрессии, Sb j = |
2 |
называется стан- |
|||
|
Sb j |
|||||
|
дартной ошибкой коэффициента регрессии. |
|||||
|
В примере 3.1 |
|||||
|
n |
|||||
|
∑ei2 |
|||||
|
i=1 |
=81,61831; |
Sb0 =24,4; Sb1 =0,361; |
Sb2 =1,88 . |
||
|
n−m−1 |
|||||
Отметим, что рассмотренная выше парная линейная регрессия также может быть изложена в матричном виде.
§ 4. Проверка статистической значимости коэффициентов уравнения регрессии
Построение эмпирического уравнения регрессии — начальный этап эконометрического анализа. Первое же построенное по выборке уравнение регрессии очень редко является удовлетвори-
71

тельным по тем или иным характеристикам. Поэтому следующей важнейшей задачей эконометрического анализа будет проверка качества уравнения регрессии. Проверка статистического качества оцененного уравнения регрессии проводится по следующим направлениям:
•проверка статистической значимости коэффициентов уравнения регрессии;
•проверка общего качества уравнения регрессии;
•проверка свойств данных, выполнимость которых предполагалась при оценивании уравнения (проверка выполнимости предпосылок МНК).
Как и в случае парной регрессии, статистическая значимость коэффициентов множественной линейной регрессии с m объясняющими переменными проверяется на основе t-статистики:
|
t = |
b j |
, |
(3.13) |
|
Sb j |
имеющей в данной ситуации распределение Стьюдента с числом степеней свободы ν=n−m−1 (n — объем выборки, m — количество объясняющих переменных в модели). При требуемом уровне значимости наблюдаемое значение t-статистики сравнивается с критической точкой t α2 , n−m−1 распределения Стьюдента.
Если t >t α2 , n−m−1 , то коэффициент bj считается статистически значимым. В противном случае ( t ≤t α2 , n−m−1) коэффициент bj счи-
тается статистически незначимым (статистически близким к нулю). Это означает, что фактор Xj линейно не связан с зависимой переменной Y. Его наличие среди объясняющих переменных не оправдано со статистической точки зрения. Он не оказывает скольконибудь серьезного влияния на зависимую переменную, а лишь искажает реальную картину взаимосвязи. Если коэффициент bj статистически незначим, рекомендуется исключить из уравнения регрессии переменную Xj. Это не приведет к существенной потере качества модели, но сделает ее более конкретной.
72

|
Впримере3.1 при α=0,05 |
(5%) t |
α |
,n−m−1 =t |
0,05 |
; 7 =2,365 . Тогда |
|||||||||||||||
|
95,5 |
0,818 |
2 |
2 |
7,68 |
||||||||||||||||
|
tb0 |
= |
b0 |
= |
=3,91;tb1 |
= |
b1 |
= |
=2,26 |
;tbj = |
b2 |
= |
=4,09. |
||||||||
|
Sb0 |
24,4 |
Sb1 |
0,361 |
Sb2 |
1,88 |
|||||||||||||||
Таким образом, при уровне значимости α=0,05 (5%) коэф-
фициенты b0 и b2 статистически значимо отличаются от нуля, а коэффициент b1 статистически незначим. Коэффициент b1 становится
статистически значимым при α≈0,058 (5,8%).
§ 5. Интервальные оценки коэффициентов теоретического уравнения регрессии
По аналогии с парной регрессией после определения точечных оценок bj коэффициентов βj (j =1, 2, …, m) теоретического урав-
нения регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов. Доверительный интервал, накрывающий с надежностью 1−α неизвестное значение параметра βj , определя-
ется неравенством:
b j −t α2 , n−m−1Sb j < βj <b j +t α2 , n−m−1Sb j ,
где t α2 , n−m−1 — критическая точка распределения Стьюдента с чис-
лом степеней свободы ν=n−m−1 (n — объем выборки, m — количество объясняющих переменных в модели) и уровнем доверия α.
|
В примере 3.1 при α=0,05 (5%) t |
α |
, n−m−1 =t |
0,05 |
; 7 =2,365 . До- |
|
|
2 |
2 |
||||
|
верительные интервалы имеют вид: |
|||||
|
95,5−2,365×24,4< β0 |
<95,5+2,365×24,4 , |
||||
|
0,818−2,365×0,361< β1 |
<0,818+2,365×0,361, |
||||
|
7,68−2,365×1,88< β2 |
<7,68+2,365×1,88 . |
По аналогии с парной регрессией может быть построена интервальная оценка для среднего значения предсказания:
73
|
ˆ |
− |
α |
, n−m−1 e |
Tp( |
TX)−1 |
p <M |
p |
Tp |
<ˆ |
+ |
α |
, n−m−1 e |
Tp( |
TX)−1 |
p . |
|||||||||||||||||
|
Y p |
t |
2 |
S |
X |
X |
X |
(Y |
X |
) |
Y p |
t 2 |
S |
X |
X |
X |
|||||||||||||||||
|
Пусть в примере 3.1 |
x p1 =60, |
x p2 =4 , тогда |
||||||||||||||||||||||||||||||
|
X Tp (X T X )−1 X p = |
||||||||||||||||||||||||||||||||
|
7,31081 |
−0,10049 |
−0,53537 |
1 |
|||||||||||||||||||||||||||||
|
(1 |
60 |
0,001593 |
||||||||||||||||||||||||||||||
|
4)× −0,10049 |
−0,006644 × 60 =0,585; |
|||||||||||||||||||||||||||||||
|
−0,006644 |
0,043213 |
|||||||||||||||||||||||||||||||
|
−0,53537 |
4 |
|||||||||||||||||||||||||||||||
|
ˆ |
||||||||||||||||||||||||||||||||
|
Y p =95,5+0,818×60−7,680×15=113,9 ; |
||||||||||||||||||||||||||||||||
|
t |
α |
,n−m−1S e |
X Tp(X T X )−1 X p =2,365× 81,6 × 0,585 =13,3 ; |
|||||||||||||||||||||||||||||
|
2 |
||||||||||||||||||||||||||||||||
|
113,9−13,3<M (Y p |
X Tp)<113,9+13,3. |
|||||||||||||||||||||||||||||||
При определении доверительного интервала для индивидуальных значений зависимой переменной необходимо произвести замену:
X Tp(X T X )−1 X p → 1+X Tp(X T X )−1X p = 1,585 =1,259 .
§ 6. Проверка общего качества уравнения регрессии
После проверки значимости каждого коэффициента регрессии обычно проверяется общее качество уравнения регрессии. Для этой цели, как и в случае парной регрессии, используется коэффициент детерминации:
|
n |
2 |
n |
n |
|||||||||||||||||
|
∑(ˆyi− |
y |
) |
∑ei2 |
n∑ei2 |
||||||||||||||||
|
R2 = |
i=1 |
= 1− |
i=1 |
=1− |
i=1 |
(3.14) |
||||||||||||||
|
n |
) |
2 |
n |
( |
) |
2 |
n |
2 |
||||||||||||
|
∑ |
y − |
y |
∑ |
y − |
y |
n |
2 |
|||||||||||||
|
i=1( |
i |
i=1 |
i |
n∑ y |
i |
− ∑ y |
||||||||||||||
|
i |
||||||||||||||||||||
|
i=1 |
i=1 |
|||||||||||||||||||
Суть данного коэффициента как доли общего разброса значений зависимой переменной Y, объясненного уравнением регрессии,
74

подробно рассмотрена ранее. Как отмечалось, в общем случае 0≤R2 ≤1. Чем ближе этот коэффициент к единице, тем больше
уравнение регрессии объясняет поведение Y. Поэтому естественно желание построить регрессию с наибольшим R2.
Для множественной регрессии коэффициент детерминации является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R2. Действительно, каждая следующая объясняющая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной. Это уменьшает (в худшем случае не увеличивает) область неопределенности в поведении переменной Y.
Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы.
Вводится так называемый скорректированный (исправленный) коэффициент детерминации:
|
n |
(n−m−1) |
||||||||||||
|
∑ei2 |
n−1 |
||||||||||||
|
2 =1− |
i=1 |
=1−(1−R2) |
, |
(3.15) |
|||||||||
|
R |
|||||||||||||
|
n |
2 |
n−m−1 |
|||||||||||
|
∑(yi−y) |
(n−1) |
||||||||||||
|
i=1 |
где n — количество наблюдений, m — число объясняющих переменных.
Такая поправка учитывает соответствующие степени свободы RSS и TSS. Выражение (3.15) можно также представить в виде:
|
n |
(n−k) |
||||||||||
|
2 =1− |
∑ei2 |
=1−(1−R2) |
n−1 |
||||||||
|
i=1 |
, |
||||||||||
|
R |
|||||||||||
|
n |
2 |
n−k |
|||||||||
|
∑(yi−y) |
(n−1) |
||||||||||
|
i=1 |
где k =(m+1) — число параметров уравнения регрессии.
Из (3.15) очевидно, что R2 <R2 для т > 1. С ростом значения m скорректированный коэффициент детерминации растет медленнее, чем (обычный) коэффициент детерминации. Другими словами, он
75

корректируется в сторону уменьшения с ростом числа объясняю-
|
щих переменных. Нетрудно заметить, что |
2 =R2 только при |
||||||||||
|
R |
|||||||||||
|
R2=1. |
2 может принимать отрицательные значения (например, |
||||||||||
|
R |
|||||||||||
|
при R2=0). Обычно полагают |
2 =max 1−(1− |
R |
2) |
n−1 |
, 0 . |
||||||
|
R |
|||||||||||
|
n−m−1 |
|||||||||||
Доказано, что R2 увеличивается при добавлении новой объяс-
няющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.
Обычно приводятся данные как по R2, так и по R2, являющиеся
суммарными мерами общего качества уравнения регрессии. Однако не следует абсолютизировать значимость коэффициентов детерминации. Существует достаточно примеров неправильно специфицированных моделей, имеющих высокие коэффициенты детерминации. Поэтому коэффициент детерминации рассматривается лишь как один из ряда показателей, который нужно проанализировать, чтобы уточнить строящуюся модель.
После оценки индивидуальной статистической значимости каждого из коэффициентов регрессии обычно анализируется совокупная значимость коэффициентов. Такой анализ осуществляется на основе проверки гипотезы об общей значимости — гипотезы об одновременном равенстве нулю всех коэффициентов регрессии при объясняющих переменных:
H 0 : β1 = β2 =…= βm =0.
Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех т объясняющих переменных X 1,X 2, …,X m модели на зависимую переменную Y можно считать
статистически несущественным, а общее качество уравнения регрессии — невысоким.
Проверка данной гипотезы осуществляется на основе дисперсионного анализа сравнения объясненной и остаточной дисперсий.
H 0 : (объясненная дисперсия) = (остаточная дисперсия),
76

H 1 : (объясненная дисперсия) > (остаточная дисперсия). Строится F-статистика:
|
n |
||||||||||||
|
∑(ˆyi − |
)2 m |
|||||||||||
|
y |
||||||||||||
|
F = |
i=1 |
, |
(3.16) |
|||||||||
|
n |
||||||||||||
|
∑(yi−ˆyi)2 (n−m−1) |
||||||||||||
|
i=1 |
||||||||||||
|
n |
)2 / m =ESS / m — объясненная |
|||||||||||
|
где ∑(ˆyi− |
y |
сумма квадратов в |
||||||||||
|
i=1 |
||||||||||||
|
расчете на одну независимую переменную; |
||||||||||||
|
n |
y |
−ˆy |
i) |
2 / (n−m−1)=RSS / (n−m−1) |
— остаточная сумма |
|||||||
|
∑ |
||||||||||||
|
i=1 ( |
i |
|||||||||||
|
квадратов в расчете на одну степень свободы. |
||||||||||||
|
При выполнении предпосылок МНК построенная F-статистика |
||||||||||||
|
имеет |
распределение |
Фишера с числами |
степеней свободы |
ν1 =m, ν2 =n−m−1. Поэтому, если при требуемом уровне значимости α, F набл >F α; m; n−m−1, где F α; m; n−m−1 — критическая точ-
ка распределения Фишера, то H0 отклоняется в пользу H1. Это означает, что объясненная дисперсия существенно больше остаточной дисперсии, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y. Если F набл <F α; m; n−m−1 , то нет оснований для отклоне-
ния H0. Значит объясненная дисперсия соизмерима с дисперсией, вызванной случайными факторами. Это дает основание считать, что совокупное влияние объясняющих переменных модели несущественно, следовательно, общее качество модели невысоко.
Однако на практике чаще вместо указанной гипотезы проверяют тесно связанную с ней гипотезу о статистической значимости коэффициента детерминации R2:
H 0 : R2 =0,
H 1 : R2 >0.
Для проверки данной гипотезы используется следующая F— статистика:
77

|
F = |
R2 |
× |
n−m−1 |
. |
(3.17) |
|
|
1−R2 |
m |
|||||
Выражение (3.17) следует из (3.16), если числитель и знаменатель разделить на TSS.
Величина F при выполнении предпосылок МНК и при справедливости H0 имеет распределение Фишера, аналогичное распределению F-статистики (3.16). Показатели F и R2 равны или не равны нулю одновременно. Для проверки нулевой гипотезы
H0:F =0, R2 =0 при заданном уровне значимости α по таблицам
критических точек распределения Фишера находится критическое значение F крит =F α; m; n−m−1 . Нулевая гипотеза отклоняется, если
F набл >F крит . Это равносильно тому, что R2 >0 , т. е. R2 статисти-
чески значим.
Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации R2 не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
n
n ∑ei2
|
В примере 3.1 R2 =1− |
i=1 |
=0,936 . |
||||||||||
|
n |
n |
2 |
||||||||||
|
2 |
||||||||||||
|
n ∑ y |
− |
∑ y |
||||||||||
|
i |
i |
|||||||||||
|
i=1 |
i=1 |
|||||||||||
|
Тогда F = |
R2 |
n−m−1 |
= |
0,936×7 |
=51,2 . По таблицам кри- |
|||||||
|
1−R2 |
0,064×2 |
|||||||||||
|
m |
найдем F0,05; 2;7 =4,74 ; |
|||||||||||
|
тических точек распределения |
Фишера |
F0,01; 2;27 =9,55 . Поскольку Fнабл =51,2 > Fкрит как при 5%-м, так и
при 1%-м уровне значимости, то нулевая гипотеза H0 в обоих случаях отклоняется в пользу H1. Это означает, что объясненная дисперсия существенно больше остаточной, следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y.
78
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #