In statistics, a relative standard error (RSE) is equal to the standard error of a survey estimate divided by the survey estimate and then multiplied by 100. The number is multiplied by 100 so it can be expressed as a percentage. The RSE does not necessarily represent any new information beyond the standard error, but it might be a superior method of presenting statistical confidence.
Relative Standard Error vs. Standard Error
Standard error measures how much a survey estimate is likely to deviate from the actual population. It is expressed as a number. By contrast, relative standard error (RSE) is the standard error expressed as a fraction of the estimate and is usually displayed as a percentage. Estimates with an RSE of 25% or greater are subject to high sampling error and should be used with caution.
Survey Estimate and Standard Error
Surveys and standard errors are crucial parts of probability theory and statistics. Statisticians use standard errors to construct confidence intervals from their surveyed data. The reliability of these estimates can also be assessed in terms of a confidence interval. Confidence intervals are important for determining the validity of empirical tests and research.
A confidence interval is a type of interval estimate, computed from the statistics of the observed data, that might contain the true value of an unknown population parameter. Confidence intervals represent the range in which the population value is likely to lie. They are constructed using the estimate of the population value and its associated standard error. For example, there is approximately a 95% chance (i.e. 19 chances in 20) that the population value lies within two standard errors of the estimates, so the 95% confidence interval is equal to the estimate plus or minus two standard errors.
In layman’s terms, the standard error of a data sample is a measurement of the likely difference between the sample and the entire population. For example, a study involving 10,000 cigarette-smoking adults may generate slightly different statistical results than if every possible cigarette-smoking adult was surveyed.
Smaller sample errors are indicative of more reliable results. The central limit theorem in inferential statistics suggests that large samples tend to have approximately normal distributions and low sample errors.
Standard Deviation and Standard Error
The standard deviation of a data set is used to express the concentration of survey results. Less variety in the data results in a lower standard deviation. More variety is likely to result in a higher standard deviation.
The standard error is sometimes confused with the standard deviation. The standard error actually refers to the standard deviation of the mean. Standard deviation refers to the variability inside any given sample, while a standard error is the variability of the sampling distribution itself.
Relative Standard Error
The standard error is an absolute gauge between the sample survey and the total population. The relative standard error shows if the standard error is large relative to the results; large relative standard errors suggest the results are not significant. The formula for relative standard error is:
Relative Standard Error
=
Standard Error
Estimate
×
1
0
0
where:
Standard Error
=
standard deviation of the mean sample
Estimate
=
mean of the sample
begin{aligned} &text{Relative Standard Error} = frac { text{Standard Error} }{ text{Estimate} } times 100 \ &textbf{where:} \ &text{Standard Error} = text{standard deviation of the mean sample} \ &text{Estimate} = text{mean of the sample} \ end{aligned}
Relative Standard Error=EstimateStandard Error×100where:Standard Error=standard deviation of the mean sampleEstimate=mean of the sample
Оценка достоверности результатов статистического исследования
В
практической и научно-практической
работе врачи обобщают результаты,
полученные, как правило, на выборочных
совокупностях. Для более
широкого распространения и применения
полученных при изучении
репрезентативной выборочной совокупности
данных и выводов надо уметь
по части явления судить о явлении и его
закономерностях в целом.
Учитывая,
как правило, что врачи проводят
исследования на выборочных совокупностях,
теория статистики позволяет с помощью
математического аппарата (формул)
переносить данные с выборочного
исследования на генеральную совокупность.
При этом врач должен уметь не только
пользоваться математическими формулами,
но и делать выводы, соответствующие
каждому способу оценки достоверности
полученных данных. С
этой целью врач должен знать способы
оценки достоверности.
В статистических
исследованиях применяются 2 вида
наблюдений — сплошное и выборочное.
Самые надежные результаты можно получить
при применении сплошного метода, т.е.
при изучении генеральной совокупности.
Между тем изучение
генеральной совокупности связано со
значительной трудоемкостью. Поэтому в
медико-биологических исследованиях,
как правило, проводятся выборочные
наблюдения. С тем, чтобы полученные при
изучении выборочной совокупности данные
можно было перенести на генеральную
совокупность, необходимо провести
оценку достоверности результатов
статистического исследования. Выборочная
совокупность может недостаточно полно
представлять генеральную совокупность,
поэтому выборочным наблюдениям всегда
сопутствуют ошибки
репрезентативности.
