Среднеквадратичная ошибка (Mean Squared Error) – Среднее арифметическое (Mean) квадратов разностей между предсказанными и реальными значениями Модели (Model) Машинного обучения (ML):

Рассчитывается с помощью формулы, которая будет пояснена в примере ниже:
$$MSE = frac{1}{n} × sum_{i=1}^n (y_i — widetilde{y}_i)^2$$
$$MSEspace{}{–}space{Среднеквадратическая}space{ошибка,}$$
$$nspace{}{–}space{количество}space{наблюдений,}$$
$$y_ispace{}{–}space{фактическая}space{координата}space{наблюдения,}$$
$$widetilde{y}_ispace{}{–}space{предсказанная}space{координата}space{наблюдения,}$$
MSE практически никогда не равен нулю, и происходит это из-за элемента случайности в данных или неучитывания Оценочной функцией (Estimator) всех факторов, которые могли бы улучшить предсказательную способность.
Пример. Исследуем линейную регрессию, изображенную на графике выше, и установим величину среднеквадратической Ошибки (Error). Фактические координаты точек-Наблюдений (Observation) выглядят следующим образом:

Мы имеем дело с Линейной регрессией (Linear Regression), потому уравнение, предсказывающее положение записей, можно представить с помощью формулы:
$$y = M * x + b$$
$$yspace{–}space{значение}space{координаты}space{оси}space{y,}$$
$$Mspace{–}space{уклон}space{прямой}$$
$$xspace{–}space{значение}space{координаты}space{оси}space{x,}$$
$$bspace{–}space{смещение}space{прямой}space{относительно}space{начала}space{координат}$$
Параметры M и b уравнения нам, к счастью, известны в данном обучающем примере, и потому уравнение выглядит следующим образом:
$$y = 0,5252 * x + 17,306$$
Зная координаты реальных записей и уравнение линейной регрессии, мы можем восстановить полные координаты предсказанных наблюдений, обозначенных серыми точками на графике выше. Простой подстановкой значения координаты x в уравнение мы рассчитаем значение координаты ỹ:

Рассчитаем квадрат разницы между Y и Ỹ:

Сумма таких квадратов равна 4 445. Осталось только разделить это число на количество наблюдений (9):
$$MSE = frac{1}{9} × 4445 = 493$$
Само по себе число в такой ситуации становится показательным, когда Дата-сайентист (Data Scientist) предпринимает попытки улучшить предсказательную способность модели и сравнивает MSE каждой итерации, выбирая такое уравнение, что сгенерирует наименьшую погрешность в предсказаниях.
MSE и Scikit-learn
Среднеквадратическую ошибку можно вычислить с помощью SkLearn. Для начала импортируем функцию:
import sklearn
from sklearn.metrics import mean_squared_errorИнициализируем крошечные списки, содержащие реальные и предсказанные координаты y:
y_true = [5, 41, 70, 77, 134, 68, 138, 101, 131]
y_pred = [23, 35, 55, 90, 93, 103, 118, 121, 129]Инициируем функцию mean_squared_error(), которая рассчитает MSE тем же способом, что и формула выше:
mean_squared_error(y_true, y_pred)
Интересно, что конечный результат на 3 отличается от расчетов с помощью Apple Numbers:
496.0Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: @mmoshikoo
Фото: @tobyelliott
From Wikipedia, the free encyclopedia
In statistics, the mean squared error (MSE)[1] or mean squared deviation (MSD) of an estimator (of a procedure for estimating an unobserved quantity) measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss.[2] The fact that MSE is almost always strictly positive (and not zero) is because of randomness or because the estimator does not account for information that could produce a more accurate estimate.[3] In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk (the average loss on an observed data set), as an estimate of the true MSE (the true risk: the average loss on the actual population distribution).
The MSE is a measure of the quality of an estimator. As it is derived from the square of Euclidean distance, it is always a positive value that decreases as the error approaches zero.
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator (how widely spread the estimates are from one data sample to another) and its bias (how far off the average estimated value is from the true value).[citation needed] For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard error.
Definition and basic properties[edit]
The MSE either assesses the quality of a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable), or of an estimator (i.e., a mathematical function mapping a sample of data to an estimate of a parameter of the population from which the data is sampled). The definition of an MSE differs according to whether one is describing a predictor or an estimator.
Predictor[edit]
If a vector of 



In other words, the MSE is the mean 

In matrix notation,

where 



The MSE can also be computed on q data points that were not used in estimating the model, either because they were held back for this purpose, or because these data have been newly obtained. Within this process, known as statistical learning, the MSE is often called the test MSE,[4] and is computed as

Estimator[edit]
The MSE of an estimator 

![{displaystyle operatorname {MSE} ({hat {theta }})=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a0e1b3bac58f9ba2d2f4ff8b85b2e35a8f4bf78)
This definition depends on the unknown parameter, but the MSE is a priori a property of an estimator. The MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data (and thus a random variable). If the estimator
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent.[5]

Proof of variance and bias relationship[edit]
![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=operatorname {E} _{theta }left[({hat {theta }}-theta )^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]+operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}+2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+operatorname {E} _{theta }left[2left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)left(operatorname {E} _{theta }[{hat {theta }}]-theta right)right]+operatorname {E} _{theta }left[left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}right]\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)operatorname {E} _{theta }left[{hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]-theta ={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+2left(operatorname {E} _{theta }[{hat {theta }}]-theta right)left(operatorname {E} _{theta }[{hat {theta }}]-operatorname {E} _{theta }[{hat {theta }}]right)+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}&&operatorname {E} _{theta }[{hat {theta }}]={text{const.}}\&=operatorname {E} _{theta }left[left({hat {theta }}-operatorname {E} _{theta }[{hat {theta }}]right)^{2}right]+left(operatorname {E} _{theta }[{hat {theta }}]-theta right)^{2}\&=operatorname {Var} _{theta }({hat {theta }})+operatorname {Bias} _{theta }({hat {theta }},theta )^{2}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac524a751828f971013e1297a33ca1cc4c38cd6)
An even shorter proof can be achieved using the well-known formula that for a random variable 


![{displaystyle {begin{aligned}operatorname {MSE} ({hat {theta }})&=mathbb {E} [({hat {theta }}-theta )^{2}]\&=operatorname {Var} ({hat {theta }}-theta )+(mathbb {E} [{hat {theta }}-theta ])^{2}\&=operatorname {Var} ({hat {theta }})+operatorname {Bias} ^{2}({hat {theta }})end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/864646cf4426e2b62a3caf9460382eec1a77fe4e)
But in real modeling case, MSE could be described as the addition of model variance, model bias, and irreducible uncertainty (see Bias–variance tradeoff). According to the relationship, the MSE of the estimators could be simply used for the efficiency comparison, which includes the information of estimator variance and bias. This is called MSE criterion.
In regression[edit]
In regression analysis, plotting is a more natural way to view the overall trend of the whole data. The mean of the distance from each point to the predicted regression model can be calculated, and shown as the mean squared error. The squaring is critical to reduce the complexity with negative signs. To minimize MSE, the model could be more accurate, which would mean the model is closer to actual data. One example of a linear regression using this method is the least squares method—which evaluates appropriateness of linear regression model to model bivariate dataset,[6] but whose limitation is related to known distribution of the data.
The term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor, in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n−p) for p regressors or (n−p−1) if an intercept is used (see errors and residuals in statistics for more details).[7] Although the MSE (as defined in this article) is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
In regression analysis, «mean squared error», often referred to as mean squared prediction error or «out-of-sample mean squared error», can also refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples[edit]
Mean[edit]
Suppose we have a random sample of size 


which has an expected value equal to the true mean
![{displaystyle operatorname {MSE} left({overline {X}}right)=operatorname {E} left[left({overline {X}}-mu right)^{2}right]=left({frac {sigma }{sqrt {n}}}right)^{2}={frac {sigma ^{2}}{n}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4647a2cc4c8f9a4c90b628faad2dcf80c4aae84)
where 
For a Gaussian distribution, this is the best unbiased estimator (i.e., one with the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance[edit]
The usual estimator for the variance is the corrected sample variance:

This is unbiased (its expected value is

where 

However, one can use other estimators for 

then we calculate:
![{displaystyle {begin{aligned}operatorname {MSE} (S_{a}^{2})&=operatorname {E} left[left({frac {n-1}{a}}S_{n-1}^{2}-sigma ^{2}right)^{2}right]\&=operatorname {E} left[{frac {(n-1)^{2}}{a^{2}}}S_{n-1}^{4}-2left({frac {n-1}{a}}S_{n-1}^{2}right)sigma ^{2}+sigma ^{4}right]\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)operatorname {E} left[S_{n-1}^{2}right]sigma ^{2}+sigma ^{4}\&={frac {(n-1)^{2}}{a^{2}}}operatorname {E} left[S_{n-1}^{4}right]-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{2}right]=sigma ^{2}\&={frac {(n-1)^{2}}{a^{2}}}left({frac {gamma _{2}}{n}}+{frac {n+1}{n-1}}right)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}&&operatorname {E} left[S_{n-1}^{4}right]=operatorname {MSE} (S_{n-1}^{2})+sigma ^{4}\&={frac {n-1}{na^{2}}}left((n-1)gamma _{2}+n^{2}+nright)sigma ^{4}-2left({frac {n-1}{a}}right)sigma ^{4}+sigma ^{4}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf22322412b8454c706d78671e5d94208675a6e0)
This is minimized when

For a Gaussian distribution, where 



Further, while the corrected sample variance is the best unbiased estimator (minimum mean squared error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian, then even among unbiased estimators, the best unbiased estimator of the variance may not be 
Gaussian distribution[edit]
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[9]
| True value | Estimator | Mean squared error |
|---|---|---|
 |
= the unbiased estimator of the population mean,  |

|
 |
= the unbiased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
|
= the biased estimator of the population variance,  |

|
Interpretation[edit]
An MSE of zero, meaning that the estimator
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs—as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best unbiased estimator or MVUE (Minimum-Variance Unbiased Estimator).
Both analysis of variance and linear regression techniques estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
In one-way analysis of variance, MSE can be calculated by the division of the sum of squared errors and the degree of freedom. Also, the f-value is the ratio of the mean squared treatment and the MSE.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications[edit]
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE can represent the difference between the actual observations and the observation values predicted by the model. In this context, it is used to determine the extent to which the model fits the data as well as whether removing some explanatory variables is possible without significantly harming the model’s predictive ability.
- In forecasting and prediction, the Brier score is a measure of forecast skill based on MSE.
Loss function[edit]
Squared error loss is one of the most widely used loss functions in statistics[citation needed], though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[3] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism[edit]
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[10]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[11] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also[edit]
- Bias–variance tradeoff
- Hodges’ estimator
- James–Stein estimator
- Mean percentage error
- Mean square quantization error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean square error
- Minimum mean squared error estimator
- Overfitting
- Peak signal-to-noise ratio
Notes[edit]
- ^ This can be proved by Jensen’s inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References[edit]
- ^ a b «Mean Squared Error (MSE)». www.probabilitycourse.com. Retrieved 2020-09-12.
- ^ Bickel, Peter J.; Doksum, Kjell A. (2015). Mathematical Statistics: Basic Ideas and Selected Topics. Vol. I (Second ed.). p. 20.
If we use quadratic loss, our risk function is called the mean squared error (MSE) …
- ^ a b Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 978-0-387-98502-2. MR 1639875.
- ^ Gareth, James; Witten, Daniela; Hastie, Trevor; Tibshirani, Rob (2021). An Introduction to Statistical Learning: with Applications in R. Springer. ISBN 978-1071614174.
- ^ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 978-0-495-38508-0.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ^ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ^ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ^ Berger, James O. (1985). «2.4.2 Certain Standard Loss Functions». Statistical Decision Theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 978-0-387-96098-2. MR 0804611.
- ^ Bermejo, Sergio; Cabestany, Joan (2001). «Oriented principal component analysis for large margin classifiers». Neural Networks. 14 (10): 1447–1461. doi:10.1016/S0893-6080(01)00106-X. PMID 11771723.
17 авг. 2022 г.
читать 1 мин
Среднеквадратическая ошибка (MSE) — это распространенный способ измерения точности предсказания модели. Он рассчитывается как:
MSE = (1/n) * Σ(фактическое – прогноз) 2
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
Чем ниже значение MSE, тем лучше модель способна точно предсказывать значения.
Как рассчитать MSE в Python
Мы можем создать простую функцию для вычисления MSE в Python:
import numpy as np
def mse(actual, pred):
actual, pred = np.array(actual), np.array(pred)
return np.square(np.subtract(actual,pred)).mean()
Затем мы можем использовать эту функцию для вычисления MSE для двух массивов: одного, содержащего фактические значения данных, и другого, содержащего прогнозируемые значения данных.
actual = [12, 13, 14, 15, 15, 22, 27]
pred = [11, 13, 14, 14, 15, 16, 18]
mse(actual, pred)
17.0
Среднеквадратическая ошибка (MSE) для этой модели оказывается равной 17,0 .
На практике среднеквадратическая ошибка (RMSE) чаще используется для оценки точности модели. Как следует из названия, это просто квадратный корень из среднеквадратичной ошибки.
Мы можем определить аналогичную функцию для вычисления RMSE:
import numpy as np
def rmse(actual, pred):
actual, pred = np.array(actual), np.array(pred)
return np.sqrt(np.square(np.subtract(actual,pred)).mean())
Затем мы можем использовать эту функцию для вычисления RMSE для двух массивов: одного, содержащего фактические значения данных, и другого, содержащего прогнозируемые значения данных.
actual = [12, 13, 14, 15, 15, 22, 27]
pred = [11, 13, 14, 14, 15, 16, 18]
rmse(actual, pred)
4.1231
Среднеквадратическая ошибка (RMSE) для этой модели оказывается равной 4,1231 .
Дополнительные ресурсы
Калькулятор среднеквадратичной ошибки (MSE)
Как рассчитать среднеквадратичную ошибку (MSE) в Excel
The mean squared error is a common way to measure the prediction accuracy of a model. In this tutorial, you’ll learn how to calculate the mean squared error in Python. You’ll start off by learning what the mean squared error represents. Then you’ll learn how to do this using Scikit-Learn (sklean), Numpy, as well as from scratch.
What is the Mean Squared Error
The mean squared error measures the average of the squares of the errors. What this means, is that it returns the average of the sums of the square of each difference between the estimated value and the true value.
The MSE is always positive, though it can be 0 if the predictions are completely accurate. It incorporates the variance of the estimator (how widely spread the estimates are) and its bias (how different the estimated values are from their true values).
The formula looks like below:

