Есть много разных методологий разработки: Waterfall, Agile, Lean и другие. Ситуацию усложняют различные схемы оплаты разработки в ИТ. Что лучше: Fixed Price, Time&Material или взять людей на аутстафф? Человеку, далёкому от коммерческой разработки, бывает сложно разобраться что и когда стоит использовать. Чтобы помочь с этим разобраться, рассмотрим разные методологии и схемы оплаты с точки зрения работы с рисками и права на ошибку. Попробую писать простым языком, чтобы было понятно всем.

Меня зовут Константин Митин, я сооснователь и руководитель компании АйТи Мегастар/АйТи Мегагруп. Когда-то был простым разработчиком, работал в L3, дорос до тимлида, затем и до руководителя филиала разработки крупной ИТ-компании. Теперь я в itMegastar.
Право на ошибку

Что такое ошибка? Это когда что-то сделано неправильно или неидеально. Человек — не идеальное существо, все мы с вами делаем ошибки. Но у ошибок есть цена — последствия и затраты на их исправление (несколько иной угол зрения представлен в статье «Почему ошибаются программисты? Часть 1/2»). Вряд ли кто-то будет спорить, что ошибка бригады интенсивной терапии, спасающей жизнь человека в реанимации, имеет цену выше, чем грамматическая ошибка школьника в первом классе, который только учится писать. Детство — волшебное время, время недорогих ошибок, которые помогают быстро учиться и получать опыт.
Не стоит стремиться к полному отсутствию ошибок, они были, есть и будут. Я предлагаю стремиться к минимизации цены ошибок. Простой бытовой пример. Нам с женой нужно выбрать, в какой цвет нужно покрасить стену в доме. Для неё этот вопрос куда важнее, чем для меня. Но у меня есть мнение, которое у меня спрашивают, и оно отличается от мнения моей жены. Например, она хочет потолок в зелёный цвет покрасить (кроме шуток), а я привык к белым потолкам.
Что может произойти дальше? Можно высказать своё мнение, потом начать обсуждение, потом поспорить, кто-то на кого-то обидится и понесётся дальше. Люди и не из-за такой фигни разводятся. В то же время можно прикинуть, что цена ошибки — стоимость банки краски и немного времени на перекраску. Пусть попробует, не получится, не понравится — просто перекрасим. И дело не в том, что мне все равно, дело в том, что цена этой ошибки для меня приемлема и я к ней готов. И тут быстрее и дешевле попробовать и получить опыт, чем вести дорогостоящие обсуждения.
Иными словами, я дал своей жене право на ошибку и заранее согласился на цену этой ошибки. После этого я уже ничего не теряю, могу лишь приобрести, если жена окажется права. Буду радоваться вместе с ней.
Деньги
Всё же мы занимаемся бизнесом. Разработка в ИТ стоит денег, а ещё нужно заключать договоры. В договоре должна быть схема оплаты и график платежей. Поговорим про схемы оплаты и доступное в них право на ошибку.
Fixed Price

Это обычный договор на оказание услуг, фиксирующий стоимость, график платежей, объём работ, график поэтапной сдачи, если есть этапы работ, дата начала и дата окончания работ. Узкое место — фиксация объёма работ. Это могут быть функциональные требования, указанные в теле договора или ссылка на техническое задание в отдельном приложении к договору. Естественно, если вы планируете использовать Fixed Price, этот формат работы подразумевает, что вы должны очень точно знать, что именно хотите разработать, ещё до старта работ.
Из Fixed Price очень легко сделать договор без права на ошибку. Заказчик не имеет права на ошибку в зафиксированных в договоре требованиях, всё, что выходит за их рамки — доработки, оплачиваемые отдельно. Если исполнитель ошибся в оценке стоимости работ, то всё, что сверху зафиксированной в договоре суммы — исполнитель выполнит за свой счёт. Ошиблись в сроках — Заказчик может разорвать договор.
Почему так? С такими договорами легче всего работать в суде. Обычно судья не имеет опыта в разработке программного обеспечения и не знает контекста ваших взаимоотношений. Основная опора судьи при принятии решения по вашему делу — ваш договор, а также наличие или отсутствие подписанных актов сдачи работ… И опыт судьи при рассмотрении других конфликтов.
В реальной жизни в договорах по Fixed Price остаётся много неопределённости. Это удобно для соблюдения баланса интересов сторон и партнёрских отношений. Всё же с точки зрения бизнеса, а не юристов, договор нужен не для того, чтобы потом ходить с ним по судам. Да, он даёт такую возможность, но пользоваться ей, на самом деле, не выгодно всем сторонам.
Time&Material

При этой схеме оплаты вы платите за фактически отработанные специалистами часы. С юридической стороны это рамочный договор услуг без конкретного объёма выполняемых работ и их конечной стоимости. Вместо этого, например, можно писать ежемесячные заявки на покупку часов специалистов. Подходит, когда вы не совсем понимаете, что хотите получить по итогу работы, и требования могут меняться в процессе разработки. Ответственность за качество и эффективность работы специалистов несёт исполнитель, и придётся доплатить за менеджера проекта.
В этой схеме у заказчика появляется право на ошибку в формировании требований, а у исполнителя в оценке бюджета работы в деньгах и сроках. Так как работа ведётся небольшими этапами, их проще планировать и оценивать. Если уровень оказания услуг перестанет устраивать, то можно быстро остановить работу с неподходящим исполнителем. Обе стороны рискуют только в объёмах последней заявки, которые обычно ограничиваются календарным месяцем.
Outstaffing
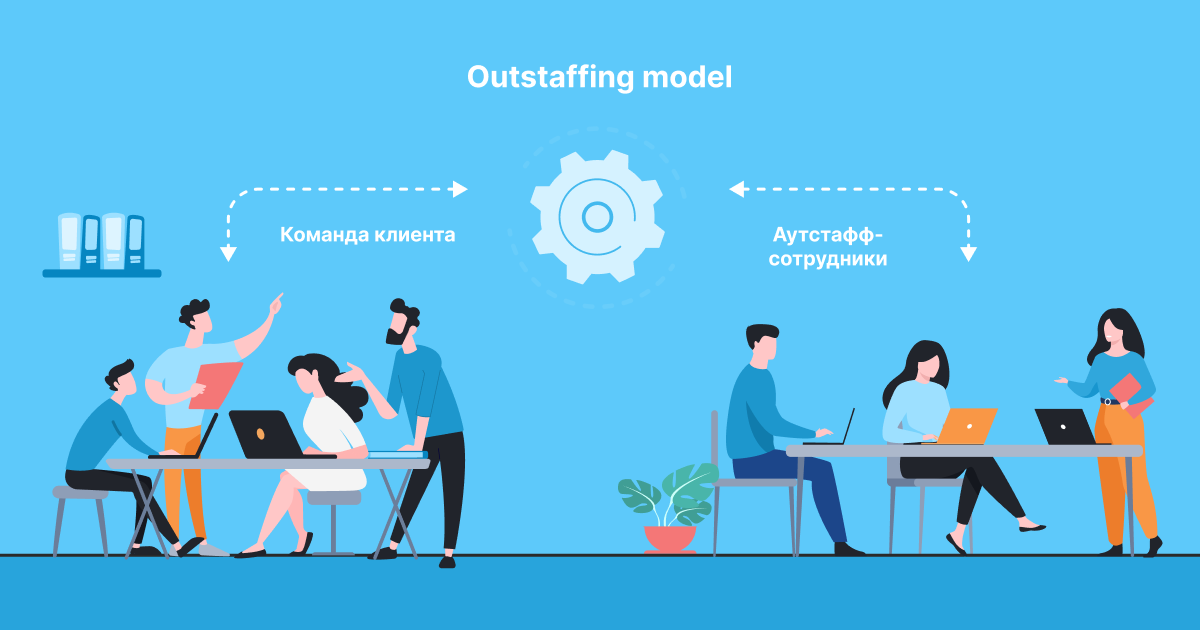
Вы арендуете специалиста, скорее всего, на несколько месяцев и больше. С юридической точки зрения все оформляется, как и при модели Time&Material. Однако постановка задач, контроль эффективности и прочие организационные моменты возлагаются на заказчика. Подходит скорее для компаний со своим штатом ИТ, которые понимают, что делают, и которым нужно временно нарастить команду. Причём так, чтобы не брать людей в штат и сэкономить на подборе персонала.
Риски исполнителя ограничиваются срочной заменой арендованного сотрудника, если он, например, уволится. Остальные риски на стороне заказчика. То есть заказчик должен иметь свои компетенции в разработке программного обеспечения и просто испытывать дефицит своих ресурсов.
Методологии разработки
Скажем прямо, методологий разработки много. Навскидку можно вспомнить каскадную модель, итеративную модель, инкрементную модель, различные вариации инкрементно-итеративных моделей, V-модель, Канбан/Lean, манифест Agile, Scrum, XP, Unified Process, RAD и целый ряд производных от этого всего. Конечно, всего не охватишь, поэтому придётся пройтись только по базовым вещам. Это не значит, что все остальное не заслуживает внимания. Наоборот, заслуживает, но придётся на каждую методологию писать по несколько статей.
Каскадная модель разработки (Waterfall / Водопад)
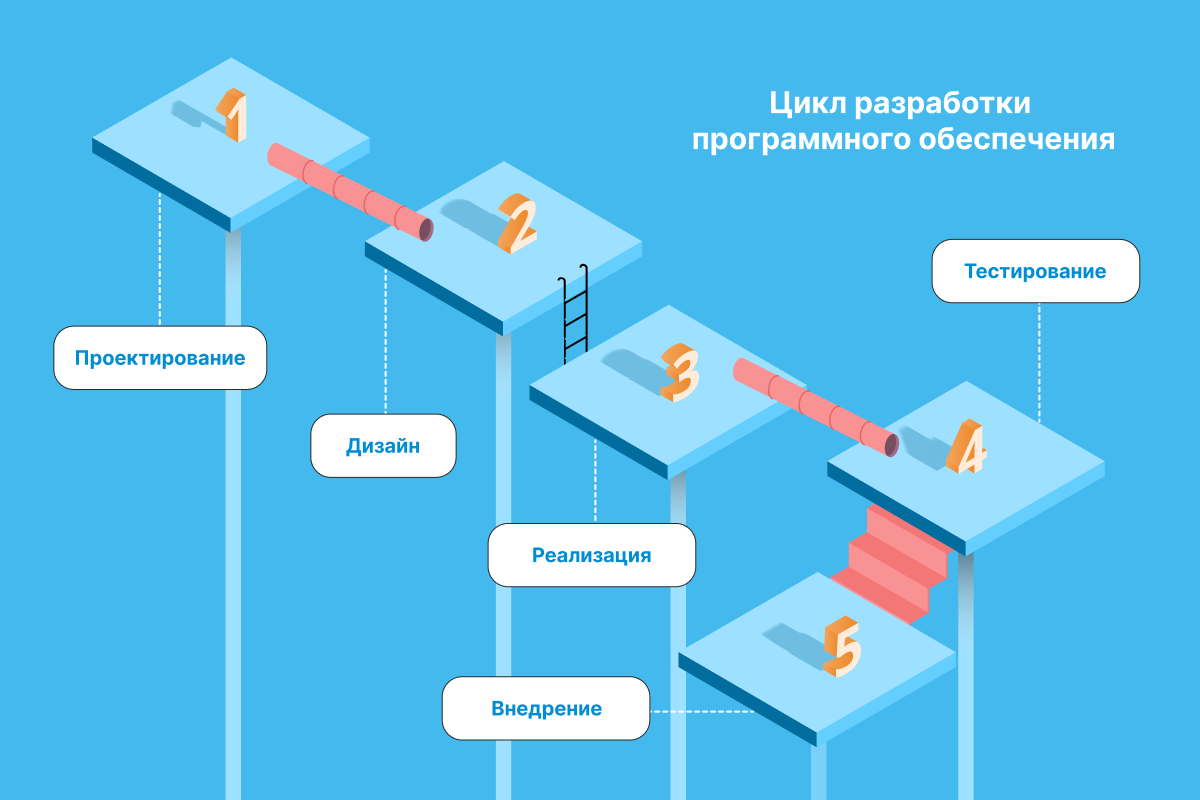
В 1970 году Уинстон Уокер Ройс описал модель разработки, как поток последовательно проходящих фаз анализа требований, проектирования, реализации, тестирования, интеграции и поддержки. Такая модель получила название каскадной модели разработки (Waterfall). Сделал он это, чтобы показать её недостатки по сравнению с итеративной разработкой.
Каскадную модель часто критикуют за недостаточную гибкость и объявление самоцелью формальное управление проектом в ущерб срокам, стоимости и качеству. В каскадной модели нет возможности сделать шаг назад и изменить требования, либо уже разработанный функционал. Все требования известны заранее, проектирование выполнено до начала разработки. Из плюсов — можно быстро провести разработку и тестирование за указанные деньги и в указанные сроки. Очень хорошо подходит под договор Fixed Price, в котором никому не даётся право на ошибку.
Каскадная модель разработки часто обсуждается, но редко используется. Это некоторый сильно упрощённый пример из учебников по разработке и тестированию начального уровня. Например, на каскадной модели можно просто и наглядно расписать основы работы QC-специалиста (quality control) и неправильно расписать основы работы QA-инженера (quality assurance). Первый работает над тем, чтобы находить ошибки в реализации программного обеспечения, а второй работает над тем, чтобы не происходило ошибок в реализации программного обеспечения. И дело тут не только и не столько в объёмах и качестве технической документации.
Также представители идеологии Agile любят критиковать каскадную модель. С одной стороны, их можно понять, получается наглядно. С другой стороны, это всё же неправильно, так как методологии, которые ни разу не уступают Agile в эффективности, обходятся стороной.
С помощью каскадной модели можно реализовывать стандартные и небольшие проекты. Например, какой-нибудь информационный сайт. Для более долгих проектов и более сложных систем ещё в процессе разработки часто выявляется упущенный либо неправильно описанный при постановке задачи или проектировании функционал. Также это может происходить на этапе приёмки либо после внедрения системы, когда появляется первый опыт использования. Как результат к первоначальному договору по Fixed Price приходится заключать ещё 2-3 дополнительных соглашения на реализацию недостающего для удобной работы функционала. То есть использовать итеративную модель разработки, о которой писал Ройс.
Когда обнаруживается какой-то недостаток, QC-специалист говорит, что такой функционал не был описан в ТЗ, поэтому его наличие, даже несмотря на всю логичность его присутствия, никто не проверял. Разработчик скажет о том, что функционала нет в ТЗ, поэтому его никто и не делал. Менеджер проекта скажет, что функционал никто не заявлял, поэтому его никто не оценивал, поэтому придётся оплачивать дополнительные работы. Кроме того, ведь ТЗ и макеты приложения согласованы с заказчиком.
Таким образом, в рамках проекта у заказчика нет права на ошибку в постановке задачи и ТЗ, а у специалистов нет права на отклонение от ТЗ. Чем больше система — тем легче допустить ошибку и тем сложнее задокументировать её описание.
Откуда тогда вообще взялась такая негибкая методология разработки? От перфокарт. Представьте, что у программиста очередь ожидания в компьютерный центр — месяц. Просто чтобы запустить свой код. Стоимость ошибки очень высока, ошибёшься в переносе кода на перфокарты, ошибёшься в программном коде, ошибёшься в алгоритме либо ещё где, то исправить свою ошибку он сможешь только через месяц. Поэтому люди очень тщательно подходили к постановке задачи, потом чертили на бумаге блок-схемы алгоритмов, там же на бумаге их отлаживали, затем писали код, также на бумаге и отлаживали его на бумаге. Долго, неделями. Только потом уже делали перфокарты и ждали своей очереди на запуск программы. Стоимость ошибки была очень высока.
В 70-х годах 20-го века уже была эра интерактивного программирования, когда стоимость ошибки резко снизилась. Ну, подождёт программист несколько десятков минут, пока код скомпилируется, всего-то делов. Потом его отладит и отдаст QA.
Нечто похожее на каскадную модель сегодня можно увидеть в радиоэлектронике. Например, разводка печатных плат и взаимодействие смонтированных на них компонент сначала проектируется и отлаживается в специальных эмуляторах. Только потом изготавливают тестовые устройства. Изготовления печатной платы приходится ждать несколько недель, затем нужно собрать устройство и протестировать его. При этом обязательно обнаруживаются ошибки, которые пробуют закрыть через драйвера (программный код). Неплохой результат — это когда вторая либо третья итерация даёт рабочее устройство.
Итеративная разработка
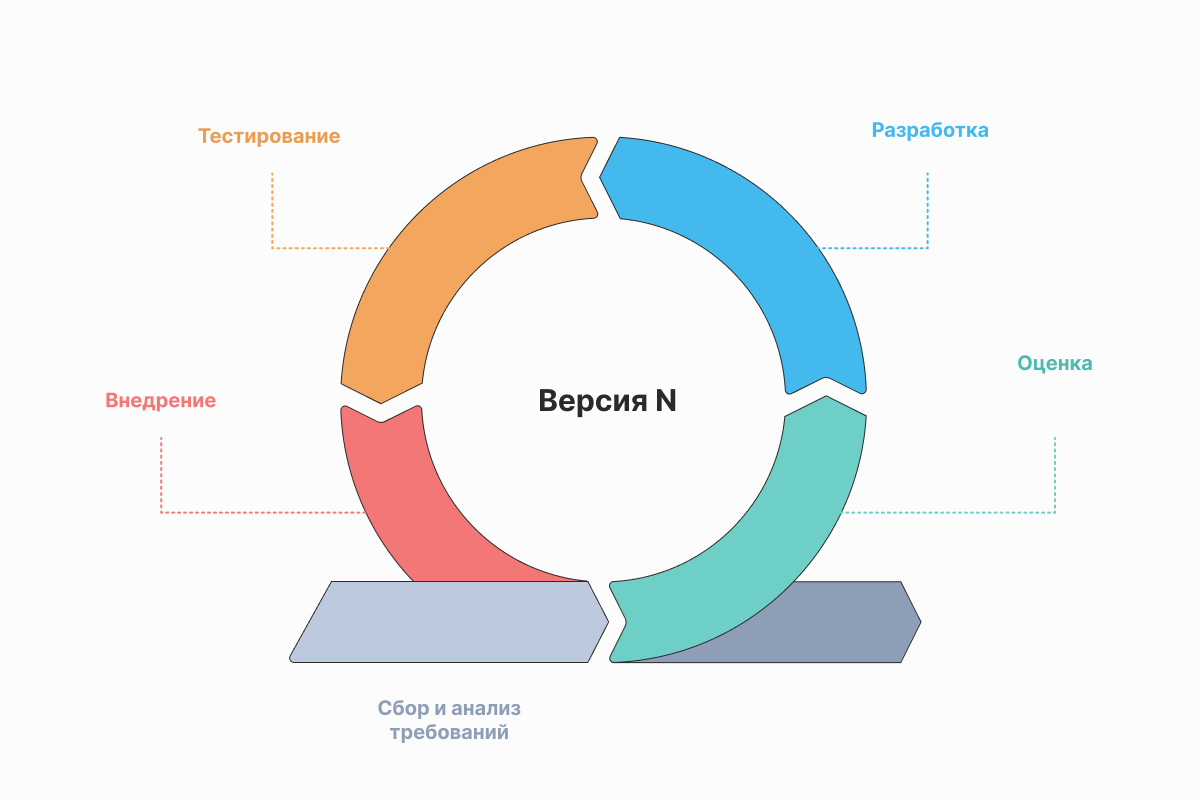
При итеративной разработке мы принимаем тот факт, что при постановке задачи и написании ТЗ могут быть допущены ошибки, либо просто мы не до конца понимаем конечный вид того, что предстоит разработать. Поэтому разработка ведётся итерациями, достаточно большими, чтобы в их рамках можно было получить какую-то бизнес-ценность в виде результата разработки, но достаточно небольших, чтобы можно было проработать и зафиксировать требования к итерации.
В самом простом подходе каждая итерация — это небольшой проект по доработке, включающий в себя сбор, анализ и формализацию требований, разработку, тестирование и внедрение. В более сложных случаях итерации идут «внахлёст», то есть пока идёт реализация текущей итерации, ведётся проработка требований к последующей итерации. Таким образом получается непрерывный поток анализа пользовательского опыта, требований, их формализация и постановка задач на следующие итерации, а так же непрерывный поток разработки, отладки и тестирования.
В итеративной модели достаточно сложно вести проекты, потому что проект подразумевает под собой фиксацию объёма работ, бюджета денег, бюджета ресурсов и явные сроки завершения. При использовании итеративной модели мы должны оставить незафиксированными либо объёмы работ и сроки, либо бюджеты денег и ресурсов. Поэтому можно использовать только схему оплаты типа Time&Material.
Больше всего итеративная модели подходит для продуктовой разработки. Обычно у нас есть продуктовые метрики, мы делаем гипотезы о том, какие изменения в продукте могут их повысить, и тестируем эти гипотезы, анализируем изменения и формируем новые гипотезы. Проверка продуктовых гипотез очень хорошо ложиться в итеративный подход.
Таким образом, итеративный подход даёт право на ошибку в требованиях либо вообще позволяет работать, когда у нас ещё не сформировалось конечное представление о продукте, который мы разрабатываем. Взамен этого мы рискуем объёмом работы в рамках итерации.
Agile

Agile — это не методология, это подход и манифест. 13 февраля 2001 года появился Agile Manifesto, в котором заявлялись 4 ценности и 12 базовых принципов.
Ценности:
-
Люди и взаимодействие важнее процессов и инструментов.
-
Работающий продукт важнее исчерпывающей документации.
-
Сотрудничество с заказчиком важнее согласования условий контракта.
-
Готовность к изменениям важнее следования первоначальному плану.
Базовые принципы:
-
Наивысшим приоритетом для нас является удовлетворение потребностей заказчика, благодаря регулярной и ранней поставке ценного программного обеспечения.
-
Изменение требований приветствуется, даже на поздних стадиях разработки. Agile-процессы позволяют использовать изменения для обеспечения заказчику конкурентного преимущества.
-
Работающий продукт следует выпускать как можно чаще, с периодичностью от пары недель до пары месяцев.
-
На протяжении всего проекта разработчики и представители бизнеса должны ежедневно работать вместе.
-
Над проектом должны работать мотивированные профессионалы. Чтобы работа была сделана, создайте условия, обеспечьте поддержку и полностью доверьтесь им.
-
Непосредственное общение является наиболее практичным и эффективным способом обмена информацией как с самой командой, так и внутри команды.
-
Работающий продукт — основной показатель прогресса.
-
Инвесторы, разработчики и пользователи должны иметь возможность поддерживать постоянный ритм бесконечно. Agile помогает наладить такой устойчивый процесс разработки.
-
Постоянное внимание к техническому совершенству и качеству проектирования повышает гибкость проекта.
-
Простота — искусство минимизации лишней работы — крайне необходима.
-
Самые лучшие требования, архитектурные и технические решения рождаются у самоорганизующихся команд.
-
Команда должна систематически анализировать возможные способы улучшения эффективности и соответственно корректировать стиль своей работы.
Сам по себе Agile Manifesto не такой простой, как кажется. На то, чтобы его разобрать, понадобится отдельная статья. И потом, возможно, ещё несколько, чтобы пройтись по нюансам.
Сейчас же нужно отметить, что Agile Manifesto имеет смысл именно для продуктовой и итеративной разработки, о чем нам явно намекает принцип №8. Да, можно провести проект в соответствии с Agile Manifesto, но для этого потребуется «мотивированный профессионал» в ведении проектов, которого достаточно сложно найти.
Scrum
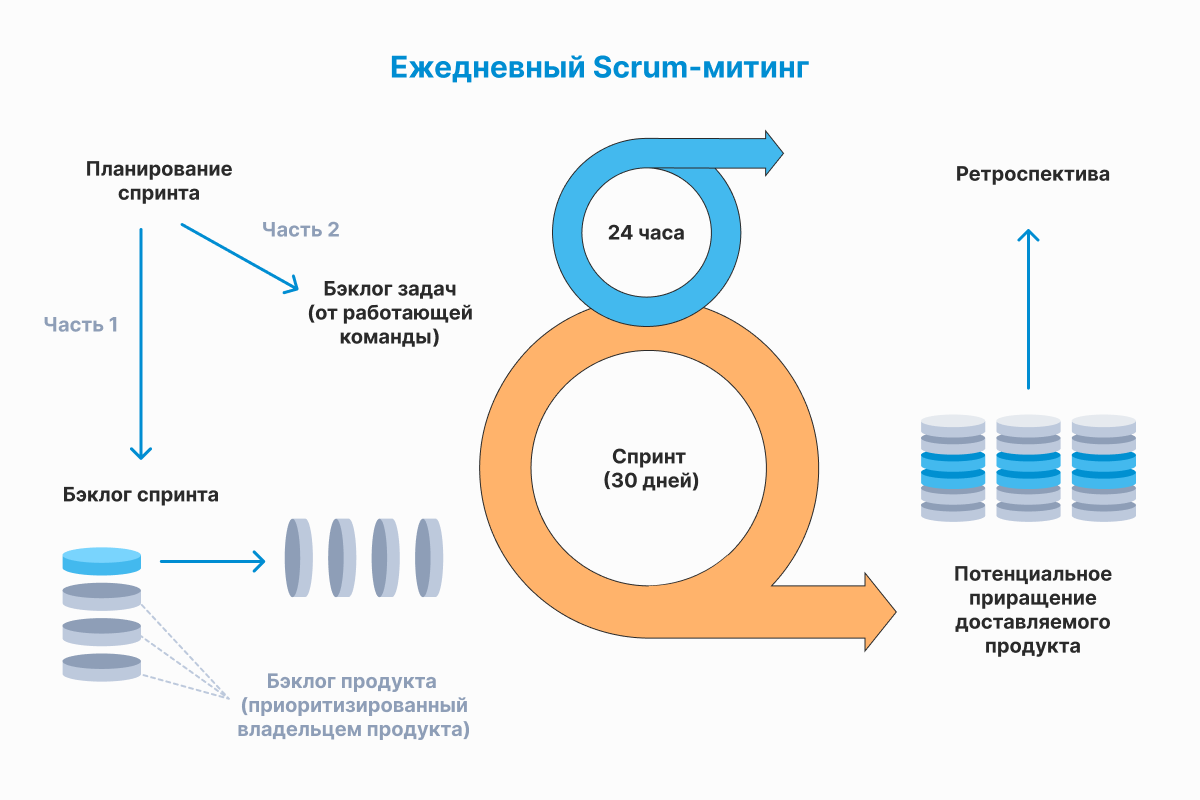
Люди часто путают Scrum и Agile. Хотя первое — это методология разработки родом из первой половины 90-х годов 20-го века, а Agile — это манифест родом из начала 21-го века. Наверное, путаницу породило название книги «Agile Software Development with SCRUM», вышедшей в 2001 году.
Scrum — популярная тема, по ней очень много всего написано. Повторять все это нужды нет. Хочется лишь отметить некоторые неочевидные вещи.
При первом описании подхода, ещё в 1986 году, было верно отмечено, что проекты, над которыми работают небольшие команды из специалистов различного профиля, обычно систематически производят лучшие результаты, и объяснили это как «подход регби» (Scrum — англ. «схватка» — термин из регби, обозначает стартовое состояние команд перед вбросом мяча). Часто это действительно так.
Scrum — достаточно формализованная и хорошо описанная методология (есть обучение и сертификация), для которой есть много вариаций и частичных реализаций (SCRUMbut, SCRUMand). Это хорошо, можно многое взять готовое и не выдумывать велосипед заново.
Важно помнить, что Scrum выстроен на базе итеративной модели разработки. В Scrum итерации называют спринтами. И как любая итеративная методология разработки Scrum скорее подходит к продуктовой разработке, нежели к разработке проектов.
Другим слабым местом Scrum является работа с «большими командами». Если ваша команда больше 11 человек, её уже нужно дробить на две команды, после чего вам понадобится SCRUM of SCRUMs (SoS) либо Nexus. Есть ещё LeSS, а потом и LeSS Huge, когда команд больше 8. Темы достойные отдельного обсуждения.
Канбан

Нет, это не тот Канбан, что нам известен из бережливого производства и был у Тойота ещё 1962 году. Это скорее Канбан-доска, на которой вы чертите колонки, отвечающие за стадии производственного процесса, например: Сделать, В работе, Тестирование, Сделано, Внедрено. А потом клеите на эту доску стикеры с задачами, после чего перемещаете их по колонкам по ходу выполнения задачи.
Канбан — это не методология, это средство визуализации. Успешно применяется в любой методологии разработки. В том же Scrum это любимый инструмент.
Не смотря на свою простоту, все же подходит для поддержки продуктов маленькими командами и разбора инцидентов.
Инкрементная модель разработки

В этой модели проект выполняется по этапам, каждый из которых представляет из себя инкремент. То есть представляет из себя модуль готового и протестированного функционала. Причём разрабатываемая система разбивается на модули таким образом, чтобы ей можно было пользоваться, как можно скорее, желательно после реализации первого же этапа, а последующие инкременты добавляли бы бизнес-ценность к «базовому» функционалу.
Что даёт такая модель? Возможность разделить изначально большую систему на набор сравнительно небольших модулей, которые можно разрабатывать последовательно либо параллельно (если повезёт). За счёт небольшого размера модуля, снижается его сложность, поэтому его легче проектировать, реализовывать и тестировать. Иногда инкрементный подход неверно называют «мульти-водопад».
Что за это с вас возьмёт такая модель? Вам понадобится либо опытный руководитель проекта, либо опытный архитектор, чтобы правильно разделить вашу систему на модули. Особенно помня о том, что целое всегда больше, чем просто сумма частей.
Инкрементная модель позволяет вам реализовывать системы, требования к которым вы себе представляете нечетко. То есть вроде понятно что и где «в целом» должно быть, но система настолько большая и сложная, что описать её целиком не получается. То есть инкрементная модель даёт право на ошибку в требованиях и постановке задачи, но требует иметь хотя бы общие представления о системе и опытного руководителя проекта либо архитектора.
А ещё эта модель даёт возможность вести крупные проекты с высокой степенью неопределённости в требованиях по схеме Fixed Price, то есть можно зафиксировать объёмы работ, календарные сроки и бюджет денег. Пусть даже для этого и до этого придётся произвести этап предпроектного проектирования.
Достаточно часто, перед тем, как заключить договор на разработку крупной системы с поэтапной сборкой, заключают отдельный договор на нулевой этап — проектирование. Без этого сложно оценить сроки и стоимость разработки.
Другой важный момент, которого мы здесь не касаемся, — это проектирование в бюджет. Применяется, когда уже известны календарные сроки либо денежный бюджет и нужно найти такое техническое решение, которое позволило бы вписаться в известные ограничения. При разработке больших и сложных систем такой подход часто применяется.
Unified Process (Инкрементно-итеративная модель разработки)
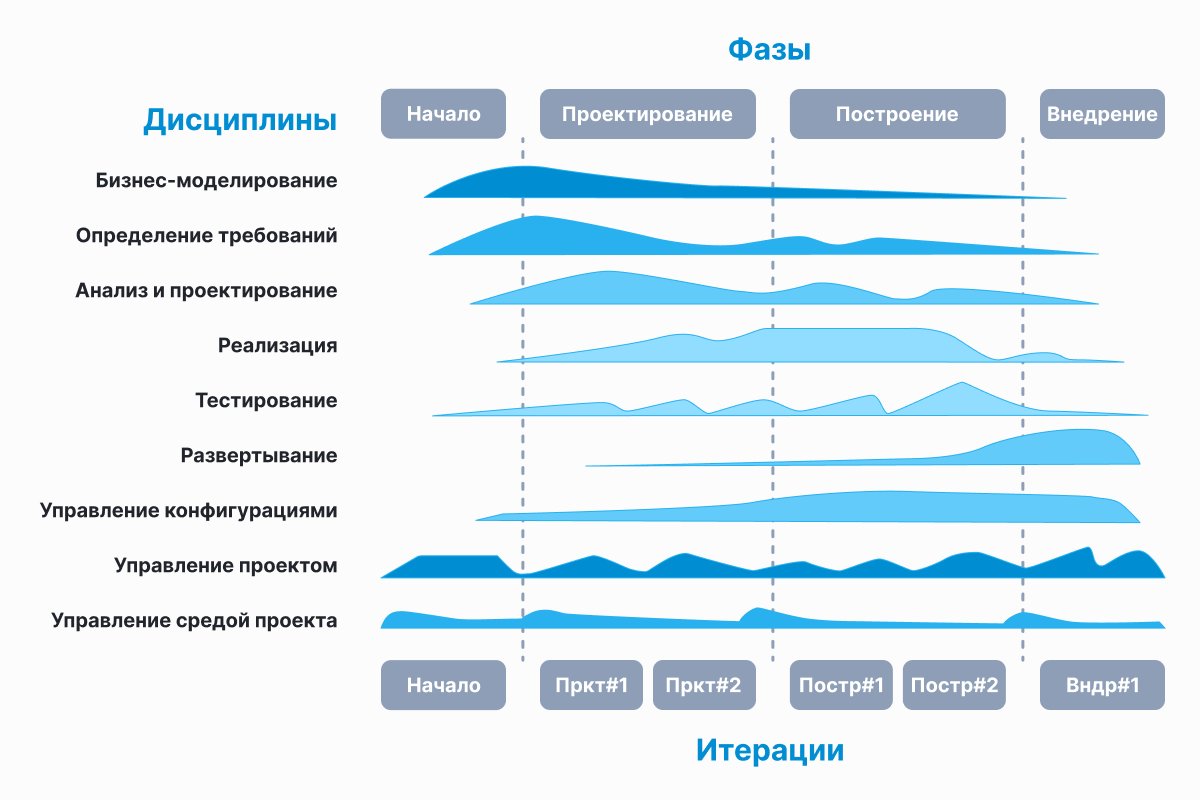
Инкрементно-итеративная модель разработки позволяет реализовывать действительно большие и сложные проекты, в том числе и с фиксацией требований, объёмов работы, бюджета денег, бюджета ресурсов и сроков. Именно такая модель заложена в основе Unified Process. А одним из самых известных представителей семейства Unified Process (UP, 1995 год) является Rational Unified Process (RUP, 1998 год).
Методология содержит множество инструментов, в частности, разработанный под эту концепцию язык UML, и весьма обширный набор спецификаций для артефактов. Но требование использовать все это не является догмой. Тот либо иной инструмент должен быть использован лишь в уместном случае.
Unified Process потребует от вас разработать сценарии использования системы, которые потребуется описать простым и понятным языком, так, чтобы быть понятным стороннему читателю. Это не только и не столько пользовательские сценарии, сколько схемы обмена данными, диаграммы изменения состояний и так далее.
Вам придётся уделить особое внимание архитектуре приложения. Это фундамент, на который встанет ваша система. Без хорошей архитектуры, следовательно без сильного архитектора, у вас ничего не получится.
И Unified Process подразумевает одновременное использование инкрементного и итеративного подхода, то есть инкрементно-итеративную модель разработки.
Таким образом, на этапе первоначального проектирования вы:
-
Даёте общее описание системы. Например в виде фиксации функциональных требований и основных сценариев использования системы.
-
Прорабатываете архитектуру приложения, понимая, что требования в ходе разработки будут меняться. То есть ваша архитектура должна позволять гибко реагировать на изменения требований, а ещё позволять легко модернизировать систему после ввода в эксплуатацию.
-
Разделяете проектируемую систему на инкременты функциональности. Причём инкремент — это целостный функционал, с которым может работать пользователь. То есть не бывает инкрементов вида «бэкенд», «фронтенд» и тому подобное.
-
Планируете этапы реализации при условии, что один этап может содержать один либо несколько инкрементов, но один инкремент не может разделяться между разными этапами.
-
Рассчитываете и закладываете буферы (календарные, денежные, ресурсные) между этапами разработки.
Затем начинаете последовательно выполнять этапы. При этом в каждый этап входит:
-
Анализ опыта использования уже реализованных инкрементов.
-
Анализ и детализация требований к текущему этапу.
-
Анализ рисков проекта в целом и текущего этапа в частности.
-
Проектирование функционала этапа, который включает в себя доработку уже реализованного функционала (для этого буферы и закладывали) и реализацию инкрементов этапа.
-
Разработка и отладка текущего этапа.
-
Тестирование текущего этапа.
-
Внедрение текущего этапа.
При этом реализация этапов может идти «внахлёст», то есть пока идёт реализация текущего этапа, ведётся проработка требований к последующему этапу.
Таким образом, мы можем зафиксировать объем работ, сроки, бюджет денег, бюджет ресурсов, то есть можем делать договор Fixed Price. Но при этом за счёт рамок проектирования в виде этапа мы снижаем риски ошибок в постановке задачи и проектировании. За счёт размещения буферов после этапов мы имеем возможность вести и итеративную разработку, то есть имеем право на ошибку в требованиях. Да и реализации тоже, такие ошибки просто исправляются в последующих этапах-итерациях.
Однако данная методология не прощает ошибок в архитектуре и ведении проекта. Ваш руководитель проекта и архитектор должны быть настоящими профессионалами.
А ещё такой подход позволит вам использовать развитые методы управления рисками на проекте. Вы можете использовать критические цепи, критические пути, строить PERT-диаграммы и много чего ещё, что необходимо на действительно крупных и сложных проектах.
Подводя итоги

Можно сказать, что не существует универсальной модели разработки программного обеспечения:
-
Каскадная модель разработки (Waterfall), на самом деле представляет из себя некий упрощённый пример, на котором удобно рассматривать, возникающие в процессе разработки, риски.
-
Agile — это не какая-то модель разработки либо методология, скорее это манифест, которому пытается соответствовать широкий ряд методологий разработки.
-
Итеративная модель разработки хорошо подходит для развития продуктов. Для неё существует набор устоявшихся фреймворков, например Scrum. Основным недостатком модели является то, что в ней сложно одновременно зафиксировать сроки и объёмы работ (следовательно и стоимость). Преимуществами модели является то, что она позволяет работать с высокой степенью неопределённости в требованиях. В том числе и в случаях, когда систему просто невозможно описать на момент начала разработки.
-
Инкрементная модель разработки хорошо подходит для проектов, у которых зафиксированы сроки и объёмы работ. Модель позволяет эффективно работать в случаях, когда в требованиях присутствует небольшая либо средняя степень неопределённости.
-
Инкрементно-итеративная модель разработки хорошо подходит для больших и сложных проектов, в том числе в условиях высокой неопределённости в требованиях. Для неё существует набор устоявшихся фреймворков, например Unified Process. Однако эта модель предъявляет высокие требования к архитектору и руководителю проекта.
Под каждую задачу — свой инструмент. Не стоит забивать мебельные гвозди кувалдой, а железнодорожные костыли столярным молотком. Не то, чтобы это не возможно, просто не удобно.
Если вы дочитали до конца и что-то для себя поняли, то спасибо вам. Не смотря на то, что много вещей осталось за рамками рассмотрения, а то. что удалось рассмотреть, было рассмотрено недостаточно подробно, получилось достаточно много текста, причём не всегда простого. Надеюсь, что он был для вас полезен.
Исследования группы
Стендиша (Standish Group) [1] свидетельствуют
о следующем. В США ежегодно тратится
более 250 миллиардов долларов на разработку
приложений информационных технологий
в рамках примерно 175 000 проектов. Средняя
стоимость проекта составляет:
-
для крупной компании
— $2 322 000; -
для средней компании
— $1 331 000; -
для мелкой компании
— $434 000.
При этом 31 % проектов
будет прекращен до завершения. Затраты
на 52,7% проектов составят 189% от первоначальной
оценки.
Исходя из этого, группа
Стендиша оценивает, что американские
компании и правительственные учреждения
потратят 81 миллиард долларов на
программные проекты, которые так и не
будут завершены. Эти же организации
заплатят дополнительно 59 миллиардов
долларов за программные проекты, которые
хотя и завершатся, но значительно
превысят первоначально отведенное на
них время.
Первым шагом на пути
решения проблемы является осознание
основных причин ее возникновения. При
проведении исследования респондентам
было предложено указать факторы,
повлиявшие на проекты, разделенные на
следующие категории:
-
успешные — завершенные
срок и в рамках отведенного бюджета; -
проблемные –
проекты, по которым возникла задержка
или проекты, не оправдавшие ожиданий; -
потерпевшие неудачу
— прекращенные проекты.
В результате были
указаны три наиболее часто встречающихся
фактора, создающие проблемы в проектах.
-
Недостаток исходной
информации от клиента: 13% всех проектов. -
Неполные требования
и спецификации: 12% проектов. -
Изменение требований
и спецификаций: 12% всех проектов.
По остальным факторам
(рис. 3.1), влияющим на успех проекта,
данные сильно расходятся:
-
проект потерпел
неудачу из-за нереалистического подхода
к составлению графика и выделению
времени — 4% проектов, -
неправильный подбор
персонала и выделения ресурсов — 6%, -
несоответствия
технологических навыков (7%) -
по другим причинам.
Если считать, что
приведенные группой Стендиша цифры,
представляют реальное положение дел
в отрасли, то, по крайней мере, третья
часть проектов нуждалась в разрешении
проблем, непосредственно связанных со
сбором, документированием и управлением
требований, как показано на рис 3.1.
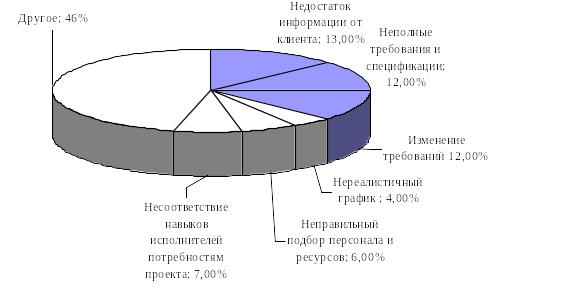
Рисунок
3.1. Факторы, влияющие на провал проекта.
Хотя большинство
проектов действительно превышают
отведенное время и бюджет, если их вообще
удается закончить, группа Стендиша
обнаружила, что около 9% проектов крупных
компаний были завершены вовремя и в
пределах бюджета; аналогичного успеха
удалось достигнуть в 16% проектов мелких
компаний. Согласно проведенному
исследованию тремя наиболее важными
«факторами успеха» были названы
следующие.
-
Подключение к
разработке пользователя: 16% всех успешных
проектов. -
Поддержка со стороны
исполнительного руководства: 14% всех
успешных проектов. -
Ясная постановка
требований: 12% всех успешных проектов.
Другие источники
приводят даже более впечатляющие
результаты. Например, организация
ESPITI (European Software Process Improvement Training Initiative —
Европейская инициатива по обучению
совершенствованию процесса программирования)
провела опрос с целью определить
относительную важность различных типов
существующих в отрасли проблем. Двумя
самыми главными проблемами, упоминавшимися
почти в половине ответов, оказались
следующие.
-
Спецификации
требований. -
Управление
требованиями клиента.
Если бы ошибки требований
можно было быстро, просто и экономно
устранять, проблема не была бы столь
серьезна. Алан Дэвис (Davis) в своей работе
[2] подвел итоги нескольких исследований
и показал, что при обнаружении ошибок
на стадии формирования требований
компания получает экономию средств в
соотношении 200:1 по сравнению с их
обнаружением на стадии сопровождения
программы.
Такая стоимость ошибок
обусловлена эффектом умножения. Многие
из ошибок в требованиях достаточно
долго остаются не обнаруженными, и
группа разработчиков тратит время и
усилия на создание проекта по этим
ошибочным требованиям. В результате
проект, вероятно, придется отбросить
или пересмотреть. Для уточнения, в чем
же состоит ошибка требований, необходимо
общение с клиентом, который участвовал
в его разработке на самом первом этапе.
Однако на практике может оказаться, что
в данный момент связаться с этим человеком
невозможно, он забыл, в чем состояла
суть инструкции, которую он давал команде
разработчиков, не помнит, чем
руководствовался при этом, или же просто
изменил свою точку зрения. Может
оказаться, что принимавший участие на
этом этапе член команды разработчиков
(бизнес-аналитик или системный аналитик)
перешел в другое подразделение. В
результате определенная часть работы
проделывается вхолостую, что приводит
к потере времени. Проблемы, связанные
с «просачиванием» недостатков из
одного этапа в другой, являются вполне
очевидными, однако подавляющее большинство
организаций ими всерьез не занималось.
Одной из организаций,
действительно работавшей над данным
вопросом, является компания “Hughes
Aircraft”. Исследование Снайдера (Snyder) [3]
обнаружило явление «просачивания»
дефектов во многих проектах, выполненных
компанией на протяжении 15 лет. В данном
исследовании говорится о том, что 74%
дефектов, связанных с формированием
требований, были обнаружены на этапе
анализа требований, когда клиенты
совместно с системными аналитиками
обсуждают, подвергают мозговому
штурму, согласовывают и документируют
требования к проекту. Этот этап работы
над проектом является идеальным с точки
зрения обнаружения таких ошибок с
наименьшими затратами. Однако исследование
также свидетельствует, что 4% дефектов
«просачиваются» на этап предварительного
(высокоуровневого) проектирования, а
7% — еще дальше, на этап детализированного
проектирования. Невыявленные ошибочные
требования жизненному циклу системы,
и 4% ошибок требований оказываются не
найденными вплоть до этапа сопровождения,
когда система уже передана клиентам и
считается полностью работоспособной.
Таким образом, в
зависимости от того, где и когда при
работе над проектом разработки
программного приложения был обнаружен
дефект, стоимость его устранения может
разниться в 50-100 раз. Причина состоит в
том, что для его исправления придется
затратить средства на некоторые (или
все) ниже перечисленные действия.
-
Повторная спецификация.
-
Повторное
проектирование. -
Повторное кодирование.
-
Повторное тестирование.
-
Создание документации.
-
Замена дефектной
версии исправленной. -
Списание части
работы, которая оказалась ненужной. -
Выплаты по гарантийным
обязательствам
Из сказанного выше
можно сделать два вывода.
-
Ошибки в определении
требований являются наиболее
распространенными. -
Стоимость устранения
таких ошибок — одна из самых высоких.
Ошибки в определении
требований приводят к затратам,
составляющим 25-40% бюджета проекта
разработки в целом. Учитывая частоту
возникновения ошибок в определении
требований и эффект умножения
стоимости их устранения, легко предсказать,
что эти ошибки обусловят до 70% затрат
на повторную работу.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Если мы заметили ошибку на этапе написания требований, то исправить ее — дело 1 минуты, просто скорректировали предложение в тексте, и все.
Пока придумывают архитектуру будущего кода, стоимость уже дороже. Представьте, что архитектор уже придумал, как это будет выглядеть, а вы хотите изменить фундамент:

Но это еще реально. А вот если мы уже все построили (написали код), то некоторые изменения просто нельзя внести и приходится мириться с багом. А даже если можно, то стоить это будет сильно дороже:
— аналитику поправить ТЗ;
— архитектору придумать, как поправить минимальными усилиями;
— разработчикам внести правки.

Почему на картинке Lee Copeland есть еще Release с самой большой стоимостью?
 |
| Картинка из книги Lee Copeland |
Потому что пока мы на этапе тестирования нашли проблему, то да, придется исправлять много кода, но все же этот код написан в последний месяц (или сколько времени у нас занимает выпуск одной версии продукта).
А вот если мы выпустили версию и уже сделали другую, третью пятую, десятую… А потом нашли баг в самой первой, то на том коде уже столько всего понастроено, в том числе и костылей. Что исправить вашу хочу-шку будет особенно сложно.

Тем не менее такой подход до сих пор используют в больших организациях на сотни человек. Там с требованиями работает один отдел аналитики, потом передают дальше и так по каскаду все приходит в тестирование. С проблемами ошибки в требованиях приходится мириться…
Так что запоминаем: чем раньше найдена ошибка, тем проще ее исправить!

Поэтому тестировщики так важны. Чем раньше они заметят проблемы, тем проще будет их исправить!
PS — это выдержка из моей книги для начинающих тестировщиков, написана в помощь студентам моей школы для тестировщиков
Цена ошибки: как экономия приводит к повышенным тратам
Время на прочтение
10 мин
Количество просмотров 3K

Когда мы обсуждаем вопрос создания программного обеспечения, то говорим не только про архитектуру, технологии, навыки, но и про экономику. Абсолютно все проекты требуют бюджета, и он не может быть бесконечным. Необходимость рационального использования средств очевидна всем, а про необоснованную экономию порой умалчивают. А зря, ведь это в конечном итоге приводит к повышенным тратам.
Экономия затрагивает самые разные сферы проекта и специалистов. В этой статье рассмотрим обеспечение качества (QA). Бизнес нередко считает, что тестирование – та часть проекта, на которой можно сэкономить, что за качество должны отвечать разработчики, а QA-специалистов иногда можно и не привлекать. Наш коллега Андрей на конкретных примерах покажет, к каким последствиям приводят наиболее популярные случаи экономии на QA.
Вариант 1. Отсутствие тестирования на ранних этапах
Начнем с классического случая экономии на проекте – отсутствия тестирования на ранних этапах жизненного цикла ПО.
Первоначальная выгода от такого решения кажется очевидной – пока не накопилось достаточного объема кода для тестирования, подключение QA-специалистов некритично. Однако оправданность такого решения при детальном рассмотрении оказывается сомнительной.
Многие слышали фразу «Чем раньше найден баг, тем проще и дешевле его исправить», давайте разберемся, почему это так и насколько дешевле. Поскольку баги появляются в фичах, представим упрощенный жизненный цикл фичи, который существует в большинстве проектов:
-
Идея
-
Написание технического задания (далее – ТЗ)
-
Реализация
-
Тестирование
-
Выход в релиз
Обратите внимание, что на этой схеме QA подключаются довольно поздно – на этапе тестирования. Используя этот алгоритм, легко вычислить, что:
-
Если в фиче нет дефектов, то каждый участник жизненного цикла затрачивает свое время 1 раз, таким образом разработка стоит 5 условных часов.
-
Если баг допущен на этапе реализации и найден на этапе тестирования, то разработчик и QA затрачивают по одной дополнительной единице времени: на фикс бага и на повторное тестирование (ретест) исправленной фичи, соответственно. В итоге получается: 5+2=7 единиц времени. У вас может возникнуть вопрос, почему мы считаем 5 часов, а не 4, если после тестирования фича не пошла в релиз? Потому что после исправлений и повторного тестирования все равно наступает релиз.
-
Если баг допущен на этапе написания ТЗ и найден на этапе тестирования, то единиц времени будет 8 (5+3 на: исправление ТЗ, фикс бага , ретест)
-
Если баг допущен в самой идее фичи и выявлен на этапе тестирования, то будет затрачено 9 единиц времени (5+4 на: коррекцию идеи, исправление ТЗ, фикс бага, ретест исправлений)
Теперь давайте представим, что QA подключается на более раннем этапе – между написанием ТЗ и разработкой – и тестирует требования. В этом случае баги можно будет выявить раньше и сэкономить время.
Тестирование постановок (ТЗ) – одно из популярных решений тренда на раннее тестирование или, как это называют некоторые компании, «shift left».

В третьем и четвертом случаях это будет 1 и 2 единицы времени соответственно. Однако можно заметить, что в первом и втором случаях происходит увеличение затрачиваемого времени на 1 единицу. Где же выгода? Добавим в теоретическую модель данные о статистике возникновения дефектов и реально затрачиваемом времени на тестирование требований и исправления постановок и кода.
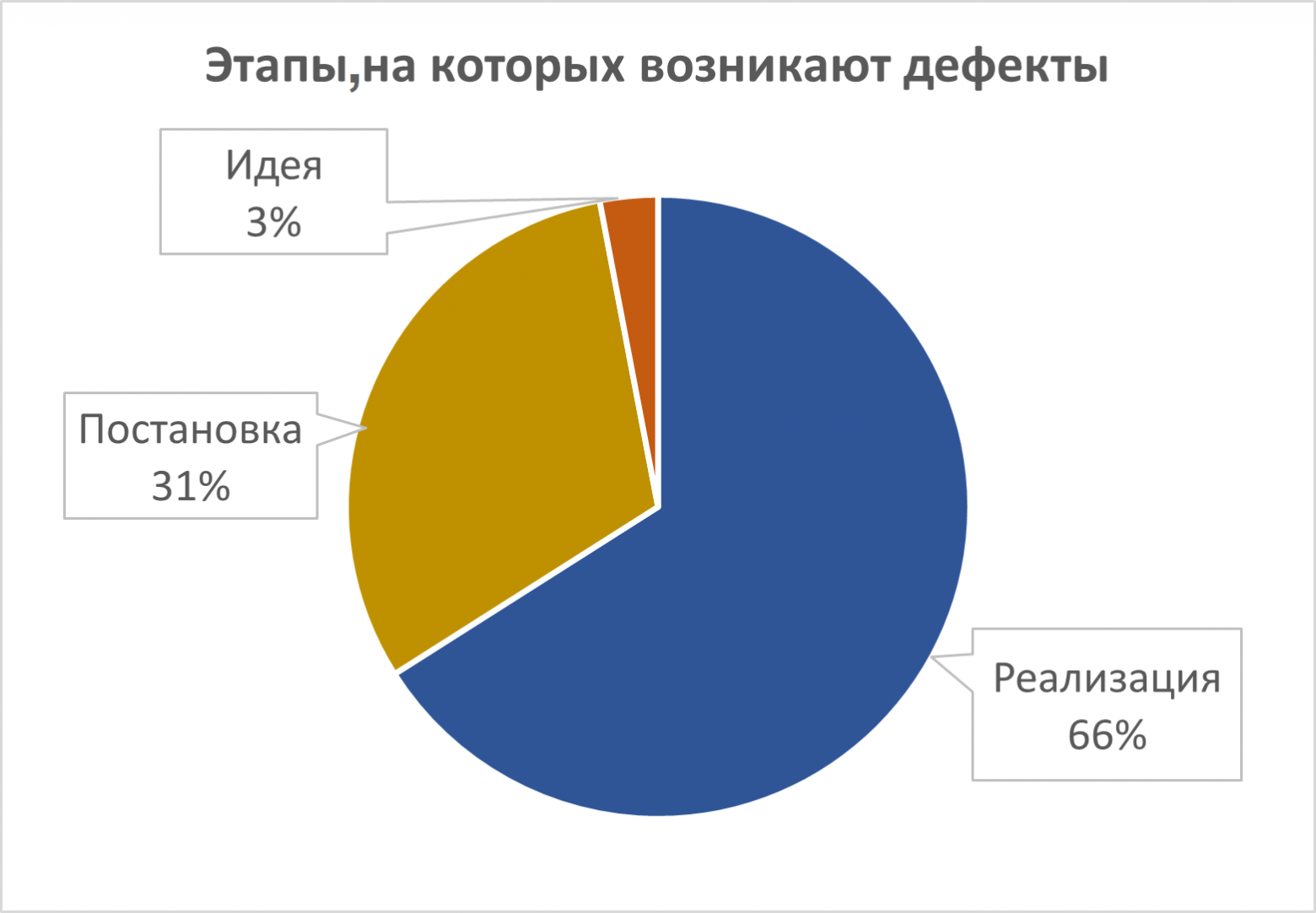
Начнем с возникновения дефектов. Мы собрали статистику со 117 проектов в различных сферах и анализ показал, что 66 % багов возникают на этапе реализации (написания кода), 31% — на этапе постановки задачи и 3% дефектов содержатся в идеях фич.
Возникает вопрос: «А как же интеграционные баги?» Фича рассматривается как самостоятельная сущность, а интеграционный баг – это либо проблема внешнего сервиса и ее не решить силами команды, либо фича неправильно взаимодействует с исправным внешним компонентом.
Представим, что ваше приложение взаимодействует с внешним сервисом файлового хранилища, которое в один момент перестало отвечать. Соответственно, в самом приложении сломаются все функции, которые связаны с внешним файл-сервером. Это и будет интеграционным багом.
Переходим ко времени, которое затрачивается на тестирование требований.
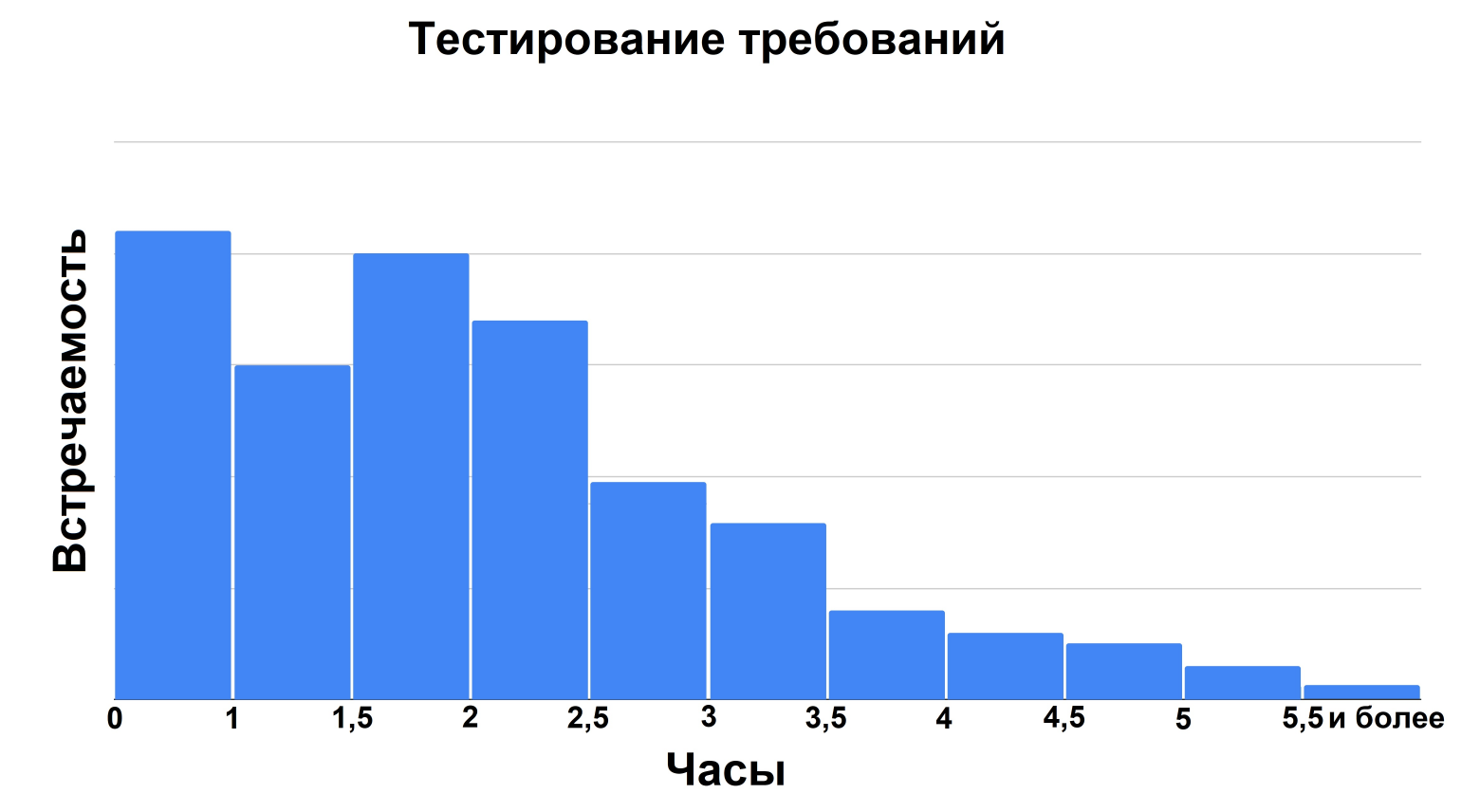
Практика показывает, что тестирование требований на одну фичу (именно требований, а не фич) в среднем занимает от 25 минут до 6 часов. Значения более 2,5 часов встречаются крайне редко, а 4 и более часа ревью свидетельствуют о том, что фича перегружена требованиями и ей требуется декомпозиция.
Теперь рассмотрим время, затрачиваемое на корректировку ТЗ.

Исправления ТЗ занимают от 10 минут в случае мелких опечаток до 9-10 часов, если нужна серьезная переработка логики, получение дополнительной информации, созвоны, согласования, ожидание ответов и т.д.
И наконец, изучим распределение времени, которое тратится на исправление кода.

На фиксы дефектов в коде уходит от 20 минут до 8 часов, в зависимости от сложности багов и если при исправлении не возникает критических противоречий с существующим кодом, стенды работоспособны, а ТЗ достаточное для работы.
Анализ диаграмм позволяет сделать несколько выводов:
-
Весомая доля (около 31%) дефектов зарождается на этапе создания ТЗ
-
Типичное время тестирования ТЗ меньше, чем типичное время исправления кода (багофикса)
Обогащение модели жизненного цикла фичи реальными данными было бы не полным без сравнения затрат времени на реализацию. Однако, тут прикладывать какие бы то ни было диаграммы распределения времени сложно, поскольку информация получена с разных проектов, где фичи сильно различаются по размеру и трудоемкости. Значит, без объяснения, что делалось при реализации задачи, трудно понять затраты времени на нее. Более показательна статистика с проектов, где внедрили тестирование требований, как один из вариантов тестирования на ранних этапах разработки.

На графике видно, что среднее время жизненного цикла фичи снизилось на величину от полутора до семи часов.
Такая экономия времени происходит не только благодаря внедрению раннего тестирования, но и оптимизации его применения. То есть в реальности, даже с учетом того что в постановке изъянов может не быть, тестирование ТЗ все равно оправдывает себя за счет того что в случае наличия таких дефектов, они выявляются до стадии реализации, при этом сохраненное время, больше затраченного.
Например, на тестирование требований не обязательно подключаться всем QA команды. Это могут делать отдельные сотрудники. Кроме того, в результате проверки требований часто происходят мелкие правки ТЗ, которые делают его более понятным и однозначным, что в итоге сокращает время, которое уходит на вопросы и пояснения при разработке.
Вариант 2. Тестирование силами разработчика
Довольно популярный способ сэкономить на проекте. Но, как показывает практика, мнимая экономия на часах QA-специалистов может обернуться серьезными потерями от исправления пропущенных багов и замедлением работы. Да и в целом является экономически невыгодной. Далее расскажем подробнее.
Тестирование ПО возникло практически одновременно с появлением софта для компьютеров. Изначально оно было исчерпывающим. При таком тестировании перебирались все возможные входные параметры программы. Занимались этим сами разработчики. Однако усложнение ПО сделало исчерпывающее тестирование слишком долгим, а в итоге и невозможным. Вследствие этого от специалистов понадобились специальные навыки, которыми не обладали разработчики. Так появились профессиональные тестировщики. Разработчик может заниматься тестированием, только он будет это делать не слишком эффективно, поскольку он не специализируется на этом виде деятельности.
Наши QA-специалисты нередко подключаются на проекты, где не было тестирования как процесса, выполняемого отдельными людьми. Приемочный аудит таких проектов показывает, что отношение количества багов критичности major и выше к общему количеству фичей составляет 26,4 %
После подключения профессиональных QA этот процент сокращается до 1,3 %. Небольшой процент сохраняется, так как в выборке присутствуют проекты, где допустимо выкатывать релизы с определенным количеством major багов.
Еще один аргумент против тестирования силами разработчика – экономическая нецелесообразность. Пока он тестирует, процесс создания новых фич стоит на месте. А если принять во внимание стоимость рабочего часа, то вывод напрашивается сам собой: использовать разработчиков для полноценного тестирования ПО – дорого, медленно и малоэффективно. При этом мы еще не учитываем упущенную выгоду из-за пользователей, которые обнаружили пропущенные дефекты в продукте и отказались от его использования, репутационные потери и прочее.
Вариант 3. Отказ от регресса
Регрессионное тестирование (далее – регресс) – проверка ранее протестированного ПО или его отдельных компонентов, которая позволяет удостовериться, что последние внесенные изменения не повлекли за собой появления дефектов в неизмененной части программы.
Важная особенность регресса – в его регулярности. При этом может возникнуть вопрос: зачем тестировать то, что уже протестировано? Это непонимание впоследствии перерождается в отказ от проведения регрессионного тестирования.
Необходимость и польза его проведения становится очевидной при детальном изучении жизненного цикла ПО.
Практически все современные проекты после выхода в релиз к пользователю продолжают развиваться: наполняться новыми функциями, переезжать на более современные технологии, оптимизироваться и т.п. Кроме того, приложения часто зависят от «внешней среды» стороннего ПО, которое тоже меняется, и не про все изменения вы можете знать.
Эти изменения, как правило, проводятся в локализованных компонентах системы и прямо влияют только на них. Тестирование изменений включает в себя стандартный набор из функциональных и нефункциональных тестов. Однако из-за сложности современных приложений корректировки в одном компоненте могут вызвать проблемы в других. И тут, конечно, можно сказать, что такие баги должно выявлять интеграционное тестирование, но часто влияние изменений не всегда очевидно.
Интеграционное тестирование предназначено для проверки связей между компонентами ПО, а также взаимодействия со сторонними программами. При этом функциональность продукта, которую пользователь ожидает видеть исправным, не должна пострадать.
Для таких случаев и существует регресс. Он позволяет убедиться, что незатронутые изменениями части ПО или всё в целом работает корректно. О важности проведения регресса говорит статистика возникновения регрессионных багов – ошибок, которые возникли в результате изменений в смежном функционале.
Для исследования мы выбрали 46 проектов, каждый из которых был выпущен в релиз и просуществовал не менее полугода.

Выборка также позволила вычислить коэффициент количества регрессионных багов в зависимости от размера проекта. При расчетах за единицу было взято количество регрессионных багов на небольшом проекте.
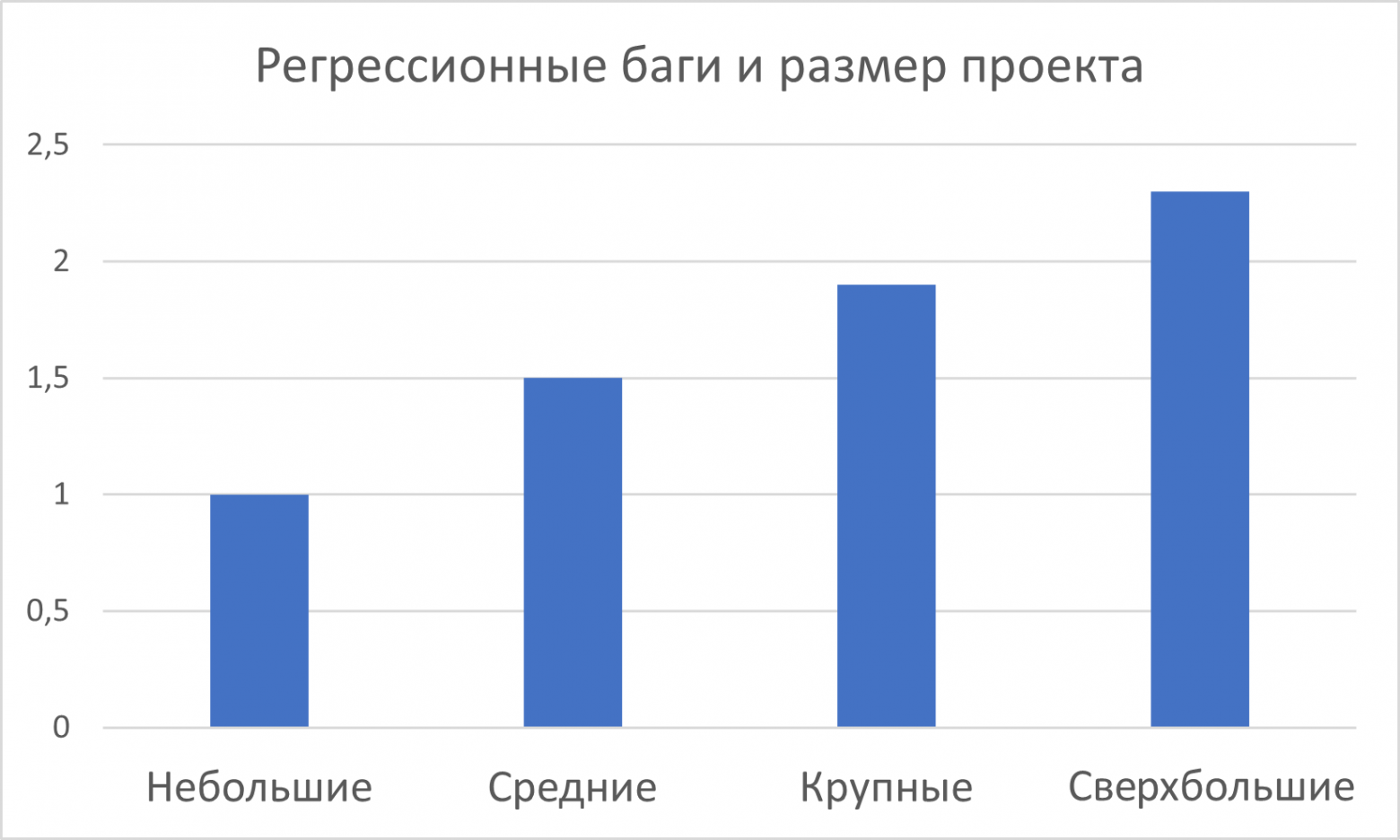
Анализ частоты возникновения регрессионных дефектов позволяет выделить два факта:
-
Появление регрессионных дефектов с развитием проекта неизбежно.
-
Чем сложнее и крупнее проект, тем больше вероятность появления регрессионных багов.
Но при этом нельзя забывать о рациональном подходе к любым процессам. Очевидно, что при регулярных прогонах полного списка тест-кейсов затраты на регресс едва ли будут себя оправдывать. Поэтому для повышения эффективности применяют различные способы оптимизации, например, логичным способом снижения затрат является автоматизация регресс-тестов.
Кроме технических решений, разумно применять оптимизацию процессов тестирования и разделять регрессы по количеству производимых проверок на:
– крупные, которые будут проводится после изменений в ключевых компонентах;
– средние – в зависимости от серьезности внесенных изменений;
– мелкие, прогоняемые после каждого изменения в ПО.
При микросервисной архитектуре проекта регрессы можно разделить по функциональным компонентам и проводить тестирование только тех модулей IT-системы, которые связаны с измененной частью.
Таким образом, проведение регрессионного тестирования – необходимый процесс в современной разработке приложений, который позволяет предотвратить встречу пользователя с дефектами. Грамотная оптимизация этого процесса помогает существенно сократить затраты при сохранении общей эффективности.
Вариант 4. Отказ от тестовой документации
Тестовая документация – совокупность документов, которые создаются перед началом тестирования, а в некоторых случаях и в процессе. Она описывает покрытие требований тестами, а также процесс выполнения проверки ПО. В документации указывается вся информация, необходимая для тестирования. С точки зрения процессов она используется для структурирования работы QA.
Тестовая документация бывает низкоуровневая, в которой описаны непосредственно проверки (тест-кейсы, тест-сьюты, чек-листы и т.д.) и высокоуровневая – с описанием процесса тестирования, необходимых ресурсов, критериев завершения тестирования и требований к качеству релиза. Все это позволяет повысить вероятность отсутствия дефектов и предоставления качественного ПО для конечных пользователей.
Разумеется, создание тестовой документации требует времени, на котором часто экономят. Бытует мнение, что тестовая документация – это неоправданная трата времени и можно тестировать ПО без нее. Такое суждение складывается из-за непонимания последствий её отсутствия и неумения применять оптимальные виды документации в зависимости от особенностей проекта.
Начнем с первого. Тестовая документация позволяет планомерно, обстоятельно и полноценно оценить смысл и масштабы проверяемого функционала и покрыть его тестами. Её отсутствие не позволяет понять полную картину проекта и необходимого объема проверок. Без четких целей, пошагового плана их достижения и указания всех важных условий ожидаемый результат не будет ясен. В таких случаях велика вероятность забыть важные проверки и пропустить критичные баги. Это особенно актуально при работе со сложными продуктами или часто меняющихся требованиях.
Теперь поговорим о рациональном применении различных видов тестовой документации. Практика показывает, что наибольшие затраты времени уходят на написание низкоуровневой документации, в частности, тест-кейсов.
Тест-кейс – своего рода «инструкция» по проверке узкой части функционала в определенных условиях. Этот вид документации содержит пошаговое описание проверки и формулировку ожидаемого поведения системы в данных условиях. Тест-кейсы удобны, понятны и подробны, они позволяют добиться минимальной вероятности пропуска дефектов. Но при этом создавать их долго, ведь для качественной проверки одной фичи могут потребоваться десятки тест-кейсов.
Этот вид документации оправдывает себя, если тестируемая функциональность сложна и наполнена неочевидной логикой или для проведения теста нужна определенная совокупность условий, которую необходимо строго выполнить.
Есть и менее трудозатратные виды тестовой документации, например, чек-лист. Он не содержит шаги, а ожидаемый результат поведения функции сформулирован в самом названии проверки. По сути, это список того, какие входные условия и выходные параметры нужно проверить в фиче. Чек-листы быстры в написании и актуализации, позволяют добиться должного уровня покрытия тестами и уверенности в отсутствии дефектов. Но минусы тоже есть. Поскольку шаги воспроизведения проверок не записаны явно и фактически хранятся в памяти специалиста, эффективно пользоваться чек-листом может только написавший его человек.
Документация позволяет фиксировать результаты тестирования, что позволяет получить данные об объеме пройденных проверок и различные показатели по найденным багам. То есть открывается возможность собирать метрики о качестве продукта, управлять развитием проекта и более эффективно вносить улучшения.
Исходя из вышесказанного, тестовая документация – не пустая трата времени, а инвестиция в качество проекта. Грамотное применение различных видов тестовой документации и их комбинаций оправдывает затраты и позволяет минимизировать риск попадания к пользователю дефектного ПО.
Вместо вывода
Подводя общий итог, хочу еще раз подчеркнуть, что рациональное использование бюджета проекта – важная задача, которая требует навыков планирования, прогнозирования и опыта. Без планирования работы команды и прогнозирования последствий управленческих решений, экономия получается сиюминутная, и зачастую она приводит к проблемам или повышенным расходам на поздних этапах жизни проекта. А без опыта работы не будет понимания причин и следствий проблем, а также примеров успешных решений.
Поделитесь в комментариях своим опытом.
Когда мы обсуждаем вопрос создания программного обеспечения, то говорим не только про архитектуру, технологии, навыки, но и про экономику. Абсолютно все проекты требуют бюджета, и он не может быть бесконечным. Необходимость рационального использования средств очевидна всем, а про необоснованную экономию порой умалчивают. А зря, ведь это в конечном итоге приводит к повышенным тратам.
Экономия затрагивает самые разные сферы проекта и специалистов. В этой статье рассмотрим обеспечение качества (QA). Бизнес нередко считает, что тестирование – та часть проекта, на которой можно сэкономить, что за качество должны отвечать разработчики, а QA-специалистов иногда можно и не привлекать. Мы постараемся на конкретных примерах показать, к каким последствиям приводят наиболее популярные случаи экономии на QA.
Вариант 1. Отсутствие тестирования на ранних этапах
Начнем с классического случая экономии на проекте – отсутствия тестирования на ранних этапах жизненного цикла ПО.
Первоначальная выгода от такого решения кажется очевидной – пока не накопилось достаточного объема кода для тестирования, подключение QA-специалистов некритично. Однако оправданность такого решения при детальном рассмотрении оказывается сомнительной.
Многие слышали фразу «Чем раньше найден баг, тем проще и дешевле его исправить», давайте разберемся, почему это так и насколько дешевле. Поскольку баги появляются в фичах, представим упрощенный жизненный цикл фичи, который существует в большинстве проектов:
- Идея
- Написание технического задания (далее – ТЗ)
- Реализация
- Тестирование
- Выход в релиз
Обратите внимание, что на этой схеме QA подключаются довольно поздно – на этапе тестирования. Используя этот алгоритм, легко вычислить, что:
- Если в фиче нет дефектов, то каждый участник жизненного цикла затрачивает свое время 1 раз, таким образом разработка стоит 5 условных часов.
- Если баг допущен на этапе реализации и найден на этапе тестирования, то разработчик и QA затрачивают по одной дополнительной единице времени: на фикс бага и на повторное тестирование (ретест) исправленной фичи, соответственно. В итоге получается: 5+2=7 единиц времени. У вас может возникнуть вопрос, почему мы считаем 5 часов, а не 4, если после тестирования фича не пошла в релиз? Потому что после исправлений и повторного тестирования все равно наступает релиз.
- Если баг допущен на этапе написания ТЗ и найден на этапе тестирования, то единиц времени будет 8 (5+3 на: исправление ТЗ, фикс бага , ретест)
- Если баг допущен в самой идее фичи и выявлен на этапе тестирования, то будет затрачено 9 единиц времени (5+4 на: коррекцию идеи, исправление ТЗ, фикс бага, ретест исправлений)
Теперь давайте представим, что QA подключается на более раннем этапе – между написанием ТЗ и разработкой – и тестирует требования. В этом случае баги можно будет выявить раньше и сэкономить время.
Тестирование постановок (ТЗ) – одно из популярных решений тренда на раннее тестирование или, как это называют некоторые компании, «shift left».
_page-0001.jpg")
В третьем и четвертом случаях это будет 1 и 2 единицы времени соответственно. Однако можно заметить, что в первом и втором случаях происходит увеличение затрачиваемого времени на 1 единицу. Где же выгода? Добавим в теоретическую модель данные о статистике возникновения дефектов и реально затрачиваемом времени на тестирование требований и исправления постановок и кода.
Начнем с возникновения дефектов. Мы собрали статистику со 117 проектов в различных сферах и анализ показал, что 66 % багов возникают на этапе реализации (написания кода), 31% — на этапе постановки задачи и 3% дефектов содержатся в идеях фич.

Возникает вопрос: «А как же интеграционные баги?» Фича рассматривается как самостоятельная сущность, а интеграционный баг – это либо проблема внешнего сервиса и ее не решить силами команды, либо фича неправильно взаимодействует с исправным внешним компонентом.
Представим, что ваше приложение взаимодействует с внешним сервисом файлового хранилища, которое в один момент перестало отвечать. Соответственно, в самом приложении сломаются все функции, которые связаны с внешним файл-сервером. Это и будет интеграционным багом.
Переходим ко времени, которое затрачивается на тестирование требований.

Практика показывает, что тестирование требований на одну фичу (именно требований, а не фич) в среднем занимает от 25 минут до 6 часов. Значения более 2,5 часов встречаются крайне редко, а 4 и более часа ревью свидетельствуют о том, что фича перегружена требованиями и ей требуется декомпозиция.
Теперь рассмотрим время, затрачиваемое на корректировку ТЗ.

Исправления ТЗ занимают от 10 минут в случае мелких опечаток до 9-10 часов, если нужна серьезная переработка логики, получение дополнительной информации, созвоны, согласования, ожидание ответов и т.д.
И наконец, изучим распределение времени, которое тратится на исправление кода.
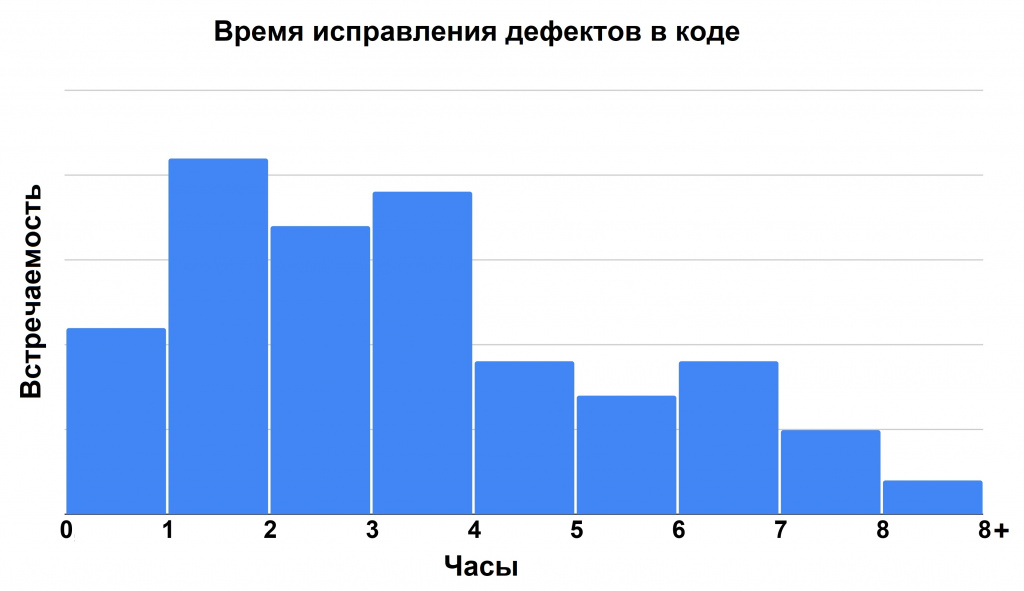
На фиксы дефектов в коде уходит от 20 минут до 8 часов, в зависимости от сложности багов и если при исправлении не возникает критических противоречий с существующим кодом, стенды работоспособны, а ТЗ достаточное для работы.
Анализ диаграмм позволяет сделать несколько выводов:
- Весомая доля (около 31%) дефектов зарождается на этапе создания ТЗ
- Типичное время тестирования ТЗ меньше, чем типичное время исправления кода (багофикса)
Обогащение модели жизненного цикла фичи реальными данными было бы не полным без сравнения затрат времени на реализацию. Однако, тут прикладывать какие бы то ни было диаграммы распределения времени сложно, поскольку информация получена с разных проектов, где фичи сильно различаются по размеру и трудоемкости. Значит, без объяснения, что делалось при реализации задачи, трудно понять затраты времени на нее. Более показательна статистика с проектов, где внедрили тестирование требований, как один из вариантов тестирования на ранних этапах разработки.

На графике видно, что среднее время жизненного цикла фичи снизилось на величину от полутора до семи часов. Такая экономия времени происходит не только благодаря внедрению раннего тестирования, но и оптимизации его применения. То есть в реальности, даже с учетом того что в постановке изъянов может не быть, тестирование ТЗ все равно оправдывает себя за счет того что в случае наличия таких дефектов, они выявляются до стадии реализации, при этом сохраненное время, больше затраченного.
Например, на тестирование требований не обязательно подключаться всем QA команды. Это могут делать отдельные сотрудники. Кроме того, в результате проверки требований часто происходят мелкие правки ТЗ, которые делают его более понятным и однозначным, что в итоге сокращает время, которое уходит на вопросы и пояснения при разработке.
Вариант 2. Тестирование силами разработчика
Довольно популярный способ сэкономить на проекте. Но, как показывает практика, мнимая экономия на часах QA-специалистов может обернуться серьезными потерями от исправления пропущенных багов и замедлением работы. Да и в целом является экономически невыгодной. Далее расскажем подробнее.
Тестирование ПО возникло практически одновременно с появлением софта для компьютеров. Изначально оно было исчерпывающим. При таком тестировании перебирались все возможные входные параметры программы. Занимались этим сами разработчики. Однако усложнение ПО сделало исчерпывающее тестирование слишком долгим, а в итоге и невозможным. Вследствие этого от специалистов понадобились специальные навыки, которыми не обладали разработчики. Так появились профессиональные тестировщики.
Разработчик может заниматься тестированием, только он будет это делать не слишком эффективно, поскольку он не специализируется на этом виде деятельности.
Наши QA-специалисты нередко подключаются на проекты, где не было тестирования как процесса, выполняемого отдельными людьми. Приемочный аудит таких проектов показывает, что отношение количества багов критичности major и выше к общему количеству фичей составляет 26,4 %.
Критичность «major» означает значительную ошибку, при которой часть основной бизнес-логики работает некорректно.
После подключения профессиональных QA этот процент сокращается до 1,3 %. Небольшой процент сохраняется, так как в выборке присутствуют проекты, где допустимо выкатывать релизы с определенным количеством major багов.
Еще один аргумент против тестирования силами разработчика – экономическая нецелесообразность. Пока он тестирует, процесс создания новых фич стоит на месте. А если принять во внимание стоимость рабочего часа, то вывод напрашивается сам собой: использовать разработчиков для полноценного тестирования ПО – дорого, медленно и малоэффективно. При этом мы еще не учитываем упущенную выгоду из-за пользователей, которые обнаружили пропущенные дефекты в продукте и отказались от его использования, репутационные потери и прочее.
Вариант 3. Отказ от регресса
Регрессионное тестирование (далее – регресс) – проверка ранее протестированного ПО или его отдельных компонентов, которая позволяет удостовериться, что последние внесенные изменения не повлекли за собой появления дефектов в неизмененной части программы.
Важная особенность регресса – в его регулярности. При этом может возникнуть вопрос: зачем тестировать то, что уже протестировано? Это непонимание впоследствии перерождается в отказ от проведения регрессионного тестирования.
Необходимость и польза его проведения становится очевидной при детальном изучении жизненного цикла ПО.
Практически все современные проекты после выхода в релиз к пользователю продолжают развиваться: наполняться новыми функциями, переезжать на более современные технологии, оптимизироваться и т.п. Кроме того, приложения часто зависят от «внешней среды» стороннего ПО, которое тоже меняется, и не про все изменения вы можете знать.
Эти изменения, как правило, проводятся в локализованных компонентах системы и прямо влияют только на них. Тестирование изменений включает в себя стандартный набор из функциональных и нефункциональных тестов. Однако из-за сложности современных приложений корректировки в одном компоненте могут вызвать проблемы в других. И тут, конечно, можно сказать, что такие баги должно выявлять интеграционное тестирование, но часто влияние изменений не всегда очевидно.
Интеграционное тестирование предназначено для проверки связей между компонентами ПО, а также взаимодействия со сторонними программами. При этом функциональность продукта, которую пользователь ожидает видеть исправным, не должна пострадать.
Для таких случаев и существует регресс. Он позволяет убедиться, что незатронутые изменениями части ПО или всё в целом работает корректно. О важности проведения регресса говорит статистика возникновения регрессионных багов – ошибок, которые возникли в результате изменений в смежном функционале.
Для исследования мы выбрали 46 проектов, каждый из которых был выпущен в релиз и просуществовал не менее полугода.

Выборка также позволила вычислить коэффициент количества регрессионных багов в зависимости от размера проекта. При расчетах за единицу было взято количество регрессионных багов на небольшом проекте.

Анализ частоты возникновения регрессионных дефектов позволяет выделить два факта:
- Появление регрессионных дефектов с развитием проекта неизбежно.
- Чем сложнее и крупнее проект, тем больше вероятность появления регрессионных багов.
Но при этом нельзя забывать о рациональном подходе к любым процессам. Очевидно, что при регулярных прогонах полного списка тест-кейсов затраты на регресс едва ли будут себя оправдывать. Поэтому для повышения эффективности применяют различные способы оптимизации, например, логичным способом снижения затрат является автоматизация регресс-тестов.
Кроме технических решений, разумно применять оптимизацию процессов тестирования и разделять регрессы по количеству производимых проверок на:
— крупные, которые будут проводится после изменений в ключевых компонентах,
— средние – в зависимости от серьезности внесенных изменений,
— мелкие, прогоняемые после каждого изменения в ПО.
При микросервисной архитектуре проекта регрессы можно разделить по функциональным компонентам и проводить тестирование только тех модулей IT-системы, которые связаны с измененной частью.
Таким образом, проведение регрессионного тестирования – необходимый процесс в современной разработке приложений, который позволяет предотвратить встречу пользователя с дефектами. Грамотная оптимизация этого процесса помогает существенно сократить затраты при сохранении общей эффективности.
Вариант 4. Отказ от тестовой документации
Тестовая документация – совокупность документов, которые создаются перед началом тестирования, а в некоторых случаях и в процессе. Она описывает покрытие требований тестами, а также процесс выполнения проверки ПО. В документации указывается вся информация, необходимая для тестирования. С точки зрения процессов она используется для структурирования работы QA.
Тестовая документация бывает низкоуровневая, в которой описаны непосредственно проверки (тест-кейсы, тест-сьюты, чек-листы и т.д.) и высокоуровневая – с описанием процесса тестирования, необходимых ресурсов, критериев завершения тестирования и требований к качеству релиза. Все это позволяет повысить вероятность отсутствия дефектов и предоставления качественного ПО для конечных пользователей.
Разумеется, создание тестовой документации требует времени, на котором часто экономят. Бытует мнение, что тестовая документация – это неоправданная трата времени и можно тестировать ПО без нее. Такое суждение складывается из-за непонимания последствий её отсутствия и неумения применять оптимальные виды документации в зависимости от особенностей проекта.
Начнем с первого. Тестовая документация позволяет планомерно, обстоятельно и полноценно оценить смысл и масштабы проверяемого функционала и покрыть его тестами. Её отсутствие не позволяет понять полную картину проекта и необходимого объема проверок. Без четких целей, пошагового плана их достижения и указания всех важных условий ожидаемый результат не будет ясен. В таких случаях велика вероятность забыть важные проверки и пропустить критичные баги.
Это особенно актуально при работе со сложными продуктами или часто меняющихся требованиях.
Теперь поговорим о рациональном применении различных видов тестовой документации. Практика показывает, что наибольшие затраты времени уходят на написание низкоуровневой документации, в частности, тест-кейсов.
Тест-кейс – своего рода «инструкция» по проверке узкой части функционала в определенных условиях. Этот вид документации содержит пошаговое описание проверки и формулировку ожидаемого поведения системы в данных условиях. Тест-кейсы удобны, понятны и подробны, они позволяют добиться минимальной вероятности пропуска дефектов. Но при этом создавать их долго, ведь для качественной проверки одной фичи могут потребоваться десятки тест-кейсов.
Этот вид документации оправдывает себя, если тестируемая функциональность сложна и наполнена неочевидной логикой или для проведения теста нужна определенная совокупность условий, которую необходимо строго выполнить.
Есть и менее трудозатратные виды тестовой документации, например, чек-лист. Он не содержит шаги, а ожидаемый результат поведения функции сформулирован в самом названии проверки. По сути, это список того, какие входные условия и выходные параметры нужно проверить в фиче. Чек-листы быстры в написании и актуализации, позволяют добиться должного уровня покрытия тестами и уверенности в отсутствии дефектов. Но минусы тоже есть. Поскольку шаги воспроизведения проверок не записаны явно и фактически хранятся в памяти специалиста, эффективно пользоваться чек-листом может только написавший его человек.
Документация позволяет фиксировать результаты тестирования, что позволяет получить данные об объеме пройденных проверок и различные показатели по найденным багам. То есть открывается возможность собирать метрики о качестве продукта, управлять развитием проекта и более эффективно вносить улучшения.
Исходя из вышесказанного, тестовая документация – не пустая трата времени, а инвестиция в качество проекта. Грамотное применение различных видов тестовой документации и их комбинаций оправдывает затраты и позволяет минимизировать риск попадания к пользователю дефектного ПО.
Вместо вывода
Подводя общий итог, хочу еще раз подчеркнуть, что рациональное использование бюджета проекта – важная задача, которая требует навыков планирования, прогнозирования и опыта. Без планирования работы команды и прогнозирования последствий управленческих решений, экономия получается сиюминутная, и зачастую она приводит к проблемам или повышенным расходам на поздних этапах жизни проекта. А без опыта работы не будет понимания причин и следствий проблем, а также примеров успешных решений.
Понравилась статья?
Подпишитесь на рассылку SimbirSoft! Пришлём письма о лайфхаках в разработке, поделимся опытом управления командами и компанией, а также расскажем о новых ивентах SimbirSoft.
Загрузка…