Занятие 3. Потоки ввода/вывода. Функции.
- Потоки ввода/вывода
- Что такое потов ввода/вывода
- Потоки в Java
- Байтовые Потоки
- Класс InputStream
- Класс OutputStream
- Работа с файлами
- Символьные потоки
- Класс Reader
- Класс Writer
- Стрруктура java.io
- Стандартые потоки
- Стандартный поток вывода
- Стандартный поток ввода
Потоки ввода/вывода
Что такое потов ввода/вывода
Отличительной чертой многих языков программирования является работа с файлами и потоками. В Java основной функционал работы с потоками сосредоточен в классах из пакета java.io.
Ключевым понятием здесь является понятие потока. Хотя понятие «поток» в программировании довольно перегружено и может обозначать множество различных концепций. В данном случае применительно к работе с файлами и вводом-выводом мы будем говорить о потоке (stream), как об абстракции, которая используется для чтения или записи информации (файлов, сокетов, текста консоли и т.д.).
Пакет java.io содержит почти каждый класс, который может потребоваться Вам для совершения ввода и вывода в Java. Все данные потоки представлены потоком ввода и адресом вывода. Поток в пакете java.io осуществляет поддержку различных данных, таких как примитивы, объекты, локализованные символы и т.д.
Поток связан с реальным физическим устройством с помощью системы ввода-вывода Java. У нас может быть определен поток, который связан с файлом и через который мы можем вести чтение или запись файла. Это также может быть поток, связанный с сетевым сокетом, с помощью которого можно получить или отправить данные в сети. Все эти задачи: чтение и запись различных файлов, обмен информацией по сети, ввод-ввывод в консоли мы будем решать в Java с помощью потоков.
Объект, из которого можно считать данные, называется потоком ввода, а объект, в который можно записывать данные, — потоком вывода. Например, если надо считать содержание файла, то применяется поток ввода, а если надо записать в файл — то поток вывода.
Потоки в Java
Потоки в Java определяются в качестве последовательности данных. Существует два типа потоков:
- InputStream – поток ввода используется для считывания данных с источника.
- OutputStream – поток вывода используется для записи данных по месту назначения.
Java предоставляет сильную, но гибкую поддержку в отношении ввода/вывода, связанных с файлами и сетями.
Байтовые Потоки
Потоки байтов в Java используются для осуществления ввода и вывода 8-битных байтов.
Класс InputStream
Класс InputStream является базовым для всех классов, управляющих байтовыми потоками ввода. Рассмотрим его основные методы:
-
int available(): возвращает количество байтов, доступных для чтения в потоке
-
void close(): закрывает поток
-
int read(): возвращает целочисленное представление следующего байта в потоке. Когда в потоке не останется доступных для чтения байтов, данный метод возвратит число -1
-
int read(byte[] buffer): считывает байты из потока в массив buffer. После чтения возвращает число считанных байтов. Если ни одного байта не было считано, то возвращается число -1
-
int read(byte[] buffer, int offset, int length): считывает некоторое количество байтов, равное length, из потока в массив buffer. При этом считанные байты помещаются в массиве, начиная со смещения offset, то есть с элемента buffer[offset]. Метод возвращает число успешно прочитанных байтов.
-
long skip(long number): пропускает в потоке при чтении некоторое количество байт, которое равно number
Класс OutputStream
Класс OutputStream является базовым классом для всех классов, которые работают с бинарными потоками записи. Свою функциональность он реализует через следующие методы:
-
void close(): закрывает поток
-
void flush(): очищает буфер вывода, записывая все его содержимое
-
void write(int b): записывает в выходной поток один байт, который представлен целочисленным параметром b
-
void write(byte[] buffer): записывает в выходной поток массив байтов buffer.
-
void write(byte[] buffer, int offset, int length): записывает в выходной поток некоторое число байтов, равное length, из массива buffer, начиная со смещения offset, то есть с элемента buffer[offset].
Пример
import java.io.*; // указываем, что будем использовать IO Api
public class InputOutputStreamExam {
private InputStream inputstream; // класс для чтения файла
private OutputStream outputStream; // класс для записи в файл
private String path; // путь к файлу который будем читать и записывать
public InputOutputStreamExam(String path) {
this.path = path;
}
// чтение файла используя InputStream
public void read() throws IOException {
// инициализируем поток на чтение
inputstream = new FileInputStream(path);
// читаем первый символ в байтах (ASCII)
int data = inputstream.read();
char content;
// по байтово читаем весь файл
while(data != -1) {
// преобразуем полученный байт в символ
content = (char) data;
// выводим посимвольно
System.out.print(content);
data = inputstream.read();
}
// закрываем поток
inputstream.close();
}
// запись в файл используя OutputStream
public void write(String st) throws IOException {
// инициализируем поток для вывода данных
// что позволит нам записать новые данные в файл
outputStream = new FileOutputStream(path);
// передаем полученную строку st и приводим её к byte массиву.
outputStream.write(st.getBytes());
// закрываем поток вывода
// только после того как мы закроем поток данные попадут в файл.
outputStream.close();
}
}
Работа с файлами
Не смотря на множество классов, связанных с потоками байтов, наиболее распространено использование следующих классов: FileInputStream и FileOutputStream.
Пример
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileInputOutputStream {
// Класс для работы потоком вывода из файла
private FileInputStream inputStream;
// Класс для работы потоком ввода в файл
private FileOutputStream outputStream;
// полный путь к файлу
private String path;
public FileInputOutputStream(String path) {
this.path = path;
}
public void read() throws IOException {
// инициализируем поток вывода из файлу
inputStream = new FileInputStream(path);
// читаем первый символ с потока байтов
int data = inputStream.read();
char content;
// если data будет равна 0 то это значит,
// что файл пуст
while(data != -1) {
// переводим байты в символ
content = (char) data;
// выводим полученный символ
System.out.print(content);
// читаем следующий байты символа
data = inputStream.read();
}
// закрываем поток чтения файла
inputStream.close();
}
public void write(String st) throws IOException {
// открываем поток ввода в файл
outputStream = new FileOutputStream(path);
// записываем данные в файл, но
// пока еще данные не попадут в файл,
// а просто будут в памяти
outputStream.write(st.getBytes());
// только после закрытия потока записи,
// данные попадают в файл
outputStream.close();
}
}
Символьные потоки
Потоки байтов в Java позволяют произвести ввод и вывод 8-битных байтов, в то время как потоки символов используются для ввода и вывода 16-битного юникода.
Класс Reader
Класс Reader предоставляет функционал для чтения текстовой информации. Рассмотрим его основные методы:
-
void close(): закрывает поток ввода
-
int read(): возвращает целочисленное представление следующего символа в потоке. Если таких символов нет, и достигнут конец файла, то возвращается число -1
-
int read(char[] buffer): считывает в массив buffer из потока символы, количество которых равно длине массива buffer. Возвращает количество успешно считанных символов. При достижении конца файла возвращает -1
-
int read(CharBuffer buffer): считывает в объект CharBuffer из потока символы. Возвращает количество успешно считанных символов. При достижении конца файла возвращает -1
-
int read(char[] buffer, int offset, int count): считывает в массив buffer, начиная со смещения offset, из потока символы, количество которых равно count
-
long skip(long count): пропускает количество символов, равное count. Возвращает число успешно пропущенных символов
Класс Writer
Класс Writer определяет функционал для всех символьных потоков вывода. Его основные методы:
-
Writer append(char c): добавляет в конец выходного потока символ c. Возвращает объект Writer
-
Writer append(CharSequence chars): добавляет в конец выходного потока набор символов chars. Возвращает объект Writer
-
void close(): закрывает поток
-
void flush(): очищает буферы потока
-
void write(int c): записывает в поток один символ, который имеет целочисленное представление
-
void write(char[] buffer): записывает в поток массив символов
-
void write(char[] buffer, int off, int len) : записывает в поток только несколько символов из массива buffer. Причем количество символов равно len, а отбор символов из массива начинается с индекса off
-
void write(String str): записывает в поток строку
-
void write(String str, int off, int len): записывает в поток из строки некоторое количество символов, которое равно len, причем отбор символов из строки начинается с индекса off
Пример
Не смотря на множество классов, связанных с потоками символов, наиболее распространено использование следующих классов: FileReader и FileWriter. Не смотря на тот факт, что внутренний FileReader использует FileInputStream, и FileWriter использует FileOutputStream, основное различие состоит в том, что FileReader производит считывание двух байтов в конкретный момент времени, в то время как FileWriter производит запись двух байтов за то же время.
import java.io.*;
public class Test {
public static void main(String args[])throws IOException {
File file = new File("Example.txt");
// Создание файла
file.createNewFile();
// Создание объекта FileWriter
FileWriter writer = new FileWriter(file);
// Запись содержимого в файл
writer.write("Это простой пример,n в котором мы осуществляемn с помощью языка Javan запись в файлn и чтение из файлаn");
writer.flush();
writer.close();
// Создание объекта FileReader
FileReader fr = new FileReader(file);
char [] a = new char[200]; // Количество символов, которое будем считывать
fr.read(a); // Чтение содержимого в массив
for(char c : a)
System.out.print(c); // Вывод символов один за другими
fr.close();
}
}
Стрруктура java.io
| InputStream | OutputStream | Reader | Writer |
|---|---|---|---|
| FileInputStream | FileOutputStream | FileReader | FileWriter |
| BufferedInpytStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| ByteArrayInpytStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| DataInputStream | DataOutputStream | ||
| ObjectInputStream | ObjectOutputStream |
Стандартые потоки
Все языки программирования обеспечивают поддержку стандартного ввода/вывода, где программа пользователя может произвести ввод посредством клавиатуры и осуществить вывод на экран компьютера. Если вы знакомы с языками программирования C либо C++, вам должны быть известны три стандартных устройства STDIN, STDOUT и STDERR. Аналогичным образом, Java предоставляет следующие три стандартных потока:
Стандартный ввод – используется для перевода данных в программу пользователя, клавиатура обычно используется в качестве стандартного потока ввода, представленного в виде System.in.
Стандартный вывод – производится для вывода данных, полученных в программе пользователя, и обычно экран компьютера используется в качестве стандартного потока вывода, представленного в виде System.out.
Стандартная ошибка – используется для вывода данных об ошибке, полученной в программе пользователя, чаще всего экран компьютера служит в качестве стандартного потока сообщений об ошибках, представленного в виде System.err.
Стандартный поток вывода
Для создания потока вывода в класс System определен объект out. В этом объекте определен метод println, который позволяет вывести на консоль некоторое значение с последующим переводом консоли на следующую строку:
System.out.println("Hello world");
В метод println передается любое значение, как правило, строка, которое надо вывести на консоль. При необходимости можно и не переводить курсор на следующую строку. В этом случае можно использовать метод System.out.print(), который аналогичен println за тем исключением, что не осуществляет перевода на следующую строку.
System.out.print("Hello world");
Но с помощью метода System.out.print также можно осуществить перевод каретки на следующую строку. Для этого надо использовать escape-последовательность n:
Если у нас есть два числа, и мы хотим вывести их значения на экран, то мы можем, например, написать так:
int x=5;
int y=6;
System.out.println("x="+x +"; y="+y);
Но в Java есть также функция для форматированного вывода, унаследованная от языка С: System.out.printf(). С ее помощью мы можем переписать предыдущий пример следующим образом:
int x=5;
int y=6;
System.out.printf("x=%d; y=%d n", x, y);
В данном случае символы %d обозначают спецификатор, вместо которого подставляет один из аргументов. Спецификаторов и соответствующих им аргументов может быть множество. В данном случае у нас только два аргумента, поэтому вместо первого %d подставляет значение переменной x, а вместо второго — значение переменной y. Сама буква d означает, что данный спецификатор будет использоваться для вывода целочисленных значений типа int.
Кроме спецификатора %d мы можем использовать еще ряд спецификаторов для других типов данных:
-
%x: для вывода шестнадцатеричных чисел
-
%f: для вывода чисел с плавающей точкой
-
%e: для вывода чисел в экспоненциальной форме, например, 1.3e+01
-
%c: для вывода одиночного символа
-
%s: для вывода строковых значений
Например:
String name = "Иван";
int age = 30;
float height = 1.7f;
System.out.printf("Имя: %s Возраст: %d лет Рост: %.2f метров n", name, age, height);
При выводе чисел с плавающей точкой мы можем указать количество знаков после запятой, для этого используем спецификатор на %.2f, где .2 указывает, что после запятой будет два знака. В итоге мы получим следующий вывод:
Имя: Иван Возраст: 30 лет Рост: 1,70 метров
Стандартный поток ввода
Для ввода данных с клавиатуры в Java имеется стандартный поток ввода — System.in.
Но у System.in есть минус – он позволяет считать с клавиатуры только коды символов. Чтобы обойти эту проблему и считывать большие порции данных за один раз, можно использовать более сложную конструкцию:
InputStream inputStream = System.in;
Reader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = bufferedReader.readLine(); //читаем строку с клавиатуры
Более компактная версия записи:
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String name = reader.readLine();
Стандартные потоки ввода-вывода
Программа, выводящая в консоль сообщение Hello, world!, с которой традиционно начинают изучение языка программирования, на языке C++ выглядит следующим образом:
#include <iostream>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
return 0;
}
Директива #include и функция main() знакомы читателю по языку C. Способ вывода строки в консоль отличается от стандартной функции printf языка C и даёт нам повод начать разговор про C++.
Глобальный объект cout отвечает за вывод в стандартный поток вывода stdout. Оператор вставки << передает различные объекты в поток вывода. Манипулятор endl выполняет перевод строки. Оператор << позволяет строить цепочки вызовов, которые будут выполняться слева направо: сначала мы вывели строку Hello, world!, а затем манипулятор endl.
Чтобы считать данные из стандартного потока ввода stdin, необходимо воспользоваться объектом cin и оператором извлечения >>.
int a;
double x;
cin >> a >> x;
Здесь мы снова построили цепочку вызовов и получили значения сразу для двух переменных. При обращении к потоку ввода мы не указывали тип данных, которые необходимо прочитать. Оператор >> сам определяет типы объектов и заполняет их из потока ввода.
Объекты cout, cin, а также операторы вставки и извлечения определены в заголовочном файле <iostream>
Работа с файлами
Все операции ввода-вывода в C++ организованы через потоки и операторы << и >>. Мы уже рассмотрели операции ввода-вывода в потоки stdout и stdin. Операции ввода-вывода с файлами устроены схожим образом. Для работы с файловыми потоками необходимо подключить заголовочный файл <fstream>. Следующая программа создает файл test.txt и записывает в него строку Hello, world!
#include <fstream>
using namespace std;
int main() {
ofstream ofile("test.txt", ios::out);
if (ofile.is_open()) {
ofile << "Hello, world!";
}
return 0;
}
Сначала мы создали объект типа ofstream. В его конструктор мы передали имя файла test.txt и флаг ios::out, указывающий на то, что мы собираемся осуществлять операции вывода. Всегда необходимо проверять, что операция открытия/создания файла прошла успешно. Если не выполнить эту проверку, то, если по какой-либо причине файл открыть не удалось, дальнейшие шаги приведут к аварийному завершению программы. Метод is_open() позволяет выполнить такою проверку. Дальше идет уже знакомый нам вызов оператора <<, который в этом случае работает с файловым потоком вывода. Обратите внимание, что нет необходимости вручную закрывать файл, если того не требует логика программы. При выходе объекта ofile из области видимости, файл будет корректно закрыт.
Чтение данных из файла производится следующим образом:
#include <fstream>
#include <string>
#include <iostream>
using namespace std;
int main() {
ifstream ifile("test.txt", ios::in);
if (ifile.is_open()) {
string line;
while (ifile >> line) {
cout << line << ' ';
}
}
return 0;
}
Здесь мы воспользовались файловым потоком ввода ifstream и флагом ios::in. В этой программе мы создали переменную line типа string, чтобы хранить считанные из файла данные. Неочевидным моментом здесь является использование цикла while. Дело в том, что оператор >> считывает символы до тех пор, пока не встретит разделитель (пробел, табуляция или перенос строки). Если бы мы вызвали этот оператор один раз, то в переменную line было бы записано Hello,, а это не то, чего мы хотели. Цикл позволяет прочитать файл до конца.
Если же мы хотим прочитать только одну строчку из файла, то можно воспользоваться функцией getline, определенной в <string>. С этой функцией наша программа примет следующий вид:
#include <fstream>
#include <string>
#include <iostream>
using namespace std;
int main() {
ifstream ifile("test.txt", ios::in);
if (ifile.is_open()) {
string line;
getline(ifile, line);
cout << line << end;
}
return 0;
}
Наконец, для чтения символов из потока по одному можно использовать метод get()
char c;
while (ifile.get(c)) {
cout << c;
}
Аналогичный метод есть и у объекта cin.
По умолчанию файловые потоки работают в текстовом режиме, т.е. передают и принимают строковые символы. В некоторых случаях необходимо работать непосредственно с последовательностью байт, которые не должны быть интерпретированы как строковые символы. Для таких случаев существует флаг ios::binary. Детали работы с бинарными файлами смотрите в документации.
Строковые потоки
Часто бывает удобно работать со строковыми потоками. Инструменты для работы со строковыми потоками подключаются с помощью заголовочного файла <sstream>. Строковые потоки позволяют удобно инициализировать объекты различных типов из их текстового представления. Представим себе, что мы получили географические координаты НГУ в виде строки "(54.847830, 83.094392)". Наша задача извлечь из строки две величины типа double. Сделать это можно следующим образом:
#include <string>
#include <sstream>
#include <iostream>
using namespace std;
int main() {
string nsucoor("(54.847830, 83.094392)");
stringstream ss(nsucoor);
double lat, lon;
ss.ignore(1); // skip '('
ss >> lat;
ss.ignore(2); // skip ", "
ss >> lon;
cout << lat << ", " << lon << endl;
return 0;
}
Резюме
Мы обсудили, что все операции ввода-вывода в С++ реализованы единообразно с помощью потоков. Вывод в поток осуществляется с помощью оператора вставки <<, ввод из потока осуществляется с помощью оператора извлечения >>. Мы рассмотрели три типа потоков: стандартные, файловые и строковые. Этого достаточно для уверенного начала работы с потоками ввода-вывода в C++.
Документация
- http://www.cplusplus.com/reference/iolibrary/
- https://en.cppreference.com/w/cpp/io
С самого начала книги мы использовали С++-систему ввода-вывода, но не давали подробных пояснений по этому поводу. Поскольку С++-система ввода-вывода построена на иерархии классов, ее теорию и детали невозможно освоить, не рассмотрев сначала классы, наследование и механизм обработки исключений. Теперь настало время для подробного изучения С++-средств ввода-вывода.
В этой главе рассматриваются средства как консольного, так и файлового ввода-вывода. Необходимо сразу отметить, что С++-система ввода-вывода — довольно обширная тема, и здесь описаны лишь самые важные и часто применяемые средства. В частности, вы узнаете, как перегрузить операторы «<<» и «>>» для ввода и вывода объектов созданных вами классов, а также как отформатировать выводимые данные и использовать манипуляторы ввода-вывода. Завершает главу рассмотрение средств файлового ввода-вывода.
Сравнение старой и новой С++-систем ввода-вывода
В настоящее время существуют две версии библиотеки объектно-ориентированного ввода-вывода, причем обе широко используются программистами: более старая, основанная на оригинальных спецификациях языка C++, и новая, определенная стандартом языка C++. Старая библиотека ввода-вывода поддерживается за счет заголовочного файла <iostream.h>, а новая — посредством заголовка <iostream>. Новая библиотека ввода-вывода, по сути, представляет собой обновленную и усовершенствованную версию старой. Основное различие между ними состоит в реализации, а не в том, как их нужно использовать.
С точки зрения программиста, есть два существенных различия между старой и новой С ++-библиотеками ввода-вывода. Во-первых, новая библиотека содержит ряд дополнительных средств и определяет несколько новых типов данных. Таким образом, новую библиотеку ввода-вывода можно считать супермножеством старой. Практически все программы, написанные для старой библиотеки, успешно компилируются при использовании новой, не требуя внесения каких-либо значительных изменений. Во-вторых, старая библиотека ввода-вывода была определена в глобальном пространстве имен, а новая использует пространство имен std. (Вспомните, что пространство имен std используется всеми библиотеками стандарта C++.) Поскольку старая библиотека ввода-вывода уже устарела, в этой книге описывается только новая, но большая часть информации применима и к старой.
Потоки C++
Поток — это последовательный логический интерфейс, который связан с физическим файлом.
Принципиальным для понимания С++-системы ввода-вывода является то, что она опирается на понятие потока. Поток (stream) — это общий логический интерфейс с различными устройствами, составляющими компьютер. Поток либо синтезирует информацию, либо потребляет ее и связывается с любым физическим устройством с помощью С++-системы ввода-вывода. Характер поведения всех потоков одинаков, несмотря на различные физические устройства, с которыми они связываются. Поскольку потоки действуют одинаково, то практически ко всем типам устройств можно применить одни и те
же функции и операторы ввода-вывода. Например, методы, используемые для записи данных на экран, также можно использовать для вывода их на принтер или для записи в дисковый файл.
В самой общей форме поток можно назвать логическим интерфейсом с файлом. С++-
определение термина «файл» можно отнести к дисковому файлу, экрану, клавиатуре, порту,
файлу на магнитной ленте и пр. Хотя файлы отличаются по форме и возможностям, все потоки одинаковы. Достоинство этого подхода (с точки зрения программиста) состоит в том, что одно устройство компьютера может «выглядеть» подобно любому другому. Это значит, что поток обеспечивает интерфейс, согласующийся со всеми устройствами.
Поток связывается с файлом при выполнении операции открытия файла, а отсоединяется от него с помощью операции закрытия.
Существует два типа потоков: текстовый и двоичный. Текстовый поток используется для ввода-вывода символов. При этом могут происходить некоторые преобразования символов. Например, при выводе символ новой строки может быть преобразован в последовательность символов: возврата каретки и перехода на новую строку. Поэтому может не быть взаимно-однозначного соответствия между тем, что посылается в поток, и тем, что в действительности записывается в файл. Двоичный поток можно использовать с данными любого типа, причем в этом случае никакого преобразования символов не выполняется, и между тем, что посылается в поток, и тем, что потом реально содержится в файле, существует взаимно-однозначное соответствие.
Текущая позиция — это место в файле, с которого будет выполняться следующая операция доступа к файлу.
Говоря о потоках, необходимо понимать, что вкладывается в понятие «текущей позиции». Текущая позиция — это место в файле, с которого будет выполняться следующая операция доступа к файлу. Например, если длина файла равна 100 байт, и известно, что уже прочитана половина этого файла, то следующая операция чтения произойдет на байте 50, который в данном случае и является текущей позицией.
Итак, в языке C++ механизм ввода-вывода функционирует с использованием логического интерфейса, именуемого потоком. Все потоки имеют аналогичные свойства, которые позволяют выполнять одинаковые функции ввода-вывода, независимо от того, с файлом какого типа существует связь. Под файлом понимается реальное физическое устройство, которое содержит данные. Если файлы различаются между собой, то потоки — нет. (Конечно, некоторые устройства могут не поддерживать все операции ввода-вывода, например операции с произвольной выборкой, поэтому и связанные с ними потоки тоже не будут поддерживать эти операции.)
Встроенные С++-потоки
В C++ содержится ряд встроенных потоков (cin, cout, cerr и clog), которые автоматически открываются, как только программа начинает выполняться. Как вы знаете, cin — это стандартный входной, а cout — стандартный выходной поток. Потоки cerr и clog (они предназначены для вывода информации об ошибках) также связаны со стандартным выводом данных. Разница между ними состоит в том, что поток clog буферизирован, а поток cerr — нет. Это означает, что любые выходные данные, посланные в поток cerr, будут немедленно выведены, а при использовании потока clog данные сначала записываются в буфер, и реальный их вывод происходит только тогда, когда буфер полностью заполняется.
Обычно потоки cerr и clog используются для записи информации об отладке или ошибках. В C++ также предусмотрены двухбайтовые (16-битовые) символьные версии
стандартных потоков, именуемые wcin, wcout, wcerr и wclog. Они предназначены для поддержки таких языков, как китайский, для представления которых требуются большие символьные наборы. В этой книге двухбайтовые стандартные потоки не используются.
По умолчанию стандартные С++-потоки связываются с консолью, но программным способом их можно перенаправить на другие устройства или файлы. Перенаправление может также выполнить операционная система.
Классы потоков
Как вы узнали в главе 2, С++-система ввода-вывода использует заголовок <iostream>, в котором для поддержки операций ввода-вывода определена довольно сложная иерархия классов. Эта иерархия начинается с системы шаблонных классов. Как отмечалось в главе 16, шаблонный класс определяет форму, не задавая в полном объеме данные, которые он должен обрабатывать. Имея шаблонный класс, можно создавать его конкретные экземпляры. Для библиотеки ввода-вывода стандарт C++ создает две специализации шаблонных классов: одну для 8-, а другую для 16-битовых («широких») символов. В этой книге описываются классы только для 8-битовых символов, поскольку они используются гораздо чаще.
С++-система ввода-вывода построена на двух связанных, но различных иерархиях шаблонных классов. Первая выведена из класса низкоуровневого ввода-вывода basic_streambuf. Этот класс поддерживает базовые низкоуровневые операции ввода и вывода и обеспечивает поддержку для всей С++-системы ввода-вывода. Если вы не собираетесь заниматься программированием специализированных операций ввода-вывода, то вам вряд ли придется использовать напрямую класс basic_streambuf. Иерархия классов, с которой С ++-программистам наверняка предстоит работать вплотную, выведена из класса basic_ios. Это — класс высокоуровневого ввода-вывода, который обеспечивает форматирование, контроль ошибок и предоставляет статусную информацию, связанную с потоками вводавывода. (Класс basic_ios выведен из класса ios_base, который определяет ряд нешаблонных свойств, используемых классом basic_ios.) Класс basic_ios используется в качестве базового для нескольких производных классов, включая классы basic_istream, basic_ostream и basic_iostream. Эти классы используются для создания потоков, предназначенных для ввода данных, вывода и ввода-вывода соответственно.
Как упоминалось выше, библиотека ввода-вывода создает две специализированные иерархии шаблонных классов: одну для 8-, а другую для 16-битовых символов. Ниже приводится список имен шаблонных классов и соответствующих им «символьных» версий.

В остальной части этой книги используются имена символьных классов, поскольку именно они применяются в программах. Те же имена используются и старой библиотекой ввода-вывода. Вот поэтому старая и новая библиотеки совместимы на уровне исходного кода.
И еще: класс ios содержит множество функций-членов и переменных, которые управляют основными операциями над потоками или отслеживают результаты их выполнения. Поэтому имя класса ios будет употребляться в этой книге довольно часто. И помните: если включить в программу заголовок <iostream>, она будет иметь доступ к этому важному классу.
Перегрузка операторов ввода-вывода
Впримерах из предыдущих глав при необходимости выполнить операцию ввода или вывода данных, связанных с классом, создавались функции-члены, назначение которых и состояло лишь в том, чтобы ввести или вывести эти данные. Несмотря на то что в самом этом решении нет ничего неправильного, в C++ предусмотрен более удачный способ выполнения операций ввода-вывода «классовых» данных: путем перегрузки операторов ввода-вывода «<<» и «>>».
Оператор «<<» выводит информацию в поток, а оператор «>>» вводит информацию из потока.
Вязыке C++ оператор «<<» называется оператором вывода или вставки, поскольку он вставляет символы в поток. Аналогично оператор «>>» называется оператором ввода или извлечения, поскольку он извлекает символы из потока.
Как вы знаете, операторы ввода-вывода уже перегружены (в заголовке <iostream>), чтобы они могли выполнять операции потокового ввода или вывода данных любых встроенных С++-типов. Здесь вы узнаете, как определить эти операторы для собственных классов.
Создание перегруженных операторов вывода
В качестве простого примера рассмотрим создание оператора вывода для следующей версии класса three_d.
class three_d {
public:
int x, у, z; // 3-мерные координаты
three_d(int a, int b, int с) { x = a; у = b; z = c; }
};
Чтобы создать операторную функцию вывода для объектов типа three_d, необходимо перегрузить оператор «<<«. Вот один из возможных способов.
/* Отображение координат X, Y, Z (оператор вывода для класса three_d).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
Рассмотрим внимательно эту функцию, поскольку ее содержимое характерно для многих функций вывода данных. Во-первых, отметьте, что согласно объявлению она возвращает ссылку на объект типа ostream. Это позволяет несколько операторов вывода объединить в одном составном выражении. Затем обратите внимание на то, что эта функция имеет два параметра. Первый представляет собой ссылку на поток, который используется в левой части оператора. Вторым является объект, который стоит в правой части этого оператора. (При необходимости второй параметр также может иметь тип ссылки на объект.) Само тело функции состоит из инструкций вывода трех значений координат, содержащихся в объекте типа three_d, и инструкции возврата потока stream.
Перед вами короткая программа, в которой демонстрируется использование оператора вывода.
// Использование перегруженного оператора вывода.
#include <iostream>
using namespace std;
class three_d {
public:
int x, y, z; // 3-мерные координаты
three_d(int a, int b, int с) { x = a; у = b; z = c; }
};
/* Отображение координат X, Y, Z (оператор вывода для класса three_d).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), c(5, 6, 7);
cout << a << b << c;
return 0;
}
При выполнении эта программа возвращает следующие результаты:
1, 2, 3
3, 4, 5
5, 6, 7
Если удалить код, относящийся конкретно к классу three_d, останется «скелет», подходящий для любой функции вывода данных.
ostream &operator<<(ostream &stream, class_type obj)
{
// код, относящийся к конкретному классу
return stream; // возвращает параметр stream
}
Как уже отмечалось, для параметра obj разрешается использовать передачу по ссылке. В широком смысле конкретные действия функции вывода определяются программистом. Но если вы хотите следовать профессиональному стилю программирования, то ваша функция вывода должна все-таки выводить информацию. И потом, всегда нелишне убедиться в том, что она возвращает параметр stream.
Прежде чем переходить к следующему разделу, подумайте, почему функция вывода для класса three_d не была закодирована таким образом.
/* Версия ограниченного применения (использованию не подлежит).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
cout << obj.x << «, «;
cout << obj.у << «, «;
cout << obj.z << «n»;
return stream; // возвращает параметр stream
}
Вэтой версии функции жестко закодирован поток cout. Это ограничивает круг ситуаций,
вкоторых ее можно использовать. Помните, что оператор «<<» можно применить к любому потоку и что поток, который использован в «<<«-выражении, передается параметру stream. Следовательно, вы должны передавать функции поток, который корректно работает во всех случаях. Только так можно создать функцию вывода данных, которая подойдет для использования в любых выражениях ввода-вывода.
Использование функций-«друзей» для перегрузки операторов вывода
Впредыдущей программе перегруженная функция вывода не была определена как член класса three_d. В действительности ни функция вывода, ни функция ввода не могут быть членами класса. Дело здесь вот в чем. Если операторная функция является членом класса, левый операнд (неявно передаваемый с помощью указателя this) должен быть объектом класса, который сгенерировал обращение к этой операторной функции. И это изменить нельзя. Однако при перегрузке операторов вывода левый операнд должен быть потоком, а правый — объектом класса, данные которого подлежат выводу. Следовательно, перегруженные операторы вывода не могут быть функциями-членами.
Всвязи с тем, что операторные функции вывода не должны быть членами класса, для которого они определяются, возникает серьезный вопрос: как перегруженный оператор вывода может получить доступ к закрытым элементам класса? В предыдущей программе переменные х, у z были определены как открытые, и поэтому оператор вывода без проблем мог получить к ним доступ. Но ведь сокрытие данных — важная часть объектноориентированного программирования, и требовать, чтобы все данные были открытыми, попросту нелогично. Однако существует решение и для этой проблемы: оператор вывода можно сделать «другом» класса. Если функция является «другом» некоторого класса, то она получает легальный доступ к его private-данным. Как можно объявить «другом» класса перегруженную функцию вывода, покажем на примере класса three_d.
// Использование «дружбы» для перегрузки оператора «<<«
#include <iostream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты (теперь это privateчлены)
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj);
};
// Отображение координат X, Y, Z (оператор вывода для класса three_d).
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает поток
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), с (5, 6, 7);
cout << a << b << c;
return 0;
}
Обратите внимание на то, что переменные х, у и z в этой версии программы являются закрытыми в классе three_d, тем не менее, операторная функция вывода обращается к ним напрямую. Вот где проявляется великая сила «дружбы»: объявляя операторные функции ввода и вывода «друзьями» класса, для которого они определяются, мы тем самым поддерживаем принцип инкапсуляции объектно-ориентированного программирования.
Перегрузка операторов ввода
Для перегрузки операторов ввода используйте тот же метод, который мы применяли при перегрузке оператора вывода. Например, следующий оператор ввода обеспечивает ввод трехмерных координат. Обратите внимание на то, что он также выводит соответствующее сообщение для пользователя.
/* Прием трехмерных координат (оператор ввода для класса three_d).
*/
istream &operator>>(istream &stream, three_d &obj)
{
cout << «Введите координаты X, Y и Z:
stream >> obj.x >> obj.у >> obj.z;
return stream;
}
Оператор ввода должен возвращать ссылку на объект типа istream. Кроме того, первый параметр должен представлять собой ссылку на объект типа istream. Этот тип принадлежит потоку, указанному слева от оператора «>>». Второй параметр является ссылкой на переменную, которая принимает вводимое значение. Поскольку второй параметр — ссылка, он может быть модифицирован при вводе информации.
Общий формат оператора ввода имеет следующий вид.
istream &operator>>(istream &stream, object_type &obj)
{
// код операторной функции ввода данных
return stream;
}
Использование функции ввода данных для объектов типа three_d демонстрируется в следующей программе.
// Использование перегруженного оператора ввода.
#include <iostream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj);
friend istream &operator>>(istream &stream, three_d &obj);
};
// Отображение координат X, Y, Z (оператор вывода для класса three_d).
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
// Прием трехмерных координат (оператор ввода для класса three_d).
istream &operator>>(istream &stream, three_d &obj)
{
cout << «Введите координаты X, Y и Z: «;
stream >> obj.x >> obj.у >> obj.z;
return stream;
}
int main()
{
three_d a(1, 2, 3);
cout << a;
cin >> a;
cout << a;
return 0;
}
Вот как выглядит один из возможных результатов выполнения этой программы.
1, 2, 3
Введите координаты X, Y и Z: 5 6 7
5, 6, 7
Подобно функциям вывода, функции ввода не должны быть членами класса, для обработки данных которого они предназначены. Они могут быть «друзьями» этого класса или просто независимыми функциями.
За исключением того, что функция ввода должна возвращать ссылку на объект типа istream, тело этой функции может содержать все, что вы считаете нужным в нее включить. Но логичнее использовать операторы ввода все же по прямому назначению, т.е. для выполнения операций ввода.
Сравнение С- и С++-систем ввода-вывода
Как вы знаете, предшественник C++, язык С, оснащен одной из самых гибких (среди структурированных языков) и при этом очень мощных систем ввода-вывода. (Не будет преувеличением сказать, что среди всех известных структурированных языков С-система ввода-вывода не имеет себе равных.) Почему же тогда, спрашивается, в C++ определяется собственная система ввода-вывода, если в ней продублирована большая часть того, что содержится в С (имеется в виду мощный набор С-функций ввода-вывода)? Ответить на этот вопрос нетрудно. Дело в том, что С-система ввода-вывода не обеспечивает никакой поддержки для объектов, определяемых пользователем. Например, если создать в С такую структуру
struct my_struct {
int count;
char s [80];
double balance;
} cust;
то существующую в С систему ввода-вывода невозможно настроить так, чтобы она могла выполнять операции ввода-вывода непосредственно над объектами типа my_struct. Но

поскольку центром объектно-ориентированного программирования являются именно объекты, имеет смысл, чтобы в C++ функционировала такая система ввода-вывода, которую можно было бы динамически «обучать» обращению с любыми объектами, создаваемыми программистом. Именно поэтому для C++ и была изобретена новая объектноориентированная система ввода-вывода. Как вы уже могли убедиться, С++-подход к вводувыводу позволяет перегружать операторы «<<» и «>>», чтобы они могли работать с классами, создаваемыми программистами.
И еще. Поскольку C++ является супермножеством языка С, все содержимое С-системы ввода-вывода включено в C++. (См. приложение А, в котором представлен обзор С- ориентированных функций ввода-вывода.) Поэтому при переводе С-программ на язык C++ вам не нужно изменять все инструкции ввода-вывода подряд. Работающие С-инструкции скомпилируются и будут успешно работать и в новой С++-среде. Просто вы должны учесть, что старая С-система ввода-вывода не обладает объектно-ориентированными возможностями.
Форматированный ввод-вывод данных
До сих пор при вводе или выводе информации в наших примерах программ действовали параметры форматирования, которые по умолчанию использует С++-система ввода-вывода. Но программист может сам управлять форматом представления данных, причем двумя способами. Первый способ предполагает использование функций-членов класса ios, а второй— функций специального типа, именуемых манипуляторами (manipulator). Мы же начнем освоение возможностей форматирования с функций-членов класса ios.
Форматирование данных с использованием функций-членов класса ios
В системе ввода-вывода C++ каждый поток связан с набором флагов форматирования, которые управляют процессом форматирования информации. В классе ios объявляется перечисление fmtflags, в котором определены следующие значения. (Точнее, эти значения определены в классе ios_base, который, как упоминалось выше, является базовым для класса ios.)
Эти значения используются для установки или очистки флагов форматирования с помощью таких функций, как setf() и unsetf(). При использовании старого компилятора может оказаться, что он не определяет тип перечисления fmtflags. В этом случае флаги форматирования будут кодироваться как целочисленные long-значения.
Если флаг skipws установлен, то при потоковом вводе данных ведущие «пробельные» символы, или символы пропуска (т.е. пробелы, символы табуляции и новой строки), отбрасываются. Если же флаг skipws сброшен, пробельные символы не отбрасываются.
Если установлен флаг left, выводимые данные выравниваются по левому краю, а если установлен флаг right — по правому. Если установлен флаг internal, числовое значение дополняется пробелами, которыми заполняется поле между ним и знаком числа или символом основания системы счисления. Если ни один из этих флагов не установлен, результат выравнивается по правому краю по умолчанию.
По умолчанию числовые значения выводятся в десятичной системе счисления. Однако основание системы счисления можно изменить. Установка флага oct приведет к выводу результата в восьмеричном представлении, а установка флага hex — в шестнадцатеричном. Чтобы при отображении результата вернуться к десятичной системе счисления, достаточно установить флаг dec.
Установка флага showbase приводит к отображению обозначения основания системы счисления, в которой представляются числовые значения. Например, если используется шестнадцатеричное представление, то значение 1F будет отображено как 0x1F.
По умолчанию при использовании экспоненциального представления чисел отображается строчной вариант буквы «е». Кроме того, при отображении шестнадцатеричного значения используется также строчная буква «х». После установки флага uppercase отображается прописной вариант этих символов.
Установка флага showpos вызывает отображение ведущего знака «плюс» перед положительными значениями.
Установка флага showpoint приводит к отображению десятичной точки и хвостовых нулей для всех чисел с плавающей точкой — нужны они или нет.
После установки флага scientific числовые значения с плавающей точкой отображаются в экспоненциальном представлении. Если установлен флаг fixed, вещественные значения отображаются в обычном представлении. Если не установлен ни один из этих флагов, компилятор сам выбирает соответствующий метод представления.
При установленном флаге unitbuf содержимое буфера сбрасывается на диск после каждой операции вывода данных.
Если установлен флаг boolalpha, значения булева типа можно вводить или выводить, используя ключевые слова true и false.
Поскольку часто приходится обращаться к полям oct, dec и hex, на них допускается коллективная ссылка ios::basefield. Аналогично поля left, right и internal можно собирательно назвать ios::adjustfield. Наконец, поля scientific и fixed можно назвать ios::floatfield.
Чтобы установить флаги форматирования, обратитесь к функции setf().
Для установки любого флага используется функция setf(), которая является членом класса ios. Вот как выглядит ее формат.
fmtflags setf(fmtflags flags);
Эта функция возвращает значение предыдущих установок флагов форматирования и устанавливает их в соответствии со значением, заданным параметром flags. Например, чтобы установить флаг showbase, можно использовать эту инструкцию.
stream.setf(ios::showbase);
Здесь элемент stream означает поток, параметры форматирования которого вы хотите изменить. Обратите внимание на использование префикса ios:: для уточнения принадлежности параметра showbase. Поскольку параметр showbase представляет собой перечислимую константу, определенную в классе ios, то при обращении к ней необходимо указывать имя класса ios. Этот принцип относится ко всем флагам форматирования. В следующей программе функция setf() используется для установки флагов showpos и scientific.
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios::showpos);
cout.setf(ios::scientific);
cout << 123 << » » << 123.23 << » «;
return 0;
}
Вот как выглядят результаты выполнения этой программы.
+123 +1.232300е+002
С помощью операции ИЛИ можно установить сразу несколько нужных флагов форматирования в одном вызове функции setf(). Например, предыдущую программу можно сократить, объединив по ИЛИ флаги scientific и showpos, поскольку в этом случае выполняется только одно обращение к функции setf().
cout.setf(ios::scientific | ios::showpos);
Чтобы сбросить флаг, используйте функцию unsetf(), прототип которой выглядит так.
void unsetf(fmtflags flags);
Для очистки флагов форматирования используется функция unsetf().
В этом случае будут обнулены флаги, заданные параметром flags. (При этом все другие
флаги остаются в прежнем состоянии.)
Чтобы получить текущие установки флагов форматирования, используйте функцию flags().
Для того чтобы узнать текущие установки флагов форматирования, воспользуйтесь функцией flags(), прототип которой имеет следующий вид.
fmtflags flags();
Эта функция возвращает текущее значение флагов форматирования для вызывающего потока.
При использовании следующего формата вызова функции flags() устанавливаются значения флагов форматирования в соответствии с содержимым параметра flags и возвращаются их предыдущие значения.
fmtflags flags(fmtflags flags);
Чтобы понять, как работают функции flags() и unsetf(), рассмотрим следующую программу. Она включает функцию showflags(), которая отображает состояние флагов форматирования.
#include <iostream>
using namespace std;
void showflags(ios::fmtflags f);
int main()
{
ios::fmtflags f;
f = cout.flags();
showflags(f);
cout.setf(ios::showpos);
cout.setf(ios::scientific);
f = cout.flags();
showflags(f);
cout.unsetf(ios:scientific);
f = cout.flags();
showflags(f);
return 0;
}
void showflags(ios::fmtflags f)
{
long i;
for(i=0x4000; i; i=i>>1)
if(i & f) cout << «1»;
else cout << «0»;
cout << «n»;
}
При выполнении эта программа отображает такие результаты. (Между этими и вашими результатами возможно расхождение, вызванное использованием различных компиляторов.)
0 0 0 0 0 1 0 0 0 0 0 0 0 0 1
0 0 1 0 0 1 0 0 0 1 0 0 0 0 1
0 0 0 0 0 1 0 0 0 1 0 0 0 0 1
В предыдущей программе обратите внимание на то, что тип fmtflags указан с префиксом ios ::. Дело в том, что тип fmtflags определен в классе ios. В общем случае при использовании имени типа или перечислимой константы, определенной в некотором
классе, необходимо указывать соответствующее имя вместе с именем класса.
Установка ширины поля, точности и символов заполнения
Помимо флагов форматирования можно также устанавливать ширину поля, символ заполнения и количество цифр после десятичной точки (точность). Для этого достаточно использовать следующие функции.
streamsize width(streamsize len);
char fill(char ch);
streamsize precision(streamsize num);
Функция width() возвращает текущую ширину поля и устанавливает новую равной значению параметра len. Ширина поля, которая устанавливается по умолчанию, определяется количеством символов, необходимых для хранения данных в каждом конкретном случае. Функция fill() возвращает текущий символ заполнения (по умолчанию используется пробел) и устанавливает в качестве нового текущего символа заполнения значение, заданное параметром ch. Этот символ используется для дополнения результата символами, недостающими для достижения заданной ширины поля. Функция precision() возвращает текущее количество цифр, отображаемых после десятичной точки, и устанавливает новое текущее значение точности равным содержимому параметра num. (По умолчанию после десятичной точки отображается шесть цифр.) Тип streamsize определен как целочисленный тип.
Рассмотрим программу, которая демонстрирует использование этих трех функций.
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios::showpos);
cout.setf(ios::scientific);
cout << 123 << » » << 123.23 << «n»;
cout.precision(2); // Две цифры после десятичной точки.
cout.width(10); // Всё поле состоит из 10 символов.
cout << 123 << » «;
cout.width(10); // Установка ширины поля равной 10.
cout << 123.23 << «n»;
cout.fill(‘#’); // Для заполнителя возьмем символ «#»
cout.width(10); // и установим ширину поля равной 10.
cout << 123 << » «;
cout.width(10); // Установка ширины поля равной 10.
cout << 123.23;
return 0;
}
Эта программа генерирует такие результаты.
+123 +1.232300е+002
+123 +1.23е+002
######+123 +1.23е+002
Внекоторых реализациях необходимо устанавливать значение ширины поля перед выполнением каждой операции вывода. Поэтому функция width() в предыдущей программе вызывалась несколько раз.
Всистеме ввода-вывода C++ определены и перегруженные версии функций width(), precision() и fill(), которые не изменяют текущие значения соответствующих параметров форматирования и используются только для их получения. Вот как выглядят их прототипы,
char fill();
streamsize width();
streamsize precision();
Использование манипуляторов ввода-вывода
Манипуляторы позволяют встраивать инструкции форматирования в выражение
ввода-вывода.
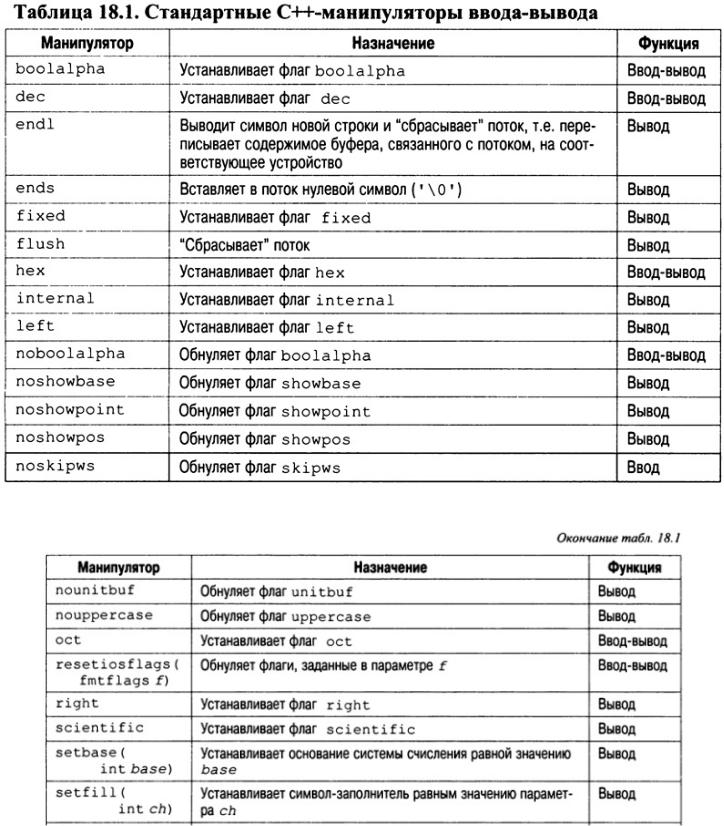
В С++-системе ввода-вывода предусмотрен и второй способ изменения параметров форматирования, связанных с потоком. Он реализуется с помощью специальных функций, называемых манипуляторами, которые можно включать в выражение ввода-вывода. Стандартные манипуляторы описаны в табл. 18.1.

При использовании манипуляторов, которые принимают аргументы, необходимо включить в программу заголовок <iomanip>.
Манипулятор используется как часть выражения ввода-вывода. Вот пример программы, в которой показано, как с помощью манипуляторов можно управлять форматированием выводимых данных.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
cout << setprecision (2) << 1000.243 << endl;
cout << setw(20) << «Всем привет! «;
return 0;
}
Результаты выполнения этой программы таковы.
1е+003
Всем привет!
Обратите внимание на то, как используются манипуляторы в цепочке операций вводавывода. Кроме того, отметьте, что, если манипулятор вызывается без аргументов (как,
например, манипулятор endl в нашей программе), то его имя указывается без пары круглых скобок.
В следующей программе используется манипулятор setiosflags() для установки флагов scientific и showpos.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
cout << setiosflags(ios::showpos);
cout << setiosflags(ios::scientific);
cout << 123 << » » << 123.23;
return 0;
}
Вот результаты выполнения данной программы.
+123 +1.232300е+002
А в этой программе демонстрируется использование манипулятора ws, который пропускает ведущие «пробельные» символы при вводе строки в массив s:
#include <iostream>
using namespace std;
int main()
{
char s[80];
cin >> ws >> s;
cout << s;
return 0;
}
Создание собственных манипуляторных функций
Программист может создавать собственные манипуляторные функции. Существует два типа манипуляторных функций: принимающие и не принимающие аргументы. Для создания параметризованных манипуляторов используются методы, рассмотрение которых выходит за рамки этой книги. Однако создание манипуляторов, которые не имеют параметров, не вызывает особых трудностей.
Все манипуляторные функции вывода данных без параметров имеют следующую структуру.
ostream &manip_name(ostream &stream)
{
// код манипуляторной функции
return stream;
}
Здесь элемент manip_name означает имя манипулятора. Важно понимать, что, несмотря на то, что манипулятор принимает в качестве единственного аргумента указатель на поток, который он обрабатывает, при использовании манипулятора в результирующем выражении ввода-вывода аргументы не указываются вообще.
В следующей программе создается манипулятор setup(), который устанавливает флаг выравнивания по левому краю, ширину поля равной 10 и задает в качестве заполняющего символа знак доллара.
#include <iostream>
#include <iomanip>
using namespace std;
ostream &setup(ostream &stream)
{
stream.setf(ios::left);
stream << setw(10) << setfill (‘$’);
return stream;
}
int main()
{
cout << 10 << » » << setup << 10;
return 0;
}
Собственные манипуляторы полезны по двум причинам. Во-первых, иногда возникает необходимость выполнять операции ввода-вывода с использованием устройства, к которому ни один из встроенных манипуляторов не применяется (например, плоттер). В этом случае создание собственных манипуляторов сделает вывод данных на это устройство более удобным. Во-вторых, может оказаться, что у вас в программе некоторая последовательность инструкций повторяется несколько раз. И тогда вы можете объединить эти операции в один манипулятор, как показано в предыдущей программе.
Все манипуляторные функции ввода данных без параметров имеют следующую структуру.
istream &manip_name(istream &stream)
{
// код манипуляторной функции
return stream;
}
Например, в следующей программе создается манипулятор prompt(). Он настраивает входной поток на прием данных в шестнадцатеричном представлении и отображает для пользователя наводящее сообщение.
#include <iostream>
#include <iomanip>
using namespace std;
istream &prompt(istream &stream)
{
cin >> hex;
cout << «Введите число в шестнадцатеричном формате: «;
return stream;
}
int main()
{
int i;
cin >> prompt >> i;
cout << i;
return 0;
}
Помните: очень важно, чтобы ваш манипулятор возвращал потоковый объект (элемент stream). В противном случае этот манипулятор нельзя будет использовать в составном выражении ввода или вывода.
Файловый ввод-вывод
В С++-системе ввода-вывода также предусмотрены средства для выполнения соответствующих операций с использованием файлов. Файловые операции ввода-вывода можно реализовать после включения в программу заголовка <fstream>, в котором определены все необходимые для этого классы и значения.
Как открыть и закрыть файл
В C++ файл открывается путем связывания его с потоком. Как вы знаете, существуют потоки трех типов: ввода, вывода и ввода-вывода. Чтобы открыть входной поток, необходимо объявить потоковый объект типа ifstream. Для открытия выходного потока нужно объявить поток класса ofstream. Поток, который предполагается использовать для операций как ввода, так и вывода, должен быть объявлен как объект класса fstream. Например, при выполнении следующего фрагмента кода будет создан входной поток, выходной и поток, позволяющий выполнение операций в обоих направлениях.
ifstream in; // входной поток
ofstream out; // выходной поток
fstream both; // поток ввода-вывода
Чтобы открыть файл, используйте функцию open().
Создав поток, его нужно связать с файлом. Это можно сделать с помощью функции open(), причем в каждом из трех потоковых классов есть своя функция-член open(). Представим их прототипы.
void ifstream::open(const char *filename, ios::openmode mode = ios::in);
void ofstream::open(const char *filename, ios::openmode mode = ios::out | ios::trunc);
void fstream::open(const char * filename, ios::openmode mode = ios::in | ios::out);
Здесь элемент filename означает имя файла, которое может включать спецификатор пути. Элемент mode определяет способ открытия файла. Он должен принимать одно или несколько значений перечисления openmode, которое определено в классе ios.
ios::арр
ios::ate
ios::rbinary
ios::in
ios::out
ios::trunc
Несколько значений перечисления openmode можно объединять посредством логического сложения (ИЛИ).
На заметку. Параметр mode для функции fstream::open() может не устанавливаться по умолчанию равным значению in | out (это зависит от используемого компилятора). Поэтому при необходимости этот параметр вам придется задавать в явном виде.
Включение значения ios::арр в параметр mode обеспечит присоединение к концу файла всех выводимых данных. Это значение можно применять только к файлам, открытым для вывода данных. При открытии файла с использованием значения ios::ate поиск будет начинаться с конца файла. Несмотря на это, операции ввода-вывода могут по-прежнему выполняться по всему файлу.
Значение ios::in говорит о том, что данный файл открывается для ввода данных, а значение ios::out обеспечивает открытие файла для вывода данных.
Значение ios::binary позволяет открыть файл в двоичном режиме. По умолчанию все файлы открываются в текстовом режиме. Как упоминалось выше, в текстовом режиме могут происходить некоторые преобразования символов (например, последовательность, состоящая из символов возврата каретки и перехода на новую строку, может быть преобразована в символ новой строки). При открытии файла в двоичном режиме никакого преобразования символов не выполняется. Следует иметь в виду, любой файл, содержащий форматированный текст или еще необработанные данные, можно открыть как в двоичном, так и в текстовом режиме. Единственное различие между этими режимами состоит в преобразовании (или нет) символов.
Использование значения ios::trunc приводит к разрушению содержимого файла, имя которого совпадает с параметром filename, а сам этот файл усекается до нулевой длины. При создании выходного потока типа ofstream любой существующий файл с именем filename автоматически усекается до нулевой длины.
При выполнении следующего фрагмента кода открывается обычный выходной файл.
ofstream out;
out.open(«тест»);
Поскольку параметр mode функции open() по умолчанию устанавливается равным значению, соответствующему типу открываемого потока, в предыдущем примере вообще нет необходимости задавать его значение.
Не открытый в результате неудачного выполнения функции open() поток при использовании в булевом выражении устанавливается равным значению ЛОЖЬ. Этот факт может служить для подтверждения успешного открытия файла, например, с помощью такой if-инструкции.
if(!mystream) {
cout << «He удается открыть файл.n»;
// обработка ошибки
}
Прежде чем делать попытку получения доступа к файлу, следует всегда проверять результат вызова функции open().
Можно также проверить факт успешного открытия файла с помощью функции is_open(), которая является членом классов fstream, ifstream и ofstream. Вот ее прототип,
bool is_open();
Эта функция возвращает значение ИСТИНА, если поток связан с открытым файлом, и ЛОЖЬ — в противном случае. Например, используя следующий код, можно узнать, открыт ли в данный момент потоковый объект mystream.
if(!mystream.is_open()) {
cout << «Файл не открыт.n»;
// …
}
Хотя вполне корректно использовать функцию open() для открытия файла, в большинстве случаев это делается по-другому, поскольку классы ifstream, ofstream и fstream включают конструкторы, которые автоматически открывают заданный файл. Параметры у этих конструкторов и их значения (действующие по умолчанию) совпадают с параметрами и соответствующими значениями функции open(). Поэтому чаще всего файл открывается так, как показано в следующем примере,
ifstream mystream(«myfile»); // файл открывается для ввода
Если по какой-то причине файл открыть невозможно, потоковая переменная, связываемая с этим файлом, устанавливается равной значению ЛОЖЬ.
Чтобы закрыть файл, вызовите функцию close().
Чтобы закрыть файл, используйте функцию-член close(). Например, чтобы закрыть файл, связанный с потоковым объектом mystream, используйте такую инструкцию,
mystream.close();
Функция close() не имеет параметров и не возвращает никакого значения.
Чтение и запись текстовых файлов
Проще всего считывать данные из текстового файла или записывать их в него с помощью операторов «<<» и «>>». Например, в следующей программе выполняется запись в файл test целого числа, значения с плавающей точкой и строки.
// Запись данных в файл.
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ofstream out(«test»);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out << 10 << » » << 123.23 << «n»;
out << «Это короткий текстовый файл.»;
out.close();
return 0;
}
Следующая программа считывает целое число, float-значение, символ и строку из файла, созданного при выполнении предыдущей программой.
// Считывание данных из файла.
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char ch;
int i;
float f;
char str[80];
ifstream in(«test»);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in >> i;
in >> f;
in >> ch;
in >> str;
cout << i << » » << f << » » << ch << «n»;
cout << str;
in.close();
return 0;
}
Следует иметь в виду, что при использовании оператора «>>» для считывания данных из текстовых файлов происходит преобразование некоторых символов. Например, «пробельные» символы опускаются. Если необходимо предотвратить какие бы то ни было преобразования символов, откройте файл в двоичном режиме доступа. Кроме того, помните, что при использовании оператора «>>» для считывания строки ввод прекращается при обнаружении первого «пробельного» символа.
Неформатированный ввод-вывод данных в двоичном режиме
Форматированные текстовые файлы (подобные тем, которые использовались в предыдущих примерах) полезны во многих ситуациях, но они не обладают гибкостью неформатированных двоичных файлов. Поэтому C++ поддерживает ряд функций файлового ввода-вывода в двоичном режиме, которые могут выполнять операции без форматирования данных.
Для выполнения двоичных операций файлового ввода-вывода необходимо открыть файл с использованием спецификатора режима ios::binary. Необходимо отметить, что функции обработки неформатированных файлов могут работать с файлами, открытыми в текстовом режиме доступа, но при этом могут иметь место преобразования символов, которые сводят на нет основную цель выполнения двоичных файловых операций.
Функция get() считывает символ из файла, а функция put() записывает символ в файл.
В общем случае существует два способа записи неформатированных двоичных данных в файл и считывания их из файла. Первый состоит в использовании функции-члена put() (для записи байта в файл) и функции-члена get() (для считывания байта из файла). Второй способ предполагает применение «блочных» С++-функций ввода-вывода read() и write(). Рассмотрим каждый способ в отдельности.
Использование функций get() и put()
Функции get() и put() имеют множество форматов, но чаще всего используются следующие их версии:
istream &get(char &ch);
ostream &put(char ch);
Функция get() считывает один символ из соответствующего потока и помещает его значение в переменную ch. Она возвращает ссылку на поток, связанный с предварительно открытым файлом. При достижении конца этого файла значение ссылки станет равным нулю. Функция put() записывает символ ch в поток и возвращает ссылку на этот поток.
При выполнении следующей программы на экран будет выведено содержимое любого заданного файла. Здесь используется функция get().
/* Отображение содержимого файла с помощью функции get().
*/
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=2) {
cout << «Применение: имя_программы <имя_файла>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
while(in) {
/* При достижении конца файла потоковый объект in примет значение false. */
in.get(ch);
if(in) cout << ch;
}
in.close();
return 0;
}
При достижении конца файла потоковый объект in примет значение ЛОЖЬ, которое остановит выполнение цикла while.
Существует более короткий вариант цикла, предназначенного для считывания и отображения содержимого файла.
while(in.get(ch)) cout << ch;
Этот вариант также имеет право на существование, поскольку функция get() возвращает потоковый объект in, который при достижении конца файла примет значение false.
В следующей программе для записи строки в файл используется функция put().
/* Использование функции put() для записи строки в файл.
*/
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char *p = «Всем привет!»;
ofstream out(«test», ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
while(*p) out.put(*p++);
out.close();
return 0;
}
Считывание и запись в файл блоков данных
Чтобы считывать и записывать в файл блоки двоичных данных, используйте функциичлены read() и write(). Их прототипы имеют следующий вид.
istream &read(char *buf, streamsize num);
ostream &write(const char *buf, int streamsize num);
Функция read() считывает num байт данных из связанного с файлом потока и помещает их в буфер, адресуемый параметром buf. Функция write() записывает num байт данных в связанный с файлом поток из буфера, адресуемого параметром buf. Как упоминалось выше, тип streamsize определен как некоторая разновидность целочисленного типа. Он позволяет хранить самое большое количество байтов, которое может быть передано в процессе любой операции ввода-вывода.
Функция read() вводит блок данных, а функция write() выводит его.
При выполнении следующей программы сначала в файл записывается массив целых чисел, а затем он же считывается из файла.
// Использование функций read() и write().
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
int n[5] = {1, 2, 3, 4, 5};
register int i;
ofstream out(«test», ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out.write((char *) &n, sizeof n);
out.close();
for(i=0; i<5; i++) // очищаем массив
n[i] = 0;
ifstream in («test», ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in.read((char *) &n, sizeof n);
for(i=0; i<5; i++) // Отображаем значения, считанные из файла.
cout << n[i] << » «;
in.close();
return 0;
}
Обратите внимание на то, что в инструкциях обращения к функциям read() и write() выполняются операции приведения типа, которые обязательны при использовании буфера, определенного не в виде символьного массива.
Функция gcount() возвращает количество символов, считанных при выполнении последней операции ввода данных.
Если конец файла будет достигнут до того, как будет считано num символов, функция read() просто прекратит выполнение, а буфер будет содержать столько символов, сколько удалось считать до этого момента. Точное количество считанных символов можно узнать с помощью еще одной функции-члена gcount(), которая имеет такой прототип.
streamsize gcount();
Функция gcount() возвращает количество символов, считанных в процессе выполнения последней операции ввода данных.
Обнаружение конца файла
Обнаружить конец файла можно с помощью функции-члена eof(), которая имеет такой прототип.
bool eof();
Эта функция возвращает значение true при достижении конца файла; в противном случае она возвращает значение false.
Функция eof() позволяет обнаружить конец файла.
В следующей программе для вывода на экран содержимого файла используется функция eof().
/* Обнаружение конца файла с помощью функции eof().
*/
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=2) {
cout << «Применение: имя_программы <имя_файла>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
while(!in.eof()) {
// использование функции eof()
in.get(ch);
if( !in.eof()) cout << ch;
}
in.close();
return 0;
}
Пример сравнения файлов
Следующая программа иллюстрирует мощь и простоту применения в C++ файловой системы. Здесь сравниваются два файла с помощью функций двоичного ввода-вывода read(), eof() и gcount(). Программа сначала открывает сравниваемые файлы для выполнения двоичных операций (чтобы не допустить преобразования символов). Затем из каждого файла по очереди считываются блоки информации в соответствующие буферы и сравнивается их содержимое. Поскольку объем считанных данных может быть меньше размера буфера, в программе используется функция gcount(), которая точно определяет количество считанных в буфер байтов. Нетрудно убедиться в том, что при использовании файловых С++-функций для выполнения этих операций потребовалась совсем небольшая по размеру программа.
// Сравнение файлов.
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
register int i;
unsigned char buf1[1024], buf2[1024];
if(argc!=3) {
cout << «Применение: имя_программы <имя_файла1> «<< » <имя_файла2>n»;
return 1;
}
ifstream f1(argv[1], ios::in | ios::binary);
if(!f1) {
cout << «He удается открыть первый файл.n»;
return 1;
}
ifstream f2(argv[2], ios::in | ios::binary);
if(!f2) {
cout << «He удается открыть второй файл.n»;
return 1;
}
cout << «Сравнение файлов …n»;
do {
f1.read((char *) buf1, sizeof buf1);
f2.read((char *) buf2, sizeof buf2);
if(f1.gcount() != f2.gcount()) {
cout << «Файлы имеют разные размеры.n»;
f1.close();
f2.close();
return 0;
}
// Сравнение содержимого буферов.
for(i=0; i<f1.gcount(); i++)
if(buf1[i] != buf2[i]) {
cout << «Файлы различны.n»;
f1.close();
f2.close();
return 0;
}
}while(!f1.eof() && !f2.eof());
cout << «Файлы одинаковы.n»;
f1.close();
f2.close();
return 0;
}
Проведите эксперимент. Размер буфера в этой программе жестко установлен равным 1024. В качестве упражнения замените это значение const-переменной и опробуйте другие размеры буферов. Определите оптимальный размер буфера для своей операционной среды.
Использование других функций двоичного ввода-вывода
Помимо приведенного выше формата использования функции get() существуют и другие ее перегруженные версии. Приведем прототипы для трех из них, которые используются чаще всего.
istream &get(char *buf, streamsize num);
istream &get(char *buf, streamsize num, char delim);
int get();
Первая версия позволяет считывать символы в массив, заданный параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не встретится символ новой строки, либо не будет достигнут конец файла. После выполнения функции get() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ новой строки, если таковой обнаружится во входном потоке, не извлекается. Он остается там до тех пор, пока не выполнится следующая операция ввода-вывода.
Вторая версия предназначена для считывания символов в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim, либо не будет достигнут конец файла. После выполнения функции get() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ-разделитель (заданный параметром delim), если таковой обнаружится во входном потоке, не извлекается. Он остается там до тех пор, пока не выполнится следующая операция ввода-вывода.
Третья перегруженная версия функции get() возвращает из потока следующий символ. Он содержится в младшем байте значения, возвращаемого функцией. Следовательно, значение, возвращаемое функцией get(), можно присвоить переменной типа char. При достижении конца файла эта функция возвращает значение EOF, которое определено в заголовке <iostream>.
Функцию get() полезно использовать для считывания строк, содержащих пробелы. Как вы знаете, если для считывания строки используется оператор «>>», процесс ввода останавливается при обнаружении первого же пробельного символа. Это делает оператор «>>» бесполезным для считывания строк, содержащих пробелы. Но эту проблему, как показано в следующей программе, можно обойти с помощью функции get(buf,num).
/* Использование функции get() для считывания строк содержащих
пробелы.
*/
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char str[80];
cout << «Введите имя: «;
cin.get (str, 79);
cout << str << ‘n’;
return 0;
}
Здесь в качестве символа-разделителя при считывании строки с помощью функции get() используется символ новой строки. Это делает поведение функции get() во многом сходным с поведением стандартной функции gets(). Однако преимущество функции get() состоит в том, что она позволяет предотвратить возможный выход за границы массива, который принимает вводимые пользователем символы, поскольку в программе задано максимальное количество считываемых символов. Это делает функцию get() гораздо безопаснее функции gets().
Рассмотрим еще одну функцию, которая позволяет вводить данные. Речь идет о функции getline(), которая является членом каждого потокового класса, предназначенного для ввода информации. Вот как выглядят прототипы версий этой функции,
istream &getline(char *buf, streamsize num);
istream &getline(char *buf, streamsize num, char delim);
Функция getline() представляет собой еще один способ ввода данных.
При использовании первой версии символы считываются в массив, адресуемый указателем buf, до тех пор, пока либо не будет считано num-1 символов, либо не встретится
символ новой строки, либо не будет достигнут конец файла. После выполнения функции getline() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ новой строки, если таковой обнаружится во входном потоке, при этом извлекается, но не помещается в массив buf.
Вторая версия предназначена для считывания символов в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim, либо не будет достигнут конец файла. После выполнения функции getline() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ-разделитель (заданный параметром delim), если таковой обнаружится во входном потоке, извлекается, но не помещается в массив buf.
Как видите, эти две версии функции getline() практически идентичны версиям get (buf, num) и get (buf, num, delim) функции get(). Обе считывают символы из входного потока и помещают их в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim. Различие между функциями get() и getline() состоит в том, что функция getline() считывает и удаляет символразделитель из входного потока, а функция get() этого не делает.
Функция реек() считывает следующий символ из входного потока, не удаляя его.
Следующий символ из входного потока можно получить и не удалять его из потока с помощью функции реек(). Вот как выглядит ее прототип.
int peek();
Функция peek() возвращает следующий символ потока, или значение EOF, если достигнут конец файла. Считанный символ возвращается в младшем байте значения, возвращаемого функцией. Поэтому значение, возвращаемое функцией реек(), можно присвоить переменной типа char.
Функция putback() возвращает считанный символ во входной поток.
Последний символ, считанный из потока, можно вернуть в поток, используя функцию putback(). Ее прототип выглядит так.
istream &putback(char с);
Здесь параметр с содержит символ, считанный из потока последним.
Функция flush() сбрасывает на диск содержимое файловых буферов.
При выводе данных немедленной их записи на физическое устройство, связанное с потоком, не происходит. Подлежащая выводу информация накапливается во внутреннем буфере до тех пор, пока этот буфер не заполнится целиком. И только тогда его содержимое переписывается на диск. Однако существует возможность немедленной перезаписи на диск хранимой в буфере информации, не дожидаясь его заполнения. Это средство состоит в вызове функции flush(). Ее прототип имеет такой вид.
ostream &flush();
К вызовам функции flush() следует прибегать в случае, если программа предназначена для выполнения в неблагоприятных средах (для которых характерны частые отключения электричества, например).
Произвольный доступ
До сих пор мы использовали файлы, доступ к содержимому которых был организован

строго последовательно, байт за байтом. Но в C++ также можно получать доступ к файлу в произвольном порядке. В этом случае необходимо использовать функции seekg() и seekp(). Вот их прототипы.
istream &seekg(off_type offset, seekdir origin);
ostream &seekp(off_type offset, seekdir origin);
Используемый здесь целочисленный тип off_type (он определен в классе ios) позволяет хранить самое большое допустимое значение, которое может иметь параметр offset. Тип seekdir определен как перечисление, которое имеет следующие значения.
Функция seekg() перемещает указатель, «отвечающий» за ввод данных, а функция seekp() — указатель, «отвечающий» за вывод.
ВС++-системе ввода-вывода предусмотрена возможность управления двумя указателями, связанными с файлом. Эти так называемые cin— и put-указатели определяют, в каком месте файла должна выполниться следующая операция ввода и вывода соответственно. При каждом выполнении операции ввода или вывода соответствующий указатель автоматически перемещается в указанную позицию. Используя функции seekg() и seekp(), можно получать доступ к файлу в произвольном порядке.
Функция seekg() перемещает текущий get-указатель соответствующего файла на offset байт относительно позиции, заданной параметром origin. Функция seekp() перемещает текущий put-указатель соответствующего файла на offset байт относительно позиции, заданной параметром origin.
Вобщем случае произвольный доступ для операций ввода-вывода должен выполняться только для файлов, открытых в двоичном режиме. Преобразования символов, которые могут происходить в текстовых файлах, могут привести к тому, что запрашиваемая позиция файла не будет соответствовать его реальному содержимому.
Вследующей программе демонстрируется использование функции seekp(). Она позволяет задать имя файла в командной строке, а за ним — конкретный байт, который нужно в нем изменить. Программа затем записывает в указанную позицию символ «X». Обратите внимание на то, что обрабатываемый файл должен быть открыт для выполнения операций чтения-записи.
/* Демонстрация произвольного доступа к файлу.
*/
#include <iostream>
#include <fstream>
#include <cstdlib>
using namespace std;
int main(int argc, char *argv[])
{
if(argc!=3) {
cout << «Применение: имя_программы » << «<имя_файла> <байт>n»;
return 1;
}
fstream out(argv[1], ios::in | ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out.seekp(atoi(argv[2]), ios::beg);
out.put(‘X’);
out.close();
return 0;
}
В следующей программе показано использование функции seekg(). Она отображает содержимое файла, начиная с позиции, заданной в командной строке.
/* Отображение содержимого файла с заданной стартовой позиции.
*/
#include <iostream>
#include <fstream>
#include <cstdlib>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=3) {
cout << «Применение: имя_программы «<< «<имя_файла> <стартовая_позиция>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in.seekg(atoi(argv[2]), ios::beg);
while(in.get (ch)) cout << ch;

return 0;
}
Функция tellg() возвращает текущую позицию get-указателя, а функция tellp() — текущую позицию put-указателя.
Текущую позицию каждого файлового указателя можно определить с помощью этих двух функций.
pos_type tellg();
pos_type tellp();
Здесь используется тип pos_type (он определен в классе ios), позволяющий хранить самое большое значение, которое может возвратить любая из этих функций.
Существуют перегруженные версии функций seekg() и seekp(), которые перемещают файловые указатели в позиции, заданные значениями, возвращаемыми функциями tellg() и tellp() соответственно. Вот как выглядят их прототипы,
istream &seekg(pos_type position);
ostream &seekp(pos_type position);
Проверка статуса ввода-вывода
С++-система ввода-вывода поддерживает статусную информацию о результатах выполнения каждой операции ввода-вывода. Текущий статус потока ввода-вывода описывается в объекте типа iostate, который представляет собой перечисление (оно определено в классе ios), включающее следующие члены.
Статусную информацию о результате выполнения операций ввода-вывода можно получать двумя способами. Во-первых, можно вызвать функцию rdstate(), которая является членом класса ios. Она имеет такой прототип.
iostate rdstate();
Функция rdstate() возвращает текущий статус флагов ошибок. Нетрудно догадаться, что, судя по приведенному выше списку флагов, функция rdstate() возвратит значение goodbit при отсутствии каких бы то ни было ошибок. В противном случае она возвращает соответствующий флаг ошибки.
Во-вторых, о наличии ошибки можно узнать с помощью одной или нескольких
следующих функций-членов класса ios.
bool bad();
bool eof();
bool fail();
bool good();
Функция eof() рассматривалась выше. Функция bad() возвращает значение ИСТИНА, если в результате выполнения операции ввода-вывода был установлен флаг badbit. Функция fail() возвращает значение ИСТИНА, если в результате выполнения операции ввода-вывода был установлен флаг failbit. Функция good() возвращает значение ИСТИНА, если при выполнении операции ввода-вывода ошибок не произошло. В противном случае они возвращают значение ЛОЖЬ.
Если при выполнении операции ввода-вывода произошла ошибка, то, возможно, прежде чем продолжать выполнение программы, имеет смысл сбросить флаги ошибок. Для этого используйте функцию clear() (член класса ios), прототип которой выглядит так.
void clear (iostate flags = ios::goodbit);
Если параметр flags равен значению goodbit (оно устанавливается по умолчанию), все флаги ошибок очищаются. В противном случае флаги устанавливаются в соответствии с заданным вами значением.
Прежде чем переходить к следующему разделу, стоит опробовать функции, которые сообщают данные о состоянии флагов ошибок, внеся в предыдущие примеры программ код проверки ошибок.
Использование перегруженных операторов ввода-вывода при работе с файлами
Выше в этой главе вы узнали, как перегружать операторы ввода и вывода для собственных классов, а также как создавать собственные манипуляторы. В приведенных выше примерах программ выполнялись только операции консольного ввода-вывода. Но поскольку все С++-потоки одинаковы, одну и ту же перегруженную функцию вывода данных, например, можно использовать для вывода информации как на экран, так и в файл, не внося при этом никаких существенных изменений. Именно в этом и заключаются основные достоинства С++-системы ввода-вывода.
В следующей программе используется перегруженный (для класса three_d) оператор вывода для записи значений координат в файл threed.
/* Использование перегруженного оператора ввода-вывода для записи объектов класса three_d в файл.
*/
#include <iostream>
#include <fstream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты; они теперь закрыты
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj); /*
Отображение координат X, Y, Z (оператор вывода для класса three_d). */
};
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает поток
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), c(5, 6, 7);
ofstream out(«threed»);
if(!out) {
cout << «He удается открыть файл.»;
return 1;
}
out << a << b << c;
out.close();
return 0;
}
Если сравнить эту версию операторной функции вывода данных для класса three_d с той, что была представлена в начале этой главы, можно убедиться в том, что для «настройки» ее на работу с дисковыми файлами никаких изменений вносить не пришлось. Если операторы ввода и вывода определены корректно, они будут успешно работать с любым потоком.
Важно! Прежде чем переходить к следующей главе, не пожалейте времени и поработайте с С++-функциями ввода-вывода. Создайте собственный класс, а затем определите для него операторы ввода и вывода. А еще создайте собственные манипуляторы.
Потоки
Язык C++ не обеспечивает средств для ввода/вывода. Ему это и не
нужно; такие средства легко и элегантно можно создать с помощью
самого языка. Описанная здесь стандартная библиотека потокового
ввода/вывода обеспечивает гибкий и эффективный с гарантией типа
метод обработки символьного ввода целых чисел, чисел с плавающей
точкой и символьных строк, а также простую модель ее расширения для
обработки типов, определяемых пользователем. Ее пользовательский
интерфейс находится в . В этой главе описывается сама
библиотека, некоторые способы ее применения и методы, которые
использовались при ее реализации.
8.1 Введение
Разработка и реализация стандартных средств ввода/вывода для
языка программирования зарекомендовала себя как заведомо трудная
работа. Традиционно средства ввода/вывода разрабатывались
исключительно для небольшого числа встроенных типов данных. Однако
в C++ программах обычно используется много типов, определенных
пользователем, и нужно обрабатывать ввод и вывод также и значений
этих типов. Очевидно, средство ввода/вывода должно быть простым,
удобным, надежным в употреблении, эффективным и гибким, и ко всему
прочему полным. Ничье решение еще не смогло угодить всем, поэтому у
пользователя должна быть возможность задавать альтернативные
средства ввода/вывода и расширять стандартные средства ввода/вывода
применительно к требованиям приложения.
C++ разработан так, чтобы у пользователя была возможность
определять новые типы столь же эффективные и удобные, сколь и
встроенные типы. Поэтому обоснованным является требование того, что
средства ввода/вывода для C++ должны обеспечиваться в C++ с
применением только тех средств, которые доступны каждому
программисту. Описываемые здесь средства ввода/вывода представляют
собой попытку ответить на этот вызов.
Средства ввода/вывода связаны исключительно с
обработкой преобразования типизированных объектов в
последовательности символов и обратно. Есть и другие схемы
ввода/вывода, но эта является основополагающей в системе UNIX, и
большая часть видов бинарного ввода/вывода обрабатывается через
рассмотрение символа просто как набор бит, при этом его
общепринятая связь с алфавитом игнорируется. Тогда для программиста
ключевая проблема заключается в задании соответствия между
типизированным объектом и принципиально не типизированной строкой.
Обработка и встроенных и определенных пользователем типов
однородным образом и с гарантией типа достигается с помощью одного
перегруженного имени функции для набора функций вывода. Например:
put(cerr,"x = "); // cerr - поток вывода ошибок put(cerr,x); put(cerr,"n");
Тип параметра определяет то, какая из функций put будет вызываться
для каждого параметра. Это решение применялось в нескольких языках.
Однако ему недостает лаконичности. Перегрузка операции
cerr
где cerr — стандартный поток вывода ошибок. Поэтому, если x
является int со значением 123, то этот оператор напечатает в
стандартный поток вывода ошибок
x = 123
и символ новой строки. Аналогично, если X принадлежит определенному
пользователем типу complex и имеет значение (1,2.4), то приведенный
выше оператор напечатает в cerr
x = 1,2.4)
Этот метод можно применять всегда, когда для x определена
операция
8.2 Вывод
В этом разделе сначала обсуждаются средства форматного и
бесформатного вывода встроенных типов, потом приводится стандартный
способ спецификации действий вывода для определяемых пользователем
типов.
8.2.1 Вывод Встроенных Типов
Класс ostream определяется вместе с операцией
class ostream {
// …
public:
ostream& operator
8.2.2 Некоторые Подробности Разработки
Возможности изобрести новый лексический символ нет (#6.2).
Операция присваивания была кандидатом одновременно и на ввод, и на
вывод, но оказывается, большинство людей предпочитают, чтобы
операция ввода отличалась от операции вывода. Кроме того, = не в ту
сторону связывается (ассоциируется), то есть cout=a=b означает
cout=(a=b).
Делались попытки использовать операции , но значения
«меньше» и «больше» настолько прочно вросли в сознание людей, что
новые операции ввода/вывода во всех реальных случаях оказались
нечитаемыми. Помимо этого, »
cout
Для таких операторов непросто выдать хорошие сообщения об ошибках.
Операции > к такого рода проблемам не приводят, они
асимметричны в том смысле, что их можно проассоциировать с «в» и
«из», а приоритет
cout
Естественно, при написании выражений, которые содержат операции с
более низкими приоритетами, скобки использовать надо. Например:
coutОперацию левого сдвига тоже можно применять в операторе вывода:
cout8.2.3 Форматированный Вывод
Пока char* oct(long, int =0); // восьмеричное представление char* dec(long, int =0); // десятичное представление char* hex(long, int =0); // шестнадцатиричное представление char* chr(int, int =0); // символ char* str(char*, int =0); // строка
Если не задано поле нулевой длины, то будет производиться усечение
или дополнение; иначе будет использоваться столько символов
(ровно), сколько нужно. Например:coutЕсли x==15, то в результате получится:
dec(15) = oct( 17) = hex( f);Можно также использовать строку в общем формате:
char* form(char* format ...); cout8.2.4 Виртуальная Функция Вывода
Иногда функция вывода должна быть virtual. Рассмотрим пример класса shape, который дает понятие фигуры (#1.18):
class shape { // ... public: // ... virtual void draw(ostream& s); // рисует "this" на "s" }; class circle : public shape { int radius; public: // ... void draw(ostream&); };То есть, круг имеет все признаки фигуры и может обрабатываться
как фигура, но имеет также и некоторые специальные свойства,
которые должны учитываться при его обработке.Чтобы поддерживать для таких классов стандартную парадигму
вывода, операция
ostream& operatordraw(s);
return s;
}Если next - итератор типа определенного в #7.3.3, то список фигур распечатывается например так:
while ( p = next() ) cout8.3 Файлы и Потоки
Потоки обычно связаны с файлами. Библиотека потоков создает
стандартный поток ввода cin, стандартный поток вывода cout и
стандартный поток ошибок cerr. Программист может открывать другие
файлы и создавать для них потоки.8.3.1 Инициализация Потоков Вывода
ostream имеет конструкторы:
class ostream { // ... ostream(streambuf* s); // связывает с буфером потока ostream(int fd); // связывание для файла ostream(int size, char* p); // связывет с вектором };Главная работа этих конструкторов — связывать с потоком буфер.
streambuf — класс, управляющий буферами; он описывается в #8.6, как и класс filebuf, управляющий streambuf для файла. Класс filebuf
является производным от класса streambuf.Описание стандартных потоков вывода cout и cerr, которое
находится в исходных кодах библиотеки потоков ввода/вывода,
выглядит так:// описать подходящее пространство буфера char cout_buf[BUFSIZE] // сделать "filebuf" для управления этим пространством // связать его с UNIX'овским потоком вывода 1 (уже открытым) filebuf cout_file(1,cout_buf,BUFSIZE); // сделать ostream, обеспечивая пользовательский интерфейс ostream cout(&cout_file); char cerr_buf[1]; // длина 0, то есть, небуферизованный // UNIX'овский поток вывода 2 (уже открытый) filebuf cerr_file()2,cerr_buf,0; ostream cerr(&cerr_file);Примеры двух других конструкторов ostream можно найти в #8.3.3 и #8.5.
8.3.2 Закрытие Потоков Вывода
Деструктор для ostream сбрасывает буфер с помощью открытого члена
функции ostream::flush():ostream::~ostream() { flush(); // сброс }Сбросить буфер можно также и явно. Например:
cout.flush();8.3.3 Открытие Файлов
Точные детали того, как открываются и закрываются файлы,
различаются в разных операционных системах и здесь подробно не
описываются. Поскольку после включения становятся
доступны cin, cout и cerr, во многих (если не во всех) программах
не нужно держать код для открытия файлов. Вот, однако, программа,
которая открывает два файла, заданные как параметры командной
строки, и копирует первый во второй:#include void error(char* s, char* s2) { cerrПоследовательность действий при создании ostream для именованного файла та же, что используется для стандартных потоков: (1) сначала создается буфер (здесь это делается посредством описания filebuf); (2) затем к нему подсоединяется файл (здесь это делается посредством открытия файла с помощью функции filebuf::open()); и, наконец, (3) создается сам ostream с filebuf в качестве параметра. Потоки ввода обрабатываются аналогично.
Файл может открываться в одной из двух мод:
enum open_mode { input, output };Действие filebuf::open() возвращает 0, если не может открыть файл в
соответствие с требованием. Если пользователь пытается открыть
файл, которого не существует для output, он будет создан.Перед завершением программа проверяет, находятся ли потоки в
приемлемом состоянии (см. #8.4.2). При завершении программы открытые файлы неявно закрываются.Файл можно также открыть одновременно для чтения и записи, но в
тех случаях, когда это оказывается необходимо, парадигма потоков
редко оказывается идеальной. Часто лучше рассматривать такой файл
как вектор (гигантских размеров). Можно определить тип, который
позволяет программе обрабатывать файл как вектор; см. Упражнения 8-
10.8.3.4 Копирование Потоков
Есть возможность копировать потоки. Например:
cout = cerr;В результате этого получаются две переменные, ссылающиеся на один и
тот же поток. Главным образом это бывает полезно для того, чтобы
сделать стандартное имя вроде cin ссылающимся на что-то другое
(пример этого см. в #3.1.6)8.4 Ввод
Ввод аналогичен выводу. Имеется класс istream, который
предоставляет операцию >> («взять из») для небольшого множества
стандартных типов. Функция operator>> может определяться для типа,
определяемого пользователем.8.4.1 Ввод Встроенных Типов
Класс istream определяется так:
class istream { // ... public: istream& operator>>(char*); // строка istream& operator>>(char&); // символ istream& operator>>(short&); istream& operator>>(int&); istream& operator>>(long&); istream& operator>>(float&); istream& operator>>(double&); // ... };Функции ввода определяются в таком духе:
istream& istream::operator>>(char& c); { // пропускает пропуски int a; // неким образом читает символ в "a" c = a; }Пропуск определяется как стандартный пропуск в C, через вызов
isspase() в том виде, как она определена в (пробел,
табуляция, символ новой строки, перевод формата и возврат каретки).В качестве альтернативы можно использовать функции get():
class istream { // ... istream& get(char& c); // char istream& get(char* p, int n, int ='n'); // строка };Они обрабатывают символы пропуска так же, как остальные символы.
Функция istream::get(char) читает один и тот же символ в свой
параметр; другая istream::get читает не более n символов в вектор
символов, начинающийся в p. Необязательный третий параметр
используется для задания символа остановки (иначе, терминатора или
ограничителя), то есть этот символ читаться не будет. Если будет
встречен символ ограничитель, он останется как первый символ
потока. По умолчанию вторая функция get будет читать самое большее
n символов, но не больше чем одну строку, ‘n’ является
ограничителем по умолчанию. Необязательный третий параметр задает
символ, который читаться не будет. Например:cin.get(buf,256,'t');будет читать в buf не более 256 символов, а если встретится
табуляция (‘t’), то это приведет к возврату из get. В этом случае
следующим символом, который будет считан из cin, будет ‘t’.Стандартный заголовочный файл определяет несколько
функций, которые могут оказаться полезными при осуществлении ввода:int isalpha(char) // 'a'..'z' 'A'..'Z' int isupper(char) // 'A'..'Z' int islower(char) // 'a'..'z' int isdigit(char) // '0'..'9' int isxdigit(char) // '0'..'9' 'a'..'f' 'A'..'F' int isspase(char) // ' ' 't' возврат новая строка // перевод формата int iscntrl(char) // управляющий символ // (ASCII 0..31 и 127) int ispunct(char) // пунктуация: ниодин из вышеперечисленных int isalnum(char) // isalpha() | isdigit() int isprint(char) // печатаемый: ascii ' '..'-' int isgraph(char) // isalpha() | isdigit() | ispunct() int isascii(char c) { return 0Все кроме isascii() реализуются внешне одинаково, с применением символа в качестве индекса в таблице атрибутов символов. Поэтому такие выражения, как
(('a'не только утомительно пишутся и чреваты ошибками (на машине с набором символов EBCDIC оно будет принимать неалфавитные символы), они также и менее эффективны, чем применение стандартной функции:
isalpha(c)8.4.2 Состояния Потока
Каждый поток (istream или ostream) имеет ассоциированное с ним
состояние, и обработка ошибок и нестандартных условий
осуществляется с помощью соответствующей установки и проверки этого
состояния.Поток может находиться в одном из следующих состояний:
enum stream_state { _good, _eof, _fail, _bad };Если состояние _good или _eof, значит последняя операция ввода
прошла успешно. Если состояние _good, то следующая операция ввода
может пройти успешно, в противном случае она закончится неудачей.
Другими словами, применение операции ввода к потоку, который не
находится в состоянии _good, является пустой операцией. Если
делается попытка читать в переменную v, и операция оканчивается
неудачей, значение v должно остаться неизменным (оно будет
неизменным, если v имеет один из тех типов, которые обрабатываются
функциями членами istream или ostream). Отличия между состояниями
_fail и _bad очень незначительно и представляет интерес только для
разработчиков операций ввода. В состоянии _fail предполагается, что
поток не испорчен и никакие символы не потеряны. В состоянии _bad
может быть все что угодно.Состояние потока можно проверять например так:
switch (cin.rdstate()) { case _good: // последняя операция над cin прошла успешно break; case _eof: // конец файла break; case _fail: // некоего рода ошибка форматирования // возможно, не слишком плохая break; case _bad: // возможно, символы cin потеряны break; }Для любой переменной z типа, для которого определены операции >, копирующий цикл можно написать так:
while (cin>>z) coutНапример, если z - вектор символов, этот цикл будет брать стандартный ввод и помещать его в стандартный вывод по одному слову (то есть, последовательности символов без пробела) на строку.
Когда в качестве условия используется поток, происходит проверка состояния потока и эта проверка проходит успешно (то есть, значение условия не ноль) только если состояние _good. В частности, в предыдущем цикле проверялось состояние istream, которое возвращает cin>>z. Чтобы обнаружить, почему цикл или проверка закончились неудачно, можно исследовать состояние. Такая проверка потока реализуется операцией преобразования (#6.3.2).
Делать проверку на наличие ошибок каждого ввода или вывода действительно не очень удобно, и обычно источником ошибок служит программист, не сделавший этого в том месте, где это существенно. Например, операции вывода обычно не проверяются, но они могут случайно не сработать. Парадигма потока ввода/вывода построена так, чтобы когда в C++ появится (если это произойдет) механизм обработки исключительных ситуаций (как средство языка или как стандартная библиотека) его будет легко применить для упрощения и стандартизации обработки ошибок в потоках ввода/вывода.
8.4.3 Ввод Типов, Определяемых Пользователем
Ввод для пользовательского типа может определяться точно так же, как вывод, за тем исключением, что для операции ввода важно, чтобы второй параметр был ссылочного типа. Например:
istream& operator>>(istream& s, complex& a) /* форматы ввода для complex; "f" обозначает float: f ( f ) ( f , f ) */ { double re = 0, im = 0; char c = 0; s >> c; if (c == '(') { s >> re >> c; if (c == ',') s >> im >> c; if (c != ')') s.clear(_bad); // установить state } else { s.putback(c); s >> re; } if (s) a = complex(re,im); return s; }Несмотря на то, что не хватает кода обработки ошибок, большую
часть видов ошибок это на самом деле обрабатывать будет. Локальная
переменная c инициализируется, чтобы ее значение не оказалось
случайно '(' после того, как операция окончится неудачно.
Завершающая проверка состояния потока гарантирует, что значение
параметра a будет изменяться только в том случае, если все идет
хорошо.Операция установки состояния названа clear() (очистить), потому
что она чаще всего используется для установки состояния потока
заново как _good. _good является значением параметра по умолчанию и
для istream::clear(), и для ostream::clear().Над операциями ввода надо поработать еще. Было бы, в частности,
замечательно, если бы можно было задавать ввод в терминах шаблона
(как в языках Снобол и Икон), а потом проверять, прошла ли успешна
вся операция ввода. Такие операции должны были бы, конечно,
обеспечивать некоторую дополнительную буферизацию, чтобы они могли
восстанавливать поток ввода в его исходное состояние после неудачной
попытки распознавания.8.4.4 Инициализация Потоков Ввода
Естественно, тип istream, так же как и ostream, снабжен
конструктором:class istream { // ... istream(streambuf* s, int sk =1, ostream* t =0); istream(int size, char* p, int sk =1); istream(int fd, int sk =1, ostream* t =0); };Параметр sk задает, должны пропускаться пропуски или нет. Параметр
t (необязательный) задает указатель на ostream, к которому
прикреплен istream. Например, cin прикреплен к cout; это значит,
что перед тем, как попытаться читать символы из своего файла, cin
выполняетcout.flush(); // пишет буфер выводаС помощью функции istream::tie() можно прикрепить (или открепить,
с помощью tie(0)) любой ostream к любому istream. Например:int y_or_n(ostream& to, istream& from) /* "to", получает отклик из "from" */ { ostream* old = from.tie(&to); for (;;) { coutКогда используется буферизованный ввод (как это происходит по умолчанию), пользователь не может набрав только одну букву ожидать отклика. Система ждет появления символа новой строки. y_or_n() смотрит на первый символ строки, а остальные игнорирует.
Символ можно вернуть в поток с помощью функции istream::putback(char). Это позволяет программе "заглядывать вперед" в поток ввода.
8.5 Работа со Строками
Можно осуществлять действия, подобные вводу/выводу, над символьным вектором, прикрепляя к нему istream или ostream. Например, если вектор содержит обычную строку, завершающуюся нулем, для печати слов из этого вектора можно использовать приведенный выше копирующий цикл:
void word_per_line(char v[], int sz) /* печатет "v" размера "sz" по одному слову на строке */ { istream ist(sz,v); // сделать istream для v char b2[MAX]; // больше наибольшего слова while (ist>>b2) coutЗавершающий нулевой символ в этом случае интерпретируется как символ конца файла.
В помощью ostream можно отформатировать сообщения, которые не нужно печатать тотчас же:
char* p = new char[message_size]; ostream ost(message_size,p); do_something(arguments,ost); display(p);Такая операция, как do_something, может писать в поток ost,
передавать ost своим подоперациям и т.д. с помощью стандартных
операций вывода. Нет необходимости делать проверку не переполнение,
поскольку ost знает свою длину и когда он будет переполняться, он
будет переходить в состояние _fail. И, наконец, display может
писать сообщения в "настоящий" поток вывода. Этот метод может
оказаться наиболее полезным, чтобы справляться с ситуациями, в
которых окончательное отображение данных включает в себя нечто
более сложное, чем работу с традиционным построчным устройством
вывода. Например, текст из ost мог бы помещаться в располагающуюся
где-то на экране область фиксированного размера.8.6 Буферизация
При задании операций ввода/вывода мы никак не касались типов
файлов, но ведь не все устройства можно рассматривать одинаково с
точки зрения стратегии буферизации. Например, для ostream,
подключенного к символьной строке, требуется буферизация другого
вида, нежели для ostream, подключенного к файлу. С этими проблемами
можно справиться, задавая различные буферные типы для разных
потоков в момент инициализации (обратите внимание на три
конструктора класса ostream). Есть только один набор операций над
этими буферными типами, поэтому в функциях ostream нет кода, их
различающего. Однако функции, которые обрабатывают переполнение
сверху и снизу, виртуальные. Этого достаточно, чтобы справляться с
необходимой в данное время стратегией буферизации. Это также служит
хорошим примером применения виртуальных функций для того, чтобы
сделать возможной однородную обработку логически эквивалентных
средств с различной реализацией. Описание буфера потока в
выглядит так:struct streambuf { // управление буфером потока char* base; // начало буфера char* pptr; // следующий свободный char char* qptr; // следующий заполненный char char* eptr; // один из концов буфера char alloc; // буфер, выделенный с помощью new // Опустошает буфер: // Возвращает EOF при ошибке и 0 в случае успеха virtual int overflow(int c =EOF); // Заполняет буфер // Возвращет EOF при ошибке или конце ввода, // иначе следующий char virtual int underflow(); int snextc() // берет следующий char { return (++qptr==pptr) ? underflow() : *qptr&0377; } // ... int allocate() // выделяет некоторое пространство буфера streambuf() { /* ... */} streambuf(char* p, int l) { /* ... */} ~streambuf() { /* ... */} };Обратите внимание, что здесь определяются указатели, необходимые
для работы с буфером, поэтому обычные посимвольные действия можно
определить (только один раз) в виде максимально эффективных inline-
функций. Для каждой конкретной стратегии буферизации необходимо
определять только функции переполнения overflow() и underflow().
Например:struct filebuf : public streambuf { int fd; // дескриптор файла char opened; // файл открыт int overflow(int c =EOF); int underflow(); // ... // Открывает файл: // если не срабатывает, то возвращает 0, // в случае успеха возвращает "this" filebuf* open(char *name, open_mode om); int close() { /* ... */ } filebuf() { opened = 0; } filebuf(int nfd) { /* ... */ } filebuf(int nfd, char* p, int l) : (p,l) { /* ... */ } ~filebuf() { close(); } }; int filebuf::underflow() // заполняет буфер из fd { if (!opened || allocate()==EOF) return EOF; int count = read(fd, base, eptr-base); if (count8.7 Эффективность
Можно было бы ожидать, что раз ввод/вывод определен с помощью общедоступных средств языка, он будет менее эффективен, чем встроенное средство. На самом деле это не так. Для действий вроде "поместить символ в поток" используются inline-функции, единственные необходимые на этом уровне вызовы функций возникают из-за переполнения сверху и снизу. Для простых объектов (целое, строка и т.п.) требуется по одному вызову на каждый. Как выясняется, это не отличается от прочих средств ввода/вывода, работающих с объектами на этом уровне.
8.8 Упражнения
Назад | Содержание | Вперед |
- (*1.5) Считайте файл чисел с плавающей точкой, составьте из пар считанных чисел комплексные числа и выведите комплексные числа.
- (*1.5) Определите тип name_and_address (имя_и_адрес). Определите для него >. Скопируйте поток объектов name_and_address.
- (*2) Постройте несколько функций для запроса и чтения различного вида информации. Простейший пример - функция y_or_n() в #8.4.4. Идеи: целое, число с плавающей точкой, имя файла, почтовый адрес, дата, личные данные и т.д. Постарайтесь сделать их защищенными от дурака.
- (*1.5) Напишите программу, которая печатает (1) все буквы в нижнем регистре, (2) все буквы, (3) все буквы и цифры, (4) все символы, которые могут встречаться в идентификаторах C++ на вашей системе, (5) все символы пунктуации, (6) целые значения всех управляющих символов, (7) все символы пропуска, (8) целые значения всех символов пропуска, и (9) все печатаемые символы.
- (*4) Реализуйте стандартную библиотеку ввода/вывода C () с помощью стандартной библиотеки ввода/вывода C++ ().
- (*4) Реализуйте стандартную библиотеку ввода/вывода C++ () с помощью стандартной библиотеки ввода/вывода C ().
- (*4) Реализуйте стандартные библиотеки C и C++ так, чтобы они могли использоваться одновременно.
- (*2) Реализуйте класс, для которого [] перегружено для реализации случайного чтения символов из файла.
- (*3) Как Упражнение 8, только сделайте, чтобы [] работало и для чтения, и для записи. Подсказка: сделайте, чтобы [] возвращало объект "дескрипторного типа", для которого присваивание означало бы присвоить файлу через дескриптор, а неявное преобразование в char означало бы чтение из файла через дескриптор.
- (*2) Как Упражнение 9, только разрешите [] индексировать записи некоторого вида, а не символы.
- (*3) Сделайте обобщенный вариант класса, определенного в Упражнении 10.
- (*3.5) Разработайте и реализуйте операцию ввода по сопоставлению с образцом. Для спецификации образца используйте строки формата в духе printf. Должна быть возможность попробовать сопоставить со вводом несколько образцов для нахождения фактического формата. Можно было бы вывести класс ввода по образцу из istream.
- (*4) Придумайте (и реализуйте) вид образцов, которые намного лучше.
Глава 10
Ввод-вывод данных
Основные навыки и понятия
- Представление о потоках ввода-вывода
- Отличия байтовых и символьных потоков
- Классы для поддержки байтовых потоков
- Классы для поддержки символьных потоков
- Представление о встроенных потоках
- Применение байтовых потоков
- Использование байтовых потоков для файлового ввода-вывода
- Автоматическое закрытие файлов с помощью оператора try с ресурсами
- Чтение и запись двоичных данных
- Манипулирование файлами с произвольным доступом
- Применение символьных потоков
- Использование символьных потоков для файлового ввода-вывода
- Применение оболочек типов Java для преобразования символьных строк в числа
В примерах программ, приводившихся в предыдущих главах, уже применялись отдельные части системы ввода-вывода в Java, в частности метод println(), но делалось это без каких-либо формальных пояснений. Система ввода-вывода основана в Java на иерархии классов, поэтому ее функции и особенности нельзя было представлять до тех пор, пока не были рассмотрены классы, наследование и исключения. А теперь настал черед и для средств ввода-вывода.
Приступая к изучению системы ввода вырода Java, приготовьтесь к длительной и кропотливой работе. Система ввода-вывода в Java довольно обширна и содержит немало классов, интерфейсов и методов. Объясняется это, в частности, тем, что в Java, по существу, определены две полноценные системы ввода-вывода: одна — для обмена байтами, другая — для обмена символами. Здесь нет возможности рассмотреть все аспекты ввода-вывода в Java, ведь для этого бы потребовалась отдельная книга. Поэтому в данной главе будут рассмотрены лишь наиболее важные и часто используемые языковые средства ввода-вывода. Правда, элементы системы ввода-вывода в Java тесно взаимосвязаны, и поэтому, уяснив основы, вы легко освоите все остальные свойства этой системы.
Прежде чем приступать к рассмотрению системы ввода-вывода, необходимо сделать следующее замечание. Классы, описанные в этой главе, предназначены для консольного и файлового ввода-вывода. Они не применяются для создания графических пользовательских интерфейсов. Поэтому ими не имеет смысла пользоваться при создании оконных приложений. Для графических интерфейсов предусмотрены другие языковые средства. Они будут представлены в главе 14 при рассмотрении апплетов, а также в главе 15, служащей введением в библиотеку Swing. (Swing — это современный набор инструментальных средств, ориентированных на создание графических пользовательских интерфейсов приложений.)
Организация системы ввода-вывода в Java на потоках
Ввод-вывод в программах на Java осуществляется посредством потоков. Поток — это некая абстракция производства или потребления информации. С физическим устройством поток связывает система ввода-вывода. Все потоки действуют одинаково — даже если они связаны с разными физическими устройствами. Поэтому классы и методы ввода-вывода могут применяться к самым разным типам устройств. Например, методами вывода на консоль можно пользоваться и для вывода в файл на диске. Для реализации потоков используется иерархия классов, содержащихся в пакете java.io.
Байтовые и символьные потоки
В современных версиях Java определены два типа потоков: байтовые и символьные. (В первоначальных версиях Java были доступны только байтовые потоки, тогда как символьные потоки были реализованы в дальнейшем.) Байтовые потоки предоставляют удобные средства для ввода и вывода байтов. Они используются, например, при чтении и записи двоичных данных. В особенности они полезны для обращения с файлами. А символьные потоки ориентированы на обмен символьными данными. В них применяется кодировка в уникоде (Unicode), а следовательно, программы, в которых используются символьные потоки, легко поддаются локализации на разные языки мира. В некоторых случаях символьные потоки обеспечивают более высокую эффективность по сравнению с байтовыми.
Необходимость поддерживать два разных типа потоков ввода-вывода привела к созданию двух иерархий классов (одна для байтовых, другая для символьных данных). Из-за того что число классов достаточно велико, на первый взгляд система ввода-вывода кажется сложнее, чем она есть на самом деле. Но не следует забывать, что функциональные возможности для байтовых потоков дублируются соответствующими средствами для символьных потоков.
Следует также иметь в виду, что на самом нижнем уровне все средства ввода-вывода имеют байтовую организацию. А символьные потоки лишь предоставляют удобные и эффективные инструменты для обработки символов.
Классы байтовых потоков
Для определения байтовых потоков служат две иерархии классов. На их вершине находятся два абстрактных класса: InputStream и OutputStream. В классе InputStream определены свойства, общие для байтовых потоков ввода, а в классе OutputStream — свойства, общие для байтовых потоков вывода.
Производными от классов InputStream и OutputStream являются конкретные подклассы, реализующие различные функциональные возможности и учитывающие особенности обмена данными с разными устройствами, например ввода-вывода в файлы на
диске. Классы байтовых потоков приведены в табл. 10.1. Не следует пугаться большого
количества этих классов: изучив один из них, легко освоить остальные.
Таблица 10.1. Классы байтовых потоков
| Класс байтового потока | Описание |
|---|---|
| BufferedlnputStream | Буферизованный поток ввода |
| BufferedOutputStream | Буферизованный поток вывода |
| ByteArrayInputStream | Поток ввода для чтения из байтового массива |
| ByteArrayOutputStream | Поток вывода для записи в байтовый массив |
| DatalnputStream | Поток ввода с методами для чтения стандартных типов данных Java |
| DataOutputStream | Поток вывода с методами для записи стандартных типов данных Java |
| FileInputStream | Поток ввода для чтения из файла |
| FileOutputStream | Поток вывода для записи в файл |
| FilterlnputStream | Подкласс, производный от класса InputStream |
| FilterOutputStream | Подкласс, производный от класса OutputStream |
| InputStream | Абстрактный класс, описывающий потоковый ввод |
| ObjectInputStream | Поток для ввода объектов |
| ObjectOutputStream | Поток для вывода объектов |
| OutputStream | Абстрактный класс, описывающий потоковый вывод |
| PipedlnputStream | Поток конвейерного ввода |
| PipedOutputStream | Поток конвейерного вывода |
| PrintStream | Поток вывода с методами print() и println() |
| PushbacklnputStream | Поток ввода с возвратом прочитанных байтов в поток |
| RandomAccessFile | Класс, поддерживающий файловый ввод-вывод с произвольным доступом |
| SequenceInputStream | Поток ввода, сочетающий в себе несколько потоков ввода для поочередного чтения данных из них |
Классы символьных потоков
Для определения символьных потоков служат две иерархические структуры классов, на вершине которых находятся абстрактные классы Reader и Writer соответственно. Класс Reader и его подклассы используются для чтения, а класс Writer и его подклассы — для записи данных. Конкретные классы, производные от классов Reader и Writer, оперируют символами в уникоде.
Классы, производные от классов Reader и Writer, предназначены для выполнения различных операций ввода-вывода символов. Символьные классы присутствуют в Java параллельно с байтовыми классами. Классы символьных потоков приведены в табл. 10.2.
Таблица 10.2. Классы символьных потоков
| Класс символьного потока | Описание |
|---|---|
| BufferedReader | Буферизованный поток ввода символов |
| BufferedWriter | Буферизованный поток вывода символов |
| CharArrayReader | Поток ввода для чтения из символьного массива |
| CharArrayWriter | Поток вывода для записи в символьный массив |
| FileReader | Поток ввода для чтения символов из файла |
| FileWriter | Поток вывода для записи символов в файл |
| FilterReader | Класс для чтения символов с фильтрацией |
| FilterWriter | Класс для записи символов с фильтрацией |
| InputStreamReader | Поток ввода с преобразованием байтов в символы |
| LineNumberReader | Поток ввода с подсчетом символьных строк |
| OutputStreamWriter | Поток вывода с преобразованием символов в байты |
| PipedReader | Поток конвейерного ввода |
| PipedWriter | Поток конвейерного вывода |
| PrintWriter | Поток вывода с методами print() и println() |
| PushbackReader | Поток ввода с возвратом прочитанных символов в поток |
| Reader | Абстрактный класс, описывающий потоковый ввод символов |
| StringReader | Поток ввода для чтения из символьной строки |
| StringWriter | Поток вывода для записи в символьную строку |
| Writer | Абстрактный класс, описывающий потоковый вывод символов |
Встроенные потоки
Как вам должно быть уже известно, во все программы на Java автоматически импортируется пакет java. lang. В этом пакете определен класс System, инкапсулирующий некоторые элементы среды выполнения программ. Помимо прочего, в нем содержатся предопределенные переменные in, out и err, представляющие стандартные потоки ввода-вывода. Эти поля объявлены как public, final и static. А это означает, что ими можно пользоваться в любой другой части программы, не ссылаясь на конкретный объект типа System.
Переменная System.out ссылается на поток стандартного вывода. По умолчанию этот поток связан с консолью. А переменная System, in ссылается на поток стандартного ввода (по умолчанию с клавиатуры). И наконец, переменная System.err ссылается на поток стандартных сообщений об ошибках, которые по умолчанию выводятся на консоль. По мере необходимости все эти потоки могут быть перенаправлены на другие совместимые устройства ввода-вывода.
Поток System.in представляет собой объект типа InputStream, а потоки System.out и System.err — объекты типа PrintStream. Хотя эти потоки обычно используются для чтения и записи символов, они на самом деле являются байтовыми потоками. Дело в том, что эти потоки были определены в первоначальной спецификации Java, где символьные потоки вообще не были предусмотрены. Как станет ясно в дальнейшем, для этих потоков можно по необходимости создать оболочки, превратив их в символьные потоки.
Применение байтовых потоков
Начнем рассмотрение системы ввода-вывода в Java с байтовых потоков. Как пояснялось ранее, на вершине иерархии байтовых потоков находятся классы InputStream и OutputStream. Методы из класса InputStream приведены в табл. 10.3, а методы из класса OutputStream — в табл. 10.4. При возникновении ошибок в процессе выполнения методы из классов InputStream и OutputStream могут генерировать исключения типа IOException. Методы, определенные в этих двух абстрактных классах, доступны во всех подклассах. Таким образом, они формируют минимальный набор функций ввода-вывода, общих для всех байтовых потоков.
Таблица 10.3. Методы, определенные в классе InputStream
| Метод | Описание |
|---|---|
int available() |
Возвращает количество байтов, доступных для чтения |
void close() |
Закрывает поток ввода. При последующей попытке чтения из потока генерируется исключение IOException |
void mark(int numBytes) |
Ставит отметку на текущей позиции в потоке. Отметка доступна до тех пор, пока на будет прочитано количество байтов, определяемое параметром numBytes |
boolean markSupported() |
Возвращает логическое значение true, если методы mark() и reset() поддерживаются в вызывающем потоке |
int read() |
Возвращает целочисленное представление следующего байта в потоке. Если достигнут конец потока, возвращается значение -1 |
int read(byte buffer[]) |
Предпринимает попытку прочитать количество байтов, определяемое выражением buffer, length, в массив buffer и возвращает фактическое количество успешно прочитанных байтов. Если достигнут конец потока, возвращается значение -1 |
int read(byte buffer[], int offset, int numBytes) |
Предпринимает попытку прочитать количество байтов, определяемое параметром numBytes, в массив buffer, начиная с элемента buffer[offset]. Если достигнут конец потока, возвращается значение -1 |
void reset() |
Устанавливает указатель ввода на помеченной ранее позиции |
long skip (long numBytes) |
Пропускает количество байтов, определяемое параметром numBytes, в потоке ввода. Возвращает фактическое количество пропущенных байтов |
Таблица 10.4. Методы, определенные в классе OutputStream
| Метод | Описание |
|---|---|
void close() |
Закрывает выходной поток. При последующей попытке записи в поток генерируется исключение IOExceptionВыводит содержимое выходного буфера вывода в |
void flush() |
Выводит содержимое выходного буфера вывода в целевой поток. По завершении этой операции выходной буфер очищается |
void write(int b) |
Записывает один байт в поток вывода. Параметр b относится к типу int, что позволяет вызывать данный метод в выражениях, не приводя результат их вычисления к типу byte |
void write(byte buffer[]) |
Записывает массив в поток вывода |
void write(byte buffer[], int offset, int numBytes) |
Записывает в поток вывода часть массива buffer длиной numBytes байтов, начиная с элемента buffer[offset] |
Консольный ввод
Первоначально единственный способ реализовать консольный ввод в Java состоял в использовании байтовых потоков, и во многих программах на Java до сих пор используются исключительно потоки данного типа. В настоящее время для разработки прикладных программ доступны как байтовые, так и символьные потоки. В коммерческих приложениях для чтения данных с консоли в основном используются символьные потоки. Такой подход упрощает локализацию программ и их сопровождение. Ведь намного удобнее оперировать непосредственно символами и не тратить время и труд на преобразование символов в байты, а байтов — в символы. Но в простых служебных и прикладных программах, где данные, введенные с клавиатуры, обрабатываются непосредственно, удобно пользоваться байтовыми потоками. Именно поэтому они здесь и рассматриваются.
Поток System, in является экземпляром класса InputStream, и благодаря этому обеспечивается автоматический доступ к методам, определенным в классе InputStream. К сожалению, в классе InputStream определен только один метод ввода, read(), предназначенный для чтения байтов. Ниже приведены разные формы объявления этого метода.
int read() throws IOException
int read(byte data[]) throws IOException
int read(byte data[], int start, int max) throws IOException
В главе 3 было показано, как пользоваться первой формой метода read() для ввода отдельных символов с клавиатуры (а по существу, из потока стандартного ввода System, in). Достигнув конца потока, этот метод возвращает значение -1. Вторая форма метода read() предназначена для чтения данных из потока ввода в массив data. Чтение завершается по достижении конца потока, па заполнении массива или при возникновении ошибки. Метод возвращает количество прочитанных байтов или значение -1, если достигнут конец потока. И третья форма данного метода позволяет разместить прочитанные данные в массиве data, начиная с элемента, обозначаемого индексом start. Максимальное количество байтов, которые могут быть введены в массив, определяется параметром max. Метод возвращает число прочитанных байтов или значение -1, если достигнут конец потока. При возникновении ошибки в каждой из этих форм метода read() генерируется исключение IOException. Условие конца потока ввода System, in устанавливается при нажатии клавиши .
Ниже приведен краткий пример программы, демонстрирующий чтение байтов из потока ввода System, in в массив. Следует иметь в виду, что исключения, которые могут быть сгенерированы при выполнении данной программы, обрабатываются за пределами метода main(). Такой подход часто используется при чтении данных с консоли. По мере необходимости вы сможете самостоятельно организовать обработку ошибок.
// Чтение байтов с клавиатуры в массив,
import java.io.*;
class ReadBytes {
public static void main(String args[])
throws IOException {
byte data[] = new byte[10];
System.out.println("Enter some characters.");
// Чтение данных, введенных с клавиатуры,
// и размещение их в байтовом массиве.
System.in.read(data);
System.out.print("You entered: ");
for(int i=0; i < data.length; i++)
System.out.print((char) data[i]);
}
}
Выполнение этой программы дает например, следующий результат:
Enter some characters.
Read Bytes
You entered: Read Bytes
Вывод на консоль
Как и для консольного ввода, в Java для консольного вывода первоначально были предусмотрены только байтовые потоки. Но уже в версии Java 1.1 были реализованы символьные потоки. Именно их и рекомендуется применять в прикладных программах, особенно в тех случаях, когда необходимо добиться переносимости кода. Но поскольку System, out является байтовым потоком вывода, он по-прежнему широко используется для побайтового вывода данных на консоль. Именно такой подход до сих пор применялся в примерах, представленных в этой книге. Поэтому он здесь и рассматривается.
Вывести данные на консоль проще всего с помощью уже знакомых вам методов print() и println(). Эти методы определены в классе PrintStream (на объект данного типа ссылается переменная потока стандартного вывода System.out). Несмотря на то что System, out является байтовым потоком вывода, пользоваться им вполне допустимо для организации элементарного вывода данных на консоль.
Класс PrintStream представляет собой выходной поток, производный от класса OutputStream, и поэтому в нем также реализуется метод write() низкоуровневого вывода. Следовательно, этот метод может быть использован для вывода данных на консоль. Самая простая форма метода write(), определенного в PrintStream, имеет следующий вид:
Этот метод записывает в поток байтовое значение, указываемое в качестве параметра byteval. Несмотря на то что этот параметр объявлен как int, учитываются только 8 младших битов его значения. Ниже приведен простой пример программы, где метод write() используется для вывода символов S и новой строки на консоль.
// Применение метода System.out.write() .
class WriteDemo {
public static void main(String args[]) {
int b;
b = 'S';
// Вывод байтов на экран.
System.out.write(b);
System.out.write('n');
}
}
На практике для вывода на консоль метод write.() применяется достаточно редко. Для этой цели намного удобнее пользоваться методами print() и println(). В классе PrintStream реализованы два дополнительных метода, printf() и format(), которые позволяют управлять форматом выводимых данных. Например, при выводе можно указать количество десятичных цифр, минимальную ширину поля или способ представления отрицательных числовых значений. И хотя эти методы не используются в примерах, представленных в данной книге, вам стоит обратить на них пристальное внимание, поскольку они могут оказаться очень полезными при написании прикладных программ.
Чтение и запись в файлы из байтовых потоков
В Java предоставляется большое количество классов и методов, позволяющих читать и записывать данные в файлы. Разумеется, чаще всего приходится обращаться к файлам, хранящимся на дисках. В Java все файлы имеют байтовую организацию, и поэтому для побайтового чтения и записи данных в такие файлы предоставляются соответствующие методы. Следовательно, организовывать чтение и запись данных в файлы из байтовых потоков приходится довольно часто. Кроме того, для байтовых потоков ввода-вывода в файлы в Java разрешено создавать специальные оболочки в виде символьных объектов. Такие оболочки будут рассмотрены далее в этой главе.
Для того чтобы создать байтовый поток и связать его с файлом, следует воспользоваться классом FilelnputStream или FileOutputStream. А для открытия файла достаточно создать объект одного из этих классов, передав имя файла конструктору в качестве параметра. В открытый файл можно записывать данные или читать их из него.
Ввод данных из файла
Файл открывается для ввода созданием объекта типа FilelnputStream. Для этой цели чаще всего используется приведенная ниже форма объявления конструктора данного класса. FilelnputStream(String имя_файла) throws FileNotFoundException
В качестве параметра этому конструктору передается имя_файла, который требуется открыть. Если указанный файл не существует, генерируется исключениеFileNotFoundException.
Для чтения данных из файла служит метод read(). Ниже приведена форма объявления этого метода, которой мы будем пользоваться в дальнейшем,
int read() throws IOException
При каждом вызове метод read() читает байт из файла и возвращает его как целочисленное значение. По достижении конца файла этот метод возвращает значение -1. При возникновении ошибки метод генерирует исключение IOException. Как видите, в этой форме метод read() выполняет те же самые действия, что и одноименный метод для ввода данных с консоли.
Завершив операции с файлом, следует закрыть его с помощью метода close(), общая форма объявления которого выглядит следующим образом:
void close() throws IOException
При закрытии файла освобождаются связанные с ним системные ресурсы, чтобы использовать их для работы с другим файлом. Если же файл не будет закрыт, могут произойти “утечки памяти” из-за того, что часть памяти остается выделенной для неиспользуемых ресурсов. Ниже приведен пример программы, где метод read() используется для ввода содержимого текстового файла. Имя файла задается с помощью параметра в командной строке при запуске программы на выполнение. Полученные данные выводятся на экран. Обратите внимание на то, что ошибки ввода-вывода обрабатываются с помощью блока try/catch.
/* Отображение текстового файла.
При вызове этой программы следует указать имя файла,
содержимое которого требуется просмотреть.
Например, для вывода на экран содержимого файла TEST.TXT,
в командной строке нужно указать следующее:
java ShowFile TEST.TXT
*/
import java.io.*;
class ShowFile {
public static void main(String args[])
{
int i;
FilelnputStream fin;
// Прежде всего следует убедиться, что файл был указан,
if(args.length != 1) {
System.out.println("Usage: ShowFile File");
return;
}
try {
// Открытие файла.
fin = new FilelnputStream(args[0]);
} catch(FileNotFoundException exc) {
System.out.println("File Not Found");
return;
}
try {
// читать из файла до тех пор, пока не встретится знак EOF.
do {
// Чтение из файла.
i = fin.read();
if(i != -1) System.out.print((char) i) ;
// Если значение переменной i равно -1,значит,
// достингут конец файла.
} while (i != -1);
} catch(IOException exc) {
System.out.println("Error reading file.");
}
try {
// Закрытие файла.
fin.close();
} catch(IOException exc) {
System.out.println("Error closing file.");
}
}
}
В приведенном выше примере поток ввода из файла закрывается после того, как чтение данных из файла завершается в блоке try. Такой способ оказывается удобным не всегда, и поэтому в Java предоставляется более совершенный и чаще употребляемый способ. А состоит он в вызове метода close() в блоке finally. В этом случае все методы, получающие доступ к файлу, помещаются в блок try, а для закрытия файла используется блок finally. Благодаря этому файл закрывается независимого от того, как завершится блок try. Если продолжить предыдущий пример, то блок try, в котором выполняется чтение из файла, можно переписать следующим образом:
try {
do {
i = fin.read();
if(i != -1) System.out.print((char) i) ;
} while(i != —1) ;
} catch(IOException exc) {
System.out.println("Error Reading File");
// Блок finally используется для закрытия файла.
} finally {
// закрыть файл при выходе из блока try.
try {
fin.close();
} catch(IOException exc) {
System.out.println("Error Closing File");
}
}
Преимущество рассмотренного выше способа состоит, в частности, в том, что если программа, получающая доступ к файлу, завершается аварийно из-за какой-нибудь ошибки ввода-вывода, генерирующей исключение, файл все равно закрывается в блоке finally. И если с аварийным завершением простых программ, как в большинстве примеров в этой книге, из-за неожиданно возникающей исключительной ситуации еще можно как-то мириться, то в крупных программах подобная ситуация вряд ли вообще допустима. Именно ее и позволяет исключить блок finally.
Иногда оказывается проще заключить в оболочку те части программы, в которых открывается файл, чтобы получить доступ к нему из единственного блока try, не разделяя его на два блока, а для закрытия файла использовать отдельный блок finally. В качестве примера ниже приведена переделанная версия рассмотренной выше программы ShowFile.
/* В этой версии программы отображения текстового файла код,
открывающий файл и получающий к нему доступ, заключается
в единственный блок try. А закрывается файл в блоке finally.
*/
import java.io.*;
class ShowFile {
public static void main(String args[])
{
int i;
FilelnputStream fin = null;
// Прежде всего следует убедиться, что файл был указан,
if (args.length != 1) {
System.out.println("Usage: ShowFile filename");
return;
}
// В следующем коде открывается файл, из которого читаются
// символы до тех пор, пока не встретится знак EOF, а затем
// файл закрывается в блоке finally,
try {
fin = new FilelnputStream(args[0]);
do {
i = fin.read() ;
if(i != -1) System.out.print((char) i);
} while(i != -1);
} catch(FileNotFoundException exc) {
System.out.println("File Not Found.");
} catch(IOException exc) {
System.out.println("An I/O Error Occurred");
} finally {
// Файл закрывается в любом случае,
try {
if (fin != null) fin.closeO;
} catch(IOException exc) {
System.out.println("Error Closing File");
}
}
}
}
Обратите внимание на то, что переменная fin инициализируется пустым значением null. А в блоке finally файл закрывается только в том случае, если значение переменной fin не является пустым. Такой способ оказывается вполне работоспособным, поскольку переменная fin не будет содержать пустое значение лишь в том случае, если файл был успешно открыт. Следовательно, метод close() не будет вызываться, если во время открытия файла возникнет исключение.
В приведенном выше примере блок try/catch можно сделать более компактным. Ведь исключение FileNotFoundException является подклассом исключения IOException, и поэтому его не нужно перехватывать отдельно. В качестве примера ниже приведен блок оператора catch, которым можно воспользоваться для перехвата обоих этих исключений, не прибегая к перехвату исключения FileNotFoundException в отдельности. В данном случае выводится стандартное сообщение о возникшем исключении с описанием характера ошибки.
} catch(IOException exc) {
System.out.println("I/O Error: " + exc);
} finally {
...
В рассматриваемом здесь способе любая ошибка, в том числе и ошибка открытия файла, будет обработана единственным оператором catch. Благодаря своей компактности именно такой способ применяется в большинстве примеров ввода-вывода, представленных в этой книге. Следует, однако, иметь в виду, что он может оказаться не вполне пригодным в тех случаях, когда требуется отдельно обрабатывать ошибку открытия файла, например, вследствие того, что пользователь введет имя файла с опечаткой. В подобных случаях рекомендуется выдать сначала приглашение правильно ввести имя файла, а затем перейти к блоку try для доступа к файлу.
### Вывод в файл
Для того чтобы открыть файл для вывода, следует создать объект типа FileOutputStream. Ниже приведены два наиболее часто употребляемых конструктора этого класса.
FileOutputStream(String имя_файла) throws FileNotFoundException
FileOutputStream(String имя_файлаг boolean append)
throws FileNotFoundException
Если файл не может быть создан, возникает исключение FileNotFoundException. В первой форме конструктора при открытии файла удаляется существовавший ранее файл с таким именем. Вторая форма отличается наличием параметра append. Если этот параметр принимает логическое значение true, записываемые данные добавляются в конец файл. В противном случае старые данные в файле перезаписываются новыми.
Для того чтобы записать данные в файл, следует вызвать метод write(). Наиболее простая форма этого метода приведена ниже,
void write(int byteval) throws IOException
Этот метод записывает в поток байтовое значение, указанное в качестве параметра byteval. Несмотря на то что этот параметр объявлен как int, учитываются только 8 младших битов его значения. Если в процессе записи возникнет ошибка, будет сгенерировано исключение IOException.
По завершении работы с файлом его нужно закрыть с помощью метода close(). Объявление этого метода выглядит следующим образом:
void close() throws IOException
При закрытии файла освобождаются связанные с ним системные ресурсы, чтобы использовать их для работы с другим файлом. Процедура закрытия файла также гарантирует, что данные, оставшиеся в буфере, будут записаны на диск.
В приведенном ниже примере программы осуществляется копирование текстового файла. Имена исходного и целевого файлов указываются в командной строке.
/* Копирование текстового файла.
При вызове этой программы следует указать имя исходного
и целевого файлов. Например, для копирования файла FIRST.TXT
в файл SECOND.TXT в командной строке нужно указать следующее:
java CopyFile FIRST.TXT SECOND.TXT
/
import java.io.;
class CopyFile {
public static void main(String args[])
{
int i;
FilelnputStream fin;
FileOutputStream fout;
// Прежде всего следует убедиться, что оба файла были указаны,
if(args.length !=2 ) {
System.out.println("Usage: CopyFile From To");
return;
}
// открыть исходный файл
try {
fin = new FilelnputStream(args[0] ) ;
} catch(FileNotFoundException exc) {
System.out.println("Input File Not Found");
return;
}
// открыть целевой файл
try {
fout = new FileOutputStream(args[1]);
} catch(FileNotFoundException exc) {
System.out.println("Error Opening Output File");
// закрыть исходный файл
try {
fin.close();
} catch(IOException exc2) {
System.out.println("Error closing input file.");
}
return;
}
// копировать файл
try {
do {
// Чтение байтов из одного файла и запись их в другой файл.
i = fin.read();
if(i != -1) fout.write (i);
} while(i != -1);
} catch(IOException exc) {
System.out.println("File Error");
}
try {
fin.close() ;
} catch(IOException exc) {
System.out.println("Error closing input file.");
}
try {
fout.close();
} catch(IOException exc) {
System.out.println("Error closing output file.");
}
}
}
## Автоматическое закрытие файлов
В примерах программ из предыдущего раздела метод с 1 о s е () вызывался явным образом для закрытия файла, когда он уже не был больше нужен. Подобным образом файлы закрывались с тех пор, как появилась первая версия Java. В итоге именно такой способ получил широкое распространение в существующих программах на Java. И до сих пор он остается вполне обоснованным и пригодным. Но в JDK 7 внедрено новое средство, предоставляющее другой, более рациональный способ управления ресурсами, в том числе и потоками файлового ввода-вывода, автоматизирующий процесс закрытия файлов. Этот способ основывается на новой разновидности оператора try, называемой оператором try с ресурсами, а иногда еще — автоматическим управлением ресурсами. Главное преимущество оператора try с ресурсами заключается в том, что он предотвращает ситуации, в которых файл (или другой ресурс) неумышленно остается неосвобожденным после того, как он уже больше не нужен. Как пояснялось ранее, если не позаботиться вовремя о закрытии файла в программе, это может привести к утечкам памяти и прочим осложнениям в работе программы.
Ниже приведена общая форма оператора try с ресурсами
try (описание_ресурса) {
// использовать ресурс
}
где описание_ресурса обозначает оператор, в котором объявляется и инициализируется конкретный ресурс, например файл. По существу, он содержит объявление переменной, в котором переменная инициализируется ссылкой на объект управляемого ресурса. По завершении блока try объявленный ресурс автоматически освобождается. Если этим ресурсом является файл, то он автоматически закрывается, что избавляет от необходимости вызывать метод close() явным образом. В блок оператора try с ресурсами могут также входить операторы catch и finally.
Оператор try с ресурсами можно применять только к тем ресурсам, в которых реализуется интерфейс AutoCloseable, определенный в пакете java. lang. Этот интерфейс внедрен в JDK 7, и в нем определен метод close(). Интерфейс AutoCloseable наследует от интерфейса Close able, определенного в пакете j ava. io. Оба интерфейса реализуются классами потоков, в том числе FilelnputStream и FileOutputStream. Следовательно, оператор try с ресурсами может применяться вместе с потоками, включая и потоки файлового ввода-вывода.
В качестве примера ниже приведена переделанная версия программы ShowFile, в которой оператор try с ресурсами применяется для автоматического закрытия файла.
/* В этой версии программы ShowFile оператор try с ресурсами
применяется для автоматического закрытия файла, когда он
уже больше не нужен.
Примечание: для компиляции этого кода требуется JDK 7 или
более поздняя версия данного комплекта.
/
import java.io.;
class ShowFile {
public static void main(String args[])
{
int i;
// Прежде всего следует убедиться, что оба файла были указаны,
if(args.length != 1) {
System.out.println(«Usage: ShowFile filename»);
return;
}
// Ниже оператор try с ресурсами применяется сначала для открытия, а
// затем для автоматического закрытия файла после выхода из блока try.
try(FilelnputStream fin = new FilelnputStream(args[0])) {
// Блок оператора try с ресурсами,
do {
i = fin.read();
if (i != -1) System.out.print((char) i) ;
} while(i != -1);
} catch(IOException exc) {
System.out.println("I/O Error: " + exc);
}
}
}
Особое внимание в данной программе обращает на себя следующая строка кода, в которой файл открывается в операторе try с ресурсами.
try(FilelnputStream fin = new FilelnputStream(args[0])) {
Как видите, в той части оператора try с ресурсами, где указывается конкретный ресурс, объявляется переменная fin типа FilelnputStream, которой затем присваивается ссылка на файл как объект, открываемый конструктором класса FilelnputStream. Следовательно, в данной версии программы переменная fin является локальной для блока try и создается при входе в этот блок. А при выходе из блока try файл, связанный с переменной fin, автоматически закрывается с помощью неявно вызываемого метода close(). Это означает, что метод close() не нужно вызывать явным образом, а следовательно, он избавляет от необходимости помнить, что файл нужно закрыть. Именно в этом и заключается главное преимущество автоматического управления ресурсами.
Следует иметь в виду, что ресурс, объявляемый в операторе try с ресурсами, неявно считается как final. Это означает, что ресурс нельзя присвоить после того, как он был создан. Кроме того, область действия ресурса ограничивается блоком оператора try с ресурсами.
С помощью одного оператора try с ресурсами можно управлять несколькими ресурсами. Для этого достаточно указать каждый из них через точку с запятой. В качестве примера ниже приведена переделанная версия рассмотренной ранее программы CopyFile. В этой версии оператор с ресурсами используется для управления переменными fin и fout, ссылающимися на два ресурса (в данном случае — оригинал и копию файла).
/* В этой версии программы CopyFile используется оператор try с
ресурсами. В ней демонстрируется управление двумя ресурсами
(в данном случае — файлами) с помощью единственного оператора try.
Примечание: для компиляции этого кода требуется JDK 7 или
более поздняя версия данного комплекта.
/
import java.io.;
class CopyFile {
public static void main.(String args[] ) throws IOException
{
int i;
// Прежде всего следует убедиться, что оба файла были указаны,
if(args.length != 2) {
System.out.println(«Usage: CopyFile from to»);
return;
}
// открыть оба файла для управления с помощью оператора try
try (FilelnputStream fin = new FilelnputStream(args[0]);
FileOutputStream fout = new FileOutputStream(args[1]))
// Управление двумя ресурсами (в данном случае — файлами).
{
do {
i = fin.read();
if(i != -1) fout.write(i);
} whiled ! = -1) ;
} catch(IOException exc) {
System.out.println("I/O Error: " + exc);
}
}
}
Обратите внимание на то, каким образом входной и выходной файлы открываются в операторе try с ресурсами, как показано ниже.
try (FilelnputStream fin = new FilelnputStream(args[0]);
FileOutputStream fout = new FileOutputStream(args[1]))
{
По завершении этого блока try оба файла, на которые ссылаются переменные fin и fout, закрываются автоматически. Если сравнить эту версию программы с предыдущей, то можно заметить, что ее исходный код намного компактнее. Возможность писать более компактный код является еще одним, дополнительным преимуществом оператора try с ресурсами.
Следует также упомянуть о еще одной особенности оператора try с ресурсами. Вообще говоря, когда выполняется блок try, в нем может возникнуть одно исключение, приводящее к другому исключению при закрытии ресурса в блоке finally. И если это блок обычного оператора try, то исходное исключение теряется, прерываясь вторым исключением. А в блоке оператора try с ресурсами второе исключение подавляется. Но оно не теряется, а добавляется в список подавленных исключений, связанных с первым исключением. Этот список можно получить, вызвав метод get Suppressed(), определенный в классе Throwable.
В силу упомянутых выше преимуществ, присущих оператору try с ресурсами, можно ожидать, что он найдет широкое применение в программировании на Java. Поэтому именно он и будет использоваться в остальных примерах программ, представленных далее в этой главе. Но не менее важным остается и умение пользоваться рассмотренным ранее традиционным способом освобождения ресурсов с помощью вызываемого явным образом оператора close(). И на то имеется ряд веских оснований. Во-первых, уже существует немало написанных и повсеместно эксплуатируемых программ на Java, в которых применяется традиционный способ управления ресурсами. Поэтому все программирующие на Java должны как следует усвоить и уметь пользоваться этим традиционным способом для сопровождения устаревшего кода. Во-вторых, переход на JDK 7 может произойти не сразу, а следовательно, придется работать с предыдущей версией данного комплекта. В этом случае воспользоваться преимуществами оператора try с ресурсами не удастся и придется применять традиционный способ управления ресурсами. И наконец, в некоторых классах закрытие ресурса явным образом может оказаться более пригодным, чем его автоматическое освобождение. Но, несмотря на все сказанное выше, новый способ автоматического управления ресурсами считается более предпочтительным при переходе к JDK 7 или более поздней версии данного комплекта, поскольку он рациональнее и надежнее традиционного способа.
Чтение и запись двоичных данных
В приведенных до сих пор примерах программ читались и записывались байтовые значения, содержащие символы в коде ASCII. Но аналогичным образом можно также организовать чтение и запись любых типов данных. Допустим, требуется создать файл, содержащий значения типа int, double или short. Для чтения и записи простых типов данных в Java предусмотрены классы DatalnputStream и DataOutputStream.
Класс DataOutputStream реализует интерфейс DataOutput, в котором определены методы, позволяющие записывать в файл значения любых простых типов. Следует, однако, иметь в виду, что данные записываются во внутреннем двоичном формате, а не в виде последовательности символов. Методы, наиболее часто применяемые для записи простых типов данных в Java, приведены в табл. 10.5. Каждый из них генерирует исключение IOException при возникновении ошибки ввода-вывода.
Таблица 10.5. Наиболее часто употребляемые методы вывода данных, определенные в классе DataOutputStream
| Метод вывода данных | Описание |
|---|---|
void writeBoolean (boolean val) |
Записывает логическое значение, определяемое параметром val |
void writeByte (int,val) |
Записывает младший байт целочисленного значения, определяемого параметром val |
void writeChar (int,val) |
Записывает значение, определяемое параметром val, интерпретируя его как символ |
void writeDouble (double val) |
Записывает значение типа double, определяемое параметром val |
void writeFloat (float val) |
Записывает значение типа float, определяемое параметром val |
void writelnt(int val) |
Записывает значение типа int, определяемое параметром val |
void writeLong (long val) |
Записывает значение типа long, определяемое параметром val |
void writeShort (int val) |
Записывает целочисленное значение, определяемое параметром val, преобразуя его в тип short |
Ниже приведен конструктор класса DataOutputStream. Обратите внимание на то, что при вызове ему передается экземпляр класса OutputStream.
DataOutputStream(OutputStream OutputStream)
где OutputStream — это поток вывода, в который записываются данные. Для того чтобы организовать запись данных в файл, следует передать конструктору в качестве параметра OutputStream объект типа FileOutputStream.
Класс DatalnputStream реализует интерфейс Datalnput, в котором объявлены методы для чтения всех простых типов данных в Java (табл. 10.6). В каждом из этих методов может быть сгенерировано исключение IOException при возникновении ошибки ввода-вывода. В качестве своего основания класс DatalnputStream использует экземпляр класса InputStream, перекрывая его методами для чтения различных типов данных в Java. Однако в потоке типа DatalnputStream данные читаются в двоичном виде, а не в удобной для чтения форме. Ниже приведен конструктор класса DatalnputStream.
DatalnputStream(InputStream inputStream)
где inputStream — это поток, связанный с создаваемым экземпляром класса DatalnputStream. Для того чтобы организовать чтение данных из файла, следует передать конструктору в качестве параметра inputStream объект типа FilelnputStream.
Таблица 10.6. Наиболее часто употребляемые методы ввода данных, определенные в классе DatalnputStream
| Метод ввода данных | Описание |
|---|---|
boolean readBoolean() |
Читает значение типа boolean |
byte readByte() |
Читает значение типа byte |
char readChar() |
Читает значение типа char |
double readDouble() |
Читает значение типа double |
float readFloat() |
Читает значение типа float |
int readlnt() |
Читает значение типа int |
long readLong() |
Читает значение типа long |
short readShort() |
Читает значение типа short |
Ниже приведен пример программы, демонстрирующий применение классов DataOutputStream и DatalnputStream. В этой программе данные разных типов сначала записываются в файл, а затем читаются из файла.
// Запись и чтение двоичных данных.Для компиляции этого кода
// требуется JDK 7 или более поздняя версия данного комплекта.
import java.io.*;
class RWData {
public static void main(String args[])
{
int i = 10;
double d = 1023.56;
boolean b = true;
// записать ряд значений
try (DataOutputStream dataOut =
new DataOutputStream(new FileOutputStream("testdata")))
{
// Запись двоичных данных в файл testdata.
System.out.println("Writing " + i) ;
dataOut.writelnt(i);
System.out.println("Writing " + d) ;
dataOut.writeDouble(d);
System.out.println("Writing " + b);
dataOut.writeBoolean(b);
System.out.println("Writing " + 12.2 * 7.4);
dataOut.writeDouble(12.2 * 7.4);
}
catch(IOException exc) {
System.out.println("Write error.");
return;
}
System.out.println() ;
// а теперь прочитать записанные значения
try (DatalnputStream dataln =
new DatalnputStream(new FilelnputStream("testdata")))
{
// Чтение двоичных данных из файла testdata.
i = dataln.readlnt();
System.out.println("Reading " + i) ;
d = dataln.readDouble();
System.out.println("Reading " + d);
b = dataln.readBoolean() ;
System.out.println("Reading " + b);
d = dataln.readDouble();
System.out.println("Reading " + d) ;
}
catch(IOException exc) {
System.out.println("Read error.");
}
}
}
Выполнение этой программы дает следующий результат:
Writing 10
Writing 1023.56
Writing true
Writing 90.28
Reading 10
Reading 1023.56
Reading true
Reading 90.28
Пример для опробования 10.1.
Утилита сравнения файлов
В этом проекте предстоит создать простую, но
очень полезную утилиту для сравнения содержимого файлов. В ходе выполнения этой сервисной программы сначала открываются два
сравниваемых файла, а затем данные читаются из них и сравниваются по соответствующему количеству байтов. Если на какой-то стадии операция сравнения дает отрицательный результат, это означает, что содержимое обоих файлов не одинаково. Если же конец
обоих файлов достигается одновременно, это означает, что они содержат одинаковые
данные.
Последовательность действий
- Создайте файл CompFiles.java.
- Введите в файл CompFiles.java приведенный ниже исходный код.
/*
Для того чтобы воспользоваться этой программой, укажите
имена сравниваемых файлов в командной строке, например:
java CompFile FIRST.TXT SECOND.TXT
Для компиляции этого кода требуется JDK 7
или более поздняя версия данного комплекта.
*/
import java.io.*;
class CompFiles {
public static void main(String args[])
{
int i=0, j=0;
// Прежде всего следует убедиться, что файлы были указаны,
if(args.length !=2 ) {
System.out.println("Usage: CompFiles fl f2");
return;
}
// сравнить файлы
try (FilelnputStream fl = new FilelnputStream(args[0]);
FilelnputStream f2 = new FilelnputStream(args[1]))
{
// проверить содержимое каждого файла
do {
i = f1.read();
j = f2.read();
if(i != j) break;
} while (i != -1 && j != -1) ;
if(i != j)
System.out.println("Files differ.");
else
System.out.println("Files are the same.");
} catch(IOException exc) {
System.out.println("I/O Error: " + exc);
}
}
}
- Для опробования программы скопируйте сначала файл CompFiles. java во временный файл temp, а затем введите в командной строке следующее:
java CompFiles CompFiles.java temp
- Программа сообщит, что файлы одинаковы. Далее сравните файл CompFiles.java с рассмотренным ранее файлом CopyFile. j ava, введя в командной строке следующее:
java CompFiles CompFiles.java CopyFile.java
- Эти файлы содержат разные данные, о чем и сообщит программа CompFiles.
- Попробуйте самостоятельно внедрить в программу CompFiles ряд дополнительных возможностей. В частности, введите в нее возможность выполнять сравнение без учета регистра символов. Программу CompFiles можно также доработать таким образом, чтобы она выводила место, где обнаружено первое отличие сравниваемых файлов.
Файлы с произвольным доступом
До сих пор нам приходилось иметь дело с последовательными файлами, содержимое которых вводилось и выводилось побайтно, т.е. строго по порядку. Но в Java предоставляется также возможность обращаться к хранящимся в файле данным в произвольном порядке. Для этой цели предусмотрен класс RandomAccessFile, инкапсулирующий файл с произвольным доступом. Класс RandomAccessFile не является производным от класса InputStream или OutputStream. Вместо этого он реализует интерфейсы Datalnput и DataOutput, в которых объявлены основные методы ввода-вывода. В нем поддерживаются также запросы позиционирования, т.е. возможность задавать положение указателя файла произвольным образом. Ниже приведен конструктор класса RandomAccessFile, которым мы будем пользоваться далее.
RandomAccessFile(String имя_файла, String доступ)
throws FileNotFoundException
Здесь конкретный файл указывается с помощью параметра имя_файла, а параметр доступ определяет, какой именно тип доступа будет использоваться для обращения к файлу. Если параметр доступ принимает значение «г», то данные могут читаться из файла, но не записываться в него. Если же указан тип доступа «rw», то файл открывается как для чтения, так и для записи.
Метод seek(), общая форма объявления которого приведена ниже, служит для установки текущего положения указателя файла,
void seek(long newPos) throws IOException
Здесь параметр newPos определяет новое положение указателя файла в байтах относительно начала файла. Операция чтения или записи, следующая после вызова метода seek(), будет выполняться относительно нового положения указателя файла.
В классе RandomAccessFile определены методы read() и write(). Этот класс также реализует интерфейсы Datalnput и DataOuput, т.е. в нем доступны методы чтения и записи простых типов, например readlnt() и writeDouble().
Ниже приведен пример программы, демонстрирующий ввод-вывод с произвольным доступом. В этой программе шесть значений типа double сначала записываются в файл, а затем читаются из него, причем порядок чтения их отличается от порядка записи.
// Демонстрация произвольного доступа к файлам.
// Для компиляции этого кода требуется JDK 7
// или более поздняя версия данного комплекта.
import java.io.*;
class RandomAccessDemo {
public static void main(String args[])
{
double data[] = { 19.4, 10.1, 123.54, 33.0, 87.9, 74.25 };
double d;
// открыть и использовать файл с произвольным доступом
// Файл с произвольным доступом открывается для записи и чтения.
try (RandomAccessFile raf = new RandomAccessFile("random.dat", "rw"))
{
// записать значения в Файл
for(int i=0; i < data.length; i++) {
raf.writeDouble(data[i]);
}
//а теперь прочитать отдельные значения из файла
// Для установки указателя файла служит метод seek().
raf.seek(0); // найти первое значение типа double
d = raf.readDouble();
System.out.println("First value is " + d) ;
raf.seek(8); // найти второе значение типа double
d = raf.readDouble();
System.out.println("Second value is " + d) ;
raf.seek(8 * 3); // найти четвертое значение типа double
d = raf.readDouble();
System.out.println("Fourth value is " + d);
System.out.println();
// а теперь прочитать значения через одно
System.out.println("Here is every other value: ");
for(int i=0; i < data.length; i+=2) {
raf.seek(8 * i); // найти i-e значение типа double
d = raf.readDouble();
System.out.print(d + " ") ;
}
}
catch(IOException exc) {
System.out.println("I/O Error: " + exc) ;
}
}
}
Результат выполнения данной программы выглядит следующим образом:
First value is 19.4
Second value is 10.1
Fourth value is 33.0
Here is every other value:
19.4 123.54 87.9
Обратите внимание на расположение каждого числового значения. Ведь значение типа double занимает 8 байтов, и поэтому каждое последующее число начинается на 8-байтовой границе предыдущего числа. Иными словами, первое числовое значение начинается на позиции нулевого байта, второе — на позиции 8-го байта, третье — на позиции 16-го байта и т.д. Поэтому для чтения четвертого числового значения нужно установить указатель файла на позиции 24-го байта при вызове метода seek().
Применение символьных потоков в Java
Как следует из предыдущих разделов этой главы, байтовые потоки в Java довольно эффективны и удобны в употреблении. Но что касается ввода-вывода символов, то байтовые потоки далеки от идеала. Поэтому для этих целей в Java определены классы символьных потоков. На вершине иерархии классов, поддерживающих символьные потоки, находятся абстрактные классы Reader и Writer. Методы класса Reader приведены в табл. 10.7, а методы класса Writer — в табл. 10.8. В большинстве этих методов может быть сгенерировано исключение IOException. Методы, определенные в указанных абстрактных классах Reader и Writer, доступны во всех их подклассах. Таким образом, они образуют минимальный набор функций ввода-вывода, необходимых для всех символьных потоков.
Таблица 10.7. Методы, определенные в классе Reader
| Метод | Описание |
|---|---|
abstract void close() |
Закрывает поток ввода данных. При последующей попытке чтения генерируется исключение IOException |
void mark (int numChars) |
Ставит отметку на текущей позиции в потоке. Отметка доступна до тех пор, пока на будет прочитано количество символов, определяемое параметром numChars |
boolean markSupported() |
Возвращает логическое значение true, если поток поддерживает методы mark() и reset() |
int read() |
Возвращает целочисленное представление очередного символа из потока ввода. Если достигнут конец потока, возвращается значение -1 |
int read(char buffer[]) |
Предпринимает попытку прочитать количество байтов, определяемое выражением buffer, length, в массив buffer и возвращает фактическое количество успешно прочитанных символов. Если достигнут конец потока, возвращается значение -1 |
abstract int read(char buffer[], int offset, int numChars) |
Предпринимает попытку прочитать количество символов, определяемое параметром numChars, в массив buffer, начиная с элемента buffer [ offset]. Если достигнут конец потока, возвращается значение -1 |
int read(CharBuffer buffer) |
Предпринимает попытку заполнить буфер, определяемый параметром buffer, символами, прочитанными из входного потока. Если достигнут конец потока, возвращается значение -1. CharBuffer — это класс, представляющий последовательность символов, например строку |
boolean ready() |
Возвращает логическое значение true, если следующий запрос на получение символа может быть выполнен немедленно. В противном случае возвращается логическое значение false |
void reset() |
Устанавливает указатель ввода на помеченной ранее позиции |
long skip(long numChars) |
Пропускает количество символов, определяемое параметром numChars, в потоке ввода. Возвращает фактическое количество пропущенных символов |
Таблица 10.8. Методы, определенные в классе Writer
| Метод | Описание |
|---|---|
Writer append(char ch) |
Записывает символ ch в конец текущего потока. Возвращает ссылку на поток |
Writer append(CharSequence chars) |
Записывает символы chars в конец текущего потока. Возвращает ссылку на поток. CharSequence — это интерфейс, в котором описаны только операции чтения последовательности символов |
Writer append(CharSequence chars, int begin, int end) |
Записывает символы chars в конец текущего потока, начинаяс позиции, определяемой параметром begin, и кончая позицией, определяемой параметром end. Возвращает ссылку на поток. CharSequence — это интерфейс, в котором описаны только операции чтения последовательности символов |
abstract void close() |
Закрывает поток вывода. При последующей попытке записи в поток генерируется исключение IOException |
abstract void flush() |
Выводит текущее содержимое буфера на устройство. В результате выполнения данной операции буфер очищается |
void write(int ch) |
Записывает в вызывающий поток вывода один символ. Параметр ch относится к типу int, что позволяет вызывать данный метод в выражениях, не приводя результат их вычисления к типу char |
void write(char buffer[]) |
Записывает в вызывающий поток вывода массив символов buffer |
abstract void write(char buffer[], int offset, int numChars) |
Записывает в вызывающий поток вывода количество символов, определяемое параметром numChars, из массива buffer, начиная с элемента buffer[ offset ] |
void write(String str) |
Записывает в вызывающий поток вывода символьную строку str |
void write(String str, int offset, int numChars) |
Записывает в вызывающий поток вывода часть numChars символов из строки str, начиная с позиции, обозначаемой параметром offset |
Консольный ввод из символьных потоков
Если программа подлежит локализации, то при организации ввода с консоли символьным потокам следует отдать предпочтение перед байтовыми. А поскольку System.in — это байтовый поток, то для него придется построить оболочку в виде класса, производного от класса Reader. Наиболее подходящим для ввода с консоли является класс Buf feredReader, поддерживающий буферизованный поток ввода. Но объект типа Buf feredReader нельзя построить непосредственно из потока стандартного ввода System, in. Сначала нужно преобразовать байтовый поток в символьный. И для этой цели служит класс InputStreamReader, преобразующий байты в символы. Для того чтобы получить объект типа InputStreamReader, связанный с потоком стандартного ввода System, in, нужно воспользоваться следующим конструктором:
InputStreamReader(InputStream inputStream)
Поток ввода System.in является экземпляром класса InputStream, и поэтому его можно указать в качестве параметра inputStream данного конструктора.
Затем на основании объекта типа InputStreamReader можно создать объект типа BufferedReader, используя следующий конструктор:
BufferedReader(Reader inputReader)
где inputReader — это поток, который связывается с создаваемым экземпляром класса Buf feredReader. Объединяя обращения к указанным выше конструкторам в одну операцию, мы получаем приведенную ниже строку кода. В ней создается объект типа BufferedReader, связанный с клавиатурой.
BufferedReader br = new BufferedReader(new
InputStreamReader(System.in));
После выполнения этого оператора присваивания переменная br будет содержать ссылку на символьный поток, связанный с консолью через поток ввода System.in.
Чтение символов
Прочитать символы из потока ввода System, in можно с помощью метода read(), определенного в классе Buf f eredReader. Чтение символов мало чем отличается от чтения данных из байтовых потоков. Ниже приведены общие формы объявления трех вариантов метода read(), предусмотренных в классе Buf f eredReader.
int read() throws IOException
int read(char data[]) throws IOException
int read(char data[], int start, int max) throws IOException
В первом варианте метод read() читает один символ в уникоде. По достижении конца потока этот метод возвращает значение -1. Во втором варианте метод read() читает данные из потока ввода и помещает их в массив. Чтение оканчивается по достижении конца потока, по заполнении массива data символами или при возникновении ошибки. В этом случае метод возвращает число прочитанных символов, а если достигнут конец потока, — значение -1. В третьем варианте метод read() помещает прочитанные символы в массив data, начиная с элемента, определяемого индексом start. Максимальное число символов, которые могут быть записаны в массив, определяется параметром max. В данном случае метод возвращает число прочитанных символов или значение -1, если достигнут конец потока. При возникновении ошибки в каждом из перечисленных выше вариантов метода read() генерируется исключение IOException. При чтении данных из потока ввода System, in конец потока устанавливается нажатием клавиши < Enter>.
Ниже приведен пример программы, демонстрирующий применение метода read() для чтения символов с консоли. Символы читаются до тех пор, пока пользователь не введет точку. Следует иметь в виду, что исключения, которые могут быть сгенерированы при выполнении данной программы, обрабатываются за пределами метода main(). Как пояснялось выше, подобный подход характерен для обработки ошибок при чтении данных с консоли. По желанию вы можете употребить другой механизм обработки ошибок.
// Применение класса BufferedReader для чтения символов с консоли,
import java.io.*;
class ReadChars {
public static void main(String args[])
throws IOException
{
char c;
// Создание объекта типа BufferedReader, связанного
// с потоком стандартного ввода System.in.
BufferedReader br = new
BufferedReader(new
InputStreamReader'(System. in) ) ;
System.out.println("Enter characters, period to quit.");
// читать символы
do {
с = (char) br.read();
System.out.println(c) ;
} while(c != '.');
}
}
Результат выполнения данной программы выглядит следующим образом:
Enter characters, period to quit.
One Two.
O
n
e
T
w
о
Чтение символьных строк
Для ввода символьной строки с клавиатуры следует воспользоваться методом readLine() из класса Buf feredReader. Ниже приведена общая форма объявления этого метода.
String readLine() throws IOException
Этот метод возвращает объект типа String, содержащий прочитанные символы. При попытке прочитать символьную строку по окончании потока метод возвращает пустое знчение null.
Ниже приведен пример программы, демонстрирующий применение класса BufferedReader и метода readLine(). В этой программе текстовые строки читаются и отображаются до тех пор, пока не будет введено слово «stop».
// Чтение символьных строк с консоли средствами класса BufferedReader.
import java.io.*;
class ReadLines {
public static void main(String args[])
throws IOException
{
// создать объект типа BufferedReader, связанный с потоком System.in
BufferedReader br = new BufferedReader(new
InputStreamReader(System.in));
String str;
System.out.println("Enter lines of text.");
System.out.println("Enter 'stop' to quit.");
do {
// использовать метод readLine() из класса BufferedReader
// для чтения текстовой строки
str = br.readLine();
System.out.println(str) ;
} while(!str.equals("stop")) ;
}
}
Консольный вывод в символьные потоки
Несмотря на то что поток стандартного вывода System, out вполне может использоваться для вывода на консоль, такой подход скорее пригоден для целей отладки или при создании очень простых программ, подобных тем, которые приводятся в качестве примеров в этой книге. Для реальных прикладных программ на Java вывод на консоль обычно организуется через поток PrintWriter, относящийся к одному из классов, представляющих символьные потоки. Как упоминалось ранее, применение символьных потоков упрощает локализацию прикладных программ.
В классе PrintWriter определен ряд конструкторов. Далее будет использоваться следующий конструктор:
PrintWriter(OutputStream OutputStream, boolean flushOnNewline)
где в качестве первого параметра OutputStream конструктору передается объект типа OutputStream, а второй параметр f lushOnNewline указывает, должен ли производиться вывод данных из буфера в поток вывода при каждом вызове метода println(). Если параметр f lushOnNewline принимает логическое значение true, данные выводятся из буфера автоматически.
В классе PrintWriter поддерживаются методы print() и println() для всех типов, включая Object. Следовательно, методы print() и println() можно использовать точно так же, как и вместе с потоком вывода System, out. Если значение аргумента не относится к простому типу, то методы из класса PrintWriter вызывают метод toString() для объекта, указываемого в качестве параметра, а затем выводят результат.
Для вывода данных на консоль через поток типа PrintWriter следует указать System.out B качестве потока вывода и обеспечить вывод данных из буфера после каждого вызова метода println(). Например, при выполнении следующей строки кода создается объект типа PrintWriter, связанный с консолью:
PrintWriter pw = new PrintWriter(System.out, true);
Ниже приведен пример прикладной программы, демонстрирующий применение класса PrintWriter для организации вывода на консоль.
// Применение класса PrintWriter.
import java.io.*;
public class PrintWriterDemo {
public static void main(String args[]) {
// Создание объекта типа PrintWriter, связанного
// с потоком стандартного вывода System.out.
PrintWriter pw = new PrintWriter(System.out, true);
int i = 10;
double d = 123.65;
pw.println("Using a PrintWriter.");
pw.println(i);
pw.println(d);
pw.println(i + " + " + d + " is " + (i+d));
}
}
Выполнение этой программы дает следующий результат:
Using a PrintWriter.
10
123.65
10 + 123.65 is 133.65
Несмотря на все удобство символьных потоков, не следует забывать, что для изучения языка Java или отладки программ можно вполне пользоваться и потоком вывода System, out. Но если в программе применяется поток PrintWriter, то ее проще локализировать. Для кратких примеров программ, представленных в этой книге, применение потока PrintWriter не имеет существенных преимуществ перед потоком System, out, поэтому в и последующих примерах для вывода на консоль будет использоваться поток System.out.
Ввод-вывод в файлы через символьные потоки
На практике чаще всего приходится обращаться с файлами, имеющими байтовую организацию, тем не менее, для этой цели можно пользоваться символьными потоками. Преимущество символьных потоков заключается в том, что они оперируют непосредственно символами в уникоде. Так, если требуется сохранить текст в уникоде, для этой цели лучше всего воспользоваться символьными потоками. Как правило, для файлового ввода-вывода символов служат классы FileReader и FileWriter.
Применение класса FileWriter
Класс FileWriter представляет поток, через который можно осуществлять запись данных в файл. Ниже приведены общие формы объявления двух наиболее часто употребляемых конструкторов данного класса.
FileWriter(String имя_файла) throws IOException
FileWriter(String имя_файла, boolean append) throws IOException
Здесь имя файла обозначает полный путь к файлу. Если параметр append принимает логическое значение true, данные записываются в конец файла, а иначе они перезаписывают прежние данные на том же месте в файле. При возникновении ошибки в каждом из указанных выше конструкторов генерируется исключение IOException. Класс FileWriter является производным от классов OutputStreamWriter и Writer. Следовательно, в нем доступны методы, объявленные в его суперклассах.
Ниже приведен краткий пример программы, демонстрирующий ввод текстовых строк с клавиатуры и последующий их вывод в файл test. txt. Набираемый текст читается до тех пор, пока пользователь не введет слово «stop». Для вывода текстовых строк в файл используется класс FileWriter.
// Простой пример утилиты ввода с клавиатуры и вывода данных
// на диск, демонстрирующий применение класса FileWriter.
// Для компиляции этого кода требуется JDK 7
// или более поздняя версия данного комплекта.
import java.io.*;
class KtoD {
public static void main(String args[])
{
String str;
BufferedReader br =
new BufferedReader(
new InputStreamReader(System.in));
System.out.println("Enter text ('stop' to quit).");
// Создание потока вывода типа FileWriter.
try (FileWriter fw = new FileWriter("test.txt"))
{
do {
System.out.print(": ");
str = br.readLine();
if(str.compareTo("stop") == 0) break;
str = str + "rn"; // add newline
// Запись текстовых строк в файл,
fw.write(str);
} while(str.compareTo("stop") != 0) ;
} catch(IOException exc) {
System.out.println("I/O Error: " + exc);
}
}
}
Применение класса FileReader
В классе FileReader создается объект типа Reader, который можно использовать для чтения содержимого файла. Чаще всего употребляется такой конструктор этого класса:
FileReader(String имя_файла) throws FileNotFoundException
где имя файла обозначает полный путь к файлу. Если указанный файл не существует, генерируется исключение FileNotFoundException. Класс FileReader является производным от классов InputStreamReader и Reader. Следовательно, в нем доступны методы, объявленные в его суперклассах.
Приведенный ниже пример демонстрирует простую утилиту для отображения на экране содержимого текстового файла test. txt. Она является своего рода дополнением к утилите, рассмотренной в предыдущем разделе.
// Простая утилита ввода с дйска и вывода на экран,
// демонстрирующая применение класса FileReader.
// Для компиляции этого кода требуется JDK 7
// или более поздняя версия данного комплекта.
import java.io.*;
class DtoS {
public static void main(String args[]) {
String s;
// Создание в классе BufferedReader оболочки с целью заключить
// в нее класс FileReader и организовать чтение данных из файла.
try (BufferedReader br = new BufferedReader(new FileReader("test.txt")))
{
while((s = br.readLine()) != null) {
System.out.println(s) ;
}
} catch(IOException exc) {
System.out.println("I/O Error: " + exc) ;
}
}
}
Обратите внимание на то, что для потока типа FileReader создана оболочка в классе BufferedReader. Благодаря этому появляется возможность обращаться к методу readLine(). Кроме того, закрытие потока типа Buf feredReader, на который в данном примере ссылается переменная br, автоматически приводит к закрытию файла.
Применение оболочек типов для преобразования символьных строк в числа
Прежде чем завершить обсуждение средств ввода-вывода, необходимо рассмотреть еще один способ, помогающий читать числовые строки. Как известно, метод println() предоставляет удобные средства для вывода на консоль различных типов данных, в том числе целых чисел и чисел с плавающей точкой. Он автоматически преобразует числовые значения в удобную для чтения форму. Но в Java отсутствует метод, который читал бы числовые строки и преобразовывал бы их во внутреннюю двоичную форму. Например, не существует варианта метода read(), который читал бы числовую строку «100» и автоматически преобразовывал ее в целое число, пригодное для хранения в переменной типа int. Но для этой цели в Java имеются другие средства. И проще всего подобное преобразование осуществляется с помощью так называемых оболочек типов.
Оболочки типов в Java представляют собой классы, которые инкапсулируют простые типы. Оболочки типов необходимы, поскольку простые типы не являются объектами, что ограничивает их применение. Так, простой тип нельзя передать методу по ссылке. Для того чтобы исключить ненужные ограничения, в Java были предусмотрены классы, соответствующие каждому из простых типов.
Оболочками типов являются классы Double, Float, Long, Integer, Short, Byte, Character и Boolean. Эти классы предоставляют обширный ряд методов, позволяющих полностью интегрировать простые типы в иерархию объектов Java. Кроме того, в классах-оболочках числовых типов содержатся методы, предназначенные для преобразования числовых строк в соответствующие двоичные эквиваленты. Эти методы приведены ниже. Каждый из них возвращает двоичное значение, соответствующее числовой строке.
| Оболочка типа | Метод преобразования |
|---|---|
| Double | static double parseDouble(String str) throws NumberFormatException |
| Float | static float parseFloat(String str) throws NumberFormatException |
| Long | static long parseLong(String str) throws NumberFormatException |
| Integer | static int parselnt(String str) throws NumberFormatException |
| Short | static short parseShort(String str) throws NumberFormatException |
| Byte | static byte parseByte(String str) throws NumberFormatException |
Оболочки целочисленных типов также предоставляют дополнительный метод синтаксического анализа, позволяющий задавать основание системы счисления.
Методы синтаксического анализа позволяют без труда преобразовать во внутренний формат числовые значения, введенные в виде символьных строк с клавиатуры или из текстового файла. Ниже приведен пример программы, демонстрирующий применение для этих целей методов parselnt() и parseDouble(). В этой программе находится среднее арифметическое ряда чисел, введенных пользователем с клавиатуры. Сначала пользователю прелагается указать количество числовых значений для обработки, а затем программа вводит числа с клавиатуры, используя метод readLine(), а с помощью метода parselnt() преобразует символьную строку в целочисленное значение. Далее осуществляется ввод числовых значений и последующее их преобразование в тип double с помощью метода parseDouble().
/* Эта программа находит среднее арифметическое для
ряда чисел, введенных пользователем с клавиатуры. */
import java.io.*;
class AvgNums {
public static void main(String args[])
throws IOException
{
// создать объект типа BufferedReader,
// использующий поток ввода System.in
BufferedReader br = new
BufferedReader(new InputStreamReader(System.in));
String str;
int n;
double sum = 0.0;
double avg, t;
System.out.print("How many numbers will you enter: ");
str = br.readLine();
try {
// Преобразование символьной строки
// в числовое значение типа int.
n = Integer.parselnt(str);
}
catch(NumberFormatException exc) {
System.out.println("Invalid format");
n = 0;
}
System.out.println("Enter " + n + " values.");
for(int i=0; i < n ; i++) {
System.out.print(" : ");
str = br.readLine();
try {
// Преобразование символьной строки
// в числовое значение типа double,
t = Double.parseDouble(str) ;
} catch(NumberFormatException exc) {
System.out.println("Invalid format");
t = 0.0;
}
sum += t;
}
avg = sum / n;
System.out.println("Average is " + avg);
}
}
Выполнение этой программы может дать, например, следующий результат:
How many numbers will you enter: 5
Enter 5 values.
: 1.1
: 2.2
: 3.3
: 4.4
: 5.5
Average is 3.3
Пример для опробования 10.2.
Создание справочной системы, находящейся на диске
В примере для опробования 4.1 был создан класс
Help, позволяющий отображать сведения об операторах Java. Справочная информация хранилась в самом классе, а пользователь выбирал требуемые сведения из меню. И хотя такая справочная система выполняет свои функции, подход к ее разработке был выбран далеко не самый лучший. Так, если требуется добавить или изменить какие-нибудь сведения в подобной справочной системе, придется внести изменения в исходный код программы, которая ее реализует. Кроме того, выбирать пункт меню по его номеру не очень удобно, а если количество пунктов велико, то такой способ оказывается вообще непригодным. В этом проекте предстоит устранить недостатки, имеющиеся в справочной системе, разместив справочную информацию на диске.
В новом варианте справочная информация должна храниться в файле. Это будет обычный текстовый файл, который можно изменять, не затрагивая исходный код программы. Для того чтобы получить справку по конкретному вопросу, следует ввести название темы. Система будет искать соответствующий раздел в файле. Если поиск завершится успешно, справочная информация будет выведена на экран.
Последовательность действий
- Создайте файл, в котором будет храниться справочная информация и который будет использоваться в справочной системе. Это должен быть обычный текстовый файл, организованный следующим образом:
#название_темы_1
Информация по теме
#название_темы_2
Информация по теме
#название_темы_N
Информация по теме
- Название каждой темы располагается в отдельной строке и предваряется символом #. Наличие специального символа в строке (в данном случае — #) позволяет программе быстро найти начало раздела. Под названием темы может располагаться любая справочная информация. После окончания одного раздела и перед началом другого должна быть введена пустая строка. Кроме того, в конце строк не должно быть лишних пробелов.
- Ниже приведен пример простого файла со справочной информацией, который можно использовать вместе с новой версией справочной системы. В нем хранятся сведения об операторах Java.
#if
if(condition) statement;
else statement;
#switch
switch(expression) {
case constant:
statement sequence
break;
// ...
}
#for
for(init; condition; iteration) statement;
#while
while(condition) statement;
#do
do {
statement;
} while (condition);
#break
break; or break label;
#continue
continue; or continue label;
- Присвойте этому файлу имя helpfile.txt.
- Создайте файл FileHelp.java.
- Начните создание новой версии класса Help со следующих строк кода:
class Help {
String helpfile; // Имя файла со справочной информацией
Help(String fname) {
helpfile = fname;
}
- Имя файла со справочной информацией передается конструктору класса Help и запоминается в переменной экземпляра helpfile. А поскольку каждый экземпляр класса Help содержит отдельную копию переменной helpf ile, то каждый из них может взаимодействовать с отдельным файлом. Это дает возможность создавать отельные наборы справочных файлов на разные темы.
- Добавьте в класс Help метод helpon(), код которого приведен ниже. Этот метод извлекает справочную информацию по заданной теме.
// отобразить справочную информацию по заданной теме
boolean helpon(String what) {
int ch;
String topic, info;
// открыть справочный файл
try (BufferedReader helpRdr =
new BufferedReader(new FileReader(helpfile)))
{
do {
// читать символы до тех пор, пока не встретится знак #
ch = helpRdr.read();
// а теперь проверить, совпадают ли темы
if(ch == '#') {
topic = helpRdr.readLine();
if(what.compareTo(topic) == 0) { // found topic
do {
info = helpRdr.readLine();
if(info != null) System.out.println(info);
} while((info != null) &&
(info.compareTo("") != 0));
return true;
}
}
} while(ch != -1);
}
catch(IOException exc) {
System.out.println("Error accessing help file.");
return false;
}
return false; // тема не найдена
}
- Прежде всего обратите внимание на то, что в методе helpon() обрабатываются все исключения, связанные с вводом-выводом, поэтому в заголовке метода не указано ключевое слово throws. Благодаря такому подходу упрощается разработка методов, в которых используется метод helpon(). В вызывающем методе достаточно обратиться к методу helpon(), не заключая его вызов в блок try/catch.
- Для открытия файла со справочной информацией служит класс FileReader, оболочкой которого является класс Buf feredReader. В справочном файле содержится текст, и поэтому справочную систему удобнее локализовать через символьные потоки ввода-вывода.
- Метод helpon ( действует следующим образом. Символьная строка, содержащая название темы, передается этому методу в качестве параметра. Метод открывает сначала файл со справочной информацией. Затем в файле производится поиск, т.е. проверяется совпадение содержимого переменной what и названия темы. Напомним, что в файле заголовок темы предваряется символом #, поэтому метод сначала ищет данный символ. Если символ найден, производится сравнение следующего за ним названия темы с содержимым переменной what. Если сравниваемые строки совпадают, то отображается справочная информация по данной теме. И если заголовок темы найден, то метод helpon() возвращает логическое значение true, иначе — логическое значение false.
- В классе Help содержится также метод getSelectionO, который предлагает задать тему и возвращает строку, введенную пользователем.
// получить тему
String getSelectionO {
String topic = "";
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in));
System.out.print("Enter topic: ") ;
try {
topic = br.readLine();
}
catch(IOException exc) {
System.out.println("Error reading console.");
}
return topic;
}
- В теле этого метода сначала создается объект типа Buf feredReader, который связывается с потоком вывода System, in. Затем в нем запрашивается название темы, которое принимается и далее возвращается вызывающей части программы.
- Ниже приведен весь исходный код программы, реализующей справочную систему, находящуюся на диске.
/*
Пример для опробования 10.2.
Справочная система, находящаяся на диске.
Для компиляции этой программы требуется JDK 7
или более поздняя версия данного комплекта.
*/
import java.io.*;
/* В классе Help открывается файл со справочной информацией,
производится поиск названия темы, а затем отображается
справочная информация по этой теме.
Обратите внимание на то, что в этом классе поддерживаются
все исключения, освобождая от этой обязанности вызывающий код. */
class Help {
String helpfile; // Имя файла со справочной информацией
Help(String fname) {
helpfile = fname;
}
// отобразить справочную информацию по заданной теме
boolean helpon(String what) {
int ch;
String topic, info;
// открыть справочный файл
try (BufferedReader helpRdr =
new BufferedReader(new FileReader(helpfile)))
{
do {
// читать символы до тех пор, пока не встретится знак #
ch = helpRdr.read();
// а теперь проверить, совпадают ли темы
if(ch =='#') {
topic = helpRdr.readLine();
if(what.compareTo(topic) == 0) { // тема найдена
do {
info = helpRdr.readLine();
if(info != null) System.out.println(info);
} while((info != null) &&
(info.compareTo("") != 0));
return true;
}
}
} while(ch != -1);
}
catch(IOException exc) {
System.out.println("Error accessing help file.");
return false;
}
return false; // тема не найдена
}
// получить тему
String getSelection() {
String topic = "";
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in));
System.out.print("Enter topic: ");
try {
topic = br.readLine();
}
catch(IOException exc) {
System.out.println("Error reading console.");
}
return topic;
}
}
// продемонстрировать справочную систему, находящуюся на диске
class FileHelp {
public static void main(String args[]) {
Help hlpobj = new Help("helpfile.txt");
String topic;
System.out.println("Try the help system. " +
"Enter ’stop' to end.");
do {
topic = hlpobj.getSelection();
if(!hlpobj.helpon(topic))
System.out.println("Topic not found.n");
} while(topic.compareTo("stop") != 0);
}
}
Упражнение для самопроверки
по материалу главы 10
- Для чего в Java определены как байтовые, так и символьные потоки?
- Как известно, ввод-вывод данных на консоль осуществляется в текстовом виде. Почему же в Java для этой цели используются байтовые потоки?
- Как открыть файл для чтения байтов?
- Как открыть файл для чтения символов?
- Как открыть файл для ввода-вывода с произвольным доступом?
- Как преобразовать числовую строку «123.23» в двоичный эквивалент?
- Напишите программу, которая будет копировать текстовые файлы. Видоизмените ее таким образом, чтобы все пробелы заменялись дефисами. Используйте при написании программы классы, представляющие байтовые потоки, а также традиционный способ закрытия файла явным вызовом метода close().
- Перепишите программу, созданную в ответ на предыдущий вопрос, таким образом, чтобы в ней использовались классы, представляющие символьные потоки. На этот раз воспользуйтесь оператором try с ресурсами для автоматического закрытия файла.
- К какому типу относится поток System. in?
- Что возвращает метод read() из класса InputStream по достижении конца потока?
- Поток какого типа используется для чтения двоичных данных?
- Классы Reader и Writer находятся на вершине иерархии классов _______ .
- Оператор try без ресурсов служит для ______ .
- Если для закрытия файла используется традиционный способ, то это лучше всего делать в блоке finally. Верно или неверно?
Стандартные потоки ввода-вывода
Программа, выводящая в консоль сообщение Hello, world!, с которой традиционно начинают изучение языка программирования, на языке C++ выглядит следующим образом:
#include <iostream>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
return 0;
}
Директива #include и функция main() знакомы читателю по языку C. Способ вывода строки в консоль отличается от стандартной функции printf языка C и даёт нам повод начать разговор про C++.
Глобальный объект cout отвечает за вывод в стандартный поток вывода stdout. Оператор вставки << передает различные объекты в поток вывода. Манипулятор endl выполняет перевод строки. Оператор << позволяет строить цепочки вызовов, которые будут выполняться слева направо: сначала мы вывели строку Hello, world!, а затем манипулятор endl.
Чтобы считать данные из стандартного потока ввода stdin, необходимо воспользоваться объектом cin и оператором извлечения >>.
int a;
double x;
cin >> a >> x;
Здесь мы снова построили цепочку вызовов и получили значения сразу для двух переменных. При обращении к потоку ввода мы не указывали тип данных, которые необходимо прочитать. Оператор >> сам определяет типы объектов и заполняет их из потока ввода.
Объекты cout, cin, а также операторы вставки и извлечения определены в заголовочном файле <iostream>
Работа с файлами
Все операции ввода-вывода в C++ организованы через потоки и операторы << и >>. Мы уже рассмотрели операции ввода-вывода в потоки stdout и stdin. Операции ввода-вывода с файлами устроены схожим образом. Для работы с файловыми потоками необходимо подключить заголовочный файл <fstream>. Следующая программа создает файл test.txt и записывает в него строку Hello, world!
#include <fstream>
using namespace std;
int main() {
ofstream ofile("test.txt", ios::out);
if (ofile.is_open()) {
ofile << "Hello, world!";
}
return 0;
}
Сначала мы создали объект типа ofstream. В его конструктор мы передали имя файла test.txt и флаг ios::out, указывающий на то, что мы собираемся осуществлять операции вывода. Всегда необходимо проверять, что операция открытия/создания файла прошла успешно. Если не выполнить эту проверку, то, если по какой-либо причине файл открыть не удалось, дальнейшие шаги приведут к аварийному завершению программы. Метод is_open() позволяет выполнить такою проверку. Дальше идет уже знакомый нам вызов оператора <<, который в этом случае работает с файловым потоком вывода. Обратите внимание, что нет необходимости вручную закрывать файл, если того не требует логика программы. При выходе объекта ofile из области видимости, файл будет корректно закрыт.
Чтение данных из файла производится следующим образом:
#include <fstream>
#include <string>
#include <iostream>
using namespace std;
int main() {
ifstream ifile("test.txt", ios::in);
if (ifile.is_open()) {
string line;
while (ifile >> line) {
cout << line << ' ';
}
}
return 0;
}
Здесь мы воспользовались файловым потоком ввода ifstream и флагом ios::in. В этой программе мы создали переменную line типа string, чтобы хранить считанные из файла данные. Неочевидным моментом здесь является использование цикла while. Дело в том, что оператор >> считывает символы до тех пор, пока не встретит разделитель (пробел, табуляция или перенос строки). Если бы мы вызвали этот оператор один раз, то в переменную line было бы записано Hello,, а это не то, чего мы хотели. Цикл позволяет прочитать файл до конца.
Если же мы хотим прочитать только одну строчку из файла, то можно воспользоваться функцией getline, определенной в <string>. С этой функцией наша программа примет следующий вид:
#include <fstream>
#include <string>
#include <iostream>
using namespace std;
int main() {
ifstream ifile("test.txt", ios::in);
if (ifile.is_open()) {
string line;
getline(ifile, line);
cout << line << end;
}
return 0;
}
Наконец, для чтения символов из потока по одному можно использовать метод get()
char c;
while (ifile.get(c)) {
cout << c;
}
Аналогичный метод есть и у объекта cin.
По умолчанию файловые потоки работают в текстовом режиме, т.е. передают и принимают строковые символы. В некоторых случаях необходимо работать непосредственно с последовательностью байт, которые не должны быть интерпретированы как строковые символы. Для таких случаев существует флаг ios::binary. Детали работы с бинарными файлами смотрите в документации.
Строковые потоки
Часто бывает удобно работать со строковыми потоками. Инструменты для работы со строковыми потоками подключаются с помощью заголовочного файла <sstream>. Строковые потоки позволяют удобно инициализировать объекты различных типов из их текстового представления. Представим себе, что мы получили географические координаты НГУ в виде строки "(54.847830, 83.094392)". Наша задача извлечь из строки две величины типа double. Сделать это можно следующим образом:
#include <string>
#include <sstream>
#include <iostream>
using namespace std;
int main() {
string nsucoor("(54.847830, 83.094392)");
stringstream ss(nsucoor);
double lat, lon;
ss.ignore(1); // skip '('
ss >> lat;
ss.ignore(2); // skip ", "
ss >> lon;
cout << lat << ", " << lon << endl;
return 0;
}
Резюме
Мы обсудили, что все операции ввода-вывода в С++ реализованы единообразно с помощью потоков. Вывод в поток осуществляется с помощью оператора вставки <<, ввод из потока осуществляется с помощью оператора извлечения >>. Мы рассмотрели три типа потоков: стандартные, файловые и строковые. Этого достаточно для уверенного начала работы с потоками ввода-вывода в C++.
Документация
- http://www.cplusplus.com/reference/iolibrary/
- https://en.cppreference.com/w/cpp/io
С самого начала книги мы использовали С++-систему ввода-вывода, но не давали подробных пояснений по этому поводу. Поскольку С++-система ввода-вывода построена на иерархии классов, ее теорию и детали невозможно освоить, не рассмотрев сначала классы, наследование и механизм обработки исключений. Теперь настало время для подробного изучения С++-средств ввода-вывода.
В этой главе рассматриваются средства как консольного, так и файлового ввода-вывода. Необходимо сразу отметить, что С++-система ввода-вывода — довольно обширная тема, и здесь описаны лишь самые важные и часто применяемые средства. В частности, вы узнаете, как перегрузить операторы «<<» и «>>» для ввода и вывода объектов созданных вами классов, а также как отформатировать выводимые данные и использовать манипуляторы ввода-вывода. Завершает главу рассмотрение средств файлового ввода-вывода.
Сравнение старой и новой С++-систем ввода-вывода
В настоящее время существуют две версии библиотеки объектно-ориентированного ввода-вывода, причем обе широко используются программистами: более старая, основанная на оригинальных спецификациях языка C++, и новая, определенная стандартом языка C++. Старая библиотека ввода-вывода поддерживается за счет заголовочного файла <iostream.h>, а новая — посредством заголовка <iostream>. Новая библиотека ввода-вывода, по сути, представляет собой обновленную и усовершенствованную версию старой. Основное различие между ними состоит в реализации, а не в том, как их нужно использовать.
С точки зрения программиста, есть два существенных различия между старой и новой С ++-библиотеками ввода-вывода. Во-первых, новая библиотека содержит ряд дополнительных средств и определяет несколько новых типов данных. Таким образом, новую библиотеку ввода-вывода можно считать супермножеством старой. Практически все программы, написанные для старой библиотеки, успешно компилируются при использовании новой, не требуя внесения каких-либо значительных изменений. Во-вторых, старая библиотека ввода-вывода была определена в глобальном пространстве имен, а новая использует пространство имен std. (Вспомните, что пространство имен std используется всеми библиотеками стандарта C++.) Поскольку старая библиотека ввода-вывода уже устарела, в этой книге описывается только новая, но большая часть информации применима и к старой.
Потоки C++
Поток — это последовательный логический интерфейс, который связан с физическим файлом.
Принципиальным для понимания С++-системы ввода-вывода является то, что она опирается на понятие потока. Поток (stream) — это общий логический интерфейс с различными устройствами, составляющими компьютер. Поток либо синтезирует информацию, либо потребляет ее и связывается с любым физическим устройством с помощью С++-системы ввода-вывода. Характер поведения всех потоков одинаков, несмотря на различные физические устройства, с которыми они связываются. Поскольку потоки действуют одинаково, то практически ко всем типам устройств можно применить одни и те
же функции и операторы ввода-вывода. Например, методы, используемые для записи данных на экран, также можно использовать для вывода их на принтер или для записи в дисковый файл.
В самой общей форме поток можно назвать логическим интерфейсом с файлом. С++-
определение термина «файл» можно отнести к дисковому файлу, экрану, клавиатуре, порту,
файлу на магнитной ленте и пр. Хотя файлы отличаются по форме и возможностям, все потоки одинаковы. Достоинство этого подхода (с точки зрения программиста) состоит в том, что одно устройство компьютера может «выглядеть» подобно любому другому. Это значит, что поток обеспечивает интерфейс, согласующийся со всеми устройствами.
Поток связывается с файлом при выполнении операции открытия файла, а отсоединяется от него с помощью операции закрытия.
Существует два типа потоков: текстовый и двоичный. Текстовый поток используется для ввода-вывода символов. При этом могут происходить некоторые преобразования символов. Например, при выводе символ новой строки может быть преобразован в последовательность символов: возврата каретки и перехода на новую строку. Поэтому может не быть взаимно-однозначного соответствия между тем, что посылается в поток, и тем, что в действительности записывается в файл. Двоичный поток можно использовать с данными любого типа, причем в этом случае никакого преобразования символов не выполняется, и между тем, что посылается в поток, и тем, что потом реально содержится в файле, существует взаимно-однозначное соответствие.
Текущая позиция — это место в файле, с которого будет выполняться следующая операция доступа к файлу.
Говоря о потоках, необходимо понимать, что вкладывается в понятие «текущей позиции». Текущая позиция — это место в файле, с которого будет выполняться следующая операция доступа к файлу. Например, если длина файла равна 100 байт, и известно, что уже прочитана половина этого файла, то следующая операция чтения произойдет на байте 50, который в данном случае и является текущей позицией.
Итак, в языке C++ механизм ввода-вывода функционирует с использованием логического интерфейса, именуемого потоком. Все потоки имеют аналогичные свойства, которые позволяют выполнять одинаковые функции ввода-вывода, независимо от того, с файлом какого типа существует связь. Под файлом понимается реальное физическое устройство, которое содержит данные. Если файлы различаются между собой, то потоки — нет. (Конечно, некоторые устройства могут не поддерживать все операции ввода-вывода, например операции с произвольной выборкой, поэтому и связанные с ними потоки тоже не будут поддерживать эти операции.)
Встроенные С++-потоки
В C++ содержится ряд встроенных потоков (cin, cout, cerr и clog), которые автоматически открываются, как только программа начинает выполняться. Как вы знаете, cin — это стандартный входной, а cout — стандартный выходной поток. Потоки cerr и clog (они предназначены для вывода информации об ошибках) также связаны со стандартным выводом данных. Разница между ними состоит в том, что поток clog буферизирован, а поток cerr — нет. Это означает, что любые выходные данные, посланные в поток cerr, будут немедленно выведены, а при использовании потока clog данные сначала записываются в буфер, и реальный их вывод происходит только тогда, когда буфер полностью заполняется.
Обычно потоки cerr и clog используются для записи информации об отладке или ошибках. В C++ также предусмотрены двухбайтовые (16-битовые) символьные версии
стандартных потоков, именуемые wcin, wcout, wcerr и wclog. Они предназначены для поддержки таких языков, как китайский, для представления которых требуются большие символьные наборы. В этой книге двухбайтовые стандартные потоки не используются.
По умолчанию стандартные С++-потоки связываются с консолью, но программным способом их можно перенаправить на другие устройства или файлы. Перенаправление может также выполнить операционная система.
Классы потоков
Как вы узнали в главе 2, С++-система ввода-вывода использует заголовок <iostream>, в котором для поддержки операций ввода-вывода определена довольно сложная иерархия классов. Эта иерархия начинается с системы шаблонных классов. Как отмечалось в главе 16, шаблонный класс определяет форму, не задавая в полном объеме данные, которые он должен обрабатывать. Имея шаблонный класс, можно создавать его конкретные экземпляры. Для библиотеки ввода-вывода стандарт C++ создает две специализации шаблонных классов: одну для 8-, а другую для 16-битовых («широких») символов. В этой книге описываются классы только для 8-битовых символов, поскольку они используются гораздо чаще.
С++-система ввода-вывода построена на двух связанных, но различных иерархиях шаблонных классов. Первая выведена из класса низкоуровневого ввода-вывода basic_streambuf. Этот класс поддерживает базовые низкоуровневые операции ввода и вывода и обеспечивает поддержку для всей С++-системы ввода-вывода. Если вы не собираетесь заниматься программированием специализированных операций ввода-вывода, то вам вряд ли придется использовать напрямую класс basic_streambuf. Иерархия классов, с которой С ++-программистам наверняка предстоит работать вплотную, выведена из класса basic_ios. Это — класс высокоуровневого ввода-вывода, который обеспечивает форматирование, контроль ошибок и предоставляет статусную информацию, связанную с потоками вводавывода. (Класс basic_ios выведен из класса ios_base, который определяет ряд нешаблонных свойств, используемых классом basic_ios.) Класс basic_ios используется в качестве базового для нескольких производных классов, включая классы basic_istream, basic_ostream и basic_iostream. Эти классы используются для создания потоков, предназначенных для ввода данных, вывода и ввода-вывода соответственно.
Как упоминалось выше, библиотека ввода-вывода создает две специализированные иерархии шаблонных классов: одну для 8-, а другую для 16-битовых символов. Ниже приводится список имен шаблонных классов и соответствующих им «символьных» версий.
В остальной части этой книги используются имена символьных классов, поскольку именно они применяются в программах. Те же имена используются и старой библиотекой ввода-вывода. Вот поэтому старая и новая библиотеки совместимы на уровне исходного кода.
И еще: класс ios содержит множество функций-членов и переменных, которые управляют основными операциями над потоками или отслеживают результаты их выполнения. Поэтому имя класса ios будет употребляться в этой книге довольно часто. И помните: если включить в программу заголовок <iostream>, она будет иметь доступ к этому важному классу.
Перегрузка операторов ввода-вывода
Впримерах из предыдущих глав при необходимости выполнить операцию ввода или вывода данных, связанных с классом, создавались функции-члены, назначение которых и состояло лишь в том, чтобы ввести или вывести эти данные. Несмотря на то что в самом этом решении нет ничего неправильного, в C++ предусмотрен более удачный способ выполнения операций ввода-вывода «классовых» данных: путем перегрузки операторов ввода-вывода «<<» и «>>».
Оператор «<<» выводит информацию в поток, а оператор «>>» вводит информацию из потока.
Вязыке C++ оператор «<<» называется оператором вывода или вставки, поскольку он вставляет символы в поток. Аналогично оператор «>>» называется оператором ввода или извлечения, поскольку он извлекает символы из потока.
Как вы знаете, операторы ввода-вывода уже перегружены (в заголовке <iostream>), чтобы они могли выполнять операции потокового ввода или вывода данных любых встроенных С++-типов. Здесь вы узнаете, как определить эти операторы для собственных классов.
Создание перегруженных операторов вывода
В качестве простого примера рассмотрим создание оператора вывода для следующей версии класса three_d.
class three_d {
public:
int x, у, z; // 3-мерные координаты
three_d(int a, int b, int с) { x = a; у = b; z = c; }
};
Чтобы создать операторную функцию вывода для объектов типа three_d, необходимо перегрузить оператор «<<«. Вот один из возможных способов.
/* Отображение координат X, Y, Z (оператор вывода для класса three_d).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
Рассмотрим внимательно эту функцию, поскольку ее содержимое характерно для многих функций вывода данных. Во-первых, отметьте, что согласно объявлению она возвращает ссылку на объект типа ostream. Это позволяет несколько операторов вывода объединить в одном составном выражении. Затем обратите внимание на то, что эта функция имеет два параметра. Первый представляет собой ссылку на поток, который используется в левой части оператора. Вторым является объект, который стоит в правой части этого оператора. (При необходимости второй параметр также может иметь тип ссылки на объект.) Само тело функции состоит из инструкций вывода трех значений координат, содержащихся в объекте типа three_d, и инструкции возврата потока stream.
Перед вами короткая программа, в которой демонстрируется использование оператора вывода.
// Использование перегруженного оператора вывода.
#include <iostream>
using namespace std;
class three_d {
public:
int x, y, z; // 3-мерные координаты
three_d(int a, int b, int с) { x = a; у = b; z = c; }
};
/* Отображение координат X, Y, Z (оператор вывода для класса three_d).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), c(5, 6, 7);
cout << a << b << c;
return 0;
}
При выполнении эта программа возвращает следующие результаты:
1, 2, 3
3, 4, 5
5, 6, 7
Если удалить код, относящийся конкретно к классу three_d, останется «скелет», подходящий для любой функции вывода данных.
ostream &operator<<(ostream &stream, class_type obj)
{
// код, относящийся к конкретному классу
return stream; // возвращает параметр stream
}
Как уже отмечалось, для параметра obj разрешается использовать передачу по ссылке. В широком смысле конкретные действия функции вывода определяются программистом. Но если вы хотите следовать профессиональному стилю программирования, то ваша функция вывода должна все-таки выводить информацию. И потом, всегда нелишне убедиться в том, что она возвращает параметр stream.
Прежде чем переходить к следующему разделу, подумайте, почему функция вывода для класса three_d не была закодирована таким образом.
/* Версия ограниченного применения (использованию не подлежит).
*/
ostream &operator<<(ostream &stream, three_d obj)
{
cout << obj.x << «, «;
cout << obj.у << «, «;
cout << obj.z << «n»;
return stream; // возвращает параметр stream
}
Вэтой версии функции жестко закодирован поток cout. Это ограничивает круг ситуаций,
вкоторых ее можно использовать. Помните, что оператор «<<» можно применить к любому потоку и что поток, который использован в «<<«-выражении, передается параметру stream. Следовательно, вы должны передавать функции поток, который корректно работает во всех случаях. Только так можно создать функцию вывода данных, которая подойдет для использования в любых выражениях ввода-вывода.
Использование функций-«друзей» для перегрузки операторов вывода
Впредыдущей программе перегруженная функция вывода не была определена как член класса three_d. В действительности ни функция вывода, ни функция ввода не могут быть членами класса. Дело здесь вот в чем. Если операторная функция является членом класса, левый операнд (неявно передаваемый с помощью указателя this) должен быть объектом класса, который сгенерировал обращение к этой операторной функции. И это изменить нельзя. Однако при перегрузке операторов вывода левый операнд должен быть потоком, а правый — объектом класса, данные которого подлежат выводу. Следовательно, перегруженные операторы вывода не могут быть функциями-членами.
Всвязи с тем, что операторные функции вывода не должны быть членами класса, для которого они определяются, возникает серьезный вопрос: как перегруженный оператор вывода может получить доступ к закрытым элементам класса? В предыдущей программе переменные х, у z были определены как открытые, и поэтому оператор вывода без проблем мог получить к ним доступ. Но ведь сокрытие данных — важная часть объектноориентированного программирования, и требовать, чтобы все данные были открытыми, попросту нелогично. Однако существует решение и для этой проблемы: оператор вывода можно сделать «другом» класса. Если функция является «другом» некоторого класса, то она получает легальный доступ к его private-данным. Как можно объявить «другом» класса перегруженную функцию вывода, покажем на примере класса three_d.
// Использование «дружбы» для перегрузки оператора «<<«
#include <iostream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты (теперь это privateчлены)
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj);
};
// Отображение координат X, Y, Z (оператор вывода для класса three_d).
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает поток
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), с (5, 6, 7);
cout << a << b << c;
return 0;
}
Обратите внимание на то, что переменные х, у и z в этой версии программы являются закрытыми в классе three_d, тем не менее, операторная функция вывода обращается к ним напрямую. Вот где проявляется великая сила «дружбы»: объявляя операторные функции ввода и вывода «друзьями» класса, для которого они определяются, мы тем самым поддерживаем принцип инкапсуляции объектно-ориентированного программирования.
Перегрузка операторов ввода
Для перегрузки операторов ввода используйте тот же метод, который мы применяли при перегрузке оператора вывода. Например, следующий оператор ввода обеспечивает ввод трехмерных координат. Обратите внимание на то, что он также выводит соответствующее сообщение для пользователя.
/* Прием трехмерных координат (оператор ввода для класса three_d).
*/
istream &operator>>(istream &stream, three_d &obj)
{
cout << «Введите координаты X, Y и Z:
stream >> obj.x >> obj.у >> obj.z;
return stream;
}
Оператор ввода должен возвращать ссылку на объект типа istream. Кроме того, первый параметр должен представлять собой ссылку на объект типа istream. Этот тип принадлежит потоку, указанному слева от оператора «>>». Второй параметр является ссылкой на переменную, которая принимает вводимое значение. Поскольку второй параметр — ссылка, он может быть модифицирован при вводе информации.
Общий формат оператора ввода имеет следующий вид.
istream &operator>>(istream &stream, object_type &obj)
{
// код операторной функции ввода данных
return stream;
}
Использование функции ввода данных для объектов типа three_d демонстрируется в следующей программе.
// Использование перегруженного оператора ввода.
#include <iostream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj);
friend istream &operator>>(istream &stream, three_d &obj);
};
// Отображение координат X, Y, Z (оператор вывода для класса three_d).
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает параметр stream
}
// Прием трехмерных координат (оператор ввода для класса three_d).
istream &operator>>(istream &stream, three_d &obj)
{
cout << «Введите координаты X, Y и Z: «;
stream >> obj.x >> obj.у >> obj.z;
return stream;
}
int main()
{
three_d a(1, 2, 3);
cout << a;
cin >> a;
cout << a;
return 0;
}
Вот как выглядит один из возможных результатов выполнения этой программы.
1, 2, 3
Введите координаты X, Y и Z: 5 6 7
5, 6, 7
Подобно функциям вывода, функции ввода не должны быть членами класса, для обработки данных которого они предназначены. Они могут быть «друзьями» этого класса или просто независимыми функциями.
За исключением того, что функция ввода должна возвращать ссылку на объект типа istream, тело этой функции может содержать все, что вы считаете нужным в нее включить. Но логичнее использовать операторы ввода все же по прямому назначению, т.е. для выполнения операций ввода.
Сравнение С- и С++-систем ввода-вывода
Как вы знаете, предшественник C++, язык С, оснащен одной из самых гибких (среди структурированных языков) и при этом очень мощных систем ввода-вывода. (Не будет преувеличением сказать, что среди всех известных структурированных языков С-система ввода-вывода не имеет себе равных.) Почему же тогда, спрашивается, в C++ определяется собственная система ввода-вывода, если в ней продублирована большая часть того, что содержится в С (имеется в виду мощный набор С-функций ввода-вывода)? Ответить на этот вопрос нетрудно. Дело в том, что С-система ввода-вывода не обеспечивает никакой поддержки для объектов, определяемых пользователем. Например, если создать в С такую структуру
struct my_struct {
int count;
char s [80];
double balance;
} cust;
то существующую в С систему ввода-вывода невозможно настроить так, чтобы она могла выполнять операции ввода-вывода непосредственно над объектами типа my_struct. Но
поскольку центром объектно-ориентированного программирования являются именно объекты, имеет смысл, чтобы в C++ функционировала такая система ввода-вывода, которую можно было бы динамически «обучать» обращению с любыми объектами, создаваемыми программистом. Именно поэтому для C++ и была изобретена новая объектноориентированная система ввода-вывода. Как вы уже могли убедиться, С++-подход к вводувыводу позволяет перегружать операторы «<<» и «>>», чтобы они могли работать с классами, создаваемыми программистами.
И еще. Поскольку C++ является супермножеством языка С, все содержимое С-системы ввода-вывода включено в C++. (См. приложение А, в котором представлен обзор С- ориентированных функций ввода-вывода.) Поэтому при переводе С-программ на язык C++ вам не нужно изменять все инструкции ввода-вывода подряд. Работающие С-инструкции скомпилируются и будут успешно работать и в новой С++-среде. Просто вы должны учесть, что старая С-система ввода-вывода не обладает объектно-ориентированными возможностями.
Форматированный ввод-вывод данных
До сих пор при вводе или выводе информации в наших примерах программ действовали параметры форматирования, которые по умолчанию использует С++-система ввода-вывода. Но программист может сам управлять форматом представления данных, причем двумя способами. Первый способ предполагает использование функций-членов класса ios, а второй— функций специального типа, именуемых манипуляторами (manipulator). Мы же начнем освоение возможностей форматирования с функций-членов класса ios.
Форматирование данных с использованием функций-членов класса ios
В системе ввода-вывода C++ каждый поток связан с набором флагов форматирования, которые управляют процессом форматирования информации. В классе ios объявляется перечисление fmtflags, в котором определены следующие значения. (Точнее, эти значения определены в классе ios_base, который, как упоминалось выше, является базовым для класса ios.)
Эти значения используются для установки или очистки флагов форматирования с помощью таких функций, как setf() и unsetf(). При использовании старого компилятора может оказаться, что он не определяет тип перечисления fmtflags. В этом случае флаги форматирования будут кодироваться как целочисленные long-значения.
Если флаг skipws установлен, то при потоковом вводе данных ведущие «пробельные» символы, или символы пропуска (т.е. пробелы, символы табуляции и новой строки), отбрасываются. Если же флаг skipws сброшен, пробельные символы не отбрасываются.
Если установлен флаг left, выводимые данные выравниваются по левому краю, а если установлен флаг right — по правому. Если установлен флаг internal, числовое значение дополняется пробелами, которыми заполняется поле между ним и знаком числа или символом основания системы счисления. Если ни один из этих флагов не установлен, результат выравнивается по правому краю по умолчанию.
По умолчанию числовые значения выводятся в десятичной системе счисления. Однако основание системы счисления можно изменить. Установка флага oct приведет к выводу результата в восьмеричном представлении, а установка флага hex — в шестнадцатеричном. Чтобы при отображении результата вернуться к десятичной системе счисления, достаточно установить флаг dec.
Установка флага showbase приводит к отображению обозначения основания системы счисления, в которой представляются числовые значения. Например, если используется шестнадцатеричное представление, то значение 1F будет отображено как 0x1F.
По умолчанию при использовании экспоненциального представления чисел отображается строчной вариант буквы «е». Кроме того, при отображении шестнадцатеричного значения используется также строчная буква «х». После установки флага uppercase отображается прописной вариант этих символов.
Установка флага showpos вызывает отображение ведущего знака «плюс» перед положительными значениями.
Установка флага showpoint приводит к отображению десятичной точки и хвостовых нулей для всех чисел с плавающей точкой — нужны они или нет.
После установки флага scientific числовые значения с плавающей точкой отображаются в экспоненциальном представлении. Если установлен флаг fixed, вещественные значения отображаются в обычном представлении. Если не установлен ни один из этих флагов, компилятор сам выбирает соответствующий метод представления.
При установленном флаге unitbuf содержимое буфера сбрасывается на диск после каждой операции вывода данных.
Если установлен флаг boolalpha, значения булева типа можно вводить или выводить, используя ключевые слова true и false.
Поскольку часто приходится обращаться к полям oct, dec и hex, на них допускается коллективная ссылка ios::basefield. Аналогично поля left, right и internal можно собирательно назвать ios::adjustfield. Наконец, поля scientific и fixed можно назвать ios::floatfield.
Чтобы установить флаги форматирования, обратитесь к функции setf().
Для установки любого флага используется функция setf(), которая является членом класса ios. Вот как выглядит ее формат.
fmtflags setf(fmtflags flags);
Эта функция возвращает значение предыдущих установок флагов форматирования и устанавливает их в соответствии со значением, заданным параметром flags. Например, чтобы установить флаг showbase, можно использовать эту инструкцию.
stream.setf(ios::showbase);
Здесь элемент stream означает поток, параметры форматирования которого вы хотите изменить. Обратите внимание на использование префикса ios:: для уточнения принадлежности параметра showbase. Поскольку параметр showbase представляет собой перечислимую константу, определенную в классе ios, то при обращении к ней необходимо указывать имя класса ios. Этот принцип относится ко всем флагам форматирования. В следующей программе функция setf() используется для установки флагов showpos и scientific.
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios::showpos);
cout.setf(ios::scientific);
cout << 123 << » » << 123.23 << » «;
return 0;
}
Вот как выглядят результаты выполнения этой программы.
+123 +1.232300е+002
С помощью операции ИЛИ можно установить сразу несколько нужных флагов форматирования в одном вызове функции setf(). Например, предыдущую программу можно сократить, объединив по ИЛИ флаги scientific и showpos, поскольку в этом случае выполняется только одно обращение к функции setf().
cout.setf(ios::scientific | ios::showpos);
Чтобы сбросить флаг, используйте функцию unsetf(), прототип которой выглядит так.
void unsetf(fmtflags flags);
Для очистки флагов форматирования используется функция unsetf().
В этом случае будут обнулены флаги, заданные параметром flags. (При этом все другие
флаги остаются в прежнем состоянии.)
Чтобы получить текущие установки флагов форматирования, используйте функцию flags().
Для того чтобы узнать текущие установки флагов форматирования, воспользуйтесь функцией flags(), прототип которой имеет следующий вид.
fmtflags flags();
Эта функция возвращает текущее значение флагов форматирования для вызывающего потока.
При использовании следующего формата вызова функции flags() устанавливаются значения флагов форматирования в соответствии с содержимым параметра flags и возвращаются их предыдущие значения.
fmtflags flags(fmtflags flags);
Чтобы понять, как работают функции flags() и unsetf(), рассмотрим следующую программу. Она включает функцию showflags(), которая отображает состояние флагов форматирования.
#include <iostream>
using namespace std;
void showflags(ios::fmtflags f);
int main()
{
ios::fmtflags f;
f = cout.flags();
showflags(f);
cout.setf(ios::showpos);
cout.setf(ios::scientific);
f = cout.flags();
showflags(f);
cout.unsetf(ios:scientific);
f = cout.flags();
showflags(f);
return 0;
}
void showflags(ios::fmtflags f)
{
long i;
for(i=0x4000; i; i=i>>1)
if(i & f) cout << «1»;
else cout << «0»;
cout << «n»;
}
При выполнении эта программа отображает такие результаты. (Между этими и вашими результатами возможно расхождение, вызванное использованием различных компиляторов.)
0 0 0 0 0 1 0 0 0 0 0 0 0 0 1
0 0 1 0 0 1 0 0 0 1 0 0 0 0 1
0 0 0 0 0 1 0 0 0 1 0 0 0 0 1
В предыдущей программе обратите внимание на то, что тип fmtflags указан с префиксом ios ::. Дело в том, что тип fmtflags определен в классе ios. В общем случае при использовании имени типа или перечислимой константы, определенной в некотором
классе, необходимо указывать соответствующее имя вместе с именем класса.
Установка ширины поля, точности и символов заполнения
Помимо флагов форматирования можно также устанавливать ширину поля, символ заполнения и количество цифр после десятичной точки (точность). Для этого достаточно использовать следующие функции.
streamsize width(streamsize len);
char fill(char ch);
streamsize precision(streamsize num);
Функция width() возвращает текущую ширину поля и устанавливает новую равной значению параметра len. Ширина поля, которая устанавливается по умолчанию, определяется количеством символов, необходимых для хранения данных в каждом конкретном случае. Функция fill() возвращает текущий символ заполнения (по умолчанию используется пробел) и устанавливает в качестве нового текущего символа заполнения значение, заданное параметром ch. Этот символ используется для дополнения результата символами, недостающими для достижения заданной ширины поля. Функция precision() возвращает текущее количество цифр, отображаемых после десятичной точки, и устанавливает новое текущее значение точности равным содержимому параметра num. (По умолчанию после десятичной точки отображается шесть цифр.) Тип streamsize определен как целочисленный тип.
Рассмотрим программу, которая демонстрирует использование этих трех функций.
#include <iostream>
using namespace std;
int main()
{
cout.setf(ios::showpos);
cout.setf(ios::scientific);
cout << 123 << » » << 123.23 << «n»;
cout.precision(2); // Две цифры после десятичной точки.
cout.width(10); // Всё поле состоит из 10 символов.
cout << 123 << » «;
cout.width(10); // Установка ширины поля равной 10.
cout << 123.23 << «n»;
cout.fill(‘#’); // Для заполнителя возьмем символ «#»
cout.width(10); // и установим ширину поля равной 10.
cout << 123 << » «;
cout.width(10); // Установка ширины поля равной 10.
cout << 123.23;
return 0;
}
Эта программа генерирует такие результаты.
+123 +1.232300е+002
+123 +1.23е+002
######+123 +1.23е+002
Внекоторых реализациях необходимо устанавливать значение ширины поля перед выполнением каждой операции вывода. Поэтому функция width() в предыдущей программе вызывалась несколько раз.
Всистеме ввода-вывода C++ определены и перегруженные версии функций width(), precision() и fill(), которые не изменяют текущие значения соответствующих параметров форматирования и используются только для их получения. Вот как выглядят их прототипы,
char fill();
streamsize width();
streamsize precision();
Использование манипуляторов ввода-вывода
Манипуляторы позволяют встраивать инструкции форматирования в выражение
ввода-вывода.
В С++-системе ввода-вывода предусмотрен и второй способ изменения параметров форматирования, связанных с потоком. Он реализуется с помощью специальных функций, называемых манипуляторами, которые можно включать в выражение ввода-вывода. Стандартные манипуляторы описаны в табл. 18.1.
При использовании манипуляторов, которые принимают аргументы, необходимо включить в программу заголовок <iomanip>.
Манипулятор используется как часть выражения ввода-вывода. Вот пример программы, в которой показано, как с помощью манипуляторов можно управлять форматированием выводимых данных.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
cout << setprecision (2) << 1000.243 << endl;
cout << setw(20) << «Всем привет! «;
return 0;
}
Результаты выполнения этой программы таковы.
1е+003
Всем привет!
Обратите внимание на то, как используются манипуляторы в цепочке операций вводавывода. Кроме того, отметьте, что, если манипулятор вызывается без аргументов (как,
например, манипулятор endl в нашей программе), то его имя указывается без пары круглых скобок.
В следующей программе используется манипулятор setiosflags() для установки флагов scientific и showpos.
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
cout << setiosflags(ios::showpos);
cout << setiosflags(ios::scientific);
cout << 123 << » » << 123.23;
return 0;
}
Вот результаты выполнения данной программы.
+123 +1.232300е+002
А в этой программе демонстрируется использование манипулятора ws, который пропускает ведущие «пробельные» символы при вводе строки в массив s:
#include <iostream>
using namespace std;
int main()
{
char s[80];
cin >> ws >> s;
cout << s;
return 0;
}
Создание собственных манипуляторных функций
Программист может создавать собственные манипуляторные функции. Существует два типа манипуляторных функций: принимающие и не принимающие аргументы. Для создания параметризованных манипуляторов используются методы, рассмотрение которых выходит за рамки этой книги. Однако создание манипуляторов, которые не имеют параметров, не вызывает особых трудностей.
Все манипуляторные функции вывода данных без параметров имеют следующую структуру.
ostream &manip_name(ostream &stream)
{
// код манипуляторной функции
return stream;
}
Здесь элемент manip_name означает имя манипулятора. Важно понимать, что, несмотря на то, что манипулятор принимает в качестве единственного аргумента указатель на поток, который он обрабатывает, при использовании манипулятора в результирующем выражении ввода-вывода аргументы не указываются вообще.
В следующей программе создается манипулятор setup(), который устанавливает флаг выравнивания по левому краю, ширину поля равной 10 и задает в качестве заполняющего символа знак доллара.
#include <iostream>
#include <iomanip>
using namespace std;
ostream &setup(ostream &stream)
{
stream.setf(ios::left);
stream << setw(10) << setfill (‘$’);
return stream;
}
int main()
{
cout << 10 << » » << setup << 10;
return 0;
}
Собственные манипуляторы полезны по двум причинам. Во-первых, иногда возникает необходимость выполнять операции ввода-вывода с использованием устройства, к которому ни один из встроенных манипуляторов не применяется (например, плоттер). В этом случае создание собственных манипуляторов сделает вывод данных на это устройство более удобным. Во-вторых, может оказаться, что у вас в программе некоторая последовательность инструкций повторяется несколько раз. И тогда вы можете объединить эти операции в один манипулятор, как показано в предыдущей программе.
Все манипуляторные функции ввода данных без параметров имеют следующую структуру.
istream &manip_name(istream &stream)
{
// код манипуляторной функции
return stream;
}
Например, в следующей программе создается манипулятор prompt(). Он настраивает входной поток на прием данных в шестнадцатеричном представлении и отображает для пользователя наводящее сообщение.
#include <iostream>
#include <iomanip>
using namespace std;
istream &prompt(istream &stream)
{
cin >> hex;
cout << «Введите число в шестнадцатеричном формате: «;
return stream;
}
int main()
{
int i;
cin >> prompt >> i;
cout << i;
return 0;
}
Помните: очень важно, чтобы ваш манипулятор возвращал потоковый объект (элемент stream). В противном случае этот манипулятор нельзя будет использовать в составном выражении ввода или вывода.
Файловый ввод-вывод
В С++-системе ввода-вывода также предусмотрены средства для выполнения соответствующих операций с использованием файлов. Файловые операции ввода-вывода можно реализовать после включения в программу заголовка <fstream>, в котором определены все необходимые для этого классы и значения.
Как открыть и закрыть файл
В C++ файл открывается путем связывания его с потоком. Как вы знаете, существуют потоки трех типов: ввода, вывода и ввода-вывода. Чтобы открыть входной поток, необходимо объявить потоковый объект типа ifstream. Для открытия выходного потока нужно объявить поток класса ofstream. Поток, который предполагается использовать для операций как ввода, так и вывода, должен быть объявлен как объект класса fstream. Например, при выполнении следующего фрагмента кода будет создан входной поток, выходной и поток, позволяющий выполнение операций в обоих направлениях.
ifstream in; // входной поток
ofstream out; // выходной поток
fstream both; // поток ввода-вывода
Чтобы открыть файл, используйте функцию open().
Создав поток, его нужно связать с файлом. Это можно сделать с помощью функции open(), причем в каждом из трех потоковых классов есть своя функция-член open(). Представим их прототипы.
void ifstream::open(const char *filename, ios::openmode mode = ios::in);
void ofstream::open(const char *filename, ios::openmode mode = ios::out | ios::trunc);
void fstream::open(const char * filename, ios::openmode mode = ios::in | ios::out);
Здесь элемент filename означает имя файла, которое может включать спецификатор пути. Элемент mode определяет способ открытия файла. Он должен принимать одно или несколько значений перечисления openmode, которое определено в классе ios.
ios::арр
ios::ate
ios::rbinary
ios::in
ios::out
ios::trunc
Несколько значений перечисления openmode можно объединять посредством логического сложения (ИЛИ).
На заметку. Параметр mode для функции fstream::open() может не устанавливаться по умолчанию равным значению in | out (это зависит от используемого компилятора). Поэтому при необходимости этот параметр вам придется задавать в явном виде.
Включение значения ios::арр в параметр mode обеспечит присоединение к концу файла всех выводимых данных. Это значение можно применять только к файлам, открытым для вывода данных. При открытии файла с использованием значения ios::ate поиск будет начинаться с конца файла. Несмотря на это, операции ввода-вывода могут по-прежнему выполняться по всему файлу.
Значение ios::in говорит о том, что данный файл открывается для ввода данных, а значение ios::out обеспечивает открытие файла для вывода данных.
Значение ios::binary позволяет открыть файл в двоичном режиме. По умолчанию все файлы открываются в текстовом режиме. Как упоминалось выше, в текстовом режиме могут происходить некоторые преобразования символов (например, последовательность, состоящая из символов возврата каретки и перехода на новую строку, может быть преобразована в символ новой строки). При открытии файла в двоичном режиме никакого преобразования символов не выполняется. Следует иметь в виду, любой файл, содержащий форматированный текст или еще необработанные данные, можно открыть как в двоичном, так и в текстовом режиме. Единственное различие между этими режимами состоит в преобразовании (или нет) символов.
Использование значения ios::trunc приводит к разрушению содержимого файла, имя которого совпадает с параметром filename, а сам этот файл усекается до нулевой длины. При создании выходного потока типа ofstream любой существующий файл с именем filename автоматически усекается до нулевой длины.
При выполнении следующего фрагмента кода открывается обычный выходной файл.
ofstream out;
out.open(«тест»);
Поскольку параметр mode функции open() по умолчанию устанавливается равным значению, соответствующему типу открываемого потока, в предыдущем примере вообще нет необходимости задавать его значение.
Не открытый в результате неудачного выполнения функции open() поток при использовании в булевом выражении устанавливается равным значению ЛОЖЬ. Этот факт может служить для подтверждения успешного открытия файла, например, с помощью такой if-инструкции.
if(!mystream) {
cout << «He удается открыть файл.n»;
// обработка ошибки
}
Прежде чем делать попытку получения доступа к файлу, следует всегда проверять результат вызова функции open().
Можно также проверить факт успешного открытия файла с помощью функции is_open(), которая является членом классов fstream, ifstream и ofstream. Вот ее прототип,
bool is_open();
Эта функция возвращает значение ИСТИНА, если поток связан с открытым файлом, и ЛОЖЬ — в противном случае. Например, используя следующий код, можно узнать, открыт ли в данный момент потоковый объект mystream.
if(!mystream.is_open()) {
cout << «Файл не открыт.n»;
// …
}
Хотя вполне корректно использовать функцию open() для открытия файла, в большинстве случаев это делается по-другому, поскольку классы ifstream, ofstream и fstream включают конструкторы, которые автоматически открывают заданный файл. Параметры у этих конструкторов и их значения (действующие по умолчанию) совпадают с параметрами и соответствующими значениями функции open(). Поэтому чаще всего файл открывается так, как показано в следующем примере,
ifstream mystream(«myfile»); // файл открывается для ввода
Если по какой-то причине файл открыть невозможно, потоковая переменная, связываемая с этим файлом, устанавливается равной значению ЛОЖЬ.
Чтобы закрыть файл, вызовите функцию close().
Чтобы закрыть файл, используйте функцию-член close(). Например, чтобы закрыть файл, связанный с потоковым объектом mystream, используйте такую инструкцию,
mystream.close();
Функция close() не имеет параметров и не возвращает никакого значения.
Чтение и запись текстовых файлов
Проще всего считывать данные из текстового файла или записывать их в него с помощью операторов «<<» и «>>». Например, в следующей программе выполняется запись в файл test целого числа, значения с плавающей точкой и строки.
// Запись данных в файл.
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ofstream out(«test»);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out << 10 << » » << 123.23 << «n»;
out << «Это короткий текстовый файл.»;
out.close();
return 0;
}
Следующая программа считывает целое число, float-значение, символ и строку из файла, созданного при выполнении предыдущей программой.
// Считывание данных из файла.
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char ch;
int i;
float f;
char str[80];
ifstream in(«test»);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in >> i;
in >> f;
in >> ch;
in >> str;
cout << i << » » << f << » » << ch << «n»;
cout << str;
in.close();
return 0;
}
Следует иметь в виду, что при использовании оператора «>>» для считывания данных из текстовых файлов происходит преобразование некоторых символов. Например, «пробельные» символы опускаются. Если необходимо предотвратить какие бы то ни было преобразования символов, откройте файл в двоичном режиме доступа. Кроме того, помните, что при использовании оператора «>>» для считывания строки ввод прекращается при обнаружении первого «пробельного» символа.
Неформатированный ввод-вывод данных в двоичном режиме
Форматированные текстовые файлы (подобные тем, которые использовались в предыдущих примерах) полезны во многих ситуациях, но они не обладают гибкостью неформатированных двоичных файлов. Поэтому C++ поддерживает ряд функций файлового ввода-вывода в двоичном режиме, которые могут выполнять операции без форматирования данных.
Для выполнения двоичных операций файлового ввода-вывода необходимо открыть файл с использованием спецификатора режима ios::binary. Необходимо отметить, что функции обработки неформатированных файлов могут работать с файлами, открытыми в текстовом режиме доступа, но при этом могут иметь место преобразования символов, которые сводят на нет основную цель выполнения двоичных файловых операций.
Функция get() считывает символ из файла, а функция put() записывает символ в файл.
В общем случае существует два способа записи неформатированных двоичных данных в файл и считывания их из файла. Первый состоит в использовании функции-члена put() (для записи байта в файл) и функции-члена get() (для считывания байта из файла). Второй способ предполагает применение «блочных» С++-функций ввода-вывода read() и write(). Рассмотрим каждый способ в отдельности.
Использование функций get() и put()
Функции get() и put() имеют множество форматов, но чаще всего используются следующие их версии:
istream &get(char &ch);
ostream &put(char ch);
Функция get() считывает один символ из соответствующего потока и помещает его значение в переменную ch. Она возвращает ссылку на поток, связанный с предварительно открытым файлом. При достижении конца этого файла значение ссылки станет равным нулю. Функция put() записывает символ ch в поток и возвращает ссылку на этот поток.
При выполнении следующей программы на экран будет выведено содержимое любого заданного файла. Здесь используется функция get().
/* Отображение содержимого файла с помощью функции get().
*/
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=2) {
cout << «Применение: имя_программы <имя_файла>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
while(in) {
/* При достижении конца файла потоковый объект in примет значение false. */
in.get(ch);
if(in) cout << ch;
}
in.close();
return 0;
}
При достижении конца файла потоковый объект in примет значение ЛОЖЬ, которое остановит выполнение цикла while.
Существует более короткий вариант цикла, предназначенного для считывания и отображения содержимого файла.
while(in.get(ch)) cout << ch;
Этот вариант также имеет право на существование, поскольку функция get() возвращает потоковый объект in, который при достижении конца файла примет значение false.
В следующей программе для записи строки в файл используется функция put().
/* Использование функции put() для записи строки в файл.
*/
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char *p = «Всем привет!»;
ofstream out(«test», ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
while(*p) out.put(*p++);
out.close();
return 0;
}
Считывание и запись в файл блоков данных
Чтобы считывать и записывать в файл блоки двоичных данных, используйте функциичлены read() и write(). Их прототипы имеют следующий вид.
istream &read(char *buf, streamsize num);
ostream &write(const char *buf, int streamsize num);
Функция read() считывает num байт данных из связанного с файлом потока и помещает их в буфер, адресуемый параметром buf. Функция write() записывает num байт данных в связанный с файлом поток из буфера, адресуемого параметром buf. Как упоминалось выше, тип streamsize определен как некоторая разновидность целочисленного типа. Он позволяет хранить самое большое количество байтов, которое может быть передано в процессе любой операции ввода-вывода.
Функция read() вводит блок данных, а функция write() выводит его.
При выполнении следующей программы сначала в файл записывается массив целых чисел, а затем он же считывается из файла.
// Использование функций read() и write().
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
int n[5] = {1, 2, 3, 4, 5};
register int i;
ofstream out(«test», ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out.write((char *) &n, sizeof n);
out.close();
for(i=0; i<5; i++) // очищаем массив
n[i] = 0;
ifstream in («test», ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in.read((char *) &n, sizeof n);
for(i=0; i<5; i++) // Отображаем значения, считанные из файла.
cout << n[i] << » «;
in.close();
return 0;
}
Обратите внимание на то, что в инструкциях обращения к функциям read() и write() выполняются операции приведения типа, которые обязательны при использовании буфера, определенного не в виде символьного массива.
Функция gcount() возвращает количество символов, считанных при выполнении последней операции ввода данных.
Если конец файла будет достигнут до того, как будет считано num символов, функция read() просто прекратит выполнение, а буфер будет содержать столько символов, сколько удалось считать до этого момента. Точное количество считанных символов можно узнать с помощью еще одной функции-члена gcount(), которая имеет такой прототип.
streamsize gcount();
Функция gcount() возвращает количество символов, считанных в процессе выполнения последней операции ввода данных.
Обнаружение конца файла
Обнаружить конец файла можно с помощью функции-члена eof(), которая имеет такой прототип.
bool eof();
Эта функция возвращает значение true при достижении конца файла; в противном случае она возвращает значение false.
Функция eof() позволяет обнаружить конец файла.
В следующей программе для вывода на экран содержимого файла используется функция eof().
/* Обнаружение конца файла с помощью функции eof().
*/
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=2) {
cout << «Применение: имя_программы <имя_файла>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
while(!in.eof()) {
// использование функции eof()
in.get(ch);
if( !in.eof()) cout << ch;
}
in.close();
return 0;
}
Пример сравнения файлов
Следующая программа иллюстрирует мощь и простоту применения в C++ файловой системы. Здесь сравниваются два файла с помощью функций двоичного ввода-вывода read(), eof() и gcount(). Программа сначала открывает сравниваемые файлы для выполнения двоичных операций (чтобы не допустить преобразования символов). Затем из каждого файла по очереди считываются блоки информации в соответствующие буферы и сравнивается их содержимое. Поскольку объем считанных данных может быть меньше размера буфера, в программе используется функция gcount(), которая точно определяет количество считанных в буфер байтов. Нетрудно убедиться в том, что при использовании файловых С++-функций для выполнения этих операций потребовалась совсем небольшая по размеру программа.
// Сравнение файлов.
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char *argv[])
{
register int i;
unsigned char buf1[1024], buf2[1024];
if(argc!=3) {
cout << «Применение: имя_программы <имя_файла1> «<< » <имя_файла2>n»;
return 1;
}
ifstream f1(argv[1], ios::in | ios::binary);
if(!f1) {
cout << «He удается открыть первый файл.n»;
return 1;
}
ifstream f2(argv[2], ios::in | ios::binary);
if(!f2) {
cout << «He удается открыть второй файл.n»;
return 1;
}
cout << «Сравнение файлов …n»;
do {
f1.read((char *) buf1, sizeof buf1);
f2.read((char *) buf2, sizeof buf2);
if(f1.gcount() != f2.gcount()) {
cout << «Файлы имеют разные размеры.n»;
f1.close();
f2.close();
return 0;
}
// Сравнение содержимого буферов.
for(i=0; i<f1.gcount(); i++)
if(buf1[i] != buf2[i]) {
cout << «Файлы различны.n»;
f1.close();
f2.close();
return 0;
}
}while(!f1.eof() && !f2.eof());
cout << «Файлы одинаковы.n»;
f1.close();
f2.close();
return 0;
}
Проведите эксперимент. Размер буфера в этой программе жестко установлен равным 1024. В качестве упражнения замените это значение const-переменной и опробуйте другие размеры буферов. Определите оптимальный размер буфера для своей операционной среды.
Использование других функций двоичного ввода-вывода
Помимо приведенного выше формата использования функции get() существуют и другие ее перегруженные версии. Приведем прототипы для трех из них, которые используются чаще всего.
istream &get(char *buf, streamsize num);
istream &get(char *buf, streamsize num, char delim);
int get();
Первая версия позволяет считывать символы в массив, заданный параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не встретится символ новой строки, либо не будет достигнут конец файла. После выполнения функции get() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ новой строки, если таковой обнаружится во входном потоке, не извлекается. Он остается там до тех пор, пока не выполнится следующая операция ввода-вывода.
Вторая версия предназначена для считывания символов в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim, либо не будет достигнут конец файла. После выполнения функции get() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ-разделитель (заданный параметром delim), если таковой обнаружится во входном потоке, не извлекается. Он остается там до тех пор, пока не выполнится следующая операция ввода-вывода.
Третья перегруженная версия функции get() возвращает из потока следующий символ. Он содержится в младшем байте значения, возвращаемого функцией. Следовательно, значение, возвращаемое функцией get(), можно присвоить переменной типа char. При достижении конца файла эта функция возвращает значение EOF, которое определено в заголовке <iostream>.
Функцию get() полезно использовать для считывания строк, содержащих пробелы. Как вы знаете, если для считывания строки используется оператор «>>», процесс ввода останавливается при обнаружении первого же пробельного символа. Это делает оператор «>>» бесполезным для считывания строк, содержащих пробелы. Но эту проблему, как показано в следующей программе, можно обойти с помощью функции get(buf,num).
/* Использование функции get() для считывания строк содержащих
пробелы.
*/
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
char str[80];
cout << «Введите имя: «;
cin.get (str, 79);
cout << str << ‘n’;
return 0;
}
Здесь в качестве символа-разделителя при считывании строки с помощью функции get() используется символ новой строки. Это делает поведение функции get() во многом сходным с поведением стандартной функции gets(). Однако преимущество функции get() состоит в том, что она позволяет предотвратить возможный выход за границы массива, который принимает вводимые пользователем символы, поскольку в программе задано максимальное количество считываемых символов. Это делает функцию get() гораздо безопаснее функции gets().
Рассмотрим еще одну функцию, которая позволяет вводить данные. Речь идет о функции getline(), которая является членом каждого потокового класса, предназначенного для ввода информации. Вот как выглядят прототипы версий этой функции,
istream &getline(char *buf, streamsize num);
istream &getline(char *buf, streamsize num, char delim);
Функция getline() представляет собой еще один способ ввода данных.
При использовании первой версии символы считываются в массив, адресуемый указателем buf, до тех пор, пока либо не будет считано num-1 символов, либо не встретится
символ новой строки, либо не будет достигнут конец файла. После выполнения функции getline() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ новой строки, если таковой обнаружится во входном потоке, при этом извлекается, но не помещается в массив buf.
Вторая версия предназначена для считывания символов в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim, либо не будет достигнут конец файла. После выполнения функции getline() массив, адресуемый параметром buf, будет иметь завершающий нуль-символ. Символ-разделитель (заданный параметром delim), если таковой обнаружится во входном потоке, извлекается, но не помещается в массив buf.
Как видите, эти две версии функции getline() практически идентичны версиям get (buf, num) и get (buf, num, delim) функции get(). Обе считывают символы из входного потока и помещают их в массив, адресуемый параметром buf, до тех пор, пока либо не будет считано num-1 символов, либо не обнаружится символ, заданный параметром delim. Различие между функциями get() и getline() состоит в том, что функция getline() считывает и удаляет символразделитель из входного потока, а функция get() этого не делает.
Функция реек() считывает следующий символ из входного потока, не удаляя его.
Следующий символ из входного потока можно получить и не удалять его из потока с помощью функции реек(). Вот как выглядит ее прототип.
int peek();
Функция peek() возвращает следующий символ потока, или значение EOF, если достигнут конец файла. Считанный символ возвращается в младшем байте значения, возвращаемого функцией. Поэтому значение, возвращаемое функцией реек(), можно присвоить переменной типа char.
Функция putback() возвращает считанный символ во входной поток.
Последний символ, считанный из потока, можно вернуть в поток, используя функцию putback(). Ее прототип выглядит так.
istream &putback(char с);
Здесь параметр с содержит символ, считанный из потока последним.
Функция flush() сбрасывает на диск содержимое файловых буферов.
При выводе данных немедленной их записи на физическое устройство, связанное с потоком, не происходит. Подлежащая выводу информация накапливается во внутреннем буфере до тех пор, пока этот буфер не заполнится целиком. И только тогда его содержимое переписывается на диск. Однако существует возможность немедленной перезаписи на диск хранимой в буфере информации, не дожидаясь его заполнения. Это средство состоит в вызове функции flush(). Ее прототип имеет такой вид.
ostream &flush();
К вызовам функции flush() следует прибегать в случае, если программа предназначена для выполнения в неблагоприятных средах (для которых характерны частые отключения электричества, например).
Произвольный доступ
До сих пор мы использовали файлы, доступ к содержимому которых был организован
строго последовательно, байт за байтом. Но в C++ также можно получать доступ к файлу в произвольном порядке. В этом случае необходимо использовать функции seekg() и seekp(). Вот их прототипы.
istream &seekg(off_type offset, seekdir origin);
ostream &seekp(off_type offset, seekdir origin);
Используемый здесь целочисленный тип off_type (он определен в классе ios) позволяет хранить самое большое допустимое значение, которое может иметь параметр offset. Тип seekdir определен как перечисление, которое имеет следующие значения.
Функция seekg() перемещает указатель, «отвечающий» за ввод данных, а функция seekp() — указатель, «отвечающий» за вывод.
ВС++-системе ввода-вывода предусмотрена возможность управления двумя указателями, связанными с файлом. Эти так называемые cin— и put-указатели определяют, в каком месте файла должна выполниться следующая операция ввода и вывода соответственно. При каждом выполнении операции ввода или вывода соответствующий указатель автоматически перемещается в указанную позицию. Используя функции seekg() и seekp(), можно получать доступ к файлу в произвольном порядке.
Функция seekg() перемещает текущий get-указатель соответствующего файла на offset байт относительно позиции, заданной параметром origin. Функция seekp() перемещает текущий put-указатель соответствующего файла на offset байт относительно позиции, заданной параметром origin.
Вобщем случае произвольный доступ для операций ввода-вывода должен выполняться только для файлов, открытых в двоичном режиме. Преобразования символов, которые могут происходить в текстовых файлах, могут привести к тому, что запрашиваемая позиция файла не будет соответствовать его реальному содержимому.
Вследующей программе демонстрируется использование функции seekp(). Она позволяет задать имя файла в командной строке, а за ним — конкретный байт, который нужно в нем изменить. Программа затем записывает в указанную позицию символ «X». Обратите внимание на то, что обрабатываемый файл должен быть открыт для выполнения операций чтения-записи.
/* Демонстрация произвольного доступа к файлу.
*/
#include <iostream>
#include <fstream>
#include <cstdlib>
using namespace std;
int main(int argc, char *argv[])
{
if(argc!=3) {
cout << «Применение: имя_программы » << «<имя_файла> <байт>n»;
return 1;
}
fstream out(argv[1], ios::in | ios::out | ios::binary);
if(!out) {
cout << «He удается открыть файл.n»;
return 1;
}
out.seekp(atoi(argv[2]), ios::beg);
out.put(‘X’);
out.close();
return 0;
}
В следующей программе показано использование функции seekg(). Она отображает содержимое файла, начиная с позиции, заданной в командной строке.
/* Отображение содержимого файла с заданной стартовой позиции.
*/
#include <iostream>
#include <fstream>
#include <cstdlib>
using namespace std;
int main(int argc, char *argv[])
{
char ch;
if(argc!=3) {
cout << «Применение: имя_программы «<< «<имя_файла> <стартовая_позиция>n»;
return 1;
}
ifstream in(argv[1], ios::in | ios::binary);
if(!in) {
cout << «He удается открыть файл.n»;
return 1;
}
in.seekg(atoi(argv[2]), ios::beg);
while(in.get (ch)) cout << ch;
return 0;
}
Функция tellg() возвращает текущую позицию get-указателя, а функция tellp() — текущую позицию put-указателя.
Текущую позицию каждого файлового указателя можно определить с помощью этих двух функций.
pos_type tellg();
pos_type tellp();
Здесь используется тип pos_type (он определен в классе ios), позволяющий хранить самое большое значение, которое может возвратить любая из этих функций.
Существуют перегруженные версии функций seekg() и seekp(), которые перемещают файловые указатели в позиции, заданные значениями, возвращаемыми функциями tellg() и tellp() соответственно. Вот как выглядят их прототипы,
istream &seekg(pos_type position);
ostream &seekp(pos_type position);
Проверка статуса ввода-вывода
С++-система ввода-вывода поддерживает статусную информацию о результатах выполнения каждой операции ввода-вывода. Текущий статус потока ввода-вывода описывается в объекте типа iostate, который представляет собой перечисление (оно определено в классе ios), включающее следующие члены.
Статусную информацию о результате выполнения операций ввода-вывода можно получать двумя способами. Во-первых, можно вызвать функцию rdstate(), которая является членом класса ios. Она имеет такой прототип.
iostate rdstate();
Функция rdstate() возвращает текущий статус флагов ошибок. Нетрудно догадаться, что, судя по приведенному выше списку флагов, функция rdstate() возвратит значение goodbit при отсутствии каких бы то ни было ошибок. В противном случае она возвращает соответствующий флаг ошибки.
Во-вторых, о наличии ошибки можно узнать с помощью одной или нескольких
следующих функций-членов класса ios.
bool bad();
bool eof();
bool fail();
bool good();
Функция eof() рассматривалась выше. Функция bad() возвращает значение ИСТИНА, если в результате выполнения операции ввода-вывода был установлен флаг badbit. Функция fail() возвращает значение ИСТИНА, если в результате выполнения операции ввода-вывода был установлен флаг failbit. Функция good() возвращает значение ИСТИНА, если при выполнении операции ввода-вывода ошибок не произошло. В противном случае они возвращают значение ЛОЖЬ.
Если при выполнении операции ввода-вывода произошла ошибка, то, возможно, прежде чем продолжать выполнение программы, имеет смысл сбросить флаги ошибок. Для этого используйте функцию clear() (член класса ios), прототип которой выглядит так.
void clear (iostate flags = ios::goodbit);
Если параметр flags равен значению goodbit (оно устанавливается по умолчанию), все флаги ошибок очищаются. В противном случае флаги устанавливаются в соответствии с заданным вами значением.
Прежде чем переходить к следующему разделу, стоит опробовать функции, которые сообщают данные о состоянии флагов ошибок, внеся в предыдущие примеры программ код проверки ошибок.
Использование перегруженных операторов ввода-вывода при работе с файлами
Выше в этой главе вы узнали, как перегружать операторы ввода и вывода для собственных классов, а также как создавать собственные манипуляторы. В приведенных выше примерах программ выполнялись только операции консольного ввода-вывода. Но поскольку все С++-потоки одинаковы, одну и ту же перегруженную функцию вывода данных, например, можно использовать для вывода информации как на экран, так и в файл, не внося при этом никаких существенных изменений. Именно в этом и заключаются основные достоинства С++-системы ввода-вывода.
В следующей программе используется перегруженный (для класса three_d) оператор вывода для записи значений координат в файл threed.
/* Использование перегруженного оператора ввода-вывода для записи объектов класса three_d в файл.
*/
#include <iostream>
#include <fstream>
using namespace std;
class three_d {
int x, y, z; // 3-мерные координаты; они теперь закрыты
public:
three_d(int a, int b, int с) { x = a; у = b; z = c; }
friend ostream &operator<<(ostream &stream, three_d obj); /*
Отображение координат X, Y, Z (оператор вывода для класса three_d). */
};
ostream &operator<<(ostream &stream, three_d obj)
{
stream << obj.x << «, «;
stream << obj.у << «, «;
stream << obj.z << «n»;
return stream; // возвращает поток
}
int main()
{
three_d a(1, 2, 3), b(3, 4, 5), c(5, 6, 7);
ofstream out(«threed»);
if(!out) {
cout << «He удается открыть файл.»;
return 1;
}
out << a << b << c;
out.close();
return 0;
}
Если сравнить эту версию операторной функции вывода данных для класса three_d с той, что была представлена в начале этой главы, можно убедиться в том, что для «настройки» ее на работу с дисковыми файлами никаких изменений вносить не пришлось. Если операторы ввода и вывода определены корректно, они будут успешно работать с любым потоком.
Важно! Прежде чем переходить к следующей главе, не пожалейте времени и поработайте с С++-функциями ввода-вывода. Создайте собственный класс, а затем определите для него операторы ввода и вывода. А еще создайте собственные манипуляторы.
���������� � ���������� ����������� ������� �����/������ ���
����� ���������������� ��������������� ���� ��� �������� �������
������. ����������� �������� �����/������ ���������������
������������� ��� ���������� ����� ���������� ����� ������. ������
� C++ ���������� ������ ������������ ����� �����, ������������
�������������, � ����� ������������ ���� � ����� ����� � ��������
���� �����. ��������, �������� �����/������ ������ ���� �������,
�������, �������� � ������������, ����������� � ������, � �� �����
������� ������. ����� ������� ��� �� ������ ������� ����, ������� �
������������ ������ ���� ����������� �������� ��������������
�������� �����/������ � ��������� ����������� �������� �����/������
������������� � ����������� ����������.
C++ ���������� ���, ����� � ������������ ���� �����������
���������� ����� ���� ����� �� ����������� � �������, ����� �
���������� ����. ������� ������������ �������� ���������� ����, ���
�������� �����/������ ��� C++ ������ �������������� � C++ �
����������� ������ ��� �������, ������� �������� �������
������������. ����������� ����� �������� �����/������ ������������
����� ������� �������� �� ���� �����.
�������� �����/������ ������� ������������� �
���������� �������������� �������������� �������� �
������������������ �������� � �������. ���� � ������ �����
�����/������, �� ��� �������� ���������������� � ������� UNIX, �
������� ����� ����� ��������� �����/������ �������������� �����
������������ ������� ������ ��� ����� ���, ��� ���� ���
������������ ����� � ��������� ������������. ����� ��� ������������
�������� �������� ����������� � ������� ������������ �����
�������������� �������� � ������������� �� �������������� �������.
��������� � ���������� � ������������ ������������� �����
���������� ������� � � ��������� ���� ����������� � ������� ������
�������������� ����� ������� ��� ������ ������� ������. ��������:
put(cerr,"x = "); // cerr - ����� ������ ������ put(cerr,x); put(cerr,"n");
��� ��������� ���������� ��, ����� �� ������� put ����� ����������
��� ������� ���������. ��� ������� ����������� � ���������� ������.
������ ��� ��������� ������������. ���������� �������� << ���������
«��������� �» ���� ����� ������� ������ � ��������� ������������
�������� ��� �������� ����� ����������. ��������:
cerr << "x = " << x << "n";
��� cerr — ����������� ����� ������ ������. �������, ���� x
�������� int �� ��������� 123, �� ���� �������� ���������� �
����������� ����� ������ ������
x = 123
� ������ ����� ������. ����������, ���� X ����������� �������������
������������� ���� complex � ����� �������� (1,2.4), �� �����������
���� �������� ���������� � cerr
x = 1,2.4)
���� ����� ����� ��������� ������, ����� ��� x ����������
�������� <<, � ������������ ����� ���������� �������� << ��� ������
����.
8.2.2 ��������� ����������� ����������
�������� ������ ������������, ����� �������� ��� ��������������,
������� ���� �� ������������� ������� ������. �� ������ < ����������� ��������� ����� ����������� ������ ��� (#6.2).
�������� ������������ ���� ���������� ������������ � �� ����, � ��
�����, �� �����������, ����������� ����� ������������, �����
�������� ����� ���������� �� �������� ������. ����� ����, = �� � ��
������� ����������� (�������������), �� ���� cout=a=b ��������
cout=(a=b).
�������� ������� ������������ �������� < � >, �� ��������
«������» � «������» ��������� ������ ������ � �������� �����, ���
����� �������� �����/������ �� ���� �������� ������� ���������
�����������. ������ �����, «<» ��������� �� ����������� ���������
��� ��� �� «,», � � ����� ���������� ��������� ����� ������:
cout < x , y , z;
��� ����� ���������� �������� ������ ������� ��������� �� �������.
�������� << � >> � ������ ���� ��������� �� ��������, ���
������������ � ��� ������, ��� �� ����� ���������������� � «�» �
«��», � ��������� << ���������� �����, ����� ����� ���� ��
������������ ������ ��� �������������� ��������� � ���� ���������.
��������:
cout << "a*b+c=" << a*b+c << "n";
�����������, ��� ��������� ���������, ������� �������� �������� �
����� ������� ������������, ������ ������������ ����. ��������:
cout << "a^b|c=" << (a^b|c) << "n";
�������� ������ ������ ���� ����� ��������� � ��������� ������:
cout << "a<
8.2.3 ��������������� �����
���� << ����������� ������ ��� ������������������ ������, � ��
����� ���� � �������� ���������� ��� ������ ��� ����� �������
������� � �����������. ������ ����� ���������� ����� ���������
������������� �������, ��������� ������������� ������ ��������� �
���� ������, ������� ������������ ��� ������. �� ������
(��������������) �������� ���������, ������� ���������� �������
������ ��������������.
char* oct(long, int =0); // ������������ ������������� char* dec(long, int =0); // ���������� ������������� char* hex(long, int =0); // ����������������� ������������� char* chr(int, int =0); // ������ char* str(char*, int =0); // ������
���� �� ������ ���� ������� �����, �� ����� ������������� ��������
��� ����������; ����� ����� �������������� ������� ��������
(�����), ������� �����. ��������:
cout << "dec(" << x
<< ") = oct(" << oct(x,6)
<< ") = hex(" << hex(x,4)
<< ")";
���� x==15, �� � ���������� ���������:
dec(15) = oct( 17) = hex( f);
����� ����� ������������ ������ � ����� �������:
char* form(char* format ...); cout<
8.3.3 �������� ������
������ ������ ����, ��� ����������� � ����������� �����,
����������� � ������ ������������ �������� � ����� �������� ��
�����������. ��������� ����� ��������� ����������
�������� cin, cout � cerr, �� ������ (���� �� �� ����) ����������
�� ����� ������� ��� ��� �������� ������. ���, ������, ���������,
������� ��������� ��� �����, �������� ��� ��������� ���������
������, � �������� ������ �� ������:
#include
void error(char* s, char* s2)
{
cerr << s << " " << s2 << "n";
exit(1);
}
main(int argc, char* argv[])
{
if (argc != 3) error("�������� ����� ����������","");
filebuf f1;
if (f1.open(argv[1],input) == 0)
error("�� ���� ������� ������� ����",argv[1]);
istream from(&f1);
filebuf f2;
if (f2.open(argv[2],output) == 0)
error("�� ���� ������� �������� ����",argv[2]);
ostream to(&f2);
char ch;
while (from.get(ch)) to.put(ch);
if (!from.eof() !! to.bad())
error("��������� ����� ��������","");
}
������������������ �������� ��� �������� ostream ��� ������������
����� �� ��, ��� ������������ ��� ����������� �������: (1) �������
��������� ����� (����� ��� �������� ����������� �������� filebuf);
(2) ����� � ���� �������������� ���� (����� ��� ��������
����������� �������� ����� � ������� ������� filebuf::open()); �,
�������, (3) ��������� ��� ostream � filebuf � �������� ���������.
������ ����� �������������� ����������.
���� ����� ����������� � ����� �� ���� ���:
enum open_mode { input, output };
�������� filebuf::open() ���������� 0, ���� �� ����� ������� ���� �
������������ � �����������. ���� ������������ �������� �������
����, �������� �� ���������� ��� output, �� ����� ������.
����� ����������� ��������� ���������, ��������� �� ������ �
���������� ��������� (��.
����� istream ������������ ���:
class istream {
// ...
public:
istream& operator>>(char*); // ������
istream& operator>>(char&); // ������
istream& operator>>(short&);
istream& operator>>(int&);
istream& operator>>(long&);
istream& operator>>(float&);
istream& operator>>(double&);
// ...
};
������� ����� ������������ � ����� ����:
istream& istream::operator>>(char& c);
{
// ���������� ��������
int a;
// ����� ������� ������ ������ � "a"
c = a;
}
������� ������������ ��� ����������� ������� � C, ����� �����
isspase() � ��� ����, ��� ��� ���������� � (������,
���������, ������ ����� ������, ������� ������� � ������� �������).
� �������� ������������ ����� ������������ ������� get():
class istream {
// ...
istream& get(char& c); // char
istream& get(char* p, int n, int ='n'); // ������
};
��� ������������ ������� �������� ��� ��, ��� ��������� �������.
������� istream::get(char) ������ ���� � ��� �� ������ � ����
��������; ������ istream::get ������ �� ����� n �������� � ������
��������, ������������ � p. �������������� ������ ��������
������������ ��� ������� ������� ��������� (�����, ����������� ���
������������), �� ���� ���� ������ �������� �� �����. ���� �����
�������� ������ ������������, �� ��������� ��� ������ ������
������. �� ��������� ������ ������� get ����� ������ ����� �������
n ��������, �� �� ������ ��� ���� ������, ‘n’ ��������
������������� �� ���������. �������������� ������ �������� ������
������, ������� �������� �� �����. ��������:
cin.get(buf,256,'t');
����� ������ � buf �� ����� 256 ��������, � ���� ����������
��������� (‘t’), �� ��� �������� � �������� �� get. � ���� ������
��������� ��������, ������� ����� ������ �� cin, ����� ‘t’.
����������� ������������ ���� ���������� ���������
�������, ������� ����� ��������� ��������� ��� ������������� �����:
int isalpha(char) // 'a'..'z' 'A'..'Z'
int isupper(char) // 'A'..'Z'
int islower(char) // 'a'..'z'
int isdigit(char) // '0'..'9'
int isxdigit(char) // '0'..'9' 'a'..'f' 'A'..'F'
int isspase(char) // ' ' 't' ������� ����� ������
// ������� �������
int iscntrl(char) // ����������� ������
// (ASCII 0..31 � 127)
int ispunct(char) // ����������: ������ �� �����������������
int isalnum(char) // isalpha() | isdigit()
int isprint(char) // ����������: ascii ' '..'-'
int isgraph(char) // isalpha() | isdigit() | ispunct()
int isascii(char c) { return 0<=c &&c<=127; }
��� ����� isascii() ����������� ������ ���������, � �����������
������� � �������� ������� � ������� ��������� ��������. �������
����� ���������, ���
(('a'<=c && c<='z') || ('A'<=c && c<='Z')) // ����������
�� ������ ����������� ������� � ������� �������� (�� ������ �
������� �������� EBCDIC ��� ����� ��������� ������������ �������),
��� ����� � ����� ����������, ��� ���������� ����������� �������:
isalpha(c)
8.4.2 ��������� ������
������ ����� (istream ��� ostream) ����� ��������������� � ���
���������, � ��������� ������ � ������������� �������
�������������� � ������� ��������������� ��������� � �������� �����
���������.
����� ����� ���������� � ����� �� ��������� ���������:
enum stream_state { _good, _eof, _fail, _bad };
���� ��������� _good ��� _eof, ������ ��������� �������� �����
������ �������. ���� ��������� _good, �� ��������� �������� �����
����� ������ �������, � ��������� ������ ��� ���������� ��������.
������� �������, ���������� �������� ����� � ������, ������� ��
��������� � ��������� _good, �������� ������ ���������. ����
�������� ������� ������ � ���������� v, � �������� ������������
��������, �������� v ������ �������� ���������� (��� �����
����������, ���� v ����� ���� �� ��� �����, ������� ��������������
��������� ������� istream ��� ostream). ������� ����� �����������
_fail � _bad ����� ������������� � ������������ ������� ������ ���
������������� �������� �����. � ��������� _fail ��������������, ���
����� �� �������� � ������� ������� �� ��������. � ��������� _bad
����� ���� ��� ��� ������.
��������� ������ ����� ��������� �������� ���:
switch (cin.rdstate()) {
case _good:
// ��������� �������� ��� cin ������ �������
break;
case _eof:
// ����� �����
break;
case _fail:
// ������� ���� ������ ��������������
// ��������, �� ������� ������
break;
case _bad:
// ��������, ������� cin ��������
break;
}
��� ����� ���������� z ����, ��� �������� ���������� �������� <<
� >>, ���������� ���� ����� �������� ���:
while (cin>>z) cout << z << "n";
��������, ���� z — ������ ��������, ���� ���� ����� �����
����������� ���� � �������� ��� � ����������� ����� �� ������ �����
(�� ����, ������������������ �������� ��� �������) �� ������.
����� � �������� ������� ������������ �����, ���������� ��������
��������� ������ � ��� �������� �������� ������� (�� ����,
�������� ������� �� ����) ������ ���� ��������� _good. � ���������,
� ���������� ����� ����������� ��������� istream, �������
���������� cin>>z. ����� ����������, ������ ���� ��� ��������
����������� ��������, ����� ����������� ���������. ����� ��������
������ ����������� ��������� �������������� (
8.4.3 ���� �����, ������������ �������������
���� ��� ����������������� ���� ����� ������������ ����� ��� ��,
��� �����, �� ��� �����������, ��� ��� �������� ����� �����, �����
������ �������� ��� ���������� ����. ��������:
istream& operator>>(istream& s, complex& a)
/*
������� ����� ��� complex; "f" ���������� float:
f
( f )
( f , f )
*/
{
double re = 0, im = 0;
char c = 0;
s >> c;
if (c == '(') {
s >> re >> c;
if (c == ',') s >> im >> c;
if (c != ')') s.clear(_bad); // ���������� state
}
else {
s.putback(c);
s >> re;
}
if (s) a = complex(re,im);
return s;
}
�������� �� ��, ��� �� ������� ���� ��������� ������, �������
����� ����� ������ ��� �� ����� ���� ������������ �����. ���������
���������� c ����������������, ����� �� �������� �� ���������
�������� ‘(‘ ����� ����, ��� �������� ��������� ��������.
����������� �������� ��������� ������ �����������, ��� ��������
��������� a ����� ���������� ������ � ��� ������, ���� ��� ����
������.
�������� ��������� ��������� ������� clear() (��������), ������
��� ��� ���� ����� ������������ ��� ��������� ��������� ������
������ ��� _good. _good �������� ��������� ��������� �� ��������� �
��� istream::clear(), � ��� ostream::clear().
��� ���������� ����� ���� ���������� ���. ���� ��, � ���������,
������������, ���� �� ����� ���� �������� ���� � �������� �������
(��� � ������ ������ � ����), � ����� ���������, ������ �� �������
��� �������� �����. ����� �������� ������ ���� ��, �������,
������������ ��������� �������������� �����������, ����� ��� �����
��������������� ����� ����� � ��� �������� ��������� ����� ���������
������� �������������.
8.4.4 ������������� ������� �����
�����������, ��� istream, ��� �� ��� � ostream, �������
�������������:
class istream {
// ...
istream(streambuf* s, int sk =1, ostream* t =0);
istream(int size, char* p, int sk =1);
istream(int fd, int sk =1, ostream* t =0);
};
�������� sk ������, ������ ������������ �������� ��� ���. ��������
t (��������������) ������ ��������� �� ostream, � ��������
���������� istream. ��������, cin ���������� � cout; ��� ������,
��� ����� ���, ��� ���������� ������ ������� �� ������ �����, cin
���������
cout.flush(); // ����� ����� ������
� ������� ������� istream::tie() ����� ���������� (��� ���������,
� ������� tie(0)) ����� ostream � ������ istream. ��������:
int y_or_n(ostream& to, istream& from)
/*
"to", �������� ������ �� "from"
*/
{
ostream* old = from.tie(&to);
for (;;) {
cout << "�������� Y ��� N: ";
char ch = 0;
if (!cin.get(ch)) return 0;
if (ch != 'n') { // ���������� ������� ������
char ch2 = 0;
while (cin.get(ch2) && ch2 != 'n') ;
}
switch (ch) {
case 'Y':
case 'y':
case 'n':
from.tie(old); // ��������������� ������ tie
return 1;
case 'N':
case 'n':
from.tie(old); // ��������������� ������ tie
return 0;
default:
cout << "��������, ���������� ��� ���: ";
}
}
}
����� ������������ �������������� ���� (��� ��� ���������� ��
���������), ������������ �� ����� ������ ������ ���� ����� �������
�������. ������� ���� ��������� ������� ����� ������. y_or_n()
������� �� ������ ������ ������, � ��������� ����������.
������ ����� ������� � ����� � ������� �������
istream::putback(char). ��� ��������� ��������� «�����������
������» � ����� �����.
8.5 ������ �� ��������
����� ������������ ��������, �������� �����/������, ���
���������� ��������, ���������� � ���� istream ��� ostream.
��������, ���� ������ �������� ������� ������, ������������� �����,
��� ������ ���� �� ����� ������� ����� ������������ �����������
���� ���������� ����:
void word_per_line(char v[], int sz)
/*
������� "v" ������� "sz" �� ������ ����� �� ������
*/
{
istream ist(sz,v); // ������� istream ��� v
char b2[MAX]; // ������ ����������� �����
while (ist>>b2) cout << b2 << "n";
}
����������� ������� ������ � ���� ������ ���������������� ���
������ ����� �����.
� ������� ostream ����� ��������������� ���������, ������� ��
����� �������� ������ ��:
char* p = new char[message_size]; ostream ost(message_size,p); do_something(arguments,ost); display(p);
����� ��������, ��� do_something, ����� ������ � ����� ost,
���������� ost ����� ������������ � �.�. � ������� �����������
�������� ������. ��� ������������� ������ �������� �� ������������,
��������� ost ����� ���� ����� � ����� �� ����� �������������, ��
����� ���������� � ��������� _fail. �, �������, display �����
������ ��������� � «���������» ����� ������. ���� ����� �����
��������� �������� ��������, ����� ����������� � ����������, �
������� ������������� ����������� ������ �������� � ���� �����
����� �������, ��� ������ � ������������ ���������� �����������
������. ��������, ����� �� ost ��� �� ���������� � ���������������
���-�� �� ������ ������� �������������� �������.
8.6 �����������
��� ������� �������� �����/������ �� ����� �� �������� �����
������, �� ���� �� ��� ���������� ����� ������������� ��������� �
����� ������ ��������� �����������. ��������, ��� ostream,
������������� � ���������� ������, ��������� ����������� �������
����, ������ ��� ostream, ������������� � �����. � ����� ����������
����� ����������, ������� ��������� �������� ���� ��� ������
������� � ������ ������������� (�������� �������� �� ���
������������ ������ ostream). ���� ������ ���� ����� �������� ���
����� ��������� ������, ������� � �������� ostream ��� ����, ��
������������. ������ �������, ������� ������������ ������������
������ � �����, �����������. ����� ����������, ����� ����������� �
����������� � ������ ����� ���������� �����������. ��� ����� ������
������� �������� ���������� ����������� ������� ��� ����, �����
������� ��������� ���������� ��������� ��������� �������������
������� � ��������� �����������. �������� ������ ������ �
�������� ���:
struct streambuf { // ���������� ������� ������
char* base; // ������ ������
char* pptr; // ��������� ��������� char
char* qptr; // ��������� ����������� char
char* eptr; // ���� �� ������ ������
char alloc; // �����, ���������� � ������� new
// ���������� �����:
// ���������� EOF ��� ������ � 0 � ������ ������
virtual int overflow(int c =EOF);
// ��������� �����
// ��������� EOF ��� ������ ��� ����� �����,
// ����� ��������� char
virtual int underflow();
int snextc() // ����� ��������� char
{
return (++qptr==pptr) ? underflow() : *qptr&0377;
}
// ...
int allocate() // �������� ��������� ������������ ������
streambuf() { /* ... */}
streambuf(char* p, int l) { /* ... */}
~streambuf() { /* ... */}
};
�������� ��������, ��� ����� ������������ ���������, �����������
��� ������ � �������, ������� ������� ������������ �������� �����
���������� (������ ���� ���) � ���� ����������� ����������� inline-
�������. ��� ������ ���������� ��������� ����������� ����������
���������� ������ ������� ������������ overflow() � underflow().
��������:
struct filebuf : public streambuf {
int fd; // ���������� �����
char opened; // ���� ������
int overflow(int c =EOF);
int underflow();
// ...
// ��������� ����:
// ���� �� �����������, �� ���������� 0,
// � ������ ������ ���������� "this"
filebuf* open(char *name, open_mode om);
int close() { /* ... */ }
filebuf() { opened = 0; }
filebuf(int nfd) { /* ... */ }
filebuf(int nfd, char* p, int l) : (p,l) { /* ... */ }
~filebuf() { close(); }
};
int filebuf::underflow() // ��������� ����� �� fd
{
if (!opened || allocate()==EOF) return EOF;
int count = read(fd, base, eptr-base);
if (count < 1) return EOF;
qptr = base;
pptr = base + count;
return *qptr & 0377;
}