По размерам средней
ошибки ( m
) можно судить, насколько найденная
выборочная средняя величина отличается
от средней генеральной совокупности.
Малая ошибка указывает на близость этих
показателей, большая ошибка такой
уверенности не дает.
На величину средней
ошибки средней арифметической влияют
следующие два обстоятельства:
-
однородность
собранного материала
чем меньше разбросанность вариант
вокруг своей средней, тем меньше ошибка
репрезентативности. -
число наблюдений
средняя ошибка будет тем меньше, чем
больше число наблюдений.
Средняя ошибка
средней арифметической
вычисляется по формуле:
![]()
Средняя ошибка
для относительных величин вычисляется
по формуле:
![]() , где
, где
Р — величина
показателя в расчете на 100, 1000, 10 000 и т.д.
q
— разность между основанием, на которое
рассчитывается показатель, и его
конкретным числовым значением (100 — Р,
1000 — Р, 10 000 — Р и т.д.).
При n
< 30 в
знаменателе n
— 1.
![]()
Пример 8.
Средний рост
восьмилетних мальчиков составил — 125,5
см, среднее квадратическое отклонение
=±3,4
см , n=73
mм=
±
=±0,4
см
Пример 9.
Численность детей
в возрасте до года по данным детской
поликлиники составила 450 ,из них ни разу
не болели 100 детей. Необходимо определить
«Индекс здоровья» (процент ни разу
не болевших детей) и вычислить ошибку
для данного показателя.
Индекс здоровья
![]()
![]()
Оценка достоверности средних и относительных величин
При оценке
достоверности средних или относительных
величин руководствуются следующим
правилом:средняя
арифметическая или относительная
величина при числе наблюдений в выборочной
совокупности 30 и более должны превышать
свою ошибку не менее чем в 2 раза.
![]() >
>
2 или
![]() >
>
2
В рассматриваемых
примерах средняя арифметическая,
характеризующая рост восьмилетних
мальчиков и показатель „индекс
здоровья”
превышают свои ошибки соответственно:
![]() раз,
раз,
![]() раз, что соответствует высокой степени
раз, что соответствует высокой степени
их статистической достоверности с
вероятностью более чем 99,7 %.
Высказанное
положение вытекает из теории «вероятности»,
под которой понимается числовая мера
объективной возможности появления
случайного события.
Вероятность —
число, которое находится между 0 и 1, или
между 0% и 100%. Математиками определено,
что той или иной вероятности, выраженной
в процентах, соответствует определенное
значение критерия t
Стьюдента.
Так, например,
вероятности равной Р
= 68,3%
соответствует t=
1,0,
вероятности равной
Р = 95,5 %
соответствует
t
= 2,0
вероятности равной
Р = 99,7 % соответствует
t
= 3,0 .
В медико-биологических
исследованиях событие является
статистически достоверным, если
вероятность его появления соответствует
значению критерия t
Стьюдента, равное 2.
Средняя ошибка
позволяет не только оценить достоверность
относительного показателя или средней
величины, но и найти доверительные
границы средней величины или относительного
показателя в генеральной совокупности
М ген.=
М выб.
±
t
![]() m
m
Р ген.
= Р выб
. ±
t
![]() m
m
Как уже было
сказано, величина средней ошибки
указывает, насколько средняя величина
и относительный показатель выборочной
совокупности отличаются от соответствующих
величин в генеральной совокупности.
Величина t*m
является тем доверительным интервалом
по отношению к средней или относительной
величине, в котором с определенной
степенью вероятности можно ожидать
нахождение средней или относительной
величины в генеральной совокупности.
Пример 10.
М выб
.= 125,5 см;
m
= ±
0,4 см.
При 95% вероятности
t
=2, при 99,7 % — t
= 3 .
М ген.=
125,5 см ±
2
![]() 0,4 см = 124,7 — 126,3 см
0,4 см = 124,7 — 126,3 см
М ген.=
125,5 см ±
3
![]() 0,4 см = 124,3 — 126,7 см.
0,4 см = 124,3 — 126,7 см.
Таким образом, с
вероятностью 95% можно ожидать, что
средняя будет находиться в пределах от
124,7 до 126,3 см и с вероятностью 99,7% — в
пределах от 124,3 до 126,7 см.
Понятно, что
действительное значение средней можно
получить только при обследовании всех
8-летних мальчиков, но как это очевидно
из полученных данных, подобное исследование
нецелесообразно, т.к. средняя арифметическая
статистически достоверна (Р >
99,7%), а доверительный интервал для средней
в генеральной совокупности является
весьма незначительным -t
![]() m-
m-
= 3
![]() 0,4 т.е. всего по 1,2 см от средней выборочной
0,4 т.е. всего по 1,2 см от средней выборочной
совокупности в большую и меньшую
сторону.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В статистике относительная стандартная ошибка (RSE) равна стандартной ошибке оценки обследования, деленной на оценку обследования, а затем умноженной на 100. Число умножается на 100, чтобы его можно было выразить в процентах. RSE не обязательно представляет какую-либо новую информацию, выходящую за рамки стандартной ошибки, но это может быть лучшим методом представления статистической достоверности.
Относительная стандартная ошибка против стандартной ошибки
Стандартная ошибка определяет, насколько оценка обследования может отличаться от фактической совокупности.Он выражается числом.Напротив, относительная стандартная ошибка (RSE) – это стандартная ошибка, выраженная как часть оценки и обычно отображается в процентах.Оценки с RSE 25% или более подвержены большой ошибке выборки и должны использоваться с осторожностью.
Оценка опроса и стандартная ошибка
Опросы и стандартные ошибки – важнейшие части теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов на основе своих обследованных данных. Достоверность этих оценок также можно оценить с помощью доверительного интервала. Доверительные интервалы важны для определения достоверности эмпирических тестов и исследований.
Доверительный интервал – это тип интервальной оценки, вычисляемой на основе статистики наблюдаемых данных, которая может содержать истинное значение неизвестного параметра совокупности.Доверительные интервалы представляют собой диапазон, в котором, вероятно, находится значение генеральной совокупности.Они построены с использованием оценки значения генеральной совокупности и связанной с ней стандартной ошибки.Например, вероятность того, что значение генеральной совокупности находится в пределах двух стандартных ошибок оценок, составляет приблизительно 95% (т.е. 19 из 20), поэтому 95% доверительный интервал равен оценке плюс или минус две стандартные ошибки.
С точки зрения непрофессионала, стандартная ошибка выборки данных – это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может дать несколько иные статистические результаты, чем при опросе всех возможных курящих сигареты взрослых.
Меньшие ошибки выборки указывают на более надежные результаты. Центральная предельная теорема в умозаключениях статистиков показывает, что большие выборки, как правило, имеют приблизительно нормальное распределение и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов обследования. Меньшее разнообразие данных приводит к более низкому стандартному отклонению. Чем больше разнообразия, тем выше стандартное отклонение.
Стандартную ошибку иногда путают со стандартным отклонением. Стандартная ошибка фактически относится к стандартному отклонению среднего значения. Стандартное отклонение относится к изменчивости внутри любой данной выборки, тогда как стандартная ошибка – это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка – это абсолютная мера между выборочным обследованием и генеральной совокупностью. Относительная стандартная ошибка показывает, велика ли стандартная ошибка по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты незначительны. Формула относительной стандартной ошибки:

Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
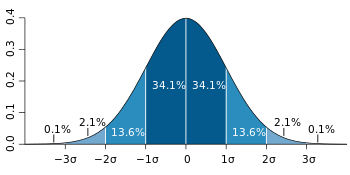
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
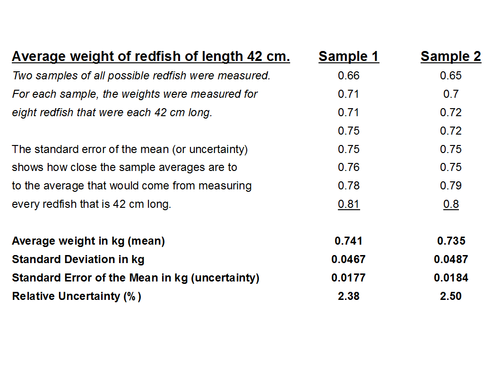
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)
Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.









Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
In statistics, a relative standard error (RSE) is equal to the standard error of a survey estimate divided by the survey estimate and then multiplied by 100. The number is multiplied by 100 so it can be expressed as a percentage. The RSE does not necessarily represent any new information beyond the standard error, but it might be a superior method of presenting statistical confidence.
Relative Standard Error vs. Standard Error
Standard error measures how much a survey estimate is likely to deviate from the actual population. It is expressed as a number. By contrast, relative standard error (RSE) is the standard error expressed as a fraction of the estimate and is usually displayed as a percentage. Estimates with an RSE of 25% or greater are subject to high sampling error and should be used with caution.
Survey Estimate and Standard Error
Surveys and standard errors are crucial parts of probability theory and statistics. Statisticians use standard errors to construct confidence intervals from their surveyed data. The reliability of these estimates can also be assessed in terms of a confidence interval. Confidence intervals are important for determining the validity of empirical tests and research.
A confidence interval is a type of interval estimate, computed from the statistics of the observed data, that might contain the true value of an unknown population parameter. Confidence intervals represent the range in which the population value is likely to lie. They are constructed using the estimate of the population value and its associated standard error. For example, there is approximately a 95% chance (i.e. 19 chances in 20) that the population value lies within two standard errors of the estimates, so the 95% confidence interval is equal to the estimate plus or minus two standard errors.
In layman’s terms, the standard error of a data sample is a measurement of the likely difference between the sample and the entire population. For example, a study involving 10,000 cigarette-smoking adults may generate slightly different statistical results than if every possible cigarette-smoking adult was surveyed.
Smaller sample errors are indicative of more reliable results. The central limit theorem in inferential statistics suggests that large samples tend to have approximately normal distributions and low sample errors.
Standard Deviation and Standard Error
The standard deviation of a data set is used to express the concentration of survey results. Less variety in the data results in a lower standard deviation. More variety is likely to result in a higher standard deviation.
The standard error is sometimes confused with the standard deviation. The standard error actually refers to the standard deviation of the mean. Standard deviation refers to the variability inside any given sample, while a standard error is the variability of the sampling distribution itself.
Relative Standard Error
The standard error is an absolute gauge between the sample survey and the total population. The relative standard error shows if the standard error is large relative to the results; large relative standard errors suggest the results are not significant. The formula for relative standard error is:
Relative Standard Error
=
Standard Error
Estimate
×
1
0
0
where:
Standard Error
=
standard deviation of the mean sample
Estimate
=
mean of the sample
begin{aligned} &text{Relative Standard Error} = frac { text{Standard Error} }{ text{Estimate} } times 100 &textbf{where:} &text{Standard Error} = text{standard deviation of the mean sample} &text{Estimate} = text{mean of the sample} end{aligned}
Relative Standard Error=EstimateStandard Error×100where:Standard Error=standard deviation of the mean sampleEstimate=mean of the sample
In statistics, a relative standard error (RSE) is equal to the standard error of a survey estimate divided by the survey estimate and then multiplied by 100. The number is multiplied by 100 so it can be expressed as a percentage. The RSE does not necessarily represent any new information beyond the standard error, but it might be a superior method of presenting statistical confidence.
Relative Standard Error vs. Standard Error
Standard error measures how much a survey estimate is likely to deviate from the actual population. It is expressed as a number. By contrast, relative standard error (RSE) is the standard error expressed as a fraction of the estimate and is usually displayed as a percentage. Estimates with an RSE of 25% or greater are subject to high sampling error and should be used with caution.
Survey Estimate and Standard Error
Surveys and standard errors are crucial parts of probability theory and statistics. Statisticians use standard errors to construct confidence intervals from their surveyed data. The reliability of these estimates can also be assessed in terms of a confidence interval. Confidence intervals are important for determining the validity of empirical tests and research.
A confidence interval is a type of interval estimate, computed from the statistics of the observed data, that might contain the true value of an unknown population parameter. Confidence intervals represent the range in which the population value is likely to lie. They are constructed using the estimate of the population value and its associated standard error. For example, there is approximately a 95% chance (i.e. 19 chances in 20) that the population value lies within two standard errors of the estimates, so the 95% confidence interval is equal to the estimate plus or minus two standard errors.
