Средняя ошибка аппроксимации
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
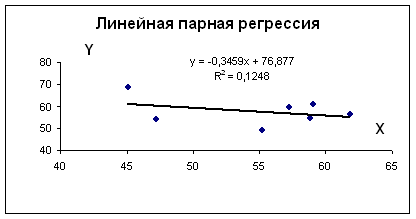
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Задача №1 Построение уравнения регрессии
Имеются следующие данные разных стран об индексе розничных цен на продукты питания (х) и об индексе промышленного производства (у).
| Индекс розничных цен на продукты питания (х) | Индекс промышленного производства (у) | |
|---|---|---|
| 1 | 100 | 70 |
| 2 | 105 | 79 |
| 3 | 108 | 85 |
| 4 | 113 | 84 |
| 5 | 118 | 85 |
| 6 | 118 | 85 |
| 7 | 110 | 96 |
| 8 | 115 | 99 |
| 9 | 119 | 100 |
| 10 | 118 | 98 |
| 11 | 120 | 99 |
| 12 | 124 | 102 |
| 13 | 129 | 105 |
| 14 | 132 | 112 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
В) равносторонней гиперболы.
2. Для каждой модели рассчитать показатели: тесноты связи и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз значения индекса промышленного производства у при прогнозном значении индекса розничных цен на продукты питания х=138.
Решение:
1. Для расчёта параметров линейной регрессии
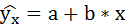
Решаем систему нормальных уравнений относительно a и b:
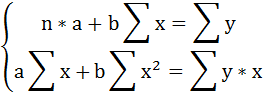
Построим таблицу расчётных данных, как показано в таблице 1.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | ху | x 2 | y 2 | 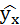 |
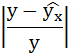 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 7000 | 10000 | 4900 | 74,26340 | 0,060906 |
| 2 | 105 | 79 | 8295 | 11025 | 6241 | 79,92527 | 0,011712 |
| 3 | 108 | 85 | 9180 | 11664 | 7225 | 83,32238 | 0,019737 |
| 4 | 113 | 84 | 9492 | 12769 | 7056 | 88,98425 | 0,059336 |
| 5 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 6 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 7 | 110 | 96 | 10560 | 12100 | 9216 | 85,58713 | 0,108467 |
| 8 | 115 | 99 | 11385 | 13225 | 9801 | 91,24900 | 0,078293 |
| 9 | 119 | 100 | 11900 | 14161 | 10000 | 95,77849 | 0,042215 |
| 10 | 118 | 98 | 11564 | 13924 | 9604 | 94,64611 | 0,034223 |
| 11 | 120 | 99 | 11880 | 14400 | 9801 | 96,91086 | 0,021102 |
| 12 | 124 | 102 | 12648 | 15376 | 10404 | 101,4404 | 0,005487 |
| 13 | 129 | 105 | 13545 | 16641 | 11025 | 107,1022 | 0,020021 |
| 14 | 132 | 112 | 14784 | 17424 | 12544 | 110,4993 | 0,013399 |
| Итого: | 1629 | 1299 | 152293 | 190557 | 122267 | 1299,001 | 0,701866 |
| Среднее значение: | 116,3571 | 92,78571 | 10878,07 | 13611,21 | 8733,357 | х | х |
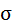 |
8,4988 | 11,1431 | х | х | х | х | х |
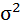 |
72,23 | 124,17 | х | х | х | х | х |
Среднее значение определим по формуле:
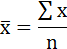
Cреднее квадратическое отклонение рассчитаем по формуле:
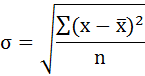
и занесём полученный результат в таблицу 1.
Возведя в квадрат полученное значение получим дисперсию:
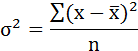
Параметры уравнения можно определить также и по формулам:
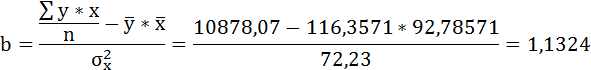
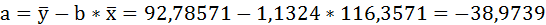
Таким образом, уравнение регрессии:
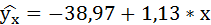
Следовательно, с увеличением индекса розничных цен на продукты питания на 1, индекс промышленного производства увеличивается в среднем на 1,13.
Рассчитаем линейный коэффициент парной корреляции:
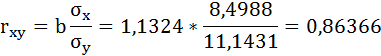
Связь прямая, достаточно тесная.
Определим коэффициент детерминации:
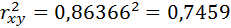
Вариация результата на 74,59% объясняется вариацией фактора х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
 ,
,
следовательно, параметры уравнения определены правильно.
Рассчитаем среднюю ошибку аппроксимации – среднее отклонение расчётных значений от фактических:
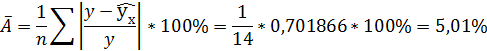
В среднем расчётные значения отклоняются от фактических на 5,01%.
Оценку качества уравнения регрессии проведём с помощью F-теста.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
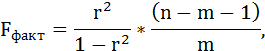
где n – число единиц совокупности;
m – число параметров при переменных х.
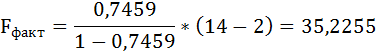
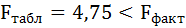
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
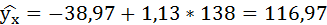
2. Степенная регрессия имеет вид:
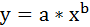
Для определения параметров производят логарифмирование степенной функции:
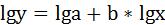
Для определения параметров логарифмической функции строят систему нормальных уравнений по способу наименьших квадратов:
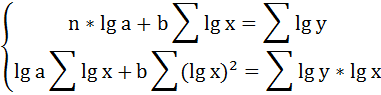
Построим таблицу расчётных данных, как показано в таблице 2.
Таблица 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | lg x | lg y | lg x*lg y | (lg x) 2 | (lg y) 2 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 2,000000 | 1,845098 | 3,690196 | 4,000000 | 3,404387 |
| 2 | 105 | 79 | 2,021189 | 1,897627 | 3,835464 | 4,085206 | 3,600989 |
| 3 | 108 | 85 | 2,033424 | 1,929419 | 3,923326 | 4,134812 | 3,722657 |
| 4 | 113 | 84 | 2,053078 | 1,924279 | 3,950696 | 4,215131 | 3,702851 |
| 5 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 6 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 7 | 110 | 96 | 2,041393 | 1,982271 | 4,046594 | 4,167284 | 3,929399 |
| 8 | 115 | 99 | 2,060698 | 1,995635 | 4,112401 | 4,246476 | 3,982560 |
| 9 | 119 | 100 | 2,075547 | 2,000000 | 4,151094 | 4,307895 | 4,000000 |
| 10 | 118 | 98 | 2,071882 | 1,991226 | 4,125585 | 4,292695 | 3,964981 |
| 11 | 120 | 99 | 2,079181 | 1,995635 | 4,149287 | 4,322995 | 3,982560 |
| 12 | 124 | 102 | 2,093422 | 2,008600 | 4,204847 | 4,382414 | 4,034475 |
| 13 | 129 | 105 | 2,110590 | 2,021189 | 4,265901 | 4,454589 | 4,085206 |
| 14 | 132 | 112 | 2,120574 | 2,049218 | 4,345518 | 4,496834 | 4,199295 |
| Итого | 1629 | 1299 | 28,90474 | 27,49904 | 56,79597 | 59,69172 | 54,05467 |
| Среднее значение | 116,3571 | 92,78571 | 2,064624 | 1,964217 | 4,056855 | 4,263694 | 3,861048 |
|
8,4988 | 11,1431 | 0,031945 | 0,053853 | х | х | х |
|
72,23 | 124,17 | 0,001021 | 0,0029 | х | х | х |
Продолжение таблицы 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | |
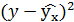 |
|
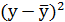 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 74,16448 | 17,34292 | 0,059493 | 519,1886 |
| 2 | 105 | 79 | 79,62057 | 0,385112 | 0,007855 | 190,0458 |
| 3 | 108 | 85 | 82,95180 | 4,195133 | 0,024096 | 60,61728 |
| 4 | 113 | 84 | 88,59768 | 21,13866 | 0,054734 | 77,1887 |
| 5 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 6 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 7 | 110 | 96 | 85,19619 | 116,7223 | 0,11254 | 10,33166 |
| 8 | 115 | 99 | 90,88834 | 65,79901 | 0,081936 | 38,6174 |
| 9 | 119 | 100 | 95,52408 | 20,03384 | 0,044759 | 52,04598 |
| 10 | 118 | 98 | 94,35840 | 13,26127 | 0,037159 | 27,18882 |
| 11 | 120 | 99 | 96,69423 | 5,316563 | 0,023291 | 38,6174 |
| 12 | 124 | 102 | 101,4191 | 0,337467 | 0,005695 | 84,90314 |
| 13 | 129 | 105 | 107,4232 | 5,872099 | 0,023078 | 149,1889 |
| 14 | 132 | 112 | 111,0772 | 0,85163 | 0,00824 | 369,1889 |
| Итого | 1629 | 1299 | 1296,632 | 446,4152 | 0,703074 | 1738,357 |
| Среднее значение | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Решая систему нормальных уравнений, определяем параметры логарифмической функции.
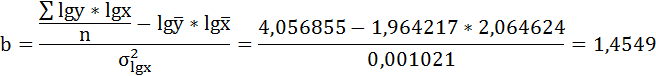
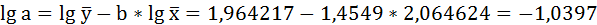
Получим линейное уравнение:
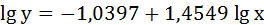
Выполнив его потенцирование, получим:
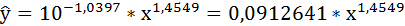
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата 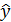 . По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
. По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
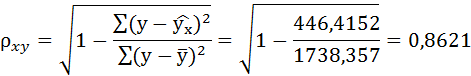
Связь достаточно тесная.
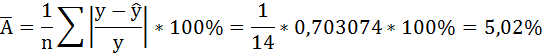
В среднем расчётные значения отклоняются от фактических на 5,02%.
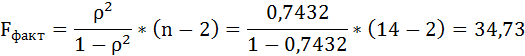
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
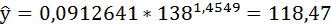
3. Уравнение равносторонней гиперболы
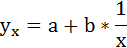
Для определения параметров этого уравнения используется система нормальных уравнений:
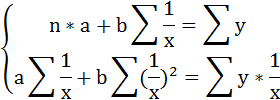
Произведем замену переменных
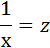
и получим следующую систему нормальных уравнений:
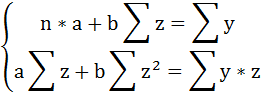
Решая систему нормальных уравнений, определяем параметры гиперболы.
Составим таблицу расчётных данных, как показано в таблице 3.
Таблица 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | z | yz | 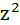 |
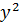 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 0,010000000 | 0,700000 | 0,0001000 | 4900 |
| 2 | 105 | 79 | 0,009523810 | 0,752381 | 0,0000907 | 6241 |
| 3 | 108 | 85 | 0,009259259 | 0,787037 | 0,0000857 | 7225 |
| 4 | 113 | 84 | 0,008849558 | 0,743363 | 0,0000783 | 7056 |
| 5 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 6 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 7 | 110 | 96 | 0,009090909 | 0,872727 | 0,0000826 | 9216 |
| 8 | 115 | 99 | 0,008695652 | 0,860870 | 0,0000756 | 9801 |
| 9 | 119 | 100 | 0,008403361 | 0,840336 | 0,0000706 | 10000 |
| 10 | 118 | 98 | 0,008474576 | 0,830508 | 0,0000718 | 9604 |
| 11 | 120 | 99 | 0,008333333 | 0,825000 | 0,0000694 | 9801 |
| 12 | 124 | 102 | 0,008064516 | 0,822581 | 0,0000650 | 10404 |
| 13 | 129 | 105 | 0,007751938 | 0,813953 | 0,0000601 | 11025 |
| 14 | 132 | 112 | 0,007575758 | 0,848485 | 0,0000574 | 12544 |
| Итого: | 1629 | 1299 | 0,120971823 | 11,13792 | 0,0010510 | 122267 |
| Среднее значение: | 116,3571 | 92,78571 | 0,008640844 | 0,795566 | 0,0000751 | 8733,357 |
|
8,4988 | 11,1431 | 0,000640820 | х | х | х |
|
72,23 | 124,17 | 0,000000411 | х | х | х |
Продолжение таблицы 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | |
|
|
|
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 72,3262 | 0,033231 | 5,411206 | 519,1886 |
| 2 | 105 | 79 | 79,49405 | 0,006254 | 0,244083 | 190,0458 |
| 3 | 108 | 85 | 83,47619 | 0,017927 | 2,322012 | 60,61728 |
| 4 | 113 | 84 | 89,64321 | 0,067181 | 31,84585 | 77,1887 |
| 5 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 6 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 7 | 110 | 96 | 86,01027 | 0,10406 | 99,79465 | 10,33166 |
| 8 | 115 | 99 | 91,95987 | 0,071112 | 49,56344 | 38,6174 |
| 9 | 119 | 100 | 96,35957 | 0,036404 | 13,25272 | 52,04598 |
| 10 | 118 | 98 | 95,28761 | 0,027677 | 7,357059 | 27,18882 |
| 11 | 120 | 99 | 97,41367 | 0,016024 | 2,516453 | 38,6174 |
| 12 | 124 | 102 | 101,46 | 0,005294 | 0,291565 | 84,90314 |
| 13 | 129 | 105 | 106,1651 | 0,011096 | 1,357478 | 149,1889 |
| 14 | 132 | 112 | 108,8171 | 0,028419 | 10,1311 | 369,1889 |
| Итого: | 1629 | 1299 | 1298,988 | 0,666742 | 435,7575 | 1738,357 |
| Среднее значение: | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Значения параметров регрессии a и b составили:
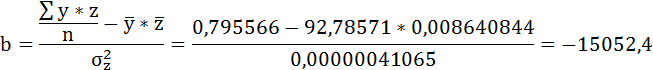
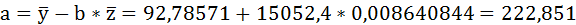
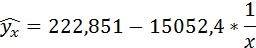
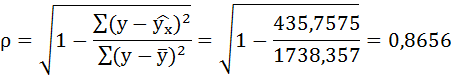
Связь достаточно тесная.
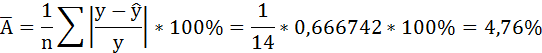
В среднем расчётные значения отклоняются от фактических на 4,76%.
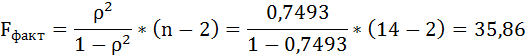
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
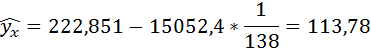
По уравнению равносторонней гиперболы получена наибольшая оценка тесноты связи по сравнению с линейной и степенной регрессиями. Средняя ошибка аппроксимации остаётся на допустимом уровне.
Оценка корреляции для нелинейной регрессии
Оценка тесноты корреляционной зависимости в случае нелинейной регрессии производится с помощью индекса корреляции (R):
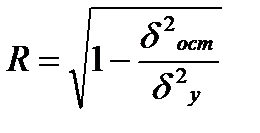 , (39.1)
, (39.1)
где 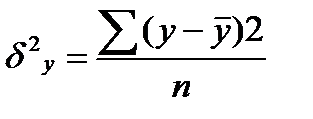 ,
, 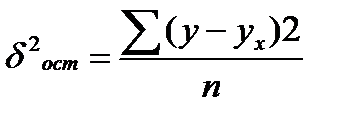 ,
, 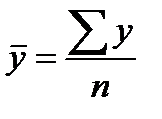 (39.2)
(39.2)
y¯x значения результативного признака, рассчитанные по уравнению регрессии.
Величина данного показателя находится в границах: 0≤ R ≤ 1 , чем она ближе к единице, тем теснее связь рассматриваемых признаков, тем надежнее найденное уравнение регрессии.
Следует помнить, что если для линейной зависимости имеет место равенство: ryx =rxy , то при криволинейной зависимости y=f(x) Ryx не равен Rxy.
Величина R 2 называется индексом детерминации.
Оценка существенности индекса корреляции проводится, так же как и оценка надежности коэффициента корреляции. Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
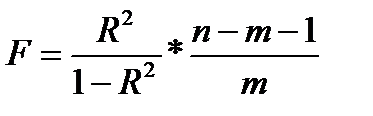 , (39.3)
, (39.3)
где R 2 — индекс детерминации;
n — число наблюдений;
m — число параметров при переменных х.
Индекс детерминации R 2 yx можно сравнивать с коэффициентом детерминации r 2 yx для обоснования возможности применения линейной функции.
Если величина (R 2 yx — r 2 yx) не превышает 0,1, то предположение о линейной форме связи считается оправданным. В противном случае проводится оценка существенности различия между R 2 yx и r 2 yx , вычисленных по одним и тем же исходным данным, через t — критерий Стьюдента:
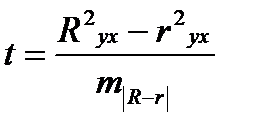 , (39.4)
, (39.4)
где 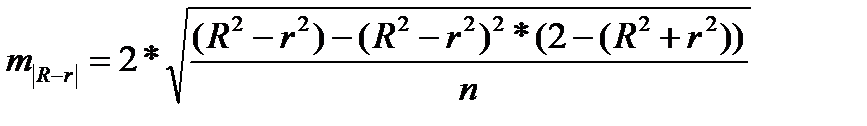 , (39.5)
, (39.5)
Если t факт> t табл, то различия между Ryx и ryx существенны и замена нелинейной регрессии линейной — невозможна. Практически, если t ≤ 2, то различия между Ryx и ryx несущественны, и, следовательно, возможно применение линейной регрессии.
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е. y и yx. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Чтобы иметь общее представление о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
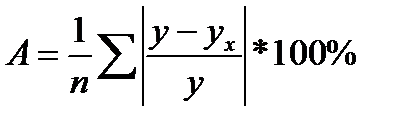 (39.6)
(39.6)
Существует и другая формула определения средней ошибки аппроксимации:
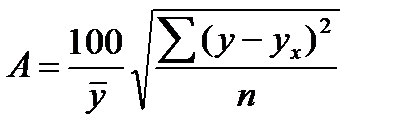 , (39.7)
, (39.7)
где 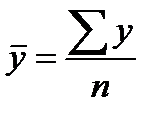 . (39.8)
. (39.8)
Ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Возможность построения нелинейных моделей, как с помощью их приведения к линейному виду, так и путем использования нелинейной регрессии, значительно повышает универсальность регрессионного анализа, но и усложняет задачу исследователя.
Возникает вопрос: с чего начать — с линейной зависимости или с нелинейной, и если с последней, то, какого типа.
Если ограничиться парной регрессией, то можно построить график наблюдений у и х и принять решение. Однако очень часто несколько разных нелинейных функцией приблизительно соответствуют наблюдениям, если они лежать на некоторой кривой. А в случае множествен6ной регрессии невозможно даже построить график.
37. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
Хотя во многих практических случаях моделирование экономических зависимостей линейными уравнениями дает вполне удовлетворительный результат, однако ограничиться рассмотрением лишь линейных регрессионных моделей невозможно. Так близость линейного коэффициента корреляции к нулю еще не значит, что связь между соответствующими экономическими переменными отсутствует. При слабой линейной связи может быть очень тесной, например, не линейная связь. Поэтому необходимо рассмотреть и нелинейные регрессии, построение и анализ которых имеют свою специфику.
В случае, когда между экономическими явлениями существует нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных эконометрических моделей.
38. Двухфакторная производственная функция Кобба-Дугласа
Производственная функцию Кобба –Дугласа выглядит следующим образом:
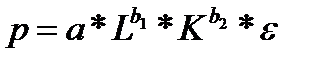 (44.1)
(44.1)
где Р –объем продукции
L— затраты труда;
К — величина капитала;
Логарифмируя ее, получим линейное в логарифмах уравнение
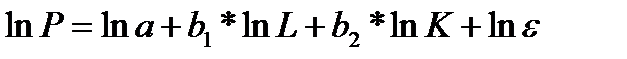 (44.2)
(44.2)
Оценив параметры этого уравнения по МНК, можно найти теоретические значения объема продукции Р^ и соответственно остаточную сумму квадратов Σ (Р — Р^) 2 которая используется в расчете индекса детерминации:
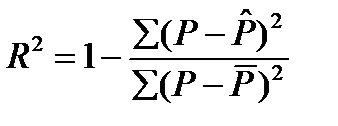 (44.3)
(44.3)
Следует помнить, что МНК применяется не к исходным данным продукции, а к их логарифмам. Поэтому в индексе корреляции с общей суммой квадратов Σ (Р — Р¯) 2 сравнивается остаточная дисперсия, которая определена по теоретическим значениям логарифмов продукции:
Σ (Р — антилогарифм (ln Р)) 2 . Т.е. Р^ находится в следствии потенцированиия ln Р.
39. Отбор факторов для экономертических моделей
Хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. Отбор факторов производится на основе качественного теоретико-экономического анализа, который обычно осуществляется в две стадии: на первой подбираются факторы исходя из сущности проблемы; на второй – на основе показателей корреляции определяют t-статистики для параметров регрессии. Коэффициенты интеркорреляции (т. е. корреляции между объясняющими переменными) позволяют исключать из модели дублирующие факторы. Считается, что две переменных явно коллинеарны, т. е. находятся между собой в линейной зависимости, если 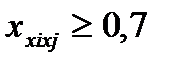 . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов (МНК). Включение в модель мультиколлинеарныхфакторов нежелательно в силу следующих последствий:
. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов (МНК). Включение в модель мультиколлинеарныхфакторов нежелательно в силу следующих последствий:
1. затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированы; параметры линейной регрессии теряют экономический смысл;
2. оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений. Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей. Для включающего три объясняющих переменных уравнения: y=a+b1x1+b2+b3x3+e.Матрица коэф-в корреляции м/у факторами имела бы определитель равный
Det 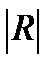 =1, т.к. rx1x1=rx2x2=1 и rx1x2=rx1x3=rx2x3=0.
=1, т.к. rx1x1=rx2x2=1 и rx1x2=rx1x3=rx2x3=0.
Если м/у факторами сущ-ет полная линейная зависимость и все коэф-ты корреляции =1, то определитель такой матрицы =0. Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
40. Метод наименьших квадратов для двухфакторной производственной функции.
Метод наименьших квадратов.Некоторые более общие типы регрессионных моделей рассмотрены в разделе Основные типы нелинейных моделей. После выбора модели возникает вопрос: каким образом можно оценить эти модели? Если вы знакомы с методами линейной регрессии (описанными в разделе Множественная регрессия) или дисперсионного анализа (описанными в разделе Дисперсионный анализ), то вы знаете, что все эти методы используют оценивание по методу наименьших квадратов. Основной смысл этого метода заключается в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной от значений, предсказанных моделью. (Термин наименьшие квадраты впервые был использован в работе Лежандра — Legendre, 1805.)
Функция потерь.В стандартной множественной регрессии оценивание коэффициентов регрессии происходит “подбором” коэффициентов, минимизирующих дисперсию остатков (сумму квадратов остатков). Любые отклонения наблюдаемых величин от предсказанных означают некоторые потери в точности предсказаний, например, из-за случайного шума (ошибок). Поэтому можно сказать, что цель метода наименьших квадратов заключается в минимизации функции потерь. В этом случае, функция потерь определяется как сумма квадратов отклонений от предсказанных значений (термин функция потерь был впервые использован в работе Вальда — Wald, 1939). Когда эта функция достигает минимума, вы получаете те же оценки для параметров (свободного члена, коэффициентов регрессии), как, если бы мы использовали Множественную регрессию. Полученные оценки называются оценками по методу наименьших квадратов.
Продолжая в том же духе, можно рассмотреть другие функции потерь. Например, при минимизации функции потерь, почему бы вместо суммы квадратов отклонений не рассмотреть сумму модулей отклонений? В самом деле, иногда это бывает полезно для уменьшения влияния выбросов. Влияние, оказываемое крупными остатками на всю сумму, существенно увеличивается при их возведении в квадрат. Однако если вместо суммы квадратов взять сумму модулей выбросов, влияние остатков на результирующую регрессионную кривую существенно уменьшится.
Существуют несколько методов, которые могут быть использованы для минимизации различных видов функций пот
41. Двухфакторная производственная функция Солоу
Производственная функция – это зависимость между набором факторов производства и максимально возможным объемом продукта, производимым с помощью данного набора факторов.
Производственная функция всегда конкретна, т.е. предназначается для данной технологии. Новая технология – новая производительная функция.
С помощью производственной функции определяется минимальное количество затрат, необходимых для производства данного объема продукта.
Производственные функции, независимо от того, какой вид производства ими выражается, обладают следующими общими свойствами:
1) Увеличение объема производства за счет роста затрат только по одному ресурсу имеет предел (нельзя нанимать много рабочих в одно помещение – не у всех будут места).
2) Факторы производства могут быть взаимодополняемы (рабочие и инструменты) и взаимозаменяемы (автоматизация производства).
В наиболее общем виде производственная функция выглядит следующим образом:
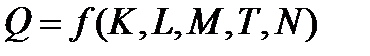 ,
,
где 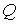 — объем выпуска;
— объем выпуска;
K- капитал (оборудование);
М- сырье, материалы;
Т – технология;
N – предпринимательские способности.
Наиболее простой является двухфакторная модель производственной функции Кобба – Дугласа, с помощью которой раскрывается взаимосвязь труда (L) и капитала (К). Эти факторы взаимозаменяемы и взаимодополняемы
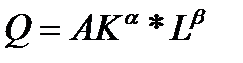 ,
,
где А – производственный коэффициент, показывающий пропорциональность всех функций и изменяется при изменении базовой технологии (через 30-40 лет);
K, L- капитал и труд;
α, β -коэффициенты эластичности объема производства по затратам капитала и труда.
Если 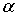 = 0,25, то рост затрат капитала на 1% увеличивает объем производства на 0,25%.
= 0,25, то рост затрат капитала на 1% увеличивает объем производства на 0,25%.
На основе анализа коэффициентов эластичности в производственной функции Кобба — Дугласа можно выделить:
1) пропорционально возрастающую производственную функцию, когда
α + β =1(Q=K 0,5 *L 0,2 ) .
2) непропорционально – возрастающую α + β > 1 (Q = K 0,9 *L 0,8 );
3) убывающую α + β 0,4 *L 0,2 ).
Рассмотрим короткий период деятельности фирмы, в котором из двух факторов переменным является труд. В такой ситуации фирма может увеличить производство за счет использования большего количества трудовых ресурсов. График производственной функции Кобба – Дугласа с одной переменной изображен на рис. 10.1 (кривая ТРн).
В краткосрочном периоде действует закон убывающей предельной производительности.
Закон убывающей предельной производительности действует в краткосрочном временном интервале, когда один производственный фактор остается неизменным. Действие закона предполагает неизменное состояние техники и технологии производства, если в производственном процессе будут применены новейшие изобретения и другие технические усовершенствования, то рост объема выпуска может быть достигнут при использовании тех же самых производственных факторов. То есть технический прогресс может изменить границы действия закона.
Если капитал является фиксированным фактором, а труд – переменным, то фирма может увеличить производство за счет использования большего количества трудовых ресурсов. Но по закону убывающей предельной производительности, последовательное увеличение переменного ресурса при неизменности других ведет к убывающей отдаче данного фактора, то есть к снижению предельного продукта или предельной производительности труда. Если же наем рабочих будет продолжаться, то в конечном итоге, они будут мешать друг другу (предельная производительность станет отрицательной) и объем выпуска сократится.
Предельная производительность труда (предельный продукт труда – MPL) – это прирост объема производства от каждой последующей единицы труда
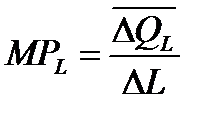 ,
,
т.е. прирост производительности к совокупному продукту (TPL)
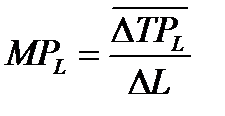 .
.
Аналогично определяется предельный продукт капитала MPK.
Основываясь на законе убывающей производительности, проанализируем взаимосвязь общего (TPL), среднего (АPL) и предельного продуктов (MPL) (рис. 10.1).
В движении кривой общего продукта (ТР) можно выделить три этапа. На этапе 1 она поднимается вверх ускоряющимися темпами, так как предельность продукта (MP) возрастает (каждый новый рабочий приносит больше продукции, чем предыдущий) и достигает максимума в точке А, то есть скорость роста функции максимальна. После точки А (этап 2) в силу действия закона убывающей отдачи, кривая MP падает, то есть каждый нанятый рабочий дает меньшее приращение общего продукта по сравнению с предшествующим, поэтому темп роста ТР после ТС замедляется. Но пока МР будет положительным, ТР будет все равно увеличиваться и достигнет максимума при МР=0.
На 3 этапе, когда количество рабочих становится избыточным по отношению к фиксированному капиталу (станки), МР приобретает отрицательное значение, поэтому ТР начинает снижаться.
Конфигурация кривой среднего продукта АР также обусловлена динамикой кривой МР. На 1 этапе обе кривые растут, пока приращение объема выпуска от вновь нанятых рабочих будет большим, чем средняя производительность (АРL) ранее нанятых рабочих. Но после точки А (max MP), когда четвертый рабочий добавляет к совокупному продукту (ТР) меньше чем третий, МР уменьшается, поэтому средняя выработка четырех рабочих также сокращается.
Производственные функции Солоу, представляют собой одно из ближайших обобщений многофакторных функций с постоянной и одинаковой эластичностью замены факторов.
42. Гомоскедастичность и гетероскедастичность остатков модели регрессии. Последствия гетероскедастичности
С определения гомоскедастичности и гетероскедастичности остатков модели регрессии строиться график зависимости остатков ei от теоретических значений результативного признака:
Если на графике получена горизонтальная полоса, то остатки ei представляют собой случайные величины и МНК оправдан, теоретические значения ух хорошо аппроксимируют фактические значения у.
Возможны варианты: если ei зависит от уx, то: 1.остатки ei не случайны.2. остатки ei, не имеют постоянной дисперсии. 3. Остатки ei носят систематический характер в данном случае отрицательные значения ei, соответствуют низким значениям ух, а положительные — высоким значениям. В этих случаях необходимо либо применять другую функцию, либо вводить дополнительную информацию.
Гомоскедастичность остатков означает, что дисперсия остатков ei одинакова для каждого значения х.Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции. а — дисперсия остатков растет по мере увеличения х; б — дисперсия остатков достигает максимальной величины при средних значениях переменной х и уменьшается при минимальных и максимальных значениях х; в — максимальная дисперсия остатков при малых значениях х и дисперсия остатков однородна по мере увеличения значений х. Графики гомо- и гетеро-ти.
Оценка отсутствия автокорреляции остатков(т.е. значения остатков ei распределены независимо друг от друга). Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений. Коэффициент корреляции между ei и ej , где ei — остатки текущих наблюдений, ej — остатки предыдущих наблюдений, может быть определен по обычной формуле линейного коэффициента корреляции 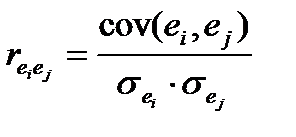 . (51.1)
. (51.1)
Если этот коэффициент окажется существенно отличным от нуля, то остатки автокоррелированы и функция плотности вероятности F(e) зависит j-й точки наблюдения и от распределения значений остатков в других точках наблюдения. Для регрессионных моделей по статической информации автокорреляция остатков может быть подсчитана, если наблюдения упорядочены по фактору х. Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и эффективность оценок коэффициентов регрессии. Особенно актуально соблюдение данной предпосылки МНК при построении регрессионных моделей по рядам динамики, где ввиду наличия тенденции последующие уровни динамического ряда, как правило, зависят от своих предыдущих уровней.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный МНК заменять обобщенным методом. Обобщенный МНК применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Обобщенный МНК для корректировки гетероскедастичности. В общем виде для уравнения yi=a+bxi+ei при 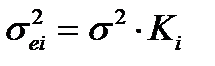 где Ki – коэффициент пропорциональности. Модель примет вид: yi=
где Ki – коэффициент пропорциональности. Модель примет вид: yi= 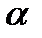 +
+ 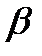 xi+
xi+ 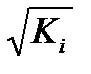 ei .
ei .
В ней остаточные величины гетероскедастичны. Предполагая в них отсутствие автокорреляции, можно перейти к уравнению с гомоскедастичными остатками, поделив все переменные, зафиксированные в ходе i-го наблюдения на 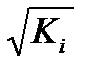 . Тогда дисперсия остатков будет величиной постоянной. От регрессии у по х перейдем к регрессии на новых переменных: y/
. Тогда дисперсия остатков будет величиной постоянной. От регрессии у по х перейдем к регрессии на новых переменных: y/ 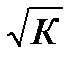 и х/ . Уравнение регрессии примет вид:
и х/ . Уравнение регрессии примет вид: 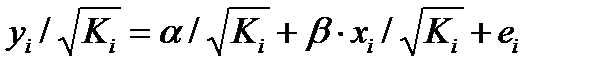 . (51.2)
. (51.2)
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляет собой взвешенную регрессию, в которой переменные у и х взяты с весами 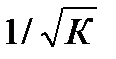 . Коэф-т регрессии b можно определить как
. Коэф-т регрессии b можно определить как 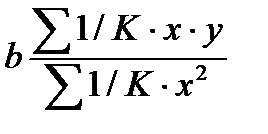 (51.3)
(51.3)
Как видим, при использовании обобщенного МНК с целью корректировки гетероскедастичности коэффициент регрессии b представляет собой взвешенную величину по отношению к обычному МНК с весами 1/К.Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Модель примет вид:
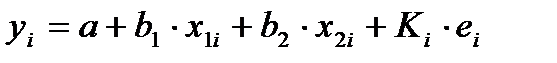 . (51.4)
. (51.4)
Модель с преобразованными переменными составит
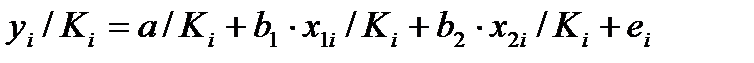 . (51.5)
. (51.5)
Это уравнение не содержит свободного члена, применяя обычный МНК получим:
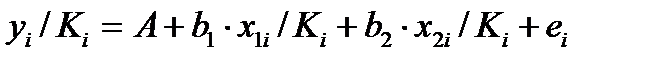 (51.5)
(51.5)
Применение в этом случае обобщенного МНК приводит к тому, что наблюдения с меньшими значениями преобразованных переменных х/К имеют при определении параметров регрессии относительно больший вес, чем с первоначальными переменными.
43. Тест Глейзера обнаружения гетероскедастичности остатков модели регрессии
Наличие гетероскедастичности в отдельных случаях может привести к смущенности оценок коэффициентов регрессии, хотя несмещенности оценок коэффициентов регрессии в основном зависит от соблюдения второй предпосылки МНК, т. е. независимости остатков и величин факторов. Гетероскедастичность будет сказываться на уменьшении эффективности оценок bi,. В частности, становится затруднительным использование формулы стандартной ошибки коэффициента регрессии mbi, предполагающую единую дисперсию остатков для любых значений фактора.
Тест Глейзера основывается на регрессии абсолютных значений остатков | ε | , т.е. рассматривается функция | εi| = a +bxi c + ui ,. Регрессия | εi| от xi cстроится при разных значениях параметра с, и далее отбирается та функция, для которой коэффициент регрессии b оказывается наиболее значимым, т.е. имеет место наибольшее значение (критерия Стьюдента или F-критерия Фишера и R 2 .
При обнаружении гетероскедастичности остатков регрессии ставится цель ее устранения, чему служит применение обобщенного метода наименьших квадратов
44. Тест Голдфелда-Квандта обнаружения гетероскедастичности остатков модели регрессии
При малом объеме выборки, для оценки гетероскедастичности используют метод Гольфреда — Квандта, разработанный в 1965 г. Гольдфельд и Квандт рассмотрели однофакторную линейную модель, для которой дисперсия остатков возрастает пропорционально Квадрату фактора. Для того чтобы оценить нарушение гомоскедастичности они предложили параметрический тест. Данный тест заключается в следующих стадиях:
1) Упорядочение n наблюдений по мере возрастания переменной х.
2) Исключение из рассмотрения С центральных наблюдений;
при этом (n — С)/ 2 > р, где р — число оцениваемых параметров.
3) Разделение совокупности из ( n — С) наблюдений на две группы (соответственно с малыми и большими значениями факторах) и определение по каждой из групп уравнений регрессии.
4) Определение остаточной суммы квадратов для первой (S1) и второй (S2) групп и нахождение их отношения R=S1/S2, где S1> S2.
При выполнении нулевой гипотезы о гомоскедастичности от ношение R будет удовлетворять F-критерию с (n — С- 2р) : 2 степенями свободы для каждой остаточной суммы квадратов. Чем сильнее R превышает табличное значение F -критерия тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
45. Устранение гетероскедастичности остатков модели регрессии
Автокорреляция остатков может быть вызвана следующими причинами:
1) Ошибками измерения при первоначальном сборе данных по результативному признаку;
2) Неправильно выбранная формулировка исходной модель.
При формировании модели мог быть упущен из виду фактор, оказывающий существенное влияние на результат. В итоге влияние этого фактора отражается в остатках в виде автокорреляции остатков. Часто этим фактором является показатель времени. Кроме того, в качестве таких существенных факторов могут выступать лаговые значения переменных включенных в модель. Либо модель не учитывает несколько равнозначных факторов, которые оказывают совместное влияние при совпадении тенденций и циклов колебаний. От истинной автокорреляции остатков следует отличать ситуации, когда причина автокорреляции заключается в неправильной спецификации функциональной формы модели. В этом случае следует изменить форму связи факторных и результативного признаков, а не использовать специальные методы расчета параметров уравнения регрессии при наличии автокорреляции остатков.
46. Автокорреляция остатков модели регрессии. Последствия автокорреляции. Автокорреляционная функция
В соответствии с третьей предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора хj остатки i имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.
Наличие гомоскедастичности или гетероскедастичности можно видеть и по рассмотренному выше графику зависимости остатков от теоретических значений результативного признака уx.
Для множественной регрессии данный вид графиков является наиболее приемлемым визуальным способом изучения гомо- и гетероскедастичности.
При построении регрессионных моделей чрезвычайно важно соблюдение четвертой предпосылки МНК – отсутствие автокорреляции остатков, т.е. значения i распределены независимо друг от друга.
Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений.
Отсутствие автокорреляции остатков обеспечивает состоятельность и эффективность оценок коэффициентов регрессии.
Предпосылка о нормальном распределении остатков позволяет проводить проверку параметров регрессии и корреляции с помощью критериев t и F. Вместе с тем оценки регрессии, найденные с применением МНК, обладает хорошими свойствами даже при отсутствии нормального распределения остатков.
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять (исключать) некоторые факторы и т.д.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный МНК заменять обобщенным МНК.
Обобщенный МНК применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии
47. Критерий Дарбина-Уотсона обнаружения автокорреляции остатков модели регрессии
Существуют два наиболее распространенных метода определения автокорреляции остатков:
1) путем построения графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции; 2) использование критерия Дарбина-Уотсона и расчет величины
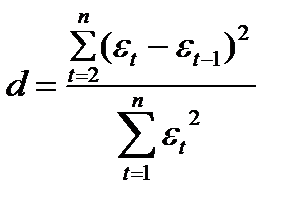 (56.1)
(56.1)
d – отношение суммы квадратов разностей последовательных занчений остатков к остаточной сумме квадратов по модели регрессии. Чащен всего критерий Дарбина –Уотсона указывается наряду с коэффициентом детерминации, значениями t- и F-критерия
Алгоритм выявления автокорреляции остатков на основе критерия Дарбина-Уотсона следующий. Выдвигается гипотеза Н0 об отсутствии автокорреляции остатков. Альтернативные гипотезы и состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона dL и dU для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости 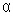 . По этим значениям числовой промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-) производится на основе данных, приведенных в таблице 5.1.
. По этим значениям числовой промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-) производится на основе данных, приведенных в таблице 5.1.
Таблица 47.1 Механизм проверки гипотезы о наличии автокорреляции остатков.
| Есть положительная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1-) принимается гипотеза Н1 | Зона неопределенности | Нет оснований отклонять Н0 (автокорреляция остатков отсутствует) | Зона неопределенности | Есть отрицательная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1- ) принимается гипотеза |
| 0 dL dU 2 4-dU 4-dL 4 |
Если фактическое значение критерия Дарбина-Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и отклоняют гипотезу Н0.
Есть несколько существенных ограничений на применение критерия Дарбина – Уотсона:
— он непременим к модели авторегрессии;
— данный критерий можно использовать только для выявления автокорреляции остатков 1-го порядка;
— критерий дает достоверные результаты только для больших выборок.
источники:
http://ecson.ru/economics/econometrics/zadacha-1.postroenie-regressii-raschyot-korrelyatsii-oshibki-approximatsii-otsenka-znachimosti-i-prognoz.html
http://helpiks.org/3-55677.html
Средняя ошибка аппроксимации
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Нелинейная регрессия. Корреляция для нелинейной регрессии. Средняя ошибка аппроксимации
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Различают два класса нелинейных регрессий:
1) Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, например

· полиномы различных степеней — , ;


- · равносторонняя гипербола — ;
- · полулогарифмическая функция — .
- 2) Регрессии, нелинейные по оцениваемым параметрам, например



Регрессии нелинейные по включенным переменным приводятся к линейному виду простой заменой переменных, а дальнейшая оценка параметров производится с помощью метода наименьших квадратов. Рассмотрим некоторые функции.

Парабола второй степени приводится к линейному виду с помощью замены: , . В результате приходим к двухфакторному уравнению , оценка параметров которого при помощи МНК, приводит к системе следующих нормальных уравнений:

А после обратной замены переменных получим

Парабола второй степени обычно применяется в случаях, когда для определенного интервала значений фактора меняется характер связи рассматриваемых признаков: прямая связь меняется на обратную или обратная на прямую.

Равносторонняя гипербола может быть использована для характеристики связи удельных расходов сырья, материалов, топлива от объема выпускаемой продукции, времени обращения товаров от величины товарооборота, процента прироста заработной платы от уровня безработицы (например, кривая А.В. Филлипса), расходов на непродовольственные товары от доходов или общей суммы расходов (например, кривые Э. Энгеля) и в других случаях. Гипербола приводится к линейному уравнению простой заменой: . Система линейных уравнений при применении МНК будет выглядеть следующим образом:


Аналогичным образом приводятся к линейному виду зависимости , и другие.
Несколько иначе обстоит дело с регрессиями нелинейными по оцениваемым параметрам, которые делятся на два типа: нелинейные модели внутренне линейные (приводятся к линейному виду с помощью соответствующих преобразований, например, логарифмированием) и нелинейные модели внутренне нелинейные (к линейному виду не приводятся).



К внутренне линейным моделям относятся, например, степенная функция -, показательная — , экспоненциальная — , логистическая — , обратная — .

К внутренне нелинейным моделям можно, например, отнести следующие модели: , .

Среди нелинейных моделей наиболее часто используется степенная функция , которая приводится к линейному виду логарифмированием:


где , , , . Т.е. МНК мы применяем для преобразованных данных:

а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр в ней имеет четкое экономическое истолкование — он является коэффициентом эластичности. (Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%.) Формула для расчета коэффициента эластичности имеет вид:

Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора , то обычно рассчитывается средний коэффициент эластичности:

Приведем формулы для расчета средних коэффициентов эластичности для наиболее часто используемых типов уравнений регрессии:
Средний коэффициент эластичности,



















Возможны случаи, когда расчет коэффициента эластичности не имеет смысла. Это происходит тогда, когда для рассматриваемых признаков бессмысленно определение изменения в процентах.
Уравнение нелинейной регрессии, так же, как и в случае линейной зависимости, дополняется показателем тесноты связи. В данном случае это индекс корреляции:



где — общая дисперсия результативного признака , — остаточная дисперсия.
Величина данного показателя находится в пределах: . Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
Квадрат индекса корреляции носит название индекса детерминации и характеризует долю дисперсии результативного признака , объясняемую регрессией, в общей дисперсии результативного признака:

т.е. имеет тот же смысл, что и в линейной регрессии;

Индекс детерминации можно сравнивать с коэффициентом детерминации для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
Индекс детерминации используется для проверки существенности в целом уравнения регрессии по -критерию Фишера:

где — индекс детерминации, — число наблюдений, — число параметров при переменной. Фактическое значение -критерия сравнивается с табличным при уровне значимости и числе степеней свободы (для остаточной суммы квадратов) и (для факторной суммы квадратов).
О качестве нелинейного уравнения регрессии можно также судить и по средней ошибке аппроксимации.
Проверить значимость уравнения регрессии — значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:

Средняя ошибка аппроксимации не должна превышать 8-10%.
По проведенному опросу восьми групп семей известны данные связи расходов населения на продукты с уровнем доходов семьи.
O линейные уравнения множественной
o нелинейные уравнения парной
o линейные уравнения парной
o нелинейные уравнения множественной
349. Способом включения случайного возмущения в регрессионную модель y=a+bx, при котором сохраняется линейная форма модели, является .
- аддитивный
- мультипликативный
- экспоненциальный
- мультиколлинеарный
350. Требованием к уравнениям регрессии, параметры которых можно найти при помощи МНК является:
O линейность параметров
o равенство нулю средних значений результативной переменной
o нелинейность параметров
o равенство нулю средних значений факторного признака
351. Укажите последовательность этапов оценки параметров нелинейной регрессии Y=aX b Z c .
352. Укажите последовательность этапов оценки параметров нелинейной регрессии, линейной относительно параметров.
- определяются оценки исходные параметры нелинейной модели, которые совпадают с параметрами линеаризованной модели
- применяется метод наименьших квадратов для оценки линеаризованной модели
- задаётся линейная спецификация модели в новых переменных
- выбирается метод линеаризации исходной модели
353. Уравнение  может быть линеаризовано при помощи подстановки …
может быть линеаризовано при помощи подстановки …
o  (верно)
(верно)
o 
o 
o 
Тема: Оценка качества нелинейных уравнений регрессии
- Выражение
 позволяет вычислить значение …
позволяет вычислить значение …
- средней ошибки аппроксимации
- F-критерия Фишера
- коэффициента эластичности
- индекса корреляции
- Гипотеза о значимости в целом уравнения нелинейной регрессии проверяется с помощью критерия …
- Дарбина–Уотсона
- Пирсона
- Фишера
- Стьюдента
356. Если значение индекса корреляции для нелинейного уравнения регрессии стремится к 1, то
O нелинейная связь достаточно тесная
o нелинейная связь отсутствует
o линейная связь достаточно тесная
o нелинейная связь недостаточно тесная
357. Значение индекса корреляции находится в пределах …
O нелинейной
359. Коэффициент эластичности показывает …
- отношение коэффициента детерминации к коэффициенту корреляции
- величину остаточной дисперсии на одну степень свободы
- на сколько единиц изменится результативный показатель при изменении величины факторного признака на единицу
- на сколько процентов изменится результативный показатель при изменении величины факторного признака на 1%
- Коэффициент эластичности является постоянной величиной в модели вида …
- Y=ab X ε
- Y=a+bX+ε
- Y=aX b ε
- Y=a+bX+cX 2 +ε
361. Назовите показатель корреляции для нелинейных моделей регрессии
O индекс корреляции
o линейный коэффициент корреляции
o индекс детерминации
o парный коэффициент линейной корреляции
362. Назовите показатель тесноты связи для нелинейных моделей регрессии:
O индекс детерминации
o индекс корреляции
o линейный коэффициент корреляции
o парный коэффициент линейной корреляции
363. Нелинейная связь между рассматриваемыми признаками тем теснее, чем значение индекса корреляции ближе к …
364. Оценить статистическую значимость нелинейного уравнения регрессии можно с помощью …
O критерия Фишера
o средней ошибки аппроксимации
o линейного коэффициента корреляции
o показателя эластичности
365. При хорошем качестве модели допустимым значением средней ошибки аппроксимации является …
366. Пусть R 2 – индекс детерминации; n – число наблюдений; m – число параметров при независимых переменных. Тогда при проверке значимости в целом уравнения нелинейной регрессии расчетное значение F-критерия Фишера вычисляется по формуле …
- Пусть yi – наблюдаемые значения зависимой переменной, а
 – её расчётные значения. В принятых обозначениях средняя ошибка аппроксимации модели может быть определена по формуле …
– её расчётные значения. В принятых обозначениях средняя ошибка аппроксимации модели может быть определена по формуле …
368. Расчёт средней ошибки аппроксимации для нелинейных уравнений регрессии связан с расчётом разности между ____________________________ переменной
источники:
http://studwood.net/1843833/matematika_himiya_fizika/nelineynaya_regressiya_korrelyatsiya_nelineynoy_regressii_srednyaya_oshibka_approksimatsii
http://lektsii.org/6-58275.html
Прогноз по линейному уравнению регрессии. Средняя ошибка аппроксимации.
Проверить значимость уравнения регрессии
– значит установить, соответствует ли
математическая модель, выражающая
зависимость между переменными,
экспериментальным данным и достаточно
ли включенных в уравнение объясняющих
переменных (одной или нескольких) для
описания зависимой переменной.
Чтобы иметь общее суждение о качестве
модели из относительных отклонений по
каждому наблюдению, определяют среднюю
ошибку аппроксимации:
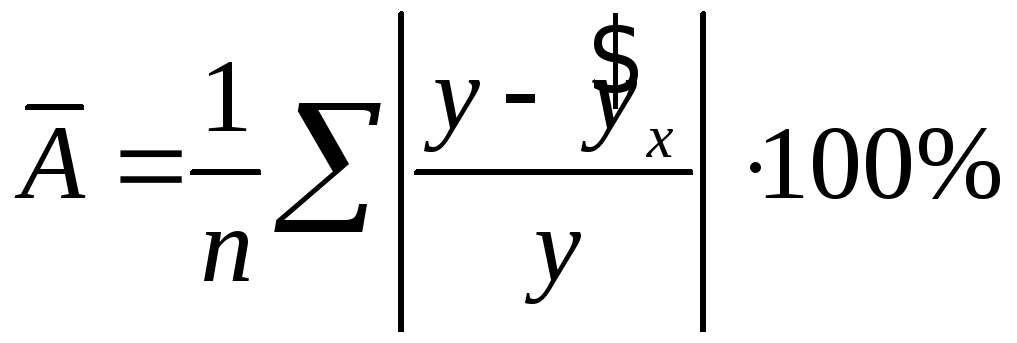 .
.
(1.8)
Средняя ошибка аппроксимации не должна
превышать 8–10%.
В прогнозных расчетах по уравнению
регрессии определяется предсказываемое
![]() значение как точечный прогноз
значение как точечный прогноз![]() при
при![]() ,
,
т.е. путем подстановки в уравнение
регрессии![]() соответствующего значения
соответствующего значения![]() .
.
Однако точечный прогноз явно не реален.
Поэтому он дополняется расчетом
стандартной ошибки![]() ,
,
т.е.![]() ,
,
и соответственно интервальной оценкой
прогнозного значения![]() :
:
![]() ,
,
где
![]() ,
,
а![]() – средняя ошибка прогнозируемого
– средняя ошибка прогнозируемого
индивидуального значения:
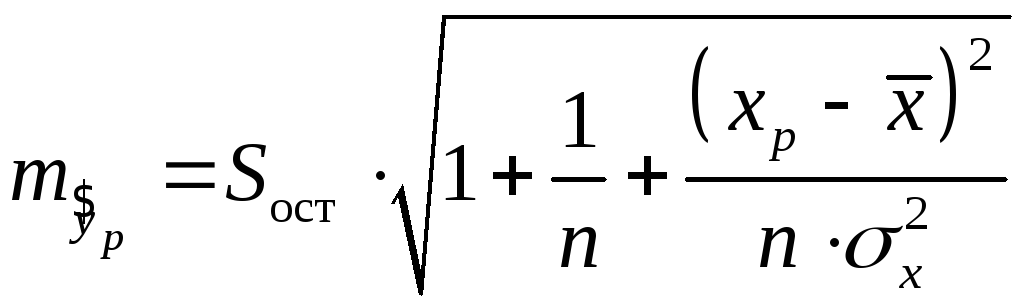 .
.
Нелинейная регрессия. Классы нелинейных регрессий. Оценка нелинейной регрессии в целом
Если между экономическими явлениями
существуют нелинейные соотношения, то
они выражаются с помощью соответствующих
нелинейных функций.
Различают два класса нелинейных
регрессий:
-
Регрессии, нелинейные относительно
включенных в анализ объясняющих
переменных, но линейные по оцениваемым
параметрам, например
– полиномы различных степеней –
![]() ,
,![]() ;
;
– равносторонняя гипербола –
![]() ;
;
– полулогарифмическая функция –
![]() .
.
-
Регрессии, нелинейные по оцениваемым
параметрам, например
– степенная –
![]() ;
;
– показательная –
![]() ;
;
– экспоненциальная –
![]() .
.
Уравнение нелинейной регрессии, так
же, как и в случае линейной зависимости,
дополняется показателем тесноты связи.
В данном случае это индекс корреляции:
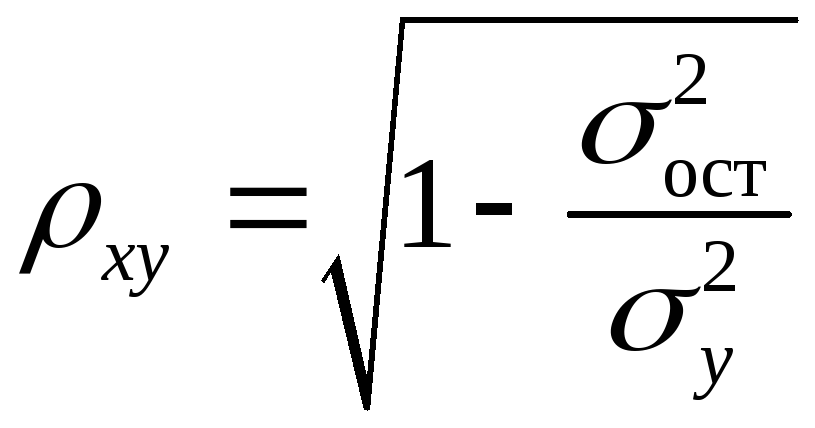 ,
,
(1.21)
где
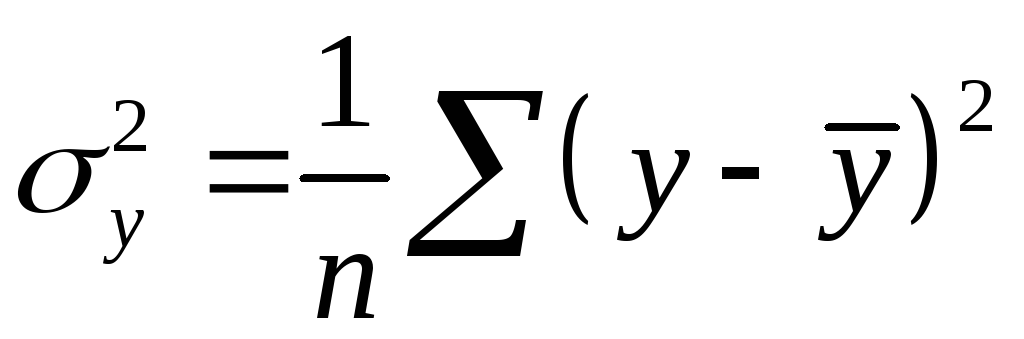 – общая дисперсия результативного
– общая дисперсия результативного
признака![]() ,
,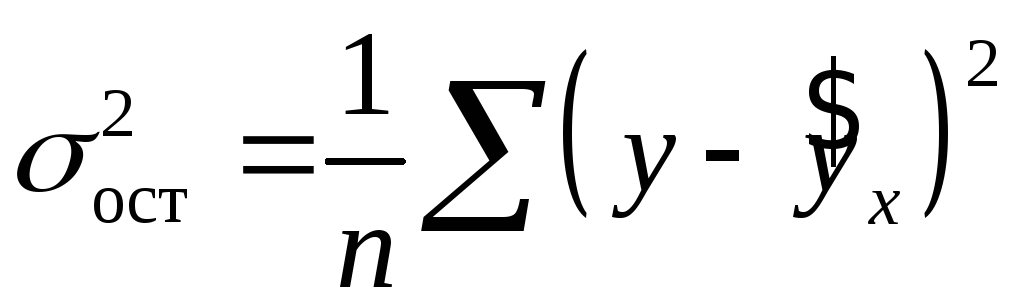 – остаточная дисперсия.
– остаточная дисперсия.
Величина данного показателя находится
в пределах:
![]() .
.
Чем ближе значение индекса корреляции
к единице, тем теснее связь рассматриваемых
признаков, тем более надежно уравнение
регрессии.
Квадрат индекса корреляции носит
название индекса детерминации и
характеризует долю дисперсии
результативного признака
![]() ,
,
объясняемую регрессией, в общей дисперсии
результативного признака:
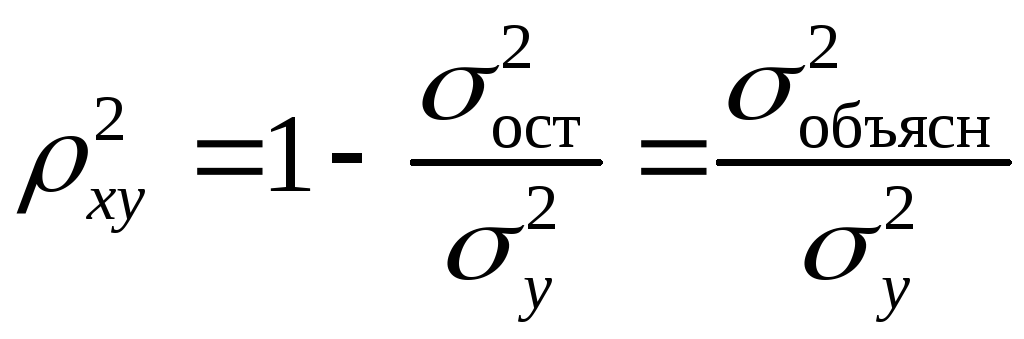 ,
,
(1.22)
т.е. имеет тот же смысл, что и в линейной
регрессии;
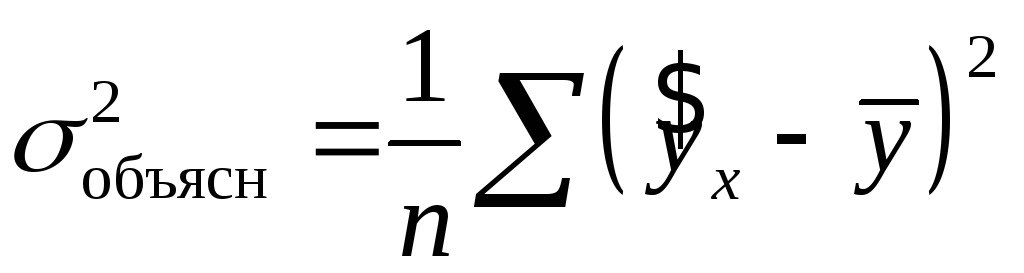 .
.
Индекс детерминации
![]() можно сравнивать с коэффициентом
можно сравнивать с коэффициентом
детерминации![]() для обоснования возможности применения
для обоснования возможности применения
линейной функции. Чем больше кривизна
линии регрессии, тем величина![]() меньше
меньше![]() .
.
А близость этих показателей указывает
на то, что нет необходимости усложнять
форму уравнения регрессии и можно
использовать линейную функцию.
Индекс детерминации используется для
проверки существенности в целом уравнения
регрессии по
![]() -критерию
-критерию
Фишера:
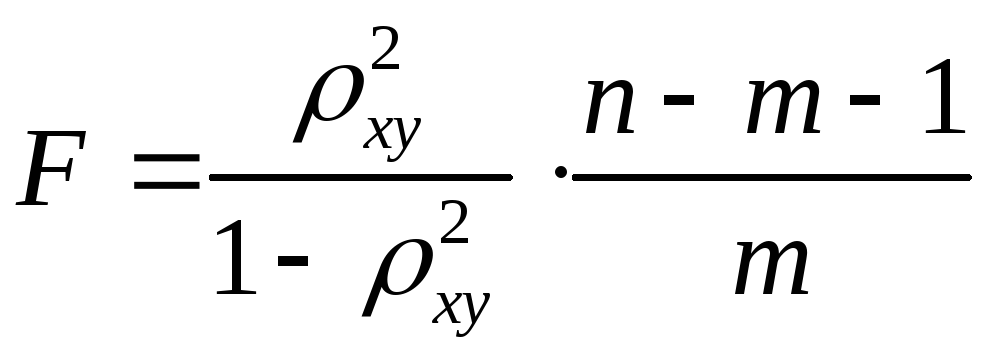 ,
,
(1.23)
где
![]() – индекс детерминации,
– индекс детерминации,![]() – число наблюдений,
– число наблюдений,![]() – число параметров при переменной
– число параметров при переменной![]() .
.
Фактическое значение![]() -критерия
-критерия
(1.23) сравнивается с табличным при уровне
значимости![]() и числе степеней свободы
и числе степеней свободы![]() (для остаточной суммы квадратов) и
(для остаточной суммы квадратов) и![]() (для факторной суммы квадратов).
(для факторной суммы квадратов).
О качестве
нелинейного уравнения регрессии можно
также судить и по средней ошибке
аппроксимации
Регрессии нелинейные относительно включенных в анализ объясняющих переменных.
Регрессии нелинейные по включенным
переменным приводятся к линейному виду
простой заменой переменных, а дальнейшая
оценка параметров производится с помощью
метода наименьших квадратов. Рассмотрим
некоторые функции.
Парабола второй степени
![]() приводится к линейному виду с помощью
приводится к линейному виду с помощью
замены:![]() .
.
В результате приходим к двухфакторному
уравнению![]() ,
,
оценка параметров которого при помощи
МНК, как будет показано в параграфе 2.2
приводит к системе следующих нормальных
уравнений:
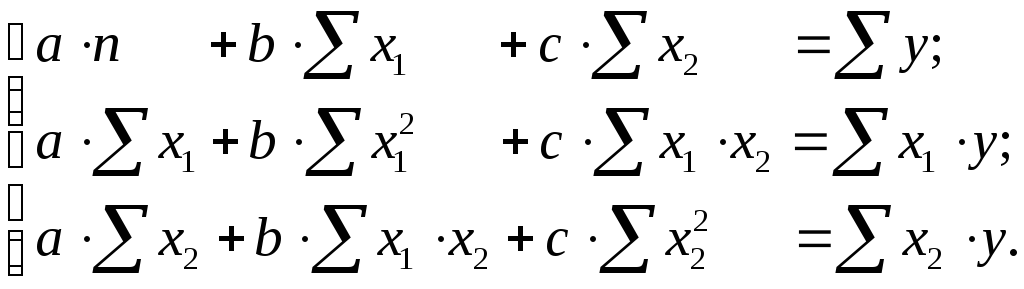
А после обратной замены переменных
получим
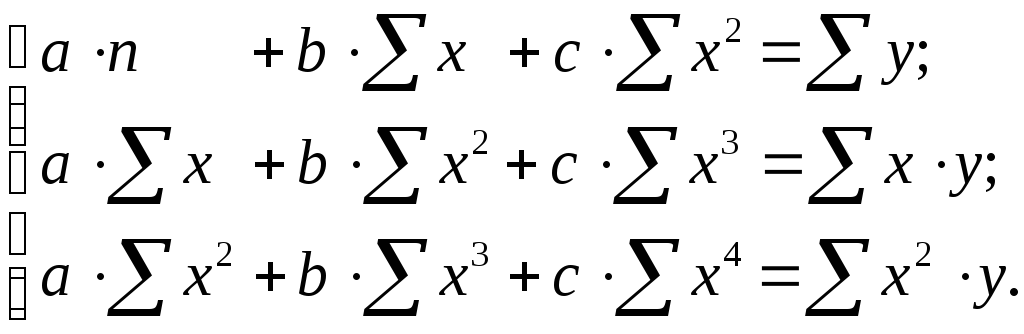 (1.17)
(1.17)
Парабола второй степени обычно применяется
в случаях, когда для определенного
интервала значений фактора меняется
характер связи рассматриваемых признаков:
прямая связь меняется на обратную или
обратная на прямую.
Равносторонняя гипербола ![]() может быть использована для характеристики
может быть использована для характеристики
связи удельных расходов сырья, материалов,
топлива от объема выпускаемой продукции,
времени обращения товаров от величины
товарооборота, процента прироста
заработной платы от уровня безработицы
(например, кривая А.В. Филлипса), расходов
на непродовольственные товары от доходов
или общей суммы расходов (например,
кривые Э. Энгеля) и в других случаях.
Гипербола приводится к линейному
уравнению простой заменой:![]() .
.
Система линейных уравнений при применении
МНК будет выглядеть следующим образом:
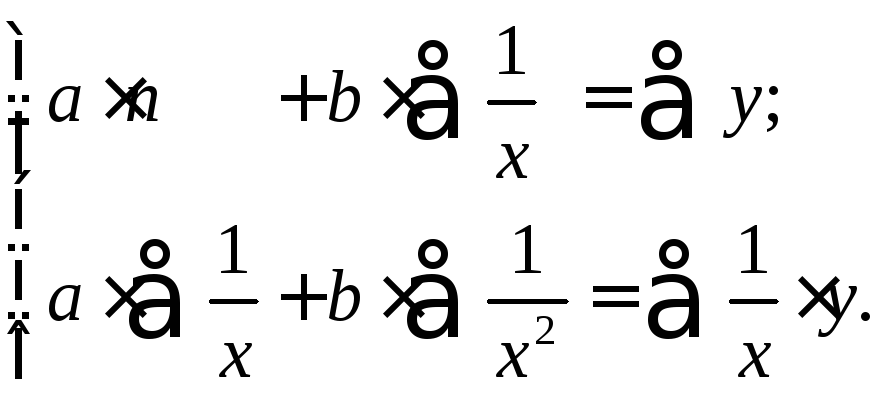 (1.18)
(1.18)
Аналогичным
образом приводятся к линейному виду
зависимости
![]() ,
,![]() и другие
и другие
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Средняя ошибка аппроксимации
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Нелинейная регрессия. Корреляция для нелинейной регрессии. Средняя ошибка аппроксимации
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Различают два класса нелинейных регрессий:
1) Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, например
· полиномы различных степеней — , ;
- · равносторонняя гипербола — ;
- · полулогарифмическая функция — .
- 2) Регрессии, нелинейные по оцениваемым параметрам, например
Регрессии нелинейные по включенным переменным приводятся к линейному виду простой заменой переменных, а дальнейшая оценка параметров производится с помощью метода наименьших квадратов. Рассмотрим некоторые функции.
Парабола второй степени приводится к линейному виду с помощью замены: , . В результате приходим к двухфакторному уравнению , оценка параметров которого при помощи МНК, приводит к системе следующих нормальных уравнений:
А после обратной замены переменных получим
Парабола второй степени обычно применяется в случаях, когда для определенного интервала значений фактора меняется характер связи рассматриваемых признаков: прямая связь меняется на обратную или обратная на прямую.
Равносторонняя гипербола может быть использована для характеристики связи удельных расходов сырья, материалов, топлива от объема выпускаемой продукции, времени обращения товаров от величины товарооборота, процента прироста заработной платы от уровня безработицы (например, кривая А.В. Филлипса), расходов на непродовольственные товары от доходов или общей суммы расходов (например, кривые Э. Энгеля) и в других случаях. Гипербола приводится к линейному уравнению простой заменой: . Система линейных уравнений при применении МНК будет выглядеть следующим образом:
Аналогичным образом приводятся к линейному виду зависимости , и другие.
Несколько иначе обстоит дело с регрессиями нелинейными по оцениваемым параметрам, которые делятся на два типа: нелинейные модели внутренне линейные (приводятся к линейному виду с помощью соответствующих преобразований, например, логарифмированием) и нелинейные модели внутренне нелинейные (к линейному виду не приводятся).
К внутренне линейным моделям относятся, например, степенная функция -, показательная — , экспоненциальная — , логистическая — , обратная — .
К внутренне нелинейным моделям можно, например, отнести следующие модели: , .
Среди нелинейных моделей наиболее часто используется степенная функция , которая приводится к линейному виду логарифмированием:
где , , , . Т.е. МНК мы применяем для преобразованных данных:
а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр в ней имеет четкое экономическое истолкование — он является коэффициентом эластичности. (Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%.) Формула для расчета коэффициента эластичности имеет вид:
Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора , то обычно рассчитывается средний коэффициент эластичности:
Приведем формулы для расчета средних коэффициентов эластичности для наиболее часто используемых типов уравнений регрессии:
Средний коэффициент эластичности,
Возможны случаи, когда расчет коэффициента эластичности не имеет смысла. Это происходит тогда, когда для рассматриваемых признаков бессмысленно определение изменения в процентах.
Уравнение нелинейной регрессии, так же, как и в случае линейной зависимости, дополняется показателем тесноты связи. В данном случае это индекс корреляции:
где — общая дисперсия результативного признака , — остаточная дисперсия.
Величина данного показателя находится в пределах: . Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
Квадрат индекса корреляции носит название индекса детерминации и характеризует долю дисперсии результативного признака , объясняемую регрессией, в общей дисперсии результативного признака:
т.е. имеет тот же смысл, что и в линейной регрессии;
Индекс детерминации можно сравнивать с коэффициентом детерминации для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
Индекс детерминации используется для проверки существенности в целом уравнения регрессии по -критерию Фишера:
где — индекс детерминации, — число наблюдений, — число параметров при переменной. Фактическое значение -критерия сравнивается с табличным при уровне значимости и числе степеней свободы (для остаточной суммы квадратов) и (для факторной суммы квадратов).
О качестве нелинейного уравнения регрессии можно также судить и по средней ошибке аппроксимации.
Проверить значимость уравнения регрессии — значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
Средняя ошибка аппроксимации не должна превышать 8-10%.
По проведенному опросу восьми групп семей известны данные связи расходов населения на продукты с уровнем доходов семьи.
O линейные уравнения множественной
o нелинейные уравнения парной
o линейные уравнения парной
o нелинейные уравнения множественной
349. Способом включения случайного возмущения в регрессионную модель y=a+bx, при котором сохраняется линейная форма модели, является .
- аддитивный
- мультипликативный
- экспоненциальный
- мультиколлинеарный
350. Требованием к уравнениям регрессии, параметры которых можно найти при помощи МНК является:
O линейность параметров
o равенство нулю средних значений результативной переменной
o нелинейность параметров
o равенство нулю средних значений факторного признака
351. Укажите последовательность этапов оценки параметров нелинейной регрессии Y=aX b Z c .
352. Укажите последовательность этапов оценки параметров нелинейной регрессии, линейной относительно параметров.
- определяются оценки исходные параметры нелинейной модели, которые совпадают с параметрами линеаризованной модели
- применяется метод наименьших квадратов для оценки линеаризованной модели
- задаётся линейная спецификация модели в новых переменных
- выбирается метод линеаризации исходной модели
353. Уравнение может быть линеаризовано при помощи подстановки …
o (верно)
o
o
o
Тема: Оценка качества нелинейных уравнений регрессии
- Выражение позволяет вычислить значение …
- средней ошибки аппроксимации
- F-критерия Фишера
- коэффициента эластичности
- индекса корреляции
- Гипотеза о значимости в целом уравнения нелинейной регрессии проверяется с помощью критерия …
- Дарбина–Уотсона
- Пирсона
- Фишера
- Стьюдента
356. Если значение индекса корреляции для нелинейного уравнения регрессии стремится к 1, то
O нелинейная связь достаточно тесная
o нелинейная связь отсутствует
o линейная связь достаточно тесная
o нелинейная связь недостаточно тесная
357. Значение индекса корреляции находится в пределах …
- R
O нелинейной
359. Коэффициент эластичности показывает …
- отношение коэффициента детерминации к коэффициенту корреляции
- величину остаточной дисперсии на одну степень свободы
- на сколько единиц изменится результативный показатель при изменении величины факторного признака на единицу
- на сколько процентов изменится результативный показатель при изменении величины факторного признака на 1%
- Коэффициент эластичности является постоянной величиной в модели вида …
- Y=ab X ε
- Y=a+bX+ε
- Y=aX b ε
- Y=a+bX+cX 2 +ε
361. Назовите показатель корреляции для нелинейных моделей регрессии
O индекс корреляции
o линейный коэффициент корреляции
o индекс детерминации
o парный коэффициент линейной корреляции
362. Назовите показатель тесноты связи для нелинейных моделей регрессии:
O индекс детерминации
o индекс корреляции
o линейный коэффициент корреляции
o парный коэффициент линейной корреляции
363. Нелинейная связь между рассматриваемыми признаками тем теснее, чем значение индекса корреляции ближе к …
364. Оценить статистическую значимость нелинейного уравнения регрессии можно с помощью …
O критерия Фишера
o средней ошибки аппроксимации
o линейного коэффициента корреляции
o показателя эластичности
365. При хорошем качестве модели допустимым значением средней ошибки аппроксимации является …
366. Пусть R 2 – индекс детерминации; n – число наблюдений; m – число параметров при независимых переменных. Тогда при проверке значимости в целом уравнения нелинейной регрессии расчетное значение F-критерия Фишера вычисляется по формуле …
- Пусть yi – наблюдаемые значения зависимой переменной, а – её расчётные значения. В принятых обозначениях средняя ошибка аппроксимации модели может быть определена по формуле …
368. Расчёт средней ошибки аппроксимации для нелинейных уравнений регрессии связан с расчётом разности между ____________________________ переменной
http://studwood.net/1843833/matematika_himiya_fizika/nelineynaya_regressiya_korrelyatsiya_nelineynoy_regressii_srednyaya_oshibka_approksimatsii
http://lektsii.org/6-58275.html
Имеются следующие данные разных стран об индексе розничных цен на продукты питания (х) и об индексе промышленного производства (у).
| Индекс розничных цен на продукты питания (х) | Индекс промышленного производства (у) | |
|---|---|---|
| 1 | 100 | 70 |
| 2 | 105 | 79 |
| 3 | 108 | 85 |
| 4 | 113 | 84 |
| 5 | 118 | 85 |
| 6 | 118 | 85 |
| 7 | 110 | 96 |
| 8 | 115 | 99 |
| 9 | 119 | 100 |
| 10 | 118 | 98 |
| 11 | 120 | 99 |
| 12 | 124 | 102 |
| 13 | 129 | 105 |
| 14 | 132 | 112 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
А) линейной;
Б) степенной;
В) равносторонней гиперболы.
2. Для каждой модели рассчитать показатели: тесноты связи и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз значения индекса промышленного производства у при прогнозном значении индекса розничных цен на продукты питания х=138.
Решение:
1. Для расчёта параметров линейной регрессии
Решаем систему нормальных уравнений относительно a и b:
Построим таблицу расчётных данных, как показано в таблице 1.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | ху | x2 | y2 | |
|
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 7000 | 10000 | 4900 | 74,26340 | 0,060906 |
| 2 | 105 | 79 | 8295 | 11025 | 6241 | 79,92527 | 0,011712 |
| 3 | 108 | 85 | 9180 | 11664 | 7225 | 83,32238 | 0,019737 |
| 4 | 113 | 84 | 9492 | 12769 | 7056 | 88,98425 | 0,059336 |
| 5 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 6 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 7 | 110 | 96 | 10560 | 12100 | 9216 | 85,58713 | 0,108467 |
| 8 | 115 | 99 | 11385 | 13225 | 9801 | 91,24900 | 0,078293 |
| 9 | 119 | 100 | 11900 | 14161 | 10000 | 95,77849 | 0,042215 |
| 10 | 118 | 98 | 11564 | 13924 | 9604 | 94,64611 | 0,034223 |
| 11 | 120 | 99 | 11880 | 14400 | 9801 | 96,91086 | 0,021102 |
| 12 | 124 | 102 | 12648 | 15376 | 10404 | 101,4404 | 0,005487 |
| 13 | 129 | 105 | 13545 | 16641 | 11025 | 107,1022 | 0,020021 |
| 14 | 132 | 112 | 14784 | 17424 | 12544 | 110,4993 | 0,013399 |
| Итого: | 1629 | 1299 | 152293 | 190557 | 122267 | 1299,001 | 0,701866 |
| Среднее значение: | 116,3571 | 92,78571 | 10878,07 | 13611,21 | 8733,357 | х | х |
|
8,4988 | 11,1431 | х | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х | х |
Среднее значение определим по формуле:
Cреднее квадратическое отклонение рассчитаем по формуле:
и занесём полученный результат в таблицу 1.
Возведя в квадрат полученное значение получим дисперсию:
Параметры уравнения можно определить также и по формулам:
Таким образом, уравнение регрессии:
Следовательно, с увеличением индекса розничных цен на продукты питания на 1, индекс промышленного производства увеличивается в среднем на 1,13.
Рассчитаем линейный коэффициент парной корреляции:
Связь прямая, достаточно тесная.
Определим коэффициент детерминации:
Вариация результата на 74,59% объясняется вариацией фактора х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
Так как
,
следовательно, параметры уравнения определены правильно.
Рассчитаем среднюю ошибку аппроксимации – среднее отклонение расчётных значений от фактических:
В среднем расчётные значения отклоняются от фактических на 5,01%.
Оценку качества уравнения регрессии проведём с помощью F-теста.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
где n – число единиц совокупности;
m – число параметров при переменных х.
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
2. Степенная регрессия имеет вид:
Для определения параметров производят логарифмирование степенной функции:
Для определения параметров логарифмической функции строят систему нормальных уравнений по способу наименьших квадратов:
Построим таблицу расчётных данных, как показано в таблице 2.
Таблица 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | lg x | lg y | lg x*lg y | (lg x)2 | (lg y)2 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 2,000000 | 1,845098 | 3,690196 | 4,000000 | 3,404387 |
| 2 | 105 | 79 | 2,021189 | 1,897627 | 3,835464 | 4,085206 | 3,600989 |
| 3 | 108 | 85 | 2,033424 | 1,929419 | 3,923326 | 4,134812 | 3,722657 |
| 4 | 113 | 84 | 2,053078 | 1,924279 | 3,950696 | 4,215131 | 3,702851 |
| 5 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 6 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 7 | 110 | 96 | 2,041393 | 1,982271 | 4,046594 | 4,167284 | 3,929399 |
| 8 | 115 | 99 | 2,060698 | 1,995635 | 4,112401 | 4,246476 | 3,982560 |
| 9 | 119 | 100 | 2,075547 | 2,000000 | 4,151094 | 4,307895 | 4,000000 |
| 10 | 118 | 98 | 2,071882 | 1,991226 | 4,125585 | 4,292695 | 3,964981 |
| 11 | 120 | 99 | 2,079181 | 1,995635 | 4,149287 | 4,322995 | 3,982560 |
| 12 | 124 | 102 | 2,093422 | 2,008600 | 4,204847 | 4,382414 | 4,034475 |
| 13 | 129 | 105 | 2,110590 | 2,021189 | 4,265901 | 4,454589 | 4,085206 |
| 14 | 132 | 112 | 2,120574 | 2,049218 | 4,345518 | 4,496834 | 4,199295 |
| Итого | 1629 | 1299 | 28,90474 | 27,49904 | 56,79597 | 59,69172 | 54,05467 |
| Среднее значение | 116,3571 | 92,78571 | 2,064624 | 1,964217 | 4,056855 | 4,263694 | 3,861048 |
|
8,4988 | 11,1431 | 0,031945 | 0,053853 | х | х | х |
|
72,23 | 124,17 | 0,001021 | 0,0029 | х | х | х |
Продолжение таблицы 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | |
|
|
|
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 74,16448 | 17,34292 | 0,059493 | 519,1886 |
| 2 | 105 | 79 | 79,62057 | 0,385112 | 0,007855 | 190,0458 |
| 3 | 108 | 85 | 82,95180 | 4,195133 | 0,024096 | 60,61728 |
| 4 | 113 | 84 | 88,59768 | 21,13866 | 0,054734 | 77,1887 |
| 5 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 6 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 7 | 110 | 96 | 85,19619 | 116,7223 | 0,11254 | 10,33166 |
| 8 | 115 | 99 | 90,88834 | 65,79901 | 0,081936 | 38,6174 |
| 9 | 119 | 100 | 95,52408 | 20,03384 | 0,044759 | 52,04598 |
| 10 | 118 | 98 | 94,35840 | 13,26127 | 0,037159 | 27,18882 |
| 11 | 120 | 99 | 96,69423 | 5,316563 | 0,023291 | 38,6174 |
| 12 | 124 | 102 | 101,4191 | 0,337467 | 0,005695 | 84,90314 |
| 13 | 129 | 105 | 107,4232 | 5,872099 | 0,023078 | 149,1889 |
| 14 | 132 | 112 | 111,0772 | 0,85163 | 0,00824 | 369,1889 |
| Итого | 1629 | 1299 | 1296,632 | 446,4152 | 0,703074 | 1738,357 |
| Среднее значение | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Решая систему нормальных уравнений, определяем параметры логарифмической функции.
Получим линейное уравнение:
Выполнив его потенцирование, получим:
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата . По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
Связь достаточно тесная.
В среднем расчётные значения отклоняются от фактических на 5,02%.
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
3. Уравнение равносторонней гиперболы
Для определения параметров этого уравнения используется система нормальных уравнений:
Произведем замену переменных
и получим следующую систему нормальных уравнений:
Решая систему нормальных уравнений, определяем параметры гиперболы.
Составим таблицу расчётных данных, как показано в таблице 3.
Таблица 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | z | yz | |
|
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 0,010000000 | 0,700000 | 0,0001000 | 4900 |
| 2 | 105 | 79 | 0,009523810 | 0,752381 | 0,0000907 | 6241 |
| 3 | 108 | 85 | 0,009259259 | 0,787037 | 0,0000857 | 7225 |
| 4 | 113 | 84 | 0,008849558 | 0,743363 | 0,0000783 | 7056 |
| 5 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 6 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 7 | 110 | 96 | 0,009090909 | 0,872727 | 0,0000826 | 9216 |
| 8 | 115 | 99 | 0,008695652 | 0,860870 | 0,0000756 | 9801 |
| 9 | 119 | 100 | 0,008403361 | 0,840336 | 0,0000706 | 10000 |
| 10 | 118 | 98 | 0,008474576 | 0,830508 | 0,0000718 | 9604 |
| 11 | 120 | 99 | 0,008333333 | 0,825000 | 0,0000694 | 9801 |
| 12 | 124 | 102 | 0,008064516 | 0,822581 | 0,0000650 | 10404 |
| 13 | 129 | 105 | 0,007751938 | 0,813953 | 0,0000601 | 11025 |
| 14 | 132 | 112 | 0,007575758 | 0,848485 | 0,0000574 | 12544 |
| Итого: | 1629 | 1299 | 0,120971823 | 11,13792 | 0,0010510 | 122267 |
| Среднее значение: | 116,3571 | 92,78571 | 0,008640844 | 0,795566 | 0,0000751 | 8733,357 |
|
8,4988 | 11,1431 | 0,000640820 | х | х | х |
|
72,23 | 124,17 | 0,000000411 | х | х | х |
Продолжение таблицы 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | |
|
|
|
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 72,3262 | 0,033231 | 5,411206 | 519,1886 |
| 2 | 105 | 79 | 79,49405 | 0,006254 | 0,244083 | 190,0458 |
| 3 | 108 | 85 | 83,47619 | 0,017927 | 2,322012 | 60,61728 |
| 4 | 113 | 84 | 89,64321 | 0,067181 | 31,84585 | 77,1887 |
| 5 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 6 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 7 | 110 | 96 | 86,01027 | 0,10406 | 99,79465 | 10,33166 |
| 8 | 115 | 99 | 91,95987 | 0,071112 | 49,56344 | 38,6174 |
| 9 | 119 | 100 | 96,35957 | 0,036404 | 13,25272 | 52,04598 |
| 10 | 118 | 98 | 95,28761 | 0,027677 | 7,357059 | 27,18882 |
| 11 | 120 | 99 | 97,41367 | 0,016024 | 2,516453 | 38,6174 |
| 12 | 124 | 102 | 101,46 | 0,005294 | 0,291565 | 84,90314 |
| 13 | 129 | 105 | 106,1651 | 0,011096 | 1,357478 | 149,1889 |
| 14 | 132 | 112 | 108,8171 | 0,028419 | 10,1311 | 369,1889 |
| Итого: | 1629 | 1299 | 1298,988 | 0,666742 | 435,7575 | 1738,357 |
| Среднее значение: | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Значения параметров регрессии a и b составили:
Получено уравнение:
Индекс корреляции:
Связь достаточно тесная.
В среднем расчётные значения отклоняются от фактических на 4,76%.
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
По уравнению равносторонней гиперболы получена наибольшая оценка тесноты связи по сравнению с линейной и степенной регрессиями. Средняя ошибка аппроксимации остаётся на допустимом уровне.
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
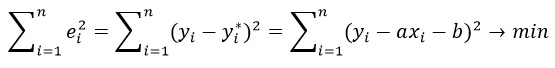
частные производные функции приравниваем к нулю
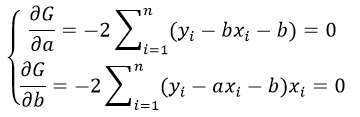
отсюда получаем систему линейных уравнений
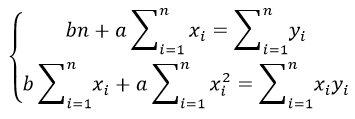
Формулы определения коэффициентов уравнения линейной регрессии:
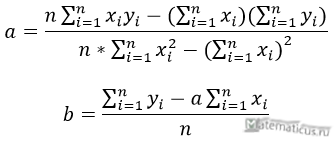
Также запишем уравнение регрессии для квадратной нелинейной функции:
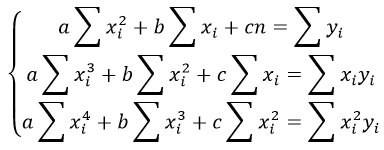
Система линейных уравнений регрессии полинома n-ого порядка:
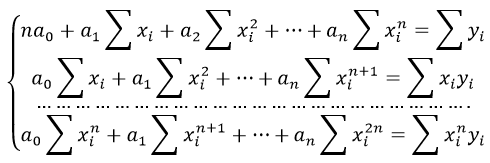
Формула коэффициента детерминации R2:
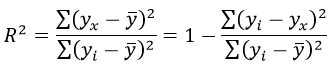
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
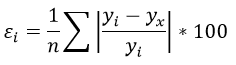
Чем меньше ε, тем лучше. Рекомендованный показатель ε<10%
Формула среднеквадратической погрешности:
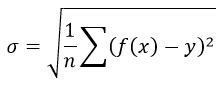
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
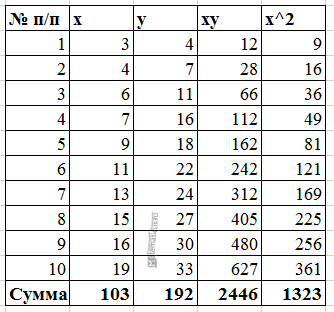
Расчет коэффициентов линейной регрессии:
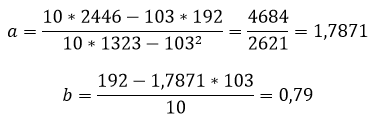
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
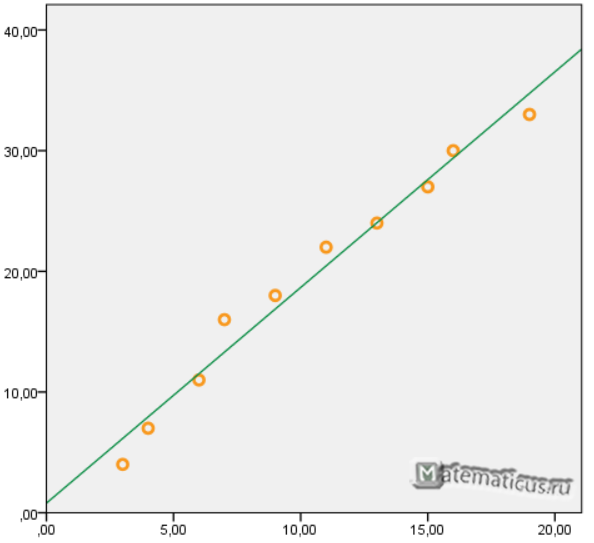
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
![]() 16988
16988