This tutorial will show you how to use the Pandas query method to subset your data.
The tutorial will explain the syntax and also show you step-by-step examples of how to use the Pandas query method.
If you need something specific (like help with syntax, examples, etc), you can click on one of the following links and it will take you to the appropriate section.
Contents:
- A Quick Review of Pandas
- Introduction to Pandas Query
- The syntax of Pandas Query
- Pandas Query Examples
- Pandas Query FAQ
But if you’re new to Pandas, or new to data manipulation in Python, I recommend that you read the whole tutorial. Everything will make more sense that way.
Ok …. let’s get to it.
A Quick Review of Pandas
Very quickly, let’s review what Pandas is.
Pandas is a package for the Python programming language.
Specifically, Pandas is a toolkit for performing data manipulation in Python. It is a critical toolkit for doing data science in Python.
Pandas works with DataFrames
To get a little more specific, Pandas is a toolkit for creating and working with a data structure called a DataFrame.
A DataFrame is a structure that we use to store data.
DataFrames have a row-and-column structure, like this:

If you’ve worked with Microsoft Excel, you should be familiar with this structure. A Pandas DataFrame is very similar to an Excel spreadsheet, in that a DataFrame has rows, columns, and cells.
There are several ways to create a DataFrame, including importing data from an external file (like a CSV file); and creating DataFrames manually from raw data using the pandas.DataFrame() function.
For more information about DataFrames, check out our tutorial on Pandas DataFrames.
Pandas methods perform operations on DataFrames
Once you have your data inside of a dataframe, you’ll very commonly need to perform data manipulation.
If your data are a little “dirty,” you might need to use some tools to clean the data up: modifying missing values, changing string names, renaming variables, adding variables, etc.
Moreover, once your data are in the DataFrame structure and the data are “clean,” you’ll still need to use some “data manipulation” techniques to analyze your data. Here, I’m talking about things like subsetting, grouping, and aggregating.
Pandas has tools for performing all of these tasks. It is a comprehensive toolkit for working with data and performing data manipulation on DataFrames.
A quick introduction to Pandas query
Among the many tools for performing data manipulation on DataFrames is the Pandas query method.
What is .query() and what does it do?
Query is a tool for querying dataframes and retrieving subsets
At a very high level, the Pandas query method is a tool for generating subsets from a Pandas DataFrame.
For better or worse, there are actually several ways to generate subsets with Pandas.
The loc and iloc methods enable you to retrieve subsets based on row and column labels or by integer index of the rows and columns.
And Pandas has a bracket notation that enables you to use logical conditions to retrieve specific rows of data.
But both of those tools can be a little cumbersome syntactically. Moreover, they are hard to use in conjunction with other data manipulation methods in a smooth, organic way.
In many ways, the Pandas .query method solves those problems.
Query enables you to “query” a DataFrame and retrieve subsets based on logical conditions.
Moreover, the syntax is a little more streamlined than Pandas bracket notation.
Additionally, the Pandas query method can be used with other Pandas methods in a streamlined way that makes data manipulation smooth and straightforward. I’ll show you a little example of that later in the tutorial.
But before we get there, let’s first take a look at the syntax of Pandas query.
The syntax of Pandas query is mostly straightforward.
In order to use this method though, you’ll need to have a Pandas DataFrame.
What that means is that you’ll need to import Pandas and use Pandas to create a DataFrame.
For more information about how to create DataFrames, you can read our introductory tutorial on Pandas DataFrames.
Pandas query syntax
Ok.
Assuming you have a DataFrame, you need to call .query() using “dot syntax”.
Basically, type the name of the DataFrame you want to subset, then type a “dot”, and then type the name of the method …. query().
Like this:

In the above syntax explanation, I’m assuming that you have a DataFrame named yourDataFrame.
Then, inside of the query method, there are a few parameters and arguments to the function.
Let’s walk through those.
The parameters of pandas query
Inside of the function, there are really only two arguments or parameters that you need to know about:
expressioninplace
Let’s talk about each of them individually.
expression (required)
Here, the expression is some sort of logical expression that describes which rows to return in the output.
If the expression is true for a particular row, the row will be included in the output. If the expression is false for a particular row, that row will be excluded from the output. I’ll show you several examples of these expressions in the examples section of this tutorial.
One note: the expression itself must be presented as a Python string. That means that the expression must be enclosed inside of quotations … either double quotations or single quotations.
Keep in mind, that you may also need to use strings inside of the expression itself. For example, if you need to reference a category called “Dog” inside of your logical expression, and you enclose that category inside of double quotation marks, you’ll need to enclose the overall expression inside of single quotes. If you’re not familiar with this, please review how strings work in Python, and review how to reference strings within strings.
inplace
The inplace parameter enables you to specify if you want to directly modify the DataFrame you’re working with.
Remember from the syntax section, when we use the .query() method, we need to type the name of the DataFrame that we want to subset. That DataFrame will serve as the input of the query method.
However, by default, the query method will produce a new DataFrame as the output, and will leave the original DataFrame unchanged.
That’s because by default, the inplace parameter is set to inplace = False. What that means is that query will not modify the original DataFrame “in place”. Instead it creates a new DataFrame. That is literally what the inplace parameter means.
But we can change that behavior by setting inplace = True.
If we override the default and set inplace = True, query will modify the original DataFrame “in place”.
But be careful … if you do this you will overwrite your original DataFrame. Make sure that your code is working the way you want it to!
Examples: how to use .query() to subset a Pandas dataframe
Ok, now that you’ve learned how the syntax works, let’s take a look at some examples.
Examples:
- Subset a pandas dataframe based on a numeric variable
- Select rows based on a categorical variable
- Subset a DataFrame by index
- Subset a pandas dataframe by comparing two columns
- Select rows based on multiple conditions
- Reference local variables inside of query
- Modify a DataFrame in Place
Run this code first
Before we actually work with the examples, we need to run some preliminary code.
We’re going to import Pandas and create a dataframe.
Import Pandas
First, let’s just import Pandas.
This is fairly straightforward, but if you’re a beginner, you might not be familiar with it.
To call any function from Pandas (or any other package), we need to first import the package. We import a package with the import statement.
Moreover, we can import a package with the original name (i.e., import pandas). But we also have the option of importing a package with a “nickname.” That’s a very common way of doing things, and that’s what we’re going to do here.
We’re going to import Pandas with the nickname “pd“.
import pandas as pd
Create Data Frame
We also need a dataframe to work with.
Here, we’ll use a create a DataFrame with some dummy sales data.
To do this, we’re just using the pd.DataFrame function from Pandas.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And if we print it out, we can see the dataset.
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000 5 Thomas West 72000 39000 6 Ethan South 49000 42000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that the DataFrame has four variables: name, region, sales, and expenses.
We’re going to use these variables (and the row index) to subset our data with .query().
EXAMPLE 1: Subset a pandas dataframe based on a numeric variable
Let’s start with a very simple example.
Here, we’re going to subset the data on a numeric variable: sales.
We’re going to retrieve the rows in the DataFrame where sales is greater than 60000.
To do this, we’re simply providing a logical expression inside of the parenthesis: 'sales > 60000'.
Let’s run the code so you can see the output.
sales_data.query('sales > 60000')
OUT:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that when we run the code, it returns 5 rows. The original DataFrame has 11 rows, but the output has 5.
Moreover, all of the rows of data in the output meet the criteria defined in the logical expression 'sales > 60000'. All of the records have sales greater than 60000.
This is really straightforward. The query method used the expression 'sales > 60000' as a sort of filtering criteria. If the criteria is true for a particular row, that row is included in the output. If the criteria is false for a particular row, it is excluded.
Now notice that in this simple example, we used the greater-than sign to filter on the sales variable. This is one thing to do, but we could also test for equivalence (==), test for greater-than-or-equal, lest-than, etc. Almost any comparison operator will work.
And as you’ll see in upcoming examples, we can combine expressions using logical operators to make more complex expressions.
EXAMPLE 2: Select rows based on a categorical variable
Next, we’re going to select a group of rows by filtering on a categorical variable.
We’re going to retrieve all of the rows where region is equal to East.
To do this, we’re going to call the .query() method using “dot notation.” We simply type the name of our DataFrame, sales_data, and then type the name of the method, .query().
Inside of the parenthesis of the query method, we have a logical expression: 'region == "East"'.
Let’s run the code and take a look at the output.
Here is the code:
sales_data.query('region == "East"')
And here is the output, which is a new dataframe:
name region sales 0 William East 50000 2 Sofia East 90000 9 Anika East 65000
Notice that the output DataFrame contains all of the records for the region East.
A few notes about this.
First, the logical expression is syntactically just a Python logical expression. Here, we’re using the equivalence operator from Python, the double equal sign (==).
Second, the whole logical expression is contained inside of single quotation marks. That is, we provide the logical expression to .query() in the form of a string. Query expects a string.
Third, we’re referencing "East", which is one of the unique values of the region variable. Notice that this value is actually contained inside of double quotation marks. This is because we treat string values of a DataFrame as strings, and as such, it needs to be inside of quotation marks. But since the overall expression is already inside of single quotes, we need to use double quotes for the value "East". If you don’t understand this, you need to review the rules for using quotes inside of quotes with Python.
EXAMPLE 3: Subset a DataFrame by index
Here, we’re going to reference the index of the DataFrame and subset the rows based on that index.
First, let’s just print out the DataFrame.
print(sales_data)
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000 5 Thomas West 72000 39000 6 Ethan South 49000 42000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that when we print out the DataFrame, each row has an integer associated with it on the left hand side, starting at zero.
This group of numbers is the index. By default, when we create a DataFrame, each row will be given a numeric index value like this (although, there are ways to change the index to something else).
We can reference these index values inside of query.
To do this, just use the word ‘index’.
Here’s an example. Here, we’re going to return the rows where index is less than 3. This will effectively return the first three rows.
sales_data.query('index < 3')
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000
Notice that in this output, the index values (on the left side of the printout) are all less than 3.
You can also use mathematical operations inside of your expressions, and this can be a useful technique to subset your data in interesting ways.
For example, we can use the modulo operator (%) on index to retrieve the «odd» rows of our DataFrame:
sales_data.query('index%2 == 1')
OUT:
name region sales expenses 1 Emma North 52000 43000 3 Markus South 34000 44000 5 Thomas West 72000 39000 7 Olivia West 55000 60000 9 Anika East 65000 44000
Using index inside of your expressions for query is a good way of conditionally subsetting on the index.
EXAMPLE 4: Subset a pandas dataframe by comparing two columns
Now, let’s make things a little more complicated.
Here, we’re going to compare two variables – sales and expenses – and return the rows where sales is less than expenses.
sales_data.query('sales < expenses')
OUT:
name region sales expenses 3 Markus South 34000 44000 7 Olivia West 55000 60000
This is pretty straightforward. Our logical expression, 'sales < expenses', instructs the query method to return rows where sales is less than expenses. And that’s what is in the output!
Keep in mind that we can use more than two variable in our expressions, or make the expressions more complicated with logical operators.
I’ll show you an example of that in the next example.
EXAMPLE 5: Subset a pandas dataframe with multiple conditions
Here, we’re going to subset the DataFrame based on a complex logical expression. The expression is composed of two smaller expressions that are being combined with the and operator.
We’re going to return rows where sales is greater than 50000 AND region is either ‘East’ or ‘West’.
Here’s the code:
sales_data.query('(sales > 50000) and (region in ["East", "West"])')
And here’s the output:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000
Notice which rows are actually in the output. The rows all have a region that’s either ‘East’ or ‘West’. Additionally, all of the rows have sales greater than 50000.
We did this by creating a compound logical expression using the and operator.
The overall expression inside of query is '(sales > 50000) and (region in ["East", "West"])'.
Notice that there are two parts. The first part is (sales > 50000). The second part is (region in ["East", "West"]). Both of these parts are small expressions themselves that will subset our DataFrame. But here, we’re combining them together with the logical ‘and‘ operator. This tells query to return rows where both parts are True.
If you want, you could also use the logical ‘or‘ operator and the logical ‘not‘ operator inside of your expressions. Essentially, you use the Python logical operators to create more complicated expressions and subset your data in more complex ways.
EXAMPLE 6: reference local variables inside of query
Now, let’s do something a little different.
So far, we’ve been referencing variables that are actually inside of the DataFrame. We’ve been referencing the names of the columns, like sales and expenses.
Now, we’re going to reference a variable outside of the dataframe.
Here, we’re going to calculate the mean of the sales variable and store it as a separate variable outside of our DataFrame.
sales_mean = sales_data.sales.mean()
And let’s take a look at the value:
print(sales_mean)
OUT:
58454.545
This variable, sales_mean, simply holds the value of the mean of our sales variable.
Next, we’re going to reference that variable.
To do this, we’re going to use the ‘@‘ character in front of the variable.
Let’s look at the code:
sales_data.query('sales > @sales_mean')
And here is the output:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that for all of the rows, sales is greater than 58454.545 (the mean of sales).
EXAMPLE 7: Modify a DataFrame in Place
Finally, let’s do one more example.
Here, we’re going to modify a DataFrame «in place».
That means that we’re going to directly modify the DataFrame that we’re operating on, instead of producing a new DataFrame.
Now keep in mind: modifying a DataFrame in place can be risky, because we will overwrite our data.
That being the case, I’m actually going to create a duplicate DataFrame first called sales_data_dupe. This way, when we modify the data, we’ll overwrite the duplicate and keep our original intact.
sales_data_dupe = sales_data.copy()
Now, let’s modify sales_data_dupe.
Here, we’re going to select rows where 'index < 5', but we’re going to modify the DataFrame directly by setting inplace = True.
sales_data_dupe.query('index < 5', inplace = True)
And let’s print out the output:
print(sales_data_dupe)
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000
Notice that the rows in sales_data_dupe meet our criteria that the index must be less than 5. Moreover, notice that query modified the DataFrame directly (instead of producing a new DataFrame).
Frequently asked questions about Pandas query
Here are a few frequently asked questions about the Pandas query method.
Frequently asked questions:
- What’s the advantage of using
.query()over brackets - How does query in Pandas compare to SQL code
What’s the advantage of using .query() over brackets
In Python, there are many ways to select rows from a Pandas dataframe.
