Почему при установке кластера ms sql, служба кластеров windows не проходит проверку?
Для тренировки и самообучения провожу установку кластера ms sql 2008 r2 на кластер windows 2012 r2 (все это на виртуальных машинах).
Имеется следующее:
— 2 виртуальные машины на hyper-v;
— iscsi хранилища (кворум-диск, диск для базы данных, диск для службы распределенных транзакций). iscsi настроен на хост сервере;
— контроллер домена на хост машине;
— служба отказоусточивого кластера поднята на виртуалках и на хост-машине. Виртуалки объединены в кластер.
Проверка кластера, в дистпетчере отказоустойчивого кластера, проходит замечательно и не выдает никаких замечаний и ошибок.
При установке кластера ms sql на виртуалку, установщик запускает свои проверки, и находит следующие ошибки:
1. Cluster_IsOnline не пройдено (Службы кластера отработки отказа SQL Server находятся вне сети, или не удается получить доступ к кластеру с одного из его узлов)
2. Cluster_SharedDiskFacet не пройдено (Для кластера на этом компьютере не доступен ни один общий диск)
3. Cluster_VerifyForErrors не пройдено (Кластер не проверялся, либо в отчете проверки присутствуют сообщения об ошибках или сбоях)
На все сервера установлены последние обновления. Перезагружался много раз. Framework установлен на всех узлах кластера.
Вот куски из логов с ошибками:
![]()
Решение найдено. Дело в том. что при установке компонента «Отказоустойчивая кластеизация» с использованием графического интерфейса, ставятся только основные пакеты.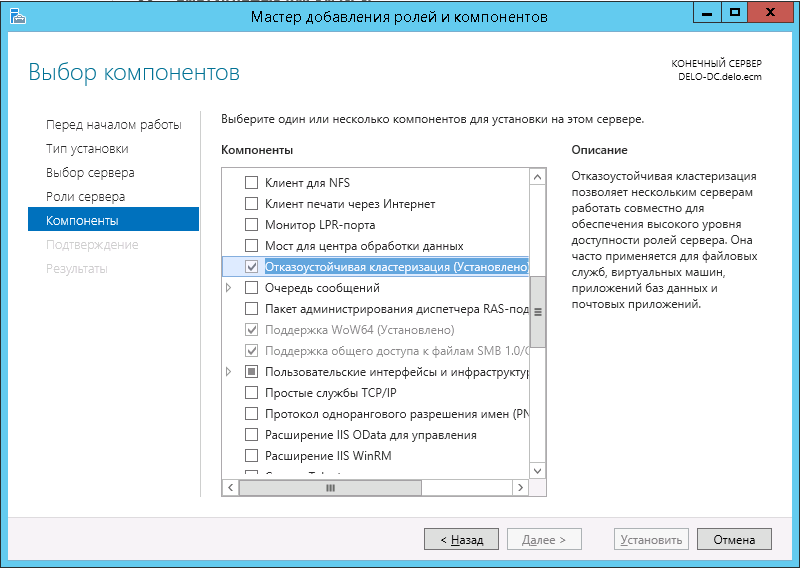
Однако, при просмотре данного компонента с консоли:
get-windowsfeature -name *clustering*
мы увидим что у него есть еще 2 пакета, которые не ставятся по умолчанию. 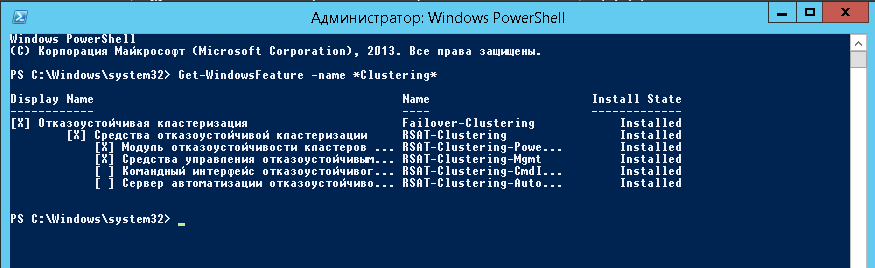
Установить их можно только с консоли.
Источник
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
- Главная
- Настраиваем отказоустойчивый кластер Hyper-V на базе Windows Server 2012
Настраиваем отказоустойчивый кластер Hyper-V на базе Windows Server 2012
 Уже на этапе планирования будущей виртуальной инфраструктуры следует задуматься об обеспечении высокой доступности ваших виртуальных машин. Если в обычной ситуации временная недоступность одного из серверов еще может быть приемлема, то в случае остановки хоста Hyper-V недоступной окажется значительная часть инфраструктуры. В связи с чем резко вырастает сложность администрирования — остановить или перезагрузить хост в рабочее время практически невозможно, а в случае отказа оборудования или программного сбоя получим ЧП уровня предприятия.
Уже на этапе планирования будущей виртуальной инфраструктуры следует задуматься об обеспечении высокой доступности ваших виртуальных машин. Если в обычной ситуации временная недоступность одного из серверов еще может быть приемлема, то в случае остановки хоста Hyper-V недоступной окажется значительная часть инфраструктуры. В связи с чем резко вырастает сложность администрирования — остановить или перезагрузить хост в рабочее время практически невозможно, а в случае отказа оборудования или программного сбоя получим ЧП уровня предприятия.
Все это способно серьезно охладить энтузиазм по поводу преимуществ виртуализации, но выход есть и заключается он в создании кластера высокой доступности. Мы уже упоминали о том, что термин «отказоустойчивый» не совсем корректен и поэтому сегодня все чаще используется другая характеристика, более точно отражающая положение дел — «высокодоступный».
Для создания полноценной отказоустойчивой системы требуется исключить любые точки отказа, что в большинстве случаев требует серьезных финансовых вложений. В тоже время большинство ситуаций допускает наличие некоторых точек отказа, если устранение последствий их отказа обойдется дешевле, чем вложение в инфраструктуру. Например, можно отказаться от недешевого отказоустойчивого хранилища в пользу двух недорогих серверов с достаточным числом корзин, один из которых настроен на холодный резерв, в случае отказа первого сервера просто переставляем диски и включаем второй.
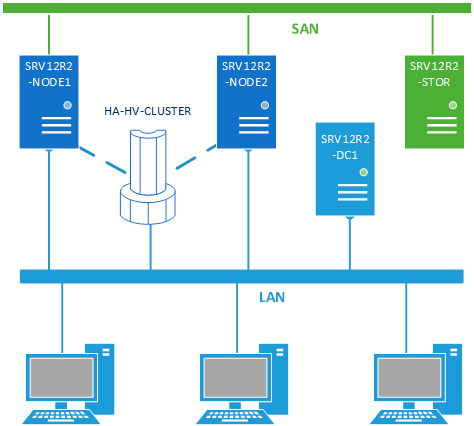
В данном материале мы будем рассматривать наиболее простую конфигурацию отказоустойчивого кластера, состоящего из двух узлов (нод) SRV12R2-NODE1 и SRV12R2-NODE2, каждый из которых работает под управлением Windows Server 2012 R2. Обязательным условием для этих серверов является применение процессоров одного производителя, только Intel или только AMD, в противном случае миграция виртуальных машин между узлами будет невозможна. Каждый узел должен быть подключен к двум сетям: сети предприятия LAN и сети хранения данных SAN.
Вторым обязательным условием для создания кластера является наличие развернутой Active Directory, в нашей схеме она представлена контроллером домена SRV12R2-DC1.
Хранилище выполнено по технологии iSCSI и может быть реализовано на любой подходящей платформе, в данном случае это еще один сервер на Windows Server 2012 R2 — SRV12R2-STOR. Сервер хранилища может быть подключен к сети предприятия и являться членом домена, но это необязательное условие. Пропускная способность сети хранения данных должна быть не ниже 1 Гбит/с.
 Будем считать, что на оба узла уже установлена операционная система, они введены в домен и сетевые подключения настроены. Откроем Мастер добавления ролей и компонентов и добавим роль Hyper-V.
Будем считать, что на оба узла уже установлена операционная система, они введены в домен и сетевые подключения настроены. Откроем Мастер добавления ролей и компонентов и добавим роль Hyper-V.
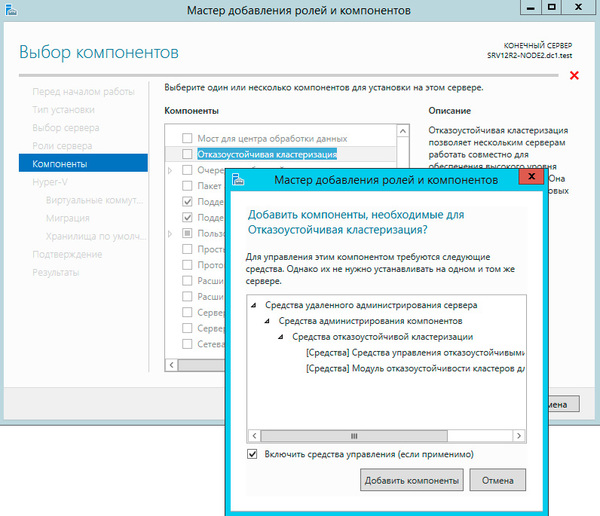
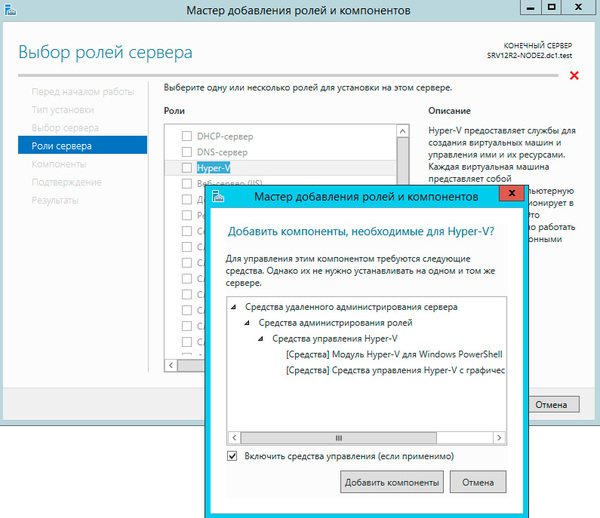 Следующим шагом добавим компоненту Отказоустойчивая кластеризация.
Следующим шагом добавим компоненту Отказоустойчивая кластеризация.
 На странице настройки виртуальных коммутаторов выбираем тот сетевой адаптер, который подключен к сети предприятия.
На странице настройки виртуальных коммутаторов выбираем тот сетевой адаптер, который подключен к сети предприятия.
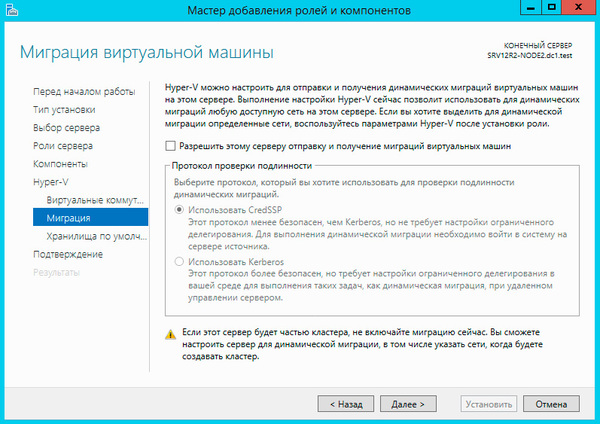
 Миграцию виртуальных машин оставляем выключенной.
Миграцию виртуальных машин оставляем выключенной.
 Остальные параметры оставляем без изменения. Установка роли Hyper-V потребует перезагрузку, после чего аналогичным образом настраиваем второй узел.
Остальные параметры оставляем без изменения. Установка роли Hyper-V потребует перезагрузку, после чего аналогичным образом настраиваем второй узел.
Затем перейдем к серверу хранилища, как настроить iSCSI-хранилище на базе Windows Server 2012 мы рассказывали в данной статье, но это непринципиально, вы можете использовать любой сервер цели iSCSI. Для нормальной работы кластера нам потребуется создать минимум два виртуальных диска: диск свидетеля кворума и диск для хранения виртуальных машин. Диск-свидетель — это служебный ресурс кластера, в рамках данной статьи мы не будем касаться его роли и механизма работы, для него достаточно выделить минимальный размер, в нашем случае 1ГБ.
Создайте новую цель iSCSI и разрешите доступ к ней двум инициаторам, в качестве которых будут выступать узлы кластера.
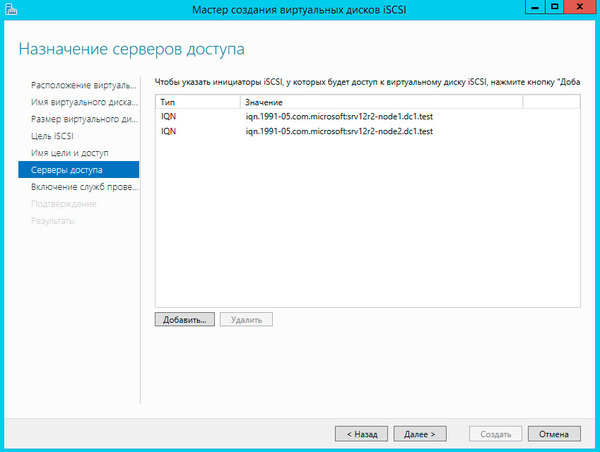 И сопоставьте данной цели созданные виртуальные диски.
И сопоставьте данной цели созданные виртуальные диски.
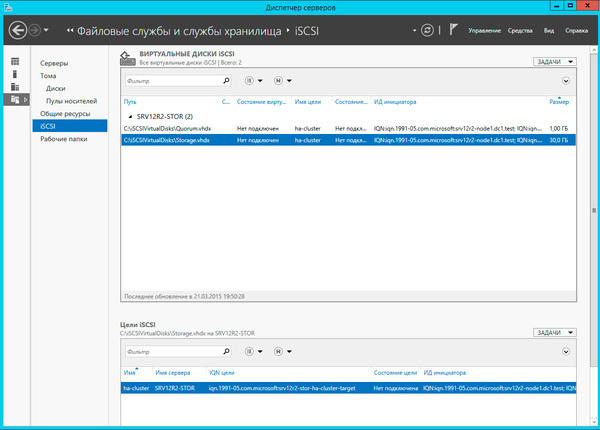 Настроив хранилище, вернемся на один из узлов и подключим диски из хранилища. Помните, что если сервер хранилища подключен также к локальной сети, то при подключении к цели iSCSI укажите для доступа сеть хранения данных.
