Средняя ошибка аппроксимации
Фактические
значения результативного признака
отличаются от теоретических, рассчитанных
по уравнению регрессии. Чем меньше эти
отличия, тем ближе теоретические значения
к эмпирическим данным, тем лучше качество
модели. Величина отклонений фактических
и расчетных значений результативного
признака каждому наблюдению представляет
собой ошибку аппроксимации. В отдельных
случаях ошибка аппроксимации может
оказаться равной нулю. Отклонения (y
–
)
несравнимы между собой, исключая
величину, равную нулю. Так, если для
одного наблюдения y
–
= 5, а для другого – 10, то это не означает,
что во втором случае модель дает вдвое
худший результат. Для сравнения
используются величины отклонений,
выраженные в процентах к фактическим
значениям. Например, если для первого
наблюдения y
= 20, а для второго y
= 50, ошибка аппроксимации составит 25 %
для первого наблюдения и 20 % – для
второго.
Поскольку
(y
–
)
может быть величиной как положительной,
так и отрицательной, ошибки аппроксимации
для каждого наблюдения принято определять
в процентах по модулю.
Отклонения
(y
–
)
можно рассматривать как абсолютную
ошибку аппроксимации, а
![]()
– как
относительную ошибку аппроксимации.
Для того, чтобы иметь общее суждение о
качестве модели из относительных
отклонений по каждому наблюдению,
находят среднюю ошибку аппроксимации
как среднюю арифметическую простую
![]()
. (2.38)
По
нашим данным представим расчет средней
ошибки аппроксимации для уравнения Y
= 6,136
Х0,474
в следующей таблице.
Таблица.
Расчет средней ошибки аппроксимации
|
y |
yx |
y |
|
|
6 |
6,135947 |
-0,135946847 |
0,022658 |
|
9 |
8,524199 |
0,475801308 |
0,052867 |
|
10 |
10,33165 |
-0,331653106 |
0,033165 |
|
12 |
11,84201 |
0,157986835 |
0,013166 |
|
13 |
13,164 |
-0,163999272 |
0,012615 |
|
Итого |
0,134471 |
A
= (0,1345 / 5)
100 = 2,69 %, что говорит о хорошем качестве
уравнения регрессии, ибо ошибка
аппроксимации в пределах 5-7 % свидетельствует
о хорошем подборе модели к исходным
данным.
Возможно
и другое определение средней ошибки
аппроксимации:
![]()
(2.39)
Для
нашего примера эта величина составит:
![]()
.
Для
расчета средней ошибки аппроксимации
в стандартных программах чаще используется
формула (2.39).
Аналогично
определяется средняя ошибка аппроксимации
и для уравнения параболы.
№11
Факторы,
включаемые во множественную регрессию,
должны отвечать следующим требованиям:
1)
быть количественно измеримы. Если
необходимо включить в модель качественный
фактор, не имеющий количественного
измерения, то нужно придать ему
количественную определенность (например,
в модели урожайности качество почвы
задается в виде баллов; в модели стоимости
объектов недвижимости учитывается
место нахождения недвижимости: районы
могут быть проранжированы);
2)
не должны быть коррелированны между
собой и тем более находиться в точной
функциональной связи.
Включение
в модель факторов с высокой интеркорреляцией,
когда ryx1
< rx1x2,
для зависимости y
= a
+ b1
x1
+ b2
x2
+ ,
может привести к нежелательным
последствиям – система нормальных
уравнений может оказаться плохо
обусловленной и повлечь за собой
неустойчивость и ненадежность оценок
коэффициентов регрессии.
Если
между факторами существует высокая
корреляция, то нельзя определить их
изолированное влияние на результативный
показатель, и параметры уравнения
регрессии оказываются неинтерпретируемыми.
Так, в уравнении y
= a
+ b1
x1
+ b2
x2
+ ,
предполагается, что факторы x1
и x2
независимы друг от друга, т.е. rx1x2
= 0. Тогда можно говорить, что параметр
b1
измеряет силу влияния фактора x1
на результат y
при неизменном значении фактора x2.
Если же rx1x2
= 1, то с изменением фактора x1
фактор x2
не может оставаться неизменным. Отсюда
b1
и b2
нельзя интерпретировать как показатели
раздельного влияния x1
и x2
на y.
Пример
3.2. При
изучении зависимости y
= f(x,
z,
v)
матрица парных коэффициентов корреляции
оказалась следующей:
|
y |
x |
z |
v |
|
|
y |
1 |
|||
|
x |
0,8 |
1 |
||
|
z |
0,7 |
0,8 |
1 |
|
|
v |
0,6 |
0,5 |
0,2 |
1 |
Очевидно,
что факторы x
и z
дублируют друг друга. В анализ целесообразно
включить фактор z,
а не x,
так как корреляция z,
с результатом y
слабее, чем корреляция фактора x
с y
(ryz
< ryx),
но зато слабее межфакторная корреляция
rzv
< rxv.
Поэтому в данном случае в уравнение
множественной регрессии включаются
факторы z,
и v.
По
величине парных коэффициентов корреляции
обнаруживается лишь явная коллинеарность
факторов. Наибольшие трудности в
использовании аппарата множественной
регрессии возникают при наличии
мультиколлинеарности
факторов, когда более чем два фактора
связаны между собой линейной зависимостью,
т.е. имеет место совокупное воздействие
факторов друг на друга. Наличие
мультиколлинеарности факторов может
означать, что некоторые факторы всегда
будут действовать в унисон. В результате
вариация в исходных данных перестает
быть полностью независимой и нельзя
оценить воздействие каждого фактора в
отдельности. Чем сильнее мультиколлинеарность
факторов, тем менее надежна оценка
распределения суммы объясненной вариации
по отдельным факторам с помощью метода
наименьших квадратов.
Если
рассматривается регрессия y
= a
+ b
x
+ c
z
+ d
v
+ ,
то для расчета параметров с применением
МНК предполагается равенство
S2y
= S2факт
+ S2,
где
S2y
– общая сумма квадратов отклонений
![]()
;
S2факт
– факторная (объясненная) сумма квадратов
отклонений
![]()
;
S2
– остаточная сумма квадратов отклонений
![]()
.
В
свою очередь, при независимости факторов
друг от друга выполнимо равенство
S2факт
= S2x
+ S2z
+ S2v,
где
S2x,
S2z,
S2v
– суммы квадратов отклонений, обусловленные
влиянием соответствующих факторов.
Если
же факторы интеркоррелированы, то данное
равенство нарушается.
