Повторный и бесповторный отбор.
Ошибка выборки
Краткая теория
На основании выборочных данных дается оценка статистических
показателей по всей (генеральной) совокупности. Подобное возможно, если выборка
основывается на принципах случайности отбора и репрезентативности
(представительности) выборочных данных. Каждая единица генеральной совокупности
должна иметь равную возможность (вероятность) попасть в выборку.
При формировании выборочной совокупности используются следующие
способы отбора: а) собственно-случайный отбор; б) механическая выборка; в)
типический (районированный) отбор; г) многоступенчатая (комбинированная)
выборка; д) моментно-выборочное наблюдение.
Выборка может осуществляться по схеме повторного и бесповторного
отбора.
В первом случае единицы совокупности, попавшие в выборку, снова
возвращаются в генеральную, а во втором случае – единицы совокупности, попавшие
в выборку, в генеральную совокупность уже не возвращаются.
Выборка может осуществляться отдельными единицами или сериями
(гнездами).
Собственно-случайная выборка
Отбор в этом случае производится либо по жребию, либо по таблицам
случайных чисел.
На основании приемов классической выборки решаются следующие
задачи:
а) определяются границы среднего значения показателя по генеральной
совокупности;
б) определяются границы доли признака по генеральной совокупности.
Предельная ошибка средней при собственно-случайном отборе
исчисляется по формулам:
а) при повторном отборе:
б) при бесповторном отборе:
где
– численность выборочной совокупности;
– численность генеральной совокупности;
– дисперсия признака;
– критерий кратности ошибки: при
;
при
;
при
.
Значения
определяются
по таблице функции Лапласа.
Границы (пределы) среднего значения признака по генеральной
совокупности определяются следующим неравенством:
где
– среднее значение признака по выборочной
совокупности.
Предельная ошибка доли при собственно-случайном отборе определяется
по формулам:
а) при повторном отборе:
при бесповторном отборе:
где
– доля единиц совокупности с заданным
значением признака в обзей численности выборки,
– дисперсия доли признака.
Границы (пределы) доли признака по всей (генеральной) совокупности
определяются неравенством:
где
– доля признака по генеральной совокупности.
Типическая (районированная) выборка
Особенность этого вида
выборки заключается в том, что предварительно генеральная совокупность по
признаку типизации разбивается на частные группы (типы, районы), а затем в
пределах этих групп производится выборка.
Предельная ошибка средней
при типическом бесповторном отборе определяется по формуле:
где
– средняя из внутригрупповых дисперсий
по каждой типичной группе.
При пропорциональном отборе из групп генеральной совокупности
средняя из внутригрупповых дисперсий определяется по формуле:
где
– численности единиц совокупности групп по выборке.
Границы (пределы) средней по генеральной совокупности на основании
данных типической выборки определяются по тому же неравенству, что при
собственно-случайной выборке. Только предварительно необходимо вычислить общую
выборочную среднюю
из частных выборочных средних
.
Для случая пропорционального отбора это определяется по формуле:
При непропорциональном отборе средняя из внутригрупповых дисперсий вычисляется по
формуле:
где
– численность единиц групп по генеральной
совокупности.
Общая выборочная средняя в этом случае определяется по формуле:
Предельная ошибка доли
признака при типическом бесповторном отборе определяется формулой:
Средняя дисперсия доли
признака из групповых дисперсий доли
при
типической пропорциональной выборке вычисляется по формуле:
Средняя доля признака по
выборке из показателей групповых долей рассчитывается формуле:
Средняя дисперсия доли при
непропорциональном типическом отборе определяется следующим образом:
а средняя доля признака:
Формулы ошибок выборки при типическом повторном отборе будут те же,
то и для случая бесповторного отбора. Отличие заключается только в том, что в
них будет отсутствовать по корнем сомножитель
.
Серийная выборка
Серийная ошибка выборки
может применяться в двух вариантах:
а) объем серий различный
б) все серии имеют
одинаковое число единиц (равновеликие серии).
Наиболее распространенной
в практике статистических исследований является серийная выборка с
равновеликими сериями. Генеральная совокупность делится на одинаковые по объему
группы-серии
и
производится отбор не единиц совокупности, а серий
. Группы (серии) для обследования отбирают в
случайном порядке или путем механической выборки как повторным, так и
бесповторными способами. Внутри каждой отобранной серии осуществляется сплошное
наблюдение. Предельные ошибки выборки
при
серийном отборе исчисляются по формулам:
а) при повторном отборе
б) при бесповторном отборе
где
– число
серий в генеральной совокупности;
– число
отобранных серий;
– межсерийная дисперсия, исчисляемая для случая равновеликих
серий по формуле:
где
–
среднее значение признака в каждой из отобранных серий;
– межсерийная
средняя, исчисляемая для случая равновеликих серий по формуле:
Определение численности выборочной совокупности
При проектировании
выборочного наблюдения важно наряду с организационными вопросами решить одну из
основных постановочных задач: какова должна быть необходимая численность
выборки с тем, чтобы с заданной степенью точности (вероятности) заранее
установленная ошибка выборки не была бы превзойдена.
Примеры решения задач
Задача 1
На основании результатов проведенного на заводе 5%
выборочного наблюдения (отбор случайный, бесповторный) получен следующий ряд
распределения рабочих по заработной плате:
| Группы рабочих по размеру заработной платы, тыс.р. | до 200 | 200-240 | 240-280 | 280-320 | 320 и выше | Итого |
| Число рабочих | 33 | 35 | 47 | 45 | 40 | 200 |
На основании приведенных данных определите:
1) с вероятностью 0,954 (t=2) возможные пределы, в которых
ожидается средняя заработная плата рабочего в целом по заводу (по генеральной
совокупности);
2) с вероятностью 0,997 (t=3) предельную ошибку и границы доли
рабочих с заработной платой от 320 тыс.руб. и выше.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычислим среднюю з/п: Для этого просуммируем произведения середин
интервалов и соответствующих частот, и полученную сумму разделим на сумму
частот.
2) Выборочная дисперсия:
Найдем доверительный интервал для средней. Предельная ошибка выборочной
средней считается по формуле:
где
—
аргумент функции Лапласа.
Искомые возможные пределы, в которых ожидается средняя заработная плата
рабочего в целом по заводу:
Найдем доверительный интервал для выборочной доли. Предельная ошибка
выборочной доли считается по формуле:
Доля рабочих с з/п от 320 тыс.р.:
Искомые границы доли рабочих с заработной платой от 320 тыс.руб. и выше:
Задача 2
В
городе 23560 семей. В порядке механической выборки предполагается определить
количество семей в городе с числом детей трое и более. Какова должна быть
численность выборки, чтобы с вероятностью 0,954 ошибка выборки не превышала
0,02 человека. На основе предыдущих обследований известно, что дисперсия равна
0,3.
Решение
Численность
выборки можно найти по формуле:
В нашем случае:
Вывод к задаче
Таким образом численность
выборки должна составить 2661 чел.
Задача 3
С
целью определения средней месячной заработной платы персонала фирмы было
проведено 25%-ное выборочное обследование с отбором
единиц пропорционально численности типических групп. Для отбора сотрудников
внутри каждого филиала использовался механический отбор. Результаты
обследования представлены в следующей таблице:
| Номер филиала |
Средняя месячная заработная плата, руб. |
Среднее квадратическое отклонение, руб. |
Число сотрудников, чел. |
| 1 | 870 | 40 | 30 |
| 2 | 1040 | 160 | 80 |
| 3 | 1260 | 190 | 140 |
| 4 | 1530 | 215 | 190 |
С
вероятностью 0,954 определите пределы средней месячной заработной платы всех
сотрудников гостиниц.
Решение
Предельная
ошибка выборочной средней:
Средняя
из внутригрупповых дисперсий:
Получаем:
Средняя
месячная заработная плата по всей совокупности филиалов:
Искомые
пределы средней месячной заработной платы:
Вывод к задаче
Таким
образом с вероятностью 0,954 средняя месячная заработная плата всех сотрудников
гостиниц находится в пределах от 1294,3 руб. до 1325,7 руб.
Выборочное наблюдение статистическое наблюдение, при котором исследованию
подвергают не все элементы изучаемой совокупности (называемой при этом «генеральной»), а только
некоторую, определённым образом отобранную их часть.
В
статистике приняты следующие условные
обозначения:
N
— объем генеральной совокупности;
п
— объем выборочной совокупности;
![]() —
—
средняя в генеральной совокупности;
![]() —
—
средняя в выборочной совокупности;
р
— доля единиц в генеральной совокупности;
w
— доля единиц в выборочной совокупности;
![]() —
—
генеральная дисперсия;
S2 —
выборочная дисперсия;
![]() —
—
среднее квадратическое отклонение
признака в генеральной совокупности;
S
— среднее квадратическое отклонение
признака в выборочной совокупности.
Виды
выборки:
![]() Простая
Простая
случайная выборка (собственно-случайная) есть
отбор единиц из генеральной совокупности
путем случайного отбора, но при условии
вероятности выбора любой единицы из
генеральной совокупности. Отбор
проводится методом жеребьевки или по
таблице случайных чисел.
![]() Типическая
Типическая
(стратифицированная) выборка предполагает
разделение неоднородной генеральной
совокупности на типологические или
районированные группы по какому-либо
существенному признаку, после чего из
каждой группы производится случайный
отбор единиц.
Для ![]() серийной
серийной
(гнездовой) выборки характерно
то, что генеральная совокупность
первоначально разбивается на определенные
равновеликие или неравновеликие серии
(единицы внутри серий связаны по
определенному признаку), из которых
путем случайного отбора отбираются
серии и затем внутри отобранных серий
проводится сплошное наблюдение.
![]() Механическая
Механическая
выборка представляет
собой отбор единиц через равные промежутки
(по алфавиту, через временные промежутки,
по пространственному способу и т.д.).
При проведении механического отбора
генеральная совокупность разбивается
на равные по численности группы, из
которых затем отбирается по одной
единице.
![]() Комбинированная
Комбинированная
выборка основана
на сочетании нескольких способов
выборки.
![]() Многоступенчатая
Многоступенчатая
выборка есть
образование внутри генеральной
совокупности вначале крупных групп
единиц, из которых образуются группы,
меньшие по объему, и так до тех пор, пока
не будут отобраны те группы или отдельные
единицы, которые необходимо исследовать.
Выборочный отбор может быть повторным
и бесповторным. При ![]() повторном
повторном
отборе вероятность
выбора любой единицы не ограничена.
При ![]() бесповторном
бесповторном
отборе выбранная
единица в исходную совокупность не
возвращается.
Для отобранных
единиц рассчитываются обобщенные
показатели (средние или относительные)
и в дальнейшем результаты выборочного
исследования распространяются на всю
генеральную совокупность.
Основной
задачей при выборочном исследовании
является определение ошибок выборки.
Принято различать среднюю и предельную
ошибки выборки. Для иллюстрации можно
предложить расчет ошибки выборки на
примере простого случайного отбора.
Расчет средней
ошибки повторной простой случайной
выборки производится
следующим образом:
cредняя
ошибка для средней
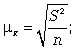 (11.1)
(11.1)
cредняя
ошибка для доли
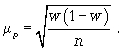 (11.2)
(11.2)
Расчет средней
ошибки бесповторной случайной выборки:
средняя
ошибка для средней
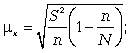 (11.3)
(11.3)
средняя
ошибка для доли
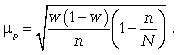 (11.4)
(11.4)
Расчет предельной
ошибки ![]() повторной
повторной
случайной выборки:
предельная
ошибка для средней
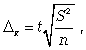
предельная
ошибка для доли
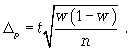 (11.5)
(11.5)
где t —
коэффициент кратности;
Расчет предельной
ошибки бесповторной случайной выборки:
предельная
ошибка для средней
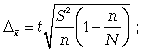 (11.6)
(11.6)
предельная
ошибка для доли
 (11.7)
(11.7)
Следует
обратить внимание на то, что под знаком
радикала в формулах при бесповторном
отборе появляется множитель, где N —
численность генеральной совокупности.
