Предлагаю ознакомиться с расшифровкой доклада начала 2019 года Алексея Лесовского — «Поиск и устранение проблем в Postgres с помощью pgCenter»
Время от времени при эксплуатации Postgres’а возникают проблемы, и чем быстрее найдены и устранены источники проблемы, тем благодарнее пользователи. pgCenter это набор CLI утилит которые является мощным средством для выявления и устранения проблем в режиме «здесь и сейчас». В этом докладе я расскажу как эффективно использовать pgCenter для поиска и устранения проблем, в каких направлениях осуществлять поиск и как реагировать на те или иные проблемы, в частности, как:
- проверить, все ли в порядке с Postgres’ом;
- быстро найти плохих клиентов и устранить их;
- выявлять тяжелые запросы;
- и другие полезные приемы с pgCenter.

Всем привет, меня зовут Алексей Лесовский. Я работаю в компании Data Egret. Это консалтинговая компания. И я вам расскажу, как мы в нашей консалтинговой компании занимаемся поиском и устранением неисправностей в PostgreSQL.
Я расскажу о том, как с помощью консольной утилиты pgCenter можно хорошо, быстро и эффективно находить самые разные проблемы и переходить к их устранению.

Немного о себе. Я долгое время был системным администратором. Занимался Linux, виртуализацией, мониторингом. И в какой-то момент времени стал заниматься больше Postgres’ом. И работа с Postgres стала занимать большую часть времени. И так я стал PostgreSQL DBA. И сейчас уже работая в консалтинговой компании, я работаю с Postgres каждый день. И каждый день наши заказчики предоставляют нам самый разный материал для новых конференций.

Все общение с нашими заказчиками происходит в виде беседы в чатах. Это самые разные чаты: Slack, Telegram. Но наши заказчики часто обнаруживают какую-нибудь проблему у себя и пишут. Мы в свою очередь должны на это отреагировать.

На слайде всем широко известная диаграмма Брендана Грэгга, как находить различные проблемы, связанные с производительностью в Linix. Это довольно познавательная диаграмма. Она показывает, как устроен Linux и какие утилиты есть для нахождения проблем. По сути, можно обложиться всеми этими утилитами и смотреть, что происходит.

Но в любом случае мы увидим то, что у нас все замыкается на Postgres. Процессорное время потребляется Postgres. Дисковый ввод-вывод так же генерируется Postgres’ом. Всю память съел тоже Postgres. Мы будем видеть только один Postgres.
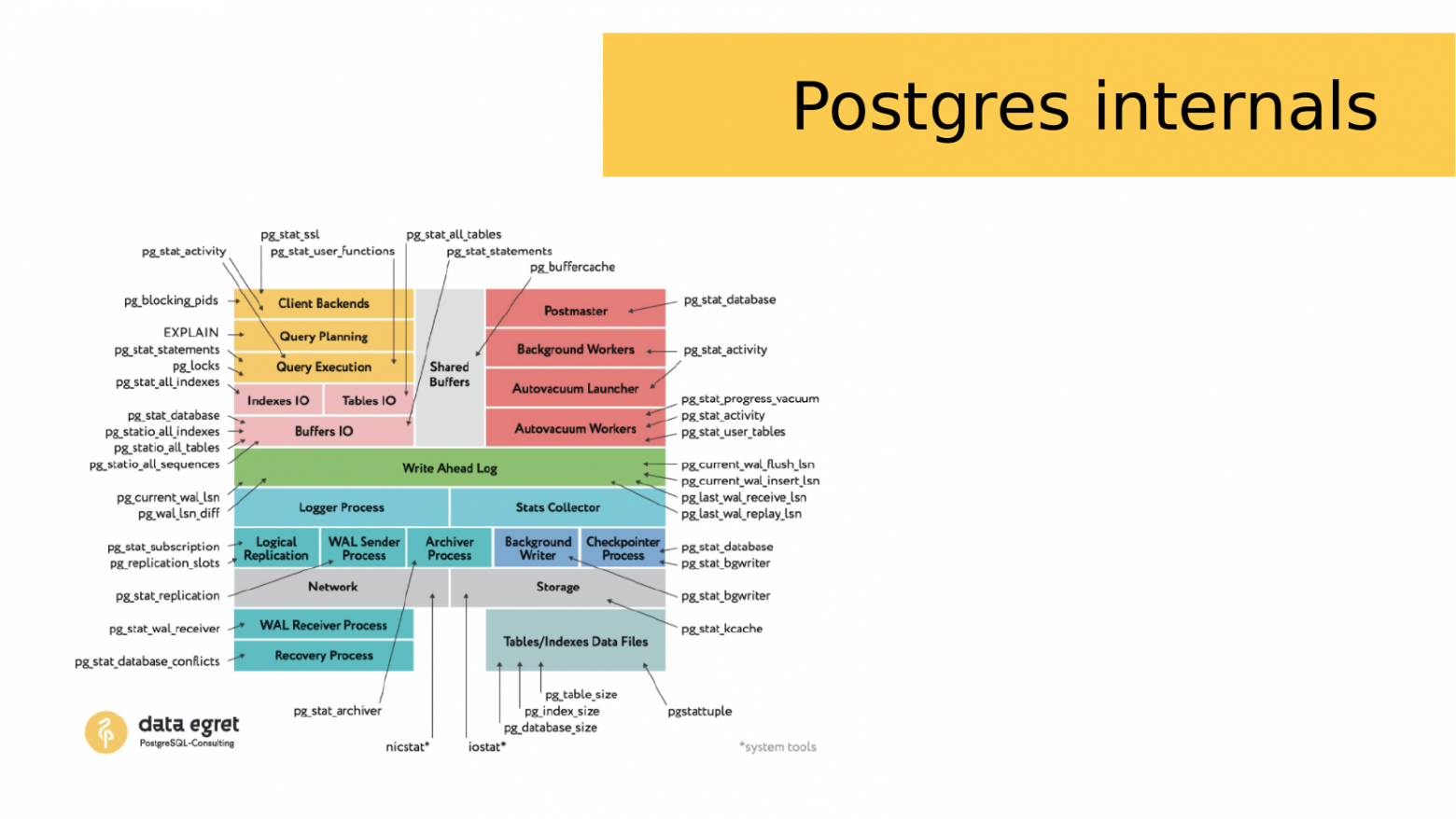
Для Postgres есть аналогичная картинка. Она также разбивает Postgres на несколько подсистем и показывает из чего состоит Postgres. Кроме того, в Postgres есть большое количество статистических представлений (views), с помощью которых можно анализировать работу этих подсистем.
И этих статистических представлений довольно много. Но во всех этих представлениях есть колонки. Эти колонки имеют собственные имена. И держать все это в голове бывает довольно-таки сложно.

И когда ты начинаешь искать какую-то проблему, нужно вспомнить имена нужных представлений, найти свои скрипты, которые ты, возможно, заранее приготовил. И это довольно-таки тяжело. И одновременно возникает масса вопросов: «Что тормозит?», «Где тормозит?» и «Что с этим делать?». На поиск всего этого нужно время, которого как обычно мало.

И разбираясь с проблемой одного из заказчиков, когда я тоже разбирал свои скрипты и пытался диагностировать проблему выполняя рутинные однообразные действия, мне пришла в голову идея, что нужна программа, которая будет это все дело облегчать. Более-менее хороших программ не нашлось и так пришла идея написать pgCenter.
Изначально она была написана на С. Это консольная утилита, которая показывала статистику в TOP-подобном виде.
Через какое-то время я понял, что C мне не очень подходит. т.к. я не профессиональный программист. И я переписал ее на Golang, этот язык показался мне более простым, но при этом напоминал С. И мне на нем легче добавлять новые функции.
Go это компилируемый язык и чтобы использовать pgCenter его нужно скомпилировать. Но в репозитории уже есть пакеты и вам как пользователю не нужно компилировать программу самостоятельно. К репозиторию подключена система сборки, которая после каждого коммита, компилирует бинарник, собирает targz, deb- и rpm-пакеты и выкладывает их в релизы. Т.е. не нужно устанавливать какие-то пакеты, ставить make, GCC или Golang. Достаточно просто зайти в релизы, скопировать нужный пакет по ссылке, распаковать руками или установить через дефолтный пакетный менеджер и можно уже пользоваться.

Изначально весь pgCenter представлял собой именно просмотрщик статистики, который в top-режиме показывает текущие изменения статистики за последнюю секунду (интервал изменений настраивается).

Однако потом я начал добавлять новые функции. И позже уже появились такие штуки, как сохранение статистики в файл и построение отчетов. И буквально совсем недавно я добавил сэмплер wait_events. Это штука позволяет смотреть, на каком месте запросы проводят время в ожидании чего-либо.

По ходу разработки я постарался сохранить синтаксис команды PSQL. Если вы работаете с Postgres, вы знаете что запустив PSQL без аргументов и параметров можно подключиться к Postgres. С pgCenter тоже самое, достаточно запустить «pgcenter top» из под postgres пользователя и она начнет показывать вам какую-то статистику (по-умолчанию, текущая активность в БД).

В более сложных случаях, если вы работаете от другого пользователя или нужно подключиться к какой-то другой базе, или к БД, которая находится на другом хосте, то можно указать те же самые ключи, которые вы используете в PSQL, которые определяют подключения к хосту, к конкретному порту, к конкретной базе и под конкретным именем пользователя.

Но можно даже не указывать хост, можно подключаться через UNIX-сокеты, т. к. go’шный драйвер, который используется под капотом pgCenter позволяет подключиться не только к сетевым сокетам, но и к UNIX.

Кроме того, тот же драйвер поддерживает переменные окружения libpq. Даже если у вас особенный случай, например, pg_stat_statements установлен в отдельной схеме и pgCenter не может его найти, то можно переопределить поведение через переменные окружения. Это тоже поддерживается.
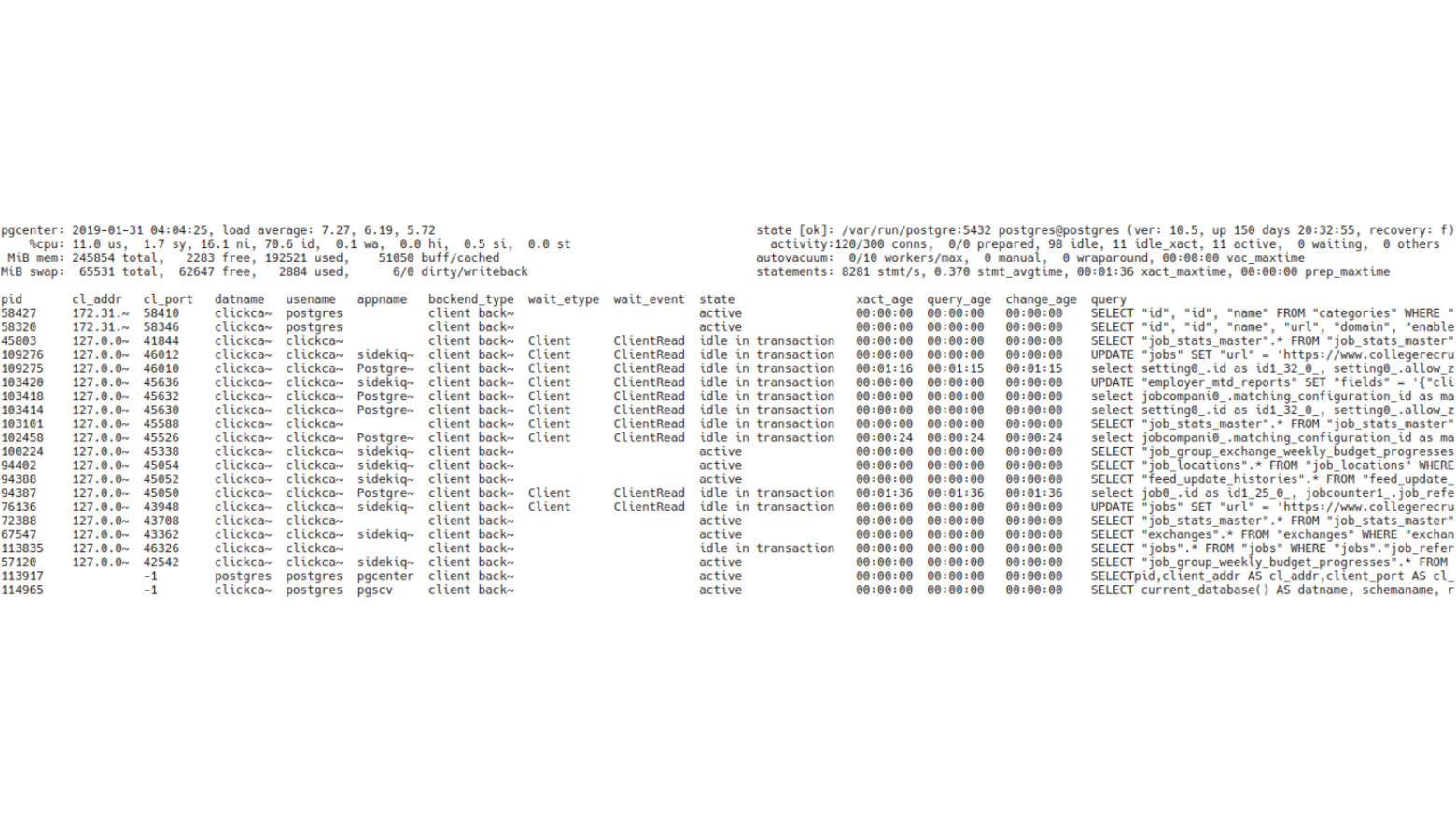
И вот так выглядит внешний вид утилиты (pgcenter top). И в первый раз, когда ее запускаешь, это может немного напрячь. Это похоже, что это какой-то центр управления полетами. Много цифр, много букв, все это быстро меняется. Но это на самом деле не важно. Здесь важно помнить, что интерфейс pgCenter, а именно top-просмотрщика, состоит из трех частей.

Первая часть – системная информация. Эта информация находится в верхнем левом углу.

Вторая часть – верхний правый угол, здесь располагается сводная информация по Postgres. Здесь можно получить уже какую-то детальную информацию о том, как Postgres работает в данный момент.

И третья часть – статистика из самих статистических представлений (views). Здесь информация из stat-представлений, которые есть в Postgres, в этой части отображаются изменения этой статистики.

Кроме того, интерфейс предоставляет дополнительные функции. Нажимая стрелки влево-вправо, вы можете менять сортировку. Вы можете указать сортировать строки по интересующему вас полю. Например, сортировку по именам таблиц, сортировку по текстам запросов, по времени и жизни транзакций, и т. д.
Если информации слишком много, можно использовать фильтры. В качестве фильтров там применяются регулярные выражения (regexp). И вы можете отфильтровать выводимую инфоормацию по интересующим вас критериям. Например, показать запросы конкретного пользователя, базы или конкретно какие-то запросы: селекты или апдейты.
Далее в докладе я расскажу, с какими конкретно кейсами вы можете столкнуться у себя в работе и какие подходы можете применять используя pgCenter. И самый основной кейс – это проверка все ли в порядке с базой и нет ли там каких-то проблем.

И здесь мы все делаем, как по известному USE методу. Нам нужно определить использование ресурсов. Если ресурсы используются более-менее хорошо и прекрасно, то мы смотрим наличие ошибок.

Для этого мы начинаем смотреть системную информацию. У нас есть информация об использовании процессора. Всем, кто знаком с утилитой линуксовой Top, вот этот раздел статистики будет очень хорошо знаком. Он показывает утилизацию процессора: системную, пользовательскую и т.д.

Если нам интересно посмотреть память, то в этой же строке также мы можем посмотреть и память: сколько у нас есть памяти вообще, сколько свободно, сколько занято.

И, соответственно, swap. Если в системе есть swap, а для базы данных он важен, то можно посмотреть еще и статистику по swap. Таким образом в части по системной статистике можно быстро определить – есть ли у нас проблема с утилизацией ресурсов.

Кто-то может спросить: «А как с блочным вводом-выводом и сетью?». Эта статистика тоже есть. Ее я покажу чуть позже, по ней тоже есть цифры.

Когда мы посмотрели нет ли у нас проблем с утилизацией ресурсов, мы можем идти к проверке – нет ли у нас каких-либо ошибок на уровне работы Postgres. Мы можем посмотреть uptime. Вообще, uptime в Postgres – не совсем честный, но тем не менее это лучше, чем совсем ничего. С аптаймом можно быстро определить, как давно у нас работает Postgres и не было ли у него незапланированных рестартов.

Кроме того мы можем посмотреть состояние по подключениям. Не все клиенты, которые работают с Postgres, могут быть хорошими. У нас могут быть ждущие транзакции, которые находятся в ожидании, или транзакции которые ничего не делают. Т. е. это та активность которую важно отслеживать и вовремя принимать меры.

И, конечно, автовакуум. Я думаю, многие из вас знают, что такое автовакуум. С ним связано много интересных историй, поэтому про вакуум тоже можно посмотреть. Например, сколько воркеров запущено и посмотреть их длительность. И после этого можно как-то реагировать на эту информацию.

И долгие транзакции, потому что Postgres MVCC база данных. В ней MVCC движок. И он очень сильно зависит от того, как долго там работают транзакции. Поэтому самые долгие транзакции тоже важно отслеживать и быстро о них узнавать.

На этом слайде было переключение на статистику баз данных с помощью горячей клавиши ‘d’.
Говоря про ошибки, важно отметить pg_stat_database которая предоставляет некоторое количество информации об ошибках, тут нас интересует поле «rollbacks». Это поле не только про команду «ROLLBACK», но еще и про различные ошибки которые привели к отмене запроса/транзакции. Это могут быть ошибки нарушения ограничений (constraints), это могут быть ошибки синтаксиса и т. п. По этой статистике можно уже отследить, что происходит в базе.
И плюс в pg_stat_database есть еще информация по конфликатм репликации (conflicts) и взаимоблокировкам (deadlocks). По сути, это тоже виды ошибок, которые говорят о том, что в базе что-то идет не так.

ОК, мы запустили pgCenter. И за относительно короткое время мы смогли посмотреть много вещей, ради которых нам бы пришлось запустить несколько утилит. Во-первых, это:
-
top
-
vmstat
-
iostat
-
nicstat
-
pg_stat_activity
-
pg_stat_statements
Плюс там еще использовали некоторые функции, которые тоже показывают информацию в более понятном виде.

Допустим, что в процессе проверки мы обнаружили, что у нас какая-то есть нагрузка на процессор.

Вот такой простой пример. Вам не обязательно все это рассматривать, важно отследить те места, которые используются в процессе оценки. Т. е. здесь CPU usage – 85 %. Это говорит о том, что у нас нагрузка на процессоры довольно-таки высокая. И нам нужно найти, кто же так активно использует процессора. Понятно, что это Postgres. Нам нужно заглянуть глубже в Postgres и посмотреть, какие типы запросов у нас больше всего потребляют процессорного времени.

Если мы посмотрим на вторую часть экрана, то мы увидим, что у нас 38 активных клиентов, которые что-то делают. При этом нужно посмотреть на соседние state: на waiting и на idle_xact. Waiting у нас 0, т. е. у нас клиенты не находятся в режиме ожидания и это хорошо. С другой стороны, у нас есть 20 idle транзакций. Соответственно, мы можем включить сортировку по длительности транзакций (xact_age) и посмотреть – сколько времени наши транзакции находятся в простое. И здесь видно, что простаивает всего одна транзакция. И ее время жизни – 15 секунд. Это не страшно, и в большинстве случаев это можно не считать криминалом.

(Примечание: На слайде переключились в pg_stat_statements. Чтобы переключится в pg_stat_statements необходимо нажать «x», там будут нужные столбцы. Второй вариант «shift + x» и в меню выбрать pg_stat_statements_timings. Если будет ошибка «pg_stat_statements not available on this database», то нужно установить расширение pg_stat_statements от юзера postgres в базу postgres: create extension pg_stat_statements;)
Но мы же ищем источник, кто у нас потребляет больше всего (процессорного) времени. Нам нужно оценить, какие запросы используют больше всего времени. Для этого мы используем pg_stat_statements. Это contrib. Он показывает нам статистику по запросам: сколько они выполнялись, сколько ресурсов потребляли. Этот contrib должен быть установлен в базе, чтобы брать с нее статистику. К сожалению, он выключен по-умолчанию. И одна из основных рекомендаций по настройке Postgres – включать pg_stat_statements.
Предположим, что он у нас стоит. Нам нужно посмотреть время, кто у нас тратить больше всего. Мы стрелочками переключаем сортировку. И видим те запросы, которые у нас тратили больше всего CPU с момента сброса статистики pg_stat_statements. Тут отражен примерно суточный разрез – за сутки конкретный тип запроса отработал 2 часа с лишним. Это запрос SELECT COUNT (*) FROM "game_competition_events". Т. е. уже имея на руках запрос, мы можем сходить в логи, взять параметры этого запроса и посмотреть, какой у него план, и попытаться с ним разобраться. Может быть, там нет какого-нибудь индекса, может быть, там запрос написан неоптимальный или еще что-то. Уже у нас есть конкретная информация о том, кто потребляет процессорное время.
Но здесь есть небольшая ловушка. Мы используем сортировку под total_time. А в total_time включается не только процессорное время, но еще и время, потраченное на операции блочного ввода/вывода: на чтение и на запись. Соответственно, нам желательно включить сортировку по полю «t_cpu_t». Оно нам более релевантно. Оно нам позволяет смотреть именно процессороемкие запросы.

Как я уже сказал, эта статистика показывает самые жадные до ресурсов запросы с момента сброса статистики. Если нам нужно смотреть запросы, которые отнимают процессорное время здесь и сейчас, то мы смотрим уже по полю «cpu_t», это, условно говоря, дельта. Мы берем snapshot статистики за прошлую секунду, за текущую секунду, считаем дельту и показываем. Здесь запрос уже совершенно другой. Это SELECT "courses_logs".* FROM course_logs. И здесь видно, что текущую секунду он съел уже 5 секунд процессорного времени. Это либо запрос, который использует параллельные воркеры, либо, возможно, он просто запускается слишком часто.
И если посмотреть на соседнюю колонку «calls», то там будет видно, что запрос выполняется один. Один запрос в секунду. Т. е. это запрос с параллельными воркерами.

Пока мы все это смотрели, мы могли использовать другие утилиты. Это Top и плюс нам нужно было заглянуть в pg_stat_activity и в pg_stat_statements. Но с помощью pgCenter это все в одном месте собрано и можно этим пользоваться.

Другой вариант – это нагрузка на ввод-вывод. Это другая противоположность, когда с процессорами у нас все в порядке, но диски слабые и нужно разобраться, кто утилизирует ввод-вывод.

Ситуация похожа на предыдущий случай. Мы смотрим на утилизацию процессоров и видим, что у нас утилизация процессоров на время ожидания блочного ввода-вывода довольно высокое – 27 %. Нам нужно найти те запросы, которые вызывают этот ввод-вывод.

Плюс мы можем еще обратить внимание на то, что многие клиенты с типом «background worker». Это явный показатель, что у нас параллелизм включен и запрос выполняется параллельно.

Посмотрим по соседним «wait_event». И тут видно, что эти клиенты находятся в ожидание ввода-вывода. Т. е. очень много времени тратится на чтение данных с диска.

И здесь нам уже понадобится статистика по блочному вводу-выводу. С помощью горячей клавиши ‘B’ мы включаем встроенный iostat. И он нам показывает утилизацию дисковых устройств. Здесь видно, что утилизация одного из устройств 99 %. Но здесь самое главное – это не попасть в ловушку, потому что устройство у нас NVME. И нужно уже смотреть не только на утилизацию, но и на latency.

Если посмотреть на latency, то latency для этого устройства будет составлять всего лишь 1 миллисекунду. И это вполне нормально.
Это значит, что у нас нет особых проблем в производительности. Это связано с тем, что современные SSD и NVME-устройства выполняют операции ввода-вывода в несколько потоков, поэтому мы можем видеть большую утилизацию, но при этом низкий latency. Если мы видим большие цифры по latency, то это значит, что у нас действительно уже есть проблемы и нужно что-то делать.
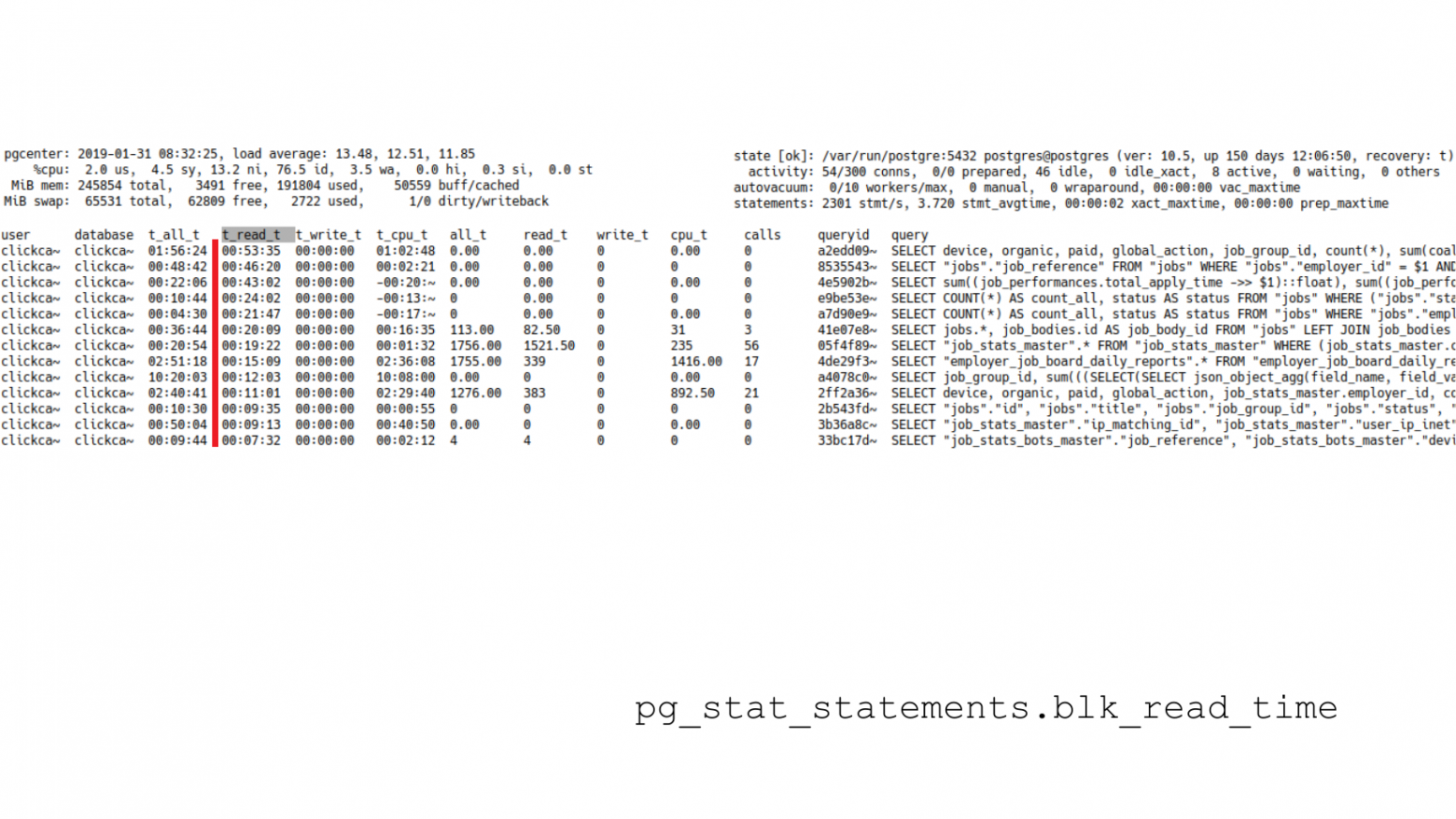
Но тем не менее давайте смотреть, какие запросы выполняют больше операций ввода-вывода. Мы переключаемся на pg_stat_statements и смотрим уже не процессорное время, а время ввода-вывода. Это колонка «t_read_t», т. е. время, потраченное на чтение данных с момента сброса статистики.
Аналогичная колонка есть и для просмотра статистики за последнюю секунду. Это колонка «read_t». Мы можем менять сортировки и смотреть, какие запросы за весь интервал времени сожрали больше всего ввода-вывода, либо за последнюю секунду.
Важно отметить что статистика по ввод/выводу собирается только при включенном track_io_timing.
И уже имея текст запроса мы можем переходить к его поиску в логах, найти его параметры и узнать, что там долго там работает. Но pgCenter еще предоставляет такую штуку как queryid. Это такой идентификатор запроса. Но это не такой идентификатор, который предоставляется в pg_stat_statements. Он немного другой. Его можно использовать для построения отчетов. Т. е. pgCenter предоставляет такую функцию как построение отчетов по конкретной группе запросов. Также через горячие клавиши мы смотрим по queryid. И pgCenter предоставляет отчет.

Отчет состоит из трех частей:
-
Первая часть – это summary, общая картина составленная на основе той статистики, которая накопилась в pg_stat_statements. Это количество запросов, затраченное время в процессорах, затраченное время ввода-вывода.
-
Вторая секция уже связана уже с нашим запросом, эта секция описывает, какой вклад запрос вносит в общую статистику в summary. И мы уже можем видеть статистику связанную с этим запросом относительно всех остальных запросов.
-
И, конечно, сам текст запроса.
Строя такие отчеты, мы можем быстро посмотреть, насколько наш запрос вносит нагрузку в суммарную картину.

И если рассматривать, что мы затронули под капотом, пока это все смотрели, то все это покрывается утилитами top, iostat и представлениями pg_stat_activity, pg_stat_statements. Плюс там есть еще несколько функций, которые приводят все это в понятный вид.

Но запросы клиентские – это не единственная вещь, которая позволяет генерировать ввод-вывод. И в Postgres есть еще всякие фоновые задачи, которые тоже могут создавать нагрузку на диск.
Это:
-
Checkpointer pocess.
-
WAL writer process.
-
Autovacuum workers.
-
Background workers.
На данный момент pgCenter показывает только прогресс по вакууму, по остальным пока информации нет, но тем не менее это уже хорошо.

Предположим, что у нас с ресурсами все в порядке: блочного ввода-вывода никто особо не потребляет, с процессорами тоже полный порядок. И мы переходим к вопросу, что нужно посмотреть, что у нас на уровне ошибок.

И чаще всего это описывается ситуациями, когда клиент пишет в чат, что у него ничего не работает. Всё лежит и нужно что-то делать.
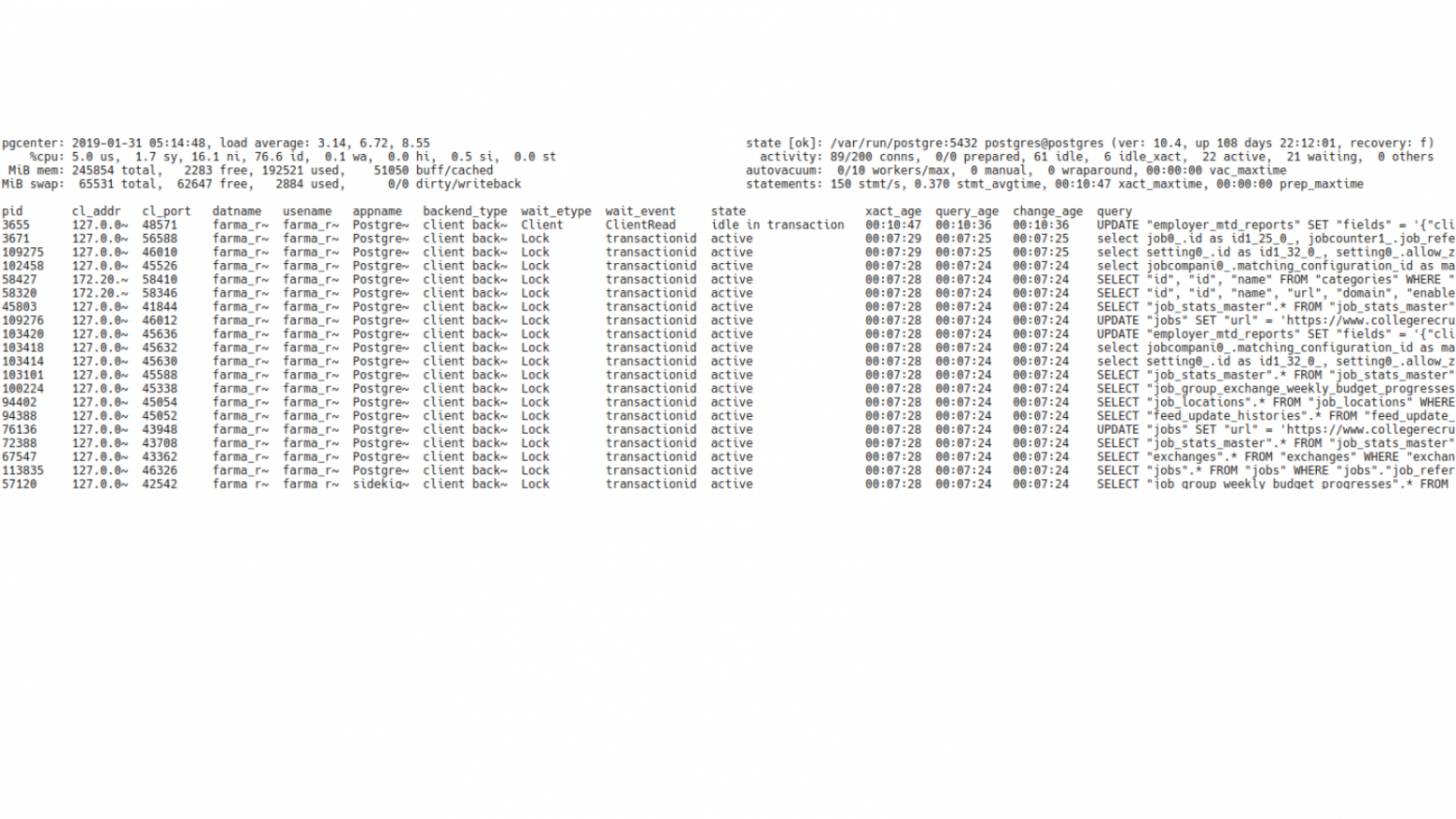
Здесь мы мельком посмотрели утилизацию ресурсов.

И тут нужно уже смотреть на состояние подключенных клиентов. Если посмотреть на клиентов, то будет видно, что у нас 22 активных клиентов и при этом 21 из них находится в режиме ожидания. Это уже показатель того, что что-то работает не так.
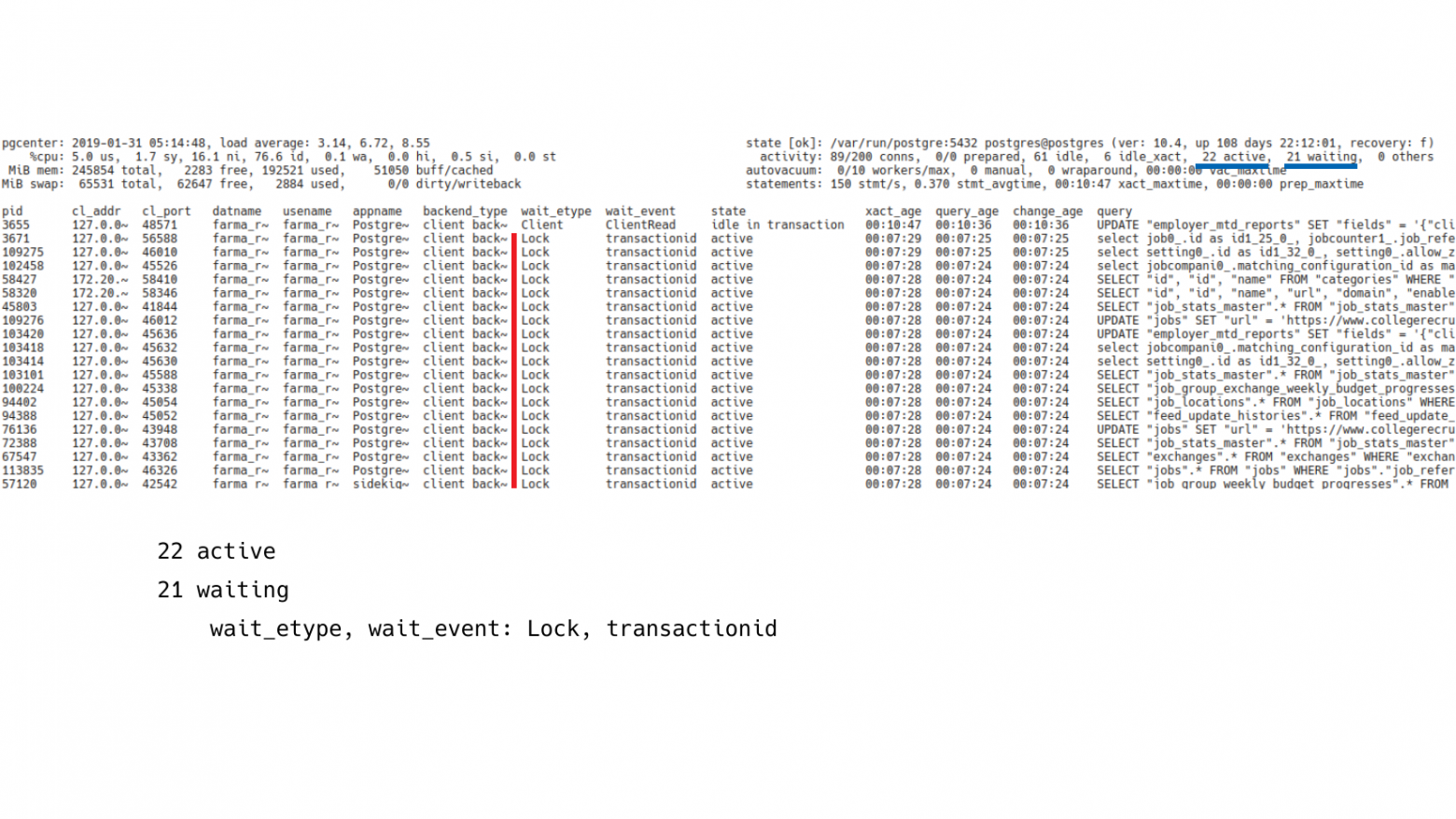
Если посмотреть на wait_event этих клиентов, то будет видно, что они все находится в режиме ожидания идентификатора транзакций. Т. е. какой-то клиент что-то делает, а остальные выстроились в некий хвост и пытаются дождаться, когда эта транзакция сделает свою работу.
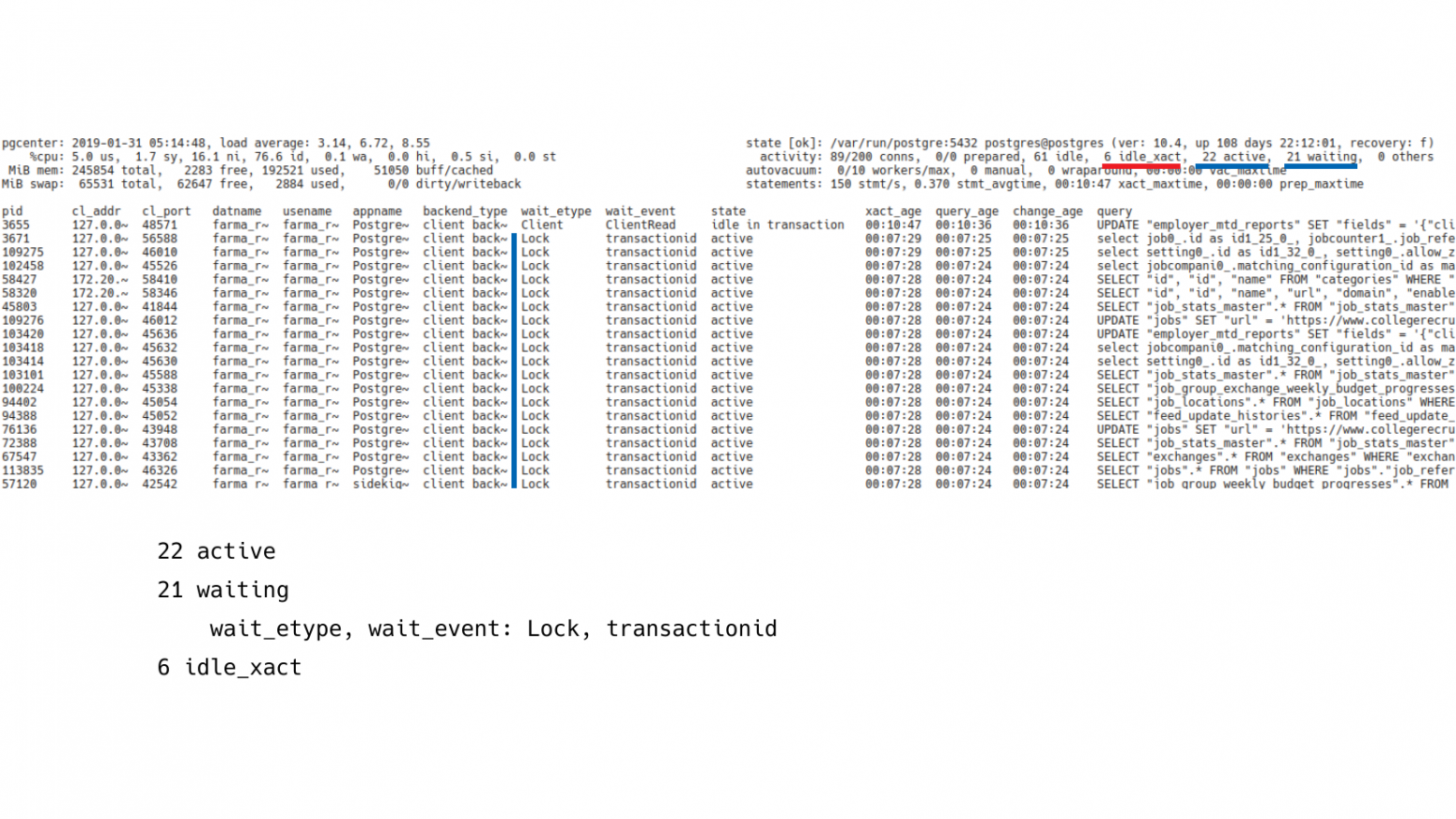
Нужно посмотреть на соседнее поле, которое показывает транзакции в режиме простоя (idle in transaction). И здесь мы видим, что их 6 штук. И нужно включить сортировку по времени работы транзакции.

Если посмотреть на отсортированное поле, то мы увидим, что у нас есть 10-минутная транзакция, которая ничего не делает в данный момент. Если мы посмотрим ниже, то есть еще куча транзакций, которые 7 минут находятся в ожидании. И они явно выстроились как раз в хвост за 10-минутной транзакцией.

Если посмотреть на wait_etype, wait_event этой транзакции, которая ничего не делает, то мы увидим, что она ждет как раз ожидания ввода со стороны клинского приложения (Client:Client Read). Приложение открыло транзакцию, что-то поделало, а потом ушло делать какую-то другую работу. И, возможно, где-то произошла ошибка, приложаени упало в том участке кода, но транзакция осталась незакрытой. Пришли другие транзакции и попытались обновить другие строки и прочитать данные, которые изменила эта транзакция, но попали в заблокированное состояние и теперь они все ждут завершения транзакции.
Самое просто решение – это отменить эту транзакцию. Есть две функции: pg_cancel_backend и pg_terminate_backend. Они позволяют отменить запрос, либо просто завершить работу этого backend. В pgCenter тоже есть эти функции. Можно с помощью горячих клавиш убивать как отдельный backend и запросы на основе pid, либо убивать их группами на основе маски.

Тем не менее под капотом здесь у нас:
-
Pg_stat_activity.
-
Pg_stat_statements.
-
Pg_cancel_backend ().
-
Pg_terminate_backend ().

Опыт показывает, что ситуации бывают разные. Бывает, не только, что собрался хвост из длинных транзакций.
Бывает долгая транзакция на таблице с очередью. Тот случай когда очередь реализована не отдельным брокером сообщений, а реализованы непосредственно в базе данных. У нас есть какая-то таблица. В нее вставляется много записей, также много строк обновляется и много строк удаляется (добавилось событие, изменился его статус, удалилось событие). Пришла какая-то долгая транзакция, которая поработала с этой таблицей, но также она перешла в состояние idle transaction и ничего не делает. И у нас также собрался длинный хвост из блокировок и все повисло — очередь перестала работать.

Другой кейс – это когда приложение в несколько потоков пытается обновлять одни и те же данные. И эти потоки начинают конфликтовать друг с другом, в результате возникают ситуации блокировок и взаимоблокировок (deadlocks) и все начинает работать совсем плохо.

Миграции. Можно сделать ALTER TABLE, добавление колонки, например, с простановкой дефолтных значений. Это очень тяжелая операция. Ее, к счастью, исправили в 11-ой версии и начиная с нее проставление дефолтов при добавлении поля работает безболезненно. Но тем не менее у многих заказчиков стоят старые версии Postgres, которые работают по старому. И любой такой тяжелый ALTER может также собрать на себе хвост ждущих транзакций и остановить работу приложения.

И классика жанра – это CREATE INDEX без CONCURRENTLY, когда кто-то по незнанию, либо просто забыл, что запустил создание индекса. Создание индекса заблокировало таблицу и появился снова хвост из блокировок.

Сейчас немного про репликацию, т.к. сегодня сложно представить, чтобы в production был сервер Postgres без реплики, поэтому бывает необходимость проверить репликацию и все ли с ней в порядке.
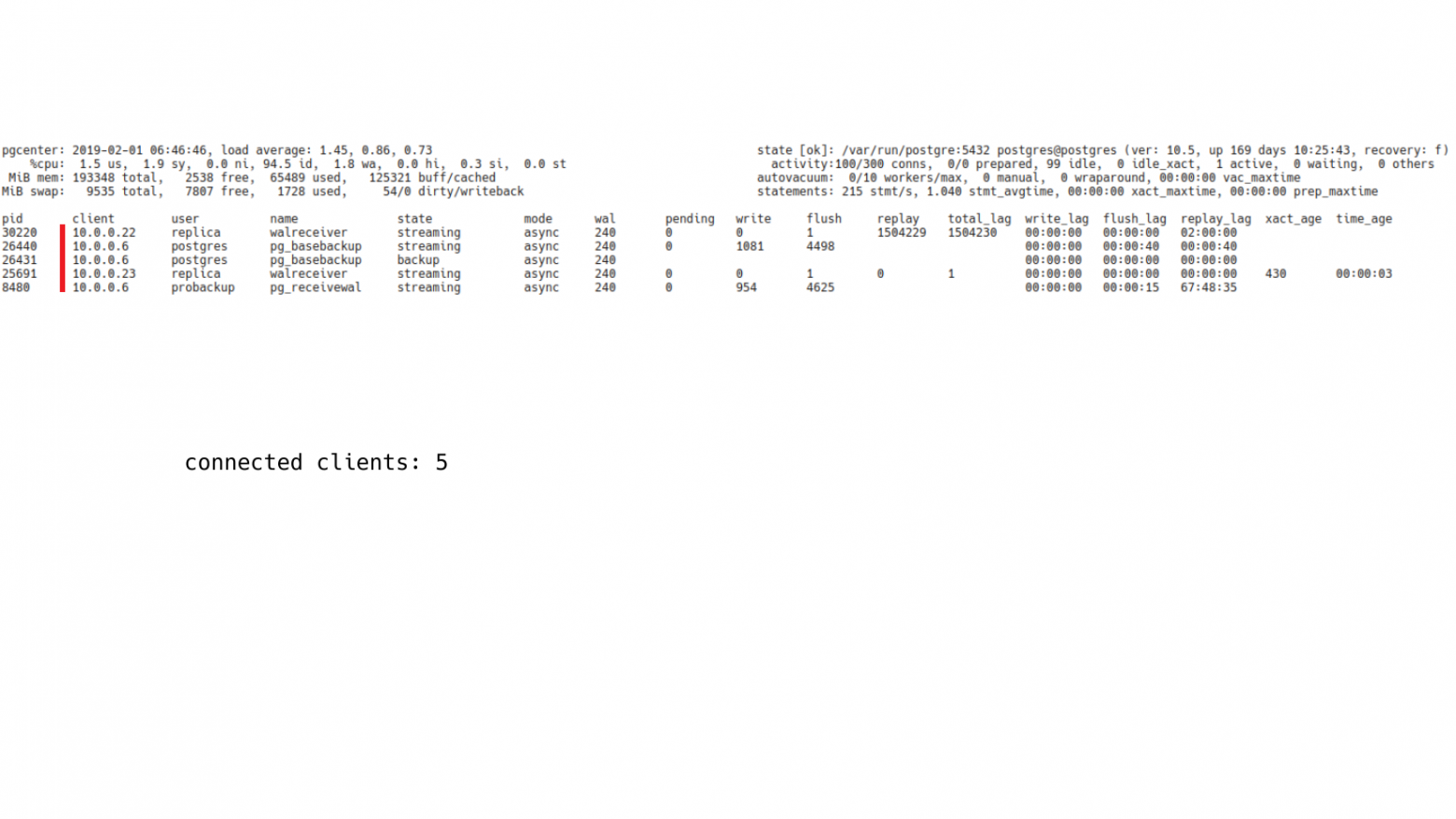
Для этого есть представление pg_stat_replication. Она показывает клиентов, подключенных к Postgres, которые принимают журнал транзакций с этого узла по протоколу репликации.
И pgCenter тоже поддерживает pg_stat_replication. И можно переключиться с помощью горячих клавиш, и посмотреть, что там происходит.
В данном случае у нас здесь 5 клиентов. Они все подключены и принимают журнал транзакций.

Если посмотреть на их имена, то можно будет понять, кто это такие и что они делают. У нас здесь 2 walreceiver, т. е. это конкретно 2 реплики.

И дальше нас интересует, какой лаг репликации у этих клиентов, потому что лаг репликации непосредственно влияет на величину проблемы, которая у нас есть. Если маленький лаг, значит, более-менее все в порядке. Большой лаг, значит, проблемы есть – реплика сильно отстает по каким-то причинам и нам нужно выяснить по каким.
Соответственно, pg_stat_replication предоставляет разную информацию, которая позволяет нам посчитать лаг в байтах и лаг в секундах. И здесь лаг у одной из реплик на уровне 1,5 GB. И replay_lag в секундах – 2 часа. На самом деле это нормальная реплика. Она просто настроена с отложенным восстановлением журнала транзакций. У нее выставлено восстановление на уровне 2-х часов. Она скачивает все журналы к себе и воспроизводит их с задержкой в 2 часа, т. е. это вполне нормальная ситуация.
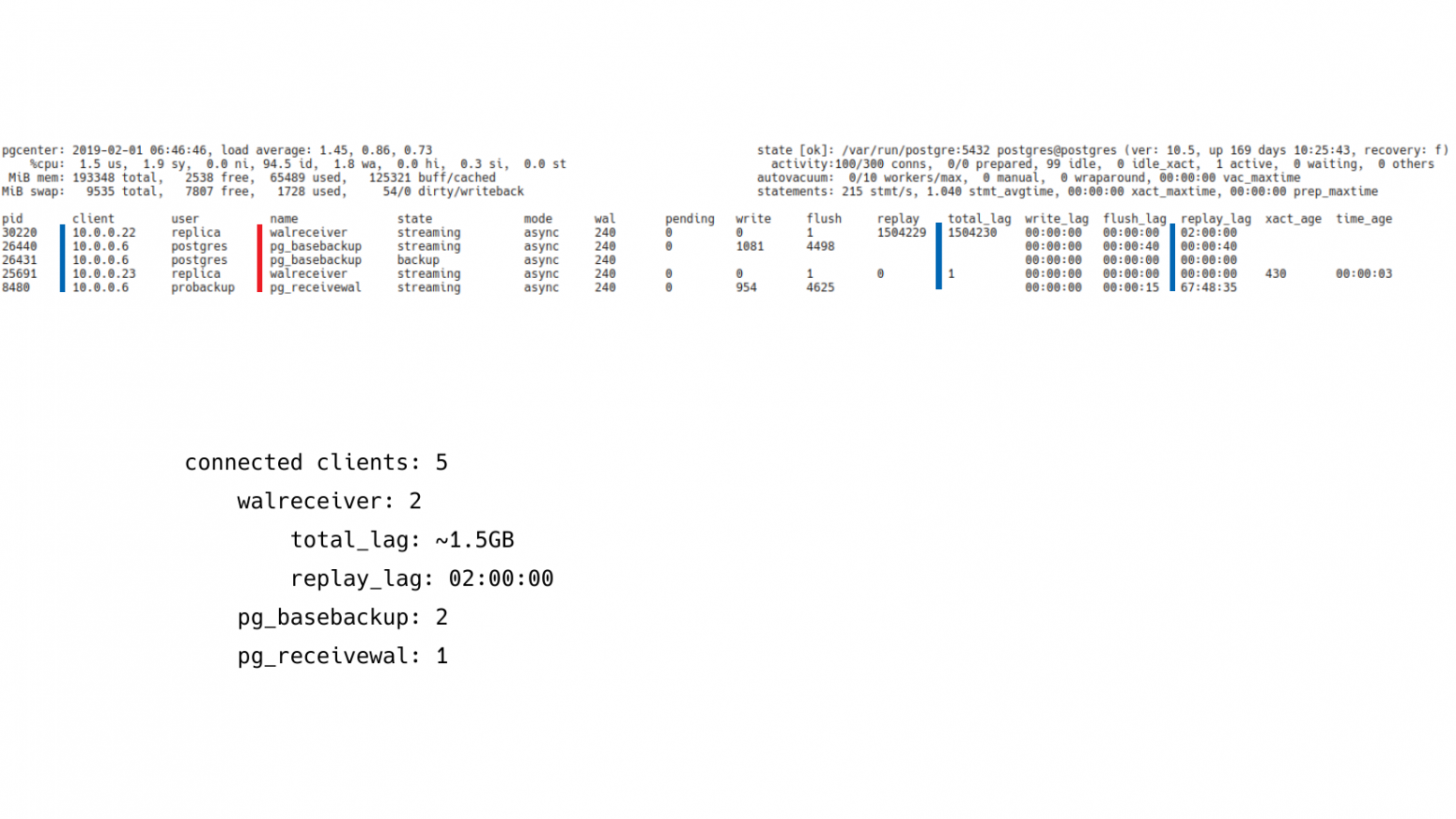
Если мы посмотрим на других клиентов, то будет видно, что у нас есть 2 pg_basebackup и 1 pg_receivewal. Pg_basebackup – это резервное копирование которое также работает по протоколу репликации. Он также виден в pg_stat_replication. И pg_receivewal – это процесс, который принимает журналы транзакций и сохраняет для задач архивирования. Т. е. здесь, в принципе, никакой проблемы нет. Здесь нет каких-то криминальных реплик, которые нужно было бы расследовать.
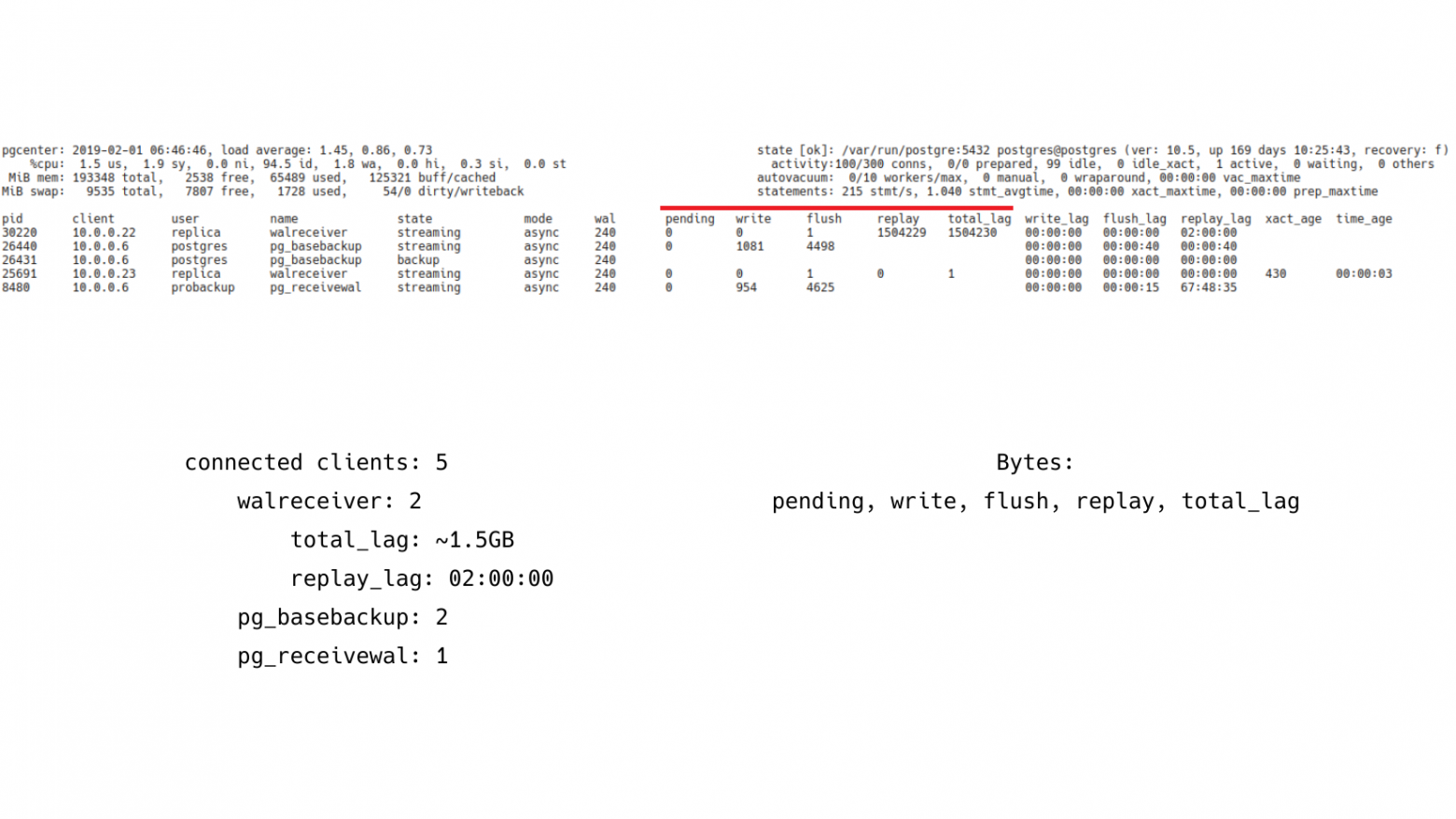
Но тем не менее pg_stat_replication позволяет показывать лаг в нескольких единицах измерениях. Это байты. И самое интересное, что этих метрик здесь аж 5 штук. Это: pending, write, flush, replay, total_lag. Т. е. лаг репликации может быть разным.
Pending – это когда журнал транзакций сгенерировался, лежит на Мастере. И Мастер его еще не успел передать реплике.
Write – это когда передача журналов уже идет, но до реплики еще не дошла, т. е. она еще не успела записаться.
Flush – это когда успели записать уже на реплику, но не успели сбросить на надежное хранилище.
Replay – это когда сбросили на надежное хранилище. И осталось только проиграть.
Total_lag – это максимальная величина от момента генерации до момента проигрывания.
Соответственно, наблюдая лаг в этих местах, в этих контрольных точках, мы можем более-менее понять, где у нас проблема. Например, проблема на дисковой подсистеме Мастера; либо ошибки сети, которые снижают скорость передачи; либо это загруженная дисковая подсистема реплики, которая не успевает все это писать, синхронизировать с диском и воспроизводить.

Кроме того, есть лаг репликации во времени. Он более человекопонятный. Когда людям говоришь про минуты, про секунды, они это лучше воспринимают.
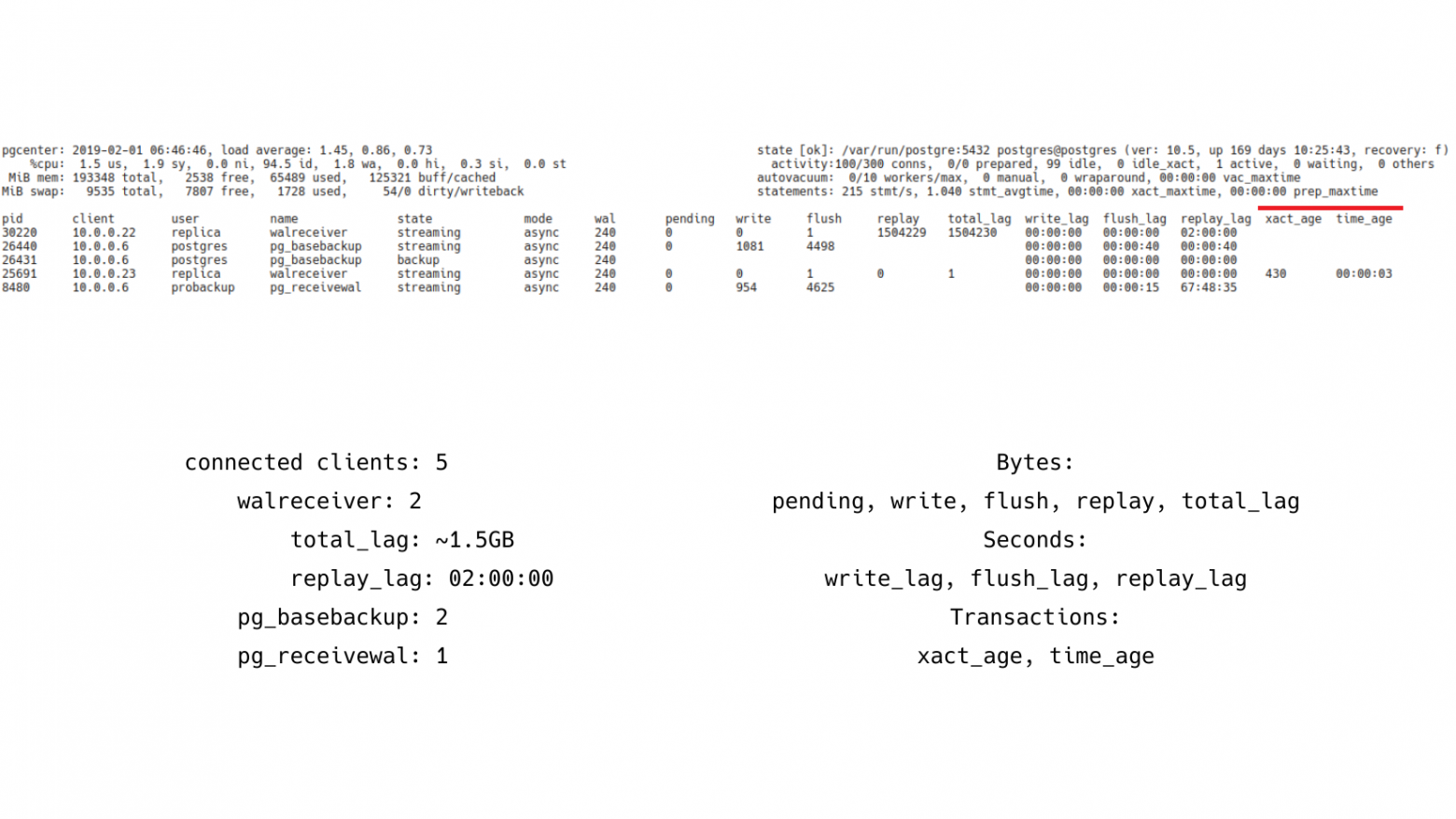
И последний момент – это лаг репликации в транзакциях, т. е. можно отследить величину – сколько транзакций нужно проиграть реплике, чтобы она догнала Мастера. Эта штука по умолчанию выключена в Postgres, ее нужно включать отдельно. Но она редко бывает нужна, только в каких-то особых случаях.

Под капотом этой всей диагностики у нас:
-
pg_stat_replication.
-
pg_wal_lsn_diff().
-
pg_current_wal_lsn().
-
pg_last_commited_xact().

Я вам рассказал все эти кейсы, но за кадром есть еще много других вещей.

Например, в top можнос смотреть статистику по таблицам. Табличные статистики – это все Seq Scan, количество update, delete, insert, живые и мертвые строки.

Статистика по индексам. Можно посмотреть утилизацию индексов. Отыскивать неиспользуемые индексы и их заносить в черный список и потом удалять.

Статистика по функциям. Можно смотреть, какие пользовательские функции запускаются больше всего, сколько времени они потребляют. Можно также сортировать, смотреть и выбирать кандидата для оптимизации.

И, конечно, pg_stat_progress_vacuum появился в 9.6. Раньше, в плане статистики, вакуум был черным ящиком, было сложно понять, как долго работает, как скоро он закончится и сколько ему еще работы надо делать. И pg_stat_progress_vacuum – это способ заглянуть в этот черный ящик и понять что там происходит. Можно оценить, сколько ему там осталось доработать. Хотя, конечно, есть недостатки, есть претензии к нему. Но тем не менее лучше, чем ничего.

И есть вспомогательные, админские функции для самого администратора. Это просмотр логов, просмотр и изменение конфигурации, т. е. мы можем через горячие клавиши открыть postgresql.conf, что-то в нем поправить и потом горячей клавишей сделать reload. Это не самая правильная практика, конечно, но тем не менее возможность есть.
Плюс есть функции по просмотру логов. Вам не нужно помнить, где же лежит лог, как он там называется и набирать руками путь до него. Нажимает хоткей и лог открывается в просмотрщике. Можно найти там нужный запрос с нужными параметрами, скопировать и дальше изучать его.
Плюс есть функция вызова psql, т. е. мы также нажимаем горячую клавишу и у нас открывается psql к той базе, к которой у нас подключен pgCenter. Таким образом если есть какие-то вещи, которые нам надо сделать и мы не можем сделать это с помощью pgCenter, мы можем быстро вызвать psql и сделать это там.

top-просмотрщик – это основная утилита, которая развивалась изначально в pgCenter. Но помимо top есть еще другие утилиты, которые тоже являются частью pgCenter. Это record и report.
Суть в том, что мы делаем мгновенные снимки статистики и сохраняем их в файле. Мы можем запускать сбор с нужным интервалом и эти снимки будут сохраняться. А потом с помощью report строить отчеты, аналогичные тому, что показывает Top. В некоторых ситуациях это бывает полезно — например отсутствие полноценого мониторинга.

Я использую это для своих микро-тестов. Когда мне нужно что-то потестировать, я запускаю record. Раз в секунду он там все записывает и мне не нужно ставить никаких мониторинговых агентов. Я могу это все так быстро на коленке посмотреть.

Плюс недавно я добавил сэмплер wait_event’ов, можно брать свои долгие запросы и смотреть, на каких участках запрос тратит свое время на ожидание.

Вот простой пример: SELECT всех строк из таблицы с последующей сортировкой. Если посмотреть, куда тратится время, то видно, что 44 % времени запрос выполняется, делает какую-то полезную работу, а оставшееся время – это ожидание ввода-вывода при чтении файлов, взаимодействие между параллельными воркерами.

Второй пример: это VACUUM FULL. Здесь видно, что большую часть времени VACUUM FULL работает с дисковым IO и читает данные, а работает он всего 12 %. Вот эта штука довольно полезная, когда есть любопытство попрофилировать свои долгие запросы и посмотреть, чем они занимаются и в каких местах проводят время в ожидании.
Вопросы
Спасибо за утилиту! Лично я ею пользуюсь. Она мне нравится. Я часто использую ее с ноутбука. И когда я смотрю, например, pg_stat_statements, у меня колонка query с текстом не влезает. Есть ли какая-то возможность поменять порядок столбцов или какие-то столбцы отключить на время?
К сожалению, такой функции нет. Архитектурно программа так устроена, что эта фичу тяжело запилить, но можно, наверное, что-то придумать там, переписать и такая функция появится. Как минимум, не перестановку колонок, а отключение-включение по желанию. Но отсюда вылезает второй вопрос. Наверняка кто-то захочет сохранить отображение этих колонок и при последующем запуске показать. Т. е. появится необходимость конфига, который нужно поддерживать, хранить где-то. Это такая задачка, которая собирает еще другие задачки, чтобы ее реализовать. Я думаю, что это можно сделать, но пока этого нет.
И второй комментарий из той же оперы. Когда режим базы данных, то у вас количество rollbacks. Иногда хотелось бы отличать rollbacks, которые были по команде от тех rollbacks, которые не по команде.
Это, к сожалению, невозможно, потому что сам интерфейс pg_stat_database не позволяет такого. Он показывает только rollbacks и все.
Там можно из pg_stat_statements считать rollbacks, вычитать.
Можно, если заморочиться. Можно расширить запрос. Мы делаем `SELECT FROM pg_stat_database JNOIN pg_stat_statements` под запрос к pg_stat_statements, где мы считаем rollbacks и плюс арифметика, которая это все высчитывает. Теоретически можно. Но нужно посмотреть, как быстро будет работать этот запрос и не займет ли выполнение больше 10-20 миллисекунд.
Алексей, спасибо за доклад! С какой минимальной версией Postgres ваша утилита работает?
Я ее тестировал с версии 9.0-9.1, когда еще на C писал. Если какие-то запросы, особенно связанные с репликацией, не работают, то она пишет небольшую ошибку и есть возможность переключится на другой скрин, на другую статистику. Go версию тестировал, начиная с 9.4. Потому что в 9.4 появился функционал, когда мы берем SELECT… where filter. Это такой синтаксис интересный. В старых версиях (9.3) его нет. А у меня часть запросов как раз используют этот синтаксис и в старых версиях это работать не будет. Либо это будет работать, но будет показывать нули там, где эта статистика используется. Но я стараюсь на всех версия тестировать, проверять, чтобы, как минимум, ошибок не было.
Алексей, спасибо за утилиту! И спасибо за то, что интерфейс там от TOP. За это двойное спасибо.
Более того, я старался горячие клавиши делать, похожими на другие утилиты. Например, кнопка фильтра – это слеш. Кто знаком с less (пейджер такой), то слеш – это поле ввода, чтобы набрать шаблон для поиска.
У меня вопрос по поводу сортировки. Там так же как в TOP подсветка поля идет сортируемого?
Да. У меня на скриншотах это не видно, я, видимо, упустил этот момент. На некоторых скриншотах видно, на некоторых не видно. Да, поле подсвечивается. Когда вы стрелками перемещаетесь, вы видите, что у вас сортировка меняется и имя в колонке подсвечивается.
Спасибо за утилиту! Сегодня в первый раз о ней узнал. Оказывается, столько много возможностей. Вы размышляете, что вот у меня 85% CPU usage, давайте проанализирую, что сейчас происходит. Для этого пойду и обращусь к временным снимкам pg_stat_statements. Но там же архив находится. А нас интересует, что сейчас происходит.
Не архив. В нагрузке на CPU есть два поля. Первое – t_all_t. Это сколько времени намотал запрос со времени сброса статистики pg_stat_statements. Условно, у нас суточный срез. Если мы раз в сутки сбрасываем статистику, то мы получим статистику за текущий момент от начала суток. Плюс есть разбивка t с подчеркиванием и они уже здесь заканчиваются. Т. е. у нас есть аналогичные поля без префикса «t». Они как раз нам показывают статистику за текущую секунду. Т. е. мы можем смотреть, сколько процессорного времени потрачено запросом прямо сейчас.
Это понятно. Но если сейчас происходит то, что еще нет в pg_stat_statements, то как мы это проанализируем?
Мы каждую секунду выходим к pg_stat_statements и берем снапшот статистики прямо в real time.
Вопрос был в том, что в pg_stat_statements залетит уже после, а цифра 85 CPU usage – она сейчас.
Да, расхождение статистики будет. Но вы все равно можете смотреть текущую статистику, которую вам pg_stat_statements показывает. Если вы видите, что у вас использование процессора упало, то вы уже не увидите тот срез статистики, который был 10 секунд назад, когда использование процессоров было высокое. Тут нет такой интроспекции на 10 секунд назад – запомнить и отмотать, как это сделано, например, в atop. Вы на atop намекаете?
Примерно, да. Тут некое будущее и прошлое pg_stat_statements, а CPU, которая сейчас, нужно потом проанализировать, что залетит в pg_stat_statements.
Для этого придумана система мониторинга. Например, Grafana, там есть отрисовка графиков и вы уже в исторической перспективе все эти графики смотрите и анализируете. Т. е. pgCenter – это инструмент, который нам нужен здесь и сейчас, чтобы быстро продиагностировать, быстро понять, что происходит.
В связи с этим же вопрос. pgCenter умеет как atop сбрасывать статистику в текстовом виде, чтобы потом можно было запихнуть в Grafana?
Есть функции pgCenter report и pgCenter record, т. е. можно снапшоты статистики сбрасывать в текстовые файлы. Единственное, что там нет интерфейса, как по стрелочкам переключаться и смотреть. Т. е., условно говоря, с помощью pgCenter report запросить нужную статистику, например, по pg_stat_database и он прочитаем там все файлы накопленной статистики и как sar покажет. Я вдохновлялся больше им. Нет такого как у atop, когда можно стрелочками работать.
Алексей, большое спасибо! В отличие от всей известной базы Х, в Postgres, к сожалению, нет, кумулятивных статистик ожиданий. Вы сделали профайлер, который показывает разброску по ожиданиям. А с какой частой вы их опрашиваете? Какая там детализация?
Дефолтный интервал в 10 миллисекунд. А через флажок «-f», можно указывать частоту детализаций. Понятно, что высокая частота детализации, например, в 10 миллисекунд тоже создает нагрузку на систему. Но учитывая, что pg_stat_activity в памяти, то запросы там довольно легковесные. Они доли миллисекунд занимают. Но если такая частота напрягает, можно менять. Поставить, например, раз в 50 миллисекунд. Я замерял, как отражается это на конечной статистике, там погрешность есть на уровне 1-2 %. Т. е. если просуммировать все столбики, то мы увидим, что у нас куда-то 0,5-2 % потерялось.
Там в конце суммарная статистика есть. Можно видеть, что что-то потерялось.
Да, там видно будет. Да, даже на нашем примере мы видим, что 0,04 % не учли. Но, я думаю, это не критично. Это не какой-то инструмент для хардкор аналитики.
Но лучше все равно ничего нет.
Интересно просто посмотреть, что там у нас происходит.
Алексей, спасибо за доклад! Вдогонку вопрос по профайлеру. Вот этот wait_event Running – это просто отсутствующий?
Да.
Я его воспринимаю как ожидание на CPU.
Да, именно так. Т. е. когда мы заметили, что wait_events у этого PID нет, то мы считаем, что backend делает какую-то полезную работу, прямо крутится на процессоре, что-то высчитывает. И мы закидываем в Running, типа он работает, т. е. он не находится в ожидании.
Но все же это ближе к CPU?
Да, это ближе к CPU, т. е. запрос делает какую-то работу. Это не ожидание.
Привет! Спасибо за доклад! Насчет пакетирования есть какие-то планы, например, Ubuntu?
Когда она была написана на C, то все майнтейнеры были радостные. Говорили, что круто, сейчас тебе пакетов насобираем. И в официальном репозитории PDGD были пакеты собраны для Ubuntu. Я на Launchpad собирал пакеты, но у них какая-то странная система сборки. Бинарник иногда сегфолтится. И я не мог понять, почему так. А сейчас на Go у меня просто Мастер-ветка, dev-ветка. В Мастере она релизы отсчитывает. И когда я делаю коммит с релизом, то travis-ci не только делает build, он еще делает build бинарника и выкатывает его в раздел релизов. Т. е. если посмотреть в Realeses, то туда релизы будут сваливаться. Вам остается только взять wget, сходить по ссылке, забрать и распаковать tar’ом архив, и можно будет пользоваться.
Есть проект Goreleaser, который позволяет автоматизировать это. И можно собирать пакеты.
Круто, я с GO не очень знаком. Я еще раз повторяю, я не профессиональный программист. Я не знаю, что такое SOLID. И то, что вы говорите, что Goreleaser есть, это интересная штука, я посмотрю, что это такое. Раньше C’шные исходники у меня собирались, и я был счастлив. А сейчас мне приходится всем говорить, что есть ссылка на Realeses. Спасибо за совет!
Updated. Goreleaser успешно добавлен, большое спасибо за идею!
Алексей, вопрос по поводу queryid. Мы там видим queryid. У вас получается, что там поле немножко урезано и мы хвост не видим. Мы можем его полностью увидеть?
Да, конечно. Если мы не будем обрезать названия, то у нас в какой-то момент ширина колонок будет прыгать. И это для глаз не очень хорошо, плохо воспринимается. Поэтому ширина колонок рассчитывается под какую-то величину. Величина рассчитывается по сложному кейсу. Но в итоге ширина колонок ужимается и не прыгает. Если мы хотим ее увеличить, то мы стрелочкой переходим на это поле через сортировку. А потом стрелкой вверх увеличиваем ширину. А стрелкой вниз можем уменьшить ширину. И она сохраняется. Вы потом дальше можете сортировку менять, у вас ширина поля останется той, какой вы задали.
Ясно, это важный момент, потому что queryid – это четкий адрес.
Да, изначально ширина колонок прыгала и это раздражало. Я в dev-ветке это поправил, а в Мастер-ветке этого пока нет. В середине февраля я хочу выпустить Event Profiler. И как раз фиксированная ширина колонок будет.
Замечательно.
Да, через стрелки можно регулировать ширину.
Спасибо, Алексей!
Спасибо большое вам!
Видео:
JavaScript
является довольно простым языком для тех, кто хочет начать его изучение, но чтобы достичь в нем мастерства, нужно приложить много усилий.
Новички часто допускают несколько распространенных ошибок, которые аукаются им и всплывают в тот момент, когда они меньше всего этого ожидают. Чтобы понять, какие это ошибки, прочитайте эту статью.
1. Пропуск фигурных скобок
Одна из ошибок, которую часто допускают новички JavaScript
— пропуск фигурных скобок после операторов типа if, else,while
и for
. Хотя это не запрещается, вы должны быть очень осторожны, потому что это может стать причиной скрытой проблемы и позже привести к ошибке.
Смотрите пример, приведенный ниже:
JS
// Этот код не делает то, что должен!
if(name === undefined)
console.log(«Please enter a username!»);
fail();
// До этой строки исполнение никогда не дойдет:
success(name);
}
function success(name){
console.log(«Hello, » + name + «!»);
}
function fail(){
throw new Error(«Name is missing. Can»t say hello!»);
}
Хотя вызов fail()
имеет отступ и, кажется, будто он принадлежит оператору if
, это не так. Он вызывается всегда. Так что это полезная практика окружать все блоки кода фигурными скобками, даже если в них присутствует только один оператор.
2. Отсутствие точек с запятой
Во время парсировки JavaScript
осуществляется процесс, известный как автоматическая расстановка точек с запятой. Как следует из названия, анализатор расставляет недостающие знаки вместо вас.
Цель этой функции — сделать JavaScript
более доступным и простым в написании для новичков. Тем не менее, вы должны всегда сами добавлять точку с запятой, потому что существует риск пропустить ее.
Вот пример:
JS
// Результатом обработки этого кода станет вывод сообщения об ошибке. Добавление точки с запятой решило бы проблему.
console.log(«Welcome the fellowship!»)
[«Frodo», «Gandalf», «Legolas», «Gimli»].forEach(function(name){
hello(name)
})
function hello(name){
console.log(«Hello, » + name + «!»)
}
Так как в строке 3 отсутствует точка с запятой, анализатор предполагает, что открывающаяся скобка в строке 5 является попыткой доступа к свойству, используя синтаксис массива аксессора (смотри ошибку № 8), а не отдельным массивом, который является не тем, что предполагалось.
Это приводит к ошибке. Исправить это просто — всегда вставляйте точку с запятой.
Некоторые опытные разработчики JavaScript
предпочитают не расставлять точки с запятой, но они прекрасно знают о возможных ошибках, и то, как их предотвратить.
3. Непонимание приведений типа
JavaScript
поддерживает динамические типы. Это означает, что вам не нужно указывать тип при объявлении новой переменной, вы можете свободно переназначить или конвертировать его значение.
Это делает JavaScript
гораздо более простым, чем, скажем, C#
или Java
. Но это таит в себе потенциальную опасность ошибок, которые в других языках выявляются на этапе компиляции.
Вот пример:
JS
// Ожидание события ввода из текстового поля
var textBox = document.querySelector(«input»);
textBox.addEventListener(«input», function(){
// textBox.value содержит строку. Добавление 10 содержит
// строку «10», но не выполняет ее добавления..
console.log(textBox.value + » + 10 = » + (textBox.value + 10));
});
HTML
Проблема может быть легко исправлена с применением parseInt(textBox.value, 10)
, чтобы перевести строку в число перед добавлением к ней 10.
В зависимости от того, как вы используете переменную, среда выполнения может решить, что она должна быть преобразована в тот или иной тип. Это называется приведение типа
.
Чтобы не допустить преобразования типа при сравнении переменных в операторе if
, вы можете использовать проверку строгого равенства
(===
).
4. Забытые var
Еще одна ошибка, допускаемая новичками — они забывают использовать ключевое слово var
при объявлении переменных. JavaScript
— очень либеральный движок.
В первый раз, когда он увидит, что вы использовали переменную без оператора var
, он автоматически объявит его глобально. Это может привести к некоторым ошибкам.
Вот пример, который кроме того иллюстрирует и другую ошибку — недостающую запятую при объявлении сразу нескольких переменных:
JS
var a = 1, b = 2, c = 3;
function alphabet(str){
var a = «A», b = «B» // Упс, здесь пропущена «,»!
c = «C», d = «D»;
return str + » » + a + b + c + «…»;
}
console.log(alphabet(«Let»s say the alphabet!»));
// О, нет! Что-то не так! У c новое значение!
console.log(a, b, c);
Когда анализатор достигает строки 4, он автоматически добавит точку с запятой, а затем интерпретирует объявления c и d в строке 5, как глобальные.
Это приведет к изменению значения другой переменной c. Больше о подводных камнях JavaScript здесь
.
5. Арифметические операции с плавающей точкой
Эта ошибка характерна практически для любого языка программирования, в том числе и JavaScript
. Из-за способа, которым числа с плавающей точкой представляются в памяти
, арифметические операции выполняются не совсем так, как вы думаете.
Например:
JS
var a = 0.1, b = 0.2;
// Сюрприз! Это неправильно:
console.log(a + b == 0.3);
// Потому что 0.1 + 0.2 не дает в сумме то число, что вы ожидали:
console.log(«0.1 + 0.2 = «, a + b);
Чтобы обойти эту проблему, вы не должны использовать десятичные числа, если вам нужна абсолютная точность — используйте целые числа, или если вам нужно работать с денежными единицами, используйте библиотеку типа bignumber.js
.
6. Использование конструкторов вместо оригинальных обозначений
Когда программисты Java
и C #
начинают писать на JavaScript, они часто предпочитают создавать объекты с использованием конструкторов: new Array(), new Object(), new String()
.
JS
var elem4 = new Array(1,2,3,4);
console.log(«Four element array: » + elem4.length);
// Создание массива из одного элемента. Это не работает так, как вы думаете:
var elem1 = new Array(23);
console.log(«One element array? » + elem1.length);
/* Объекты строки также имеют свои особенности */
var str1 = new String(«JavaScript»),
str2 = «JavaScript»;
// Строгое равенство не соблюдается:
console.log(«Is str1 the same as str2?», str1 === str2);
Решение этой проблемы просто: попробуйте всегда использовать буквальные оригинальные
обозначения. Кроме того, в JS
не обязательно указывать размер массивов заранее.
7. Непонимание того, как разделяются диапазоны
Одна из трудных для понимания новичками вещей в JS
, это правила разграничения и закрытия диапазонов. И это действительно не просто:
JS
for(var i = 0; i
Функции сохраняют связь с переменными в пределах родительских диапазонов. Но поскольку мы откладываем выполнение через setTimeout
, когда наступит время для запуска функций, то цикл будет уже фактически завершен и переменная i
увеличивается до 11.
Самовыполняющаяся функция в комментариях работает, потому что она копирует значение переменной i
и хранит его копию для каждой задержки выполнения функции. Больше о диапазонах вы можете узнать здесь
и здесь
.
8. Использование Eval
Eval есть зло
. Это считается плохой практикой, и в большинстве случаев, когда вы думаете его применить, можно найти лучший и более быстрый способ.
JS
// Это плохая практика. Пожалуйста, не делайте так:
console.log(eval(«obj.name + » is a » + obj.» + access));
// Вместо этого для доступа к свойствам динамически используйте массив примечаний:
console.log(obj.name + » is a » + obj);
/* Использование eval в setTimout */
// Это также неудачная практика. Она медленна и сложна для проверки и отладки:
setTimeout(» if(obj.age == 30) console.log(«This is eval-ed code, » + obj + «!»);», 100);
// Так будет лучше:
setTimeout(function(){
if(obj.age == 30){
console.log(«This code is not eval-ed, » + obj + «!»);
}
}, 100);
Код внутри eval
— это строка. Отладочные сообщения, связанные с Eval-блоками непонятны, и вам придется поломать голову, чтобы правильно расставить одинарные и двойные кавычки.
Не говоря уже о том, что это будет работать медленнее, чем обычный JavaScript
. Не используйте Eval
если вы не знаете точно, что вы делаете.
9. Непонимание асинхронного кода
Что действительно выделяет JavaScript
и делает его уникальным, это то, что почти все элементы работают асинхронно, и вы должны передавать функции обратного вызова для того, чтобы получать уведомления о событиях.
Новичкам еще трудно понимать это интуитивно, и они быстро заходят в тупик, сталкиваясь с ошибками, которые трудно понять.
Вот пример, в котором я использую сервис FreeGeoIP
для определения вашего местоположения по IP-адресу:
JS
// Определение данных местоположения текущего пользователя.
load();
// Вывод местоположения пользователя. Упс, это не работает! Почему?
console.log(«Hello! Your IP address is » + userData.ip + » and your country is » + userData.country_name);
// Загружаемая функция будет определять ip текущего пользователя и его местоположение
// через ajax, используя сервис freegeoip. Когда это сделано она поместит возвращаемые
// данные в переменную userData.
function load(){
$.getJSON(«http://freegeoip.net/json/?callback=?», function(response){
userData = response;
// Выведите из комментариев следующую строку, чтобы увидеть возвращаемый
// результат:
// console.log(response);
});
}
Несмотря на то, что console.log
располагается после вызова функции load()
, на самом деле он выполняется перед определением данных.
10. Злоупотребление отслеживанием событий
Давайте предположим, что вы хотите отслеживать клик кнопки, но только при условии установленного чеккера.
Допустим, я пишу
If(someVal)
alert(«True»);
Затем приходит следующий разработчик и говорит: «О, мне нужно сделать что-то еще», поэтому они пишут
If(someVal)
alert(«True»);
alert(«AlsoTrue»);
Теперь, как вы можете видеть, «AndTrue» всегда будет правдой, потому что первый разработчик не использовал фигурные скобки.
2018-12-04T00:00Z
Абсолютно да
Забудьте о «Это личное предпочтение», «код будет работать отлично», «он отлично работает для меня», «это более читаемо» yada yada BS.
Аргумент: «Это личное предпочтение»
Нет. Если вы не один человек, выходящий на Марс, нет. Большую часть времени будут другие люди, читающие / изменяющие ваш код. В любой серьезной команде кодирования это будет рекомендуемым способом, поэтому это не «личное предпочтение».
Аргумент: «код будет работать просто отлично»
Так же и код спагетти! Означает ли это, что это нормально, чтобы создать его?
Аргумент: «Он отлично работает для меня»
В моей карьере я видел так много ошибок, созданных из-за этой проблемы. Вероятно, вы не помните, сколько раз вы прокомментировали «DoSomething()» и сбиты с толку, почему «SomethingElse()» вызывается:
If (condition)
DoSomething();
SomethingElse();
If (condition)
DoSomething();
SomethingMore();
Вот пример реальной жизни. Кто-то хотел включить все протоколирование, чтобы они запускали find & replace «Console.println» => //»Console.println» :
If (condition)
Console.println(«something»);
SomethingElse();
См. Проблему?
Даже если вы думаете: «Это настолько тривиально, что я никогда этого не сделаю»; помните, что всегда будет член команды с более низкими навыками программирования, чем вы (надеюсь, вы не худшие в команде!)
Аргумент: «это более читаемо»
Если я что-то узнал о программировании, то это очень просто. Очень распространено, что это:
If (condition)
DoSomething();
превращается в следующее после того, как он был протестирован с различными браузерами / средами / примерами использования или добавлены новые функции:
If (a != null)
if (condition)
DoSomething();
else
DoSomethingElse();
DoSomethingMore();
else
if (b == null)
alert(«error b»);
else
alert(«error a»);
И сравните это с этим:
If (a != null) {
if (condition) {
DoSomething();
}
else {
DoSomethingElse();
DoSomethingMore();
}
} else if (b == null) {
alert(«error b»);
} else {
alert(«error a»);
}
PS: Бонусные очки идут к тому, кто заметил ошибку в приведенном выше примере
2018-12-11T00:00Z
В дополнение к причине, упомянутой @Josh K (что также относится к Java, C и т. Д.), Одной из специальных проблем в JavaScript является автоматическая вставка точки с запятой . Из примера в Википедии:
Return
a + b;
// Returns undefined. Treated as:
// return;
// a + b;
Таким образом, это может также дать неожиданные результаты, если они используются следующим образом:
If (x)
return
a + b;
На самом деле не намного лучше писать
If (x) {
return
a + b;
}
но, может быть, здесь ошибка немного легче обнаружить (?)
2018-12-18T00:00Z
Вопрос спрашивает о заявлениях на одной строке. Тем не менее, во многих примерах приводятся причины не оставлять фигурные скобки на основе нескольких строк. Вполне безопасно не использовать скобки на одной линии, если это стиль кодирования, который вы предпочитаете.
Например, вопрос спрашивает, нормально ли это:
If (condition) statement;
Он не спрашивает, все ли в порядке:
If (condition)
statement;
Я думаю, что оставлять скобки предпочтительнее, потому что это делает код более читаемым с менее излишним синтаксисом.
Мой стиль кодирования заключается в том, чтобы никогда не использовать скобки, если код не является блоком. И никогда не использовать несколько операторов в одной строке (разделенных точкой с запятой). Я считаю, что это легко читать и очищать и никогда не иметь проблем, связанных с высказываниями «если». В результате, используя скобки в одном условии if, требуется 3 строки. Как это:
If (condition) {
statement;
}
Использование одной строки, если оператор предпочтительнее, потому что он использует меньше вертикального пространства, а код более компактен.
Я бы не принуждал других использовать этот метод, но он работает для меня, и я не мог больше не соглашаться с примерами, приведенными в том, как исключить скобки из-за ошибок кодирования / определения области видимости.
2018-12-25T00:00Z
нет
Это совершенно верно
If (cond)
alert(«Condition met!»)
else
alert(«Condition not met!»)
Эта же практика следует во всех языках стиля синтаксиса C с привязкой. C, C ++, Java, даже PHP все поддерживают один оператор строки без брекетов. Вы должны понимать, что вы сохраняете только два персонажа,
а с помощью некоторых стилей для некоторых людей вы даже не сохраняете линию. Я предпочитаю полный стиль фигурной скобки (например, следующий), поэтому он имеет тенденцию быть немного дольше. Компромисс встречается очень хорошо с тем, что у вас очень четкая читаемость кода.
If (cond)
{
alert(«Condition met!»)
}
else
{
alert(«Condition not met!»)
}
2019-01-01T00:00Z
Начальный уровень отступа оператора должен быть равен числу открытых фигурных скобок над ним. (исключая цитируемые или комментируемые фигурные скобки или символы в директивах препроцессора)
В противном случае K & R будет хорошим отступом. Чтобы исправить их стиль, я рекомендую размещать короткие простые операторы if на одной строке.
Get Started With PostgreSQL
Duration 00:41:44
Get Started With PostgreSQL — Полный список уроков
Развернуть / Свернуть
- Урок 1. Create a Postgres Table
00:01:45
- Урок 2. Insert Data into Postgres Tables
00:04:24
- Урок 3. Filter Data in a Postgres Table with Query Statements
00:03:35
- Урок 4. Update Data in Postgres
00:01:55
- Урок 5. Delete Postgres Records
00:02:43
- Урок 6. Group and Aggregate Data in Postgres
00:06:45
- Урок 7. Sort Postgres Tables
00:01:20
- Урок 8. Ensure Uniqueness in Postgres
00:03:53
- Урок 9. Use Foreign Keys to Ensure Data Integrity in Postgres
00:02:18
- Урок 10. Create Foreign Keys Across Multiple Fields in Postgres
00:03:08
- Урок 11. Enforce Custom Logic with Check Constraints in Postgres
00:02:07
- Урок 12. Speed Up Postgres Queries with Indexes
00:02:33
- Урок 13. Find Intersecting Data with Postgres_ Inner Join
00:04:26
- Урок 14. Select Distinct Data in Postgres
00:00:52
Курс «Get Started With PostgreSQL» заставить вас сказать что вы «знаете SQL» — создание таблиц, вставки, выборки, обновления, удаления, агрегации, индексы, объединения и ограничения. По пути мы будем моделировать проблемы реального мира, чтобы вы могли увидеть, насколько мощный PostgreSQL!
24-04-2016
30-11—0001
ru
15 уроков
Если Вы начали осваивать SQL, то в процессе изучения Вам предстоит столкнуться со множеством вопросов и непонятных моментов, ответы на которые подготовил данный видеокурс. В процессе обучения будут разобраны такие темы, как: создание базы данных, ее изменение и удаление, оператор вставки INSERT, использование запроса SELECT и конструкций WHERE, операторы UPDATE и DELETE, создание различных связей между таблицами с использованием операторов…
Duration 01:26:19
24-04-2016
30-11—0001
ru
9 уроков
Duration 08:50:57
17-06-2018
30-11—0001
ru
6 уроков
Курс СУБД PostgreSQL состоит из 6 уроков, рассчитан для новичков, которые впервые встречают такое понятием как СУБД. Курс включает в себя как теоретическую, так и практическую часть. На данном курсе учащиеся спроектируют небольшую базу данных сети продуктовых магазинов, определят необходимую структуру. Функционал (индексы, представления, триггеры, функции). После прохождения курса, учащиеся будут понимать принципы проектирования БД,…
Duration 03:05:26
28-11-2018
12-09-2018
en
164 урока
Создайте 9 проектов — освойте две основные и современные технологии в Python и PostgreSQL. Всегда хотели узнать один из самых популярных языков программирования на планете? Почему бы не изучить два из самых популярных одновременно? Python и SQL используются многими технологическими компаниями, малыми и большими. Это потому, что они мощные, но чрезвычайно гибкие.
Duration 21:53:10
27-12-2018
ru
10 уроков
Данный курс предназначен для изучения основ SQL: теоретических основ реляционной модели, операций реляционной алгебры, правил и назначение нормализации, использования ER диаграммы для моделирования предметной области, практического использования всех операторов SQL (операторов определения данных (Data Definition Language, DDL): CREATE, ALTER, DROP; манипуляции данными (Data Manipulation Language, DML):…
Duration 05:23:59
Последнее добавленное
en
13-03-2019
В дополнение к обновлению всех инструментов до последних и самых лучших версий Complete Intro to React v5 реструктурировал семинар, чтобы больше сосредоточиться на обучении основным принципам React, не жертвуя при этом какими-либо инструкциями по инструментарию. В этом двухдневном тренинге Брайан…
en
13-03-2019
Единственный курс, который вам нужен для изучения веб-разработки — HTML, CSS, JS, Node и многое другое! Привет! Добро пожаловать в The Web Developer Bootcamp, единственный курс, который вам нужен для изучения веб-разработки. Существует множество вариантов онлайн-обучения разработчиков…
en
13-03-2019
Знание – сила, и набор материалов по PostgreSQL тому подтверждение. Представляем книги и курсы, с которыми полнофункциональная СУБД станет доступной.
Эта книжка-малышка доступна в электронном и бумажном вариантах. Но важно другое: книга собрала необходимый костяк. Здесь представлена информация о кроссплатформенности, запросах, полнотекстовом поиске и о многом другом. Книгу можно смело назвать «От А до Я». Установкой и настройкой открытой СУБД на разных ОС книга не ограничивается, поэтому будьте готовы к первой практике.
Начинается просто: введение, история, форки и т. д. Дальше – больше: архитектура, включающая в себя разделы о структуре памяти, многоверсионности и расширяемости системы, создание БД из шаблона, табличные пространства, системный каталог, схемы, холодное и горячее резервирование. Это настоящий курс, наполненный слайдами, практическими примерами и видео-уроками.
«Продвинутым» подойдет расширенная версия. Курс дополнен журналированием, репликацией с подключением, видами и вариантами, основами оптимизации, локализацией, обновлением сервера и другой полезной информацией. Кроме слайдов, в архив заключены справочник по Unix-командам, которые используются в курсе, и инструкция по практическим заданиям.
8 лекций и море новых знаний. Здесь есть как общие сведения о подсистемах, так и подробный разбор инструментов разработчика, расширяемости, исходного кода, физического представления данных, разделяемой и локальной памяти, а также устройства экзекутора и планировщика запросов. Лекции сопровождаются обратной связью «вопрос/ответ», примерами и картинками.
Без нее никуда. Наиболее лаконичная и исчерпывающая информация, которая должна быть у каждого, кто работает со свободной объектно-реляционной СУБД. Только актуальные обновляемые версии.
System Administration
Этот пост — краткая инструкция для начинающих, для тех кто впервые установил PostgreSQL. Здесь вся необходимая информация для того, чтобы начать работу с PostgreSQL.
Подключение к СУБД
Первое, что нужно сделать — получить доступ к PostgreSQL, доступ в качестве суперпользователя.
Настройки аутентификации находятся в файле pg_hba.conf.
- local all postgres peer
Эта строка говорит о том, что пользователь postgres может подключаться к любой базе данных локальной СУБД PostgreSQL через сокет. Пароль при этом вводить не надо, операционная система передаст имя пользователя, и оно будет использовано для аутентификации.
Подключаемся:
- $ sudo -u postgres psql postgres postgres
Чтобы иметь возможность подключаться по сети, надо в pg_hdba.conf добавить строку:
- # TYPE DATABASE USER ADDRESS METHOD
- hostssl all all 0.0.0.0/0 md5
Метод аутентификации md5
означает, что для подключения придется ввести пароль. Это не очень удобно, если вы часто пользуетесь консолью psql. Если вы хотите автоматизировать какие-то действия, то плохая новость в том, что psql не принимает пароль в качестве аргумента. Есть два пути решения этих проблем: установка соответствующей переменной окружения и хранение пароля в специальном файле.pgpass .
Установка переменной окружения PGPASSWORD
Сразу скажу, что лучше этот способ не использовать, потому что некоторые операционные системы позволяют просматривать обычным пользователям переменные окружение с помощью ps. Но если хочется, то надо написать в терминале:
- export PGPASSWORD=mypasswd
Переменная будет доступна в текущей сессии. Если нужно задать переменную для всех сессий, то надо добавить строку из примера в файл.bashrc или.bash_profile
Хранение пароля в файле.pgpass
Если мы говорим о Linux, то файл должен находится в $HOME (/home/username). Права на запись и чтение должны быть только у владельца (0600). В файл нужно записывать строки вида:
- hostname:port:database:username:password
В первые четыре поля можно записать «*», что будет означать отсутствие фильтрации (полную выборку).
Получение справочной информации
? — выдаст все доступные команды вместе с их кратким описанием,
h — выдаст список всех доступных запросов,
h CREATE — выдаст справку по конкретному запросу.
Управление пользователями СУБД
Как получить список пользователей PostgreSQL?
Или можно сделать запрос к таблице pg_user.
- SELECT
*
FROM
pg_user
;
Создание нового пользователя PostgreSQL
Из командной оболочки psql это можно сделать с помощью команды CREATE.
- CREATE
USER
username
WITH
password
«password»
;
Или можно воспользоваться терминалом.
- createuser -S -D -R -P username
Ввод пароля будет запрошен.
Изменение пароля пользователя
- ALTER
USER
username
WITH
PASSWORD
«password»
;
Изменение ролей пользователя
Чтобы пользователь имел право создавать базы данных, выполните запрос:
- ALTER
ROLE
username
WITH
CREATEDB
;
Управление базами данных
Вывод списка баз данных в терминале psql:
Тоже самое из терминала Linux:
- psql -l
Создание базы данных из psql (PostgreSQL Terminal)
- CREATE
DATABASE
dbname
OWNER
dbadmin
;
Создание новой базы данных при помощи терминала:
- createdb -O username dbname;
Настройка прав доступа к базе данных
Если пользователь является владельцем (owner) базы данных, то у него есть все права. Но если вы хотите дать доступ другому пользователю, то сделать это можно с помощью команды GRANT. Запрос ниже позволит пользователю подключаться к базе данных. Но не забывайте о конфигурационном файле pg_hba.conf, в нем тоже должны быть соответствующие разрешения на подключение.
- GRANT
CONNECT
ON
DATABASE
dbname
TO
dbadmin
;
PostgreSQL — ýòî ñâîáîäíî ðàñïðîñòðàíÿåìàÿ îáúåêòíî-ðåëÿöèîííàÿ ñèñòåìà
óïðàâëåíèÿ áàçàìè äàííûõ (ORDBMS), íàèáîëåå ðàçâèòàÿ èç îòêðûòûõ ÑÓÁÄ â ìèðå
è ÿâëÿþùàÿñÿ ðåàëüíîé àëüòåðíàòèâîé êîììåð÷åñêèì áàçàì äàííûõ.
PostgreSQL ïðîèçíîñèòñÿ êàê post-gress-Q-L (ìîæíî ñêà÷àòü mp3 ôàéë postgresql.mp3),
â ðàçãîâîðå ÷àñòî óïîòðåáëÿåòñÿ postgres (ïîñò-ãðåññ). Òàêæå, óïîòðåáëÿåòñÿ
ñîêðàùåíèå pgsql (ïý-æý-ýñ-êó-ýëü).
Àäðåñ ýòîé ñòàòüè:
http://www.sai.msu.su/~megera/postgres/talks/what_is_postgresql.html
Èñòîðèÿ ðàçâèòèÿ PostgreSQL
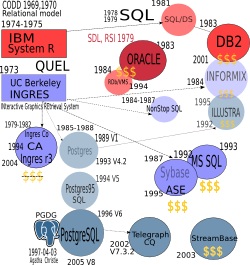
Êðàòêóþ èñòîðèþ PostgreSQL ìîæíî ïðî÷èòàòü â äîêóìåíòàöèè, ðàñïðîñòðàíÿåìîé
ñ äèñòðèáóòèâîì èëè íà ñàéòå.
Òàêæå, åñòü ïåðåâîä íà
ðóññêèé ÿçûê. Èç íåå ñëåäóåò, ÷òî ñîâðåìåííûé ïðîåêò PostgreSQL âåäåò
ïðîèñõîæäåíèå èç ïðîåêòà POSTGRES, êîòîðûé ðàçðàáàòûâàëñÿ ïîä ðóêîâîäñòâîì
Ìàéêëà Ñòîóíáðåéêåðà (Michael Stonebraker), ïðîôåññîðà Êàëèôîðíèéñêîãî
óíèâåðñèòåòà â Áåðêëè (UCB). Ìíå çàõîòåëîñü íåñêîëüêî ïîäðîáíåå ïîêàçàòü
âçàèìîñâÿçè ðîäîñëîâíûõ áàç äàííûõ, ÷òîáû ëó÷øå ïîíÿòü ìåñòî PostgreSQL ñðåäè
îñíîâíûõ èãðîêîâ ñîâðåìåííîãî ðûíêà áàç äàííûõ.
ß ïîïûòàëñÿ ãðàôè÷åñêè
( áîëüøàÿ âåðñèÿ êàðòèíêè
îòêðîåòñÿ â íîâîì îêíå) îòîáðàçèòü âñå
íàèáîëåå çàìåòíûå RDBMS è ñâÿçè ìåæäó íèìè è ïðèáëèçèòåëüíî ïðèâåë äàòû
èõ ñîçäàíèÿ è êîíöà. Ïåðåñå÷åíèå îáúåêòîâ îçíà÷àåò ïîãëîùåíèå, ïðè ýòîì
ïîãëîùàåìûé îáúåêò áîëåå áëåäåí è íå îêàíòîâàí. Çíàê äîëëàðà îçíà÷àåò,
÷òî áàçà äàííûõ ÿâëÿåòñÿ êîììåð÷åñêîé.
Ïðè ýòîì, ÿ îñíîâûâàëñÿ íà èíôîðìàöèè, äîñòóïíîé
â èíòåðíåòå, â ÷àñòíîñòè â Wikipedia,
â íàó÷íûõ ñòàòüÿõ, êîòîðûå ÿ ÷èòàë è êîììåíòàðèÿõ íåïîñðåäñòâåííûõ ïîëüçîâàòåëåé
ÁÄ, êîòîðûå ÿ ïîëó÷èë ïîñëå ïóáëèêàöèè ýòîé êàðòèíêè â èíòåðíåòå.
Íàäî ñêàçàòü, ÷òî íåñìîòðÿ íà òî, ÷òî âñÿ èñòîðèÿ ðåëÿöèîííûõ áàç äàííûõ
íàñ÷èòûâàåò ìåíåå 4 äåñÿòêîâ ëåò, ìíîãèå ôàêòû èç èñòîðèè ñîçäàíèÿ òðàêòóþòñÿ
ïî-ðàçíîìó, äàòû íå ñîãëàñóþòñÿ, à ñàìè ó÷àñòíèêè ñîáûòèé çà÷àñòóþ ïðîñòî
âîëüíî òðàêòóþò ïðîøëîå.Çäåñü íàäî ïðèíèìàòü âî âíèìàíèå òîò ôàêò, ÷òî
áàçû äàííûõ — ýòî áîëüøîé áèçíåñ, â êîòîðîì ðàçâèòèå îäíèõ ÁÄ ÷àñòî ñâÿçàíî ñ
êîíöîì äðóãèõ. Êðîìå òîãî, ÁÄ
â òî âðåìÿ áûëè ïðåäìåòîì íàó÷íûõ èññëåäîâàíèé, ïîýòîìó ïðèîðèòåòíîñòü
ðàáîò ÿâëÿåòñÿ íå ïîñëåäíèì àðãóìåíòîì ïðè íàïèñàíèè âîñïîìèíàíèé è èíòåðâüþ.
Íàâåðíîå, ó÷èòûâàÿ òàêóþ çàïóòàííîñòü, ïðåìèÿ ACM Software System Award #6
áûëà ïðèñóæäåíà
îäíîâðåìåííî äâóì ñîïåðíè÷àþùèì ãðóïïàì èññëåäîâàòåëåé èç IBM çà ðàáîòó íàä
«System R» è Áåðêëè — çà INGRES, õîòÿ Ñòîóíáðåéêåð ïîëó÷èë íàãðàäó îò
ACM SIGMOD (ñåé÷àñ ýòî ïðåìèÿ íàçâàíà â ÷åñòü
Òåäà Êîääà — àâòîðà ðåëÿöèîííîé òåîðèè áàç äàííûõ) #1 â 1992 ã.,
à Ãðåé (Jim Gray, Microsoft) — #2 â 1993 ãîäó.
Èòàê, êàê ñëåäóåò èç ðèñóíêà, âèäíî äâå âåòâè ðàçâèòèÿ áàç äàííûõ —
îäíà ñëåäóåò èç «System R», êîòîðàÿ ðàçðàáàòûâàëàñü â IBM â íà÷àëå 70-õ,
è äðóãàÿ èç ïðîåêòà «INGRES», êîòîðûì ðóêîâîäèë Ñòîóíáðåéêåð ïðèáëèçèòåëüíî
â òîæå âðåìÿ. Ýòè äâà ïðîåêòà íà÷àëèñü êàê íåîáõîäèìîñòü ïðàêòè÷åñêîãî
èñïîëüçîâàíèÿ ðåëÿöèîííîé ìîäåëè áàç äàííûõ, ðàçðàáîòàííîé Òåäîì Êîääîì (Ted Codd)
èç IBM â 1969,1970 ãîäàõ. Íàäî ïîìíèòü, ÷òî â òî âðåìÿ èìåëîñü äâå àëüòåðíàòèâíûå
ìîäåëè áàç äàííûõ — ñåòåâàÿ è èåðàðõè÷åñêàÿ, ïðè÷åì çà íèìè ñòîÿëè ìîùíûå
ñèëû — CODASYL Data Base Task Group (ñåòåâàÿ) è ñàìà IBM ñ åå áàçîé IMS
(Information Management System ñ èåðàðõè÷åñêîé ìîäåëüþ äàííûõ).
Íåìíîãî â ñòîðîíå ñòîèò «Oracle», âçëåò êîòîðîé âî ìíîãîì
ñâÿçàí ñ êîììåð÷åñêèì òàëàíòîì Ýëëèñîíà áûòü â íóæíîì ìåñòå è â íóæíîå âðåìÿ,
êàê ñêàçàë Ñòîóíáðåéêåð â ñâîåì
èíòåðâüþ,
õîòÿ îíà âìåñòå ñ IBM ñûãðàëà áîëüøóþ ðîëü â ñîçäàíèè è ïðîäâèæåíèè SQL.
«System R» ñûãðàëà áîëüøóþ ðîëü â ðàçâèòèè ðåëÿöèîííûõ áàç äàííûõ,
ñîçäàíèè ÿçûêà SQL (èçíà÷àëüíî SEQUEL, íî èç-çà ïðîáëåì ñ óæå
ñóùåñòâóþùåé òîðãîâîé ìàðêîé ïðèøëîñü âûêèíóòü âñå ãëàñíûå áóêâû).
Èç «System R» ðàçâèëàñü SQL/DS è DB2. Íà ñàìîì äåëå, â IBM áûëî åùå íåñêîëüêî
ïðîåêòîâ, íî îíè áûëè ÷èñòî âíóòðåííèìè.
Ïîäðîáíåå îá ýòîé âåòâè ìîæíî ïðî÷èòàòü â âåñüìà ïîó÷èòåëüíîì äîêóìåíòå
«The 1995 SQL Reunion: People, Projects, and Politics»,
òàêæå äîñòóïåí ðóññêèé ïåðåâîä.
INGRES (èëè Ingres89), â îòëè÷èå îò «System R», âïîëíå â äóõå Áåðêëè ðàçâèâàëàñü êàê
îòêðûòàÿ áàçà äàííûõ, êîäû êîòîðîé ðàñïðîñòðàíÿëèñü íà ëåíòàõ ïðàêòè÷åñêè
áåñïëàòíî (îïëà÷èâàëèñü ïî÷òîâûå ðàñõîäû è ñòîèìîñòü ëåíòû). Ê 1980 ãîäó
áûëî ðàñïðîñòðàíåíî ïîðÿäêà 1000 êîïèé.
Íàçâàíèå
ðàñøèôðîâûâàåòñÿ êàê «INteractive Graphics (and) REtrieval System»
è ñîâåðøåííî ñëó÷àéíî ñâÿçàíî
ñ ôðàíöóçñêèì õóäîæíèêîì Jean Auguste Dominique Ingres.
Îòëè÷èòåëüíîé
îñîáåííîñòüþ ýòîé ñèñòåìû ÿâëÿëîñü òî, ÷òî îíà ðàçðàáàòûâàëàñü äëÿ îïåðàöèîííîé
ñèñòåìû UNIX, êîòîðàÿ ðàáîòàëà íà ðàñïðîñòðàíåííûõ òîãäà PDP 11, ÷òî è
ïðåäîïðåäåëèëî åå ïîïóëÿðíîñòü, â òî âðåìÿ êàê «System R» ðàáîòàëà òîëüêî íà
áîëüøèõ è äîðîãèõ mainframe. Áûë ðàçðàáîòàí ÿçûê çàïðîñîâ QUEL, êîòîðûé,
êàê ïèñàë Ñòîóíáðåéêåð, ïîõîæ íà SEQUEL â òîì îòíîøåíèè, ÷òî ïðîãðàììèñò
ñâîáîäåí îò çíàíèÿ î ñòðóêòóðå äàííûõ è àëãîðèòìàõ, ÷òî ñïîñîáñòâóåò
çíà÷èòåëüíîé ñòåïåíè íåçàâèñèìîñòè îò äàííûõ. Äîñòóïíîñòü INGRES è î÷åíü
ëèáåðàëüíàÿ ëèöåíçèÿ BSD, à òàêæå òâîð÷åñêàÿ äåÿòåëüíîñòü, ñïîñîáñòâîâàëè
ïîÿâëåíèþ áîëüøîãî êîëè÷åñòâà ðåëÿöèîííûõ áàç äàííûõ, êàê ïîêàçàíî íà ðèñóíêå.
Ñòîóíáðåéêåð ëè÷íî ñïîñîáñòâîâàë èõ ïîÿâëåíèþ, òàê îí êîíöå 70-õ îí
îðãàíèçîâàë êîìïàíèþ Ingres Corporation (êàê îí ñàì îáúÿñíÿåò, åìó ïðèøëîñü íà
ýòî ïîéòè, òàê êàê Àðèçîíñêèé óíèâåðñèòåò, ïîòðåáîâàë ïîääåðæêè), êîòîðàÿ âûïóñòèëà êîììåð÷åñêóþ
âåðñèþ Ingres, â 1994 ãîäó îíà áûëà êóïëåíà CA (Computer Associates) è êîòîðàÿ
â 2004 ãîäó ñòàëà îòêðûòîé êàê Ingres r3.
«NonStop SQL» êîìïàíèè Tandem Computers ÿâëÿëàñü ìîäèôèöèðîâàííîé âåðñèåé
Ingres, êîòîðàÿ ýôôåêòèâíî ðàáîòàëà íà ïàðàëëåëüíûõ êîìïüþòåðàõ è ñ
ðàñïðåäåëåííûìè äàííûìè. Îíà óìåëà âûïîëíÿòü çàïðîñû ïàðàëëåëüíî è ìàñøòàáèðîâàëàñü
ïî÷òè ëèíåéíî ñ êîëè÷åñòâîì ïðîöåññîðîâ. Åå àâòîðàìè áûëè âûïóñêíèêè èç Áåðêëè. Âïîñëåäñòâèè,
Tandem Computers áûëà êóïëåíà êîìïàíèåé Compaq (2000 ã.), à çàòåì
êîìïàíèåé HP.
Êîìïàíèÿ Sybase òîæå áûëà îðãàíèçîâàíà ÷åëîâåêîì èç Áåðêëè (Ðîáåðò Ýïñòåéí)
è íà îñíîâå Ingres. Èçâåñòíî, ÷òî áàçà äàííûõ êîìïàíèè Ìaéêðîñîôò «SQL Server» —
ýòî íå ÷òî èíîå êàê áàçà äàííûõ Sybase, êîòîðàÿ áûëà ëèöåíçèðîâàíà äëÿ
Windows NT. Ñ 1993 ãîäà ïóòè Sybase è Mirosoft ðàçîøëèñü è óæå â 1995 ãîäó
Sybase ïåðåèìåíîâûâàåò ñâîþ áàçó äàííûõ â ASE (Adaptive Server Enterprise),
à Microsoft ñòàëà ïðîäîëæàòü ðàçâèâàòü MS SQL.
Informix òîæå âîçíèê èç Ingres, íî íà ýòî ðàç ëþäüìè íå èç Áåðêëè, õîòÿ
Ñòîóíáðåéêåð âñå-òàêè ïîðàáîòàë â íåé CEO ïîñëå òîãî, êàê Informix êóïèëà
â 1995 ãîäó êîìïàíèþ Ilustra, ÷òîáû ïðèáàâèòü ñåáå îáúåêòíî-ðåëÿöèîííîñòè
è ðàñøèðÿåìîñòè (DataBlade), êîòîðóþ îðãàíèçîâàë âñå òîò æå Ìàéêë Ñòîóíáðåéêåð êàê ðåçóëüòàò
êîììåðöèàëèçàöèè Postgres â 1992 ãîäó. Â 2001 ãîäó îíà áûëà êóïëåíà IBM,
êîòîðàÿ ïðèîáðåòàëà íåìàëîå êîëè÷åñòâî ïîëüçîâàòåëåé Informix è òåõíîëîãèþ.
Òàêèì îáðàçîì, DB2 òàêæå ïðèîáðåëà íåìíîãî îáúåêòíî-ðåëÿöèîííîñòè.
Ïðîåêò Postgres âîçíèê êàê ðåçóëüòàò îñìûñëåíèÿ îøèáîê Ingres è æåëàíèÿ
ïðåîäîëåòü îãðàíè÷åííîñòü òèïîâ äàííûõ, çà ñ÷åò âîçìîæíîñòè îïðåäåëåíèÿ
íîâûõ òèïîâ äàííûõ. Ðàáîòà íàä ïðîåêòîì íà÷àëàñü â 1985 è â ïåðèîä 1985-1988
áûëî îïóáëèêîâàíî íåñêîëüêî ñòàòåé, îïèñûâàþùèõ ìîäåëü äàííûõ, ÿçûê çàïðîñîâ
POSTQUEL, è õðàíèëèùå Postgres. POSTGRES èíîãäà åùå îòíîñÿò ê òàê íàçûâàåìûì
ïîñòðåëÿöèîííûì ÑÓÁÄ. Îãðàíè÷åííîñòü ðåëÿöèîííîé ìîäåëè
âñåãäà ÿâëÿëàñü ïðåäìåòîì êðèòèêè, õîòÿ âñå ïîíèìàëè, ÷òî ýòî ÿâëÿåòñÿ
ñëåäñòâèåì åå ïðîñòîòû è åå çàñëóãîé. Îäíàêî, ïðîíèêíîâåíèå êîìïüþòåðíûõ
òåõíîëîãèé âî âñå ñôåðû æèçíè òðåáîâàëè íîâûõ ïðèëîæåíèé, à îò áàç äàííûõ —
ïîääåðæêè íîâûõ òèïîâ äàííûõ è âîçìîæíîñòåé, íàïðèìåð, ïîääåðæêà íàñëåäîâàíèÿ,
ñîçäàíèå è óïðàâëåíèå ñëîæíûìè îáúåêòàìè.
Åùå ïðè ïðîåêòèðîâàíèè îðèãèíàëüíîé âåðñèè POSTGRES îñíîâíîå âíèìàíèå
áûëî óäåëåíî ðàñøèðÿåìîñòè è îáúåêòíî-îðèåíòèðîâàííûì âîçìîæíîñòÿì. Óæå
òîãäà áûëî ÿñíà íåîáõîäèìîñòü ðàñøèðåíèÿ ôóíêöèîíàëüíîñòè DMBS îò óïðàâëåíèÿ
äàííûìè (data management) â ñòîðîíó óïðàâëåíèÿ îáúåêòàìè
(object management) è çíàíèÿìè (knowledge management).
Ïðè ýòîì îáúåêòíàÿ ôóíêöèîíàëüíîñòü ïîçâîëèò ýôôåêòèâíî õðàíèòü è
ìàíèïóëèðîâàòü íåòðàäèöèîííûìè òèïàìè äàííûõ, à óïðàâëåíèå çíàíèÿìè ïîçâîëÿåò
õðàíèòü è îáåñïå÷èâàòü âûïîëíåíèÿ êîëëåêöèè ïðàâèë (rules), êîòîðûå
íåñóò ñåìàíòèêó ïðèëîæåíèÿ. Ñòîóíáðåéêåð òàê è îïðåäåëèë îñíîâíóþ çàäà÷ó
POSTGRES êàê «îáåñïå÷èòü ïîääåðæêó ïðèëîæåíèé, êîòîðûå òðåáóþò
ñëóæáû óïðàâëåíèÿ äàííûìè, îáúåêòàìè è çíàíèÿìè«.
Îäíèì èç ôóíäàìåíòàëüíûì ïîíÿòèåì POSTGRES ÿâëÿåòñÿ class. Class åñòü
èìåíîâàííàÿ êîëëåêöèÿ ýêçåìïëÿðîâ (instances) îáúåêòîâ. Êàæäûé ýêçåìïëÿð
èìååò êîëëåêöèþ èìåíîâàííûõ àòðèáóòîâ è êàæäûé àòðèáóò èìååò
îïðåäåëåííûé òèï. Êëàññû ìîãóò áûòü òðåõ òèïîâ — ýòî îñíîâíîé êëàññ,
÷üè ýêçåìïëÿðû õðàíÿòñÿ â áàçå äàííûõ, âèðòóàëüíûé (view), ÷üè ýêçåìïëÿðû
ìàòåðèàëèçóþòñÿ òîëüêî ïðè çàïðîñå (îíè ïîääåðæèâàþòñÿ ñèñòåìîé óïðàâëåíèÿ
ïðàâèëàìè), è ìîæåò áûòü âåðñèåé äðóãîãî (parent) êëàññà.
Ïåðâàÿ âåðñèÿ áûëà âûïóùåíà â 1989 ãîäó,
çàòåì ïîñëåäîâàëî åùå íåñêîëüêî ïåðåïèñûâàíèé ñèñòåìû ïðàâèë (rule system).
Îòìåòèì, ÷òî êîäû Ingres è Postgres íå èìåëè íè÷åãî îáùåãî !
 POSTGRES áûëà ðåàëèçîâàíà ïîääåðæêà òàêèõ òèïîâ êàê ìíîãîìåðíûå ìàññèâû,
÷òî óæå øëî â ïðîòèâîðå÷èå ñ ðåëÿöèîííîé ìîäåëüþ, timetravel — õðàíåíèå
âåðñèîííîñòè îáúåêòîâ (âïîñëåäñòâèè, â âåðñèè 6.3 ýòîò òèï áûë óäàëåí, òàê êàê
åãî ïîääåðæêà òðåáîâàëà áîëüøèõ óñèëèé, à âåðñèîííîñòü ìîãëà áûòü
ðåàëèçîâàíà íà ñòîðîíå ïðèëîæåíèÿ ñ ïîìîùüþ òðèããåðîâ).
 1992 ãîäó áûëà îáðàçîâàíà êîìïàíèÿ Illustra, à ñàì ïðîåêò áûë çàêðûò â
1993 ãîäó âûïócêîì âåðñèè 4.2. Îäíàêî, íåñìîòðÿ íà îôèöèàëüíîå çàêðûòèå ïðîåêòà,
îòêðûòûé êîä è BSD ëèöåíçèÿ ñïîäâèãëè âûïóñêíèêîâ Áåðêëè Andrew Yu è Jolly Chen
â 1994 ãîäó âçÿòüñÿ çà åãî äàëüíåéøåå ðàçâèòèå. Â 1995 ãîäó îíè çàìåíèëè
ÿçûê çàïðîñîâ POSTQUEL íà îáùåïðèíÿòûé SQL, ïðîåêò ïîëó÷èë íàçâàíèå Postgres95,
èçìåíèëàñü íóìåðàöèÿ âåðñèé, áûë ñîçäàí âåá ñàéò ïðîåêòà è ïîÿâèëèñü ìíîãî
íîâûõ ïîëüçîâàòåëåé (ñðåäè êîòîðûõ áûë è àâòîð).
Ê 1996 ãîäó ñòàëî ÿñíî, ÷òî íàçâàíèå «Postgres95» íå âûäåðæèò èñïûòàíèåì
âðåìåíåì è áûëî âûáðàíî íîâîå èìÿ — «PostgreSQL», êîòîðîå îòðàæàåò ñâÿçü
ñ îðèãèíàëüíûì ïðîåêòîì POSTGRES è ïðèîáðåòåíèåì SQL. Òàêæå, âåðíóëè
ñòàðóþ íóìåðàöèþ âåðñèé, òàêèì îáðàçîì íîâàÿ âåðñèÿ ñòàðòîâàëà êàê 6.0.
 1997 áûë ïðåäëîæåí ñëîí â êà÷åñòâå ëîãîòèïà, ñîõðàíèëîñü
ïèñüìî â
àðõèâàõ ðàññûëêè -hackers çà 3 ìàðòà 1997 ãîäà è ïîñëåäóþùàÿ äèñêóññèÿ.
Ñëîí áûë ïðåäëîæåí Äýâèäîì ßíãîì â ÷åñòü ðîìàíà Àãàòû Êðèñòè
«Elephants can remember» (Ñëîíû ìîãóò âñïîìèíàòü). Äî ýòîãî, ëîãîòèïîì
áûë áåãóùèé ëåîïàðä (ÿãóàð). Ïðîåêò ñòàë áîëüøîé è óïðàâëåíèå íà ñåáÿ âçÿëà
íåáîëüøàÿ âíà÷àëå ãðóïïà èíèöèàòèâíûõ ïîëüçîâàòåëåé è ðàçðàáîò÷èêîâ, êîòîðàÿ
è ïîëó÷èëà íàçâàíèå PGDG (PostgreSQL Global Development Group).
Äàëüíåéøåå ðàçâèòèå ïðîåêòà ïîëíîñòüþ
äîêóìåíòèðîâàíî
â äîêóìåíòàöèè è îòðàæåíî â àðõèâàõ ñïèñêà ðàññûëêè -hackers.
×òî åñòü PostgreSQL ñåãîäíÿ ?
Íà ñåãîäíÿøíèé äåíü âûïóùåíà âåðñèÿ PostgreSQL v8 (19 ÿíâàðÿ 2005 ãîäà), êîòîðàÿ ÿâëÿåòñÿ
çíà÷èòåëüíûì ñîáûòèåì â ìèðå áàç äàííûõ, òàê êàê êîëè÷åñòâî íîâûõ âîçìîæíîñòåé
äîáàâëåííûõ â ýòîé âåðñèè, ïîçâîëÿåò ãîâîðèòü î âîçíèêíîâåíèè èíòåðåñà êðóïíîãî
áèçíåñà êàê â èñïîëüçîâàíèè, òàê è åãî ïðîäâèæåíèè. Òàê, êðóïíåéøàÿ êîìïàíèÿ â ìèðå, Fujitsu ïîääåðæàëà ðàáîòû íàä
âåðñèåé 8, âûïóñòèëà êîììåð÷åñêèé ìîäóëü
Extended Storage Management.
Ëèáåðàëüíàÿ BSD-ëèöåíçèÿ
ïîçâîëÿåò êîììåð÷åñêèì êîìïàíèÿì âûïóñêàòü ñâîè âåðñèè PostgreSQL ïîä ñâîèì
èìåíåì è îñóùåñòâëÿòü êîììåð÷åñêóþ ïîääåðæêó. Íàïðèìåð, êîìïàíèÿ
Pervasive îáúÿâèëà î âûïóñêå Pervasive Postgres.
PostgreSQL ïîääåðæèâàåòñÿ íà âñåõ ñîâðåìåííûõ Unix ñèñòåìàõ (34 ïëàòôîðìû),
âêëþ÷àÿ íàèáîëåå ðàñïðîñòðàíåííûå, òàêèå êàê Linux, FreeBSD, NetBSD, OpenBSD, SunOS, Solaris,
DUX, à òàêæå ïîä Mac OS X. Íà÷èíàÿ ñ âåðñèè 8.X PostgreSQL ðàáîòàåò â «native»
ðåæèìå ïîä MS Windows NT, Win2000, WinXP, Win2003.
Èçâåñòíî, ÷òî åñòü óñïåøíûå ïîïûòêè
ðàáîòàòü ñ PostgreSQL ïîä Novell Netware 6 è OS2.
PostgreSQL íåîäíîêðàòíî ïðèçíàâàëàñü áàçîé ãîäà, íàïðèìåð,
Linux New Media AWARD 2004,
2003 Editors’ Choice Awards,
2004 Editors’ Choice Awards.
PostgreSQL èñïîëüçóåòñÿ êàê ïîëèãîí äëÿ èññëåäîâàíèé íîâîãî òèïà
áàç äàííûõ, îðèåíòèðîâàííûõ íà ðàáîòó ñ ïîòîêàìè äàííûõ — ýòî
ïðîåêò TelegraphCQ,
ñòàðòîâàâøèé â 2002 ãîäó â Áåðêëè ïîñëå óñïåøíîãî ïðîåêòà Telegraph
(íàçâàíèå ãëàâíîé óëèöû â Áåðêëè).
Èíòåðåñíî, ÷òî êîìïàíèÿ Streambase,
êîòîðàÿ áûëà îñíîâàíà Ìàéêîì Ñòîóíáðåéêåðîì â 2003 ãîäó (èçíà÷àëüíî «Grassy Brook»)
äëÿ êîììåð÷åñêîãî ïðîäâèæåíèÿ ýòîãî íîâîãî ïîêîëåíèÿ áàç äàííûõ, íèêàêèì îáðàçîì
íå àññîöèèðóåòñÿ ñ ïðîåêòîì Áåðêëè.
Îñíîâíûå âîçìîæíîñòè è ôóíêöèîíàëüíîñòü
Ïîëíûé ñïèñîê âñåõ âîçìîæíîñòåé ïðåäîñòàâëÿåìûõ PostgreSQL è ïîäðîáíîå
îïèñàíèå ìîæíî íàéòè â îáúåìíîé
äîêóìåíòàöèè (1300 ñòðàíèö).
- Íàäåæíîñòü PostgreSQL ÿâëÿåòñÿ ïðîâåðåííûì è äîêàçàííûì ôàêòîì
è îáåñïå÷èâàåòñÿ ñëåäóþùèìè âîçìîæíîñòÿìè:- ïîëíîå ñîîòâåòñòâèå ïðèíöèïàì ACID — àòîìàðíîñòü, íåïðîòèâîðå÷èâîñòü, èçîëèðîâàííîñòü, ñîõðàííîñòü äàííûõ.
- Atomicity — òðàíçàêöèÿ ðàññìàòðèâàåòñÿ êàê åäèíàÿ ëîãè÷åñêàÿ åäèíèöà,
âñå åå èçìåíåíèÿ èëè ñîõðàíÿþòñÿ öåëèêîì, èëè ïîëíîñòüþ îòêàòûâàþòñÿ. - Consistency — òðàíçàêöèÿ ïåðåâîäèò áàçó äàííûõ èç îäíîãî íåïðîòèâîðå÷èâîãî
ñîñòîÿíèÿ (íà ìîìåíò ñòàðòà òðàíçàêöèè) â äðóãîå íåïðîòèâîðå÷èâîå ñîñòîÿíèå
(íà ìîìåíò çàâåðøåíèÿ òðàíçàêöèè).
Íåïðîòèâîðå÷èâûì ñ÷èòàåòñÿ ñîñòîÿíèå áàçû, êîãäà âûïîëíÿþòñÿ âñå îãðàíè÷åíèÿ
ôèçè÷åñêîé è ëîãè÷åñêîé öåëîñòíîñòè áàçû äàííûõ, ïðè ýòîì
äîïóñêàåòñÿ íàðóøåíèå îãðàíè÷åíèé öåëîñòíîñòè â
òå÷åíèå òðàíçàêöèè, íî íà ìîìåíò çàâåðøåíèÿ âñå îãðàíè÷åíèÿ öåëîñòíîñòè,
êàê ôèçè÷åñêèå, òàê è ëîãè÷åñêèå, äîëæíû áûòü ñîáëþäåíû. - Isolation — èçìåíåíèÿ äàííûõ ïðè êîíêóðåíòíûõ òðàíçàêöèÿõ èçîëèðîâàíû
äðóã îò äðóãà íà îñíîâå ñèñòåìû âåðñèîííîñòè - Durability — PostgreSQL çàáîòèòñÿ î òîì, ÷òî ðåçóëüòàòû óñïåøíûõ
òðàíçàêöèé ãàðàíòèðîâàíî ñîõðàíÿþòñÿ íà æåñòêèé äèñê âíå çàâèñèìîñòè
îò ñáîåâ àïïàðàòóðû.
- Atomicity — òðàíçàêöèÿ ðàññìàòðèâàåòñÿ êàê åäèíàÿ ëîãè÷åñêàÿ åäèíèöà,
- ìíîãîâåðñèîííîñòü (Multiversion Concurrency Control,MVCC)
èñïîëüçóåòñÿ äëÿ ïîääåðæàíèÿ ñîãëàñîâàííîñòè äàííûõ â êîíêóðåíòíûõ
óñëîâèÿõ, â òî âðåìÿ êàê â òðàäèöèîííûõ áàçàõ äàííûõ èñïîëüçóþòñÿ
áëîêèðîâêè. MVCC îçíà÷àåò, ÷òî êàæäàÿ òðàíçàêöèÿ âèäèò êîïèþ äàííûõ (âåðñèþ áàçû äàííûõ)
íà âðåìÿ íà÷àëà òðàíçàêöèè, íåñìîòðÿ íà òî, ÷òî ñîñòîÿíèå áàçû ìîãëî óæå èçìåíèòüñÿ.
Ýòî çàùèùàåò òðàíçàêöèþ îò íåñîãëàñîâàííûõ èçìåíåíèé äàííûõ, êîòîðûå ìîãëè
áûòü âûçâàíû (äðóãîé) êîíêóðåíòíîé òðàíçàêöèåé, è îáåñïå÷èâàåò èçîëÿöèþ
òðàíçàêöèé. Îñíîâíîé âûèãðûø îò èñïîëüçîâàíèÿ MVCC ïî ñðàâíåíèþ ñ
áëîêèðîâêîé çàêëþ÷àåòñÿ â òîì, ÷òî áëîêèðîâêà, êîòîðóþ ñòàâèò MVCC äëÿ ÷òåíèÿ íå
êîíôëèêòóåò ñ áëîêèðîâêîé íà çàïèñü, è ïîýòîìó ÷òåíèå íèêîãäà íå áëîêèðóåò
çàïèñü è íàîáîðîò. Êîíêóðåíòíûå îïåðàöèè çàïèñè «ìåøàþò» äðóã äðóãó
òîëüêî ïðè ðàáîòå ñ îäíîé è òîé æå çàïèñüþ. - íàëè÷èå Write Ahead Logging (WAL) — îáùåïðèíÿòûé ìåõàíèçì ïðîòîêîëèðîâàíèÿ
âñåõ òðàíçàêöèé, ÷òî ïîçâîëÿåò âîññòàíîâèòü ñèñòåìó ïîñëå âîçìîæíûõ ñáîåâ.
Îñíîâíàÿ èäåÿ WAL ñîñòîèò â òîì, ÷òî âñå èçìåíåíèÿ äîëæíû çàïèñûâàòüñÿ â
ôàéëû íà äèñê òîëüêî ïîñëå òîãî, êàê ýòè çàïèñè æóðíàëà, îïèñûâàþùèå ýòè
èçìåíåíèÿ áóäóò è ãàðàíòèðîâàíî çàïèñàíû íà äèñê. Ýòî ïîçâîëÿåò
íå ñáðàñûâàòü ñòðàíèöû äàííûõ íà äèñê ïîñëå ôèêñàöèè êàæäîé òðàíçàêöèè, òàê
êàê ìû çíàåì è óâåðåíû, ÷òî ñìîæåì âñåãäà âîññòàíîâèòü áàçó äàííûõ èñïîëüçóÿ
æóðíàë òðàíçàêöèé. - Point in Time Recovery (PITR) — âîçìîæíîñòü âîññòàíîâëåíèÿ
áàçû äàííûõ (èñïîëüçóÿ WAL) íà ëþáîé ìîìåíò â ïðîøëîì, ÷òî ïîçâîëÿåò
îñóùåñòâëÿòü íåïðåðûâíîå ðåçåðâíîå êîïèðîâàíèå êëàñòåðà PostgreSQL. - Ðåïëèêàöèÿ òàêæå ïîâûøàåò íàäåæíîñòü PostgreSQL. Ñóùåñòâóåò
íåñêîëüêî ñèñòåì ðåïëèêàöèè, íàïðèìåð, Slony (òåñòèðóåòñÿ âåðñèÿ 1.1),
êîòîðûé ÿâëÿåòñÿ ñâîáîäíûì è ñàìûì èñïîëüçóåìûì ðåøåíèåì, ïîääåðæèâàåò
master-slaves ðåïëèêàöèþ. Îæèäàåòñÿ, ÷òî Slony-II áóäåò ïîääåðæèâàòü
multi-master ðåæèì. - Öåëîñòíîñòü äàííûõ ÿâëÿåòñÿ ñåðäöåì PostgreSQL. Ïîìèìî MVCC, PostgreSQL
ïîääåðæèâàåò öåëîñòíîñòü äàííûõ íà óðîâíå ñõåìû — ýòî âíåøíèå êëþ÷è (foreign keys),
îãðàíè÷åíèÿ (constraints). - Ìîäåëü ðàçâèòèÿ PostgreSQL, êîòîðàÿ àáñîëþòíî ïðîçðà÷íà
äëÿ ëþáîãî, òàê êàê âñå ïëàíû, ïðîáëåìû è ïðèîðèòåòû îòêðûòî îáñóæäàþòñÿ.
Ïîëüçîâàòåëè è ðàçðàáîò÷èêè íàõîäÿòñÿ â ïîñòîÿííîì äèàëîãå ÷åðåç ìýéëèíã
ëèñòû. Âñå ïðåäëîæåíèÿ, ïàò÷è ïðîõîäÿò òùàòåëüíîå òåñòèðîâàíèå äî ïðèíÿòèÿ
èõ â ïðîãðàììíîå äåðåâî. Áîëüøîå êîëè÷åñòâî áåòà-òåñòåðîâ ñïîñîáñòâóåò
òåñòèðîâàíèþ âåðñèè äî ðåëèçà è âû÷èùåíèþ ìåëêèõ îøèáîê. - Îòêðûòîñòü êîäîâ PostgreSQL îçíà÷àåò èõ àáñîëþòíóþ äîñòóïíîñòü
äëÿ ëþáîãî, à ëèáåðàëüíàÿ BSD ëèöåíçèÿ íå íàêëàäûâàåò íèêàêèõ îãðàíè÷åíèé
íà èñïîëüçîâàíèå êîäà.
- ïîëíîå ñîîòâåòñòâèå ïðèíöèïàì ACID — àòîìàðíîñòü, íåïðîòèâîðå÷èâîñòü, èçîëèðîâàííîñòü, ñîõðàííîñòü äàííûõ.
- Ïðîèçâîäèòåëüíîñòü PostgreSQL îñíîâûâàåòñÿ íà èñïîëüçîâàíèè
èíäåêñîâ, èíòåëëåêòóàëüíîì ïëàíèðîâùèêå çàïðîñîâ, òîíêîé ñèñòåìû áëîêèðîâîê,
ñèñòåìå óïðàâëåíèÿ áóôåðàìè ïàìÿòè è êýøèðîâàíèÿ, ïðåâîñõîäíîé ìàñøòàáèðóåìîñòè
ïðè êîíêóðåíòíîé ðàáîòå.- Ïîääåðæêà èíäåêñîâ
- Ñòàíäàðòíûå èíäåêñû — B-tree, hash, R-tree, GiST (îáîáùåííîå
ïîèñêîâîå äåðåâî) - ×àñòè÷íûå èíäåêñû (partial indices) — ìîæíî ñîçäàâàòü èíäåêñ
ïî îãðàíè÷åííîìó ïîäìíîæåñòâó çíà÷åíèé, íàïðèìåð,
create index idx_partial on foo (x) where x > 0;
- Ôóíêöèîíàëüíûå èíäåêñû (expressional indices) ïîçâîëÿþò ñîçäàâàòü
èíäåêñû èñïîëüçóÿ çíà÷åíèÿ ôóíêöèè îò ïàðàìåòðà, íàïðèìåð,
create index idx_functional on foo ( length(x) );
- Ñòàíäàðòíûå èíäåêñû — B-tree, hash, R-tree, GiST (îáîáùåííîå
- Ïëàíèðîâùèê çàïðîñîâ îñíîâûâàåòñÿ íà ñòîèìîñòè ðàçëè÷íûõ ïëàíîâ,
ó÷èòûâàÿ ìíîæåñòâî ôàêòîðîâ. Îí ïðåäîñòàâëÿåò âîçìîæíîñòü ïîëüçîâàòåëþ
îòëàæèâàòü çàïðîñû è íàñòðàèâàòü ñèñòåìó. - Ñèñòåìà áëîêèðîâîê ïîääåðæèâàåò áëîêèðîâêè íà íèæíåì óðîâíå, ÷òî
ïîçâîëÿåò ñîõðàíÿòü âûñîêèé óðîâåíü êîíêóðåíòíîñòè ïðè çàùèòå öåëîñòíîñòè
äàííûõ. Áëîêèðîâêà ïîääåðæèâàåòñÿ íà óðîâíå òàáëèö è çàïèñåé. Íà íèæíåì
óðîâíå, áëîêèðîâêà äëÿ îáùèõ ðåñóðñîâ îïòèìèçèðîâàíà ïîä êîíêðåòíóþ
ÎÑ è àðõèòåêòóðó. - Óïðàâëåíèå áóôåðàìè è êýøèðîâàíèå èñïîëüçóþò
ñëîæíûå àëãîðèòìû
äëÿ ïîääåðæàíèÿ ýôôåêòèâíîñòè èñïîëüçîâàíèÿ âûäåëåííûõ ðåñóðñîâ ïàìÿòè. - Tablespaces (òàáëè÷íûå ïðîñòðàíñòâà) äëÿ
óïðàâëåíèÿ õðàíåíèÿ äàííûõ íà óðîâíå îáúåêòîâ, òàêèõ êàê
áàçû äàííûõ, ñõåìû, òàáëèöû è èíäåêñû. Ýòî ïîçâîëÿåò ãèáêî èñïîëüçîâàòü
äèñêîâîå ïðîñòðàíñòâî è ïîâûøàåò íàäåæíîñòü, ïðîèçâîäèòåëüíîñòü, à òàêæå
ñïîñîáñòâóåò ìàñøòàáèðóåìîñòè ñèñòåìû. - Ìàñøòàáèðóåìîñòü îñíîâûâàåòñÿ íà îïèñàííûõ âûøå âîçìîæíîñòÿõ.
Íèçêàÿ òðåáîâàòåëüíîñòü PostgreSQL ê ðåñóðñàì è ãèáêàÿ ñèñòåìà áëîêèðîâîê
îáåñïå÷èâàþò åãî øêàëèðîâàíèå, â òî âðåìÿ êàê èíäåêñû è óïðàâëåíèå áóôåðàìè
îáåñïå÷èâàþò õîðîøóþ óïðàâëÿåìîñòü ñèñòåìû äàæå ïðè âûñîêèõ çàãðóçêàõ.
- Ïîääåðæêà èíäåêñîâ
- Ðàñøèðÿåìîñòü PostgreSQL îçíà÷àåò, ÷òî ïîëüçîâàòåëü ìîæåò
íàñòðàèâàòü ñèñòåìó ïóòåì îïðåäåëåíèÿ íîâûõ ôóíêöèé, àãðåãàòîâ, òèïîâ,ÿçûêîâ,
èíäåêñîâ è îïåðàòîðîâ. Îáúåêòíî-îðèåíòèðîâàííîñòü PostgreSQL ïîçâîëÿåò
ïåðåíåñòè ëîãèêó ïðèëîæåíèÿ íà óðîâåíü áàçû äàííûõ, ÷òî ñèëüíî óïðîùàåò
ðàçðàáîòêó êëèåíòîâ, òàê êàê âñÿ áèçíåñ ëîãèêà íàõîäèòñÿ â áàçå äàííûõ.
Ôóíêöèè â PostgreSQL îäíîçíà÷íî îïðåäåëÿþòñÿ íàçâàíèåì, êîëè÷åñòâîì è òèïàìè àðãóìåíòîâ.Íà ðèñóíêå ïðèâåäåíà ER äèàãðàììà ñèñòåìíîãî êàòàëîãà PostgreSQL,
â êîòîðîì çàëîæåíû âñå ñâåäåíèÿ îá îáúåêòàõ ñèñòåìû, îïåðàòîðàõ è ìåòîäàõ äîñòóïà
ê íèì. Ïðè èíèöèàëèçàöèè PostgreSQL êëàñòåðà (êîìàíäà initdb) ñîçäàþòñÿ
äâå áàçû äàííûõ — template0 è template1, êîòîðûå ñîäåðæàò
ïðåäîïðåäåëåííûé ïî óìîë÷àíèþ íàáîð ôóíêöèîíàëüíîñòåé. Ëþáàÿ äðóãàÿ áàçà äàííûõ
íàñëåäóåò template1, òàêèì îáðàçîì, ÷àñòî èñïîëüçóåìûå îáúåêòû è ìåòîäû
ìîæíî äîáàâèòü â ñèñòåìíûé êàòàëîã template1.
PostgreSQL ïðåäîñòàâëÿåò êîìàíäíûé èíòåðôåéñ äëÿ ðàáîòû ñ ñèñòåìíûì êàòàëîãîì,
ñ ïîìîùüþ êîòîðîãî ìîæíî íå òîëüêî ïîëó÷àòü èíôîðìàöèþ îá îáúåêòàõ ñèñòåìû, íî
è ñîçäàâàòü íîâûå. Íàïðèìåð, ñîçäàâàòü áàçû äàííûõ ñ ïîìîùüþ
CREATE DATABASE, íîâûé äîìåí — CREATE DOMAIN, îïåðàòîð —
CREATE OPERATOR, òèï äàííûõ — CREATE TYPE.Äëÿ ñîçäàíèÿ íîâîãî òèïà äàííûõ è èíäåêñíûõ ìåòîäîâ äîñòóïà äîñòàòî÷íî:
- Íàïèñàòü ôóíêöèè ââîäà/âûâîäà è
çàðåãèñòðèðîâàòü èõ â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE FUNCTION - Îïðåäåëèòü òèï â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE TYPE
- Ñîçäàòü îïåðàòîðû äëÿ ýòîãî òèïà äàííûõ ñ ïîìîùüþ CREATE OPERATOR
- Íàïèñàòü ôóíêöèè ñðàâíåíèÿ è
çàðåãèñòðèðîâàòü èõ â ñèñòåìíîì êàòàëîãå ñ ïîìîùüþ CREATE FUNCTION - Ñîçäàòü îïåðàòîð ïî óìîë÷àíèþ, êîòîðûé áóäåò èñïîëüçîâàòüñÿ äëÿ ñîçäàíèÿ
èíäåêñà ïî primary key — CREATE OPERATOR CLASS
Îïèñàííûé ñöåíàðèé èñïîëüçóåò ñóùåñòâóþùèõ âèä èíäåêñà. Äëÿ ñîçäàíèÿ íîâûõ
èíäåêñîâ íàäî èñïîëüçîâàòü GiST.Îäíîé èç ïðèìå÷àòåëüíûõ îñîáåííîñòüþ PostgreSQL ÿâëÿåòñÿ îáîáùåííîå ïîèñêîâîå
äåðåâî èëè GiST (äîìàøíÿÿ ñòðàíèöà ïðîåêòà),
êîòîðîå äàåò âîçìîæíîñòü ñïåöèàëèñòàì â êîíêðåòíîé îáëàñòè çíàíèé ñîçäàâàòü
ñïåöèàëèçèðîâàííûå òèïû äàííûõ è îáåñïå÷èâàåò èíäåêñíûé äîñòóï ê íèì íå áóäó÷è
ýêñïåðòàìè â îáëàñòè áàç äàííûõ. Àíàëîãîì GiST ÿâëÿåòñÿ òåõíîëîãèÿ DataBlade,
êîòîðîé ñåé÷àñ âëàäååò IBM (ñì. èñòîðè÷åñêóþ ñïðàâêó âûøå).
Èäåÿ GiST áûëà ïðèäóìàíà ïðîôåññîðîì Áåðêëè
Äæîçåôîì Õåëëåðñòåéíîì(Joseph M. Hellerstein)
è îïóáëèêîâàíà
â ñòàòüå Generalized Search Trees for Database Systems.
Îðèãèíàëüíàÿ âåðñèÿ GiST áûëà ðàçðàáîòàíà â Áåðêëè êàê ïàò÷ ê POSTGRES è
ïîçäíåå áûëà èíêîðïîðèðîâàíà â PostgreSQL. Ïîçæå, â 2001 ãîäó êîä áûë ñèëüíî
ìîäèôèöèðîâàí äëÿ ïîääåðæêè êëþ÷åé ïåðåìåííîé äëèíû, ìíîãî-àòðèáóòíûõ èíäåêñîâ
è áåçîïàñíîé ðàáîòû ñ NULL, òàêæå áûëè èñïðàâëåíî íåñêîëüêî îøèáîê. Ê íàñòîÿùåìó âðåìåíè íàïèñàíî
äîâîëüíî ìíîãî èíòåðåñíûõ ðàñøèðåíèé íà îñíîâå GiST, â òîì ÷èñëå:- ìîäóëü ïîëíîòåêñòîâîãî ïîèñêà tsearch2.
Ñ âåðñèè 8.3 ïîëíîòåêñòîâûé ïîèñê áóäåò âñòðîåí â ÿäðî PostgreSQL
(ñì. Ââåäåíèå â ïîëíîòåêñòîâûé ïîèñê). - ìîäóëü äëÿ ðàáîòû ñ èåðàðõè÷åñêèìè äàííûìè (tree-like) ltree
- ìîäóëü äëÿ ðàáîòû ñ ìàññèâàìè öåëûõ ÷èñåë intarray
Äèñòðèáóòèâ PostgreSQL â ïîääèðåêòîðèè contrib/ ñîäåðæèò áîëüøîå
êîëè÷åñòâî (îêîëî 80) òàê íàçûâàåìûõ êîíòðèá-ìîäóëåé, ðåàëèçóþùèõ ðàçíîîáðàçíóþ
äîïîëíèòåëüíóþ ôóíêöèîíàëüíîñòü, òàêóþ êàê, ïîëíîòåêñòîâûé ïîèñê, ðàáîòà ñ xml,
ôóíêöèè ìàòåìàòè÷åñêîé ñòàòèñòèêè, ïîèñê ñ îøèáêàìè, êðèïòîãðàôè÷åñêèå ìîäóëè è ò.ä.
Òàêæå, åñòü óòèëèòû, îáëåã÷àþùèå ìèãðàöèþ ñ mysql, oracle, äëÿ àäìèíèñòðàòèâíûõ
ðàáîò. - Íàïèñàòü ôóíêöèè ââîäà/âûâîäà è
- Ïîääåðæêà SQL, êðîìå îñíîâíûõ âîçìîæíîñòåé, ïðèñóùèõ ëþáîé
SQL áàçå äàííûõ, PostgreSQL ïîääåðæèâàåò:- Î÷åíü âûñîêèé óðîâåíü ñîîòâåòñòâèÿ ANSI SQL 92, ANSI SQL 99 è ANSI SQL 2003.
Ïîäðîáíåå ìîæíî ïðî÷èòàòü â äîêóìåíòàöèè. - Ñõåìû, êîòîðûå îáåñïå÷èâàþò ïðîñòðàíñòâî èìåí íà óðîâíå SQL.
Ñõåìû ñîäåðæàò òàáëèöû, â íèõ ìîæíî îïðåäåëÿòü òèïû äàííûõ, ôóíêöèè è îïåðàòîðû.
Èñïîëüçóÿ ïîëíîå èìÿ îáúåêòà ìîæíî îäíîâðåìåííî ðàáîòàòü ñ íåñêîëüêèìè
ñõåìàìè. Ñõåìû ïîçâîëÿþò îðãàíèçîâàòü áàçû äàííûõ ñîâîêóïíîñòü
íåñêîëüêèõ ëîãè÷åñêèõ ÷àñòåé, êàæäàÿ èõ êîòîðûõ èìååò ñâîþ ïîëèòèêó äîñòóïà,
òèïû äàííûõ. Äëÿ ïðèëîæåíèé, êîòîðûå ñîçäàþò íîâûå îáúåêòû â áàçå äàííûõ óäîáíî
è áåçîïàñíî ñîçäàâàòü îòäåëüíóþ ñõåìó (è âêëþ÷àòü åå â SEARCH_PATH) ñ òåì,
÷òîáû èçáåæàòü âîçìîæíîé êîëëèçèè ñ èìåíàìè îáúåêòîâ è óäîáñòâîì îáíîâëåíèÿ
ïðèëîæåíèÿ. - Subqueries — ïîäçàïðîñû (subselects), ïîëíàÿ ïîääåðæêà SQL92.
Ïîäçàïðîñû äåëàþò ÿçûê SQL áîëåå ãèáêèì è çà÷àñòóþ áîëåå ýôôåêòèâíûì. - Outer Joins — âíåøíèå ñâÿçêè (LEFT,RIGHT, FULL)
- Rules — ïðàâèëà, ñîãëàñíî êîòîðûì ìîäèôèöèðóåòñÿ èñõîäíûé çàïðîñ.
Ãëàâíîå îòëè÷èå îò òðèããåðîâ ñîñòîèò â òîì, ÷òî rule ðàáîòàåò íà óðîâíå
çàïðîñà è ïåðåä èñïîëíåíèåì çàïðîñà, à òðèããåð — ýòî ðåàêöèÿ ñèñòåìû íà
èçìåíåíèå äàííûõ, ò.å. òðèããåð çàïóñêàåòñÿ â ïðîöåññå èñïîëíåíèÿ çàïðîñà
äëÿ êàæäîé èçìåíåííîé çàïèñè (PER ROW). Ïðàâèëà èñïîëüçóþòñÿ äëÿ óêàçàíèÿ ñèñòåìå,
êàêèå äåéñòâèÿ íàäî ïðîèçâåñòè ïðè ïîïûòêå îáíîâëåíèÿ view. - Views — ïðåäñòàâëåíèÿ, âèðòóàëüíûå òàáëèöû. Ðåàëüíûõ ýêçåìïëÿðîâ ýòèõ
òàáëèö íå ñóùåñòâóþò, îíè ìàòåðèàëèçóþòñÿ òîëüêî ïðè çàïðîñå. Îäíèì èç îñíîâíûõ ïðåäíàçíà÷åíèé ‘view’ ÿâëÿåòñÿ
ðàçäåëåíèå ïðàâ äîñòóïà ê ðîäèòåëüñêèì òàáëèöàì è ê ‘view, à òàêæå îáåñïå÷åíèå
ïîñòîÿíñòâà ïîëüçîâàòåëüñêîãî èíòåðôåéñà ïðè èçìåíåíèè ðîäèòåëüñêèõ òàáëèö.
Îáíîâëåíèå ‘view’ (ìàòåðèàëèçàöèÿ) âîçìîæíî â
PostgreSQL ñ ïîìîùüþ pl/pgsql. - Cursors — êóðñîðû, ïîçâîëÿþò óìåíüøèòü òðàôèê ìåæäó êëèåíòîì è
ñåðâåðîì, à òàêæå ïàìÿòü íà êëèåíòå, åñëè òðåáóåòñÿ ïîëó÷èòü íå âåñü ðåçóëüòàò
çàïðîñà, à òîëüêî åãî ÷àñòü. - Table Inheritance — íàñëåäîâàíèå òàáëèö, ïîçâîëÿþùåå ñîçäàâàòü îáúåêòû,
êîòîðûå íàñëåäóþò ñòðóêòóðó ðîäèòåëüñêîãî îáúåêòà è äîáàâëÿòü ñâîè
ñïåöèôè÷åñêèå àòðèáóòû. Ïðè ýòîì íàñëåäóþòñÿ çíà÷åíèÿ àòðèáóòîâ ïî óìîë÷àíèþ
(DEFAULTS) è îãðàíè÷åíèå öåëîñòíîñòè (CONSTRAINTS).
Ïîèñê ïî ðîäèòåëüñêîé òàáëèöå àâòîìàòè÷åñêè âêëþ÷àåò ïîèñê ïî äî÷åðíèì
îáúåêòàì, ïðè ýòîì ñîõðàíÿåòñÿ âîçìîæíîñòü ïîèñêà òîëüêî ïî íåé
(only). Íàñëåäîâàíèå ìîæíî èñïîëüçîâàòü äëÿ ðàáîòû ñ î÷åíü áîëüøèìè òàáëèöàìè äëÿ
ýìóëÿöèè partitioning. - Prepared Statements (ïðåïîäãîòîâëåííûå çàïðîñû) — ýòî îáúåêòû, æèâóùèå
íà ñòîðîíå ñåðâåðà, êîòîðûå ïðåäñòàâëÿþò ñîáîé îðèãèíàëüíûé çàïðîñ
ïîñëå êîìàíäû PREPARE, êîòîðûé óæå ïðîøåë ñòàäèè ðàçáîðà çàïðîñà
(parser), ìîäèôèêàöèè çàïðîñà (rewriting rules) è ñîçäàíèÿ ïëàíà âûïîëíåíèÿ
çàïðîñà (planner), â ðåçóëüòàòå ÷åãî, ìîæíî èñïîëüçîâàòü êîìàíäó EXECUTE,
êîòîðàÿ óæå íå òðåáóåò ïðîõîæäåíèÿ ýòèõ ñòàäèé. Äëÿ ñëîæíûõ çàïðîñîâ ýòî ìîæåò
áûòü áîëüøèì âûèãðûøåì. - Stored Procedures — ñåðâåðíûå (õðàíèìûå) ïðîöåäóðû ïîçâîëÿþò ðåàëèçîâûâàòü
áèçíåñ ëîãèêó ïðèëîæåíèÿ íà ñòîðîíå ñåðâåðà. Êðîìå òîãî, îíè ïîçâîëÿþò ñèëüíî
óìåíüøèòü òðàôèê ìåæäó êëèåíòîì è ñåðâåðîì. - Savepoints(nested transactions) — â îòëè÷èå îò «ïëîñêèõ òðàíçàêöèé», êîòîðûå
íå èìåþò ïðîìåæóòî÷íûõ òî÷åê ôèêñàöèè, èñïîëüçîâàíèå savepoints ïîçâîëÿåò
îòìåíÿòü ðàáîòó ÷àñòè òðàíçàêöèè, íàïðèìåð âñëåäñòâèè îøèáî÷íî ââåäåííîé êîìàíäû,
áåç âëèÿíèÿ íà îñòàâøóþñÿ ÷àñòü òðàíçàêöèè. Ýòî áûâàåò î÷åíü ïîëåçíî äëÿ
òðàíçàêöèé, êîòîðûå ðàáîòàþò ñ áîëüøèìè îáúåìàìè äàííûõ. - Ïðàâà äîñòóïà ê îáúåêòàì ñèñòåìû íà îñíîâå ñèñòåìû ïðèâèëåãèé. Âëàäåëåö
îáúåêòà èëè ñóïåðþçåð ìîæåò êàê ðàçðåøàòü äîñòóï (GRANT), òàê è îòìåíÿòü
(REVOKE). - Ñèñòåìà îáìåíà ñîîáùåíèÿìè ìåæäó ïðîöåññàìè — LISTEN è NOTIFY
ïîçâîëÿþò îðãàíèçîâûâàòü ñîáûòèéíóþ ìîäåëü âçàèìîäåéñòâèÿ ìåæäó êëèåíòîì è
ñåðâåðîì (êëèåíòó ïåðåäàåòñÿ íàçâàíèå ñîáûòèÿ, íàçíà÷åííîå êîìàíäîé
notify è PID ïðîöåññà). - Òðèããåðû ïîçâîëÿþò óïðàâëÿòü ðåàêöèåé ñèñòåìû íà èçìåíåíèå äàííûõ
(INSERT,UPDATE,DELETE), êàê ïåðåä ñàìîé îïåðàöèåé (BEFORE), òàê è ïîñëå (AFTER).
Âî âðåìÿ âûïîëíåíèÿ òðèããåðà äîñòóïíû ñïåöèàëüíûå ïåðåìåííûå NEW (çàïèñü,
êîòîðàÿ áóäåò âñòàâëåíà èëè îáíîâëåíà) è OLD (çàïèñü ïåðåä îáíîâëåíèåì). - Cluster table — óïîðÿäî÷èâàíèå çàïèñåé òàáëèöû íà äèñêå ñîãëàñíî èíäåêñó,
÷òî èíîãäà çà ñ÷åò óìåíüøåíèÿ äîñòóïà ê äèñêó óñêîðÿåò âûïîëíåíèå çàïðîñà.
- Î÷åíü âûñîêèé óðîâåíü ñîîòâåòñòâèÿ ANSI SQL 92, ANSI SQL 99 è ANSI SQL 2003.
- Áîãàòûé íàáîð òèïîâ äàííûõ PostgreSQL âêëþ÷àåò:
- Ñèìâîëüíûå òèïû (character(n)) êàê îïðåäåëåíî â ñòàíäàðòå SQL è òèï text
ñ ïðàêòè÷åñêè íåîãðàíè÷åííîé äëèíîé. - Numeric òèï ïîääåðæèâàåò ïðîèçâîëüíóþ òî÷íîñòü, î÷åíü âîñòðåáîâàííóþ â íàó÷íûõ
è ôèíàíñîâûõ ïðèëîæåíèÿõ. - Ìàññèâû ñîãëàñíî ñòàíäàðòó SQL:2003
- Áîëüøèå îáúåêòû (Large Objects) ïîçâîëÿþò õðàíèòü â áàçå äàííûõ áèíàðíûå äàííûå ðàçìåðîì äî 2Gb
- Ãåîìåòðè÷åñêèå òèïû (point, line, circle,polygon, box,…) ïîçâîëÿþò ðàáîòàòü ñ ïðîñòðàíñòâåííûìè äàííûìè íà ïëîñêîñòè.
- ÃÈÑ (GIS) òèïû â PostgreSQL ÿâëÿþòñÿ äîêàçàòåëüñòâîì ðàñøèðÿåìîñòè PostgreSQL è ïîçâîëÿþò
ýôôåêòèâíî ðàáîòàòü ñ òðåõìåðíûìè äàííûìè. Ïîäðîáíîñòè ìîæíî íàéòè íà ñàéòå
ïðîåêòà PostGis. - Ñåòåâûå òèïû (Network types) ïîääåðæèâàþò òèïû äàííûõ inet äëÿ IPV4, IPV6,
à òàêæå cidr (Classless Internet Domain Routing) áëîêè è macaddr - Êîìïîçèòíûå òèïû (composite types) îáúåäèíÿþò îäèí èëè íåñêîëüêî
ýëåìåíòàðíûõ òèïîâ è ïîçâîëÿþò ïîëüçîâàòåëÿì ìàíèïóëèðîâàòü ñî ñëîæíûìè îáúåêòàìè. - Âðåìåííûå òèïû (timestamp, interval, date, time) ðåàëèçîâàíû ñ î÷åíü áîëüøîé òî÷íîñòüþ
- Ïñåâäîòèïû serial è bigserial ïîçâîëÿþò îðãàíèçîâàòü óïîðÿäî÷åííóþ ïîñëåäîâàòåëüíîñòü
öåëûõ ÷èñåë (AUTO_INCREMENT ó íåêîòîðûõ ÑÓÁÄ).
- Ñèìâîëüíûå òèïû (character(n)) êàê îïðåäåëåíî â ñòàíäàðòå SQL è òèï text
- PostgreSQL èìååò î÷åíü áîãàòûé íàáîð âñòðîåííûõ ôóíêöèé è îïåðàòîðîâ äëÿ ðàáîòû ñ äàííûìè,
ïîëíûé ñïèñîê êîòîðûõ ìîæíî ïîñìîòðåòü â äîêóìåíòàöèè. - Ïîääåðæêà 25 ðàçëè÷íûõ íàáîðîâ ñèìâîëîâ (charsets), âêëþ÷àÿ ASCII, LATIN, WIN, KOI8 è UNICODE,
à òàêæå ïîääåðæêà locale, ÷òî ïîçâîëÿåò êîððåêòíî ðàáîòàòü ñ äàííûìè íà
ðàçíûõ ÿçûêàõ. - Ïîääåðæêà NLS(Native Language Support) — äîêóìåíòàöèÿ, ñîîáùåíèÿ îá îøèáêàõ äîñòóïíû íà ðàçëè÷íûõ
ÿçûêàõ, âêëþ÷àÿ ÿïîíñêèé, íåìåöêèé, èòàëüÿíñêèé, ôðàíöóçñêèé, ðóññêèé, èñïàíñêèé, ïîðòóãàëüñêèé,
ñëîâåíñêèé, ñëîâàöêèé è íåñêîëüêî äèàëåêòîâ êèòàéñêîãî ÿçûêîâ. - Èíòåðôåéñû â PostgreSQL ðåàëèçîâàíû äëÿ äîñòóïà ê áàçå äàííûõ èç ðÿäà
ÿçûêîâ (C,C++,C#,python,perl,ruby,php,Lisp è äðóãèå) è ìåòîäîâ äîñòóïà ê äàííûì (JDBC, ODBC). - Ïðîöåäóðíûå ÿçûêè ïîçâîëÿþò ïîëüçîâàòåëÿì ðàçðàáàòûâàòü ñâîè ôóíêöèè
íà ñòîðîíå ñåðâåðà, òåì ñàìûì ïåðåíîñèòü ëîãèêó ïðèëîæåíèÿ íà ñòîðîíó áàçû äàííûõ,
èñïîëüçóÿ ÿçûêè ïðîãðàììèðîâàíèÿ, îòëè÷íûå îò âñòðîåííûõ
SQL è C. Ê íàñòîÿùåìó âðåìåíè ïîääåðæèâàþòñÿ (âêëþ÷åíû â ñòàíäàðòíûé äèñòðèáóòèâ)
PL/pgSQL, pl/Tcl, Pl/Perl è pl/Python. Êðîìå íèõ, ñóùåñòâóåò ïîääåðæêà
PHP, Java, Ruby, R, shell. - Ïðîñòîòà èñïîëüçîâàíèÿ âñåãäà ÿâëÿëàñü âàæíûì ôàêòîðîì äëÿ
ðàçðàáîò÷èêîâ.Óòèëèòà psql (âõîäèò â äèñòðèáóòèâ) ïðåäîñòàâëÿåò óäîáíûé èíòåðôåéñ äëÿ ðàáîòû
ñ áàçîé äàííûõ, ñîäåðæèò êðàòêèé ñïðàâî÷íèê ïî SQL, îáëåã÷àåò ââîä êîìàíä
(èñïîëüçóÿ ñòðåëêè äëÿ ïîâòîðà è òàáóëÿòîð äëÿ ðàñøèðåíèÿ), ïîääåðæèâàåò
èñòîðèþ è áóôåð çàïðîñîâ, à òàêæå ïîçâîëÿåò ðàáîòàòü êàê â èíòåðàêòèâíîì
ðåæèìå, òàê è ïîòîêîâîì ðåæèìå.phpPgAdmin (ëèöåíçèÿ GPL)
ïðåäñòàâëÿåò âîçìîæíîñòü ñ ïîìîùüþ âåá áðàóçåðà àäìèíèñòðèðîâàòü PostgreSQL êëàñòåð.pgAdmin III (GNU Artistic license) ïðåäîñòàâëÿåò
óäîáíûé èíòåðôåéñ äëÿ ðàáîòû ñ áàçàìè äàííûõ PostgreSQL è ðàáîòàåò ïîä Linux, FreeBSD è
Windows 2000/XP.PgEdit — ïðîãðàììíàÿ ñðåäà äëÿ ðàçðàáîòêè ïðèëîæåíèé è
SQL-ðåäàêòîð, äîñòóïíà äëÿ Windows è Mac. - Áåçîïàñíîñòü äàííûõ òàêæå ÿâëÿåòñÿ âàæíåéøèì àñïåêòîì ëþáîé ÑÓÁÄ. Â PostgreSQL
îíà îáåñïå÷èâàåòñÿ 4-ìÿ óðîâíÿìè áåçîïàñíîñòè:- PostgreSQL íåëüçÿ çàïóñòèòü ïîä ïðèâèëåãèðîâàííûì ïîëüçîâàòåëåì — ñèñòåìíûé êîíòåêñò
- SSL,SSH øèôðîâàíèå òðàôèêà ìåæäó êëèåíòîì è ñåðâåðîì — ñåòåâîé êîíòåêñò
- ñëîæíàÿ ñèñòåìà àóòåíòèôèêàöèè íà óðîâíå õîñòà èëè IP àäðåñà/ïîäñåòè.
Ñèñòåìà àóòåíòèôèêàöèè ïîääåðæèâàåò ïàðîëè, øèôðîâàííûå ïàðîëè, Kerberos, IDENT
è ïðî÷èå ñèñòåìû, êîòîðûå ìîãóò ïîäêëþ÷àòüñÿ èñïîëüçóÿ ìåõàíèçì ïîäêëþ÷àåìûõ
àóòåíòèôèêàöèîííûõ ìîäóëåé. - Äåòàëèçèðîâàííàÿ ñèñòåìà ïðàâ äîñòóïà êî âñåì îáúåêòàì áàçû
äàííûõ, êîòîðàÿ ñîâìåñòíî ñî ñõåìîé, îáåñïå÷èâàþùàÿ èçîëÿöèþ íàçâàíèé îáúåêòîâ
äëÿ êàæäîãî ïîëüçîâàòåëÿ, PostgreSQL ïðåäîñòàâëÿåò áîãàòóþ è ãèáêóþ èíôðàñòðóêòóðó.
Íåêîòîðûå ïðåäåëû PostgreSQL
| Íàçâàíèå | Çíà÷åíèå |
|---|---|
| Ìàêñèìàëüíûé ðàçìåð ÁÄ | Unlimited |
| Ìàêñèìàëüíûé ðàçìåð òàáëèöû | 32 TB |
| Ìàêñèìàëüíàÿ äëèíà çàïèñè | 400Gb |
| Ìàêñèìàëüíûé äëèíà àòðèáóòà | 1 GB |
| Ìàêñèìàëüíîå êîëè÷åñòâî çàïèñåé â òàáëèöå | Unlimited |
| Ìàêñèìàëüíîå êîëè÷åñòâî àòðèáóòîâ â òàáëèöå | 250 — 1600 â çàâèñèìîñòè îò òèïà àòðèáóòà |
| Ìàêñèìàëüíîå êîëè÷åñòâî èíäåêñîâ íà òàáëèöó | Unlimited |
Ñâîäíàÿ òàáëèöà îñíîâíûõ ðåëÿöèîííûõ áàç äàííûõ
Çà îñíîâó âçÿòû äàííûå èç Wikipedia
| Íàçâàíèå | ASE | DB2 | FireBird | InterBase | MS SQL | MySQL | Oracle | PostgreSQL |
|---|---|---|---|---|---|---|---|---|
| Ëèöåíçèÿ | $$$ | $$$ | IPL2 | $$$ | $$$ | GPL/$$$ | $$$ | BSD |
| ACID | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Referential integrity | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Transaction | Yes | Yes | Yes | Yes | Yes | Depends1 | Yes | Yes |
| Unicode | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Schema | Yes | Yes | Yes | Yes | No5 | No | Yes | Yes |
| Temporary table | No | Yes | No | Yes | Yes | Yes | Yes | Yes |
| View | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes |
| Materialized view | No | Yes | No | No | No | No | Yes | No3 |
| Expression index | No | No | No | No | No | No | Yes | Yes |
| Partial index | No | No | No | No | No | No | Yes | Yes |
| Inverted index | No | No | No | No | No | Yes | Yes | Yes6 |
| Bitmap index | No | Yes | No | No | No | No | Yes | No |
| Domain | No | No | Yes | Yes | No | No | Yes | Yes |
| Cursor | Yes | Yes | Yes | Yes | Yes | No | Yes | Yes |
| User Defined Functions | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Trigger | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Stored procedure | Yes | Yes | Yes | Yes | Yes | No4 | Yes | Yes |
| Tablespace | Yes | Yes | No | ? | No5 | No1 | Yes | Yes |
| Íàçâàíèå | ASE | DB2 | FireBird | InterBase | MS SQL | MySQL | Oracle | PostgreSQL |
Çàìå÷àíèÿ:
- 1 — äëÿ ïîääåðæêè òðàíçàêöèé è ññûëî÷íîé öåëîñòíîñòè òðåáóåòñÿ InnoDB (íå ÿâëÿåòñÿ òèïîì òàáëèöû ïî óìîë÷àíèþ)
- 2 — Interbase Public License
- 3 — Materialized view (îáíîâëÿåìûå ïðåäñòàâëåíèÿ) ìîãóò áûòü ýìóëèðîâàíû íà PL/pgSQL
- 4 — òîëüêî â MySQL 5.0, êîòîðàÿ ÿâëÿåòñÿ ýêñïåðèìåíòàëüíîé âåðñèåé
- 5 — òîëüêî â MS SQL Server 2005 (Yukon)
- 6 — GIN (Generalized Inverted Index) ñ âåðñèè 8.2
×òî îæèäàåòñÿ â áóäóùèõ âåðñèÿõ
Ïîëíûé ñïèñîê íîâûõ âîçìîæíîñòåé ïðèâåäåí â áîëüøîì ñïèñêå
TODO,
êîòîðûé óæå ìíîãî ëåò ïîääåðæèâàåò Áðþñ Ìîìæàí (Bruce Momjian),
îäíàêî ïðèîðèòåòû äëÿ âåðñèè 8.1 åùå íå îïðåäåëåíû, áîëåå òîãî,
ïîêà íå îïðåäåëåíà ïðîäîëæèòåëüíîñòü öèêëà ðàçðàáîòêè.
Ïîêà ìîæíî äîñòàòî÷íî óâåðåííî óòâåðæäàòü, ÷òî â 8.1 âåðñèè, ïîìèìî
èñïðàâëåíèé îøèáîê è óëó÷øåíèÿ ñóùåñòâóþùåé ôóíêöèîíàëüíîñòè èëè
ïðèâåäåíèå ñèíòàêñèñà ê ñòàíäàðòó SQL, áóäóò:
- bitmap èíäåêñû (initial submit CVS)
- èíòåãðèðîâàíèå autovacuum â ñåðâåðíûé ïðîöåññ
- Two phase commit JDBC driver
- ïîääåðæêà IN,OUT,INOUT ïàðàìåòðîâ äëÿ pl/pgsql (CVS)
- óâåëè÷åíèå ïðåäåëà ìàêñèìàëüíîãî êîëè÷åñòâà àðãóìåíòîâ ó ôóíêöèè (100 ïî óìîë÷àíèþ)
(CVS) - Îïòèìèçàöèÿ MIN,MAX çà ñ÷åò èñïîëüçîâàíèÿ èíäåêñîâ (CVS)
- Ïîääåðæêà UTF-16
- GiST Concurrency & Recovery ! (CVS)
Òàêæå, íåäàâíî ïðîõîäèëî îáñóæäåíèå î âîçìîæíûõ ïëàíàõ î ïîääåðæêå
table partitioning, ÷òî ñèëüíî óâåëè÷èâàåò ïðîèçâîäèòåëüíîñòü áàçû
äàííûõ ïðè ðàáîòå ñ áîëüøèìè òàáëèöàìè.
Íîâîñòü:
Âûøëà âåðñèÿ 8.0.2, â êîòîðîé, ïîìèìî èñïðàâëåíèÿ îøèáîê è èçìåíåíèÿ
âåðñèè áèáëèîòåêè libpq (ÂÍÈÌÀÍÈÅ ! Âñå êëèåíòñêèå ïðèëîæåíèÿ,
êîòîðûå èñïîëüçóþò libpq, òðåáóåòñÿ ïåðåñîáðàòü, íàïðèìåð DBD::Pg),
àëãîðèòì êýøèðîâàíèÿ ñòðàíèö «ARC», êîòîðûì âëàäååò IBM, áûë
çàìåíåí íà äðóãîé, «ïàòåíòíî-÷èñòûé» àëãîðèòì «2Q».
Ïîñêîëüêó èñòîðèÿ ñ çàìåíîé àëãîðèòìà «ARC» â PostgreSQL
âûçâàëà áîëüøîé èíòåðåñ è îáñóæäåíèå â ñåòè (à îíà ñâÿçàíà ñ î÷åíü «ãîðÿ÷åé»
òåìîé âûäà÷è è èñïîëüçîâàíèÿ ïàòåíòîâ íà ïðîãðàììíîå îáåñïå÷åíèå),
ÿ îñòàíîâëþñü ïîäðîáíåå íà îïèñàíèè ìåõàíèçìà êýøèðîâàíèÿ (buffer management)
â PostgreSQL. ß èñïîëüçîâàë àðõèâ îáñóæäåíèé,
îðèãèíàëüíûå ðàáîòû è ñòàòüþ Ýëåéí Ìóñòýéí (A. Elein Mustain)
The Saga of the ARC Algorithm and Patent.
Óïðàâëåíèå áóôåðàìè â PostgreSQL
Êýøèðîâàíèå ñòðàíèö, èëè ñîõðàíåíèå ïðî÷èòàííûõ ñ äèñêà
ñòðàíèö â ïàìÿòè, î÷åíü âàæíî äëÿ ýôôåêòèâíîé ðàáîòû ëþáîé ÑÓÁÄ,
òàê êàê âðåìåíà äîñòóïà ê äèñêó è ïàìÿòè îòëè÷àþòñÿ íà ìíîãèå ïîðÿäêè.
 èäåàëå, ìû õîòèì, ÷òîáû âñå ñòðàíèöû, ê êîòîðûì ïðîèñõîäèò îáðàùåíèå,
ïîïàäàëè â ïàìÿòü, ñ òåì, ÷òîáû ïîñëåäóþùåå åå èñïîëüçîâàíèå íå òðåáîâàëî
îáðàùåíèÿ ê äèñêó.
Îäíàêî, òàê êàê êîëè÷åñòâî äîñòóïíîé ïàìÿòè îãðàíè÷åííî, òî âîçíèêàåò
ñèòóàöèÿ, êîãäà òðåáóåòñÿ ïðèíèìàòü ðåøåíèå, êàêóþ ñòðàíèöó íàäî îñâîáîäèòü
(çàìåñòèòü) äëÿ òîãî, ÷òîáû ïîìåñòèòü â êýø íîâóþ ñòðàíèöó.
Ïðàêòè÷åñêè âñå êîììåð÷åñêèå ñèñòåìû èñïîëüçóþò òó èëè èíóþ
âàðèàöèþ LRU (Least Recently Used) àëãîðèòìà,
â êîòîðîì âûñâîáîæäàåòñÿ òà ñòðàíèöà, ê êîòîðîé äîëüøå âñåãî íå îáðàùàëèñü.
 ÷èñòîì âèäå ýòîò àëãîðèòì íå î÷åíü õîðîø äëÿ èñïîëüçîâàíèÿ â ÑÓÁÄ â ñèëó
áîëüøîé ðàçíîîáðàçíîñòè ïîñëåäîâàòåëüíîñòè çàïðîñîâ, íàïðèìåð,
íå ó÷èòûâàåò ÷àñòîòó îáðàùåíèÿ ê ñòðàíèöå, íå çàùèùåí îò
«cache flooding», êîãäà âñåãî
îäíî åäèíè÷íîå ïîñëåäîâàòåëüíîå ÷òåíèå áîëüøîãî êîëè÷åñòâà ñòðàíèö
(sequential scan) ìîæåò çàïîëíèòü êýø ñòðàíèöàìè, ê êîòîðûì ìîæåò íå áûòü
áîëüøå îáðàùåíèÿ, ò.å., ê ïîëíîé ïîòåðå ýôôåêòèâíîñòè êýøèðîâàíèÿ.
Èíîãäà, èñïîëüçóþò òåðìèí «scan-resistant», êîãäà ãîâîðÿò, ÷òî õîðîøèé àëãîðèòì
äîëæåò áûòü óñòîé÷èâ ïî îòíîøåíèþ ê «cache flooding».
PostgreSQL èñïîëüçîâàë ðàçíîâèäíîñòü ýòîãî àëãîðèòìà,
èçâåñòíóþ êàê LRU/K,
ðåàëèçîâàííóþ Òîìîì Ëàéíîì (Tom Lane). Â ýòîì àëãîðèòìå èñïîëüçóåòñÿ
èñòîðèÿ K-ïîñëåäíèõ îáðàùåíèé ê ñòðàíèöå (èìåííî ïîñëåäíèõ, ÷òî ïîçâîëÿåò
ýòîìó àëãîðèòìó àäàïòèðîâàòüñÿ ê èçìåíåíèÿì øàáëîíà çàïðîñîâ, â îòëè÷èå îò
LFU àëãîðèòìà), êîòîðàÿ ïîçâîëÿåò îòëè÷èòü ïîïóëÿðíûå ñòðàíèöû îò
äàâíî íå èñïîëüçóåìûõ. Äëÿ ýòîãî ñòðîèòñÿ óïîðÿäî÷åííàÿ î÷åðåäü (priority queue)
óêàçàòåëåé íà ñòðàíèöû â êýøå íà îñíîâå âðåìåíè îáðàùåíèÿ ê ñòðàíèöå ïî ïðàâèëó:
åñëè ó ñòðàíèöû P1
K-òîå îáðàùåíèå (ïðåäïîñëåäíåå, äëÿ íàèáîëåå âàæíîãî ñëó÷àÿ K=2, LRU/2 ) ÿâëÿåòñÿ áîëåå
ñâåæèì ÷åì ó P2, òî P1 áóäåò çàìåùåíî ïîñëå P2. Êëàññè÷åñêèé LRU àëãîðèòì
ìîæíî ðàññìàòðèâàòü êàê LRU/1,
òàê êàê îí èñïîëüçîâàë èíôîðìàöèþ òîëüêî îá îäíîì (ïîñëåäíåì) îáðàùåíèè
ê ñòðàíèöå. Âàæíûì ÿâëÿåòñÿ íå òî, ÷òî ïðîèçîøëî åäèíè÷íîå îáðàùåíèå
ê ñòðàíèöå, à òî, íàñêîëüêî ýòà ñòðàíèöà áûëà ïîïóëÿðíà â òå÷åíèå íåêîòîðîãî âðåìåíè.
Îäíàêî, ýòîò àëãîðèòì òðåáîâàë íåòðèâèàëüíîé íàñòðîéêè è
âðåìÿ íà ïîñòðîåíèå î÷åðåäè ðàñòåò ëîãàðèôìè÷åñêè â çàâèñèìîñòè îò ðàçìåðà áóôåðà.
ARC
(Adaptive Replacement Cache) àëãîðèòì áûë ïðèâëåêàòåëåí òåì, ÷òî îí ó÷èòûâàë
íå òîëüêî êàê ÷àñòî ñòðàíèöà áûëà èñïîëüçîâàíà, íî è íàñêîëüêî
íåäàâíî ýòî ïðîèñõîäèëî è íå ñèëüíî «íàãðóæàë» ïðîöåññîð,
êàê ýòî ïðîèñõîäèëî ñ LRU/K àëãîðèòìîì. Îí äèíàìè÷åñêè ïîääåðæèâàåò áàëàíñ
ìåæäó ÷àñòî èñïîëüçóåìûìè è íåäàâíî èñïîëüçóåìûìè ñòðàíèöàìè.
Ýòîò àëãîðèòì áûë ðåàëèçîâàí ßíîì Âèêîì
(Jan Wieck) äëÿ âåðñèè 7.5 (âïîñëåäñòâèè 8.0), êîòîðûé âïîñëåäñòâèè áûë
íåñêîëüêî óëó÷øåí ïîñëå ñòàòüè,
îïèñûâàþùåé CAR (Clock with Adaptive Replacement) àëãîðèòì.
Îäíàêî, íåçàäîëãî (çà äâà äíÿ) äî âûõîäà PostgreSQL 8.0 áûëî îáíàðóæåíî
(ñì. ïîñòèíã
Íåéëà Êîíâåÿ (Neil Conway) è ïîñëåäóþùåå îáñóæäåíèå), ÷òî IBM ïîäàëà
çàÿâêó íà àëãîðèòì ARC
åùå â 2002 ãîäó.
Òàê êàê áûëî óæå ïîçäíî ÷òî-ëèáî ìåíÿòü áûëî ðåøåíî âûïóñòèòü 8.0 âåðñèþ
êàê åñòü, à ïîòîì çàíÿòüñÿ ðåøåíèåì ïðîáëåìû. Íåñìîòðÿ íà òî, ÷òî IBM
åùå íå ïîëó÷èëà ïàòåíò íà ARC àëãîðèòì è òî, ÷òî IBM èìååò õîðîøóþ ïðàêòèêó
ïîääåðæêè OSS ïðîåêòîâ,
è ìîæíî áûëî íàäåÿòüñÿ íà ïîëó÷åíèÿ îôèöèàëüíîãî ðàçðåøåíèÿ íà åãî èñïîëüçîâàíèå
â PostgreSQL, êàê ïðåäëàãàëè ìíîãèå, áûëî ðåøåíî èññëåäîâàòü âîïðîñ
î äåéñòâèòåëüíîì íàðóøåíèå ïàòåíòà è âûÿñíèòü âîçìîæíîñòü çàìåíû ARC
àëãîðèòìà íà «ïàòåíòíî-÷èñòûé» àëãîðèòì.
Îñíîâíûì àðãóìåíòîâ â ïîëüçó çàìåíû àëãîðèòìà áûëî æåëàíèå ñîõðàíèòü
PostgreSQL äîñòóïíûì äëÿ «ëþáîãî èñïîëüçîâàíèÿ» ñîãëàñíî
BSD ëèöåíçèè, êîòîðàÿ ïîçâîëÿåò êîììåð÷åñêîå èñïîëüçîâàíèå PostgreSQL
áåç êàêèõ-ëèáî ëèöåíçèîííûõ îò÷èñëåíèé.  íà÷àëå ôåâðàëÿ 2005 ãîäà Òîì Ëýéí
ïðåäëîæèë èçìåíåííóþ âåðñèþ ARC àëãîðèòìà, áëèçêóþ ê
2Q è
îïóáëèêîâàííóþ â 1994 ãîäó çàäîëãî äî ARC, è êîòîðàÿ ðåøàëà
ïðîáëåìó «cache flooding» («scan resistant») è íå òðåáîâàëà áîëüøèõ èçìåíåíèé
â êîäå (â îñíîâíîì óäàëåíèå êîäà), êîòîðàÿ è áûëà ðåàëèçîâàíà â âåðñèè 8.0.2.
2Q àëãîðèòì (Two Queue) ïî÷òè òàêæå ýôôåêòèâåí êàê LRU/K, íî ïðîùå,
íå òðåáóåò íàñòðîéêè è áûñòðåå. Îí äîáèâàåòñÿ ýòîãî òåì, ÷òî õðàíèò â
îñíîâíîì áóôåðå òîëüêî «ãîðÿ÷èå» ñòðàíèöû, à íå çàíèìàåòñÿ
î÷èùåíèåì «õîëîäíûõ» ñòðàíèö â îñíîâíîì áóôåðå êàê LRU/2.
Óïðîùåííî àëãîðèòì âûãëÿäèò òàê: ïðè ïåðâîì
îáðàùåíèè óêàçàòåëü íà ñòðàíèöó ïîìåùàåòñÿ â î÷åðåäü A1 (FIFO), è åñëè âî âðåìÿ âòîðîãî
îáðàùåíèÿ ñòðàíèöà åùå íàõîäèëàñü â A1, òî ñòðàíèöà íàçûâàåòñÿ ãîðÿ÷åé è
ïîìåùàåòñÿ â îñíîâíîé áóôåð, êîòîðûé óæå êîíòðîëèðóåòñÿ êàê LRU î÷åðåäü.
Åñëè ê ñòðàíèöå íå îáðàùàëèñü ïîêà îíà áûëà â A1, òî ñòðàíèöà, âåðîÿòíî,
«õîëîäíàÿ» è 2Q àëãîðèòì óäàëÿåò åå èç áóôåðà.
PGDG — PostgreSQL Global Development Group
PostgreSQL ðàçâèâàåòñÿ ñèëàìè ìåæäóíàðîäíîé ãðóïïû ðàçðàáîò÷èêîâ (PGDG),
â êîòîðóþ âõîäÿò êàê íåïîñðåäñòâåííî ïðîãðàììèñòû, òàê è òå, êòî îòâå÷àþò
çà ïðîäâèæåíèå PostgreSQL (Public Relation), çà ïîääåðæàíèå ñåðâåðîâ
è ñåðâèñîâ, íàïèñàíèå è ïåðåâîä äîêóìåíòàöèè, âñåãî íà 2005 ãîä íàñ÷èòûâàåòñÿ
îêîëî 200 ÷åëîâåê. Äðóãèìè ñëîâàìè, PGDG — ýòî
ñëîæèâøèéñÿ êîëëåêòèâ, êîòîðûé ïîëíîñòüþ ñàìîäîñòàòî÷åí è óñòîé÷èâ.
Ïðîåêò ðàçâèâàåòñÿ ïî îáùåïðèíÿòîé ñðåäè îòêðûòûõ ïðîåêòîâ ñõåìå, êîãäà
ïðèîðèòåòû îïðåäåëÿþòñÿ ðåàëüíûìè íóæäàìè è âîçìîæíîñòÿìè. Ïðè ýòîì,
ïðàêòèêóåòñÿ ïóáëè÷íîå îáñóæäåíèå âñåõ âîïðîñîâ â ñïèñêå ðàññûëêå, ÷òî
ïðàêòè÷åñêè èñêëþ÷àåò âîçìîæíîñòü íåïðàâèëüíûõ è íåñîãëàñîâàííûõ ðåøåíèé.
Ýòî îòíîñèòñÿ è ê òåì ïðåäëîæåíèÿì, êîòîðûå óæå èìåþò èëè ðàññ÷èòûâàþò íà
ôèíàíñîâóþ ïîääåðæêó êîììåð÷åñêèõ êîìïàíèé.
Öèêë ðàçðàáîòêè
Öèêë ðàáîòîé íàä íîâîé âåðñèåé îáû÷íî äëèòñÿ 10-12 ìåñÿöåâ
(ñåé÷àñ âåäåòñÿ äèñêóññèÿ î áîëåå êîðîòêîì öèêëå 2-3 ìåñÿöà) è ñîñòîèò èç
íåñêîëüêèõ ýòàïîâ (óïðîùåííàÿ âåðñèÿ):
- Îáñóæäåíèå ïðåäëîæåíèé â ñïèñêå
-hackers. Íà ñîáñòâåííîì îïûòå ìîãó
çàâåðèòü, ÷òî ýòî î÷åíü íåïðîñòîé ïðîöåññ è ïëîõî ïîäãîòîâëåííûé proposal
íå ïðîéäåò. Ó÷èòûâàþòñÿ ìíîãî ôàêòîðîâ — àëãîðèòìû, ñòðóêòóðû äàííûõ,
ñîâìåñòèìîñòü ñ ñóùåñòâóþùåé àðõèòåêòóðîé, ñîâìåñòèìîñòü ñ SQL è òàê äàëåå. - Ïîñëå ïðèíÿòèÿ ðåøåíèÿ î ðàáîòå íàä íîâîé âåðñèåé â CVS îòêðûâàåòñÿ
íîâàÿ âåòêà è ñ ýòîãî ìîìåíòà âñå èçìåíåíèÿ, êàñàþùèåñÿ íîâûõ âîçìîæíîñòåé,
âíîñÿòñÿ òóäà. Òàêæå, àíàëèçèðóþòñÿ ïàò÷è, êîòîðûå ïðèñûëàþòñÿ â ñïèñîê
-patches.
Âñå èçìåíåíèÿ ïðîòîêîëèðóþòñÿ è äîñòóïíû ëþáîìó äëÿ ðàññìîòðåíèÿ
(anonymous CVS,
-commiters ëèñò ðàññûëêè èëè ÷åðåç
âåá-èíòåðôåéñ ê CVS).
Èíîãäà, â ïðîöåññå ðàáîòû íàä íîâîé âåðñèåé âñêðûâàþòñÿ èëè
èñïðàâëÿþòñÿ ñòàðûå îøèáêè, â ýòîì ñëó÷àå, íàèáîëåå êðèòè÷åñêèå èñïðàâëÿþòñÿ
è â ïðåäûäóùèõ âåðñèÿõ (backporting). Ïî ìåðå íàêîïëåíèÿ òàêèõ èñïðàâëåíèé
ïðèíèìàåòñÿ ðåøåíèå î âûïóñêå íîâîé ñòàáèëüíîé âåðñèè, êîòîðàÿ ñîâìåñòèìà
ñî ñòàðîé è íå òðåáóåò îáíîâëåíèÿ õðàíèëèùà. Íàïðèìåð, 7.4.7 — ÿâëÿåòñÿ
bugfix-îì ñòàáèëüíîé âåðñèè 7.4. - Â íåêîòîðûé ìîìåíò îáúÿâëÿåòñÿ ýòàï code freeze(çàìîðàæèâàíèÿ êîäà),
ïîñëå êîòîðîãî â CVS íå äîïóñêàåòñÿ íîâàÿ ôóíêöèîíàëüíîñòü, à òîëüêî èñïðàâëåíèå
èëè óëó÷øåíèå êîäà. Ãðàíèöà ìåæäó íîâîé ôóíêöèîíàëüíîñòüþ è óëó÷øåíèåì êîäà
íå îïèñàíà è èíîãäà âîçíèêàþò ðàçíîãëàñèÿ íà ýòîò ñ÷åò, ê äîêóìåíòàöèè è
ðàñøèðåíèÿì (contribution modules â ïîääèðåêòîðèè contrib/) îáû÷íî îòíîñÿòñÿ áîëåå ëèáåðàëüíî.
Çàìå÷ó, ÷òî âñå ýòî âðåìÿ âñå CVS âåðñèÿ ïðîõîäèò íåïðåðûâíîå òåñòèðîâàíèå
íà áîëüøîì êîëè÷åñòâå ìàøèí, ïîä ðàçíûìè àðõèòåêòóðàìè, îïåðàöèîííûìè
ñèñòåìàìè è êîìïèëÿòîðàìè. Âñå ýòî ñòàëî âîçìîæíî áëàãîäàðÿ ïðîåêòó
pgbuildfarm, êîòîðûé ÿâëÿåòñÿ
ðàñïðåäåëåííîé ñèñòåìîé òåñòèðîâàíèÿ, îáúåäèíÿþùàÿ äîáðîâîëüöåâ, êîòîðûå
ïðåäîñòàâëÿþò ñâîè ìàøèíû äëÿ òåñòèðîâàíèÿ. Ïðîâåðÿåòñÿ íå òîëüêî êîððåêòíîñòü
ñáîðêè, íî è, áëàãîäàðÿ îáøèðíîìó íàáîðó òåñòîâ (regression test),
è ïðàâèëüíîñòü ðàáîòû. Òåêóùèé ñòàòóñ (âñåõ ïîääåðæèâàåìûõ âåðñèé, íå òîëüêî CVS)
ìîæíî ïîñìîòðåòü íà
ýòîé ñòðàíèöå.
Èñõîäíûå òåêñòû CVS âåðñèè PostgreSQL ïðîõîäÿò òåñòèðîâàíèå
â OSDL
÷òî ïîìîãàåò â
îáíàðóæåíèè ñèñòåìàòè÷åñêèõ èçìåíåíèé ïðîèçâîäèòåëüíîñòè (â îáå ñòîðîíû),
èíîãäà òàêèå îáíàðóæåíèÿ ïðèâîäÿò ê íåîáõîäèìîñòè «ðàçìîðàæèâàíèÿ êîäà».
Íà÷èíàÿ ñ âåðñèè 8 òàêèå òåñòèðîâàíèÿ áóäóò ðåãóëÿðíî ïðîâîäèòüñÿ â
OSDL STP è PLM (STP — Scalable Test Platform è PLM — Patch Lifecycle Manager). - Ïîñëå âíóòðåííåãî òåñòèðîâàíèÿ «ñîáèðàåòñÿ» äèñòðèáóòèâ è îáúÿâëÿåòñÿ
âûõîä áåòà âåðñèè, íà òåñòèðîâàíèå è èñïðàâëåíèå îøèáîê îòâîäèòñÿ
1-3 ìåñÿöà. Áåòà âåðñèÿ íå ðåêîìåíäóåòñÿ äëÿ èñïîëüçîâàíèÿ â ïðîäàêøí ïðîåêòàõ
(production), íî ïðàêòèêà ïîêàçàëà õîðîøåå êà÷åñòâî òàêèõ âåðñèé è
ìíîãèå íà÷èíàþò åå èñïîëüçîâàòü ðàäè àïðîáèðîâàíèÿ íîâîé ôóíêöèîíàëüíîñòè.
Êàê ïðàâèëî, îêîí÷àòåëüíàÿ âåðñèÿ ñîâìåñòèìà ñ áåòà-âåðñèåé è íå òðåáóåò
îáíîâëåíèÿ õðàíèëèùà. Ïî ìåðå èñïðàâëåíèÿ çàìå÷åííûõ îøèáîê âûïóñêàþòñÿ íîâûå
áåòà-âåðñèè. - Ïîñëå èñïðàâëåíèÿ âñåõ çàìå÷åííûõ îøèáîê, âûïóñêàåòñÿ
ðåëèç-êàíäèäàò, êîòîðûé óæå ïðàêòè÷åñêè íè÷åì íå îòëè÷àåòñÿ îò
îêîí÷àòåëüíîé âåðñèè, ðàçâå ÷òî íå õâàòàåò äîêóìåíòàöèè è ñïèñêà èçìåíåíèé. -  òå÷åíèè ìåñÿöà âûõîäèò îêîí÷àòåëüíàÿ âåðñèÿ, êîòîðàÿ àíîíñèðóåòñÿ
íà ãëàâíîì âåá-ñàéòå ïðîåêòà è åãî
çåðêàëàõ, ìýéëèíã ëèñòàõ. Òàêæå,
PR ãðóïïà, êîòîðàÿ ê ýòîìó ìîìåíòó ïîäãîòîâèëà àíîíñû íà ðàçíûõ ÿçûêàõ,
ðàñïðîñòðàíÿåò èõ ïî âñåì âåäóùèì ñàéòàì è ÑÌÈ. Îíè ïðèíèìàþò ó÷àñòèå
â êîíôåðåíöèÿõ, ñåìèíàðàõ è ïðî÷èõ îáùåñòâåííûõ ìåðîïðèÿòèÿõ.
Íà êàðòå îáîçíà÷åíû òî÷êè, ãäå æèâóò è ðàáîòàþò ÷ëåíû PGDG, îðèãèíàëüíàÿ
âåðñèÿ ñ áîëüøåé ôóíêöèîíàëüíîñòüþ íàõîäèòñÿ íà îôèöèàëüíîì
ñàéòå ðàçðàáîò÷èêîâ.
Ñòðóêòóðà
- Óïðàâëÿþùèé êîìèòåò (6 ÷åëîâåê).
Ïðèíèìàåò ðåøåíèå î ïëàíàõ ðàçâèòèÿ è âûïóñêàõ íîâûõ âåðñèé. - Çàñëóæåííûå ðàçðàáîò÷èêè ( 2 ÷åëîâåêà ).
Áûâøèå ÷ëåíû óïðàâëÿþùåãî êîìèòåòà, êîòîðûå îòîøëè îò ó÷àñòèÿ â ïðîåêòå.
- Îñíîâíûå ðàçðàáîò÷èêè (23).
- Ðàçðàáîò÷èêè (22)
Êðîìå PGDG, çíà÷èòåëüíîå ó÷àñòèå â ðàçâèòèè PostgreSQL ïðèíèìàåò íåêîììåð÷åñêàÿ
îðãàíèçàöèÿ «The PostgreSQL Foundation», ñîçäàííàÿ äëÿ ïðîäâèæåíèÿ è
ïîääåðæêè PostgreSQL. Ñàéò ôîíäà íàõîäèòñÿ ïî àäðåñó
www.thepostgresqlfoundation.org.
Ñïîíñîðñêàÿ ïîìîùü íà ðàçâèòèå PostgreSQL ïîñòóïàåò êàê îò ÷àñòíûõ ëèö,
òàê è îò êîììåð÷åñêèõ êîìïàíèé, êîòîðûå:
- ïðèíèìàþò íà ðàáîòó ÷ëåíîâ PGDG
- îïëà÷èâàþò ðàçðàáîòêó êàêèõ-ëèáî íîâûõ âîçìîæíîñòåé
- ïðåäîñòàâëÿþò óñëóãè â âèäå õîñòèíãà èëè îïëàòû òðàôèêà
- ïîääåðæèâàþò ïóáëè÷íûå ìåðîïðèÿòèÿ PGDG
- âûäåëÿþò ñâîèõ ïðîãðàììèñòîâ íà ó÷àñòèå â ðàçðàáîòêå
Êðîìå òîãî, íåêîòîðûå ðàçðàáîòêè ïîääåðæèâàþòñÿ ãîñóäàðñòâåííûìè ôîíäàìè,
íàïðèìåð, Ðîññèéñêèé Ôîíä Ôóíäàìåíòàëüíûõ Èññëåäîâàíèé.
Ãäå èñïîëüçóåòñÿ
Åñëè èçíà÷àëüíî POSTGRES èñïîëüçîâàëñÿ â îñíîâíîì â àêàäåìè÷åñêèõ ïðîåêòàõ
äëÿ èññëåäîâàíèÿ àëãîðèòìîâ áàç äàííûõ, â óíèâåðñèòåòàõ êàê îòëè÷íàÿ áàçà
äëÿ îáó÷åíèÿ, òî ñåé÷àñ PostgreSQL ïðèìåíÿåòñÿ ïðàêòè÷åñêè ïîâñåìåñòíî.
Íàïðèìåð, çîíû .org, .info ïîëíîñòüþ îáñëóæèâàþòñÿ PostgreSQL, èçâåñòíû
ìíîãîòåðàáàéòíûå õðàíèëèùà àñòðîíîìè÷åñêèõ äàííûõ, Lycos, BASF.
Èç ðîññèéñêèõ ïðîåêòîâ,
èñïîëüçóþùèõ PostgreSQL, íàèáîëåå èçâåñòíûìè ÿâëÿåòñÿ ïîðòàë
Ðàìáëåð, â ðàçðàáîòêå êîòîðîãî ÿ ïðèíèìàë
ó÷àñòèå â 2000-2002 ãîäàõ, ôåäåðàëüíûå ïîðòàëû Ìèíîáðàçîâàíèÿ.
Ñîîáùåñòâî
Ñîîáùåñòâî PostgreSQL ñîñòîèò èç áîëüøîãî êîëè÷åñòâà ïîëüçîâàòåëåé, îáúåäèíåííûõ
ðàçíûìè èíòåðåñàìè, òàêèìè êàê ó÷àñòèå â ðàçðàáîòêå, ïîèñê ñîâåòîâ, ðåøåíèé,
âîçìîæíîñòü êîììåð÷åñêîãî èñïîëüçîâàíèÿ.
Ïîääåðæêà
- Îñíîâíîé èñòî÷íèê àêòóàëüíîé èíôîðìàöèè î PostgreSQL ÿâëÿåòñÿ åãî
îôèöèàëüíûé ñàéò www.postgresql.org, êîòîðûé èìååò çåðêàëà ïî âñåìó ìèðó.
Íà íåì ïóáëèêóþòñÿ ñâåäåíèÿ î âñåõ ñîáûòèÿõ (àíîíñû ðåëèçîâ, ñåìèíàðîâ,
êîíôåðåíöèé), ïîääåðæèâàåòñÿ ñïèñîê ðåñóðñîâ, îòíîñÿùèõñÿ ê PostgreSQL. - Îñíîâíàÿ ïîääåðæêà îñóùåñòâëÿåòñÿ ÷åðåç ïî÷òîâóþ ðàññûëêó, àðõèâû êîòîðîé
äîñòóïíû ÷åðåç Web ïî àäðåñàì:- archives.postgresql.org
Àðõèâ pgsql-ru-general —
ðóññêîÿçû÷íîãî ñïèñêà ðàññûëêè,êàê ïîäïèñàòüñÿ. - www.pgsql.ru/db/mw
Êàê ïîêàçàëà ìíîãîëåòíÿÿ ïðàêòèêà, ñïèñêè ðàññûëîê ÿâëÿþòñÿ íàèáîëåå
ýôôåêòèâíûì è î÷åíü ïîëåçíûì èñòî÷íèêîì çíàíèé, îáìåíà ìíåíèÿìè è
ïîìîùè â ñàìûõ ðàçëè÷íûõ ñèòóàöèÿõ. Íà ìàðò 2005 ãîäà çàðåãèñòðèðîâàíî
32812 ïîëüçîâàòåëåé, êîòîðûå êîãäà-ëèáî ïèñàëè â ìýéëèíã ëèñò.Íåáîëüøàÿ ñòàòèñòèêà ñïèñêîâ ðàññûëîê PostgreSQL ïî äàííûì www.pgsql.ru
íà 1 àïðåëÿ 2005 ãîäà.Ïåðâàÿ 20-êà ìýéëèíã ëèñòîâ
ïî êîëè÷åñòâó ïîñòèíãîâÐàñïðåäåëåíèå ïîñòèíãîâ ïî ãîäàì name | count --------------------+-------- HACKERS | 107696 GENERAL | 93272 SQL | 27574 COMMITTERS | 21384 ADMIN | 20397 PATCHES | 17354 NOVICE | 13772 BUGS | 13700 MISC | 13545 INTERFACES | 13029 JDBC | 12705 QUESTIONS | 7865 ADVOCACY | 6676 CYGWIN | 6166 WWW | 5636 PERFORMANCE | 5359 ODBC | 5182 PORTS | 4769 DOCS | 3991 PHP | 3106
# | Year ------------- 19355 | 2005 68403 | 2004 71884 | 2003 61604 | 2002 58072 | 2001 38793 | 2000 25258 | 1999 16779 | 1998 15315 | 1997 612 | 1996 7 | 1995 - archives.postgresql.org
- Ïîèñêîâàÿ ñèñòåìà PGsearch
(ðàçðàáîòàíà ïðè ïîääåðæêå ÐÔÔÈ è
Äåëüòà-Ñîôò)
ïðåäîñòàâëÿåò ïîèñê ïî ñàéòàì ñîîáùåñòâà. Íà ìîìåíò íàïèñàíèÿ ýòîé ñòàòüè
ïðîèíäåêñèðîâàíî 480000 ñòðàíèö èç 67 ñàéòîâ, èíäåêñ îáíîâëÿåòñÿ åæåíåäåëüíî. - Ìíîãî ïîëåçíîé èíôîðìàöèè ïî PostgreSQL ìîæíî íàéòè íà ñàéòàõ
- techdocs.postgresql.org
- Varlena
- Powerpostgresql
- PGnotes
- Äîêóìåíòàöèÿ íà ðóññêîì (ïåðåâîäû è îðèãèíàëüíûå ñòàòüè) äîñòóïíû
íà ñàéòå ðóññêîÿçû÷íîãî ñîîáùåñòâà
http://www.linuxshare.ru/postgresql/. - Îòâåòû íà âàøè âîïðîñû ìîæíî íàéòè â «PostgreSQL FAQ « (÷àñòî çàäàâàåìûå âîïðîñû):
- Îðèãèíàëüíàÿ âåðñèÿ
- íà ðóññêîì ÿçûêå
- Äèñòðèáóòèâû PostgreSQL äîñòóïíû äëÿ ñêà÷èâàíèÿ ñ îñíîâíîãî ftp-ñåðâåðà ïðîåêòà è åãî çåðêàë.
Ïîäðîáíàÿ èíôîðìàöèÿ äîñòóïíà ñî ñòðàíèöû http://www.postgresql.org/download/.
Êðîìå òîãî, ìíîãèå äèñòðèáóòèâû Linux ðàñïðîñòðàíÿþòñÿ ñ áèíàðíîé âåðñèåé
PostgreSQL è îáåñïå÷èâàþò ïîääåðæêó îáíîâëåíèé. Äëÿ îçíàêîìëåíèÿ
ñ PostgreSQL ìîæíî ñêà÷àòü îáðàç çàãðóçî÷íîãî CD (Live CD) —
bittorent ôîðìàò
èëè â ISO ôîðìàòå.
Èíôîðìàöèþ î òîì, êàê èíñòàëëèðîâàòü PostgreSQL ïîä Mac OS X ìîæíî íàéòè
çäåñü.
Èíñòàëëÿòîð äëÿ Win32 ìîæíî ñêà÷àòü ñ ñàéòà ïðîåêòà
Pginstaller. - Êîììåð÷åñêàÿ ïîääåðæêà îñóùåñòâëÿåòñÿ ðÿäîì êîìïàíèé, ñïèñîê êîòîðûõ
äîñòóïåí ïî àäðåñó www.postgresql.org/support/.
Òàêæå íà ðîññèéñêîì ñàéòå âåäåòñÿ ñïèñîê ðîññèéñêèõ êîìïàíèé,
êîòîðûå çàÿâèëè î ïîääåðæêå PostgreSQL.
Ðàçðàáîòêà
Äëÿ ïðîåêòîâ, èìåþùèõ îòíîøåíèå ê PostgreSQL, ïðåäîñòàâëÿåòñÿ âîçìîæíîñòü
ðàçìåùàòü èõ íà ñïåöèàëüíûõ ñàéòàõ, ïîääåðæèâàåìûå PGDG è ïðåäîñòàâëÿþùèå
ïðàêòè÷åñêè âñå, íåîáõîäèìûå äëÿ ðàçðàáîò÷èêîâ, ñåðâèñû:
- gborg.postgresql.org
- pgfoundry.org
Çàêëþ÷åíèå
PostgreSQL ÿâëÿåòñÿ ïîëíîôóíêöèîíàëüíîé îáúåêòíî-ðåëÿöèîííîé ÑÓÁÄ, ãîòîâîé
äëÿ ïðàêòè÷åñêîãî èñïîëüçîâàíèÿ. Åå ôóíêöèîíàëüíîñòü è íàäåæíîñòü
îáóñëîâëåíû áîãàòîé èñòîðèåé ðàçâèòèÿ,ïðîôåññèîíàëèçìîì ðàçðàáîò÷èêîâ è
òåõíîëîãèåé òåñòèðîâàíèÿ, à åå ïåðñïåêòèâû çàëîæåíû â åå ðàñøèðÿåìîñòè è
ñâîáîäíîé ëèöåíçèè.
Áëàãîäàðíîñòè
Àâòîð áëàãîäàðèò ðóññêîÿçû÷íîå ñîîáùåñòâî çà êðèòèêó è äîïîëíåíèÿ, Ðîññèéñêèé Ôîíä Ôóíäàìåíòàëüíûõ Èññëåäîâàíèé
(ÐÔÔÈ) çà ïîääåðæêó ãðàíòà 05-07-90225-â.
Òåêñò íàïèñàí Îëåãîì Áàðòóíîâûì â 2005 ãîäó, ïîïðàâêè è êîììåíòàðèè
ïðèâåòñòâóþòñÿ.
Êðàòêàÿ ñïðàâêà:

Îëåã Áàðòóíîâ (îñíîâíàÿ ñïåöèàëüíîñòü àñòðîíîì, ðàáîòàåò â ÃÀÈØ ÌÃÓ) ÿâëÿåòñÿ ÷ëåíîì PGDG (îñíîâíîé ðàçðàáîò÷èê) ñ 1996 ãîäà, áûë â
÷èñëå îñíîâàòåëåé êîìïàíèè «GreatBridge», ÿâëÿåòñÿ ÷ëåíîì
«The PostgreSQL Foundation». Ïîìèìî èñïîëüçîâàíèÿ PostgreSQL â ïðîåêòàõ
(ñàìûå èçâåñòíûå — ýòo ïîðòàë Ðàìáëåð,
Íàó÷íàÿ Ñåòü, Àñòðîíåò), îí
â 1996 ãîäó äîáàâèë ïîääåðæêó locale â PostgreSQL, çàòåì
ñîâìåñòíî ñ Ôåäîðîì Ñèãàåâûì (êîìïàíèÿ Delta-Soft)
çàíèìàëñÿ ïîääåðæêîé è ðàçðàáîòêîé
GiST â PostgreSQL,
íà îñíîâå êîòîðîãî áûëè ðàçðàáîòàíû òàêèå ïîïóëÿðíûå ìîäóëè êàê
ïîëíîòåêñòîâûé ïîèñê, ðàáîòà ñ ìàññèâàìè, ïîèñê ñ îøèáêàìè, ïîääåðæêà
èåðàðõè÷åñêèõ äàííûõ. Ñîàâòîð ñâîáîäíîãî ïîëíîòåêñòîâîãî ïîèñêà äëÿ
PostgreSQL OpenFTS.
ßâëÿåòñÿ àâòîðîì è ñîçäàòåëåì
(ñîâìåñòíî ñ Ôåäîðîì Ñèãàåâûì) ñàéòà pgsql.ru.
Çàíèìàåòñÿ ïðîäâèæåíèåì PostgreSQL äëÿ èñïîëüçîâàíèÿ â àñòðîíîìèè, â ÷àñòíîñòè,
äëÿ ðàáîòû ñ î÷åíü áîëüøèìè àñòðîíîìè÷åñêèìè êàòàëîãàìè, ïðîåêò
pgSphere — õðàíåíèå äàííûõ ñî ñôåðè÷åñêèìè
êîîðäèíàòàìè è èíäåêñíûå ìåòîäû äîñòóïà ê íèì.
20 марта, 2019 12:10 пп
14 208 views
| Комментариев нет
Cloud Server, VPS
Управляемые базы данных позволяют масштабировать БД PostgreSQL несколькими способами. Одним из них является встроенный преобразователь подключений, который позволяет эффективно обрабатывать большое количество клиентских подключений и уменьшить использование их ЦП и памяти. Используя пул соединений и распределяя фиксированный набор перерабатываемых соединений, вы можете обрабатывать значительно больше одновременных клиентских соединений и повысить производительность вашей базы данных PostgreSQL.
В этом мануале вы научитесь использовать pgbench, встроенный в PostgreSQL инструмент тестирования производительности, для запуска нагрузочных тестов в управляемой базе данных PostgreSQL. Мы расскажем вам про пулы соединений, опишем, как они работают, и покажем, как их создавать. По результатам тестов pgbench вы увидите, что использование пула соединений может стать недорогим средством увеличения пропускной способности базы данных.
Требования
- Управляемая БД PostgreSQL.
- Клиентская машина с экземпляром PostgreSQL. По умолчанию установка PostgreSQL содержит утилиту тестирования производительности pgbench и клиент psql, которые мы будем использовать в этом мануале. Чтобы узнать, как установить PostgreSQL, читайте мануал Установка и использование PostgreSQL в Ubuntu 18.04.
1: Создание и инициализация БД benchmark
Прежде чем создать пул соединений для базы данных, создайте базу данных benchmark в вашем кластере PostgreSQL и заполните ее фиктивными данными, на которых pgbench будет выполнять свои тесты. Утилита pgbench многократно запускает серию из пяти SQL команд (включая запросы SELECT, UPDATE и INSERT), используя несколько потоков и клиентов, и вычисляет показатель полезной производительности под названием «транзакции в секунду» (TPS, transactions per second). TPS – это показатель пропускной способности базы данных, который показывает количество транзакций, обработанных базой данных за одну секунду. Чтобы узнать больше о командах, выполняемых pgbench, обратитесь к официальной документации pgbench.
Итак, подключитесь к кластеру PostgreSQL и создайте БД benchmark.
Процесс создания будет зависеть от вашего провайдера.
При этом вам понадобятся такие данные (мы используем условные данные, которые вы должны заменить):
- Имя администратора: myadmin
- your_password
- Пароль: your_password
- Конечная точка кластера: укажите свою точку
- Порт: 25060
- База данных: defaultdb
- Режим SSL: require (чтобы использовать зашифрованное соединение SSL)
Эти параметры вам понадобятся в дальнейшей работе с клиентом psql и инструментом pgbench, потому запомните или запишите их.
Подключитесь к кластеру с помощью клиента psql (для этого вам может понадобиться строка подключения).
Вы попадете в командную строку клиента PostgreSQL, если подключение будет удачно создано.
psql (10.6 (Ubuntu 10.6-0ubuntu0.18.04.1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
defaultdb=>
Создайте БД benchmark:
CREATE DATABASE benchmark;
CREATE DATABASE
Выйдите из кластера:
q
Перед запуском тестов pgbench необходимо заполнить эту тестовую базу данных несколькими таблицами и фиктивными данными.
Для этого мы запустим pgbench со следующими флагами:
- -h: конечная точка кластера PostgreSQL
- -p: порт кластера PostgreSQL
- -U: имя пользователя базы данных
- -i: инициализирует базу данных benchmark с помощью таблиц и их фиктивных данных.
- -s: устанавливает масштабный коэффициент 150, который умножит размеры таблицы на 150. Стандартный масштабный коэффициент 1 создает таблицу следующих размеров:
table # of rows
---------------------------------
pgbench_branches 1
pgbench_tellers 10
pgbench_accounts 100000
pgbench_history 0
Масштабный коэффициент 150 создаст таблицу pgbench_accounts в 15 000 000 строк.
Примечание: Чтобы избежать чрезмерного количества заблокированных транзакций, убедитесь, что значение масштабного коэффициента как минимум равно количеству одновременно работающих клиентов, которые используются в тестировании. В этом мануале мы протестируем максимум 150 клиентов, поэтому мы установили здесь значение -s 150. Чтобы узнать больше, ознакомьтесь с этими рекомендациями из официальной документации pgbench.
Запустите команду pgbench:
pgbench -h your_cluster_endpoint -p 25060 -U myadmin -i -s 150 benchmark
После этого вам будет предложено ввести пароль указанного пользователя БД. Введите пароль и нажмите Enter.
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data...
100000 of 15000000 tuples (0%) done (elapsed 0.19 s, remaining 27.93 s)
200000 of 15000000 tuples (1%) done (elapsed 0.85 s, remaining 62.62 s)
300000 of 15000000 tuples (2%) done (elapsed 1.21 s, remaining 59.23 s)
400000 of 15000000 tuples (2%) done (elapsed 1.63 s, remaining 59.44 s)
500000 of 15000000 tuples (3%) done (elapsed 2.05 s, remaining 59.51 s)
. . .
14700000 of 15000000 tuples (98%) done (elapsed 70.87 s, remaining 1.45 s)
14800000 of 15000000 tuples (98%) done (elapsed 71.39 s, remaining 0.96 s)
14900000 of 15000000 tuples (99%) done (elapsed 71.91 s, remaining 0.48 s)
15000000 of 15000000 tuples (100%) done (elapsed 72.42 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done.
На данный момент у вас есть база данных benchmark, заполненная таблицами и данными, необходимыми для запуска тестов pgbench. Теперь можно запустить базовый тест, который позволит нам сравнить производительность до и после включения пула соединений.
2: Запуск базового теста pgbench
Прежде чем начать первый тест, стоит остановиться на том, что именно мы пытаемся оптимизировать с помощью пулов соединений.
Обычно, когда клиент подключается к БД PostgreSQL, основной процесс PostgreSQL переходит в дочерний процесс, соответствующий этому новому соединению. Если у вас только несколько соединений, это не вызовет проблем. Однако по мере масштабирования клиентов и соединений расходы ресурсов процессора и памяти на создание и поддержание этих соединений начинают накладываться, особенно если рассматриваемое приложение неэффективно использует соединения с БД. Кроме того, параметр PostgreSQL max_connections может ограничивать количество разрешенных клиентских подключений, в результате чего после превышения этого значения соединения будут отклонены или сброшены.
Пул соединений сохраняет открытым фиксированное количество соединений с базой данных (это размер пула, который он затем использует для распределения и выполнения клиентских запросов). Это означает, что вы можете обслужить гораздо больше одновременных соединений, эффективно обработать неактивных или застойных клиентов, а также поставить клиентские запросы в очередь во время всплесков трафика (вместо того чтобы отклонять их). Повторно используя соединения, вы можете более эффективно применить ресурсы вашего компьютера в среде с большим объемом подключений и оптимизировать производительность БД.
Пул соединений можно реализовать либо на стороне приложения, либо в качестве промежуточного программного обеспечения между БД и приложением. Пул соединений для управляемых баз данных разработан на основе pgBouncer (это легкий промежуточный пул соединений с открытым исходным кодом для PostgreSQL).
Откройте панель управления своими базами данных. в меню найдите опцию типа Connection Pools и создайте пул соединений.
Для этого вам понадобятся такие данные:
- Pool Name: уникальное имя вашего пула соединений.
- Database: База данных, соединения которой вы хотите объединить в пул.
- User: пользователь PostgreSQL, с помощью которого пул соединений будет аутентифицироваться
- Mode: режим. Эта опция контролирует, как долго пул назначает клиентскому серверу бэкэнд-соединение.
-
- Session: Клиент удерживает соединение до тех пор, пока оно явно не отключится.
- Transaction: Клиент получает соединение до завершения транзакции, после чего соединение возвращается в пул.
- Statement: Пул агрессивно перезапускает соединения после каждого оператора клиента. В этом режиме транзакции с несколькими операторами не поддерживаются.
- Pool Size: количество соединений, которые пул будет держать открытым между собой и базой данных.
Прежде чем создать пул соединений, давайте запустим базовый тест, с результатами которого вы сможете сравнить производительность базы данных до и после внедрения пула соединений.
В этом мануале мы используем 4 ГБ RAM, 2 vCPU, 80 ГБ дискового пространства, управляемую базу данных (только ведущая нода). Вы можете масштабировать параметры теста производительности в соответствии с вашими спецификациями кластера PostgreSQL.
Итак, давайте запустим первый тест pgbench.
Войдите на клиентскую машину. Запустите pgbench, указав конечную точку, порт и пользователя. Также нужно добавить эти опции:
- -c: количество одновременных клиентов или сеансов БД, которое нужно симулировать. Мы установим здесь 50, чтобы имитировать количество одновременных соединений, меньшее, чем параметр max_connections данного кластера PostgreSQL.
- -j: количество рабочих потоков, которые pgbench будет использовать во время теста. Если вы используете многопроцессорную машину, вы можете увеличить зто значение, чтоб распределить клиентов по потокам. На двухъядерном компьютере нужно установить значение 2.
- -P: отображает прогресс и метрики каждые 60 секунд.
- -T: запустит тест на 600 секунд (10 минут). Чтобы получить согласованные, воспроизводимые результаты, важно, чтобы тест длился в течение нескольких минут или один цикл контрольных точек.
Также нужно указать, что тест нужно запустить в БД benchmark.
Запустите эту команду:
pgbench -h your_db_endpoint -p 25060 -U myadmin -c 50 -j 2 -P 60 -T 600 benchmark
Нажмите клавишу Enter и введите пароль пользователя myadmin, чтобы начать выполнение теста. Вы должны увидеть подобный вывод (результаты будут зависеть от характеристик вашего кластера PostgreSQL):
starting vacuum...end.
progress: 60.0 s, 157.4 tps, lat 282.988 ms stddev 40.261
progress: 120.0 s, 176.2 tps, lat 283.726 ms stddev 38.722
progress: 180.0 s, 167.4 tps, lat 298.663 ms stddev 238.124
progress: 240.0 s, 178.9 tps, lat 279.564 ms stddev 43.619
progress: 300.0 s, 178.5 tps, lat 280.016 ms stddev 43.235
progress: 360.0 s, 178.8 tps, lat 279.737 ms stddev 43.307
progress: 420.0 s, 179.3 tps, lat 278.837 ms stddev 43.783
progress: 480.0 s, 178.5 tps, lat 280.203 ms stddev 43.921
progress: 540.0 s, 180.0 tps, lat 277.816 ms stddev 43.742
progress: 600.0 s, 178.5 tps, lat 280.044 ms stddev 43.705
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 150
query mode: simple
number of clients: 50
number of threads: 2
duration: 600 s
number of transactions actually processed: 105256
latency average = 282.039 ms
latency stddev = 84.244 ms
tps = 175.329321 (including connections establishing)
tps = 175.404174 (excluding connections establishing)
Здесь можно видеть, что за 10 минут работы с 50 одновременными соединениями кластер обработал 105 256 транзакций с пропускной способностью примерно 175 транзакций в секунду.
Теперь давайте запустим тот же тест, но на этот раз используем 150 одновременных клиентов. Это значение выше, чем max_connections для этой базы данных, это позволяет симулировать массовый приток клиентских подключений:
pgbench -h your_db_endpoint -p 25060 -U myadmin -c 150 -j 2 -P 60 -T 600 benchmark
Вы получите результат:
starting vacuum...end.
connection to database "pgbench" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connections
progress: 60.0 s, 182.6 tps, lat 280.069 ms stddev 42.009
progress: 120.0 s, 253.8 tps, lat 295.612 ms stddev 237.448
progress: 180.0 s, 271.3 tps, lat 276.411 ms stddev 40.643
progress: 240.0 s, 273.0 tps, lat 274.653 ms stddev 40.942
progress: 300.0 s, 272.8 tps, lat 274.977 ms stddev 41.660
progress: 360.0 s, 250.0 tps, lat 300.033 ms stddev 282.712
progress: 420.0 s, 272.1 tps, lat 275.614 ms stddev 42.901
progress: 480.0 s, 261.1 tps, lat 287.226 ms stddev 112.499
progress: 540.0 s, 272.5 tps, lat 275.309 ms stddev 41.740
progress: 600.0 s, 271.2 tps, lat 276.585 ms stddev 41.221
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 150
query mode: simple
number of clients: 150
number of threads: 2
duration: 600 s
number of transactions actually processed: 154892
latency average = 281.421 ms
latency stddev = 125.929 ms
tps = 257.994941 (including connections establishing)
tps = 258.049251 (excluding connections establishing)
Обратите внимание на ошибку FATAL – она указывает на то, что pgbench достиг порогового значения в 100 соединений (max_connections), что привело к отказу в соединении. И все же pgbench смог закончить тест с TPS примерно в 257.
На этом этапе вы можете определить, как пул соединений потенциально может улучшить пропускную способность базы данных.
3: Создание и тестирование пула соединений
Теперь давайте создадим пул соединений и повторно запустим предыдущий тест pgbench, чтобы посмотреть, сможет ли это улучшить пропускную способность базы данных.
В общем, настройки max_connections и параметры пула соединений поднимаются вместе, чтобы максимально увеличить нагрузку на базу данных. Однако если вы не можете настроить max_connections в управляемых базах данных, используйте настройки режима и размера пула соединений.
Для начала нужно создать пул соединений в режиме Transaction, который сохраняет открытыми все доступные внутренние соединения.
Перейдите панели управления откройте меню баз данных, а затем кликните по кластеру PostgreSQL. Откройте меню пулов подключения и создайте такой пул.
В появившемся окне конфигурации заполните предложенные поля и нажмите Создать.
Скопируйте появившийся URI.
Вы должны заметить, что в результате в URI будет другой порт и, возможно, другая конечная точка и имя базы данных, соответствующее имени пула (в данном случае test-pool).
Теперь, когда мы создали пул соединений test-pool, мы можем снова запустить тест pgbench, который мы запускали ранее.
Повторный запуск pgbench
На своем клиентском компьютере выполните следующую команду pgbench (укажите 150 одновременных клиентов), убедившись, что выделенные значения заменены значениями в URI пула соединений:
pgbench -h pool_endpoint -p pool_port -U myadmin -c 150 -j 2 -P 60 -T 600 test-pool
Здесь мы снова используем 150 одновременных клиентов, запуская тест в двух потоках. Команда будет отображать прогресс каждые 60 секунд, тест будет продолжаться в течение 600 секунд. Имя базы данных должно быть test-pool, как и имя пула соединений.
После завершения теста вы должны увидеть подобный вывод (обратите внимание, что эти результаты будут отличаться в зависимости от характеристик вашей ноды БД).
starting vacuum...end.
progress: 60.0 s, 240.0 tps, lat 425.251 ms stddev 59.773
progress: 120.0 s, 350.0 tps, lat 428.647 ms stddev 57.084
progress: 180.0 s, 340.3 tps, lat 440.680 ms stddev 313.631
progress: 240.0 s, 364.9 tps, lat 411.083 ms stddev 61.106
progress: 300.0 s, 366.5 tps, lat 409.367 ms stddev 60.165
progress: 360.0 s, 362.5 tps, lat 413.750 ms stddev 59.005
progress: 420.0 s, 359.5 tps, lat 417.292 ms stddev 60.395
progress: 480.0 s, 363.8 tps, lat 412.130 ms stddev 60.361
progress: 540.0 s, 351.6 tps, lat 426.661 ms stddev 62.960
progress: 600.0 s, 344.5 tps, lat 435.516 ms stddev 65.182
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 150
query mode: simple
number of clients: 150
number of threads: 2
duration: 600 s
number of transactions actually processed: 206768
latency average = 421.719 ms
latency stddev = 114.676 ms
tps = 344.240797 (including connections establishing)
tps = 344.385646 (excluding connections establishing)
Обратите внимание, мы смогли увеличить пропускную способность базы данных с 257 TPS до 344 TPS при 150 одновременных соединениях (это увеличение на 33%) и не столкнулись с превышением max_connections, как было без пула соединений. Пул соединений позволяет избежать разрыва соединений и значительно увеличить пропускную способность базы данных в среде с большим количеством одновременных соединений.
Если вы запустите этот же тест, но со значением -c 50 (уменьшив количество клиентов), плюсы использования пула соединений станут гораздо менее очевидными:
starting vacuum...end.
progress: 60.0 s, 154.0 tps, lat 290.592 ms stddev 35.530
progress: 120.0 s, 162.7 tps, lat 307.168 ms stddev 241.003
progress: 180.0 s, 172.0 tps, lat 290.678 ms stddev 36.225
progress: 240.0 s, 172.4 tps, lat 290.169 ms stddev 37.603
progress: 300.0 s, 177.8 tps, lat 281.214 ms stddev 35.365
progress: 360.0 s, 177.7 tps, lat 281.402 ms stddev 35.227
progress: 420.0 s, 174.5 tps, lat 286.404 ms stddev 34.797
progress: 480.0 s, 176.1 tps, lat 284.107 ms stddev 36.540
progress: 540.0 s, 173.1 tps, lat 288.771 ms stddev 38.059
progress: 600.0 s, 174.5 tps, lat 286.508 ms stddev 59.941
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 150
query mode: simple
number of clients: 50
number of threads: 2
duration: 600 s
number of transactions actually processed: 102938
latency average = 288.509 ms
latency stddev = 83.503 ms
tps = 171.482966 (including connections establishing)
tps = 171.553434 (excluding connections establishing)
Этот вывод говорит, что вы не смогли увеличить пропускную способность с помощью пула соединений. Пропускная способность снизилась до 171 TPS со 175 TPS.
В этом мануале мы используем pgbench с фиктивной БД benchmark. Но чтобы лучше понять, следует ли использовать пул соединений, вы должны тестировать нагрузку, которая точно отражает производственную нагрузку на БД. Создание пользовательских сценариев тестирования и данных выходит за рамки этого мануала, но дополнительную информацию вы можете получить в официальной документации pgbench.
Примечание: Настройка размера пула сильно зависит от рабочей нагрузки. В этом мануале мы настроили пул соединений для использования всех доступных подключений к базе данных. Это связано с тем, что на протяжении всего теста база данных редко использовалась по максимуму. В зависимости от загрузки вашей базы данных, это значение параметра может быть не оптимальным. При постоянной загрузке БД сокращение пула соединений может увеличить пропускную способность и повысить производительность: дополнительные запросы попадут в очередь вместо того, БД не будет пытаться выполнить их все одновременно на уже загруженном сервере.
Заключение
В этом мануале вы научились использовать встроенный инструмент PostgreSQL pgbench для тестирования вашей БД. В любом сценарии производства необходимо тестировать нагрузку, и чем ближе она к реальной ситуации, тем лучше – так вы сможете настроить вашу БД под конкретные условия работы.
Существуют и другие инструменты для нагрузочного тестирования базы данных. Одним из таких инструментов является sysbench-tpcc, разработанный Percona. Еще есть Apache JMeter, который может загружать тестовые базы данных и веб-приложения.
Читайте также:
- Управляемые базы данных: преимущества, узкие места, практические рекомендации
- Фрагментация базы данных: основные методы и случаи использования
- Официальная документация pgbench
Tags: pgbench, PostgreSQL, SQL
pg_verifybackup — verify the integrity of a base backup of a PostgreSQL cluster
Synopsis
pg_verifybackup [option…]
Description
pg_verifybackup is used to check the integrity of a database cluster backup taken using pg_basebackup against a backup_manifest generated by the server at the time of the backup. The backup must be stored in the «plain» format; a «tar» format backup can be checked after extracting it.
It is important to note that the validation which is performed by pg_verifybackup does not and cannot include every check which will be performed by a running server when attempting to make use of the backup. Even if you use this tool, you should still perform test restores and verify that the resulting databases work as expected and that they appear to contain the correct data. However, pg_verifybackup can detect many problems that commonly occur due to storage problems or user error.
Backup verification proceeds in four stages. First, pg_verifybackup reads the backup_manifest file. If that file does not exist, cannot be read, is malformed, or fails verification against its own internal checksum, pg_verifybackup will terminate with a fatal error.
Second, pg_verifybackup will attempt to verify that the data files currently stored on disk are exactly the same as the data files which the server intended to send, with some exceptions that are described below. Extra and missing files will be detected, with a few exceptions. This step will ignore the presence or absence of, or any modifications to, postgresql.auto.conf, standby.signal, and recovery.signal, because it is expected that these files may have been created or modified as part of the process of taking the backup. It also won’t complain about a backup_manifest file in the target directory or about anything inside pg_wal, even though these files won’t be listed in the backup manifest. Only files are checked; the presence or absence of directories is not verified, except indirectly: if a directory is missing, any files it should have contained will necessarily also be missing.
Next, pg_verifybackup will checksum all the files, compare the checksums against the values in the manifest, and emit errors for any files for which the computed checksum does not match the checksum stored in the manifest. This step is not performed for any files which produced errors in the previous step, since they are already known to have problems. Files which were ignored in the previous step are also ignored in this step.
Finally, pg_verifybackup will use the manifest to verify that the write-ahead log records which will be needed to recover the backup are present and that they can be read and parsed. The backup_manifest contains information about which write-ahead log records will be needed, and pg_verifybackup will use that information to invoke pg_waldump to parse those write-ahead log records. The --quiet flag will be used, so that pg_waldump will only report errors, without producing any other output. While this level of verification is sufficient to detect obvious problems such as a missing file or one whose internal checksums do not match, they aren’t extensive enough to detect every possible problem that might occur when attempting to recover. For instance, a server bug that produces write-ahead log records that have the correct checksums but specify nonsensical actions can’t be detected by this method.
Note that if extra WAL files which are not required to recover the backup are present, they will not be checked by this tool, although a separate invocation of pg_waldump could be used for that purpose. Also note that WAL verification is version-specific: you must use the version of pg_verifybackup, and thus of pg_waldump, which pertains to the backup being checked. In contrast, the data file integrity checks should work with any version of the server that generates a backup_manifest file.
Options
pg_verifybackup accepts the following command-line arguments:
-e--exit-on-error-
Exit as soon as a problem with the backup is detected. If this option is not specified,
pg_verifybackupwill continue checking the backup even after a problem has been detected, and will report all problems detected as errors. -ipath--ignore=path-
Ignore the specified file or directory, which should be expressed as a relative path name, when comparing the list of data files actually present in the backup to those listed in the
backup_manifestfile. If a directory is specified, this option affects the entire subtree rooted at that location. Complaints about extra files, missing files, file size differences, or checksum mismatches will be suppressed if the relative path name matches the specified path name. This option can be specified multiple times. -mpath--manifest-path=path-
Use the manifest file at the specified path, rather than one located in the root of the backup directory.
-n--no-parse-wal-
Don’t attempt to parse write-ahead log data that will be needed to recover from this backup.
-q--quiet-
Don’t print anything when a backup is successfully verified.
-s--skip-checksums-
Do not verify data file checksums. The presence or absence of files and the sizes of those files will still be checked. This is much faster, because the files themselves do not need to be read.
-wpath--wal-directory=path-
Try to parse WAL files stored in the specified directory, rather than in
pg_wal. This may be useful if the backup is stored in a separate location from the WAL archive.
Other options are also available:
-V--version-
Print the pg_verifybackup version and exit.
-?--help-
Show help about pg_verifybackup command line arguments, and exit.
Examples
To create a base backup of the server at mydbserver and verify the integrity of the backup:
$pg_basebackup -h mydbserver -D /usr/local/pgsql/data$pg_verifybackup /usr/local/pgsql/data
To create a base backup of the server at mydbserver, move the manifest somewhere outside the backup directory, and verify the backup:
$pg_basebackup -h mydbserver -D /usr/local/pgsql/backup1234$mv /usr/local/pgsql/backup1234/backup_manifest /my/secure/location/backup_manifest.1234$pg_verifybackup -m /my/secure/location/backup_manifest.1234 /usr/local/pgsql/backup1234
To verify a backup while ignoring a file that was added manually to the backup directory, and also skipping checksum verification:
$pg_basebackup -h mydbserver -D /usr/local/pgsql/data$edit /usr/local/pgsql/data/note.to.self$pg_verifybackup --ignore=note.to.self --skip-checksums /usr/local/pgsql/data
Your privacy
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.