Включение
в модель мультиколлинеарных факторов
нежелательно по следующим причинам:
– затрудняется
интерпретация параметров множественной
регрессии как характеристик действия
факторов в «чистом» виде, ибо факторы
коррелированны; параметры линейной
регрессии теряют экономический смысл;
– оценки
параметров ненадежны, обнаруживают
большие стандартные ошибки и меняются
с изменением объема наблюдений (не
только по величина, но и по знаку), что
делает модель непригодной для анализа
и прогнозирования.
Для
оценки факторов может использоваться
определитель матрицы
парных коэффициентов корреляции между
факторами.
Если
бы факторы не коррелировали между собой,
то матрицы парных коэффициентов
корреляции между ними была бы единичной,
поскольку все недиагональные элементы
rxixj
(xi
xj)
были бы равны нулю. Так, для уравнения,
включающего три объясняющих переменных,
y
= a
+ b1
x1
+ b2
x2
+ b3
x3
+ ,
матрица
коэффициентов корреляции между факторами
имела бы определитель, равный единице
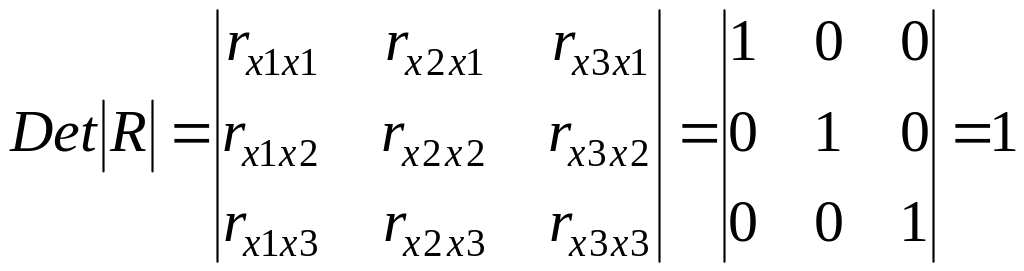
,
поскольку
rx1x1
= rx2x2
= rx3x3
= 1 и rx1x2
= rx1x3
= rx2x3
= 0.
Если
же между факторами существует полная
линейная зависимость и все коэффициенты
корреляции равны единице, то определитель
такой матрицы равен нулю
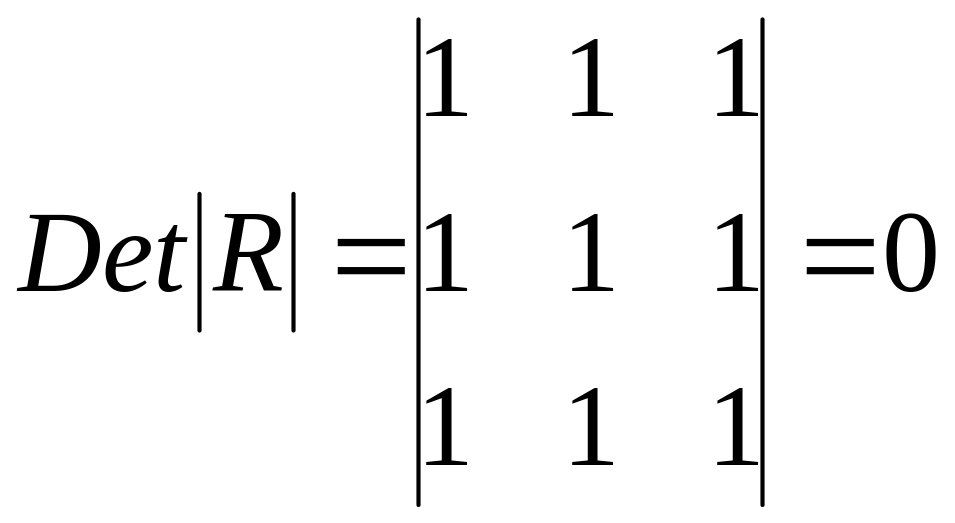
.
Чем
ближе к нулю определитель матрицы
межфакторной корреляции, тем сильнее
мультиколлинеарность факторов и
ненадежнее результаты множественной
регрессии. И, наоборот, чем ближе к
единице определитель матрицы межфакторной
корреляции, тем меньше мультиколлинеарность
факторов.
Оценка
значимости мультиколлинеарности
факторов может быть проведена методом
испытания гипотезы о независимости
переменных H0:
DetR
= 1. Доказано, что величина
![]()
имеет приближенное распределение 2
с df
= m
(m
– 1)/2 степенями
свободы. Если фактическое значение 2
превосходит табличное (критическое):
2факт
> 2табл(df,)
то гипотеза H0
отклоняется. Это означает, что DetR
1, недиагональные ненулевые коэффициенты
корреляции указывают на коллинеарность
факторов. Мультиколлинеарность считается
доказанной.
Через
коэффициенты множественной детерминации
можно найти переменные, ответственные
за мультиколлинеарность факторов. Для
этого в качестве зависимой переменной
рассматривается каждый из факторов.
Чем ближе значение коэффициента
множественной детерминации к единице,
тем сильна проявляется мультиколлинеарность
факторов. Сравнивая между собой
коэффициенты множественной детерминации
факторов
R2x1x2x3…xp;
R2x2x1x3…xp
и т.п., можно выделить переменные,
ответственные за мультиколлинеарность,
следовательно, можно решать проблему
отбора факторов, оставляя в уравнении
факторы с минимальной величиной
коэффициента множественной детерминации.
Имеется
ряд подходов преодоления сильной
межфакторной корреляции. Самый простой
из них состоит в исключении из модели
одного или нескольких факторов. Другой
путь связан с преобразованием факторов,
при котором уменьшается корреляция
между ними. Например, при построении
модели на основе рядов динамики переходят
от первоначальных данных к первым
разностям уровней y
= yt
– yt–1,
чтобы исключить влияние тенденции, или
используются такие методы, которые
сводят к нулю межфакторную корреляцию,
т.е. переходят от исходных переменных
к их линейным комбинациям, не коррелированным
друг с другом (метод главных компонент).
Одним
из путей учета внутренней корреляции
факторов является переход к совмещенным
уравнениям регрессии, т.е. к уравнениям,
которые отражают не только влияние
факторов, но и их взаимодействие. Так,
если y
= f(x1,
x2,
x3).
то можно построить следующее совмещенное
уравнение:
y
= a
+ b1
x1
+ b2
x2
+ b3
x3
+ b12
x1
x2
+ b13
x1
x3
+ b23
x2
x3
+ .
Рассматриваемое
уравнение включает эффект взаимодействия
первого порядка. Можно включать в модель
и взаимодействие более высоких порядков,
если будет доказана его статистическая
значимость, например включение
взаимодействия второго порядка b123
x1
x2
x3
и т.д. Как правила, взаимодействие
третьего и более высоких порядков
оказывается статистически незначимым;
совмещенные уравнения регрессии
ограничиваются взаимодействием первого
и второго порядков. Но и оно может
оказаться несущественным. Тогда
нецелесообразно включать в модель
взаимодействие всех факторов и всех
порядков. Так, если анализ совмещенного
уравнения показал значимость только
взаимодействия факторов x1и
x3,
то уравнение будет иметь вид:
y
= a
+ b1
x1
+ b2
x2
+ b3
x3
+ b13
x1
x3
+ .
Взаимодействие
факторов x1и
x3
означает, что на разных уровнях фактора
x3
влияние фактора x1на
y
будет неодинаково, т.е. оно зависит от
значений фактора x3.
На рис. 3.1 взаимодействие факторов
представляется непараллельными линиями
связи x1с
результатом y.
И, наоборот, параллельные линии влияния
фактора x1на
y
при разных уровнях фактора x3
означают отсутствие взаимодействия
факторов x1и
x3.
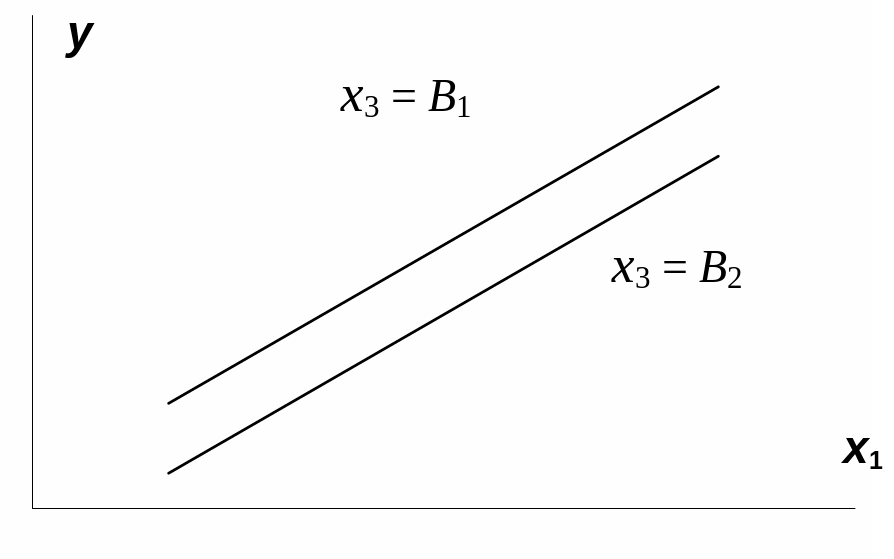
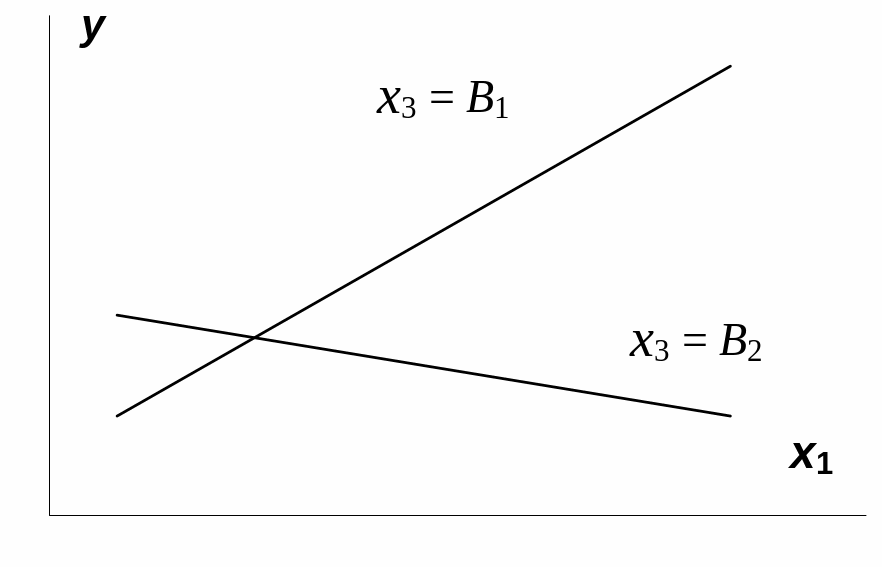
Рис.
3.1. Графическая иллюстрация взаимодействия
факторов
Совмещенные
уравнения регрессии строятся, например,
при исследовании эффекта влияния на
урожайность разных видов удобрений
(комбинаций азота и фосфора).
Решению
проблемы устранения мультиколлинеарности
факторов может помочь и переход к
уравнениям приведенной формы. С этой
целью в уравнение регрессии подставляют
рассматриваемый фактор, выраженный из
другого уравнения.
Пусть,
например, рассматривается двухфакторная
регрессия вида yx
= a
+ b1
x1
+ b2
x2,
для которой факторы x1и
x2
обнаруживают высокую корреляцию. Если
исключить один из факторов, то мы придем
к уравнению парной регрессии. Вместе с
тем можно оставить факторы в модели, но
исследовать данное двухфакторное
уравнение регрессии совместно с другим
уравнением, в котором фактор (например,
x2)
рассматривается как зависимая переменная.
Предположим, что x2
= A
+ B
y
+ C
x3.
Подставив это уравнение в искомое вместо
x2,
получим:
yx
= a
+ b1
x1
+ b2
(A
+ B
y
+ C
x3)
или
yx
(1 – b2
B)
= (a
+ b2
A)
+ b1
x1
+ C
b2
x3.
Если
(1 – b2
B)
0, то, разделив обе части равенства на
(1 – b2
B),
получим уравнение вида
![]()
,
которое
принято называть приведенной формой
уравнения для определения результативного
признака y.
Это уравнение может быть представлено
в виде
yx
= a’
+ b’1
x1
+ b’3
x3.
К
нему для оценки параметров может быть
применен метод наименьших квадратов.
Отбор
факторов, включаемых в регрессию,
является одним из важнейших этапов
практического использования методов
регрессии. Подходы к отбору факторов
на основе показателей корреляции могут
быть разные. Они приводят построение
уравнения множественной регрессии
соответственно к разным методикам. В
зависимости от того, какая методика
построения уравнения регрессии принята,
меняется алгоритм её решения на
компьютере.
Наиболее
широкое применение получили следующие
методы построения уравнения множественной
регрессии:
– метод
исключения;
– метод
включения;
– шаговый
регрессионный анализ.
Каждый
из этих методов по-своему решает проблему
отбора факторов, давая в целом близкие
результаты – отсев факторов из полного
его набора (метод исключения), дополнительное
введение фактора (метод включения),
исключение ранее введенного фактора
(шаговый регрессионный анализ).
На
первый взгляд может показаться, что
матрица парных коэффициентов корреляции
играет главную роль в отборе факторов.
Вместе с тем вследствие взаимодействия
факторов парные коэффициенты корреляции
не могут в полной мере решать вопрос о
целесообразности включения в модель
того или иного фактора. Эту роль выполняют
показатели частной корреляции, оценивающие
в чистом виде тесноту связи фактора с
результатом. Матрица частных коэффициентов
корреляции наиболее широко используется
в процедуре отсева факторов. Отсев
факторов можно проводить и по t-критерию
Стьюдента для коэффициентов регрессии:
из уравнения исключаются факторы с
величиной t-критерия
меньше табличного. Так, например,
уравнение регрессии составило:
y
= 25 + 5x1
+ 3x2
+ 4x3
+ .
(4,0) (1,3) (6,0)
В
скобках приведены фактические значения
t-критерия
для соответствующих коэффициентов
регрессии, как правило, при t
< 2 коэффициент регрессии незначим и,
следовательно, рассматриваемый фактор
не должен присутствовать в регрессионной
модели. В данном случае – это фактор
x2.
При
отборе факторов рекомендуется пользоваться
следующим правилом: число включаемых
факторов обычно в 6-7 раз меньше объема
совокупности, по которой строится
регрессия. Если это соотношение нарушено,
то число степеней свободы остаточной
вариации очень мало. Это приводит к
тому, что параметры уравнения регрессии
оказываются статистически незначимыми,
а F-критерий
меньше табличного значения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Метод наименьших квадратов регрессия
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
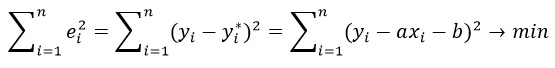
частные производные функции приравниваем к нулю
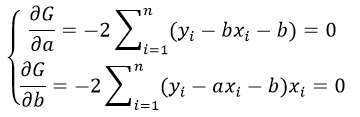
отсюда получаем систему линейных уравнений
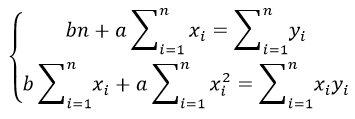
Формулы определения коэффициентов уравнения линейной регрессии:
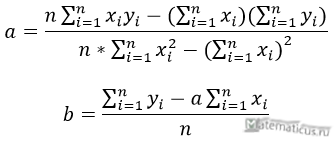
Также запишем уравнение регрессии для квадратной нелинейной функции:
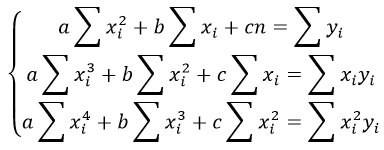
Система линейных уравнений регрессии полинома n-ого порядка:
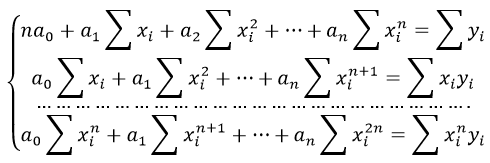
Формула коэффициента детерминации R 2 :
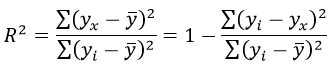
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
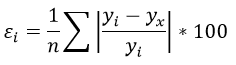
Чем меньше ε, тем лучше. Рекомендованный показатель ε
Формула среднеквадратической погрешности: 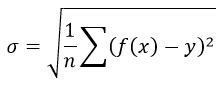
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
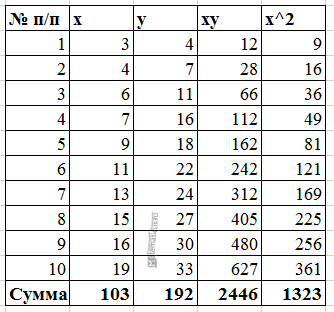
Расчет коэффициентов линейной регрессии:
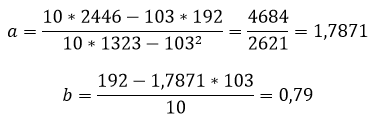
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
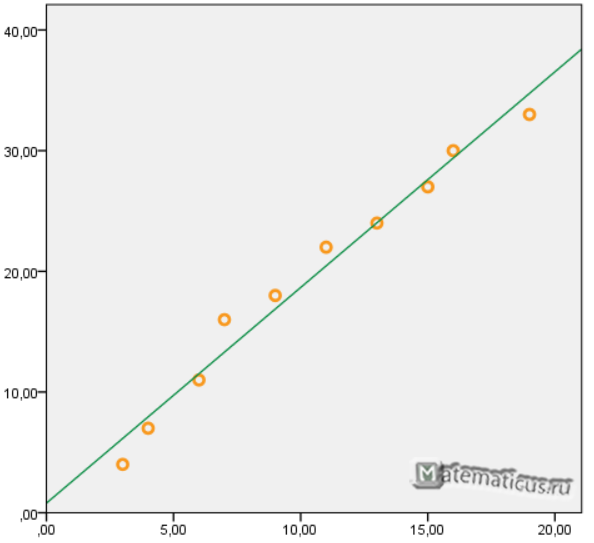
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
Решения задач: метод наименьших квадратов
Метод наименьших квадратов применяется для решения различных математических задач и основан на минимизации суммы квадратов отклонений функций от исходных переменных. Мы рассмотриваем его приложение к математической статистике в простейшем случае, когда нужно найти зависимость (парную линейную регрессию) между двумя переменными, заданными выборочными данным. В этом случае речь идет об отклонениях теоретических значений от экспериментальных.
Краткая инструкция по методу наименьших квадратов для чайников: определяем вид предполагаемой зависимости (чаще всего берется линейная регрессия вида $y(x)=ax+b$), выписываем систему уравнений для нахождения параметров $a, b$. По экспериментальным данным проводим вычисления и подставляем значения в систему, решаем систему любым удобным методом (для размерности 2-3 можно и вручную). Получается искомое уравнение.
Иногда дополнительно к нахождению уравнения регрессии требуется: найти остаточную дисперсию, сделать прогноз значений, найти значение коэффициента корреляции, проверить качество аппроксимации и значимость модели. Примеры решений вы найдете ниже. Удачи в изучении!
Примеры решений МНК
Пример 1. Методом наименьших квадратов для данных, представленных в таблице, найти линейную зависимость
Пример 2. Прибыль фирмы за некоторый период деятельности по годам приведена ниже:
Год 1 2 3 4 5
Прибыль 3,9 4,9 3,4 1,4 1,9
1) Составьте линейную зависимость прибыли по годам деятельности фирмы.
2) Определите ожидаемую прибыль для 6-го года деятельности. Сделайте чертеж.
Пример 3. Экспериментальные данные о значениях переменных х и y приведены в таблице:
1 2 4 6 8
3 2 1 0,5 0
В результате их выравнивания получена функция Используя метод наименьших квадратов, аппроксимировать эти данные линейной зависимостью (найти параметры а и b). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Пример 4. Данные наблюдений над случайной двумерной величиной (Х, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X.
Пример 5. Считая, что зависимость между переменными x и y имеет вид $y=ax^2+bx+c$, найти оценки параметров a, b и c методом наименьших квадратов по выборке:
x 7 31 61 99 129 178 209
y 13 10 9 10 12 20 26
Пример 6. Проводится анализ взаимосвязи количества населения (X) и количества практикующих врачей (Y) в регионе.
Годы 81 82 83 84 85 86 87 88 89 90
X, млн. чел. 10 10,3 10,4 10,55 10,6 10,7 10,75 10,9 10,9 11
Y, тыс. чел. 12,1 12,6 13 13,8 14,9 16 18 20 21 22
Оцените по МНК коэффициенты линейного уравнения регрессии $y=b_0+b_1x$.
Существенно ли отличаются от нуля найденные коэффициенты?
Проверьте значимость полученного уравнения при $alpha = 0,01$.
Если количество населения в 1995 году составит 11,5 млн. чел., каково ожидаемое количество врачей? Рассчитайте 99%-й доверительный интервал для данного прогноза.
Рассчитайте коэффициент детерминации
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Остатки нормально распределены с нулевым средним значением;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
источники:
http://www.matburo.ru/ex_ms.php?p1=msmnk
http://statistica.ru/theory/osnovy-lineynoy-regressii/
Имеются следующие данные разных стран об индексе розничных цен на продукты питания (х) и об индексе промышленного производства (у).
| Индекс розничных цен на продукты питания (х) | Индекс промышленного производства (у) | |
|---|---|---|
| 1 | 100 | 70 |
| 2 | 105 | 79 |
| 3 | 108 | 85 |
| 4 | 113 | 84 |
| 5 | 118 | 85 |
| 6 | 118 | 85 |
| 7 | 110 | 96 |
| 8 | 115 | 99 |
| 9 | 119 | 100 |
| 10 | 118 | 98 |
| 11 | 120 | 99 |
| 12 | 124 | 102 |
| 13 | 129 | 105 |
| 14 | 132 | 112 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
А) линейной;
Б) степенной;
В) равносторонней гиперболы.
2. Для каждой модели рассчитать показатели: тесноты связи и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз значения индекса промышленного производства у при прогнозном значении индекса розничных цен на продукты питания х=138.
Решение:
1. Для расчёта параметров линейной регрессии
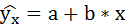
Решаем систему нормальных уравнений относительно a и b:
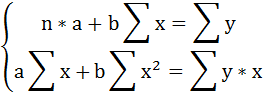
Построим таблицу расчётных данных, как показано в таблице 1.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | ху | x2 | y2 | 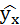 |
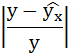 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 7000 | 10000 | 4900 | 74,26340 | 0,060906 |
| 2 | 105 | 79 | 8295 | 11025 | 6241 | 79,92527 | 0,011712 |
| 3 | 108 | 85 | 9180 | 11664 | 7225 | 83,32238 | 0,019737 |
| 4 | 113 | 84 | 9492 | 12769 | 7056 | 88,98425 | 0,059336 |
| 5 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 6 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 7 | 110 | 96 | 10560 | 12100 | 9216 | 85,58713 | 0,108467 |
| 8 | 115 | 99 | 11385 | 13225 | 9801 | 91,24900 | 0,078293 |
| 9 | 119 | 100 | 11900 | 14161 | 10000 | 95,77849 | 0,042215 |
| 10 | 118 | 98 | 11564 | 13924 | 9604 | 94,64611 | 0,034223 |
| 11 | 120 | 99 | 11880 | 14400 | 9801 | 96,91086 | 0,021102 |
| 12 | 124 | 102 | 12648 | 15376 | 10404 | 101,4404 | 0,005487 |
| 13 | 129 | 105 | 13545 | 16641 | 11025 | 107,1022 | 0,020021 |
| 14 | 132 | 112 | 14784 | 17424 | 12544 | 110,4993 | 0,013399 |
| Итого: | 1629 | 1299 | 152293 | 190557 | 122267 | 1299,001 | 0,701866 |
| Среднее значение: | 116,3571 | 92,78571 | 10878,07 | 13611,21 | 8733,357 | х | х |
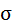 |
8,4988 | 11,1431 | х | х | х | х | х |
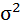 |
72,23 | 124,17 | х | х | х | х | х |
Среднее значение определим по формуле:
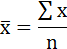
Cреднее квадратическое отклонение рассчитаем по формуле:
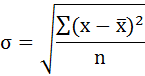
и занесём полученный результат в таблицу 1.
Возведя в квадрат полученное значение получим дисперсию:
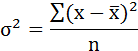
Параметры уравнения можно определить также и по формулам:
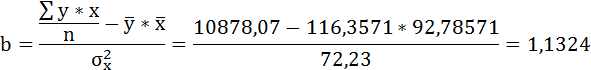
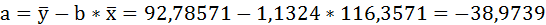
Таким образом, уравнение регрессии:
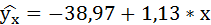
Следовательно, с увеличением индекса розничных цен на продукты питания на 1, индекс промышленного производства увеличивается в среднем на 1,13.
Рассчитаем линейный коэффициент парной корреляции:
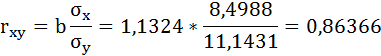
Связь прямая, достаточно тесная.
Определим коэффициент детерминации:
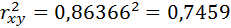
Вариация результата на 74,59% объясняется вариацией фактора х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
Так как
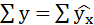 ,
,
следовательно, параметры уравнения определены правильно.
Рассчитаем среднюю ошибку аппроксимации – среднее отклонение расчётных значений от фактических:
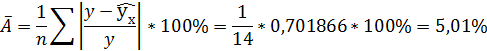
В среднем расчётные значения отклоняются от фактических на 5,01%.
Оценку качества уравнения регрессии проведём с помощью F-теста.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
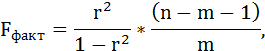
где n – число единиц совокупности;
m – число параметров при переменных х.
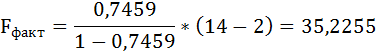
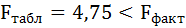
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
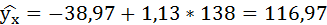
2. Степенная регрессия имеет вид:
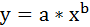
Для определения параметров производят логарифмирование степенной функции:
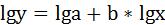
Для определения параметров логарифмической функции строят систему нормальных уравнений по способу наименьших квадратов:
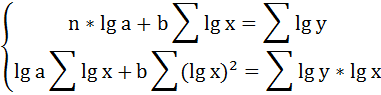
Построим таблицу расчётных данных, как показано в таблице 2.
Таблица 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | lg x | lg y | lg x*lg y | (lg x)2 | (lg y)2 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 2,000000 | 1,845098 | 3,690196 | 4,000000 | 3,404387 |
| 2 | 105 | 79 | 2,021189 | 1,897627 | 3,835464 | 4,085206 | 3,600989 |
| 3 | 108 | 85 | 2,033424 | 1,929419 | 3,923326 | 4,134812 | 3,722657 |
| 4 | 113 | 84 | 2,053078 | 1,924279 | 3,950696 | 4,215131 | 3,702851 |
| 5 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 6 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 7 | 110 | 96 | 2,041393 | 1,982271 | 4,046594 | 4,167284 | 3,929399 |
| 8 | 115 | 99 | 2,060698 | 1,995635 | 4,112401 | 4,246476 | 3,982560 |
| 9 | 119 | 100 | 2,075547 | 2,000000 | 4,151094 | 4,307895 | 4,000000 |
| 10 | 118 | 98 | 2,071882 | 1,991226 | 4,125585 | 4,292695 | 3,964981 |
| 11 | 120 | 99 | 2,079181 | 1,995635 | 4,149287 | 4,322995 | 3,982560 |
| 12 | 124 | 102 | 2,093422 | 2,008600 | 4,204847 | 4,382414 | 4,034475 |
| 13 | 129 | 105 | 2,110590 | 2,021189 | 4,265901 | 4,454589 | 4,085206 |
| 14 | 132 | 112 | 2,120574 | 2,049218 | 4,345518 | 4,496834 | 4,199295 |
| Итого | 1629 | 1299 | 28,90474 | 27,49904 | 56,79597 | 59,69172 | 54,05467 |
| Среднее значение | 116,3571 | 92,78571 | 2,064624 | 1,964217 | 4,056855 | 4,263694 | 3,861048 |
|
8,4988 | 11,1431 | 0,031945 | 0,053853 | х | х | х |
|
72,23 | 124,17 | 0,001021 | 0,0029 | х | х | х |
Продолжение таблицы 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | |
 |
|
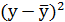 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 74,16448 | 17,34292 | 0,059493 | 519,1886 |
| 2 | 105 | 79 | 79,62057 | 0,385112 | 0,007855 | 190,0458 |
| 3 | 108 | 85 | 82,95180 | 4,195133 | 0,024096 | 60,61728 |
| 4 | 113 | 84 | 88,59768 | 21,13866 | 0,054734 | 77,1887 |
| 5 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 6 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 7 | 110 | 96 | 85,19619 | 116,7223 | 0,11254 | 10,33166 |
| 8 | 115 | 99 | 90,88834 | 65,79901 | 0,081936 | 38,6174 |
| 9 | 119 | 100 | 95,52408 | 20,03384 | 0,044759 | 52,04598 |
| 10 | 118 | 98 | 94,35840 | 13,26127 | 0,037159 | 27,18882 |
| 11 | 120 | 99 | 96,69423 | 5,316563 | 0,023291 | 38,6174 |
| 12 | 124 | 102 | 101,4191 | 0,337467 | 0,005695 | 84,90314 |
| 13 | 129 | 105 | 107,4232 | 5,872099 | 0,023078 | 149,1889 |
| 14 | 132 | 112 | 111,0772 | 0,85163 | 0,00824 | 369,1889 |
| Итого | 1629 | 1299 | 1296,632 | 446,4152 | 0,703074 | 1738,357 |
| Среднее значение | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Решая систему нормальных уравнений, определяем параметры логарифмической функции.
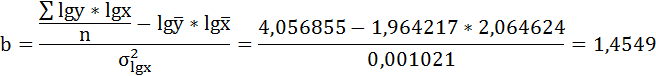
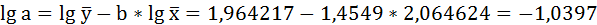
Получим линейное уравнение:
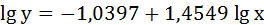
Выполнив его потенцирование, получим:
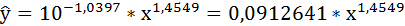
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата 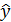 . По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
. По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
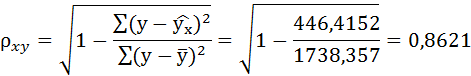
Связь достаточно тесная.
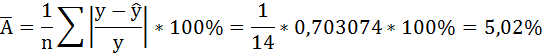
В среднем расчётные значения отклоняются от фактических на 5,02%.
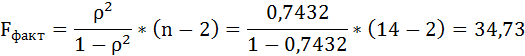
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
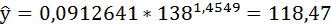
3. Уравнение равносторонней гиперболы
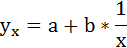
Для определения параметров этого уравнения используется система нормальных уравнений:
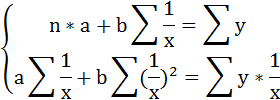
Произведем замену переменных
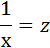
и получим следующую систему нормальных уравнений:
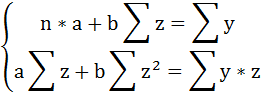
Решая систему нормальных уравнений, определяем параметры гиперболы.
Составим таблицу расчётных данных, как показано в таблице 3.
Таблица 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | z | yz | 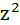 |
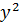 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 0,010000000 | 0,700000 | 0,0001000 | 4900 |
| 2 | 105 | 79 | 0,009523810 | 0,752381 | 0,0000907 | 6241 |
| 3 | 108 | 85 | 0,009259259 | 0,787037 | 0,0000857 | 7225 |
| 4 | 113 | 84 | 0,008849558 | 0,743363 | 0,0000783 | 7056 |
| 5 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 6 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 7 | 110 | 96 | 0,009090909 | 0,872727 | 0,0000826 | 9216 |
| 8 | 115 | 99 | 0,008695652 | 0,860870 | 0,0000756 | 9801 |
| 9 | 119 | 100 | 0,008403361 | 0,840336 | 0,0000706 | 10000 |
| 10 | 118 | 98 | 0,008474576 | 0,830508 | 0,0000718 | 9604 |
| 11 | 120 | 99 | 0,008333333 | 0,825000 | 0,0000694 | 9801 |
| 12 | 124 | 102 | 0,008064516 | 0,822581 | 0,0000650 | 10404 |
| 13 | 129 | 105 | 0,007751938 | 0,813953 | 0,0000601 | 11025 |
| 14 | 132 | 112 | 0,007575758 | 0,848485 | 0,0000574 | 12544 |
| Итого: | 1629 | 1299 | 0,120971823 | 11,13792 | 0,0010510 | 122267 |
| Среднее значение: | 116,3571 | 92,78571 | 0,008640844 | 0,795566 | 0,0000751 | 8733,357 |
|
8,4988 | 11,1431 | 0,000640820 | х | х | х |
|
72,23 | 124,17 | 0,000000411 | х | х | х |
Продолжение таблицы 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | |
|
|
|
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 72,3262 | 0,033231 | 5,411206 | 519,1886 |
| 2 | 105 | 79 | 79,49405 | 0,006254 | 0,244083 | 190,0458 |
| 3 | 108 | 85 | 83,47619 | 0,017927 | 2,322012 | 60,61728 |
| 4 | 113 | 84 | 89,64321 | 0,067181 | 31,84585 | 77,1887 |
| 5 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 6 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 7 | 110 | 96 | 86,01027 | 0,10406 | 99,79465 | 10,33166 |
| 8 | 115 | 99 | 91,95987 | 0,071112 | 49,56344 | 38,6174 |
| 9 | 119 | 100 | 96,35957 | 0,036404 | 13,25272 | 52,04598 |
| 10 | 118 | 98 | 95,28761 | 0,027677 | 7,357059 | 27,18882 |
| 11 | 120 | 99 | 97,41367 | 0,016024 | 2,516453 | 38,6174 |
| 12 | 124 | 102 | 101,46 | 0,005294 | 0,291565 | 84,90314 |
| 13 | 129 | 105 | 106,1651 | 0,011096 | 1,357478 | 149,1889 |
| 14 | 132 | 112 | 108,8171 | 0,028419 | 10,1311 | 369,1889 |
| Итого: | 1629 | 1299 | 1298,988 | 0,666742 | 435,7575 | 1738,357 |
| Среднее значение: | 116,3571 | 92,78571 | х | х | х | х |
|
8,4988 | 11,1431 | х | х | х | х |
|
72,23 | 124,17 | х | х | х | х |
Значения параметров регрессии a и b составили:
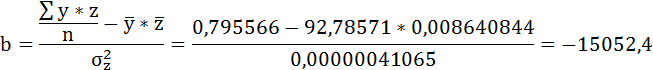
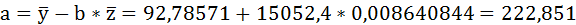
Получено уравнение:
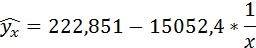
Индекс корреляции:
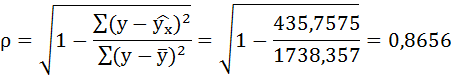
Связь достаточно тесная.
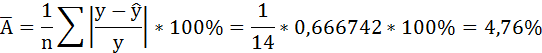
В среднем расчётные значения отклоняются от фактических на 4,76%.
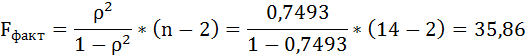
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
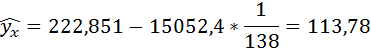
По уравнению равносторонней гиперболы получена наибольшая оценка тесноты связи по сравнению с линейной и степенной регрессиями. Средняя ошибка аппроксимации остаётся на допустимом уровне.
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Метод наименьших квадратов регрессия
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
частные производные функции приравниваем к нулю
отсюда получаем систему линейных уравнений
Формулы определения коэффициентов уравнения линейной регрессии:
Также запишем уравнение регрессии для квадратной нелинейной функции:
Система линейных уравнений регрессии полинома n-ого порядка:
Формула коэффициента детерминации R 2 :
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
Чем меньше ε, тем лучше. Рекомендованный показатель ε
Формула среднеквадратической погрешности:
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
Расчет коэффициентов линейной регрессии:
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
Решения задач: метод наименьших квадратов
Метод наименьших квадратов применяется для решения различных математических задач и основан на минимизации суммы квадратов отклонений функций от исходных переменных. Мы рассмотриваем его приложение к математической статистике в простейшем случае, когда нужно найти зависимость (парную линейную регрессию) между двумя переменными, заданными выборочными данным. В этом случае речь идет об отклонениях теоретических значений от экспериментальных.
Краткая инструкция по методу наименьших квадратов для чайников: определяем вид предполагаемой зависимости (чаще всего берется линейная регрессия вида $y(x)=ax+b$), выписываем систему уравнений для нахождения параметров $a, b$. По экспериментальным данным проводим вычисления и подставляем значения в систему, решаем систему любым удобным методом (для размерности 2-3 можно и вручную). Получается искомое уравнение.
Иногда дополнительно к нахождению уравнения регрессии требуется: найти остаточную дисперсию, сделать прогноз значений, найти значение коэффициента корреляции, проверить качество аппроксимации и значимость модели. Примеры решений вы найдете ниже. Удачи в изучении!
Примеры решений МНК
Пример 1. Методом наименьших квадратов для данных, представленных в таблице, найти линейную зависимость
Пример 2. Прибыль фирмы за некоторый период деятельности по годам приведена ниже:
Год 1 2 3 4 5
Прибыль 3,9 4,9 3,4 1,4 1,9
1) Составьте линейную зависимость прибыли по годам деятельности фирмы.
2) Определите ожидаемую прибыль для 6-го года деятельности. Сделайте чертеж.
Пример 3. Экспериментальные данные о значениях переменных х и y приведены в таблице:
1 2 4 6 8
3 2 1 0,5 0
В результате их выравнивания получена функция Используя метод наименьших квадратов, аппроксимировать эти данные линейной зависимостью (найти параметры а и b). Выяснить, какая из двух линий лучше (в смысле метода наименьших квадратов) выравнивает экспериментальные данные. Сделать чертеж.
Пример 4. Данные наблюдений над случайной двумерной величиной (Х, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X.
Пример 5. Считая, что зависимость между переменными x и y имеет вид $y=ax^2+bx+c$, найти оценки параметров a, b и c методом наименьших квадратов по выборке:
x 7 31 61 99 129 178 209
y 13 10 9 10 12 20 26
Пример 6. Проводится анализ взаимосвязи количества населения (X) и количества практикующих врачей (Y) в регионе.
Годы 81 82 83 84 85 86 87 88 89 90
X, млн. чел. 10 10,3 10,4 10,55 10,6 10,7 10,75 10,9 10,9 11
Y, тыс. чел. 12,1 12,6 13 13,8 14,9 16 18 20 21 22
Оцените по МНК коэффициенты линейного уравнения регрессии $y=b_0+b_1x$.
Существенно ли отличаются от нуля найденные коэффициенты?
Проверьте значимость полученного уравнения при $alpha = 0,01$.
Если количество населения в 1995 году составит 11,5 млн. чел., каково ожидаемое количество врачей? Рассчитайте 99%-й доверительный интервал для данного прогноза.
Рассчитайте коэффициент детерминации
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.
Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.
Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины остаток равен разнице и соответствующего предсказанного Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению , которая подчиняется распределению с степенями свободы, где стандартная ошибка коэффициента
,
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :
где процентная точка распределения со степенями свободы что дает вероятность двустороннего критерия
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем, мы можем аппроксимировать значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид
а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:
а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:
Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:
Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии
Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .
Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»
Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.
Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости
Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
http://www.matburo.ru/ex_ms.php?p1=msmnk
http://statistica.ru/theory/osnovy-lineynoy-regressii/
Метод наименьших квадратов (МНК) заключается в том, что сумма квадратов отклонений значений y от полученного уравнения регрессии — минимальное. Уравнение линейной регрессии имеет вид
y=ax+b
a, b – коэффициенты линейного уравнения регрессии;
x – независимая переменная;
y – зависимая переменная.
Нахождения коэффициентов уравнения линейной регрессии через метод наименьших квадратов:
частные производные функции приравниваем к нулю
отсюда получаем систему линейных уравнений
Формулы определения коэффициентов уравнения линейной регрессии:
Также запишем уравнение регрессии для квадратной нелинейной функции:
Система линейных уравнений регрессии полинома n-ого порядка:
Формула коэффициента детерминации R2:
Формула средней ошибки аппроксимации для уравнения линейной регрессии (оценка качества модели):
Чем меньше ε, тем лучше. Рекомендованный показатель ε<10%
Формула среднеквадратической погрешности:
Для примера, проведём расчет для получения линейного уравнения регрессии аппроксимации функции, заданной в табличном виде:
| x | y |
| 3 | 4 |
| 4 | 7 |
| 6 | 11 |
| 7 | 16 |
| 9 | 18 |
| 11 | 22 |
| 13 | 24 |
| 15 | 27 |
| 16 | 30 |
| 19 | 33 |
Решение
Расчеты значений суммы, произведения x и у приведены в таблицы.
Расчет коэффициентов линейной регрессии:
при этом средняя ошибка аппроксимации равна:
ε=11,168%
Получаем уравнение линейной регрессии с помощью метода наименьших квадратов:
y=1,7871x+0,79
График функции линейной зависимости y=1,7871x+0,79 и табличные значения, в виде точек
Коэффициент корреляции равен 0,988
Коэффициента детерминации равен 0,976
![]() 16990
16990
Коэффициент корреляции
Тесноту (силу) связи изучаемых показателей в предмете эконометрика оценивают с помощью коэффициента корреляции Rxy, который может принимать значения от -1 до +1.
Если Rxy > 0,7 — связь между изучаемыми показателями сильная, можно проводить анализ линейной модели
Если 0,3 < Rxy < 0,7 — связь между показателями умеренная, можно использовать нелинейную модель при отсутствии Rxy > 0,7
Если Rxy < 0,3 — связь слабая, модель строить нельзя

Для нелинейной регрессии используют индекс корреляции (0 < Рху < 1):

Средняя ошибка аппроксимации
Для оценки качества однофакторной модели в эконометрике используют коэффициент детерминации и среднюю ошибку аппроксимации.
Средняя ошибка аппроксимации определяется как среднее отклонение полученных значений от фактических

Допустимая ошибка аппроксимации не должна превышать 10%.
В эконометрике существует понятие среднего коэффициента эластичности Э – который говорит о том, на сколько процентов в среднем изменится показатель у от своего среднего значения при изменении фактора х на 1% от своей средней величины.
Пример нахождения коэффициента корреляции
Исходные данные:
|
Номер региона |
Среднедушевой прожиточный минимум в день одного трудоспособного, руб., |
Среднедневная заработная плата, руб., |
|
1 |
81 |
124 |
|
2 |
77 |
131 |
|
3 |
85 |
146 |
|
4 |
79 |
139 |
|
5 |
93 |
143 |
|
6 |
100 |
159 |
|
7 |
72 |
135 |
|
8 |
90 |
152 |
|
9 |
71 |
127 |
|
10 |
89 |
154 |
|
11 |
82 |
127 |
|
12 |
111 |
162 |
Рассчитаем параметры парной линейной регрессии, составив таблицу
| x |
x2 |
y |
xy |
y2 |
|
|
1 |
81 |
6561 |
124 |
10044 |
15376 |
|
2 |
77 |
5929 |
131 |
10087 |
17161 |
|
3 |
85 |
7225 |
146 |
12410 |
21316 |
|
4 |
79 |
6241 |
139 |
10981 |
19321 |
|
5 |
93 |
8649 |
143 |
13299 |
20449 |
|
6 |
100 |
10000 |
159 |
15900 |
25281 |
|
7 |
72 |
5184 |
135 |
9720 |
18225 |
|
8 |
90 |
8100 |
152 |
13680 |
23104 |
|
9 |
71 |
5041 |
127 |
9017 |
16129 |
|
10 |
89 |
7921 |
154 |
13706 |
23716 |
|
11 |
82 |
6724 |
127 |
10414 |
16129 |
|
12 |
111 |
12321 |
162 |
17982 |
26244 |
|
Среднее |
85,8 |
7491 |
141,6 |
12270,0 |
20204,3 |
|
Сумма |
1030,0 |
89896 |
1699 |
147240 |
242451 |
| σ |
11,13 |
12,59 |
|||
| σ2 |
123,97 |
158,41 |
формула расчета дисперсии σ2 приведена здесь.
Коэффициенты уравнения y = a + bx определяются по формуле

Получаем уравнение регрессии: y = 0,947x + 60,279.
Коэффициент уравнения b = 0,947 показывает, что при увеличении среднедушевого прожиточного минимума в день одного трудоспособного на 1 руб. среднедневная заработная плата увеличивается на 0,947 руб.
Коэффициент корреляции рассчитывается по формуле:

Значение коэффициента корреляции более — 0,7, это означает, что связь между среднедушевым прожиточным минимумом в день одного трудоспособного и среднедневной заработной платой сильная.
Коэффициент детерминации равен R2 = 0.838^2 = 0.702
т.е. 70,2% результата объясняется вариацией объясняющей переменной x.