7. В процессе работы в тегах иногда появляются недостоверные значения.
Такая ситуация может возникать при работе по радио и GSM каналам по протоколу Modbus RTU и ASCII (при работе по Modbus TCP такая ситуация не возможна). Это происходит из-за «наслоения» ответов. В Modbus RTU нет специального поля, по которому можно было бы определить соответствие ответа определенному запросу (в Modbus TCP такое поле есть – Transaction ID). Представим ситуацию, ОРС сервер послал запрос в устройство, устройство ответило, но возникла задержка в сети (в GSM сетях это обычное явление), ОРС сервер не получил ответ и отправил запрос повторно, ему пришел ответ на предыдущий запрос – он корректен, ОРС сервер разобрал его и послал следующий запрос (следующего регистра), ему приходит ответ от предыдущего запрос – но в нем содержаться данные совершенно от других регистров! ОРС сервер производит анализ полученного ответа, например, если ОРС сервер запросил 2 регистра, а пришло 4, то такой запрос он отбросит. Если запрос пришел не от запрошенного устройства или с другой функцией, то этот запрос будет также отброшен. Но если запрос по структуре совпадает с предыдущим, сервер его примет и запишет значения в теги, которые будут некорректными. Избежать данной ситуации можно установив несколько настроек – включите реинициализацию узла при ошибке, а количество попыток установите равным 1. В этом случае, при первом же неудачном опросе сервер закроет порт, тем самым очистив буфер, а затем откроет его снова.
Предмет описываемой проблемы
При работе с базой данных в PostgreSQL необходимо не забывать, в какой локали (locale) был инициализирован кластер БД — так в постгре называется директория (обычно /var/lib/pgsql/data), в которой хранятся данные всех баз этой установки PostgreSQL.
Проблема
Сегодня я столкнулся с такой проблемой. В запросе выборки при использовании функции lower() приведение кириллического текста к нижнему регистру не происходило, при этом английские значения охотно «уменьшались».
Первая попытка решить проблему
Гугло-поиск по полвине Интернета дал информацию о том, что неплохо было бы, если бы искомая база данных была в кодировке UTF-8 (в моем случае, по недосмотру, она была в дефолтной SQL_ASCII).
Ок. Сказано — сделано! Относительно быстро нашлась инструкция о том, как пересоздать базу данных в новой кодировке без потери данных.
[bash] # su - postgres ~ vacuumdb --full --analyze --username postgres --dbname mydatabase ~ pg_dump mydatabase -Ft -v -U postgres -f /tmp/mydatabase.tar ~ dropdb mydatabase --username postgres ~ createdb --encoding UNICODE mydatabase --username postgres ~ pg_restore /tmp/mydatabase.tar | psql --dbname mydatabase --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydatabase
Проверка показала, что данные этой базы не испортились, но требуемые действия (приведение к нижнему регистру функцией lower() всё равно не происходили.
Решение проблемы становится интересным
Вместе с продолженным гугло-чтением пришло понимание того, что кластер баз данных этого PostgreSQL сервера был инициализирован в локали «C», а для функий lower() и upper() это значит очень многое!
Пришлось выяснить, как пере-инициализировать кластер баз данных, не погубив при этом уже существующие базы и данные в них. При этом, сервер этот является production — на него по крону (crontab) раз в час сливаются кое-какие дампы данных. Благо то, что он не столько продакшн, что не нашлось бы свободного «окна» для пере-инициализации.
«Окно» в 60 минут и полчаса на подготовку
До конца рабочего дня оставалось 1,5 часа и одно свободное «окошко» продолжительностью в 60 минут.
Начинать я решил с разминки на локальном ноуте. Здесь стоит упомянуть о разнице в операционных системах: ноут — Ubuntu 8.10, сервер — CentOS 5. Подготовив три окна терминала и ещё окно текстового редактора, приступил к подготовительным работам.
Во-первых, первый способ необходимо было разделить надвое — дамп существующих данных и восстановление их после ре-инициализации кластера.
Дамп баз состоялся без сильных нареканий, только пару раз pg_drop ругнулся на подключенных пользователей к тем же базам (решилось закрытием pgAdmin’а).
Затем была найдена (в случае с Убунтой) спрятанная в достаточно необычном месте (/usr/lib/postgresql/8.3/bin) команда (initdb) и выполнена в нужными параметрами.
[bash] # su - postgres ~ vacuumdb --full --analyze --username postgres --dbname mydatabase ~ pg_dump mydatabase -Ft -v -U postgres -f /tmp/mydatabase.tar ~ dropdb mydatabase --username postgres ~ initdb --locale=ru_RU.utf8 data/
Damn! Error…
Мда, оказалось, что нужно вручную удалить содержимое директории кластера баз данных.
Предупреждение! Не делайте сразу
rm -rf data/*. Это я понял после того, как сделал это на ноуте, а после восстановления, у меня сбились права доступа пользователей к серверу (которые хранятся вpg_hba.conf).
Необходимо сделать копию файла pg_hba.conf куда-нибудь на время перемен.
[bash] ~ cp data/pg_hba.conf /home/cr0t/pg_hba.2009.03.24_1654.conf
После удаления содержимого директории и остановки демона PostgreSQL без ошибки прошла ре-инициализация кластера.
[bash] ~ exit # /etc/init.d/postgresql stop # su - postgres ~ rm -rf data/* ~ initdb --locale=ru_RU.utf8 data/
Оставалось только запустить заново сервер и восстановить из дампов старые базы в уже новый кластер, инициализированный в «правильной» локали.
[bash] ~ exit # /etc/init.d/postgresql start # su - postgres ~ createdb --encoding UNICODE mydatabase --username postgres ~ pg_restore /tmp/mydatabase.tar | psql --dbname mydatabase --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydatabase
Успех. Итоги
После этих успешных действий функция lower() стала правильно «прижимать» кириллические символы. Все рады. Но я даже не подумал о пользовательских ролях PostgreSQL (так в 8.х версии стали называться пользователи). Их не стало. Хорошо, что мне требовалось создать их всего парочку. Но у кого их много, будьте бдительны, не повторите моей ошибки!
P.S. Шаги для ре-инициализации, если есть несколько баз данных
В моём случае необходимо было задампить и впоследствии восстановить 3 базы.
Для решения этой задачи необходимо добавить всего лишь дополнительные повторы некоторых действий по снятию дампа и последующему восстановлению (при большом желании, даже автоматизирующий скрипт можно написать ).
[bash] # su - postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb1 ~ pg_dump mydb1 -Ft -v -U postgres -f /tmp/mydb1.tar ~ dropdb mydb1 --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb2 ~ pg_dump mydb2 -Ft -v -U postgres -f /tmp/mydb2.tar ~ dropdb mydb2 --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb3 ~ pg_dump mydb3 -Ft -v -U postgres -f /tmp/mydb3.tar ~ dropdb mydb3 --username postgres ~ cp data/pg_hba.conf ./ ~ exit # /etc/init.d/postgresql stop # su - postgres ~ rm -rf data/* ~ initdb --locale=ru_RU.utf8 data/ ~ cp pg_hba.conf data/ ~ exit # /etc/init.d/postgresql start # su - postgres ~ createdb --encoding UNICODE mydb1 --username postgres ~ pg_restore /tmp/mydb1.tar | psql --dbname mydb1 --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb1 ~ createdb --encoding UNICODE mydb2 --username postgres ~ pg_restore /tmp/mydb2.tar | psql --dbname mydb2 --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb2 ~ createdb --encoding UNICODE mydb3 --username postgres ~ pg_restore /tmp/mydb3.tar | psql --dbname mydb3 --username postgres ~ vacuumdb --full --analyze --username postgres --dbname mydb3
Кросс-пост с моего блога Summer code
Пост похож на уже опубликованный недавно Патчим UTF-8 Collation под FreeBSD, но мне кажется, что там описано решение проблемы специфичное для FreeBSD, я же привожу для Ubuntu’ы. Когда я решал свою проблему этой информацией даже не пользовался — только гугло-чтение.
Спасибо за карму!, перенёс в блог PostgreSQL.
Документ из архива «РД 45.134-2000»,
который расположен в категории «».
Всё это находится в предмете «другие» из , которые можно найти в файловом архиве .
Не смотря на прямую связь этого архива с , его также можно найти и в других разделах. Архив можно найти в разделе «остальное», в предмете «другие» в общих файлах.
Инициировать изменение портов, отличных от установленных по умолчанию, может только PI клиента. (команда PORT).
2.3.2. Процедура разрыва соединения.
Закрытие соединения, как правило, инициирует сервер.
Исключением является случай, когда DTP клиента посылает данные в режиме, определяющем закрытие соединения для индикации EOF. Сервер должен закрыть соединение при следующих условиях:
1. сервер выполнил передачу данных в режиме, требующем закрытия для индикации EOF.
2. сервер получил команду ABORT от клиента
3. спецификация порта изменена командой от клиента
4. управляющее соединение закрыто
5. произошла невосстановимая ошибка
В остальных случаях сервер инициирует закрытие соединения данных посылкой процессу клиента ответов 250 или 226.
2.3.3. Управление соединением данных
2.3.3.1.На стороне сервера номер порта соединения данных по умолчанию должен быть на 1 меньше номера порта управляющего соединения.
2.3.3.2. Процедура согласования портов данных, отличных от установленных по умолчанию (нестандартных)
PI клиента определяет нестандартный порт на стороне клиента командой PORT либо запрашивает о нестандартном порте на стороне сервера командой PASV. Эти команды могут использоваться вместе или по отдельности.
2.3.3.3. Переустановка соединения данных
При использовании режима передачи данных stream mode конец файла определяется закрытием соединения. Проблема передачи нескольких файлов может иметь два решения:
1. установка нестандартного порта.
2. использование другого режима передачи данных
2.3.4. Режимы передачи данных
Передающий узел должен преобразовывать знаки конца строки и конца записи, используемые для внутреннего хранения файла, в представление, соответствующее режиму передачи данных и файловой структуре. Принимающий узел должен выполнять обратную операцию.
Обязательно должны быть реализованы stream mode и block mode.
2.3.4.1. Stream mode (режим потока).
Данные передаются как поток байтов (в том числе байтов данных). Нет ограничений на используемый тип представления, позволяется использовать структуры записей.
Если файл имеет структуру записей (структурирован по записям), символы EOR и EOF индицируются двухбайтовым кодом. Причем первым байтом должен быть escape-символ, а второй байт должен быть 1 (единица в менее значащем бите) для EOR и 2 (единица во втором бите) для EOF. Последовательность из escape-символа и символа 3 (два младших бита равны 1) означает одновременное присутствие EOR и EOF.
Если файл неструктурирован, символ EOF индицируется передающим узлом путем закрытия соединения данных. Все передаваемые байты являются байтами данных.
Данный тип передачи устанавливается по умолчанию.
2.3.4.2. Block mode — поблочный режим
Файл передается как серия блоков данных с заголовками.
Длина заголовка — 3 байта — 16 младших бит занимает поле counter, 8 старших бит — descriptor.
|
Descriptor 8 бит |
Count 16 бит |
Заголовок содержит поля:
1. Поле счета (counter) — показывает общую длину блока в байтах (без учета заголовка), тем самым определяя начало следующего блока (блоки передаются один за другим без пауз и разрывов)
2. Поле описателя (дескриптора) (descriptor):
|
Код |
Значение |
|
128 |
EOF — последний блок файла |
|
64 |
EOR — последний блок записи |
|
16 |
restart marker — в блоке данных содержится символ рестарта |
|
32 |
suspect data — передаваемые данные в блоке могут содержать ошибку |
Допускается наличие нескольких дескрипторов в одном блоке (коды логически складываются — операция «И»).
Данными маркера рестарта может быть набор печатных символов используемого алфавита (NVT-ASCII например), в который не должен входить пробел (Space).
2.3.4.3. Compressed mode — режим сжатия
Посылается три вида информации — регулярные данные (в виде строки байтов), сжатые данные (состоящие из репликаторов и заполнителей) и управляющая информация в виде двухбайтовой escape-последовательности. Если посылаются от 1 до 127 байт регулярных данных, этим данным должен предшествовать байт, в самом левом бите которого установлен 0, а в остальных содержится число байт регулярных данных.
2.3.4.3.1. Блок несжатых данных
|
1 |
7 |
8 |
8 |
||
|
0 |
n |
d(1) |
d(n) |
||
|
n байт данных |
2.3.4.3.2. Блок репликатора
Для сжатия строки из n репликаций (копий) байта данных d посылаются два байта:
|
2 |
6 |
8 |
||
|
1 |
0 |
n |
d |
2.3.4.3.3. Блок заполнителя
Строка из n байтов заполнителя может быть сжата в один байт. Байт заполнителя зависит от типа представления данных (для ASCII и EBCDIC — это (Space, 32 — ASCII, 64-EBCDIC), для типов Image и Local — 0).
Escape — последовательность — это сдвоенные байты, первый из которых — это escape-символ — 0, а второй содержит код дескриптора, определенный в Block Mode. Код дескриптора имеет то же значение, что и в Block Mode и применяется к строке байтов.
3. Требования к типам данных
При передаче информации по соединению данных могут использоваться следующие типы данных как: ASCII, EBCDIC, IMAGE и LOCAL, а также могут поддерживаться структуры данных: file, record, page. Обязательными для реализации являются типы данных ASCII и IMAGE, а также структуры данных file и record. Должен поддерживаться режим управления форматом Nonprint.
3.1. Типы данных
Тип данных определяет размер логических байтов и кодировку передаваемых байтов. Длина передаваемых байтов всегда составляет 8 бит. Размер логических байтов в типах ASCII, EBCDIC и IMAGE составляет 8 бит, а в типе LOCAL определяется параметром команды TYPE.
Могут поддерживаться следующие типы данных:
1. тип ASCII (NVT-ASCII). Этот тип должен использоваться по умолчанию.
2. тип EBCDIC.
3. тип IMAGE.
4. тип LOCAL.
3.2. Управление форматом
При использовании типов данных ASCII и EBCDIC для управления вертикальным форматированием при выдаче на печать (на экран) могут использоваться управляющие символы.
При использовании типов данных ASCII и EBCDIC могут быть реализованы следующие режимы форматирования:
3.2.1. Nonprint
3.2.2. Telnet CONTROLS
3.2.3. CARRIAGE CONTROLS ASA
По умолчанию устанавливается тип Nonprint.
3.3. Структуры данных.
Определены три типа структуры файлов.
3.3.1. Cтруктура file. Файл считается непрерывной последовательностью байтов данных. Устанавливается по умолчанию.
3.3.2. Структура record. Файл состоит из последовательных записей. Данная структура применима для типов данных ASCII и EBCDIC.
3.3.3. Структура page. Файл состоит из независимых индексированных страниц. Каждая страница должна иметь заголовок, состоящий из следующих полей:
— длина заголовка (в логических байтах) минимум 4.
— индекс страницы (идентификатор страницы в файле)
— длина данных (количество логических байт данных)
— тип страницы
0 — последняя, при этом длина заголовка должна быть 4, длина данных — 0
1 — простая (длина заголовка должна быть 4)
2 — страница описателя (служит для передачи информации о файле в целом)
3 — страница контроля доступа (включает дополнительное поле заголовка для информации управления доступом. Длина заголовка — 5.
Все поля заголовка страницы имеют длину один логический байт.
4. Требования к восстановлению от ошибок и рестарту
В ТС FTP может быть реализована функция рестарта.
4.1. Процедура рестарта
Процедура рестарта предоставляется для защиты клиентов от грубых ошибок системы (включая ошибки узла, процесса FTP и сети передачи данных). Процедура определена только для режимов передачи Block mode и Compressed mode. Отправитель данных периодически вставляет в поток передаваемых данных маркер рестарта с данными маркера рестарта. Принимающий узел выделяет из потока данных маркеры рестарта и отправляет их клиенту. Для выдачи клиенту сообщения о рестарте на удаленном узле должен использоваться ответ 110. В случае системной ошибки клиент может начать заново передачу данных, идентифицируя контрольную точку с помощью процедуры рестарта. Для этого посылается команда рестарта с кодом маркера в качестве аргумента.
4.2. Формат маркера рестарта
Данные маркера рестарта кодируются печатными символами алфавита, установленного по умолчанию (ASCII или EBCDIC). Маркер должен содержать информацию о счетчике битов, записей и любую другую информацию, в соответствии с контрольной точкой данных. Конкретное содержание маркера имеет значение только для передающего узла и поэтому не оговаривается.
5. Требования к структуре и составу сообщений сервера FTP и клиента FTP
5.1. Команды FTP
От клиента FTP к серверу FTP по управляющему соединению информация передается в форме команды клиента FTP.
5.1.1. Формат команд FTP
Команды FTP являются строками символов алфавита NVT-ASCII. Возможно использование другого языка. Аргументы отделяются символом . Конец определяется символом . Не должно делаться различия между прописными и строчными буквами как в команде, так и в аргументе.
5.1.2. Перечень команд FTP приведен в табл. 1.
Таблица 1
Перечень команд FTP
|
№ |
Команда |
Сокращение |
Описание |
Поле аргумента |
|
Команды управления доступом |
||||
|
|
USER NAME |
USER |
Имя клиента |
идентификатор клиента. |
|
|
PASSWORD |
PASS |
Пароль |
пароль клиента |
|
|
ACCOUNT |
ACCT |
Полномочия |
идентификатор клиентских полномочий |
|
|
Change working directory |
CWD |
Сменить рабочую директорию |
новая рабочая директория |
|
|
Change to parent directory |
CDUP |
Вернуться в родительскую директорию |
— |
|
|
Structure mount |
SMNT |
Смонтировать структуру |
имя пути, определяющее директорию |
|
|
Reinitialize |
REIN |
Реинициализация. (закрытие соединения данных и сброс всех установок на по умолчанию) |
|
|
|
Logout |
QUIT |
Выход |
|
|
Команды параметров передачи. Аргументы команд параметров передачи являются необязательными. Команда без параметров сбрасывает установки на по умолчанию. |
||||
|
|
Data port |
PORT |
Порт данных |
h1, h2, h3, h4, p1, p2, где h1 .. h4 – адреса узла интернет, p1, p2 – адреса порта TCP. |
|
|
Passive |
PASV |
Пассивный режим |
|
|
|
Representation type |
TYPE |
Тип представления данных |
A – ASCII E – EBCDIC I – Image L — Local Byte Для A и E определен второй параметр: N – непечатный T – Telnet C – ASA По умолч. — A N |
|
|
File structure |
STRU |
Структура файла |
F – неструктурирован R – структ. Записей P – структура страниц По умолч. — F |
|
|
Transfer mode |
MODE |
Режим передачи |
S – Stream (поток) B – Block C – Compressed По умолч.- S |
|
Команды услуг FTP |
||||
|
|
Retrieve |
RETR |
Пересылка от DTP сервера к DTP клиента (второго сервера) |
имя файла |
|
|
Store |
STOR |
Прием процессом DTP сервера данных и сохранение в виде файла с замещением данных в случае совпадения имени файла. |
имя файла |
|
|
Store Unique |
STOU |
Прием процессом DTP сервера данных и сохранение с генерацией уникального имени файла |
имя файла |
|
|
Append |
APPE |
Прием процессом DTP сервера данных и добавление к существующему файлу |
имя файла |
|
|
Allocate |
ALLO |
резервирование памяти |
Число байт (логических) [ R <максимальный размер записи или страницы> ] |
|
|
Restart |
REST |
Рестарт. За этой командой должна немедленно следовать команда передачи файла. |
|
|
|
Rename from |
RNFR |
Старое имя переименовываемого файла. За этой командой должна немедленно следовать команда RNTO. |
старое имя файла |
|
|
Rename to |
RNTO |
Переименование файла. Этой команде должна предшествовать команда RNFR. |
новое имя файла |
|
|
Abort |
ABOR |
Отмена предыдущей команды услуг FTP и соответствующего процесса передачи данных. |
|
|
|
Delete |
DELE |
Удаление файла на сервере |
имя файла |
|
|
Remove directory |
RMD |
удаление директории (субдиректории) |
имя директории |
|
|
Make directory |
MKD |
Создание директории (субдиректории) |
имя директории |
|
|
Print working directory |
PWD |
Вызов ответа с информацией о рабочей директории |
|
|
|
List |
LIST |
Вызов ответа со списком файлов в произвольном формате типа ASCII (EBCDIC) по соединению данных. Только при типе представления ASCII и EBCDIC. |
[путь файла (маска)] |
|
|
Name list |
NLST |
Вызов ответа со списком директорий в формате путей, разделенных или по соединению данных. Только при типе представления ASCII и EBCDIC. |
[путь файла (маска)] |
|
|
Site parameters |
SITE |
Дополнительные услуги сервера |
|
|
|
System |
SYST |
Вызов ответа с типом операционной системы сервера, обозначенным в соответствии с RFC 943 [28]. |
|
|
|
Status |
STAT |
Вызов ответа статуса по управляющему соединению. |
[путь файла (маска)] |
|
|
Help |
HELP |
Вызов ответа с информацией помощи по управляющему соединению |
[имя команды] |
|
|
Noop |
NOOP |
Вызов ответа сервера OK. |
5.1.3. Синтаксис команд приведен в п.7.
Восстановление УРИБа, спасение периферии после обновления из центра

30.06.2019
Столкнулся со следующей ситуацией: имеется РИБ, Розница 2.1, обновил базу до новой версии, и пока файл разносился на магазины, внес изменения в конфигурацию и обновил еще раз, 5 периферийных баз удалось спасти, а три отказывались запускаться.
Сообщения, которые выдавали на разных этапах, следующие:
xmlSAX2CharactersSystemId: file://C:/Users/Пользователь/AppData/Local/Temp/Exchange82 {EE35FF55-3129-408B-8B78-97DBA1D68513}/Message_БП_ЗД.xml
{ОбщийМодуль.ОбменДаннымиСервер.Модуль(1285)}: Ошибка при вызове метода контекста (Прочитать) Пока ФайлОбмена.Прочитать() Цикл

Не удалось установить обновление программы, полученное из…
Получение данных из главного узла завершились с ошибками.
Подробности см. в журнале регистрации.
Правильный вариант действий:
Открываем командную строку. Туда пишем bcdedit /set IncreaseUserVa 3072
Перезагружаем компьютер и пробуем синхронизацию.
Так же можно скачать бат файл и запустить от имени администратора далее перезагрузить компьютер и пробуем синхронизацию.
В этом примере показано, как использовать блок EtherCAT Notifications, чтобы обнаружить отказ в связанной сети и перезапустить сеть, когда отказ корректируется.
Только разъединенный кабель Ethernet в первое ведомое устройство обнаруживается этим примером. Более сложные ситуации с отказом могут быть обнаружены, если вы изучаете шаблон уведомлений, которые заканчиваются и пишут встроенный блок MATLAB с учетом тех.
Требования
Чтобы запустить этот пример, как представлено, вам нужен Beckhoff EK1100 с EL1202, EL2202-0100, EL3102 и ведомыми модулями EL4032. Модель не пишет ни в какие объекты процесса. Заменение файла ENI с одним соответствующим вашей сети работает также.
EtherCAT в Simulink Real-Time требует специализированного сетевого порта на целевом компьютере, который резервируется для использования EtherCAT при помощи инструмента конфигурирования Ethernet. Сконфигурируйте выделенный порт для коммуникации EtherCAT, не с IP-адресом. Выделенный порт должен быть отличен от порта, используемого для подключения Ethernet между разработкой и целевыми компьютерами.
Протестировать эту модель:
-
Соедините порт, который резервируется для EtherCAT в целевом компьютере к порту EtherCAT IN модуля интерфейса EK1100.
-
Убедитесь, что EK1100 предоставляется источником питания на 24 вольта.
-
Создайте и загрузите модель на цель.
Для полного примера, который конфигурирует сеть EtherCAT, конфигурирует модель главного узла EtherCAT и создает, затем запускает приложение реального времени, смотрите Моделирование Сети EtherCAT.
Откройте модель
Эта модель является началом полного внедрения отловить отказы сети и повторно инициализировать сеть, если отказ фиксируется. Простой конечный автомат во встроенном блоке MATLAB может быть заменен реализацией Потока состояния, которая может быть необходимой для более сложного обнаружения отказа и восстановления.
Блок инициализации EtherCAT требует, что настройка, файл ENI присутствует в текущей папке или на пути MATLAB, потому что имя файла присутствует без информации о директории.
Если вы хотите изменить эту модель, чтобы экспериментировать с ним, скопируйте конфигурационный файл в качестве примера и файл модели от папки в качестве примера до текущей папки. Чтобы открыть модель, в командном окне MATLAB, введите:
open_system(fullfile(matlabroot,'toolbox','slrealtime','examples','slrt_ex_ethercat_notifyreset'));

Рисунок 1: модель EtherCAT для обнаружения разъединенного кабеля Ethernet в первом ведомом устройстве и переинициализации сети однажды кабель повторно подключена.
Сконфигурируйте модель
Откройте диалоговое окно параметра для блока EtherCAT Init и наблюдайте предварительно сконфигурированные значения. Ведомыми устройствами EtherCAT, которые объединяются в гирляндную цепь вместе с кабелем Ethernet, является Устройство, также называемое сетью EtherCAT. Индекс Устройства выбирает одну такую цепочечную сеть EtherCAT. Номер порта Ethernet идентифицирует который порт Ethernet использовать, чтобы получить доступ к тому Устройству. Блок EtherCAT Init соединяет эти два так, чтобы другие блоки EtherCAT использовали индекс Устройства, чтобы связаться с ведомыми устройствами в той сети EtherCAT.
Если у вас только есть тот соединенная сеть ведомых устройств EtherCAT, и вы только зарезервировали один порт Ethernet с инструментом конфигурирования Ethernet, используйте индекс Устройства = 0 и Номер порта Ethernet = 1.
Создайте файл ENI для различной ведомой сети
Если необходимо создать новый файл ENI, необходимо использовать сторонний конфигуратор EtherCAT, такой как TwinCAT 3 от Beckhoff, который вы устанавливаете на компьютере разработчика. Настройкой EtherCAT (ENI) файл, предварительно сконфигурированный для этой модели, является Stack4_BS_1ms.xml.
Каждый файл ENI характерен для точной сетевой настройки, для которой он был создан (например, сеть, обнаруженная на шаге 1 процесса создания конфигурационного файла). Конфигурационный файл предусмотрел этот пример, допустимо, если и только если сеть EtherCAT состоит из Beckhoff EK1100 с EL1202, EL2202-0100, EL3102 и ведомыми модулями EL4032. Если вы сделали, чтобы различный EtherCAT управлял, этот пример все еще работает, но необходимо создать новый файл ENI, который использует ведомые устройства.
Для обзора процесса для создания файла ENI смотрите, Конфигурируют Сеть EtherCAT при помощи TwinCAT 3.
Создайте, загрузите и запустите модель
Чтобы создать, загрузите и запустите модель:
-
В Редакторе Simulink, из списка целей на вкладке Real-Time, выбирают целевой компьютер, на котором можно запустить приложение реального времени.
-
Нажмите Run on Target.
Если вы открываете два осциллографа путем двойного щелчка по каждому, данные переданы от цели назад к компьютеру разработчика и отображены там.
Модель предварительно сконфигурирована, чтобы запуститься в течение 15 секунд. Если вы хотите запустить модель дольше, выпадающий меню Run on Target и изменить номер на нижней строке. Нажмите зеленую стрелу, чтобы сконфигурировать, создать, и запуститься.
Отобразите данные о Целевом компьютере
Если при запуске модель с помощью Запуска на Целевой кнопке, режим external mode соединяется, и можно дважды щелкнуть по блокам scope и видеть данные по компьютеру разработчика. Блоки Отображения также работают.
При выполнении этой модели, чтобы продемонстрировать этапы реинициализации, необходимо отключить и повторно подключить кабель Ethernet между целевой машиной и ведомой сетью EtherCAT. Когда вы повторно подключаете кабель, вы видите, что DC синхронизировать выполняет ту же пересинхронизацию, которая происходит во время начального периода.

При использовании Работавшего Цель Осциллограф показывает, что ошибка синхронизации DC между основным кодом на цели и первым DC включила ведомое устройство. Поскольку ошибка возвращена как наносекунды, этот график показывает, что различие в синхронизации успокаивается к порядку 3-5 микросекунд (3 000 — 5 000 наносекунд), различие между DC включило ведомые устройства и целевую машину, запускающую код. Остаточное рассеяние только отражает изменчивость планирования задач в целевом компьютере RTOS.
В этом экспериментальном запуске кабель Ethernet был отключен дважды во время 30-секундного запуска. Разъединение произошло приблизительно в 7 секунд, повторное соединение приблизительно в 12 секунд. Этот процесс повторяется приблизительно в 18 секунд и 21 секунду. Каждый раз, когда кабель повторно подключен, ошибка синхронизации показывает импульс, который показывает дрейф между целью и сетью EtherCAT в течение времени, кабель был отключен и является ожидаемым поведением пересинхронизации.

Scope1 показывает несколько логических сигналов с вертикальными смещениями, чтобы показать анализатор логики как отображение. От верхней части изображения это:
-
Соедините (желтое) состояние
-
Работающая (синяя) ошибка количества
-
Структурируйте (красную) ошибку ответа
-
Все ведомые устройства Операционный (зеленый)
-
Ведомая (фиолетовая) ошибка
-
(Голубая) ошибка Scanbus
Разъединение кабеля вызвало scanbus ошибку, как замечено на голубой трассировке. Ничего не происходит, пока кабель не подключен повторно приблизительно в 12 секунд. Состояние ссылки отражает одно уведомления о временном шаге, которые указывают на ссылку, уходящую и ссылку возвращение. На первом разъединении вы не видите, что ссылка уходит уведомление, но вы действительно видите, что ссылка возвращается. Встроенный блок MATLAB сохраняет персистентную переменную с состоянием ссылки с начальным значением 2 и изменяет его в зависимости от уведомлений.
После того, как ссылка возвращается, существует оба ведомая ошибка ответа ошибки и системы координат перед Всеми Ведомыми устройствами Операционные движения вниз для шага расчета. В той точке запускается пересинхронизация синхронизации, и вы видите, что ослабленная волна показывает синхронизацию errot падающий на в течение нескольких микросекунд после ошибки.

Scope2 показывает большему состоянию выходные параметры с:
-
(желтый) statechange
-
(синий) sbdone
-
(красный) dcinsync
-
(зеленый) запрос statechange
-
(фиолетовый) newstate
-
(голубое) текущее состояние
Когда ссылка понижается, стек замечает, что и выполняет скан устройств на шине. Это — метка sbdone приблизительно в 7 секунд, которые также привели к sbscan ошибке, показанной в Scope1. Затем, когда ссылка восстанавливается в 12 секунд, другой скан шины выполнен, показан в 12 секунд в синей трассировке. Встроенный блок MATLAB запрашивает изменение состояния к PreOp (=2) показанный в зеленых и фиолетовых трассировках. Если Preop достигнут, вы видите, что другое изменение состояния запрашивает перейти к Op (=8) состояние, которое является вторым изменением зеленого и фиолетового цвета. Это запускает пересинхронизацию часов между разработкой comptuer и целевым компьютером, который занимает несколько секунд, пока вы не видите dcinsync приблизительно в 14 секунд (красный trace) с переходом к состоянию Op прямо после.
Отключите кабель снова, чтобы повторить целую последовательность, снова запускающуюся приблизительно в 18 секунд.
В то время как для этого примера нужно ручное вмешательство, чтобы отключить и повторно подключить кабель Ethernet, тот же перезапуск может быть вызван, только запросив, чтобы PreOp утвердили follwed по запросу о состоянии Op, пропустив взаимодействие с состоянием ссылки, если инициировано некоторым другим условием в модели.
Если при запуске модель из командной строки, можно использовать Инспектора Данных моделирования, чтобы просмотреть любой сигнал, который отмечен для логгирования сигнала. Сигналы, отмеченные для логгирования, появляются с точкой с двумя дугами выше его в редакторе моделей.
Смотрите также
-
Моделирование сетей EtherCAT
-
EtherCAT® Communication — Упорядоченное пишущее ведомое устройство переменные настройки CoE
-
EtherCAT® Communication — Упорядоченное пишущее ведомое устройство переменные настройки SoE
close_system( 'slrt_ex_ethercat_notifyreset' );
Реинициализация
Прототип:
void rewind(FILE
*_stream);
Описание:
Помещает
указатель позиции файла на начало файла
и сбрасывает индикаторы ошибок и конца
файла. rewind(stream)
эквивалентно fseek(stream,
0L, SEEK_SET) (см.
далее),
за исключением того, что rewind()
обнуляет признаки конца файла и
ошибки, в то время как fseek()
обнуляет только признак конца файла.
Функции для ввода-вывода по символам
Чтение
символов из потока
Чтение
символов осуществляют функции
getc()
и fgetc()
Прототипы:
int getc(FILE
*_fp);
int fgetc(FILE
*_fp);
Описание:
Обе
функции (getc()
представляет собой макрокоманду),
получают следующий по порядку символ
из входного потока _fp
и увеличивают указатель текущего
положения в потоке на 1.
Возвращаемое
значение:
При
успешном завершении функции getc()
и
fgetc()
возвращают считанный символ после
предварительного преобразования его
в целое без расширения знака. При
возникновении ситуации EOF или при ошибке
они возвращают EOF.
Пример
1:
#include<stdio.h>
int
main(void)
{
char
ch;
printf(«Введите
символ :»);
/*
ввести символ из стандартного входного
потока stdin */
ch
= getc(stdin);
printf(«Был
введен символ ‘%c’n»,ch);
return
0;
}
Пример
2:
#include
<conio.h>
#include
<iostream>
using
namespace
std;
//
Обработка текстового файла, созданного
// обычным
текстовым редактором
int
main()
{
char
namein[15]; char
ch; FILE *fp;
system(«chcp
1251»);
printf(«Введите
путь и имя вводного файла,например,test1n»);
gets(namein);
if((fp=fopen(namein,
«r»))==NULL)
{
perror(»
Не могу открыть вводной файл… «);
//
perror(namein );
getch();exit(1);
}
do
{
/*
ввести символ из файла */
ch = fgetc(fp);
/*
вывести символ на экран */
printf(«%c»,ch);
}
while(ch!=EOF);
getch();fclose(fp);
return0;
}
Для
ввода символов со стандартного вводного
потока (с клавиатуры) используется
функцияgetchar().
Прототип:
int getchar(void);
Описание:
getchar()
— это макрокоманда, вводящая символ из
потока stdin.
Она определена следующим образом:
getc(stdin).
Возвращаемое
значение:
При
успешном завершении функция getchar()
возвращает считанный символ после
предварительного преобразования его
в целое без расширения знака. При
возникновении ситуации EOF или при ошибке
она возвращает EOF.
Пример:
#include<stdio.h>
int
main(void)
{
char
c;
/*
Замечание. getchar читает символы с stdin,
который имеет
буфер
на одну строку. Поэтому она ничего не
возвращает до
тех
пор, пока вы не нажмете Enter */
while((c=getchar())!=’n’)
printf(«%c»,c);
return
0;
}
Запись
символов
в поток
Запись
символов осуществляют функции
putc()
и
fputc().
Прототипы:
int putc(int
_c, FILE *_fp);
int fputc(int
_c, FILE *_fp);
Описание:
Обе
функции (функция putc()
представляет собой макрокоманду)
выводят символ _c
в указанный выходной поток _fp.
Возвращаемое
значение:
При
успешном завершении функции putc()
и
fputc()
возвращают символ _c.
При возникновении ошибки обе функции
возвращают значение EOF.
Пример:
#include
<stdio.h>
int
main(void)
{
char
msg[] = «Здравствуй
мир»;
int
i=0;
while(msg[i])
{
fputc(msg[i],stdout);
i++;
}
return
0;
}
Для
вывода символов в стандартный выводной
поток (дисплей) используется функция
putchar().
Прототип:
int putchar(int
_c);
Описание:
putchar()
– это макрокоманда, определенная как
putc(_c,
stdout);
Возвращаемое
значение:
При
успешном завершении putchar()
возвращает выведенный символ _c.
При ошибке она возвращает EOF.
Пример:
#include<stdio.h>
int
main(void)
{
char
msg[] = «Тестовый
пример»;
int
i=0;
while(msg[i])
{
putchar(msg[i]);
i++;
}
return
0;
}
Задача
163.Программа
создает программным путем текстовый
файл (посимвольно) на диске, затем
переносит из этого файла в другой файл
каждый третий (0, 3, 6, …) символ исходного
файла. Попутно результат обработки
выводится на экран.
#include
<conio.h>
#include
<stdio.h>
#include
<iostream>
using
namespace
std;
int
main()
{
//
программа печатает каждый 3-й символ
текстового файла, созданного
//
программным путем с возможным добавлением
текста (режим а+)
system(«chcp
1251»);//переключаем
консоль в кодировку win1251
char
nameout[15]; FILE *out, *in; char
ch;
//для
русских int ch не обязательно для норм
работы EOF !
cout<< «Введите
имя cоздаваемого файла,например,D:eddy.txtn»;
gets(nameout);
if((out
= fopen(nameout, «a+»))==NULL)
//для
чтения
и
записи
{
cout<<«Не могу создать
файл …!»;//perror(nameout);
getch(); exit(1);
}
cout<< «Введите
последовательность символов, в конце
– Ctrl+Zn»;
while
((ch=getchar())!=EOF)
fputc (ch, out );
cout<< «nфайл
создан»;//getch();
// в
случае a+ файл можно не закрывать, а
сделать так:
rewind(out); //возврат
к началу файла
in=out; //просто
переустановим указатель
cout<< «nВведите
имя преобразованного файла «;
gets(nameout);
out=fopen(nameout,
«w»);
if(out==NULL)
{
cout<< «n
Не могу открыть выводной файл… «;
exit(2);
}
//
Обработка созданного файла, содержащего
фразы:
// Даже
Эдди нас опередил с детским хором
// So even
Eddy came oven ready
int
k=0;
//while((ch=getc(in))!=EOF)
while(!feof(in))
{ ch=fgetc(in);
if(ch==’n’)
{ putc(‘n’,out);putchar(‘n’);}
if(k++%3==0)
{ putc(ch, out);putchar(ch);}
}
fclose(in); fclose(out);
cout<<
«конец
работы»;
getch(); return0;
}
Для
проверки программы мы ввели следующий
текст:
Даже
Эдди нас опередил с детским хором
So
even Eddy came oven ready
И
вот результат:
Дед спел тихо
Send money
Функции
для ввода-вывода по строкам
Чтение
строки
из потока
Чтение
по
строкам осуществляет функция
fgets()
Прототип:
char
* fgets(char
*_s, int
_size, FILE *_fp);
Описание:
fgets()
считывает из потока _fp
строку символов и помещает ее в _s.
Ввод завершается после считывания
_size-1
символов или при вводе символа перехода
на следующую строку, смотря, что произойдет
раньше. fgets()
прекращает ввод строки при получении
символа перехода на следующую строку.
Нулевой байт добавляется в конец строки
для индикации ее конца. Символ конца
строки не отбрасывается и располагается
непосредственно перед нуль-символом.
Возвращаемое
значение:
При
успешном завершении возвращает указатель
на _s,
при ошибке или конце файла возвращает
указатель NULL.
Для
ввода строки со стандартного вводного
потока (с клавиатуры) используется
функция gets().
Прототип:
char
* gets(char
*_s);
Описание:
Функция
gets()
читает строку символов, оканчивающуюся
символом перевода строки , в
переменную *_s
из стандартного входного потока
stdin.
Данная символьная строка оканчивается
символом перехода на новую строку,
который при записи в *_s
заменяется на нулевое окончание ().
В
отличие от scanf(),
gets()
позволяет вводить строки, содержащие
символы пробела и табуляции. Все, что
было введено до перевода каретки,
помещается в _s.
Возвращаемое
значение:
При
успешном завершении, функция gets()
возвращает строку _s;
при достижении конца файла (EOF)
или ошибке возвращается NULL.
Пример:
#include
<stdio.h>
int
main(void)
{
char
string[133];
printf(«Введите
строку:»);
gets(string);
printf(«Cтрока
= ‘%s’n,string);
}
Запись
строки
в поток
Запись
в поток по строкам
осуществляет функция
fputs()
Прототип:
int fputs(char
*_s, FILE *_fp);
Описание:
Функция
fputs()
копирует строку
_s
, ограниченную нулевым байтом, в поток
_fp.
Она добавляет в конец строки символ
перехода на новую строку. Нулевой символ
в файл не переносится.
Возвращаемое
значение:
При
успешном завершении fputs()
возвращает последний выведенный символ.
В противном случае возвращает EOF.
Пример:
#include<stdio.h>
int
main(void)
{
/*
вывести строку в поток */
fputs(«Тестовый
пример»,stdout);
return
0;
}
Для
вывода строки в стандартный выводной
поток (на экран) используется функция
puts().
Прототип:
int puts(char
*_s);
Описание:
Функция
puts()
копирует строку символов с нулевым
окончанием в стандартный выходной
поток stdout,
причем добавляет в конец символ перехода
на новую строку.
Возвращаемое
значение:
При
успешном завершении, функция puts()
возвращает
ненулевое значение. В противном случае
возвращается EOF.
Пример:
#include<stdio.h>
int
main(void)
{
/*
вывести строку в поток */
puts(«Тестовый
пример»);
return
0;
}
Задача
164.Программа
создает программным путем (по строкам)
текстовый файл на диске. Ввод строк с
клавиатуры осуществляет функция fgets(),
вывод на диск построчно – функция
fputs().
//
fget_fput3_rus.cpp : 14.05.2012г
// Ввод
строк с клавиатуры(fgets) и создание
текстового файла(fputs)
//
Использование fgets и fputs для обычного в/ы
(stdin / stdout)
#include<conio.h>
#include<stdio.h>
#include
<stdlib.h>
#include
<iostream>
using
namespace
std;
const
int
size=120;
int
main()
{
char
line[size]; char
nameout[15]; FILE *out;
system(«chcp
1251»);//переключаем
консоль в кодировку win1251
//
ОБЯЗАТЕЛЬНО ПЕРЕКЛЮЧИТЬ ШРИФТЫ С
ТОЧЕЧНЫХ НА Lucida console
// после
запуска программы щелчком мыши в левом
верхнем углу
cout<< «Введите
имя создаваемого файла,например,D:omar.txtn»;
gets(nameout);
if((out=fopen(nameout,
«a+»))==NULL)
{
cout<< »
Не могу открыть выводной файл… «;
getch(); exit(1);
}
cout<< «Введите
несколько строк текста, потом Ctrl+Z n»;
while(fgets(line,size,stdin)
!=NULL && line[0] !=’n’)
{
fputs(line,out);
fputs(line,
stdout); //
puts(line);
}
cout<<
«Файл
создан»;
fclose(out);
getch(); return
0;
}
Задача
165.
В
программе решается следующая задача.
На основе файла, созданного предыдущей
программой (см.Задачу 164), строится новый
файл, в котором каждая строка:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Планирование перехвата IP-адреса
Перехват IP-адреса (IP Address Takeover, IPAT) представляет собой механизм, используемый HACMP для перемещения сервисных адресов между коммуникационными
интерфейсами.
Существует два метода: перехват IP-адреса посредством замены (IPAT via replacement)
и перехват IP-адреса посредством синонимов (IPAT via aliases). Конфигурация
вашей сети зависит от применяемого метода управления интерфейсами.
Для любой новой инсталляции мы рекомендуем использовать перехват IP-адреса
посредством синонимов, так как этот метод прост в реализации и более гибок, чем
перехват IP-адреса посредством замены. Можно применять несколько сервисных
адресов для одного адаптера в любое время; кроме того, в случае перемещения при
сбое имеет место некоторая экономия времени, так как HACMP просто нужно добавить синоним, а не выполнять повторное конфигурирование базового IP-адреса
адаптера, что гораздо быстрее.
Некоторые конфигурации потребуют использования мониторинга пульса через
синонимы. Например, если оба локальных базовых адаптера относятся к одной подсети или же если все базовые адаптеры на всех узлах относятся к разным подсетям.
Все варианты подробно рассматриваются в следующем разделе. В нашем примере
применяется перехват IP-адреса посредством синонимов и мониторинг пульса через
синонимы.
Перехват IP-адреса посредством замены
Этот способ конфигурирования сетей HACMP является более традиционным. HACMP
при запуске осуществляет замену загрузочного адреса на сервисный адрес.
Для кластера из двух узлов требуется использование по меньшей мере одной подсети на коммуникационный интерфейс на узел (при использовании одинаковой
маски подсети во всех подсетях). Для кластера с несколькими коммуникационными
интерфейсами на узел требуется следующее:
- базовый и сервисный адреса основного коммуникационного интерфейса должны
относиться к одной подсети; - базовые IP-адреса всех дополнительных коммуникационных интерфейсов должны относиться к различным подсетям (относительно друг друга и относительно
основного интерфейса).
Преимущество перехвата IP-адреса посредством замены состоит в том, что оно разрешает выполнять перехват аппаратного адреса (Hardware Address Takeover, HWAT) вместе с перехватом IP-адреса посредством замены. Эта возможность позволяет осуществлять
перемещение (локально администрируемого) MAC-адреса адаптера, соответствующего
сервисному IP-адресу, вместе с IP-адресом на дежурный адаптер. Это устраняет необходимость обновления ARP-кеша на стороне клиента в случае переноса IP-адресов.
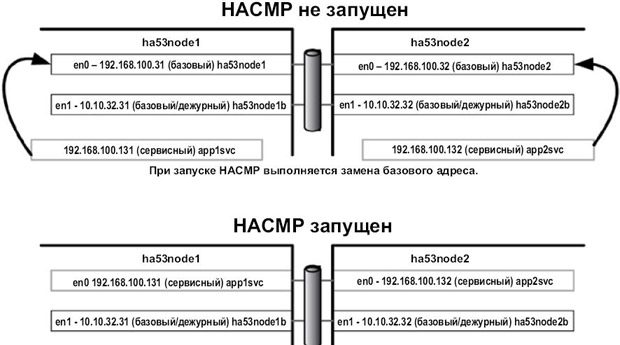
Рис.
3.9.
Перехват IP-адреса посредством замены
На рис. 3.9 показано состояние сетевых адаптеров до и после запуска HACMP на
узлах. Обратите внимание на то, что HACMP при запуске заменяет загрузочный/базовый адрес сервисным адресом. Перемещение при сбое выполняется на дополнительный (дежурный) адаптер(ы), где, опять же, базовый (дежурный) адрес заменяется
сервисным адресом. Количество сервисных адресов ограничено количеством резервных адаптеров, определенных в той же сети HACMP.
Перехват IP-адреса посредством синонимов
Этот метод назначения сервисных адресов является более новым и более гибким,
чем перехват IP-адреса посредством замены. Используя перехват IP-адреса посредством синонимов, можно осуществлять назначение нескольких IP-адресов одному
коммуникационному интерфейсу.
HACMP позволяет использовать перехват IP-адреса посредством IP-синонимов
для следующих типов сетей, поддерживающих gratuious ARP-запросы (в AIX):
- Ethernet;
- Token Ring;
- FDDI;
- SP Switch1 и SP Switch2.
Примечание. Перехват IP-адреса посредством IP-синонимов не поддерживается
в сетях ATM.
При запуске HACMP выполняется конфигурирование сервисного синонима поверх существующего базового IP-адреса доступного адаптера.
При использовании перехвата IP-адреса посредством синонимов следует учитывать следующие требования:
- Требования подсетей:
- Каждый базовый адаптер должен относиться к отдельной подсети, чтобы можно было осуществлять мониторинг пульса. Базовые адреса не обязательно
должны быть маршрутизируемыми вне кластера.Примечание. Это ограничение снимается при использовании мониторинга пульса
через синонимы. - Сервисные адреса должны относиться к отдельной подсети относительно любой из базовых подсетей. Можно использовать несколько сервисных адресов,
и все они могут относиться как к одной подсети, так и к различным подсетям. - Постоянный синоним может относиться либо к той же подсети, либо к другой
подсети относительно сервисного адреса. - Все маски подсети должны быть одинаковыми.
- Каждый базовый адаптер должен относиться к отдельной подсети, чтобы можно было осуществлять мониторинг пульса. Базовые адреса не обязательно
- Несколько сервисных меток могут совместно существовать как синонимы для заданного интерфейса.
- Нельзя сконфигурировать перехват аппаратного адреса (Hardware Address Takeover,
HWAT).
Мы рекомендуем использовать постоянный синоним и включить его в одну подсеть с маршрутом по умолчанию. Это обычно означает, что постоянный адрес должен быть включен в одну подсеть с сервисными адресами. Постоянный синоним
можно использовать для доступа к узлу при отключенном HACMP, а также для преодоления проблем с маршрутом по умолчанию.
Можно выполнить настройку параметров размещения сервисных IP-меток, сконфигурированных в HACMP V5.3. Можно настроить размещение синонимов через
меню SMIT с использованием следующих вариантов:
- Без совместного размещения (Anti-Collocation). Используется по умолчанию. HACMP распределяет сервисные IP-метки по всем доступным коммуникационным интерфейсам с использованием выбора по принципу наименьшей загруженности.
- С совместным размещением (Collocation). HACMP размещает все сервисные
IP-метки на одном коммуникационном интерфейсе (NIC). - Без совместного размещения и с постоянной меткой (Anti-Collocation
with persistent label). HACMP размещает все сервисные IP-метки по всем активным коммуникационным интерфейсам, не содержащим постоянную IP-метку синонима. HACMP размещает сервисную IP-метку на интерфейсе, содержащем постоянную метку только в том случае, если другие сетевые интерфейсы недоступны.
Если постоянные IP-метки не были сконфигурированы, HACMP позволяет выбрать
метод размещения Anti-Collocation with Persistent (Без совместного размещения и
с постоянной меткой), однако при этом выдается предупреждение и по умолчанию используется обычный метод без совместного размещения.
Рис.
3.10.
Перехват IP-адреса посредством синонимов - С совместным размещением и с постоянной меткой (Collocation with
persistent label). Все сервисные IP-метки располагаются на одной сетевой карте,
содержащей постоянную IP-метку. Этот вариант может быть полезен при конфигурациях виртуальной частной сети (VPN) с брандмауэром, где только один интерфейс имеет внешний выход и все IP-адреса (постоянные и сервисные) должны
располагаться на одном коммуникационном интерфейсе. Если постоянные IP-метки не были сконфигурированы, HACMP позволяет выбрать метод размещения
Collocation with Persistent (С совместным размещением и с постоянной меткой),
однако при этом выдается предупреждение и по умолчанию используется обычный метод с совместным размещением.
На рис. 3.10 показано состояние сетевых адаптеров до и после запуска HACMP на
узлах. Обратите внимание на то, базовые адреса не изменяются. HACMP добавляет на
базовые адаптеры сервисные и постоянные синонимы. Постоянные адреса всегда
доступны, тогда как сервисные метки добавляются и удаляются при запуске и остановке HACMP. Перемещение при сбое выполняется путем переноса сервисной метки
на другой доступный коммуникационный интерфейс. В нашем примере только сеть
192.168.100/24 является маршрутизируемой вне кластера.
Мониторинг пульса через синонимы
HACMP требует использования отдельной подсети для мониторинга каждого базового адаптера. При конфигурации с применением двух Ethernet-адаптеров на узле
требуется две подсети. При употреблении трех адаптеров требуется три подсети. Эти
подсети не обязательно должны быть маршрутизируемыми вне сетей кластера.
Чтобы обеспечить средство мониторинга этих адаптеров (без изменения адреса
базового адаптера), а также чтобы избежать возникновения проблем с подсетями,
HACMP предоставляет функцию мониторинга пульса через синонимы. Этот метод
не требует внесения каких-либо изменений в существующие базовые адреса. HACMP
просто игнорирует базовые адреса и добавляет собственный набор синонимов для
осуществления мониторинга пульса.
При использовании мониторинга пульса через IP-синонимы, IP-адреса, используемые при загрузке, могут располагаться либо в той же подсети, либо в других подсетях;
однако IP-адрес, применяемый во время загрузки, должен располагаться в подсети,
не включающей сервисные IP-метки. Как оказалось, если все адреса (базовые и сервисные) попадают в одну подсеть, возникают проблемы с маршрутизацией в связи с
функцией чередования маршрутов (route striping) операционной системы AIX.
Чтобы установить мониторинг пульса через IP-синонимы, следует настроить параметр «IP Address Offset for Heartbeating over IP Aliases» («Смещение IP-адреса для
мониторинга пульса через IP-синонимы») как часть конфигурирования сетей HACMP.
IP-адреса, используемые для мониторинга пульса, определяются и назначаются системой HACMP с применением этого значения смещения. Маска подсети совпадает с
той, которая используется для сервисных и несервисных адресов.
Например, можно в качестве параметра смещения IP-адреса употреблять значение
1.1.1.1. При использовании сети с двумя NIC на каждом узле следует добавить маску подсети 255.255.255.0; в результате получим следующие IP-синонимы мониторинга пульса:
- node01:
- en0 1.1.1.1;
- en1 1.1.2.1.
- node02:
- en0 1.1.1.2;
- en1 1.1.2.2.
IP-синонимы мониторинга пульса добавляются при запуске HACMP на узле и удаляются при остановке HACMP. Эти IP-синонимы используются только для сообщений
пульса. Для них не требуется осуществлять маршрутизацию, и их не следует применять для какого-либо другого трафика. Маска подсети совпадает с используемой для
сервисных и несервисных синонимов.
На рис. 3.11 показано состояние сетевых адаптеров до и после запуска HACMP на
узлах. Обратите внимание на то, базовые адреса не изменяются. Помимо сервисных
и постоянных синонимов, добавляемых HACMP на базовые адаптеры, также добавляются синонимы пульса. Последние удаляются при остановке HACMP вместе с сервисными синонимами. В нашем примере только сеть 192.168.100/24 является маршрутизируемой вне кластера.
Команда netstat -i выводит три IP-адреса для каждого адаптера при запущенном HACMP.
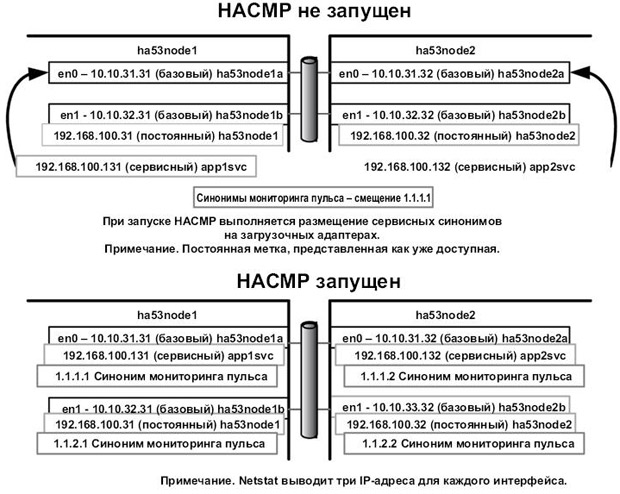
Рис.
3.11.
Мониторинг пульса через синонимы
Планирование сети, отличной от IP
Сети типа «точка-точка» играют важную роль в обеспечении высокой доступности
кластера. Достаточно небезопасно применять одну лишь TCP/IP-сеть для обеспечения доступности кластера и недопущения разделения кластера. Поэтому важно создавать сети типа «точка-точка». При использовании больших кластеров необходимо
создавать соответствующие пути между всеми узлами в кластере.
Назначение топологии последовательной сети или сети «точка-точка» состоит
в том, чтобы обеспечить достаточное количество путей между узлами кластера, чтобы RSCT могла правильно оценить серьезность сбоя в кластере.
Разделение кластера
Разделение кластера (также называемое изоляцией узла или split brain) возникает в
том случае, когда узел HACMP перестает получать весь трафик пульса с другого узла
(по всем доступным сетям) и предполагает, что на этом узле произошел отказ.
Проблема разделения кластера состоит в том, что узлы с одной стороны раздела воспринимают отсутствие пакетов пульса от узлов с другой стороны раздела как
признак отказа узлов, генерируя события отказа для этих узлов. После этого узлы с
каждой стороны кластера пытаются перехватить ресурсы (если настроен перехват)
с узла, который на самом деле все еще активен и потому является законным владельцем этих ресурсов. Такие попытки перехвата могут привести к непредсказуемым результатам в кластере, например к повреждению данных в связи с реинициализацией
дисков.
Наилучшая защита от возникновения подобных ситуаций состоит в том, чтобы использовать несколько сетей, как TCP/IP-сетей, так и сетей типа «точка-точка»,
чтобы обеспечить правильность оценки серьезности проблемы. Помните о том, что
HACMP (в частности, RSCT) отправляет и получает пакеты пульса по всем доступным
сетям, поэтому чем больше сетей, тем точнее HACMP сможет определить, имеет ли
место отказ узла или отказ сети.
Следующий набор из четырех рисунков показывает, каким образом следует осуществлять добавление сетей в кластер, чтобы обеспечить наилучшую защиту от разделения кластера.
На рис. 3.12 показан кластер из четырех узлов с одним Ethernet-подключением к
каждому серверу. Так как используется только одна сеть, то при потере любой связи
часть кластера будет разделена. В примере показан разрыв связи между двумя Ethernetкоммутаторами, вызывающий отделение двух узлов слева от двух узлов справа. В
данном случае могут возникнуть проблемы в результате попыток выполнить перехват ресурсов с активного узла.
Рис. 3.13 несколько более реалистичен; на нем представлены двойные Ethernetподключения с каждого узла. Каждый Ethernet-адаптер подключен к отдельному коммутатору. В этом случае для разделения кластера необходимо, чтобы произошел отказ двух коммутаторов или же обоих Ethernet-подключений на узле. Однако сама по
себе сеть TCP/IP остается единой точкой отказа.

Рис.
3.12.
Разделение кластера

Рис.
3.13.
Кластер без разделения с двойными Ethernet-подключениями
На рис. 3.14 представлена рекомендованная конфигурация. Имеются двойные
Ethernet-подключения к нескольким Ethernet-коммутаторам, а также добавлена кольцевая сеть типа «точка-точка». В кольцевой сети каждый узел подключен к своим
непосредственным соседям. При потере одного подключения RSCT все еще сможет
подключиться ко всем оставшимся узлам. Для разделения кластера потребуется возникновение двойного отказа на узле и отказа сети TCP/IP.
Для построения надежной конфигурации рассмотрим реализацию звездной топологии. При такой конфигурации, помимо сети TCP/IP, каждый узел подключен
ко всем другим узлам кластера сетями типа «точка-точка». Это позволяет обеспечить
связь RSCT с работающими узлами при отказе нескольких узлов. Эта конфигурация
представлена на рис. 3.15.

Рис.
3.14.
Конфигурация с использованием Ethernet-сети и кольцевой сети типа «точка-точка»

Рис.
3.15.
Конфигурация с использованием сети Ethernet и сети типа «точка-точка» звездной топологии
7. В процессе работы в тегах иногда появляются недостоверные значения.
Такая ситуация может возникать при работе по радио и GSM каналам по протоколу Modbus RTU и ASCII (при работе по Modbus TCP такая ситуация не возможна). Это происходит из-за «наслоения» ответов. В Modbus RTU нет специального поля, по которому можно было бы определить соответствие ответа определенному запросу (в Modbus TCP такое поле есть – Transaction ID). Представим ситуацию, ОРС сервер послал запрос в устройство, устройство ответило, но возникла задержка в сети (в GSM сетях это обычное явление), ОРС сервер не получил ответ и отправил запрос повторно, ему пришел ответ на предыдущий запрос – он корректен, ОРС сервер разобрал его и послал следующий запрос (следующего регистра), ему приходит ответ от предыдущего запрос – но в нем содержаться данные совершенно от других регистров! ОРС сервер производит анализ полученного ответа, например, если ОРС сервер запросил 2 регистра, а пришло 4, то такой запрос он отбросит. Если запрос пришел не от запрошенного устройства или с другой функцией, то этот запрос будет также отброшен. Но если запрос по структуре совпадает с предыдущим, сервер его примет и запишет значения в теги, которые будут некорректными. Избежать данной ситуации можно установив несколько настроек – включите реинициализацию узла при ошибке, а количество попыток установите равным 1. В этом случае, при первом же неудачном опросе сервер закроет порт, тем самым очистив буфер, а затем откроет его снова.
Группа ДИАГНОСТИКА
![]() @e_SIAD
@e_SIAD
![]() @e_Alarm_Report
@e_Alarm_Report
![]() @e_Logger
@e_Logger
![]() @Net_Code
@Net_Code
![]() @e_M_LINK_Host
@e_M_LINK_Host
![]() @e_DCS
@e_DCS
![]() @e_MODBUS
@e_MODBUS
![]() @e_PLC1Type
@e_PLC1Type
![]() @e_PLC2Type
@e_PLC2Type
![]() @Above
@Above
![]() @Modem
@Modem
![]() @SIAD_Synchronize
@SIAD_Synchronize
![]() @e_TCP_ModBus
@e_TCP_ModBus
![]() @RS_Reinit
@RS_Reinit
![]() @e_OPC
@e_OPC
![]() @Redundant
@Redundant
![]() @e_Dump
@e_Dump
![]() @e_DDE
@e_DDE
![]() @e_MLink_Slave
@e_MLink_Slave
![]() @e_Connect
@e_Connect
![]() @q_SIAD_Lost
@q_SIAD_Lost
![]() @e_IO_Error
@e_IO_Error
![]() @q_Lost_Alarms
@q_Lost_Alarms
![]() @Idle_Loop
@Idle_Loop
![]() @Graphics_Loop
@Graphics_Loop
![]() @q_Queue_Alarms
@q_Queue_Alarms
![]() @Calc_Loop
@Calc_Loop
![]() @q_IP_Lost
@q_IP_Lost
![]() @q_IP_Send_Q
@q_IP_Send_Q
![]() @q_SIAD_Q
@q_SIAD_Q
![]() @Node_Lock
@Node_Lock
В переменные типа INPUT данной группы записываются
результаты диагностики различных параметров.
Как правило, посылка положительного значения в
переменную типа OUTPUT обнуляет значение аналогичной
переменной-счетчика типа INPUT.
Каналы, связанные с переменными данной группы,
имеют подтип 15.
@e_SIAD
Дополнение к подтипу – 0.
В зависимости от атрибута Параметр (см.
sysdiag_siad.tmc), данная
переменная типа INPUT индицирует результаты соответствующей
диагностики архивов SIAD.
![]() Если Параметр равен номеру архива (0 –
Если Параметр равен номеру архива (0 –
System; 1 – SIAD1; 2 – SIAD2; 3 –
SIAD3), то значение переменной индицирует код ошибки
соответствующего архива (см. Коды диагностируемых ошибок ).
![]() Если Параметр = 128 (DEC), Work
Если Параметр = 128 (DEC), Work
Mask, то установленные в 1 биты значения переменной
указывают на работоспособность соответствующих архивов (бит 0 –
System, бит 1 – SAID1 и т.д.).
![]() Если Параметр = 129 (DEC), Error
Если Параметр = 129 (DEC), Error
Mask, то установленные в 1 биты значения переменной
указывают на наличие критической ошибки соответствующих архивов
(бит 0 – System, бит 1 – SAID1 и т.д.).
@e_Alarm_Report
Дополнение к подтипу – 1.
В данную переменную типа INPUT записываются
результаты диагностики отчета тревог (см. Коды диагностируемых ошибок ).
@e_Logger
Дополнение к подтипу – 2.
Данная переменная зарезервирована.
@Net_Code
Дополнение к подтипу – 4.
В данную переменную типа INPUT записываются коды
ошибок обмена по IP операционной системы.
@e_M_LINK_Host
Дополнение к подтипу – 5.
В данную переменную типа INPUT записывается код
ошибки при обмене по протоколу M-LINK в режиме MASTER (см. Коды диагностируемых ошибок ).
@e_DCS
Дополнение к подтипу – 6.
В данную переменную типа INPUT записывается код
ошибки при обмене по протоколу DCS (см. Коды диагностируемых ошибок ).
@e_MODBUS
Дополнение к подтипу – 7.
В данную переменную типа INPUT записывается код
ошибки при обмене по протоколу MODBUS (см. Коды диагностируемых ошибок ).
@e_PLC1Type
Дополнение к подтипу – 8.
В данную переменную типа INPUT записывается код
ошибки при обмене через драйвер t11 (см. Коды диагностируемых ошибок ).
@e_PLC2Type
Дополнение к подтипу – 9.
В данную переменную типа INPUT записывается код
ошибки при обмене через драйвер t12 (см. Коды диагностируемых ошибок ).
@Above
Дополнение к подтипу – 10.
Значение этой переменной типа INPUT равно
количеству ситуаций, когда реальное время цикла CALC превышало
заданное.
@Modem
Дополнение к подтипу – 11.
В данную переменную типа INPUT записывается код
ошибки при обмене по коммутируемым линиям (см. Коды диагностируемых ошибок ).
@SIAD_Synchronize
Дополнение к подтипу – 12.
Данная переменная зарезервирована.
@e_TCP_ModBus
Дополнение к подтипу – 13.
Если Параметр=0, в данную переменную типа
INPUT записывается код ошибки при обмене по протоколу MODBUS TCP/IP
(см. Коды диагностируемых ошибок ).
Если Параметр<>0, он задает номер
устройства MODBUS TCP/IP, для которого данная переменная типа INPUT
диагностирует ошибки:
![]() 2, In – ошибка WINDOWS обмена по TCP (DEC,
2, In – ошибка WINDOWS обмена по TCP (DEC,
>=10000);
![]() 95, C2 – ошибка устройства; если бит 7
95, C2 – ошибка устройства; если бит 7
(0x80) не установлен – ошибка, генерируемая самим устройством, если
установлен – ошибка, генерируемая МРВ:
![]() 0x80 – ошибка соединения;
0x80 – ошибка соединения;
![]() 0x81 – соединение с устройством принудительно
0x81 – соединение с устройством принудительно
разорвано;
![]() 96, C3 – число неудачных попыток
96, C3 – число неудачных попыток
соединения;
![]() 97, C4 – число очисток приемного буфера;
97, C4 – число очисток приемного буфера;
буфер принудительно очищается в случае некорректного ответа
устройства на запрос (например, если ответ содержит неверное число
байтов);
![]() 98, C5 – разница между текущим временем ОС
98, C5 – разница между текущим временем ОС
и последним обменом (в секундах, <=255).
При посылке значений в данную переменную типа
OUTPUT выполняются следующие команды (номер устройства задается
атрибутом Параметр<>0):
![]() 3, 5 или 7 – блокировать обмен с устройством
3, 5 или 7 – блокировать обмен с устройством
(разрыв соединения);
![]() 2 – сбросить блокировку обмена;
2 – сбросить блокировку обмена;
![]() 1 – сбросить ошибку TCP;
1 – сбросить ошибку TCP;
![]() 16 – реинициализировать обмен;
16 – реинициализировать обмен;
![]() 17 – реинициализировать обмен с инвертированием
17 – реинициализировать обмен с инвертированием
битов байта XXX.xxx.xxx.xxx IP-адреса;
![]() 18 – реинициализировать обмен с инвертированием
18 – реинициализировать обмен с инвертированием
младшего бита байта xxx.xxx.XXX.xxx IP-адреса;
![]() 19 – реинициализировать обмен с инвертированием 2
19 – реинициализировать обмен с инвертированием 2
младших битов в байтах xxx.xxx.XXX.XXX IP-адреса.
@RS_Reinit
Дополнение к подтипу – 14.
Значение байта 0 (0x00FF) переменной типа OUTPUT
задает номер последовательного порта (1 – COM1 и т.д.). Отличное от
0 значение байта 1 (0xFF00) инициализирует обмен через порт. При
нулевом значении старшего байта реинициализируется указанный порт,
инициализированный ранее.
@e_OPC
Дополнение к подтипу – 15.
В данную переменную типа INPUT записывается
результат диагностики обмена по OPC (см. Коды диагностируемых ошибок ).
Если переменная имеет тип OUTPUT, то посылка в нее
0 сбрасывает код ошибки, а посылка любого другого числа
переинициализирует все связи с OPC-серверами. При этом если в
начальный момент времени сервер не был найден, то надо использовать
полную реинициализацию (значение больше 255). Если связь была
оборвана уже при работе, то можно провести частичную
реинициализацию (значение меньше 255).
@Redundant
Дополнение к подтипу – 16.
Значение этой переменной типа INPUT равно времени
(в секундах) отсутствия данных от резерва, указанного атрибутом
Параметр.
@e_Dump
Дополнение к подтипу – 17.
В данную переменную типа INPUT записываются
результаты диагностики дампа узла (см. Коды диагностируемых ошибок ).
@e_DDE
Дополнение к подтипу – 18.
В данную переменную типа INPUT записывается код
ошибки при обмене по DDE (см. Коды диагностируемых ошибок ).
@e_MLink_Slave
Дополнение к подтипу – 19.
В данную переменную типа INPUT записывается код
ошибки при обмене по протоколу M-LINK в режиме SLAVE (см. Коды диагностируемых ошибок ).
@e_Connect
Дополнение к подтипу – 20.
В эту переменную типа INPUT записывается код ошибки
при обмене по TCP.
@q_SIAD_Lost
Дополнение к подтипу – 21.
Данная переменная типа INPUT индицирует число
сообщений, которые не удалось вставить в очередь на запись в архив,
заданный атрибутом Параметр (0 – System; 1 –
SIAD1; 2 – SIAD2; 3 – SIAD3).
@e_IO_Error
Дополнение к подтипу – 22.
Эта переменная типа INPUT используется для
индикации ошибок обмена с платами ввода/вывода, установленными в
слоты контроллера (при ошибке устанавливается бит с номером, равным
номеру слота).
@q_Lost_Alarms
Дополнение к подтипу – 23.
Данная переменная типа INPUT индицирует число
сообщений, которые не удалось вставить в очередь на запись в отчет
тревог.
@Idle_Loop
Дополнение к подтипу – 24.
В данную переменную типа INPUT записывается
реальное время цикла 18, IDLE (см. Потоки
монитора ).
@Graphics_Loop
Дополнение к подтипу – 25.
В данную переменную типа INPUT записывается
реальное время цикла потока 16 (вызов графики) (см. Потоки
монитора ).
@q_Queue_Alarms
Дополнение к подтипу – 26.
![]() Параметр=0 – значение переменной индицирует
Параметр=0 – значение переменной индицирует
(INPUT) или задает (OUTPUT) величину первой очереди сообщений,
генерируемых монитором. Эта очередь предназначена для сообщений,
передаваемых по направлениям AR и G. Значение по
умолчанию – 64000 строк.
![]() Параметр=1 – значение переменной индицирует
Параметр=1 – значение переменной индицирует
(INPUT) или задает (OUTPUT) величину второй очереди сообщений,
генерируемых монитором. Эта очередь предназначена для сообщений,
передаваемых по всем направлениям, кроме AR и G.
Значение по умолчанию – 64000 строк.
![]() Параметр=2 – значение переменной INPUT
Параметр=2 – значение переменной INPUT
индицирует текущую величину первой очереди сообщений.
![]() Параметр=3 – значение переменной INPUT
Параметр=3 – значение переменной INPUT
индицирует текущую величину второй очереди сообщений.
![]() Параметр=4 – значение переменной INPUT
Параметр=4 – значение переменной INPUT
индицирует максимальный размер первой очереди, достигнутый за все
время работы (отрабатывается только в профайлере).
![]() Параметр=5 – значение переменной INPUT
Параметр=5 – значение переменной INPUT
индицирует максимальный размер второй очереди, достигнутый за все
время работы (отрабатывается только в профайлере).
Если с помощью переменной с атрибутом
Параметр=0,1 задать размер очереди меньше, чем текущее число
сообщений в ней, из очереди удаляется соответствующее количество
сообщений с младшими временами.
При посылке положительного значения в переменную
OUTPUT с атрибутом Параметр=2,3 соответствующие очереди
очищаются.
При посылке положительного значения в переменную
OUTPUT с атрибутом Параметр=4,5 соответствующие переменные
INPUT обнуляются.
@Calc_Loop
Дополнение к подтипу – 27.
![]() Параметр=0 – реальное время цикла CALC, мс
Параметр=0 – реальное время цикла CALC, мс
(INPUT) (см. Время цикла монитора );
![]() Параметр=5 – заданный цикл TF, мс
Параметр=5 – заданный цикл TF, мс
(INPUT/OUTPUT);
![]() Параметр=6 – реальное время цикла TF, мс
Параметр=6 – реальное время цикла TF, мс
(INPUT);
![]() Параметр=9 – заданный цикл FAST, мс
Параметр=9 – заданный цикл FAST, мс
(INPUT/OUTPUT);
![]() Параметр=10 – реальное время цикла FAST, мс
Параметр=10 – реальное время цикла FAST, мс
(INPUT);
![]() Параметр=18 – заданный цикл IDLE, мс
Параметр=18 – заданный цикл IDLE, мс
(INPUT/OUTPUT);
![]() Параметр=19 – реальное время цикла IDLE, мс
Параметр=19 – реальное время цикла IDLE, мс
(INPUT).
Время циклов CALC, TF, IDLE и FAST может быть
задано также в конфигурационном файле узла – см. Файл
CNF в разделе Задание параметров работы мониторов
.
@q_IP_Lost
Дополнение к подтипу – 28.
Значение данной переменной типа INPUT равно
количеству потерянных данных для отправки по IP.
@q_IP_Send_Q
Дополнение к подтипу – 29.
![]() Параметр=0 – переменная INPUT индицирует
Параметр=0 – переменная INPUT индицирует
текущий размер очереди на отправку по IP (число пакетов);
![]() Параметр=1 – переменная INPUT (OUTPUT)
Параметр=1 – переменная INPUT (OUTPUT)
индицирует (задает) максимальный размер очереди на отправку по IP.
Данный параметр может быть задан также с помощью ключа QUEUE
в файле *.cnf;
![]() Параметр=2 – переменная INPUT индицирует
Параметр=2 – переменная INPUT индицирует
максимальный размер очереди, достигнутый за все время работы.
@q_SIAD_Q
Дополнение к подтипу – 30.
Атрибут Параметр этой переменной может
принимать следующие значения (см.
sysdiag_queuesiad.tmc):
![]() 0…11, Queue System …
0…11, Queue System …
Queue SIAD3 Copy2 (функция 0)
![]() 16…27, Lost System …
16…27, Lost System …
Lost SIAD3 Copy2 (функция 1)
![]() 32…43, Used System …
32…43, Used System …
Used SIAD3 Copy2 (функция 2)
![]() 48…59, K System … K
48…59, K System … K
SIAD3 Copy2 (функция 3)
![]() 64…75, Count System …
64…75, Count System …
Count SIAD3 Copy2 (функция 4)
![]() 80…91, S System … S
80…91, S System … S
SIAD 3 Copy2 (функция 5)
![]() 96…107, First
96…107, First
System…First SIAD 3 Copy2
(функция 6)
![]() 112…123, Last
112…123, Last
System…Last SIAD 3 Copy2
(функция 7)
Значение переменной INPUT индицирует следующие
характеристики:
![]() Параметр=0…11 – размер текущей очереди на
Параметр=0…11 – размер текущей очереди на
запись в соответствующий архив (в процентах к максимальному числу
записей);
![]() Параметр=16…27 – число потерянных сообщений
Параметр=16…27 – число потерянных сообщений
для записи в соответствующий архив;
![]() Параметр=32…43 – приблизительный процент
Параметр=32…43 – приблизительный процент
заполнения соответствующего архива. При старте МРВ значение этого
параметра соответствует текущему уровню заполнения архива. После
достижения значения 100 параметр обнуляется и затем снова растет до
100 по мере затирания старых записей новыми;
![]() Параметр=48…59 – коэффициент полезного
Параметр=48…59 – коэффициент полезного
использования объема соответствующего архива (в процентах);
![]() Параметр=64…75 – число сообщений, посланных
Параметр=64…75 – число сообщений, посланных
в соответствующий архив с момента старта монитора;
![]() Параметр=80…91 – число запросов на выборку
Параметр=80…91 – число запросов на выборку
из соответствующего архива в очереди;
![]() Параметр=96…107 – время первой записи в
Параметр=96…107 – время первой записи в
соответствующем архиве;
![]() Параметр=112…123 – время последней записи в
Параметр=112…123 – время последней записи в
соответствующем архиве.
Значения 48-59 и 64-75 атрибута Параметр
отрабатываются только в профайлере.
Номер выполняемой функции (0-7) и индекс архива
(0-11) записываются соответственно в старший (0xF0) и младший
(0x0F) полубайты байта 0 атрибута 93, C0 канала.
@Node_Lock
Дополнение к подтипу – 31.
Для удержания связи с узлом N при обмене
через модем или по GPRS нужно присвоить значение
N+1 переменной
@Node_Lock типа OUTPUT:
![]() Параметр=0 – по всем RS;
Параметр=0 – по всем RS;
![]() Параметр=<номер
Параметр=<номер
RS> – по заданному RS (1 – COM1).
В этом примере показано, как использовать блок EtherCAT Notifications, чтобы обнаружить отказ в связанной сети и перезапустить сеть, когда отказ корректируется.
Только разъединенный кабель Ethernet в первое ведомое устройство обнаруживается этим примером. Более сложные ситуации с отказом могут быть обнаружены, если вы изучаете шаблон уведомлений, которые заканчиваются и пишут встроенный блок MATLAB с учетом тех.
Требования
Чтобы запустить этот пример, как представлено, вам нужен Beckhoff EK1100 с EL1202, EL2202-0100, EL3102 и ведомыми модулями EL4032. Модель не пишет ни в какие объекты процесса. Заменение файла ENI с одним соответствующим вашей сети работает также.
EtherCAT в Simulink Real-Time требует специализированного сетевого порта на целевом компьютере, который резервируется для использования EtherCAT при помощи инструмента конфигурирования Ethernet. Сконфигурируйте выделенный порт для коммуникации EtherCAT, не с IP-адресом. Выделенный порт должен быть отличен от порта, используемого для подключения Ethernet между разработкой и целевыми компьютерами.
Протестировать эту модель:
-
Соедините порт, который резервируется для EtherCAT в целевом компьютере к порту EtherCAT IN модуля интерфейса EK1100.
-
Убедитесь, что EK1100 предоставляется источником питания на 24 вольта.
-
Создайте и загрузите модель на цель.
Для полного примера, который конфигурирует сеть EtherCAT, конфигурирует модель главного узла EtherCAT и создает, затем запускает приложение реального времени, смотрите Моделирование Сети EtherCAT.
Откройте модель
Эта модель является началом полного внедрения отловить отказы сети и повторно инициализировать сеть, если отказ фиксируется. Простой конечный автомат во встроенном блоке MATLAB может быть заменен реализацией Потока состояния, которая может быть необходимой для более сложного обнаружения отказа и восстановления.
Блок инициализации EtherCAT требует, что настройка, файл ENI присутствует в текущей папке или на пути MATLAB, потому что имя файла присутствует без информации о директории.
Если вы хотите изменить эту модель, чтобы экспериментировать с ним, скопируйте конфигурационный файл в качестве примера и файл модели от папки в качестве примера до текущей папки. Чтобы открыть модель, в командном окне MATLAB, введите:
open_system(fullfile(matlabroot,'toolbox','slrealtime','examples','slrt_ex_ethercat_notifyreset'));

Рисунок 1: модель EtherCAT для обнаружения разъединенного кабеля Ethernet в первом ведомом устройстве и переинициализации сети однажды кабель повторно подключена.
Сконфигурируйте модель
Откройте диалоговое окно параметра для блока EtherCAT Init и наблюдайте предварительно сконфигурированные значения. Ведомыми устройствами EtherCAT, которые объединяются в гирляндную цепь вместе с кабелем Ethernet, является Устройство, также называемое сетью EtherCAT. Индекс Устройства выбирает одну такую цепочечную сеть EtherCAT. Номер порта Ethernet идентифицирует который порт Ethernet использовать, чтобы получить доступ к тому Устройству. Блок EtherCAT Init соединяет эти два так, чтобы другие блоки EtherCAT использовали индекс Устройства, чтобы связаться с ведомыми устройствами в той сети EtherCAT.
Если у вас только есть тот соединенная сеть ведомых устройств EtherCAT, и вы только зарезервировали один порт Ethernet с инструментом конфигурирования Ethernet, используйте индекс Устройства = 0 и Номер порта Ethernet = 1.
Создайте файл ENI для различной ведомой сети
Если необходимо создать новый файл ENI, необходимо использовать сторонний конфигуратор EtherCAT, такой как TwinCAT 3 от Beckhoff, который вы устанавливаете на компьютере разработчика. Настройкой EtherCAT (ENI) файл, предварительно сконфигурированный для этой модели, является Stack4_BS_1ms.xml.
Каждый файл ENI характерен для точной сетевой настройки, для которой он был создан (например, сеть, обнаруженная на шаге 1 процесса создания конфигурационного файла). Конфигурационный файл предусмотрел этот пример, допустимо, если и только если сеть EtherCAT состоит из Beckhoff EK1100 с EL1202, EL2202-0100, EL3102 и ведомыми модулями EL4032. Если вы сделали, чтобы различный EtherCAT управлял, этот пример все еще работает, но необходимо создать новый файл ENI, который использует ведомые устройства.
Для обзора процесса для создания файла ENI смотрите, Конфигурируют Сеть EtherCAT при помощи TwinCAT 3.
Создайте, загрузите и запустите модель
Чтобы создать, загрузите и запустите модель:
-
В Редакторе Simulink, из списка целей на вкладке Real-Time, выбирают целевой компьютер, на котором можно запустить приложение реального времени.
-
Нажмите Run on Target.
Если вы открываете два осциллографа путем двойного щелчка по каждому, данные переданы от цели назад к компьютеру разработчика и отображены там.
Модель предварительно сконфигурирована, чтобы запуститься в течение 15 секунд. Если вы хотите запустить модель дольше, выпадающий меню Run on Target и изменить номер на нижней строке. Нажмите зеленую стрелу, чтобы сконфигурировать, создать, и запуститься.
Отобразите данные о Целевом компьютере
Если при запуске модель с помощью Запуска на Целевой кнопке, режим external mode соединяется, и можно дважды щелкнуть по блокам scope и видеть данные по компьютеру разработчика. Блоки Отображения также работают.
При выполнении этой модели, чтобы продемонстрировать этапы реинициализации, необходимо отключить и повторно подключить кабель Ethernet между целевой машиной и ведомой сетью EtherCAT. Когда вы повторно подключаете кабель, вы видите, что DC синхронизировать выполняет ту же пересинхронизацию, которая происходит во время начального периода.

При использовании Работавшего Цель Осциллограф показывает, что ошибка синхронизации DC между основным кодом на цели и первым DC включила ведомое устройство. Поскольку ошибка возвращена как наносекунды, этот график показывает, что различие в синхронизации успокаивается к порядку 3-5 микросекунд (3 000 — 5 000 наносекунд), различие между DC включило ведомые устройства и целевую машину, запускающую код. Остаточное рассеяние только отражает изменчивость планирования задач в целевом компьютере RTOS.
В этом экспериментальном запуске кабель Ethernet был отключен дважды во время 30-секундного запуска. Разъединение произошло приблизительно в 7 секунд, повторное соединение приблизительно в 12 секунд. Этот процесс повторяется приблизительно в 18 секунд и 21 секунду. Каждый раз, когда кабель повторно подключен, ошибка синхронизации показывает импульс, который показывает дрейф между целью и сетью EtherCAT в течение времени, кабель был отключен и является ожидаемым поведением пересинхронизации.

Scope1 показывает несколько логических сигналов с вертикальными смещениями, чтобы показать анализатор логики как отображение. От верхней части изображения это:
-
Соедините (желтое) состояние
-
Работающая (синяя) ошибка количества
-
Структурируйте (красную) ошибку ответа
-
Все ведомые устройства Операционный (зеленый)
-
Ведомая (фиолетовая) ошибка
-
(Голубая) ошибка Scanbus
Разъединение кабеля вызвало scanbus ошибку, как замечено на голубой трассировке. Ничего не происходит, пока кабель не подключен повторно приблизительно в 12 секунд. Состояние ссылки отражает одно уведомления о временном шаге, которые указывают на ссылку, уходящую и ссылку возвращение. На первом разъединении вы не видите, что ссылка уходит уведомление, но вы действительно видите, что ссылка возвращается. Встроенный блок MATLAB сохраняет персистентную переменную с состоянием ссылки с начальным значением 2 и изменяет его в зависимости от уведомлений.
После того, как ссылка возвращается, существует оба ведомая ошибка ответа ошибки и системы координат перед Всеми Ведомыми устройствами Операционные движения вниз для шага расчета. В той точке запускается пересинхронизация синхронизации, и вы видите, что ослабленная волна показывает синхронизацию errot падающий на в течение нескольких микросекунд после ошибки.

Scope2 показывает большему состоянию выходные параметры с:
-
(желтый) statechange
-
(синий) sbdone
-
(красный) dcinsync
-
(зеленый) запрос statechange
-
(фиолетовый) newstate
-
(голубое) текущее состояние
Когда ссылка понижается, стек замечает, что и выполняет скан устройств на шине. Это — метка sbdone приблизительно в 7 секунд, которые также привели к sbscan ошибке, показанной в Scope1. Затем, когда ссылка восстанавливается в 12 секунд, другой скан шины выполнен, показан в 12 секунд в синей трассировке. Встроенный блок MATLAB запрашивает изменение состояния к PreOp (=2) показанный в зеленых и фиолетовых трассировках. Если Preop достигнут, вы видите, что другое изменение состояния запрашивает перейти к Op (=8) состояние, которое является вторым изменением зеленого и фиолетового цвета. Это запускает пересинхронизацию часов между разработкой comptuer и целевым компьютером, который занимает несколько секунд, пока вы не видите dcinsync приблизительно в 14 секунд (красный trace) с переходом к состоянию Op прямо после.
Отключите кабель снова, чтобы повторить целую последовательность, снова запускающуюся приблизительно в 18 секунд.
В то время как для этого примера нужно ручное вмешательство, чтобы отключить и повторно подключить кабель Ethernet, тот же перезапуск может быть вызван, только запросив, чтобы PreOp утвердили follwed по запросу о состоянии Op, пропустив взаимодействие с состоянием ссылки, если инициировано некоторым другим условием в модели.
Если при запуске модель из командной строки, можно использовать Инспектора Данных моделирования, чтобы просмотреть любой сигнал, который отмечен для логгирования сигнала. Сигналы, отмеченные для логгирования, появляются с точкой с двумя дугами выше его в редакторе моделей.
Смотрите также
-
Моделирование сетей EtherCAT
-
EtherCAT® Protocol Sequenced Writing CoE Slave Configuration Variables
-
EtherCAT® Protocol Sequenced Writing SoE Slave Configuration Variables
close_system( 'slrt_ex_ethercat_notifyreset' );
1. Архитектуры компьютерных сетей, их характеристики.
Архитектура — спецификации связи, разработанные для определения функций сети и установления стандартов различных моделей вычислительных систем, предназначенных для обмена и обработки данных.
Для стандартизации сетей Международная организация стандартов (ISO/OSI) предложила семиуровневую сетевую архитектуру. Это предложение хорошо в теории, но конкретные реализации сетей не используют все уровни международного стандарта. Однако этот стандарт дает общее представление о взаимодействии отдельных подсистем сети и потому выступает «эталоном».
Семиуровневая сетевая архитектура
-
Физический уровень (Physical Layer). Обеспечивает виртуальную линию связи для передачи данных между узлами сети. На этом уровне выполняется преобразование данных, поступающих от следующего, более высокого уровня, в сигналы, передающиеся по физическим носителям. Элемент информации – бит. Примеры протоколов, действующих на этом уровне — Wi-Fi, Bluetooth.
-
Канальный (Data Link Layer). Обеспечивает виртуальную линию связи более высокого уровня, способную безошибочно передавать данные в асинхронном режиме. При этом данные обычно передаются блоками, содержащими дополнительную управляющую информацию. Такие блоки называют кадрами. При возникновении ошибок автоматически выполняется повторная посылка кадра. Кроме того, на уровне управления линией передачи данных обычно обеспечивается правильная последовательность передаваемых и принимаемых кадров. Последнее означает, что если один компьютер передает другому несколько блоков данных, то принимающий компьютер получит эти блоки данных именно в той последовательности, в какой они были переданы. Пример протокола, действующего на этом уровне — Token ring.
-
Сетевой уровень (Network Layer). Предполагает, что с каждым узлом сети связан некий процесс. Процессы, работающие на узлах сети, взаимодействуют друг с другом и обеспечивают выбор маршрута передачи данных в сети (маршрутизацию), а также управление потоком данных в сети. В частности, на этом уровне должна выполняться буферизация данных. Элемент информации – дейтаграмма (пакет). Пример протокола, действующего на этом уровне — IPv4, IPv6, ICMP.
-
Транспортный уровень (Transport Layer). Выполняет разделение передаваемых сообщений на пакеты на передающем конце и сборку на приемном конце. На этом уровне может выполняться согласование сетевых уровней различных несовместимых между собой сетей через специальные шлюзы. Например, такое согласование потребуется для объединения локальных сетей в глобальные. Элемент информации – пакет (сегмент, дейтаграмма). Пример протоколов, действующих на этом уровне – UDP, TCP, SCTP.
-
Сеансовый уровень (Session Layer). Обеспечивает поддержание/разрыв сеанса связи, позволяя приложениям взаимодействовать между собой длительное время. Уровень управляет созданием/завершением сеанса, обменом информацией, синхронизацией задач, определением права на передачу данных и поддержанием сеанса в периоды неактивности приложений. На практике этот уровень зачастую «отпадает». Элемент информации – сообщение. Пример протокола, действующего на этом уровне – SOCKS.
-
Уровень представления (Presentation Layer). Описывает шифрование данных, их сжатие и кодовое преобразование. На практике этот уровень зачастую «отпадает». Элемент информации – сообщение. Например, к этому уровню можно отнести шифрование ASCII.
-
Прикладной уровень (Application Layer). Отвечает за поддержку прикладного программного обеспечения конечного пользователя. Элемент информации – сообщение. Пример протоколов, действующих на этом уровне – TELNET, POP3, SMTP, HTTP.
Уровни с межсетевого по прикладной реализуются програмно.
Архитектуры КС
- ODNA (DECNet) — Основным коммутационным элементом сетевой архитектуры DNA является узел. Все узлы равноправны, т.е. каждый узел, может выступать в качестве любого функционального элемента ИВС. Узлы закреплены за различными областями (подобластями). Каждая область имеет своего администратора и средства маршрутизации. Каждый узел имеет свой уникальный адрес. Структура адреса DECnet-4: 1 байт -номер области, 1 байт — номер подобласти, 6 байт — Ethernet адрес.
- SNA
- DARPA (TCP/IP, Internet)
- Novell Netware
- SMB
- AppleTalk
- XNS
- IPv6
Характеристики:
-
Иерархия протоколов
-
Соответствие модели ISO
-
Адресация
- Узлов
- Индивидуальная
- Групповая
- Широковещательная
- Приложений
- Узлов
-
Связь сетевого и канального уровней
- Разрешение адресов
- Фрагментация
- Поузловая // IPv4
- На источнике // IPv6
-
Сетевые протоколы
-
Маршрутизация
- По типу маршрута
- Индивидуальная
- Групповая
- По адаптивности к изменениям в сети
- Статическая
- Динамическая
- Предопределенная («от источника»)
- По месту проведения маршрутных вычислений
- Централизованная
- Децентрализованная // Характерно для TCP/IP
- Гибридная
- По числу возможных маршрутов
- Однопутевые
- Многопутевые
- По характеру используемой информации
- Глобальные
- Локальные // Большинство
- Смешанные
- По типу маршрута
-
Транспортные механизмы
- Дейтаграммные транспортные протоколы
- Потоковые транспортные протоколы
- Многопоточные транспортные протоколы
-
Именование ресурсов
- Одноуровневое
- Двухуровневое
- Иерархическое
-
Прикладные протоколы
- Протоколы удаленного терминала
- Протоколы передачи файлов
- Протоколы электронной почты
- …
-
Управление
-
Защита информации
2. Архитектура TCP/IP. Иерархия протоколов.

- Физический
- Канальный
- Сетевой
- Транспортный
- Сеансовый
- Представления
- Прикладной
ARP Address Resolution Protocol — Отвечает за получение MAC адреса хоста, размещенного в текущей сети, по его IP адресу. Использует broadcast. Для передачи данных по сети хост должен знать MAC адрес хоста, которому передаются данные. Для получения МАС адреса по известному IP адресу служит протокол ARP.
ICMP Internet Control Message Protocol — Посылка сообщений об ошибках, обнаруженных в процессе передачи пакетов. Служит для общения маршрутизатора с хостом, отправляющим или посылающим данные контрольными сообщениями и сообщениями об ошибках. Использует для передачи IP и является его составной частью.
IGMP Internet Group Management Protocol — Информирует маршрутизаторы о наличии в данной сети multicast группы. Информация рассылается по маршрутизаторам, поддерживающим рассылку таких сообщений.
IP Internet Protocol — Обеспечивает маршрутизацию пакетов. IP не устанавливает непосредственное соединение между хостами, а используют адреса, помещенные в заголовок IP пакета, для передачи их получателям. Выбор пути передачи называется маршрутизацией. IP используют поля в заголовке для фрагментации и восстановления датаграмм Internet, когда это необходимо для их передачи через сети с малым размером пакетов. Не требует подтверждения получения данных. Это означает, что отправитель и получатель не информируются о пропаже пакета или неправильной последовательности получения пакетов.
TCP Transmission Control Protocol — Обеспечивает соединение между двумя хостами, с гарантируемой доставкой пакетов. Транспортный протокол с гарантированной доставкой пакетов. Данные представляются как поток байтов и могут передаваться в обоих направлениях. Некоторое количество октетов могут упаковываться в сегменты для передачи через системы Internet. Достоверность передачи информации достигается присваиванием каждому сегменту уникального номера в последовательности. Для проверки доставки сегмента используются подтверждения (ACK), которые возвращаются для каждого посланного сегмента. Если подтверждение не получено, то данные посылаюся еще раз через некоторый интервал времени (timeout). Если сегмент пришел поврежденным, то хост уничтожает этот пакет и не посылает подтверждение получения.
UDP User Datagram Protocol — Обеспечивает соединение между двумя хостами, при котором не гарантируется доставка пакетов. Обеспечивает соединение с негарантированной доставкой пакетов. Используется в приложениях, не требующих подтверждения получения пакетов (NetBIOS name service, NetBIOS datagram service, SNMP).
3. IP-адресация. Классы IP-сетей.
IP адрес состоит из 32 разрядов и записывается в виде четырех десятичных октетов через точку. Это позволяет адресовать 232 (около 4 млрд) узлов. Поддерживается индивидуальная, широковещательная и групповая адресации. Адресуется конкретный сетевой интерфейс, а не узел, однако одному интерфейсу можно придать несколько IP-адресов.
Адресное пространство поделено на 5 классов:
- класс A – для сетей большого размера
- класс B – для сетей среднего размера
- класс C – для небольших сетей
- класс D – для групповых адресов
- класс E – зарезервировано для экспериментов
Адреса класса А.
Формат адреса:
0nnnnnnn.hhhhhhhh.hhhhhhhh.hhhhhhhh
- n – разряды номера сети
- h – разряды номера узла
В итоге получается 126 сетей (2 зарезервированы) и 224-2 узлов в сети (около 16 млн.).
Адреса класса B.
Формат адреса:
10nnnnnn.nnnnnnnn.hhhhhhhh.hhhhhhhh
- n – разряды номера сети
- h – разряды номера узла
В итоге получается 214 = 16384 сетей и 216-2 = 65534 узлов в сети.
Адреса класса С.
Формат адреса:
110nnnnn.nnnnnnnn.nnnnnnnn.hhhhhhhh
- n – разряды номера сети
- h – разряды номера узла
В итоге получается 221 сетей (около 2 млн.) и 28-2 = 254 узла в сети.
Адреса класса D.
Формат адреса:
1110xxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx
- x – разряды адреса
В итоге получается 228 адресов (около 256 млн.).
Адреса класса E.
Формат адреса:
1111xxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx
- x – разряды адреса
В итоге получается 228 адресов (около 256 млн.).
Валидные пакеты в Internet не должны иметь адреса класса Е.
Зарезервированные IP-адреса
- адрес 0.0.0.0 – маршрут по умолчанию
- узел данной IP-сети:
- А:
00000000.hhhhhhhh.hhhhhhhh.hhhhhhhh - B:
10000000.00000000.hhhhhhhh.hhhhhhhh - C:
11000000.00000000.00000000.hhhhhhhh
- А:
- конкретная IP-сеть
- A:
0nnnnnnn.00000000.00000000.00000000 - B:
10nnnnnn.nnnnnnnn.00000000.00000000 - C:
110nnnnn.nnnnnnnn.nnnnnnnn.00000000
- A:
- все узлы данной IP-сети (*)
- A:
0nnnnnnn.11111111.11111111.11111111 - B:
10nnnnnn.nnnnnnnn.11111111.11111111 - C:
110nnnnn.nnnnnnnn.nnnnnnnn.11111111
- A:
- все узлы данной локальной сети: 255.255.255.255`
- петля обратной связи: 127.x.x.x`
- IANA зарезервировала несколько диапазонов адресов:
10.0.0.0–10.255.255.255172.16.0.0–172.31.255.255192.168.0.0–192.168.255.255
224.0.0.1– все узлы данной подсети224.0.0.2– все маршрутизаторы данной подсети224.0.0.5– все OSPF маршрутизаторы224.0.0.6– все назначенные OSPF маршрутизаторы224.0.0.9– все RIP-2 маршрутизаторы224.0.0.10– все IGRP маршрутизаторы
4. Структуризация IP-сетей. Понятие маски сети. Организация подсетей, префикс сети.
Маска подсети:
- 32-х разрядный вектор флагов
- «1» в i-ом разряде маски – i-ый разряд адреса содержит часть номера сети или подсети
- «0» в i-ом разряде маски – i-ый разряд адреса содержит часть номера узла
Пример макси для сети класса С:
Формат адреса класса С: 110nnnnn.nnnnnnnn.nnnnnnnn.hhhhhhhh
- n – разряды номера сети;
- h – разряды номера узла;
если маска = 11111111.11111111.11111111.11000000 (`255.255.255.1921), то 4 подсети по 64 адреса в каждой.
Два адреса в подсети зарезервированы (первый – адрес подсети, последний – широковещательный адрес подсети). Допускается в одной сети иметь подсети разного размера (VLSM).
Префикс – число единиц в маске. Для сети А префикс равен 8, для В = 16, а для С = 24.
Надсети – объединение нескольких сетей.
Пример 1:
- Сети
195.19.212.0и195.19.213.0 - Общая надсеть на 512 адресов:
195.19.212.0/255.255.254.0
Если А – IP-адрес узла, М – маска подсети, то
Адрес подсети = A & M
Широковещательный адрес = A v (!M)
Максимальное число узлов сети = !M — 1
Адресация сервисов (приложений):
Порт – уникальный номер приложения на узле, использующего конкретный транспортный протокол.
В TCP/IP порт – 16 разрядов (0 … 65535)
Приложение идентифицируется сокетом:
- IP-адресом узла
- Типом транспортного протокола
- Номером порта
Примеры:
- TCP-сокет: 195.19.212.13:80
- UDP-сокет: 195.19.212.10:53
5. Архитектура сетей ТСP/IP. Протокол IP.
IP – Internet Protocol – межсетевой протокол. Нужен, чтобы объединить разные сети, использующие разные технологии передачи данных. IP – основной протокол, использующийся в Интернете.
В модели ISO/OSI расположен на Сетевом уровне

В модели TCP/IP расположен на Сетевом уровне

IP передает данные без установления соединения. IP обеспечивает передачу данных без гарантии доставки и без сохранения порядка следования сообщений
IP просто посылает пакет в сеть. Если пакет не дошел, то IP никак об этом не оповещает и не пытается заново отправить недошедший пакет. Такие ошибки должны быть исправлены протоколами на вышестоящих уровнях
Задачи IP:
- объединение сетей с разными технологиями в одну крупную сеть
- маршрутизация. поиск маршрута от отправителя к получателю
- качество обслуживания
Формат пакета:

- Version — Версия протокола. Текущая версия 4 (0100).
- Header Length — Количество 32 битных слов в заголовке пакета. Минимальная размер заголовка 20 байт, то есть в Header Length = 0x5. Наличие информации в поле Options может увеличить размер заголовка максимум на 4 байта. Если это поле заполнено не полностью, то заполненные биты покрываются 32 битными словами и незаполненная часть заполняется нулями.
- Type of Service — Желаемое качество обслуживания пакета при его доставке.
- Total Length — Общая длина IP пакета.
- Identifier — Идентификатор пакета. Если пакет фрагментирован, то все фрагменты имеют одинаковый идентификатор. Это необходимо для восстановления исходного пакета.
- Fragmentation Flags — Флаги фрагментации. В настоящее время используется только два бита. Один показывает, фрагментирован пакет или нет, второй говорит о наличии фрагментов, следующих за текущим.
- Fragment Offset — Позиция фрагмента внутри пакета. Если пакет не фрагментирован то 0x0.
- Time to Live — количество раз, которое пакет может пройти через маршрутизаторы. При прохождении через маршрутизатор, TTL уменьшается на 1. При TTL = 0 пакет уничтожается. Такой механизм помогает, если пакет попал в «петлю». Чтобы сеть со временем не перегрузилась пакетами, они сами уничтожаются когда TTL достигает 0.
- Protocol — Тип транспортного протокола, используемого при передаче (TCP или UDP)
- Header Checksum — Контрольная сумма.
- Source Address — Идентификатор отправителя пакета.
- Destination Address — Идентификатор получателя пакета.
- Options and Padding — Переменное число 32 битных слов (максимум 4 байта) используются для дополнительной информации о пакете.
6. Связь c канальным уровнем в ТСP/IP. Протокол разрешения адреса ARP.
ARP – Address Resolution Protocol – протокол разрешения адресов
Нужен для определения MAC-адреса устройства по его IP-адресу
Для определения MAC-адреса использует схему ARP-запрос – ARP-ответ
Алгоритм:
-
Компьютер, который хочет узнать MAC-адрес определенного компьютера в сети посылает широковещательный ARP-запрос на все компьютеры в сети с вопросом «У кого IP 192.168.10.43?»
-
Компьютер с IP адресом = 192.168.10.43, отправляет ARP-ответ со своим MAC-адресом
-
Компьютер-отправитель получает ARP-ответ, вытаскивает из него MAC-адрес и использует его для дальнейшей передачи данных по сети

- Network Type – тип канального протокола. Ethernet = 1
- Protocol — протокол сетевого уровня. IP = 2048
- HAL — длина канального адреса
- PAL — длина сетевого адреса
- Operation — тип операции. 1 = запрос. 2 = ответ.
- Source Hardware Address — MAC адрес отправителя
- Source IP Address — IP адрес отправителя
- Dest. Hardware Address — MAC адрес получателя
- Dest. IP Address — IP адрес получателя


7. Групповая доставка в TCP/IP. Протокол IGMP.
В TCP/IP в качестве multicast’а используется Internet Group Management Protocol (IGMP)
- Протокол сетевого уровня.
- Предназначен для решения задач:
- Управления.
- Нотификации об ошибках и проблемах.
- Тестирования и мониторинга.
- Описан в стандарте RFC792.
- Инкапсулируется в IP.
- Используется только в сетях IPv4; в IPv6 есть аналог.
IGMP (англ. Internet Group Management Protocol — протокол управления группами Интернета) — протокол управления групповой (multicast) передачей данных в сетях, основанных на протоколе IP. IGMP используется маршрутизаторами и IP-узлами для организации сетевых устройств в группы. Информирует маршрутизаторы о наличии в данной сети multicast группы. Информация рассылается по маршрутизаторам, поддерживающим рассылку таких сообщений.
Всего есть три версии, обратно совместимые с предыдущими.
1. Стандарт 1ой версии – RFC 1112.
Маршрутизатор регулярно посылает запросы вида «Хей, есть кто с такой группой?». Отчет посылается с задержкой, чтобы множество ответов, иначе бы высланные в унисон, не уронили сеть.
Хост должен посылать отчет о каждой группе.
Если на запрос не присылаются отчеты => членов групп больше нет.
Типы — определяет тип IGMP сообщения: «1» соответствует запросу, «2» ответу.
Адрес группы: В запросе – 0, в ответе – существующий номер группы
При этом, в IP-пакете-«обёртке» используется: адрес 224.0.0.1 и TTL = 1 (чтобы пакет не «улетел» из сети)
2. Активно используется вторая версия, её стандарт – RFC 2236.
Появились типы сообщений:
- 0x11 – запрос о членстве в группах или конкретной группе
- 0x16 – отчет о членстве v2
- 0x17 – запрос-нотификация о покидании группы
- 0x12 – отчет о членстве v1 (для совместимости)
Макс. время – максимальное время ответа в 0.1 с

3. Стандарт – RFC3376. IGMP V3 Позволяет:
- В одном пакете запросить несколько групп
- В одном пакете отчитаться о нескольких группах
8. Управляющий протокол ICMP. Сигнализирующие сообщения.
Общие сведения
- Протокол сетевого уровня;
- Решает задачи
- управления,
- нотификации об ошибках,
- тестирования и мониторинга;
- Инкапсулируется в IP (да, протокол сетевого уровня в протоколе сетевого уровня);
- Описан в RFC792.
Задачи управления и нотификации – базовые функции сетевого уровня. При этом авторы архитектуры не зашили это в протокол IP, а выделили в отдельный протокол. Один из важнейших для стека TCP/IP.
ICMP-трафик обычно не пускают на широковещательные адреса.
Организация протокола ICMP
Общая часть заголовка (8, 8, 16 бит):

- Тип – тип пакета;
- Код – расшифровка типа (подтип);
- Контрольная сумма вычисляется для всего пакета.
Остальная часть пакета зависит от типа ICMP-пакета.
Нотификационные (сигнализирующие) сообщения
Информируют отправителя о каком-либо событии в сети.
Нотификационные сообщения фильтровать нельзя!
Основные типы:
- 3 – получатель недостижим (нельзя фильтровать в своей сети):

- Тип (3);
- Код (причина «недостижимости»):
- 0 – сеть недостижима;
- 1 – узел недостижим;
- 2 – протокол недостижим (например, хотим доставить по TCP, но приемная сторона его не поддерживает);
- 3 – порт недостижим (когда никто {сервис, приложение} не прослушивает порт);
- 4 – требуется фрагментация (в IP-пакете установлен флаг, запрещающий фрагментацию, но сам пакет слишком большой для передачи целиком по каналу);
- 5 – ошибка маршрутизации от источника (когда не можем строго пройти через указанные адреса {строгая маршрутизация от источника в IP});
- 6 – сеть назначения неизвестна (обычно – попытки маршрутизации в сеть класса Е, то есть в адреса, которые не маршрутизируются в сетях TCP/**IP);
- 7 – узел назначения неизвестен (c**м. 6);
- 8 – отправитель изолирован (обычно – нет действующих интерфейсов для отправки пакета);
- 9 – взаимодействие с сетью назначения административно запрещено (фаервол – стоит правило REJECT {а вообще есть accept, deny, reject, но обычно во избежание перегрузки сети ответными пакетами ставят DENY и молча отбрасывают пакеты});
- 10 – взаимодействие с узлом назначения административно запрещено (см 9).
- 11 – сеть недостижима из-за класса обслуживания (используются разряды TOS, на всех маршрутизаторах внутри сети настроено управление качеством обслуживания, а мы запросили сервис выше нашего уровня);
- 12 – узел недостижим из-за класса обслуживания (см. 11).
- Контрольная сумма;
- Нулевое слово;
- Заголовок и первые два слова пакета (который не смогли доставить);
- 11 – превышено время (нельзя фильтровать в своей сети):

- Тип (11);
- Код:
- 0 – превышено TTL;
- 1 – превышено время ожидания фрагмента при сборке;
- Последнее поле содержит первую часть пакета, фрагмент которого не дошел;
- 12 – ошибка параметра (нельзя фильтровать в своей сети):

- Тип (12);
- Указатель (байтовый). (В случае, если какой-либо из промежуточных маршрутизаторов или конечный узел, проанализировав заголовок IP-пакета, определил, что произошла ошибка {невалидное значение поля, неверная контрольная сумма…}, он сообщает о ней, указывая номер ошибочного байта);
- Последнее поле содержит первую часть пакета, в котором обнаружена ошибка;
9. Управляющий протокол ICMP. Управляющие и тестовые сообщения
(!TODO)
Общие сведения ICMP – 8 вопрос
Управляющие сообщения
Управляющие сообщения – попытка «повлиять» на саму сеть.
Основные типы:
Тестовые и контрольные сообщения
Позволяют проводить диагностику сети.
Обычно идут парами «запрос-ответ».
Типы:
-
Запрос эха (8) и ответ на запрос эха (0) (ping и pong. Проверка работоспособности удаленного узла. Используется в утилитах типа ping и ей подобных, позволяющих проверить достижимость узла в сети):

Идея: станция посылает удаленной станции пакет с типом 8, промежуточные маршрутизаторы доводят его до последней станции. Та, получив его, уничтожает, в ответ формирует такой же пакет с типом 0, а в поле данных копирует те необязательные данные, которые были в поле эхо-запроса, после чего посылает обратно.
Обычно в своей сети разрешаем 8 на выход и 0 на вход. Остальное отрубаем. Иногда – ставим прокси (ICMP-сервер), чтобы он формировал фейковые сообщения за все компьютеры в сети.- Тип (8 или 0);
- Идентификатор (для различения пар потоков ping-ов и pong-ов. По нему определяется процесс, которому отдают ответный трафик);
- Последовательный номер (номер пакета в серии. Для посылки не одного, а нескольких пакетов. Для сопоставления ответа запросу);
- Необязательные данные (тестирование на прохождение пакетов данных определенного размера по каналу связи. Могут расширить ICMP-пакет до 64 Кб. Большие пакеты могут фильтроваться по размеру из-за имевшей место атаки «ping of death»);
-
Запрос временной метки (13) и ответ на запрос временной метки (14):


(позволяют определить временные параметры функционирования сети)- Идентификатор – номер потока сообщений;
- Последовательный номер – номер пакета в потоке;
- (T1) Временная метка отправителя заполняется источником (время, когда пакет улетел из отправителя);
- (T2) Временная метка приема фиксируется при получении запроса приемником (время, когда пакет пришел на приемную станцию);
- (T3) Временная метка передачи заполняется приемником (когда был послан ответ);
- (T4) Еще мы знаем время, когда мы получим ответ обратно от приемника;
- Проблемы:
- Синхронизация часов;
- Фильтрация.
-
Запрос маски адреса (17) и ответ на запрос маски адреса (18):

(Чаще всего – чтобы узнать топологию удаленной сети. Считается опасным, не рекомендуется к использованию вне текущей сети).-
Идентификатор – номер потока сообщений;
-
Последовательный номер – номер пакета в потоке;
-
Маска – записанная маска адреса приемника.
-
10. Адресация приложений. Понятие портов.
Понятие портов
- Порт – уникальный номер приложения на узле, использующего конкретный транспортный протокол
- В TCP/IP порт – 16 разрядов (0…65535)
- Приложение идентифицируется сокетом:
- IP-адресом узла
- Типом транспортного протокола
- Номером порта
- Примеры:
- TCP-сокет: 195.19.212.13:80
- UDP-сокет: 195.19.212.10:53
- Есть некоторые правила по умолчанию, которые все стараются соблюдать:
- Сервер обычно использует фиксированные номера портов из диапазона от 0 до 1023.
- Клиент обычно использует непривилегированные номера портов из диапазона 1024+. В некоторых ОС для того, чтобы выдать приложению порт меньше 1024, требуется, чтобы приложение имело достаточно привилегий и прав.
- Философия, которую пыталась сделать IANA, а теперь ICANN:
- 1024 адреса – это зарезервированные адреса, которые мы выдаём всем известным сервисам, а то, что выше 1024 – это свободно распространяемые номера портов.
- Для сервера важно иметь предопределённый номер, потому что мы должны из разных узлов должны к нему обращаться и знать его номер, нам важно, чтобы он был фиксированный и публичный. А для клиента неважно, чтобы его номер был фиксированный, потому что к клиенту никто напрямую не обращается за редким исключением. Поэтому адрес клиента не должен быть публичным, его можно выдавать временно на 1 сеанс, что и сделано в большинстве протоколов.
Транспортный протокол UDP
Является транспортным механизмом архитектуры TCP/IP.
UDP – User Datagram Protocol, протокол без установления соединения.
Дейтаграмный обмен:
- Не гарантирует последовательность доставки
- Не обеспечивает квитирование
- Реализуется протоколом UDP
Особенности (по сравнению с другими):
- Более высокая скорость
- Меньшая надежность
Зарезервирован номер 17 в IP-пакете
Для адресации используются UDP-порты
Сервер обычно использует фиксированные номера портов (1-1023)
Клиент обычно использует непривилегированные номера портов (1024-65535)
Формат пакета:
| Порт отправителя | Порт получателя |
|---|---|
| Длина сообщения | Контрольная сумма |
| Данные |
Длина сообщения включает заголовок и данные.
Контрольная сумма:
- Вычисляется по всему пакету
- Если контрольная сумма равна 0, то она не вычислялась (для сверхнадежного канала)
- Контрольная сумма вычисляется с учетом псевдозаголовка:

Приложения, использующие UDP:
- TFTP – 69
- DNS – 53
- SNMP – 161, 162
- BOOTP, DHCP – 67,
- 68RIP — 520
12. Транспортный протокол TCP. Формат пакета TCP.
Общая информация:
- TCP – Transmission Control Protocol
- Стандарт – RFC793
- По сравнению с UDP имеет:
- Более низкую скорость
- Большую надежность
- Зарезервирован номер 6 в IP-пакете
- Адресация приложений осуществляется с помощью TCP-портов
- Передача – потоковая
- Данные для передачи хранятся в буфере:
- Данные от приложения добавляются конец буфера
- Данные для передачи в сеть берутся из начала буфера
- Пересылаемая порция данных называется – сегмент.
- Каждый передаваемый байт – пронумерован
- Сегменту присваивается номер его первого байта (номер очереди)

- При посылке в сеть сегмента:
- Сегмент копируется в буфер повторной передачи
- Взводится таймаут
Передача сегмента в сеть:

- Каждый посланный в сеть байт должен быть подтвержден
- При получении подтверждения от сегмента подтвержденными считаются все байты сегмента
- Если подтверждение не получено в течение определенного времени – сегмент из буфера повторной передачи посылается заново
- Подтверждение содержит номер следующего ожидаемого байта
- В TCP отрицательные квитанции не посылаются
Формат пакета:

- Номер очереди
- Номер посланного сегмента при обмене
- Синхронизация номеров сегментов при установлении соединения
- Номер подтверждения
- Подтверждение принятого сегмента
- Синхронизация номеров сегментов при установлении соединения
- Смещение данных – длина заголовка TCP
- Окно – величина скользящего окна
- Контрольная сумма – сегмента
- Указатель срочности – объем срочных данных
Порт источника
Порт источника идентифицирует приложение клиента, с которого отправлены пакеты. По возвращении данные передаются клиенту на основании номера порта источника.
Порт назначения
Порт назначения идентифицирует порт, на который отправлен пакет.
TCP-порты
Существует набор служб (использующих для передачи данных TCP), за которыми закреплены определенные порты.
Номер последовательности
Номер последовательности выполняет две задачи:
-
Если установлен флаг SYN, то это начальное значение номера последовательности — ISN (Initial Sequence Number), и первый байт данных, которые будут переданы в следующем пакете, будет иметь номер последовательности, равный ISN + 1.
-
В противном случае, если SYN не установлен, первый байт данных, передаваемый в данном пакете, имеет этот номер последовательности.
Номер подтверждения
Если установлен флаг ACK, то это поле содержит номер последовательности, ожидаемый получателем в следующий раз. Помечает этот сегмент как подтверждение получения.
Смещение данных
Это поле определяет размер заголовка пакета TCP в 4-байтных (4-октетных) словах. Минимальный размер составляет 5 слов, а максимальный — 15, что составляет 20 и 60 байт соответственно. Смещение считается от начала заголовка TCP.
Флаги:

- URG – задействовано поле «Указатель срочности»
- ACK — задействовано поле «Подтверждение»
- PSH – включена функция проталкивания
- RST – перезагрузка соединения
- SYN – синхронизация номеров очередей
- FIN – завершение соединения
13. Транспортный протокол TCP. Алгоритм функционирования.
Установка соединения:


Процесс начала сеанса TCP — обозначаемое как «рукопожатие» (handshake), состоит из 3 шагов.
-
Клиент, который намеревается установить соединение, посылает серверу сегмент с номером последовательности и флагом SYN.
- Сервер получает сегмент, запоминает номер последовательности и пытается создать сокет (буферы и управляющие структуры памяти) для обслуживания нового клиента.
- В случае успеха сервер посылает клиенту сегмент с номером последовательности и флагами SYN и ACK, и переходит в состояние SYN-RECEIVED.
- В случае неудачи сервер посылает клиенту сегмент с флагом RST.
-
Если клиент получает сегмент с флагом SYN, то он запоминает номер последовательности и посылает сегмент с флагом ACK.
- Если он одновременно получает и флаг ACK (что обычно и происходит), то он переходит в состояние ESTABLISHED.
- Если клиент получает сегмент с флагом RST, то он прекращает попытки соединиться.
- Если клиент не получает ответа в течение 10 секунд, то он повторяет процесс соединения заново.
-
Если сервер в состоянии SYN-RECEIVED получает сегмент с флагом ACK, то он переходит в состояние ESTABLISHED.
- В противном случае после тайм-аута он закрывает сокет и переходит в состояние CLOSED.
Процесс называется «трехэтапным согласованием» («three way handshake»), так как несмотря на то что возможен процесс установления соединения с использованием 4 сегментов (SYN в сторону сервера, ACK в сторону клиента, SYN в сторону клиента, ACK в сторону сервера), на практике для экономии времени используется 3 сегмента.

Завершение соединения можно рассмотреть в три этапа:
-
Посылка серверу от клиента флагов FIN и ACK на завершение соединения.
-
Сервер посылает клиенту флаги ответа ACK , FIN, что соединение закрыто.
-
После получения этих флагов клиент закрывает соединение и в подтверждение отправляет серверу ACK , что соединение закрыто.


Срочные данные:
- Срочные данные
- Используется для немедленной доставки данных приложению на приемной стороне
- Флаг URG – признак наличия срочных данных
- Поле Offset – указатель на первые несрочные данные
- Проталкивание данных
- Используется для немедленной отсылки сегмента в сеть
- Для проталкивания устанавливается флаг PSH
Управление скоростью передачи:
- Идея: передавать в сеть больше неподтвержденных данных
- В сеть могут передаваться сегменты, которые попали в скользящее окно
- Окно сдвигается только тогда, когда приходит подтверждение на первый посланный сегмент


14. Транспортный протокол SCTP
SCTP – Stream Control Transmission Protocol (протокол передачи с управлением потоком). Относительно новый транспортный протокол.
Первым его стандартом был RFC2960, 2002г.
Нынешний стандарт RFC4960, сентябрь 2007г.
Основная идея создания протокола была объеденить в себе достоинства и исправить недостатки двух других известных транспортных протоколов (TCP и UDP).
Одними из главных нововведений SCTP были многопоточность, защита от DdoS атак и multi-homing(синхронное соединение между двумя хостами по двум и более независимым физическим каналам) (дополнительно после формата пакетов).
Целый пакет состоит из общего заголовка(12 байт=64 бита) и субпакетов (чанков). Каждый чанк же в свою очередь состоит из своего заголовка и данных.
Формат общего заголовка:

Где:
- Verification tag – метка для проверки
отправителя пакета (32-битное случайное значение, созданное во время инициализации, чтобы отличать устаревшие пакеты от предыдущего соединения) - Check Sum – контрольная сумма
Формат чанков (субпакета):

Под тип выделен один байт,значит возможно 255 различных типов. На данный момент в RFC определены 15 типов. 0 означает, что чанк несет полезные данные, остальные — служебные.
Под флаги тоже 8 бит, состав флагов определяется типом чанка.
Длина чанка — 0 … 65535, общая длина субпакета с заголовками.
Безопасное установление соединения:

В TCP трехэтапный хэндшейк, в чем есть одна потенциальная уязвимость, обусловленная тем, что нарушитель, устанавливая фальшивые IP-адреса отправителя, может послать серверу множество пакетов SYN. При получении пакета SYN сервер выделяет часть своих ресурсов для установления нового соединения. Обработка множества пакетов SYN рано или поздно затребует все ресурсы сервера и сделает невозможной обработку новых запросов. Такой вид атак называется «SYN-флуд».
Протокол SCTP защищён от подобных атак с помощью механизма четырёхэтапного квитирования (four-way handshake) и вводом маркера (cookie). По протоколу SCTP клиент начинает процедуру установления соединения, посылая пакет INIT. В ответ сервер посылает пакет INIT-ACK, который содержит маркер (уникальный ключ, идентифицирующий новое соединение). Затем клиент отвечает посылкой пакета COOKIE-ECHO, в котором содержится маркер, полученный от сервера. Только после этого сервер выделяет свои ресурсы новому подключению и подтверждает это отправкой клиенту пакета COOKIE-ACK.
Многопоточность

Термин «многопоточность» (англ. multi-streaming) обозначает способность SCTP параллельно передавать по нескольким независимым потокам сообщений. Например, мы передаём несколько фотографий через HTTP-приложение (например, браузер). Можно использовать для этого связку из нескольких TCP-соединений, однако также допустима SCTP-ассоциация (англ. SCTP-association), управляющая несколькими потоками сообщений для этой цели. Потоки являются однонаправленными, то есть передают информацию только в одном направлении (картинка выше является неточной).
TCP достигает правильного порядка байт в потоке, абстрактно назначая порядковый номер каждой отосланной единице, а упорядочивая принятые байты, используя назначенные порядковые номера, по мере их прибывания. С другой стороны, SCTP присваивает различные порядковые номера сообщениям, посылаемым в конкретном потоке. Это разрешает независимое упорядочивание сообщений по разным потокам. Так или иначе, многопоточность является опцией в SCTP. В зависимости от желаний пользовательского приложения, сообщения могут быть обработаны не в порядке их отправления, а в порядке их поступления.
Другие достоинства SCTP:
Multihoming (Использование множественных интерфейсов, мультидомность по Ицыксоновски) — Допустим, у нас есть два хоста. И хотя бы один из них имеет несколько сетевых интерфейсов, и соответственно несколько IP-адресов. В TCP, понятие «соединение» означает обмен данными между двумя точками, в то время, как в SCTP имеет место концепция «ассоциации» (англ. association), обозначащая всё происходящее между двумя хостами
Механизмы валидации и проверки подлинности — Защита адресата от flood-атак (технология 4-way handshake), и уведомление о потерянных пакетах и нарушенных цепочках.

Из недостатков
Бóльшая занимаемая полоса, то есть относительный объём служебного трафика больше, чем при использовании TCP/UDP.

15. Маршрутизация в TCP/IP. Маршрутизаторы и шлюзы. Процесс доставки пакетов в сети.
Internet Protocol служит для пересылки ip-datagrams от ip-адреса отправителя до ip-адреса получателя (адреса при пересылке остаются неизменными, в отличии от аппаратных адресов). Маршрутизация же является ключевой функцией IP, т.к. необходима для поиска маршрутки доставки этого пакета.
Маршрутизация
-
Функция сетевого уровня
- Заключается в поиске оптимального маршрута для доставки пакетов через сеть от ip-адреса узла-отправителя до ip-адреса узла-получателя
- Сбор и хранение информации о других маршрутизаторах и хостах в сети
-
Маршрутизация:
- Индивидуальная (два узел устанавливают между собой отдельный маршрут)
- Групповая (один узел устанавливает маршруты с группой других и пересылает данные членам группы)
-
В TCP/IP сетях маршрутизация является частью протокола IP (Internet Protocol) и используется в сочетании с другими службами сетевых протоколов для обеспечения передачи данных между узлами, расположенными в разных сегментах более крупной TCP/IP-сети.
Маршрутизаторы и шлюзы
- Другие названия:
- Шлюз
- Router
- Gateway
- Устройство сетевого уровня, реализующее функции маршрутизации (обеспечивающее доставку пакетов от одного узла сети к другим)
- Отличие маршрутизатора от обычного сетевого узла – пересылка входящих пакетов, у которых адрес назначения не совпадает с локальными адресами узла
- IP-forwarding. Переадресация IP, также известная как интернет-маршрутизация, представляет собой процесс, используемый для определения того, по какому пути может быть отправлен пакет или дейтаграмма. Процесс использует информацию о маршрутизации для принятия решений и предназначен для отправки пакета по нескольким сетям.
- Виды маршрутизаторов:
- Аппаратные (маршрутизатор, router)
- Программно-аппаратные (шлюз, gateway)
Аппаратные маршрутизаторы (маршрутизатор)
-
Особенности:
-
Поддержка различных канальных сред
-
Наличие нескольких сетевых интерфейсов
-
Высокая производительность
-
Высокая надежность
-
Хорошая защищенность
-
Дополнительные функции:
- Фильтрация
- Трансляция адресов
- Сбор статистики
-
Обычно высокая стоимость
-
-
Производители:
- CISCO
- Intel
- HP
- Dlink
Программно-аппаратные маршрутизаторы (шлюз)
- Реализуются функциями ОС общего назначения
- Характеризуются
- Невысокой производительностью
- Невысокой стоимостью
- Могут совмещать функции с обычными функциями ОС
Процесс маршрутизации
В процессе маршрутизации на стороне отправителя данные проходят все 7 уровней модели ISO/OSI сверху-вниз постепенно инкапсулируясь на каждом из уровней. В итоге получается такой большой «конверт с конвертами», который пересылается получателю. На стороне получателя данные постепенно декапсулируются («конверт» постепенно раскрывается) на каждом уровне, пока идут снизу-вверх и пока не достигнут прикладного уровня.

- A, B – компьютеры
- R1, R2 – маршрутизаторы
- 1–7 – это уровни в OSI/ISO
- Компьютер использует все 7 уровней модели, а маршрутизатор только 3, так как их достаточно, чтобы продолжить маршрут в любой сети.
16. Статическая маршрутизация. Таблицы маршрутизации.
Статическая маршрутизация – вид маршрутизации, при котором маршруты указываются в явном виде при конфигурации маршрутизатора администратором. Вся маршрутизация при этом происходит без участия каких-либо протоколов маршрутизации. Статический маршрут хранится в таблицах до выключения.
При задании статического маршрута указывается:
- Адрес сети (на которую маршрутизируется трафик), маска сети
- Адрес шлюза (узла), который отвечает за дальнейшую маршрутизацию (или подключен к маршрутизируемой сети напрямую)
- (опционально) метрика («цена») маршрута.
Достоинства:
- Лёгкость отладки и конфигурирования в малых сетях
- Отсутствие дополнительных накладных расходов (из-за отсутствия протоколов маршрутизации)
- Мгновенная готовность (не требуется интервал для конфигурирования/подстройки)
- Низкая нагрузка на процессор маршрутизатора
- Предсказуемость в каждый момент времени
Недостатки:
- Очень плохое масштабирование
- Низкая устойчивость к повреждениям линий связи
- Отсутствие динамического балансирования нагрузки
- Необходимость в ведении отдельной документации к маршрутам
В реальных условиях статическая маршрутизация используется в условиях наличия шлюза по умолчанию (узла, обладающего связностью с остальными узлами) и 1-2 сетями.
Таблицы маршрутизации

Атрибуты маршрутных записей:
- Сеть/узел назначения
- Сетевой интерфейс
- Маршрутизатор
- Метрика маршрута
- Флаги
Псевдомаршруты – дополнительные записи в таблице маршрутизации, которые используются для унификации процедуры поиска маршрута. Типы:
- Псевдомаршрут на IP-адреса собственных интерфейсов
- Псевдомаршрут на подключенные IP-сети
Маршрут «по умолчанию» – специальный маршрут, которые используется в случае отсутствия явных маршрутов на целевую сеть, обозначение: 0.0.0.0/0.0.0.0
Утилита route предназначена для просмотра и управления таблицей маршрутизации.
В некоторых системах поддерживается несколько таблиц маршрутизации, в таких таблицах используется коммутация по адресу источника – в зависимости от адреса источника выбирается подчиненная таблица маршрутизации.
17. Маршрутизация. Виды маршрутизации. Алгоритм выбора маршрута в РС.
Маршрутизация — 15 вопрос
Маршрутизацию можно классифицировать по нескольким признакам:
По адаптивности
- Статическая маршрутизация (Вопрос 16)
- Динамическая маршрутизация (Вопрос 17)
- Маршрутизация «от источника» (в зависимости от адреса источника выбирается подчиненная таблица маршрутизации)
По месту маршрутных вычислений
- Централизованные (выбор маршрута для каждого пакета осуществляется сервером управления сетью, а узлы сети реализуют за данную маршрутизацию)
- Децентрализованные (управления маршрутизацией осуществляется узлами, обладающие соответствующим функционалом)
По требуемой информации
- Локальные (адрес локальной сети)
- Глобальные (адрес глобальной сети)
- Смешанные (обеспечивается доступ как в локальную сети, так и в глобальную)
Задача оптимальной маршрутизации – найти оптимальный путь данных до получателя.
Обеспечиваемая оптимальность
- Минимальное время доставки
- Минимальная стоимость доставки
- Минимальная задержка
- …
При выборе статической маршрутизации адреса назначаются вручную заранее в таблицу маршрутизации, по которой и будет выбираться, на какой интерфейс отправить пакет с соответствующей адресной информацией (Вопрос 16).
Динамические алгоритмы — Вопрос 18
18. Динамическая маршрутизация. Алгоритм Беллмана-Форда поиска кратчайшего пути.
В динамической адресации таблица маршрутизации обновляются автоматически путем сбора информации при помощи обмена информации между служебными программами (демоны маршрутизации) на разных узлах. Таким образом динамическая маршрутизация учитывает множество изменяющихся параметров сети:
- Топология сети
- Появление новых узлов
- Появление новых каналов
- …
- Каналы связи
- Выход из строя канала
- Ввод в строй канала
- Узлы сети
- Выход из строя маршрутизатора
- Ввод в строй маршрутизатора
- Изменение нагрузки в сети
В случае динамической маршрутизации задача заключается в поиске оптимального пути для пакета в данный момент времени. Задача сводится к задаче поиска пути на графе.
Алгоритм Беллмана-Форда поиска кратчайшего пути.
Краткое описание
Алгоритм оценивает расстояние до каждого из N узла начиная с первого. Оценка высчитывается исходя из веса ребра ri,j (переход между вершинами i и j). На каждую итерацию ставится ограничение переходов между узлами. В конце h-й итерации фиксируются минимальные уникальные пути D(h), i (от 1го узла до посещенного узла i) длинной не более h переходов. Перебор останавливается при достижении количества переходов равному количеству ребер (а если точнее N — 1) или если оценка перестала изменяться.
Алгоритм
- Шаг 1. Начальные условия
- Граф дополняется до полного. Вес новых дуг — ∞.
- h := 0
- Вводится начальная разметка:
- D(h), 1 = 0
- D(h), i = ∞, i ≠ 1
- Шаг 2. Перерасчет оценок
- Для всех i: D(h+1), i = minj [D(h), j + ri,j]
- h := h + 1
- Шаг 3.
- Если h = N – выход
- Если оценки не изменились – выход
- Иначе – переход к шагу 2






Общее число операций:
- N – число вершин
- N-1 – число шагов
- N – операций при минимизации на каждом шаге
- W = O(N3)
Достоинства алгоритма:
- Хорошо распараллеливается
- Просто реализуется
- Не требует ресурсов памяти
- Требуется информация только о соседних вершинах
- Часто заканчивается раньше N-1 итерации
Недостатки алгоритма:
- В худшем случае количество операций — ~N3
19. Динамическая маршрутизация. Алгоритм Дэйкстры поиск кратчайшего пути.
Динамические алгоритмы — Вопрос 18
Алгоритм Дэйкстры поиска кратчайшего пути (Shortest Path First).
Краткое описание
Каждой вершине из V сопоставляется метка (минимальное известное расстояние от этой вершины до 1й). Изначально у 1й вершины метка равна 0, а у всех остальных бесконечности. Далее итеративно обходятся вершины. Из каждой вершины (начиная с 1й) оцениваются ребра к другим вершинам. На основании этой оценки проверяется, можно ли при помощи нового пути, включающего это ребро, сократить время до узла (новое значение сравнивается с меткой узла, если новое значение меньше — оно заменяется). Перебор заканчивается после обхода всех узлов.
Алгоритм
-
P — множество помеченных вершин (для которых найден кратчайший маршрут)
-
Si – текущая оценка пути от 1-ой до i-ой
-
m – номер текущего шага
-
Шаг 1. Начальные условия
- Множество P: P={1}
- Оценка пути:
- S1 := 0
- Si := r1,i
- m = 1
-
Шаг 2.
- Sn := minj Sj
- P := P ∪ {n}
- Для всех i ∉ P:
- Si := min (Si , Sn + rn,i)
- m := m+1
-
Шаг 3.
- Если m = N -> выход
- Иначе – переход к шагу 2






Общее число операций:
- N-1 – число шагов
- N – операций при пересчете оценок на каждом шаге
- W = O(N2)
Достоинства алгоритма:
- Высокая скорость (~N2)
Недостатки алгоритма:
- Плохо распараллеливается
- Требуется иметь информацию о топологии всей сети
- Требует существенных ресурсов памяти (~N2)
20. Автономные системы. Внутренние и внешние протоколы маршрутизации. Характеристики протоколов маршрутизации.
Автономная система (AS) в интернете — это система IP-сетей и маршрутизаторов, управляемых одним или несколькими операторами, имеющими единую политику маршрутизации с Интернетом.
Протоколы маршрутизации внутри AS
- Внутренние протоколы маршрутизации
- IGP – Interior Gateway Protocol
Протоколы маршрутизации между AS
- Внешние протоколы маршрутизации
- EGP – Exterior Gateway Protocol
Типы
Автономные системы можно сгруппировать в 3 категории, в зависимости от их соединений и режима работы.
Многоинтерфейсная (multihomed) AS — это AS, которая имеет соединения с более чем одним Интернет-провайдером. Это позволяет данной AS оставаться подключенной к Интернету в случае выхода из строя соединения с одним из Интернет-провайдеров. Кроме того, этот тип AS не разрешает транзитный трафик от одного Интернет-провайдера к другому.
Ограниченная (stub) AS — это AS, имеющая единственное подключение к одной внешней автономной системе. Это расценивается как бесполезное использование номера AS, так как сеть размещается полностью под одним Интернет-провайдером и, следовательно, не нуждается в уникальной идентификации.
Транзитная (transit) AS — это AS, которая пропускает через себя транзитный трафик сетей, подключенных к ней. Таким образом, сеть A может использовать транзитную AS для связи с сетью B.
Протоколы маршрутизации:
Протокол маршрутизации — сетевой протокол, используемый маршрутизаторами для определения возможных маршрутов следования данных в составной компьютерной сети. Применение протокола маршрутизации позволяет избежать ручного ввода всех допустимых маршрутов, что, в свою очередь, снижает количество ошибок, обеспечивает согласованность действий всех маршрутизаторов в сети и облегчает труд администраторов.
Характеристики протоколов маршрутизации
- Название
- Стандартизирующие документы
- Алгоритм поиска маршрута
- Метрика протокола
- Сходимость
- Избежание петель маршрутизации
- Загрузка сети
- Ресурсоемкость
- Поддержка нескольких маршрутов на сеть
- Аутентификации
- Ограничения применения
- Конфигурирование
- Поддержка в маршрутизаторах
- Достоинства
- Недостатки
Метрики маршрутов
Метрика маршрута может зависеть от:
- Числа промежуточных маршрутизаторов
- Пропускной способности канала связи
- Задержек в канале связи
- Надежности канала связи
- Загрузки канала связи.
Сходимость протокола – способность протокола оперативно реагировать на изменения в сети и приводить маршрутизаторы к соответствующее состояние
Время сходимости – время за которое маршрутные таблицы переходят в состояние, адекватное изменившейся ситуации сети.
21. Маршрутизация в сетях TCP/IP. Протокол маршрутизации RIP.
Протокол маршрутной информации (англ. Routing Information Protocol) — один из самых простых протоколов маршрутизации. Применяется в небольших компьютерных сетях, позволяет маршрутизаторам динамически обновлять маршрутную информацию, получая ее от соседних маршрутизаторов.
Алгоритм маршрутизации RIP (алгоритм Беллмана — Форда) был впервые разработан в 1969 году, как основной для сети ARPANET.
RIP. Метрика
- Целое число из диапазона 0..15
- Измеряется числом промежуточных маршрутизаторов до сети назначения
- Для непосредственно подсоединенных сетей – значение «0»
- Значение «16» – сеть недоступна.
Не зависит от:
- Задержек
- Пропускной способности
- Надежности
- Загрузки
Каждый RIP-маршрутизатор по умолчанию вещает в сеть свою полную таблицу маршрутизации раз в 30 секунд, довольно сильно нагружая низкоскоростные линии связи. RIP работает на прикладном уровне стека TCP/IP, используя UDP порт 520.
Коррекция маршрута (таблицы):
Вместе с обновлением активируется таймер Tm
Состояния маршрутных записей
- Tm ≤ 180c: маршрут в рабочем состоянии
- Используется для маршрутизации пакетов
- Рассылается соседним маршрутизаторам
- 180c < Tm ≤ 300c (маршрут устарел)
- Используется для маршрутизации пакетов
- Не рассылается соседним маршрутизаторам
- Tm > 300c: маршрут не действителен
- Удаляется из таблицы маршрутизации
При приходе очередного обновления таймер сбрасывается и маршрут переводится в рабочее состояние
22. Маршрутизация в сетях TCP/IP. Методы борьбы с петлями маршрутизации в протоколе RIP. Протокол маршрутизации RIP2.
Петли маршрутизации относятся к недостаткам RIP протокола.
В течение нескольких минут маршруты находятся в некорректном состоянии.
Сходимость протокола – плохая.
Способы преодоления петель маршрутизации.
Для того, чтобы это преодолеть, были разработаны различные методы борьбы с петлями:
- Split Horizon — расщепление горизонта
- Обновления маршрута не посылаются на интерфейс, из которого этот маршрут получен O Блокируется обратная круговая передача маршрутной информации
- Poison Reverse – обратный яд
- Обновления маршрута посылаются на интерфейс, из которого этот маршрут получен, но с метрикой 16 O Во время штатного работы такие обновления – игнорируются O В случае сбоя – сразу определяется недоступность маршрута.
- Triggered Updates – мгновенные обновления
- В случае изменения метрики маршрута маршрутизатор посылает обновления немедленно, не дожидаясь 30-секундного интервала O Позволяет улучшить сходимость протокола O Лавинообразно увеличивается трафик
- Hold Down
- Кратковременное прекращение приема обновлений маршрута после получения его обновления от автора с метрикой 16 O В течение 120 с маршрутизатор не принимает обновления этого маршрута, пережидая переходные процессы в сети.
На практике – используют несколько технологий ! Никакие технологии не спасают от петли маршрутизации, включающей более 2 узлов !
Протокол маршрутизации RIP-II
Стандарт RFC 1721, 1994 год
Нововведения:
- Аутентификация
- Маска сети
- Групповая адресация
- Метки маршрута
- Ссылка на следующий маршрутизатор
- Для адресации соседних маршрутизаторов используется групповая адресация
- Адрес рассылки обновлений – 224.0.0.9
- Для совместимости оставлена возможность использовать широковещание
- Пакет RIP-II использует UDP, порт 520
- В один пакет – до 24 маршрутных записей.
Формат пакета:

- Идентификатор семейства адресов
- 0xFFFF – для аутентификации
- Аутентификационная информация
- Используется для проверки подлинности пакета
- Маска сети
- Используется для передачи маршрутов на подсети
- Следующий переход
- Для исключения лишних шагов в маршрутизации
- Для возможности использовать информацию из других источников
- Метка маршрута
- Для упрощения взаимодействия с протоколами EGP Формат пакета совместим с RIP-1.
23. Маршрутизация в сетях TCP/IP. Протокол маршрутизации OSPF.
OSPF (Open Shortest Path First) – протокол динамической маршрутизации, основанный на технологии отслеживания состояния канала (link-state technology) и использующий для нахождения кратчайшего пути алгоритм Дейкстры. Стандарт – RFC 1247, версии OSPF 1, 2, 3.
Один из основных внутренних протоколов маршрутизации.
Протокол состояния канала — в Link-state протоколах каждый маршрутизатор должен не просто знать лучшие маршруты во все удалённые сети, но и иметь в памяти полную карту сети со всеми существующими связями между другими маршрутизаторами в том числе.
Метрика
Задается числом (0…65535). Отображает скорость передачи информации.
Определение: Метрика – количество секунд, требуемое для передачи 100 Мб информации через физическую среду данной сети.
Значения по умолчанию:
- 10Base-T Ethernet — 10
- 56 кбит/с — 1785
- Метрика канала со скоростью передачи данных
- 100 мбит/с и выше — 1
Если скорость сети большая, можно задать свое значение метрики.
Алгоритм работы:
-
Каждый OSPF маршрутизатор периодически рассылает информацию о себе – пакеты LSA (Link State Advertisement). В них содержится информация о подключенных каналах и их состояниях (метриках). Рассылает соседям, они другим соседям и т.д. Т.о. маршрутизаторы получают информацию о всех других маршрутизаторах. LSA пакеты позволяют построить всю топологию сети, необходимую в алгоритме Дейкстры.
- Рассылка осуществляется при изменении какого-либо канала. Другие причины: изменилось состояние интерфейса; произошли изменения в маршрутизаторе сети (или в одном из соседних маршрутизаторов); изменилось состояние одного из внутренних маршрутов; возраст маршрута достиг предельного значения (30 минут) и др.
- В результате лавинного обмена все узлы OSPF получают информацию обо всех каналах сети.
-
После получения пакетов все маршрутизаторы строят LSD – Link State Database (база данных всех состояний подключенных каналов («линков»)). Все базы, построенные разными маршрутизаторами, должны быть идентичны – условие корректного функционирования протокола.
-
Далее каждый маршрутизатор по LSD строит LST – Link State Tree – дерево достижимости в соответствии с алгоритмом Дейкстры. LSD одинаковые, но LST получатся разные, т.к каждый маршрутизатор в качестве корня будет использовать себя. LST в дальнейшем используется для маршрутизации.
Таблица маршрутизации

Назначенные маршрутизаторы
Назначенный маршрутизатор (Designated Router) – маршрутизатор, к которому, если он есть в сети, все маршрутизаторы посылают свои LSA пакеты, а он рассылает обновления всем маршрутизаторам.
Позволяет сэкономить на лавинном обмене пакетами.
Есть также запасной назначенный маршрутизатор (Backup Designated Router), заменяет назначенный маршрутизатор, если тот выйдет из строя.
Транспортировка данных
OSPF не использует транспортного протокола. Инкапсулируется непосредственно в IP (код 89).
Используется групповая передача:

Домены маршрутизации
Область OSPF можно разделить на отдельные домены.

В протоколе OSPF требуется много расчетов, (количество операций на узле – N2). Если разделить область OSPF на домены, то в каждом домене будет меньше узлов, чем в общей области (например, 250 вместо 1000) => уменьшится общее количество операций на узле.

24. Маршрутизация в сетях TCP/IP. Протоколы маршрутизации EIGRP
EIGRP – Enhanced Interior Gateway Routing Protocol.
Разработан для замены устаревшего IGRP компанией Cisco. Стандарт RFC отсутствует.
Гибридный протокол: дистанционно-векторный (алгоритм Беллмана-Форда) с элементами протокола состояния канала (алгоритм Дейкстры).
(В Distance-Vector протоколах, маршрутизатор узнает информацию о маршрутах посредством маршрутизаторов, непосредственно подключенных в один с ним сегмент сети. То есть, маршрутизатор имеет информацию о топологии только в границах его соседних маршрутизаторов и понятия не имеет как устроена топология за этими маршрутизаторами, ориентируясь только по метрикам.)

Метрика


В общем случае метрика 8 байт.
Метрика сложнее и сильнее чем в других протоколах маршрутизации.
Вычисляется по формулам:

B – полоса пропускания, L — нагрузка, D — задержка, R — надежность, K1-K5 – коэффициенты, определяются пользователем.
 , тогда M=B + D
, тогда M=B + D
Обнаружение соседей

Таблица топологии

- Минимальная полоса пропускания, т.к. пакеты с участка с большей полосой пропускания застопорятся на участке с меньшей полосой пропускания. Пример: 1000 п./с – 10 п./с – 1000 п./с, минимальная полоса – 10 п./с.
- Текущая дистанция – дистанция данного маршрута (полная метрика маршрута). Отчетная дистанция – дистанция, которую прислал узел, являющийся источником маршрута (метрика маршрута без последнего шага).
Выбор путей


ACFN – оптимальный маршрут (самый короткий) = 45.
Заместитель: ABFN т.к. отчетная дистанция BFN = 40 < чем текущая дистанция оптимального маршрута 45. Также гарантированно здесь не будет петли.





Используется групповой механизм рассылки маршрутных объявлений.

25. Именование ресурсов в сетях TCP/IP. Доменная система имен.
DNS (англ. Domain Name System — система доменных имён) — компьютерная распределённая система для получения информации о доменах. Чаще всего используется для получения IP-адреса по имени хоста (компьютера или устройства), получения информации о маршрутизации почты, обслуживающих узлах для протоколов в домене (SRV-запись).
Распределённая база данных DNS поддерживается с помощью иерархии DNS-серверов, взаимодействующих по определённому протоколу.
Основой DNS является представление об иерархической структуре доменного имени и зонах. Каждый сервер, отвечающий за имя, может делегировать ответственность за дальнейшую часть домена другому серверу (с административной точки зрения — другой организации или человеку), что позволяет возложить ответственность за актуальность информации на серверы различных организаций (людей), отвечающих только за «свою» часть доменного имени.
DNS обладает следующими характеристиками:
Распределённость администрирования. Ответственность за разные части иерархической структуры несут разные люди или организации.
Распределённость хранения информации. Каждый узел сети в обязательном порядке должен хранить только те данные, которые входят в его зону ответственности и (возможно) адреса корневых DNS-серверов.
Кеширование информации. Узел может хранить некоторое количество данных не из своей зоны ответственности для уменьшения нагрузки на сеть.
Иерархическая структура, в которой все узлы объединены в дерево, и каждый узел может или самостоятельно определять работу нижестоящих узлов, или делегировать (передавать) их другим узлам.
Резервирование. За хранение и обслуживание своих узлов (зон) отвечают (обычно) несколько серверов, разделённые как физически, так и логически, что обеспечивает сохранность данных и продолжение работы даже в случае сбоя одного из узлов.
Количество уровней не ограничено. Уровни доменов вкладываются один в другой.
Зарезервированы: example, localhost, invalid, test
Домены верхнего уровня: «.» полный адрес сети интернет. Не используется
Домены первого уровня: .gov, .com, .edu, .net, .org, .mil, .int,. arpa. Были изначально. Потом добавились .uk, .ru, .fr и тд 200+ доменов
Домены второго уровня – то, что слева от точки домена первого уровня и тд.
26. Архитектура DNS. Рекурсивные и нерекурсивные серверы имен. Ретрансляторы.
По способу ответа на запрос
-
Рекурсивные серверы:
- Самостоятельно выполняют весь поиск
- Кэшируют полученную информацию
-
Нерекурсивные серверы:
- Указывают, где есть необходимая информация
- Не кэшируют информацию.
DNS-запрос может быть рекурсивным — требующим полного поиска, — и нерекурсивным — не требующим полного поиска.
Аналогично, DNS-сервер может быть рекурсивным (умеющим выполнять полный поиск) и нерекурсивным (не умеющим выполнять полный поиск). Некоторые программы DNS-серверов, например, BIND, можно сконфигурировать так, чтобы запросы одних клиентов выполнялись рекурсивно, а запросы других — нерекурсивно.
При ответе на нерекурсивный запрос, а также — при неумении или запрете выполнять рекурсивные запросы, — DNS-сервер либо возвращает данные о зоне, за которую он ответствен, либо возвращает адреса серверов, которые обладают большим объёмом информации о запрошенной зоне, чем отвечающий сервер, чаще всего — адреса корневых серверов.
В случае рекурсивного запроса DNS-сервер опрашивает серверы (в порядке убывания уровня зон в имени), пока не найдёт ответ или не обнаружит, что домен не существует. (На практике поиск начинается с наиболее близких к искомому DNS-серверов, если информация о них есть в кеше и не устарела, сервер может не запрашивать другие DNS-серверы.).
При рекурсивной обработке запросов все ответы проходят через DNS-сервер, и он получает возможность кэшировать их. Повторный запрос на те же имена обычно не идет дальше кэша сервера, обращения к другим серверам не происходит вообще.
Ретрансляторы: используются для сокращения внешнего трафика Кэшируют информацию всех запросов Должны конфигурироваться как ретрансляторы.
27. Архитектура ДНС. Прямой поиск.
Архитектура:
DNS (domain name system) — распределённая иерархическая система, чаще всего используется для преобразования доменного имени в IP-адрес или для обеспечения работы почтовой системы.
Структура:
- Вся система имеет древовидную структуру, корневой элемент которой — «.», обслуживается 13 серверами (обозначаются буквами a-m) или зеркалами этих серверов (в РФ нет корневых серверов, только зеркала).
- Всё дерево имён поделено на участки ответственности — «зоны», каждая из которых обслуживается своим сервером.
- Сервер, который ответственен за данную зону, называется авторитетным.
- DNS-клиент всегда обращается к серверу через resolver
Для каждой зоны должно быть несколько авторитетных серверов, находящихся в разных подсетях (для надёжности):
- Первичный (один)
- содержит оригинал информации о подконтрольной зоне (e.g. в локальной сети)
- Вторичный (несколько)
- содержит копии информации о подконтрольной зоне (e.g. арендованный у хостинга, у провайдера)
- периодически обновляет информацию
- в конфигурации вторичного сервера указывается, что делать, если первичный не отвечает
По способу ответа DNS-серверы бывают:
- Рекурсивные
- САМИ выполняют всю процедуру поиска
- Кэшируют полученный результат
- Нерекурсивные
- Перенаправляют на сервер с необходимой информацией
- Не занимаются кэшированием
Стоит учесть, что рекурсивный поиск — долгая и более ресурсозатратная процедура, поэтому чем «выше» мы поднимаемся, тем меньшая вероятность встретить рекурсивный сервер. Все корневые серверы («.») и все домены 1 уровня — нерекурсивные.
Прямой поиск:
Пример: мы (office.school.server.ru) хотим обратиться к сайту (www.support.ibm.com). Тогда первое (некэшированное) обращение будет выглядеть следующим образом:
- Resolver на нашем компьютере обращается к сохранённому в конфигурации TCP/IP DNS-серверу
- DNS-серверы по умолчанию имеют префикс ns, допустим, наш сохранённый — ns.school.server.ru
- ns.school.server.ru — рекурсивный. Первый его запрос — к корневому серверу («.» — e.g. a.root-servers.net)
- Корневой сервер нерекурсивен — он перенаправит нас на сервер, ответственный за домен «com»
- Обращаемся к домену «com» — он нерекурсивен, отправит нас на сервер, ответственный за ibm.com (ns.ibm.com)
- ns.ibm.com — рекурсивный — сам обращается к DNS-серверу зоны support.ibm.com (ns.support.ibm.com)
- www — последний уровень домена — ns.support.ibm.com возвращает информацию на ns.ibm.com, попутно её кэшируя
- ns.ibm.com возвращает информацию на ns.school.server.ru, попутно её кэшируя
- ns.school.server.ru возвращает информацию нам, попутно её кэшируя
При последующем обращении по тому же адресу (пока не истекло время жизни кэшированной записи) ns.school.server.ru будет сразу возвращать нам требуемый адрес. При обращении по тому же адресу после истечения времени жизни записи вся процедура будет повторена снова.
28. База данных DNS. Ресурсные записи DNS. Адресные записи, записи о сервере имен.
База данных DNS состоит из отдельных ресурсных записей (Resource record — RR), каждая из которых хранит определённый тип информации.
Записи имеют следующие поля:
- Имя
- При неуказанном имени будет использовано предыдущее
- Класс записи (почти всегда IN — internet)
- Тип записи
- Основные типы: A, AAAA, NS, MX, etc.
- Время актуальности
- Время, которое запись может храниться в кэше
- При отсутствии — значение по умолчанию
- Параметры записи
- Зависят от типа записи
- При описании часто используется формат BIND
- A: Доменное имя узла, адрес узла
- school IN A 195.19.212.16 на сервере ns.server.ru -> school.server.ru по адресу 195.19.212.16
- NS: Имя домена, адрес сервера имён
- school.server.ru. IN NS 195.19.212.13 -> скорее всего, вторичный name-server для домена server.ru.
- Зависят от типа записи
29. База данных DNS. Главная ресурсная запись. Маршрутизация электронной почты.
База данных DNS состоит из ресурсных записей – записи помогают выполнять запросы. Ресурсные записи хранят определенный тип информации, каждая запись содержит определенное количество полей.
Главная ресурсная запись SOA (start of authority). Предназначена для описания параметров домена. Имеет много параметров, так как является неким паспортом домена:
- Имя домена – имя домена, для которого сформирована главная запись
- Имя первичного DNS-сервера – сервер, который отвечает за адрес домена
- Почтовый адрес администратора – связь при проблемах
- Серийный номер зоны (Serial) – уникальный ID текущей зоны, увеличивается при изменении зоны
- Период обновления(Refresh) – время в секундах, как часто вторичный сервер должен обращаться к первичному
- Время валидности данных(Expire) – если первичный сервер не отвечает, Expire отвечает на запросы о зоне информации
- Период повторных попыток (Retry) — указывает задержку перед следующим обращением после неудачной попытки
- Значение по умолчанию (DefaultTTL) — Время жизни для всех записей в зоне
Главная ресурсная запись одна на зону.

AXFR – копируется вся зона.
Запись о сервере эл.почты
- DNS используется для маршрутизации почты
- Почтовый домен не всегда связан с конкретным IP адресом.
- MX связывает IP- адреса и почтовые домены
- Приоритет задает желаемое качество доставки.

30. База данных DNS. Записи о псевдонимах, сервисах.
Запись о псевдониме – позволяет выдать новое имя уже известному адресу.

В реальном мире мало веб-серверов с именем www, практически всегда используется псевдоним. В конце 90-х появились веб-хостинги, в этом случае псевдоним используется как переключатель, что позволяет на одном физическом IP разместить неограниченное количество виртуальных адресов. Web-server узнает, к которому узлу обращаться благодаря особенностям http (URL хранится в заголовке http).
НЕ ИСОЛЬЗУЮТСЯ ДЛЯ МАРШРУТИЗАЦИИ ПОЧТЫ
Запись о сервисе
Запись анонсирует наличие сервиса и его местонахождение. Запись о сервисе – относительно новая запись, расширяет идею MX, делает универсальным обращение к какой-либо службе. Вес используется чтобы распределять нагрузку между сервисами.

31. DNS. Обратный поиск.
Если прямой поиск в DNS — по домену найти ip адрес, то обратный поиск — обратная задача: по ip адресу найти доменное имя.
Цель обратного поиска — убедиться в подлинности доменного имени, т. е. Это используется в целях безопасности.
Как организуется обратный поиск.
Прямой поиск: мы идем по дереву имён, начиная с ближайшего к нам днс сервера, а потом через корневой находим необходимый сервис в соответствии с доменным именем.
Обратный поиск: здесь ситуация гораздо хуже у нас нет домена, у нас есть ай пи адрес разработчики не стали разрабатывать отдельный протокол обратного днс.
Они свели задачу к уже ранее решенным и по сути для обеспечения обратного поиска используют прямой поиск.
для преобразования создан специальный домен: In-addr.arpa, который отвечает за обратное преобразование. структура имен в этом домене соответствует октетам айпи адреса в обратном порядке.
При запросе имени для адреса X.Y.Z.T строится запрос для имени:
- T.Z.Y.X.in-addr.arpa
- Такой запрос обслуживается как прямой
превращается в символическое имя, где в обратном порядке записаны десятичные октеты и получаем стандартный домен. И по нему делается запрос. По какой ресурсной записи? Ptr
PTR
Введена новая ресурсная запись: PTR. Обратный смысл по отношению к адресной записи. Задача – показать каким именам соответствуют какие имена.
Обеспечивает преобразование имен из домена in-addr.arpa. в доменное имя
Запись PTR: Использовано для обратного преобразования имен из домена in.addr.arpa в доменное имя.
Параметры:
-
Имя узла – перевернутый ip адрес.
-
Доменное имя узла
Формат bind — in-addr-name IN PTR name
Примеры: 11.12.19.195.in-addr.arpa. IN PTR ya.ru. — Адресу 195.19.12.11 соответвует ya.ru
16 IN PTR office.school.server.ru — Для всей сети класса с описать обратное преобразование, можно использовать только последний октет.
Система bind
Самая популярная система организации днс в мире. эта система разработана очень давно. изначально в университете беркли. Предназначена для организации базы данных днс.
Если хотим организовать систему днс, обслуживающие домен:
-
Создаем главный файл конфигурации. Описываются все зоны, которые ведутся данным сервером. Типы зон – первичный (сами отвечаем за эту зону ) и вторичная (копируем данные с первичного)
-
Файл прямого преобразования. Для зоны, которую мы ведем, содержатся все адресные записи, записи о name сервере, записи soa(главная запись домена) , необходимое число записей mx/ cname
-
Файлы обратного преобразования. Должно быть столько, сколько обратных зон. В нем записи soa, ns, ptr,
-
Файл кэша корневых серверов. Файл, где указаны текущие ip адреса 13 корневых серверов.
-
Файл обратного преобразования для локальной зоны – 127 0 0 1, если хотим получить обратное имя, то должны завести зону, где будет единственная запись, и выдавать localhost
Чтобы DNS заработал нужно правильно зарегистрировать зону, правильно проделегировать права и т д.
Проблемы:
- если я хочу полностью ввести систему днс. то мне нужно отдельно ввести прямой домен (school.server.ru). Я должен завести домен, авторитетный сервер, завести в нем первичные вторичные днс серверы, которые отвечают запросы. но если я хочу чтобы работало обратное преобразование, я должен еще завести еще одну зону, но например в данном случае зона 12 19 195.in-addr.arpa и в ней тоже завести несколько днс серверов которые отвечают за эту зону и тоже правильно зарегистрировать и делегировать.
Вопрос: Если не одна сеть класса с, а например 10. Доменное имя у всех одно? Как сделать, чтобы обратный днс тоже работал? Какие зоны нужно ввести?
Для прямого: 2к пк в сети. В файле прямой зоны (schoolserverru) будет 2.5к запись. Слева один домен, справа 10 сетей класса с.
Для обратного: нужно будет сделать 10 зон для каждого класса сетей.
Вопрос: Маленькая компания. Всего 16 ip адресов. Как ввести свою обратную зону? Не могу ввести, так как ей пользуются другие. Что делать? Провайдер должен предоставить. Но если часто меняем ip адреса, то постоянно дергаем провайдера
32. DNS. Динамические обновления; нотификации об изменениях; инкрементальные обновления.
Динамические обновления:
Причина появления: наличие динамических систем управления адресами DHCP
DNS Dynamic Update – RFC 2136
Позволяет внешним авторизованным источникам менять адреса.
Принцип работы: Авторизованный клиент посылает DNS серверу запрос об изменении информации о ресурсной записи. Если сервер не первичен, то запрос пересылается наверх. Когда дошли до первичного DNS, то первичный сервер модифицирует свою базу данных, изменяет серийный номер зоны. Через какое то время вторичные серверы получают от первичного обновленную информацию.
Нотификация об изменениях:
Асинхронное информирование об изменении информации.
Раньше вторичные серверы получали информацию от первичных синхронно, то есть, в соответствии с записью зоны синхронно получали обновление. Это не всегда удобно, хотелось бы получать уведомления об изменениях, данных от первичного сервера как можно раньше. Например, в случае динамических обновлений, надо чтобы эту информацию быстро узнал интернет.
DNS Notify – RFC 1996
Если включена эта опция, то первичный сервер посылает обновление всем известным ему вторичным серверам. Далее вторичные посылают другим вторичным. Каждое сообщение об нотификации подтверждается. Когда дошли «до конца» , вторичные серверы осуществляют запрос зоны как при периодическом обновлении.
Инкрементальная передача зон (инкрементальные обновления):
Классический DNS передавал всю зону. То есть если что-то изменилось, то первичный передаёт вторичному весь огромный файл зоны, сколько бы там записей не было. При динамических обновлениях происходит слишком много трансферов зон.
Для уменьшения передаваемой информации, передаётся только инкремента (приращение) зоны, вместо всей зоны. В запросе вторичный указывает серийный номер зоны, которая у него есть, а первичный вычисляет разницу содержимого и высылает её.
Тип запроса изменяется на IXFR.
33. Автоматизированная настройка параметров. Протоколы BOOTP и DHCP.
Управление сетевыми параметрами.
Два подхода:
-
Ручная настройка: вручную задаются IP адреса, маски, DNS серверы и прочие маршрутизаторы.
-
Автоматизированная настройка: перечисленные выше параметры настраиваются автоматически либо автоматизировано.
Идея автоматизированной настройки пришла от того, что когда имеется большая компьютерная сеть, то снабжать всех пользователей инструкцией как и что надо настроить, для администратора становится очень сложно. Тем более при изменении, какого либо параметра придется объяснять ещё раз. Появилась идея сделать так, чтобы компьютер сам настраивал параметры забирая их из сериализованного хранилища.
Для этого было разработано несколько протоколов:
-
RARP (Reverse Address Resolution Protocol) – устаревший протокол
-
BOOTP (Bootstrap Protocol) – устаревший протокол
-
DHCP (Dynamic Host Configuration Protocol)
RARP:
Описан в RFC 903
Принцип работы: в сети должен быть RARP сервер, при включении в сеть клиент делает запрос на этот сервер. В ответ приходит IP адрес и присваивается сетевому адаптеру. Разделяет один формат пакетов с ARP.
Используется только для получения IP, чего недостаточно в современных сетях.
BOOTP:
Описан в RFC 951, 1533, 1542
Принцип работы: в сети должен быть BOOTP сервер. В момент, когда бездисковая или автоконфигурируемая станция собирается загрузиться, делается широковещательный запрос по протоколу BOOTP к этому серверу. BOOTP :
-
IP адрес.
-
Маска сети.
-
Маршрутизатор по умолчанию.
Выдается достаточно параметров, чтобы компьютер стал автономным, и всё остальное, при необходимости, мог загрузить из сети.
Протокол позволяет делать цепочку BOOTP ретрансляторов до BOOTP сервера. То есть, если в вашей сети нет BOOTP сервера, то отправляется запрос к BOOTP ретранслятору, ретранслятор отправляет запрос дальше, пока не будет достигнут BOOTP сервер и не будет получена информация.
Реализация: у BOOTP сервера имеется статическая таблица соответствий MAC адресов и параметров узла. То есть, администратор, когда хочет сконфигурировать BOOTP сеть, то заходит на сервер, и, зная все компьютеры в сети, для каждого из них прописывает необходимые параметры.
DHCP:
Протокол разработан компанией Microsoft
Описан в RFC 2131, 2132
Разработан не как самостоятельный протокол, а как расширение BOOTP протокола. Все новые, получаемые дополнительно поля, располагаются в поле опций протокола BOOTP.
Поддерживается 3 режима:
-
Ручное распределение адресов: точно такое же, как в BOOTP, администратор пишет соответствие MAC адресов и выдаваемых параметров.
-
Автоматическое распределение: формируется пул адресов, которые раздаются клиентам по мере их подключения. После чего выданные данные заносятся в таблицу, и в будущем никому кроме выбранной станции, адрес не выдается. Количество подключаемых станций соответствует количеству свободных адресов. Не подходит для современного интернета.
-
Динамическое распределение адресов: адреса не закрепляются за конкретным устройством навсегда, выдаются в аренду, по истечению срока аренды, адрес становится вновь свободным и может быть выдан любому устройству, которое захочет подключиться.
Информация передается через опции протокола BOOTP.
Типы опций:
-
Базовые параметры:
-
маска сети
-
default gateway (маршрутизатор по умолчанию)
-
DNS сервер
-
название вашего узла (текстовое)
-
название домена по умолчанию
-
-
Параметры узла:
-
IP forwarding
-
Default TTL
-
и так далее
-
-
Параметры интерфейсов
-
MTU (maximum transfer unit)
-
Broadcast
-
Static routes
-
-
Параметры TCP:
-
TCP default TTL
-
KeepAlive time
-
И тому подобное
-
-
Параметры приложений:
-
NIS, NIS+
-
WINS
-
POP3, SMTP, NNTP
-
-
Параметры аренды:
-
Запрашиваемый IP
-
Срок аренды
-
Идентификатор сервера, который сделал эту аренду
-
и тому подобное
-
Для управления арендой есть утилита ipconfig
34. Управление доставкой. Серверы-посредники.
Управление доставкой — 3 способа:
- Маршрутизация
- Шлюзы уровня приложений (ALG — application level gateway)
- Серверы посредники
- Трансляторы протоколов
- Стандартные трансляторы (SOCKS)
- Специализированные трансляторы
- Трансляция адресов (NAT)
Серверы-посредники:
Основная идея – использовать посредников (proxy) для получения информации из Internet.
Решаемые задачи (или зачем посредники нужны):
- Кэширование информации (трафик дорогой, сокращаем кол-во запросов)
- Сокрытие внутренней части сети (скрываем от сервера карту нашей сети)
- Сокращение времени доступа в сеть (медленная внешняя связь, экономим деньги и время, т.е. вместо запросов ищем информацию в локальном кэше)
Используют протоколы HTTP и FTP (т.к. обычно информация файлового типа), для других протоколов кэширование не делается, т.к обычно они обычно связаны с аутентификацией)
Для доступа к серверу-посреднику обычно используется HTTP. Чтобы запрос к серверу отправился к посреднику, на прикладном уровне в пакет пишем адрес сервера, а в канальный адрес посредника.
Proxy-серверы для протокола FTP
- HTTP-proxy для FTP
- Используется протокол HTTP для доступа к proxy-серверу (т.к. проще указать адрес посредника)
- Адрес FTP-сервера указывается в строке URL: ftp://ftp.example.com
- Требует специального клиента(который работает и с http и ftp)
http://kspt.icc.spbstu.ru/media/files/2021/course/networks/Networks2021-06-Configuring.pdf — 10 слайд.
- FTP-proxy – серверы
- Используется протокол FTP для доступа к proxy-серверу
- Адрес FTP-сервера указывается в строке аутентификационных команд (USER или PASS) — т.е. вместо логина John будет John@ftp адрес
- Не требует модификации клиента
Серверы посредники
- Обычно используют протокол доступа HTTP
- Используемые порты TCP:
- 3128
- 8080
- 80 (если порт занимают и сервер, и прокси, тогда используется специальное программное обеспечение, которое анализирует url в запросе: если после днс-запроса ip адрес не совпадает, запрос переадресовывается на прокси, else на сервер.
- 8000
- Программные пакеты
- squid
- Microsoft Forefront Threat Management Gateway
- Ранее – MS ISA Server,MS Proxy Server
- …
Иерархии
Например у организации есть общий прокси и у каждого департамента организации есть прокси
- Два типа отношений (внешние запросы делают только родительские прокси, родственные только у друг друга в кэше):
- Родительские/дочерние (parent)
- Родственные (sibling)
Используется для
- Сокращение трафика
- Сокращение времени
Существует ограничение на уровень иерархии (т.к. при большой глубине иерархии скорей всего запрос будет быстрее отправить напрямую на веб-сервер). Ограничение обычно на 2 уровня.
На лекции был вопрос, кто должен платить за трафик в иерархической сети и должны ли платить те, кто воспользовался кэшем. Ответа точного нет, обычно иерархические схемы умирают, когда встает такой вопрос.
http://kspt.icc.spbstu.ru/media/files/2021/course/networks/Networks2021-06-Configuring.pdf — 13 слайд.
Синхронизация кэшей — обмен информации об имеющихся ресурсах и формирование соответствующих запросов.
- Синхронизация кэшей
- Протокол ICP (Internet Cache Protocol) (легковесный)
- RFC 2186 и RFC2187 (ICPv2)
- Использует UDP, порт 3130
- Протокол ICP (Internet Cache Protocol) (легковесный)
Если используете прокси, надо явно это указать в настройках браузера(если для доступа используются браузер). В настройках надо указать параметры веб-прокси, ip адрес, порт, аутентификационные данные. То есть технология не работает без явной настройки пользователя.
35. Управление доставкой. Протокол SOCKS.
Общее
Используется для обесечения доступа локальным неанонсированным сетям к Internet.
Сейчас есть 2 живые версии SOCKS 4 & SOCKS 5. SOCKS 5 описана в rfc 1928 и 1929.
Сравнение с proxy
Недостатки:
- Требует реализации на стороне клиента, т.е. приложения должны быть перекомпилированны для использования
SOCKS(поверх реализации необходимого протокола ftp скажем). - Клиент-серверный механизм запросов(плюс контроль доступа)
Преимущества:
- Поддерживает практически все протоколы(proxy только ftp и tcp)
- Можно пробросить соединение как клиент->сеть, так и сеть->клиент
Организация протокола
Предусмотрено 2 вида команд:
- Connect(TCP) — запрос на отправку данных по SOCKS
- Bind(TCP) — запрос на получение данных из internet в неанонсированную сеть
Транспорт — ТСР, порт — 1080.
Что нового в SOCKS 5: аутентификация, поддержка UDP(т.е. можно отправить практически любой трафик).
Получение трафика по SOCKS
(цифры — порты)
отправка трафика по SOCKS
36. Управление доставкой. Технология NAT. Transparent Proxy.
Общее NAT
NAT — Network Address Translation. Используется для обесечения доступа локальным неанонсированным сетям к Internet.
Описана в rfc 1631 и 2663. Поддерживает протоколы TCP, UDP, ICMP
Сравнение с proxy и socks
Преимущества:
- Прозрачен для пользователей(не нужна настройка)
- Защищает клиентские станции от внешних сетей
Организация протокола
При «встраивании» между клиентом и сервером выделяет ассоциированные порты, имитирующие участников соединения(сервер общается с клиентом, клиент с сервером).
NAT поддерживает все протоколы, кроме случаев, когда существует явная адресация клиента сервером:
-
FTP в активном режиме
-
SNMP ловушки
Transparent proxy
Является надстройкой на NAT сервер. Решает проблему кэширования вдобавок к прозрачности и защищенности NAT.
37. Управление в сетях. Протокол SNMP.
Модель систем управления компьютерными сетями:
Классическая модель ISP/OSI ( ITU – T X.700 ) рассматривает 5 задач управления:
-
Управление конфигурацией
-
Управление учетом использования ресурсов
-
Управление неисправностями
-
Управление эффективностью
-
Управление защитой
Архитектура систем управления сетями:
-
Management entities: управляющие элементы, управляющие программы, в задачи которых входит управление другими устройствами.
-
Managed devices: управляемые устройства, которые должны в своём составе иметь:
-
Управляющий агент, через которого management entities управляет устройством
-
Управляющая БД, которая проецирует сетевые параметры на стандартные схемы представления параметров в современных протоколах
-
-
Management proxies: посредники управления, используются когда управляемое устройство очень «глупое» , то есть само не может реализовывать элемент архитектуры, тогда для этого нужен посредник.
-
Управляющий агент
-
Управляющая БД
-
-
Management environment: среда управления, та компьютерная сеть, по которой происходит передача управляющих команд. В современных компьютерных сетях, это одна и та же среда, что используется для прикладных задач
- Обычно используется прикладная КС
Архитектура систем управления сетями

Основная задача, которая реализуется – задача управления конфигурацией.
Управление конфигурацией:
-
Контролирование информации о сетевой и системной конфигурации.
-
Управление программными компонентами
-
Управление аппаратными компонентами
Реализация архитектуры в TCP/IP сделана с помощью протокола SNMP
SNMP (Simple Network Management Protocol):
Первый стандарт 1988 г. Является основным протоколом управления в TCP/IP.
Стандарты:
- RFC 1157
- RFC 1441-1450, RFC 1901-1910, RFC2263-2265, RFC 2273-2275, RFC 2573-2575
- RFC 3411 – 3418
Существует три основных версии протокола:
-
SNMPv1,
-
SNMPv2 (v2c, v2p,v2u – реализуют разные методы аутентификации)
-
SNMPv3
Цель: хотим с помощью одного универсального протокола управлять разными устройствами: коммутаторы, маршрутизаторы, серверы, NAT серверы, web серверы, системы защиты информации и так далее. Поэтому необходимо общее представление управляющих команд.
Для этого была придумана общая среда – база управления MIB (management information database). Эта база представляет все задачи управления в виде дерева переменных, которые одинаковы для всех устройств, которые используются. Также SNMP устройства должны представлять информацию в виде этого дерева переменных. То есть SNMP агент на управляемых устройствах должен понимать это дерево переменных, и в таком виде отдавать данные SNMP менеджеру и отвечать в таком виде на запросы SNMP менеджера.
Концепция переменных:
-
Операция чтения переменных
-
Операция записи переменной
-
Операция чтения следующей переменной (в случае если переменная списочная)
Переменные:
-
Скалярные
-
Таблицы
Протокол SNMP:
-
Независим от транспортного протокола, однако обычно используют UDP
-
На уровне представлений используется нотация ASN.1 Basic Encoding Rules, для кодирования сообщений для передачи по сети.
-
Порт управления – 161 (передача команд от менеджера к агенту)
-
Порт уведомлений (snmp trap(ловушки)) – 162 (сообщение менеджеру о чём-то, что произошло в управляемом устройстве)
-
Концепция «ловушек» — при нештатной ситуации менеджер оповещается об этом
Часть дерева системы MIB

Используется не только для интернета, а во всех телекоммуникациях.
Объект SNMP:
-
Текстовое имя
-
Тип объекта
-
Network address
-
IP address
-
Counter (счетчик со сбросом)
-
Gauge (счетчик без сброса)
-
Ticks (для измерения временных параметров
-
Opaque (строки)
-
-
Определение объекта
-
Доступ к объекту
-
Read-only
-
Write-only (для подачи управляющих команд)
-
Read-write
-
No-access
-
-
Статус
-
Обязательный (переменная должна быть реализована в любом устройстве)
-
Необязательный
-
Устаревший
-
Безопасность протокола SNMP:
-
Модель безопасности на основе сообществ
-
Вводится понятие сообщества, нешифруемая строка, которая используется в запросе менеджеру, если строка совпадает, то можем подавать управляющие команды.
-
Используется:
- SNMPv1
- SNMPv2c
-
-
Модель безопасности на основе сторон
- Вводится понятие стороны:
- идентификатор стороны
- логический сетевой адрес
- протокол аутентификации и связанные параметры
- протокол шифрования и связанные параметры
- Используется:
- SNMPv2p
- Вводится понятие стороны:
-
Модель безопасности на основе пользователей
- Вводится понятие пользователь
- идентификатор пользователя
- протокол аутентификации
- протокол шифрования
- ключи шифрования
- ключи аутентификации
- Используется:
- SNMPv2u
- SNMPv3
- Вводится понятие пользователь
38. Электронная почта. Механизм работы. Система MIME.
Электронная почта
- Формат почтового адреса: name@host.domain
На самом деле адрес электронной почты может быть почти любым. Но обязательно должна быть одна собака и хотя бы одна точка (не может быть адрес name@ru)
- Формат сообщения (RFC 822): Гарантирует, что передаются только текстовые данные (остальное не гарантируется, так как в сети могут быть сервера которые не поддерживают например символы национальных алфавитов.
Для того чтобы поддерживать не только текстовые данные разработано расширение MIME
Механизм работы

Сервер передачи почты (MTA — mail transfer agent) — взаимодействуют с другими серверами по SMTP
-
Клиент обращается к серверу электронной почты тоже по SMTP, а для получения почты по протоколам POP3 и IMAP4
-
Сейчас, используется еще способ обращения почтовому серверу через web-интерфейс. Тогда клиент обращается к серверу через HTTP, а сервер представляет почтовые папки в виде web-страниц. Но сообщения хранятся только на сервере
Дополнение к картиночке
Картиночка:
- Клиент_1: отправил сообщение по SMTP
- Сервер_1: анализирует доменную информацию выесняет к какому серверу нужно обратиться и передает сообщение на Сервер_2
- Сервер_2: сохраняет сообщение в базу данных
- Клиент_2: когда хочет получить почту. Скачивает ее с Сервера_2 по протоколам POP3 и IMAP4
Система MIME
MIME — стандарт для передачи нетекстовой информации внутри писем
Позваляют закодировать нетекстовую в символы текста:
- BASE64 — выбирается 64 символа, которые гарантировано не меняются при передачи на почту.Данные увеличиваются на 1/3
- Quoted-printable — Каждый байт кодируется знаком
=и шестнацатеричным кодом. Данные увеличиваются в 3 раза. Используют, когда нужно закодировать маленький объем информации, потому что просто
Заголовки (вставляются в начало сообщение)
Формат: =? Charset ? Encoding ? Encoded-text ?=
- Charset — набор символов
- Encoding — кодировка
- B — BASE64
- Q — Quoted-Printable
39. Протокол передачи электронной почты SMTP.
SMTP — Simple Mail Transfer Protocol
Общая информация:
- Клиент ↔ Почтовый сервер
- Почтовый сервер ↔ Почтовый сервер
- Использует TCP порт 25
- Не поддерживает шифрование
- [Самая большая проблема протокола] Базовая версия не поддерживает аутентификацию
- Тектовый протокол (Сообщения об ошибках тоже, чтобы можно было отлаживать протокол)
Формат сообщения об ошибках
Формат: XYZ text message
- XYZ — код сообщения
- X — тип сообщения
- 1 — информационное сообщение
- 2 — сообщение об успешной операции
- 3 — предупреждение
- 4 — ошибка на стороне клиента
- 5 — ошибка на стороне сервера
- YZ — номер сообщения внутри типа ошибки(X)
- X — тип сообщения
- text message — тектовое описание сообщения или данные
Команды
- Соединение (ответ либо все ок, либо нет)
HELO <домен>— если домен правильный и сервер может передавать сообщения, то ок, иначе ошибкиMAIL FROM: <почтовый адрес>— Сообщаем от кого сообщениеRCPT TO: <почтовый адрес>— Кому сообщениеDATA— передача сообщения- Сервер ответит warning с сообщением, что нужно ввести тектс и закончить . на пустой строке
- Дальше в тот же tcp-сокет помещается сообщение от клиента
- [не обязательно]
NOOP— проверка, что соединение живо - [не обязательно]
QUIT
Для поддержки аутентификации появилась расширенная версии протокола ESMTP
Команды ESMTP
EHLO— поддерживает ли сервер расширенный набор командVRFY <почтовый адрес>— можно проверить на существование почтовый адресEXPN <список рассылки>— кто входит в список рассылки
Сейчас последние две комады запрещены, потому что спамеры могут получить все существующие адреса
Для нормальной аутентификации появилось расширение для SMTP
- Клиент: отправляет
EHLO - Сервер: отвечает какие команды аутентификации он поддерживает
- Аутентификация командой
AUTH <Механизм> [<строка>] - Или Секция команды
MAIL FROM: <адрес> AUTH=строка(используется в доверительный сообществах) - Или POP3 before SMTP, так как POP3 имел аутентификацию, то человек аутентифицировался, а потом не закрывая сокет соединялся с сервером
40. Маршрутизация почты. Методы борьбы со спамом.
Электронная почта сама по себе не маршрутизироваться, потому что она маршрутизируется средствами TCP/IP, то есть почтовый сервер получив запрос от клиента на посылку электронной почты сам соединяется с целевым сервером.
Почтовый трафик может быть довольно таки большой и может существенно забивать канал. Была одна очень неприятная история в начале 2000 х годов с компанией P&G компания одна из крупнейших в мире компаний. у них по моему сейчас работает чуть ли не 900 тысяч человек и гигантская корпоративная сеть даже в начале 2000 х это была огромная компания сотни тысяч сотрудников. история была следующая что какая то секретарша в какой то момент решила по корпоративной почте послать письмо о том что у нее будет вечеринка но и по ошибке вместо того чтобы послать письмо десяти своим подругам она воспользовалась адресом все клиенты P&G. Ну и несколько сотен тысяч человек получили письмо личного содержания о том что будет вечеринка. Многие возмутились ответили секретарше что вообще то недопустимо использовать адрес рассылки общей для посылки писем личного характера, чтобы больше она так не делала. причем примерно %10 из тех кто и ответил они точно так же как она ошиблась и ответили на общую рассылку. И после этого была еще. В ответ на это возмущенные пользовались стали писать что не нужно использовать письма для личных целей корпоративную почту и тоже примерно 10 процентов из них ответила кнопка ответить всем в том числе в эту самую рассылку. В итоге в корпоративной почте P&G одновременно существовала. Миллиарды писем одинакового содержания которые заняли весь трафик P&G и все серверы только и занимались тем что передавали электронную почту между собой. это на несколько дней вывела из строя все коммуникации компании P&G. у нее был полнейший электронный коллапс. пока администраторы не смогли собственную рассылку этих миллиардов писем остановить и очистить почтовый сервер то есть даже такое простое не преднамеренное действие действие если оно сделано не слишком умно может привести к тому что электронный трафик электронной почты может забить основные каналы.
По этому поводу необходимы механизмы как это самый трафиком управлять чтобы можно было трафик электронной почты пускать отдельно по тем каналам которым хотелось бы его послать. ну и подход здесь примерно следующий:

В одну сторону почта ходит. По такому маршруту в другую сторону почта ходит по такому маршруту и специальный маршрут выбран таким образом чтобы например не забивать обычной магистрали а использовать для них например какие то дешевые но может быть не самые быстрые каналы. То есть подразумевается что мы имеем в данном случае два маршрута один маршрут из сервера 1 в 3 в 4 во 2 и один маршрут из 2го сервера в 6й в 5 в 1ый, в этом случае мы можем разделить трафики и управлять им в зависимости от корпоративной политики, в зависимости от типологии сетей и так далее и так далее.
Как это технически сделать.

Есть расширение SMTP которая называется SMTP маршрутизация, сделано следующим образом, изменяется формат адреса назначения, если раньше в RCPT TO у нас был только адрес назначения то теперь перед ним через запятую добавляются список почтовых сервисов через который мы хотим послать почту. например здесь написано что для того чтобы посылать в домен gmail, мы сначала должны послать в сервер first, а он должен послать сервер second. и обратная система MAIL FROM будет постепенно помещаться те адреса через которые уже почта прошла. то есть поместив изначально нужный список адресов команда RCPT TO мы управляем как будет идти почта в одну сторону и если специально сконфигурировано не будет, то обратно она пойдет ровно в обратном направлении потому что в MAIL FROM указаны все те маршруты через которые данное почтовое сообщение прошло.
При работе с электронной почтой не всегда это является проблемой. иногда трафик почты по умолчанию так же как делается и в обычном маршрутизации. но принципиальная возможность есть. Протокол поддерживать есть необходимость маршрутизации почты есть, то это можно реализовать. вот наверное основные расширения протокола SMTP.
Вопрос: Откуда взялся спам. почему он вдруг появился?
Ответ: хотят делать дешевую рекламу. То есть основная причина спама в том что технологии электронной почте позволяют очень дешево рассылать рекламу очень большому количеству людей.
Например бумажный спам в почтовый ящик кинули. его нужно напечатать он стоит денег пусть небольших но стоит денег. например какая нибудь компания захочет сделать рассылку. например компания по доставке пиццы захочет например по всему петербургу разослать такие сообщения бумажные. ей придется напечатать пять миллионов этих самых баннеров и это будет на самом деле очень дорого. При этом же если они делают спам рассылку — то это очень дешево.
Вопрос как можно от спама защититься?
Идея следующая давайте мы заставим спамера выполнять ресурс съемки вычисления. например мы будем каждый кто хочет послать мне письмо он должен будет вычислить какую то сложную функцию или выполнить какую то другую сложную операцию которая кушает определенное время его почтового сервиса. Например каждый кто будет посылать письмо мне должен например потратить например одну секунду машинного времени например современного компьютера. Стандартная рассылка 10 миллионов адресов а где я возьму ресурсов на то чтобы сделать 10 миллионов секундах расчетов. это дикая вычислительная мощность требуется для этого всего. поэтому для меня обычного пользователя это абсолютно бесплатная вещь. мой почтовый сервер или мой клиент например вычисляют какую то функцию. это заметили только тогда когда рассылки массовые рассылки на сотни тысяч миллионы адресов и в этот момент выяснится что эта операция перестанет работать. Сейчас разрабатывается определенное количество протоколов. Единственное что начинает работать только в тот момент когда весь мир переходит на такие почтовые сервисы которые требуют выполнения этих самых тяжелых операций. сейчас же используются другие способы борьбы со спамом и мы на следующей лекции с вами об этом поговорим.
Серьезно озаботились борьбой со спамом примерно в конце прошлого — начале этого века, когда это стало серьезной проблемой и было одновременно разработано несколько технологий которые серьезно помогают в этом.
Первая технология это SPF(Sender Policy Framework), была выпущена в 2003-ем году, и почти одновременно Microsoft предложила свою похожую технологию, которая называется Caller ID for E-mail (2004 г). В итоге, между собой смогли договориться и объединенная технология, которая называется Sender ID, вошла в стандарты Internet. В 2006 году вышла серия RFC 4400, четыре RFC, и это сейчас один из новых методов борьбы со спамом. На самом деле, не совсем со спамом, а с mail spoofing-ом.

Что такое mail spoofing. Mail spoofing – это когда кто-то использует какие то разные слабости в протоколе, в настройке серверов или еще в чем то и посылает вам письма от чьего-то имени, то есть это подделка исходного адреса письма. Для чего это делается? Если бы спамер присылал почту все время с одного адреса, то мы бы просто отфильтровали этот адрес и спам бы не получали. Это было бы слишком просто. Поэтому спамерами было придумано, что спам приходит каждый раз с разных адресов и сами эти адреса могут быть от разных почтовых серверов, разных ящиков и так далее. И просто так простым фильтром это невозможно отфильтровать. И все это работает, потому что из-за особенностей организации протокола SMTP, а также из-за особенностей организации самих серверов, можно относительно несложно послать письма от чужого имени. Когда в протоколе SMTP не было аутентификации, это было совсем просто. Сейчас, когда есть аутентификация, это сложнее, но тоже возможно сделать.
В итоге, что из себя представляет эта технология (Sender ID), в чем же заложена идея. Когда мы получаем спамовские письма, мы их получаем, как письма с каких-то несуществующих или непонятных адресов, а может быть даже с существующих, но с известных доменов.
Идея в следующем — а давайте-ка мы сделаем некий сервис, где владелец домена публикует в открытом доступе те адреса, с помощью которых можно отправлять почту от имени данного домена.
Например, есть сервис mail.ru. Если кто-то хочет отправлять почту с сервиса mail.ru, он должен отправлять её исключительно с нескольких IP адресов. Например, у Mail.ru есть официальный сервис, с помощью которого можно посылать почту, он называется, по-моему, SMTP mail.ru или ещё MXS mail.ru, ну несколько всего адресов, которые обслуживают домен mail.ru. И вот только с них можно будет посылать почту от имени пользователя mail.ru.
Чем это упростит жизнь нам? Тем, что у нас не получится так, что мы можем воспользоваться особенностями протокола SMTP, тем, что отсылающий сервер никак не связан с доменом почтовым, от которого идёт отсылка. Если вы вспомните протокол SMTP, мы пишем MAIL FROM, RCPT TO и всё. И этот MAIL FROM может быть, собственно, с любого домена. И вот как раз так с этой особенностью хочется бороться.
При этом, получатель, получив сообщение, по заголовкам письма смотрит что, например, письмо с обратным адресом с mail.ru пришло с таких-то IP адресов и смотрит, разрешенные эти адреса были или нет. Если адреса разрешенные, то письма мы получаем, если нет, то не получаем.
Соответственно, появляется такая сущность как PRA (Purported Responsible Address) — предполагаемый адрес отправителя, ну и задача почтового сервера — это извлечение из текста письма этого самого PRA, и последующая проверка его на валидность.

Вопрос следующий, а где хранить вот эти вот разрешенные домены? У нас, например, почтовый сервер, тот же mail.ru, где нам хранить IP адреса тех серверов, с которых мы считаем, что валидно принимать почту от нас?
Где-то в облаке возможно, в пространстве пользователя?
Видите, в чём дело, речь идёт не о пользователе, а о сервере, то есть мы не для одного пользователя говорим, а для всего почтового домена, в данном случае mail.ru. И мы должны хранить это в таком месте, чтобы это место было доступно всем другим почтовым сервисам. Не знаете ли вы такой базы данных, которая доступна всем? Для этого используются записи DNS. Либо используют запись TXT, либо используются некоторые другие записи, там разные технологии существуют. Собственно, поиск PRA осуществляется по цепочкам заголовков письма. Если вы посмотрите какое-нибудь письмо, которое прошло через несколько почтовых серверов, там есть такое понятие “цепочки заголовков”, через которое полетел этот сервер (пролетело письмо?). По ним, собственно, вычисляется исходный сервер, с которого было переслано сообщение, и дальше через DNS это проверяется.
Как это делается? Во первых, не всегда этот PRA можно найти по цепочкам заголовков, но если нашли, то определяется так называемый PRD — домен предполагаемый, дальше осуществляется запрос к DNS-серверу, отвечающему за домен PRD, ну и в зависимости от ответа принимается решение о дальнейших действиях.
Если же не найден, тут есть две политики:
- жесткая политика — это мы просто это письмо игнорируем
- не жесткая – отсылаем письмо на дополнительную проверку на спам.

Ну и надо сказать что технологии эти действуют. Например, компания Microsoft уже много лет их использует, и вы не сможете послать письмо на почтовый сервер DNS, если ваш почтовый сервер не поддерживает технологию Sender ID. Вы просто не сможете им послать письмо.
Ну и это очень сильно уменьшает для пользователей поток спама. Технология стандартизирована, есть RFC, и возможность настройки технологии Sender ID есть сейчас во всех современных почтовых серверах, поэтому если вдруг с вашего почтового сервера кто-то перестал принимать почту, посмотрите в чём произошла проблема. Если действительно дело в том, что там сообщение, что не поддерживается Sender ID, надо его настроить у себя, настроить в DNS правильные реквизиты серверов и этим помогаете вашим партнёрам работать с вами не получая спам.
Как было сказано, технология Sender ID служит для борьбы с mail spoofing-ом, а для борьбы с самим спамом используются спам фильтры.
Обычно это довольно-таки интеллектуальные системы, сделанные с помощью технологии машинного обучения, которая использует одно большое преимущество почтовых серверов, особенно публичных почтовых серверов. В чем их преимущество, этих серверов, почему на них легко сделать фильтрацию от спама? Почему на вашем корпоративном сервере сложнее сделать фильтрацию от спама, чем на публичном сервере? Например, на яндексе сделать фильтрацию спама проще, чем на каком-нибудь почтовом сервере какой-нибудь небольшой фирмы.
Может быть потому что больше данных приходит?
Естественно, там ситуация очень простая. Спам, он чем хорош, одинаковое рекламное письмо отсылается огромному числу пользователей. Ну, предположим, у нас пять миллионов подписчиков в спам рассылке, предположим, из них полмиллиона попали на сервер яндекса и яндекс может проанализировав то, что одинаковое письмо или очень похоже письмо попало огромному количеству пользователей, он может с гораздо большей долей вероятности определить, что это спам. Ну а соответственно получив информацию, что одно и то же письмо или не сильно модифицированное письмо пришло большой группе, он может сделать по нему так называемый шингл — это слепок письма, по которому может находиться не только этот спам, но и его клоны. Спамеры они хитрые, они при рассылке не всем рассылают одинаковые письма, они рассылают похожие письма именно для того, чтобы фильтры не работали, но доступ к огромной базе пользователей, который есть в таких больших публичных почтовых серверах позволяет очень хорошо настраивать эти спам фильтры.
41. Протокол доступа к почтовым ящикам POP3.
Что касается получения почты. Для получения почты существуют несколько протоколов и на текущий момент используются два.
Первый, самый простой из них, это протокол POP-3. Расшифровывается это как Post Office Protocol, версия 3.
Это протокол доступа к почтовым ящикам. Вы не сможете с помощью него послать письмо. Вы сможете обратиться к почтовому серверу и просмотреть свой почтовый ящик. Протокол довольно таки старый, появился в конце 80-х, та версия, которой мы пользуемся сейчас — это середина 90-х. Он заменил устаревший протокол POP-2. Наверное, когда-то был протокол POP-1.

Сам по себе протокол POP-3 – это, как уже было сказано, протокол доступа к почтовому ящику, он поддерживает функцию аутентификации пользователя ( потому что только сам пользователь, знающий логин и пароль, имеет право доступа к своему почтовому ящику), а также поддерживает несколько ключевых команд:
- просмотр списка писем, которые в настоящий момент есть на сервере
- копирование письма в локальный почтовый ящик, который находится на вашем локальном клиенте
- удаление писем с сервера
Это, собственно, основные функции, которые есть, то есть POP-3 предполагает, что основная работа с электронной почтой происходит на локальном компьютере, а сервер используют только для того, чтобы хранить вновь поступившие письма, ну или в крайнем случае архив писем. При этом, на сервере ящик представляется одной большой почтовой папкой (условно называющейся Inbox) и POP-3 не предполагает возможности хранения на сервере разных почтовых папок. Если вы хотите иметь много разных почтовых папок, то это всё делается на клиенте, уже средствами какогото клиента протокола POP-3. POP-3 использует TCP, для него зарезервирован 110-ый порт.

Сам протокол POP-3 очень простой. Он использует текстовый интерфейс, но, при этом, он использует RFC формат команд, но формат ответов там не RFC, а значительно более простой.
Формат ответов здесь – это не код ошибки и сообщение об ошибке, а два ключевых слова: ключевое слово +OK означает, что ошибки не было, ключевое слово –ERR означает, что ошибка была.
Итак, начинается все с аутентификации. Когда клиент подключается к серверу, мы проводим аутентификацию (передача логина и пароля).
Передача логина происходит командой USER с параметром “имя почтового ящика”.
Как вы думаете, какой будет ответ, если такого ящика, пользователя не существует, ok или error?
- OK
- Почему?
- Чтобы нельзя было узнать, что этого пользователя не существует.
- Конечно, иначе бы это была мечта спамеров.
Поэтому, если у нас ошибка с именем пользователя, всё-равно выдаётся OK, если правильный пользователь, выдаётся OK. ERROR выдаётся только в том случае, если мы не поддерживаем передачу пароля в открытом виде (может, имя пользователя? Тут то мы пароль пока не передаём никакой). Как вы видите, в команде USER, это же просто поток TCP, имя пользователя передаётся просто в открытом виде.
Пароль передается командой PASS.
И уже здесь выдаётся OK в случае, если пара “логин пароль” правильная и ERROR, если пара неправильная. Обращаю ваше внимание, пароль передается тоже в открытом виде. Но это всё верно только для plaintext authentication.
После того, как мы успешно прошли аутентификацию, у нас есть несколько команд:
- команда STAT показывает статус почтового ящика, в котором два параметра: N и M. N — сколько всего писем в настоящий момент имеется в почтовом ящик. M — их общая длина в байтах.
- команда LIST — пролистать почтовый ящик. Она выдает сначала сообщение +OK, а потом показывает список всех писем (их номера и длины). То есть вы можете посмотреть, сколько есть писем, и какой длины каждое письмо. В основном, длина писем в байтах и количество писем — это информация для почтового клиента чтобы он мог показать процедуру скачивания писем в виде красивого прогресс бара.
- команда LIST — это посмотреть информацию об одном конкретном сообщении. Если оно есть с таким параметром, то выдаётся его длина, если нет, то ошибка.
- команда RETR — это команда получения письма. По сути, команда скачивания письма. Указывается номер того письма, которое необходимо скачать и дальше, если все хорошо, то вам говорят +OK и прямо в канал TCP выкидывается всё сообщение, и, когда оно закончится, будет точка на отдельной строке. Дальше, почтовый клиент, посмотрев это сообщение, копируют его себе в локальную папку, ну и -ERR приходит, если сообщения нет.
- команда DELE — помечает сообщение на удаление. А удалять его или нет — зависит от того, как мы закончим транзакцию.
- команда RSET — это сброс транзакции и сброс всех флагов сообщений.
- команда QUIT — завершение транзакции и удаление всех сообщений, помеченных для удаления.



Итого, подключились, прошли аутентификацию, посмотрели состояние ящика, посмотрели список писем, скачали нужные письма, удалили ненужные письма, закрыли соединение.
Это тот минимум, который нужен для общения с почтовым ящиком. Дополнительно к этому, в RFC 96-го года появилось несколько команд, которые помогают более осмысленно работать с почтовым ящиком:
- команда TOP — позволяет сделать маленький предпросмотр сообщения. Она показывает для N-го сообщения его заголовок, пустую строку и первые M строк сообщения (в почтовых сообщениях используется формат, что заголовок отделяется от самого сообщения пустой строкой). Таким образом, мы можем посмотреть все заголовки сообщения, не скачивая само тело сообщения. Особенно это полезное, если сообщение очень большого объема и мы даже не знаем нужно нам его скачивать или нет.
- команда UIDL (с параметром или без параметра) — эта команда присылает нам уникальный идентификатор сообщения с номером N, или всех сообщений, если команда без параметра. Уникальный идентификатор присваивается почтовым сервером всем письмам, которые сервер получает и он уникальный в пределах данного сервера. То есть, если у вас сервер функционирует, то каждое следующее сообщение будет отличаться идентификатором от предыдущего. Для чего это делается? Если, например, вы хотите сохранить свои сообщения не только на клиентской папке, а еще и на сервере. Зачем, кстати это нужно будет? Почему нам недостаточно хранить сообщения только на своём клиенте? Чтобы можно было с нескольких клиентов посмотреть сообщения. Действительно, если мы хотим иметь доступ с рабочего компьютера, с домашнего, и, например, с планшета, то если первый же будет забирать сообщения и удалять их, то у вас будут разные копии на всех локальных клиентах. Но, с другой стороны, если вы все сообщения храните на сервере, то они у вас там будут накапливаться, и каждый раз при соединении у вас будет показано что на сервере есть сначала 10 писем, потом 20 30 писем, 1000 писем. Но вы же хотите увидеть только новое письмо, а не все которые пришли. А POP-3 этого не позволяет делать, потому что все сообщения представлены одной папкой Inbox. Но вот, собственно, UIDL — уникальный идентификатор сообщения, как раз позволяет отличить новые от старых. Когда почтовый клиент загружает себе все сообщения, которые есть на сервере, он в том числе загружает эти идентификаторы, и в следующий раз, когда он подсоединяется к этому серверу, тот показывает ему список сообщений, мы получаем их уникальные идентификаторы и сравниваем, те, которые были, это старые, те которых не было — это новые. Ну и таким образом мы можем сказать сколько реально новых сообщений находится на сервере, ну и, например, позволить пользователю скачать только их.


В последних версиях протокола POP-3 есть не plaintext аутентификация. Аутентификация командой APOP <имя> <дайджест> (Authenticated POP) заменяет пару команд USER и PASS. Эта команда передает имя пользователя в открытом виде, а вместо пароля передает криптографический дайджест от этого пароля. В итоге, сам пароль почти не передается.

Теперь вопрос на засыпку. А нужно ли хакеру знать сам пароль, если он может прослушивать команду APOP, увидеть имя, увидеть hash пароля и в следующий раз подсоединиться от имени пользователя с этими данными, не зная пароля? А там сервер отправляет какуюнибудь соль при этом? Да, все именно так, конечно, hash считается не только от пароля, но и от строки, которую высылает сервер. Строка примерно такого вида:

В ней есть pid процесса, системный таймер и, собственно, hostname сервера. Эта строка уникальна, она каждый раз меняется и поэтому дайджест, вычисленный по паролю и по этой строке, фактически каждый раз разный. Поэтому даже если злоумышленник прослушал ваш hash, в следующий раз hash будет другой и это никак ему не поможет.
- Ну и существует еще второй способ аутентификации. Он похож на аутентификацию такую же, как происходит в протоколе SMTP и IMAP4. В SMTP была команда AUTH. Здесь такая же команда AUTH <тип аутентификации> существует в альтернативных реализациях, как
в SMTP. Но, насколько я знаю, используется она реже, чем команда APOP. APOP в этом смысле конечно значительно проще и по реализации, и по пониманию, и именно с точки зрения протокола все проще. А форматы для этой команды, какие могут быть типы методов аутентификации, указано в RFC 1731.

Ну вот собственно и всё про POP-3, крайне простой протокол, его очень легко разработать. У него есть достоинства и недостатки:

Из достоинств, понятно, это простота реализации и большая распространенность, все почтовые сервисы поддерживают этот протокол.
Из недостатков, трафик не шифруется. Все ваши письма могут прочитать те, кто читает трафик. То есть нужно уже средствами почтовых программ шифровать сообщения.
Кроме того, существует два варианта аутентификации и один из них опасный (через команды USER и PASS). То, что я вам не рассказал, но что является фактом, POP-3 блокирует почтовый ящик. То есть на время работы с почтовым ящиком клиент блокирует ящик на сервере и никакой другой клиент к нему в этот момент не может присоединиться. Это сделано из-за особенностей POP3, так как там есть команды, которые выдают конкретный список папок и так далее и сообщений и у вас конечно может быть проблема, если параллельно кто-то присоединился и какие то сообщения удалил, например. Кроме того, к минусам можно отнести отсутствие серверных папок, то что сообщение-это единый блок это, конечно, очень плохо. Ну и нет возможности вешать на сообщения метки, что было бы очень полезно сейчас (важное там сообщение, новое и тд, POP-3 ничего этого не поддерживает).
42. Протокол доступа к почтовым ящикам IMAP4.
Следующий почтовый протокол – IMAP-4. Расшифровывается он вот так:

Он пришел на смену протоколу POP-3. Несмотря на то, что они сейчас существуют параллельно, разработчики протокола IMAP-4 позиционировали его как протокол, который полностью заменит протокол POP-3. Первый стандарт появился в 1994 году. Действующий стандарт, которым пользуются сейчас, появился в том же 96-ом году, когда и появился последний стандарт протокола POP-3. Современные почтовые серверы в основном поддерживают оба протокола.

Какие особенности протокола IMAP-4, и в чем он сильно отличается от протокола POP-3.

- Во-первых, он позволяет хранить удалённую структуру папок сообщений. То есть мы можем на сервере создавать сколь угодно много папок и размещать сообщения в этих папках.
- Во-вторых, он обеспечивает асинхронный обмен командами с поддержкой так называемого уникального номера команды и номер ответа. Это позволяет нескольким клиентам одновременно подключаться к серверу и не блокировать почтовый ящик.
- В-третьих, он поддерживает флаги сообщений, причем как системные флаги предопределенные, так и пользовательские флаги и этим активно пользуются почтовые клиенты.
- Так же, как в POP-3, все сообщения имеют уникальные идентификаторы.
- Есть механизмы работы с сообщениями на сервере, без закачивания их клиентам (механизмы копирования и перемещения сообщений).
- Есть несколько возможностей поиска сообщений прямо на сервере.
- Есть два варианта аутентификации: login(опасный) и authenticate(безопасный).
Технически реализуется поверх протокола TCP, номер порта — 143.
Поговорим подробнее об особенностях, начнём с флагов сообщений.
Это очень удобная вещь. Есть два типа флагов:
- системные флаги. Поддерживаются 5 системных флагов они начинаются с ****.
 **
**
- Seen** — просмотренные письма,
- Answered — отвеченные письма,
- Deleted — удаленные письма (помеченные на удаление),
- Draft – черновики,
- Recent — новые сообщения.
- пользовательские флаги. Плюс к этому разрешается создавать пользовательские флаги. То есть пользователь может создать флаг сообщения и он как метаинформация будет храниться вместе с вашим сообщением, а клиенты имеют возможность делать выборку сообщений по этому флагу, фильтровать сообщения по флагам и т.д.
Команды IMAP-4
В IMAP-4 также используется текстовый формат команд, но, при этом, протокол более новый и уже нет ограничений на то, что команды должны быть четырехбуквенными. Здесь могут команды любой длины быть. И, кроме всего прочего, для организации асинхронной работы, каждая команда может предваряться уникальным идентификатором сообщения.
Список команд:

Независимо от того, в какой стадии работы мы находимся, всегда есть несколько команд.
- Команда CAPABILITY показывает те возможности, которые реализованы в данном IMAP-4 сервере (некоторые серверы не все возможности реализуют).
- NOOP — тестовая команда “нет операции”.
- LOGOUT – выйти.
На стадии, когда мы еще не аутентифицированы, у нас есть команда LOGIN , которая позволяет подсоединиться к ящику небезопасным способом, команда AUTHENTICATE , которая позволяет то же самое сделать, но безопасно, используя RFC 1731 в качестве каталога методов аутентификации.
Если аутентификация прошла успешно, есть набор команд, который может происходить на стадии “Аутентифицирован”. (В терминах IMAP-4, почтовые папки называются ящиками). Итак, есть следующие команды:


- SELECT <имя ящика> — выбор конкретной папки в качестве текущей.
- EXAMINE <имя ящика> — то же самое, но ящик открывается только для чтения (только на просмотр).
- CREATE <имя ящика> — создать почтовую папку.
- DELETE <имя ящика> — удалить почтовую папку.
- RENAME <старое_имя> <новое_имя> — переименовать.
- SUBSCRIBE <имя ящика> — подписка на папку. Фокус в том, что клиент может захотеть видеть у себя не все папки. У тех папок, на которые он подписался, будет добавляться специальный флаг, который будет показывать необходимо ли копировать сообщения данной папки при связи с сервером.
- UNSUBSCRIBE <имя ящика> — то же самое, но флаг будет убран.
- APPEND <имя_ящика> — одна из команд, которая позволяет перемещать сообщения на сервере.
На стадии, когда мы уже сделали выборку, есть определенное количество команд уже внутри папки:

EXPUNGE – удаление сообщений без закрытия ящика.
SEARCH и FETCH – команды поиска с разными атрибутами, где можно осуществлять поиск на сервере средствами сервера приложений.
В отличие от протокола POP-3 здесь может быть много разных ответов, порядка пятнадцати разных ответов:

Важно, что и команды, и ответы начинаются с идентификатора.
Когда мы выдаем какую-то команду, например, долгая команда счетчик, то она начинается с уникального идентификатора.
Она может выполняться несколько минут, а мы хотим продолжать работать с сервером. В этом случае команда синхронно работает. И мы выполняем какие-то другие команды.
По идентификации ответа мы можем понять, к какой команде он относится и это делает полностью параллельный процесс общения с ящиком, чего невозможно было бы сделать в протоколе POP-3.
Возьмем за пример почтовый ящик, к которому привязано несколько устройств. Это дает такую возможность в любой момент обновить информацию о почте, т.к. у вас одновременно асинхронно подключаются несколько устройств, они делают разные команды и делают их асинхронно и никаких проблем с подключением большого числа клиентов нет.
43. Протокол передачи файлов FTP. Активный режим.
FTP – один из важнейших, базовый протокол передачи файлов в компьютерных сетях.
Первый стандарт RFC 114, 1971 г.
Действующий стандарт RFC 959, 1985 г.
Один из базовых протоколов TCP/IP
Использует транспорт TCP, использует передачу текстовых команд для организации управления, то есть в одну сторону передаются текстовые команды с параметрами в другую передаются текстовые ответы с статусами.
Поддерживает 2 режима передачи, это базовый (активный) и пассивный.
Один из немногих 2-х канальных протоколов TCP/IP:
- Управляющий канал – по нему передаются управляющие сообщеня и получаются коды ответов и этот канал существует на протяжении всего обмена и обычно использует 21 порт (порт передачи команд)
- Канал данных – используется только тогда, когда требуется передать при помощи FTP большие данные (файлы либо каталоги). При этом это одноразовый временный канал, он организуется только на время передачи данных и потом закрывается. В зависимости от режима работы использует либо 20 порт в активном режиме либо непривилигорованный в пассивном
Активность в режиме означает то, какая сторона является активной с точки зрения открытия канала данных.
В активном режиме активной стороной является сервер, он сам организует канал данных с клиентом, в пассивном режиме наоборот
Активный режим
- Режим «по умолчанию»
- Сервер инициирует соединение данных
- Клиент открывает слушающий порт . На клиенте FTP организуется слушающий сокет, то есть серверный сокет
- Номер TCP-порта сервера – 20. Из-за того, что в этом режиме сервер сам открывает соединение клиенту он должен знать IP адрес клиента и этот адрес должен быть доступен из вне и, как следствие, невозможно использовать с технологиями типа NAT, Proxy
- Обычно запрещён в межсетевых экранах

Клиент, когда хочет организовать канал обмена данными он организует канал команд и организует соединение с 21 портом сервера. В момент когда понадобиться передача данных сервер самостоятельно организует связь с клиентским сокетом по которому будут передаваться данные, при этом данные могут передаваться в обе стороны как на прием так и на передачу. Стрелка это только указатель того, кто был инициализатором установления соединения для передачи.
44. Протокол передачи файлов FTP. Пассивный режим.
[FTP — Вопрос 43](#43.-протокол-передачи-файлов-ftp.-активный режим.)
Пассивный режим
- Клиент инициирует соединение данных
- Сервер информирует о параметрах канала данных
- Сервер открывает слушающий порт
- Изначально поддерживается не всеми реализациями

Канал связи открывает клиент. Номер порта выбирается непривилигированный, он каждый раз выбирается новый и информация об этом номере передается клиенту. Это может быть не очень удобно, что номер порта будет абстрактный, с точки зрения построения фаервола это тоже не очень просто, так как редко когда серверный порт заранее не определен и данном случае он как раз не определен
Теперь на уровне описания самого протокола
Описание команд FTP
- USER – имя. Команда аутентификации
- PASS – пароль. Команда аутентификации. Команды передаются в открытом виде и протокол уязъвим.
Команды передаются в открытом виде и протокол уязвим. По поводу USER и PASS, так как FTP используется не только для доступа к частным архивам но и для доступа к публичным архивам, для публичных архивов есть соглашение, что пользователи подключающиеся к публичному архиву в качестве имени пользователя указывают предопределенное слово анонимус а в качестве пароля свою электронную почту. Но как таковое это не проверялось. И вроде получается, что в пароле просто достаточно указать строку с собачкой
- REIN – реинициализация
- ABOR – прервать обмены
- QUIT – завершение сесии
Команды, оперирующие с файловой системой
- DELE <имя> – удалить файла Если позволяют права. Анонимному пользователю обычно ничего не позволялось удалять
- RNFR <имя> — переименовать из
- RNTO <имя> — переименовать в
- Перед RNTO выполняется RNFR
- CWD <путь> — сменить каталог
- CDUP – перейти в родительский каталог
- RMD <имя> — удалить каталог
- MKD <имя> — создать каталог
- PWD – показать текущий каталог
Команды управления режимом работы сервера
-
PORT a1, a2, a3, a4, p1, p2 — перевод сервера в активный режи
- Клиент выдает такую команду. Параметры это 6 байт или октетов, первые 4 байта это IP адрес а последние два это номер порта. Клиент говорит, что он ждет соединение по адресу a1.a2.a3.a4 и по номеру порта вычисляющему по формуле. Передав эти значения клиент инфмирт сервер куда над содиняться и сервер когда требуется создать канал данных соединяться с этим адресом и портом. Так команда переводит в активный режим
- Address = ‘a1.a2.a3.a4’
- Port = p1*256+p2 . Клиент выдает такую команду.
-
PASV <без параметров> – перевод сервера в пассивный режим.
- В качестве ответа сервер присылает те же 6 чисел, то есть он ждет от клиента соединение по адресу a1, a2, a3, a4 и номеру порта где p1 и p2 это старший и младший актет. Режимы разделяются на сессии а не сам сервер, то есть сервер формально может работать с клиентами в разных режимах но по сути мы говорим, что ближайшая передача будет такая. Чаще всего все пользуются одним режимом и этот PASV (Этот момент уточнил Стас)
- 227 a1, a2, a3, a4, p1, p2 (что тут за 227 Ицыксон не говорит, не знаю удалять или нет)
-
TYPE {A|E|I} – представление информации.
- Первая два режима это текстовый режим а последний бинарный режим. FTP реализует небольшую функцию представительского уровня, в TCP/IP нет явно представительского уровня и он реализуется протоколами (так предложение сформулировал Ицыксон). Одна из функций этого уровня это согласование форматов. Так сложилось, что в Windows и Unix используется разное кодирование элементов текстового файла, например в win перевод строки это 2 символа а в unix 1 символом. Соответственно FTP предлагает согласование форматов в случае передачи текстового файла и в режиме TYPE A (стандартный режим передачи текстовых файлов) можно попросить клиента с севрвером согласовали передачув файлов. Полученный с сервера файл в нем происходит перекодировка 2 символов перевода строки в одну сторону и в другую, то есть формально текстовый файл мы передаем как текстовый файл. Если выбрать бинарный режим, то в нем передача происходит без искажений. Актуалосчка 80-90.
- A — ASCII
- E — EDCDIC
- I – Image
-
MODE {S|B|C} – режим передачи данных. Можно попросить сервер передавать в разном режиме. В Compressed режиме файл перед тем как передаваться архивируется в алгоритм похожий на zip.
- S – Stream
- B – Block
- C – Compressed
Команды, использующие канал данных
- RETR < имя > — получить файл
- STOR < имя > — записать файл
- LIST [<путь>] – получить список файлов с атрибутами. По стандарту FTP присылается в формате команды ls системы unix
- NLST [<путь>] – получить список имен файлов
Как только клиент выбирает одну из этих команд сразу происходит соединение по второму сокету по которому происходит реальная передача данных.

Из-за того, что клиент и сервер присылают друг другу не только порт но и IP адресс, это позволяет сделать следующее. У нас есть 2 сервера и мы хотим передавать между ними данные, сам по себе протокол без всяких хитростей заставил бы сначала скачать с S1 скачать на клиента а потом на S2, но можно обйтись без клиентского канала и передавать между серверами. Клиент соединяться с серверами, s1 сервер в пассивный, s1 передает клиенту данные где он ожидает соединение а s2 в активный режим а в качестве параметров передаются данные сервера и в итоге канал данных получается между серверами
Недостатки
- Не поддерживает шифрования
- Не поддерживает безопасной аутентификации
- Не поддерживает современных средств адресации. Не работает с URL, надо переходить по каталогам
- Сложность работы с защищенными сетями
Достоинства
- Эффективность. Использует 2 канала данных
- Гибкость. Для определенной степени, позволяет обеспечить навигацию потоково каталогов
45. Протокол HTTP. Формат запроса.
- Протокол передачи файлов. Но данные могут передаваться по разному, как передача объектов или гипертекстовой информации
- HTTP/1.0 RFC 1945, 1996 г.
- HTTP/1.1 RFC 2068, 1997 г.
- Действующий стандарт HTTP/1.1 RFC 2616, 1999г.
HTTP запрос формируется как запрос состоящий из заголовков и тела запроса следующего формата
Формат HTTP-запроса
Сначала идет некоторое колисчетсво заголовков потом пустая строка и потом тело. Все что <> кроме первой строчки это целый список возможных заголовков. Особенность HTTP в том, что у него может быть очень много заголовков при помози которых мы можем управлять тем, что происходит в сети
<Request-line> — строка запроса. Используется только в запросе
<General-header> — общий заголовок Используется только в запросе
<Request-header> — заголовок запроса Может быть и в запросе и в ответе
<Entity-header> — заголовок сообщения Может быть и в запросе и в ответе
<Body> — тело
Строка запрса
HTTP-запрос начинается со строки запроса. Имеет 3 параметра
Формат: < METHOD > < URL > < HTTP-VERSION >
< METHOD >— что мы хотим сделать с ресурсом< URL >— это ресурс который мы запрашиваем. В большинстве случаев ресурс HTTP-шный поэтому это скорее всего адрес веб страницы или ресурса на ней< HTTP-VERSION >— поддерживаемая версия HTTP. 1.0, 0.9, 1.1, 2.0
Методы:
- GET – запросить с помощью HTTP ресурс
- POST – передать в ресурс какие-то параметры в теле запроса. Например для передачи данных для поискового сервера
- HEAD – запросить только заголовок ресурса, например если ресурс не изменился и находиться в кэше
- PUT — поместить ресурс
- DELETE – удалить ресур
- PUT и DELETE используются в системах публикации
- OPTIONS – передача опций
- и т.п.
URL:
[method://][user[:pass]@]host[:port][/path][?name=val{&name=val}][#anchor]
URL – стандартизированный по RFC формат доступа к ресурсу
Версия:
- HTTP/1.0, HTTP/1.1 или HTTP/2 (new)
Заголовки
Общий заголовок (General-header)
Присутствует, когда есть тело сообщения
- Connection – должны ли сохранять соединение. В отличии от всех протоколов которые поддерживают состояние соединения штатный вариант работы HTTP это соединились, послали запрос, получили ответ и разорвали соединение, то есть это протокол без сохранения соединения чтобы не использовать ресурсы сервера. В Connection можно передать опцию которая соохранит соединение но это внештатный режим работы
- Data
- Pragma
- Transfer-encoding
- Upgrade
- no-cache
- И т.д.
Заголовок запроса (Request-header)
- Accept: принимаемый контент
- Accept-Charset: принимаемый набор символов
- Accept-Encoding: compress, zip
- Accept-Language: da, ru
Заголовки Accept указывают на те параметры контента которые приемлмы для клиента. Например чтобы передавали страницу на русском языке. Так работает что одну страничку выдают разным пользователям на разном языке
- Authorization: basic xxx=******. Один из способов передачи логина и пароля на сервер. После Authorization используется ключевое слово как здесь basic
- From:
- Host:
- If-modified-since:… -выдать стриницу если она модифицированна только с какого-то времени
- Referrer: — для построение цепоцек связи. Показывает откуда мы пришли на текущую страницку
- User-agent: — что за пользовательский агент у нас используется это тип браузера, но при этом всегда првый текст что они предают это что браузер mozila
- И т.д.
Заголовок сообщения (Entity-header)
- Allow: GET, POST, HEAD – какие команды поддерживает
- Content-Encoding: x-zip
- Content-Language:
- Content-Length: 1245
- Content-Type: …text/html; charset=win-1251
Content описывает то, что находиться в теле
- Expires:
- Last-Modified:
46. Протокол HTTP. Формат ответа.
Протокол HTTP — Вопрос 45
Формат ответа.
<Status-line>— Строка статуса- Формат:
<HTTP-VERSION> <Code> <Phrase><HTTP-VERSION>— Используемая версия Http<Code>— Код ошибки- 1xx — информационные
- 2хх — ОК
- 3хх — переадресация
- 4хх — ошибка клиента
- 5хх — ошибка сервера
<Phrase>— Кодовая фраза
- Формат:
<General-Header>— Общий заголовок<Response-header>— Заголовок ответаLocation— переадресация (если, например, ресурс переехал, указывает новый актуальный адрес)Server— спецификация сервера (инфо о сервере, аналогUSER-AGENT)WWW-Authenticate: basic realm=’localzone’— сопровождает ошибку о том, что требуется аутентификация (указывает режим аутентификации и область, в которую нужно войти)
<Entity-header>— Заголовок сообщения<Body>— тело
47. Архитектура IPv6. Адресация.
Длина адреса — 128 разрядов
Общий формат адреса

Типы адресов:
- Unicast:
- Global — Глобальный адрес
- Link-local — Адрес линии (без деления на подсети)
- Site-local — Адрес узла(с делением на подсети)
- Anycast
- Multicast
Префикс:


Специальные адреса:
- Петля обратной связи: 0:0:0:0:0:0:0:1
- Не специфицированный адрес: 0:0:0:0:0:0:0:0
- Локальные адреса для линии 1111111010 000..000 iii.iii
- Используются для адресации в локальных сегментах сетей (соединениях «точка-точка» и т.п.) Должны НЕ маршрутизироваться!
- Локальные адреса для сети 1111111011 000..000 sss..sss iii.iii
- Используются для организации адресации во внутренних сетях При включении в сеть Интернет префикс может быть заменен на «Адрес идент. провайдера». НЕ должны маршрутизироваться вне данной сети!
Anycast адресация:

Групповая адресация:


48. Архитектура IPv6. Сетевой уровень.

В стандартном заголовке нет опций , но у нас есть цепочки заголовков. Цепочки заголовков — это технология придуманная для того чтобы упростить основной заголовок и все ненужные данные разнести в разные заголовки.
Виды заголовков:
- Hop-by-hop options header — заголовок опций которые передаются всем маршрутизаторам.
- Fragmentation header — если требуется фрагментация.
- Routing header — если требуется маршрутизация от источника.
- Destination options header
- Authentication header (AH) — заголовок аутентификации
- Encapsulation security payload header (ESP) — заголовок шифрования
Фрагментация:

Протокол ARP заменен на NDP.

Протокол ICMPv6:

49. Архитектура IPv6. Транспортный уровень, DNS, безопасность.
Транспортный уровень
(!TODO)
Протокол UDP – 11 вопрос
Протокол TCP – 12-13 вопросы
Протокол SCTP – 14 вопрос
Транспортные механизмы в IPv6 не изменились – по-прежнему используются протоколы TCP, UDP, а также с самого начала IPv6 есть поддержка протокола SCTP. RFC 2960, RFC 3257.
DNS
(!TODO)
DNS – 26-32 вопросы
DNS. Прямой поиск – 27 вопрос
DNS. Обратный поиск – 31 вопрос
- Для прямого преобразования добавлена одна ресурсная запись стандарта DNS, кроме записи
Aпоявилась записьAAAA(A— 32 разряда, а теперь 128 разрядов, т.е. 4*A, соответственно и длина адреса в 4 раза больше). Описано в RFC 1886. - Обратное преобразование сделано также, как и в IPv4, через обратную зону, только теперь не через in-addr.arpa, а через ip6.arpa. Описано в RFC 3152.
Безопасность
- Есть архитектура безопасности IPSEC, которая была разработана еще для IPv4 как внешнее дополнение. В IPv6 эта архитектура уже встроена.
- 2 протокола: Заголовок аутентификации AH и Заголовок шифрования ESP. Они по сути и реализуют эту архитектуру IPSEC, которая позволяет в двух режимах (транпортном и туннельном) обеспечивать полную защиту трафика, поэтому IPv6 изначально хорошо защищенная сеть.
50. Архитектура IPv6. Переход от IPv4 к IPv6.
Предпосылки развития связаны с недостатками протокола IPv4:
- Малое адресное пространство (32-битная адресация -> 232 = 4294967296 адресов)
- Неудобный формат адреса
- Сложная маршрутизация
- Низкая защищенность
- Отсутствие шифрования
- Отсутствие аутентификации
- Низкая эффективность передачи
Сосуществование стеков
В 1995 году, когда вышел RFC на IPv6, было сказано, что в 2000 году IPv4 не останется, все перейдут на IPv6. Потом сказали, что к 2000 году не удалось, перейдем к 2005, потом к 2010, к 2015, к 2020. Сейчас есть оптимистичный прогноз на 2025 год, но в отличие от всех предыдущих случаев уже сейчас, примерно с 2015 года вся инфраструктура сети Интернет уже готова к переходу на IPv6, все маршрутизаторы поддерживают IPv6, все программные маршрутизаторы поддерживают, все ОС имеют стек протоколов IPv6. И сейчас вопрос перехода не технический, а организационный.
Как происходит сейчас переход на IPv6 (а уже существенная часть сети перешла на IPv6)? Есть несколько способов:
-
Двойные стеки протоколов: компьютере поднимаются оба стека протоколов и часть приложений привязывается к стеку протоколов IPv4, а часть к IPv6)
-
Туннелирование: вид маршрутизации, когда трафик одного типа запаковывается в трафик другого типа (используется в VPN). Островки сети IPv6 туннелируются сквозь сети IPv4 через программные туннели и для узлов IPv6 это прозрачно, потому что туннели — это прозрачная технология для прикладных программ.
-
Трансляция адресов: когда пакет из сети IPv6 пришел на границу сети и дальше идут сети IPv4, то происходит трансляция одного адреса в другой.