By far, the most common is to subset by using «bracket notation». Here’s an example (note that we’re using the DataFrame sales_data created above):
sales_data[sales_data['sales'] > 50000]
This is essentially equivalent to this code using query:
sales_data.query('sales > 50000')
Notice how much cleaner the code is when we use query. It’s easier to read. The code looks more like «English» and less like jumbled computer syntax.
In the «bracket» version, we need to repeatedly type the name of the DataFrame. Just to reference a variable, we need to type the name of the DataFrame (i.e., sales_data['sales']).
In the query version though, we just type the name of the column.
Moreover, when we use the Pandas query method, we can use the method in a «chain» of Pandas methods, similar to how you use pipes in R’s dplyr.
Ultimately, using the query method is easier to write, easier to read, and more powerful because you can use it in conjunction with other methods.
How does query in Pandas compare to SQL code
If you’re coming from an SQL background, you might be trying to figure out how to re-write your SQL queries with Pandas.
If that’s the case, you need to know how to translate SQL syntax into Pandas.
So if you were trying to translate SQL into Pandas, how does .query() fit in?
The query method is like a where statement in SQL.
You can use query to specify conditions that your rows must meet in order to be returned.
Leave your other questions in the comments below
Do you have more questions about the Pandas query method?
Leave your question in the comments section below.
Join our course to learn more about Pandas
If you’re serious about learning Pandas, you should enroll in our premium Pandas course called Pandas Mastery.
Pandas Mastery will teach you everything you need to know about Pandas, including:
- How to subset your Python data
- Data aggregation with Pandas
- How to reshape your data
- and more …
Moreover, it will help you completely master the syntax within a few weeks. You’ll discover how to become «fluent» in writing Pandas code to manipulate your data.
Find out more here:
Learn More About Pandas Mastery
Pandas DataFrame.query() method is used to query the rows based on the expression (single or multiple column conditions) provided and returns a new DataFrame. In case you wanted to update the existing referring DataFrame use inplace=True argument.
In this article, I will explain the syntax of the Pandas DataFrame query() method and several working examples like query with multiple conditions and query with string contains to new few.
Related:
- pandas.DataFrame.filter() – To filter rows by index and columns by name.
- pandas.DataFrame.loc[] – To select rows by indices label and column by name.
- pandas.DataFrame.iloc[] – To select rows by index and column by position.
- pandas.DataFrame.apply() – To custom select using lambda function.
1. Quick Examples of pandas query()
If you are in hurry, below are quick examples of how to use pandas.DataFrame.query() method.
# Query Rows using DataFrame.query()
df2=df.query("Courses == 'Spark'")
#Using variable
value='Spark'
df2=df.query("Courses == @value")
#inpace
df.query("Courses == 'Spark'",inplace=True)
#Not equals, in & multiple conditions
df.query("Courses != 'Spark'")
df.query("Courses in ('Spark','PySpark')")
df.query("`Courses Fee` >= 23000")
df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000")
If you are a learner, Let’s see with sample data and run through these examples and explore the output to understand better. First, let’s create a pandas DataFrame from Dict.
import pandas as pd
import numpy as np
technologies= {
'Courses':["Spark","PySpark","Hadoop","Python","Pandas"],
'Fee' :[22000,25000,23000,24000,26000],
'Duration':['30days','50days','30days', None,np.nan],
'Discount':[1000,2300,1000,1200,2500]
}
df = pd.DataFrame(technologies)
print(df)
Note that the above DataFrame also contains None and Nan values on Duration column that I would be using in my examples below to select rows that has None & Nan values or select ignoring these values.
3. Using DataFrame.query()
Following is the syntax of DataFrame.query() method.
# query() method syntax
DataFrame.query(expr, inplace=False, **kwargs)
expr– expression takes conditions to query rowsinplace– Defaults toFalse. When set toTrue, it updates the referring DataFrame andquery()method returnsNone.**kwargs– Keyword arguments that works with eval()
DataFrame.query() takes condition in expression to select rows from a DataFrame. This expression can have one or multiple conditions.
# Query all rows with Courses equals 'Spark'
df2=df.query("Courses == 'Spark'")
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
In case you wanted to use a variable in the expression, use @ character.
# Query Rows by using Python variable
value='Spark'
df2=df.query("Courses == @value")
print(df2)
If you notice the above examples return a new DataFrame after filtering the rows. if you wanted to update the existing DataFrame use inplace=True
# Replace current esisting DataFrame
df.query("Courses == 'Spark'",inplace=True)
print(df)
If you wanted to select based on column value not equals then use != operator.
# not equals condition
df2=df.query("Courses != 'Spark'")
Yields below output.
Courses Courses Fee Duration Discount
1 PySpark 25000 50days 2300
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
4 Pandas 26000 NaN 2500
4. Select Rows Based on List of Column Values
If you have values in a python list and wanted to select the rows based on the list of values, use in operator, it’s like checking a value contains in a list of string values.
# Query Rows by list of values
print(df.query("Courses in ('Spark','PySpark')"))
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
You can also write with a list of values in a python variable.
# Query Rows by list of values
values=['Spark','PySpark']
print(df.query("Courses in @values"))
To select rows that are not in a list of column values can be done using not in operator.
# Query Rows not in list of values
values=['Spark','PySpark']
print(df.query("Courses not in @values"))
If you have column names with special characters using column name surrounded by tick ` character .
# Using columns with special characters
print(df.query("`Courses Fee` >= 23000"))
5. Query with Multiple Conditions
In Pandas or any table-like structures, most of the time we would need to select the rows based on multiple conditions by using multiple columns, you can do that in Pandas DataFrame as below.
# Query by multiple conditions
print(df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000"))
Yields below output. Alternatively, you can also use pandas loc with multiple conditions.
Courses Courses Fee Duration Discount
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
6. Query Rows using apply()
pandas.DataFrame.apply() method is used to apply the expression row-by-row and return the rows that matched the values. The below example returns every match when Courses contains a list of specified string values.
# By using lambda function
print(df.apply(lambda row: row[df['Courses'].isin(['Spark','PySpark'])]))
Yields below output. A lambda expression is used with pandas to apply the function for each row.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
8. Other Examples using df[] and loc[]
# Other examples you can try to query rows
df[df["Courses"] == 'Spark']
df.loc[df['Courses'] == value]
df.loc[df['Courses'] != 'Spark']
df.loc[df['Courses'].isin(values)]
df.loc[~df['Courses'].isin(values)]
df.loc[(df['Discount'] >= 1000) & (df['Discount'] <= 2000)]
df.loc[(df['Discount'] >= 1200) & (df['Fee'] >= 23000 )]
# Select based on value contains
print(df[df['Courses'].str.contains("Spark")])
# Select after converting values
print(df[df['Courses'].str.lower().str.contains("spark")])
#Select startswith
print(df[df['Courses'].str.startswith("P")])
Conclusion
In this article, I have explained multiple examples of how to query Pandas DataFrame Rows based on single and multiple conditions, from a list of values (checking column value exists in list of string values) e.t.c. Remember when you query DataFrame Rows, it always returns a new DataFrame with selected rows, in order to update existing df you have to use inplace=True. I hope this article helps you learn Pandas.
Happy Learning !!
