From Wikipedia, the free encyclopedia

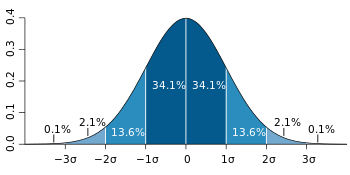
For a value that is sampled with an unbiased normally distributed error, the above depicts the proportion of samples that would fall between 0, 1, 2, and 3 standard deviations above and below the actual value.
The standard error (SE)[1] of a statistic (usually an estimate of a parameter) is the standard deviation of its sampling distribution[2] or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM).[1]
The sampling distribution of a mean is generated by repeated sampling from the same population and recording of the sample means obtained. This forms a distribution of different means, and this distribution has its own mean and variance. Mathematically, the variance of the sampling mean distribution obtained is equal to the variance of the population divided by the sample size. This is because as the sample size increases, sample means cluster more closely around the population mean.
Therefore, the relationship between the standard error of the mean and the standard deviation is such that, for a given sample size, the standard error of the mean equals the standard deviation divided by the square root of the sample size.[1] In other words, the standard error of the mean is a measure of the dispersion of sample means around the population mean.
In regression analysis, the term «standard error» refers either to the square root of the reduced chi-squared statistic or the standard error for a particular regression coefficient (as used in, say, confidence intervals).
Standard error of the sample mean[edit]
Exact value[edit]
Suppose a statistically independent sample of 




.
Practically this tells us that when trying to estimate the value of a population mean, due to the factor 
Estimate[edit]
The standard deviation 
.
As this is only an estimator for the true «standard error», it is common to see other notations here such as:
or alternately
.
A common source of confusion occurs when failing to distinguish clearly between:
Accuracy of the estimator[edit]
When the sample size is small, using the standard deviation of the sample instead of the true standard deviation of the population will tend to systematically underestimate the population standard deviation, and therefore also the standard error. With n = 2, the underestimate is about 25%, but for n = 6, the underestimate is only 5%. Gurland and Tripathi (1971) provide a correction and equation for this effect.[3] Sokal and Rohlf (1981) give an equation of the correction factor for small samples of n < 20.[4] See unbiased estimation of standard deviation for further discussion.
Derivation[edit]
The standard error on the mean may be derived from the variance of a sum of independent random variables,[5] given the definition of variance and some simple properties thereof. If

which due to the Bienaymé formula, will have variance

where we’ve approximated the standard deviations, i.e., the uncertainties, of the measurements themselves with the best value for the standard deviation of the population. The mean of these measurements
.
The variance of the mean is then

The standard error is, by definition, the standard deviation of
.
For correlated random variables the sample variance needs to be computed according to the Markov chain central limit theorem.
Independent and identically distributed random variables with random sample size[edit]
There are cases when a sample is taken without knowing, in advance, how many observations will be acceptable according to some criterion. In such cases, the sample size 

[6]
If 




(since the standard deviation is the square root of the variance)
Student approximation when σ value is unknown[edit]
In many practical applications, the true value of σ is unknown. As a result, we need to use a distribution that takes into account that spread of possible σ’s.
When the true underlying distribution is known to be Gaussian, although with unknown σ, then the resulting estimated distribution follows the Student t-distribution. The standard error is the standard deviation of the Student t-distribution. T-distributions are slightly different from Gaussian, and vary depending on the size of the sample. Small samples are somewhat more likely to underestimate the population standard deviation and have a mean that differs from the true population mean, and the Student t-distribution accounts for the probability of these events with somewhat heavier tails compared to a Gaussian. To estimate the standard error of a Student t-distribution it is sufficient to use the sample standard deviation «s» instead of σ, and we could use this value to calculate confidence intervals.
Note: The Student’s probability distribution is approximated well by the Gaussian distribution when the sample size is over 100. For such samples one can use the latter distribution, which is much simpler.
Assumptions and usage[edit]
An example of how 
- Upper 95% limit
and
- Lower 95% limit