Что касается
расчета ошибки выборки в других видах
выборочного отбора (например, типической
и серийной), то необходимо отметить
следующее.
Для типической
выборки величина
стандартной ошибки зависит от точности
определения групповых средних. Так, в
формуле предельной ошибки типической
выборки учитывается средняя из групповых
дисперсий, т.е.
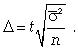 (11.8)
(11.8)
При серийной
выборке величина
ошибки выборки зависит не от числа
исследуемых единиц, а от числа обследованных
серий (s) и от величины межгрупповой
дисперсии:
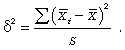 (11.9)
(11.9)
Серийная
выборка, как правило, проводится как
бесповторная, и формула ошибки выборки
в этом случае имеет вид
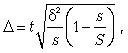 (11.10)
(11.10)
где ![]() —
—
межсерийная дисперсия; s — число отобранных
серий; S — число серий в генеральной
совокупности.
Все
вышеприведенные формулы применимы
для большой
выборки. Кроме большой
выборки используются так называемые малые
выборки (n
< 30), которые могут иметь место в случаях
нецелесообразности использования
больших выборок.
При расчете
ошибок малой выборки необходимо учесть
два момента:
1) формула
средней ошибки имеет вид
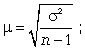 (11.11)
(11.11)
2) при определении доверительных
интервалов исследуемого показателя в
генеральной совокупности или при
нахождении вероятности допуска той или
иной ошибки необходимо использовать
таблицы вероятности ![]() Стьюдента,
Стьюдента,
где Р = S (t, n), при этом Р определяется в
зависимости от объема выборки и t.
В статистических
исследованиях с помощью формулы
предельной ошибки можно решать ряд
задач.
1. Определять
возможные пределы нахождения характеристики
генеральной совокупности на основе
данных выборки.
Доверительные
интервалы для генеральной средней можно
установить на основе соотношений
![]() (11.12)
(11.12)
где
— ![]() генеральная
генеральная
и выборочная средние соответственно; ![]() —
—
предельная ошибка выборочной средней.
Доверительные
интервалы для генеральной доли устанавливаются
на основе соотношений
![]()
![]() (11.13)
(11.13)
2. Определять
доверительную вероятность, которая
означает, что характеристика генеральной
совокупности отличается от выборочной
на заданную величину.
Доверительная
вероятность является функцией от t, где
![]() (11.14)
(11.14)
Доверительная
вероятность по величине t определяется
по специальной таблице.
3. Определять
необходимый объем выборки с помощью
допустимой величины ошибки:
![]() (11.15)
(11.15)
Чтобы
рассчитать численность п повторной и
бесповторной простой случайной выборки,
можно использовать следующие формулы:
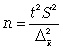 (для
(для
средней при повторном способе); (11.16)
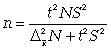 (для
(для
средней при бесповторном способе);
(11.17)
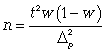 (для
(для
доли при повторном способе); (11.18)
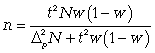 (для
(для
доли при бесповторном способе). (11.19)
Анализ
ряда динамики.
Изучение
изменения различных явлений во времени
— одна из важнейших задач статистики.
Решается эта задача путем составления
и анализа рядов динамики (иногда их
также называют временными или
хронологическими рядами).
Ряд
динамикипредставляет
собой числовые значения определенного
статистического показателя в
последовательные моменты или периоды
времени (т.е. расположенные в хронологическом
порядке).
Числовые
значения того или иного статистического
показателя, составляющие ряд динамики,
называютуровнямиряда
и обычно обозначают через у. Первый
член ряда у0 (или у1) называют начальнымуровнем,
а последний уn — конечным. Моменты
или периоды времени, к которым относятся
уровни, обозначают черезt. Ряды
динамики представляют в виде таблицы
или графически.
В
статистике различают моментные и
интервальные ряды динамики.
Моментным называется
ряд, уровни которого характеризуют
значение показателя (явления) по состоянию
на определенные моменты времени (дату).
