Что такое валидатор файла robots.txt?
Инструмент проверки Robots.txt создан для того, чтобы показать, правильно ли составлен ваш файл robots.txt, нет ли в нем ошибок. Robots.txt — этот файл, который является частью вашего веб-сайта и описывает правила индексации для роботов поисковых машин, чтобы веб-сайт индексировался правильно, и первыми на сайте индексировались самые важные данные (без каких-либо скрытых платежей).Это очень простой инструмент, который создает отчет уже через несколько секунд сканирования: вам просто ввести в поле URL своего веб-сайта, через слэш /robots.txt (например, yourwebsite.com/robots.txt), а затем нажать на кнопку “проверить”. Наш инструмент для тестирования файлов robots.txt находит все ошибки (опечатки, синтаксические и “логические”) и выдает советы по оптимизации файла robots.txt.
Зачем нужно проверять файл robots.txt?
Проблемы с файлом robots.txt или его отсутствие могут негативно отразиться на SEO-оптимизации сайта: ваш сайт может не выдаваться на странице результатов выдачи поисковых машин (SERP). Это происходит из-за того, что нерелевантный контент может обходиться до или вместо важного контента.Проверить свой файл перед тем, как обходить контент важно, чтобы вы смогли избежать проблем, когда весь контент на сайте индексируется, а не только самый релевантный. Например, вы хотите, чтобы доступ к основному контенту вашего веб-сайта пользователи получали только после того, как заполнят форму подписки или войдут в свою учетную запись, но вы не исключаете ее в правилах файла robot.txt, и поэтому она может проиндексироваться.
Что означают ошибки и предупреждения?
Есть определенный список ошибок, которые могут повлиять на эффективность файла robots.txt, а также вы можете увидеть при проверке файла список определенных рекомендаций. Это вещи, которые могут повлиять на SEO-оптимизацию сайта, и которые нужно исправить. Предупреждения менее критичны, и это просто советы о том, как улучшить ваш сайт robots.txt.Ошибки, которые вы можете увидеть:Invalid URL: эта ошибка сообщает о том, что файл robots.txt на сайте отсутствует.Potential wildcard error: технически это больше предупреждение, чем сообщение об ошибке. Это сообщение обычно означает, что в вашем файле robots.txt содержится символ (*) в поле Disallow (например, Disallow: /*.rss). Это проблема приемлемого использования синтаксиса: Google не запрещает использование символов в поле Disallow, но это не рекомендуется.Generic and specific user-agents in the same block of code: это синтаксическая ошибка в файле robots.txt, которую нужно исправить, чтобы избежать проблем с индексацией контента на вашем веб-сайте.Предупреждения, которые вы можете увидеть:Allow: / : порядок разрешения не повредит и не повлияет на ваш веб-сайт, но это не стандартная практика. Самые крупные поисковые машины, включая Google и Bing, примут эту директиву, но не все программы-кроулеры будут такими же неразборчивыми. Если говорить начистоту, то всегда лучше сделать файл robots.txt совместимым со всеми программами-индексаторами, а не только с самыми популярными.Field name capitalization: несмотря на то, что имена полей не чувствительны к регистру, некоторые индексаторы могут требовать писать их заглавными буквами, так что хорошей идеей будет делать это по умолчанию — специально для самых привередливых программ.Sitemap support: во многих файлах robots.txt содержатся данные о карте сайта, но это не считается хорошим решением. Однако, Google и Bing поддерживают эту возможность.
Как исправить ошибки в файле Robots.txt?
Насколько просто будет исправить ошибки в файле robots.txt? Зависит от платформы, которую вы используете. Если это WordPress, то лучше воспользоваться плагином типа WordPress Robots.txt Optimization или Robots.txt Editor. Если вы подключили свой веб-сайт к веб-службе Google Search Console, вы сможете редактировать свой файл robots.txt прямо в ней.Некоторые конструкторы веб-сайтов типа Wix не дают возможности редактировать файл robots.txt напрямую, но позволяют добавлять неиндексируемые теги для определенных страниц.
10 апреля 2023
Файл robots.txt знаком всем SEO-специалистам, ведь он оказывает большое влияние на ранжирование веб-ресурса в поисковых системах. Он дает поисковым роботам рекомендации о том, какие разделы и веб-страницы сайта индексировать необходимо, а какие не должны попасть в результаты поисковой выдачи. Кроме того, если сайт переезжает на новый домен, файл помогает ему не потерять трафик и результаты поисковой оптимизации. Поисковые системы называют такие правила директивами, однако, сами себе противореча, могут проигнорировать их. Ошибки при составлении файла приводят к некорректной индексации сайта и отсутствию возможности вывести сайт в ТОП-10 поисковых результатов. Начинающим SEO-специалистам не повредит помощь сервисов, которые могут проверить robots.txt и дать рекомендации по его улучшению. Обзор пяти бесплатных сервисов по чек-апу robots.txt — в статье.
Сервисы для анализа файла robots.txt онлайн
- Анализ robots.txt в Яндекс.Вебмастер.
- Инструмент от Google Search Console.
- Проверка файла от Websiteplanet.
- Сервис Tools.discript.ru.
- Проверка от Pixelplus.

Изображение от pch.vector на Freepik.
Не все страницы сайта содержат оригинальный, релевантный и качественный контент. Некоторые и вовсе содержат конфиденциальные данные и не должны попадать в открытый доступ. Если владелец сайта знает о всех недостатках и особенностях веб-ресурса, он может повлиять на его индексирование. Разместив в корневом каталоге сайта файл robots.txt, можно не беспокоиться о том, что поисковые алгоритмы будут оценивать каждую веб-страницу. Изучив ваши рекомендации, они посетят только те, в качестве контента которых вы уверены.
№1. Анализ robots.txt в Яндекс.Вебмастер
Яндекс.Вебмастер — инструмент от главной поисковой системы Рунета. Его использование является абсолютно свободным и бесплатным. Однако вам придется подтвердить, что вы имеете права на управление сайтом. Добавив сайт в панель управления Вебмастера и пройдя аутентификацию в качестве владельца веб-ресурса, вы можете перейти к работе с инструментами для анализа SEO-показателей сайта и продвижения в поисковой системе Яндекс.
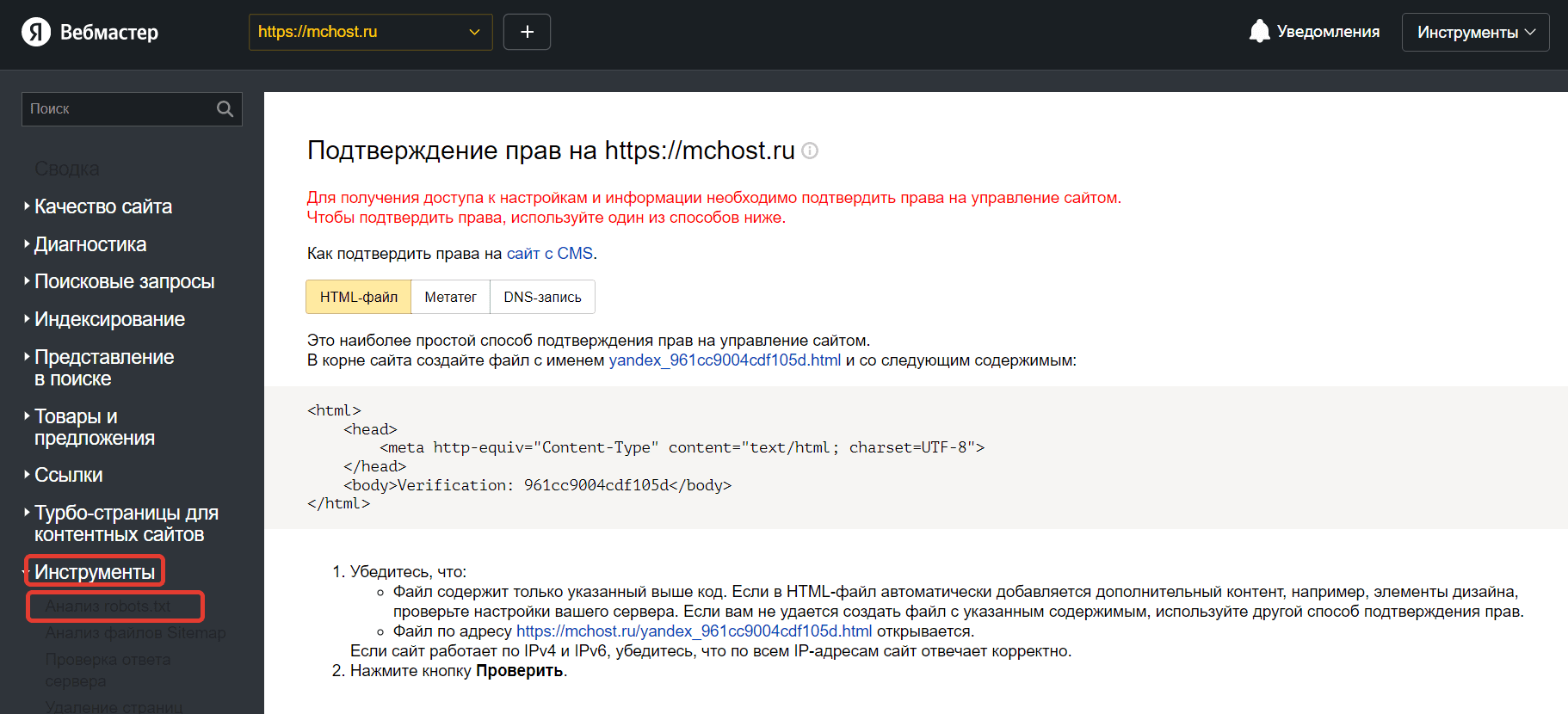
Алгоритм проверки robots.txt с помощью валидатора Яндекс:
- В левом меню найдите раздел «Инструменты», выберете инструемент «Анализ robots.txt».
- Содержимое файла должно появиться в поле проверки автоматически. При отсутствии результата скопируйте код и вставьте его в поле самостоятельно. Нажмите на кнопку проверки.
- Результаты анализа появился ниже. При наличии ошибок валидатор выделит их цветом и оставит комментарий.
№2. Инструмент от Google Search Console
Google Search Console — простой инструмент для проверки файла robots.txt от Google. Он также потребует от вас подтверждения прав на владение веб-ресурсом.
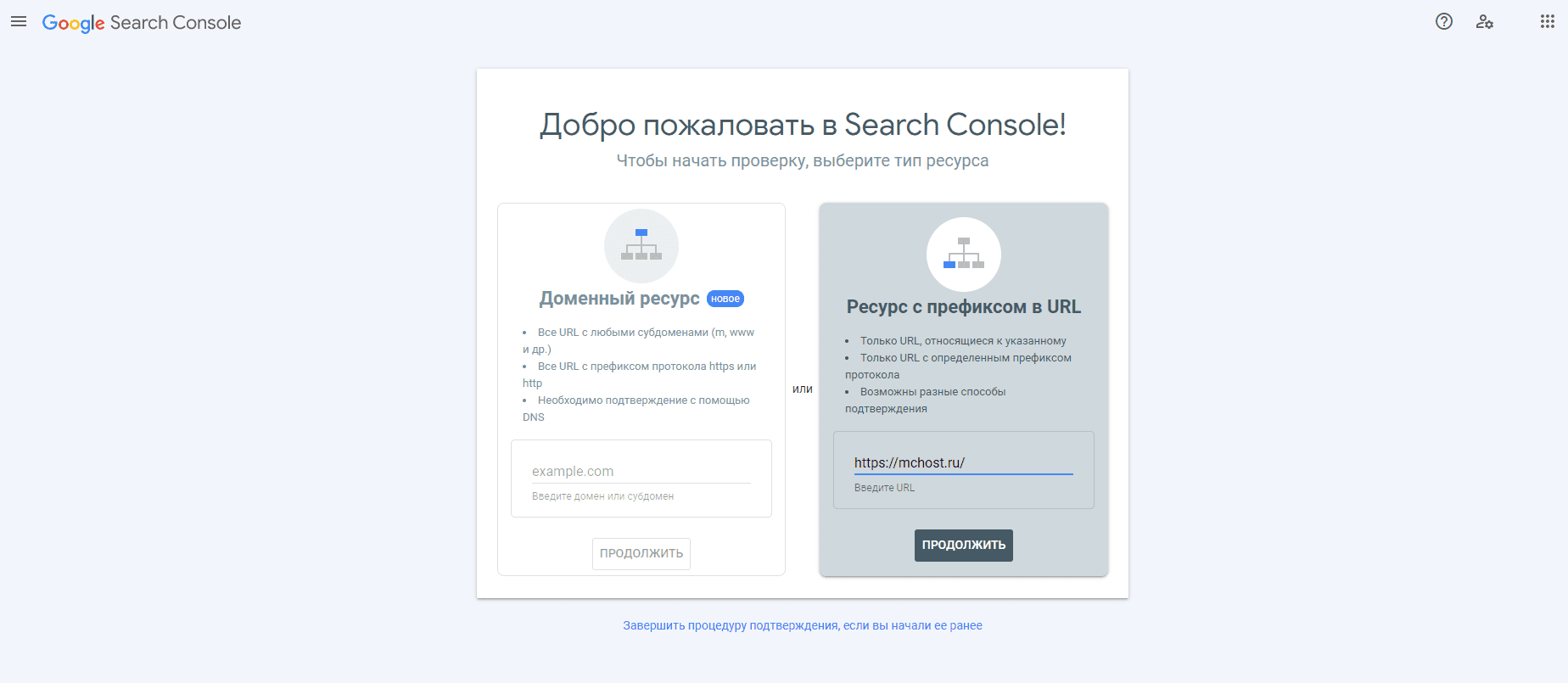
После того как вы пройдете данную формальную процедуру, можно будет переходить к работу с файлом с директивами.
- Откройте страницу «Инструменты проверки».
- Если автоматически открылся файл с устаревшей версией robots.txt, отправьте актуальный файл и следуйте инструкциям сервиса.
- Обновите страницу и подождите появления директивов. Ошибки будут перечислены под кодом.
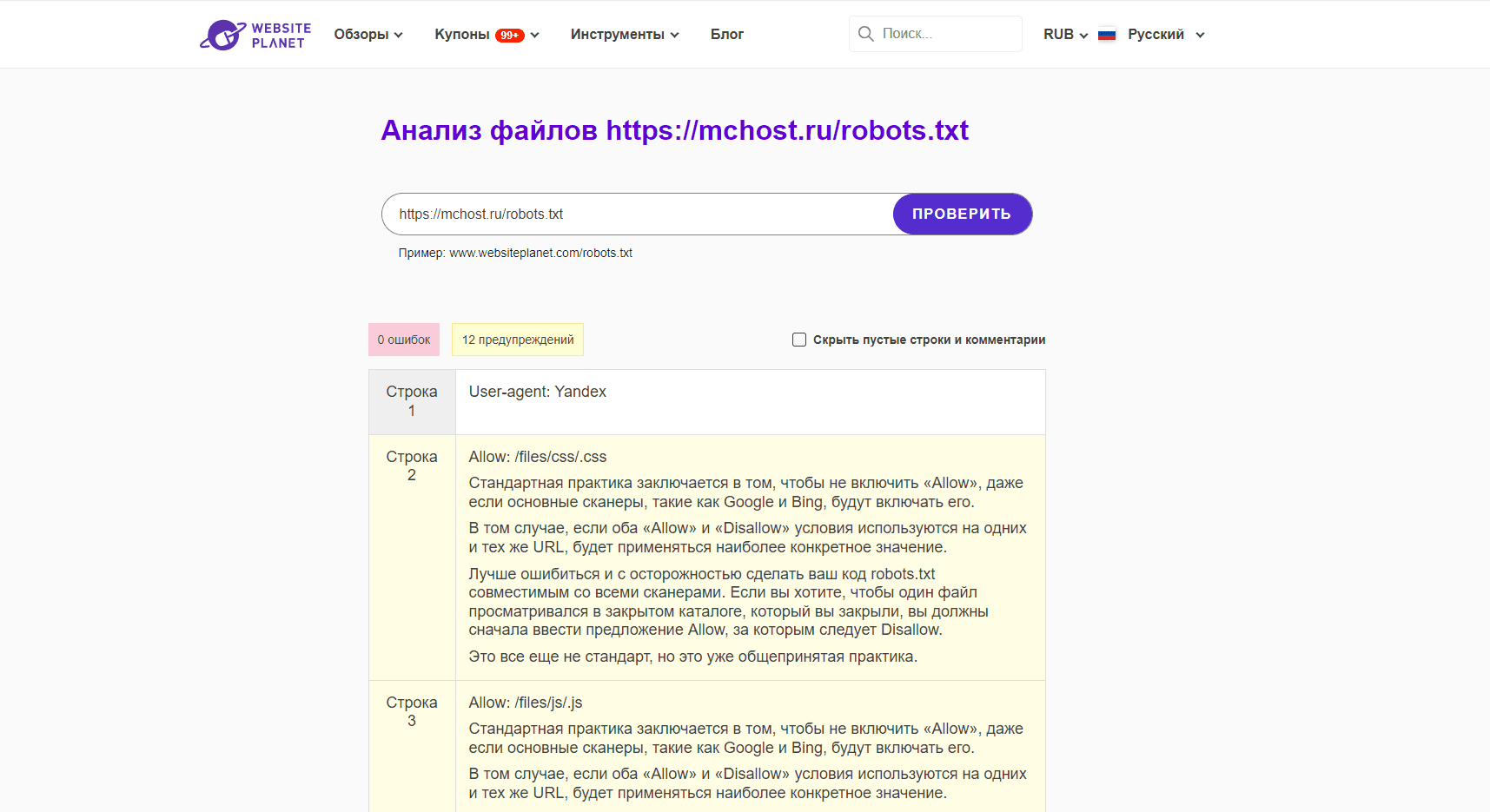
№3. Проверка файла от Websiteplanet
Сервис работает быстро. Он не требует от пользователей подтверждения прав на владение сайтом. Чтобы запустить проверку файла с директивами, достаточно указать место его расположения, например, у нас это https://mchost.ru/robots.txt. Инструмент показывает не только ошибки, но и предупреждения. Каждый недочет сопровождается развернутым комментарием.
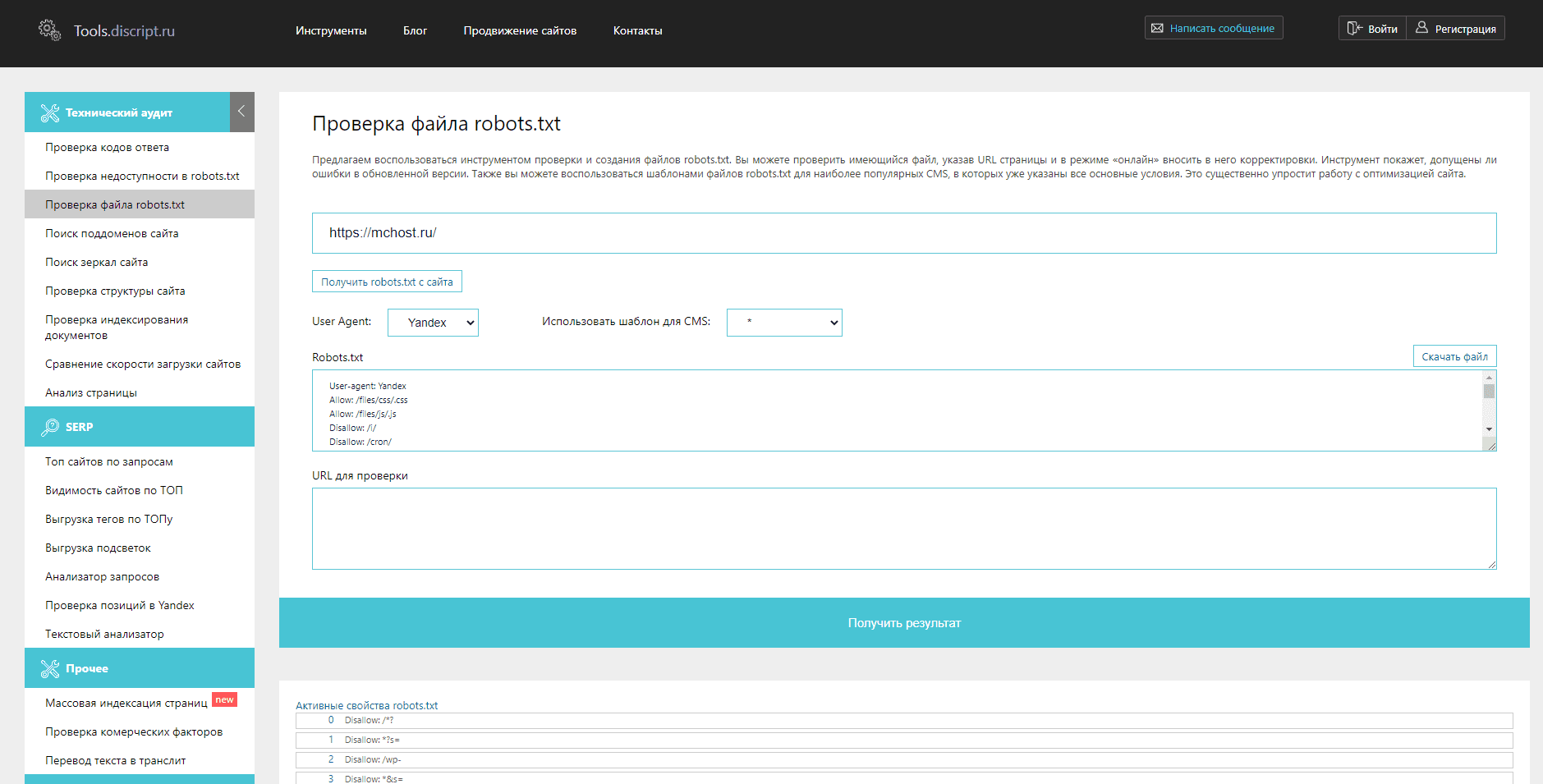
№4. Сервис Tools.discript.ru
Инструмент позволяет проверять robots.txt на ошибки, редактировать его в режиме онлайн, оптимизировать под CMS сайта и конкретного поискового агента, создавать новый файл и скачивать готовую версию.
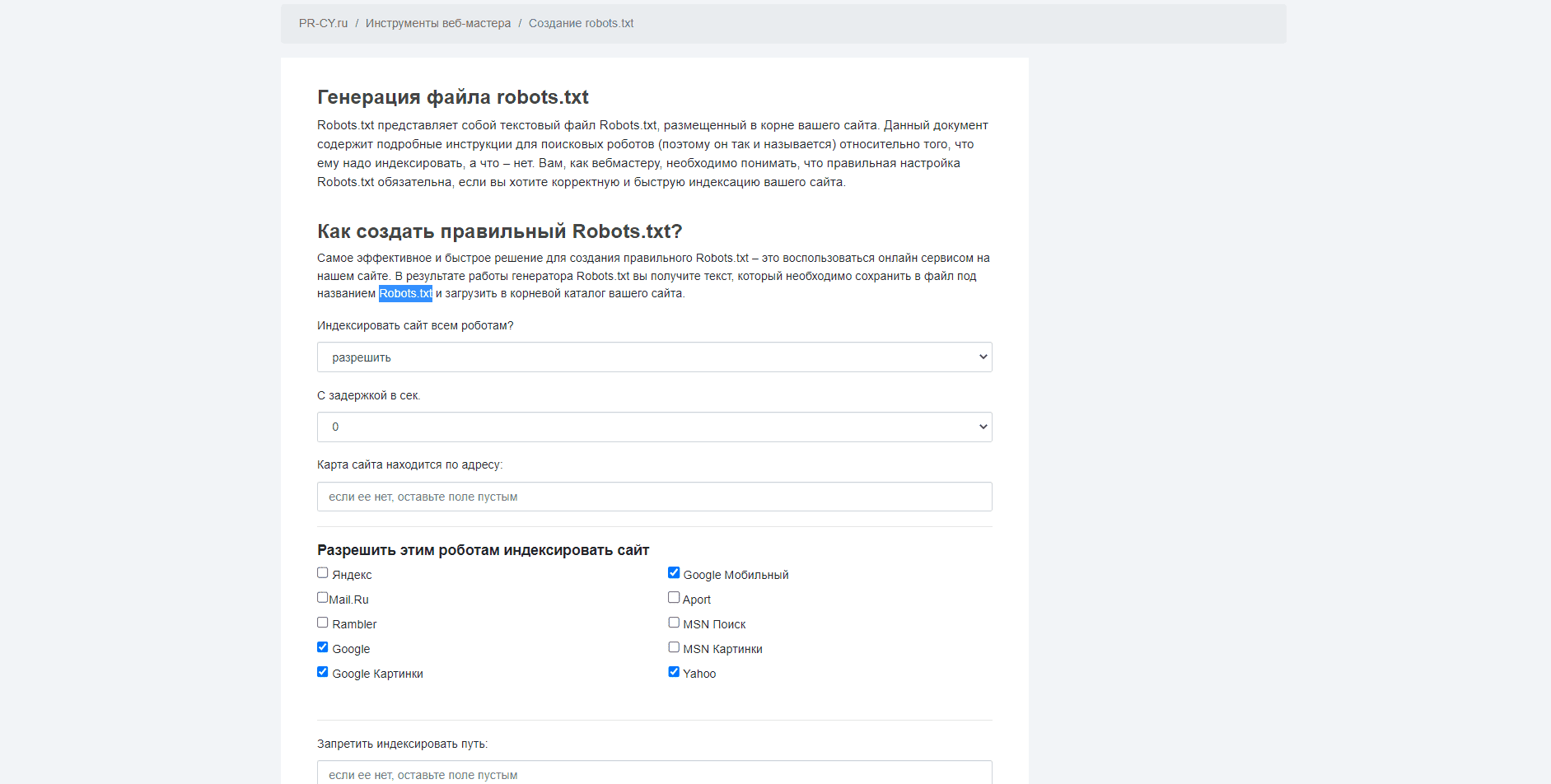
№5. Проверка от PR-CY
Сервис предлагает бесплатное создание файла с директивами для поисковых систем. Пользователю нужно настроить параметры будущего robots.txt, указав какие поисковые системы смогут его индексировать, путь к карте сайта, страницы, которые индексировать нельзя. В результате сервис формирует текст robots.txt, который необходимо сохранить в файле под одноименным названием и добавить в корневой каталог сайта.
Заключение
От правильной записи директив в файле robots.txt зависит успех продвижения сайта в сети. Начинающие SEO-специалисты могут воспользоваться онлайн-сервисами, чтобы проверить свой файл, перед его размещением в корневом каталоге.
Сервисы для анализа файла robots.txt онлайн
№1. Анализ robots.txt в Яндекс.Вебмастер
№2. Инструмент от Google Search Console
№3. Проверка файла от Websiteplanet
№4. Сервис Tools.discript.ru
№5. Проверка от PR-CY
Заключение
The robots.txt Tester tool shows you whether your robots.txt file blocks Google web crawlers from specific URLs on your site. For example, you can use this tool to test whether the Googlebot-Image crawler can crawl the URL of an image you wish to block from Google Image Search.
Open robots.txt Tester
You can submit a URL to the robots.txt Tester tool. The tool operates as Googlebot would to check your robots.txt file and verifies that your URL has been blocked properly.
Test your robots.txt file
- Open the tester tool for your site, and scroll through the
robots.txtcode to locate the highlighted syntax warnings and logic errors. The number of syntax warnings and logic errors is shown immediately below the editor. - Type in the URL of a page on your site in the text box at the bottom of the page.
- Select the user-agent you want to simulate in the dropdown list to the right of the text box.
- Click the TEST button to test access.
- Check to see if TEST button now reads ACCEPTED or BLOCKED to find out if the URL you entered is blocked from Google web crawlers.
- Edit the file on the page and retest as necessary. Note that changes made in the page are not saved to your site! See the next step.
- Copy your changes to your robots.txt file on your site. This tool does not make changes to the actual file on your site, it only tests against the copy hosted in the tool.
Limitations of the robots.txt Tester tool:
- The tool works only with URL-prefix properties; it does not work with Domain properties.
- Changes you make in the tool editor are not automatically saved to your web server. You need to copy and paste the content from the editor into the
robots.txtfile stored on your server. - The robots.txt Tester tool only tests your
robots.txtwith Google user-agents or web crawlers, like Googlebot. We cannot predict how other web crawlers interpret yourrobots.txtfile.
Was this helpful?
How can we improve it?
What is Robots.txt File?
Robots.txt file allows or disallows the crawlers from accessing and crawling the
web
pages. Think of Robots.txt file as an instruction manual for the search engine
crawlers.
It provides a set of instructions to specify which parts of the website are
accessible
and which are not.
More clearly, the robots.txt file enables the webmasters to control the crawlers
—
what
to access and how. You must know that a crawler never directly lands on the site
structure rather it accesses the robots.txt file of the respetive website to
know
which
URLs are allowed to be crawled and which URLs are disallowed.
Uses of Robots.txt File
A Robots.txt file
helps
the webmasters to keep the web pages, media files, and resource files out of the
reach
of all the search engine crawlers. In simple words, it is used for keeping URLs
or
images, videos, audios, scripts, and style files off of the SERPs.
The majority of the SEOs tend to leverage Robots.txt file as the means to block
web
pages
from appearing in the search engine results. However, it shouldn’t be used for
this
purpose as there are other ways to do it such as the application of meta robots
directives and password encryption.
Keep in mind that the Robots.txt file should only be used to prevent the crawlers
from
overloading a website with crawling requests. Moreover, if required then the
Robots.txt
file can be used to save the crawl budget by blocking the web pages which are
either
unimportant or underdevelopment.
Benefits of Using Robots.txt File
Robots.txt file can be both an ace in the hole and a danger for your website SEO.
Except
for the risky possibilty that you unintetionally disallow the search engine bots
from
crawling your entire website, Robots.txt file always comes in handy.
Using a Robots.txt file, the webmasters can:
-
Specify the location of sitemap
-
Forbid the crawling of duplicate content
-
Prevent certain URLs and files from appearing in SERPs
-
Set the crawl delay
-
Save the crawl budget
All of these practicies are considered best for the website SEO and only
Robots.txt
can
help you to apply
Limitations on Using Robots.txt File
All the webmasters must know that in some cases, Robots Exclusion Standard
probably
fails
to prevent the crawling of web pages. There are certain limitation on the use of
Robots.txt File such as:
-
Not all search engine crawlers follows the robots.txt directives
-
Each crawler has its own way of understanding the robots.txt syntax
-
There’s a possibility that the Googlebot can crawl a disallowed URL
Certain SEO practicies can be done in order to make sure that the blocked URLs
remains
hidden from all of the search engine crawlers.
Creating Robots.txt File
Have a look at these sample formats to know how you can create and modify your
Robots.txt
file:
User-agent: * Disallow: / indicates that every search engine crawler is
prohibited from crawling all of the web pages
User-agent: * Disallow: indicates that every search engine crawler is
allowed
to
crawl the entire website
User-agent: Googlebot Disallow: / indicates that only the Google crawler
is
disallowed from crawling all of the pages on the website
User-agent: * Disallow: /subfolder/ indicates that no search engine
crawler
can
access any web page of this specific subfolder or category
You can create and modify your Robots.txt file in the same way. Just be catious
about
the
syntax and format the Robots.txt according to the prescribed rules.
Robots.txt Syntax
Robots.txt syntax refers to the language we use to format and structure the
robots.txt
files. Let us provide you with information about the basic terms which make up
Robots.txt Syntax.
User-agent is the search engine crawler to which you provide crawl
instructions
including which URLs should be crawled and which shouldn’t be.
Disallow is a robots meta directive that instructs the user-agents not to
crawl
the respective URL
Allow is a robots meta directive that is only applicable to Googlebot. It
instructs the Google crawler that it can access, crawl, and then index a web
page or
subfolder.
Crawl-delay determines the time period in seconds that a crawler should
wait
before crawling web content. For the record, Google crawler doesn’t follow this
command.
Anyhow, if required then you can set the crawl rate through Google Search
Console.
Sitemap specifies the location of the given website’s XML sitemap(s). Only
Google,
Ask, Bing, and Yahoo acknowledge this command.
Special Characters including * , / , and $ makes it easier for the
crawlers to
understand the directives. As the name says, each one of these characters has a
special
meaning:
* means that all the crawlers are allowed/disallowed to crawl the respective
website
. /
means that the allow/disallow directive is for all web pages
Robots.txt Quick Facts
- ➔ The Robots.txt file of a subdomain is separatly created
- ➔ The name of the Robots.txt file must be saved in small letter
cases
as “ robots.txt “ because it is case-sensitive. - ➔ The Robots.txt file must be placed in the top-level directory
of
the
website - ➔ Not all crawlers (user-agents) support the robots.txt file
- ➔ The Google crawler can find the blocked URLs from linked
websites - ➔ The Robots.txt file of every website is publiclly accessible
which
means that anyone can access it
PRO Tip : In case of a dire need, use other URL blocking methods such as
password
encryption and robots meta tags rather than robots.txt file to prevent crawling
of
certain web pages.
Первым делом необходимо проверить доступность файла robots.txt. Переходим и смотрим его визуально https://robotstxt.ru/robots.txt, открывается ли он.
Дальше нам необходимо проверить его техническую доступность, заходим в сервис проверки ответа сервера Яндекса.
Вводим путь к вашему файлу robots.txt и нажимаем проверить.
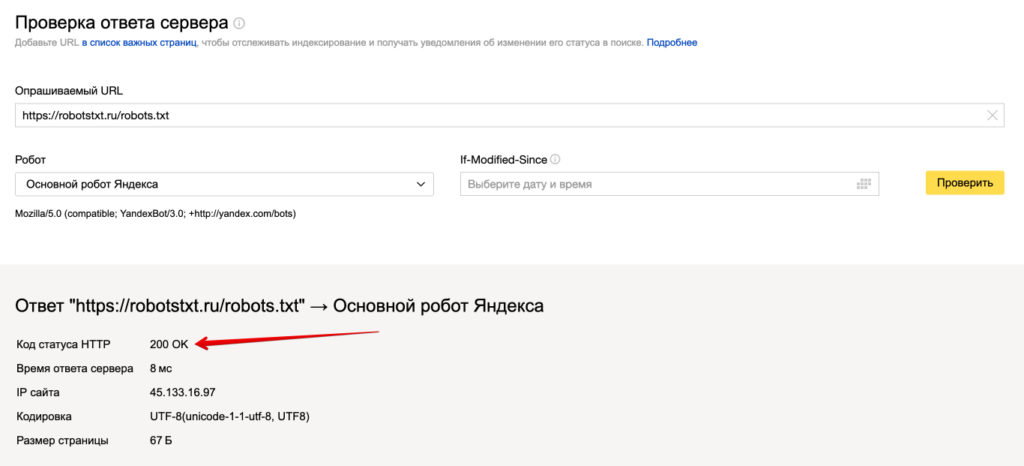
Должен отображаться ответ сервера 200. Если вы видите другие цифры, то значит robots.txt не доступен и поисковая система не сможет его прочитать.
Как проверить в Яндекс?
В разработке…
Как проверить в Google?
Благодаря данному инструменту любой вебмастер и оптимизатор может посмотреть, открыты ли в robots.txt конкретные URL и файлы для индексирования роботами поисковой системы Google?
Допустим, на вашем сайте есть картинка, которую вы не желаете видеть в результатах выдачи Гугла по картинкам. В инструменте Robots Testing Tool вы узнаете, закрыт ли доступ к изображению боту Googlebot-Image.
Здесь нужно прописать URL-адрес, по которому располагается изображение. Далее
инструмент обработает robots.txt таким же способом, что и
робот Гугла по картинкам, чтобы выяснить, запрещен ли указанный УРЛ для
индексирования.
Инструкция по проверке
- Зайдите в Google Search Console и укажите свой сайт.
- Выберите инструмент проверки и проверьте инструкции, прописанные в файле Robots. Любые логические и синтаксические ошибки будут подчеркнуты, а их общее количество можно узнать внизу окна редактирования.
- В самом низу страницы найдите поле, предназначенное для указания необходимого URL-адреса.
- В меню, которое откроется справа, выберите бота.
- Кликните “Проверить”.
- После проверки инструмент покажет статус адреса: “Доступен” либо “Недоступен”. Если статус “Доступен”, значит роботам Гугла не запрещено включать в поиск изображение, а если “Недоступен”, то картинка не будет участвовать в поиске.
- Если нужно, сделайте необходимые исправления в меню и проверьте роботс снова. Имейте ввиду, что все изменения не вносятся в файл robots.txt вашего веб-ресурса автоматически.
- Сделайте копию измененного содержания и вставьте ее в robots на вашем сервере.
Что нужно знать
- Никакие изменения в редакторе не сохраняются на
сервере в автоматическом режиме. Нужно скопировать измененный код и внести его
в файл роботс. - Инструмент для проверки Robots показывает
результаты только для юзер-агентов Google и роботов данной поисковой системы.
При этом сотрудники компании не могут давать никаких гарантий, что роботы
других поисковиков будут учитывать содержание файла так же, как и Гугл.
Как отправить измененный robots.txt в
Google?
В инструменте проверки роботса есть кнопка “Проверить”,
благодаря которой ускоряется обход и включение в индекс нового robots.txt. Для передачи его в поисковую
систему Google необходимо:
1. В правом нижнем углу редактора файла Robots кликнуть на
кнопку “Проверить”. Так вы откроете диалоговое окно передачи.
2. Для выгрузки из инструмента кода файла, который был
изменен, нажмите кнопку “Загрузить”.
3. Загрузите новый Robots в корневую папку сайта. Необходимо, чтобы URL файла
выглядел следующим образом: /robots.txt.
На заметку. Если у вас нет доступа к админке, из-за чего нет возможности загружать файлы в корневой каталог домена, свяжитесь с его администратором.
Допустим, главная страница вашего веб-ресурса находится по
адресу subdomain.site.ru/site/example.
Тогда есть вероятность, что вы не сможете обновить файл robots, расположенный по адресу subdomain.site.ru/robots.txt.
Тогда напишите владельцу домена с просьбой изменить файл.
4. Нажмите “Проверить”. Так вы узнаете, применяется ли новая
версия Robots, которую
вы хотите, чтобы роботы просканировали.
5. Кликните “Отправить в Google” для отправки поисковой машине сигнала, что файл был изменен
и его необходимо проверить.
6. Удостоверьтесь в том, что измененный файл был успешно проверен роботами. Для этого необходимо обновить страницу “Инструмент проверки файла robots.txt”. После этого обновится окно редактирование, где отобразится новый код файла. В меню, открывающемся над текстовым редактором, вы узнаете, когда Googlebot первый раз увидел актуальную версию роботса.
Проверка с помощью Google Robots.txt Parser и Matcher Library
На Github доступен официальный парсер Robots.txt от Google. В 2019 году Google предоставил к нему доступ после того, как Robots Exclusion Protocol (REP) был объявлен официальным стандартом.
Эту библиотеку использует и сама компания Google для парсинга файла robots.txt на сайтах и сопоставления правил в нем. Поэтому, если вы знакомы с программированием, то сможете самостоятельно установить ее к себе и протестировать свой robots.txt на наличие ошибок.
Заключение
Следуя инструкциям выше, вы будете уверены в том, что настроили
Robots.txt правильно
и поисковые системы сканируют файл так, как вам нужно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.