In particular, the standard error of a sample statistic (such as sample mean) is the actual or estimated standard deviation of the sample mean in the process by which it was generated. In other words, it is the actual or estimated standard deviation of the sampling distribution of the sample statistic. The notation for standard error can be any one of SE, SEM (for standard error of measurement or mean), or SE.
Standard errors provide simple measures of uncertainty in a value and are often used because:
- in many cases, if the standard error of several individual quantities is known then the standard error of some function of the quantities can be easily calculated;
- when the probability distribution of the value is known, it can be used to calculate an exact confidence interval;
- when the probability distribution is unknown, Chebyshev’s or the Vysochanskiï–Petunin inequalities can be used to calculate a conservative confidence interval; and
- as the sample size tends to infinity the central limit theorem guarantees that the sampling distribution of the mean is asymptotically normal.
Standard error of mean versus standard deviation[edit]
In scientific and technical literature, experimental data are often summarized either using the mean and standard deviation of the sample data or the mean with the standard error. This often leads to confusion about their interchangeability. However, the mean and standard deviation are descriptive statistics, whereas the standard error of the mean is descriptive of the random sampling process. The standard deviation of the sample data is a description of the variation in measurements, while the standard error of the mean is a probabilistic statement about how the sample size will provide a better bound on estimates of the population mean, in light of the central limit theorem.[7]
Put simply, the standard error of the sample mean is an estimate of how far the sample mean is likely to be from the population mean, whereas the standard deviation of the sample is the degree to which individuals within the sample differ from the sample mean.[8] If the population standard deviation is finite, the standard error of the mean of the sample will tend to zero with increasing sample size, because the estimate of the population mean will improve, while the standard deviation of the sample will tend to approximate the population standard deviation as the sample size increases.
Extensions[edit]
Finite population correction (FPC)[edit]
The formula given above for the standard error assumes that the population is infinite. Nonetheless, it is often used for finite populations when people are interested in measuring the process that created the existing finite population (this is called an analytic study). Though the above formula is not exactly correct when the population is finite, the difference between the finite- and infinite-population versions will be small when sampling fraction is small (e.g. a small proportion of a finite population is studied). In this case people often do not correct for the finite population, essentially treating it as an «approximately infinite» population.
If one is interested in measuring an existing finite population that will not change over time, then it is necessary to adjust for the population size (called an enumerative study). When the sampling fraction (often termed f) is large (approximately at 5% or more) in an enumerative study, the estimate of the standard error must be corrected by multiplying by a »finite population correction» (a.k.a.: FPC):[9]
[10]

which, for large N:

to account for the added precision gained by sampling close to a larger percentage of the population. The effect of the FPC is that the error becomes zero when the sample size n is equal to the population size N.
This happens in survey methodology when sampling without replacement. If sampling with replacement, then FPC does not come into play.
Correction for correlation in the sample[edit]

Expected error in the mean of A for a sample of n data points with sample bias coefficient ρ. The unbiased standard error plots as the ρ = 0 diagonal line with log-log slope −½.
If values of the measured quantity A are not statistically independent but have been obtained from known locations in parameter space x, an unbiased estimate of the true standard error of the mean (actually a correction on the standard deviation part) may be obtained by multiplying the calculated standard error of the sample by the factor f:

where the sample bias coefficient ρ is the widely used Prais–Winsten estimate of the autocorrelation-coefficient (a quantity between −1 and +1) for all sample point pairs. This approximate formula is for moderate to large sample sizes; the reference gives the exact formulas for any sample size, and can be applied to heavily autocorrelated time series like Wall Street stock quotes. Moreover, this formula works for positive and negative ρ alike.[11] See also unbiased estimation of standard deviation for more discussion.
See also[edit]
- Illustration of the central limit theorem
- Margin of error
- Probable error
- Standard error of the weighted mean
- Sample mean and sample covariance
- Standard error of the median
- Variance
- Variance of the mean and predicted responses
References[edit]
- ^ a b c d Altman, Douglas G; Bland, J Martin (2005-10-15). «Standard deviations and standard errors». BMJ: British Medical Journal. 331 (7521): 903. doi:10.1136/bmj.331.7521.903. ISSN 0959-8138. PMC 1255808. PMID 16223828.
- ^ Everitt, B. S. (2003). The Cambridge Dictionary of Statistics. CUP. ISBN 978-0-521-81099-9.
- ^ Gurland, J; Tripathi RC (1971). «A simple approximation for unbiased estimation of the standard deviation». American Statistician. 25 (4): 30–32. doi:10.2307/2682923. JSTOR 2682923.
- ^ Sokal; Rohlf (1981). Biometry: Principles and Practice of Statistics in Biological Research (2nd ed.). p. 53. ISBN 978-0-7167-1254-1.
- ^ Hutchinson, T. P. (1993). Essentials of Statistical Methods, in 41 pages. Adelaide: Rumsby. ISBN 978-0-646-12621-0.
- ^ Cornell, J R, and Benjamin, C A, Probability, Statistics, and Decisions for Civil Engineers, McGraw-Hill, NY, 1970, ISBN 0486796094, pp. 178–9.
- ^ Barde, M. (2012). «What to use to express the variability of data: Standard deviation or standard error of mean?». Perspect. Clin. Res. 3 (3): 113–116. doi:10.4103/2229-3485.100662. PMC 3487226. PMID 23125963.
- ^ Wassertheil-Smoller, Sylvia (1995). Biostatistics and Epidemiology : A Primer for Health Professionals (Second ed.). New York: Springer. pp. 40–43. ISBN 0-387-94388-9.
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
- ^ Bondy, Warren; Zlot, William (1976). «The Standard Error of the Mean and the Difference Between Means for Finite Populations». The American Statistician. 30 (2): 96–97. doi:10.1080/00031305.1976.10479149. JSTOR 2683803. (Equation 2)
- ^ Bence, James R. (1995). «Analysis of Short Time Series: Correcting for Autocorrelation». Ecology. 76 (2): 628–639. doi:10.2307/1941218. JSTOR 1941218.
![]()
Загрузить PDF
![]()
Загрузить PDF
Стандартной ошибкой называется величина, которая характеризует стандартное (среднеквадратическое) отклонение выборочного среднего. Другими словами, эту величину можно использовать для оценки точности выборочного среднего. Множество областей применения стандартной ошибки по умолчанию предполагают нормальное распределение. Если вам нужно рассчитать стандартную ошибку, перейдите к шагу 1.
-