Related Articles
- Different Ways to Rename Pandas DataFrame Column
- How to Drop Column From Pandas DataFrame
- Pandas- How to get a Specific Cell Value from DataFrame
- Pandas Filter DataFrame by Multiple Conditions
- Pandas apply map (applymap()) Explained
- Apply Multiple Filters to Pandas DataFrame or Series
- Pandas Filter Rows by Conditions
- Pandas Filter by Column Value
References
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
- https://pandas.pydata.org/docs/reference/api/pandas.eval.html#pandas.eval
Время прочтения: 3 мин.
Pandas, безусловно, является одним из основных инструментов, необходимых для работы с данными в Python. Он предлагает множество различных способов фильтрации фреймов данных. Один из них я сегодня покажу на примере.
Недавно подошла сотрудница с задачей — в файле нужно найти материалы на складах и сформировать файл для фильтрации по группам, чтобы можно удобно просмотреть в Excel. Количество материалов более 300 тысяч.
Пример:

При использовании библиотеки Левенштейна пришлось бы использовать цикл в цикле, при большом количестве данных проверка могла бы затянутся на долго. Анализ данных требует много операций фильтрации. Pandas предоставляют множество методов для фильтрации фрейма данных, и Dataframe.query() является одним из них.
import pandas as pd
pd.options.display.max_columns = None
mPath1=r"C:UsersnikiDesktopRACK"
PATH = mPath1+"\Материалы.XLSX"
f1 = open((mPath1+ '\1205_01_sort.csv'),mode="a", encoding="utf-8")
df = pd.read_excel(PATH,'Sheet1')
При загрузке файла в колонке Материала, все привел к верхнему регистру, удалил лишние пробелы и знаки
df['Lt'] = df['Material].str.replace('W+',' ').str.replace('_',' ').str.strip().str.replace(' ',' ')
df['IND1']=0
df['IND2']=0
slist=df.iloc[0,4].split(' ')
kl=0
Col_text=2 # По двум текстам совпадения
Dl_text=2 # Кол-во символов в тексте
df['Lt'] = df['Lt'].fillna(' ')
while len(df)!=0:
kl=kl+1
kol=0
ql=''
df=df.loc[df['IND1']==0]
if len(df.iloc[0,4])>=3:
slist=df.iloc[0,4].split(' ')
if len(slist)>1:
for i in range(len(slist)):
if len(slist[i])> Dl_text:
kol=kol+1
if kol<= Col_text: # По двум текстам совпадения. При условии текст больше 2 символов
ql=ql+'and Lt.str.contains("'+slist[i]+'") '
else:
ql=ql+'and Lt.str.contains("'+slist[0]+'") '
# Формировалась строка ql для фильтрации датафрейма
if len(ql)>4:
ql=ql[4:]
ind_m = df.query(ql, engine='python').index
df.at[ind_m, 'IND1'] = 1
df.at[ind_m, 'IND2'] = kl
for j in range(len(ind_m)):
sk1=df.loc[ind_m[j]][0]
sk2=df.loc[ind_m[j]][2]
sk3=df.loc[ind_m[j]][5]
sk4=df.loc[ind_m[j]][6]
IND1 по умолчанию равен 0, после, если товар попадает под фильтр, получает значение 1.
IND2 (после фильтрации IND1) получает значение kol – это индекс для фильтрации в Excel, который используется в полученном файле
sks='"'+str(sk1)+'";"'+str(sk2)+'";"'+str(sk3)+'";"'+str(sk4)+'"'
f1.write(sks + 'n')
print(kl,len(df))
else:
df.iloc[0,5]=1
f1.close()
Результат:

Теперь загрузив файл в Excel, можно сделать фильтрацию по колонке IND2. Сохранение в файл сделал по запросу сотрудника, чтобы видеть результат по заполнения файла в работе программы, файл можно просматривать в реальном времени либо с FAR, Notepad++. Программы доступны в SberUserSoft.
Преимущество этого способа является подходящим для анализа данных. В этом примере я использовал функцию запроса по элементам списка.
В заключение хотелось бы сказать, что Pandas, при работе с большими объемами данных, является большой альтернативой Excel.
This tutorial will show you how to use the Pandas query method to subset your data.
The tutorial will explain the syntax and also show you step-by-step examples of how to use the Pandas query method.
If you need something specific (like help with syntax, examples, etc), you can click on one of the following links and it will take you to the appropriate section.
Contents:
- A Quick Review of Pandas
- Introduction to Pandas Query
- The syntax of Pandas Query
- Pandas Query Examples
- Pandas Query FAQ
But if you’re new to Pandas, or new to data manipulation in Python, I recommend that you read the whole tutorial. Everything will make more sense that way.
Ok …. let’s get to it.
A Quick Review of Pandas
Very quickly, let’s review what Pandas is.
Pandas is a package for the Python programming language.
Specifically, Pandas is a toolkit for performing data manipulation in Python. It is a critical toolkit for doing data science in Python.
Pandas works with DataFrames
To get a little more specific, Pandas is a toolkit for creating and working with a data structure called a DataFrame.
A DataFrame is a structure that we use to store data.
DataFrames have a row-and-column structure, like this:
If you’ve worked with Microsoft Excel, you should be familiar with this structure. A Pandas DataFrame is very similar to an Excel spreadsheet, in that a DataFrame has rows, columns, and cells.
There are several ways to create a DataFrame, including importing data from an external file (like a CSV file); and creating DataFrames manually from raw data using the pandas.DataFrame() function.
For more information about DataFrames, check out our tutorial on Pandas DataFrames.
Pandas methods perform operations on DataFrames
Once you have your data inside of a dataframe, you’ll very commonly need to perform data manipulation.
If your data are a little “dirty,” you might need to use some tools to clean the data up: modifying missing values, changing string names, renaming variables, adding variables, etc.
Moreover, once your data are in the DataFrame structure and the data are “clean,” you’ll still need to use some “data manipulation” techniques to analyze your data. Here, I’m talking about things like subsetting, grouping, and aggregating.
Pandas has tools for performing all of these tasks. It is a comprehensive toolkit for working with data and performing data manipulation on DataFrames.
A quick introduction to Pandas query
Among the many tools for performing data manipulation on DataFrames is the Pandas query method.
What is .query() and what does it do?
Query is a tool for querying dataframes and retrieving subsets
At a very high level, the Pandas query method is a tool for generating subsets from a Pandas DataFrame.
For better or worse, there are actually several ways to generate subsets with Pandas.
The loc and iloc methods enable you to retrieve subsets based on row and column labels or by integer index of the rows and columns.
And Pandas has a bracket notation that enables you to use logical conditions to retrieve specific rows of data.
But both of those tools can be a little cumbersome syntactically. Moreover, they are hard to use in conjunction with other data manipulation methods in a smooth, organic way.
In many ways, the Pandas .query method solves those problems.
Query enables you to “query” a DataFrame and retrieve subsets based on logical conditions.
Moreover, the syntax is a little more streamlined than Pandas bracket notation.
Additionally, the Pandas query method can be used with other Pandas methods in a streamlined way that makes data manipulation smooth and straightforward. I’ll show you a little example of that later in the tutorial.
But before we get there, let’s first take a look at the syntax of Pandas query.
The syntax of Pandas query is mostly straightforward.
In order to use this method though, you’ll need to have a Pandas DataFrame.
What that means is that you’ll need to import Pandas and use Pandas to create a DataFrame.
For more information about how to create DataFrames, you can read our introductory tutorial on Pandas DataFrames.
Pandas query syntax
Ok.
Assuming you have a DataFrame, you need to call .query() using “dot syntax”.
Basically, type the name of the DataFrame you want to subset, then type a “dot”, and then type the name of the method …. query().
Like this:
In the above syntax explanation, I’m assuming that you have a DataFrame named yourDataFrame.
Then, inside of the query method, there are a few parameters and arguments to the function.
Let’s walk through those.
The parameters of pandas query
Inside of the function, there are really only two arguments or parameters that you need to know about:
expressioninplace
Let’s talk about each of them individually.
expression (required)
Here, the expression is some sort of logical expression that describes which rows to return in the output.
If the expression is true for a particular row, the row will be included in the output. If the expression is false for a particular row, that row will be excluded from the output. I’ll show you several examples of these expressions in the examples section of this tutorial.
One note: the expression itself must be presented as a Python string. That means that the expression must be enclosed inside of quotations … either double quotations or single quotations.
Keep in mind, that you may also need to use strings inside of the expression itself. For example, if you need to reference a category called “Dog” inside of your logical expression, and you enclose that category inside of double quotation marks, you’ll need to enclose the overall expression inside of single quotes. If you’re not familiar with this, please review how strings work in Python, and review how to reference strings within strings.
inplace
The inplace parameter enables you to specify if you want to directly modify the DataFrame you’re working with.
Remember from the syntax section, when we use the .query() method, we need to type the name of the DataFrame that we want to subset. That DataFrame will serve as the input of the query method.
However, by default, the query method will produce a new DataFrame as the output, and will leave the original DataFrame unchanged.
That’s because by default, the inplace parameter is set to inplace = False. What that means is that query will not modify the original DataFrame “in place”. Instead it creates a new DataFrame. That is literally what the inplace parameter means.
But we can change that behavior by setting inplace = True.
If we override the default and set inplace = True, query will modify the original DataFrame “in place”.
But be careful … if you do this you will overwrite your original DataFrame. Make sure that your code is working the way you want it to!
Examples: how to use .query() to subset a Pandas dataframe
Ok, now that you’ve learned how the syntax works, let’s take a look at some examples.
Examples:
- Subset a pandas dataframe based on a numeric variable
- Select rows based on a categorical variable
- Subset a DataFrame by index
- Subset a pandas dataframe by comparing two columns
- Select rows based on multiple conditions
- Reference local variables inside of query
- Modify a DataFrame in Place
Run this code first
Before we actually work with the examples, we need to run some preliminary code.
We’re going to import Pandas and create a dataframe.
Import Pandas
First, let’s just import Pandas.
This is fairly straightforward, but if you’re a beginner, you might not be familiar with it.
To call any function from Pandas (or any other package), we need to first import the package. We import a package with the import statement.
Moreover, we can import a package with the original name (i.e., import pandas). But we also have the option of importing a package with a “nickname.” That’s a very common way of doing things, and that’s what we’re going to do here.
We’re going to import Pandas with the nickname “pd“.
import pandas as pd
Create Data Frame
We also need a dataframe to work with.
Here, we’ll use a create a DataFrame with some dummy sales data.
To do this, we’re just using the pd.DataFrame function from Pandas.
sales_data = pd.DataFrame({"name":["William","Emma","Sofia","Markus","Edward","Thomas","Ethan","Olivia","Arun","Anika","Paulo"]
,"region":["East","North","East","South","West","West","South","West","West","East","South"]
,"sales":[50000,52000,90000,34000,42000,72000,49000,55000,67000,65000,67000]
,"expenses":[42000,43000,50000,44000,38000,39000,42000,60000,39000,44000,45000]})
And if we print it out, we can see the dataset.
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000 5 Thomas West 72000 39000 6 Ethan South 49000 42000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that the DataFrame has four variables: name, region, sales, and expenses.
We’re going to use these variables (and the row index) to subset our data with .query().
EXAMPLE 1: Subset a pandas dataframe based on a numeric variable
Let’s start with a very simple example.
Here, we’re going to subset the data on a numeric variable: sales.
We’re going to retrieve the rows in the DataFrame where sales is greater than 60000.
To do this, we’re simply providing a logical expression inside of the parenthesis: 'sales > 60000'.
Let’s run the code so you can see the output.
sales_data.query('sales > 60000')
OUT:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that when we run the code, it returns 5 rows. The original DataFrame has 11 rows, but the output has 5.
Moreover, all of the rows of data in the output meet the criteria defined in the logical expression 'sales > 60000'. All of the records have sales greater than 60000.
This is really straightforward. The query method used the expression 'sales > 60000' as a sort of filtering criteria. If the criteria is true for a particular row, that row is included in the output. If the criteria is false for a particular row, it is excluded.
Now notice that in this simple example, we used the greater-than sign to filter on the sales variable. This is one thing to do, but we could also test for equivalence (==), test for greater-than-or-equal, lest-than, etc. Almost any comparison operator will work.
And as you’ll see in upcoming examples, we can combine expressions using logical operators to make more complex expressions.
EXAMPLE 2: Select rows based on a categorical variable
Next, we’re going to select a group of rows by filtering on a categorical variable.
We’re going to retrieve all of the rows where region is equal to East.
To do this, we’re going to call the .query() method using “dot notation.” We simply type the name of our DataFrame, sales_data, and then type the name of the method, .query().
Inside of the parenthesis of the query method, we have a logical expression: 'region == "East"'.
Let’s run the code and take a look at the output.
Here is the code:
sales_data.query('region == "East"')
And here is the output, which is a new dataframe:
name region sales 0 William East 50000 2 Sofia East 90000 9 Anika East 65000
Notice that the output DataFrame contains all of the records for the region East.
A few notes about this.
First, the logical expression is syntactically just a Python logical expression. Here, we’re using the equivalence operator from Python, the double equal sign (==).
Second, the whole logical expression is contained inside of single quotation marks. That is, we provide the logical expression to .query() in the form of a string. Query expects a string.
Third, we’re referencing "East", which is one of the unique values of the region variable. Notice that this value is actually contained inside of double quotation marks. This is because we treat string values of a DataFrame as strings, and as such, it needs to be inside of quotation marks. But since the overall expression is already inside of single quotes, we need to use double quotes for the value "East". If you don’t understand this, you need to review the rules for using quotes inside of quotes with Python.
EXAMPLE 3: Subset a DataFrame by index
Here, we’re going to reference the index of the DataFrame and subset the rows based on that index.
First, let’s just print out the DataFrame.
print(sales_data)
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000 5 Thomas West 72000 39000 6 Ethan South 49000 42000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that when we print out the DataFrame, each row has an integer associated with it on the left hand side, starting at zero.
This group of numbers is the index. By default, when we create a DataFrame, each row will be given a numeric index value like this (although, there are ways to change the index to something else).
We can reference these index values inside of query.
To do this, just use the word ‘index’.
Here’s an example. Here, we’re going to return the rows where index is less than 3. This will effectively return the first three rows.
sales_data.query('index < 3')
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000
Notice that in this output, the index values (on the left side of the printout) are all less than 3.
You can also use mathematical operations inside of your expressions, and this can be a useful technique to subset your data in interesting ways.
For example, we can use the modulo operator (%) on index to retrieve the «odd» rows of our DataFrame:
sales_data.query('index%2 == 1')
OUT:
name region sales expenses 1 Emma North 52000 43000 3 Markus South 34000 44000 5 Thomas West 72000 39000 7 Olivia West 55000 60000 9 Anika East 65000 44000
Using index inside of your expressions for query is a good way of conditionally subsetting on the index.
EXAMPLE 4: Subset a pandas dataframe by comparing two columns
Now, let’s make things a little more complicated.
Here, we’re going to compare two variables – sales and expenses – and return the rows where sales is less than expenses.
sales_data.query('sales < expenses')
OUT:
name region sales expenses 3 Markus South 34000 44000 7 Olivia West 55000 60000
This is pretty straightforward. Our logical expression, 'sales < expenses', instructs the query method to return rows where sales is less than expenses. And that’s what is in the output!
Keep in mind that we can use more than two variable in our expressions, or make the expressions more complicated with logical operators.
I’ll show you an example of that in the next example.
EXAMPLE 5: Subset a pandas dataframe with multiple conditions
Here, we’re going to subset the DataFrame based on a complex logical expression. The expression is composed of two smaller expressions that are being combined with the and operator.
We’re going to return rows where sales is greater than 50000 AND region is either ‘East’ or ‘West’.
Here’s the code:
sales_data.query('(sales > 50000) and (region in ["East", "West"])')
And here’s the output:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 7 Olivia West 55000 60000 8 Arun West 67000 39000 9 Anika East 65000 44000
Notice which rows are actually in the output. The rows all have a region that’s either ‘East’ or ‘West’. Additionally, all of the rows have sales greater than 50000.
We did this by creating a compound logical expression using the and operator.
The overall expression inside of query is '(sales > 50000) and (region in ["East", "West"])'.
Notice that there are two parts. The first part is (sales > 50000). The second part is (region in ["East", "West"]). Both of these parts are small expressions themselves that will subset our DataFrame. But here, we’re combining them together with the logical ‘and‘ operator. This tells query to return rows where both parts are True.
If you want, you could also use the logical ‘or‘ operator and the logical ‘not‘ operator inside of your expressions. Essentially, you use the Python logical operators to create more complicated expressions and subset your data in more complex ways.
EXAMPLE 6: reference local variables inside of query
Now, let’s do something a little different.
So far, we’ve been referencing variables that are actually inside of the DataFrame. We’ve been referencing the names of the columns, like sales and expenses.
Now, we’re going to reference a variable outside of the dataframe.
Here, we’re going to calculate the mean of the sales variable and store it as a separate variable outside of our DataFrame.
sales_mean = sales_data.sales.mean()
And let’s take a look at the value:
print(sales_mean)
OUT:
58454.545
This variable, sales_mean, simply holds the value of the mean of our sales variable.
Next, we’re going to reference that variable.
To do this, we’re going to use the ‘@‘ character in front of the variable.
Let’s look at the code:
sales_data.query('sales > @sales_mean')
And here is the output:
name region sales expenses 2 Sofia East 90000 50000 5 Thomas West 72000 39000 8 Arun West 67000 39000 9 Anika East 65000 44000 10 Paulo South 67000 45000
Notice that for all of the rows, sales is greater than 58454.545 (the mean of sales).
EXAMPLE 7: Modify a DataFrame in Place
Finally, let’s do one more example.
Here, we’re going to modify a DataFrame «in place».
That means that we’re going to directly modify the DataFrame that we’re operating on, instead of producing a new DataFrame.
Now keep in mind: modifying a DataFrame in place can be risky, because we will overwrite our data.
That being the case, I’m actually going to create a duplicate DataFrame first called sales_data_dupe. This way, when we modify the data, we’ll overwrite the duplicate and keep our original intact.
sales_data_dupe = sales_data.copy()
Now, let’s modify sales_data_dupe.
Here, we’re going to select rows where 'index < 5', but we’re going to modify the DataFrame directly by setting inplace = True.
sales_data_dupe.query('index < 5', inplace = True)
And let’s print out the output:
print(sales_data_dupe)
OUT:
name region sales expenses 0 William East 50000 42000 1 Emma North 52000 43000 2 Sofia East 90000 50000 3 Markus South 34000 44000 4 Edward West 42000 38000
Notice that the rows in sales_data_dupe meet our criteria that the index must be less than 5. Moreover, notice that query modified the DataFrame directly (instead of producing a new DataFrame).
Frequently asked questions about Pandas query
Here are a few frequently asked questions about the Pandas query method.
Frequently asked questions:
- What’s the advantage of using
.query()over brackets - How does query in Pandas compare to SQL code
What’s the advantage of using .query() over brackets
In Python, there are many ways to select rows from a Pandas dataframe.
By far, the most common is to subset by using «bracket notation». Here’s an example (note that we’re using the DataFrame sales_data created above):
sales_data[sales_data['sales'] > 50000]
This is essentially equivalent to this code using query:
sales_data.query('sales > 50000')
Notice how much cleaner the code is when we use query. It’s easier to read. The code looks more like «English» and less like jumbled computer syntax.
In the «bracket» version, we need to repeatedly type the name of the DataFrame. Just to reference a variable, we need to type the name of the DataFrame (i.e., sales_data['sales']).
In the query version though, we just type the name of the column.
Moreover, when we use the Pandas query method, we can use the method in a «chain» of Pandas methods, similar to how you use pipes in R’s dplyr.
Ultimately, using the query method is easier to write, easier to read, and more powerful because you can use it in conjunction with other methods.
How does query in Pandas compare to SQL code
If you’re coming from an SQL background, you might be trying to figure out how to re-write your SQL queries with Pandas.
If that’s the case, you need to know how to translate SQL syntax into Pandas.
So if you were trying to translate SQL into Pandas, how does .query() fit in?
The query method is like a where statement in SQL.
You can use query to specify conditions that your rows must meet in order to be returned.
Leave your other questions in the comments below
Do you have more questions about the Pandas query method?
Leave your question in the comments section below.
Join our course to learn more about Pandas
If you’re serious about learning Pandas, you should enroll in our premium Pandas course called Pandas Mastery.
Pandas Mastery will teach you everything you need to know about Pandas, including:
- How to subset your Python data
- Data aggregation with Pandas
- How to reshape your data
- and more …
Moreover, it will help you completely master the syntax within a few weeks. You’ll discover how to become «fluent» in writing Pandas code to manipulate your data.
Find out more here:
Learn More About Pandas Mastery
Pandas DataFrame.query() method is used to query the rows based on the expression (single or multiple column conditions) provided and returns a new DataFrame. In case you wanted to update the existing referring DataFrame use inplace=True argument.
In this article, I will explain the syntax of the Pandas DataFrame query() method and several working examples like query with multiple conditions and query with string contains to new few.
Related:
- pandas.DataFrame.filter() – To filter rows by index and columns by name.
- pandas.DataFrame.loc[] – To select rows by indices label and column by name.
- pandas.DataFrame.iloc[] – To select rows by index and column by position.
- pandas.DataFrame.apply() – To custom select using lambda function.
1. Quick Examples of pandas query()
If you are in hurry, below are quick examples of how to use pandas.DataFrame.query() method.
# Query Rows using DataFrame.query()
df2=df.query("Courses == 'Spark'")
#Using variable
value='Spark'
df2=df.query("Courses == @value")
#inpace
df.query("Courses == 'Spark'",inplace=True)
#Not equals, in & multiple conditions
df.query("Courses != 'Spark'")
df.query("Courses in ('Spark','PySpark')")
df.query("`Courses Fee` >= 23000")
df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000")
If you are a learner, Let’s see with sample data and run through these examples and explore the output to understand better. First, let’s create a pandas DataFrame from Dict.
import pandas as pd
import numpy as np
technologies= {
'Courses':["Spark","PySpark","Hadoop","Python","Pandas"],
'Fee' :[22000,25000,23000,24000,26000],
'Duration':['30days','50days','30days', None,np.nan],
'Discount':[1000,2300,1000,1200,2500]
}
df = pd.DataFrame(technologies)
print(df)
Note that the above DataFrame also contains None and Nan values on Duration column that I would be using in my examples below to select rows that has None & Nan values or select ignoring these values.
3. Using DataFrame.query()
Following is the syntax of DataFrame.query() method.
# query() method syntax
DataFrame.query(expr, inplace=False, **kwargs)
expr– expression takes conditions to query rowsinplace– Defaults toFalse. When set toTrue, it updates the referring DataFrame andquery()method returnsNone.**kwargs– Keyword arguments that works with eval()
DataFrame.query() takes condition in expression to select rows from a DataFrame. This expression can have one or multiple conditions.
# Query all rows with Courses equals 'Spark'
df2=df.query("Courses == 'Spark'")
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
In case you wanted to use a variable in the expression, use @ character.
# Query Rows by using Python variable
value='Spark'
df2=df.query("Courses == @value")
print(df2)
If you notice the above examples return a new DataFrame after filtering the rows. if you wanted to update the existing DataFrame use inplace=True
# Replace current esisting DataFrame
df.query("Courses == 'Spark'",inplace=True)
print(df)
If you wanted to select based on column value not equals then use != operator.
# not equals condition
df2=df.query("Courses != 'Spark'")
Yields below output.
Courses Courses Fee Duration Discount
1 PySpark 25000 50days 2300
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
4 Pandas 26000 NaN 2500
4. Select Rows Based on List of Column Values
If you have values in a python list and wanted to select the rows based on the list of values, use in operator, it’s like checking a value contains in a list of string values.
# Query Rows by list of values
print(df.query("Courses in ('Spark','PySpark')"))
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
You can also write with a list of values in a python variable.
# Query Rows by list of values
values=['Spark','PySpark']
print(df.query("Courses in @values"))
To select rows that are not in a list of column values can be done using not in operator.
# Query Rows not in list of values
values=['Spark','PySpark']
print(df.query("Courses not in @values"))
If you have column names with special characters using column name surrounded by tick ` character .
# Using columns with special characters
print(df.query("`Courses Fee` >= 23000"))
5. Query with Multiple Conditions
In Pandas or any table-like structures, most of the time we would need to select the rows based on multiple conditions by using multiple columns, you can do that in Pandas DataFrame as below.
# Query by multiple conditions
print(df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000"))
Yields below output. Alternatively, you can also use pandas loc with multiple conditions.
Courses Courses Fee Duration Discount
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
6. Query Rows using apply()
pandas.DataFrame.apply() method is used to apply the expression row-by-row and return the rows that matched the values. The below example returns every match when Courses contains a list of specified string values.
# By using lambda function
print(df.apply(lambda row: row[df['Courses'].isin(['Spark','PySpark'])]))
Yields below output. A lambda expression is used with pandas to apply the function for each row.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
8. Other Examples using df[] and loc[]
# Other examples you can try to query rows
df[df["Courses"] == 'Spark']
df.loc[df['Courses'] == value]
df.loc[df['Courses'] != 'Spark']
df.loc[df['Courses'].isin(values)]
df.loc[~df['Courses'].isin(values)]
df.loc[(df['Discount'] >= 1000) & (df['Discount'] <= 2000)]
df.loc[(df['Discount'] >= 1200) & (df['Fee'] >= 23000 )]
# Select based on value contains
print(df[df['Courses'].str.contains("Spark")])
# Select after converting values
print(df[df['Courses'].str.lower().str.contains("spark")])
#Select startswith
print(df[df['Courses'].str.startswith("P")])
Conclusion
In this article, I have explained multiple examples of how to query Pandas DataFrame Rows based on single and multiple conditions, from a list of values (checking column value exists in list of string values) e.t.c. Remember when you query DataFrame Rows, it always returns a new DataFrame with selected rows, in order to update existing df you have to use inplace=True. I hope this article helps you learn Pandas.
Happy Learning !!
Related Articles
- Different Ways to Rename Pandas DataFrame Column
- How to Drop Column From Pandas DataFrame
- Pandas- How to get a Specific Cell Value from DataFrame
- Pandas Filter DataFrame by Multiple Conditions
- Pandas apply map (applymap()) Explained
- Apply Multiple Filters to Pandas DataFrame or Series
- Pandas Filter Rows by Conditions
- Pandas Filter by Column Value
References
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
- https://pandas.pydata.org/docs/reference/api/pandas.eval.html#pandas.eval
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages that makes importing and analyzing data much easier. Analyzing data requires a lot of filtering operations. Pandas Dataframe provide many methods to filter a Data frame and Dataframe.query() is one of them.
Pandas query() method Syntax
Syntax: DataFrame.query(expr, inplace=False, **kwargs)
Parameters:
- expr: Expression in string form to filter data.
- inplace: Make changes in the original data frame if True
- kwargs: Other keyword arguments.
Return type: Filtered Data frame
Pandas DataFrame query() Method
Dataframe.query() method only works if the column name doesn’t have any empty spaces. So before applying the method, spaces in column names are replaced with ‘_’ . To download the CSV file used, Click Here.
Pandas DataFrame query() Examples
Example 1: Single condition filtering In this example, the data is filtered on the basis of a single condition. Before applying the query() method, the spaces in column names have been replaced with ‘_’.
Python3
import pandas as pd
data = pd.read_csv("employees.csv")
data.columns =
[column.replace(" ", "_") for column in data.columns]
data.query('Senior_Management == True',
inplace=True)
data
Output:
As shown in the output image, the data now only have rows where Senior Management is True.
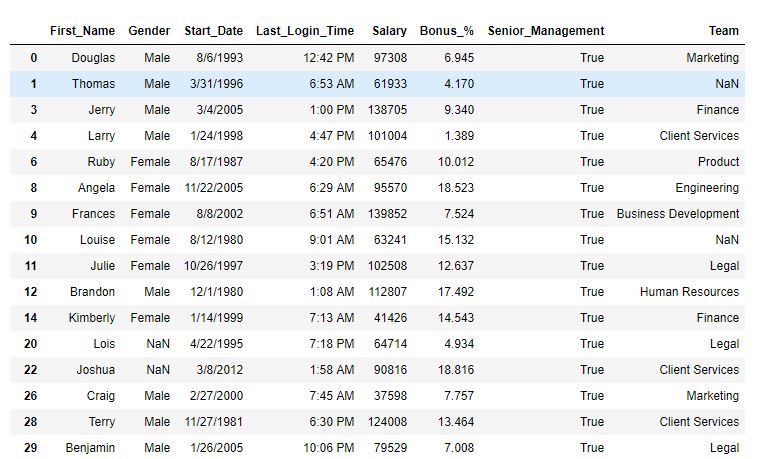
Example 2: Multiple conditions filtering In this example, Dataframe has been filtered on multiple conditions. Before applying the query() method, the spaces in column names have been replaced with ‘_’.