Now that you have an understanding of how to calculate the MSE, let’s take a look at how it can be calculated using Python.
Interpreting the Mean Squared Error
The mean squared error is always 0 or positive. When a MSE is larger, this is an indication that the linear regression model doesn’t accurately predict the model.
An important piece to note is that the MSE is sensitive to outliers. This is because it calculates the average of every data point’s error. Because of this, a larger error on outliers will amplify the MSE.
There is no “target” value for the MSE. The MSE can, however, be a good indicator of how well a model fits your data. It can also give you an indicator of choosing one model over another.
Loading a Sample Pandas DataFrame
Let’s start off by loading a sample Pandas DataFrame. If you want to follow along with this tutorial line-by-line, simply copy the code below and paste it into your favorite code editor.
# Importing a sample Pandas DataFrame
import pandas as pd
df = pd.DataFrame.from_dict({
'x': [1,2,3,4,5,6,7,8,9,10],
'y': [1,2,2,4,4,5,6,7,9,10]})
print(df.head())
# x y
# 0 1 1
# 1 2 2
# 2 3 2
# 3 4 4
# 4 5 4You can see that the editor has loaded a DataFrame containing values for variables x and y. We can plot this data out, including the line of best fit using Seaborn’s .regplot() function:
# Plotting a line of best fit
import seaborn as sns
import matplotlib.pyplot as plt
sns.regplot(data=df, x='x', y='y', ci=None)
plt.ylim(bottom=0)
plt.xlim(left=0)
plt.show()This returns the following visualization:
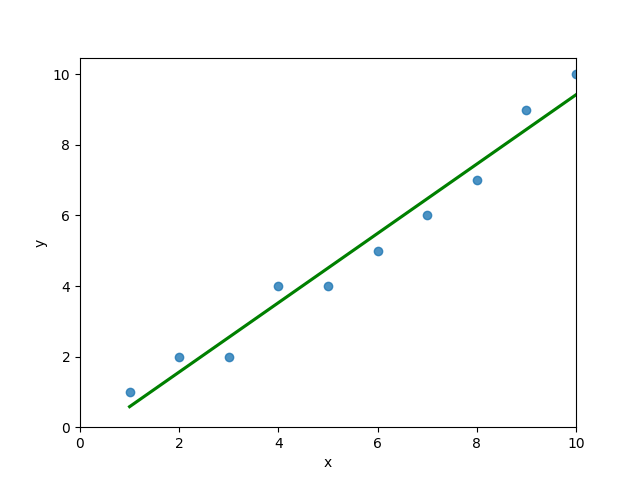
The mean squared error calculates the average of the sum of the squared differences between a data point and the line of best fit. By virtue of this, the lower a mean sqared error, the more better the line represents the relationship.
We can calculate this line of best using Scikit-Learn. You can learn about this in this in-depth tutorial on linear regression in sklearn. The code below predicts values for each x value using the linear model:
# Calculating prediction y values in sklearn
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(df[['x']], df['y'])
y_2 = model.predict(df[['x']])
df['y_predicted'] = y_2
print(df.head())
# Returns:
# x y y_predicted
# 0 1 1 0.581818
# 1 2 2 1.563636
# 2 3 2 2.545455
# 3 4 4 3.527273
# 4 5 4 4.509091Calculating the Mean Squared Error with Scikit-Learn
The simplest way to calculate a mean squared error is to use Scikit-Learn (sklearn). The metrics module comes with a function, mean_squared_error() which allows you to pass in true and predicted values.
Let’s see how to calculate the MSE with sklearn:
# Calculating the MSE with sklearn
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(df['y'], df['y_predicted'])
print(mse)
# Returns: 0.24727272727272714This approach works very well when you’re already importing Scikit-Learn. That said, the function works easily on a Pandas DataFrame, as shown above.
In the next section, you’ll learn how to calculate the MSE with Numpy using a custom function.
Calculating the Mean Squared Error from Scratch using Numpy
Numpy itself doesn’t come with a function to calculate the mean squared error, but you can easily define a custom function to do this. We can make use of the subtract() function to subtract arrays element-wise.
# Definiting a custom function to calculate the MSE
import numpy as np
def mse(actual, predicted):
actual = np.array(actual)
predicted = np.array(predicted)
differences = np.subtract(actual, predicted)
squared_differences = np.square(differences)
return squared_differences.mean()
print(mse(df['y'], df['y_predicted']))
# Returns: 0.24727272727272714The code above is a bit verbose, but it shows how the function operates. We can cut down the code significantly, as shown below:
# A shorter version of the code above
import numpy as np
def mse(actual, predicted):
return np.square(np.subtract(np.array(actual), np.array(predicted))).mean()
print(mse(df['y'], df['y_predicted']))
# Returns: 0.24727272727272714Conclusion
In this tutorial, you learned what the mean squared error is and how it can be calculated using Python. First, you learned how to use Scikit-Learn’s mean_squared_error() function and then you built a custom function using Numpy.
The MSE is an important metric to use in evaluating the performance of your machine learning models. While Scikit-Learn abstracts the way in which the metric is calculated, understanding how it can be implemented from scratch can be a helpful tool.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Pandas Variance: Calculating Variance of a Pandas Dataframe Column
- Calculate the Pearson Correlation Coefficient in Python
- How to Calculate a Z-Score in Python (4 Ways)
- Official Documentation from Scikit-Learn
Improve Article
Save Article
Improve Article
Save Article
The Mean Squared Error (MSE) or Mean Squared Deviation (MSD) of an estimator measures the average of error squares i.e. the average squared difference between the estimated values and true value. It is a risk function, corresponding to the expected value of the squared error loss. It is always non – negative and values close to zero are better. The MSE is the second moment of the error (about the origin) and thus incorporates both the variance of the estimator and its bias.
Steps to find the MSE
- Find the equation for the regression line.
(1)

- Insert X values in the equation found in step 1 in order to get the respective Y values i.e.
(2)

- Now subtract the new Y values (i.e.
 ) from the original Y values. Thus, found values are the error terms. It is also known as the vertical distance of the given point from the regression line.
) from the original Y values. Thus, found values are the error terms. It is also known as the vertical distance of the given point from the regression line.
(3)

- Square the errors found in step 3.
(4)

- Sum up all the squares.
(5)

- Divide the value found in step 5 by the total number of observations.
(6)

Example:
Consider the given data points: (1,1), (2,1), (3,2), (4,2), (5,4)
You can use this online calculator to find the regression equation / line.
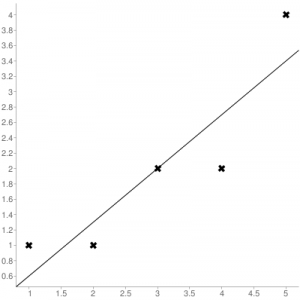
Regression line equation: Y = 0.7X – 0.1
| X | Y | |
|---|---|---|
| 1 | 1 | 0.6 |
| 2 | 1 | 1.29 |
| 3 | 2 | 1.99 |
| 4 | 2 | 2.69 |
| 5 | 4 | 3.4 |
Now, using formula found for MSE in step 6 above, we can get MSE = 0.21606
MSE using scikit – learn:
from sklearn.metrics import mean_squared_error
Y_true = [1,1,2,2,4]
Y_pred = [0.6,1.29,1.99,2.69,3.4]
mean_squared_error(Y_true,Y_pred)
Output: 0.21606
MSE using Numpy module:
import numpy as np
Y_true = [1,1,2,2,4]
Y_pred = [0.6,1.29,1.99,2.69,3.4]
MSE = np.square(np.subtract(Y_true,Y_pred)).mean()
Output: 0.21606
29.12.2019Python, Программы Python, Продвинутые компьютерные предметы
Среднее квадратичное отклонение (MSE) или Среднее квадратичное отклонение (MSD) оценщика измеряет среднее квадратов ошибок, то есть среднее квадратическое различие между оценочными значениями и истинным значением. Это функция риска, соответствующая ожидаемому значению квадрата потери ошибок. Это всегда неотрицательно, и значения, близкие к нулю, лучше. MSE является вторым моментом ошибки (относительно источника) и, таким образом, включает в себя как дисперсию оценки, так и ее смещение.
Шаги, чтобы найти MSE
- Найти уравнение для линии регрессии.
(1)

- Вставьте значения X в уравнение, найденное на шаге 1, чтобы получить соответствующие значения Y, т.е.
(2)

- Теперь вычтите новые значения Y (т.е.
 ) из исходных значений Y. Таким образом, найденные значения являются ошибочными терминами. Это также известно как вертикальное расстояние данной точки от линии регрессии.
) из исходных значений Y. Таким образом, найденные значения являются ошибочными терминами. Это также известно как вертикальное расстояние данной точки от линии регрессии.
(3)

- Возведите в квадрат ошибки, найденные в шаге 3.
(4)

- Подведите итог всех квадратов.
(5)

- Разделите значение, найденное на шаге 5, на общее количество наблюдений.
(6)

Пример:
Рассмотрим данные точки: (1,1), (2,1), (3,2), (4,2), (5,4)
Вы можете использовать этот онлайн калькулятор, чтобы найти уравнение / линию регрессии.

Уравнение линии регрессии: Y = 0,7X — 0,1
| X | Y | |
|---|---|---|
| 1 | 1 | 0.6 |
| 2 | 1 | 1.29 |
| 3 | 2 | 1.99 |
| 4 | 2 | 2.69 |
| 5 | 4 | 3.4 |
Теперь, используя формулу, найденную для MSE на шаге 6 выше, мы можем получить MSE = 0.21606
MSE, используя scikit — учиться:
from sklearn.metrics import mean_squared_error
Y_true = [1,1,2,2,4]
Y_pred = [0.6,1.29,1.99,2.69,3.4]
mean_squared_error(Y_true,Y_pred)
Output: 0.21606
MSE с использованием модуля Numpy:
import numpy as np
Y_true = [1,1,2,2,4]
Y_pred = [0.6,1.29,1.99,2.69,3.4]
MSE = np.square(np.subtract(Y_true,Y_pred)).mean()
Output: 0.21606
Рекомендуемые посты:
- ML | Потеря журнала и средняя квадратическая ошибка
- ML | Математическое объяснение СКО и R-квадрата ошибки
- Ошибка NZEC в Python
- Python | Ошибка подтверждения
- Ошибка с плавающей точкой в Python
- Python | 404 Обработка ошибок во Flask
- Python | Запрос пароля во время выполнения и завершение с сообщением об ошибке
- Python | Индекс ненулевых элементов в списке Python
- Python | Конвертировать список в массив Python
- Важные различия между Python 2.x и Python 3.x с примерами
- Чтение файловоподобных объектов Python из C | питон
- Python | Объединить значения ключа Python в список
- Python | Сортировать словари Python по ключу или значению
- Python | Набор 4 (словарь, ключевые слова в Python)
- Python | Добавить запись в библиотеки Python
Python | Средняя квадратическая ошибка
0.00 (0%) 0 votes
- sklearn.metrics.mean_squared_error(y_true, y_pred, *, sample_weight=None, multioutput=‘uniform_average’, squared=True)[source]¶
-
Mean squared error regression loss.
Read more in the User Guide.
- Parameters:
-
- y_truearray-like of shape (n_samples,) or (n_samples, n_outputs)
-
Ground truth (correct) target values.
- y_predarray-like of shape (n_samples,) or (n_samples, n_outputs)
-
Estimated target values.
- sample_weightarray-like of shape (n_samples,), default=None
-
Sample weights.
- multioutput{‘raw_values’, ‘uniform_average’} or array-like of shape (n_outputs,), default=’uniform_average’
-
Defines aggregating of multiple output values.
Array-like value defines weights used to average errors.- ‘raw_values’ :
-
Returns a full set of errors in case of multioutput input.
- ‘uniform_average’ :
-
Errors of all outputs are averaged with uniform weight.
- squaredbool, default=True
-
If True returns MSE value, if False returns RMSE value.
- Returns:
-
- lossfloat or ndarray of floats
-
A non-negative floating point value (the best value is 0.0), or an
array of floating point values, one for each individual target.
Examples
>>> from sklearn.metrics import mean_squared_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_squared_error(y_true, y_pred) 0.375 >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_squared_error(y_true, y_pred, squared=False) 0.612... >>> y_true = [[0.5, 1],[-1, 1],[7, -6]] >>> y_pred = [[0, 2],[-1, 2],[8, -5]] >>> mean_squared_error(y_true, y_pred) 0.708... >>> mean_squared_error(y_true, y_pred, squared=False) 0.822... >>> mean_squared_error(y_true, y_pred, multioutput='raw_values') array([0.41666667, 1. ]) >>> mean_squared_error(y_true, y_pred, multioutput=[0.3, 0.7]) 0.825...
Examples using sklearn.metrics.mean_squared_error¶
Improve Article
Save Article
Improve Article
Save Article
In this article, we discussed the implementation of weighted mean square error using python.
Mean squared error is a vital statistical concept, that is nowadays widely used in Machine learning and Deep learning algorithm. Mean squared error is basically a measure of the average squared difference between the estimated values and the actual value. It is also called a mean squared deviation and is most of the time used to calibrate the accuracy of the predicted output. In this article, let us discuss a variety of mean squared errors called weighted mean square errors.
Weighted mean square error enables to provide more importance or additional weightage for a particular set of points (points of interest) when compared to others. When handling imbalanced data, a weighted mean square error can be a vital performance metric. Python provides a wide variety of packages to implement mean squared and weighted mean square at one go, here we can make use of simple functions to implement weighted mean squared error.
Formula to calculate the weighted mean square error:
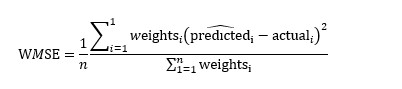
Implementation of Weighted Mean Square Error
- For demonstration purposes let us create a sample data frame, with augmented actual and predicted values, as shown.
- Calculate the squared difference between actual and predicted values.
- Define the weights for each data point based on the importance
- Now, use the weights to calculate the weighted mean square error as shown
Code Implementation:
Python3
import pandas as pd
import numpy as np
import random
d = {'Actual': np.arange(0, 20, 2)*np.sin(2),
'Predicted': np.arange(0, 20, 2)*np.cos(2)}
data = pd.DataFrame(data=d)
y_weights = np.arange(2, 4, 0.2)
diff = (data['Actual']-data['Predicted'])**2
weighted_mean_sq_error = np.sum(diff * y_weights) / np.sum(y_weights)
Output:

Weighted Mean Square Error
Let us cross verify the result with the result of the scikit-learn package. to verify the correctness,
Code:
Python3
weighted_mean_sq_error_sklearn = np.average(
(data['Actual']-data['Predicted'])**2, axis=0, weights=y_weights)
weighted_mean_sq_error_sklearn
Output:

verify the result
Improve Article
Save Article
Improve Article
Save Article
In this article, we discussed the implementation of weighted mean square error using python.
Mean squared error is a vital statistical concept, that is nowadays widely used in Machine learning and Deep learning algorithm. Mean squared error is basically a measure of the average squared difference between the estimated values and the actual value. It is also called a mean squared deviation and is most of the time used to calibrate the accuracy of the predicted output. In this article, let us discuss a variety of mean squared errors called weighted mean square errors.
Weighted mean square error enables to provide more importance or additional weightage for a particular set of points (points of interest) when compared to others. When handling imbalanced data, a weighted mean square error can be a vital performance metric. Python provides a wide variety of packages to implement mean squared and weighted mean square at one go, here we can make use of simple functions to implement weighted mean squared error.
Formula to calculate the weighted mean square error:
Implementation of Weighted Mean Square Error
- For demonstration purposes let us create a sample data frame, with augmented actual and predicted values, as shown.
- Calculate the squared difference between actual and predicted values.
- Define the weights for each data point based on the importance
- Now, use the weights to calculate the weighted mean square error as shown
Code Implementation:
Python3
import pandas as pd
import numpy as np
import random
d = {'Actual': np.arange(0, 20, 2)*np.sin(2),
'Predicted': np.arange(0, 20, 2)*np.cos(2)}
data = pd.DataFrame(data=d)
y_weights = np.arange(2, 4, 0.2)
diff = (data['Actual']-data['Predicted'])**2
weighted_mean_sq_error = np.sum(diff * y_weights) / np.sum(y_weights)
Output:
Weighted Mean Square Error
Let us cross verify the result with the result of the scikit-learn package. to verify the correctness,
Code:
Python3
weighted_mean_sq_error_sklearn = np.average(
(data['Actual']-data['Predicted'])**2, axis=0, weights=y_weights)
weighted_mean_sq_error_sklearn
Output:
verify the result
Перевод
Ссылка на автора
Показатели эффективности прогнозирования по временным рядам дают сводку об умениях и возможностях модели прогноза, которая сделала прогнозы.
Есть много разных показателей производительности на выбор. Может быть непонятно, какую меру использовать и как интерпретировать результаты.
В этом руководстве вы узнаете показатели производительности для оценки прогнозов временных рядов с помощью Python.
Временные ряды, как правило, фокусируются на прогнозировании реальных значений, называемых проблемами регрессии. Поэтому показатели эффективности в этом руководстве будут сосредоточены на методах оценки реальных прогнозов.
После завершения этого урока вы узнаете:
- Основные показатели выполнения прогноза, включая остаточную ошибку прогноза и смещение прогноза.
- Вычисления ошибок прогноза временного ряда, которые имеют те же единицы, что и ожидаемые результаты, такие как средняя абсолютная ошибка.
- Широко используются вычисления ошибок, которые наказывают большие ошибки, такие как среднеквадратическая ошибка и среднеквадратичная ошибка.
Давайте начнем.

Ошибка прогноза (или остаточная ошибка прогноза)
ошибка прогноза рассчитывается как ожидаемое значение минус прогнозируемое значение.
Это называется остаточной ошибкой прогноза.
forecast_error = expected_value - predicted_valueОшибка прогноза может быть рассчитана для каждого прогноза, предоставляя временной ряд ошибок прогноза.
В приведенном ниже примере показано, как можно рассчитать ошибку прогноза для серии из 5 прогнозов по сравнению с 5 ожидаемыми значениями. Пример был придуман для демонстрационных целей.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
print('Forecast Errors: %s' % forecast_errors)При выполнении примера вычисляется ошибка прогноза для каждого из 5 прогнозов. Список ошибок прогноза затем печатается.
Forecast Errors: [-0.2, 0.09999999999999998, -0.1, -0.09999999999999998, -0.2]Единицы ошибки прогноза совпадают с единицами прогноза. Ошибка прогноза, равная нулю, означает отсутствие ошибки или совершенный навык для этого прогноза.
Средняя ошибка прогноза (или ошибка прогноза)
Средняя ошибка прогноза рассчитывается как среднее значение ошибки прогноза.
mean_forecast_error = mean(forecast_error)Ошибки прогноза могут быть положительными и отрицательными. Это означает, что при вычислении среднего из этих значений идеальная средняя ошибка прогноза будет равна нулю.
Среднее значение ошибки прогноза, отличное от нуля, указывает на склонность модели к превышению прогноза (положительная ошибка) или занижению прогноза (отрицательная ошибка). Таким образом, средняя ошибка прогноза также называется прогноз смещения,
Ошибка прогноза может быть рассчитана непосредственно как среднее значение прогноза. В приведенном ниже примере показано, как среднее значение ошибок прогноза может быть рассчитано вручную.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
bias = sum(forecast_errors) * 1.0/len(expected)
print('Bias: %f' % bias)При выполнении примера выводится средняя ошибка прогноза, также известная как смещение прогноза.
Bias: -0.100000Единицы смещения прогноза совпадают с единицами прогнозов. Прогнозируемое смещение нуля или очень маленькое число около нуля показывает несмещенную модель.
Средняя абсолютная ошибка
средняя абсолютная ошибка или MAE, рассчитывается как среднее значение ошибок прогноза, где все значения прогноза вынуждены быть положительными.
Заставить ценности быть положительными называется сделать их абсолютными. Это обозначено абсолютной функциейабс ()или математически показано как два символа канала вокруг значения:| Значение |,
mean_absolute_error = mean( abs(forecast_error) )кудаабс ()делает ценности позитивными,forecast_errorодна или последовательность ошибок прогноза, иимею в виду()рассчитывает среднее значение.
Мы можем использовать mean_absolute_error () функция из библиотеки scikit-learn для вычисления средней абсолютной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_absolute_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mae = mean_absolute_error(expected, predictions)
print('MAE: %f' % mae)При выполнении примера вычисляется и выводится средняя абсолютная ошибка для списка из 5 ожидаемых и прогнозируемых значений.
MAE: 0.140000Эти значения ошибок приведены в исходных единицах прогнозируемых значений. Средняя абсолютная ошибка, равная нулю, означает отсутствие ошибки.
Средняя квадратическая ошибка
средняя квадратическая ошибка или MSE, рассчитывается как среднее значение квадратов ошибок прогноза. Возведение в квадрат значений ошибки прогноза заставляет их быть положительными; это также приводит к большему количеству ошибок.
Квадратные ошибки прогноза с очень большими или выбросами возводятся в квадрат, что, в свою очередь, приводит к вытягиванию среднего значения квадратов ошибок прогноза, что приводит к увеличению среднего квадрата ошибки. По сути, оценка дает худшую производительность тем моделям, которые делают большие неверные прогнозы.
mean_squared_error = mean(forecast_error^2)Мы можем использовать mean_squared_error () функция из scikit-learn для вычисления среднеквадратичной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_squared_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
print('MSE: %f' % mse)При выполнении примера вычисляется и выводится среднеквадратическая ошибка для списка ожидаемых и прогнозируемых значений.
MSE: 0.022000Значения ошибок приведены в квадратах от предсказанных значений. Среднеквадратичная ошибка, равная нулю, указывает на совершенное умение или на отсутствие ошибки.
Среднеквадратическая ошибка
Средняя квадратичная ошибка, описанная выше, выражается в квадратах единиц прогнозов.
Его можно преобразовать обратно в исходные единицы прогнозов, взяв квадратный корень из среднего квадрата ошибки Это называется среднеквадратичная ошибка или RMSE.
rmse = sqrt(mean_squared_error)Это можно рассчитать с помощьюSQRT ()математическая функция среднего квадрата ошибки, рассчитанная с использованиемmean_squared_error ()функция scikit-learn.
from sklearn.metrics import mean_squared_error
from math import sqrt
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
rmse = sqrt(mse)
print('RMSE: %f' % rmse)При выполнении примера вычисляется среднеквадратичная ошибка.
RMSE: 0.148324Значения ошибок RMES приведены в тех же единицах, что и прогнозы. Как и в случае среднеквадратичной ошибки, среднеквадратическое отклонение, равное нулю, означает отсутствие ошибки.
Дальнейшее чтение
Ниже приведены некоторые ссылки для дальнейшего изучения показателей ошибки прогноза временных рядов.
- Раздел 3.3 Измерение прогнозирующей точности, Практическое прогнозирование временных рядов с помощью R: практическое руководство,
- Раздел 2.5 Оценка точности прогноза, Прогнозирование: принципы и практика
- scikit-Learn Metrics API
- Раздел 3.3.4. Метрики регрессии, scikit-learn API Guide
Резюме
В этом руководстве вы обнаружили набор из 5 стандартных показателей производительности временных рядов в Python.
В частности, вы узнали:
- Как рассчитать остаточную ошибку прогноза и как оценить смещение в списке прогнозов.
- Как рассчитать среднюю абсолютную ошибку прогноза, чтобы описать ошибку в тех же единицах, что и прогнозы.
- Как рассчитать широко используемые среднеквадратические ошибки и среднеквадратичные ошибки для прогнозов.
Есть ли у вас какие-либо вопросы о показателях эффективности прогнозирования временных рядов или об этом руководстве?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
In this article, we are going to learn how to calculate the mean squared error in python? We are using two python libraries to calculate the mean squared error. NumPy and sklearn are the libraries we are going to use here. Also, we will learn how to calculate without using any module.
MSE is also useful for regression problems that are normally distributed. It is the mean squared error. So the squared error between the predicted values and the actual values. The summation of all the data points of the square difference between the predicted and actual values is divided by the no. of data points.
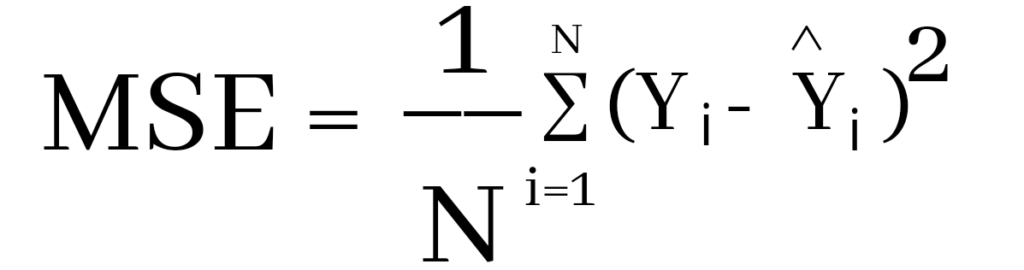
Where Yi and Ŷi represent the actual values and the predicted values, the difference between them is squared.
Derivation of Mean Squared Error
First to find the regression line for the values (1,3), (2,2), (3,6), (4,1), (5,5). The regression value for the value is y=1.6+0.4x. Next to find the new Y values. The new values for y are tabulated below.
| Given x value | Calculating y value | New y value |
|---|---|---|
| 1 | 1.6+0.4(1) | 2 |
| 2 | 1.6+0.4(2) | 2.4 |
| 3 | 1.6+0.4(3) | 2.8 |
| 4 | 1.6+0.4(4) | 3.2 |
| 5 | 1.6+0.4(5) | 3.6 |
Now to find the error ( Yi – Ŷi )
We have to square all the errors
By adding all the errors we will get the MSE
Line regression graph
Let us consider the values (1,3), (2,2), (3,6), (4,1), (5,5) to plot the graph.
The straight line represents the predicted value in this graph, and the points represent the actual data. The difference between this line and the points is squared, known as mean squared error.
Also, Read | How to Calculate Square Root in Python
To get the Mean Squared Error in Python using NumPy
import numpy as np true_value_of_y= [3,2,6,1,5] predicted_value_of_y= [2.0,2.4,2.8,3.2,3.6] MSE = np.square(np.subtract(true_value_of_y,predicted_value_of_y)).mean() print(MSE)
Importing numpy library as np. Creating two variables. true_value_of_y holds an original value. predicted_value_of_y holds a calculated value. Next, giving the formula to calculate the mean squared error.
Output
3.6400000000000006
To get the MSE using sklearn
sklearn is a library that is used for many mathematical calculations in python. Here we are going to use this library to calculate the MSE
Syntax
sklearn.metrices.mean_squared_error(y_true, y_pred, *, sample_weight=None, multioutput='uniform_average', squared=True)
Parameters
- y_true – true value of y
- y_pred – predicted value of y
- sample_weight
- multioutput
- raw_values
- uniform_average
- squared
Returns
Mean squared error.
Code
from sklearn.metrics import mean_squared_error true_value_of_y= [3,2,6,1,5] predicted_value_of_y= [2.0,2.4,2.8,3.2,3.6] mean_squared_error(true_value_of_y,predicted_value_of_y) print(mean_squared_error(true_value_of_y,predicted_value_of_y))
From sklearn.metrices library importing mean_squared_error. Creating two variables. true_value_of_y holds an original value. predicted_value_of_y holds a calculated value. Next, giving the formula to calculate the mean squared error.
Output
3.6400000000000006
Calculating Mean Squared Error Without Using any Modules
true_value_of_y = [3,2,6,1,5]
predicted_value_of_y = [2.0,2.4,2.8,3.2,3.6]
summation_of_value = 0
n = len(true_value_of_y)
for i in range (0,n):
difference_of_value = true_value_of_y[i] - predicted_value_of_y[i]
squared_difference = difference_of_value**2
summation_of_value = summation_of_value + squared_difference
MSE = summation_of_value/n
print ("The Mean Squared Error is: " , MSE)
Declaring the true values and the predicted values to two different variables. Initializing the variable summation_of_value is zero to store the values. len() function is useful to check the number of values in true_value_of_y. Creating for loop to iterate. Calculating the difference between true_value and the predicted_value. Next getting the square of the difference. Adding all the squared differences, we will get the MSE.
Output
The Mean Squared Error is: 3.6400000000000006
Calculate Mean Squared Error Using Negative Values
Now let us consider some negative values to calculate MSE. The values are (1,2), (3,-1), (5,0.6), (4,-0.7), (2,-0.2). The regression line equation is y=1.13-0.33x
The line regression graph for this value is:
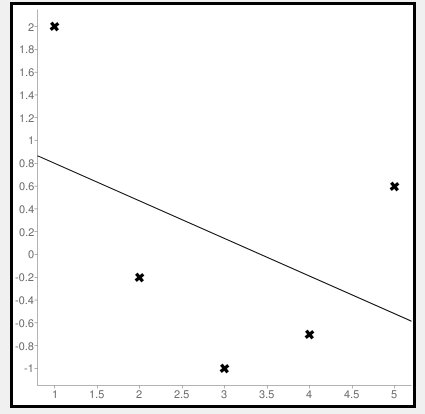
New y values for this will be:
| Given x value | Calculating y value | New y value |
|---|---|---|
| 1 | 1.13-033(1) | 0.9 |
| 3 | 1.13-033(3) | 0.1 |
| 5 | 1.13-033(5) | -0.4 |
| 4 | 1.13-033(4) | -0.1 |
| 2 | 1.13-033(2) | 0.6 |
Code
>>> from sklearn.metrics import mean_squared_error >>> y_true = [2,-1,0.6,-0.7,-0.2] >>> y_pred = [0.9,0.1,-0.4,-0.1,0.6] >>> mean_squared_error(y_true, y_pred)
First, importing a module. Declaring values to the variables. Here we are using negative value to calculate. Using the mean_squared_error module, we are calculating the MSE.
Output
0.884
Bonus: Gradient Descent
Gradient Descent is used to find the local minimum of the functions. In this case, the functions need to be differentiable. The basic idea is to move in the direction opposite from the derivate at any point.
The following code works on a set of values that are available on the Github repository.
Code:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from numpy import *
def compute_error(b, m, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (m * x + b)) ** 2
return totalError / float(len(points))
def gradient_step(
b_current,
m_current,
points,
learningRate,
):
b_gradient = 0
m_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
b_gradient += -(2 / N) * (y - (m_current * x + b_current))
m_gradient += -(2 / N) * x * (y - (m_current * x + b_current))
new_b = b_current - learningRate * b_gradient
new_m = m_current - learningRate * m_gradient
return [new_b, new_m]
def gradient_descent_runner(
points,
starting_b,
starting_m,
learning_rate,
iterations,
):
b = starting_b
m = starting_m
for i in range(iterations):
(b, m) = gradient_step(b, m, array(points), learning_rate)
return [b, m]
def main():
points = genfromtxt('data.csv', delimiter=',')
learning_rate = 0.00001
initial_b = 0
initial_m = 0
iterations = 10000
print('Starting gradient descent at b = {0}, m = {1}, error = {2}'.format(initial_b,
initial_m, compute_error(initial_b, initial_m, points)))
print('Running...')
[b, m] = gradient_descent_runner(points, initial_b, initial_m,
learning_rate, iterations)
print('After {0} iterations b = {1}, m = {2}, error = {3}'.format(iterations,
b, m, compute_error(b, m, points)))
if __name__ == '__main__':
main()
Output:
Starting gradient descent at b = 0, m = 0, error = 5671.844671124282
Running...
After 10000 iterations b = 0.11558415090685024, m = 1.3769012288001614, error = 212.262203123587941. What is the pip command to install numpy?
pip install numpy
2. What is the pip command to install sklearn.metrices library?
pip install sklearn
3. What is the expansion of MSE?
The expansion of MSE is Mean Squared Error.
Conclusion
In this article, we have learned about the mean squared error. It is effortless to calculate. This is useful for loss function for least squares regression. The formula for the MSE is easy to memorize. We hope this article is handy and easy to understand.
Среднеквадратичная ошибка (Mean Squared Error) – Среднее арифметическое (Mean) квадратов разностей между предсказанными и реальными значениями Модели (Model) Машинного обучения (ML):
Рассчитывается с помощью формулы, которая будет пояснена в примере ниже:
$$MSE = frac{1}{n} × sum_{i=1}^n (y_i — widetilde{y}_i)^2$$
$$MSEspace{}{–}space{Среднеквадратическая}space{ошибка,}$$
$$nspace{}{–}space{количество}space{наблюдений,}$$
$$y_ispace{}{–}space{фактическая}space{координата}space{наблюдения,}$$
$$widetilde{y}_ispace{}{–}space{предсказанная}space{координата}space{наблюдения,}$$
MSE практически никогда не равен нулю, и происходит это из-за элемента случайности в данных или неучитывания Оценочной функцией (Estimator) всех факторов, которые могли бы улучшить предсказательную способность.
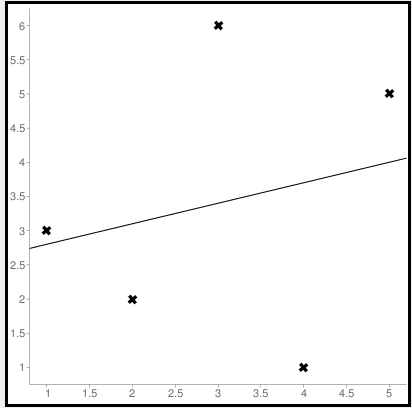
Пример. Исследуем линейную регрессию, изображенную на графике выше, и установим величину среднеквадратической Ошибки (Error). Фактические координаты точек-Наблюдений (Observation) выглядят следующим образом:
Мы имеем дело с Линейной регрессией (Linear Regression), потому уравнение, предсказывающее положение записей, можно представить с помощью формулы:
$$y = M * x + b$$
$$yspace{–}space{значение}space{координаты}space{оси}space{y,}$$
$$Mspace{–}space{уклон}space{прямой}$$
$$xspace{–}space{значение}space{координаты}space{оси}space{x,}$$
$$bspace{–}space{смещение}space{прямой}space{относительно}space{начала}space{координат}$$
Параметры M и b уравнения нам, к счастью, известны в данном обучающем примере, и потому уравнение выглядит следующим образом:
$$y = 0,5252 * x + 17,306$$
Зная координаты реальных записей и уравнение линейной регрессии, мы можем восстановить полные координаты предсказанных наблюдений, обозначенных серыми точками на графике выше. Простой подстановкой значения координаты x в уравнение мы рассчитаем значение координаты ỹ:
Рассчитаем квадрат разницы между Y и Ỹ:
Сумма таких квадратов равна 4 445. Осталось только разделить это число на количество наблюдений (9):
$$MSE = frac{1}{9} × 4445 = 493$$
Само по себе число в такой ситуации становится показательным, когда Дата-сайентист (Data Scientist) предпринимает попытки улучшить предсказательную способность модели и сравнивает MSE каждой итерации, выбирая такое уравнение, что сгенерирует наименьшую погрешность в предсказаниях.
MSE и Scikit-learn
Среднеквадратическую ошибку можно вычислить с помощью SkLearn. Для начала импортируем функцию:
import sklearn
from sklearn.metrics import mean_squared_errorИнициализируем крошечные списки, содержащие реальные и предсказанные координаты y:
y_true = [5, 41, 70, 77, 134, 68, 138, 101, 131]
y_pred = [23, 35, 55, 90, 93, 103, 118, 121, 129]Инициируем функцию mean_squared_error(), которая рассчитает MSE тем же способом, что и формула выше:
mean_squared_error(y_true, y_pred)
Интересно, что конечный результат на 3 отличается от расчетов с помощью Apple Numbers:
496.0Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: @mmoshikoo
Фото: @tobyelliott
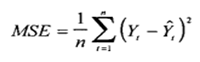 Из данной статьи вы узнаете:
Из данной статьи вы узнаете:
- Для чего нужна среднеквадратическая ошибка прогноза;
- Как она рассчитывается.
+ сможете скачать пример расчета в Excel.
MSE (mean squared error) – среднеквадратическая ошибка прогноза.
MSE – среднеквадратическая ошибка прогноза применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза.
Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
Как рассчитать среднеквадратическую ошибку?
- Рассчитываем ошибку для каждого значения модели;
- Возводим ошибку в квадрат;
- Рассчитываем среднее по квадрату ошибки, т.е. среднеквадратическую ошибку MSE:
Скачайте файл с примером расчета ошибки MSE
1. Ошибка = фактические продаж минус значения прогнозной модели для каждого момента времени:
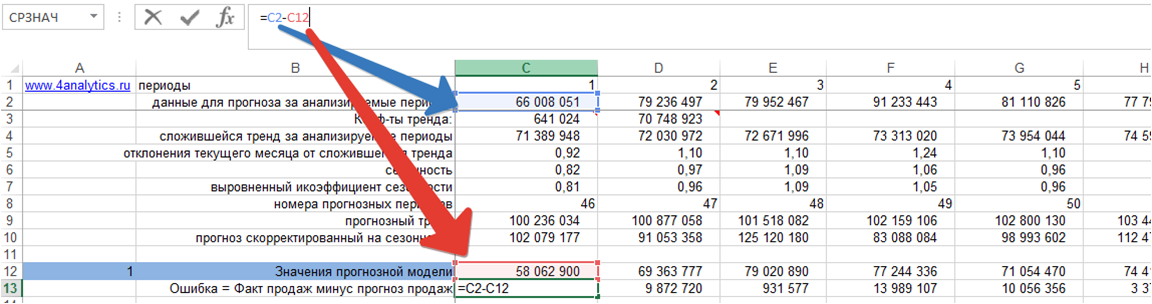
2. Возводим ошибку в квадрат для каждого момента времени:
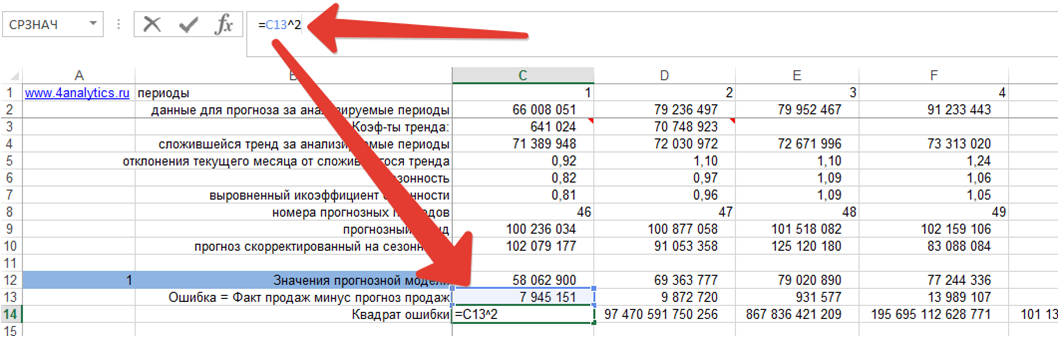
3. Рассчитываем среднеквадратическую ошибку MSE, для этого определяем среднее значение квадратов ошибок:
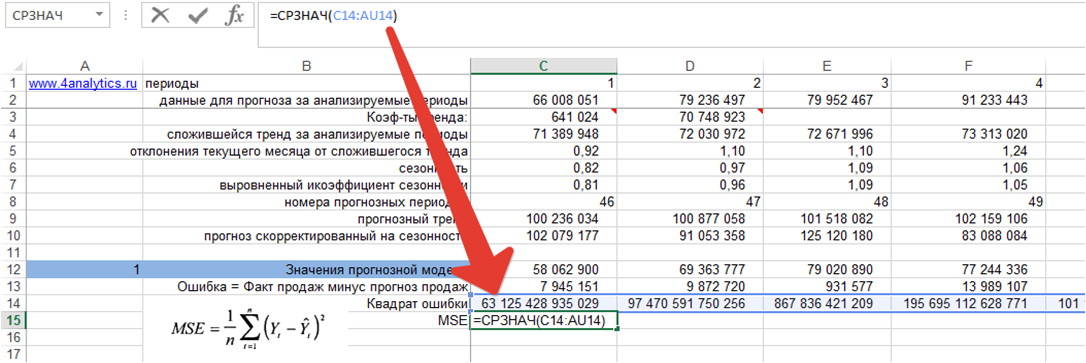
Скачайте файл с примером расчета ошибки MSE
Из данной статьи вы узнали, для чего использовать среднеквадратическую ошибку прогноза и как ее рассчитать. Если у вас остались вопросы, пожалуйста, задавайте в комментариях, буду рад помочь!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
17 авг. 2022 г.
читать 2 мин
Одной из наиболее распространенных метрик, используемых для измерения точности прогноза модели, является MSE , что означает среднеквадратичную ошибку.Он рассчитывается как:
MSE = (1/n) * Σ(факт – прогноз) 2
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
Чем ниже значение MSE, тем лучше модель способна точно прогнозировать значения.
Как рассчитать MSE в Excel
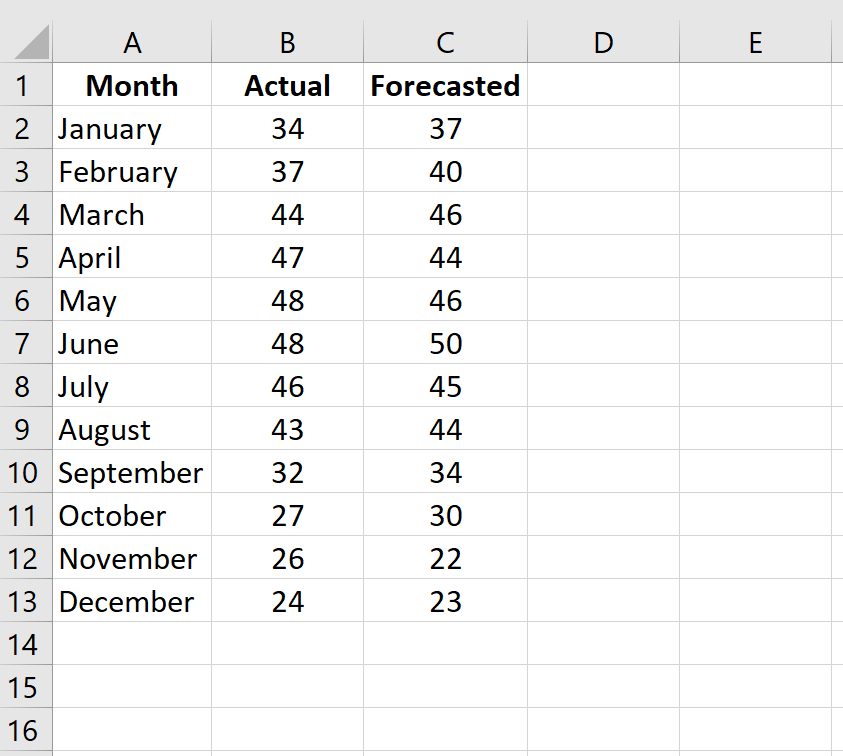
Чтобы рассчитать MSE в Excel, мы можем выполнить следующие шаги:
Шаг 1: Введите фактические значения и прогнозируемые значения в два отдельных столбца.
Шаг 2: Рассчитайте квадрат ошибки для каждой строки.
Напомним, что квадрат ошибки рассчитывается как: (факт – прогноз) 2.Мы будем использовать эту формулу для расчета квадрата ошибки для каждой строки.
Столбец D отображает квадрат ошибки, а столбец E показывает формулу, которую мы использовали:
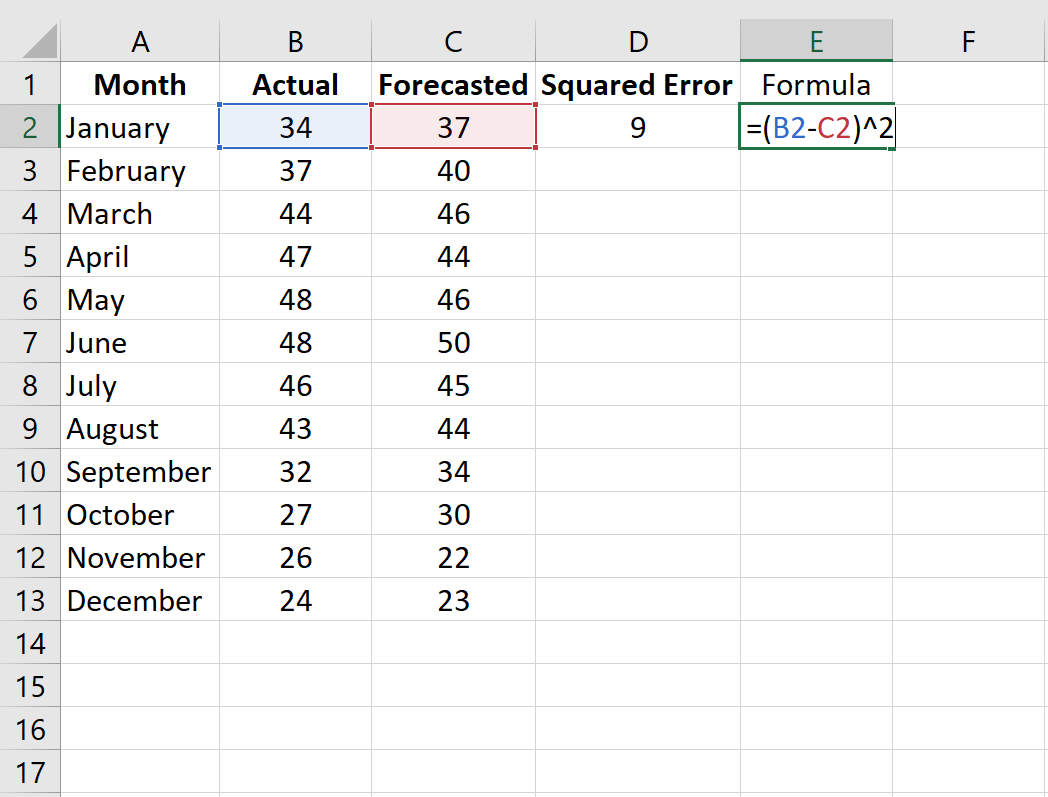
Повторите эту формулу для каждой строки:
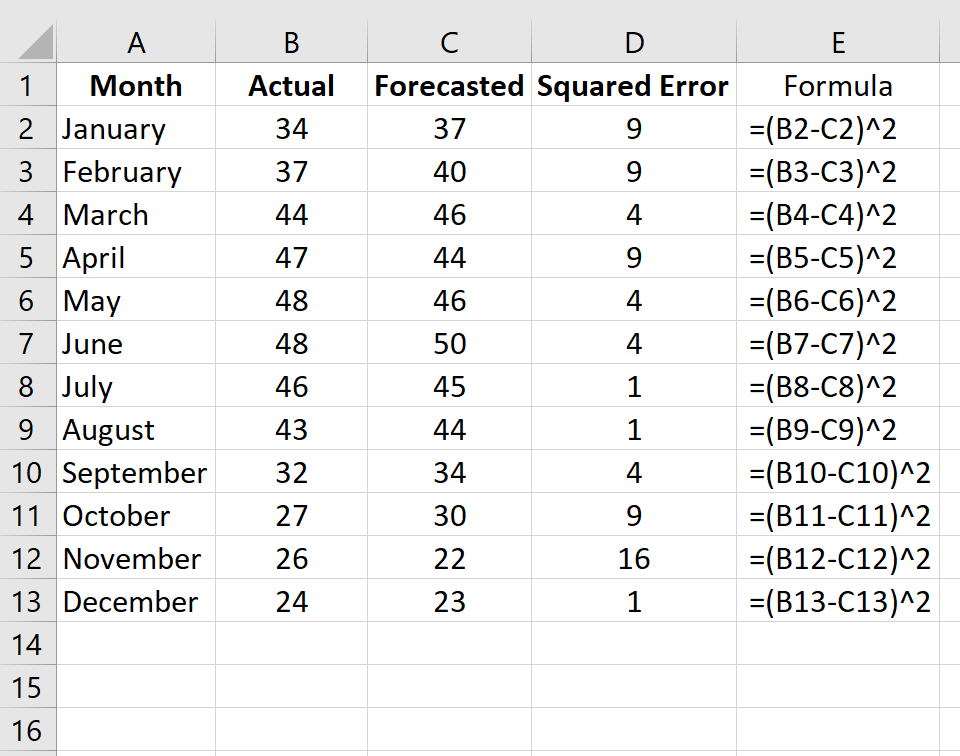
Шаг 3: Рассчитайте среднеквадратичную ошибку.
Рассчитайте MSE, просто найдя среднее значение в столбце D:
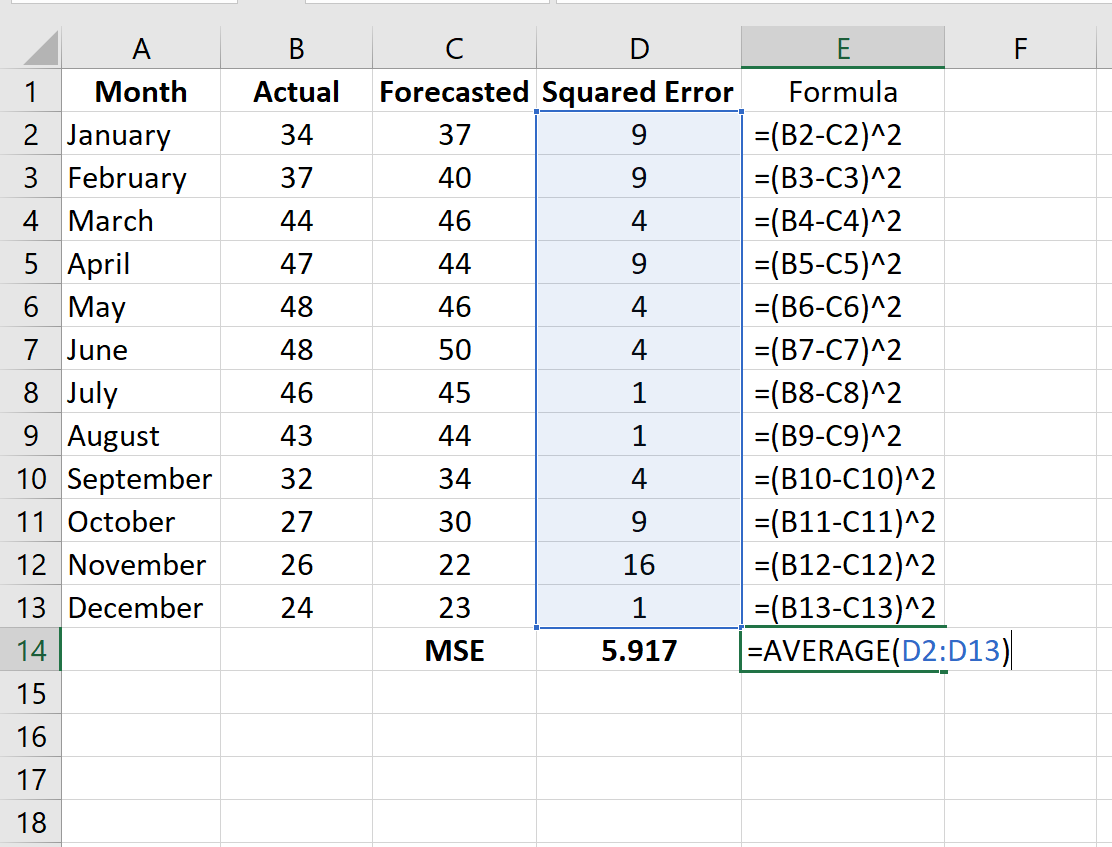
MSE этой модели оказывается равным 5,917 .
Дополнительные ресурсы
Двумя другими популярными показателями, используемыми для оценки точности модели, являются MAD — среднее абсолютное отклонение и MAPE — средняя абсолютная процентная ошибка. В следующих руководствах объясняется, как рассчитать эти показатели в Excel:
Как рассчитать среднее абсолютное отклонение (MAD) в Excel
Как рассчитать среднюю абсолютную ошибку в процентах (MAPE) в Excel
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.