1
Запомните определение среднеквадратического отклонения. Среднеквадратическое отклонение выборки – это мера рассеянности значения. Среднеквадратическое отклонение выборки обычно обозначается буквой s. Математическая формула среднеквадратического отклонения приведена выше.
-

2
Узнайте, что такое истинное среднее значение. Истинное среднее является средним группы чисел, включающим все числа всей группы – другими словами, это среднее всей группы чисел, а не выборки.
-

3
Научитесь рассчитывать среднеарифметическое значение. Среднеаримфетическое означает попросту среднее: сумму значений собранных данных, разделенную на количество значений этих данных.
-

4
Узнайте, что такое выборочное среднее. Когда среднеарифметическое значение основано на серии наблюдений, полученных в результате выборок из статистической совокупности, оно называется “выборочным средним”. Это среднее выборки чисел, которое описывает среднее значение лишь части чисел из всей группы. Его обозначают как:
-

5
Усвойте понятие нормального распределения. Нормальные распределения, которые используются чаще других распределений, являются симметричными, с единичным максимумом в центре – на среднем значении данных. Форма кривой подобна очертаниям колокола, при этом график равномерно опускается по обе стороны от среднего. Пятьдесят процентов распределения лежит слева от среднего, а другие пятьдесят процентов – справа от него. Рассеянность значений нормального распределения описывается стандартным отклонением.
-

6
Запомните основную формулу. Формула для вычисления стандартной ошибки приведена выше.
Реклама
-

1
Рассчитайте выборочное среднее. Чтобы найти стандартную ошибку, сначала нужно определить среднеквадратическое отклонение (поскольку среднеквадратическое отклонение s входит в формулу для вычисления стандартной ошибки). Начните с нахождения средних значений. Выборочное среднее выражается как среднее арифметическое измерений x1, x2, . . . , xn. Его рассчитывают по формуле, приведенной выше.
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
Вы сможете рассчитать выборочное среднее, подставив значения массы в формулу:
- Допустим, например, что вам нужно рассчитать стандартную ошибку выборочного среднего результатов измерения массы пяти монет, указанных в таблице:
-

2
Вычтите выборочное среднее из каждого измерения и возведите полученное значение в квадрат. Как только вы получите выборочное среднее, вы можете расширить вашу таблицу, вычтя его из каждого измерения и возведя результат в квадрат.
- Для нашего примера расширенная таблица будет иметь следующий вид:
-

3
Найдите суммарное отклонение ваших измерений от выборочного среднего. Общее отклонение – это сумма возведенных в квадрат разностей от выборочного среднего. Чтобы определить его, сложите ваши новые значения.
- В нашем примере нужно будет выполнить следующий расчет:
Это уравнение дает сумму квадратов отклонений измерений от выборочного среднего.
- В нашем примере нужно будет выполнить следующий расчет:
-

4
Рассчитайте среднеквадратическое отклонение ваших измерений от выборочного среднего. Как только вы будете знать суммарное отклонение, вы сможете найти среднее отклонение, разделив ответ на n -1. Обратите внимание, что n равно числу измерений.
- В нашем примере было сделано 5 измерений, следовательно n – 1 будет равно 4. Расчет нужно вести следующим образом:
-

5
Найдите среднеквадратичное отклонение. Сейчас у вас есть все необходимые значения для того, чтобы воспользоваться формулой для нахождения среднеквадратичного отклонения s.
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
Следовательно, среднеквадратичное отклонение равно 0,0071624.
Реклама
- В нашем примере вы будете рассчитывать среднеквадратичное отклонение следующим образом:
-

1
Чтобы вычислить стандартную ошибку, воспользуйтесь базовой формулой со среднеквадратическим отклонением.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Таким образом в нашем примере стандартная ошибка (среднеквадратическое отклонение выборочного среднего) составляет 0,0032031 грамма.
- В нашем примере вы сможете рассчитать стандартную ошибку следующим образом:
Советы
- Стандартную ошибку и среднеквадратическое отклонение часто путают. Обратите внимание, что стандартная ошибка описывает среднеквадратическое отклонение выборочного распределения статистических данных, а не распределения отдельных значений
- В научных журналах понятия стандартной ошибки и среднеквадратического отклонения несколько размыты. Для объединения двух величин используется знак ±.
Реклама
Об этой статье
Эту страницу просматривали 48 054 раза.
Была ли эта статья полезной?
Провести анализ этих данных, используя один из статистических ППП, на основе описательной статистики.
1. Рассчитать для всех трех переменных среднюю арифметическую, моду, медиану, стандартное отклонение, верхний и нижний квартили, асимметрию, эксцесс и коэффициент вариации.
2.На основе рассчитанных статистик провести сравнительный анализ средних оценок удовлетворенности и их стандартных отклонений по каждой из приведенных позиций.
3.Прокомментировать значения коэффициентов вариации.
4.Прокомментировать в сравнительном анализе значения квартилей.
5.Прокомментировать в сравнительном анализе значения асимметрий.
6.Прокомментировать в сравнительном анализе значения эксцессов.
7.Прокомментировать различия в средних арифметических и медианах внутри каждой из позиции и соотнести это со значениями асимметрии.
8.Построить для каждой переменной полигон, гистограмму (частот и относительных частот, накопленных частот), а также ящичковые диаграммы. Прокомментировать их вид с точки зрения анализа ответов..
9.Провести сравнительный анализ информации для каждого предприятия.
|
Пример 2. Имеются данные о средних сроках (в днях) оборота наличных денежных |
|||||||||||||||||||
|
средств для 39 фирм: |
13,9 |
11,1 |
9,5 |
19,6 |
8,5 |
29,8 |
6,2 5,9 40,9 4 10,3 |
31,8 |
|||||||||||
|
65,2 |
38,2 |
10,8 |
13,7 |
18,8 |
8,1 |
16,7 |
26,1 |
28,2 |
11,1 |
17,2 |
10,3 |
38,8 |
54,11 |
12,2 |
|||||
|
18 |
37 |
14,4 |
19,7 |
10,2 |
68,1 |
6,7 |
9,5 |
10,3 |
3,8 |
11,65 |
16,8. |
||||||||
|
Проанализировать эту информацию, рассчитав для нее описательные статистики и |
|||||||||||||||||||
|
построив гистограмму и »ящик-с-усами». |
|||||||||||||||||||
|
Известно, |
что |
распределения с |
более |
длинным правым |
хвостом |
путем |
логарифмирования можно преобразовать в приближенно симметричные. Проверить это на данном примере.
Пример 3. Любой статистический ППП поставляется с набором учебных файлов. Проанализируйте, например, в ППП Statgraphics Plus в файле Cardata с помощью описательной статистики переменные “price” и “ mpg”.
Исследователь имеет дело, как правило, с выборкой и по выборочным данным пытается сделать выводы о свойствах генеральной совокупности. Характеристики генеральной совокупности будем называть параметрами. Параметры, как правило, нам неизвестны, и мы можем лишь приближенно оценивать их на основе выборочных данных. Тем самым мы получаем оценки параметров генеральной совокупности. Отметим, что оценка будет давать верное представление о параметре, если она получена из генеральной совокупности на основе случайной выборки. Выборка называется случайной, если для каждого элемента совокупности вероятность попасть в эту выборку известна и одинакова. Только случайная выборка может представлять генеральную совокупность, и только на ее основе можно получить “хорошие” оценки. Как известно, “хорошая” оценка должна удовлетворять следующим четырем критериям: состоятельности, несмещенности, эффективности и достаточности. Напомним два из них.
Оценка называется эффективной, если она обладает наименьшей дисперсией, и несмещенной, если ее математическое ожидание совпадает со значением параметра.
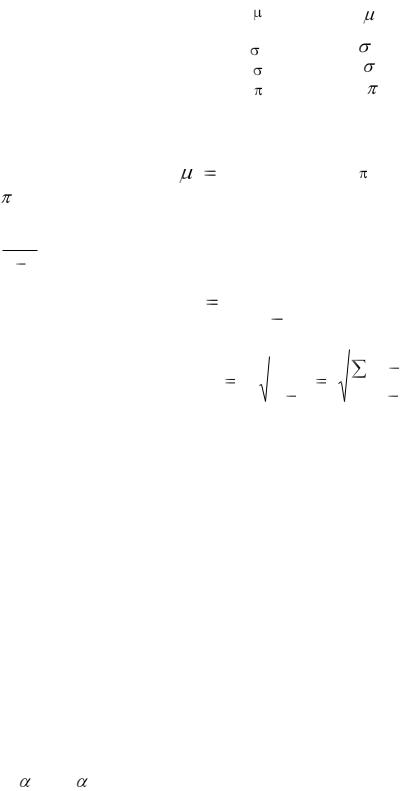
Введем обозначения, которым будем придерживаться в дальнейшем:
|
Характеристика |
Параметр |
Оценка |
Выборочное |
|||
|
значение |
||||||
|
Средняя |
ˆ |
|||||
|
х |
||||||
|
Дисперсия |
2 |
ˆ |
2 |
2 |
||
|
S |
||||||
|
Станд. отклонение |
ˆ |
|||||
|
S |
||||||
|
Доля |
ˆ |
|||||
|
р |
Оценивание некоторого отдельного параметра дает точечную оценку. Известно, что «хорошей» оценкой средней арифметической генеральной совокупности является
|
выборочная средняя, т. е. ˆ |
||
|
х ; аналогично для : |
ˆ = р. Но выборочная дисперсия дает смещенную (заниженную) оценку генеральной дисперсии. Чтобы убрать эффект смещенности, вводят поправочный коэффициент
n
n 1 , тогда несмещенной оценкой генеральной дисперсии является исправленная
|
выборочная дисперсия: σˆ2 |
S2 |
n |
и, |
соответственно, несмещенной оценкой |
||||||||||||
|
n |
1 |
|||||||||||||||
|
стандартного отклонения является |
||||||||||||||||
|
σˆ |
n |
(x |
x)2 |
|||||||||||||
|
S |
. |
|||||||||||||||
|
n |
1 |
n |
1 |
Следует отметить, что в литературе можно встретить обозначение S и для исправленного выборочного стандартного отклонения.
До сих пор речь шла о точечных оценках параметров генеральной совокупности. Как известно, оценка – это приближенное значение параметра генеральной совокупности. О мере точности и надежности точечной оценки судить сложно, поскольку значение оценки вычисляется на основе случайной выборки и является случайным. Единственное, что можно здесь утверждать, так это то, что в соответствии с критерием состоятельности уверенность в точности точечной оценки увеличивается по мере увеличения объема выборки.
Когда речь идет о точечной оценке, нелегко продемонстрировать влияние объема выборки на точность оценки, однако это влияние очевидно при вычислении интервальной оценки. Заметим, что, переходя от точечных оценок к интервальным, мы тем самым переходим от описательной статистики к аналитической статистике или статистике вывода.
Интервальной оценкой параметра генеральной совокупности называют интервал, который с заданной вероятностью накрывает истинное значение параметра. Интервальную оценку называют доверительным интервалом, а связанную с ним и указанную выше вероятность – доверительной вероятностью. Интервальная оценка обладает такими свойствами, как точность и надежность. Точность интервальной оценки определяется величиной интервала, а надежность – степенью доверия, равной (1- ), где — вероятность того, что доверительный интервал не содержит параметр.
Интервальное оценивание связано с понятием стандартной ошибки оцениваемого параметра, которая, в свою очередь, связана с выборочным распределением. Если, например, осуществить несколько независимых случайных выборок из одной и той же генеральной совокупности и для каждой из них рассчитать выборочную среднюю, то

полученные выборочные средние можно представить как элементы отдельной выборки и их распределение называется выборочным распределением.
|
Известно, что если исходная совокупность имеет параметры |
и , то выборочное |
|
|
распределение выборочных средних при достаточно больших объемах выборки (n |
30) |
|
|
может быть аппроксимировано нормальным распределением, |
независимо от |
вида |
исходного распределения, с параметрами и x = / 
 n . x называется стандартной ошибкой выборки или просто стандартной ошибкой и характеризует меру вариации выборочных средних вокруг генеральной средней. Как видно из определения, стандартная ошибка уменьшается при увеличении объема выборки.
n . x называется стандартной ошибкой выборки или просто стандартной ошибкой и характеризует меру вариации выборочных средних вокруг генеральной средней. Как видно из определения, стандартная ошибка уменьшается при увеличении объема выборки.
Оценка стандартной ошибки рассчитывается по формуле
|
S |
S |
, |
(2.1) |
|||||
|
x |
||||||||
|
n |
1 |
|||||||
если генеральная совокупность бесконечна, и по формуле
|
S |
N |
n |
S |
, |
(2.2) |
||||||
|
x |
N |
1 |
|||||||||
|
n 1 |
|||||||||||
если генеральная совокупность конечна (объема N).
Рассмотрим доверительный интервал для средней арифметической генеральной совокупности. Известно, что он симметричен относительно точечной оценки параметра и рассчитывается из соотношений:
|
x |
z / 2 S |
или |
x t / 2 |
S |
|||||||||
|
x |
x |
||||||||||||
|
в зависимости от того, какое распределение используется при его определении: |
|||||||||||||
|
нормальное или Стьюдента. |
|||||||||||||
|
Здесь: |
|||||||||||||
|
z /2— значения z–статистики, справа и слева от которых находятся площади под |
|||||||||||||
|
кривой нормального распределения, равные |
/2 (определяются по таблице значений |
||||||||||||
|
стандартизованного нормального распределения при фиксированной вероятности |
); |
||||||||||||
|
t /2 — значения статистики Стьюдента, справа и слева от которых находятся |
|||||||||||||
|
площади под кривой распределения Стьюдента, равные |
/2 (определяются по таблице |
||||||||||||
|
значений распределения Стьюдента при фиксированной |
вероятности |
и |
чиcле |
||||||||||
|
степеней свободы |
= n-1); |
sх – оценка стандартной ошибки выборки.
Отметим, что z-статистика используется при определении доверительного интервала в случае, если известно, что исследуемая совокупность имеет нормальный закон распределения и объем выборки достаточно велик, в противном случае используется статистика Стьюдента. Известно, что статистика Стьюдента может использоваться и в том случае, когда выполняются условия применимости z- статистики, поэтому в дальнейшем будем использовать t-статистику, если это не будет противоречить условиям решаемой задачи.
Во многих случаях появляется необходимость найти интервальную оценку для
разности средних двух совокупностей, т.е. для 1 — 2, по выборочным средним х1 и
|
х2 . Приведем эту оценку: |
||||||||||||||||
|
x1 x2 |
t /2 |
. S |
, |
|||||||||||||
|
x1 |
x 2 |
|||||||||||||||
|
здесь S |
— стандартная ошибка разности средних. |
|||||||||||||||
|
x |
x |
|||||||||||||||
|
1 |
2 |
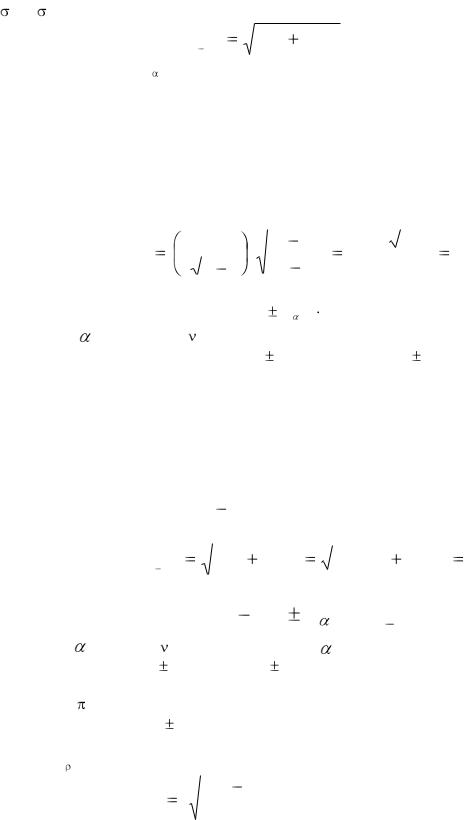
Стандартная ошибка разности средних и число степеней свободы для статистики Стьюдента определяются по-разному, в зависимости от того, равны или не равны объемы выборок и равны или нет дисперсии совокупностей. Например, приближенная формула для определения значения стандартной ошибки разности двух средних, основанная на допущениях о большом объеме двух выборок и их независимом отборе из двух генеральных совокупностей, характеризующихся одинаковой дисперсией (т.е.
12 = 22) имеет вид:
|
S |
S |
2 |
S |
2 |
, |
|||||
|
x |
x |
x |
x |
|||||||
|
1 |
2 |
1 |
2 |
|||||||
|
а число степеней для t /2 равно n1 + n2 |
–2. |
Рассмотрим решение задачи на принятие решения, в котором оказывается полезной интервальная оценка средней генеральной совокупности. Пусть составлена случайная выборка из 37 рабочих фирмы, в которой работает 785 человек. Причем средняя месячная зарплата для рабочих, попавших в выборку, равна 1100 руб. со стандартным отклонением 105 руб.
Используя 95 % — е доверительные пределы, вычислить среднюю месячную зарплату рабочих фирмы и общие расходы фирмы на зарплату.
Стандартную ошибку для средней в этом случае вычислим по формуле (2.2):
|
S |
S |
N |
n |
105 |
748 |
17,1. |
|||||||||||||||||
|
x |
N |
1 |
6 |
28 |
|||||||||||||||||||
|
n |
1 |
||||||||||||||||||||||
|
Доверительные пределы равны: |
|||||||||||||||||||||||
|
x t |
/ 2 |
S |
. |
||||||||||||||||||||
|
x |
|||||||||||||||||||||||
|
При |
= 0,05 и |
= 36 |
tα/2 = 2,03 ( из таблицы t-распределения). Тогда |
||||||||||||||||||||
|
доверительный интервал равен: |
1 100 |
2,03 · 17,1 = 1 100 34,7 или |
(1 065,3 ; |
1 134,7) (руб.).
Умножив на численность рабочих фирмы, получим оценку общих расходов фирмы на зарплату: от 836 260,5 до 890 739,5 (руб.).
Предположим теперь, что нам необходимо оценить наиболее вероятную разницу в средней зарплате для двух фирм, если во второй фирме для выборки из 30 рабочих средняя зарплата равна 1 000 руб. при стандартной ошибке средней в 20 руб.
|
Точечная оценка разности равна: |
||||||||||||||||||||||||||
|
x1 |
x2 = 1 100 – 1 000 = 100 (руб.). |
|||||||||||||||||||||||||
|
Вычислим стандартную ошибку разности средних: |
||||||||||||||||||||||||||
|
2 |
2 |
|||||||||||||||||||||||||
|
S |
S |
S |
(17,1)2 |
(20)2 26,3. |
||||||||||||||||||||||
|
x |
1 |
x |
2 |
x |
1 |
x |
2 |
|||||||||||||||||||
|
Тогда интервальная оценка равна: |
||||||||||||||||||||||||||
|
x1 |
x 2 |
t /2 S |
. |
|||||||||||||||||||||||
|
x1 |
x2 |
|||||||||||||||||||||||||
|
При |
= 0,05 и |
= n1 + n2 –2 = 65 |
t /2 = 2. Тогда имеем |
|||||||||||||||||||||||
|
100 |
2 . 26,3 = 100 |
52,6 |
или (47,4 |
; 152,6) (руб.). |
Доверительный интервал для доли генеральной совокупности (относительной
|
величины) |
определяется из соотношения: |
|||||
|
p |
Zα/2 Sp , |
(2.3) |
||||
|
где р – |
выборочная доля, |
|||||
|
S — |
оценка стандартной ошибки доли. |
|||||
|
Известно, что Sρ |
ρ (1 |
ρ) |
. |
|||
|
n |
||||||

