Второй этап
исследования называют «полевым этапом»,
т.к. зона практических действий социологов
— это поле, с которого собирается урожай
в виде надежной и представительной
информации. В ходе сбора информации
применяются различные методы, каждый
из которых имеет свои особенности.
Основными методами являются опрос,
наблюдение, анализ документов, экспертная
оценка, эксперимент, социометрия,
измерение социальных установок. Самый
распространенный из них — опрос, с его
помощью собирается 90% социологической
информации. Каждый метод имеет свои
предназначение и ограничения. Выбор
методов исследования зависит не от
желания исследователя, не от его прихоти
или произвола, а от решаемых им задач и
содержания проверяемых гипотез.
1. Одной из
наиболее распространенных и наиболее
грубых ошибок является неграмотное
составление инструментария. Его
формирование достаточно сложная
процедура, и чем проще выглядит вопросник,
тем больше в него труда вложено. Кроме
того, что в анкете должны умело сочетаться
«открытые и закрытые» вопросы, «вопросы
– меню», «прожективные», «табличные»,
«дополнительные», «проверочные» из
которых делают различные панели, чтобы
основная идее, гипотеза, запрос, была
подтверждена неоднократно, и в сумме
средних баллов выявила устойчивость
мнения той или иной группы. 2. Следующей
важной составляющей «корректного»
социологического исследования является
правильно определенная выборочная
совокупность, т.е. число опрашиваемых
(выборка) в должно соответствовать в
заданной пропорции генеральной
совокупности. (Общему количеству)3.Третьей
группой причин некорректных результатов
являются «ошибки поля», которые в свою
очередь можно отнести к «ошибкам маршрута
выборки» и «ошибкам интервьюеров».
социологические центры не располагают
собственным штатом интервьюеров и
вынуждены прибегать к услугам случайных
или более или менее подготовленных
людей.4.Следующая группа причин ошибок
связана с расчетом результатов.5 . ошибки
интерпретации данных
Типичные
ошибки и трудности в проведении опрос
1. Подготовка
вопросника начинается без разработки
программы опроса, не выделены категории
анализа.2. Познавательная задача
расходится со смысловым содержанием
формулировки вопроса. Произошла замена
индикатора: вместо вопроса об
информированности задается вопрос о
самооценке информированности.2.1. Вопрос
содержит термины, смысл которых непонятен
респонденту или по-разному понимается
респондентами.2.2. Перед респондентом
при ответе на вопрос ставятся задачи,
к решению которых он не подготовлен
(установить сложные зависимости, провести
ранжирование, классификацию, выявить
критерий).2.3. Респонденту задается вопрос
об оценке фактов без предварительного
выяснения, какое отношение он имеет к
этим фактам.2.4. Респондент выражает
опасения в связи с участием в опросе.2.5.
Респондент участвует в опросе неохотно,
с видимым безразличием.3. Респондент
слишком разговорчив и уводит интервьюера
от темы вопроса.3.1. Респондент выражает
сомнение относительно качества вопросника
(отдельных вопросов).4. Неаккуратно
заполнены анкеты.5. В ходе опроса собран
большой объем статистической информации.
Однако оказалось, что она не имеет
прямого отношения к гипотезам и задачам
исследования.
Ошибки и
трудности в применении экспертного
опроса
1. Нечеткость
в определении целей экспертизы. Опрос
экспертов проводится без специально
разработанной программы.2. Неэффективное
использование экспертов. Экспертиза
предназначена для получения информации,
которая могла быть собрана другими,
менее сложными методами.3. Недостаточно
тщательный подбор экспертов, появление
в группе экспертов случайных людей.4.
Привлеченные к опросу эксперты не
проявляют интереса к экспертизе. Часть
экспертов заинтересована в искажении
информации.5. Возникли трудности
интерпретации данных из-за значительного
разброса ответов, их неоднородности.6.
Стремление ускорить опрос привело к
поверхностному анализу проблем
экспертами.7. Излишний оптимизм в оценке
результатов опроса. Данные экспертизы
не подтверждены другими объективными
данными.
Типичные
ошибки анализа документов в социологическом
исследовании
1. Исследователь
использует документальную информацию
в качестве первичной, без предварительного
ее анализа; не проверены: подлинность,
достоверность, авторство документа,
назначение информации.2. Анализ
документов ведется без предварительного
плана, программы.3. Выбранные для
анализа документы имеют сходство с
темой исследования лишь по названию.4.
Категории анализа не сопоставлены
со смысловым содержанием и языком
текста. В терминологическом обозначении
категорий есть двусмысленность.5. Не
подготовлены заранее и не апробированы
методические документы сбора данных.
6 Нет списка (каталога) используемых в
анализе документов.
Типичные
ошибки в применении метода наблюдения
1. Наблюдение
ведется без специальной программы.2.
Выделенные признаки наблюдения не
связаны с проблемной ситуацией и
гипотезой исследования.3. Не введены
ограничения на условия наблюдения и
наблюдатели столкнулись с принципиально
различными ситуациями.4. Введены
только оценочные или только описательные
категории наблюдения.5. В терминологическом
обозначении категорий имеется
двусмысленность.6. В состав регистрируемых
признаков в карточке наблюдения не
вошли часто повторяющиеся и довольно
значимые свойства наблюдаемой ситуации.
7 Не подготовлены и не апробированы
методические документы, и в ходе сбора
данных возникли трудности с регистрацией
признаков.
Типичные
ошибки и трудности применения эксперимента
1.
Сформулированные гипотезы не отражают
проблемных ситуаций, существенных
зависимостей в изучаемом объекте.2.
В качестве независимой переменной
выделен фактор, который не может быть
причиной происходящих в изучаемом
явлении процессов.3. Связи между
зависимой и независимой переменными
носят случайный характер.4. Допущены
ошибки в предварительном описании
объекта, что привело к выбору неверных
(неадекватных) показателей.5. Были
допущены ошибки при формировании
экспериментальных и контрольных групп.
В ходе эксперимента обнаружилось
значительное различие групп, что делает
проблематичным сравнение этих групп
по составу переменных.6. Для
экспериментальной группы трудно
подобрать контрольную.7. Не поддается
нейтрализации действие побочных
факторов, трудно создать экспериментальную
ситуацию.8. Среди организаторов
экспериментальных работ оказались
люди, не заинтересованные в положительных
результатах эксперимента.9. В ходе
исследования среди участников возникли
конфликты по поводу вовлеченности в
эксперимент.
28. Методы
политических исследований
Политика —
совокупность социальных идей и
обусловленная ими целенаправленная
деятельность, связанная с формированием
жизненно важных отношений между
государствами, народами, нациями,
социальными группами.
Институциональный
метод — широко применим в политологии.
Он ориентирует на изучение институтов,
с помощью которых осуществляется
политическая деятельность (государства,
партий, других организаций и объединений
и .п.).
Социологический
— представляет собой совокупность
приемов конкретных социальных
исследований, направленных на сбор
фактов и практических материалов, путем
анкет, опросов и т.п. Социологический
метод используется для выявления
состояния общественного мнения, создания
представлений об ориентациях участников
политического процесса.
Сравнительный
— сопоставлении политических объектов
или процессов, выявлении их подобия и
отличительных черт. (сравнение одинаковых
явлений в разных странах). Антропологический
— исходит из природы человека. Исследует
влияние национального характера на
политическое развитие.
Психологический
— заключается в изучении в изучении
соотношения личности и власти.
Коммуникативный
— разрабатывает кибернетическую модель
политического процесса, рассматривая
структуры как информационные потоки.
В рамках
рассматриваются политические исследования
применительно к избирательным аспектам.
1) опросы на входе (изменение ориентации)
проводится за месяц, неделю до начала
выборов. Во всех предвыборных опросах
следует иметь ввиду парадокс Лапьера.
Суть парадокса заключается в расхождении
заявленные установки и поступками
людей. Даже при наличии избирательной
политической потребности, избиратели
могут не явиться. Праймелис- пробное
голосование перед выборами. Цель :
выявить наиболее популярного кандидата.
Но результаты могут отличаться от
выборов. 2) опросы на выходе (анализ
поведения). Отличаются от предвыборных
тем, что определяют реальное мнение
активных участников. Цель опроса на
выходе: 1) выяснить за какую партию
проголосовали, применяется метод
интервью.2) позволяет оценить честность.3)
узнать кто именно пришел голосовать (
портрет).
Политический
рейтинг ( конкурентная оценка партий).
Рейтинг- индивидуальная процентная
оценка.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Я продолжаю делиться опытом ошибок и находок в анкетных исследованиях. В первой статье я рассказала, как можно привлечь релевантных респондентов и увеличить возврат заполненных анкет.
Читать первую статью Ошибки анкетных опросов. 1 ошибка: смещение выборки. 8 способов привлечь нужных респондентов

В этой статье я расскажу, почему проблема понятности анкеты для участников опроса гораздо важнее, чем кажется на первый взгляд. Рассмотрим также примеры манипуляции мнением респондентов, фальсификации результатов опроса и использования опросов в маркетинговых целях.
Преимущество анкетных опросов – большой охват и быстрый результат – становится и их основным недостатком. Теряя возможность коммуникации с конечным респондентом, мы вынуждены делать дорогое допущение: «все респонденты понимают смысл анкеты и заполняют ее корректно». Если сделать это допущение, можно выдохнуть и работать с результатами опроса, как с релевантными фактами и мнениями. А если такое допущение не сделать, исследование может превратиться в череду перепроверок и согласований и в итоге полностью парализоваться.
Если честно, пройдя через сложности привлечения респондентов и возврата анкет, меньшее, чего хочется исследователю – это сомневаться в том, что анкеты заполнены корректно. Но еще грустнее – осознать, что анкеты испорчены из-за неверного понимания участниками инструкции, или вопросов. И чтобы оградить себя и заказчика от этих сомнений, можно соблюсти ряд подготовительных этапов, которые значительно повысят доверие к исследованию. Мы рассмотрим эти этапы в следующей статье. Вначале разберемся, где могут крыться сложности понимания, и к чему это может привести.
Можно выделить, как минимум, следующие части анкетного исследования, где может возникнуть непонимание:
1. Непонимание слов и специальных терминов.
2. Непонимание инструкции.
3. Непонимание направленности опроса.
4. Непонимание формулировки вопросов.
5. Непонимание критериев оценки.
1. Непонимание слов и специальных терминов
Здесь все просто. Респонденты, действительно, часто не понимают значение слов, которые кажутся исследователю очевидными. И это не всегда касается профессионального сленга. Иногда, казалось бы, обычные слова русского языка вызывают затруднения у участников опроса, но у экспериментатора редко появляется возможность узнать об этом.

На картинке: комментарий пользователя к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
Пример: Мы проводили исследование людей разного социального статуса и разных возрастных групп. В числе исследовательских методик использовался тест Т. Лири – авторитетный психологический тест, адаптированный для русскоязычных респондентов, применяемый десятилетиями для оценки личности и отношений. Тысячи исследований проведены в России с использованием этого теста. В нашем исследовании уже приняло участие несколько сотен человек, когда мы пришли опрашивать студентов престижного вуза. Студенты заполняли анкеты прямо в аудитории. Через несколько минут они стали поднимать руки и говорить, что не понимают значение некоторых слов из теста. Вот список этих слов: мягкотелый, самобичующий, деспотичный, тщеславный, покладистый, легко расположен, легко впадает впросак, черствый. Для нас это стало открытием. Оказалось, адаптация классического авторитетного теста уже устарела для некоторых респондентов этого возраста и статуса. Собранные к тому времени сотни анкет от респондентов других возрастов и статусов тоже оказались под сомнением: люди не уточняли у нас значения слов, значит – либо понимали их, либо стеснялись спросить и отвечали наугад.
Вторая угроза исходит от употребления в анкетах сленга, который может либо не пониматься участниками, либо раздражать их. Такое может случиться, если исследователь пытается заигрывать с целевой аудиторией и употребляет в анкете их сленг, не являясь носителем этой культуры.
Пример 2: Когда мы исследовали коммуникацию между отделами в одной ИТ-компании, несколько ее разработчиков рассказали на интервью, что их очень злит, когда HR-менеджеры, проводя внутренние опросы, или делая рассылки, копируют особенности языка и вставляют англицизмы. Хотя сами разработчики часто этим грешили, их раздражало, когда сотрудники, не включенные в контекст их работы, перенимали этот сленг.
2. Непонимание инструкции
Непонимание инструкции – самый очевидный пункт в этой статье и, казалось бы, бесполезный. Почти все исследователи проясняют во введении к анкете, на что направлено исследование, и как стоит заполнять бланк. Почти все респонденты уже имеют опыт участия в каких-нибудь опросах, и сейчас редко можно услышать взволнованные вопросы, которые нам задавали лет 8 назад: «А в квадратик нужно ставить плюсик, или галочку?» и «А можно зачеркнуть ответ, если я передумал?».

На картинке: Анкета с неточными инструкциями для соискателей (источник: pikabu.ru).
Несмотря на опытность обычного респондента, вопрос юзабилити анкет снова возникает, если исследователь пробует новые формы (например, on-line опросы и анкетирование на мобильных устройствах с неочевидными инструкциями или невозможностью пропустить ответ), забывает про опцию «один вариант ответа/ несколько вариантов ответа», или забывает дать корректную инструкцию к сложным вопросам (например, вопросам с ранжированием, или попарным сравнением). И для исследователя большая удача, когда получается узнать о затруднениях участника, как в примере на картинке ниже.

На картинке: комментарий пользователя к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
То, что кажется очевидным исследователю и большинству респондентов, может представлять сложности для менее опытных участников.

На картинке: Анкета с неточными инструкциями, не адаптированная для участника опроса (источник: adme.ru).
Пример 1: Мы проводили исследование сотрудников компании, имеющей филиалы в маленьких городах и поселках. Представители филиалов съехались на обучение в столицу, поэтому опросить их всех после обучения показалось хорошей идеей. Мы выступили перед сотрудниками, дали инструкции и раздали опросники, пообещав выслать результаты на e-mail каждому участнику, или принести на следующий день. Опросник был довольно большой, люди в тишине заполняли его. Как только первый участник отдал заполненную анкету, в конце комнаты поднялась женщина и направилась к двери. Когда мы спросили, где ее анкета, она ответила: «Я не понимаю, что такое имейл, и не понимаю, куда и что вы мне хотите выслать. Лучше я пойду». Оказалось, она просидела больше получаса, так как не поняла наши слова, но стеснялась уточнить инструкцию. Для нас это был вопиющий случай: мы узнали, каких масштабов может достичь непонимание инструкции. А при удаленных и on-line опросах у исследователя обычно не появляется возможности понять, что пошло не так: анкеты либо не возвращаются, либо заполняются некорректно.
Пример 2. Однажды мы организовали большое тестирование людей разных возрастов с использованием психологических опросников, которые включали шкалу лжи. По правилам таких тестов, запрещено интерпретировать результаты, если показатель лжи превышает установленный порог. Одна из участниц получила критический балл по шкале лжи и, когда мы отказались анализировать результаты, была крайне удивлена, сказав, что всегда старается говорить правду и уж точно не стала бы врать в психологическом тесте. Мы взялись с ней разбирать ответы, среди которых было, например: «Я всегда перехожу дорогу на зеленый свет», «Я всегда говорю правду» и другие очевидные вопросы на социальную желательность. На все она ответила «Да». Тогда я спросила:
– Ну, а если задуматься, за всю жизнь вы точно ни разу не перешли дорогу на красный?
– Было, конечно. Но я же старалась отвечать так, как считаю правильным себя вести, а не как веду. А так – в жизни разное бывает.Оказалось, подробная и четкая инструкция к тесту все-таки была осмыслена женщиной по-своему.
Пример 3: Во время исследования стилей поведения в служебных отношениях среди директоров предприятий, как всегда, нам удалось привлечь намного больше женщин, намечался сильный перекос выборки, и потому мы очень обрадовались, когда узнали, что завтра поступит сразу несколько анкет от мужчин, директоров крупных гос. организаций. Мы были готовы на следующий день приступить к обработке, но вечером мне позвонил один из директоров. Он бодро сообщил, что с несколькими директорами заполняет наши анкеты и хотел бы получить пояснения по некоторым ситуациям из теста, так как у них возникли споры в выборе вариантов ответа. Оказалось, директора, приехав на повышение квалификации, решили совместить общение и заполнение интересного теста, и принялись заполнять наши анкеты вместе в номере гостиницы, бурно обсуждать каждую ситуацию, спорить и убеждать друг друга. Индивидуальное исследование личных стилей поведения превратилось в групповое принятие решений, все анкеты оказались заполнены одинаково и потеряли всякую ценность для нашего исследования.
3. Непонимание формулировки вопросов
В создании анкеты, или планировании интервью есть одно правило: «Вопрос – это уже почти ответ». Информативный ответ можно получить только при очень хорошо продуманном вопросе. Для того, чтобы создать такие вопросы, проводится большая подготовительная работа (в следующей части статьи я расскажу про этапы этой подготовки).
Но наш опыт общения с исследователями показывает, что на такую подготовку почти никто не обращает внимания. Ответственность за ответ часто возлагается на респондента, делается существенное предположение, что респонденты имеют сформулированное мнение по нашему вопросу и очень хотят высказать его. Часто это совершенно ошибочное предположение. Не только проблемы исследователей, но язык их вопросов часто не воспринимаются респондентами.

На картине: Кадр из фильма «Автостопом по галактике».
Википедия: «Окончательный Ответ на величайший вопрос Жизни, Вселенной и Всего Такого (…): «Сорок два». Реакция была такой:
— Сорок два! — взвизгнул Лунккуоол. — И это всё, что ты можешь сказать после семи с половиной миллионов лет работы?
— Я всё очень тщательно проверил, — сказал компьютер, — и со всей определённостью заявляю, что это и есть ответ. Мне кажется, если уж быть с вами абсолютно честным, то всё дело в том, что вы сами не знали, в чём вопрос.
— Но это же великий вопрос! Окончательный вопрос жизни, Вселенной и всего такого! — почти завыл Лунккуоол.
— Да, — сказал компьютер голосом страдальца, просвещающего круглого дурака. — И что же это за вопрос?»
Пример 1: Однажды со мной поделилась идеей исследования ТОП-менеджер производственной компании. В тот момент она заканчивала обучение в MBA и заинтересовалась изучением мотивации рабочих на производстве. Исследование мотивации – сложная тема, мы спросили, какие методы она будет использовать. «А какие тут нужны методы? – удивилась она. – Раздам им бумажки с вопросом «Что вас мотивирует?» и соберу ответы». Жаль, общение с ней не продолжилось, и мы не узнали, как рабочие завода восприняли ее анкеты, и как она использовала результаты такого исследования.

Пример 2: Второй пример несоответствия языка исследовательских анкет языку заполнявших их людей тоже из производства. HR-директор крупного производственного холдинга как-то похвастался нам в личной беседе, что ему за несколько лет удалось увеличить вовлеченность персонала на 12% (!). Рабочий персонал и средний менеджмент заводов – специфическая группа для исследований. Как он изучал их вовлеченность? Оказалось, опросником от компании «Gallup».
Тут нужно пояснить. Самый большой недостаток использования опросника – не столько расплывчатые и неадаптированные для людей рабочих специальностей формулировки вопросов (например, вопросы №5, 6, 8), сколько его применение в качестве теста с подсчетом интегрального числового показателя вовлеченности. Другими словами, даже если у участников возникнет непонимание формулировок анкеты, исследователь не проанализирует ответы отдельно, не проследит за выбросами, а подсчитает суммарный показатель. Текст опросника приведен на картинке.

На картинке: Один из вариантов русскоязычного перевода опросника вовлеченности персонала от компании «Gallup» (Источник: antropos.ru).
Нам не удалось найти ссылки на публикации с адаптацией и валидизацией опросника «Gallup» (обязательными этапами при использовании переводных методик). Тем не менее, можно найти несколько вариантов его вольного перевода, много рекомендаций его применения в бизнес-изданиях и еще больше предложений от консалтинговых компаний, которые используют 12 невалидизированных и неадаптированных вопросов, как единственный инструмент для измерения вовлеченности персонала.
Естественно, когда клиент видит в отчете только обобщенные показатели вовлеченности и – еще лучше – рост таких показателей, он редко спрашивает о методах, которыми они были получены.
4. Непонимание направленности опроса
Непонимание направленности вопроса – куда более сложная и распространенная ошибка в анкетных исследованиях. Иногда и предположить нельзя, как человек может интерпретировать, казалось бы, однозначно сформулированный вопрос.
Для этой проблемы есть изящное решение, которое мы обсудим в следующей части. А пока, можно поговорить о случаях, когда исследователи намеренно прячут истинный смысл вопроса, или вносят путаницу в формулировки, чтобы получить желаемый ответ.
Иллюзия выбора. В практике социальной манипуляции есть такой ход: предоставление собеседнику иллюзии выбора, при которой любой его ответ будет выгоден манипулятору. Классический пример иллюзии выбора из продаж сетевых ресторанов быстрого питания: При заказе клиентом кофе официант спрашивает: «Вы к кофе возьмете маффин, или пирожок?» (вопрос «Не желаете ли что-нибудь к кофе?» считается куда менее эффективным с точки зрения продаж). Такой ход часто применяется в анкетных опросах, когда организатор исследования заинтересован в определенных ответах.

Пример: Несколько лет назад наша компания выступала организатором корпоративной игры для менеджеров среднего и высшего звена известного завода. Незадолго до этого контрольный пакет акций этого завода был куплен немецкой компанией, которая сразу начала внедрение корпоративных стандартов поведения. Стандарты эти на русском языке представляли не вполне корректно переведенный и не всегда понятный для русского менталитета свод правил, и перед нами поставили задачу организовать игру так, чтобы менеджмент усвоил эти стандарты. На игру отводилось всего несколько часов, и мы сразу объяснили, что за такое время нельзя сформировать поведенческие паттерны и нельзя даже развить принятие и согласие с чуждыми нормами. Сошлись на том, что целью игры будет уменьшить эмоциональное напряжение, которое вызывали новые стандарты. Итак, мы разработали игры и конкурсы, в основе которых было взаимодействие с каждым правилом, сделали акцент на вовлечении, групповой работе и положительных эмоциях.
Игра прошла хорошо, все руководители вовлеклись и расходились довольными. А через несколько дней HR-служба компании попросила нас провести опрос удовлетворенности игрой, чтобы предоставить отчет руководству. Мы понимали, что новые нормы не были усвоены сотрудниками и, тем более, не перешли в привычки. Но цель свою – уменьшить напряжение – мы выполнили. Поэтому, наша анкета была сосредоточена исключительно на положительных эмоциях после игры (см. рисунок).

На картинке: Фрагмент анкеты обратной связи для участников игры.
Вопросы 5, 6 и 9 – вопросы с иллюзией выбора. Они выглядят довольно полно. Но, если присмотреться, любой вариант ответа либо отражает положительную оценку, либо перекладывает ответственность на заполняющего (по принципу «это не игра была плохая – это я все еще не понимаю стандарты поведения, которые мне объясняют уже несколько месяцев», или «я и так хорошо понимаю суть стандартов»).
Последний вопрос – образец вопроса с иллюзией выбора. Все его варианты положительные. Формулируя его, мы знали, как результаты будут выглядеть в отчете: как в диаграммах будут смотреться положительные эффекты, заданные нами заранее в анкете, и как приятно руководителю будет рассматривать их. Когда человек просматривает такой отчет, у него редко появляется вопрос, были ли предусмотрены анкетой негативные варианты ответов.
Расстановка акцентов
Если заказчик исследования не интересуется исходным текстом анкеты и не уточняет, какие варианты были предоставлены участникам, организаторы могут подменить смысл результатов, расставив акценты.
Пример: Недавняя публикация результатов исследования общественного мнения россиян вызвала бурное обсуждение в Интернете (см. рисунок). В основном, обсуждение крутится вокруг термина «удовлетворительно». А для нашей статьи интересно, как результаты опроса преобразились в заголовке статьи за счет игры слов русского языка. В заголовке значится «половину россиян удовлетворяет экономика страны», в то время как в расшифровке статьи сказано, что только 6% оценили экономику положительно. Если бы в отчете были представлены только «существенные» результаты и был упущен вариант с положительной оценкой, то, благодаря богатству смыслов языка, понятие «удовлетворяет» воспринималось бы, как очень хороший результат опроса (а не как оценка «на троечку»).

На картинке: фрагмент новости о результатах соцопроса (источник: www.solidarnost.org).
Пример 2: Еще один веселый пример расстановки акцентов. Если ввести в поисковике фразу «почти половина россиян не доверяет полиции», выдаются ссылки на источники vedomosti.ru, rbc.ru, echo.msk.ru и др. А если ввести “почти половина россиян доверяет полиции», выдаются ссылки на ria.ru, news.sputnik.ru, www.business-gazeta.ru, ridus.ru (последний источник – на удивление, в отличие от скриншота).
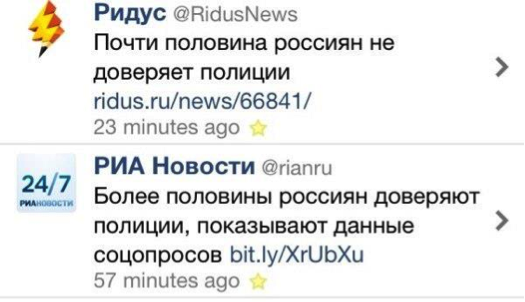
На картинке: скриншот новостной ленты – расстановка акцентов разными изданиями (источник: joyreactor.cc)
Подмена понятий. По сути, практика защиты перед заказчиком одних только результатов исследования без предварительного рассмотрения сырых данных и способов их сбора, оставляет огромное поле для подделки данных и манипуляции результатами без всякой подделки. В таких случаях важно обращать внимание на логику и направленность вопросов в анкете перед тем, как анализировать ее результаты.
Поэтому особенно забавно смотрятся предложения обучающих и консалтинговых компаний самостоятельно оценить эффект от обучения персонала, или проведенных внедрений, и предоставить заказчику отчет о возврате на инвестиции. В анкетах обратной связи подрядчики могут спрашивать сотрудников совсем не о том, а в итоговом отчете подменять понятия. Но заказчики обычно с готовностью принимают такие отчеты, так как они выглядят вполне авторитетно, и не требуют усилий со стороны внутренних служб.
Пример: Недавно нам представили компанию, оказывающую PR-услуги. Представили, с гордостью пояснив, что эта компания – одна из немногих в отрасли, дающая четкий отчет по KPI (ключевым показателям эффективности) своей деятельности в процентах. Действительно, оценить эффективность маркетинговых и PR-кампаний, очистить замеры от всех влияющих условий рынка, непросто. Мы заинтересовались методикой. И, когда мы спросили, как именно проводится измерение эффективности PR-деятельности и вычисляются проценты, выяснилось, что в качестве единиц измерения используется план (например, «написать 10 статей в отраслевых изданиях»), а в качестве отчета – подсчет выполнения этого плата (по логике этой компании, если написано 9 статей, то KPI по PR выполнены на 90%). Конечно, существует разделение на процессные и фактические KPI и есть бизнесы, где важно именно четкое выполнение процесса. Но это не касается тех сфер, где процесс не имеет значения, если не достигнут результат. И у меня есть подозрение, что, предоставляя заказчику отчет об эффективности PR-кампании в численных показателях, эти подрядчики совершали грубую подмену понятий.
Наводящие формулировки. Тональность вопроса в анкете, или его направленность могут наводить участника на определенный ответ. Выгода организатора исследования от таких ответов заключается в подтверждении собственной позиции (например, при фальсификации теорий, или оправдании управленческих решений).
Пример: Хорошо этот эффект иллюстрирует «Теория перспектив» А. Тверски и Д. Канемана об экономии интеллектуальных затрат (за исследования иррациональной природы принимаемых людьми решений они получили Нобелевскую премию).
В одном из экспериментов по исследованию принятия решения в зависимости от контекста подаваемой информации, известном как «Азиатская болезнь», участникам предлагалось решить задачу: «Представьте, что Соединенные Штаты Америки готовятся к вспышке эпидемии неизвестной «азиатской болезни», вследствие которой, как ожидается, погибнет 600 человек. Для борьбы с этой болезнью предложены две альтернативные программы. Какую из них стоит выбрать?» Далее двум разным группам участников сообщалась одна и та же информация, но в разных формулировках (с позитивным и негативным фокусом). Авторы эксперимента доказали, что, стремясь сэкономить усилия при принятии решения, люди предпочитают полагаться на интуицию, прошлый опыт и более простые и оптимистичные варианты.

На картинке: Формулировки «программ» эксперимента «Азиатская болезнь» и предпочтение ответов участниками.
Еще один распространенный пример из исследований Д. Канемана: если одну группу испытуемых спросить: «Дожил ли Ганди до 114 лет? В каком возрасте он умер?», а другую: «Дожил ли Ганди до 35 лет? В каком возрасте он умер?», то первая группа оценит жизнь Ганди как гораздо более долгую, чем вторая.
Так, удачно формулируя вопросы анкеты, делая акцент на положительных вариантах, или используя наводящие цифры, исследователи создают «эффект привязки» и могут манипулировать ответами участников.
Второй вариант, при котором применяется техника наводящих формулировок, — это постепенное изменение убеждений участника исследования с помощью анкеты. В этом случае от вопроса к вопросу создается канва, при которой респондент вынужден отвечать определенным образом, сталкивается со своими ответами, как с новыми представлениями, и постепенно меняет точку зрения. Продолжением такого метода являются вопросы, создающие потребность (см. следующий пункт).
Пример: Однажды я сама стала жертвой жесткого манипулятивного опроса. Его проводила авторитетная организация, предлагая пройти on-line анкетирование людям со всего мира. Исследование подавалось под видом «Оцените, насколько правильно вы питаетесь». Начало анкеты было стандартным, задавались вопросы о разных продуктах, но постепенно анкета стала сужаться до фильтрующих вопросов о мясе (употребляете ли мясо, сколько раз в неделю, и т.д.). После моих ответов следующие вопросы анкеты стали предлагать мне просмотреть фотографии и видео о том, как умертвляют животных на фермах, как разделывают туши, как утилизируют отходы и др. И уже совсем скоро вопросы приобрели такой характер: «Зная, как страдают животные на фермах, вы по-прежнему будете регулярно употреблять мясо?» и «Не считаете ли вы, что стоит предпочесть растительные белки, такие же полезные и питательные, чтобы прекратить издевательство над животными?». Эти вопросы сыпались градом: никто уже не интересовался моим рационом. Казалось, завершить этот поток можно, только отвечая в духе «я все осознал и пойду теперь убеждать всех, кого встречу на пути». Впервые у меня был такой травматический опыт от заполнения анкеты. Я прекратила отвечать на вопросы, и мне потребовалось время, чтобы снова укрепиться в своих представлениях о питании, которые оказались под большим влиянием из-за этого опроса.
Опросы, создающие потребность. Создание у участников нужных потребностей с помощью правильно сформулированных вопросов – еще одна тактика манипуляций и продаж. И анкетные опросы в этом мероприятии оказывают хорошую поддержку продающим компаниям.
Никого уже не обманут псевдо-социологические опросы в стиле «Правильно ли вы ухаживаете за кожей?», или «Все ли вы знаете об очищении организма?», где после третьего вопроса появляется: «Знакомы ли вы с продукцией компании N?». Лет десять назад в нашей стране эти опросы были очень популярными.
Сейчас тактику создания потребностей используют более тонко. Первый вариант – это скрытое информирование участника с помощью анкеты об ассортименте и новых продуктах компании, что рождает осведомленность и вызывает любопытство (см. рисунок).

На картинке: фрагмент анкеты, рекомендованной Минздравом для определения группы риска по употреблению наркотиков подростками. Среди вопросов были также такие: «Сколько раз, если такое случалось, вы нюхали ингаляты – клей, аэрозоль, бензин – специально, чтобы получить «необычные ощущения»?». Анкеты предлагалось раздавать детям 10-13 лет, что вызвало бурное возмущение родителей. (Источники: Ridus.ru, RG.ru).
Второй вариант создания потребности – предложить клиенту анкету, якобы помогающую сориентироваться в том, какого вида услуга (товар) на самом деле ему нужна. Нельзя сказать, что это однозначная «политика зла». Такие анкеты, действительно, помогают уточнить потребности клиента, но они и очень хорошо помогают продавать.
Суть продажи заключается в том, что под видом опроса:
а) респондента подводят к мысли, что у него чего-то нет, или что-то используется неэффективно (вызывают чувство тревоги),
б) информируют о новых услугах (товарах, опциях), которые помогут решить его проблему (о которой он не знал до начала опроса).
Примерный алгоритм анкеты, создающей потребность:
1. Вводные нейтральные вопросы по теме, «айс-брейкеры».
2. Вопросы об актуальном состоянии респондента, которые постепенно подводят его к идее, что у него чего-то не хватает, или что-то устарело.
3. Вопросы, уточняющие, понимает ли респондент, какие последствия имеет эта нехватка, и чем она может обернуться лично для него или его бизнеса.
4. Вопросы о том, знаком ли респондент с некоторыми решениями (товарами, услугами, технологиями).
5. Вопросы, информирующие респондента, как именно эти решения помогают справиться с его проблемой.
6. Вопросы, наводящие на мысль о покупке (информирующие о цене, скидке, условиях).
7. Вопросы, подтверждающие, что при покупке этого решения проблемы респондента будут решены, и он получит дополнительную выгоду.
Пример: Если бы я хотела продать эту статью с помощью анкеты, я вначале задала бы несколько формальных вопросов о вашем опыте анкетных исследований и о том, получили ли вы специальное образование для проведения исследований (уже здесь начинается работа с тревогой). Потом спросила бы, с помощью каких процедур вы устанавливаете и доказываете, что респонденты правильно понимают инструкцию, формулировки и критерии оценки в ваших опросах. Затем спросила бы, знакомы ли вы с такими-то примерами из вашей сферы, когда результаты дорогих опросов приходилось выбрасывать из-за того, что не все респонденты верно понимали инструкцию, или суть вопросов. Упомянула бы, какой позор постиг организаторов таких опросов из такой-то компании. Потом я спросила бы, знакомы ли вы с процедурами концептуализации, операционализации, валидизации, адаптации, апробации и пилотного запуска, и в каком объеме вы их используете. Затем привела бы примеры, как эти процедуры помогли спасти дорогостоящие исследования. И, наконец, я поинтересовалась бы, что должно произойти в вашей компании для изменения подхода к опросным исследованиям и сколько, по-вашему, может стоить статья, в которой содержится алгоритм применения этих процедур, чтобы ваши исследования стали надежными, принесли успех вашей компании и лично вам.
В этом примере все еще отчетливо видны «белые нитки» продажи, но, чем ближе ваш респондент к статусу клиента (например, заполняет анкету на сайте продукта) и чем ближе он к покупке, тем лучше будет воспринята им такая анкета и тем легче получится увеличить объем его покупки за счет дополнительных продаж.
Третий вариант создающих потребность анкет, очень популярный сейчас, это развлекательные тесты. Интернет-пользователей до сих пор привлекают тесты в стиле «Хорошо ли вы разбираетесь в компьютерных играх?» (где можно невзначай добавить несколько вопросов с перечислением игровых новинок определенной компании), «Умеете ли вы управлять своим временем?» (здесь уместно упомянуть несколько специализированных мобильных приложений, которые вы хотите продать) и т.д. Такие тесты иногда выглядят профессионально и доставляют положительные эмоции, даже когда их рекламная природа очевидна.
Пример: Несколько дней назад друг предложил мне пройти тест на знание итальянских сыров на сайте «Медуза». Тест был отмечен значком «партнерский материал», а в названии упоминался бренд производителя сыров, но друг этого не заметил. Он зачитывал вопросы, а я воспринимала их на слух. Тест был, действительно, интересным.
И в какой-то момент, захотев уже салат с сочной полезной моцареллой, я шутя воскликнула:
– Да похоже, они продают эти сыры!
– Действительно, смотри, тут в конце теста написано: «Ну и конечно теперь мы просто обязаны вам рассказать, что U. тоже производит все сыры, о которых мы упомянули в тесте, – и не только. Они свежие и полезные, и даже кальций в них – со вкусом Италии».Много зная о маркетинговых уловках и манипуляции, мы все равно восприняли этот тест положительно и заинтересовались компанией, так как форма подачи и полезность контента перевысили знание об истинных целях организаторов теста.
Один из вопросов теста представлен на рисунке.
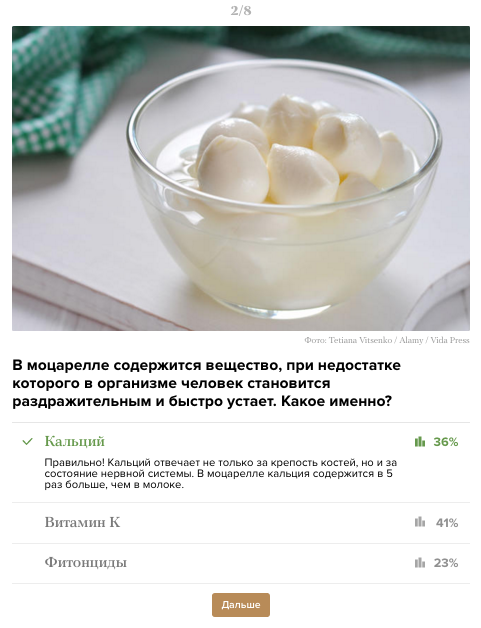
На картинке: Один из вопросов теста на знание итальянских сыров (Источник).
Опросы со смещенной целью. Особняком в этом списке опросов со скрытыми мотивами стоят опросы со смещенной целью, так как они используются, в основном, не для манипуляции, а для более изящного исследования мотивов респондентов, когда такое невозможно сделать с помощью прямых вопросов.
Пример: Об этом опросе рассказала моя ученица, директор частной мебельной фабрики. Она пыталась понять причины плохих продаж в фирменных магазинах. Несколько месяцев назад фабрика (изготавливавшая до этого только мягкую мебель) приобрела производство кухонь. Соответственно, в фирменных магазинах, кроме мягкой мебели, началась продажа кухонь. Но, на фоне стабильных продаж мягкой мебели, кухни продавались очень плохо. У директора возникла гипотеза, что причина плохих продаж не в плохом качестве продукции (у нее была возможность проверить реальный спрос), а в предвзятом отношении продавцов, которые саботировали продажи. Напрямую спросить об этом продавцов было невозможно, и потому она организовала среди них опрос в стиле «Почему, на ваш взгляд, кухни плохо продаются». Продавцы обрадовались возможности высказать, наконец, все свое недовольство от инноваций, и красноречиво отвечали на вопросы анкеты. Так ей удалось подтвердить свою гипотезу, собрать основные предубеждения продавцов против нового товара, понять их сопротивление и получить базу для работы с возражениями (в ее случае – с возражениями самих продавцов, а не клиентов).
5. Непонимание критериев оценки
Исследователи не всегда разъясняют критерии оценки, ожидая, что они интуитивно понятны участникам.
Пример: Традиционно из десятков анкет, присылаемых мне на экспертизу, около 30% содержат вопросы с просьбой оценить какой-то параметр (услугу, товар) от 1 до 5 баллов, но не содержат расшифровки значений, или хотя бы указания, какой полюс является положительным. Иногда все исследование пропадает, если организаторы обращают внимание на диаметральные различия в оценках респондентов и только потом догадываются, что некоторые респонденты ставили «1», предполагая, что это «первое место» в рейтинге, а другие ставили «1», как самый низкий балл.
Как выход из таких ситуаций, принято использовать шкалу Лайкерта (Лейкерта, Ликерта), содержащую более детальные формулировки для оценки (например, от «Совершенно не нравится» до «Очень нравится», или от «Никогда» до «Очень часто»). Можно найти или придумать много формулировок этой шкалы для самых разных вариантов вопросов. Но и у этой шкалы есть недостатки, так как субъективное понимание, например, частоты каких-то действий у разных людей может различаться. И если нам важно знать не их мнение о частоте, а более-менее точный показатель, лучше конкретизировать такие варианты ответов точными промежутками (например: «Реже одного раза в год» — «…» — «Несколько раз в день»).

На картинке: комментарии участников к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
Проработка вариантов ответа становится особенно важной, когда анкетный опрос применяется для оценки сложных, субъективно-значимых параметров. В таких случаях респонденты склонны к «ментальной экономии» и выбирают варианты оценки, соответствующие их общему представлению об объекте, не задумываясь над вопросом (например, «игра мне, в общем, нравится, проставлю везде 4 и 5 – не важно, оцениваю я звук, или уровень обратной связи с игроками»).
Такие усредненные оценки встречаются часто при проведении оценки сотрудников методом 360 градусов. Оценивая своих коллег, люди склонны ставить положительные баллы «любимым» и нейтральные, или отрицательные, баллы «нелюбимым», независимо от того, по какому параметру ставятся оценки (нелюбимый сотрудник может быть сильным лидером, или ни с кем не конфликтовать, но «рука не поднимется» поставить ему высокие баллы даже за эти показатели). В итоге, такая оценка оказывается совершенно бесполезной для организаторов исследования, так как не дает возможности выделить реальные проблемные точки у сотрудников компании.
Точно так же обстоят дела при оценке пользовательского опыта при работе с ИТ-продуктами. Если сайт, или компания, в общем, нравятся пользователю, он будет склонен ставить, в общем, высокие оценки, чтобы «никого не обидеть». И такой опрос не поможет разработчикам сделать продукт лучше.
Пример: Забавный случай случился с моей знакомой, когда только начал развиваться сервис «Одноклассники». Заведя аккаунт значительно позже своих знакомых и еще не зная негласных правил поведения на сайте, она стала просматривать профили друзей и ставить оценки фотографиям. Очень скоро несколько подруг ее заблокировали. Она была крайне удивлена и смогла разговорить одну из них, чтобы вяснить причину. Оказалось, подруг (уже давно закончивших школу) сильно задели низкие оценки, которые она ставила их фотографиям. «Как ты не понимаешь? Ты понизила мне общий балл своими двойками!» – призналась одна из них. А моя знакомая, в отличие от большинства пользователей «Одноклассников», была убеждена, что механизм оценки фотографий существует для того, чтобы искренне высказываться насчет удачности кадра, цвета, перспективы и др., а не для выполнения социальной функции поддержки друзей.
В таких случаях высшим пилотажем исследователя становится разработка «поведенческих» вариантов ответа, описывающих примеры проявления качества в поведении человека (или – при оценке продукта – особенности взаимодействия пользователя с ним). По поведенческим вариантам нельзя однозначно определить, какой из них положительный, и какой отрицательный, и респонденту приходится выбирать вариант, наиболее приближенный к реальности.
Пример: Можно предложить такие поведенческие варианты для оценки конфликтности: «Этот человек никогда не повышает голос и всегда держится в стороне от любых разногласий и споров» (самый низкий балл) – «Этот человек остро реагирует, когда его точка зрения не принимается коллегами, или когда поведение коллег кажется ему несправедливым; он может повышать голос, или даже решать разногласия силой» (самый высокий балл). Соответственно, в таком же ключе формулируются остальные промежуточные варианты оценки.

На картинке: Пример вопроса оценки «ориентации на команду» для оценки сотрудников методом 360 градусов. В каждом варианте можно заметить положительные и негативные черты, что увеличивает вероятность честной оценки, в отличие от простого приписывания высоких, или низких баллов сотруднику (Источник).
Разработка поведенческих вариантов оценки – сложный этап. Особенно сложно подобрать адекватные варианты, когда не совсем понятно, как они проявляются в реальном поведении (или взаимодействии пользователя с продуктом). Например, при оценке звуковых эффектов в игре высшей оценкой звука будет: «Звуки не отвлекают от игры, создают хороший фон», или «Звуки играют важнейшую роль, помогают следить за динамикой игры, во время подсказывают действия игрокам». Для того, чтобы варианты оценки получились наиболее соответствующими реальному опыту пользователя, используется этап операционализации, о котором я подробно расскажу в следующей части статьи.
Краткие выводы
Я попыталась описать примеры, когда очевидные для организаторов исследований этапы анкетирования неверно понимаются участниками. Респонденты могут неверно понимать слова и фразы, формулировки вопросов, инструкции к анкете, критерии оценки и направленность вопросов. Эти сложности приводят к сбору нерелевантной информации, или невозврату анкет.
Также мы рассмотрели примеры, когда замешательство респондентов провоцируется намеренно с целью манипуляции результатами опроса. Среди таких манипуляций:
— предоставление иллюзии выбора;
— расстановка акцентов;
— подмена понятий;
— наводящие формулировки;
— использование эффекта привязки;
— создание потребности: 1) через информирование и любознательность, 2) через провокацию тревоги, 3) через развлекательные тесты,
— опросы со смещенной целью.
Чтобы оценить, не манипулируют ли вашим мнением исследователи, предоставляя результаты анкетного опроса, можно задать им несколько вопросов по процедуре исследования:
1. Попросите посмотреть исходный текст анкеты и попробуйте самостоятельно ее заполнить перед тем, как знакомиться с результатами (еще лучше – перед тем, как санкционировать исследование).
2. Представьте, как заполняет эту анкету ваш типичный клиент, или сотрудник (все ли термины и формулировки будут ему понятны).
3. Обратите внимание на формулировку вопросов и вариантов ответа: есть ли негативные варианты, занимают ли они равное место с позитивными вариантами.
4. Обратите внимание, нет ли в вопросах анкеты наводящих формулировок и «привязок».
5. Просмотрите, насколько однозначно и конкретно сформулированы критерии оценки в вопросах анкеты (не провоцируют ли они на «ментальную экономию» – на нейтральные, или исключительно положительные ответы). Лучший вариант – если критерии оценки сформулированы в поведенческих примерах.
6. При анализе итогового отчета обратите внимание, на основе каких вопросов анкеты построены выводы: не подменяют ли исследователи понятия, не выдают ли мнения респондентов за факты.
7. Если используется зарубежная методика (например, от известной компании), поинтересуйтесь ссылками на публикации с описанием процедуры ее перевода, адаптации и валидизации. Без этих процедур методику нельзя считать авторитетным методом исследования, независимо от статуса ее разработчика.
8. Запросите точное распределение участников опроса по группам (пол, возраст, социальный статус, или: отделы, должности), чтобы избежать перекоса выборки (подробнее об этом – в предыдущей статье о выборке).
В следующих статьях:
Ошибка 2. Формулировки вопросов: почему вы решили, что вас понимают? (2 часть)
Ошибка 3. Виды лжи в опросах: почему вы верите ответам?
Ошибка 4. Мнение не равно поведению: вы действительно спрашиваете о том, что хотите узнать?
Ошибка 5. Виды опросов: вам нужно узнать, или подтвердить?
Ошибка 6. Разделяйте и насыщайте выборку: среднее ничего не помогает понять.
Ошибка 7. Пресловутый «Net Promouter Score» – это НЕ изящное решение.
Более ста лет назад Герберт Уэллс сказал: «Настанет тот день, когда статистическое мышление будет настолько важным для эффективной деятельности человека, как и умение читать и писать».
Процесс опроса общественного мнения превратился в индустрию – одну из самых процветающих на сегодняшний день. Мы спрашиваем людей о том, что они думают о коллективных переговорах, профсоюзах, постоянно растущем дефиците бюджета, экономическом кризисе, всеобщем хаосе и так далее, независимо от того, знает ли респондент что-либо по этой теме. Мы спрашиваем рабочих, что им не нравиться в их работе, и в лучшем случае в своем ответе человек может выразить свое недовольство. Когда мы задаем вопрос генеральным и финансовым директорам о том, какие экономические прогнозы они могут сделать на ближайшее будущее, то мы заведомо знаем, что они не могут этого знать.
СМИ ежедневно ссылаются на результаты проведенных опросов. Но это не что иное, как общественное мнение, формирование которого зависит от трех факторов, а именно: самого вопроса, ответа и анализа. Многие книги и статьи были посвящены проблеме злоупотребления и нарушений (в процедуре)проведения опроса, а также исследования процесса выборки. Но в современном, быстро меняющимся медиапространстве, наука правильного сбора данных, а также обобщение, анализ и применение полученной информации, кажется занудным и неинтересным. Законодатели более заинтересованы в результатах опросов, чем в том, как они были получены. До недавнего времени никому не приходило в голову, что «результаты опроса» и то, «как эти результаты были получены» — это неразделимые понятия.
Забытая истина об общественном мнении
Нил Постмен в своей замечательной книге «Technopoly» описывает слабую сторону процесса интерпретации данных: «Социологи задают вопрос, на который необходимо ответить да или нет. Опрос не принимает во внимание тот факт, что люди могут ничего не знать о том, о чем их спрашивают. В культуре, в которой нет определенных измерений и классификаций вещей, это упущение, возможно, будет выглядеть странным. Давайте представим ситуацию, когда могут одновременно задаваться два вопроса о том, что «думают» и что люди «знают» о предмете обсуждения. К примеру, последний опрос показывает, что 72% американцев считают необходимым снять экономическую помощь Никарагуа. Но 28% опрошенных «полагали», что Никарагуа находится в Центральной Азии, а 18% «считали», что это остров возле Новой Зеландии, и 27, 4% «говорили», что «африканцы должны сами себе помогать», при этом принимая Никарагуа за Нигерию. Более того, 61.8% участников опроса не знали, что США оказывает экономическую помощь Никарагуа, а 23% и вовсе не знали, что такое «экономическая помощь». Если социологи будут предоставлять и использовать такую информацию, то авторитет и значение опроса общественного мнения будет очень низким».
Опрос общественного мнения оказывает поддержку работникам государственного сектора
28 февраля 2011 года опрос общественного мнения, который был проведен New York Times/CBS, показал, что большинство людей выступают против попытки уменьшить права на ведение коллективных переговоров. Они также не согласны с сокращением зарплаты или пособия общественных работников, которое, в свою очередь, могло бы привести к снижению дефицита государственного бюджета. Недавно проведенный национальный опрос (national Gallup survey) свидетельствует о том, что большинство американцев также выступают против введения мер, предложенных в Висконсине, которые ограничивают права на ведение коллективных переговоров на государственной службе. В такой ситуации необходимо вспомнить комментарии Постмена, который утверждал, что «люди не всегда понимают, о чем их спрашивают». Один остроумный посетитель сайта New York Times оставил такой комментарий: «Американцы предпочитают поднять налоги, чем сократить льготы для госслужащих,…что могло бы стать настоящей новостью, если бы это оказалось правдой».
Как можно сделать неправильные выводы из опросов или результатов исследования?
Давайте прямо к делу. Социологи классической школы называют это «статистической вселенной» или «населением». Что являет собой статистическая вселенная (совокупность)? Она состоит из всех явлений, о которых необходимо сделать выводы. Например, в исследовании ценовых колебаний цен на топочный мазут в Нью-Йорке с 2007 по 2010 год, статистическая совокупность будет включать все изменения цен в течение этого периода. Если рамки исследования были расширены, чтобы изучить большую территорию или более длительный период времени, то статистическая совокупность, соответственно, увеличивается. Совершенно очевидно, что термин «статистическая вселенная» можно назвать универсальным, так как его можно применять для любого статистического исследования. Подводя итог, необходимо сказать, что «статистическая совокупность» может быть определена как совокупность, которая включает каждый пункт, который необходимо изучить или взять под наблюдение.
Выборочное исследование
Из-за нехватки времени и средств, иногда невозможно провести полный анализ статистической информации. К счастью, нет необходимости исследовать всю статистическую совокупность. Но почему? Потому что трудолюбивые, компетентные статистики нашли способ, как можно получить одну и ту же информацию из небольших, тщательно отобранных образцов. Умение выделить небольшие экземпляры с объемных, иногда бесконечных статистических данных, является предметом изучения базовой и расширенной статистики. Если отбор образцов осуществляется надлежащим образом, то их анализ позволяет получить информацию о статистической совокупности с наименьшей долей погрешности. К сожалению, многие базовые курсы по статистике не выделяют один важный момент, а именно, если статистическая совокупность определена неправильно, то серьезный логический анализ (на основе представленных образцов) может не принести желаемых результатов.
Пример неправильно определенной статистической совокупности
Безусловно, самым ярким примером неправильного определения статистической совокупности является опубликованное в Литературном Дайджесте прогноз победителя президентских выборов в 1936 году. Этот пример часто приводит приводит Эдвардс Деминг. Во время избирательной компании 1936 года, когда претендентами выступали демократ Франклин Рузвельт и республиканец Альфред Лэндон, «Литературный дайджест» разослал образцы бюллетеней для голосования большому количеству людей, чьи имена были в телефонных справочниках и в списках регистрации транспортных средств. (В этот перечень также входили и их подписчики, члены клуба и т.д.). Более 10 млн. таких бюллетеней были разосланы. Только 2,4 млн. респондентов отослали свои бюллетени назад в редакцию, а 7,6 млн. бюллетеней были утеряны. На основе этих 2,4 млн. бюллетеней дайджест сделал прогноз, что с большим преимуществом на выборах победит Лэндон. Как оказалось на самом деле, Рузвельт получил 61% голосов избирателей, что составило одно из самых больших преимуществ в истории американских президентских выборов.
Как же они могли настолько ошибаться?
Результаты опроса представили только ту информацию, которая была получена от респондентов, которые вернули образцы бюллетеней. Несмотря на то, что было разослано огромное количество бюллетеней, те президентские выборы стали ярким примером необъективной выборки, так как практически все респонденты были сторонниками Республиканской партии.
Давайте рассмотрим ситуацию более детально. В процессе прогнозирования были совершены две серьезные ошибки, а именно:
1.Статистическая совокупность была неправильно определена.
2. Не учитывалось уклонение от ответов.
Люди, чьи имена были взяты из телефонной книги или реестра автомобилей, в 1936 году принадлежали к более обеспеченному слою населения, в отличие от остальных респондентов. Такая разница присуща статистической совокупности. Большой процент избирателей не внесен в телефонную книгу, автомобильный реестр или в список членов клуба. Статистическая совокупность была неправильно определена, так как был сделан уклон, в основном, в сторону более состоятельных людей. Обеспеченные слои населения были приверженцами республиканцев. В 1936 году наблюдалась сильная «взаимосвязь» между доходами людей и их партийными предпочтениями. Те, кто принадлежал к менее обеспеченным слоям населения, поддерживали Демократическую партию.
Пример ошибки (смещения) в процессе выборки
Статистики изклассической школы определяют «смещение» как постоянную ошибку в одном направлении. Что это значит? Практически не имеет значения, кого бы вы могли выделить из статистической совокупности, взятой из «Литературного дайджеста», так как существовала большая вероятность того, что именно состоятельный человек может быть избран на президентских выборах. Следует заметить, что статистическая информация была получена, в основном, от состоятельных людей, а мнение избирателей с низким доходом не было учтено. А в 1936 году большая часть населения имела очень низкий доход. В то время 9 млн. жителей были безработными. «Опрос, проведенный «Литературным дайджестом», не смог охватить все слои населения. Тогда, как и сейчас, избиратели голосуют за кандидатов «по своему карману», то есть за тех, кто выступает за интересы определенных групп населения». Следует отметить, что Джордж Гэллап смог предсказать победу Рузвельта, сделав выборку из 50 тыс. человек. Статистическая совокупность, которую он создал, состояла из различных слоев населения. Выборка, которую сделал «Литературный дайджест», охватила 2.4 млн. человек. Она является отличным примером того, что неправильно определенная статистическая совокупность не может дать объективную информацию только за счет увеличения масштабов выборки.
Уклонение от ответов
Второй проблемой, с которой столкнулся «Литературный дайджест», было то, что из 10 млн. человек только 2.4 млн. респондентов приняли участие в опросе. В то время обеспеченные жители более охотно отвечали на различную корреспонденцию, чем представители бедных слоев населения. 7.6 млн. людей, которые не приняли участие в опросе, принадлежали к группе с низким экономическим статусом. А 2.4 млн. респондентов – были представителями обеспеченных слоев населения.
Исследование, которое провел Лэндон, представляет ситуацию следующим образом: «Если уровень ответов низкий (как было в том случае – 24%), то информация, полученная в результате опроса, не может быть объективной. Это особый тип отбора, в котором исключены люди, которые не ответили на полученную корреспонденцию».
Резюме и выводы
Если использовать статистическую совокупность, которая может существенно отличаться от «идеальной» совокупности, на основе которой необходимо сделать выводы, то это может привести к серьезным ошибкам в анализе полученных данных. Необходимо потратить много времени, чтобы определить «идеальную» статистическую совокупность, а затем сделать правильную выборку. Каждый день мы слышим, к примеру, о ценовой политике (чтобы привлечь больше покупателей), которая базируется на «выборочной» информации, полученной в результате опроса потребителей. Статистическая совокупность, в большинстве случаев, также должна содержать мнение не только покупателей, но и тех людей, которые не используют продукцию той или иной компании, не смотря на то, что эти люди имеют/могли бы иметь отношение к рынку и могут реагировать на изменение цен.
Всегда нужно быть начеку, чтобы определить неверно созданную статистическую совокупность. Расчеты, сделанные на основе неправильной выборки, интервальное оценивание и статистические тесты не принесут никаких результатов, если статистическая совокупность определена неверно. И на последок, не относитесь предвзято к отсутствию ответов. В результате исследования, проведенного школой Wharton, был сделан следующий вывод: «Люди, которые принимают участие в социологических исследованиях, отличаются от тех, кто их игнорирует. Это отличие заключается не только в их отношении к подобным мероприятиям; оно носит более глубокий смысл».
Второй этап
исследования называют «полевым этапом»,
т.к. зона практических действий социологов
— это поле, с которого собирается урожай
в виде надежной и представительной
информации. В ходе сбора информации
применяются различные методы, каждый
из которых имеет свои особенности.
Основными методами являются опрос,
наблюдение, анализ документов, экспертная
оценка, эксперимент, социометрия,
измерение социальных установок. Самый
распространенный из них — опрос, с его
помощью собирается 90% социологической
информации. Каждый метод имеет свои
предназначение и ограничения. Выбор
методов исследования зависит не от
желания исследователя, не от его прихоти
или произвола, а от решаемых им задач и
содержания проверяемых гипотез.
1. Одной из
наиболее распространенных и наиболее
грубых ошибок является неграмотное
составление инструментария. Его
формирование достаточно сложная
процедура, и чем проще выглядит вопросник,
тем больше в него труда вложено. Кроме
того, что в анкете должны умело сочетаться
«открытые и закрытые» вопросы, «вопросы
– меню», «прожективные», «табличные»,
«дополнительные», «проверочные» из
которых делают различные панели, чтобы
основная идее, гипотеза, запрос, была
подтверждена неоднократно, и в сумме
средних баллов выявила устойчивость
мнения той или иной группы. 2. Следующей
важной составляющей «корректного»
социологического исследования является
правильно определенная выборочная
совокупность, т.е. число опрашиваемых
(выборка) в должно соответствовать в
заданной пропорции генеральной
совокупности. (Общему количеству)3.Третьей
группой причин некорректных результатов
являются «ошибки поля», которые в свою
очередь можно отнести к «ошибкам маршрута
выборки» и «ошибкам интервьюеров».
социологические центры не располагают
собственным штатом интервьюеров и
вынуждены прибегать к услугам случайных
или более или менее подготовленных
людей.4.Следующая группа причин ошибок
связана с расчетом результатов.5 . ошибки
интерпретации данных
Типичные
ошибки и трудности в проведении опрос
1. Подготовка
вопросника начинается без разработки
программы опроса, не выделены категории
анализа.2. Познавательная задача
расходится со смысловым содержанием
формулировки вопроса. Произошла замена
индикатора: вместо вопроса об
информированности задается вопрос о
самооценке информированности.2.1. Вопрос
содержит термины, смысл которых непонятен
респонденту или по-разному понимается
респондентами.2.2. Перед респондентом
при ответе на вопрос ставятся задачи,
к решению которых он не подготовлен
(установить сложные зависимости, провести
ранжирование, классификацию, выявить
критерий).2.3. Респонденту задается вопрос
об оценке фактов без предварительного
выяснения, какое отношение он имеет к
этим фактам.2.4. Респондент выражает
опасения в связи с участием в опросе.2.5.
Респондент участвует в опросе неохотно,
с видимым безразличием.3. Респондент
слишком разговорчив и уводит интервьюера
от темы вопроса.3.1. Респондент выражает
сомнение относительно качества вопросника
(отдельных вопросов).4. Неаккуратно
заполнены анкеты.5. В ходе опроса собран
большой объем статистической информации.
Однако оказалось, что она не имеет
прямого отношения к гипотезам и задачам
исследования.
Ошибки и
трудности в применении экспертного
опроса
1. Нечеткость
в определении целей экспертизы. Опрос
экспертов проводится без специально
разработанной программы.2. Неэффективное
использование экспертов. Экспертиза
предназначена для получения информации,
которая могла быть собрана другими,
менее сложными методами.3. Недостаточно
тщательный подбор экспертов, появление
в группе экспертов случайных людей.4.
Привлеченные к опросу эксперты не
проявляют интереса к экспертизе. Часть
экспертов заинтересована в искажении
информации.5. Возникли трудности
интерпретации данных из-за значительного
разброса ответов, их неоднородности.6.
Стремление ускорить опрос привело к
поверхностному анализу проблем
экспертами.7. Излишний оптимизм в оценке
результатов опроса. Данные экспертизы
не подтверждены другими объективными
данными.
Типичные
ошибки анализа документов в социологическом
исследовании
1. Исследователь
использует документальную информацию
в качестве первичной, без предварительного
ее анализа; не проверены: подлинность,
достоверность, авторство документа,
назначение информации.2. Анализ
документов ведется без предварительного
плана, программы.3. Выбранные для
анализа документы имеют сходство с
темой исследования лишь по названию.4.
Категории анализа не сопоставлены
со смысловым содержанием и языком
текста. В терминологическом обозначении
категорий есть двусмысленность.5. Не
подготовлены заранее и не апробированы
методические документы сбора данных.
6 Нет списка (каталога) используемых в
анализе документов.
Типичные
ошибки в применении метода наблюдения
1. Наблюдение
ведется без специальной программы.2.
Выделенные признаки наблюдения не
связаны с проблемной ситуацией и
гипотезой исследования.3. Не введены
ограничения на условия наблюдения и
наблюдатели столкнулись с принципиально
различными ситуациями.4. Введены
только оценочные или только описательные
категории наблюдения.5. В терминологическом
обозначении категорий имеется
двусмысленность.6. В состав регистрируемых
признаков в карточке наблюдения не
вошли часто повторяющиеся и довольно
значимые свойства наблюдаемой ситуации.
7 Не подготовлены и не апробированы
методические документы, и в ходе сбора
данных возникли трудности с регистрацией
признаков.
Типичные
ошибки и трудности применения эксперимента
1.
Сформулированные гипотезы не отражают
проблемных ситуаций, существенных
зависимостей в изучаемом объекте.2.
В качестве независимой переменной
выделен фактор, который не может быть
причиной происходящих в изучаемом
явлении процессов.3. Связи между
зависимой и независимой переменными
носят случайный характер.4. Допущены
ошибки в предварительном описании
объекта, что привело к выбору неверных
(неадекватных) показателей.5. Были
допущены ошибки при формировании
экспериментальных и контрольных групп.
В ходе эксперимента обнаружилось
значительное различие групп, что делает
проблематичным сравнение этих групп
по составу переменных.6. Для
экспериментальной группы трудно
подобрать контрольную.7. Не поддается
нейтрализации действие побочных
факторов, трудно создать экспериментальную
ситуацию.8. Среди организаторов
экспериментальных работ оказались
люди, не заинтересованные в положительных
результатах эксперимента.9. В ходе
исследования среди участников возникли
конфликты по поводу вовлеченности в
эксперимент.
28. Методы
политических исследований
Политика —
совокупность социальных идей и
обусловленная ими целенаправленная
деятельность, связанная с формированием
жизненно важных отношений между
государствами, народами, нациями,
социальными группами.
Институциональный
метод — широко применим в политологии.
Он ориентирует на изучение институтов,
с помощью которых осуществляется
политическая деятельность (государства,
партий, других организаций и объединений
и .п.).
Социологический
— представляет собой совокупность
приемов конкретных социальных
исследований, направленных на сбор
фактов и практических материалов, путем
анкет, опросов и т.п. Социологический
метод используется для выявления
состояния общественного мнения, создания
представлений об ориентациях участников
политического процесса.
Сравнительный
— сопоставлении политических объектов
или процессов, выявлении их подобия и
отличительных черт. (сравнение одинаковых
явлений в разных странах). Антропологический
— исходит из природы человека. Исследует
влияние национального характера на
политическое развитие.
Психологический
— заключается в изучении в изучении
соотношения личности и власти.
Коммуникативный
— разрабатывает кибернетическую модель
политического процесса, рассматривая
структуры как информационные потоки.
В рамках
рассматриваются политические исследования
применительно к избирательным аспектам.
1) опросы на входе (изменение ориентации)
проводится за месяц, неделю до начала
выборов. Во всех предвыборных опросах
следует иметь ввиду парадокс Лапьера.
Суть парадокса заключается в расхождении
заявленные установки и поступками
людей. Даже при наличии избирательной
политической потребности, избиратели
могут не явиться. Праймелис- пробное
голосование перед выборами. Цель :
выявить наиболее популярного кандидата.
Но результаты могут отличаться от
выборов. 2) опросы на выходе (анализ
поведения). Отличаются от предвыборных
тем, что определяют реальное мнение
активных участников. Цель опроса на
выходе: 1) выяснить за какую партию
проголосовали, применяется метод
интервью.2) позволяет оценить честность.3)
узнать кто именно пришел голосовать (
портрет).
Политический
рейтинг ( конкурентная оценка партий).
Рейтинг- индивидуальная процентная
оценка.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Я продолжаю делиться опытом ошибок и находок в анкетных исследованиях. В первой статье я рассказала, как можно привлечь релевантных респондентов и увеличить возврат заполненных анкет.
Читать первую статью Ошибки анкетных опросов. 1 ошибка: смещение выборки. 8 способов привлечь нужных респондентов
В этой статье я расскажу, почему проблема понятности анкеты для участников опроса гораздо важнее, чем кажется на первый взгляд. Рассмотрим также примеры манипуляции мнением респондентов, фальсификации результатов опроса и использования опросов в маркетинговых целях.
Преимущество анкетных опросов – большой охват и быстрый результат – становится и их основным недостатком. Теряя возможность коммуникации с конечным респондентом, мы вынуждены делать дорогое допущение: «все респонденты понимают смысл анкеты и заполняют ее корректно». Если сделать это допущение, можно выдохнуть и работать с результатами опроса, как с релевантными фактами и мнениями. А если такое допущение не сделать, исследование может превратиться в череду перепроверок и согласований и в итоге полностью парализоваться.
Если честно, пройдя через сложности привлечения респондентов и возврата анкет, меньшее, чего хочется исследователю – это сомневаться в том, что анкеты заполнены корректно. Но еще грустнее – осознать, что анкеты испорчены из-за неверного понимания участниками инструкции, или вопросов. И чтобы оградить себя и заказчика от этих сомнений, можно соблюсти ряд подготовительных этапов, которые значительно повысят доверие к исследованию. Мы рассмотрим эти этапы в следующей статье. Вначале разберемся, где могут крыться сложности понимания, и к чему это может привести.
Можно выделить, как минимум, следующие части анкетного исследования, где может возникнуть непонимание:
1. Непонимание слов и специальных терминов.
2. Непонимание инструкции.
3. Непонимание направленности опроса.
4. Непонимание формулировки вопросов.
5. Непонимание критериев оценки.
1. Непонимание слов и специальных терминов
Здесь все просто. Респонденты, действительно, часто не понимают значение слов, которые кажутся исследователю очевидными. И это не всегда касается профессионального сленга. Иногда, казалось бы, обычные слова русского языка вызывают затруднения у участников опроса, но у экспериментатора редко появляется возможность узнать об этом.
На картинке: комментарий пользователя к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
Пример: Мы проводили исследование людей разного социального статуса и разных возрастных групп. В числе исследовательских методик использовался тест Т. Лири – авторитетный психологический тест, адаптированный для русскоязычных респондентов, применяемый десятилетиями для оценки личности и отношений. Тысячи исследований проведены в России с использованием этого теста. В нашем исследовании уже приняло участие несколько сотен человек, когда мы пришли опрашивать студентов престижного вуза. Студенты заполняли анкеты прямо в аудитории. Через несколько минут они стали поднимать руки и говорить, что не понимают значение некоторых слов из теста. Вот список этих слов: мягкотелый, самобичующий, деспотичный, тщеславный, покладистый, легко расположен, легко впадает впросак, черствый. Для нас это стало открытием. Оказалось, адаптация классического авторитетного теста уже устарела для некоторых респондентов этого возраста и статуса. Собранные к тому времени сотни анкет от респондентов других возрастов и статусов тоже оказались под сомнением: люди не уточняли у нас значения слов, значит – либо понимали их, либо стеснялись спросить и отвечали наугад.
Вторая угроза исходит от употребления в анкетах сленга, который может либо не пониматься участниками, либо раздражать их. Такое может случиться, если исследователь пытается заигрывать с целевой аудиторией и употребляет в анкете их сленг, не являясь носителем этой культуры.
Пример 2: Когда мы исследовали коммуникацию между отделами в одной ИТ-компании, несколько ее разработчиков рассказали на интервью, что их очень злит, когда HR-менеджеры, проводя внутренние опросы, или делая рассылки, копируют особенности языка и вставляют англицизмы. Хотя сами разработчики часто этим грешили, их раздражало, когда сотрудники, не включенные в контекст их работы, перенимали этот сленг.
2. Непонимание инструкции
Непонимание инструкции – самый очевидный пункт в этой статье и, казалось бы, бесполезный. Почти все исследователи проясняют во введении к анкете, на что направлено исследование, и как стоит заполнять бланк. Почти все респонденты уже имеют опыт участия в каких-нибудь опросах, и сейчас редко можно услышать взволнованные вопросы, которые нам задавали лет 8 назад: «А в квадратик нужно ставить плюсик, или галочку?» и «А можно зачеркнуть ответ, если я передумал?».
На картинке: Анкета с неточными инструкциями для соискателей (источник: pikabu.ru).
Несмотря на опытность обычного респондента, вопрос юзабилити анкет снова возникает, если исследователь пробует новые формы (например, on-line опросы и анкетирование на мобильных устройствах с неочевидными инструкциями или невозможностью пропустить ответ), забывает про опцию «один вариант ответа/ несколько вариантов ответа», или забывает дать корректную инструкцию к сложным вопросам (например, вопросам с ранжированием, или попарным сравнением). И для исследователя большая удача, когда получается узнать о затруднениях участника, как в примере на картинке ниже.
На картинке: комментарий пользователя к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
То, что кажется очевидным исследователю и большинству респондентов, может представлять сложности для менее опытных участников.
На картинке: Анкета с неточными инструкциями, не адаптированная для участника опроса (источник: adme.ru).
Пример 1: Мы проводили исследование сотрудников компании, имеющей филиалы в маленьких городах и поселках. Представители филиалов съехались на обучение в столицу, поэтому опросить их всех после обучения показалось хорошей идеей. Мы выступили перед сотрудниками, дали инструкции и раздали опросники, пообещав выслать результаты на e-mail каждому участнику, или принести на следующий день. Опросник был довольно большой, люди в тишине заполняли его. Как только первый участник отдал заполненную анкету, в конце комнаты поднялась женщина и направилась к двери. Когда мы спросили, где ее анкета, она ответила: «Я не понимаю, что такое имейл, и не понимаю, куда и что вы мне хотите выслать. Лучше я пойду». Оказалось, она просидела больше получаса, так как не поняла наши слова, но стеснялась уточнить инструкцию. Для нас это был вопиющий случай: мы узнали, каких масштабов может достичь непонимание инструкции. А при удаленных и on-line опросах у исследователя обычно не появляется возможности понять, что пошло не так: анкеты либо не возвращаются, либо заполняются некорректно.
Пример 2. Однажды мы организовали большое тестирование людей разных возрастов с использованием психологических опросников, которые включали шкалу лжи. По правилам таких тестов, запрещено интерпретировать результаты, если показатель лжи превышает установленный порог. Одна из участниц получила критический балл по шкале лжи и, когда мы отказались анализировать результаты, была крайне удивлена, сказав, что всегда старается говорить правду и уж точно не стала бы врать в психологическом тесте. Мы взялись с ней разбирать ответы, среди которых было, например: «Я всегда перехожу дорогу на зеленый свет», «Я всегда говорю правду» и другие очевидные вопросы на социальную желательность. На все она ответила «Да». Тогда я спросила:
– Ну, а если задуматься, за всю жизнь вы точно ни разу не перешли дорогу на красный?
– Было, конечно. Но я же старалась отвечать так, как считаю правильным себя вести, а не как веду. А так – в жизни разное бывает.Оказалось, подробная и четкая инструкция к тесту все-таки была осмыслена женщиной по-своему.
Пример 3: Во время исследования стилей поведения в служебных отношениях среди директоров предприятий, как всегда, нам удалось привлечь намного больше женщин, намечался сильный перекос выборки, и потому мы очень обрадовались, когда узнали, что завтра поступит сразу несколько анкет от мужчин, директоров крупных гос. организаций. Мы были готовы на следующий день приступить к обработке, но вечером мне позвонил один из директоров. Он бодро сообщил, что с несколькими директорами заполняет наши анкеты и хотел бы получить пояснения по некоторым ситуациям из теста, так как у них возникли споры в выборе вариантов ответа. Оказалось, директора, приехав на повышение квалификации, решили совместить общение и заполнение интересного теста, и принялись заполнять наши анкеты вместе в номере гостиницы, бурно обсуждать каждую ситуацию, спорить и убеждать друг друга. Индивидуальное исследование личных стилей поведения превратилось в групповое принятие решений, все анкеты оказались заполнены одинаково и потеряли всякую ценность для нашего исследования.
3. Непонимание формулировки вопросов
В создании анкеты, или планировании интервью есть одно правило: «Вопрос – это уже почти ответ». Информативный ответ можно получить только при очень хорошо продуманном вопросе. Для того, чтобы создать такие вопросы, проводится большая подготовительная работа (в следующей части статьи я расскажу про этапы этой подготовки).
Но наш опыт общения с исследователями показывает, что на такую подготовку почти никто не обращает внимания. Ответственность за ответ часто возлагается на респондента, делается существенное предположение, что респонденты имеют сформулированное мнение по нашему вопросу и очень хотят высказать его. Часто это совершенно ошибочное предположение. Не только проблемы исследователей, но язык их вопросов часто не воспринимаются респондентами.
На картине: Кадр из фильма «Автостопом по галактике».
Википедия: «Окончательный Ответ на величайший вопрос Жизни, Вселенной и Всего Такого (…): «Сорок два». Реакция была такой:
— Сорок два! — взвизгнул Лунккуоол. — И это всё, что ты можешь сказать после семи с половиной миллионов лет работы?
— Я всё очень тщательно проверил, — сказал компьютер, — и со всей определённостью заявляю, что это и есть ответ. Мне кажется, если уж быть с вами абсолютно честным, то всё дело в том, что вы сами не знали, в чём вопрос.
— Но это же великий вопрос! Окончательный вопрос жизни, Вселенной и всего такого! — почти завыл Лунккуоол.
— Да, — сказал компьютер голосом страдальца, просвещающего круглого дурака. — И что же это за вопрос?»
Пример 1: Однажды со мной поделилась идеей исследования ТОП-менеджер производственной компании. В тот момент она заканчивала обучение в MBA и заинтересовалась изучением мотивации рабочих на производстве. Исследование мотивации – сложная тема, мы спросили, какие методы она будет использовать. «А какие тут нужны методы? – удивилась она. – Раздам им бумажки с вопросом «Что вас мотивирует?» и соберу ответы». Жаль, общение с ней не продолжилось, и мы не узнали, как рабочие завода восприняли ее анкеты, и как она использовала результаты такого исследования.
Пример 2: Второй пример несоответствия языка исследовательских анкет языку заполнявших их людей тоже из производства. HR-директор крупного производственного холдинга как-то похвастался нам в личной беседе, что ему за несколько лет удалось увеличить вовлеченность персонала на 12% (!). Рабочий персонал и средний менеджмент заводов – специфическая группа для исследований. Как он изучал их вовлеченность? Оказалось, опросником от компании «Gallup».
Тут нужно пояснить. Самый большой недостаток использования опросника – не столько расплывчатые и неадаптированные для людей рабочих специальностей формулировки вопросов (например, вопросы №5, 6, 8), сколько его применение в качестве теста с подсчетом интегрального числового показателя вовлеченности. Другими словами, даже если у участников возникнет непонимание формулировок анкеты, исследователь не проанализирует ответы отдельно, не проследит за выбросами, а подсчитает суммарный показатель. Текст опросника приведен на картинке.
На картинке: Один из вариантов русскоязычного перевода опросника вовлеченности персонала от компании «Gallup» (Источник: antropos.ru).
Нам не удалось найти ссылки на публикации с адаптацией и валидизацией опросника «Gallup» (обязательными этапами при использовании переводных методик). Тем не менее, можно найти несколько вариантов его вольного перевода, много рекомендаций его применения в бизнес-изданиях и еще больше предложений от консалтинговых компаний, которые используют 12 невалидизированных и неадаптированных вопросов, как единственный инструмент для измерения вовлеченности персонала.
Естественно, когда клиент видит в отчете только обобщенные показатели вовлеченности и – еще лучше – рост таких показателей, он редко спрашивает о методах, которыми они были получены.
4. Непонимание направленности опроса
Непонимание направленности вопроса – куда более сложная и распространенная ошибка в анкетных исследованиях. Иногда и предположить нельзя, как человек может интерпретировать, казалось бы, однозначно сформулированный вопрос.
Для этой проблемы есть изящное решение, которое мы обсудим в следующей части. А пока, можно поговорить о случаях, когда исследователи намеренно прячут истинный смысл вопроса, или вносят путаницу в формулировки, чтобы получить желаемый ответ.
Иллюзия выбора. В практике социальной манипуляции есть такой ход: предоставление собеседнику иллюзии выбора, при которой любой его ответ будет выгоден манипулятору. Классический пример иллюзии выбора из продаж сетевых ресторанов быстрого питания: При заказе клиентом кофе официант спрашивает: «Вы к кофе возьмете маффин, или пирожок?» (вопрос «Не желаете ли что-нибудь к кофе?» считается куда менее эффективным с точки зрения продаж). Такой ход часто применяется в анкетных опросах, когда организатор исследования заинтересован в определенных ответах.
Пример: Несколько лет назад наша компания выступала организатором корпоративной игры для менеджеров среднего и высшего звена известного завода. Незадолго до этого контрольный пакет акций этого завода был куплен немецкой компанией, которая сразу начала внедрение корпоративных стандартов поведения. Стандарты эти на русском языке представляли не вполне корректно переведенный и не всегда понятный для русского менталитета свод правил, и перед нами поставили задачу организовать игру так, чтобы менеджмент усвоил эти стандарты. На игру отводилось всего несколько часов, и мы сразу объяснили, что за такое время нельзя сформировать поведенческие паттерны и нельзя даже развить принятие и согласие с чуждыми нормами. Сошлись на том, что целью игры будет уменьшить эмоциональное напряжение, которое вызывали новые стандарты. Итак, мы разработали игры и конкурсы, в основе которых было взаимодействие с каждым правилом, сделали акцент на вовлечении, групповой работе и положительных эмоциях.
Игра прошла хорошо, все руководители вовлеклись и расходились довольными. А через несколько дней HR-служба компании попросила нас провести опрос удовлетворенности игрой, чтобы предоставить отчет руководству. Мы понимали, что новые нормы не были усвоены сотрудниками и, тем более, не перешли в привычки. Но цель свою – уменьшить напряжение – мы выполнили. Поэтому, наша анкета была сосредоточена исключительно на положительных эмоциях после игры (см. рисунок).
На картинке: Фрагмент анкеты обратной связи для участников игры.
Вопросы 5, 6 и 9 – вопросы с иллюзией выбора. Они выглядят довольно полно. Но, если присмотреться, любой вариант ответа либо отражает положительную оценку, либо перекладывает ответственность на заполняющего (по принципу «это не игра была плохая – это я все еще не понимаю стандарты поведения, которые мне объясняют уже несколько месяцев», или «я и так хорошо понимаю суть стандартов»).
Последний вопрос – образец вопроса с иллюзией выбора. Все его варианты положительные. Формулируя его, мы знали, как результаты будут выглядеть в отчете: как в диаграммах будут смотреться положительные эффекты, заданные нами заранее в анкете, и как приятно руководителю будет рассматривать их. Когда человек просматривает такой отчет, у него редко появляется вопрос, были ли предусмотрены анкетой негативные варианты ответов.
Расстановка акцентов
Если заказчик исследования не интересуется исходным текстом анкеты и не уточняет, какие варианты были предоставлены участникам, организаторы могут подменить смысл результатов, расставив акценты.
Пример: Недавняя публикация результатов исследования общественного мнения россиян вызвала бурное обсуждение в Интернете (см. рисунок). В основном, обсуждение крутится вокруг термина «удовлетворительно». А для нашей статьи интересно, как результаты опроса преобразились в заголовке статьи за счет игры слов русского языка. В заголовке значится «половину россиян удовлетворяет экономика страны», в то время как в расшифровке статьи сказано, что только 6% оценили экономику положительно. Если бы в отчете были представлены только «существенные» результаты и был упущен вариант с положительной оценкой, то, благодаря богатству смыслов языка, понятие «удовлетворяет» воспринималось бы, как очень хороший результат опроса (а не как оценка «на троечку»).
На картинке: фрагмент новости о результатах соцопроса (источник: www.solidarnost.org).
Пример 2: Еще один веселый пример расстановки акцентов. Если ввести в поисковике фразу «почти половина россиян не доверяет полиции», выдаются ссылки на источники vedomosti.ru, rbc.ru, echo.msk.ru и др. А если ввести “почти половина россиян доверяет полиции», выдаются ссылки на ria.ru, news.sputnik.ru, www.business-gazeta.ru, ridus.ru (последний источник – на удивление, в отличие от скриншота).
На картинке: скриншот новостной ленты – расстановка акцентов разными изданиями (источник: joyreactor.cc)
Подмена понятий. По сути, практика защиты перед заказчиком одних только результатов исследования без предварительного рассмотрения сырых данных и способов их сбора, оставляет огромное поле для подделки данных и манипуляции результатами без всякой подделки. В таких случаях важно обращать внимание на логику и направленность вопросов в анкете перед тем, как анализировать ее результаты.
Поэтому особенно забавно смотрятся предложения обучающих и консалтинговых компаний самостоятельно оценить эффект от обучения персонала, или проведенных внедрений, и предоставить заказчику отчет о возврате на инвестиции. В анкетах обратной связи подрядчики могут спрашивать сотрудников совсем не о том, а в итоговом отчете подменять понятия. Но заказчики обычно с готовностью принимают такие отчеты, так как они выглядят вполне авторитетно, и не требуют усилий со стороны внутренних служб.
Пример: Недавно нам представили компанию, оказывающую PR-услуги. Представили, с гордостью пояснив, что эта компания – одна из немногих в отрасли, дающая четкий отчет по KPI (ключевым показателям эффективности) своей деятельности в процентах. Действительно, оценить эффективность маркетинговых и PR-кампаний, очистить замеры от всех влияющих условий рынка, непросто. Мы заинтересовались методикой. И, когда мы спросили, как именно проводится измерение эффективности PR-деятельности и вычисляются проценты, выяснилось, что в качестве единиц измерения используется план (например, «написать 10 статей в отраслевых изданиях»), а в качестве отчета – подсчет выполнения этого плата (по логике этой компании, если написано 9 статей, то KPI по PR выполнены на 90%). Конечно, существует разделение на процессные и фактические KPI и есть бизнесы, где важно именно четкое выполнение процесса. Но это не касается тех сфер, где процесс не имеет значения, если не достигнут результат. И у меня есть подозрение, что, предоставляя заказчику отчет об эффективности PR-кампании в численных показателях, эти подрядчики совершали грубую подмену понятий.
Наводящие формулировки. Тональность вопроса в анкете, или его направленность могут наводить участника на определенный ответ. Выгода организатора исследования от таких ответов заключается в подтверждении собственной позиции (например, при фальсификации теорий, или оправдании управленческих решений).
Пример: Хорошо этот эффект иллюстрирует «Теория перспектив» А. Тверски и Д. Канемана об экономии интеллектуальных затрат (за исследования иррациональной природы принимаемых людьми решений они получили Нобелевскую премию).
В одном из экспериментов по исследованию принятия решения в зависимости от контекста подаваемой информации, известном как «Азиатская болезнь», участникам предлагалось решить задачу: «Представьте, что Соединенные Штаты Америки готовятся к вспышке эпидемии неизвестной «азиатской болезни», вследствие которой, как ожидается, погибнет 600 человек. Для борьбы с этой болезнью предложены две альтернативные программы. Какую из них стоит выбрать?» Далее двум разным группам участников сообщалась одна и та же информация, но в разных формулировках (с позитивным и негативным фокусом). Авторы эксперимента доказали, что, стремясь сэкономить усилия при принятии решения, люди предпочитают полагаться на интуицию, прошлый опыт и более простые и оптимистичные варианты.
На картинке: Формулировки «программ» эксперимента «Азиатская болезнь» и предпочтение ответов участниками.
Еще один распространенный пример из исследований Д. Канемана: если одну группу испытуемых спросить: «Дожил ли Ганди до 114 лет? В каком возрасте он умер?», а другую: «Дожил ли Ганди до 35 лет? В каком возрасте он умер?», то первая группа оценит жизнь Ганди как гораздо более долгую, чем вторая.
Так, удачно формулируя вопросы анкеты, делая акцент на положительных вариантах, или используя наводящие цифры, исследователи создают «эффект привязки» и могут манипулировать ответами участников.
Второй вариант, при котором применяется техника наводящих формулировок, — это постепенное изменение убеждений участника исследования с помощью анкеты. В этом случае от вопроса к вопросу создается канва, при которой респондент вынужден отвечать определенным образом, сталкивается со своими ответами, как с новыми представлениями, и постепенно меняет точку зрения. Продолжением такого метода являются вопросы, создающие потребность (см. следующий пункт).
Пример: Однажды я сама стала жертвой жесткого манипулятивного опроса. Его проводила авторитетная организация, предлагая пройти on-line анкетирование людям со всего мира. Исследование подавалось под видом «Оцените, насколько правильно вы питаетесь». Начало анкеты было стандартным, задавались вопросы о разных продуктах, но постепенно анкета стала сужаться до фильтрующих вопросов о мясе (употребляете ли мясо, сколько раз в неделю, и т.д.). После моих ответов следующие вопросы анкеты стали предлагать мне просмотреть фотографии и видео о том, как умертвляют животных на фермах, как разделывают туши, как утилизируют отходы и др. И уже совсем скоро вопросы приобрели такой характер: «Зная, как страдают животные на фермах, вы по-прежнему будете регулярно употреблять мясо?» и «Не считаете ли вы, что стоит предпочесть растительные белки, такие же полезные и питательные, чтобы прекратить издевательство над животными?». Эти вопросы сыпались градом: никто уже не интересовался моим рационом. Казалось, завершить этот поток можно, только отвечая в духе «я все осознал и пойду теперь убеждать всех, кого встречу на пути». Впервые у меня был такой травматический опыт от заполнения анкеты. Я прекратила отвечать на вопросы, и мне потребовалось время, чтобы снова укрепиться в своих представлениях о питании, которые оказались под большим влиянием из-за этого опроса.
Опросы, создающие потребность. Создание у участников нужных потребностей с помощью правильно сформулированных вопросов – еще одна тактика манипуляций и продаж. И анкетные опросы в этом мероприятии оказывают хорошую поддержку продающим компаниям.
Никого уже не обманут псевдо-социологические опросы в стиле «Правильно ли вы ухаживаете за кожей?», или «Все ли вы знаете об очищении организма?», где после третьего вопроса появляется: «Знакомы ли вы с продукцией компании N?». Лет десять назад в нашей стране эти опросы были очень популярными.
Сейчас тактику создания потребностей используют более тонко. Первый вариант – это скрытое информирование участника с помощью анкеты об ассортименте и новых продуктах компании, что рождает осведомленность и вызывает любопытство (см. рисунок).
На картинке: фрагмент анкеты, рекомендованной Минздравом для определения группы риска по употреблению наркотиков подростками. Среди вопросов были также такие: «Сколько раз, если такое случалось, вы нюхали ингаляты – клей, аэрозоль, бензин – специально, чтобы получить «необычные ощущения»?». Анкеты предлагалось раздавать детям 10-13 лет, что вызвало бурное возмущение родителей. (Источники: Ridus.ru, RG.ru).
Второй вариант создания потребности – предложить клиенту анкету, якобы помогающую сориентироваться в том, какого вида услуга (товар) на самом деле ему нужна. Нельзя сказать, что это однозначная «политика зла». Такие анкеты, действительно, помогают уточнить потребности клиента, но они и очень хорошо помогают продавать.
Суть продажи заключается в том, что под видом опроса:
а) респондента подводят к мысли, что у него чего-то нет, или что-то используется неэффективно (вызывают чувство тревоги),
б) информируют о новых услугах (товарах, опциях), которые помогут решить его проблему (о которой он не знал до начала опроса).
Примерный алгоритм анкеты, создающей потребность:
1. Вводные нейтральные вопросы по теме, «айс-брейкеры».
2. Вопросы об актуальном состоянии респондента, которые постепенно подводят его к идее, что у него чего-то не хватает, или что-то устарело.
3. Вопросы, уточняющие, понимает ли респондент, какие последствия имеет эта нехватка, и чем она может обернуться лично для него или его бизнеса.
4. Вопросы о том, знаком ли респондент с некоторыми решениями (товарами, услугами, технологиями).
5. Вопросы, информирующие респондента, как именно эти решения помогают справиться с его проблемой.
6. Вопросы, наводящие на мысль о покупке (информирующие о цене, скидке, условиях).
7. Вопросы, подтверждающие, что при покупке этого решения проблемы респондента будут решены, и он получит дополнительную выгоду.
Пример: Если бы я хотела продать эту статью с помощью анкеты, я вначале задала бы несколько формальных вопросов о вашем опыте анкетных исследований и о том, получили ли вы специальное образование для проведения исследований (уже здесь начинается работа с тревогой). Потом спросила бы, с помощью каких процедур вы устанавливаете и доказываете, что респонденты правильно понимают инструкцию, формулировки и критерии оценки в ваших опросах. Затем спросила бы, знакомы ли вы с такими-то примерами из вашей сферы, когда результаты дорогих опросов приходилось выбрасывать из-за того, что не все респонденты верно понимали инструкцию, или суть вопросов. Упомянула бы, какой позор постиг организаторов таких опросов из такой-то компании. Потом я спросила бы, знакомы ли вы с процедурами концептуализации, операционализации, валидизации, адаптации, апробации и пилотного запуска, и в каком объеме вы их используете. Затем привела бы примеры, как эти процедуры помогли спасти дорогостоящие исследования. И, наконец, я поинтересовалась бы, что должно произойти в вашей компании для изменения подхода к опросным исследованиям и сколько, по-вашему, может стоить статья, в которой содержится алгоритм применения этих процедур, чтобы ваши исследования стали надежными, принесли успех вашей компании и лично вам.
В этом примере все еще отчетливо видны «белые нитки» продажи, но, чем ближе ваш респондент к статусу клиента (например, заполняет анкету на сайте продукта) и чем ближе он к покупке, тем лучше будет воспринята им такая анкета и тем легче получится увеличить объем его покупки за счет дополнительных продаж.
Третий вариант создающих потребность анкет, очень популярный сейчас, это развлекательные тесты. Интернет-пользователей до сих пор привлекают тесты в стиле «Хорошо ли вы разбираетесь в компьютерных играх?» (где можно невзначай добавить несколько вопросов с перечислением игровых новинок определенной компании), «Умеете ли вы управлять своим временем?» (здесь уместно упомянуть несколько специализированных мобильных приложений, которые вы хотите продать) и т.д. Такие тесты иногда выглядят профессионально и доставляют положительные эмоции, даже когда их рекламная природа очевидна.
Пример: Несколько дней назад друг предложил мне пройти тест на знание итальянских сыров на сайте «Медуза». Тест был отмечен значком «партнерский материал», а в названии упоминался бренд производителя сыров, но друг этого не заметил. Он зачитывал вопросы, а я воспринимала их на слух. Тест был, действительно, интересным.
И в какой-то момент, захотев уже салат с сочной полезной моцареллой, я шутя воскликнула:
– Да похоже, они продают эти сыры!
– Действительно, смотри, тут в конце теста написано: «Ну и конечно теперь мы просто обязаны вам рассказать, что U. тоже производит все сыры, о которых мы упомянули в тесте, – и не только. Они свежие и полезные, и даже кальций в них – со вкусом Италии».Много зная о маркетинговых уловках и манипуляции, мы все равно восприняли этот тест положительно и заинтересовались компанией, так как форма подачи и полезность контента перевысили знание об истинных целях организаторов теста.
Один из вопросов теста представлен на рисунке.
На картинке: Один из вопросов теста на знание итальянских сыров (Источник).
Опросы со смещенной целью. Особняком в этом списке опросов со скрытыми мотивами стоят опросы со смещенной целью, так как они используются, в основном, не для манипуляции, а для более изящного исследования мотивов респондентов, когда такое невозможно сделать с помощью прямых вопросов.
Пример: Об этом опросе рассказала моя ученица, директор частной мебельной фабрики. Она пыталась понять причины плохих продаж в фирменных магазинах. Несколько месяцев назад фабрика (изготавливавшая до этого только мягкую мебель) приобрела производство кухонь. Соответственно, в фирменных магазинах, кроме мягкой мебели, началась продажа кухонь. Но, на фоне стабильных продаж мягкой мебели, кухни продавались очень плохо. У директора возникла гипотеза, что причина плохих продаж не в плохом качестве продукции (у нее была возможность проверить реальный спрос), а в предвзятом отношении продавцов, которые саботировали продажи. Напрямую спросить об этом продавцов было невозможно, и потому она организовала среди них опрос в стиле «Почему, на ваш взгляд, кухни плохо продаются». Продавцы обрадовались возможности высказать, наконец, все свое недовольство от инноваций, и красноречиво отвечали на вопросы анкеты. Так ей удалось подтвердить свою гипотезу, собрать основные предубеждения продавцов против нового товара, понять их сопротивление и получить базу для работы с возражениями (в ее случае – с возражениями самих продавцов, а не клиентов).
5. Непонимание критериев оценки
Исследователи не всегда разъясняют критерии оценки, ожидая, что они интуитивно понятны участникам.
Пример: Традиционно из десятков анкет, присылаемых мне на экспертизу, около 30% содержат вопросы с просьбой оценить какой-то параметр (услугу, товар) от 1 до 5 баллов, но не содержат расшифровки значений, или хотя бы указания, какой полюс является положительным. Иногда все исследование пропадает, если организаторы обращают внимание на диаметральные различия в оценках респондентов и только потом догадываются, что некоторые респонденты ставили «1», предполагая, что это «первое место» в рейтинге, а другие ставили «1», как самый низкий балл.
Как выход из таких ситуаций, принято использовать шкалу Лайкерта (Лейкерта, Ликерта), содержащую более детальные формулировки для оценки (например, от «Совершенно не нравится» до «Очень нравится», или от «Никогда» до «Очень часто»). Можно найти или придумать много формулировок этой шкалы для самых разных вариантов вопросов. Но и у этой шкалы есть недостатки, так как субъективное понимание, например, частоты каких-то действий у разных людей может различаться. И если нам важно знать не их мнение о частоте, а более-менее точный показатель, лучше конкретизировать такие варианты ответов точными промежутками (например: «Реже одного раза в год» — «…» — «Несколько раз в день»).
На картинке: комментарии участников к анкетному опросу, опубликованному на сайте (источник: pikabu.ru)
Проработка вариантов ответа становится особенно важной, когда анкетный опрос применяется для оценки сложных, субъективно-значимых параметров. В таких случаях респонденты склонны к «ментальной экономии» и выбирают варианты оценки, соответствующие их общему представлению об объекте, не задумываясь над вопросом (например, «игра мне, в общем, нравится, проставлю везде 4 и 5 – не важно, оцениваю я звук, или уровень обратной связи с игроками»).
Такие усредненные оценки встречаются часто при проведении оценки сотрудников методом 360 градусов. Оценивая своих коллег, люди склонны ставить положительные баллы «любимым» и нейтральные, или отрицательные, баллы «нелюбимым», независимо от того, по какому параметру ставятся оценки (нелюбимый сотрудник может быть сильным лидером, или ни с кем не конфликтовать, но «рука не поднимется» поставить ему высокие баллы даже за эти показатели). В итоге, такая оценка оказывается совершенно бесполезной для организаторов исследования, так как не дает возможности выделить реальные проблемные точки у сотрудников компании.
Точно так же обстоят дела при оценке пользовательского опыта при работе с ИТ-продуктами. Если сайт, или компания, в общем, нравятся пользователю, он будет склонен ставить, в общем, высокие оценки, чтобы «никого не обидеть». И такой опрос не поможет разработчикам сделать продукт лучше.
Пример: Забавный случай случился с моей знакомой, когда только начал развиваться сервис «Одноклассники». Заведя аккаунт значительно позже своих знакомых и еще не зная негласных правил поведения на сайте, она стала просматривать профили друзей и ставить оценки фотографиям. Очень скоро несколько подруг ее заблокировали. Она была крайне удивлена и смогла разговорить одну из них, чтобы вяснить причину. Оказалось, подруг (уже давно закончивших школу) сильно задели низкие оценки, которые она ставила их фотографиям. «Как ты не понимаешь? Ты понизила мне общий балл своими двойками!» – призналась одна из них. А моя знакомая, в отличие от большинства пользователей «Одноклассников», была убеждена, что механизм оценки фотографий существует для того, чтобы искренне высказываться насчет удачности кадра, цвета, перспективы и др., а не для выполнения социальной функции поддержки друзей.
В таких случаях высшим пилотажем исследователя становится разработка «поведенческих» вариантов ответа, описывающих примеры проявления качества в поведении человека (или – при оценке продукта – особенности взаимодействия пользователя с ним). По поведенческим вариантам нельзя однозначно определить, какой из них положительный, и какой отрицательный, и респонденту приходится выбирать вариант, наиболее приближенный к реальности.
Пример: Можно предложить такие поведенческие варианты для оценки конфликтности: «Этот человек никогда не повышает голос и всегда держится в стороне от любых разногласий и споров» (самый низкий балл) – «Этот человек остро реагирует, когда его точка зрения не принимается коллегами, или когда поведение коллег кажется ему несправедливым; он может повышать голос, или даже решать разногласия силой» (самый высокий балл). Соответственно, в таком же ключе формулируются остальные промежуточные варианты оценки.
На картинке: Пример вопроса оценки «ориентации на команду» для оценки сотрудников методом 360 градусов. В каждом варианте можно заметить положительные и негативные черты, что увеличивает вероятность честной оценки, в отличие от простого приписывания высоких, или низких баллов сотруднику (Источник).
Разработка поведенческих вариантов оценки – сложный этап. Особенно сложно подобрать адекватные варианты, когда не совсем понятно, как они проявляются в реальном поведении (или взаимодействии пользователя с продуктом). Например, при оценке звуковых эффектов в игре высшей оценкой звука будет: «Звуки не отвлекают от игры, создают хороший фон», или «Звуки играют важнейшую роль, помогают следить за динамикой игры, во время подсказывают действия игрокам». Для того, чтобы варианты оценки получились наиболее соответствующими реальному опыту пользователя, используется этап операционализации, о котором я подробно расскажу в следующей части статьи.
Краткие выводы
Я попыталась описать примеры, когда очевидные для организаторов исследований этапы анкетирования неверно понимаются участниками. Респонденты могут неверно понимать слова и фразы, формулировки вопросов, инструкции к анкете, критерии оценки и направленность вопросов. Эти сложности приводят к сбору нерелевантной информации, или невозврату анкет.
Также мы рассмотрели примеры, когда замешательство респондентов провоцируется намеренно с целью манипуляции результатами опроса. Среди таких манипуляций:
— предоставление иллюзии выбора;
— расстановка акцентов;
— подмена понятий;
— наводящие формулировки;
— использование эффекта привязки;
— создание потребности: 1) через информирование и любознательность, 2) через провокацию тревоги, 3) через развлекательные тесты,
— опросы со смещенной целью.
Чтобы оценить, не манипулируют ли вашим мнением исследователи, предоставляя результаты анкетного опроса, можно задать им несколько вопросов по процедуре исследования:
1. Попросите посмотреть исходный текст анкеты и попробуйте самостоятельно ее заполнить перед тем, как знакомиться с результатами (еще лучше – перед тем, как санкционировать исследование).
2. Представьте, как заполняет эту анкету ваш типичный клиент, или сотрудник (все ли термины и формулировки будут ему понятны).
3. Обратите внимание на формулировку вопросов и вариантов ответа: есть ли негативные варианты, занимают ли они равное место с позитивными вариантами.
4. Обратите внимание, нет ли в вопросах анкеты наводящих формулировок и «привязок».
5. Просмотрите, насколько однозначно и конкретно сформулированы критерии оценки в вопросах анкеты (не провоцируют ли они на «ментальную экономию» – на нейтральные, или исключительно положительные ответы). Лучший вариант – если критерии оценки сформулированы в поведенческих примерах.
6. При анализе итогового отчета обратите внимание, на основе каких вопросов анкеты построены выводы: не подменяют ли исследователи понятия, не выдают ли мнения респондентов за факты.
7. Если используется зарубежная методика (например, от известной компании), поинтересуйтесь ссылками на публикации с описанием процедуры ее перевода, адаптации и валидизации. Без этих процедур методику нельзя считать авторитетным методом исследования, независимо от статуса ее разработчика.
8. Запросите точное распределение участников опроса по группам (пол, возраст, социальный статус, или: отделы, должности), чтобы избежать перекоса выборки (подробнее об этом – в предыдущей статье о выборке).
В следующих статьях:
Ошибка 2. Формулировки вопросов: почему вы решили, что вас понимают? (2 часть)
Ошибка 3. Виды лжи в опросах: почему вы верите ответам?
Ошибка 4. Мнение не равно поведению: вы действительно спрашиваете о том, что хотите узнать?
Ошибка 5. Виды опросов: вам нужно узнать, или подтвердить?
Ошибка 6. Разделяйте и насыщайте выборку: среднее ничего не помогает понять.
Ошибка 7. Пресловутый «Net Promouter Score» – это НЕ изящное решение.
Более ста лет назад Герберт Уэллс сказал: «Настанет тот день, когда статистическое мышление будет настолько важным для эффективной деятельности человека, как и умение читать и писать».
Процесс опроса общественного мнения превратился в индустрию – одну из самых процветающих на сегодняшний день. Мы спрашиваем людей о том, что они думают о коллективных переговорах, профсоюзах, постоянно растущем дефиците бюджета, экономическом кризисе, всеобщем хаосе и так далее, независимо от того, знает ли респондент что-либо по этой теме. Мы спрашиваем рабочих, что им не нравиться в их работе, и в лучшем случае в своем ответе человек может выразить свое недовольство. Когда мы задаем вопрос генеральным и финансовым директорам о том, какие экономические прогнозы они могут сделать на ближайшее будущее, то мы заведомо знаем, что они не могут этого знать.
СМИ ежедневно ссылаются на результаты проведенных опросов. Но это не что иное, как общественное мнение, формирование которого зависит от трех факторов, а именно: самого вопроса, ответа и анализа. Многие книги и статьи были посвящены проблеме злоупотребления и нарушений (в процедуре)проведения опроса, а также исследования процесса выборки. Но в современном, быстро меняющимся медиапространстве, наука правильного сбора данных, а также обобщение, анализ и применение полученной информации, кажется занудным и неинтересным. Законодатели более заинтересованы в результатах опросов, чем в том, как они были получены. До недавнего времени никому не приходило в голову, что «результаты опроса» и то, «как эти результаты были получены» — это неразделимые понятия.
Забытая истина об общественном мнении
Нил Постмен в своей замечательной книге «Technopoly» описывает слабую сторону процесса интерпретации данных: «Социологи задают вопрос, на который необходимо ответить да или нет. Опрос не принимает во внимание тот факт, что люди могут ничего не знать о том, о чем их спрашивают. В культуре, в которой нет определенных измерений и классификаций вещей, это упущение, возможно, будет выглядеть странным. Давайте представим ситуацию, когда могут одновременно задаваться два вопроса о том, что «думают» и что люди «знают» о предмете обсуждения. К примеру, последний опрос показывает, что 72% американцев считают необходимым снять экономическую помощь Никарагуа. Но 28% опрошенных «полагали», что Никарагуа находится в Центральной Азии, а 18% «считали», что это остров возле Новой Зеландии, и 27, 4% «говорили», что «африканцы должны сами себе помогать», при этом принимая Никарагуа за Нигерию. Более того, 61.8% участников опроса не знали, что США оказывает экономическую помощь Никарагуа, а 23% и вовсе не знали, что такое «экономическая помощь». Если социологи будут предоставлять и использовать такую информацию, то авторитет и значение опроса общественного мнения будет очень низким».
Опрос общественного мнения оказывает поддержку работникам государственного сектора
28 февраля 2011 года опрос общественного мнения, который был проведен New York Times/CBS, показал, что большинство людей выступают против попытки уменьшить права на ведение коллективных переговоров. Они также не согласны с сокращением зарплаты или пособия общественных работников, которое, в свою очередь, могло бы привести к снижению дефицита государственного бюджета. Недавно проведенный национальный опрос (national Gallup survey) свидетельствует о том, что большинство американцев также выступают против введения мер, предложенных в Висконсине, которые ограничивают права на ведение коллективных переговоров на государственной службе. В такой ситуации необходимо вспомнить комментарии Постмена, который утверждал, что «люди не всегда понимают, о чем их спрашивают». Один остроумный посетитель сайта New York Times оставил такой комментарий: «Американцы предпочитают поднять налоги, чем сократить льготы для госслужащих,…что могло бы стать настоящей новостью, если бы это оказалось правдой».
Как можно сделать неправильные выводы из опросов или результатов исследования?
Давайте прямо к делу. Социологи классической школы называют это «статистической вселенной» или «населением». Что являет собой статистическая вселенная (совокупность)? Она состоит из всех явлений, о которых необходимо сделать выводы. Например, в исследовании ценовых колебаний цен на топочный мазут в Нью-Йорке с 2007 по 2010 год, статистическая совокупность будет включать все изменения цен в течение этого периода. Если рамки исследования были расширены, чтобы изучить большую территорию или более длительный период времени, то статистическая совокупность, соответственно, увеличивается. Совершенно очевидно, что термин «статистическая вселенная» можно назвать универсальным, так как его можно применять для любого статистического исследования. Подводя итог, необходимо сказать, что «статистическая совокупность» может быть определена как совокупность, которая включает каждый пункт, который необходимо изучить или взять под наблюдение.
Выборочное исследование
Из-за нехватки времени и средств, иногда невозможно провести полный анализ статистической информации. К счастью, нет необходимости исследовать всю статистическую совокупность. Но почему? Потому что трудолюбивые, компетентные статистики нашли способ, как можно получить одну и ту же информацию из небольших, тщательно отобранных образцов. Умение выделить небольшие экземпляры с объемных, иногда бесконечных статистических данных, является предметом изучения базовой и расширенной статистики. Если отбор образцов осуществляется надлежащим образом, то их анализ позволяет получить информацию о статистической совокупности с наименьшей долей погрешности. К сожалению, многие базовые курсы по статистике не выделяют один важный момент, а именно, если статистическая совокупность определена неправильно, то серьезный логический анализ (на основе представленных образцов) может не принести желаемых результатов.
Пример неправильно определенной статистической совокупности
Безусловно, самым ярким примером неправильного определения статистической совокупности является опубликованное в Литературном Дайджесте прогноз победителя президентских выборов в 1936 году. Этот пример часто приводит приводит Эдвардс Деминг. Во время избирательной компании 1936 года, когда претендентами выступали демократ Франклин Рузвельт и республиканец Альфред Лэндон, «Литературный дайджест» разослал образцы бюллетеней для голосования большому количеству людей, чьи имена были в телефонных справочниках и в списках регистрации транспортных средств. (В этот перечень также входили и их подписчики, члены клуба и т.д.). Более 10 млн. таких бюллетеней были разосланы. Только 2,4 млн. респондентов отослали свои бюллетени назад в редакцию, а 7,6 млн. бюллетеней были утеряны. На основе этих 2,4 млн. бюллетеней дайджест сделал прогноз, что с большим преимуществом на выборах победит Лэндон. Как оказалось на самом деле, Рузвельт получил 61% голосов избирателей, что составило одно из самых больших преимуществ в истории американских президентских выборов.
Как же они могли настолько ошибаться?
Результаты опроса представили только ту информацию, которая была получена от респондентов, которые вернули образцы бюллетеней. Несмотря на то, что было разослано огромное количество бюллетеней, те президентские выборы стали ярким примером необъективной выборки, так как практически все респонденты были сторонниками Республиканской партии.
Давайте рассмотрим ситуацию более детально. В процессе прогнозирования были совершены две серьезные ошибки, а именно:
1.Статистическая совокупность была неправильно определена.
2. Не учитывалось уклонение от ответов.
Люди, чьи имена были взяты из телефонной книги или реестра автомобилей, в 1936 году принадлежали к более обеспеченному слою населения, в отличие от остальных респондентов. Такая разница присуща статистической совокупности. Большой процент избирателей не внесен в телефонную книгу, автомобильный реестр или в список членов клуба. Статистическая совокупность была неправильно определена, так как был сделан уклон, в основном, в сторону более состоятельных людей. Обеспеченные слои населения были приверженцами республиканцев. В 1936 году наблюдалась сильная «взаимосвязь» между доходами людей и их партийными предпочтениями. Те, кто принадлежал к менее обеспеченным слоям населения, поддерживали Демократическую партию.
Пример ошибки (смещения) в процессе выборки
Статистики изклассической школы определяют «смещение» как постоянную ошибку в одном направлении. Что это значит? Практически не имеет значения, кого бы вы могли выделить из статистической совокупности, взятой из «Литературного дайджеста», так как существовала большая вероятность того, что именно состоятельный человек может быть избран на президентских выборах. Следует заметить, что статистическая информация была получена, в основном, от состоятельных людей, а мнение избирателей с низким доходом не было учтено. А в 1936 году большая часть населения имела очень низкий доход. В то время 9 млн. жителей были безработными. «Опрос, проведенный «Литературным дайджестом», не смог охватить все слои населения. Тогда, как и сейчас, избиратели голосуют за кандидатов «по своему карману», то есть за тех, кто выступает за интересы определенных групп населения». Следует отметить, что Джордж Гэллап смог предсказать победу Рузвельта, сделав выборку из 50 тыс. человек. Статистическая совокупность, которую он создал, состояла из различных слоев населения. Выборка, которую сделал «Литературный дайджест», охватила 2.4 млн. человек. Она является отличным примером того, что неправильно определенная статистическая совокупность не может дать объективную информацию только за счет увеличения масштабов выборки.
Уклонение от ответов
Второй проблемой, с которой столкнулся «Литературный дайджест», было то, что из 10 млн. человек только 2.4 млн. респондентов приняли участие в опросе. В то время обеспеченные жители более охотно отвечали на различную корреспонденцию, чем представители бедных слоев населения. 7.6 млн. людей, которые не приняли участие в опросе, принадлежали к группе с низким экономическим статусом. А 2.4 млн. респондентов – были представителями обеспеченных слоев населения.
Исследование, которое провел Лэндон, представляет ситуацию следующим образом: «Если уровень ответов низкий (как было в том случае – 24%), то информация, полученная в результате опроса, не может быть объективной. Это особый тип отбора, в котором исключены люди, которые не ответили на полученную корреспонденцию».
Резюме и выводы
Если использовать статистическую совокупность, которая может существенно отличаться от «идеальной» совокупности, на основе которой необходимо сделать выводы, то это может привести к серьезным ошибкам в анализе полученных данных. Необходимо потратить много времени, чтобы определить «идеальную» статистическую совокупность, а затем сделать правильную выборку. Каждый день мы слышим, к примеру, о ценовой политике (чтобы привлечь больше покупателей), которая базируется на «выборочной» информации, полученной в результате опроса потребителей. Статистическая совокупность, в большинстве случаев, также должна содержать мнение не только покупателей, но и тех людей, которые не используют продукцию той или иной компании, не смотря на то, что эти люди имеют/могли бы иметь отношение к рынку и могут реагировать на изменение цен.
Всегда нужно быть начеку, чтобы определить неверно созданную статистическую совокупность. Расчеты, сделанные на основе неправильной выборки, интервальное оценивание и статистические тесты не принесут никаких результатов, если статистическая совокупность определена неверно. И на последок, не относитесь предвзято к отсутствию ответов. В результате исследования, проведенного школой Wharton, был сделан следующий вывод: «Люди, которые принимают участие в социологических исследованиях, отличаются от тех, кто их игнорирует. Это отличие заключается не только в их отношении к подобным мероприятиям; оно носит более глубокий смысл».

Кунилова Ксения
Эксперт по предмету «Социология»
преподавательский стаж — 5 лет
Предложить статью
Роль социологических исследований в современности
Современную ситуацию в социологической науке практически все без исключения ученые характеризуют как своеобразный «социологический бум». Это связано с тем, что данные, которые получены в результате упорного труда социологов, используются для принятия ключевых управленческих решений, направленных на снятие острых социальных противоречий.
Предметом современных социологических все чаще становятся ключевые для общества и государства социальные процессы и явления, в том числе конкуренция в экономической сфере и борьба за политическое лидерство.
Тем не менее, рост востребованности работы социологов и результатов их деятельности способствовал формированию своеобразного рынка услуг. Теперь на нем задействовано большое количество специалистов, данные анализируются абсолютно разнообразные, что является несомненным преимуществом. Но и это не исключает того явления, что не все социологические исследования способны дать качественный результат. Причина этого – ошибки, которые допускают исследователи в разных областях.
![]()
Сдай на права пока
учишься в ВУЗе
Вся теория в удобном приложении. Выбери инструктора и начни заниматься!
Получить скидку 4 500 ₽
Понятие ошибок в социологической сфере
Определение 1
Ошибка социологических исследований – это понятие, которое принято в социологии для обозначения неверных действий исследователя в ходе осуществления необходимого комплекса социологических процедур, которые обязательны на каждом этапе исследования для получения корректного результата.
Следует отметить, что неверные (неправильные) действия социолога могут определяться рядом основных причин.
Причины неправильных действий исследователя
Во-первых, исследователь обладает низким профессиональным уровнем или недостаточной образовательной подготовкой. Это все базируется на недостатке специальных знаний и умений, а также на отсутствии мотивации, инициаторских качеств и творческого потенциала.
Во-вторых, неправильные действия определяются случайными причинами, которые связаны с недостаточным количеством времени для проведения работ, а также недостатком в финансировании и слабой материальной базой.
«Ошибки в социологических исследованиях» 👇
В-третьих, ошибки могут быть из-за умышленного искажения фактов и результатов посредством применения неадекватных целям и задачам методам исследования, обработки и анализа первичных данных, неверной интерпретацией и объяснения полученных результатов.
Научная классификация ошибок в социологических исследованиях
Изучая ряд исследовательских проектов, ученые выделили классификацию самых распространенных ошибок в социологических исследованиях:
- Организационные ошибки – к ним могут быть отнесены все те, что связаны с непосредственной подготовкой интервьюеров, операторов ввода социологической информации, курьеров, а также неисправностью технических средств и оборудования;
- Технологические ошибки – неправильный выбор методов сбора и обработки информации, недостатки в построении выборочных моделей, несоответствие логической программы обработки информации выдвинутым гипотезам;
- Методологические ошибки – связаны с неправильной операционализацией понятий, «перекосами» в шкалах инструментария, а также отсутствием сравнения данных как разных замеров, так и в рамках одного исследования.
Замечание 1
Наибольшее количество ошибок допускается на этапе подготовки и организации исследования. Вот перечень таких ошибок:
- Выбор для изучения такого события, в котором нет противоречий или конфликтов;
- Недостаточно глубокий анализ проблемы или проблемной ситуации;
- Неправильное понимание подходов и методов осуществления анализа проблемы и проблемной ситуации;
- Игнорирование правил формальной логики в процессе операционализации основных понятий и терминов;
- Несоблюдение последовательности при организации каждого этапа социологического исследования.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
- Исследователь использует документальную информацию в качестве первичной социологической информации без предварительного ее анализа; не проверены: подлинность, достоверность, авторство документа, назначение информации.
568
2. Анализ документов ведется без предварительного плана, про граммы.
3. Выбранные для анализа документы имеют сходство с темой исследования лишь по названию. Информация, содержащаяся в них, не связана с гипотезами исследования.
4. Категории анализа не сопоставлены со смысловым содер жанием и языком текста документов. В терминологическом обо значении категорий анализа имеется двусмысленность; в одну и ту же категорию анализа попадают существенно различающиеся смысловые единицы текста.
5. Не подготовлены заранее и не апробированы методические документы обзора данных. Возникли трудности регистрации при знаков.
6. Не проведен инструктаж среди регистраторов и кодировщи ков, они не прошли специальную подготовку.
7. Кодировка не соответствует программе обработки данных.
8. Плохо организовано рабочее место регистратора.
9. Нет списка (каталога) документов, используемых в анализе
2.3. Методология и методика контент-анализа
Контент-анализ представляет собой перевод в количественные показатели массовой информации (текстовой, аудиовизуальной цифровой) с последующей статистической ее обработкой. Его идея очень проста и повторяет ту, что лежит в основе любого другого количественного метода в социологии, будь то анкетирование или наблюдение. Надо сосчитать наиболее часто повторяющиеся сло ва или темы, например в газетном материале, и определить, что за этим кроется. Особенность заключается именно в применении статистических процедур для анализа однотипных текстов.
Контент-анализ (англ. content analysis — анализ содержания) — количе ственный анализ текстов и текстовых массивов с целью последующей со держательной интерпретации выявленных числовых закономерностей.
А в известной у нас переводной книге Дж. Мангейма и Р. Рича сказано так: контент-анализ — это систематическая числовая об работка, оценка и интерпретация формы и содержания информа ционного источника. Этот тип неопросного исследования назы вают еще формализованным анализом документов.
569
Под текстами в контент-анализе понимают книги, книжные главы, эссе, интервью, дискуссии, заголовки газетных статей и сами статьи, исторические документы, дневниковые записи, речи выступлений, рекламные тексты и т.д. Когда говорят о контент-анализе текстов, то главный интерес всегда заключается не в самих характеристиках содержания, а во внеязыковой реальности, которая за ними стоит, — личных характеристиках автора текста, преследуемых им целях, характеристиках адресата текста, различных событиях общественной жизни и др.
Как любой другой социологический метод, контент-анализ используется не сам по себе, а в составе крупного исследовательского проекта, под который составлена научная программа, где четко прописаны цели и задачи, проблема и объект, теоретическая модель и предмет исследования, выдвинуты гипотезы и проведены все другие операции, которые требует научный метод. Когда становится ясным, что поставленных целей никаким иным способом, как только анализом документов, достичь нельзя, социолог прописывает все этапы его применения: устанавливает объект, выделяет единицы анализа (их нередко называют еще единицами наблюдения и т.п.), выбирает статистический метод анализа данных, идет в библиотеку за источниками или садится за Интернет (полевая стадия), а потом ищет, суммирует, считает и интерпретирует. Контент-анализ позволяет обнаружить в документе то, что ускользает от поверхностного взгляда при его традиционном изучении. Он позволяет вписать содержание документа в социальный контекст, осмыслить его одновременно и как проявление, и как оценку социальной жизни.
Принято считать, что контент-анализ состоит из трех основных этапов: 1) выделяются единицы анализа, которые затем сводятся в категории анализа и переводятся в машиночитаемый вид; 2) проводится подсчет частотных распределений, применяется математический аппарат для выявления взаимосвязей единиц анализа; 3) осуществляется интерпретация полученных результатов.
Выбор объекта и единиц анализа — чуть ли не самые сложные шаги на этом пути. Нужно найти ответы на вопросы: где мне это искать и как проявляется изучаемое мною явление, событие, процесс.
Объектом контент-анализа могут быть экземпляры книг, плакатов или листовок, номера газет, фильмы, публичные выступления, теле- и радиопередачи, общественные и личные документы, журналистские интервью, ответы на открытые вопросы анкет и др. Они составляют то, что называется выборкой, — ту часть текстов, которые достаточны для анализа всего массива публикаций, и обеспечивают репрезентативность данных.
570
Это довольно просто, зато с выбором единиц анализа придется помучиться, поскольку эту роль может выполнять что угодно: темы и проблемы, пропозиции, образы, идеологемы, метафоры, примеры и аналогии, каламбуры, аллитерации, мифологемы, ко чующие образы и многое другое, иногда очень экзотическое, ска Жем, надписи на стенах публичных туалетов. Единицами анализа могут служить, например, упоминания о российских политичес ких деятелях и политических партиях и движениях (фамилии, имена политиков и названия партий). В такой роли могут высту пать также фрагменты текста или его признаки, фотографии, за головки, названия профессий, события, города, страны, органи зации, оценки, суждения на определенную тему и т.п.
А теперь внимание. Хотя в природе контент-анализа не зало жено никаких ограничений, а потому ничто не препятствует eго применению к отдельному тексту, тем не менее существует ряд причин, по которым его используют только в информационных массивах, состоящих из большого количества текстов. Во-первых, статистические закономерности проявляются тем более отчетли во, чем больше объем выборки. Во-вторых, в большинстве случа ев контент-анализ используется в компаративных, т.е. историко сравнительных, целях. Он силен, когда раскрывает не oднoмoмент ные срезы, а динамику изменений.
Таким образом, идея контент-анализа предполагает анализ боль ших информационных массивов; с другой стороны, его относитель ная дешевизна и технологичность делают такой анализ принципи ально возможным. Поэтому не приходится удивляться тому, что в истории контент-анализа имеются такие проекты, как анализ 427 школьных учебников, 481 частной беседы, 4022 рекламных сло ганов, 8039 (в 1938) и 19 533 (в 1952) редакционных статей или 15 000 персонажей в 1000 часов телевизионного эфирного времени.
Выбор единиц анализа зависит от исследовательской програм мы, объекта, предмета, цели, задач и гипотез исследования. Если, скажем, нам предстоит выяснить перспективы забастовки рабочих Предприятия, то станет очевидной потребность контент-анализа, как минимум, протоколов собраний рабочих, решений соответству кзщих профсоюзных комитетов, распоряжений руководителей, за конов, регулирующих забастовочную борьбу, и т.п. Переход от за дачи к единицам анализа аналогичен процедуре теоретической и эмпирической интерпретации понятий и поиска индикаторов.
Выяснение того, что считать, т.е. установление единиц анали за, — главная, решающая, ключевая (или как угодно еще) пред посылка контент-анализа. Допущенные здесь ошибки трещинами разойдутся по всему зданию. Обязательное условие: такие едини
571
цы должны быть единообразными, тогда социолог получит четкие статистические показатели. Добиваются подобного единообразия благодаря стандартизации процедуры анализа текста, которая, устраняя субъективные смещения, раскрывает свои возможности только при достаточно больших массивах текстов. Единицы анализа должны легко и по возможности однозначно идентифицироваться в тексте. В идеале их лучше всего свести к самым употребляемым формальным значкам, например запятым или точкам. Тогда подсчет не представит никаких трудностей, а интерпретация результатов будет однозначной и объективной. Только кому нужен такой счет? Социологу он ничего не даст. Его задача — за внешними признаками, например отдельными словами или фразами, распознать таящееся в глубине социальное явление. А это уже качественный подход. Слова, выбранные для счета, должны обладать распознавательной силой, выступать диагностическим инструментом. Иными словами, единицы анализа должны быть интересными для последующей (политологической, культурологической, социологической и т.д.) интерпретации. Тут необходимы оригинальное видение мира, необычный подход.
Количественный подсчет встречаемости слов в тексте — самый простой вариант контент-анализа, который, однако, приводит к интересным результатам. Чаще всего подсчитывают «интересные» или «ключевые» слова и (или) словосочетания, например названия ценностных категорий типа свобода, стабильность, доверие, территориальная целостность; сценариев типа предательство или разочарование; достаточно однозначные обозначения тех или иных общественно значимых явлений, например коррупция, преступность или терроризм, и др.
С научно-познавательной точки зрения социолога интересуют все-таки не отдельные слова, а стоящие за их «спиной» понятийные категории, объединяющие множество разрозненных слов-признаков в тематическое целое. Исследователь, интересующийся тем, какое место в общественном сознании занимает, скажем, проблема преступности, обязан принимать во внимание не только присутствие в анализируемом информационном массиве слова «преступность», но и упоминания заказных и всяких прочих убийств, бандитского беспредела, «крыши», «братков», авторитетов, власти криминала и т.п.
По отношению к единицам анализа, сгруппированным по единому основанию, иначе говоря, составляющим концептуальное целое, специалисты употребляют другой термин — «категории анализа».
Категории анализа — его смысловые единицы, обозначающие эмпирические признаки текстовой информации, которые являются 572
результатом операционализации опорных теоретических понятий в концепции исследования. К категориям анализа предъявляются оп ределенные требования: они должны выражать теоретические поня тия исследования, иметь в соответствии признаки (смысловые еди ницы) в тексте, обладать возможностями однозначной регистрации признаков, составляющих эти категории. Основная задача сбора ин формации в ходе анализа — поиск индикатора, указывающего на наличие в документе выделенной проблемы, идеи, темы (например, «справедливое распределение благ»). Категории анализа вы ража ют ся определенными признаками (подкатегориями), характеризующи ми интенсивность, направленность, значимость выраженной в ка тегории идеи, проблемы. К ним могут относиться понятия из лю бой сферы жизни общества: формы собственности, приватизация, финансовая система, научно-технический прогресс, методы хозяй ствования, национализм, авторитаризм, демократия, международное сотрудничество, права человека, гуманизм, активность, деловая предприимчивость, нарушение законности, коррупция и др.
С помощью категорий выделяют концептуальные связи, модели, микропроблемы, тематические поля. В качестве примера можно привести анализ президентских посланий стране, с которыми обра тился Б. Клинтон в 1994 и 1995 гг. Эти послания содержат от 7 тыс. до 10 тыс. слов. Были сформированы категории слов, относящихся к экономике, бюджету страны, образованию, преступности, вопро сам семьи, международным делам, социальной помощи и др. В ка тегорию «экономика» входили слова: экономика, безработица, инф ляция; в категорию «семья» — ребенок, семья, родители, мать, отец. Именно учет частот встречаемости категорий, а не отдельных слов позволяет судить о внимании, уделенном в послании тем или иным вопросам. По изменению относительных частот в посланиях 1994 и 1995 гг. были сделаны выводы об изменении политики государства в различных областях. Эти темы нашли отражение в обоих послани ях, но в одном из них некоторым темам уделялось больше внимания, а в другом меньше. Скажем, в послании 1995 г. больше внимания было уделено вопросам образования, семьи, но меньше внимания — пре ступности, международным делам, социальной помощи. Отсюда пос ледовал вывод о стратегических приоритетах правительства США.
Другой пример использования контент-анализа — изучение должностных инструкций на предприятии20. Исследователь осно вывался на следующих предпосылках. Содержание инструкции как нормативного документа, координирующего взаимодействие лю
573
дей, должно обеспечивать четкую регламентацию ролевых позиций. Чем она полнее, тем эффективнее взаимодействие и отношения людей. Ключевым явилось понятие «регламентация». Основные стороны производственной деятельности, подлежащие регламентации, составили ее предметное содержание. Они названы «категориями регламентации»: 1) место должности в структуре организации; 2) основные цели деятельности лиц, занимающих данную должность; 3) квалификационные требования; 4) обязанности работников; 5) подчиненность и права; 6) ответственность.
Благодаря этому появилась возможность расчленить текст на смысловые блоки по названным шести категориям, по каждой из них сделать стандартизованное заключение о наличии или отсутствии в тексте данной категории. Единицей счета выступил фрагмент текста, содержащий упоминание категории и характеристику ее содержания (независимо от полноты и точности этой характеристики). Далее на этом весьма обобщенном уровне анализа текста можно отличить более полную и четкую инструкцию от поверхностной и фрагментарной. Заключение о качестве инструкции здесь не интуитивное (как в случае экспертной оценки), а аргументированное.
Углубление контент-анализа идет за счет конкретизации понятия «категория регламентации», т.е. поиска детальных индикаторов. Таковыми оказались «элементы регламентации», например «ответственность», «подчиненность» и т.д. Категории «подчиненность» и «права лиц, занимающих данную должность» раскрывались через суждения — индикаторы типа «как увольняются и назначаются лица, занимающие данную должность», «кому они подчиняются». Дробное членение содержания служебной деятельности и выявило в тексте такие единицы учета (суждения, сочетания слов, предложения), которые давали возможность построить числовые показатели, характеризующие отдельные качества должностных инструкций: подробность, четкость и т.д.
Категории анализа, по мнению СИ. Григорьева и Ю.Е. Рас-това, должны быть: а) уместными, т.е. соответствовать решению исследовательских задач; б) исчерпывающими, т.е. достаточно полно отражать смысл основных понятий исследования; в) взаимоисключающими (одно и то же содержание не должно входить в различные категории в одинаковом объеме); г) надежными, т.е. такими, которые не вызывали бы разногласий между исследователями по поводу того, что следует относить к той или иной категории в процессе анализа документа.
574
Однако указанные требования соблюдаются далеко не всегда. Сведение единиц анализа в категории всегда выступает способом их классификации, критерии которой не только чрезвычайно расплыв чаты и туманны, но разнятся от одного исследователя к другому. Они опираются на экспертные оценки социолога, зависят от общего уров ня его подготовки и знания социальных реалий. Количество caмих категорий будет зависеть от степени допускаемого обобщения социального материала. В результате может нарушаться один из принци пов научного исследования — возможность воспроизведения резуль татов опыта разными исследователями, хотя известно: каким бы об разом ни были введены категории, воспроизведение проделанных частотных процедур контент-анализа вполне осуществимо. Однако слабым звеном остается выбор единиц анализа и единиц счета.. Для того чтобы избежать априорной категоризации, в качестве единиц анализа зарубежные социологи проводят категоризацию с помощью тематических словарей или каталогов. Для подобных целей еще в конце 1960-х гг. предлагалось применять компьютерные программы, в основе которых лежал факторный анализ.
В любом случае в контент-анализе категории выполняют фун кцию, аналогичную абстрактным объектам, которые в теоретичес кой модели предмета исследования (см. разд. I гл. 3) приходится операционализировать, разбивая их на совокупность конкретных терминов и признаков. Роль последних в контент-анализе выпол няют «низшие чины» — слова.
Хотя о единицах анализа мы рассказали раньше, чем о его кате гориях, при построении программы контент-анализа социологи часто идут в обратном порядке — от общего к частному, от катего рий к единицам. Подобная логика совпадает с методологией раз работки программы фундаментального исследования в социологии.
В таком случае методолого-методическая часть программы раз бивается на три этапа. Первым шагом будет определение систе мы категорий анализа, вторым — соответствующая им единица анализа текста, а третьим — установление единиц счета, т.е. ко личественной меры единиц анализа (их еще называют индикато рами контент-анализа), позволяющей регистрировать частоту (ре гулярность) появления признака категории анализа в тексте.
Единица счета — количественная характеристика единицы анализа, она фиксирует регулярность, с которой встречается в тексте та или иная смыс ловая единица.
575
За единицу счета могут быть приняты: 1) частота появления признака категории анализа; 2) объем внимания, уделяемого категории анализа в содержании текста. Для установления объема внимания могут быть учтены количество печатных знаков, абзацы, площадь текста, выраженная в физических пространственных единицах. Для газетных и других стандартных текстов — ширина колонки и высота высказывания. Для текстов, передаваемых устно, в качестве единицы счета могут использоваться единицы времени.
Единицами счета могут быть число определенных слов или их сочетаний, частота упоминаний слов, количество строк, печатных знаков, страниц, абзацев, авторских листов, площадь текста, выраженная в физических величинах, эфирное время и многое другое. Единицы счета «могут и совпадать и не совпадать с единицами анализа. В первом случае квантификация сводится к определению частот упоминания выделенной смысловой единицы по отношению к другим категориям (как в случае построения индекса самостоятельности инженеров). Во втором случае единицей счета избирают физическую протяженность или площадь текстов, заполненную смысловыми единицами: число строк, абзацев, квадратных миллиметров, знаков, колонок — в печатных текстах; длительность трансляции по радио или телевидению, метраж пленки при магнитофонных записях»23.
Процедура контент-анализа включает в себя применение стандартных правил выделения в изучаемом тексте однотипных единиц анализа (счета, наблюдения) и подсчет частоты встречаемости этих единиц в выборке (количество документов, подвергаемых непосредственному счету) как в абсолютных (число раз), так и в относительных (проценты) величинах. Обязательный момент в такой процедуре — использование математико-статистических методов счета. Ведь основу контент-анализа составляет подсчет встречаемости некоторых компонентов в анализируемом информационном массиве, дополняемый выявлением статистических взаимосвязей и анализом структурных связей между ними, а также снабжением их теми или иными количественными или качественными характеристиками.
Связь между категориями устанавливают методом совместной встречаемости (сооссигепсе) слов различных категорий: для каждого предложения текста выясняют, слова каких категорий в нем встречаются. После этого легко подсчитать обычный коэффициент корреляции, который выражает силу связи между категориями и знак этой связи.
576
Контент-анализ текстов с использованием категорий иногда называют концептуальным анализом. Сфера его применения до вольно широка. С его помощью решают два основных типа задач:
1. Есть два или более текстов, которые необходимо сравнить в отношении нагрузки на определенные категории. Например, за дача выяснить, какое внимание уделяют две разные газеты опре деленным темам. Если эти газеты рассчитаны на одну аудиторию, то существенное различие в частотах позволит судить о различи ях в политике, проводимой людьми, стоящими за ними.
2. Задача отслеживания динамики изменения нагрузки на опре деленные категории. Например, выяснить частоту упоминания темы внешнего долга России в фиксированном наборе центральных газет на протяжении какого-то времени и соотнести ее с колебаниями курса доллара путем простого корреляционного анализа.
Из истории разведки известно, как по изменению в специаль ной литературе частоты упоминания определенных научных тем и фамилий ученых делались достоверные выводы об успехах, до стигнутых в конкретных областях исследований.
Относительные частоты употребления тех или иных единиц анализа позволяют сравнивать два и более текстов, делать важные| теоретические обобщения. Например, в тексте выступления депу тата Думы можно оценить уровень агрессивности, для чего кон струируется категория агрессивно окрашенной лексики. После этого сравнивают текст выступления данного депутата с другими выступлениями и выявляют, кто агрессивнее. Можно сравнивать данный текст не с другими текстами, а с некой нормой, своеоб разной нулевой отметкой агрессивности. Мы получим ее, если выясним относительную частоту употребления агрессивно окра шенных слов средним носителем русского языка. Помощь в этом могут оказать частотные словари. Сравнивая относительную час тоту употребления агрессивно окрашенной лексики в выступле нии депутата с частотой ее употребления средним носителем рус ского языка, можно сделать вывод о степени агрессивности. Но и это еще не все. Небольшие отклонения частот в большую или меньшую сторону могут быть следствием случайных колебаний. На вопрос о значимости отклонения частот позволяет ответить статистическая оценка, известная под названием z—score и вычис ляемая по формуле (N— .^/(стандартное отклонение), где N— ко личество слов данной категории, реально встретившихся в тексте, а Е— ожидаемое число вхождений слов данной категории в текст.
577
Величина Е вычисляется путем умножения нормальной частоты категории на число слов в анализируемом тексте25.
Квантификация данных в контент-анализе проводится самыми разными способами. Помимо анализа частотного распределения к ним относятся анализ различного рода корреляций между переменными, ассоциаций, анализ сопряженности, кластерный анализ, их оценка по тем или иным градуированным качественным шкалам.
После квантификации, т.е. перевода данных в числовую форму, их математическая и, в частности, статистическая обработка может осуществляться многими разными программными средствами, в том числе стандартными статистическими пакетами типа SPSS. При анализе текста и последующем сохранении результатов этого анализа в базах данных могут использоваться специальные программы, предназначенные для целей лингвистических исследований.
Аналитические исследования СМИ предполагают проведение статистического и качественного анализа информации за конкретный период. В частности, составляется полный статистический отчет упоминаний в СМИ интересующей клиента темы с отражением характера упоминаний (положительные, нейтральные или негативные отзывы). На основе этих данных выявляются тенденции, разрабатываются рекомендации по ответной реакции в СМИ и улучшению имиджевой ситуации.
В настоящее время различается четыре методологии контент-анализа: грамматический (лингвистический) — по размеру абзацев, длине фраз, порядку слов в предложении, метрическому составу и другим формальным признакам языка; семантический (социологический) — по экспертным оценкам содержания; документа-листический (кибернетический) — по параметрам языка, текста и документа как сообщения (дескрипторы и их нагрузка, компактность, информационная плотность, аспектность, проточность, физический и информационный объемы, информационная емкость и информативность); цитационный — анализ библиографических ссылок в научной литературе26.
Проведение контент-анализа требует предварительной разработки ряда исследовательских инструментов. Разные специалисты и источники называют неодинаковое число таких документов. По
578
мнению СИ. Григорьева и Ю.Е. Растова, их должно быть пять: 1) классификатор контент-анализа; 2) протокол итогов анализа (он еще называется — бланк контент-анализа); 3) регистрационная кар-точка (кодировальная матрица); 4) инструкция исследователю, не посредственно занимающемуся регистрацией и кодировкой единиц счета; 5) каталог (список) проанализированных документов. Классификатором контент-анализа авторы называют общую таблицу , в которую сведены все категории (и подкатегории) анализа и единицу,в цы анализа. Ее основное предназначение — предельно четко зафик-сировать то, в каких единицах выражается каждая категория, ис пользуемая в исследовании. Классификатор уподобляется социоло гической анкете, где категории анализа играют роль вопросов,а единицы анализа — ответов, и считается основным методическим документом контент-анализа, предопределяющим содержание дру гих документов. Протокол (бланк) контент-анализа содержит: во первых, сведения о документе (его авторе, времени издания, объе ме и т.п.); во-вторых, итоги его анализа (количество случаев упот ребления в нем определенных единиц анализа и следующие отсюда выводы относительно категорий анализа). Протоколы заполняют ся, как правило, в закодированном виде, но не ради сохранения тайны контент-анализа, а исходя из желания на одном листе бума ги уместить всю информацию о документе (так удобнее сопостав лять друг с другом итоги анализа разных документов). Регистра ционная карточка представляет собой кодировальную матрицу, В которой отмечается количество единиц счета, характеризующих единицы анализа. Протокол контент-анализа каждого конкретно го документа заполняется на основе подсчета данных всех pегист рационных карточек, относящихся к этому документу.
По другим источникам, главными среди методических доку ментов контент-анализа являются кодировочная карточка (коди фикатор, код, бланк кодировки) и инструкция кодировщику.
Первый нормативный документ принимает разные формы, может быть менее и более подробным, но в любом своем виде он представляет собой таблицу.
В более подробном варианте в кодировочной карточке, т.е. специальной таблице, перечислены единицы наблюдения с необ ходимой степенью дробности, указаны правила их регистрации и оставлено место для записей результатов наблюдений (подсчета
579
числа упоминаний и других показателей). В ней указываются также общие характеристики анализируемого текста (название источника, дата и номер анализируемого экземпляра, название анализируемой публикации, автор, жанр). В сокращенном варианте, иногда называемом бланком кодировки, количество сообщаемых сведений меньше. Бланк кодировки составляется в соответствии со схемой операциональных понятий, содержит единицы анализа и все элементы описания проблемной ситуации, устанавливает однозначное соответствие между лексикой текста и кодами, над которыми производятся вычислительные операции.
В качестве примера приведем фрагмент бланка, с помощью которого можно осуществить кодирование29 (рис. 2.1).
Кодирование данных при контент-анализе обычно осуществляется с помощью достаточно простых анкет или компьютерных программ, в которых фиксируется каждое появление в анализируемом тексте искомой единицы. Операции кодирования проводит кодировщик — сотрудник, который работает с текстом, фиксирует частоту употребления единиц счета.
Инструкция кодировщику. Ее содержанием выступает описание правил соотнесения единиц текста с перечнем категорий анализа, а также правил регистрации в Кодировочной карточке. Примером может служить список категорий и элементов регламентации, который называют кодификатором (кодом). Карточка содержит не только список наблюдаемых индикаторов, но и данные в документе, который подвергся кодированию (например, номер или название подразделения, в котором используется данная инструкция, ее объем в страницах, число разделов и т.п.).
Инструкция кодировщику содержит обычно не только правила поиска и регистрации единиц текста, соответствующих делениям кодификатора, но и примеры таких единиц, слова, высказывания, суждения и т.п.
После разработки инструкция проверяется на однозначность ее понимания различными кодировщиками. Цель — выяснить, помогает ли инструкция кодировщикам получать единообразные, стандартные результаты, не зависящие от субъективных особенностей восприятия кодировщиков. Делается это следующим образом: один и тот же текст дается группе кодировщиков, которые работают с едиными кодификаторами (кодировочными карточками) и инструкциями. Затем проверяется совпадение результатов. Случаи расхождения результатов выясняются, обсуждаются их причины. Те указания инструкции, которые не обеспечивают од-580
нозначного восприятия кодировщиками, уточняются, после чего проводится новая проверка инструкции до получения необходимого уровня совпадения результатов.
| № | Признак, градация признака | Коды | |
| 1. | Тип автора | ||
| — один человек | 001 | ||
| —два и более человека | 002 | ||
| — ситуация не ясна | 003 | ||
| 2. | Группа, к которой принадлежит автор | ||
| — неформальная группа (семья, друзья и т.д.) | 004 | ||
| — формальная группа (производственная группа, учебный | 005 | ||
| коллектив и т.д.) | |||
| — ситуация не ясна | 006 | ||
| 3. | Пол автора | ||
| — автор (авторы)—мужчина (мужчины) | 007 | ||
| — автор (авторы)—женщина (женщины) | 008 | ||
| — смешанная группа | 009 | ||
| — ситуация не ясна | 010 | ||
| 4. | Возраставтора | ||
| — молодежь (до 30 лет) | 011 | ||
| —лица среднего возраста (30—49 лет) | 012 | ||
| —лица старшего возраста (свыше 50 лет) | 013 | ||
| — смешанная группа | 014 | ||
| — ситуация не ясна | 015 | ||
| 5. | Количество проблем, рассматриваемых в письме | ||
| —одна | 016 | ||
| -две | 017 | ||
| — более двух | 018 | ||
| 6. | Локальность проблем, поднятых в письме | Проблема№1 | Проблема Ns2 |
| — мир | 019 | 024 | |
| — страна | 020 | 025 | |
| — город | 021 | 026 | |
| —предприятие, учреждение | 022 | 027 | |
| — частная жизнь | 023 | 028 | |
| 7. | Сфера общественной жизни (страна, область, город) | ||
| —промышленность | 029 | 035 | |
| —сельское хозяйство | 030 | 036 | |
| —транспорт | 031 | 037 | |
| —строительство | 032 | 038 | |
| — вопросы распределения жилья | 033 | 039 | |
| — вопросы социального обеспечения | 034 | 040 | |
| 8. | Типы суждений | ||
| —суждение оценочное | 041 | 045 | |
| —суждение конструктивное | 042 | 046 | |
| —суждение аналитическое | 043 | 047 | |
| —другие типы суждения | 044 | 048 |
Рис. 2.1. Фрагмент бланка
581
В контент-анализе изучение любого текста проливает свет на его автора и те социальные условия, в которых создавался текст. В результате обнаруживаются авторство анонимной работы и плагиат, определяются жанр и авторский стиль, степень новизны и достоверности и даже характер интеллекта автора. Отсюда принадлежащее А.Г. Здравомыслову полушутливое определение контент-анализа как «научно обоснованного метода чтения между строк».
Контент-анализ позволяет социологу изучать более глубокий слой социальных явлений, чем это доступно другим методам. Чтобы обнаружить явление, стоящее за суждениями, в социологии ищут связанные с ним слова. А для понимания их важности сравнивают с другими основополагающими понятиями. События в Косове и вторая чеченская война изменили политический и культурный климат России. Они отразились в публикациях СМИ и электронной базе Интернета. Анализ частоты употребления слов «Косово», «беженцы», «албанцы», «Югославия», «НАТО» и подобных им демонстрирует, насколько было взбудоражено общественное сознание россиян этими событиями. Контент-анализ электронных изданий, проведенный А. Костинским, выявил удивительную вещь: в период косовского кризиса слово «НАТО» встречалось 132 раза на 100 тыс. слов, США — более 80. Для сравнения: даже сумма частот употребления слов «Чечня», «чечен», «чеченцы», «чеченская» ни в первую, ни во вторую чеченскую войну не превышала 16 слов на 100 тыс. Создается впечатление, будто НАТО и США — главная забота россиян. Размытый прежде враждебный образ Запада сосредоточился для нас в этих двух понятиях30.
Если контент-анализ применяется впервые, то допускаются многочисленные ошибки. Среди них специалисты31 отмечают наиболее типичные просчеты:
Анализ документов опережает разработку исследовательской программы.
Анализируются документы, не связанные с гипотезами исследования (имеющие сходство с темой исследования лишь по названию).
Не проверена подлинность документа.
Не уточнено его авторство.
Неполно учтено его предназначение.
Категории анализа не определены до такой степени, которая позволяет четко различать смысловые единицы текста документа. 582
Категории анализа не субординарны и не приведены в соответствие с теми дефинициями и операционализирующими их терминами, которые зафиксированы в программе исследования.
Категории анализа несопоставимы со смыслом и языком текста анализируемого документа.
Единицы анализа характеризуют категории анализа лишь внешне, а не по существу, поэтому единицы анализа не позволяют идентифицировать содержание документа в полном соответствии с категориями анализа.
Анализ документа ведется без предварительной подготовки всего комплекса методических инструментов.
Классификатор имеет недочеты, составлен с нарушением правил логики.
Регистраторы (кодировщики) не получили должной методической подготовки.
Инструкция по регистрации и кодировке недостаточно полная, составлена исследователем, который сам предварительно не апробировал инструментарий.
Кодировка не соответствует программе математической обработки данных исследования.
Результаты контент-анализа не перепроверены информацией, собранной иными методами.
Контент-анализ прессы требует сравнительно больших затрат времени и средств, поэтому может использоваться и метод экспресс-анализа. В его основе лежит количественный подсчет содержательных элементов текста (факт, конфликт, аргумент, тема, обобщение), а также учет качественных характеристик публикаций (соответствие цели, информативность, актуальность, доказательность, конструктивность). Как и при контент-анализе, эти характеристики текста кодируются, обозначаются определенной цифрой, и затем при чтении текста исследователь их фиксирует32.