Настроив хранилище, вернемся на один из узлов и подключим диски из хранилища. Помните, что если сервер хранилища подключен также к локальной сети, то при подключении к цели iSCSI укажите для доступа сеть хранения данных.
Подключенные диски инициализируем и форматируем.
 Затем переходим на второй узел и также подключаем диски, форматировать их уже не надо, просто присваиваем им такие же самые буквы и метки тома. Это необязательно, но желательно сделать в целях единообразия настроек, когда одинаковые диски на всех узлах имеют одни и те-же обозначения запутаться и сделать ошибку гораздо труднее.
Затем переходим на второй узел и также подключаем диски, форматировать их уже не надо, просто присваиваем им такие же самые буквы и метки тома. Это необязательно, но желательно сделать в целях единообразия настроек, когда одинаковые диски на всех узлах имеют одни и те-же обозначения запутаться и сделать ошибку гораздо труднее.
После чего откроем Диспетчер Hyper-V и перейдем к настройке виртуальных коммутаторов. Их название на обоих узлах должно полностью совпадать.
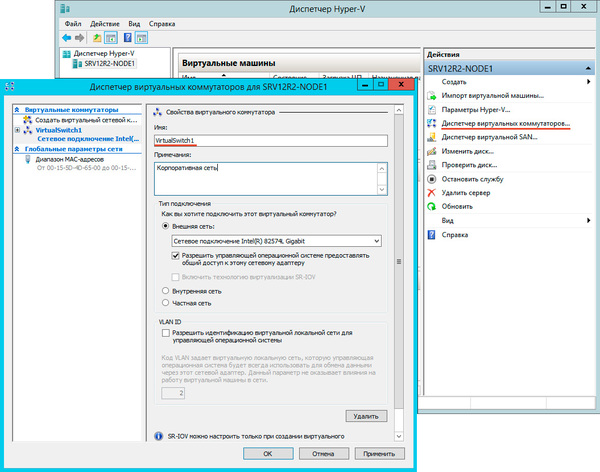 Теперь у нас все готово к созданию кластера. Запустим оснастку Диспетчер отказоустойчивых кластеров и выберем действие Проверить конфигурацию.
Теперь у нас все готово к созданию кластера. Запустим оснастку Диспетчер отказоустойчивых кластеров и выберем действие Проверить конфигурацию.
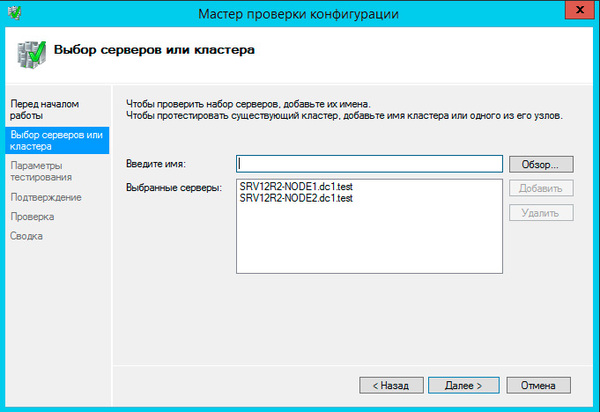
 В настройках мастера добавим настроенные нами узлы и выберем выполнение всех тестов.
В настройках мастера добавим настроенные нами узлы и выберем выполнение всех тестов.
 Проверки занимают ощутимое время, при возникновении каких-либо ошибок их необходимо исправить и повторить проверку.
Проверки занимают ощутимое время, при возникновении каких-либо ошибок их необходимо исправить и повторить проверку.
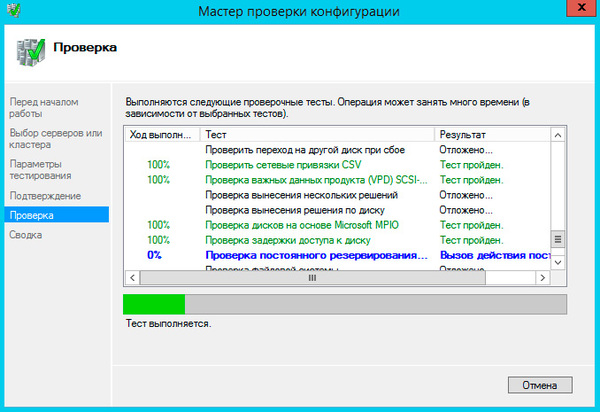 Если существенных ошибок не обнаружено работа мастера завершится и он предложит вам создать на выбранных узлах кластер.
Если существенных ошибок не обнаружено работа мастера завершится и он предложит вам создать на выбранных узлах кластер.
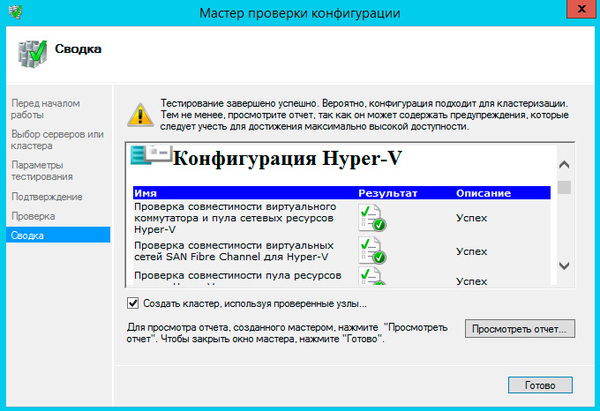 Однако, если проверка выдала предупреждения, мы советуем изучить отчет и выяснить на что влияет данное предупреждение и что нужно сделать для его устранения. В нашем случае мастер предупреждал нас об отсутствии избыточности в сетевых подключениях кластера, по умолчанию кластер не использует сети iSCSI, что нетрудно исправить позднее.
Однако, если проверка выдала предупреждения, мы советуем изучить отчет и выяснить на что влияет данное предупреждение и что нужно сделать для его устранения. В нашем случае мастер предупреждал нас об отсутствии избыточности в сетевых подключениях кластера, по умолчанию кластер не использует сети iSCSI, что нетрудно исправить позднее.
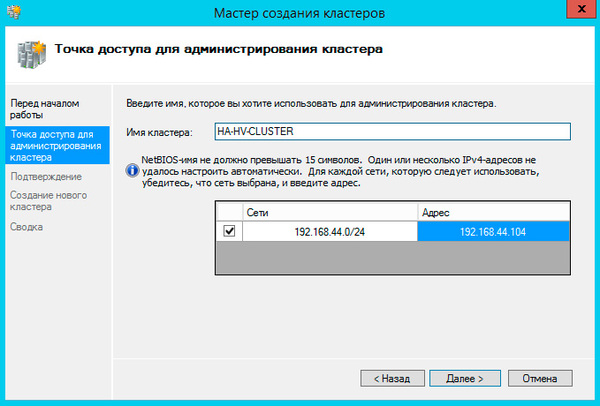
 При создании кластера для него создается виртуальный объект, обладающий сетевым именем и адресом. Укажем их в открывшемся Мастере создания кластеров.
При создании кластера для него создается виртуальный объект, обладающий сетевым именем и адресом. Укажем их в открывшемся Мастере создания кластеров.
На следующем шаге советуем снять флажок Добавление всех допустимых хранилищ в кластер, так как мастер не всегда правильно назначает роли дискам и все равно придется проверять и, при необходимости исправлять, вручную.
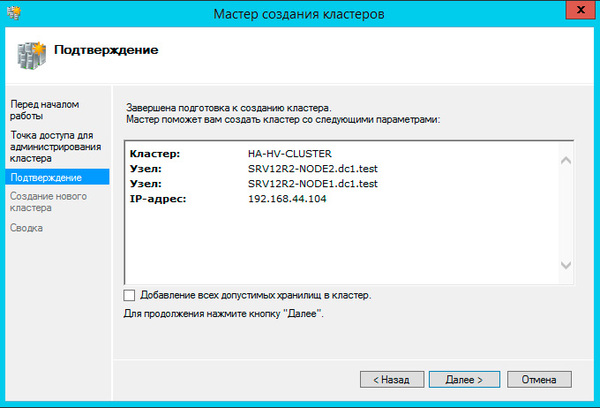
Больше вопросов не последует и мастер сообщит нам, что кластер создан, выдав при этом предупреждение об отсутствии диска-свидетеля.
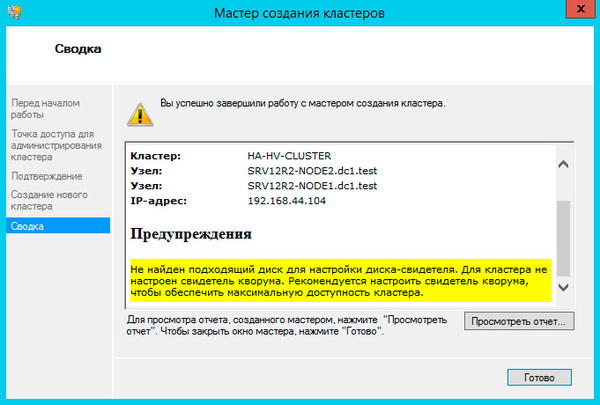 Закроем мастер и развернем дерево слева до уровня Хранилище — Диски, в доступных действиях справа выберем Добавить диск и укажем подключаемые диски в открывшемся окне, в нашем случае их два.
Закроем мастер и развернем дерево слева до уровня Хранилище — Диски, в доступных действиях справа выберем Добавить диск и укажем подключаемые диски в открывшемся окне, в нашем случае их два.
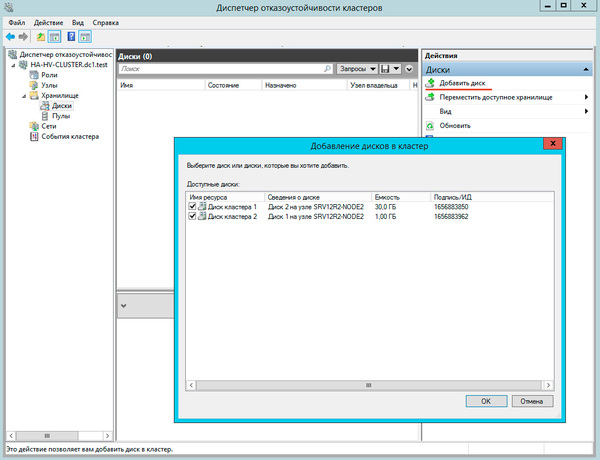 Затем щелкнем правой кнопкой мыши на объекте кластера в дереве слева и выберем Дополнительные действия — Настроить параметры кворума в кластере.
Затем щелкнем правой кнопкой мыши на объекте кластера в дереве слева и выберем Дополнительные действия — Настроить параметры кворума в кластере.
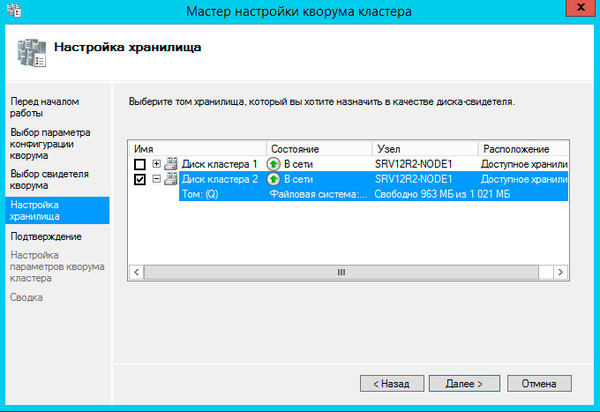
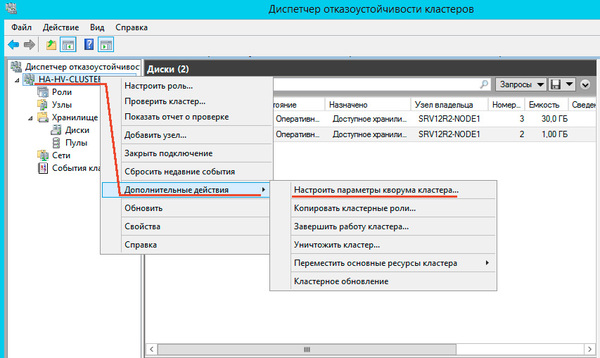 Далее последовательно выбираем: Выбрать свидетель кворума — Настроить диск-свидетель и указываем созданный для этих целей диск.
Далее последовательно выбираем: Выбрать свидетель кворума — Настроить диск-свидетель и указываем созданный для этих целей диск.
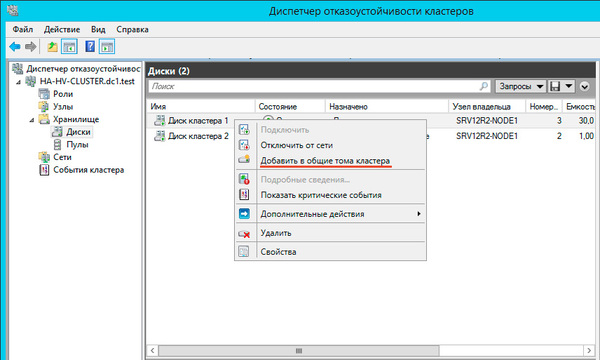
 Теперь настроим диск хранилища, с ним все гораздо проще, просто щелкаем на диске правой кнопкой и указываем: Добавить в общие хранилища кластера.
Теперь настроим диск хранилища, с ним все гораздо проще, просто щелкаем на диске правой кнопкой и указываем: Добавить в общие хранилища кластера.
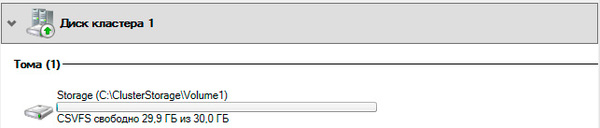
 Для того, чтобы диск мог использоваться сразу несколькими участниками кластера на нем создается CSVFS — реализуемая поверх NTFS кластерная файловая система, впервые появившаяся в Windows Server 2008 R2 и позволяющая использовать такие функции как Динамическая (Живая) миграция, т.е. передачу виртуальной машины между узлами кластера без остановки ее работы.
Для того, чтобы диск мог использоваться сразу несколькими участниками кластера на нем создается CSVFS — реализуемая поверх NTFS кластерная файловая система, впервые появившаяся в Windows Server 2008 R2 и позволяющая использовать такие функции как Динамическая (Живая) миграция, т.е. передачу виртуальной машины между узлами кластера без остановки ее работы.
Общие хранилища становятся доступны на всех узлах кластера в расположении C:ClusterStorageVolumeN. Обратите внимание, что это не просто папки на системном диске, а точки монтирования общих томов кластера.
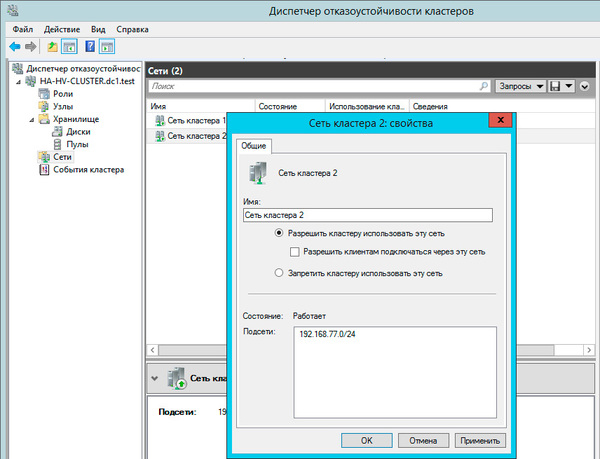
 Закончив с дисками, перейдем к настройкам сети, для этого перейдем в раздел Сети. Для сети, которая подключена к сети предприятия указываем Разрешить кластеру использовать эту сеть и Разрешить клиентам подключаться через эту сеть. Для сети хранения данных просто оставим Разрешить кластеру использовать эту сеть, таким образом обеспечив необходимую избыточность сетевых соединений.
Закончив с дисками, перейдем к настройкам сети, для этого перейдем в раздел Сети. Для сети, которая подключена к сети предприятия указываем Разрешить кластеру использовать эту сеть и Разрешить клиентам подключаться через эту сеть. Для сети хранения данных просто оставим Разрешить кластеру использовать эту сеть, таким образом обеспечив необходимую избыточность сетевых соединений.
 На этом настройка кластера закончена. Для работы с кластеризованными виртуальными машинами следует использовать Диспетчер отказоустойчивости кластеров, а не Диспетчер Hyper-V, который предназначен для управления виртуалками расположенными локально.
На этом настройка кластера закончена. Для работы с кластеризованными виртуальными машинами следует использовать Диспетчер отказоустойчивости кластеров, а не Диспетчер Hyper-V, который предназначен для управления виртуалками расположенными локально.
Чтобы создать виртуальную машину перейдите в раздел Роли в меню правой кнопки мыши выберите Виртуальные машины — Создать виртуальную машину, это же можно сделать и через панель Действия справа.
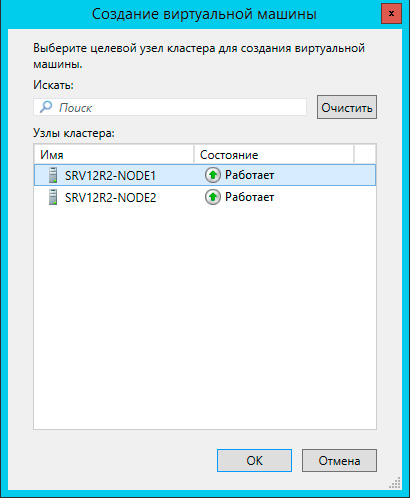
 Прежде всего выберите узел, на котором будет создана виртуальная машина. Каждая виртуалка работает на определенном узле кластера, мигрируя на другие узлы при остановке или отказе своей ноды.
Прежде всего выберите узел, на котором будет создана виртуальная машина. Каждая виртуалка работает на определенном узле кластера, мигрируя на другие узлы при остановке или отказе своей ноды.
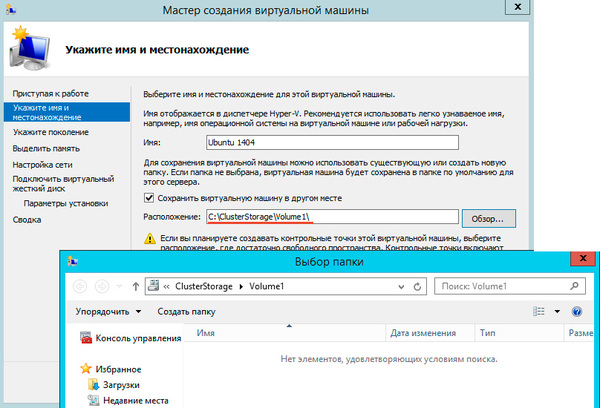
 После выбора узла откроется стандартный Мастер создания виртуальной машины, работа с ним не представляет сложности, поэтому остановимся только на значимых моментах. В качестве расположения виртуальной машины обязательно укажите один из общих томов кластера C:ClusterStorageVolumeN.
После выбора узла откроется стандартный Мастер создания виртуальной машины, работа с ним не представляет сложности, поэтому остановимся только на значимых моментах. В качестве расположения виртуальной машины обязательно укажите один из общих томов кластера C:ClusterStorageVolumeN.
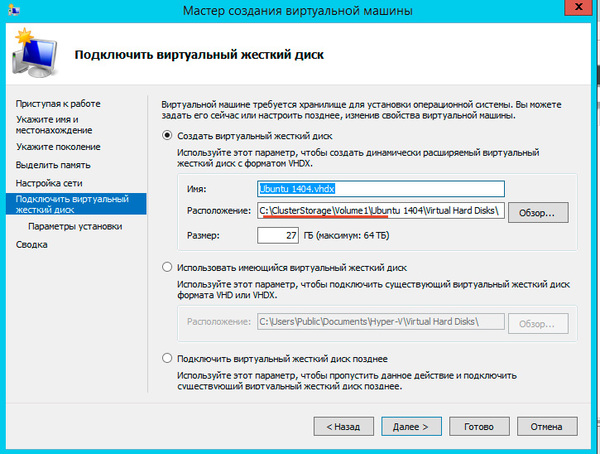
 Здесь же должен располагаться и виртуальный жесткий диск, вы также можете использовать уже существующие виртуальные жесткие диски, предварительно скопировав их в общее хранилище.
Здесь же должен располагаться и виртуальный жесткий диск, вы также можете использовать уже существующие виртуальные жесткие диски, предварительно скопировав их в общее хранилище.
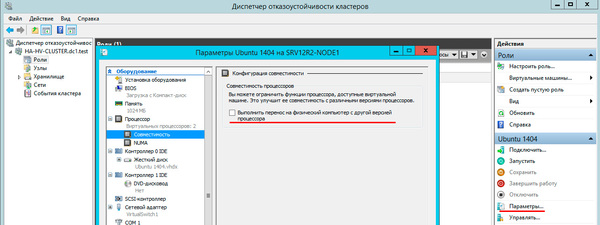
 После создания виртуальной машины перейдите в ее Параметры и в пункте Процессоры — Совместимость установите флажок Выполнить перенос на физический компьютер с другой версией процессора, это позволит выполнять миграцию между узлами с разными моделями процессоров одного производителя. Миграция с Intel на AMD или наоборот невозможна.
После создания виртуальной машины перейдите в ее Параметры и в пункте Процессоры — Совместимость установите флажок Выполнить перенос на физический компьютер с другой версией процессора, это позволит выполнять миграцию между узлами с разными моделями процессоров одного производителя. Миграция с Intel на AMD или наоборот невозможна.
 Затем перейдите в Сетевой адаптер — Аппаратное ускорение и убедитесь, что выбранные опции поддерживаются сетевыми картами всех узлов кластера или отключите их.
Затем перейдите в Сетевой адаптер — Аппаратное ускорение и убедитесь, что выбранные опции поддерживаются сетевыми картами всех узлов кластера или отключите их.
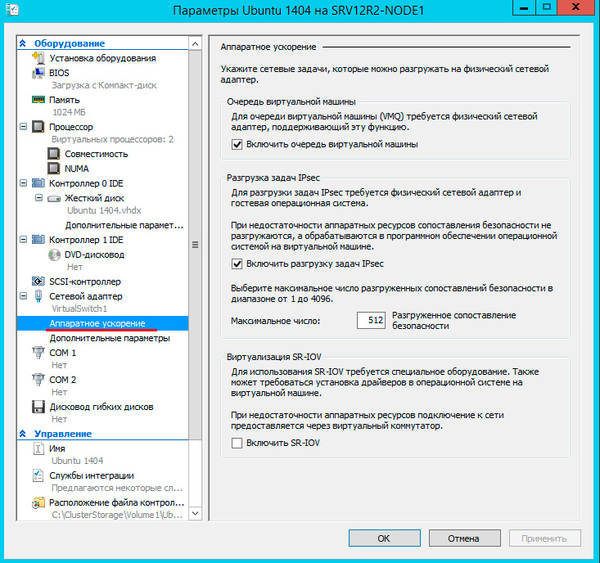 Не забудьте настроить автоматические действия при запуске и завершении работы узла, при большом количестве виртуальных машин не забывайте устанавливать задержку запуска, чтобы избежать чрезмерной нагрузки на систему.
Не забудьте настроить автоматические действия при запуске и завершении работы узла, при большом количестве виртуальных машин не забывайте устанавливать задержку запуска, чтобы избежать чрезмерной нагрузки на систему.
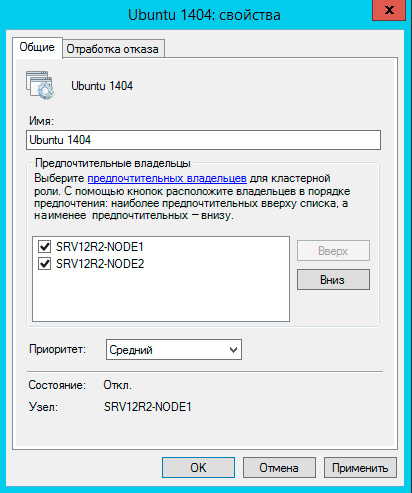
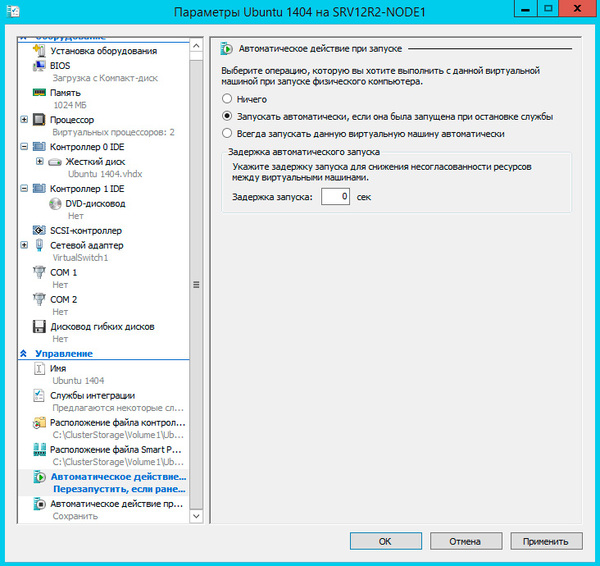 Закончив с Параметрами перейдите в Свойства виртуальной машины и укажите предпочтительные узлы владельцев данной роли в порядке убывания и приоритет, машины имеющие более высокий приоритет мигрируют первыми.
Закончив с Параметрами перейдите в Свойства виртуальной машины и укажите предпочтительные узлы владельцев данной роли в порядке убывания и приоритет, машины имеющие более высокий приоритет мигрируют первыми.
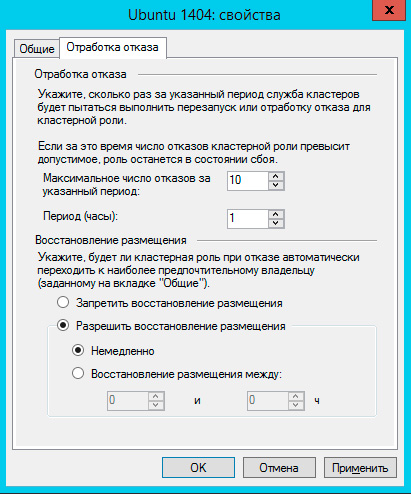
 На закладке Обработка отказа задайте количество допустимых отказов для виртуальной машины за единицу времени, помните, что отказом считается не только отказ узла, но и потеря пульса виртуальной машины, например, ее зависание. На время настройки и тестов есть смысл указать значения побольше.
На закладке Обработка отказа задайте количество допустимых отказов для виртуальной машины за единицу времени, помните, что отказом считается не только отказ узла, но и потеря пульса виртуальной машины, например, ее зависание. На время настройки и тестов есть смысл указать значения побольше.
Также настройте Восстановление размещения, эта опция позволяет передавать виртуальные машины обратно наиболее предпочтительному владельцу при восстановлении его нормальной работы. Чтобы избежать чрезмерных нагрузок воспользуйтесь опцией задержки восстановления.
 На этом настройка виртуальной машины закончена, можем запускать и работать с ней.
На этом настройка виртуальной машины закончена, можем запускать и работать с ней.
Теперь самое время проверить миграцию, для этого щелкните на машине правой кнопкой мыши и выберите Переместить — Динамическая миграция — Выбрать узел. Виртуалка должна переместиться на выбранную ноду не завершая работы.
Каким образом происходит миграция в рабочей обстановке? Допустим нам надо выключить или перезагрузить первый узел, на котором в данный момент выполняется виртуальная машина. Получив команду на завершение работы узел инициирует передачу виртуальных машин:
 Завершение работы приостанавливается до тех пор, пока не будут переданы все виртуальные машины.
Завершение работы приостанавливается до тех пор, пока не будут переданы все виртуальные машины.
 Когда работа узла будет восстановлена, кластер, если включено восстановление размещения, инициирует обратный процесс, передавая виртуальную машину назад предпочтительному владельцу.
Когда работа узла будет восстановлена, кластер, если включено восстановление размещения, инициирует обратный процесс, передавая виртуальную машину назад предпочтительному владельцу.
 Что произойдет если узел, на котором размещены виртуальные машины аварийно выключится или перезагрузится? Все виртуалки также аварийно завершат свою работу, но тут-же будут перезапущены на исправных узлах согласно списка предпочтительных владельцев.
Что произойдет если узел, на котором размещены виртуальные машины аварийно выключится или перезагрузится? Все виртуалки также аварийно завершат свою работу, но тут-же будут перезапущены на исправных узлах согласно списка предпочтительных владельцев.
Как мы уже говорили, прижившийся в отечественной технической литературе термин «отказоустойчивый» неверен и более правильно его было бы переводить как «с обработкой отказа», либо использовать понятие «высокая доступность», которое отражает положение дел наиболее верно.
Кластер Hyper-V не обеспечивает отказоустойчивости виртуальным машинам, отказ узла приводит к отказу всех размещенных на нем машин, но он позволяет обеспечить вашим службам высокую доступность, автоматически восстанавливая их работу и обеспечивая минимально возможное время простоя. Также он позволяет значительно облегчить администрирование виртуальной инфраструктуры позволяя перемещать виртуальные машины между узлами без прерывания их работы.
Источник
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
.
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Card1 IP Address: 10.10.10.1 Subnet Mask: 255.0.0.0 Card2 IP Address: 10.10.10.2 Subnet Mask: 255.0.0.0
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Card1 IP Address: 192.168.0.1 (Cluster Network 1) Subnet Mask: 255.255.255.0 Card2 IP Address: 10.10.10.1 (Cluster Network 2) Subnet Mask: 255.0.0.0
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
Get-ClusterLog
Команда инициирует создание журнала кластера на каждом узле. Для построения журнала кластера только на одном узле можно добавить параметр -Node и указать имя узла. Можно также добавить параметр -TimeSpan для создания журнала только за последние x минут. Например, приведенная ниже команда предписывает построить журнал кластера на узле Node2 за последние 15 минут:
Get-ClusterLog –Node Node2 –TimeSpan 15
В результатах, представленных на экране 1, указано состояние «status 5035.».
 |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Это сообщение об ошибке указывает на неработоспособное состояние сети кластера. Если администратор перейдет в диспетчер отказоустойчивости кластеров, то в разделе «Сети» он увидит, что сеть 192.168.0.0/24 содержит только один сетевой адаптер для узла Node1. Однако имеется новая сеть 192.0.0.0/8, обслуживаемая сетевым адаптером узла Node2. Администратор, поменяв IP-адрес сетевого адаптера на узле Node2, не поменял маску подсети. Таким образом, ошибка 5035 возникла из-за неверной настройки сетевого адаптера.
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
|
|
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
|
|
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
|
|
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
|
|
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
- сетевой доступ (не разрешать перечисление учетных записей SAM анонимными пользователями);
- сетевой доступ (не разрешать перечисление учетных записей SAM и общих ресурсов анонимными пользователями).
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
|
|
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
|
|
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
- основы сетей – объявление поиска соседей;
- основы сетей – запрос поиска соседей.
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
|
|
| Экран 8. Добавление счетчика отброшенных принятых пакетов в системный монитор |
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
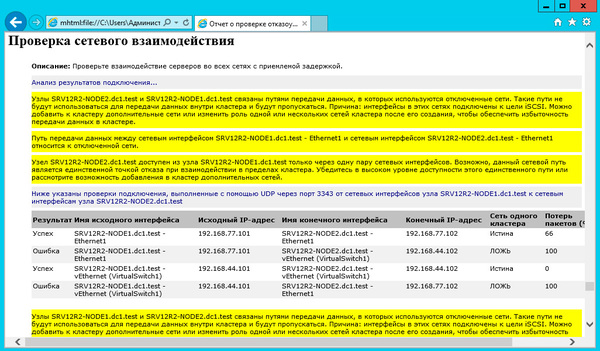
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
Иногда диспетчер отказоустойчивости кластеров не открывается, выдавая сообщение об ошибке (см. экран 9). В процессе открытия диспетчер отказоустойчивости кластеров устанавливает WMI-соединение с каждым узлом кластера. Сообщение об ошибке, приведенное на экране 9, указывает на то, что один из узлов имеет недопустимое пространство имен, то есть с узла был удален экземпляр Cluster WMI (Cluswmi.mof). Остается выяснить, на котором из узлов он удален, поскольку в сообщении об ошибке эта информация отсутствует.
|
|
| Экран 9. Сообщение о недопустимом пространстве имен |
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Set-Location C:WindowsSystem32Wbem Mofcomp.exe Cluswmi.mof
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012 R2» (support.microsoft.com/kb/2920151/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012» (support.microsoft.com/kb/2784261/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2008 R2» (support.microsoft.com/kb/980054/EN-US).
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
$NodeNames = Get-ClusterNode
ForEach ($ClusterName in $NodeNames)
{
Write-Host -NoNewline «Testing $ClusterName»
Try
{
$result = (Get-WmiObject -Class «MSCluster_CLUSTER» `
-namespace «rootMSCluster» `
-authentication PacketPrivacy `
-computername $ClusterName -erroraction stop).__SERVER
Write-host «: Successfully queried cluster node»
}
Catch
{
Write-host -NoNewline «: Failed to query cluster node»
Write-host -ForegroundColor Red -BackgroundColor Black `
$_.Exception.Message
}
}
Физический дисковый ресурс остается в состоянии Online Pending, или утилита Chkdsk автоматически запускается на сервере, который работает Windows Server 2008
Эта статья помогает устранить проблему, из-за которой при ввозе ресурса физического диска в сеть могут быть зарегистрированы различные сообщения об ошибках.
Применяется к: Windows Server 2012 R2
Исходный номер КБ: 977516
Симптомы
При подвозе ресурса физического диска на сервере, который работает Windows Server 2008, может возникнуть один из следующих симптомов:
Симптом 1
При просмотре ресурса физического диска в оснастке управления кластерами failover ресурс может показывать состояние Online Pending. Кроме того, следующее сообщение об ошибке регистрируется в журнале System:
Имя журнала: System
Источник: Microsoft-Windows-FailoverClustering
ID события: 1066
Категория задач: ресурс физического диска
Уровень: предупреждение
Описание:
Кластерный дисковый ресурс «Кластерный диск 3» указывает на развращение для тома ? Volume‘. В Хкдске ведется работа по устранению проблем. Диск будет недоступен до завершения chkdsk. Выход chkdsk будет входить в журнал для файла «C: Windows кластерных отчетов ChkDsk_ResCluster диск 3_Disk2Part1.log».
Chkdsk также может записывать сведения в журнал событий приложения.
Кроме того, следующее сообщение об ошибке регистрируется в журнале кластера:
Физический диск ERR [RES]: VerifyFS: Failed to open file? GlobalROOT Device Harddisk2 Partition1 TextDocument.txt ошибка: 5.
Симптом 2
При просмотре ресурса физического диска в утилите администратора кластера Майкрософт может возникнуть один или несколько следующих симптомов:
Этот ресурс может не выйти в интернет или выйти в интернет после короткой задержки.
Утилита Chkdsk вместе с переключателем /F автоматически запускается на совместном жестком диске.
ИД события 1066, который имеет описание, аналогичное следующему, отображается в журнале System viewer событий:
Кластерный ресурс Disk Y:: поврежден. Запуск chkDsk /F для устранения проблем.
Причина
Эти проблемы возникают по одной из следующих причин.
Причина симптома 1
Эта проблема возникает из-за того, что файл только для чтения находится в корневом каталоге ресурса. Когда общий физический дисковый ресурс занесен в сеть, служба кластера передает файлы корневого каталога и пытается открыть каждый файл вместе с полным доступом. Это поведение происходит, чтобы убедиться, что файловая система является последовательной и чтобы объем не поврежден. Если любой из файлов только для чтения в корневом каталоге ресурса, объем считается поврежденным и chkdsk запущен. Чтобы решить эту проблему, воспользуйтесь обходным решением, которое упоминается в разделе Обходной путь в разделе Symptom 1.
Причина симптома 2
Эта проблема возникает из-за заданного «грязного» флага для тома. Когда общий физический дисковый ресурс занесен в сеть, служба кластера передает файлы корневого каталога и пытается открыть каждый файл вместе с полным доступом. Это поведение происходит, чтобы убедиться, что файловая система является последовательной и чтобы объем не поврежден. Если любой из файлов имеет «грязный» флаг в корневом каталоге ресурса, объем считается поврежденным и chkdsk запущен. Чтобы решить эту проблему, используйте обходное решение, упомянутое в разделе Обход симптомов 2.
Обход симптома 1
Чтобы решить эту проблему, сделайте одно из следующих задач:
- Очистить атрибут только для чтения из файлов, просматривая свойства файла или используя команду по attrib -r командной подсказке.
- Переместите файлы, которые имеют атрибут только для чтения, из корневого каталога ресурса в соответствующий подстановщик.
Если вы не сможете привести диск в интернет и выполнить дополнительную проверку файлов, установите частное свойство Physical DiskRunChkDsk для свойства 4 (ChkDskDontRun). Это отключит проверки крепления тома.
Обход симптома 2
Чтобы решить эту проблему, сначала определите, задан ли «грязный» флаг для указанного тома.
Чтобы определить, установлен ли «грязный» флаг для тома в Windows Server 2008, используйте средство Chkntfs.
Дополнительные сведения о средстве Chkntfs можно получить на следующем веб-сайте Microsoft TechNet:
Chkntfs
Чтобы определить, установлен ли «грязный» флаг для тома в Windows Server 2008 R2, используйте мастер проверки конфигурации.
Дополнительные сведения о мастере проверки конфигурации можно получить на следующем веб-сайте Microsoft TechNet:
Проверка конфигурации кластера failover
Если для громкости установлен «грязный» флаг, запустите утилиту Chkdsk вместе с переключателем /F.
Дополнительные сведения о утилите Chkdsk можно получить на следующем веб-сайте Microsoft TechNet:
Chkdsk
Статус
Корпорация Майкрософт подтвердила, что это проблема в продуктах Майкрософт, перечисленных в начале этой статьи.
Источник
Устранение неполадок Локальные дисковые пространства
Область применения: Windows Server 2022, Windows Server 2019, Windows Server 2016
Используйте следующие сведения, чтобы устранить неполадки с развертыванием Локальные дисковые пространства.
Как правило, начните со следующих шагов:
- Убедитесь, что модель ssd сертифицирована для Windows Server 2016 и Windows Server 2019 с помощью каталога Windows Server. Убедитесь, что диски поддерживаются для Локальные дисковые пространства.
- Проверьте хранилище на наличие неисправных дисков. Используйте программное обеспечение для управления хранилищем, чтобы проверить состояние дисков. Если какой-либо из дисков неисправен, обратитесь к поставщику.
- При необходимости обновите встроенное ПО хранилища и диска. Убедитесь, что на всех узлах установлены последние Обновления Windows. Последние обновления для Windows Server 2016 можно получить из журнала обновлений Windows 10 и Windows Server 2016 и для Windows Server 2019 из журнала обновлений Windows 10 и Windows Server 2019.
- Обновление драйверов и встроенного ПО сетевого адаптера.
- Запустите проверку кластера и просмотрите раздел «Локальный объем дискового пространства», убедитесь, что диски, которые будут использоваться для кэша, отображаются правильно и не будут возникать ошибки.
Если у вас по-прежнему возникли проблемы, ознакомьтесь с приведенными ниже сценариями.
Ресурсы виртуального диска находятся в состоянии «Без избыточности»
Узлы Локальные дисковые пространства перезагрузки системы неожиданно из-за сбоя или сбоя питания. Затем один или несколько виртуальных дисков могут не подключены, и вы увидите описание «Недостаточно избыточности информации».
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Размер | PSComputerName |
|---|---|---|---|---|---|---|
| Диск 4 | Зеркальное отображение | ОК | Работоспособно | Верно | 10 ТБ | Node-01.conto. |
| Диск 3 | Зеркальное отображение | ОК | Работоспособно | Верно | 10 ТБ | Node-01.conto. |
| Диск 2 | Зеркальное отображение | Отсутствие избыточности | Unhealthy | Верно | 10 ТБ | Node-01.conto. |
| Диск 1 | Зеркальное отображение | Unhealthy | Верно | 10 ТБ | Node-01.conto. |
Кроме того, после попытки подключить виртуальный диск к сети в журнал кластера (DiskRecoveryAction) регистрируется следующая информация.
Состояние эксплуатации избыточности может произойти, если произошел сбой диска или если системе не удается получить доступ к данным на виртуальном диске. Эта проблема может возникнуть, если перезагрузка происходит на узле во время обслуживания на узлах.
Чтобы устранить эту проблему, выполните следующие действия.
Удалите затронутые виртуальные диски из CSV-файла. Они будут помещены в группу «Доступное хранилище» в кластере и начнут отображаться как ResourceType физического диска.
На узле, которому принадлежит группа «Доступное хранилище», выполните следующую команду на каждом диске, который находится в состоянии «Без избыточности». Чтобы определить, на каком узле находится группа «Доступное хранилище», можно выполнить следующую команду.
Задайте действие восстановления диска, а затем запустите диски.
Восстановление должно запускаться автоматически. Дождитесь завершения восстановления. Он может перейти в приостановленное состояние и запустить снова. Чтобы отслеживать ход выполнения, выполните следующие действия.
- Запустите Командлет Get-StorageJob , чтобы отслеживать состояние восстановления и узнать, когда оно будет завершено.
- Запустите Get-VirtualDisk и убедитесь, что пробел возвращает значение HealthStatus работоспособности.
После завершения восстановления и работоспособности виртуальных дисков измените параметры виртуального диска обратно.
Переключите диски в автономный режим, а затем снова в сети, чтобы действие DiskRecoveryAction включено:
Добавьте затронутые виртуальные диски обратно в CSV-файл.
DiskRecoveryAction — это параметр переопределения, который позволяет подключать том Пробел в режиме чтения и записи без каких-либо проверок. Это свойство позволяет выполнять диагностику по причине того, почему том не будет подключен к сети. Это очень похоже на режим обслуживания, но его можно вызвать в ресурсе в состоянии сбоя. Он также позволяет получить доступ к данным, которые могут быть полезны в таких ситуациях, как «Отсутствие избыточности», где можно получить доступ к любым данным, которые можно использовать и скопировать. Свойство DiskRecoveryAction было добавлено в 22 февраля 2018 г., обновление базы знаний 4077525.
Состояние отсоединения в кластере
При запуске командлета Get-VirtualDisk operationalStatus для одного или нескольких Локальные дисковые пространства виртуальных дисков отсоединяется. Тем не менее, HealthStatus, сообщаемый командлетом Get-PhysicalDisk , указывает, что все физические диски находятся в работоспособном состоянии.
Ниже приведен пример выходных данных командлета Get-VirtualDisk .
| FriendlyName | ResiliencySettingName | OperationalStatus | HealthStatus | IsManualAttach | Размер | PSComputerName |
|---|---|---|---|---|---|---|
| Диск 4 | Зеркальное отображение | ОК | Работоспособно | Верно | 10 ТБ | Node-01.conto. |
| Диск 3 | Зеркальное отображение | ОК | Работоспособно | Верно | 10 ТБ | Node-01.conto. |
| Диск 2 | Зеркальное отображение | Отсоединен | Неизвестно | Верно | 10 ТБ | Node-01.conto. |
| Диск 1 | Зеркальное отображение | Отсоединен | Неизвестно | Верно | 10 ТБ | Node-01.conto. |
Кроме того, на узлах могут быть зарегистрированы следующие события:
Состояние отсоединения может произойти, если журнал отслеживания «грязных регионов» (DRT) заполнен. дисковые пространства использует отслеживание «грязных областей» (DRT) для зеркальных пространств, чтобы убедиться в том, что при сбое питания регистрируются все обновления метаданных в тестовом режиме, чтобы обеспечить повторную или отмену операций хранения для возврата дискового пространства в гибкое и согласованное состояние при восстановлении питания и резервное копирование системы. Если журнал DRT заполнен, виртуальный диск не может быть подключен к сети, пока метаданные DRT не будут синхронизированы и удалены. Для этого процесса требуется выполнить полную проверку, которая может занять несколько часов.
Чтобы устранить эту проблему, выполните следующие действия.
Удалите затронутые виртуальные диски из CSV-файла.
Выполните следующие команды на каждом диске, который не подключен к сети.
Выполните следующую команду на каждом узле, в котором отключенный том подключен к сети.
Эта задача должна быть инициирована на всех узлах, на которых отключенный том находится в сети. Восстановление должно запускаться автоматически. Дождитесь завершения восстановления. Он может перейти в приостановленное состояние и запустить снова. Чтобы отслеживать ход выполнения, выполните следующие действия.
- Запустите Командлет Get-StorageJob , чтобы отслеживать состояние восстановления и узнать, когда оно будет завершено.
- Запустите Get-VirtualDisk и убедитесь, что пробел возвращает значение HealthStatus работоспособности.
«Проверка целостности данных для аварийного восстановления» — это задача, которая не отображается как задание хранилища, и индикатор хода выполнения отсутствует. Если задача отображается как запущенная, она выполняется. По завершении она будет отображаться завершена.
Кроме того, можно просмотреть состояние выполняемой задачи расписания с помощью следующего командлета:
Как только завершится проверка целостности данных для аварийного восстановления, восстановление завершится и виртуальные диски работоспособны, измените параметры виртуального диска обратно.
Переключите диски в автономный режим, а затем снова в сети, чтобы действие DiskRecoveryAction включено:
Добавьте затронутые виртуальные диски обратно в CSV-файл.
Значение 7 diskRunChkdsk используется для подключения тома Space и секции в режиме только для чтения. Это позволяет Пространствам самостоятельно обнаруживать и самовосстановлять путем активации восстановления. Восстановление будет выполняться автоматически после подключения. Он также позволяет получить доступ к данным, которые могут быть полезны для получения доступа к любым данным, которые можно скопировать. Для некоторых условий сбоя, таких как полный журнал DRT, необходимо запустить проверку целостности данных для запланированной задачи аварийного восстановления.
Задача «Проверка целостности данных для аварийного восстановления » используется для синхронизации и очистки полного журнала отслеживания «грязных регионов» (DRT). Выполнение этой задачи может занять несколько часов. «Проверка целостности данных для аварийного восстановления» — это задача, которая не отображается как задание хранилища, и индикатор хода выполнения отсутствует. Если задача отображается как запущенная, она выполняется. По завершении он будет отображаться как завершенный. Если вы отмените задачу или перезапустите узел во время выполнения этой задачи, задача должна начаться с самого начала.
Событие 5120 с STATUS_IO_TIMEOUT c00000b5
Для Windows Server 2016. Чтобы снизить вероятность возникновения этих симптомов при применении обновления с исправлением, рекомендуется использовать приведенную ниже процедуру режима обслуживания хранилища, чтобы установить накопительный пакет обновления для Windows Server 2016 или более поздней версии, если узлы установлены в настоящее время Windows Server 2016 накопительный пакет обновления, выпущенный с 8 мая 2018 г. по 9 октября 2018 г.
Вы можете получить событие 5120 с STATUS_IO_TIMEOUT c00000b5 после перезапуска узла на Windows Server 2016 с накопительным обновлением, выпущенным с 8 мая 2018 г. 4103723 базы знаний до9 октября 2018 г. 4462917 кб.
При перезапуске узла событие 5120 регистрируется в журнале системных событий и включает один из следующих кодов ошибок:
При регистрации события 5120 создается динамический дамп для сбора сведений об отладке, которые могут вызвать дополнительные симптомы или оказать влияние на производительность. При создании динамического дампа создается краткая пауза, позволяющая создавать моментальные снимки памяти для записи файла дампа. Системы с большим объемом памяти и находятся под стрессом, могут привести к удалению узлов из членства в кластере, а также к регистрации следующего события 1135.
Изменение, введенное 8 мая 2018 г. на Windows Server 2016, которое было накопительным обновлением для добавления устойчивых дескрипторов SMB для Локальные дисковые пространства сетевых сеансов SMB внутри кластера. Это было сделано для повышения устойчивости к временным сбоям сети и улучшения обработки перегрузки сети RoCE. Эти улучшения также случайно увеличили время ожидания при попытке повторного подключения SMB и ожидания ожидания при перезапуске узла. Эти проблемы могут повлиять на систему, которая находится под стрессом. Во время незапланированного простоя время ввода-вывода приостанавливается до 60 секунд, пока система ожидает истечения времени ожидания подключений. Чтобы устранить эту проблему, установите накопительное обновление для Windows Server 2016 или более поздней версии 18 октября 2018 г.
Примечание Это обновление согласует время ожидания CSV с истечением времени ожидания подключения SMB, чтобы устранить эту проблему. Он не реализует изменения, чтобы отключить создание динамического дампа, упомянутое в разделе обходного решения.
Процесс завершения работы:
Запустите командлет Get-VirtualDisk и убедитесь, что значение HealthStatus является работоспособным.
Очистите узел, выполнив следующий командлет:
Поместите диски на этот узел в режим обслуживания хранилища, выполнив следующий командлет:
Запустите командлет Get-PhysicalDisk и убедитесь, что значение OperationalStatus находится в режиме обслуживания.
Запустите командлет Restart-Computer , чтобы перезапустить узел.
После перезапуска узла удалите диски на этом узле из режима обслуживания хранилища, выполнив следующий командлет:
Возобновите узел, выполнив следующий командлет:
Проверьте состояние заданий повторной синхронизации, выполнив следующий командлет:
Отключение динамических дампов
Чтобы снизить влияние создания динамического дампа на системы с большим объемом памяти и находятся под стрессом, вы можете дополнительно отключить создание динамического дампа. Ниже приведены три варианта.
Эта процедура может предотвратить сбор диагностических сведений, которые служба поддержки Майкрософт, возможно, потребуется исследовать эту проблему. Агенту поддержки может потребоваться повторно включить создание динамического дампа в зависимости от конкретных сценариев устранения неполадок.
Существует два способа отключения динамических дампов, как описано ниже.
Метод 1 (рекомендуется в этом сценарии)
Чтобы полностью отключить все дампы, включая динамические дампы на уровне системы, выполните следующие действия.
- Создайте следующий раздел реестра: HKLMSystemCurrentControlSetControlCrashControlForceDumpsDisabled
- В разделе нового ключа ForceDumpsDisabled создайте свойство REG_DWORD как GuardedHost, а затем задайте его значение 0x10000000.
- Примените новый раздел реестра к каждому узлу кластера.
Чтобы изменения nregistry вступили в силу, необходимо перезагрузить компьютер.
После установки этого раздела реестра создание динамического дампа завершится ошибкой и приведет к ошибке «STATUS_NOT_SUPPORTED».
Метод 2
По умолчанию отчеты об ошибках Windows разрешает только один liveDump для каждого типа отчета в течение 7 дней и только 1 LiveDump на компьютер в течение 5 дней. Это можно изменить, задав следующие разделы реестра, чтобы разрешить на компьютере только один LiveDump.
Примечание Чтобы изменения вступили в силу, необходимо перезагрузить компьютер.
Метод 3
Чтобы отключить создание динамических дампов кластера (например, при регистрации события 5120), выполните следующий командлет:
Этот командлет немедленно влияет на все узлы кластера без перезагрузки компьютера.
Низкая производительность операций ввода-вывода
Если вы видите низкую производительность ввода-вывода, проверьте, включен ли кэш в конфигурации Локальные дисковые пространства.
Проверить можно двумя способами.
Использование журнала кластера. Откройте журнал кластера в текстовом редакторе и выполните поиск по запросу «[=== SBL Disks ===]». Это будет список дисков на узле, в который был создан журнал.
Пример дисков с поддержкой кэша. Обратите внимание, что здесь находится состояние CacheDiskStateInitializedAndBound и есть GUID.
Кэш не включен: здесь мы видим, что guid отсутствует, а состояние — CacheDiskStateNonHybrid.
Кэш не включен: если все диски имеют одинаковый вариант типа, по умолчанию не включен. Здесь мы видим, что guid отсутствует, а состояние CacheDiskStateIneligibleDataPartition отсутствует.
Использование Get-PhysicalDisk.xml из SDDCDiagnosticInfo
- Откройте XML-файл с помощью команды «$d = Import-Clixml GetPhysicalDisk.XML»
- Запуск хранилища ipmo
- выполните команду «$d». Обратите внимание, что параметр «Использование» выбран автоматически, а не журнал, вы увидите следующие выходные данные:
FriendlyName SerialNumber MediaType CanPool OperationalStatus HealthStatus Использование Размер NVMe INTEL SSDPE7KX02 PHLF733000372P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504008J2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504005F2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504002A2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504004T2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7504002E2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330002Z2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF733000272P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330001J2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF733000302P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ NVMe INTEL SSDPE7KX02 PHLF7330004D2P0LGN SSD Неверно ОК Работоспособно Автоматическое выделение 1,82 ТБ - Удалите физический диск из пула и добавьте его обратно.
- Import-Module Clear-PhysicalDiskHealthData.ps1
- Запустите скриптClear-PhysicalDiskHealthData.ps1 , чтобы очистить намерение. (Доступно для скачивания в виде файла .TXT. Прежде чем его можно будет запустить, необходимо сохранить в виде файла .PS1.)
Как уничтожить существующий кластер, чтобы снова можно было использовать одни и те же диски.
В кластере Локальные дисковые пространства после отключения Локальные дисковые пространства и использования процесса очистки, описанного в разделе «Очистка дисков», кластеризованный пул носителей по-прежнему остается в автономном состоянии, а служба работоспособности удаляется из кластера.
Следующим шагом является удаление пула фантомных носителей:
Теперь, если запустить Get-PhysicalDisk на любом из узлов, вы увидите все диски, которые находились в пуле. Например, в лаборатории с кластером с 4 узлами с 4 дисками SAS каждый из них представляет 100 ГБ для каждого узла. В этом случае после отключения direct дискового пространства, который удаляет SBL (уровень шины хранилища), но оставляет фильтр, если вы запускаете Get-PhysicalDisk, он должен сообщить о 4 дисках, за исключением локального диска ОС. Вместо этого он сообщил 16. Это одинаково для всех узлов в кластере. При выполнении команды Get-Disk вы увидите локальные подключенные диски, нумеруемые как 0, 1, 2 и т. д., как показано в этом примере выходных данных:
| число; | Понятное имя | Серийный номер | HealthStatus | OperationalStatus | Общий размер | Стиль секции |
|---|---|---|---|---|---|---|
| Msft Virtu. | Работоспособно | Миграция по сети | 127 ГБ | GPT | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| 1 | Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | |
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| 2 | Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | |
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| 4 | Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | |
| 3 | Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | |
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW | ||
| Msft Virtu. | Работоспособно | Автономная миграция | 100 ГБ | RAW |
Сообщение об ошибке «неподдерживаемый тип носителя» при создании кластера Локальные дисковые пространства с помощью Enable-ClusterS2D
При запуске командлета Enable-ClusterS2D могут возникнуть ошибки, аналогичные этой ошибке:

Чтобы устранить эту проблему, убедитесь, что адаптер HBA настроен в режиме HBA. В режиме RAID не нужно настраивать HBA.
Enable-ClusterStorageSpacesDirect зависает на «Ожидание, пока диски SBL не будут отображаться» или на 27 %
В отчете о проверке появятся следующие сведения:
Диск , подключенный к узлу , вернул связь портов SCSI и не удалось найти соответствующее устройство корпуса. Оборудование несовместимо с Локальные дисковые пространства (S2D), обратитесь к поставщику оборудования, чтобы проверить поддержку служб корпусов SCSI (SES).
Проблема связана с картой расширения HPE SAS, которая находится между дисками и картой HBA. Расширитель SAS создает повторяющийся идентификатор между первым диском, подключенным к расширительу, и самим расширителем. Эта проблема устранена в встроенном ПО расширителя SAS контроллеров смарт-массивов HPE: 4.02.
Серия Intel SSD DC P4600 имеет неуникальное NGUID
В приведенном ниже примере может возникнуть проблема, из-за которой устройство серии INTEL DC P4600, похоже, сообщало аналогичные 16 байтов NGUID для нескольких пространств имен, таких как 010000000014E25C000014E214 или 01000000000E4D25C0000EEE214.
| uniqueid | deviceid | MediaType | BusType | serialnumber | size | canpool | Friendlyname | OperationalStatus |
|---|---|---|---|---|---|---|---|---|
| 5000CCA251D12E30 | HDD | SAS | 7PKR197G | 10000831348736 | False | HGST | HUH721010AL4200 | |
| eui.0100000001000000E4D25C00014E214 | 4 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Верно | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C00014E214 | 5 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_0014_E214. | 1600321314816 | Верно | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 6 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | Верно | INTEL | SSDPE2KE016T7 |
| eui.0100000001000000E4D25C0000EEE214 | 7 | SSD | NVMe | 0100_0000_0100_0000_E4D2_5C00_00EE_E214. | 1600321314816 | Верно | INTEL | SSDPE2KE016T7 |
Чтобы устранить эту проблему, обновите встроенное ПО на дисках Intel до последней версии. Версия встроенного ПО QDV101B1 с мая 2018 года известна для устранения этой проблемы.
Выпуск intel SSD Data Center Tool за май 2018 г. включает обновление встроенного ПО QDV101B1 для серии Intel SSD DC P4600.
Физический диск «Работоспособен», а состояние эксплуатации — «Удаление из пула»
В кластере Windows Server 2016 Локальные дисковые пространства можно увидеть healthStatus для одного или нескольких физических дисков как «Работоспособный», а operationalStatus — «(Удаление из пула, ОК).»
«Удаление из пула» — это набор намерений, если вызывается Remove-PhysicalDisk , но сохраняется в работоспособности для поддержания состояния и разрешает восстановление, если операция удаления завершается сбоем. Вы можете вручную изменить OperationalStatus на «Работоспособный» одним из следующих методов:
Ниже приведены некоторые примеры запуска скрипта:
Используйте параметр SerialNumber , чтобы указать диск, который необходимо задать для параметра «Работоспособный». Серийный номер можно получить из WMI MSFT_PhysicalDisk или Get-PhysicalDIsk. (Мы используем только 0 для серийного номера ниже.)
Используйте параметр UniqueId , чтобы указать диск (снова из WMI MSFT_PhysicalDisk или Get-PhysicalDIsk).
Копирование файлов выполняется медленно
Возможно, возникла проблема с использованием проводник для копирования большого виртуального жесткого диска на виртуальный диск. Копирование файлов занимает больше времени, чем ожидалось.
Использование проводник, Robocopy или Xcopy для копирования большого виртуального жесткого диска на виртуальный диск не рекомендуется, так как это приведет к снижению производительности. Процесс копирования не проходит через стек Локальные дисковые пространства, который находится ниже в стеке хранилища и действует как локальный процесс копирования.
Если вы хотите протестировать Локальные дисковые пространства производительность, рекомендуется использовать VMFleet и Diskspd для загрузки и стресс-тестирования серверов, чтобы получить базовую строку и задать ожидания производительности Локальные дисковые пространства.
Ожидаемые события, которые будут отображаться на остальных узлах во время перезагрузки узла.
Эти события можно игнорировать.
Если вы используете виртуальные машины Azure, это событие можно игнорировать: Event ID 32: The driver detected that the device DeviceHarddisk5DR5 has its write cache enabled. Data corruption may occur.
Низкая производительность или «Потерянное взаимодействие», «Ошибка ввода-вывода», «Отсоединенная» или «Избыточность» для развертываний, использующих устройства NVMe Intel P3x00
Мы определили критически важную проблему, которая затрагивает некоторые Локальные дисковые пространства пользователей, использующих оборудование на основе семейства устройств NVM Express (NVMe) Intel P3x00 до выпуска обслуживания 8.
Отдельные изготовители оборудования могут иметь устройства, основанные на семействе устройств NVMe Intel P3x00 с уникальными строками версии встроенного ПО. Для получения дополнительных сведений о последней версии встроенного ПО обратитесь к изготовителю оборудования.
Если вы используете оборудование в развертывании на основе семейства устройств NVMe Intel P3x00, рекомендуется немедленно применить последнее доступное встроенное ПО (по крайней мере выпуск обслуживания 8).
Источник
Обновлено: 30.01.2023
В этой статье мы рассмотрим подробный процесс ремонта HDD и поделимся с вами информацией о том как можно восстановить данные даже в условиях тяжело поврежденного диска. Однако прежде рекомендуем вам ознакомиться с некоторой технической информацией, которая позволит вам понять суть неполадки.
Тяжело переоценить роль информации в современном мире. От нее зависит не только уровень наших знаний, но и, зачастую, профессиональная карьера — то, что всегда дается большим трудом. Любое повреждение физических дисков компьютера способно повлечь за собой самые неприятные последствия, включая крах устройства и полную потерю личных данных. Как поступить в случае, если на диске обнаружились битые сектора и существует риск его гибели?
Что такое битый сектор?
Битый сектор — это определенное пространство жесткого диска, которое невозможно использовать в связи с его физическим повреждением или отсутствием доступа к нему. Данная неполадка проявляется прежде всего в медленной работе HDD, неспособности системы полноценно загрузиться и отказе WIndows в запросе на форматирование устройства. Возникновение этих явлений может уверенно свидетельствовать о наличии битых секторов на диске.
Виды повреждений HDD
Существует всего два типа битых секторов жесткого диска: физический и логический. Давайте рассмотрим их подробнее.
Физически битый сектор — это кластер жесткого диска, который был поврежден физически. Если головка HDD в процессе работы касается вращающейся пластины, то она гарантированно будет повреждена. Отремонтировать такой сектор невозможно.
Логически битый сектор — это кластер, который перестал работать должным образом. Когда операционная система пытается считать с него данные или записать новые, она сталкивается с ошибкой и теряет любую возможность взаимодействия с сектором. Такие сектора могут быть с легкостью восстановлены.
Признаки повреждения HDD
Жесткий диск является, пожалуй, одним из самых хрупких компонентов компьютера. Если не следить должным образом за его состоянием, рано или поздно может настать момент его отказа и полной потери данных. Точно так же как и любое другое устройство, HDD обладает собственными уникальными симптомами, сигнализирующими о возникших ошибках. Давайте рассмотрим некоторые признаки, указывающие на явное повреждение секторов жесткого диска.
Причины возникновения битых секторов
Кластеры жесткого диска могут быть легко повреждены по ряду причин. Они могут в существенной мере затруднить работу с ПК или вовсе приведут к гибели жесткого диска. Чтобы предотвратить данную неполадку, рекомендуем ознакомиться с некоторыми распространенными причинами ее возникновения.
- Устаревание жесткого диска.
Как и любое другое устройство, жесткий диск имеет свой строго отведенный срок службы и по его истечению вероятность возникновения разного рода ошибок существенно возрастает. - Некорректное выключение компьютера.
В связи с высокой скоростью вращения компонентов жесткого диска, внезапная перезагрузка или выключение питания могут привести к тому, что головка HDD коснется пластины и спровоцирует физическое повреждение. - Встряхивания и удары по жесткому диску.
Несмотря на то что производители HDD всячески стремятся упрочнить конструкцию своих устройств, неаккуратное обращение с ними может с легкостью привести к серьезным повреждениям. - Загрязнение устройства.
Пыль — одна из тех причин возникновения битых секторов, о которых пользователи вспоминают в последнюю очередь. Если накопится достаточное количество грязи, в жестком диске незамедлительно появятся поврежденные кластеры.
Итак, мы разобрались с технической стороной вопроса и теперь самое время приступить к практике!
Сканирование и ремонт HDD
Как вы наверняка знаете, существует большое количество всевозможных приложений цель которых помочь пользователю проверить и восстановить поврежденный диск. Тем не менее не все они отличаются эффективностью или доступностью к пониманию интерфейса, что в определенной степени усложняет процесс восстановления устройства. Поэтому мы подготовили для вас список, на наш взгляд, лучших приложений по ремонту HDD.
Проводник Windows
Открывает наш топ встроенная утилита операционной системы Windows — Проводник. Если вы не большой любитель эксплуатации стороннего ПО, то данная программа придется вам по душе, поскольку она избавляет вас от необходимости утомительных поисков подходящего софта на просторах интернета. Как ею воспользоваться?
1. Откройте Мой компьютер/Этот компьютер (горячие клавиши Win + E ).
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
Команда инициирует создание журнала кластера на каждом узле. Для построения журнала кластера только на одном узле можно добавить параметр -Node и указать имя узла. Можно также добавить параметр -TimeSpan для создания журнала только за последние x минут. Например, приведенная ниже команда предписывает построить журнал кластера на узле Node2 за последние 15 минут:
В результатах, представленных на экране 1, указано состояние «status 5035.».
.jpg) |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
.jpg) |
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
.jpg) |
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
.jpg) |
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
.jpg) |
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
- сетевой доступ (не разрешать перечисление учетных записей SAM анонимными пользователями);
- сетевой доступ (не разрешать перечисление учетных записей SAM и общих ресурсов анонимными пользователями).
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
.jpg) |
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
.jpg) |
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
- основы сетей – объявление поиска соседей;
- основы сетей – запрос поиска соседей.
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
В случае возникновения ошибок при работе с Backup Exec в кластерной среде просмотрите вопросы и ответы, представленные в этом разделе.
Табл.: Устранение неполадок кластеров — вопросы и ответы
После восстановления кластера и всех общих дисков служба кластера не запускается. Почему она не запускается и что необходимо сделать, чтобы запустить ее?
Служба кластера может не запускаться потому, что сигнатура диска на диске кворума отличается то исходной сигнатуры. Если у вас есть Microsoft 2000 Resource Kit, запустите программу Dumpcfg.exe или программу Clusterrecovery из Microsoft 2003 Resource Kit, чтобы заменить диск. Например, введите:
dumpcfg.exe /s 12345678 0
Замените 12345678 на сигнатуру диска, а 0 — на номер диска. Сигнатуру диска и номер диска можно найти в журнале событий.
Если у вас нет Microsoft 2000 Resource Kit, то для изменения сигнатуры диска кворума можно воспользоваться параметром -Fixquorum.
Эта ошибка связана с тем, что переключение произошло во время резервного копирования ресурса, поэтому набор данных резервного копирования не был полностью записан на носитель. Однако для объектов, резервные копии которых были частично созданы в первом наборе данных резервного копирования, были созданы полные резервные копии во время перезапуска, тем самым была обеспечены целостность данных. Таким образом, необходимо восстановить и проверить все объекты на носителе для данного набора данных резервного копирования.
Я объединил первичный сервер SAN со вторичным сервером SAN. После этого служба устройств и носителей на вторичном сервере выдает ошибку. Почему?
Такое поведение связано с тем, что вторичный сервер стал активным узлом и попытался подключиться к базе данных Backup Exec на первичном сервере, который сейчас недоступен. Для исправления этой ситуации воспользуйтесь программой Backup Exec Utility (BEUTILITY.EXE) или заново установите вторичный сервер в качестве первичного сервера.
Произошел сбой резервного копирования Advanced Disk Based Backup в результате переключения виртуального сервера приложений. Как очистить Veritas Storage Foundation для групп дисков кластера Windows и связанные с ними тома?
Если при использовании источника моментальных копий Veritas Storage Foundation for Windows (SFW) для выполнения расширенного резервного копирования на диск произошел сбой виртуального сервера приложения, задание восстановления не может быть запущено. Исходная группа дисков кластера, которой принадлежат поврежденные тома, перемещена из исходного узла во вторичный узел, восстановление синхронизации поврежденных томов с исходным томами будет невозможно.
Ниже перечислены шаги для расширенного резервного копирования на диск:
Поврежденные тома отделяются от исходных томов.
Отделенные поврежденные тома помещаются в новую группу дисков кластера.
Новая группа дисков кластера удаляется из физического узла, в котором работает виртуальный сервер, а затем добавляются на сервер резервного копирования Symantec Backup Exec.
Новая группа дисков кластера будет в результате удалена с сервера резервного копирования и возвращена на физический узел, на котором она находилась прежде, независимо от текущего расположения виртуального сервера.
Новая группа дисков кластера присоединяется к исходной группе дисков кластера, если она расположена в том же узле.
Поврежденные тома синхронизируются с исходными томами.
В случае переключения сервера с текущего активного узла на вторичный узел, новая группа дисков кластера не может повторно присоединиться к исходной группе дисков кластера.
После выполнения ручного переключения ресурса кластера Veritas произошло зависание заданий резервного копирования. Почему невозможно завершить задания резервного копирования?
Во время переключения ресурса кластера Veritas вручную сервер Veritas Cluster Server не отключает ресурсы MountV, если есть открытые указатели. Перед выполнением переключения вручную рекомендуется завершить все задания резервного копирования. В случае зависания задания восстановления необходимо вручную отменить это задание перед процедурой очистки вручную.
В прошлом месяце я рассмотрел некоторые наиболее популярные сложности с отказоустойчивыми кластерами в Windows Server 2008 R2 и рассказал о способах корректного устранения этих неполадок.
Вспомните, что текущая политика поддержки предполагает, что решение отказоустойчивой кластеризации в Windows Server 2008 и Windows Server 2008 R2 может считаться официально поддерживаемым службой поддержки потребителей Microsoft (Customer Support Services, CSS), только если удовлетворяет следующим критериям:
- Все компоненты, включая оборудование и программное обеспечение, должны удовлетворять требованиям для получения логотипа «Certified for Windows Server 2008 R2».
- Окончательно настроенное решение должно пройти проверочный тест в оснастке «Failover Cluster Management» (Управление отказоустойчивыми кластерами).
Есть несколько сценариев устранения неполадок. Они представляют самые популярные неполадки отказоустойчивых кластеров Windows Server 2008 R2 и шаги по их устранению.
Сценарий 1. В процессе ежемесячной очистки объектов Active Directory по неосторожности был удален Cluster Name Object. Вновь созданный объект не переходит в интерактивный режим.
Объект CNO (Cluster Name Object) это общий идентификатор кластера, и поэтому он очень важен. Он создается автоматически мастером создания кластера (Create cluster) и носит то же имя, что и кластер. По мере настройки новых служб и приложений в этой учетной записи, CNO создает другие виртуальные объекты. При удалении CNO или его разрешений он не может создавать другие необходимые кластеру объекты до тех пор, пока не будет восстановлен или ему не будут назначены соответствующие разрешения.
Как и в случае с другими объектами Active Directory, у CNO есть связанный идентификатор objectGUID. По нему отказоустойчивый кластер узнает, что имеет дело с правильным объектом. Если просто создать новый объект, то у него будет новый objectGUID. Нужно восстановить правильный объект, чтобы отказоустойчивый кластер мог продолжить нормальную работу.
При устранении этой неполадки нужно найти две вещи, относящиеся к ресурсу кластера. В Windows PowerShell выполните команду:
Get-ClusterResource «Cluster Name» | Get-ClusterParameterCreatingDC,objectGUID
Эта команда сообщает необходимые значения. Первый параметр — CreatingDC. Когда отказоустойчивый кластер создает CNO, отмечается контроллер домена, в котором он был создан. При любой выполняемой с кластером операции (создание виртуального объекта, перевод в интерактивное состояние и т.п.) к этому контроллеру обращаются за объектом CNO и информацией безопасности. Если контроллер домена найти не удается или он недоступен, тогда уже выполняется поиск любого другого ответственного контроллера.
Второй параметр – objectGUID – отвечает за то, чтобы можно было быть уверенным, что получен правильный объект. В нашем случае имя кластера —CLUSTER1, контроллер, на котором он был создан, — DC1, а значение objectGUID — 1a3cf049cf79614ebd94670560da6f04:
Надо войти в систему DC1 и открыть консоль Active Directory Users and Computers (Active Directory — пользователи и компьютеры). Если в ней есть текущий объект CLUSTER1, можно проверить наличие в нем правильных атрибутов. Редактор атрибутов Active Directory не показывает GUID, поскольку он не отражается в шестнадцатеричном формате.
В противном случае мы увидели бы такое значение 49f03c1a-79cf-4e61-bd94-670560da6f04. Шестнадцатеричный формат преобразуется и работает в парах, что немного смущает. Если взять первые восемь пар и выполнить преобразование, то 49f03c1a станет 1a3cf049. В следующих двух парах 79cf станет cf79, а 4e61 — 614e. Оставшиеся пары останутся такими же.
Чтобы увидеть в шестнадцатеричном формате то, что видит отказоустойчивый кластер, свойства объекта objectGUID нужно передать в редактор атрибутов. Поскольку это неправильный объект, сначала надо удалить объект, чтобы было возможно восстановить правильный объект.
Восстановить объект можно несколькими способами. Можно воспользоваться Active Directory Restore, утилитой, подобной ADRESTORE, или новой корзиной Active Directory (если это контроллер домена Windows 2008 R2 с обновленной схемой). Новая корзина значительно упрощает процесс и делает его самым удобным для восстановления объектов Active Directory.
С помощью корзины Active Directory можно найти объект восстановления, выполнив команду Windows PowerShell:
Эта команда выполняет поиск всех удаленных объектов с именем CLUSTER1 в корзине Active Directory. В результате получаем имя учетной записи и objectGUID. Если найдены несколько элементов, все они будут показаны. При просмотре нужного элемента мы увидим:
Теперь его надо восстановить. После удаления неправильного объекта для восстановления следует использовать такую команду Windows PowerShell:
Restore-ADObject –identity 49f03c1a-79cf-4e61-bd94-670560da6f04
В результате объект будет восстановлен в том же месте (подразделении) с теми же разрешениями и паролем, известным Active Directory.
Это одно из преимуществ корзины Active Directory по сравнению с аналогами утилиты ADRESTORE. При восстановлении эти утилиты сбрасывают пароль, перемещают объект в соответствующий контейнер, восстанавливают объект в отказоустойчивом кластере и т.д.
Используя корзину, мы просто переводим ресурс в интерактивный режим. Это более удачный вариант, чем восстановление Active Directory, особенно если позже были созданы новые объекты пользователя или компьютера, удалены старые объекты и т. п.
Во-первых, уточним определение общих томов кластера. Они упрощают настройку и управление виртуальными машинами Hyper-V в отказоустойчивых кластерах. Благодаря наличию общих томов в отказоустойчивом кластере, работающие под управлением Hyper-V, множество виртуальных машин могут использовать один LUN и при этом перемещаться между узлами независимо друг от друга. Общий том кластера обеспечивает повышение гибкости томов в кластерном хранилище. Например, для оптимизации дисковой производительности можно хранить системные файлы отдельно от данных, даже если системные файлы и данные размещены в файлах виртуального жесткого диска.
Надо позаботиться, чтобы в параметрах всех сетевых адаптеров, обеспечивающих связь кластеров, были установлены компоненты Client for Microsoft Networks (Клиент для сетей Microsoft) и File and Printer Sharing for Microsoft Networks (Общий доступ к файлам и принтерам в сетях Microsoft), для поддержки протокола SMB (Server Message Block). Это необходимо для общего тома. Сервер работает под управлением Windows Server 2008 R2, что автоматически обеспечивает версию SMB, необходимую для общего тома, а именно SMB2.Используется только одна предпочтительная коммуникационная сеть для общего тома, но включение этих параметров во множестве сетей поможет кластеру противостоять отказам.
Перенаправление доступа подразумевает, что все операции ввода-вывода «перенаправляются» по сети на другой узел, имеющий доступ к диску. Могут быть три причины для перехода в режим перенаправления доступа:
- Режим настроен вручную.
- Идет процесс резервного копирования.
- Имеются неполадки с оборудованием, и узел не может напрямую получить доступ к диску.
В нашем сценарии мы исключили первые два варианта. Остается третий. Если заглянуть в журнал системных событий System Event Log, можно увидеть событие отказоустойчивой кластеризации «Event ID: 5121».
Определение этой записи журнала: Общий том кластера CSV «Cluster Disk x» более не доступен напрямую с этого узла кластера. Ввод-вывод будет перенаправлен на устройство хранения по сети через узел-владелец, которому принадлежит этот том. Это может привести к снижению производительности. Если перенаправление доступа к этому тому включено, отключите его. Если перенаправление доступа отключено, устраните неполадки связи этого узла с устройством хранения; после восстановления связи с устройством хранения работоспособность ввода-вывода будет также восстановлена.
В такой ситуации надо тщательно изучить все предшествующие этому события, связанные с оборудованием. Это значит, что надо искать такие события, как 9, 11, 15, которые указывают на неполадки оборудования или связи. Стоит провести физическую проверку диску в панели Disk Management (Управление диском). В большинстве случаев так удается обнаружить другие ошибки. Решив проблему, можно вывести диск из этого режима.
Следует помнить, что общий том остается включенным на протяжении всего времени, пока есть хотя бы один узел, подключенный с сети хранения. Именно поэтому будет установлен режим перенаправления. Все операции записи на диск отправляются в узел, который поддерживает связь, и виртуальные машины Hyper-V будут продолжать работу. Это может повлиять на их производительность, но они останутся работоспособными. В результате производственные серверы никогда не отключаются, а это уже хорошо.
Сценарий 3. Я только что создал новый отказоустойчивый кластер Windows 2008 R2 для виртуальных машин с высоким уровнем доступности. Диски настроены для работы с общим томом, но при попытке доступа к ним с помощью проводника или панели «Управление диском» происходит зависание. Я не могу скопировать на том файлы виртуального диска.
Существует только один «истинный» владелец диска и он называется узел-координатор (Coordinator Node). Запись любого типа метаданных выполняется только этим узлом.
Проводник или панель управления диском открывает диск с возможностью записи любых метаданных (если такое предполагается). По этой причине любой диск, не находящийся в собственности, перенаправляется по сети на узел-координатор. Это не совсем то же, что «перенаправление доступа».
В процессе устранения этой неполадки в оснастке «Управление отказоустойчивым кластером» можно увидеть, что диск находится в интерактивном режиме. Поэтому сначала надо изучить события в журнале. В журнале системных событий можно увидеть события отказоустойчивой кластеризации:
Событие ID: 5120
Общий том кластера «Cluster Disk x» больше не доступен на этом узле из-за «STATUS_BAD_NETWORK_PATH(c00000be)». Все операции ввода-вывода будут временно поставлены в очередь, пока путь к тому не будет восстановлен. (Cluster Shared Volume ‘Cluster Disk x’ is no longer available on this node because of ‘STATUS_BAD_NETWORK_PATH(c00000be).’ All I/O will temporarily be queued until a path to the volume is reestablished.)
Событие ID: 5142
Эти события говорят о попытках подключения к узлу-координатору, которые завершаются таймаутом. Поэтому загляните в журнал системных событий и проверьте, нет ли там других ошибок, указывающих на связь узлов по сети. При наличии таковых необходимо устранить их. Ошибки могут быть вызваны поломкой или отключением сетевой карты.
Далее надо проверить возможность связь узлов по сети. Первым делом нужно проверить сеть, по которой передается трафик общего тома. В отказоустойчивом кластере сеть для общего тома выбирается, исходя из максимального значения метрики. Это отличается от того, как Windows идентифицирует сети.
Сетевой отказоустойчивый адаптер для отказоустойчивого кластера (Failover Cluster Network Fault Tolerance, NETFT) имеет свою собственную внутреннюю систему метрик. Все выявленные им сети имеют шлюз по умолчанию и получают метрики 10000, 10100 и т. д. Метрики всех сетей без шлюза по умолчанию начинаются с 1000, 1100 и т. д. Чтобы узнать, как адаптер NETFT определил их, можно использовать команду Windows PowerShell:
Вы увидите примерно следующее:
Name Metric
——————-
Management 10100
CSV Traffic 1000
LAN-WAN 10000
Private 1100
Среди этих сетей сеть, которую я определил как сеть общего тома, — CSV Traffic. Для узла Node1 я использовал IP-адрес 1.1.1.1 и 1.1.1.2 для узла Node2, поэтому я проверяю сетевое соединение с помощью команды PING.
Следующим шагом будет попытка соединения по протоколу SMB к указанным IP-адресам. Это то, что делает служба кластеризации. Чтобы получить ответ, достаточно выполнить простую команду:
Для работы с общим томом необходимы компоненты «Client for Microsoft Networks» и «File and Printer Sharing for Microsoft Networks». Если они отсутствуют, то возникает проблема с зависанием Проводника.
В Windows 2003 Server Cluster и ниже рекомендовалось отключать эти компоненты. Сейчас в этом нет необходимости.
Другие факторы
Есть несколько факторов, которые следует принять во внимание. Если узлы кластера вызывают отказ подсистемы размещения ресурсов (Resource Host Subsystem, RHS), первым делом нужно вспомнить о природе RHS и ее функциях. RHS — это компонент отказоустойчивого кластера, выполняющий проверку работоспособности множества ресурсов для обеспечения работоспособности. Что касается IP-адресов, то этот компонент проверяет, находится ли адрес в сетевом стеке и реагирует ли на запросы. Проверяя диски, он пытается соединиться и выполнить команду DIR.
Если сбоит RHS, проверьте журнал системных событий на наличие записей с идентификаторами 1230 и 1146. В событии 1230 фактически указывается ресурс и используемые библиотеки DLL. Если произошел сбой, это означает, что ресурс не отвечает должным образом и возможна взаимная блокировка. Если сбой произошел на дисковом ресурсе, следует просмотреть наличие ошибок, связанных с диском или слишком большим временем отклика диска. Неплохо начать с использования монитора производительности (Performance Monitor). Также приветствуется обновление драйверов и микропрограммы карт или компонентов сети.
Помимо этого следует сделать некоторые наблюдения. Служба кластеризации проводит проверку работоспособности пользовательских процессов из режима ядра, чтобы выявить, когда пользовательский режим перестает отвечать или происходит зависание. Для вывода из этого состояния служба кластеризации проводит проверку ошибкой. Если это происходит, будет получена ошибка Stop 0x0000009E. Чтобы устранить неполадку, надо изучить файл дампа, созданный для поиска причин зависания. Также можно запустить монитор производительности и посмотреть, будут ли возникать зависания, утечки памяти и т. п.
Служба кластеризации зависит от инструментария управления Windows (Windows Management Instrumentation, WMI). Если возникают проблемы с WMI, это ведет к проблемам с кластеризацией (с созданием и добавлением узлов, миграцией и т. п.). Проверьте WMI, например, WBEMTEST.EXE или даже удаленные сценарии WMI.
Один сценарий можно попытаться выполнить в консоли Windows PowerShell (здесь NODE1 — имя узла):
Он создает соединение WMI с кластером и предоставляет информацию о группах.
Неудачное завершение сценария указывает на проблемы с WMI. Перезапустите службу WMI, если она остановлена. Может быть повреждена база данных WMI (для проверки целостности воспользуйтесь командой Windows PowerShell: winmgmt /salvagerepository) и т. д.
Помните о ряде правил устранения неполадок:
- Проверяйте, проверяйте и еще раз проверяйте. При устранении неполадок используйте тесты для проверки кластера. Используйте их при изменении системы.
- Все больше систем переводятся на Windows PowerShell, поэтому начните изучать эту технологию, если вы ее еще не освоили.
- Если вы зависите от объектов Active Directory, защитите их. Разрешите использование корзины Active Directory и защитите объекты от случайного удаления.
- При устранении неполадок общего тома не забывайте, что проблема может быть не только в неполадках оборудования.
- При устранении неполадки сделайте шаг назад и внимательно проанализируйте все, на что она может оказывать влияние, и постепенно сужайте поле поиска.
Служба отказоустойчивой кластеризации создана для выявления, восстановления и предоставления отчетов об ошибках. Когда кластер «говорит», что есть или была неполадка, это не значит, что он вызвал ее. Как говорится, «не убивайте гонца, принесшего дурную весть».
Читайте также:
- Если оперативная память 3000 мгц а материнская плата 2933
- Как отформатировать жесткий диск полностью перед установкой виндовс
- Windows vista как сделать загрузочный диск windows
- Выбор sfx блока питания
- Какой процессор в htc one m8
HI there, I’m new to Hyper-V failover clustering and I’m still at the testing stage, thankfully! I am trying to sort out a problem and finding precious little info online…
I have a two node setup and a SAN configured for iSCSI, with that configured for a quorum disk and a VM storage disk. I did the cluster validation check and my config passed. I created the cluster and then added the shared storage volume as a cluster shared
volume. I then created a test VM and had no problems live migrating between the two nodes.
I’ve been testing shutting down the nodes and/or the cluster and restarting to see how things work out and so far things have been a bit unpredictable. Following the basic steps from
https://blogs.msdn.microsoft.com/clustering/2013/08/23/how-to-properly-shutdown-a-failover-cluster-or-a-node/ I was able to shutdown the nodes and restart no problem. I was able to shut down the cluster and reboot the nodes, and everything came
back up as either UP or paused, in which case I just resumed that node.
I tried shutting down the cluster (from Failover Cluster Manager > More Actions > Shut Down cluster) a second time. it shut down the cluster. But when I tried to restart the cluster from the same menu, it fails! I see both nodes repeatedly trying to
start back up, then stop again. The Event log shows error ID 1793 and 1795 and I’m not finding a lot of info online about these errors:
Event ID 1795
Cluster physical disk resource terminate encountered an error.
Physical Disk resource name: Cluster Disk 1
Device Number: 1
Device Guid: {24086498-7f4a-8063-3fff-00d17be885ff}
Error Code: 21
Additional reason: DismountVolumesFailure
Additional reason: ReleaseDiskPRFailure
Event ID 1795
Cluster physical disk resource terminate encountered an error.
Physical Disk resource name: Cluster Disk 1
Device Number: 4294967295
Device Guid: {24086498-7f4a-8063-3fff-00d17be885ff}
Error Code: 1168
Additional reason: ReleaseDiskPRFailure
Followed by:
Event ID 1793
Cluster physical disk resource online failed.
Physical Disk resource name: Cluster Disk 1
Device Number: 1
Device Guid: {24086498-7f4a-8063-3fff-00d17be885ff}
Error Code: 1168
Additional reason: IOCTL_DISK_CLUSTER_MONITOR_ONLINE_STATE_Failure
When I go to c:ClusterStorage,
I see the Volume1 mountpoint that should be there is missing.
When I go to Disk Management, both nodes see the storage volume and the Quorum disks, but both disks are offline. Attempting to mark it online there brings the message «The specified disk or volume is managed by the Microsoft Failover Clustering component.
The disk must be in cluster maintenance mode and the cluster resource status must be online to perform this operation.»
Tried restarting both nodes. No change. In the end, I chose the «Force cluster start» option, which I was trying to avoid thanks to the warning message «Forcing the cluster to start can have unexpected results. This includes the loss of cluster
configuration.» I briefly saw a message about forcing the quorum or something or other…and then the cluster came back up. Both nodes were back in business. My test VM came back online. The Quorum and VM storage disks were both online in Disk management
again (neither one is assigned a drive letter.) My «Volume1» mountpoint in C:ClusterStorage was back, obviously.
So I guess the problem I’m having is I’m not sure why the shutdown procedure worked as expected the first time but not the second time. It’s great that the force cluster start option worked, but that doesn’t sound like an ideal fix. Do the 1793 and 1795
events mean an error with my iSCSI configuration? The storage disk is a Cluster Shared Volume, but the quorum disk is not, based on what I’ve read online…Neither disk is assigned a drive letter in Disk Management to avoid potential NTFS corruption issues.
I only access the storage via the Volume1 mountpoint in c:ClusterStorage.
Any ideas would be greatly appreciated, thanks!
Добрый день. Хотя для меня не очень) Случилась катастрофа. Имеется 8 узлов кластера. В качестве узлов Hyper-V Server 2008R2. Развернуты службы Hyper-V.
Произошла неприятность — полностью пропала связь с хранилкой на несколько минут. Естественно кластер отключился. После запуска обнаружилось, что общий том кластера не может перейти в оперативный режим.
В логах фигурирует:
Код события 1230
Ресурс кластера «Диск кластера 2» (тип ресурса «», DLL «clusres.dll») либо поврежден, либо заблокирован. Будет выполнена попытка завершить процесс RHS, а ресурс будет помечен для запуска в отдельном сеансе монитора.
———————-
Код события 1069
Ошибка ресурса кластера «Диск кластера 2» в службе кластеров или в приложении Доступное хранилище.
———————-
Код события 1034
Ресурс физического диска кластера «Диск кластера 2» невозможно подключить, поскольку не удается найти связанный диск. Ожидаемая подпись диска: «{3858275a-3ea7-4e2d-ada0-d6f81815b2fa}». Если этот диск замещен или восстановлен,
в оснастке управления отказоустойчивыми кластерами с помощью функции «Восстановить» (на странице свойств диска) можно воссоздать новый или восстановленный диск. Если диск не был замещен, удалите соответствующий ресурс.
———————-
Если зайти в свойства хранилища в диспетчере отказоустойчивости, то указано что диск в нерабочем состоянии. При попытке добавить связь (через кнопку «восстановить»), выдает сообщение
«Пригодные для кластера диски не найдены. Чтобы получить диагностические сведения о доступных кластеру дисках, воспользуйтесь мастером проверки конфигурации для выполнения тестов хранилища».
Делал тесты хранилища на «Перечень потенциальных дисков кластера». Выдавал такое предупреждение «На диске с идентификатором {3858275a-3ea7-4e2d-ada0-d6f81815b2fa} имеется постоянное резервирование. Диск может
быть частью другого кластера. Диск исключается из проверяемого набора». Загуглил — нашел решение, что надо убрать резервирование с данного диска командой в моем случае cluster node hostname /clearpr:2
После этого при проведении вышесказанного теста предупреждение не появилось. В конце отчета написал:
Диски подходят для кластерной проверки
Диск кластера 0 имеет идентификатор {3858275a-3ea7-4e2d-ada0-d6f81815b2fa}
Но через кнопку «Восстановить» всё равно пишет, что пригодные диски не найдены.
Попробовали удалить вообще этот диск из хранилищ в диспетчере отказоустойчивых кластеров. Удалил, добавил заново — диск так же опять не может перейти в оперативный режим. Пробовал выключить кластер — погасил все хосты. Подключил нужный LUN с
хранилки на отдельной некластеризованной машине. Диск подключился, данные на нем имеются.
Подскажите пожалуйста что ещё можно сделать. А то это просто катастрофа — куча систем в нерабочем состоянии((
-
#1
Доброго времени суток, есть отдельная виртуальная машина с сервером 1с 8.3 так же есть два SQL SERVER 2019 собранные в кластер. Хочу создать информационную базу и при создании появляется ошибка —
Не удается завершить вход в систему из-за задержки при открытии соединения с сервером

Подскажите в чем может быть дело?
-
#2
Так же теперь вылезает сообщение
Ни один рабочий процесс не доступен
-
#3
а в SQL Server management studio пускает ?
-
#4
а в SQL Server management studio пускает ?
Истекло время ожидания соединения. Время ожидания истекло при попытке обработки подтверждения предварительного согласования. Возможно, произошел сбой во время предварительного согласования, или сервер не смог ответить вовремя. Время, затраченное на попытки подключиться к этому серверу, составило: [Pre-Login] initialization=29270; handshake=26242; (Microsoft SQL Server, ошибка: -2)
-
#5
а работало то изначально ? После чего перестало работать?
Проверьте состояние узлов кластера
-
#6
а работало то изначально ? После чего перестало работать?
Проверьте состояние узлов кластера
На sql1 накопились обновления — они установились и windows server 2019 перезагрузился, заметил что на этой виртуалке отвалился диск с базами. Диск в статусе offline — при попытке его включить винда выдает сообщение:
Указанным диском или томом управляет средство отказоустойчивой кластеризации (Майкрософт). Для выполнения этой операции диск должен находиться в режиме обслуживания кластера, а кластерный ресурс должен быть в сети.
. Далее в оснастке Диспетчер отказоустойчивости кластеров появилась ошибка —
Дисковый ресурс кластера «Диск кластера 1» обнаружил повреждения тома «\?Volume{9423efec-3ebd-43c9-82d0-3b365503f715}». Для устранения неполадок запущена программа Chkdsk. Диск будет недоступен до завершения выполнения команды Chkdsk. Все сведения, выводимые программой Chkdsk, будут записаны в файл C:WindowsClusterReportsSpotfix_ResДиск кластера 1_Disk1Part2.log.
Программа Chkdsk также может заносить сведения в журнал событий приложения.
-
#7
Короче с диском разобрался — это штатная работа кластера. Диск стал ресурсом кластера и переезжает туда сюда. Теперь вопрос в другом — не удается создать информационную базу. Нашел вот такой совет на другом форуме:
на сервере named pipes выключить, оставить только tcp/ip
на сервере 1с у клиента sql поставить приоритет tcp/ip выше, чем у named pipes
А где эти настройки named pipes ???
-
#8
Короче с диском разобрался — это штатная работа кластера. Диск стал ресурсом кластера и переезжает туда сюда. Теперь вопрос в другом — не удается создать информационную базу. Нашел вот такой совет на другом форуме:
А где эти настройки named pipes ???
Диспетчер конфигурации SQL Server

Последнее редактирование модератором: 03.09.2020
-
#9
в общем разобрался. Помогло — выключение брандмауэров на всех трех серверах 1с и sql server. Так же включил параметр Включить сетевое обнаружение
Онастка кластера не видит физические диски
Модераторы: Trinity admin`s, Free-lance moderator`s
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Онастка кластера не видит физические диски
В наличии имеется два сервера под управлением Windows Server 2003 Ent. Edition, система хранения данных Proware SB-3163-S3A3 с схемой подключения SAS. Оба сервера подключены к системе хранения данных.
ОС на серверах установлены на локальные жесткие диски.
Жесткие диски в Proware сконфигурированы в RAID1+0. Создан LUN, VolumeSet.
Диспетчер дисков на обоих серверах видит соответственно созданный диск на внешнем хранилище.
Создан раздел, отформатирован в НТФС.
Второй сервер погашен.
Создан кластер (пока на одной ноде) с локальным размещением кворума.
Далее хочется перенести кворум на соответственно созданный раздел на внешнее хранилище.
Проблема:
При попытке создания ресурса типа «физический диск» в оснастке управления кластером (для размещения на нем кворума), мастер добавления ресурса не видит ни одного диска/раздела доступного в мастере «Управления дисками».
Собственно, как создать «физический диск» для кластера?
-

gs
- Сотрудник Тринити

- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 12 авг 2008, 13:28
Поясните по поводу Volume Set.
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 13:41
Volume Set Name QUORUM
Raid Set Name Raid Set # 00
Volume Capacity 0.5GB
SAS Port/Lun 0&1 For Cluster/0
Raid Level Raid 0+1
Stripe Size 64KBytes
Block Size 512Bytes
Member Disks 4
Cache Mode Write Back
Tagged Queuing Enabled
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 12 авг 2008, 13:44
Я не очень понимаю терминологию этого аппарата. Но это не виндовый вольюм сет?
Дисковый том бейсик или динамик? Нужен бейсик.
Сделайте лучше под кворум отдельный лунчик.
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 13:48
В терминологиях этого аппарата это отдельный ЛУН.
Это вольюм сет внешнего хранилища.
Дисковый том основной, не динамик.
-

Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Сообщение
Stranger03 » 12 авг 2008, 14:03
Я тоже не очень понял. В диспетчере устройств созданный LUN виден как физический диск?
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 14:08
Совершенно верно
Диспетчер устройств — Дисковые устройства
RAID1
SB-3163-QUORUM SCSI DISK DEVICE
^^^^^^^^^^^^^^^^^^^^^^^^^^
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 14:26
В процессе работы над проблемой обнаружилось кое что
Как все было
— выключены обе ноды
— на внешнем хранилище создан лун
— включена первая нода, обнаружился новый диск. Создан том типа бэйсик, отформатирован в NTFS, назначена буква Q.
— выключена первая нода
— включена вторая, определился новый диск. Тому назначена буква Q
— погашена вторая нода
— активирована первая нода
— запущен мастер создания нового кластера, задано имя
— в процессе анализа конфигурации мастер создания кластера вот что выдал:
Поиск общих ресурсов на узлах:
+ Поиск дисков на той же шине хранилища где размещен загрузочный диск
Не удается управлять физическим диском «Диск Q», так как он находится на той же шине хранилища что и загрузочный жесткий диск
![]()
Повторюсь: загрузочный жесткий (на котором ОС) находится физически в сервере. Диск Q — на внешнем хранилище на другом контроллере.
Почему ругается анализатор конфигурации?
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 12 авг 2008, 14:28
Может быть внешний массив висит на том же SAS контроллере, что и бутовый диск? Это мысль вслух.
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 15:02
gs писал(а):Может быть внешний массив висит на том же SAS контроллере, что и бутовый диск? Это мысль вслух.
Ирония в том, что бутовый диск на интегрированном SATA-контроллере, а внешний массив на PCI-E внешнем SAS 
Чую без бубнов большого калибра не обойтись
-
gs
- Сотрудник Тринити
- Сообщения: 16650
- Зарегистрирован: 23 авг 2002, 17:34
- Откуда: Москва
- Контактная информация:
Сообщение
gs » 12 авг 2008, 15:05
Фигня какая-то. Может быть очистить кластерный конфиг к едрене фене и поднять кластер заново, положив кворум сразу куда надо? Тут кто-то уже писал про утиль для полной прочистки кластерных мозгов.
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Сообщение
Stranger03 » 12 авг 2008, 15:10
gs писал(а):Фигня какая-то. Может быть очистить кластерный конфиг к едрене фене и поднять кластер заново, положив кворум сразу куда надо? Тут кто-то уже писал про утиль для полной прочистки кластерных мозгов.
Да там особенно не надо ничего чистить, достаточно просто зайти в кластернуб консоль и прибить сам кластер оттуда. Перегрузиться и заново сделать.
-
Stranger03
- Сотрудник Тринити
- Сообщения: 12979
- Зарегистрирован: 14 ноя 2003, 16:25
- Откуда: СПб, Екатеринбург
- Контактная информация:
Сообщение
Stranger03 » 12 авг 2008, 15:13
Cherepulya писал(а):Чую без бубнов большого калибра не обойтись
Но если у вас система на внутренних САТА дисках, в сервере стоит контроллер САС, к которому подключен массив, то вообще-то действительно на бубны смахивает. Не далее как неделю назад настраивали кластер на Заратексе сасовском, все прошло на ура без запинок.
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 15:21
кластер прибивался.
Тут действительно имеет место быть шаманство: http://www.3nity.ru/viewtopic.htm?p=8867
Вот что поиском нарыл. У товарища Sherman возникала точно такая же ошибка: «004-01-06 13:00:32.920 [INFO] CLUST-1: Не удается управлять физическим диском «Диск E: Q:», так как он находится на той же шине хранилища, что и загрузочный диск.»
Вот что он пишет: «Дело было в том, что в OEM серваки при сборке добавили аппаратный RAID-контроллер Intel уж не помню маркировку помимо штатного Adaptec 39320. При отключении дополнительного контроллера и установке драйверов на Адаптек всё сработало штатно.»
А встроенный SATA-контроллер с системным диском именно Intel в моем случае.
-
Cherepulya
- Junior member
- Сообщения: 9
- Зарегистрирован: 12 авг 2008, 13:01
- Откуда: Moscow
Сообщение
Cherepulya » 12 авг 2008, 17:18
После смены контроллера с Intel на Adaptec для системного диска все увиделось и завелось с полупинка.
Вернуться в «Кластеры, Программное обеспечение»
Перейти
- Серверы
- ↳ Серверы — Конфигурирование
- ↳ Конфигурации сервера для 1С
- ↳ Серверы — Решение проблем
- ↳ Серверы — ПО, Unix подобные системы
- ↳ Серверы — ПО, Windows система, приложения.
- ↳ Серверы — ПО, Базы Данных и их использование
- ↳ Серверы — FAQ
- Дисковые массивы, RAID, SCSI, SAS, SATA, FC
- ↳ Массивы — RAID технологии.
- ↳ Массивы — Технические вопросы, решение проблем.
- ↳ Массивы — FAQ
- Майнинг, плоттинг, фарминг (Добыча криптовалют)
- ↳ Proof Of Work
- ↳ Proof Of Space
- Кластеры — вычислительные и отказоустойчивые ( SMP, vSMP, NUMA, GRID , NAS, SAN)
- ↳ Кластеры, Аппаратная часть
- ↳ Deep Learning и AI
- ↳ Кластеры, Программное обеспечение
- ↳ Кластеры, параллельные файловые системы
- Медиа технологии, и цифровое ТВ, IPTV, DVB
- ↳ Станции видеомонтажа, графические системы, рендеринг.
- ↳ Видеонаблюдение
- ↳ Компоненты Digital TV решений
- ↳ Студийные системы, производство ТВ, Кино и рекламы
- Инфраструктурное ПО и его лицензирование
- ↳ Виртуализация
- ↳ Облачные технологии
- ↳ Резервное копирования / Защита / Сохранение данных
- Сетевые решения
- ↳ Сети — Вопросы конфигурирования сети
- ↳ Сети — Технические вопросы, решение проблем
- Общие вопросы
- ↳ Обсуждение общих вопросов
- ↳ Приколы нашего IT городка
- ↳ Регистрация на форуме