In layman’s terms, the standard error of a data sample is a measurement of the likely difference between the sample and the entire population. For example, a study involving 10,000 cigarette-smoking adults may generate slightly different statistical results than if every possible cigarette-smoking adult was surveyed.
Smaller sample errors are indicative of more reliable results. The central limit theorem in inferential statistics suggests that large samples tend to have approximately normal distributions and low sample errors.
Standard Deviation and Standard Error
The standard deviation of a data set is used to express the concentration of survey results. Less variety in the data results in a lower standard deviation. More variety is likely to result in a higher standard deviation.
The standard error is sometimes confused with the standard deviation. The standard error actually refers to the standard deviation of the mean. Standard deviation refers to the variability inside any given sample, while a standard error is the variability of the sampling distribution itself.
Relative Standard Error
The standard error is an absolute gauge between the sample survey and the total population. The relative standard error shows if the standard error is large relative to the results; large relative standard errors suggest the results are not significant. The formula for relative standard error is:
Relative Standard Error
=
Standard Error
Estimate
×
1
0
0
where:
Standard Error
=
standard deviation of the mean sample
Estimate
=
mean of the sample
begin{aligned} &text{Relative Standard Error} = frac { text{Standard Error} }{ text{Estimate} } times 100 &textbf{where:} &text{Standard Error} = text{standard deviation of the mean sample} &text{Estimate} = text{mean of the sample} end{aligned}
Relative Standard Error=EstimateStandard Error×100where:Standard Error=standard deviation of the mean sampleEstimate=mean of the sample
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
a:
В статистике относительная стандартная ошибка или RSE равна стандартной ошибке оценки опроса, деленной на оценку опроса, а затем умножается на 100. Число умножается на 100 так его можно выразить в процентах. RSE не обязательно представляет какую-либо новую информацию за пределами стандартной ошибки, но это может быть превосходный метод представления статистической достоверности.
Оценка и стандартная ошибка
Обследования и стандартные ошибки являются важными частями теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов из своих опрошенных данных. Доверительные интервалы важны для определения действительности эмпирических тестов и исследований.
В условиях непрофессионала стандартная ошибка выборки данных — это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может генерировать несколько иные статистические результаты, чем если бы были опрошены все возможные взрослые курильщики сигарет.
Меньшие ошибки выборки свидетельствуют о более надежных результатах. Центральная предельная теорема в статистических выводах показывает, что большие образцы имеют тенденцию иметь приблизительно нормальные распределения и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов опроса. Меньшее разнообразие данных приводит к более низкому стандартным отклонениям. Больше разнообразия, вероятно, приведет к более высокому стандартным отклонениям.
Стандартная ошибка иногда путается со стандартным отклонением. Стандартная ошибка на самом деле относится к стандартным отклонениям среднего значения. Стандартное отклонение относится к изменчивости внутри любого данного образца, в то время как стандартная ошибка — это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка — это абсолютная величина между выборочным обследованием и общей численностью населения. Относительная стандартная ошибка показывает, является ли стандартная ошибка большой по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты не значительны. Формула относительной стандартной ошибки (стандартная ошибка / оценка) x 100.
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}}
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Оценка достоверности результатов статистического исследования
В
практической и научно-практической
работе врачи обобщают результаты,
полученные, как правило, на выборочных
совокупностях. Для более
широкого распространения и применения
полученных при изучении
репрезентативной выборочной совокупности
данных и выводов надо уметь
по части явления судить о явлении и его
закономерностях в целом.
Учитывая,
как правило, что врачи проводят
исследования на выборочных совокупностях,
теория статистики позволяет с помощью
математического аппарата (формул)
переносить данные с выборочного
исследования на генеральную совокупность.
При этом врач должен уметь не только
пользоваться математическими формулами,
но и делать выводы, соответствующие
каждому способу оценки достоверности
полученных данных. С
этой целью врач должен знать способы
оценки достоверности.
В статистических
исследованиях применяются 2 вида
наблюдений — сплошное и выборочное.
Самые надежные результаты можно получить
при применении сплошного метода, т.е.
при изучении генеральной совокупности.
Между тем изучение
генеральной совокупности связано со
значительной трудоемкостью. Поэтому в
медико-биологических исследованиях,
как правило, проводятся выборочные
наблюдения. С тем, чтобы полученные при
изучении выборочной совокупности данные
можно было перенести на генеральную
совокупность, необходимо провести
оценку достоверности результатов
статистического исследования. Выборочная
совокупность может недостаточно полно
представлять генеральную совокупность,
поэтому выборочным наблюдениям всегда
сопутствуют ошибки
репрезентативности.
По размерам средней
ошибки ( m
) можно судить, насколько найденная
выборочная средняя величина отличается
от средней генеральной совокупности.
Малая ошибка указывает на близость этих
показателей, большая ошибка такой
уверенности не дает.
На величину средней
ошибки средней арифметической влияют
следующие два обстоятельства:
-
однородность
собранного материала
чем меньше разбросанность вариант
вокруг своей средней, тем меньше ошибка
репрезентативности. -
число наблюдений
средняя ошибка будет тем меньше, чем
больше число наблюдений.
Средняя ошибка
средней арифметической
вычисляется по формуле:
![]()
Средняя ошибка
для относительных величин вычисляется
по формуле:
![]() , где
, где
Р — величина
показателя в расчете на 100, 1000, 10 000 и т.д.
q
— разность между основанием, на которое
рассчитывается показатель, и его
конкретным числовым значением (100 — Р,
1000 — Р, 10 000 — Р и т.д.).
При n
< 30 в
знаменателе n
— 1.
![]()
Пример 8.
Средний рост
восьмилетних мальчиков составил — 125,5
см, среднее квадратическое отклонение
=±3,4
см , n=73
mм=
±
=±0,4
см
Пример 9.
Численность детей
в возрасте до года по данным детской
поликлиники составила 450 ,из них ни разу
не болели 100 детей. Необходимо определить
«Индекс здоровья» (процент ни разу
не болевших детей) и вычислить ошибку
для данного показателя.
Индекс здоровья
![]()
![]()
Оценка достоверности средних и относительных величин
При оценке
достоверности средних или относительных
величин руководствуются следующим
правилом:средняя
арифметическая или относительная
величина при числе наблюдений в выборочной
совокупности 30 и более должны превышать
свою ошибку не менее чем в 2 раза.
![]() >
>
2 или
![]() >
>
2
В рассматриваемых
примерах средняя арифметическая,
характеризующая рост восьмилетних
мальчиков и показатель „индекс
здоровья”
превышают свои ошибки соответственно:
![]() раз,
раз,
![]() раз, что соответствует высокой степени
раз, что соответствует высокой степени
их статистической достоверности с
вероятностью более чем 99,7 %.
Высказанное
положение вытекает из теории «вероятности»,
под которой понимается числовая мера
объективной возможности появления
случайного события.
Вероятность —
число, которое находится между 0 и 1, или
между 0% и 100%. Математиками определено,
что той или иной вероятности, выраженной
в процентах, соответствует определенное
значение критерия t
Стьюдента.
Так, например,
вероятности равной Р
= 68,3%
соответствует t=
1,0,
вероятности равной
Р = 95,5 %
соответствует
t
= 2,0
вероятности равной
Р = 99,7 % соответствует
t
= 3,0 .
В медико-биологических
исследованиях событие является
статистически достоверным, если
вероятность его появления соответствует
значению критерия t
Стьюдента, равное 2.
Средняя ошибка
позволяет не только оценить достоверность
относительного показателя или средней
величины, но и найти доверительные
границы средней величины или относительного
показателя в генеральной совокупности
М ген.=
М выб.
±
t
![]() m
m
Р ген.
= Р выб
. ±
t
![]() m
m
Как уже было
сказано, величина средней ошибки
указывает, насколько средняя величина
и относительный показатель выборочной
совокупности отличаются от соответствующих
величин в генеральной совокупности.
Величина t*m
является тем доверительным интервалом
по отношению к средней или относительной
величине, в котором с определенной
степенью вероятности можно ожидать
нахождение средней или относительной
величины в генеральной совокупности.
Пример 10.
М выб
.= 125,5 см;
m
= ±
0,4 см.
При 95% вероятности
t
=2, при 99,7 % — t
= 3 .
М ген.=
125,5 см ±
2
![]() 0,4 см = 124,7 — 126,3 см
0,4 см = 124,7 — 126,3 см
М ген.=
125,5 см ±
3
![]() 0,4 см = 124,3 — 126,7 см.
0,4 см = 124,3 — 126,7 см.
Таким образом, с
вероятностью 95% можно ожидать, что
средняя будет находиться в пределах от
124,7 до 126,3 см и с вероятностью 99,7% — в
пределах от 124,3 до 126,7 см.
Понятно, что
действительное значение средней можно
получить только при обследовании всех
8-летних мальчиков, но как это очевидно
из полученных данных, подобное исследование
нецелесообразно, т.к. средняя арифметическая
статистически достоверна (Р >
99,7%), а доверительный интервал для средней
в генеральной совокупности является
весьма незначительным -t
![]() m-
m-
= 3
![]() 0,4 т.е. всего по 1,2 см от средней выборочной
0,4 т.е. всего по 1,2 см от средней выборочной
совокупности в большую и меньшую
сторону.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
В статистике относительная стандартная ошибка (RSE) равна стандартной ошибке оценки обследования, деленной на оценку обследования, а затем умноженной на 100. Число умножается на 100, чтобы его можно было выразить в процентах. RSE не обязательно представляет какую-либо новую информацию, выходящую за рамки стандартной ошибки, но это может быть лучшим методом представления статистической достоверности.
Относительная стандартная ошибка против стандартной ошибки
Стандартная ошибка определяет, насколько оценка обследования может отличаться от фактической совокупности.Он выражается числом.Напротив, относительная стандартная ошибка (RSE) — это стандартная ошибка, выраженная как часть оценки и обычно отображается в процентах.Оценки с RSE 25% или более подвержены большой ошибке выборки и должны использоваться с осторожностью.
Оценка опроса и стандартная ошибка
Опросы и стандартные ошибки — важнейшие части теории вероятностей и статистики. Статистики используют стандартные ошибки для построения доверительных интервалов на основе своих обследованных данных. Достоверность этих оценок также можно оценить с помощью доверительного интервала. Доверительные интервалы важны для определения достоверности эмпирических тестов и исследований.
Доверительный интервал — это тип интервальной оценки, вычисляемой на основе статистики наблюдаемых данных, которая может содержать истинное значение неизвестного параметра совокупности.Доверительные интервалы представляют собой диапазон, в котором, вероятно, находится значение генеральной совокупности.Они построены с использованием оценки значения генеральной совокупности и связанной с ней стандартной ошибки.Например, вероятность того, что значение генеральной совокупности находится в пределах двух стандартных ошибок оценок, составляет приблизительно 95% (т.е. 19 из 20), поэтому 95% доверительный интервал равен оценке плюс или минус две стандартные ошибки.
С точки зрения непрофессионала, стандартная ошибка выборки данных — это измерение вероятной разницы между выборкой и всей совокупностью. Например, исследование с участием 10 000 взрослых, курящих сигареты, может дать несколько иные статистические результаты, чем при опросе всех возможных курящих сигареты взрослых.
Меньшие ошибки выборки указывают на более надежные результаты. Центральная предельная теорема в умозаключениях статистиков показывает, что большие выборки, как правило, имеют приблизительно нормальное распределение и низкие ошибки выборки.
Стандартное отклонение и стандартная ошибка
Стандартное отклонение набора данных используется для выражения концентрации результатов обследования. Меньшее разнообразие данных приводит к более низкому стандартному отклонению. Чем больше разнообразия, тем выше стандартное отклонение.
Стандартную ошибку иногда путают со стандартным отклонением. Стандартная ошибка фактически относится к стандартному отклонению среднего значения. Стандартное отклонение относится к изменчивости внутри любой данной выборки, тогда как стандартная ошибка — это изменчивость самого распределения выборки.
Относительная стандартная ошибка
Стандартная ошибка — это абсолютная мера между выборочным обследованием и генеральной совокупностью. Относительная стандартная ошибка показывает, велика ли стандартная ошибка по сравнению с результатами; большие относительные стандартные ошибки предполагают, что результаты незначительны. Формула относительной стандартной ошибки: