![]()
Загрузить PDF
![]()
Загрузить PDF
После сбора данных их нужно проанализировать. Обычно нужно найти среднее значение, квадратичное отклонение и погрешность. Мы расскажем вам, как это сделать.
-

1
Запишите числовые значения, которые вы собираетесь анализировать. Мы проанализируем случайно подобранные числовые значения в качестве примера.
- Например, 5 школьникам был предложен письменный тест. Их результаты (в баллах по 100 бальной системе): 12, 55, 74, 79 и 90 баллов.
Реклама
-

1
Для того чтобы посчитать среднее значение, нужно сложить все имеющиеся числовые значения и разделить получившееся число на их количество.
- Среднее значение (μ) = Σ/N, где Σ сумма всех числовых значений, а N количество значений.
- То есть, в нашем случае μ равно (12+55+74+79+90)/5 = 62.
-

1
Мы будем считать среднее отклонение. Среднее отклонение = σ = квадратный корень из [(Σ((X-μ)^2))/(N)].
- Для вышеуказанного примера это квадратный корень из [((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27,4. (Обратите внимание, что если это выборочное среднеквадратическое отклонение, то делить нужно на N-1, где N количество значений.)
Реклама
-

1
Считаем среднюю погрешность (среднего значения). Это оценка того, насколько сильно округляется общее среднее значение. Чем больше числовых значений, тем меньше средняя погрешность, тем точнее среднее значение. Для расчета погрешности надо разделить среднее отклонение на корень квадратный от N. Стандартная погрешность = σ/кв.корень(n).
- Если в нашем примере 5 школьников, а всего в классе 50 школьников, и среднее отклонение, посчитанное для 50 школьников равно 17 (σ = 21), средняя погрешность = 17/кв. корень(5) = 7.6.
Советы
- Расчеты среднего значения, среднего отклонения и погрешности годятся для анализа равномерно распределенных данных. Среднее отклонение математического среднего значения распределения относится приблизительно к 68% данных, 2 средних отклонения – к 95% данных, а 3 – к 99.7% данных. Стандартная погрешность же уменьшается при увеличении количества значений.
- Простой в использовании калькулятор для расчета среднего отклонения.
Реклама
Предупреждения
- Считайте дважды. Все делают ошибки.
Реклама
Об этой статье
Эту страницу просматривали 65 201 раз.
Была ли эта статья полезной?
Среднее
квадратическое отклонение
характеризует среднее отклонение
всех вариант вариационного ряда от
средней арифметической
величины. Поскольку отклонения вариант
от средней,
имеют значения с «+» и «-», то при
суммировании
они взаимоуничтожаются. Чтобы избежать
этого, отклонения возводятся
во вторую степень, а затем, после
определенных вычислений,
производится обратное действие —
извлечение корня квадратного. Поэтому
среднее отклонение именуется
квадратическим.
Среднее
квадратическое отклонение определяют
по формуле:

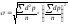
(отклонение
d
— это разность между каждой вариантой
и средней величиной, т. е. d
= V-M;
р –частота; количество вариант n
(при числе наблюдений менее 30 сумма
делится
на n-1);
При
вычислении среднеквад. отклонения по
способу
моментов используется следующая формула.
Т.о.
, формула вычисления сред. отклонения
по способу моментов будет читаться как
корень квадратный
из
разности момента второй степени и
квадрата момента первой степени.
Результаты
вычисления сред. отклонения обычным
способом и способом моментов идентичны.
Однако, как указывалось
выше, второй способ значительно убыстряет
и упрощает
расчеты. Итак,
нахождение сред. отклонения позволяет
судить о характере однородности
исследуемой группы наблюдений. Если
величина среднеквад. отклонения
небольшая, то
это свидетельствует о достаточно высокой
однородности изучаемого
явления. Среднюю арифметическую в таком
случае следует признать
вполне характерной для данного
вариационного ряда. Однако
слишком малая величина сигмы заставляет
думать об искусственном
подборе наблюдений. При очень большой
сигме средняя арифметическая в меньшей
степени характеризует вариационный
ряд,
что говорит о значительной вариабельности
изучаемого признака
или явления или о неоднородности
исследуемой группы. Значение:
Определение
среднеквад. отклонения представляет
немалую ценность для медицинской науки
и практики. При диагностике
отдельных заболеваний очень важно
оценить на основании конкретных
исследований, какие признаки проявляются
у соответствующей
группы больных относительно одинаково,
с небольшими колебаниями,
а для каких признаков характерны большие
индивидуальные
колебания. Очень широко используется
это свойство при оценке
физического развития отдельных групп
населения, при выработке
стандартов школьной меб.
Ошибка
репрезентативности (сред.
ошибка сред. арифметич.)
Чтобы
определить степень точности выборочного
наблюдения, необходимо оценить величину
ошибки, которая может
случайно произойти в процессе выборки.
Такие ошибки носят название
случайных ошибок репрезентативности
т.
Они
фактически являются разностью
между средними числами, полученными
при выборочном статистическом
наблюдении, и аналогичными величинами,
которые были бы
получены при сплошном исследовании
того же объекта (т. е. при исследовании
генеральной совокупности).
Ошибки
репрезентативности вытекают из самой
сущности выборочного
исследования. С помощью ошибок
репрезентативности числовые характеристики
выборочной совокупности распространяются
на всю генеральную совокупность, то
есть она характеризуется с учетом
определенной погрешности. Величины
ошибок репрезентативности определяются
как объемом
выборки, так и разнообразием признака.
Чем больше число наблюдений,
тем меньше ошибка, чем больше изменчив
признак, тем больше
величина статистической ошибки.
На
практике для определения средней ошибки
выборки в статистических
исследованиях пользуются следующей
формулой:
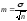
(где
m
— ошибка репрезентативности;
σ
— среднее квадратическое отклонение;
n
— число наблюдений в выборке (при числе
наблюдений менее 30
в подкоренное выражение вносится
значение п-1)).
Размер
средней ошибки прямо пропорционален
среднему квадратичному отклонению, т.
е. вариабельности изучаемого
признака, и обратно пропорционален
корню квадратному из
числа наблюдений
Билет 25
From Wikipedia, the free encyclopedia
The root-mean-square deviation (RMSD) or root-mean-square error (RMSE) is a frequently used measure of the differences between values (sample or population values) predicted by a model or an estimator and the values observed. The RMSD represents the square root of the second sample moment of the differences between predicted values and observed values or the quadratic mean of these differences. These deviations are called residuals when the calculations are performed over the data sample that was used for estimation and are called errors (or prediction errors) when computed out-of-sample. The RMSD serves to aggregate the magnitudes of the errors in predictions for various data points into a single measure of predictive power. RMSD is a measure of accuracy, to compare forecasting errors of different models for a particular dataset and not between datasets, as it is scale-dependent.[1]
RMSD is always non-negative, and a value of 0 (almost never achieved in practice) would indicate a perfect fit to the data. In general, a lower RMSD is better than a higher one. However, comparisons across different types of data would be invalid because the measure is dependent on the scale of the numbers used.
RMSD is the square root of the average of squared errors. The effect of each error on RMSD is proportional to the size of the squared error; thus larger errors have a disproportionately large effect on RMSD. Consequently, RMSD is sensitive to outliers.[2][3]
Formula[edit]
The RMSD of an estimator 


For an unbiased estimator, the RMSD is the square root of the variance, known as the standard deviation.
The RMSD of predicted values 


(For regressions on cross-sectional data, the subscript t is replaced by i and T is replaced by n.)
In some disciplines, the RMSD is used to compare differences between two things that may vary, neither of which is accepted as the «standard». For example, when measuring the average difference between two time series 

the formula becomes

Normalization[edit]
Normalizing the RMSD facilitates the comparison between datasets or models with different scales. Though there is no consistent means of normalization in the literature, common choices are the mean or the range (defined as the maximum value minus the minimum value) of the measured data:[4]
or
.
This value is commonly referred to as the normalized root-mean-square deviation or error (NRMSD or NRMSE), and often expressed as a percentage, where lower values indicate less residual variance. In many cases, especially for smaller samples, the sample range is likely to be affected by the size of sample which would hamper comparisons.
Another possible method to make the RMSD a more useful comparison measure is to divide the RMSD by the interquartile range. When dividing the RMSD with the IQR the normalized value gets less sensitive for extreme values in the target variable.
where

with 

When normalizing by the mean value of the measurements, the term coefficient of variation of the RMSD, CV(RMSD) may be used to avoid ambiguity.[5] This is analogous to the coefficient of variation with the RMSD taking the place of the standard deviation.

Mean absolute error[edit]
Some researchers have recommended the use of the Mean Absolute Error (MAE) instead of the Root Mean Square Deviation. MAE possesses advantages in interpretability over RMSD. MAE is the average of the absolute values of the errors. MAE is fundamentally easier to understand than the square root of the average of squared errors. Furthermore, each error influences MAE in direct proportion to the absolute value of the error, which is not the case for RMSD.[2] However, MAE is not a substitute, as it accounts only for the systematic errors, while RMSD accounts for both systematic and random errors[according to whom?].
Applications[edit]
- In meteorology, to see how effectively a mathematical model predicts the behavior of the atmosphere.
- In bioinformatics, the root-mean-square deviation of atomic positions is the measure of the average distance between the atoms of superimposed proteins.
- In structure based drug design, the RMSD is a measure of the difference between a crystal conformation of the ligand conformation and a docking prediction.
- In economics, the RMSD is used to determine whether an economic model fits economic indicators. Some experts have argued that RMSD is less reliable than Relative Absolute Error.[6]
- In experimental psychology, the RMSD is used to assess how well mathematical or computational models of behavior explain the empirically observed behavior.
- In GIS, the RMSD is one measure used to assess the accuracy of spatial analysis and remote sensing.
- In hydrogeology, RMSD and NRMSD are used to evaluate the calibration of a groundwater model.[7]
- In imaging science, the RMSD is part of the peak signal-to-noise ratio, a measure used to assess how well a method to reconstruct an image performs relative to the original image.
- In computational neuroscience, the RMSD is used to assess how well a system learns a given model.[8]
- In protein nuclear magnetic resonance spectroscopy, the RMSD is used as a measure to estimate the quality of the obtained bundle of structures.
- Submissions for the Netflix Prize were judged using the RMSD from the test dataset’s undisclosed «true» values.
- In the simulation of energy consumption of buildings, the RMSE and CV(RMSE) are used to calibrate models to measured building performance.[9]
- In X-ray crystallography, RMSD (and RMSZ) is used to measure the deviation of the molecular internal coordinates deviate from the restraints library values.
- In control theory, the RMSE is used as a quality measure to evaluate the performance of a State observer.[10]
See also[edit]
- Root mean square
- Mean absolute error
- Average absolute deviation
- Mean signed deviation
- Mean squared deviation
- Squared deviations
- Errors and residuals in statistics
References[edit]
- ^ Hyndman, Rob J.; Koehler, Anne B. (2006). «Another look at measures of forecast accuracy». International Journal of Forecasting. 22 (4): 679–688. CiteSeerX 10.1.1.154.9771. doi:10.1016/j.ijforecast.2006.03.001.
- ^ a b Pontius, Robert; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y.
- ^ Willmott, Cort; Matsuura, Kenji (2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976.
- ^ «Coastal Inlets Research Program (CIRP) Wiki — Statistics». Retrieved 4 February 2015.
- ^ «FAQ: What is the coefficient of variation?». Retrieved 19 February 2019.
- ^ Armstrong, J. Scott; Collopy, Fred (1992). «Error Measures For Generalizing About Forecasting Methods: Empirical Comparisons» (PDF). International Journal of Forecasting. 8 (1): 69–80. CiteSeerX 10.1.1.423.508. doi:10.1016/0169-2070(92)90008-w.
- ^ Anderson, M.P.; Woessner, W.W. (1992). Applied Groundwater Modeling: Simulation of Flow and Advective Transport (2nd ed.). Academic Press.
- ^ Ensemble Neural Network Model
- ^ ANSI/BPI-2400-S-2012: Standard Practice for Standardized Qualification of Whole-House Energy Savings Predictions by Calibration to Energy Use History
- ^ https://kalman-filter.com/root-mean-square-error
From Wikipedia, the free encyclopedia
The root-mean-square deviation (RMSD) or root-mean-square error (RMSE) is a frequently used measure of the differences between values (sample or population values) predicted by a model or an estimator and the values observed. The RMSD represents the square root of the second sample moment of the differences between predicted values and observed values or the quadratic mean of these differences. These deviations are called residuals when the calculations are performed over the data sample that was used for estimation and are called errors (or prediction errors) when computed out-of-sample. The RMSD serves to aggregate the magnitudes of the errors in predictions for various data points into a single measure of predictive power. RMSD is a measure of accuracy, to compare forecasting errors of different models for a particular dataset and not between datasets, as it is scale-dependent.[1]
RMSD is always non-negative, and a value of 0 (almost never achieved in practice) would indicate a perfect fit to the data. In general, a lower RMSD is better than a higher one. However, comparisons across different types of data would be invalid because the measure is dependent on the scale of the numbers used.
RMSD is the square root of the average of squared errors. The effect of each error on RMSD is proportional to the size of the squared error; thus larger errors have a disproportionately large effect on RMSD. Consequently, RMSD is sensitive to outliers.[2][3]
Formula[edit]
The RMSD of an estimator
For an unbiased estimator, the RMSD is the square root of the variance, known as the standard deviation.
The RMSD of predicted values
(For regressions on cross-sectional data, the subscript t is replaced by i and T is replaced by n.)
In some disciplines, the RMSD is used to compare differences between two things that may vary, neither of which is accepted as the «standard». For example, when measuring the average difference between two time series
the formula becomes
Normalization[edit]
Normalizing the RMSD facilitates the comparison between datasets or models with different scales. Though there is no consistent means of normalization in the literature, common choices are the mean or the range (defined as the maximum value minus the minimum value) of the measured data:[4]
This value is commonly referred to as the normalized root-mean-square deviation or error (NRMSD or NRMSE), and often expressed as a percentage, where lower values indicate less residual variance. In many cases, especially for smaller samples, the sample range is likely to be affected by the size of sample which would hamper comparisons.
Another possible method to make the RMSD a more useful comparison measure is to divide the RMSD by the interquartile range. When dividing the RMSD with the IQR the normalized value gets less sensitive for extreme values in the target variable.
with
When normalizing by the mean value of the measurements, the term coefficient of variation of the RMSD, CV(RMSD) may be used to avoid ambiguity.[5] This is analogous to the coefficient of variation with the RMSD taking the place of the standard deviation.
Mean absolute error[edit]
Some researchers have recommended the use of the Mean Absolute Error (MAE) instead of the Root Mean Square Deviation. MAE possesses advantages in interpretability over RMSD. MAE is the average of the absolute values of the errors. MAE is fundamentally easier to understand than the square root of the average of squared errors. Furthermore, each error influences MAE in direct proportion to the absolute value of the error, which is not the case for RMSD.[2] However, MAE is not a substitute, as it accounts only for the systematic errors, while RMSD accounts for both systematic and random errors[according to whom?].
Applications[edit]
- In meteorology, to see how effectively a mathematical model predicts the behavior of the atmosphere.
- In bioinformatics, the root-mean-square deviation of atomic positions is the measure of the average distance between the atoms of superimposed proteins.
- In structure based drug design, the RMSD is a measure of the difference between a crystal conformation of the ligand conformation and a docking prediction.
- In economics, the RMSD is used to determine whether an economic model fits economic indicators. Some experts have argued that RMSD is less reliable than Relative Absolute Error.[6]
- In experimental psychology, the RMSD is used to assess how well mathematical or computational models of behavior explain the empirically observed behavior.
- In GIS, the RMSD is one measure used to assess the accuracy of spatial analysis and remote sensing.
- In hydrogeology, RMSD and NRMSD are used to evaluate the calibration of a groundwater model.[7]
- In imaging science, the RMSD is part of the peak signal-to-noise ratio, a measure used to assess how well a method to reconstruct an image performs relative to the original image.
- In computational neuroscience, the RMSD is used to assess how well a system learns a given model.[8]
- In protein nuclear magnetic resonance spectroscopy, the RMSD is used as a measure to estimate the quality of the obtained bundle of structures.
- Submissions for the Netflix Prize were judged using the RMSD from the test dataset’s undisclosed «true» values.
- In the simulation of energy consumption of buildings, the RMSE and CV(RMSE) are used to calibrate models to measured building performance.[9]
- In X-ray crystallography, RMSD (and RMSZ) is used to measure the deviation of the molecular internal coordinates deviate from the restraints library values.
- In control theory, the RMSE is used as a quality measure to evaluate the performance of a State observer.[10]
See also[edit]
- Root mean square
- Mean absolute error
- Average absolute deviation
- Mean signed deviation
- Mean squared deviation
- Squared deviations
- Errors and residuals in statistics
References[edit]
- ^ Hyndman, Rob J.; Koehler, Anne B. (2006). «Another look at measures of forecast accuracy». International Journal of Forecasting. 22 (4): 679–688. CiteSeerX 10.1.1.154.9771. doi:10.1016/j.ijforecast.2006.03.001.
- ^ a b Pontius, Robert; Thontteh, Olufunmilayo; Chen, Hao (2008). «Components of information for multiple resolution comparison between maps that share a real variable». Environmental Ecological Statistics. 15 (2): 111–142. doi:10.1007/s10651-007-0043-y.
- ^ Willmott, Cort; Matsuura, Kenji (2006). «On the use of dimensioned measures of error to evaluate the performance of spatial interpolators». International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976.
- ^ «Coastal Inlets Research Program (CIRP) Wiki — Statistics». Retrieved 4 February 2015.
- ^ «FAQ: What is the coefficient of variation?». Retrieved 19 February 2019.
- ^ Armstrong, J. Scott; Collopy, Fred (1992). «Error Measures For Generalizing About Forecasting Methods: Empirical Comparisons» (PDF). International Journal of Forecasting. 8 (1): 69–80. CiteSeerX 10.1.1.423.508. doi:10.1016/0169-2070(92)90008-w.
- ^ Anderson, M.P.; Woessner, W.W. (1992). Applied Groundwater Modeling: Simulation of Flow and Advective Transport (2nd ed.). Academic Press.
- ^ Ensemble Neural Network Model
- ^ ANSI/BPI-2400-S-2012: Standard Practice for Standardized Qualification of Whole-House Energy Savings Predictions by Calibration to Energy Use History
- ^ https://kalman-filter.com/root-mean-square-error
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом  (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее  мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![[ begin{array}{l} 1: 600-394 = 206 2: 470-394 = 76 3: 170-394 = -224 4: 430-394 = 36 5: 300-394 = -94 end{array} ]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png "Rendered by QuickLaTeX.com")
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия  мм2.
мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть  значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки =  мм2.
мм2.
При этом стандартное отклонение по выборке равно  мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
 .
.
Для второго примера получится:
 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение «xср» вместо «μ».
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с «n–1»),
- полностью все данные – используется формула σ (с «n»).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Среднее квадратичное отклонение двух, трех, четырех и более чисел. Оно же стандартное отклонение, среднеквадратическое отклонение, среднеквадратичное отклонение, средняя квадратическая, стандартный разброс — показатель рассеивания значений случайной величины относительно её математического ожидания в теории вероятностей и статистике.
Как правило перечисленные термины равны квадратному корню дисперсии.
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»

Смотрите также

Статистические данные
Слово статистика образовано от латинского status, которое обозначает состояние. От этого корня произошли слова stato (государство), statistica (сумма знаний о государстве). Математическая статистика — наука, которая изучает методы сбора и обработки информации, представленной в численном виде. Эта информация появляется как результат экспериментов. Во многом математическая статистика опирается на теорию вероятностей, которая позволяет оценить точность и надёжность заключений, сделанных на основании изучения ограниченных статистических данных.
Метод не исследует сущность процессов, а формулирует и описывает их количественную сторону. Термином генеральная совокупность обозначается общность всех объектов, относительно которых необходимо сделать выводы при изучении научной проблемы. Выборочная совокупность или выборка — множество объектов, отобранных из генеральной совокупности для исследования. Основные цели математической статистики:

- указание способов сбора и систематизации статистических данных;
- определение закона распределения случайной величины;
- поиск неопределённых параметров;
- проверка подлинности выдвинутых гипотез.
Главный метод математической статистики — выборочный метод, состоящий в исследовании представительной выборочной совокупности для получения достоверной характеристики генеральной. Отбор объектов в выборку производится случайно, а исследуемое свойство должно обладать статистической устойчивостью, то есть иметь высокую частоту повторений при многократных испытаниях.
Выборочный метод сокращает время и трудоёмкость исследований, так как изучение всей совокупности оказывается более тяжёлым или невозможным. Математическая статистика выявляет закономерности массовых явлений и предсказывает появление внешних влияний.
Размах вариации
Вариация — это различия значений признака у единиц исследуемой совокупности. Она образуется из-за того, что индивидуальные значения формируются при различных условиях. Выборка должна быть представительной, чтобы по результатам её исследований можно было сделать правильные выводы о характеристиках всей совокупности.
Количественная репрезентативность достигается при использовании достаточного числа наблюдений в выборке, которое может обеспечить получение достоверных результатов. Качественная репрезентативность заключается в одинаковой структуре выборочной и генеральной совокупностей по признакам, имеющим влияние на получение конечного результата. К абсолютным показателям вариации относятся:
- размах, R;
- среднее линейное отклонение, a;
- среднеквадратичное отклонение, σ (сигма);
- дисперсия, D.

Размах вариации показывает абсолютную разницу между максимумом и минимумом значений признака:
R = x max — x min, где x — значения признака.
Основным недостатком показателя R можно назвать то обстоятельство, что колебания значений признака могут вызываться случайными причинами и искажать характерный для исследуемой совокупности размах.
Показатели отклонения
Существуют показатели вариации, учитывающие все значения величин, а не только наибольшие или наименьшие. Одним из них можно назвать среднее линейное отклонение — показатель, характеризующий меру разброса значений. Сначала требуется определить точку отсчёта разброса. Как правило, ею становится среднее арифметическое значение, входящее в исследование величин. Потом необходимо измерить, отклонение от среднего для каждого значения. Все отклонения вычисляются по модулю и определяется среднее значение уже среди них. Формула для расчёта отклонения:
a = Σ n i=1 (x — x̅) / n, где:
- a — среднее линейное отклонение;
- n — количество значений в исследуемой совокупности;
- x — анализируемый показатель;
- x̅ — среднее значение показателя.

СКО характеризует разброс значений относительно среднего математического ожидания. Оно измеряется в единицах измерения само́й величины. Существует правило, согласно которому для нормально распределённых данных диапазон разброса 997 значений из 1 тыс. составляет три сигмы от средней арифметической, [x̅ — 3σ; x̅ + 3σ].
Коэффициент вариации
Квадратичное отклонение — это абсолютная оценка меры разброса. Для того чтобы сравнить величину разброса с самими значениями величины, необходимо применить относительный показатель — коэффициент вариации:
V = σ / x̅, где σ — стандартное отклонение из выборки, x̅ — среднее арифметическое.
Коэффициент вариации измеряется в процентах. Показатель полезен для сравнивания однородности разных процессов.

Математическое ожидание — среднее значение случайной величины. Для дискретной выборки оно определяется по формуле:
M (X)= Σ ni=1 xi ⋅ pi, где xi — случайные значения, pi — их вероятность.
Дисперсией называется среднее значение квадрата отклонения случайной величины от её математического ожидания:
D (X) = M (X2) — (M (X))2
Для дискретной случайной величины формула приобретает вид:
D (X) = Σ ni=1 xi2 ⋅ pi — M (X)2.
Среднеквадратическое отклонение или стандартный разброс — это корень квадратный из дисперсии, формула которого имеет вид:
σ(X) = √ D (X).
Дисперсия и стандартный разброс — взаимозависимые характеристики. Стандартная ошибка среднего — величина, которая характеризует квадратическое отклонение выборочного среднего, рассчитанного по выборке размера из генеральной совокупности. Величина ошибки SDx̅ зависит от дисперсии генеральной совокупности и объёма выборки и рассчитывается по формуле:
SDx̅ = σ / √ n, где σ — величина стандартного разброса генеральной совокупности, а n — объём выборки.

Статистическая закономерность — это количественная форма проявления причинной связи. Она возникает как результат воздействия большого числа причин, действующих либо постоянно, либо только временами. Существует ряд статистических критериев, которые позволяют сравнивать экспериментально полученное распределение с нормальным, полученным в теории. Погрешность измерения — отклонение измеренного значения величины от действительного, являющиеся характеристикой точности измерения. Вместе с полученным результатом должна указываться погрешность измерений.
Пример расчёта
Пример расчёта по формулам для среднеквадратичного отклонения и дисперсии при решении следующей задачи по теории вероятностей: для выполнения ремонтных работ рабочему необходима краска определённого цвета. В городе имеется четыре строительных магазина, в каждом из которых эта краска может находиться в продаже с вероятностью 0,41. Записать закон распределения количества посещаемых магазинов. Рассчитать дисперсию и среднеквадратичное отклонение случайной величины. Обход заканчивается после того, как необходимая краска будет куплена или после посещения всех четырёх магазинов.

x = 1 — краска куплена в первом магазине.
p (1) = 0,41.
x = 2 — краски не нашлось в первом магазине, но она была во втором.
p (2) = (1 — 0,41) · 0,41 = 0,59 · 0,41 = 0,242.
x = 3 — краски не нашлось в двух первых магазинах, но она была в третьем.
p (3) = (1 — 0,41)2 · 0,41 = 0,592 · 0,41 = 0,143.
x = 4 — краски не было в первых трёх магазинах, рабочий зашёл в четвёртый магазин, купил краску или просто закончил обход.
p (4) = 0,593 · 0,41 + 0,594 = 0,205.
Закон распределения:
| xi | 1 | 2 | 3 | 4 |
| p (X) | 0,41 | 0,242 | 0,143 | 0.205 |
Математическое ожидание: M (X) = 1 · 0,41 + 2 · 0.242 + 3 · 0,143 + 4 · 0,205 = 2,143.
Дисперсия: D (X) = Σ ni=1 xi2 ⋅ pi — M (X)2 = 12 · 0,41 + 22 · 0,242 + 32 · 0,143 + 42 · 0,205 — 2,1432 = 1,353.
Стандартное отклонение: σ(X) = √ D (X) = √1,353 = 1,163.
Ответ: Дисперсия 1,353; квадратическое отклонение 1,163.
Для вычисления среднеквадратичного отклонения в онлайн-калькуляторе достаточно внести в таблицу значения случайной величины xi и их количество.
Среднеквадратичное отклонение применяется для определения погрешности при проведении последовательных измерений. Эта характеристика играет важную роль для сравнения изучаемого процесса с теоретически предсказанным. Если СКО велико, то полученные результаты или метод их получения нужно проверить.

Эксперт по предмету «Математика»
Задать вопрос автору статьи
При рассмотрении какой-либо величины и её изменения важным является не только понятие среднего арифметического этой величины, но и её отклонение.
Для оценки отклонения и разброса измеряемой величины пользуются несколькими различными критериями, например, абсолютной погрешностью, иначе называемой отклонением от среднего каждой конкретной величины.
Но абсолютная погрешность не является критерием, показывающим разброс измеряемой величины, так как сумма всех абсолютных погрешностей равна нулю.
Поэтому для оценки погрешности вводится другая величина, называемая средним квадратическим отклонением.
Основные понятия
Для объяснения термина «среднеквадратичное отклонение» необходимо ознакомиться с используемой терминологией.
Определение 1
Средним арифметическим или средней величиной называют число, являющееся суммой всех проведённых измерений, разделённой на количество этих измерений.
Научись программировать
Получи навыки для отличной карьеры в IT под руководством ведущих экспертов
Выбрать занятия
Для пяти чисел $a_1, a_2, a_3, a_4$ и $a_5$ средняя величина $M$ определяется по формуле
$M=frac{a_1+ a_2+ a_3+ a_4+ a_5}{5}$.
Со средним арифметическим также связано другое понятие — математическое ожидание.
Определение 2
Математическое ожидание — это значение среднего арифметического некоторой величины при стремлении количества измерений этой величины к бесконечности.
Математическое ожидание также могут обозначать буквой $M$, а среднее арифметическое некоторого количества измерений исследуемой величины могут называть оценкой математического ожидания.
Определение 3
Абсолютной погрешностью измеряемой единичной величины, иногда также называемой вариантой, является её разность со средним значением $M$.
Для того чтобы найти абсолютную погрешность некоторого единичного измерения $x_i$, обозначаемую греческой буквой $Δ$ (произносится как «дельта»), необходимо отнять от измеренного значения $x_i$ среднее арифметическое $M$: $Δx_i=x_i – M$.
«Среднеквадратичное отклонение» 👇
Часто для оценки единичного измерения пользуются не только абсолютной погрешностью, но и относительной погрешностью $δ$, она рассчитывается по формуле:
$δ=frac{|Δx_i|}{M} cdot 100$%.
Оценив относительную погрешность каждого измерения, можно отбросить значения, погрешность которых слишком большая и при дальнейших расчётах использовать только значения с небольшими относительными погрешностями.
Определение 4
Среднее арифметическое квадратов всех абсолютных погрешностей называют дисперсией и обозначают буквой $D$.
Дисперсия является характеристикой разброса значений некоторой измеряемой случайной величины $x$.
Что такое среднее квадратичное отклонение и как его определять
Теперь перейдём непосредственно к термину «среднеквадратическое отклонение».
Среднеквадратическим отклонением называют значение квадратного корня из дисперсии случайной величины $D$.
Обозначается среднее квадратичное отклонение греческой буквой $ϭ$ (читается как «сигма»).
Формула для среднего квадратичного отклонения для пяти измеренных значений величины $X$ выглядит так:
$ϭ=sqrt{frac{Δx_1^2 + Δx_2^2 + Δx_3^2 + Δx_4^2 + Δx_5^2}{5}}$,
где $Δx_1… Δx_5$ — абсолютные погрешности каждого конкретного измерения.
Если дисперсия и, соответственно, среднее квадратическое отклонение достаточно малы, то это значит, что величина большинства погрешностей не велика по модулю и все значения измеряемой величины достаточно близки к среднему.
В идеальном случае когда дисперсия равна нулю, наблюдается соотношение $x_1=x_2=x_3=….=x_n=M$, то есть каждое измеренное значение равно среднему арифметическому.
Покажем, как применять полученную информацию.
Пример 1
Задача:
В ходе эксперимента по физике ребята пять раз измерили напряжение и получили следующие значения: $U_1= 5,22$ В; $U_2= 5,30$ В; $U_3=5,27$ В; В $U_4=5,23$ В; $U_5=5,20$ В. Найдите абсолютные и относительные погрешности каждого измерения, дисперсию и среднее квадратичное отклонение.
Решение:
Найдём среднее арифметическое, оно равно:
$U_ср=frac{U_1+U_2+ U_3 + U_4 + U_5}{5}=frac{5,22 + 5,30+ 5,27+5,23+5,20}{5}=5,244$ В.
Теперь найдём абсолютную и относительную погрешность каждого измерения:
$ΔU_1=U_ср-U_1= 5,244-5,22 =0,024; δ_1=frac{|U_1|}{U_ср} cdot 100%=frac{0,024}{5,244}cdot 100$%$=0.50$%;
$ΔU_2=U_ср-U_2= 5,244-5,30=-0,056; δ_2=frac{|U_2|}{U_ср} cdot 100%=frac{0,056}{5,244}cdot 100$%$=1,06$%;
$ΔU_3=U_ср-U_3= 5,244-5,27=-0,026; δ_3=frac{|U_3|}{U_ср}cdot 100%=frac{0,026}{5,244}cdot 100$%$=0,50$%;
$ΔU_4=U_ср-U_4= 5,244-5,23=0,014; δ_4=frac{|U_4|}{U_ср}cdot 100%=frac{0,014}{5,244}cdot 100$%$=0,25$%;
$ΔU_5=U_ср-U_5= 5,244-5,20=0,044; δ_5=frac{|U_5|}{U_ср}cdot 100%=frac{0,044}{5,244}cdot 100$%$=0,84$%.
Сосчитаем дисперсию:
$D=frac{ΔU_1^2+ΔU_2^2+ ΔU_3^2 + ΔU_4^2 + ΔU_5^2}{5}=frac{0,024^2+ (-0,056)^2 + (-0,026)^2+ 0,014^2 + 0,044^2)}{5}=0,001304$;
И квадратичное отклонение:
$ϭ=sqrt{D}=sqrt{0,001304}=0,0361$.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Среднее
квадратическое отклонение
характеризует среднее отклонение
всех вариант вариационного ряда от
средней арифметической
величины. Поскольку отклонения вариант
от средней,
имеют значения с «+» и «-», то при
суммировании
они взаимоуничтожаются. Чтобы избежать
этого, отклонения возводятся
во вторую степень, а затем, после
определенных вычислений,
производится обратное действие —
извлечение корня квадратного. Поэтому
среднее отклонение именуется
квадратическим.
Среднее
квадратическое отклонение определяют
по формуле:
(отклонение
d
— это разность между каждой вариантой
и средней величиной, т. е. d
= V-M;
р –частота; количество вариант n
(при числе наблюдений менее 30 сумма
делится
на n-1);
При
вычислении среднеквад. отклонения по
способу
моментов используется следующая формула.
Т.о.
, формула вычисления сред. отклонения
по способу моментов будет читаться как
корень квадратный
из
разности момента второй степени и
квадрата момента первой степени.
Результаты
вычисления сред. отклонения обычным
способом и способом моментов идентичны.
Однако, как указывалось
выше, второй способ значительно убыстряет
и упрощает
расчеты. Итак,
нахождение сред. отклонения позволяет
судить о характере однородности
исследуемой группы наблюдений. Если
величина среднеквад. отклонения
небольшая, то
это свидетельствует о достаточно высокой
однородности изучаемого
явления. Среднюю арифметическую в таком
случае следует признать
вполне характерной для данного
вариационного ряда. Однако
слишком малая величина сигмы заставляет
думать об искусственном
подборе наблюдений. При очень большой
сигме средняя арифметическая в меньшей
степени характеризует вариационный
ряд,
что говорит о значительной вариабельности
изучаемого признака
или явления или о неоднородности
исследуемой группы. Значение:
Определение
среднеквад. отклонения представляет
немалую ценность для медицинской науки
и практики. При диагностике
отдельных заболеваний очень важно
оценить на основании конкретных
исследований, какие признаки проявляются
у соответствующей
группы больных относительно одинаково,
с небольшими колебаниями,
а для каких признаков характерны большие
индивидуальные
колебания. Очень широко используется
это свойство при оценке
физического развития отдельных групп
населения, при выработке
стандартов школьной меб.
Ошибка
репрезентативности (сред.
ошибка сред. арифметич.)
Чтобы
определить степень точности выборочного
наблюдения, необходимо оценить величину
ошибки, которая может
случайно произойти в процессе выборки.
Такие ошибки носят название
случайных ошибок репрезентативности
т.
Они
фактически являются разностью
между средними числами, полученными
при выборочном статистическом
наблюдении, и аналогичными величинами,
которые были бы
получены при сплошном исследовании
того же объекта (т. е. при исследовании
генеральной совокупности).
Ошибки
репрезентативности вытекают из самой
сущности выборочного
исследования. С помощью ошибок
репрезентативности числовые характеристики
выборочной совокупности распространяются
на всю генеральную совокупность, то
есть она характеризуется с учетом
определенной погрешности. Величины
ошибок репрезентативности определяются
как объемом
выборки, так и разнообразием признака.
Чем больше число наблюдений,
тем меньше ошибка, чем больше изменчив
признак, тем больше
величина статистической ошибки.
На
практике для определения средней ошибки
выборки в статистических
исследованиях пользуются следующей
формулой:
(где
m
— ошибка репрезентативности;
σ
— среднее квадратическое отклонение;
n
— число наблюдений в выборке (при числе
наблюдений менее 30
в подкоренное выражение вносится
значение п-1)).
Размер
средней ошибки прямо пропорционален
среднему квадратичному отклонению, т.
е. вариабельности изучаемого
признака, и обратно пропорционален
корню квадратному из
числа наблюдений
Билет 25
![]()
Загрузить PDF
![]()
Загрузить PDF
После сбора данных их нужно проанализировать. Обычно нужно найти среднее значение, квадратичное отклонение и погрешность. Мы расскажем вам, как это сделать.
-
1
Запишите числовые значения, которые вы собираетесь анализировать. Мы проанализируем случайно подобранные числовые значения в качестве примера.
- Например, 5 школьникам был предложен письменный тест. Их результаты (в баллах по 100 бальной системе): 12, 55, 74, 79 и 90 баллов.
Реклама
-
1
Для того чтобы посчитать среднее значение, нужно сложить все имеющиеся числовые значения и разделить получившееся число на их количество.
- Среднее значение (μ) = Σ/N, где Σ сумма всех числовых значений, а N количество значений.
- То есть, в нашем случае μ равно (12+55+74+79+90)/5 = 62.
-
1
Мы будем считать среднее отклонение. Среднее отклонение = σ = квадратный корень из [(Σ((X-μ)^2))/(N)].
- Для вышеуказанного примера это квадратный корень из [((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27,4. (Обратите внимание, что если это выборочное среднеквадратическое отклонение, то делить нужно на N-1, где N количество значений.)
Реклама
-
1
Считаем среднюю погрешность (среднего значения). Это оценка того, насколько сильно округляется общее среднее значение. Чем больше числовых значений, тем меньше средняя погрешность, тем точнее среднее значение. Для расчета погрешности надо разделить среднее отклонение на корень квадратный от N. Стандартная погрешность = σ/кв.корень(n).
- Если в нашем примере 5 школьников, а всего в классе 50 школьников, и среднее отклонение, посчитанное для 50 школьников равно 17 (σ = 21), средняя погрешность = 17/кв. корень(5) = 7.6.
Советы
- Расчеты среднего значения, среднего отклонения и погрешности годятся для анализа равномерно распределенных данных. Среднее отклонение математического среднего значения распределения относится приблизительно к 68% данных, 2 средних отклонения – к 95% данных, а 3 – к 99.7% данных. Стандартная погрешность же уменьшается при увеличении количества значений.
- Простой в использовании калькулятор для расчета среднего отклонения.
Реклама
Предупреждения
- Считайте дважды. Все делают ошибки.
Реклама
Об этой статье
Эту страницу просматривали 66 624 раза.
Была ли эта статья полезной?
Среднее квадратичное отклонение двух, трех, четырех и более чисел. Оно же стандартное отклонение, среднеквадратическое отклонение, среднеквадратичное отклонение, средняя квадратическая, стандартный разброс — показатель рассеивания значений случайной величины относительно её математического ожидания в теории вероятностей и статистике.
Как правило перечисленные термины равны квадратному корню дисперсии.
Пример вычисления стандартного отклонения по следующим формулам:
Вычислим среднюю оценку ученика: 2; 4; 5; 6; 8.
Cредняя оценка будет равна:

Вычисляем квадраты отклонений оценок от их средней оценки:

Вычислим среднее арифметическое (дисперсию) этих значений:

Стандартное отклонение равно квадратному корню дисперсии:

Эта формула справедлива только если эти пять значений и являются генеральной совокупностью. Если бы эти данные были случайной выборкой из какой-то большой совокупности (например, оценки пяти случайно выбранных учеников большого города), то в знаменателе формулы для вычисления дисперсии вместо n = 5 нужно было бы поставить n − 1 = 4:

Тогда стандартное отклонение будет равняться:

Этот результат называется стандартным отклонением на основании несмещённой оценки дисперсии. Деление на n − 1 вместо n даёт неискажённую оценку дисперсии для больших генеральных совокупностей.
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»
Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»
Смотрите также
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки = мм2.
При этом стандартное отклонение по выборке равно мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
.
Для второго примера получится:
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич