Ошибка
репрезентативности
— расхождение между выборочной
характеристикой и характеристикой
генеральной совокупности.
Ошибки
репрезентативности
-
Систематические
— возникают в результате нарушения
научных принципов отбора единиц
совокупности (преднамеренные и
непреднамеренные). -
Случайные
возникают в результате несплошного
характера наблюдения (средняя и
предельная ошибки выбора).
Случайные
ошибки могут быть доведены до незначительных
размеров, а главное, их размеры и пределы
можно определить с достаточной точностью
на основании закона больших чисел.
Средняя
ошибка выборки
— такое расхождение между средними
выборочной и генеральной совокупностями,
которое не превышает ±.
В
математической статистике доказывается,
что значения средней ошибки выборки
определяются по формулам:
Формула
для определения величины средней ошибки
выборки для количественного признака:
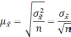
Формула
для определения величины средней ошибки
выборки для альтернативного признака:

Полученное
значение средней ошибки необходимо для
установления возможного значения 
 .
.
Которое определяется по формуле:
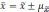
Но
такое суждение можно гарантировать не
с абсолютной
достоверностью, а лишь с определенной
степенью
вероятности.
В
математической статистике доказывается,
что пределы значений характеристик
генеральной совокупности отличаются
от характеристик выборочной совокупности
лишь с вероятностью, которая определена
числом 0,683.
Это
означает, что в 683 случаях из 1000 генеральная
средняя будет находиться в установленных
пределах, т.е. отклонение ГС от ВС не
превысит однократной средней ошибки
выборки. В остальных 317 случаях они могут
выйти за эти пределы. Вероятность можно
повысить, если расширить пределы
отклонений. Так, при удвоенном значении

 ,
,
вероятность достигает 0,954 (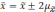
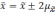 ).
).
Если утроить значение то вероятность
увеличится до 0,997 (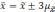
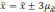 ).
).
|
Возможное |
Вероятность |
|
|
0,683 |
|
|
0,954 |
|
|
0,997 |
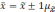
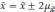
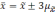
Если
обозначить значение увеличения 

за
t,
то можно записать в общем виде:
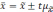
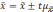
Множитель
t
называется коэффициентом
доверия.
Известный русский математик А.М.Ляпунов
дал выражение конкретных значений
множителя t
для различных степеней вероятности в
виде функции:
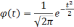
На
практике пользуются готовыми таблицами
этой функции.
|
t |
0 |
0,1 |
0,5 |
1 |
1,5 |
2 |
2,5 |
2,6 |
3 |
4 |
|
(t) |
0,1 |
0,0797 |
0,3829 |
0,6827 |
0,8664 |
0,9545 |
0,9876 |
0,9907 |
0,9973 |
0,99994 |
Из
вышесказанного следует, что лишь с
определенной степенью вероятности
можно утверждать, что показатели
генеральной совокупности и их отклонения
не превысят величину 
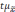 .
.
Полученную величину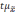
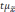 называетсяпредельной
называетсяпредельной
ошибкой выборки.
Предельная
ошибка выборки
—
максимально
возможное расхождение выборочной и
генеральной средних,
т.е.
максимум ошибки при заданной вероятности
ее появления.
Предельная
ошибка выборки для количественного
признака:
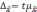
Предельная
ошибка выборки для альтернативного
признака:
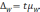
В
связи с тем, что существуют различные
методы, виды и способы отбора единиц из
генеральной совокупности формулы для
расчета средней ошибки выборки также
будут различаться:
|
Способ |
Оцениваемый |
Повторный |
Бесповторный |
|
Собственно случайный механический |
Средняя |
|
|
|
Доля |
|
|
|
|
Типический |
Средняя |
|
|
|
Доля |
|
|
|
|
Серийный |
Средняя |
|
|
|
Доля |
|
|
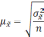
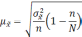
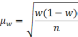
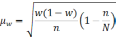
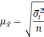
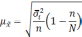
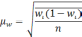
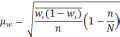
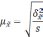
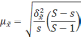

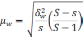
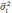
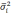
— средняя из групповых дисперсий;
wi
— доля
единиц совокупности, обладающих изучаемым
признаком в i-й
типической
группе;
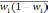
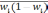
— средняя из групповых дисперсий для
доли. В табл. 6.6 представлены формулы
для исчисления средней ошибки выборки
при типическом отборе;
S
– общее число серий;
s
– число отобранных серий;

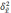 —
—
межгрупповая дисперсия средних,
определяемая по формуле:
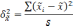
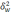
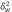 —
—
межгрупповая дисперсия доли, определяемая
по формуле:
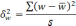
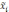
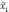
— средняя
i-й
серии;


—
средняя по всей выборочной совокупности;
w
— доля признака i-й
серии;


— общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

О размере выборки и статистической ошибке измерений подробно написано в статье «Выборка. Размер – не главное. Или главное» . В этой статье будет рассмотрено второе требование к выборке, также обеспечивающее качество исследования – репрезентативность.
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность. Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1. приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.



Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность. Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить. Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен. Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта. Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся). Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности. Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов). Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой. Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет. Пример репрезентативной и нерепрезентативной выборки показан на рис.2.

Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.

Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки. Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности. В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами. Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел). При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка. Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.4 – это репрезентативная выборка из пиццы.
")
Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны. Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его. Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).

Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы. Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла. Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов. Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
ПРИМЕРЫ НАРУШЕНИЯ РЕПРЕЗЕНТАТИВНОСТИ ВЫБОРКИ
ПРЕДВЫБОРНЫЙ ОПРОС
Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов. Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала. Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте. Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось. Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
СИСТЕМАТИЧЕСКАЯ ОШИБКА ВЫЖИВШЕГО
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу. На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе. Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони.
Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу. А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.

Рис .7. Пробоины на вернувшихся самолётах.
Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
НЕПРАВИЛЬНЫЕ МЕСТА ОПРОСА
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку. Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
ОТСУТСТВИЕ КВОТИРОВАНИЯ
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать. В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др. Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
ОНЛАЙН-ОПРОСЫ (ОНЛАЙН-ПАНЕЛИ)
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
ВЫВОДЫ
Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
«Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.
Вы можете подписаться на уведомления о новых материалах СканМаркет
6. Достоверность статистических данных и
ошибки статистического наблюдения
Важнейшим требованием
предъявляемым к статистическим данным является их достоверность. Под достоверностью
данных наблюдения понимается степень приближения, соответствия
данных тому, что есть на самом деле. Расхождение межу фактическим значением и
результатом наблюдения называют погрешностью (ошибкой) наблюдения.
Ошибки наблюдения
разнообразны по происхождению и своему содержанию. В зависимости от
причин возникновения различают следующие виды ошибок:
• методические ошибки;
• ошибки регистрации;
• ошибки
репрезентативности (представительности).
Методические ошибки возникают
в результате использования несовершенных методик, неправильных теоретических
концепций, лежащих в основе исследования.
Ошибки регистрации возникают при
получении данных об отдельных единицах совокупности вследствие неправильного
установления фактов в процессе наблюдения или неправильной их записи. Они
подразделяются на:
-объективные (непреднамеренные)
причиной появления которых является неправильное восприятие наблюдаемых фактов,
неисправность измерительных приборов и неправильная регистрация. Такие ошибки
являются результатом добросовестного заблуждения регистратора;
— субъективные (преднамеренные)
ошибки, возникающие по причине сознательного искажения фактов. К ним относятся
всевозможные преднамеренные ошибки и приписки, при которых опрашиваемый
преднамеренно сообщает неправильные сведения; регистратор преднамеренно
воздействует на респондента с целью получения нужного ответа; регистратор
преднамеренно искажает в формулярах результаты наблюдения.
Ошибки репрезентативности
(представительности) характерны только для несплошного наблюдения.
Они возникают в результате того, что состав отобранной для обследования части
единиц совокупности (выборки) не полностью отражает состав и свойства всей
изучаемой совокупности, несмотря на то, что регистрация сведений по каждой
отобранной единице была проведена точно.
По форме проявления (по
влиянию на результат) ошибки делятся на:
• систематически;
• случайные.
Систематические ошибки возникают
по какой-то определенной причине и вызывают одностороннее искажение значений
признака у наблюдаемых единиц (увеличение или уменьшение). Они очень опасны,
так как величина показателя, рассчитанная в целом по всей совокупности будет
включать накопленную ошибку.
Случайные ошибки являются
результатом действия различных случайных факторов. Они не имеют какой-либо
направленности. В больших совокупностях в результате действия закона больших
чисел эти ошибки взаимно погашаются и не оказывают существенного влияния на
точность наблюдения.
Оба вида ошибок в любом
исследовании выступают совместно и составляют совокупную ошибку наблюдения Δ:
Δ=σ+ε;
где σ — систематическая
ошибка наблюдения,
ε — случайная ошибка
наблюдения.
Для выявления и
исправления ошибок, данные наблюдения необходимо тщательно контролировать.
Процедура контроля сводится к следующему:
• Проверка материалов
наблюдения на полноту и правильность оформления. Проверяется полнота охвата
статистических единиц наблюдения, правильность заполнения каждого формуляра.
• Арифметический
(счетный) контроль. Этот вид контроля основан на использовании
количественных связей между показателями, которые могут быть проверены
арифметическими действиями. Такие связи обычно отражаются в заголовках граф или
строк формуляров. Например, графа x = графа y — графа z и т.д. Арифметический
контроль используется для проверки итоговых данных, с его помощью устанавливается
наличие ошибки.
• Логический контроль основан
на использовании логической взаимосвязи показателей, установлении логического
соответствия между ними. Он не выявляет ошибки наблюдения, а лишь ставит под
сомнение правильность полученных данных. Логический контроль заключается в
проверке ответов на вопросы программы наблюдения путем их логического
осмысления или сравнения полученных данных с другими источниками по данному
вопросу. Классическим примером логического контроля является соответствие данных
при переписи населения о возрасте, образовании и семейном положении. Для
проверки данных наблюдения обычно составляется схема контроля, в которую
включаются различные виды контроля. При обнаружении ошибок нельзя
самостоятельно их исправлять. Для этого необходимо получить дополнительную
информацию путем повторного наблюдения. Данные наблюдения считаются принятыми,
если они прошли контроль, и в них внесены все необходимые исправления.
Проверкой собранных данных заканчивается начальная стадия статистического
исследования. После этого можно переходить ко второй стадии исследования
обработке данных наблюдения. Обработка заключается в классификации и
систематизации полученного статистического материала, осуществляемых через
сводку и группировку.
О сводке и группировке мы
поговорим с Вами в следующей лекции.
-
Оценка достоверности результатов статистического исследования. Ошибка репрезентативности средних и относительных величин.
См. 16?
Оценить достоверность результатов
выборочного исследования означает
определить, с какой вероятностью можно
перенести сделанные для него выводы
(результаты изучения признаков) с
выборочной совокупности на всю генеральную
совокупность (т.е., по части явления
судить о явлении в целом, о его
закономерностях).
При проведении выборочного исследования
мы можем сталкиваться с общими
погрешностями и погрешностями выборки.
Общие погрешности (ошибки) могут иметь
как систематический характер (методические,
недостатки измерительной аппаратуры),
так и случайный (ошибки исследователя).
Погрешности выборочного наблюдения
связаны с отбором его единиц. Это
погрешности типичности, репрезентативности.
В процессе анализа рассчитанные
показатели рассматривают как обобщающие
величины. Если результаты получены на
основе достаточного по количеству и
качественно однородного материала, то
можно считать, что они достаточно точно
характеризуют исследуемые явления.
Ошибки представительности
(репрезентативности) свойственны только
несплошному наблюдению (обследование
только части единицы совокупности).
Отклонение величины изучаемого признака
в отобранной для обследования части
совокупности от его величины во всей
совокупности, называются ошибкой
репрезентативности.
Случайные ошибки репрезентативности
возникают в силу того, что совокупность
отобранных на основе принципа случайности
единиц наблюдения неполно воспроизводит
совокупность в целом. Величина этой
ошибки может быть оценена.
Систематические ошибки репрезентативности
возникают вследствие нарушения принципа
случайности отбора тех единиц изучаемой
совокупности, которые должны быть
подвергнуты наблюдению. Размеры этих
ошибок обычно не поддаются количественному
измерению.
-
Оценка достоверности результатов статистического исследования. Доверительные границы. Методика определения доверительных границ.
См 16?
Границы достоверности (доверительные
границы):
Р ± 2m (при t = 2) дают возможность определить
пределы колебания показателя с
вероятностью 95,5 % (р = 0,05);
(t = 2 является округленным результатом.
Точное
значение t = 1,96);
Р ±3m (при t = 3) дают возможность определить
пределы колебания показателя с
вероятностью 99,7 % (р = 0,01).
Не менее важным, чем знание сути
параметрического критерия достоверности
t, есть осознание значения риска
погрешности Р, которое нуждается в
понимании логики проверки статистической
гипотезы.
Р – это вероятность достоверности
нулевой гипотезы или вероятность
погрешности, а именно погрешности
первого типа – ошибочное утверждение
существования расхождений, которых в
действительности нет.
Вероятность безошибочного прогноза
(p) и доверительный критерий (t) определяют
на этапе планирования статистического
исследования.
При заданных степенях вероятности
доверительный критерий (t) имеет неизменную
величину, а доверительный интервал ™
зависит от величины средней ошибки (m),
значение которой уменьшается при
увеличении числа и качественного состава
наблюдений.
В медико-биологических исследованиях
часто возникают ситуации, когда при
сравнении отдельных параметров необходимо
оценить существенность (достоверность)
разницы между ними.
Существенная разница между отдельными
показателями выборочного исследования
свидетельствует о возможности перенесения
полученных выводов на генеральную
совокупность.
Параметрическим критерием оценки
существенности разности является
коэффициент достоверности (критерий
Госсета (Стьюдента):
|(Х_1 ) ̅-(Х_2 ) ̅ |/√(m_1^2+m_2^2 ) для средних
величин;
|(Р_1 ) ̅-(Р_2 ) ̅ |/√(m_1^2+m_2^2 ) для
относительных величин
При n > 30 разность между показателями
является существенной, если:
t > 2 (отвечает достоверности безошибочного
прогноза 95,5 %);
t > 3 (отвечает достоверности безошибочного
прогноза 99,7 %).
При условии t<2 степень достоверности
безошибочного прогноза составляет
менее 95 %. В этом случае мы не можем
утверждать, что разница между показателями
является существенной.
Часто при клинических или
экспериментальных исследованиях
приходится иметь дело с малыми наблюдениями
(если исследование правильно организовано,
отобраны однородные группы, которые
можно использовать, как выборочные с
малым числом наблюдений). Но при n<30
оценка достоверности разницы между
параметрами отдельных групп проводится
на основе сравнения результата не с
предельными значениями критерия Госсета
(Стьюдента), а с его табличными значениями
для соответствующего числа степеней
свободы (n`= n1+ n2 — 2).
Если определенный t-критерий превышает
табличное значение— разница между
показателями становится статистически
доказана.
Критерий достоверности (t) используют
при попар¬ном сравнении исследуемых
параметров.
Однако при проведении статистического
анализа иногда необходимо оценить
достоверность разницы более двух
показателей клинико-статистических
групп. Их попарное сравнение не позволяет
получить обобщающую оценку. Другими
словами, необходимо провести сравнение
совокуп¬ности не только по обобщающим
показателям, но и по характеру распределения
признаков в исследуемых группах. Для
данной цели используют другие критерии.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
О размере выборки и статистической ошибке измерений подробно написано в статье «Выборка. Размер – не главное. Или главное» . В этой статье будет рассмотрено второе требование к выборке, также обеспечивающее качество исследования – репрезентативность.
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность. Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1. приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.
Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность. Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить. Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен. Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта. Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся). Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности. Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов). Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой. Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет. Пример репрезентативной и нерепрезентативной выборки показан на рис.2.
Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.
Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки. Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности. В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами. Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел). При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка. Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.4 – это репрезентативная выборка из пиццы.
Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны. Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его. Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).
Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы. Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла. Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов. Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
ПРИМЕРЫ НАРУШЕНИЯ РЕПРЕЗЕНТАТИВНОСТИ ВЫБОРКИ
ПРЕДВЫБОРНЫЙ ОПРОС
Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов. Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала. Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте. Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось. Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
СИСТЕМАТИЧЕСКАЯ ОШИБКА ВЫЖИВШЕГО
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу. На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе. Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони.
Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу. А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.
Рис .7. Пробоины на вернувшихся самолётах.
Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
НЕПРАВИЛЬНЫЕ МЕСТА ОПРОСА
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку. Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
ОТСУТСТВИЕ КВОТИРОВАНИЯ
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать. В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др. Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
ОНЛАЙН-ОПРОСЫ (ОНЛАЙН-ПАНЕЛИ)
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
ВЫВОДЫ
Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
«Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Расхождение между действительными значениями изучаемых величин и значениями, установленными в процессе статистического наблюдения, и называют ошибкой наблюдения. Ошибки являются следствием неточности при установлении и регистрации значений изучаемых признаков.
В зависимости от причин возникновения различают следующие виды ошибок:
1) ошибки регистрации;
2) ошибки репрезентативности (представительности);
3) случайные ошибки;
4) систематические ошибки;
5) преднамеренные ошибки;
6) непреднамеренные ошибки.
Ошибки регистрации — это отклонения между значением показателя, полученным в ходе статистического наблюдения, и фактическим, действительным его значением. Этот вид ошибок возникает при сплошном и несплошном наблюдениях.
Ошибки репрезентативности (представительности) — собственное расхождение величины изучаемого признака в отобранной части совокупности и во всей совокупности. Ошибки репрезентативности свойственны только несплошному наблюдению.
Случайная ошибка — это результат действия различных случайных факторов, оговорок при ответах, описок, неправильности измерения. Случайные ошибки действуют как в направлении увеличения, так и в направлении уменьшения значений изучаемых признаков.
При достаточно большой обследуемой совокупности в результате действия закона больших чисел эти ошибки взаимно погашаются.
Систематические ошибки регистрации всегда имеют одинаковую тенденцию либо к увеличению, либо к уменьшению значения показателей по каждой единице наблюдения, и поэтому величина показателя по совокупности в целом будет включать в себя накопленную ошибку. Систематические ошибки могут появляться в результате несовершенства измерительных приборов, неправильности округлений результатов, неясной формулировки программы.
Преднамеренные и непреднамеренные ошибки определяются степенью тенденциозности подхода к установлению факта. Преднамеренные ошибки выражаются в сознательном искажении значений признаков. Непреднамеренные ошибки возникают независимо от сознания людей, участвующих в статистическом наблюдении.
Для выявления ошибок наблюдения применяют следующие виды контроля:
1) счетный контроль. Заключается в проверке итогов подсчета данных, а также в использовании количественных связей между показателями;
2) логический контроль. Осуществляется путем проверки содержательной связи между значениями признаков. При логическом контроле отыскиваются недопустимые отклонения значений признака от наиболее вероятных.
20. Понятие о выборочном наблюдении
Выборочное наблюдение — это такое наблюдение, при котором обследованию подвергается часть единиц изучаемой совокупности, отобранных на основе научно разработанных принципов, обеспечивающих получение достаточного количества достоверных данных для характеристики совокупности в целом.
Основные принципы выборочного наблюдения следующие: случайность отбора наблюдаемого явления; репрезентативность выборки.
В основе принципа случайности лежит равная возможность для каждой единицы попасть в выборку. Репрезентативные выборки обеспечивают достаточным числом отобранных единиц. Средние и относительные показатели, полученные на основе выборочных данных, должны достаточно полно воспроизводить или представлять соответствующие показатели совокупности в целом.
Выборочное наблюдение предполагает проведение таких этапов, как:
1) определение объекта и целей выборочного наблюдения;
2) выбор схемы отбора единиц наблюдения;
3) расчет объема выборки;
4) проведение случайного отбора установленного числа единиц из генеральной совокупности;
5) наблюдение отобранных единиц по установленной программе;
6) расчет выборочных характеристик в соответствии с программой выборочного наблюдения;
7) определение ошибки, ее размера;
 распространение выборочных данных на генеральную совокупность;
распространение выборочных данных на генеральную совокупность;
9) анализ полученных данных.
Выборочное наблюдение имеет следующие основные преимущества и недостатки:
1) преимущества:
а) его можно осуществить по более широкой программе;
б) его требует меньше затрат на проведение;
в) его организуют в тех случаях, когда невозможно воспользоваться отчетностью;
2) недостатки:
а) полученные данные всегда содержат ошибку;
б) о результатах наблюдения можно судить лишь с определенной степенью достоверности.
Вся совокупность единиц, из которых производится отбор, называется генеральной совокупностью. Часть единиц генеральной совокупности, отобранная в случайном порядке, составляет выборочную совокупность. Характеристиками генеральной и выборочной совокупности служат доля и средняя величина, а также дисперсия и среднее квадратическое отклонение. Средняя величина является характеристикой количественных признаков, а дол я — характеристикой альтернативных признаков.
Среднее значение признака генеральной совокупности называется генеральной средней, обозначается 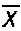 , выборочной совокупности — выборочной средней, обозначается
, выборочной совокупности — выборочной средней, обозначается 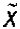 .
.
Доля генеральной совокупности называется генеральной долей и обозначается р, доля выборочной совокупности называется выборочной долей и обозначается w. Численность генеральной совокупности обозначается N, а численность выборочной — n.
12. Ошибки выборочного наблюдения
Ошибка выборки — расхождение между характеристиками выборки и характеристиками генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методов отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования. Ошибка выборки состоит из ошибки регистрации и ошибки репрезентативности, которые бывают систематическими и случайными.
Конец бесплатного ознакомительного фрагмента