Отличительная
особенность интервальных рядов: их
уровни можно дробить и складывать
(суммировать). Например, зная добычу
угля по годам, можно разделить каждый
уровень на 12 и получить новые данные –
о среднемесячной добыче угля за указанный
период. Или же, суммируя данные о
численности родившихся по месяцам,
можно получить численность родившихся
за год. Подобные действия в уровнями
моментного ряда не имеют смысла.
Одно
из требований, которые предъявляются
к анализируемым рядам динамики –
сопоставимость уровней ряда. Если данные
несопоставимы, то исходя из цели
исследования, необходимо повести
дополнительные расчеты. Для сопоставимости
должна быть обеспечена одинаковая
полнота охвата различных частей явления
(например, при характеристики численности
студентов нельзя в одни годы учитывать
только дневное отделение, а в другие
еще и заочное) и одинаковость границ
территории (например, при изучении
темпов экономического развития
целесообразно использовать ежегодно
данные по территории в одних и тех же
границах).
Одна
из первых задач изучения рядов динамики
— выявить основную тенденцию
(закономерность) в изменении уровней
ряда, именуемую трендом. Закономерность
в изменении уровней ряда в одних случаях
проявляется довольно наглядно, в других
— может затушевываться колебаниями,
вызванными случайными и неслучайными
причинами.
При
изучении рядов динамики перед статистикой
стоят следующие задачи:
—
охарактеризовать интенсивность развития
явления от периода к периоду;
—
охарактеризовать среднюю интенсивность
развития за исследуемый период;
—
выявить основную тенденцию в развитии
явления;
—
осуществить прогноз развития на будущее;
—
изучить сезонные колебания.
Показатели
ряда динамики:
Анализ
рядов динамики начинается с определения
того, как именно изменяются уровни ряда
(увеличиваются, уменьшаются или остаются
неизменными) в абсолютном и относительном
выражении. Чтобы проследить за направлением
и размером изменений уровней во времени,
для рядов динамики рассчитывают такие
показатели, как:
• абсолютные
приросты (изменения) уровней;
• темпы
роста;
• темпы
прироста (снижения) уровней;
Абсолютный
прирост(абсолютное
изменение) уровней рассчитывается как
разность между двумя уровнями ряда. Он
показывает, на сколько (в единицах
измерения показателей ряда) уровень
одного периода больше или меньше уровня
какого-либо предшествующего периода,
и, следовательно, может иметь знак «+»
(при увеличении уровней) или «—» (при
уменьшении уровней).
В
зависимости от базы сравнения абсолютные
приросты могут рассчитываться как
цепные и как базисные.
Вычитая
из каждого уровня предыдущий ( ![]() ),
),
получаем абсолютные изменения уровней
ряда за отдельные периоды как цепные. Вычитая
из каждого уровня начальный ![]() получаем
получаем
накопленные итоги прироста (изменения)
показателя с начала изучаемого периода,
т.е. абсолютные изменения рассчитываются
какбазисные.
Если
значения цепных абсолютных изменений
постоянны, то уровни ряда изменяются
равномерно. Если же абсолютные приросты
от периода к периоду возрастают (или
убывают), то уровни изменяются ускоренно
(или замедленно).
Наряду
с абсолютными изменениями уровней ряда
важно измерить также их относительное
изменение.
Темп
роста —
относительный показатель, рассчитываемый
как отношение двух уровней ряда.
В
зависимости от базы сравнения темпы
роста могут рассчитываться
как цепные, когда
каждый уровень сопоставляется с уровнем
предыдущего периода ![]() и
и
как базисные, когда
все уровни сопоставляются с уровнем
одного какого-то периода, принятого за
базу сравнения, часто это начальный
уровень ряда: ![]() .
.
Соответственно, цепные темпы роста
характеризуют интенсивность изменения
в каждом отдельном периоде, а базисные
— за отрезок времени, отделяющий данный
уровень от базисного.
Темпы
роста как относительные величины могут
выражаться в виде коэффициентов, т.е.
простого кратного отношения (если база
сравнения принимается за единицу), и в
процентах (если база сравнения принимается
за 100 единиц). Говоря о темпах, чаще всего
имеют в виду отношение уровней в
процентах.
Выраженные
в коэффициентах темпы роста показывают,
во сколько раз уровень данного периода
больше уровня базы сравнения или какую
часть его составляет. При процентном
выражении темп роста показывает,
сколько процентов составляет уровень
данного периода по сравнению с уровнем
базы сравнения.
Между
цепными и базисными коэффициентами
роста существует связь, позволяющая
при необходимости переходить от цепных
к базисным и наоборот. В частности:
• произведение
цепных коэффициентов роста равно
базисному;
• результат
деления двух базисных коэффициентов
равен цепному (промежуточному).
Темп
прироста —
относительный показатель, показывающий,
на сколько процентов данный уровень
больше (или меньше) другого, принимаемого
за базу сравнения. Этот показатель можно
рассчитать двумя способами:
• путем
вычитания 100% из темпа роста (снижения),
т.е. ![]() ;
;
• как
процентное отношение абсолютного
прироста к тому уровню, по сравнению с
которым рассчитан абсолютный прирост,
т. е. ![]() или
или ![]() .
.
Иногда
для анализа рассчитывается такой
показатель, как абсолютное
значение 1% прироста—
отношение абсолютного прироста уровня
к темпу прироста (за соответствующий
период):
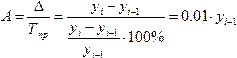
Абсолютное
значение 1 % прироста равно одной сотой
предыдущего уровня.
Для
базисных абсолютных приростов и темпов
прироста расчет А не имеет смысла, так
как при сравнении всех накопленных
приростов с одним и тем же первоначальным
уровнем у0 для
всех периодов будет получаться одно и
то же значение 1 % прироста.
Для
характеристики интенсивности развития
за длительный период рассчитываются
средние показатели рядов динамики.
Обобщенной
характеристикой динамического ряда
может служить прежде всего средний
уровень ряда у. Поскольку
средняя величина в данном случае
рассчитывается из меняющихся во времени
показателей, то она называется средней
хронологической.
Для
разных видов рядов динамики средний
уровень рассчитывается неодинаково.
В
интервальном ряду абсолютных величин
с равными периодами (интервалами) средний
уровень рассчитывается как средняя
арифметическая простая из уровней ряда:
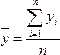
где yi — отдельные
уровни ряда; n –
число уровней.
Для
моментного ряда, содержащего n уровней
с равными промежутками между датами
(моментами), средний уровень определяется
по формуле:
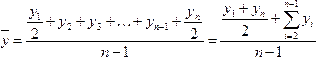 .
.
Пример. По
даннымГосударственного внешнего долга
Российской федерации рассчитать средний
уровень ряда:
|
Дата |
1.01.1999 |
1.01.2000 |
1.01.2001 |
1.01.2002 |
1.01.2003 |
1.01.2004 |
|
Гос. |
156,7 |
158,4 |
142,4 |
130,1 |
122,1 |
119,1 |
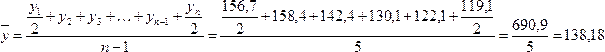 ,
,
то
есть в среднем за рассматриваемый
промежуток времени государственный
внешний долг составил 138,18 млрд. долл.
Средний
абсолютный прирост (изменение)
уровней рассчитывается как средняя
арифметическая простая из отдельных
цепных приростов или на основе накопленного
абсолютного прироста за n периодов:
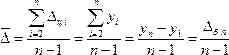 .
.
Средний
темп роста рассчитывается
как средняя геометрическая из цепных
темпов роста:
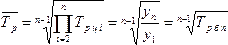 .
.
Средний
темп прироста рассчитываются
на основе средних темпов роста путем
вычитания из последних 100%:
![]() .
.
Методы
выявления основной тенденции (тренда)
в рядах динамики
Уровни
ряда динамики формируются под влиянием
взаимодействия многих факторов, одни
из которых, будучи основными, главными,
определяют закономерность, тенденцию
развития, другие — случайные — вызывают
колебания уровней. Изучая ряды динамики,
пытаются разделить эти компоненты и
выявить основную закономерность развития
явления в отдельные периоды, т.е. выявить
общую тенденцию в изменении уровней
рядов, освобожденную от действия
случайных факторов. С этой целью
(устранить колебания, вызванные случайными
причинами) ряды динамики подвергают
обработке. Существует несколько методов
обработки рядов динамики: метод укрупнения
интервалов, метод скользящей средней
и аналитическое выравнивание. Во всех
методах вместо фактических уровней при
обработке ряда рассчитываются иные
(расчетные) уровни, в которых взаимопогашается
действие случайных факторов и тем самым
уменьшается колеблемость уровней.
Уровни в результате становятся как бы
«выравненными», «сглаженными» по
отношению к исходным фактическим данным.
Такие методы обработки рядов
называются сглаживаниемили выравниваниемрядов
динамики.
Метод
укрупнения интервалов.
Простейший
метод сглаживания уровней ряда —
укрупнение интерваловвремени, для
которых определяется итоговое значение
или средняя величина исследуемого
показателя. Этот метод особенно
эффективен, если первоначальные уровни
ряда относятся к коротким промежуткам
времени. Например, если имеются данные
о ежесуточной погрузке грузов по
какой-либо железной дороге за месяц, то
в таком ряду возможны значительные
колебания уровней, так как чем меньше
период, за который приводятся данные,
тем больше влияние случайных факторов.
Чтобы
устранить это влияние, рекомендуется
укрупнить интервалы времени, например
до 5 или 10 дней, и для этих укрупненных
интервалов рассчитать общий или
среднесуточный объем погрузок
(соответственно по пятидневкам или
декадам). В ряду с укрупненными
интервалами времени закономерность
изменения уровней будет более наглядной.
Метод
скользящей средней
В
данном случае фактические уровни
заменяются средними уровнями, рассчитанными
для последовательно подвижных (скользящих)
укрупненных интервалов, охватывающих т уровней
ряда.
Например,
если принять т
= 3,
то сначала рассчитывается средняя
величина из первых трех уровней, затем
находится средняя величина из второго,
третьего и четвертого уровней, потом
из третьего, четвертого и пятого и
т.д., т.е. каждый раз в сумме трех уровней
появляется один новый уровень, а два
остаются прежними. Это и обусловливает
взаимопогашение случайных колебаний
в средних уровнях. Рассчитанные
из т членов
скользящие средние относятся к середине
(центру) каждого рассматриваемого
интервала.
Сглаживание
методом скользящей средней можно
проводить по любому числу членов т, но
удобнее, если т
— нечетное
число, так как в этом случае скользящая
средняя сразу относится к конкретной
временной точке — середине (центру)
интервала. Недостатком метода скользящей
средней является то, что сглаженный ряд
«укорачивается» по сравнению с фактическим
с двух концов: при нечетном т на ![]() с
с
каждого конца, а при четном — на т/2 с
каждого конца. Этот метод сглаживает
(устраняет) лишь случайные колебания.
Если же, например, ряд содержит сезонную
волну, она сохранится и после сглаживания.
Метод
скользящей средней и укрупнения
интервалов являются механическими,
эмпирическими и не позволяют выразить
общую тенденцию изменения уровней в
виде математической модели.
Аналитическое
выравнивание.
Более
совершенный метод обработки рядов
динамики в целях устранения случайных
колебаний и выявления тренда. Суть
аналитического выравнивания заключается
в замене эмпирических (фактических)
уровней yi теоретическими ![]() ,которые
,которые
рассчитаны по определенному уравнению,
принятому за математическую модель
тренда, где теоретические уровни
рассматриваются как функция времени: ![]()
Задача
аналитического выравнивания сводится
к следующему:
• определение
на основе фактических данных вида
(формы) гипотетической функции ![]() способной
способной
наиболее адекватно отразить тенденцию
развития исследуемого показателя;
• нахождение
по эмпирическим данным параметров
указанной функции (уравнения);
• расчет
по найденному уравнению теоретических
(выравненных) уровней.
Виды
функций, с помощью которых можно описать
поведение рядов динамики были рассмотрены
в теме «Изучение корреляционных
взаимосвязей». Выбор той или иной функции
для выравнивания ряда динамики
осуществляется, как правило, на основании
графического изображения эмпирических
данных, дополняемого содержательным
анализом особенностей развития
исследуемого показателя (явления) и
специфики разных функций. Определенную
вспомогательную роль при выборе
аналитической функции играют также
механические приемы сглаживания
(укрупнение интервалов и метод скользящей
средней). Частично устраняя случайные
колебания, они помогают более точно
определить тренд и выбрать адекватную
модель (уравнение) для аналитического
выравнивания. Кроме того, существуют
некоторые условия, которыми полезно
руководствоваться при выборе функции.
Так, например, выравнивание по прямой
линии (линейной функции) yt =
а0 +
a1 t эффективно
для рядов, уровни которых изменяются
примерно в арифметической прогрессии,
т.е. когда первые разности уровней
(абсолютные приросты более или менее
постоянны.
Параметры
искомых уравнений при аналитическом
выравнивании могут быть определены
по-разному. Чаще всего их определяют,
решая систему уравнений, полученных
методом наименьших квадратов.
Выравнивание
по линейной функцииyt =
а0 +
a1 t.
Способ
получения параметров этого уравнения
был рассмотрен выше. Но для рядов динамики
расчеты можно упростить, если отсчет
времени вести от середины ряда. Например,
при нечетном числе
уровней серединная точка (год, месяц)
принимается за ноль, тогда предшествующие
периоды обозначаются соответственно
-1, -2, -3, и т. д., а следующие за средним –
соответственно +1, -2, -3 и т. д. При четном числе
уровней два серединных момента (периода)
времени обозначаются -1 и +1, а все
последующие и предыдущие, соответственно
через два интервала: ![]() и
и
т. д.
При
таком порядке отсчета времени ![]() .
.
Поэтому система уравнений упрощается
до двух уравнений, каждое их которых
решается самостоятельно:
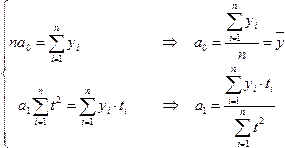 .
.
Изучая
и анализируя ряды динамики, стремятся
на основе выявленных особенностей
изменения явлений в прошлом предугадать
поведение рядов в будущем, т.е построить
различные прогнозы путем экстраполяции
(продления) рядов.
Экстраполяцию
ряда динамики можно осуществить
различными способами. Однако независимо
от применяемого способа экстраполяции
обязательно предполагается, что
закономерность (тенденция) изменения,
выявленная для определенного периода
в прошлом, сохранится на ограниченном
отрезке времени в будущем. Поэтому
любому прогнозированию в виде экстраполяции
ряда должно предшествовать тщательное
изучение длительных рядов динамики,
которое позволило бы определять тенденцию
изменения. Поскольку тенденция развития
также может изменяться, то данные,
полученные путем экстраполяции ряда,
надо рассматривать как вероятностные,
то есть своего рода оценки.
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна

- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности

Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
Здесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:

- Средняя из внутригрупповых дисперсий

- Средняя ошибка выборки:

С вероятностью 0,954 находим предельную ошибку выборки:

- Доверительные границы для среднего значения признака в генеральной совокупности:

Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно

- Значение среднего квадратического отклонения составляет

- Средняя ошибка выборки:

- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:

- Доверительный интервал для среднего значения признака в генеральной совокупности:

То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ().
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
— при оценивании среднего значения признака;
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
— для среднего значения признака;
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки () равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Таблица
11.2.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:
Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Таблица
11.3.
Формулы для расчета средней ошибки собственно случайной и механической выборки ()
|
|
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
Таблица
11.4.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
Таблица
11.5.
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя
Выборочная дисперсия изучаемого признака
- Определяем среднюю ошибку повторной случайной выборки
- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.
Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности
Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле
Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:
Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:
Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
;
- средняя ошибка выборки при использовании повторной схемы отбора составит
Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит
- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):
- установим границы для генеральной доли с вероятностью 0,997:
Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Таблица
11.6.
Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп
Здесь — средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Таблица
11.7.
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:
аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:
Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле
Предельная ошибка малой выборки:
Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:
То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Таблица
11.8.
Формулы для определения численности выборочной совокупности
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить
При бесповторном случайном отборе потребуется проверить
Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.
Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.