Python3
import pandas as pd
data = pd.read_csv("employees.csv")
data.columns =
[column.replace(" ", "_") for column in data.columns]
data.query('Senior_Management == True
and Gender == "Male" and Team == "Marketing"
and First_Name == "Johnny"', inplace=True)
data
Output:
As shown in the output image, only two rows have been returned on the basis of filters applied.

Last Updated :
29 Mar, 2023
Like Article
Save Article
Время чтения 4 мин.
Pandas Dataframe.filter() — это встроенная функция, которая фильтрует, возвращает подмножество столбцов или строк DataFrame в соответствии с метками в конкретном индексе. Следует отметить, что эта процедура не фильтрует DataFrame по его содержимому. Функция filter() применяется к меткам индекса.
Содержание
- Как фильтровать фрейм данных Pandas
- Использование метода DataFrame.filter()
- Синтаксис
- Параметры
- Пример
- Фильтр Pandas с регулярным выражением Python
- Выбор строк в DataFrame, используя filter()
- Фильтрация в Pandas с df.query()
- Фильтрация несколько столбцов в Pandas DataFrame
- Заключение
Python Pandas позволяет нам нарезать данные несколькими способами. Часто вам может понадобиться подмножество фрейма данных pandas на основе одного или нескольких значений определенного столбца. Обязательно мы хотели бы выбрать строки на основе одного значения или нескольких значений, присутствующих в столбце.
Для фильтрации данных в Pandas у нас есть следующие параметры.
- Метод Pandas filter().
- Функция Pandas query().
- Индексы Pandas DataFrame.
Использование метода DataFrame.filter()
Синтаксис
|
DataFrame.filter(self: ~FrameOrSeries, items=None, like: Union[str, NoneType] = None, regex: Union[str, NoneType] = None, axis=None) |
Параметры
- items: в виде списка
Сохраняйте метки от оси, которые находятся в элементах.
- like: str
Сохраняйте метки от оси, для которой «like in label == True».
- regex: str(регулярное выражение)
Сохраняйте метки от оси, для которой re.search(regex, label) == True.
- axis: {0 или «index», 1 или «columns», «None}», значение по умолчанию — «None».
Ось для фильтрации, выраженная индексом(int) или именем оси(str).
По умолчанию это информационная ось, «index» для серии, «columns» для DataFrame.

Пример
Давайте использовать внешний файл CSV для этого примера. Файл, который я использую, называется файлом People.csv, и мы будем импортировать данные с помощью функции pandas read_csv(). Затем мы создадим DataFrame из данных CSV.
В этом примере мы выбираем только первые 10 строк, поэтому я использовал функцию DataFrame.head(), чтобы ограничить количество строк до 10.
Затем мы будем использовать функцию filter() для выбора данных на основе меток.
См. приведенный ниже код.
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) print(df10) |
Выход:
|
python3 app.py Name Sex Age Height Weight 0 Alex M 41 74 170 1 Bert M 42 68 166 2 Carl M 32 70 155 3 Dave M 39 72 167 4 Elly F 30 66 124 5 Fran F 33 66 115 6 Gwen F 26 64 121 7 Hank M 30 71 158 8 Ivan M 53 72 175 9 Jake M 32 69 143 |
Вы можете видеть, что у нас всего 5 столбцов и 10 строк.
Теперь мы выберем только Name, Height и Weight, используя метод Pandas filter().
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) print(df10) dFilter = df10.filter([‘Name’, ‘Height’, ‘Weight’]) print(dFilter) |
Выход:
|
python3 app.py Name Height Weight 0 Alex 74 170 1 Bert 68 166 2 Carl 70 155 3 Dave 72 167 4 Elly 66 124 5 Fran 66 115 6 Gwen 64 121 7 Hank 71 158 8 Ivan 72 175 9 Jake 69 143 |
Фильтр Pandas с регулярным выражением Python
Давайте передадим параметр регулярного выражения в функцию filter(). Python RegEx или регулярное выражение — это последовательность символов, формирующая шаблон поиска. Python RegEx можно использовать для проверки того, содержит ли строка указанный шаблон поиска.
Выберем столбцы по имени, которые содержат «A».
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) dFilter = df10.filter(regex =‘[A]’) print(dFilter) |
Выход:
|
python3 app.py Age 0 41 1 42 2 32 3 39 4 30 5 33 6 26 7 30 8 53 9 32 |
Регулярное выражение «[A]» ищет все имена столбцов, в которых есть «A».
У нас есть только один столбец, содержащий A; вот почему он возвращает столбец Age.
Выбор строк в DataFrame, используя filter()
Давайте выберем данные на основе индекса DataFrame.
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) dFilter = df10.filter(like=‘6’, axis=0) print(dFilter) |
В приведенном выше коде мы выбираем строку с индексом 6.
В Pandas DataFrame индекс начинается с 0. Таким образом, 6 должен быть 7-м индексом в DataFrame.
|
python3 app.py Name Sex Age Height Weight 6 Gwen F 26 64 121 |
Фильтрация в Pandas с df.query()
filter() — не единственная функция, которую мы можем использовать для фильтрации строк и столбцов.
Pandas DataFrame.query() — это встроенная функция, полезная для фильтрации строк.
См. следующий код.
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) dFilter = df10.query(‘Age>40’) print(dFilter) |
Выход:
|
python3 app.py Name Sex Age Height Weight 0 Alex M 41 74 170 1 Bert M 42 68 166 8 Ivan M 53 72 175 |
В приведенном выше примере мы фильтруем строки с Age > 40 и получаем всех людей, чей возраст больше 40.
Это похоже на запрос SQL SELECT с предложением WHERE.
Фильтрация несколько столбцов в Pandas DataFrame
Мы можем фильтровать несколько столбцов в Pandas DataFrame с помощью оператора &, не забудьте свернуть подоператоры with().
См. следующий код.
|
# app.py import pandas as pd dt = pd.read_csv(‘people.csv’) df = pd.DataFrame(data=dt) df10 = df.head(10) dFilter = df10[(df10.Age >= 40) &(df10.Sex == ‘M’)] print(dFilter) |
Выход:
|
python3 app.py Name Sex Age Height Weight 0 Alex M 41 74 170 1 Bert M 42 68 166 8 Ivan M 53 72 175 |
В приведенном выше коде мы фильтруем данные на основе двух условий.
- Age > 40
- Sex == М
Если один из них имеет значение False, он отфильтровывает эти данные.
Возвращаемые данные будут удовлетворять нашим условиям.
Заключение
Мы можем фильтровать Pandas DataFrame, используя методы индексов df.filter(), df.query() и df[].
Мы также можем фильтровать несколько столбцов с помощью оператора &.