11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна

- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности

Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
Здесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:

- Средняя из внутригрупповых дисперсий

- Средняя ошибка выборки:

С вероятностью 0,954 находим предельную ошибку выборки:

- Доверительные границы для среднего значения признака в генеральной совокупности:

Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно

- Значение среднего квадратического отклонения составляет

- Средняя ошибка выборки:

- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:

- Доверительный интервал для среднего значения признака в генеральной совокупности:

То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
Ошибка
выборки
![]() (илиошибка
(илиошибка
репрезентативности)
представляет собой разность соответствующих
выборочных и генеральных характеристик:
–
для средней
количественного признака
![]()
–
для доли
(альтернативного признака)
![]()
Ошибка
выборки свойственна только выборочным
наблюдениям. Чем больше значение этой
ошибки, тем в большей степени выборочные
показатели отличаются от соответствующих
генеральных показателей.
3.1.2. Средние ошибки выборки.
Выборочная
средняя и выборочная доля по своей сути
являются случайными
величинами,
которые могут принимать различные
значения в зависимости от того, какие
единицы совокупности попали в выборку.
Следовательно, ошибки выборки также
являются случайными величинами и могут
принимать различные значения. Поэтому
принимают среднюю их возможных ошибок
– среднюю
ошибку выборки,
которая зависит:
а)
от объема
выборки: чем
больше численность при прочих равных
условиях, тем меньше величина средней
ошибки выборки;
б)
от степени
варьирования
(которая, как известно, характеризуется
дисперсией
![]()
или w(1-w)
– для доли): чем меньше вариация признака,
а следовательно, и дисперсия, тем меньше
средняя ошибка выборки, и наоборот.
Средние
теоретические ошибки
(при случайном повторном отборе):
–
для средней
количественного признака
![]() ;
;
–
для доли
(альтернативного признака)
![]()
Поскольку
практически дисперсия признака в
генеральной совокупности
![]() точно неизвестна, на практике пользуются
точно неизвестна, на практике пользуются
значением дисперсии![]() ,
,
рассчитанным на основании закона больших
чисел, согласно которому выборочная
совокупность при достаточно большом
объеме выборки достаточно точно
воспроизводит характеристики генеральной
совокупности.
Таким образом, расчетные
формулы средней ошибки выборки будут
следующие.
При
повторном
отборе
–
для средней
количественного признака
![]() ;
;
–
для доли
(альтернативного признака)
![]() .
.
При
бесповторном
отборе
–
для средней
количественного признака
![]() ;
;
– для
доли (альтернативного признака)
![]() .
.
Так
как n всегда
меньше N,
то множитель (1 – n
/N) всегда
будет меньше единицы, т.е. средняя ошибка
при бесповторном отборе всегда будет
меньше, чем при повторном.
Учитывая,
что генеральная дисперсия выражается
через выборочную соотношением
![]() ,
,
формула для средней
ошибки малой выборки будет
следующая:
![]()
3.1.3. Распространение выборочных результатов на генеральную совокупность.
Конечной
целью выборочного наблюдения является
характеристика генеральной совокупности
на основе выборочных результатов.
Выборочные оценки отличаются от
генеральных за счет ошибки наблюдения
и ошибки выборки:
|
Выборочная оценка |
= |
Генеральный параметр |
|
Ошибка наблюдения |
|
Ошибка выборки |
Выборочные
средние и относительные величины
распространяют на генеральную совокупность
с учетом предела их возможной ошибки.
В каждой конкретной выборке расхождение
между выборочной средней и генеральной,
т.е.
![]() может быть меньше средней ошибки выборки
может быть меньше средней ошибки выборки![]() ,
,
равно ей или больше ее. Причем каждое
из этих расхождений имеет различнуювероятность.
Поэтому
фактическое расхождение
![]() можно рассматривать как некую предельную
можно рассматривать как некую предельную
ошибку, связанную со средней ошибкой и
гарантируемую с определенной вероятностьюP.
Таким
образом, предельная
ошибка выборки
![]()
есть
отклонение выборочной средней от
генеральной средней (причем принимается
определенный уровень вероятности
суждения о точности данной выборки;
вероятность, которая принимается при
расчете ошибки выборочной характеристики,
называется доверительной).
Формулы
для вычисления предельной
ошибки выборки
следующие:
При
повторном
отборе
–
для средней
![]() ;
;
–
для доли
![]() .
.
При
бесповторном
отборе
–
для средней
![]() ;
;
–
для доли
![]() ,
,
где
t
– нормированное отклонение («коэффициент
доверия»),
зависящее от вероятности, с которой
гарантируется предельная ошибка выборки:
![]() ,
,
(![]() ).
).
Вероятность, которая принимается при
расчете ошибки выборочной характеристики,
называется доверительной.
Предельная
ошибка выборки отвечает на вопрос о
точности выборки с определенной
вероятностью, значение которой
определяется кооэффициентом t.
Наиболее
часто применяемые значения t
следующие (для выборок объема n
> 30):
|
P |
0.683 68.3% |
0.950 95% |
0.954 95.4% |
0.990 99% |
0.997 99.7 |
|
t |
1 |
1.960 |
2 |
2.580 |
3 |
Таким
образом, если t
= 1, предельная ошибка составит
![]() =
=![]() .
.
Следовательно, можно утверждать, что с
вероятностью 0,683 (т.е. в 68.3% случаев)
ошибка репрезентативности не выйдет
за пределы![]() (другими словами, разность между
(другими словами, разность между
выборочными и генеральными показателями
не превысит одной средней ошибок
выборки). Приt
= 2 с вероятностью 0.954 она не выйдет за
пределы
![]() ,t
,t
= 3 с вероятностью 0.997 – за пределы
![]() и т.д.
и т.д.
Заметим,
вероятность появления ошибки, равной
или большей утроенной средней ошибки
выборки, т.е.
![]() ,
,
крайне мала:P
= 1 – 0.997 = 0.003. Такие маловероятные события
считаются практически невозможными,
поэтому величину
![]() = 3
= 3![]() можно принять запредел
можно принять запредел
возможной ошибки выборки.
Предельная
ошибка выборки позволяет определить
предельные
значения характеристик генеральной
совокупности,
т.е. те значения генеральных характеристик,
за пределы которых с заданной вероятностью
значения исследуемых величин выйти не
могут, и их доверительные
интервалы.
Предельные
значения характеристик генеральной
совокупности:
–
для генеральной
средней:
![]() или
или![]() ;
;
–
для генеральной
доли:
![]() или
или![]() .
.
Доверительные
интервалы:
–
для средней:
![]() ;
;![]() ;
;
–
для доли:
![]() ;
;![]() .
.
Это
означает, в частности, что с заданной
вероятностью можно утверждать, что
значение генеральной средней следует
ожидать в пределах от
![]() до
до![]() .
.
Наряду
с абсолютным значением предельной
ошибки выборки рассчитывается и
предельная
относительная ошибка выборки:
–
для средней,
%:
![]() ;
;
–
для доли,
%:
![]() .
.
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ().
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
— при оценивании среднего значения признака;
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
— для среднего значения признака;
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки () равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Таблица
11.2.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:
Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Таблица
11.3.
Формулы для расчета средней ошибки собственно случайной и механической выборки ()
|
|
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
Таблица
11.4.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
Таблица
11.5.
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя
Выборочная дисперсия изучаемого признака
- Определяем среднюю ошибку повторной случайной выборки
- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности
Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле
Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:
Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:
Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
;
- средняя ошибка выборки при использовании повторной схемы отбора составит
Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит
- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):
- установим границы для генеральной доли с вероятностью 0,997:
Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Таблица
11.6.
Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп
Здесь — средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Таблица
11.7.
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:
аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:
Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле
Предельная ошибка малой выборки:
Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:
То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Таблица
11.8.
Формулы для определения численности выборочной совокупности
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить
При бесповторном случайном отборе потребуется проверить
Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.
Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Содержание:
Математическая статистика возникла (XVII в.) и создавалась параллельно с теорией вероятностей. Дальнейшее развитие математической статистики (вторая половина ХІХ и начало ХХ вв.) обязано, в первую очередь, П.Л.Чебышеву, А.А.Маркову, А.М.Ляпунову, а также К.Гауссу, А.Кетле, К.Пирсону и др. В ХХ в. наиболее существенный вклад в математическую статистику был сделан советскими математиками (В.И.Романовский, А.Н.Колмогоров и др.), а также английскими (Стьюдент, Р.Фишер, Э.Пирсон) и американскими (Ю.Нейман,
А.Вальд) учёными.
Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении статистических данных – результатах наблюдений, то есть основу исследований в математической статистике составляют данные наблюдений или опытов над случайными величинами.
Первая задача математической статистики – указать способы сбора и группировки (если данных
очень много) статистических сведений, в том числе определение объёма необходимых экспериментов до начала и в ходе исследования. Вторая задача математической статистики – разработать методы анализа статистических данных, в зависимости от целей исследования.
Изучение тех или иных явлений методами математической статистики служит средством решения многих вопросов, выдвигаемых наукой и практикой (правильная организация технологического процесса, наиболее целесообразное планирование и др.). Итак, задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводов.
Генеральная и выборочная совокупности
Пусть требуется изучить совокупность однородных объектов относительно некоторого качественного или количественного признака, характеризующего эти объекты. Например, если имеется партия деталей, то качественным признаком может служить стандартность детали, а количественным – контролируемый размер детали. Иногда проводят сплошное обследование, то есть обследуют каждый из
объектов совокупности относительно признака, которым интересуются. На практике, однако, сплошное обследование применяется сравнительно редко. Например, если совокупность содержит очень большое число объектов, то провести сплошное обследование физически невозможно. Если обследование объекта связано с его уничтожением или требует больших материальных затрат, то проводить сплошное обследование практически не имеет смысла. В таких случаях случайно отбирают из всей совокупности ограниченное число объектов и
подвергают их изучению.
Выборочной совокупностью, или просто выборкой, называют совокупность случайно отобранных объектов.
Генеральной совокупностью называют совокупность объектов, из которых производится выборка.
Объёмом совокупности (выборочной или генеральной) называют число объектов этой совокупности.

Например, если из 1000 деталей отобрано для обследования 100 деталей, то объём генеральной совокупности N = 1 000, а объём выборки n = 100. Часто генеральная совокупность содержит конечное число объектов. Однако, если это число достаточно велико, то иногда в целях упрощения
вычислений, или для облегчения теоретических выводов, допускают, что генеральная совокупность состоит из бесчисленного множества объектов. Такое допущение оправдывается тем, что увеличение объёма генеральной совокупности (достаточно большого объёма) практически не сказывается на результатах обработки данных выборки. При этом, что важно, для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем нас признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли. Это требование коротко формулируют так: выборка должна быть репрезентативной (представительной). В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если её осуществить случайно: каждый объект выборки отобран случайно из генеральной совокупности, при этом все объекты имеют одинаковую вероятность попасть в выборку.
При составлении выборки можно поступать двояко: после того, как объект отобран и над ним произведено наблюдение, он может быть возвращён, либо не возвращён в генеральную совокупность. В соответствии с этим, выборки подразделяют на повторные и бесповторные. Повторной называют выборку, при которой отобранный объект (перед отбором следующего) возвращается в генеральную совокупность. Бесповторной называют выборку, при которой отобранный объект в генеральную совокупность не возвращается. Если объём генеральной совокупности достаточно велик, а выборка составляет лишь незначительную часть этой совокупности, то различие между повторной и бесповторной выборкам стирается; в предельном случае, когда рассматривается бесконечная генеральная совокупность, а выборка имеет конечный объём, это различие исчезает.
На практике применяются различные способы отбора. Принципиально эти способы можно подразделить на два вида:
1. Отбор, не требующий расчленения генеральной совокупности на части. Сюда относится, так называемый, простой случайный отбор (как повторный, так и бесповторный), то есть отбор, при котором объекты извлекают по одному из всей генеральной совокупности.
2. Отбор, при котором генеральная совокупность разбивается на части. Сюда относятся:
- — типический отбор – отбор, при котором объекты отбираются не из всей генеральной совокупности, а из каждой её «типической» части (например, если детали изготавливают на нескольких станках, то отбор производят не из всей совокупности деталей, произведённых всеми станками, а из продукции каждого станка в отдельности);
- — механический отбор – отбор, при котором генеральная совокупность «механически» делится на столько групп, сколько объектов должно войти в выборку, и затем из каждой группы отбирается один объект (например, если нужно отобрать 20% изготовленных станком деталей, то отбирают каждую пятую деталь; если требуется отобрать 5% деталей, то отбирают каждую двадцатую деталь и т. д.);
- — серийный отбор – отбор, при котором объекты отбирают из генеральной совокупности не по одному, а «сериями», которые подвергаются сплошному обследованию. Например, если изделия изготавливаются большой группой станков-автоматов, то подвергают сплошному обследованию продукцию только нескольких станков.
Заметим, что серийным отбором пользуются тогда, когда обследуемый признак колеблется в различных сериях незначительно.
Статистическое распределение выборки
В результате статистической обработки материалов можно подсчитать число единиц, обладающих конкретным значением того или иного признака. Каждое отдельное значение признака будем обозначать 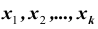
Если при изучении результатов выборки отдельные значения признака (варианты) расположим в возрастающем или убывающем порядке и относительно каждой варианты укажем, как часто она встречается в данной совокупности, тополучим статистическое распределение признака, или вариационный ряд. Он характеризует изменение (варьирование) какого-нибудь количественного признака. Следовательно, вариационный ряд представляет собой две строки (или колонки). В одной из них приводятся варианты, в другой – частоты.
Вариация признака может быть дискретной и непрерывной:
- Дискретной называется вариация, при которой отдельные значения признака (варианты) отличаются друг от друга на некоторую конечную величину (обычно целое число). Например: количество детей в семье; оценки, полученные студентами на экзамене; размеры обуви, проданной магазином за день. Если число элементов вариационного ряда велико, то для удобства его изучения образуют интервальный ряд, группируя значения в интервалы. Для интервального ряда частота i m равна числу значений, наблюдавшихся в i -ом интервале. Длина интервала чаще всего берётся одинаковой.
- Непрерывной называется вариация, при которой значения признака могут отличаться одно от другого на сколь угодно малую величину. Например: уровень рентабельности предприятия; процент занятости трудоспособного населения; депозитная ставка коммерческих банков. При непрерывной вариации распределение признака называется интервальным. Частоты относятся не к отдельному значению признака, а ко всему интервалу. Часто значением интервала принимают его середину, то есть центральное значение.
Нередко вместо абсолютных значений частот используют относительные. Для этого можно использовать долю частоты того или иного варианта (а также интервала) в сумме всех частот. Такая величина называется относительной частотой и обозначается w . Для получения относительных частот необходимо соответствующую частоту разделить на сумму всех частот:
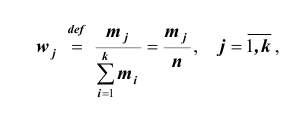 где
где 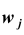 — относительная частота j -ой варианты или интервала
— относительная частота j -ой варианты или интервала 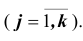 . Сумма
. Сумма
всех относительных частот равна единице: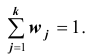 Относительные частоты можно выражать и в процентах, тогда их сумма равна 100%.
Относительные частоты можно выражать и в процентах, тогда их сумма равна 100%.
В интервальном вариационном ряду в каждом интервале различают нижнюю и верхнюю границы интервала: нижняя граница интервала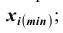 ; верхняя граница интервала
; верхняя граница интервала 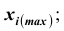 ; величина интервала
; величина интервала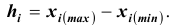 . Как правило, при построении интервальных вариационных рядов в каждый интервал включаются варианты, числовые значения которых больше нижней границы и меньше или равны верхней границе. Интервальные вариационные ряды бывают с одинаковыми и неодинаковыми интервалами. В последнем случае чаще всего встречаются
. Как правило, при построении интервальных вариационных рядов в каждый интервал включаются варианты, числовые значения которых больше нижней границы и меньше или равны верхней границе. Интервальные вариационные ряды бывают с одинаковыми и неодинаковыми интервалами. В последнем случае чаще всего встречаются
последовательно увеличивающиеся интервалы. Для выбора оптимальной величины интервала, то есть такой величины, при которой вариационный ряд не будет громоздким и, при этом, будут сохранены все особенности данного явления, можно рекомендовать формулу:
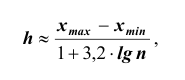 где n – число единиц в совокупности. Так, если в совокупности 200 единиц, наибольший вариант равен 49,961,
где n – число единиц в совокупности. Так, если в совокупности 200 единиц, наибольший вариант равен 49,961,
а наименьший – 49,918, то 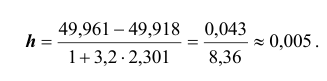
Другими словами, в данном случае оптимальной величиной интервала может служить 0,005.
Гистограмма и полигон статистических распределений
Для наглядности представления вариационного ряда большое значение имеют его графические изображения. Графически вариационный ряд может быть изображён в виде полигона, гистограммы и кумуляты. Полигон распределения (дословно – многоугольник распределения) называют ломанную, которая строится в прямоугольной системе координат. Величина признака 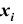 откладывается на оси абсцисс, соответствующие частоты
откладывается на оси абсцисс, соответствующие частоты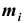 (или относительные частоты
(или относительные частоты 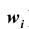 ) – по оси ординат. Точки
) – по оси ординат. Точки 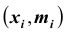
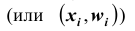 соединяют отрезками прямых и получают полигон распределения. Чаще всего полигоны применяются для изображения дискретных вариационных рядов, но их
соединяют отрезками прямых и получают полигон распределения. Чаще всего полигоны применяются для изображения дискретных вариационных рядов, но их
можно применять также и для интервальных рядов. В этом случае на оси абсцисс откладываются точки, соответствующие серединам данных интервалов. Гистограммой распределения называют ступенчатую фигуру , состоящую из прямоугольников, основанием которых служат частичные интервалы длиною h, а высоты пропорциональны частотам (или относительным частотам) и равны
, состоящую из прямоугольников, основанием которых служат частичные интервалы длиною h, а высоты пропорциональны частотам (или относительным частотам) и равны 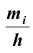 плотность частоты (или
плотность частоты (или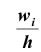 – плотность относительной частоты). Для построения гистограммы на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии
– плотность относительной частоты). Для построения гистограммы на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии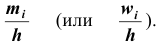 Заметим, что площадь гистограммы частот (относительных частот) равна сумме всех частот (относительных частот), то есть, равна объему выборки (то есть – единице).
Заметим, что площадь гистограммы частот (относительных частот) равна сумме всех частот (относительных частот), то есть, равна объему выборки (то есть – единице).
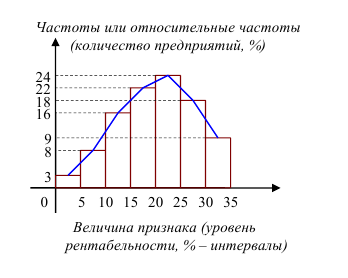
Пример №1
Уровень рентабельности предприятий лёгкой промышленности характеризуется следующими данными:
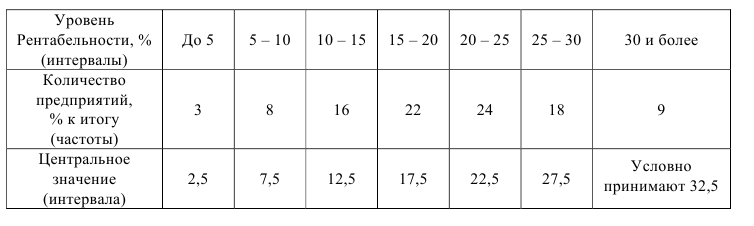
По приведённым данным построить полигон распределения и гистограмму.
Решение. Воспользовавшись определениями, нетрудно построить полигон распределения и гистограмму (см. рис.)
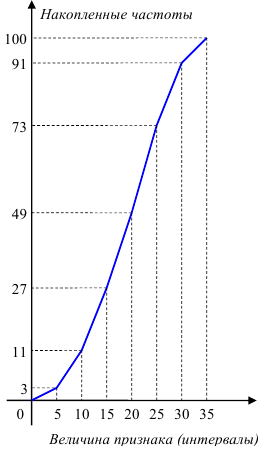
Кумулятивная кривая (кривая сумм – кумулята) получается при изображении вариационного ряда с накопленными частотами (или относительными частотами) в прямоугольной системе координат. Накопленная частота (или относительная частота) определённой варианты получается суммированием всех частот (относительных частот) вариант, предшествующих данной, с частотой (относительной частотой) этой варианты. При построении кумуляты дискретного признака по оси абсцисс откладывают значения признака (варианты). Ординатами
служат вертикальные отрезки, длина которых пропорциональна накопленной частоте (или относительной частоте) той или иной варианты. Соединением вершин ординат прямыми линиями получаем ломанную (кривую) кумуляту. При построении кумуляты интервального вариационного ряда нижней границе первого интервала соответствует частота (относительная частота), равная нулю, а верхней – вся частота (относительная частота) интервала. Верхней границе второго интервала соответствует накопленная частота (относительная частота) первых двух интервалов (то есть сумма частот (относительных частот) этих интервалов) и т. д.
Пример №2
По данным примера 1 построить кумуляту распределения.
Решение. Воспользовавшись определением и правилом построения кумуляты интервального вариационного ряда, нетрудно построить кумулятивную кривую данного распределения (см. рисунок).
Пример №3
В результате эксперимента получены следующие значения случайной величины X:
3; 6; 8; 11; 6; 10; 7; 9; 7; 3; 4; 8;
7; 9; 4; 9; 11; 7; 8; 4; 10; 5; 6; 7; 2.
Требуется:
а) составить статистический ряд;
б) построить статистическое распределение;
в) изобразить полигон распределения.
Решение. а) Объем выборки n = 25.
Построим статистический ряд данной выборки: в первой строке таблицы укажем все различные значения, принимаемые случайной величиной X; во второй строке укажем, сколько раз она приняла эти значения.

б) Найдем статистическое распределение случайной величины X, для чего в табл. 7.2 заменим вторую строку строкой, содержащей относительные частоты 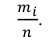

Контроль:
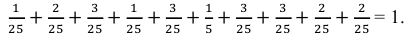
в) На плоскости  построим точки:
построим точки:
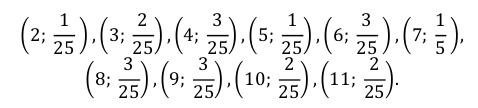
Соединим их (рис. 7.3). Полученная ломаная – полигон данного распределения.
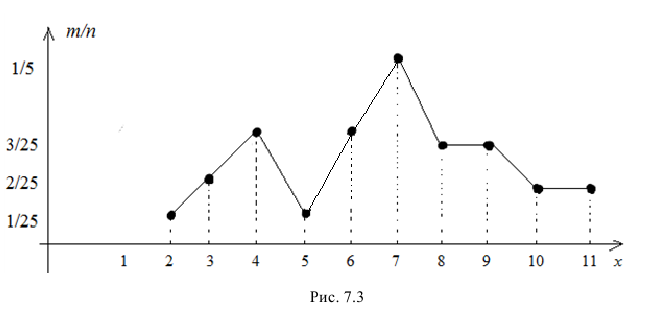
Ответ: а) табл. 7.2, б) табл. 7.3, в) рис. 7.3.
Пример №4
В результате эксперимента получены следующие значения случайной величины X:
16; 17; 9; 13; 21; 11; 7; 7; 19; 5; 17; 5; 20;
18; 11; 4; 6; 22; 21; 15; 15; 23; 19; 25; 1.
Требуется:
а) построить интервальный статистический ряд, разбив промежуток [0; 25] на 5 промежутков равной длины;
б) построить гистограмму относительных частот.
Решение.
а) Объем выборки n = 25. По экспериментальным данным составим таблицу (табл. 7.4). В её первой строке укажем промежутки разбиения: [0; 5), [5; 10), [10; 15), [15; 20) [20; 25].
Во второй строке укажем соответствующие числа  − сколько раз случайная величина X приняла значение из этого промежутка.
− сколько раз случайная величина X приняла значение из этого промежутка.

Контроль: 2 + 6 + 3 + 8 + 6 = 25.
По табл. 7.4 составим интервальный статистический ряд, где во второй строке указаны относительные частоты (табл. 7.5).

б) На оси Ox отложим промежутки:
[0; 5), [5; 10), [10; 15), [15; 20) [20; 25]
интервального статистического ряда, а на оси  – относительные частоты. Построив по этим данным прямоугольники с основаниями
– относительные частоты. Построив по этим данным прямоугольники с основаниями 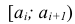 и высотами
и высотами 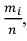 получим ступенчатую фигуру – гистограмму (рис.7.4)
получим ступенчатую фигуру – гистограмму (рис.7.4)
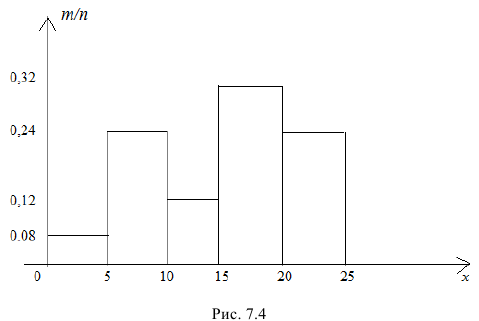
Ответ: а) табл. 7.4; б) рис. 7.5.
Пример №5
Дан статистический ряд

Найти статистическую функцию распределения и построить её график.
Решение. Воспользовавшись формулой
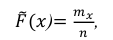
где n – объем выборки; 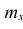 – число выборочных значений, меньших x, вычисляем:
– число выборочных значений, меньших x, вычисляем:
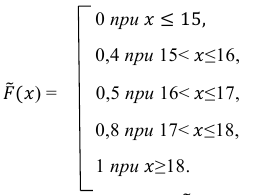 (1)
(1)
Построим график функции 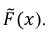
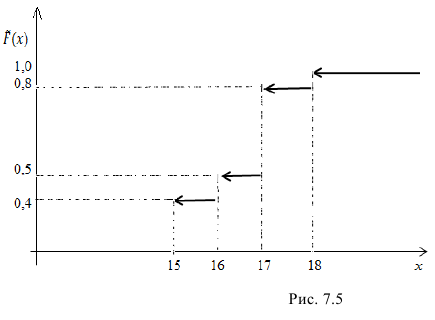
Ответ: а) формула (1); б) рис. 7.5.
Числовые характеристики выборки
В качестве одной из важнейших характеристик вариационного ряда применяют среднюю величину. Математическая статистика различает несколько типов средних величин: арифметическую, геометрическую, гармоническую, квадратическую, кубическую и др. Все перечисленные типы средних могут быть рассчитаны для случаев, когда каждая из вариант вариационного ряда встречается только один раз (тогда средняя называется простой, или невзвешенной) и когда варианты или интервалы повторяются. При этом число повторений вариант или интервалов называют частотой, или статистическим весом, а среднюю, вычисленную с учётом статистического веса, – взвешенной средней.
Для характеристики вариационного ряда один из перечисленных типов средних выбирается не произвольно, а в зависимости от особенностей изучаемого явления и цели, для которой среднее вычисляется.
Практически при выборе того или иного типа средней следует исходить из принципа осмысленности результата при суммировании или при взвешивании. Только тогда средняя применена правильно, когда в результате взвешивания или суммирования получаются величины, имеющие реальный смысл.
Обычно затруднения при выборе типа средней возникают лишь в использовании средней арифметической, или гармонической. Что же касается геометрической и квадратической средних, то их применение обусловлено особыми случаями (см. далее).
Следует иметь в виду, что средняя только в том случае является обобщающей характеристикой, если она применяется к однородной совокупности. В случае использования средней для неоднородных совокупностей можно прийти к неверным выводам. Научной основой статистического анализа является метод статистических группировок, то есть расчленения совокупности на качественно однородные группы.
Все указанные типы средних величин можно получить из формул степенной средней. Если имеются варианты 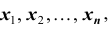 , то среднюю из данных вариант можно рассчитать по формуле простой невзвешенной степенной средней порядка
, то среднюю из данных вариант можно рассчитать по формуле простой невзвешенной степенной средней порядка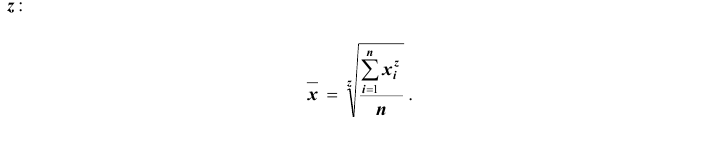
При наличии соответствующих частот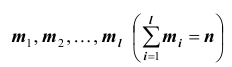 средняя рассчитывается по формуле взвешенной степенной средней:
средняя рассчитывается по формуле взвешенной степенной средней:
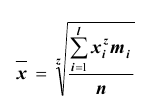 Здесь
Здесь 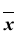 – степенная средняя;
– степенная средняя; 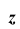 – показатель степени, определяющий тип средней;
– показатель степени, определяющий тип средней;
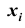 – варианты;
– варианты; 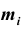 – частоты или статистические веса вариантов.
– частоты или статистические веса вариантов.
Средняя арифметическая получается из формулы степенной средней при
подстановке значения 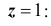
Средняя гармоническая получается при подстановке в формулу степенной средней значения 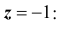
Средняя гармоническая вычисляется тогда, когда средняя предназначается для расчёта сумм слагаемых, обратно пропорциональных величине данного признака, то есть, когда суммированию подлежат не сами варианты, а обратные им величины 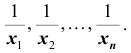
Средняя квадратическая получается из формулы степенной средней при подстановке
Средняя квадратическая используется только тогда, когда варианты представляют собой отклонения фактических величин от их средней
арифметической или от заданной нормы.
Средняя геометрическая получается из формулы степенной средней при предельном переходе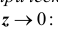
Вычисления средней геометрической в значительной мере упрощаются, если воспользоваться логарифмированием. В этом случае получаем:
Таким образом, логарифм средней геометрической есть средняя арифметическая из логарифмов вариант. Средняя геометрическая используется главным образом при изучении динамики. Средние коэффициенты и темпы роста также рассчитывают по формулам средней геометрической. Если вычислить различные типы средних для одного и того же вариационного ряда, то числовые их значения будут различаться. При этом средние по своей величине расположатся в определённом порядке. Наименьшей из перечисленных средних окажется средняя гармоническая, затем геометрическая и т. д., наибольшей будет средняя квадратическая. При этом порядок возрастания средних определяется показателем степени z в формуле степенной средней. Так, при z =1 получаем среднюю гармоническую, при z =0 – геометрическую, при z =1 – арифметическую, при z = 2 – квадратическую:
В качестве характеристики вариационного ряда используют медиану , то есть такое значение варьирующего признака, которое приходится на середину упорядоченного вариационного ряда. Если в вариационном ряду 2m +1 случаев, то значение признака у случая m +1 будет медианным. Если в ряду чётное число 2m случаев, то медиана равна средней арифметической из двух серединных значений.
, то есть такое значение варьирующего признака, которое приходится на середину упорядоченного вариационного ряда. Если в вариационном ряду 2m +1 случаев, то значение признака у случая m +1 будет медианным. Если в ряду чётное число 2m случаев, то медиана равна средней арифметической из двух серединных значений.
Таким образом, медиана рассчитывается по формуле
При расчёте медианы интервального вариационного ряда сначала находят интервал, содержащий медиану, путём использования накопленных частот (или относительных частот). Медианному интервалу соответствует первая из накопленных частот (или относительных частот), превышающая половину всего объёма совокупности. Для нахождения медианы при постоянстве плотности внутри интервала, содержащего медиану, используют формулу:
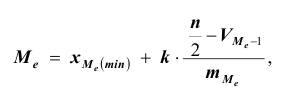 где
где  нижняя граница медианного интервала; k – величина медианного интервала;
нижняя граница медианного интервала; k – величина медианного интервала;  – накопленная частота интервала, предшествующая медианному;
– накопленная частота интервала, предшествующая медианному;  – частота медианного интервала.
– частота медианного интервала.
Медиану можно также определить графически – по кумуляте. Для этого последнюю ординату, пропорциональную суме всех частот (или относительных частот), делят пополам. Из полученной точки восстанавливают перпендикуляр до пересечения с кумулятой. Абсцисса точки пересечения – значение медианы.
Медиана обладает таким свойством: сумма абсолютных величин отклонений вариантов от медианы меньше, чем от любой другой величины (в том числе и от средней арифметической). Другими словами:
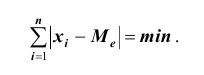
Это свойство медианы можно использовать при проектировании расположения трамвайных и троллейбусных остановок, бензоколонок и т. д.
Пример №6
На шоссе 100км имеется 10 гаражей. Для проектирования строительства бензоколонки были собраны данные о числе предполагаемых поездок на заправку с каждого гаража. Результаты обследования приведены в следующей таблице:

Бензоколонку нужно поставить так, чтобы общий пробег машин на заправку был наименьшим.
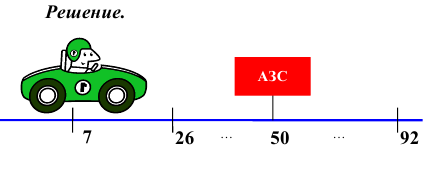
1-й способ:
Если бензоколонку поставить на середине шоссе, то есть на 50-м километре (средняя арифметическая), то пробеги с учётом числа поездок составят
— в одном направлении:
(50-7)-10 +(50-26)-15+ (50-28)-5+ (50-37)-20 +(50-40)-5 +(50-46)-25 = 1310 км;
— в противоположном:
(60 — 50)-15 + (78 — 50)- 30 + (86 — 50)-10 + (92-50)- 65 = 4080 км .
Общий пробег в оба направления окажется равным 5390 км.
2-й способ:
Уменьшения пробега можно достичь, если бензоколонку поставить на 63,85-м километре, то есть на среднем участке шоссе с учётом числа поездок (средняя арифметическая взвешенная). В этом случае пробеги составят по 2475,75 км в оба направления. Таким образом, общий пробег составит 4951,5 км и окажется меньше, чем в первом способе решения, на 438,5 км.
3-й способ:
Наилучший результат, то есть минимальный общий пробег, получим, если поставить бензоколонку на 78-м километре, что будет соответствовать медиане. Заметим, что медиана вычислена по формуле: 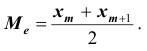 При этом вариационный ряд записываем в виде
При этом вариационный ряд записываем в виде
Следовательно 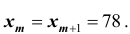 Тогда пробеги составят 3820 км и 990 км
Тогда пробеги составят 3820 км и 990 км
соответственно. Общий пробег, в этом случае, равен 4810 км, то есть он оказался меньше общих пробегов, рассчитанных в предыдущих способах. Модой 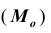 называется варианта, наиболее часто встречающаяся в данном вариационном ряду. Для дискретного ряда мода, являющаяся характеристикой вариационного ряда, определяется по частотам вариант и соответствует варианте с наибольшей частотой. В случае интервального распределения с равными интервалами, модальный интервал (то есть интервал, содержащий моду) определяется по наибольшей частоте, а при неравных интервалах – по наибольшей плотности. Мода рассчитывается по формуле:
называется варианта, наиболее часто встречающаяся в данном вариационном ряду. Для дискретного ряда мода, являющаяся характеристикой вариационного ряда, определяется по частотам вариант и соответствует варианте с наибольшей частотой. В случае интервального распределения с равными интервалами, модальный интервал (то есть интервал, содержащий моду) определяется по наибольшей частоте, а при неравных интервалах – по наибольшей плотности. Мода рассчитывается по формуле:

где 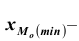 – нижняя граница модального интервала; k – величина модального интервала;
– нижняя граница модального интервала; k – величина модального интервала; 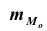 – частота модального интервала;
– частота модального интервала; 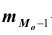 – частота интервала, предшествующего модальному;
– частота интервала, предшествующего модальному;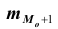 – частота интервала, следующего за модальным.
– частота интервала, следующего за модальным.
Вариационные ряды, в которых частоты вариант, равноотстоящих от средней, равны между собой, называются симметричными. Особенность симметричны вариационных рядов состоит в равенстве трёх характеристик – средней арифметической, моды и медианы, то есть:
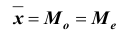
(это необходимое, но не достаточное, условие симметричности вариационного ряда). Вариационные ряды, в которых расположение вариант вокруг средней не одинаково, то есть частоты по обе стороны от средней изменяются по-разному, называются асимметричными, или скошенными. Различают асимметрию – левостороннюю и правостороннюю. Средние величины, характеризую вариационный ряд одним числом, не учитывают вариацию признака, между тем эта вариация существует. Для измерения вариации признака в математической статистике применяют ряд способов.
Вариационный размах ( R), или широта распределения, есть разность между наибольшим и наименьшим значениями вариационного ряда:
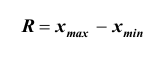
Вариационный размах представляет собой величину неустойчивую, чрезвычайно зависящую от случайных обстоятельств; применяется для приблизительной оценки вариации.
Среднее линейное отклонение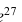 (обозначается d ) представляет собой среднюю арифметическую из абсолютных значений отклонений вариант от средней. В зависимости от отсутствия или наличия частот вычисляют среднее линейное отклонение невзвешенное или взвешенное:
(обозначается d ) представляет собой среднюю арифметическую из абсолютных значений отклонений вариант от средней. В зависимости от отсутствия или наличия частот вычисляют среднее линейное отклонение невзвешенное или взвешенное: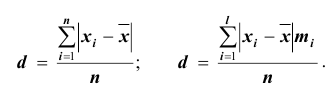
Средний квадрат отклонения, или дисперсия (обозначается D) наиболее часто применяется как мера колеблемости признака. Дисперсии невзвешенную и взвешенную вычисляют по формулам: 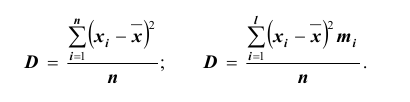 Таким образом, дисперсия есть средняя арифметическая из квадратов отклонений вариант от их средней арифметической. Квадратный корень из дисперсии
Таким образом, дисперсия есть средняя арифметическая из квадратов отклонений вариант от их средней арифметической. Квадратный корень из дисперсии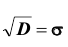 называется среднеквадратическим отклонением. Обобщающими характеристиками вариационных рядов являются моменты
называется среднеквадратическим отклонением. Обобщающими характеристиками вариационных рядов являются моменты
распределения. Характер распределения можно определить с помощью небольшого количества моментов. Средняя из k — х степеней отклонений вариант x от некоторой постоянной величины A (ложный ноль) называется моментом k -го порядка:
При расчёте средних в качестве весов можно использовать частоты, относительные частоты или вероятности. При использовании в качестве весов частот или относительных частот моменты называются эмпирическими, а при использовании вероятностей – теоретическими. Порядок момента определяется величиной k . Эмпирический момент k -го порядка находится как отношение суммы произведений k -х степеней отклонений вариант 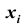 от постоянной величины A на соответствующие частоты
от постоянной величины A на соответствующие частоты 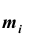 к сумме частот
к сумме частот 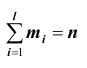 (объём
(объём
выборки), то есть 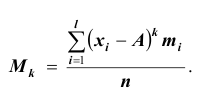
В зависимости от выбора постоянной величины A различают следующее моменты:
1. Если A= 0, то моменты называются начальными. Будем обозначать их через 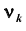 и вычислять по формуле:
и вычислять по формуле:
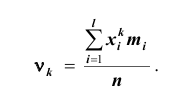
Тогда:
и так далее. На практике чаще всего используют моменты первых четырёх порядков.
2. Если  то моменты называются начальными относительно
то моменты называются начальными относительно , обозначаются
, обозначаются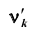 и рассчитываются по формуле:
и рассчитываются по формуле:
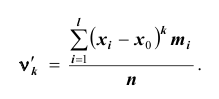
3. Если средняя), то моменты называются центральными, обозначаются
средняя), то моменты называются центральными, обозначаются  и вычисляются так:
и вычисляются так:
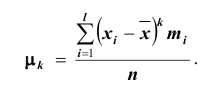
Тогда
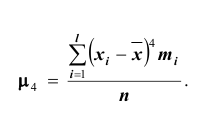
Коэффициентом асимметрии  называется отношение центрального момента третьего порядка к кубу среднеквадратического отклонения:
называется отношение центрального момента третьего порядка к кубу среднеквадратического отклонения:
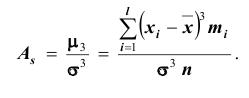
Если полигон вариационного ряда скошен, то есть одна из его ветвей, начиная от вершины, зримо короче другой, то такой ряд называют асимметричным.
Эксцессом называют уменьшенное на три единицы отношение центрального момента четвёртого порядка к четвёртой степени среднеквадратического отклонения:
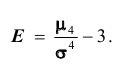 Кривые распределения, у которых
Кривые распределения, у которых 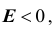 , менее крутые, имеют более плоскую вершину и называются плосковершинными. Кривые распределения, у которых
, менее крутые, имеют более плоскую вершину и называются плосковершинными. Кривые распределения, у которых 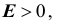 более крутые, имеют более острую вершину и называются островершинными.
более крутые, имеют более острую вершину и называются островершинными.
Выборки и доверительные интервалы
Пусть у нас имеется большое количество предметов, с нормальным распределением некоторых характеристик (например, полный склад однотипных овощей, размер и вес которых варьируется). Вы хотите знать средние характеристики всей партии товара, но у Вас нет ни времени, ни желания измерять и взвешивать каждый овощ. Вы понимаете, что в этом нет необходимости. Но сколько штук надо было бы взять на выборочную проверку?
Прежде, чем дать несколько полезных для этой ситуации формул напомним некоторые обозначения.
Во-первых, если бы мы все-таки промерили весь склад овощей (это множество элементов называется генеральной совокупностью), то мы узнали бы со всей доступной нам точностью среднее значение веса всей партии. Назовем это среднее значение Х ср.ген. — генеральным средним. Мы уже знаем, что нормальное распределение определяется полностью, если известно его среднее значение и отклонение s. Правда, пока мы ни 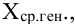 ни s генеральной совокупности не знаем. Мы можем только взять некоторую выборку, замерить нужные нам значения и посчитать для этой выборки как среднее значение
ни s генеральной совокупности не знаем. Мы можем только взять некоторую выборку, замерить нужные нам значения и посчитать для этой выборки как среднее значение 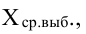 так и среднее квадратическое отклонение
так и среднее квадратическое отклонение 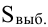
Известно, что если наша выборочная проверка содержит большое количество элементов (обычно n больше 30), и они взяты действительно случайным образом, то s генеральной совокупности почти не будет отличаться от 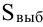
Кроме того, для случая нормального распределения мы можем пользоваться следующими формулами:
С вероятностью 95% 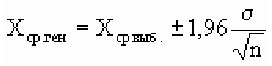
С вероятностью 99% 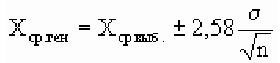
В общем виде с вероятностью P(t)
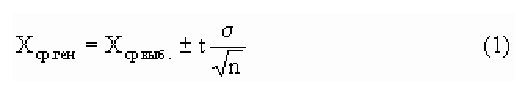
Связь значения t со значением вероятности P(t), с которой мы хотим знать доверительный интервал, можно взять из следующей таблицы: 
Таким образом, мы определили, в каком диапазоне находится среднее значение для генеральной совокупности (с данной вероятностью). Если у нас нет достаточно большой выборки, мы не можем утверждать, что генеральная совокупность имеет 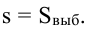 Кроме того, в этом случае проблематична близость выборки к нормальному распределению. В этом случае также пользуются
Кроме того, в этом случае проблематична близость выборки к нормальному распределению. В этом случае также пользуются  вместо s в формуле:
вместо s в формуле: 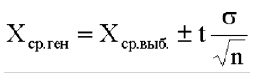
но значение t для фиксированной вероятности P(t) будет зависеть от количества элементов в выборке n. Чем больше n, тем ближе будет полученный доверительный интервал к значению, даваемому формулой (1). Значения t в этом случае берутся из другой таблицы (t-критерий Стьюдента), которую мы приводим ниже:
Значения t-критерия Стьюдента для вероятности 0,95 и 0,99
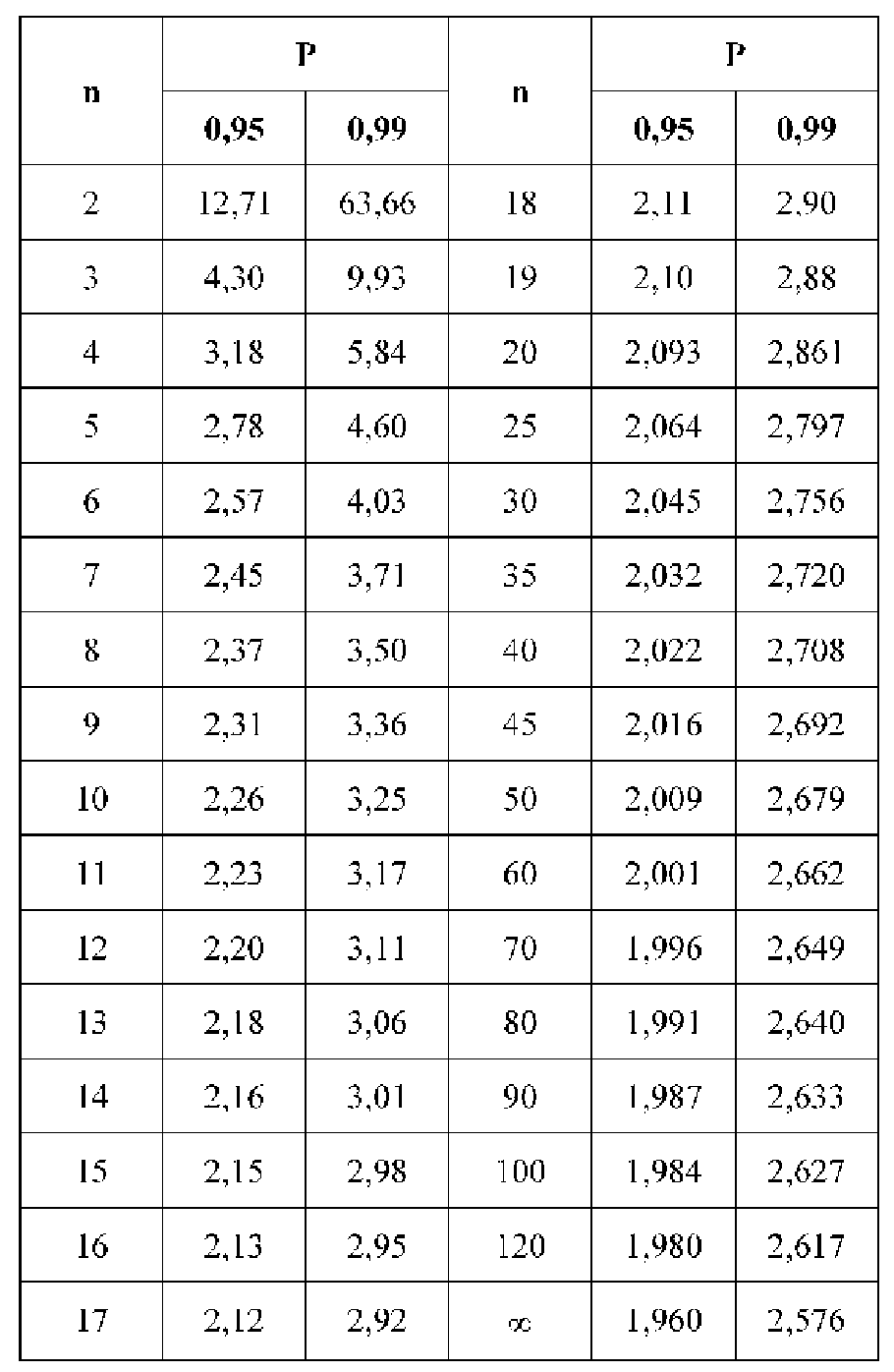
Пример №7
Из работников фирмы случайным образом отобрано 30 человек. По выборке оказалось, что средняя зарплата (в месяц) составляет 10 тыс. рублей при среднем квадратическом отклонении 3 тыс. рублей. С вероятностью 0,99 определить среднюю зарплату в фирме.
Решение:
По условию имеем  Для нахождения доверительного интервала воспользуемся формулой, соответствующей критерию Стьюдента. По таблице для n = 30 и Р = 0,99 находим t = 2,756, следовательно,
Для нахождения доверительного интервала воспользуемся формулой, соответствующей критерию Стьюдента. По таблице для n = 30 и Р = 0,99 находим t = 2,756, следовательно,
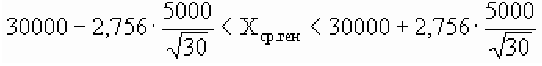
т.е. искомый доверительный интервал 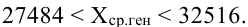 Итак, вероятностью 0,99 можно утверждать, что интервал (27484; 32516) содержит внутри себя среднюю зарплату в фирме. Мы надеемся, что Вы будете пользоваться этим методом, при этом не обязательно, чтобы при Вас каждый раз была таблица. Подсчеты можно проводить в Excel автоматически. Находясь в файле Excel, нажмите в верхнем меню кнопку
Итак, вероятностью 0,99 можно утверждать, что интервал (27484; 32516) содержит внутри себя среднюю зарплату в фирме. Мы надеемся, что Вы будете пользоваться этим методом, при этом не обязательно, чтобы при Вас каждый раз была таблица. Подсчеты можно проводить в Excel автоматически. Находясь в файле Excel, нажмите в верхнем меню кнопку  Затем, выберите среди функций тип «статистические», и из предложенного перечня в окошке — СТЬЮДРАСПОБР. Затем, по подсказке, поставив курсор в поле «вероятность» наберите значение обратной вероятности (т.е. в нашем случае вместо вероятности 0,95 надо набирать вероятность 0,05). Видимо, электронная таблица составлена так, что результат отвечает на вопрос, с какой вероятностью мы можем ошибиться. Аналогично в поле «степень свободы» введите значение (n-1) для своей выборки.
Затем, выберите среди функций тип «статистические», и из предложенного перечня в окошке — СТЬЮДРАСПОБР. Затем, по подсказке, поставив курсор в поле «вероятность» наберите значение обратной вероятности (т.е. в нашем случае вместо вероятности 0,95 надо набирать вероятность 0,05). Видимо, электронная таблица составлена так, что результат отвечает на вопрос, с какой вероятностью мы можем ошибиться. Аналогично в поле «степень свободы» введите значение (n-1) для своей выборки.
Понятие о статистике
«Статистика знает все», — утверждали И. Ильф и Е. Петров в своем знаменитом романе «Двенадцать стульев» и продолжали: «Известно, сколько какой пищи съедает в год средний гражданин республики… Известно, сколько в стране охотников, балерин, станков, собак всех пород, велосипедов, памятников, девушек, маяков и швейных машинок… Как много жизни, полной пыла, страстей и мысли, глядит на нас из статистических таблиц!»
Это ироничное описание дает достаточно точное представление о статистике (от латинского status — состояние) — науке, изучающей, обрабатывающей и анализирующей количественные данные о разнообразнейших массовых явлениях в жизни. Экономическая статистика изучает изменение цен, спроса и предложения товаров, прогнозирует рост и падение производства и потребления. Медицинская статистика изучает эффективность разных лекарств и методов лечения, вероятность возникновения некоторых заболеваний в зависимости от возраста, пола, наследственности, условий жизни, вредных привычек, прогнозирует распространение эпидемий. Демографическая статистика изучает рождаемость, численность населения, его состав (возрастной, национальный, профессиональный). А есть еще статистика финансовая, налоговая, биологическая, метеорологическая…
Статистика имеет многовековую историю. Уже в Древнем мире вели статистический учет населения. Однако случайное толкование статистических данных, отсутствие строгой научной базы статистических прогнозов даже в середине XIX в. еще не позволяли говорить о статистике как науке. Только в XX в. появилась математическая статистика — наука, опирающаяся на законы теории вероятностей. Выяснилось, что статистические методы обработки данных из самых разных областей жизни имеют много общего. Это позволило создать универсальные научно обоснованные методы статистических исследований и проверки статистических гипотез.
Таким образом:
Математическая статистика — это раздел математики, изучающий математические методы обработки и использования статистических данных для научных и практических выводов.
В математической статистике рассматриваются методы, которые дают возможность по результатам экспериментов (статистическим данным) делать определенные выводы вероятностного характера.
Математическая статистика подразделяется на две обширные области: 1) описательная статистика, которая рассматривает методы описания статистических данных, их табличное и графическое представление и пр.; 2) аналитическая статистика (теория статистических выводов), которая рассматривает обработку данных, полученных в ходе эксперимента, и формулировку выводов, имеющих прикладное значение для конкретной области человеческой деятельности. Теория статистических выводов тесно связана с теорией вероятностей и базируется на ее математическом аппарате. Среди основных задач математической статистики можно отметить следующие. 1. Оценка вероятности. Пусть некоторое случайное событие имеет вероятность p > 0, но ее значение нам неизвестно. Требуется оценить эту вероятность по результатам экспериментов, то есть решить задачу об оценке вероятности через частоту.
Оценка закона распределения:
Исследуется некоторая случайная величина, точное выражение для закона распределения которой нам неизвестно. Необходимо по результатам экспериментов найти приближенное выражение для функции, задающей закон распределения.
Оценка числовых характеристик случайной величины (например, математического ожидания ).
Проверка статистических гипотез (предположений).
Исследуется некоторая случайная величина. Исходя из определенных рассуждений, выдвигается, например, гипотеза о распределении этой случайной величины. Необходимо по результатам экспериментов принять или отвергнуть эту гипотезу. Результаты исследований, проводимых методами математической статистики, применяются для принятия решений. В частности, при планировании и организации производства, при контроле качества продукции, при выборе оптимального времени наладки или замены действующей аппаратуры (например, при определении времени замены двигателя самолета, отдельных частей станков и т. д.). Как и в каждой науке, в статистике используются свои специфические термины и понятия. Некоторые из них приведены в табл. 37. Запоминать их определения необязательно, достаточно понимать их смысл.
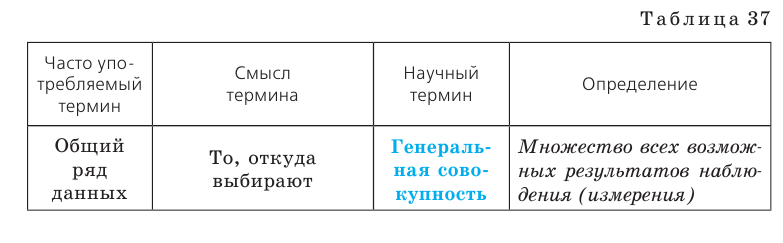
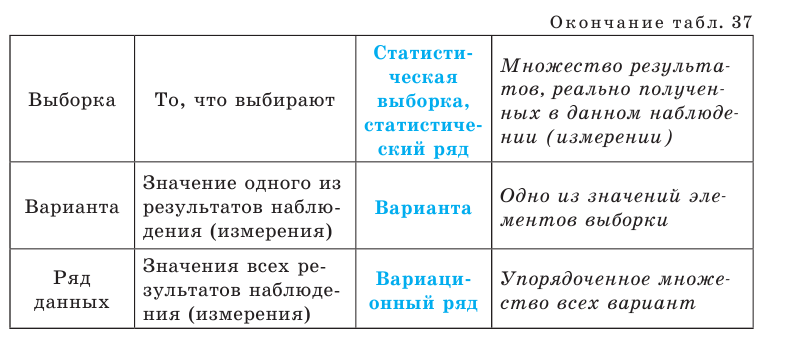
Генеральная совокупность и выборка
Для изучения различных массовых явлений проводятся специальные статистические исследования. Любое статистическое исследование начинается с целенаправленного сбора информации об изучаемом явлении или процессе. Этот этап называют этапом статистических наблюдений.
Для получения статистических данных в результате наблюдений похожие элементы некоторой совокупности сравнивают по разным признакам. Например, учащихся 11 классов можно сравнивать по росту, размеру одежды, успеваемости и пр. Болты можно сравнивать по длине, диаметру, массе, материалу и другим характеристикам. Практически любой признак или непосредственно измеряется, или может получить условную числовую характеристику (см. пример с выпадением «герба» или «числа» при подбрасывании монеты).
Таким образом, некоторый признак элементов совокупности можно рассматривать как величину, принимающую те или иные числовые значения. При изучении реальных явлений часто бывает невозможно обследовать все элементы совокупности.
Например, практически невозможно выяснить размеры обуви у всех людей планеты. А проверить, например, наличие листов некачественной фотобумаги в большой партии хотя и реально, но бессмысленно, потому что полная проверка приведет к уничтожению всей партии бумаги. В подобных случаях вместо изучения всех элементов совокупности, называемой генеральной совокупностью, обследуют ее значительную часть, выбранную случайным образом. Эту часть называют выборкой, а число элементов в выборке называется объемом выборки. Eсли в выборке все основные признаки генеральной совокупности представлены в той же пропорции и с той же относительной частотой, с которой данный признак выступает в данной генеральной совокупности, то эту выборку называют репрезентативной (от французского représentatif — показательный).
Иными словами, репрезентативная выборка представляет собой меньшую по размеру, но точную модель той генеральной совокупности, которую она должна отражать. В той степени, в какой выборка является репрезентативной, выводы, основанные на изучении этой выборки, можно с большой долей уверенности считать применимыми ко всей генеральной совокупности.
Понятие репрезентативности отобранной выборки не означает ее полного представительства по всем признакам генеральной совокупности, поскольку это практически обеспечить невозможно. Отобранная из всей совокупности часть должна быть репрезентативной относительно тех признаков, которые изучаются.
Чтобы выборка была репрезентативной, она должна быть выделена из генеральной совокупности случайным образом. Этого можно достичь различными способами.
Чаще всего используют следующие виды выборок:
- собственно-случайную;
- механическую;
- типическую;
- серийную.
Кратко охарактеризуем каждую из них.
1) Члены генеральной совокупности можно предварительно занумеровать и каждый номер записать на отдельной карточке. После тщательного перемешивания будем отбирать наугад из пачки таких карточек по одной и таким образом получим выборочную совокупность любого нужного объема, которая называется собственно-случайной выборкой. Номера на отобранных карточках укажут, какие члены генеральной совокупности попали в выборку. (Заметим, что при этом возможны два принципиально различных способа отбора карточек в зависимости от того, возвращается или не возвращается обратно вынутая карточка после записи ее номера.) Собственно-случайную выборку заданного объема п можно образовать и с помощью так называемых таблиц случайных чисел или генератора случайных чисел на компьютере. При образовании собственно-случайной выборки каждый член генеральной совокупности с одинаковой вероятностью может попасть в выборку.
2) Выборка, в которую члены из генеральной совокупности отбираются через определенный интервал, называется механической. Например, если объем выборки должен составлять 5% объема генеральной совокупности (5%-ная выборка), то отбирается ее каждый 20-й член, при 10%-ной выборке — каждый 10-й член генеральной совокупности и т. д. Механическую выборку можно образовать, если имеется определенный порядок следования членов генеральной совокупности, например, если они следуют друг за другом в определенной последовательности во времени. Именно так появляются изготовленные на станке детали, приборы, сошедшие с конвейера, и т. п. При этом необходимо убедиться, что в следующих один за другим членах генеральной совокупности значения признака не изменяются с той же (или кратной ей) периодичностью, что и периодичность отбора элементов в выборку. Например, пусть из продукции металлообрабатывающего станка в выборку попадает каждая пятая деталь, а после каждой десятой детали рабочий производит смену (или заточку) режущего инструмента и наладку станка. Эти операции рабочего направлены на улучшение качества деталей (износ режущего инструмента происходит более или менее равномерно). Следовательно, в выборочную совокупность попадут детали, на качество которых работа станка влияет в одну и ту же сторону, и значения признака выборочной совокупности могут неправильно отразить соответствующие значения признака генеральной совокупности.
3) Если из предварительно разбитой на непересекающиеся группы генеральной совокупности образовать собственно-случайные выборки из каждой группы (с повторным или бесповторным отбором членов), то отобранные элементы составят выборочную совокупность, которая называется типической.
4) Если генеральную совокупность предварительно разбить на непересекающиеся серии (группы), а затем, рассматривая серии как элементы, образовать собственно-случайную выборку (с повторным или бесповторным отбором серий), то все члены отобранных серий составят выборочную совокупность, которая называется серийной. Например, пусть на заводе 150 станков (10 цехов по 15 станков) производят одинаковые изделия. Если в выборку отбирать изделия из тщательно перемешанной продукции всех 150 станков, то образуется собственно-случайная выборка. Но можно отбирать изделия отдельно из продукции первого, второго и т. д. станков. Тогда будет образована типическая выборка. Если же членами генеральной совокупности считать цеха и сначала образовать собственно-случайную выборку цехов, а потом в каждом из отобранных цехов взять все произведенные изделия, то все отобранные изделия (из всех отобранных цехов) составят серийную выборку. Как уже отмечалось, практически любой изучаемый признак X может быть непосредственно измерен или получить числовую характеристику. Поэтому первичные экспериментальные данные, характеризующие выделенную выборку, обычно представлены в виде набора чисел, записанных исследователем в порядке их поступления. Количество (n) чисел в этом наборе — объем выборки, а численность (m) варианты (одного из значений элементов выборки) называют частотой варианты. Отношение m n называют относительной частотой (W) варианты.
Используя эти понятия, запишем соотношение между ними в репрезентативной выборке.
Пусть S — объем генеральной совокупности, n — объем репрезентативной выборки, в которой k значений исследуемых признаков распределены по частотам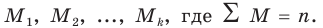 . Тогда в генеральной совокупности частотам
. Тогда в генеральной совокупности частотам 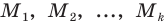 будут соответствовать частоты
будут соответствовать частоты 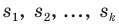 тех же значений признака, что и в выборке
тех же значений признака, что и в выборке 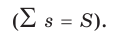 По определению репрезентативной выборки получаем:
По определению репрезентативной выборки получаем: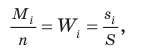 , где і — порядковый номер значения признака
, где і — порядковый номер значения признака 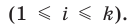 Из этого соотношения находим:
Из этого соотношения находим:
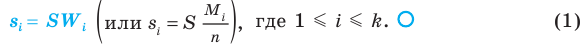
Пример №8
Обувной цех должен выпустить 1000 пар кроссовок молодежного фасона. Для того чтобы определить, сколько кроссовок и какого размера необходимо выпустить, были выявлены размеры обуви у 50 случайным образом выбранных подростков. Распределение размеров обуви по частотам представлено в таблице:

Сколько кроссовок разного размера будет изготавливать фабрика?
Решение:
 Будем считать рассмотренную выборку объемом n = 50 подростков репрезентативной. Тогда в генеральной совокупности (объемом S = 1000) количество кроссовок каждого размера пропорционально количеству кроссовок соответствующего размера в выборке (и для каждого размера находится по формуле (1)). Результаты расчетов будем записывать в таблицу:
Будем считать рассмотренную выборку объемом n = 50 подростков репрезентативной. Тогда в генеральной совокупности (объемом S = 1000) количество кроссовок каждого размера пропорционально количеству кроссовок соответствующего размера в выборке (и для каждого размера находится по формуле (1)). Результаты расчетов будем записывать в таблицу:
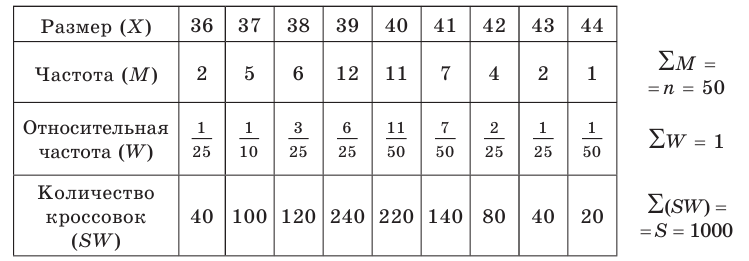
Ответ:

В сельском хозяйстве для определения количественного соотношения продукции разного сорта пользуются так называемым выборочным
методом. Суть этого метода будет ясна из описания следующего опыта, теоретическую основу которого составляет закон больших чисел. В коробке тщательно перемешан горох двух сортов: зеленый и желтый. Небольшой емкостью, например ложкой, вынимают из разных мест коробки порции гороха. В каждой порции подсчитывают число М желтых горошин и число n всех горошин. Для каждой порции находят относительную частоту появления желтой горошины 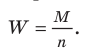 Так делают k раз (на практике обычно берут 5 < k < 10) и каждый раз вычисляют относительную частоту. За статистическую вероятность извлечения желтой горошины из коробки принимают среднее арифметическое полученных относительных частот
Так делают k раз (на практике обычно берут 5 < k < 10) и каждый раз вычисляют относительную частоту. За статистическую вероятность извлечения желтой горошины из коробки принимают среднее арифметическое полученных относительных частот 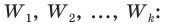
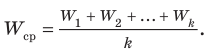
Табличное и графическое представление данных. Числовые характеристики рядов данных
Ранжирование ряда данных:
Под ранжированием ряда данных понимают расположение элементов этого ряда в порядке возрастания (имеется в виду, что каждое следующее число или больше, или не меньше предыдущего).
Пример:
Если ряд данных выборки имеет вид 5, 3, 7, 4, 6, 4, 6, 9, 4, то после ранжирования он превращается в ряд 3, 4, 4, 4, 5, 6, 6, 7, 9. (*)
Размах выборки (R)
Размах выборки — это разность между наибольшим и наименьшим значениями величины в выборке.
Для ряда (*) размах выборки: R = 9 – 3 = 6.
Мода (Mo)
Мода — это значение элемента выборки, встречающееся чаще остальных.
В ряду (*) значение 4 встречается чаще всего, итак, Mo = 4.
Медиана (Me)
Медиана — это так называемое серединное значение упорядоченного ряда значений: — если количество чисел в ряду нечетное, то медиана — это число, записанное посередине; — если количество чисел в ряду четное, то медиана — это среднее арифметическое двух чисел, стоящих посередине.
Для ряда (*), в котором 9 членов, медиана — это среднее (то есть пятое) число 5: Me = 5. Если рассмотреть ряд 3, 3, 4, 4, 4, 5, 6, 6, 7, 9, в котором 10 членов, то медиана — это среднее арифметическое пятого и шестого членов: 
Среднее значение 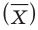 выборки
выборки
Средним значением выборки называется среднее арифметическое всех чисел ряда данных выборки. Если в ряду данных записаны значения 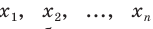 (среди которых могут быть и одинаковые), то
(среди которых могут быть и одинаковые), то 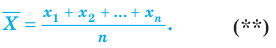
Если известно, что в ряду данных различные значения 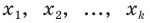 встречаются соответственно с частотами
встречаются соответственно с частотами 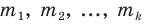 (тогда
(тогда 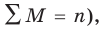 то среднее арифметическое можно вычислить по формуле
то среднее арифметическое можно вычислить по формуле 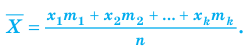
Пусть ряд данных задан таблицей распределения его различных значений по частотам M:
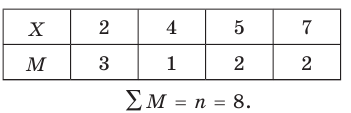
Тогда по формуле (**) 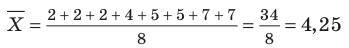 или по другой формуле
или по другой формуле
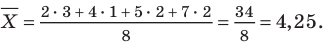
Табличное и графическое представление данных. Полигоны частот
Как уже отмечалось, практически любой изучаемый признак X может быть непосредственно измерен или получить числовую характеристику. Поэтому первичные экспериментальные данные, характеризующие выделенную выборку, обычно представлены в виде набора чисел, записанных исследователем в порядке их поступления.
Если данных много, то полученный набор чисел трудно обозрим и сделать по нему какие-то выводы очень сложно. Поэтому первичные данные нуждаются в обработке, которая обычно начинается с их группировки. Группировка выполняется различными методами в зависимости от целей исследования, вида изучаемого признака и количества экспериментальных данных (объема выборки). Наиболее часто группировка сводится к представлению данных в виде таблиц, в которых различные значения элементов выборки упорядочены по возрастанию и указаны их частоты (то есть количество каждого элемента в выборке).
При необходимости в этой таблице указывают также относительные частоты для каждого элемента, записанного в первой строке. Такую таблицу часто называют рядом распределения (или вариационным рядом). Например, пусть при изучении размера обуви 30 мальчиков 11 класса получили набор чисел (результаты записаны в порядке опроса): 39; 44; 41; 39; 40; 41; 45; 42; 44; 41; 41; 43; 42; 43; 41; 44; 42; 38; 40; 38; 41; 40; 42; 43; 42; 41; 43; 40; 40; 42. Чтобы удобнее было анализировать информацию, в подобных ситуациях числовые данные сначала ранжируют, располагая их в порядке возрастания (когда каждое следующее число или больше, или не меньше предыдущего). В результате ранжирования получаем следующий ряд: 38; 38; 39; 39; 40; 40; 40; 40; 40; 41; 41; 41; 41; 41; 41; 41; 42; 42; 42; 42; 42; 42; 43; 43; 43; 43; 44; 44; 44; 45. Затем составляем таблицу, в первой строке которой указаны все различные значения полученного ряда данных (X размер обуви выбранных 30 мальчиков 11 класса), а во второй строке — их частоты М:

Получаем ряд распределения рассматриваемого признака X по частотам. Иногда удобно проводить анализ ряда распределения на основе его графического изображения. Отметим на координатной плоскости точки с координатами
 и соединим их последовательно отрезками (рис. 23.1). Полученную ломаную линию называют полигоном частот.
и соединим их последовательно отрезками (рис. 23.1). Полученную ломаную линию называют полигоном частот.
Итак, полигоном частот называют ломаную, отрезки которой последовательно соединяют точки с координатами 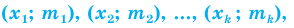 , где
, где 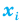 — значения различных элементов ряда данных, а
— значения различных элементов ряда данных, а 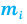 — соответствующие им частоты. Аналогично определяется и строится полигон относительных частот для рассматриваемого признака X (строятся точки с координатами
— соответствующие им частоты. Аналогично определяется и строится полигон относительных частот для рассматриваемого признака X (строятся точки с координатами — значения различных элементов ряда данных, а
— значения различных элементов ряда данных, а 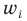 — соответствующие им относительные частоты.
— соответствующие им относительные частоты.
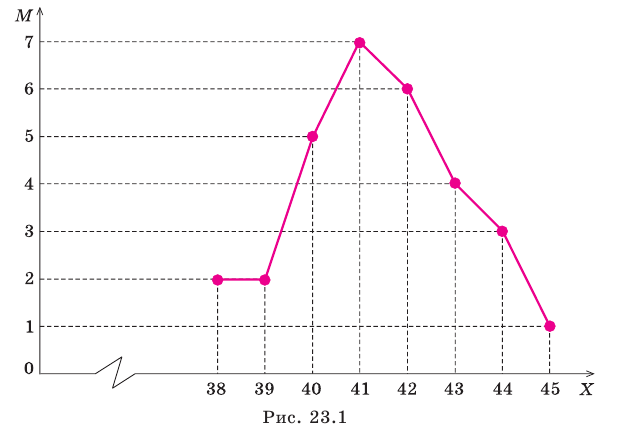
Если вычислить относительные частоты для каждого из различных значений ряда данных, рассмотренного в начале этого пункта, то распределение значений рассматриваемого признака X по относительным частотам можно задать таблицей:

Распределение значений рассматриваемого признака X по относительным частотам можно представить также в виде полигона относительных частот (рис. 23.2), в виде линейной диаграммы (рис. 23.3) или в виде круговой диаграммы, предварительно записав значения относительной частоты в процентах (рис. 23.4).
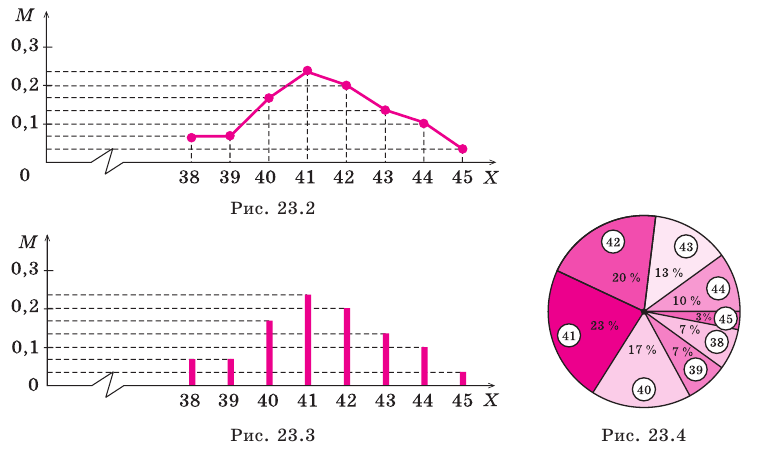
Напомним, что для построения круговой диаграммы круг разбивается на секторы, центральные углы которых пропорциональны относительным частотам, вычисленным для каждого из различных значений ряда данных. Обратим внимание, что круговая диаграмма сохраняет свою наглядность и выразительность только при небольшом количестве полученных секторов. В противном случае ее применение малоэффективно. Если рассматриваемый признак принимает много различных значений, то его распределение можно лучше себе представить после разбиения всех значений ряда данных на классы.
Количество классов может быть любым, удобным для исследования (обычно от 4 до 12). При этом величины (объемы) классов должны быть одинаковыми. Например, в следующей таблице представлены сведения о заработной плате 100 рабочих одного предприятия (в некоторых условных единицах). При этом значения зарплаты (округлены до целого числа условных единиц) сгруппированы в 7 классов, каждый объемом в 100 условных единиц.
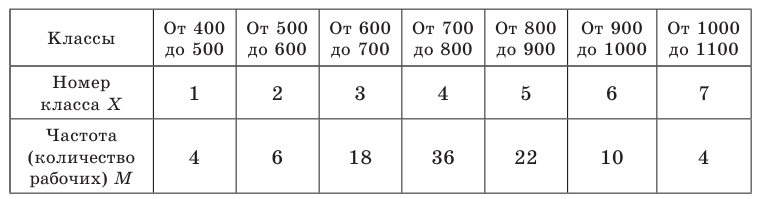
(проверка:  = 100) Наглядно частотное распределение зарплат по классам можно представить с помощью полигона частот (рис. 23.5) или столбчатой диаграммы (рис. 23.6).
= 100) Наглядно частотное распределение зарплат по классам можно представить с помощью полигона частот (рис. 23.5) или столбчатой диаграммы (рис. 23.6).
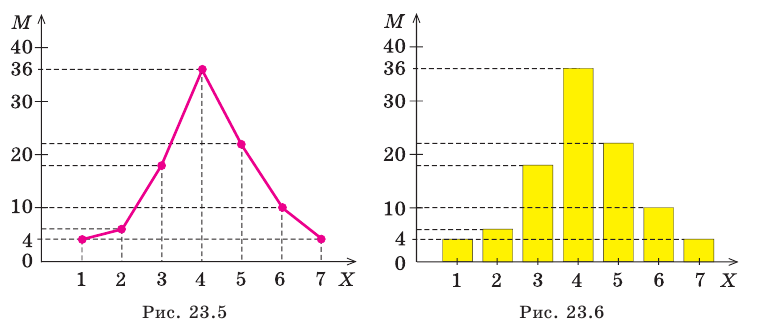
Числовые характеристики рядов данных. Размах, мода и медиана ряда данных
Иногда выборку случайных величин или всю генеральную совокупность этих величин приходится характеризовать одним числом. На практике это необходимо, например, для быстрого сравнения двух или больше совокупностей по общему признаку. Рассмотрим конкретный пример. Пусть после летних каникул провели опрос 10 девочек и 9 мальчиков одного класса о количестве книг, прочитанных ими за каникулы. Результаты были записаны в порядке опроса. Получили следующие ряды чисел:
- для девочек: 4, 3, 5, 3, 8, 3, 12, 4, 5, 5;
- для мальчиков: 5, 3, 3, 4, 6, 4, 4, 7, 4.
Как уже отмечалось, чтобы удобнее было анализировать информацию, в подобных случаях числовые данные ранжируют, располагая их в порядке возрастания (когда каждое следующее число или больше, или не меньше предыдущего). В результате ранжирования получили следующие ряды:
- для девочек: 3, 3, 3, 4, 4, 5, 5, 5, 8, 12; (1)
- для мальчиков: 3, 3, 4, 4, 4, 4, 5, 6, 7. (2)
Тогда распределение по частотам M величин: X — число книг, прочитанных за каникулы девочками, и Y — число книг, прочитанных за каникулы мальчиками, можно задать таблицами:

Эти распределения можно проиллюстрировать также графически с помощью полигона частот (рис. 23.7, а, б).
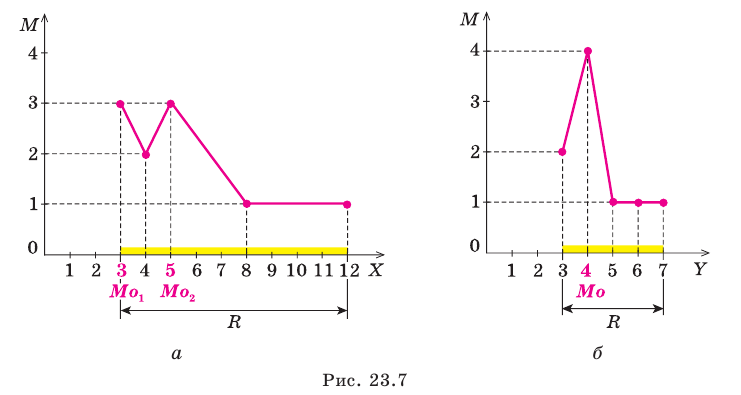
Для сравнения рядов (1) и (2) используют различные характеристики. Приведем некоторые из них. Размахом ряда чисел (обозначается R) называют разность между наибольшим и наименьшим из этих чисел. Поскольку мы анализируем выборку некоторых величин, то размах выборки — это разность между наибольшим и наименьшим значениями величины в выборке.
Для ряда (1) размах R = 12 – 3 = 9, а для ряда (2) размах R = 7 – 3 = 4. На графике размах — это длина области определения полигона частот (рис. 23.7). Одной из статистических характеристик ряда данных является его мода (обозначается Mo, от латинского слова modus — мера, правило).
Мода — это значение элемента выборки, встречающееся чаще остальных.
Так, в ряду (1) две моды — числа 3 и 5:  = 5, а в ряду (2) одна мода — число 4: Mo = 4. На графике мода — это значение абциссы точки, в которой достигается максимум полигона частот (см. рис. 23.7). Отметим, что моды может и не быть, если все значения рассматриваемого признака встречаются одинаково часто. Моду ряда данных обычно находят тогда, когда хотят выяснить некоторый типовой показатель. Например, когда изучают данные о моделях мужских рубашек, проданных в определенный день в универмаге, то удобно использовать такой показатель, как мода, который характеризует модель, пользующуюся наибольшим спросом (собственно, этим и объясняется название «мода»). Еще одной статистической характеристикой ряда данных является его медиана. Медиана — это так называемое серединное значение упорядоченного ряда значений (обозначается Me). Медиана делит упорядоченный ряд данных на две равные по количеству элементов части.
= 5, а в ряду (2) одна мода — число 4: Mo = 4. На графике мода — это значение абциссы точки, в которой достигается максимум полигона частот (см. рис. 23.7). Отметим, что моды может и не быть, если все значения рассматриваемого признака встречаются одинаково часто. Моду ряда данных обычно находят тогда, когда хотят выяснить некоторый типовой показатель. Например, когда изучают данные о моделях мужских рубашек, проданных в определенный день в универмаге, то удобно использовать такой показатель, как мода, который характеризует модель, пользующуюся наибольшим спросом (собственно, этим и объясняется название «мода»). Еще одной статистической характеристикой ряда данных является его медиана. Медиана — это так называемое серединное значение упорядоченного ряда значений (обозначается Me). Медиана делит упорядоченный ряд данных на две равные по количеству элементов части.
Если количество чисел в ряду нечетное, то медиана — это число, записанное посередине. Например, в ряду (2) нечетное количество элементов (n = 9). Тогда его медианой является число, стоящее посередине, то есть на пятом месте: Me =4

Следовательно, о мальчиках можно сказать, что одна половина из них прочитала не больше 4 книг, а вторая — не меньше 4 книг. (Отметим, что в случае нечетного n номер среднего члена ряда равен 
Если количество чисел в ряду четное, то медиана — это среднее арифметическое двух чисел, стоящих посередине. Например, в ряду (1) четное количество элементов (n = 10). Тогда его медианой является число, равное среднему арифметическому чисел, стоящих посередине, то есть на пятом и шестом местах: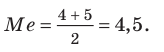
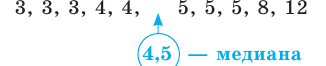
Следовательно, о девочках можно сказать, что одна половина из них прочитала меньше 4,5 книги, а вторая — больше 4,5 книги. (Отметим, что в случае четного n номера средних членов ряда равны 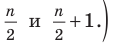
Среднее значение выборки
Средним значением выборки (обозначается  называется среднее арифметическое всех чисел ряда данных выборки. Если в ряду данных записаны значения
называется среднее арифметическое всех чисел ряда данных выборки. Если в ряду данных записаны значения 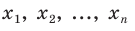 (среди которых могут быть и одинаковые), то
(среди которых могут быть и одинаковые), то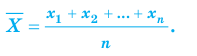
Если известно, что в ряду данных различные значения  встречаются соответственно с частотами
встречаются соответственно с частотами 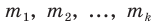 (тогда ∑M = n ), то, заменяя одинаковые слагаемые в числителе на соответствующие произведения, получаем, что среднее арифметическое можно вычислять по формуле
(тогда ∑M = n ), то, заменяя одинаковые слагаемые в числителе на соответствующие произведения, получаем, что среднее арифметическое можно вычислять по формуле
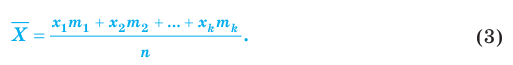
Последнюю формулу удобно использовать в тех случаях, когда в выборке распределение величины по частотам задано в виде таблицы. Напомним, что распределение по частотам M величин: X — число книг, прочитанных за каникулы девочками, и Y — число книг, прочитанных за каникулы мальчиками, было задано такими таблицами:

Тогда средние значения заданных выборок равны:
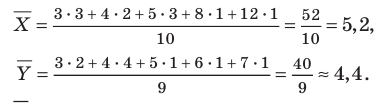
Поскольку 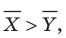 то можно сказать, что за один и тот же промежуток времени девочки в классе читают книг больше, чем мальчики. Обратим внимание, что в пособиях по статистике моду, медиану и среднее значение выборки объединяют одним термином — меры центральной тенденции, подчеркивая тем самым возможность охарактеризовать ряд выборки одним числом. Не для каждого ряда данных имеет смысл формально находить центральные тенденции.
то можно сказать, что за один и тот же промежуток времени девочки в классе читают книг больше, чем мальчики. Обратим внимание, что в пособиях по статистике моду, медиану и среднее значение выборки объединяют одним термином — меры центральной тенденции, подчеркивая тем самым возможность охарактеризовать ряд выборки одним числом. Не для каждого ряда данных имеет смысл формально находить центральные тенденции.
Например, если исследуется ряд 5, 5, 8, 110 (5) годовых доходов четырех людей (в тыс. у. е.), то очевидно, что ни мода (5), ни медиана (6,5), ни среднее значение (32) не могут выступать в роли единой характеристики всех значений ряда данных. Это объясняется тем, что размах ряда (105) является соизмеримым с наибольшим из его значений. В данном случае можно искать центральные тенденции, например, для части ряда (5): 5, 5, 8, условно назвав его выборкой годового дохода низкооплачиваемой части населения. Если в выборке среднее значение существенно отличается от моды, то его нецелесообразно выбирать в качестве типичной характеристики рассматриваемой совокупности данных (чем больше значение моды отличается от среднего значения, тем «более несимметричным» является полигон частот совокупности).
Сведения из истории:
Элементарные задачи, которые позднее были отнесены к стохастике, то есть к комбинаторике, теории вероятностей и математической статистике, ставились и решались еще во времена Древних Египта, Греции и Рима. Этот период так называемой предыстории теории вероятностей заканчивается в XVI в. работами итальянских математиков Д. Кардано (1501–1576) «Книга об игре в кости», Н. Тартальи (1499–1557) «Общий трактат о числе и мере», Г. Г а л и л е я (1564–1642) «О выпадении очков при игре в кости» и др. В этих работах уже фигурирует понятие вероятности, используется теорема о вероятности произведения независимых событий, высказываются некоторые соображения относительно так называемого закона больших чисел. В XVII–XVIII вв. вопросами теории вероятностей заинтересовались французские математики П. Ферма (1601–1665) и Б. Паскаль (1623–1662), нидерландский математик X. Гюйгенс (1629– 1695), швейцарские математики Я. Бернулли (1654–1705), И. Бернулли (1687–1759), Д. Бернулли (1700–1782) и российский математик Л. Эйлер (1707–1783). В своих работах они уже использовали теоремы сложения и умножения вероятностей, понятия зависимых и независимых событий, математического ожидания. Большую роль в распространении идей теории вероятностей и математической статистики в России сыграли выдающиеся российские математики В. Я. Буняковский (1804–1889) и М. В. Остроградский (1801–1862). Дальнейшее развитие теории вероятностей потребовало уточнения основных ее положений. Большую работу в этом направлении провел выдающийся российский математик П. Л. Чебышёв (1821–1894). Его ученик А. А. Марков (1856– 1922) стал выдающимся математиком именно благодаря своим исследованиям в теории вероятностей.
Книга А. А. Маркова «Исчисление вероятностей», первое издание которой вышло в 1900 г., а четвертое — в 1924 г., в течение многих лет была лучшей из тех, по которым учились российские математики. В этой книге, в частности, раскрывается, в каком понимании статистическая вероятность 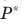 (А) близка к вероятности Р (А) при больших п: вероятность значительного отклонения
(А) близка к вероятности Р (А) при больших п: вероятность значительного отклонения  от Р (А) близка к нулю, но это не означает, что значительные отклонения невозможны при больших п. В XX в. теория вероятностей постепенно превращается в строгую аксиоматическую теорию. Это произошло благодаря работам многих математиков. Но действительно решающим этапом в развитии теории вероятностей стала работа А. Н. Колмогорова (1903–1987) «Основные понятия теории вероятностей» (изданная в 1937 г.), в которой он изложил свою аксиоматику теории вероятностей и после которой теория вероятностей заняла равноправное место среди других математических дисциплин. Большие достижения в теории вероятностей и математической статистике имели также российские математики А. Я. Хинчин (1894–1959), Е. Е. Слуцкий (1880–1948), Б. В. Генеденко (1911–1995), математики И. И. Гихман (1918–1985), В. С. Михалевич (1930–1994), и другие.
от Р (А) близка к нулю, но это не означает, что значительные отклонения невозможны при больших п. В XX в. теория вероятностей постепенно превращается в строгую аксиоматическую теорию. Это произошло благодаря работам многих математиков. Но действительно решающим этапом в развитии теории вероятностей стала работа А. Н. Колмогорова (1903–1987) «Основные понятия теории вероятностей» (изданная в 1937 г.), в которой он изложил свою аксиоматику теории вероятностей и после которой теория вероятностей заняла равноправное место среди других математических дисциплин. Большие достижения в теории вероятностей и математической статистике имели также российские математики А. Я. Хинчин (1894–1959), Е. Е. Слуцкий (1880–1948), Б. В. Генеденко (1911–1995), математики И. И. Гихман (1918–1985), В. С. Михалевич (1930–1994), и другие.
Выборка, вариационный ряд и гистограмма
Если теория вероятностей оперирует с известными законами распределения и их параметрами (числовыми характеристиками), то математическая статистика по результатам экспериментов проверяет, правильно ли подобрано распределение (нормальное, биномиальное, экспоненциальное и т. д.), оценивает параметры этого распределения, проверяет гипотезы о параметрах принятого распределения. Это позволяет заменить большое число экспериментальных данных небольшим числом параметров распределения, которые в сжатом виде характеризуют случайную величину и позволяют прогнозировать результаты эксперимента при известном комплексе условий.
Пусть проводится 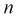 измерений. В результате измерений получено
измерений. В результате измерений получено 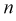 чисел
чисел 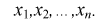 . Если повторить еще раз
. Если повторить еще раз 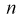 измерений, то получатся другие
измерений, то получатся другие 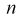 чисел, отличные от первого набора. Процесс из
чисел, отличные от первого набора. Процесс из 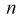 измерений можно описать как и независимых случайных величин.
измерений можно описать как и независимых случайных величин.
Результат и наблюдений 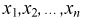 случайной величины X называется выборкой,
случайной величины X называется выборкой, 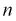 — объем выборки, а сама случайная величина X — называется генеральной случайной величиной.
— объем выборки, а сама случайная величина X — называется генеральной случайной величиной.
Результат эксперимента 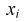 может быть интерпретирован либо апостериорной величиной, либо априорной. В первом случае это результат опыта. Во втором случае является случайной величиной (т. к. до опыта неизвестна), которая получит свое конкретное значение в результате какого-то
может быть интерпретирован либо апостериорной величиной, либо априорной. В первом случае это результат опыта. Во втором случае является случайной величиной (т. к. до опыта неизвестна), которая получит свое конкретное значение в результате какого-то  опыта. В этом случае можно предполагать, что закон распределения
опыта. В этом случае можно предполагать, что закон распределения 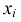 , совпадает с законом распределения генеральной случайной величиной X и
, совпадает с законом распределения генеральной случайной величиной X и 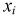 , можно рассматривать как экземпляр генеральной случайной величины X.
, можно рассматривать как экземпляр генеральной случайной величины X.
Далее мы будем считать выборки априорными. При этом будем полагать, что элементы выборки — независимые случайные величины с одинаковым законом распределения, т. е. мы можем широко использовать теоремы независимых случайных величинах.
Упорядоченная в порядке возрастания последовательность выборочных значений образует вариационный ряд:
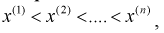
члены вариационного ряда  называются порядковыми статистиками. Если объем выборки
называются порядковыми статистиками. Если объем выборки  — велик, то выборка позволяет приблизительно оценить закон распределения случайной величиной X. Для этого необходимо построить гистограмму. Есть два способа построения гистограммы — равноинтервальный и равновероятностный.
— велик, то выборка позволяет приблизительно оценить закон распределения случайной величиной X. Для этого необходимо построить гистограмму. Есть два способа построения гистограммы — равноинтервальный и равновероятностный.
Рассмотрим равноинтервалъный способ.
- Разобьем весь диапазон выборочных значений от
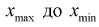 на
на 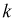 равных частей. Величину
равных частей. Величину 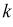 выбирают достаточно произвольно, можно так:
выбирают достаточно произвольно, можно так: 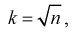 где
где 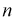 — объем выборки.
— объем выборки. - Определяем длину каждого интервала:
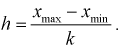
- Находим границы каждого интервала: для первого:
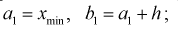 для второго:
для второго: 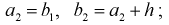 для
для 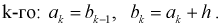
Определим середины каждого интервала: 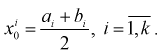
4. Подсчитываем (используя вариационный ряд) количество выборочных значений, попадающих в  интервал —
интервал — 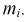
5. Находим относительную частоту 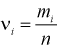 попадания случайной величиной X в
попадания случайной величиной X в  интервал.
интервал.
Полученные данные заносим в таблицу.

Эта таблица называется статистическим рядом.
Графическое изображение статистического ряда — это гистограмма.
Рисуем оси координат, делаем разметку осей, наносим на ось X границы интервалов и их середины. После этого строим на каждом отрезке прямоугольники высотой  . Аппроксимируем фигуру из прямоугольников пунктирной линией (рис. 8.1). По виду этой кривой можно выдвинуть предположение (гипотезу) о виде закона распределения генеральной случайной величиной X (на рис. 8.1. видно, что пунктирная линия похожа на кривую Гаусса, которая относится к нормальному закону).
. Аппроксимируем фигуру из прямоугольников пунктирной линией (рис. 8.1). По виду этой кривой можно выдвинуть предположение (гипотезу) о виде закона распределения генеральной случайной величиной X (на рис. 8.1. видно, что пунктирная линия похожа на кривую Гаусса, которая относится к нормальному закону).
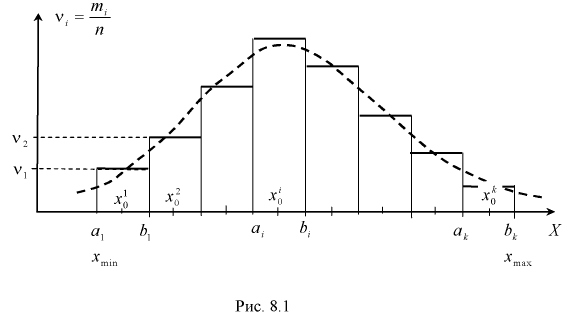
Имея статистический ряд можно оценить числовые характеристики генеральной случайной величиной X :
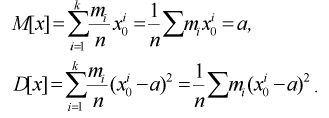
Выборочный метод
Группа предметов или явлений, объединенных каким-либо общим признаком или свойством качественного или количественного характера, называется совокупностью. Предметы или явления, образующие совокупность, называются единицами совокупности. Если совокупность содержит ограниченное число единиц, то она называется конечной. Если число единиц совокупности безгранично, то ее называют бесконечной совокупностью.
Теоретические основы выборочного метода содержатся в теоремах Чебышева и Ляпунова.
Основной предпосылкой применения выборочного метода является возможность судить о характеристиках генеральной (общей) совокупности по отобранной, так называемой выборочной совокупности. Наиболее важным принципом в применении выборочного метода является обеспечение равной возможности всем единицам, входящим в состав генеральной совокупности, быть избранными. При таком объективном подходе к отбору единиц, при котором ни одна единица не обладает преимуществом попасть в отбираемую совокупность по сравнению с другими единицами, характеристики выборочной совокупности при увеличении объема выборки стремятся к характеристикам генеральной совокупности.
Теорема Чебышева (применительно к выборочному методу) может быть записана в следующем виде:
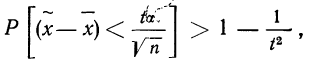
где  —средняя по совокупности выбранных единиц;
—средняя по совокупности выбранных единиц;
 — средняя по генеральной совокупности;
— средняя по генеральной совокупности;
 — среднее квадратическое отклонение в генеральной совокупности.
— среднее квадратическое отклонение в генеральной совокупности.
Теорема формулируется так: с вероятностью, сколь угодно близкой к единице (достоверности), можно утверждать, что при достаточно большом объеме выборки, и ограниченной дисперсии генеральной совокупности разность между выборочной средней 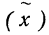 и генеральной средней
и генеральной средней 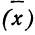 будет сколь угодно мала.
будет сколь угодно мала.
Примечания. 1. Выражение 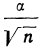 часто обозначают
часто обозначают 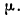
2. При практическом использовании теоремы Чебышева генеральную-дисперсию 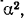 которая неизвестна, заменяют выборочной дисперсией
которая неизвестна, заменяют выборочной дисперсией 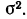
Теорема Ляпунова
Ляпунов с помощью разработанного им метода характеристических функций доказал в 1900 г. центральную предельную теорему, носящую его имя. Эта теорема выясняет общие условия, при осуществлении которых распределение суммы независимых случайных величин стремится к нормальному распределению вероятностей. В частности, эта теорема дает возможность оценить погрешность приближенных равенств: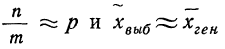
при достаточно больших n (modo Bernulliano). Если 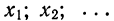
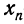 —независимые случайные величины и
—независимые случайные величины и 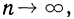 то вероятность их средней
то вероятность их средней 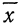 находится в пределе от а до b и может быть определена равенством:
находится в пределе от а до b и может быть определена равенством:
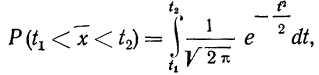
где
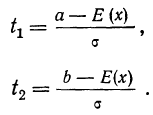
Ограничительные условия теоремы Ляпунова сводятся в основном к тому, чтобы среди слагаемых случайных величин не было сильно выделяющихся (таких, колеблемость которых значительно превосходила бы большинство остальных). В приложении к выборочному методу данная теорема может быть сформулирована следующим образом:
При достаточно большом объеме выборки и ограниченной дисперсии генеральной совокупности вероятность того, что разность между выборочной средней и генеральной средней будет в пределах 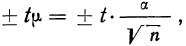 равна
равна 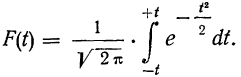
Формулировка Ляпунова придает теореме Чебышева полную определенность и записывается так:
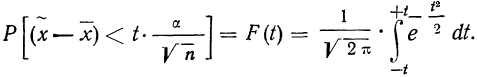
Замечание о практическом использовании ее то же, что и для формулы на стр. 125.
Теорема Я. Бернулли, опубликованная в 1713 г., послужила началом возникновения большой группы теорем, именуемых в общем законом больших чисел. Она представляет собой частный случай теоремы Чебышева и может быть из нее получена
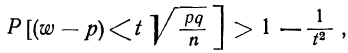
где 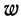 — доля признака среди отобранных единиц (частость);
— доля признака среди отобранных единиц (частость);
р — доля признака в генеральной совокупности.
Теорема Бернулли применяется в тех случаях, когда из генеральной совокупности производится отбор единиц и доля признака не меняется от испытания к испытанию. Формулировка теоремы Бернулли применительно к выборке: с вероятностью, сколь угодно близкой к единице, можно утверждать, что разность между частостью и долей в генеральной совокупности при достаточно большом объеме выборки будет сколь угодно мала. При практическом использовании данной теоремы величина 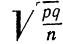 рассчитывается путем замены р на
рассчитывается путем замены р на 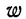 и q на
и q на 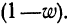
Теорема Пуассона также является частным случаем теоремы Чебышева, когда доля признака в генеральной совокупности (р) с ходом выборки все время меняется. В этом случае
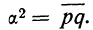
Тогда:
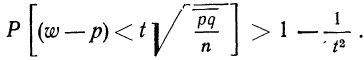
Ошибка репрезентативности (представительства  представляет собой разность между характеристиками выборочной и генеральной совокупности. Генеральная средняя
представляет собой разность между характеристиками выборочной и генеральной совокупности. Генеральная средняя 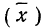 вычитается из выборочной средней
вычитается из выборочной средней 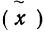 или доля признака в генеральной совокупности (р) вычитается из доли признака в выборочной совокупности, т. е. частости
или доля признака в генеральной совокупности (р) вычитается из доли признака в выборочной совокупности, т. е. частости 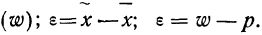
Если  представляет собой предел,которого не превосходит абсолютная величина
представляет собой предел,которого не превосходит абсолютная величина 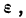 то
то
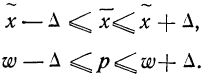
В формулах выборочного метода фигурирует дисперсия генеральной совокупности (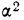 ). Но при производстве выборки характеристики генеральной совокупности неизвестны. Однако обычно (за исключением очень малочисленных выборок) без большой погрешности можно заменить дисперсию генеральной совокупности дисперсией выборочной совокупности (
). Но при производстве выборки характеристики генеральной совокупности неизвестны. Однако обычно (за исключением очень малочисленных выборок) без большой погрешности можно заменить дисперсию генеральной совокупности дисперсией выборочной совокупности (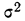 ), которая вычисляется по формулам:
), которая вычисляется по формулам:

Предельная и средние ошибки выборки
Теория устанавливает соотношение между пределом ошибки выборки (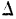 ), гарантируемым с некоторой вероятностью (P), величиной t, связанной с этой вероятностью (см. приложение III), и так называемой средней ошибкой выборки (
), гарантируемым с некоторой вероятностью (P), величиной t, связанной с этой вероятностью (см. приложение III), и так называемой средней ошибкой выборки (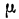 ):
):
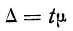
или
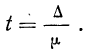
Предельная ошибка выборки равна t-кратному числу средних ошибок выборки.
По способу организации выборки различают:
- собственно случайный отбор;
- типический отбор;
- механический отбор;
- серийный отбор;
- комбинированный отбор.
Собственно случайный отбор ориентирован на выборку единиц из генеральной совокупности без всякого расчленения ее на части или группы. При этом теоретически возможно применение собственно случайного повторного отбора и собственно случайного бесповторного отбора.
Формулы средней ошибки выборки при собственно случайном методе отбора: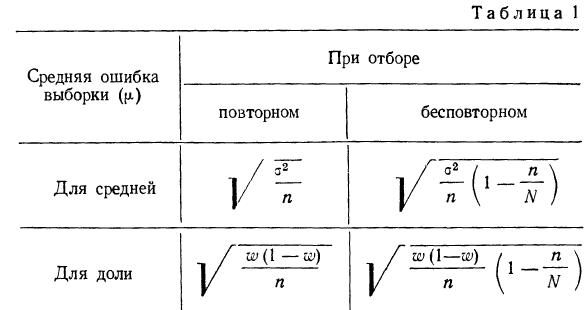
Для большей точности вместо множителя 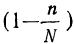 следует брать множитель
следует брать множитель 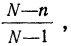 но при большой численности N различие между этими выражениями практически значения не имеет.
но при большой численности N различие между этими выражениями практически значения не имеет.
Пример №9
Из совокупности 10 000 деталей отобрано собственно случайным бесповторным методом 1000 деталей, для которых средний вес детали оказался равным 50 г, дисперсия 49. Бракованных деталей было обнаружено 20 штук. Вычислить средние ошибки выборки для средней и доли.
Дано:
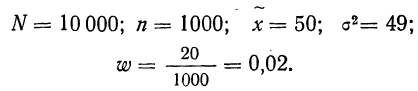
По формулам табл. 1 находим средние ошибки выборки: для среднего веса детали при бесповторном отборе:
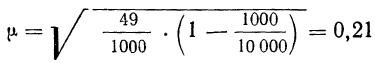
и для доли брака:
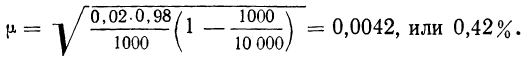
Случайные числа и таблицы случайных чисел
Однозначные числа, расположенные в случайном порядке, называются случайными числами. Случайность расположения чисел состоит в отсутствии закона, определяющего их расположение, и вместе с тем в приближенно равной частоте каждой из десяти цифр.
При организации собственно случайной выборки для соблюдения основного принципа выборки — равной возможности каждой единице генеральной совокупности быть отобранной — используются таблицы случайных чисел, позволяющие производить случайный отбор единиц наудачу, т. е. без привнесения элементов субъективности.
Таблицы случайных чисел составляются различными методами. Так, например, М. Кодыров выписывал 50 000 однозначных чисел из результатов переписи населения 1926 г. Брались срединные цифры одна за другой, в том порядке, в каком они встречались в сводках по городам и губерниям. Для избежания неслучайности крайние цифры из сводок вследствие тенденций к округлениям отбрасывались. А. К. Митропольский для получения таблиц случайных чисел брал 16—19-е знаки двадцатизначной таблицы логарифмов чисел от 90 000 до 100 000. Случайные цифры объединяются в четырехзначные числа.
Таблицы случайных чисел используются путем нумерации всех единиц генеральной совокупности и выписки из таблиц стольких чисел, сколько требуется для выборки. Из генеральной совокупности отбираются те единицы, порядковый номер которых соответствует выписанным из таблицы случайных чисел. Если число единиц в генеральной совокупности не более 999, то последнюю или первую цифру четырехзначного числа отбрасывают. Выборка с помощью таблицы случайных чисел может быть произведена по схеме возвращенного шара (повторная) и по схеме невозвращенного шара (бесповторная). В последнем случае одинаковые числа опускаются.
Пример №10
Генеральная совокупность состоит из 500 единиц. Производится 10-процентный бесповторный отбор. Пронумеруем все 500 единиц генеральной совокупности и возьмем из таблицы случайных чисел (приложение XI) 50 различных трехзначных чисел, начиная с первого числа 3-й колонки. Числа большие, чем 500, отбрасываем.
Получаем: 315, 255, 337, 179, 210, 455, 235-, 364, 489, 80, 117, 118, 174, 476, 111, 341, 296, 332, 4, 307, 22, 430, 52, 22, 83, 248, 319, 262, 36, 101, 27, 342, 470, 330, 170, 443, 499, 109, 42, 70, 490, 422, 336, 67, 121, 225, 57, 319, 499, 362, 198, 50, 286.
Эти числа означают номера тех единиц из 500, которые попали в случайную бесповторную выборку (в данном случае совпадают только три числа: 22, 319, 499; поэтому заменяем их другими).
Для случая, когда частость даже приблизительно неизвестна, можно произвести «грубый» расчет средней ошибки выборки для доли, вводя в расчет максимальную величину произведения 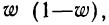 равную 0,25. Тогда для повторного отбора получим:
равную 0,25. Тогда для повторного отбора получим:
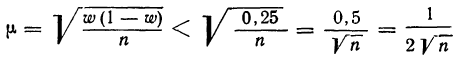
и для бесконечного отбора:
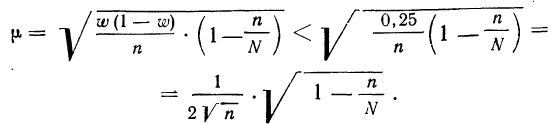
Пример №11
Из совокупности численностью в 900 деталей взята на выборку 81 деталь. Никаких данных, даже предположительных, об удельном весе деталей I сорта в генеральной совокупности нет.
Определить среднюю ошибку выборки для доли продукции I сорта.
Дано: N = 900; n = 81; допускаем, что 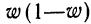 =0,25, тогда получаем:
=0,25, тогда получаем:
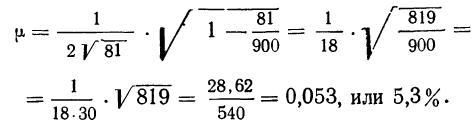
Как было показано в § 7, 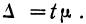 Из приложения III возьмем три значения t, тогда
Из приложения III возьмем три значения t, тогда
при t=1 F(t) = 0,683;
t=2 F(t) = 0,954;
t=3 F(t) = 0,997.
Это показывает, что 0,683 измеряет вероятность того, что ошибка выборки не превысит предела, равного одной средней ошибке. Значительно больше вероятность того, что ошибка не превысит двойной средней ошибки, и т. д.
Вероятность 0,997 практически принимают за достоверность, т. е. считают, что предельная ошибка выборки равна трехкратной средней ошибке.
Иногда для определения размеров предельной ошибки связывают величину t с объемом выборки, применяя эмпирическую формулу:
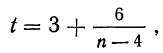
тогда
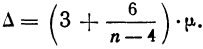
Чем больше объем выборки, тем ближе предельная ошибка к утроенным средним ошибкам.
Численность выборки
При проектировке выборочного наблюдения предполагают заранее заданными величину допустимой ошибки выборки и вероятность ответа. Неизвестным, следовательно, остается тот минимальный объем выборки, который должен обеспечить требуемую точность. Из формулы 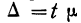 и формул средних ошибок выборки устанавливаем необходимую численность выборки (называемую иногда достаточно большим числом).
и формул средних ошибок выборки устанавливаем необходимую численность выборки (называемую иногда достаточно большим числом).
Формулы для определения численности выборки (n) при собственно случайном способе отбора:
Примечание. При проектировании объема необходимой выборки величины 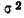 и
и 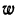 неизвестны, поэтому вместо точного их значения берут приближенные, установленные на основании уже проведенного другого наблюдения или нескольких пробных наблюдений, избирая из найденных результатов наибольшие значения
неизвестны, поэтому вместо точного их значения берут приближенные, установленные на основании уже проведенного другого наблюдения или нескольких пробных наблюдений, избирая из найденных результатов наибольшие значения 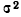 и
и 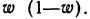
Пример №12
Проектируется выборочное наблюдение, целью которого является установление среднего размера деталей в совокупности, состоящей из 10 000 деталей. Требуемая точность 1 см. Произведенные пробные выборки дали наибольшую дисперсию, равную 49. Нужно определить необходимую численность случайной бесповторной выборки, обеспечивающей с вероятностью 0,95 заданную точность.
Дано: N= 10 000;  =1; F(y)=0,95;
=1; F(y)=0,95; 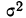 =49.
=49.
По приложению III находим по F(t) значение t= 1,96 и по формуле для бесповторной выборки, взятой из табл. 2, получаем:
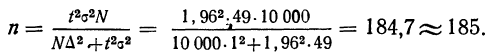
Типический отбор дает более точные результаты. Генеральная совокупность делится по некоторому признаку на типические группы. Количество отбираемых единиц из каждой типической группы устанавливается в следующих размерах (см. табл. 3).

При отборе, не пропорциональном объему типических групп, общее число отбираемых единиц делится на число типических групп и полученная величина дает численность отбора из каждой типической группы.
При отборе, пропорциональном объему типических групп, число наблюдений по каждой группе определяется по формуле:
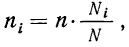
где 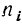 —объем выборки из i-й типической группы;
—объем выборки из i-й типической группы;
n— общий объем выборки;
 — объем i-й типической группы;
— объем i-й типической группы;
N—объем генеральной совокупности.
При отборе с учетом колеблемости признака, дающем наименьшую величину ошибки выборки, процент выборки из каждой типической группы должен быть пропорционален среднему квадратическому отклонению в этой группе 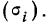 Расчет численности
Расчет численности 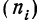 производится по формулам:
производится по формулам:
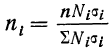 — для средней;
— для средней;
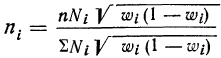 — для доли.
— для доли.
Для вычисления средних ошибок выборки используют формулы табл. 3.
Пример №13
Для определения средней из совокупности 10 000 единиц производится выборка типическим методом. Вся совокупность делится на 5 типических групп. Отбор единиц внутри типических групп производится случайным бесповторным методом пропорционально объему каждой группы. Отбирается 2000 единиц. При отборе получены следующие результаты:
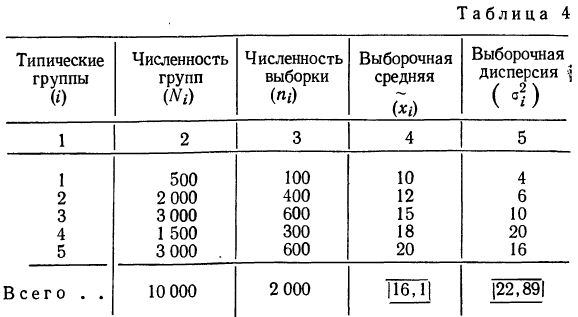
Вычислить: а) среднюю ошибку для каждой группы и для всей выборочной совокупности (при собственно случайном и типическом способах отбора); б) границы, в которых с вероятностью 0,997 находится генеральная средняя по группам и по всей совокупности (при собственно случайном и типическом методах отбора).
Прежде всего рассчитывают численность отбираемых единиц из каждой типической группы пропорционально ее объему (см. колонку 3 табл. 4). Так, для первой типической группы имеем при заданном объеме всей выборки, равном 2000 единиц:
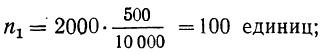
для второй типической группы:
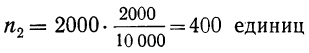
и т. д.
Для определения средней ошибки выборки по группам и общей средней ошибки выборки при собственно случайном способе отбора (бесповторном) используем формулы из табл. 1, Получаем среднюю ошибку выборки:
для первой типической группы
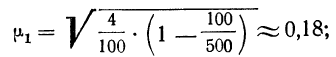
для второй типической группы
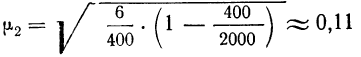
и т. д. по всем группам (см. колонку 2 табл. 5).
Для удобства располагаем все получаемые результаты в таблицу (см. табл. 5).
Для расчета средней ошибки выборки всей совокупности при собственно случайном методе отбора и границ генеральной средней при этом же методе отбора нужно знать общую выборочную среднюю и общую дисперсию выборочной совокупности. Производим расчет общей выборочной средней из групповых выборочных средних путем взвешивания последних по численности отобранных групп
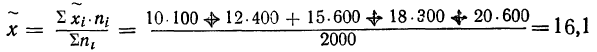
(см. итог колонки 4 табл. 4).
Для определения общей выборочной дисперсии используют теорему сложения вариации.
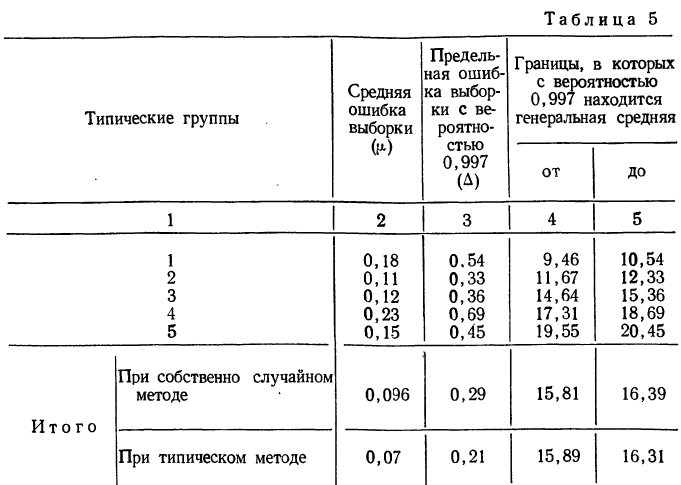
Находим сначала среднюю взвешенную из выборочных дисперсий:
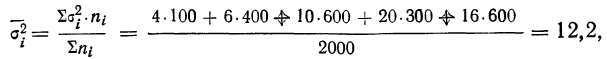
а затем межгрупповую дисперсию:
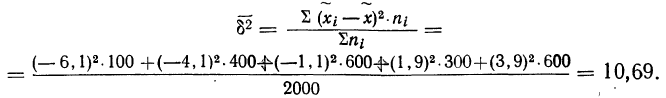
Получаем общую дисперсию выборочной совокупности:
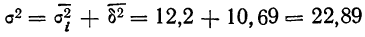
(см. итог колонки 5 табл. 4).
Находим среднюю ошибку выборки всей совокупности при собственно случайном методе отбора
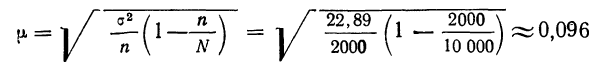
(см. первую строку итога колонки 2 табл. 5).
Предельная ошибка собственно случайной выборки:
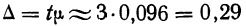
(см. первую строку итога колонки 3 табл. 5).
Соответственно находим границы генеральной средней при собственно случайном методе отбора:
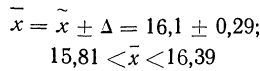
(см. первую строку итога колонок 4 и 5 табл. 5).
Рассчитываем среднюю ошибку типической выборки, пропорциональной объему типических групп, по формуле из табл. 3. Получим:
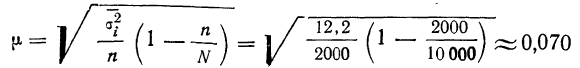
(см. вторую строку итога колонки 2 табл. 5).
Далее определяем ошибку типической выборки 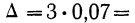
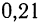 и границы генеральной средней
и границы генеральной средней 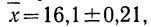 т. е.
т. е. 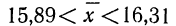 (см. вторую строку итога колонок 4 и 5 табл. 5).
(см. вторую строку итога колонок 4 и 5 табл. 5).
Пример №14
Для определения доли признака производится типическая выборка 400 единиц из совокупности 10 500 единиц, разбитых на 3 типические группы численностью в 5000, 2500 и 3000 единиц. Имеются основания (прошлое обследование) считать, что искомая доля по типическим группам составляет около 10, 20 и 50%.
В каком объеме произвести выборку из типических групп, чтобы пропорции отбора были наивыгоднейшими?
Определяем численность первой типической группы по соответствующей формуле при объеме всей выборки, равной 400 единицам:
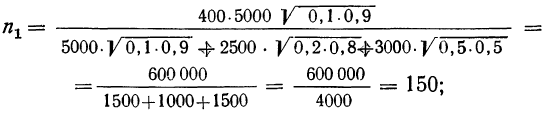
для второй типической группы:
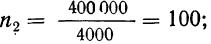
для третьей типической группы:
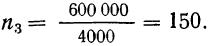
При механической выборке совокупность делится на столько групп, сколько единиц должно войти в выборку, и из 1 каждой группы отбирается одна единица.
Средняя ошибка выборки подсчитывается по формулам ( собственно случайной выборки (табл. 1).
При серийном отборе с равновеликими сериями генеральную совокупность делят на одинаковые по объему группы — серии и производят выборку не единиц совокупности, а серий. Попавшие в выборку серии обследуются сплошь. Серии могут отбираться повторным и бесповторным методами.
Средние ошибки выборки при таком отборе рассчитывают по формулам:

где К — число серий в генеральной совокупности;
r — число отобранных серий;
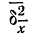 — межсерийная (межгрупповая) дисперсия средних;
— межсерийная (межгрупповая) дисперсия средних;
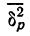 — межсерийная (межгрупповая) дисперсия доли.
— межсерийная (межгрупповая) дисперсия доли.
Пример №15
Генеральная совокупность состоит из 5000 единиц, разбитых на 50 равных по величине серий (по 100 единиц). Бесповторным методом отобрано 10 серий. Результаты выборки представлены в следующей таблице:

Исчислить среднюю ошибку серийной бесповторной выборки. Вычисляем: а) общую среднюю всей выборочной совокупности по серийным средним: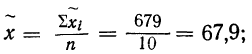
б) межсерийную (межгрупповую) дисперсию средних:
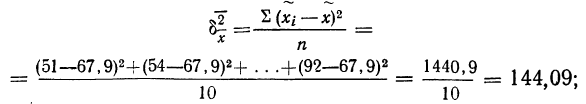
в) среднюю ошибку серийной выборки:
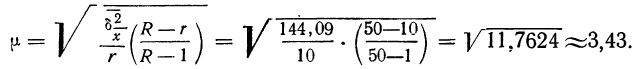
Необходимая численность отбираемых серий при серийном отборе получается из формул табл. 2, в которых вместо N, n и  подставляют R, r и
подставляют R, r и 
Пример №16
Совокупность разбита на 50 серий. Имеются основания предполагать, что межсерийная дисперсия равна 16. Сколько серий нужно отобрать бесповторным методом, чтобы с вероятностью 0,954 утверждать, что ошибка выборочной средней не превысит 2,3.
Дано:
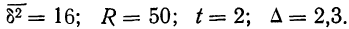
Находим необходимое число серий, отбор которых обеспечит требуемую точность:
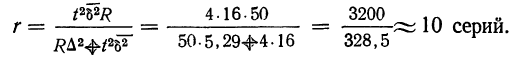
Комбинированная выборка (равновеликие серии) предполагает комбинацию серийного отбора с индивидуальным отбором.
Генеральная совокупность разбивается на одинаковые по объему серии. Сначала отбираются серии, а затем из отобранных серий производится индивидуальная выборка единиц.
Квадрат средних ошибок выборки  рассчитывают по следующим формулам (см. табл. 8),
рассчитывают по следующим формулам (см. табл. 8),
где  — общее число единиц, попавших в выборку при отборе серий, определяется по формуле:
— общее число единиц, попавших в выборку при отборе серий, определяется по формуле:
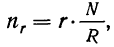
n — число единиц, попавших в выборку из серий.

Пример №17
Генеральная совокупность состоит из 100 000 единиц, разбитых на 200 равных по объему серий. Произведена бесповторная выборка 50% серий и из каждой серии по 20% единиц. Средняя из серийных дисперсий оказалась равной 12, а межсерийная дисперсия — 5. Определить среднюю ошибку выборки. Дано:
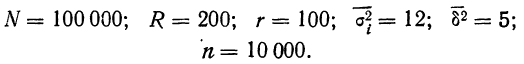
Определяем общее число единиц, попавших в выборку:
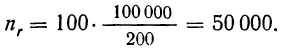
Определяем среднюю ошибку выборки:
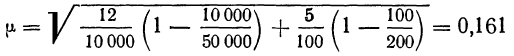
(по формуле из табл. 8 для бесповторного отбора).
Мы получили среднюю ошибку комбинированной выборки при отборе из генеральной совокупности 10 000 единиц. Можно было бы произвести выборку такого же объема, но отобрав 20% серий и 50% единиц из каждой серии.
При тех же значениях — средней из серийных дисперсий и межсерийной дисперсии — средняя ошибка выборки была бы равна:
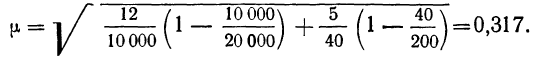
Таким образом, величина ошибки увеличилась бы больше чем в два раза.
В иных случаях большая точность достигается большим числом наблюдений в пределах отобранных серий за счет сокращения числа последних.
Средняя ошибка разности выборочных средних
Выборочная средняя отличается от генеральной средней на t-кратное число средних ошибок  Если в результате выборок получены две выборочные средние
Если в результате выборок получены две выборочные средние  для каждой из которых найдена средняя ошибка выборки
для каждой из которых найдена средняя ошибка выборки  то среднюю ошибку разности этих двух выборочных средних
то среднюю ошибку разности этих двух выборочных средних 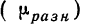 можно определить по средним ошибкам этих выборочных средних
можно определить по средним ошибкам этих выборочных средних
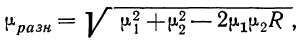
где R—коэффициент корреляции между вариантами двух выборочных совокупностей (см. раздел VII).
В случае некоррелированности признаков, т. е. равенства коэффициента корреляции нулю, формула примет следующий вид:
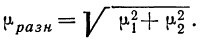
Пример №18
Из генеральной совокупности произведены две выборки. При этом средние ошибки выборочных средних оказались равными 0,48 и 0,43. Признаки некоррелированы. Найти среднюю ошибку разности двух выборочных средних. Она равна
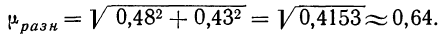
Распределение выборочных средних
Имеется случайная величина х, распределенная в генеральной совокупности по закону нормального распределения со средней 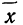 и дисперсией
и дисперсией 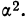 Если произвести достаточно много выборок из указанной совокупности собственно случайным методом и для каждой из выборок вычислить выборочную среднюю, то их распределение будет также подчинено закону нормального распределения со средней
Если произвести достаточно много выборок из указанной совокупности собственно случайным методом и для каждой из выборок вычислить выборочную среднюю, то их распределение будет также подчинено закону нормального распределения со средней 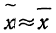 и дисперсией
и дисперсией 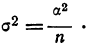
Такое распределение выборочных средних не будет зависеть от объема выборок.
Доверительная вероятность
Для суждения о том, являются ли достоверными характеристики, полученные с помощью выборочных наблюдений, применяют доверительную вероятность, т. е. такую вероятность, которую исследователь признает достаточной при установлении границ случайного колебания изучаемого явления.
В качестве доверительной вероятности принимают Р(t), равное 0,95 или 0,99. Последняя наиболее достаточна.
Достоверность существенного различия
Сравнивая несколько статистических характеристик, например средние или коэффициенты вариации, исчисленные по результатам случайных выборок из генеральной совокупности, хотят установить, существенна ли разность между ними.
Существенным различием называют различие между средними или коэффициентами вариации, превосходящее по величине то, которое можно было бы объяснить случайными колебаниями.
Для признания достоверности существенного различия, приведшего к резкому качественному сдвигу величины изучаемого признака, сравнивают разность между характеристиками с доверительной границей, выражающей пределы случайной вариации. Если эта разность больше доверительной границы, то различие называют существенным, и оно выражает систематическое различие сравниваемых характеристик.
Нулевая гипотеза
При проверке статистической гипотезы об отсутствии существенных различий между несколькими выборочными совокупностями используют так называемую нулевую гипотезу, состоящую в признании того, что они взяты наудачу из одной генеральной совокупности.
Проверка нулевой гипотезы производится с помощью различных критериев согласия, позволяющих с помощью доверительных вероятностей сделать вывод об ее опровержении или неопровержении. При этом следует иметь в виду, что неопро-вержение нулевой гипотезы не означает ее подтверждения, а свидетельствует лишь о необходимости проведения дальнейшей проверки, в частности путем увеличения числа наблюдений. При проверке нулевой гипотезы наибольшее значение придается практической неосуществимости маловероятных событий. Так, если вероятность критерия согласия, выражающего вероятность случайного расхождения, очень мала (<0,05), то это свидетельствует о существенном различии, и нулевая гипотеза опровергается; если же она достаточна велика (>0,05), то вопрос о существенности различия остается без ответа.
В качестве критерия согласия, т. е. оценки существенности расхождения или различия двух выборочных средних, в случае,.если число отобранных единиц в каждой выборке больше 25, принимается неравенство:
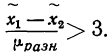
При этом нулевая гипотеза состоит в отрицании существенности различия средних.
Пример №19
Произведем проверку нулевой гипотезы по следующим данным.
Выделено 5 участков лесонасаждений и с каждого участка взяты пробные площадки. В среднем на 1 га по пяти участкам получилось следующее распределение деревьев по толщине: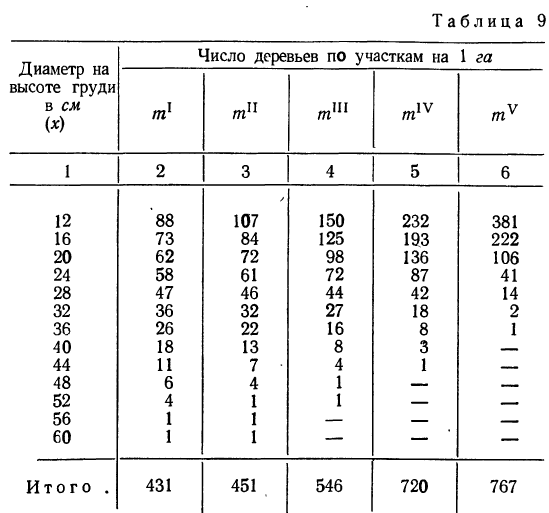
Определить существенность расхождения средних диаметров деревьев по участкам:
а) Находим средние диаметры деревьев по участкам:
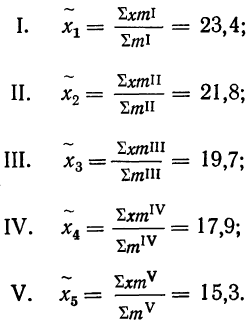
б) Вычисляем средние квадратические отклонения по участкам:

в) Вычисляем средние ошибки выборочных средних:
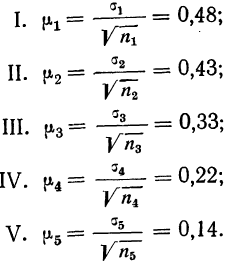
г) Находим, например, следующие разности выборочных средних по участкам:
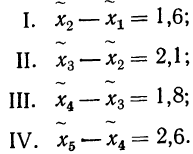
д) Находим средние ошибки разности соответствующих пар выборочных средних:
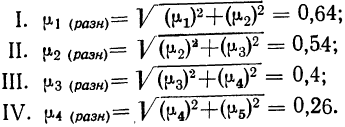
е) Находим критерий оценки существенности расхождения соответствующих выборочных средних:
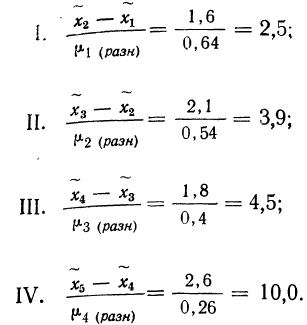
Вывод. Из критериев оценки существенности заключаем, что выделения II, III, IV и V участков произведены правильно, так как критерии оценки существенности больше трех. И следовательно, мы имеем разные насаждения.
При сравнении I и II участков вопрос остается открытым.
Смещенные и несмещенные оценки
Если из генеральной совокупности производится выборка и по ее результатам вычисляются характеристики:
1) выборочная средняя 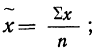
2) выборочная дисперсия 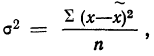 то при большом
то при большом
числе отобранных единиц (n) эти характеристики будут приближаться к соответствующим математическим ожиданиям: Е(х)
и 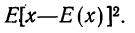
При малом,числе отобранных единиц эти две характеристики могут значительно отличаться от соответствующих математических ожиданий. Поэтому, принимая эти выборочные характеристики в качестве оценок генеральных характеристик, мы допускаем определенную ошибку. Эта ошибка может быть несистематической, когда при неограниченном повторении выборок средняя из выборочных характеристик совпадет с генеральной; при этом систематической ошибки, т. е. регулярного завышения или занижения, не будет. В случае, если среднее значение принятых в качестве оценок выборочных характеристик совпадает с генеральной характеристикой, эти оценки называются несмещенными.
Можно доказать, что  поэтому величина
поэтому величина  является несмещенной оценкой генеральной средней. Что же касается выборочной дисперсии, то ее математическое ожидание не равно генеральной дисперсии.
является несмещенной оценкой генеральной средней. Что же касается выборочной дисперсии, то ее математическое ожидание не равно генеральной дисперсии. 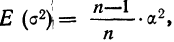 и поэтому
и поэтому  является смещенной оценкой. Для устранения систематической ошибки и получения несмещенной оценки нужно
является смещенной оценкой. Для устранения систематической ошибки и получения несмещенной оценки нужно  умножить на
умножить на 
Тогда дисперсию при малом числе наблюдений следует вычислять по формуле:
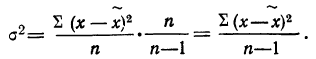
Малая выборка
При необходимости оценки генеральной совокупности по результатам малого числа наблюдений, т. е. при n меньше 20, формулы для обычной (большой) выборки, основанные на нормальном распределении вероятностей, дают значительные неточности.
Оценка результатов малой выборки производится путем «исправления» выборочного среднего квадратического отклонения и использования закона распределения вероятностей Стюдента.
Выборочное среднее квадратическое отклонение малой выборки исчисляется по формуле:
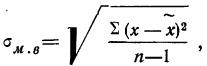
где n—1 представляет собой «Число степеней свободы», т. е. количество вариантов, могущих принимать произвольные значения, не меняющие величины средней.
Таким образом, выборочное среднее квадратическое отклонение малой выборки отличается от выборочного среднего квадратического отклонения ( ) тем, что сумму квадратов отклонений от выборочной средней делят не на n, а на n—1. Зная выборочное среднее квадратическое отклонение
) тем, что сумму квадратов отклонений от выборочной средней делят не на n, а на n—1. Зная выборочное среднее квадратическое отклонение  можно путем его «исправления» вычислить выборочное среднее квадратическое отклонение малой выборки
можно путем его «исправления» вычислить выборочное среднее квадратическое отклонение малой выборки 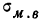 по формуле:
по формуле:
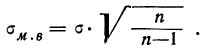
Пример №20
Произведена выборка 16 единиц. Выборочное среднее квадратическое отклонение (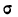 ) оказалось равным 100.
) оказалось равным 100.
Вычислить выборочное среднее квадратическое отклонение малой выборки 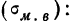
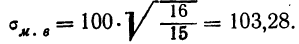
Средняя ошибка малой выборки исчисляется по формуле:
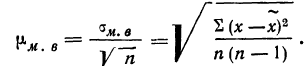
Пример №21
На основе данных примера 12 можно вычислить среднюю ошибку малой выборки:
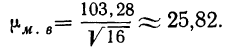
Среднюю ошибку малой выборки можно получить и путем использования «неисправленного» выборочного среднего квадратического отклонения
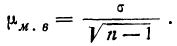
Среднюю ошибку разности двух выборочных средних исчисляют по формуле:
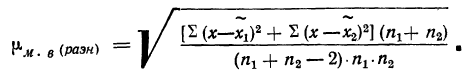
Нормированное отклонение или стандартизованная разность малой выборки (t) получается аналогично тому, как это получалось в обычной выборке:
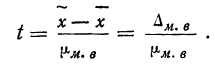
Предельная ошибка малой выборки:
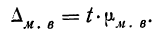
Опираясь на предположение о нормальном распределении признака в генеральной совокупности, Стюдент в 1908 г. нашел закон распределения t, который называется распределением Стюдента:
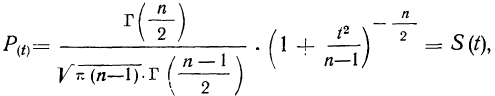
где P(t) =S(t) — вероятности того, что стандартизованная разность между выборочной и генеральной средней имеет величину t;
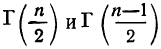 — гаммы-функции, которые можно рассматривать как обобщение факториала натурального числа.
— гаммы-функции, которые можно рассматривать как обобщение факториала натурального числа.
Для любого положительного числа n гамма-функция определяется следующим равенством:
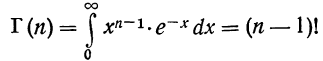
Частные случаи:
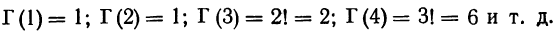
Свойства гаммы-функции:
1)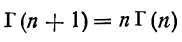 и 2)
и 2)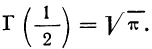
Первый частный случай гаммы-функции и первое указанное ее свойство дают:
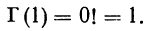
Свойство гаммы-функции позволяет находить Г(n) при n, кратном 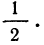 Например:
Например:
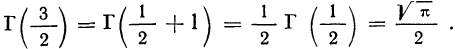
Особенностью распределения Стюдента является то, что вероятность того или иного значения t зависит только от двух величин: объема выборки (n) и величины t. При возрастании объема выборки распределение Стюдента приближается к нормальному:
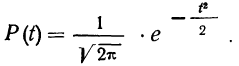
Если сделать определенные допущения о величине Генеральной средней, то можно вычислить фактическое нормированное отношение 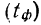 при помощи интеграла Стюдента:
при помощи интеграла Стюдента:
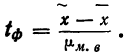
Тогда
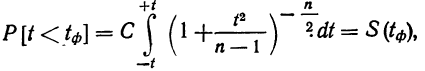
где
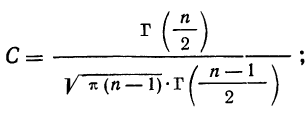
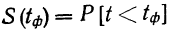 —вероятность того, что стандартизованная разность (t) между действительной генеральной средней и выборочной средней будет меньше стандартизованной разности, вычисленной по результатам малой выборки
—вероятность того, что стандартизованная разность (t) между действительной генеральной средней и выборочной средней будет меньше стандартизованной разности, вычисленной по результатам малой выборки 
 —определяется из приложения IV. При этом значение n определяется вычитанием единицы из числа наблюдений.
—определяется из приложения IV. При этом значение n определяется вычитанием единицы из числа наблюдений.
Интеграл Стюдента используют для решения ряда обычных задач малой выборки как для случаев, когда генеральная совокупность обладает нормальным распределением, так и для случаев, когда распределение признака в генеральной совокупности не совсем совпадает с нормальным.
Функция 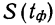 используется для определения также вероятностей того, что: 1)
используется для определения также вероятностей того, что: 1) 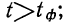 2)
2)  и 3)
и 3) 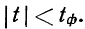
Так, вероятность того, что 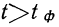 будет:
будет:
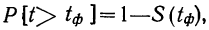
где 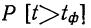 — вероятность значений t, больших, чем
— вероятность значений t, больших, чем 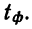 И далее:
И далее:
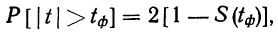
где 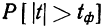 — вероятность значений t, абсолютная величина которых больше, чем
— вероятность значений t, абсолютная величина которых больше, чем 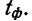
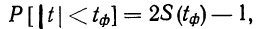
где 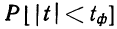 — вероятность значений t, абсолютная величина которых меньше, чем
— вероятность значений t, абсолютная величина которых меньше, чем 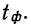
Пример №22
Первая типовая задача малой выборки. Оценка выборочной средней.
Произведена малая выборка урожая пшеницы. Срок уборки урожая своевременный. На выборку собственно случайным повторным методом взято 8 участков. Результаты выборки по отдельным участкам следующие:
Определить вероятность того, что разность между выборочным и генеральным средним урожаем не больше 0,5 ц с 1 га.
Дано:
Находим  по формуле (см. раздел I, стр. 58):
по формуле (см. раздел I, стр. 58): 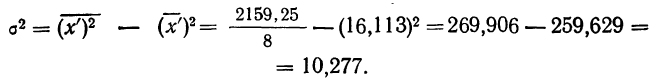
Определяем:

«Исправляем» 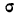 и получаем:
и получаем:
Вычисляем среднюю ошибку малой выборки 
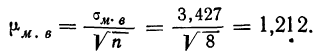
Определяем величину нормированного отклонения по выборочным данным и предполагаемым границам генеральной средней 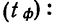
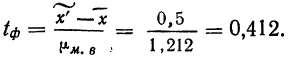
Находим: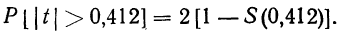
Так как число наблюдений равно 8, то берем n=7; тогда по приложению IV находим: 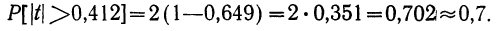
Следовательно:
Р[ |/| >0,412] = 2 (1—0,649) = 2 • 0,351 = 0,702« 0,7.
Таким образом видно, что вероятность нормированных отклонений, по абсолютной величине превышающих 0,412, или, иными словами, вероятность отклонений генеральной средней от выборочной средней на абсолютную величину, превышающую 0,5 ц с 1 га, не мала (0,7). Поэтому разность между генеральной и выборочной средними легко могла превысить 0,5 ц с 1 га.
Можно было воспользоваться другой формулой и определить вероятность нормированных отклонений, абсолютная величина которых меньше 0,412, и прийти к тому же заключению:
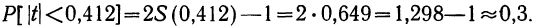
Вероятность того, что генеральная средняя находится в определенных границах, определяется по формуле:
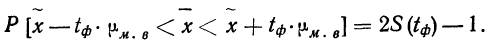
Пример №23
Вторая типовая задача малой выборки: определение границ интервала, в которых находится генеральная средняя.
Из данных предыдущего примера 14 найти с вероятностью 0,954 границы интервала, в которых содержится генеральная средняя урожая.
Дано:
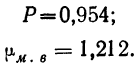
Находим 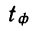 по соответствующей формуле:
по соответствующей формуле:
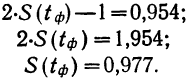
По приложению IV находим  равное 2,5.
равное 2,5.
Следовательно, границы генеральной средней 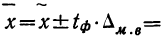
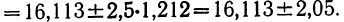
С вероятностью 0,954 можно утверждать, что 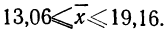
Теория малой выборки дает возможность оценить существенность различия между двумя .выборочными средними. Вероятность значений разностей между двумя выборочными средними, по абсолютной величине не меньших, чем разность, полученная в результате опыта, т. е. фактическая, определяется по формуле:
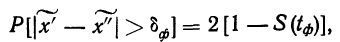
где 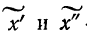 — выборочные средние;
— выборочные средние;
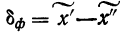 — фактическая разность между двумя выборочными средними;
— фактическая разность между двумя выборочными средними;
а величина 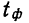 определяется по формуле:
определяется по формуле:
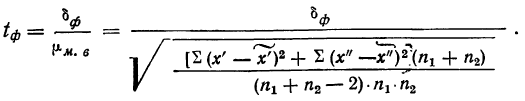
Примечания: 1. При определении вероятности, равной 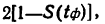 по приложению IV в качестве n следует брать
по приложению IV в качестве n следует брать 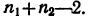
2. Если вероятность (Р) получается большой, то это свидетельствует о том, что следовало ожидать разностей, превышающих ту, которую мы получили фактически. И следовательно, фактическая разность, будучи меньше тех, которых следовало ожидать с большой вероятностью, не дает основания считать, что различия между средними существенны.
При полученной малой вероятности (Р) различие между средними не случайно, а существенно.
3. При вычислении 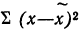 можно использовать равенство
можно использовать равенство 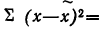
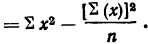
Пример №24
Третья типовая задача малой выборки. Оценка разности двух выборочных средних. Произведена малая выборка девяти участков аналогично тому, как это сделано в примере 14. Урожай убрали с большим опозданием.
Результат сбора урожая по участкам представлен в табл. 11 (в колонках 1 и 2).
Оценить расхождение между средним урожаем, полученным при своевременной уборке урожая (пример 14) и уборке его с большим опозданием.
Дано:
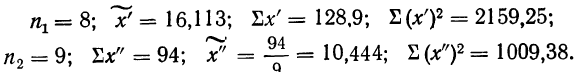
Вычисляем:
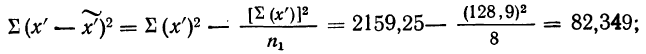

По соответствующей формуле получаем:
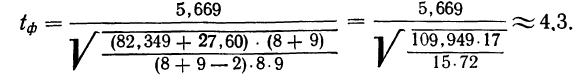
Из приложения IV для n = 8+9—2=15 находим:
S (4,3) =0,999.
Тогда:
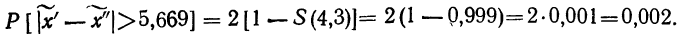
Так как вероятность (Р) очень мала, то следует считать, что средние урожаи существенно отличаются друг от друга, т. е. что опоздание в сроках уборки существенно снижает урожай.
При оценке существенности расхождения между двумя выборочными средними часто применяют правило трех сигм:
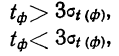
где 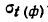 —среднее квадратическое отклонение, вычисляемое по формуле:
—среднее квадратическое отклонение, вычисляемое по формуле:
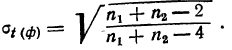
В первом случае, т. е. если 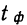 больше трех сигм, расхождение между средними двух выборок полагают не случайным.
больше трех сигм, расхождение между средними двух выборок полагают не случайным.
Пример №25
По данным примеров 14 и 16 оценить расхождение между двумя выборочными средними по указанным формулам:
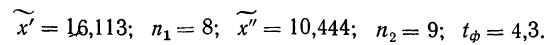
Находим:
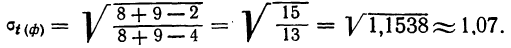
Получаем:
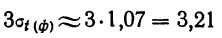
и, следовательно,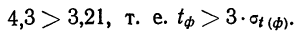
Поэтому расхождение между двумя выборочными средними следует считать существенным, что согласуется с выводом примера 16.
Оценка существенности различия двух выборочных средних может быть произведена также путем использования критерия, основанного на подсчете инверсий. В данном случае нулевой гипотезой является предположение, что две выборочные средние отличаются друг от друга несущественно. Подсчет инверсий производится путем расположения ранжированных результатов двух полученных выборок последовательно. Инверсия образуется в том случае, если какому-нибудь варианту из первой выборки (х) предшествует вариант из второй выборки (у). Например, соединенные в одну последовательность ранжированные варианты двух выборок расположились следующим образом:
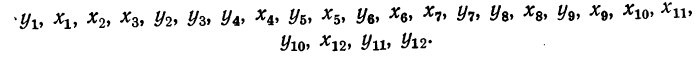
Тогда подсчет инверсий для 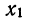 дает 1, для
дает 1, для 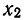 и
и 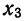 — тоже единицу, для
— тоже единицу, для 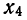 инверсий —4, для
инверсий —4, для 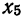 — 5 и т. д.
— 5 и т. д.
После подсчета числа инверсий находят математическое ожидание инверсии по формуле:
где 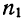 и
и 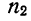 — объемы выборок.
— объемы выборок.
Далее находят дисперсию: 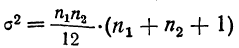
и 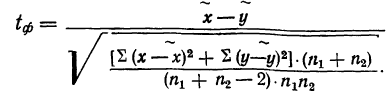
Путем вычитания и прибавления к E(z) произведения 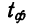 на
на  находят ожидаемые границы г. Если z находится в найденных границах, то нулевая гипотеза не опровергается. При выходе z за найденные границы нулевая гипотеза опровергается и делается вывод о существенности различий средних.
находят ожидаемые границы г. Если z находится в найденных границах, то нулевая гипотеза не опровергается. При выходе z за найденные границы нулевая гипотеза опровергается и делается вывод о существенности различий средних.
Данный метод обоснован в случаях, когда объем выборок больше 10, но может быть использован и при n, близком к 10.
Пример №26
Используя данные примеров 14 и 16, найдем существенность различия двух средних урожаев, полученных в результате сбора урожая своевременно и с большим опозданием.
Располагаем результаты обеих выборок в ранжированном порядке.

Имеем: 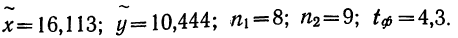 Подсчитываем:
Подсчитываем: 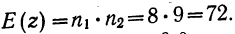
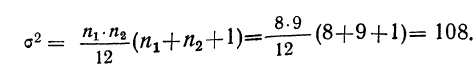

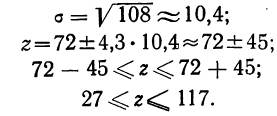
Подсчитываем фактическое число инверсий: z=1 +1 + 1 + + 2 = 5.
В данном случае нулевая гипотеза опровергается и результат свидетельствует о существенном расхождении двух средних урожаев, что согласуется с выводами, полученными ранее другими способами.
При проверке гипотезы случайности выборки можно использовать метод последовательных разностей.
Пусть выборка n единиц из генеральной совокупности со средней 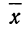 и дисперсией
и дисперсией 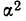 расположились по значению признака в следующем порядке:
расположились по значению признака в следующем порядке: 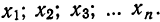 Находим сначала разности между значениями признака в последовательности их отбора.
Находим сначала разности между значениями признака в последовательности их отбора.
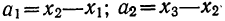 и т. д. до
и т. д. до 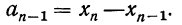 Определяем среднюю из квадратов разностей по формуле:
Определяем среднюю из квадратов разностей по формуле:
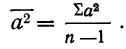
Находим:
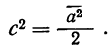
Вычисляем выборочную дисперсию:
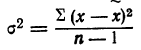
и для получения критерия 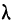 делим
делим 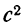 на
на 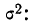
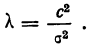
Сравнение найденного критерия с теоретическим (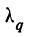 ) в зависимости от объема выборки производится так.
) в зависимости от объема выборки производится так.
Если n<20, то используют следующую таблицу (см. табл. 13):

Из таблицы находят 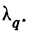 При этом если найденная
При этом если найденная 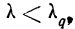 то это указывает на неверность рассматриваемой гипотезы. Если
то это указывает на неверность рассматриваемой гипотезы. Если 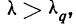 то гипотеза верна.
то гипотеза верна.
При большом числе отобранных единиц (n>20) 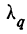 определяется по формуле:
определяется по формуле:
где находится по табличному значению 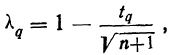
где 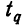 находится по табличному значению
находится по табличному значению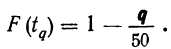
При q = 5% имеем 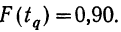 Из приложения III находим, что
Из приложения III находим, что 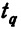 = 1,65, значит
= 1,65, значит
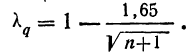
Пример №27
Используя данные примера 16 о результатах сбора урожая по участкам с большим опозданием, оценим гипотезу случайности выборки.
1) Находим разности:
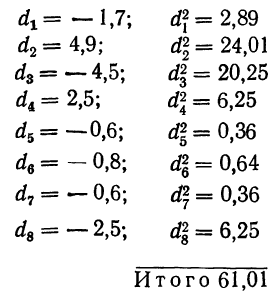
и вычисляем 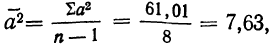 а затем
а затем 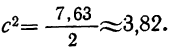
2) Определяем сначала среднюю:
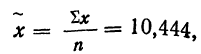 а затем дисперсию:
а затем дисперсию:
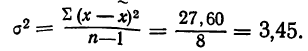
3) Находим критерий:
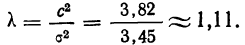
4) По табл. 13 определяем верхнюю допустимую границу 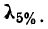 При n = 9
При n = 9 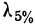 = 0,512.
= 0,512.
5) Делаем вывод о том, что найденная  превосходит допустимую верхнюю границу
превосходит допустимую верхнюю границу  и поэтому наша гипотеза о случайности выборки верна.
и поэтому наша гипотеза о случайности выборки верна.
Пример №28
Пусть отобрано 35 единиц. При q = 5% получаем:
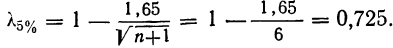
Следовательно, если при выборке 35 единиц 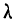 будет меньше 0,725, то это укажет на неверность нашей гипотезы; если же больше, то гипотеза верна.
будет меньше 0,725, то это укажет на неверность нашей гипотезы; если же больше, то гипотеза верна.
Оценка существенности различия коэффициентов вариации устанавливается аналогично тому, как это делается при оценке существенности различия выборочных средних по критерию согласия. Если принять:
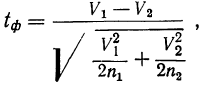
то при  >3 различие коэффициентов вариации полагают неслучайным.
>3 различие коэффициентов вариации полагают неслучайным.
Во всех случаях  <3 делают вывод, что при данном числе наблюдений нулевая гипотеза не подтверждается и тем самым существенность различия не доказана.
<3 делают вывод, что при данном числе наблюдений нулевая гипотеза не подтверждается и тем самым существенность различия не доказана.
Пример №29
Используя данные примера 11 о выделении участков лесонасаждений, оценим существенность различия коэффициентов вариации по двум участкам — IV и V.
Имеем: 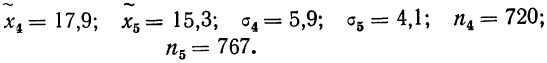
Определяем коэффициенты вариации:
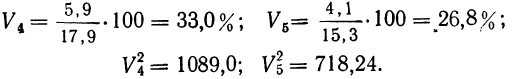
Находим
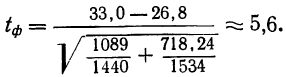
Так как 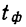 > 3, делаем вывод, что рассматриваемые коэффициенты вариации отличаются существенно, т. е. неслучайно.
> 3, делаем вывод, что рассматриваемые коэффициенты вариации отличаются существенно, т. е. неслучайно.
- Статистическая проверка гипотез
- Статистические оценки
- Теория статистической проверки гипотез
- Линейный регрессионный анализ
- Регрессионный анализ
- Корреляционный анализ
- Статистические решающие функции
- Случайные процессы
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.