Для определения доверительного интервала при этом используется аппроксимация биноминального распределения нормальным, поэтому использовать статистику
|
Стьюдента здесь нельзя. |
||||||||||
|
Как известно, такая аппроксимация возможна |
при достаточно больших объемах |
|||||||||
|
выборки (n |
50) и при выполнении условий np 5 |
и n(1 — p) 5. |
||||||||
|
Аналогично определяется доверительный интервал (интервальная оценка) для |
||||||||||
|
разности долей двух генеральных совокупностей ( |
1 — 2): |
|||||||||
|
p1 – p2 |
Z |
/2 |
. S p1–p2 , |
(2.4) |
||||||
|
где Sp |
p |
Sp |
2 |
Sp |
2 |
— одна из формул для вычисления стандартной ошибки |
||||
|
1 |
2 |
1 |
2 |
разности долей (в предположениях, аналогичных предыдущим).
Рассмотрим пример. Пусть фирмой при маркетинговом исследовании был организован опрос жителей одного из районов города относительно предпочтения товаров этой фирмы. Из 200 случайно отобранных жителей района 120 высказались в пользу товаров этой фирмы. Найти интервальную оценку доли жителей района, предпочитающих товары этой фирмы.
Точечная оценка доли: p = 120/200 = 0,6. Интервальную оценку вычислим по соотношению (2.3):
|
Sp |
0,6 (1 |
0,6) |
0,035. |
||||
|
200 |
|||||||
|
Z /2 при |
= 0,05 определим по таблице: Z0,025 = 1,96. |
Тогда имеем: |
|||||
|
0,6 1,96 · 0,035 |
или |
0,53 |
0,67. |
Итак, в данном районе города товары этой фирмы предпочитают от 53 % до 67 % жителей.
Предположим, что в другом районе города в случайной выборке из 150 человек 55 % опрошенных предпочитают товары этой фирмы со стандартной ошибкой доли, равной 0,04. Тогда интервальная оценка разности долей жителей двух районов города определится из соотношения (2.4).
|
2 |
2 |
|||||||||
|
Sp |
p |
Sp |
Sp |
0,0352 |
0,042 0,053. |
|||||
|
1 |
2 |
1 |
2 |
|||||||
|
Получим: 0,6 – 0,55 |
1,96 |
0,053 |
или -0,054 |
0,154. |
Как известно, если доверительный интервал для разности двух величин содержит нуль, то эти величины различаются незначимо. Для нашего примера это означает, что в обоих исследуемых районах предпочтения для товаров этой фирмы примерно одинаковы.
2.1. Определение объема выборки, обеспечивающего заданную точность расчетов
Как уже отмечалось, интервальная оценка устанавливает прямую зависимость точности оценки от объема выборки. Запишем доверительный интервал для средней арифметической генеральной совокупности в виде:
|
S |
||||||||
|
x t |
/2 |
. |
||||||
|
n |
1 |
|||||||
Выражение, прибавляемое и вычитаемое из выборочной средней, задает размах доверительного интервала и определяет, тем самым, точность интервальной оценки. При фиксированном стандартном отклонении точность оценки изменяется при
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-

1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-

1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-

1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-

1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?

To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?

The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?

The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,281 times.
Did this article help you?
![]()
Download Article
![]()
Download Article
After collecting data, oftentimes the first thing you need to do is analyze it. This usually entails finding the mean, the standard deviation, and the standard error of the data. This article will show you how it’s done.
Cheat Sheets
-
1
Obtain a set of numbers you wish to analyze. This information is referred to as a sample.
- For example, a test was given to a class of 5 students, and the test results are 12, 55, 74, 79 and 90.
Advertisement
-
1
Calculate the mean. Add up all the numbers and divide by the population size:[1]
- Mean (μ) = ΣX/N, where Σ is the summation (addition) sign, xi is each individual number, and N is the population size.
- In the case above, the mean μ is simply (12+55+74+79+90)/5 = 62.
-
1
Calculate the standard deviation. This represents the spread of the population.
Standard deviation = σ = sq rt [(Σ((X-μ)^2))/(N)].[2]
- For the example given, the standard deviation is sqrt[((12-62)^2 + (55-62)^2 + (74-62)^2 + (79-62)^2 + (90-62)^2)/(5)] = 27.4. (Note that if this was the sample standard deviation, you would divide by n-1, the sample size minus 1.)
Advertisement
-
1
Calculate the standard error (of the mean). This represents how well the sample mean approximates the population mean. The larger the sample, the smaller the standard error, and the closer the sample mean approximates the population mean. Do this by dividing the standard deviation by the square root of N, the sample size.[3]
Standard error = σ/sqrt(n)[4]
- So for the example above, if this were a sampling of 5 students from a class of 50 and the 50 students had a standard deviation of 17 (σ = 21), the standard error = 17/sqrt(5) = 7.6.
Add New Question
-
Question
How do you find the mean given number of observations?
To find the mean, add all the numbers together and divide by how many numbers there are. e.g to find the mean of 1,7,8,4,2: 1+7+8+4+2 = 22/5 = 4.4.
-
Question
The standard error is calculated as 0.2 and the standard deviation of a sample is 5kg. Can it be said to be smaller or larger than the standard deviation?
The standard error (SE) must be smaller than the standard deviation (SD), because the SE is calculating by dividing the SD by something — i.e. making it smaller.
-
Question
How can I find out the standard deviation of 50 samples?
The results of all your figures (number plus number plus number etc.) divided by quantity of samples 50 =SD.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Video
-
Calculations of the mean, standard deviation, and standard error are most useful for analysis of normally distributed data. One standard deviation about the central tendency covers approximately 68 percent of the data, 2 standard deviation 95 percent of the data, and 3 standard deviation 99.7 percent of the data. The standard error gets smaller (narrower spread) as the sample size increases.
Thanks for submitting a tip for review!
Advertisement
-
Check your math carefully. It is very easy to make mistakes or enter numbers incorrectly.
Advertisement
References
About This Article
Article SummaryX
The mean is simply the average of a set of numbers. You can work it out by adding up all the numbers and dividing the total by the amount of numbers. For example, if you wanted to find the average test score of 3 students who scored 74, 79, and 90, you’d add the 3 numbers together to get 243, then divide it by 3 to get 81. The standard error represents how well the sample mean approximates the population mean. All you need to do is divide the standard deviation by the square root of the sample size. For instance, if you were sampling 5 students from a class of 50 and the 50 students had a standard deviation of 17, you’d divide 17 by the square root of 5 to get 7.6. For more tips, including how to calculate the standard deviation, read on!
Did this summary help you?
Thanks to all authors for creating a page that has been read 995,281 times.
Did this article help you?
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.

Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:

Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:

Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:

Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:

Стандартное отклонение этих средних значений известно как стандартная ошибка.

Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартное отклонение и стандартная ошибка: в чем разница?
17 авг. 2022 г.
читать 2 мин
В статистике студенты часто путают два термина: стандартное отклонение и стандартная ошибка .
Стандартное отклонение измеряет, насколько разбросаны значения в наборе данных.
Стандартная ошибка — это стандартное отклонение среднего значения в повторных выборках из совокупности.
Давайте рассмотрим пример, чтобы ясно проиллюстрировать эту идею.
Пример: стандартное отклонение против стандартной ошибки
Предположим, мы измеряем вес 10 разных черепах.
Для этой выборки из 10 черепах мы можем вычислить среднее значение выборки и стандартное отклонение выборки:
Предположим, что стандартное отклонение оказалось равным 8,68. Это дает нам представление о том, насколько распределен вес этих черепах.
Но предположим, что мы собираем еще одну простую случайную выборку из 10 черепах и также проводим их измерения. Более чем вероятно, что эта выборка из 10 черепах будет иметь немного другое среднее значение и стандартное отклонение, даже если они взяты из одной и той же популяции:
Теперь, если мы представим, что мы берем повторные выборки из одной и той же совокупности и записываем выборочное среднее и выборочное стандартное отклонение для каждой выборки:
Теперь представьте, что мы наносим каждое среднее значение выборки на одну и ту же строку:
Стандартное отклонение этих средних значений известно как стандартная ошибка.
Формула для фактического расчета стандартной ошибки:
Стандартная ошибка = s/ √n
куда:
- s: стандартное отклонение выборки
- n: размер выборки
Какой смысл использовать стандартную ошибку?
Когда мы вычисляем среднее значение данной выборки, нас на самом деле интересует не среднее значение этой конкретной выборки, а скорее среднее значение большей совокупности, из которой взята выборка.
Однако мы используем выборки, потому что для них гораздо проще собирать данные, чем для всего населения. И, конечно же, среднее значение выборки будет варьироваться от выборки к выборке, поэтому мы используем стандартную ошибку среднего значения как способ измерить, насколько точна наша оценка среднего значения.
Вы заметите из формулы для расчета стандартной ошибки, что по мере увеличения размера выборки (n) стандартная ошибка уменьшается:
Стандартная ошибка = s/ √n
Это должно иметь смысл, поскольку большие размеры выборки уменьшают изменчивость и увеличивают вероятность того, что среднее значение нашей выборки ближе к фактическому среднему значению генеральной совокупности.
Когда использовать стандартное отклонение против стандартной ошибки
Если мы просто заинтересованы в измерении того, насколько разбросаны значения в наборе данных, мы можем использовать стандартное отклонение .
Однако, если мы заинтересованы в количественной оценке неопределенности оценки среднего значения, мы можем использовать стандартную ошибку среднего значения .
В зависимости от вашего конкретного сценария и того, чего вы пытаетесь достичь, вы можете использовать либо стандартное отклонение, либо стандартную ошибку.
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
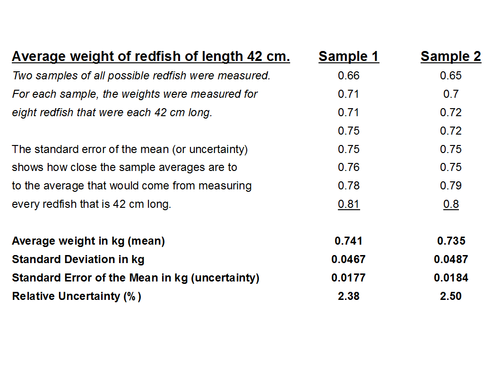
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
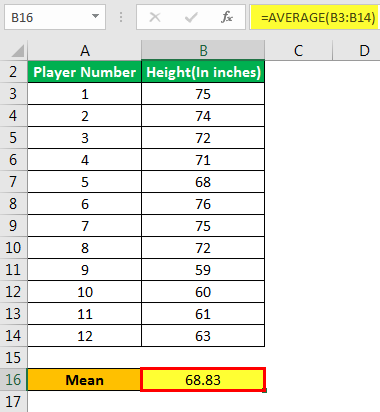
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности