Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
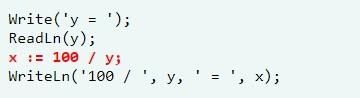
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
#Руководства
- 30 июн 2020
-

14
Что такое баги, ворнинги и исключения в программировании
Разбираемся, какие бывают типы ошибок в программировании и как с ними справляться.
vlada_maestro / shutterstock

Пишет о программировании, в свободное время создаёт игры. Мечтает открыть свою студию и выпускать ламповые RPG.
Многим известно слово баг (англ. bug — жук), которым называют ошибки в программах. Однако баг — это не совсем ошибка, а скорее неожиданный результат работы. Также есть и другие термины: ворнинг, исключение, утечка.
В этой статье мы на примере C++ разберём, что же значат все эти слова и как эти проблемы влияют на эффективность программы.
Словом «ошибка» (англ. error) можно описать любую проблему, но чаще всего под ним подразумевают синтаксическую ошибку — некорректно написанный код, который даже не скомпилируется:
//В конце команды забыли поставить точку с запятой (;)
int a = 5
Компилятор тут же скажет, что в коде ошибка и скорее всего не хватает запятой или точки с запятой.
Также существуют ворнинги (англ. warning — предупреждение). Они не являются ошибками, поэтому программа всё равно будет собрана. Вот пример:
int main()
{
//Мы создаём две переменные, которые просто занимают память и никак не используются
int a, b;
}
Мы можем попросить компилятор показать нам все предупреждения с помощью флага -Wall:
Предупреждения не являются чем-то критичным, но могут иметь негативные последствия. Например, ваша программа будет использовать больше памяти, чем должна. Так как C++ нужен в том числе и для разработки высоконагруженных систем, этого допускать нельзя.

После восклицательного знака в треугольнике — количество предупреждений
Третий вид ошибок — ошибки сегментации (англ. segmentation fault, сокр. segfault, жарг. сегфолт). Они возникают, если программа пытается записать что-то в ячейку, недоступную для записи. Например:
//Создаём константный массив символов
const char * s = "Hello World";
//Если мы попытаемся перезаписать значение константы, компилятор выдаст ошибку
//Но с помощью указателей мы можем обойти её, поэтому программа успешно скомпилируется
//Однако во время работы она будет выдавать ошибку сегментации
* (char *) s = 'H';
Вот результат работы такого кода:
Мы выяснили, что баг — это не совсем ошибка, а скорее неожиданное поведение программы или результат такого поведения. Баги могут быть чем-то забавным или неприятным. Например, как в играх:
Но они могут привести и к более серьёзным последствиям. Если неправильно спроектировать работу многопоточного приложения, то потоки будут постоянно опережать друг друга. Например, сообщение об ошибке из одного потока может опоздать на миллисекунду, из-за чего второй поток подумает, что никакой ошибки не было, и продолжит работу.
Если ваш код приводит в действие какое-нибудь потенциально опасное устройство, то ценой такой ошибки может быть чья-нибудь жизнь. Такое случилось с кодом для аппарата лучевой терапии Therac-25 — как минимум два человека умерло и ещё больше пострадали из-за превышения дозы радиации.
Также во время работы программы могут возникать ситуации, которые мешают корректной работе программы. Например, если вы просите пользователя ввести число, а он вводит строку.
Конвертировать введённое значение не всегда возможно, поэтому функция, которая занимается преобразованием, «выбрасывает» исключение (англ. exception). Это специальное сообщение говорит о том, что что-то идёт не так.
Если разработчик не описывает логику работы программы при вы выбрасывании исключения, то программа аварийно закрывается. Подробнее мы рассказали об этом в статье про ввод и конвертацию в C++.
Одно из самых известных исключений — переполнение стека (англ. stack overflow). В честь него даже назвали сайт, на котором программисты ищут помощь в решении своих проблем.
int main()
{
//Бесконечная рекурсия - одна из причин переполнения стека вызовов
main();
}
Компилятор C++ при этом может выдать ошибку сегментации, а не сообщение о переполнении стека:
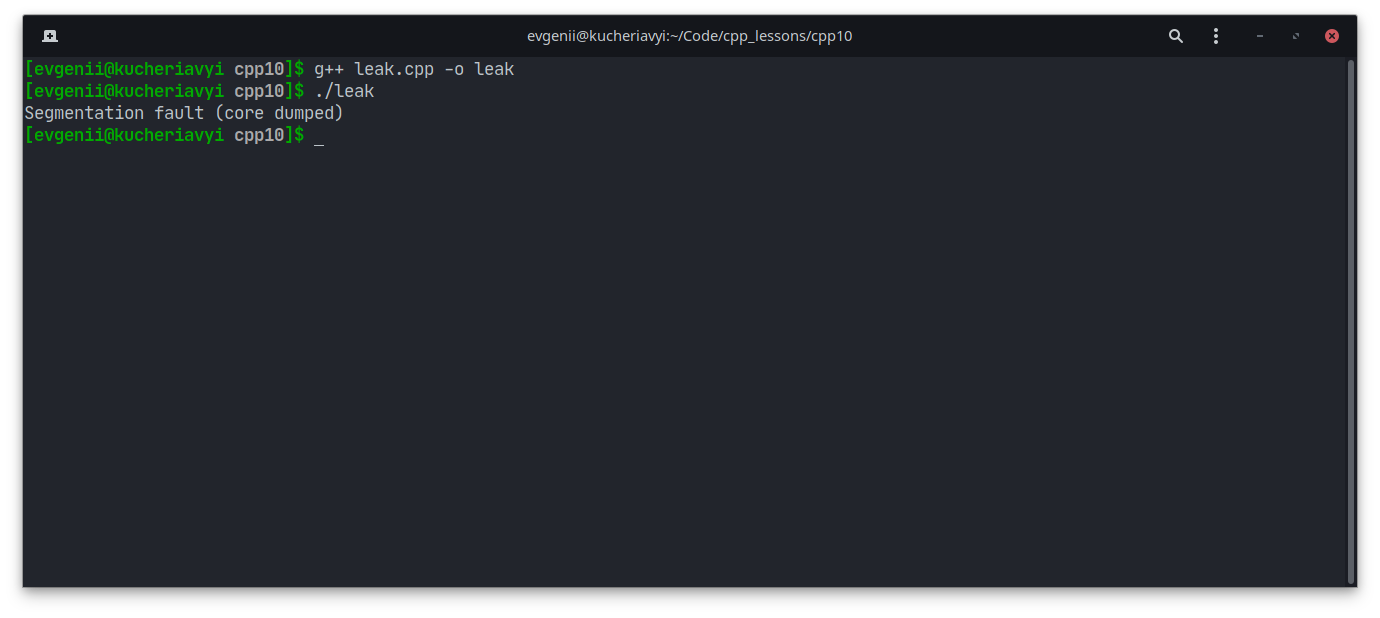
Вот аналогичный код на языке C#:
class Program
{
static void Main(string[] args)
{
Main(args);
}
}
Однако сообщение в этот раз более конкретное:
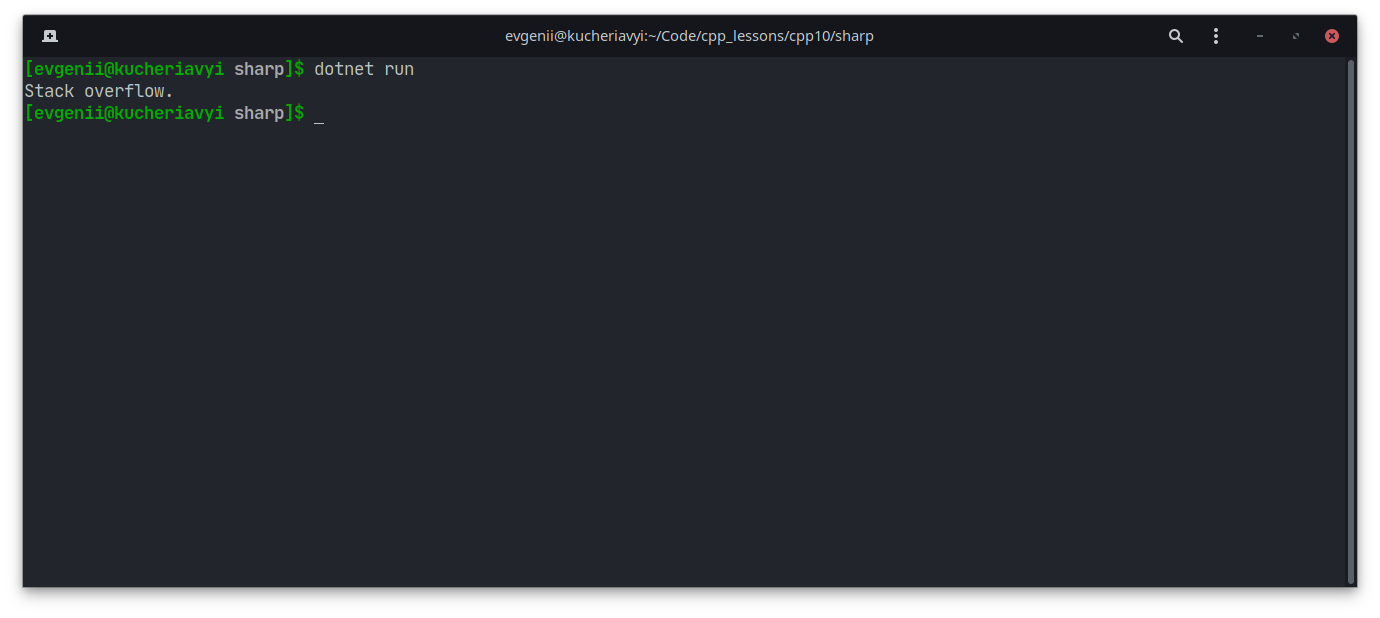
В обоих случаях программа завершается, потому что не может дальше корректно работать.
Похожая ситуация — переполнение буфера (англ. buffer overflow). Она происходит, когда записываемое значение больше выделенной области в памяти.
//Пробуем записать в переменную типа int значение, которое превышает лимит
//Константа INT_MAX находится в библиотеке climits
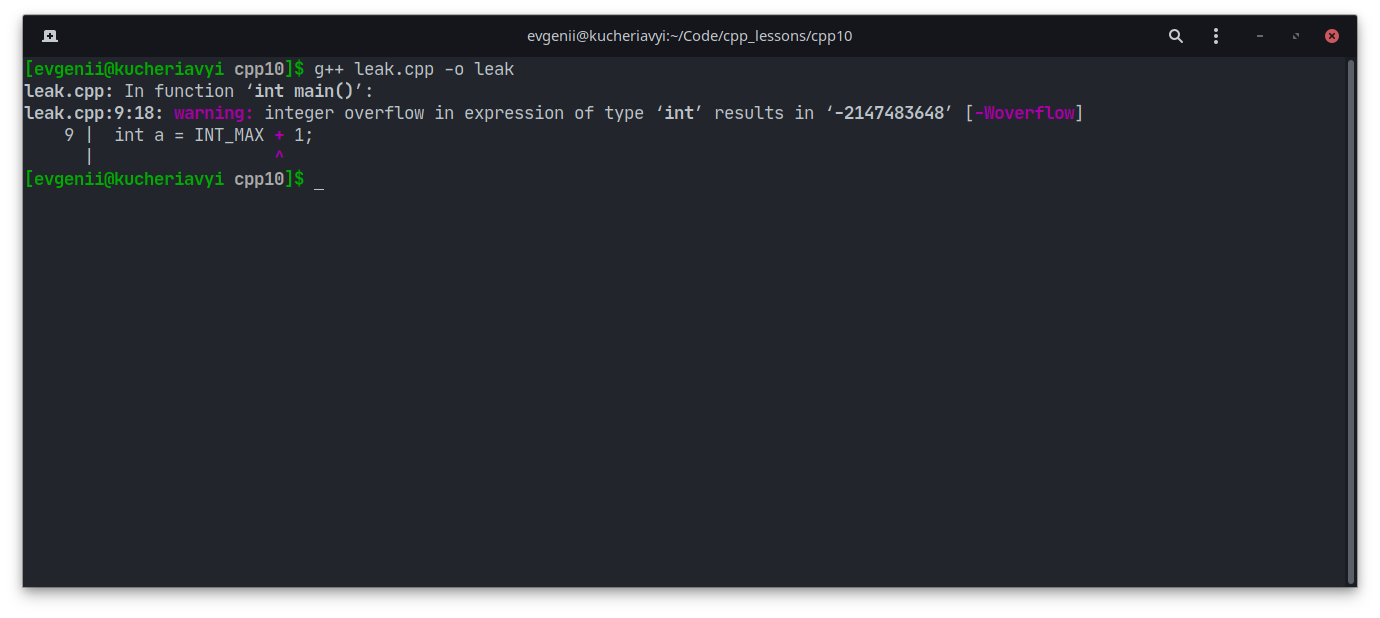
int a = INT_MAX + 1;
Обратите внимание, что мы получили предупреждение об арифметическом переполнении (англ. integer overflow):
Тем не менее программа скомпилировалась. Если же такая ситуация возникнет во время вычислений, то мы можем не получить предупреждения.
Арифметическое переполнение стало причиной одной из самых дорогих аварий, произошедших из-за ошибки в коде. В 1996 году ракета-носитель «Ариан-5» взорвалась на 40-й секунде полёта — потери оценивают в 360–500 миллионов долларов.
К сожалению, вручную всё это заметить и исправить не получится. Однако существуют различные инструменты и технологии, которые могут помочь.
Один из таких инструментов — отладчик. Он помогает контролировать ход работы программы, чтобы отслеживать разные показатели.
Второй, более эффективный метод — unit-тесты. Они представляют из себя набор описанных ситуаций для каждого компонента программы с указанием ожидаемого поведения.
Например, у вас есть функция sum (int a, int b), которая возвращает сумму двух чисел. Вы можете написать unit-тесты, чтобы проверять следующие ситуации:
| Входные данные | Ожидаемый результат |
|---|---|
| 5, 10 | 15 |
| 99, 99 | 198 |
| 8, -9 | -1 |
| -1, -1 | -2 |
| fff, 8 | IllegalArgumentException |
Если какой-то из этих тестов не пройден, вы узнаете об этом и сможете всё исправить. Это намного быстрее, чем проверять всё вручную.
Ошибок существует слишком много. При этом самые опасные тяжелее обнаружить, что только усугубляет ситуацию.

Научитесь: Профессия Разработчик на C++ с нуля
Узнать больше
“Where there is code, there will be errors”
If you have ever been into programming/coding, you must have definitely come across some errors. It is very important for every programmer to be aware of such errors that occur while coding. In this post, we have curated the most common types of programming errors and how you can avoid them.
1. Syntax errors:
These are the type of errors that occur when code violates the rules of the programming language such as missing semicolons, brackets, or wrong indentation of the code,
Example:
Write a function int fib(int n) that returns Fn. For example, if n = 0, then fib() should return 0. If n = 1, then it should return 1. For n > 1, it should return Fn-1 + Fn-2.
For n = 9
Output: 34
Wrong Implementation of Code for the above Problem Statement:
C++
#include <bits/stdc++.h>
using namespace std;
int fib(int n)
{
if (n <= 1)
return n
return fib(n - 1) + fib(n - 2);
int main()
{
int n = 9;
cout << fib(n);
getchar();
return 0;
}
If we review the above code, we can see that a semicolon (;) is missing after the return statement in the ,fib() function and the closing bracket is also missing for the fib() function.
Below is the screenshot of the error.

2. Logical errors:
These are the type of errors that occurs when incorrect logic is implemented in the code and the code produces unexpected output.
Example:
Find GCD (Greatest Common Divisor) or HCF (Highest Common Factor) of two numbers that is the largest number that divides both of them.
For finding the GCD of two numbers we will first find the minimum of the two numbers and then find the highest common factor of that minimum which is also the factor of the other number.
Wrong Implementation of Code for the above Problem Statement:
C++
#include <iostream>
using namespace std;
int gcd(int a, int b)
{
int result = min(a, b);
while (result > 0) {
if (a % result != 0 && b % result != 0) {
break;
}
result--;
}
return result;
}
int main()
{
int a = 98, b = 56;
cout << "GCD of " << a << " and " << b << " is "
<< gcd(a, b);
return 0;
}
Output
GCD of 98 and 56 is 55
Expected Output: GCD of 98 and 56 is 14
In the above code, the Output produced by the code and the expected output are different. Hence, we can say that there is a logical error in the above code. If we review the above code, we can see the condition, if (a % result != 0 && b % result != 0) is not correct. It should be if (a % result == 0 && b % result == 0).
3. Runtime errors:
These are the errors caused by unexpected condition encountered while executing the code that prevents the code to compile. These can be null pointer references, array out-of-bound errors, etc.
Example:
C++
#include <iostream>
using namespace std;
int main()
{
int a = 5;
cout << a / 0;
return 0;
}
Below is the error produced by the above code:

4. Time Limit exceeded error:
Time Limit Exceeded error is caused when a code takes too long to execute and execution time exceeds the given time in any coding contest. TLE comes because the online judge has some restrictions that the code for the given problem must be executed within the given time limit.
How to Overcome Time Limit Exceed(TLE)?
Example:
Given two arrays, arr1 and arr2 of equal length N, the task is to find if the given arrays are equal or not. Two arrays are said to be equal if: both of them contain the same set of elements, arrangements (or permutations) of elements might/might not be the same. If there are repetitions, then counts of repeated elements must also be the same for two arrays to be equal.
Expected Time Complexity: O(N)
One possible approach can be to Sort both arrays, then linearly compare the elements of both arrays. If all are equal then return true, else return false. The time complexity for this approach will be O(N*log(N)). But the expected time complexity is O(N), so this code will give Time Limit Exceeded error. In online judges, we need to write code that executes within a given time limit. Hence, we need to optimize the approach.
Another possible approach can be to store the count of all elements of arr1[] in a hash table. Then traverse arr2[] and check if the count of every element in arr2[] matches with the count of elements of arr1[]. The time complexity for this approach will be O(N). Hence code for this approach will not give a time limit error and will get submitted successfully.
Below is the code for the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
bool areEqual(int arr1[], int arr2[], int N, int M)
{
if (N != M)
return false;
unordered_map<int, int> mp;
for (int i = 0; i < N; i++)
mp[arr1[i]]++;
for (int i = 0; i < N; i++) {
if (mp.find(arr2[i]) == mp.end())
return false;
if (mp[arr2[i]] == 0)
return false;
mp[arr2[i]]--;
}
return true;
}
int main()
{
int arr1[] = { 3, 5, 2, 5, 2 };
int arr2[] = { 2, 3, 5, 5, 2 };
int N = sizeof(arr1) / sizeof(int);
int M = sizeof(arr2) / sizeof(int);
if (areEqual(arr1, arr2, N, M))
cout << "Yes";
else
cout << "No";
return 0;
}
Last Updated :
24 May, 2023
Like Article
Save Article
Готовая программа не всегда работает как надо. Бывает, возникают баги, предупреждения, исключения. В итоге программа зависает, дает сбой или вылетает. Но это не конец света. Любую ошибку в коде можно исправить, если знать, почему она возникла.
Программная ошибка: что это и почему возникает
Программная ошибка — это дефект в коде. Из-за него программа сбоит или выдает неверные результаты. Некоторые ошибки серьезные — например, блокируют логин и пароль, из-за чего пользователь не может попасть в личный кабинет. А другие незаметны. Некоторое время программа работает как будто бы исправно — и только потом начинает глючить.
Ошибка в программировании — это зачастую ошибки разработчиков, которые находят тестировщики. Запускают разные тесты и отладку, чтобы определить источники проблемы.
Научитесь находить ошибки в приложениях и на сайтах до того, как ими начнут пользоваться клиенты. Для этого освойте профессию «Инженер по тестированию». Изучать язык программирования необязательно. Тестировщик работает с готовыми сайтами, приложениями, сервисами, а не с кодом. В программе от Skypro: четыре проекта для портфолио, практика с обратной связью, все основные инструменты тестировщика.
Ошибки часто называют багами, но подразумевают под ними разное, например:
❗ Ворнинги, или предупреждения. Возникают, когда программа начинает вести себя не так, как задумывалось. Не являются критичными ошибками. Программа с ворнингами работает, но с аномалиями.
❗ Исключения. Это не ошибки, а особые ситуации, которые нужно обработать.
❗ Синтаксические ошибки. Это ошибка в программе, связанная с написанием кода. Пример: программист забыл поставить точку или неверно написал название оператора. Если не исправить, код программы не запустится, а останется просто текстом.
Классификация багов
У багов есть два атрибута — серьезности (Severity) и приоритета (Priority). Серьезность касается технической стороны, а приоритет — организационной.
🚨 По серьезности. Атрибут показывает, как сильно ошибка влияет на общую функциональность программы. Чем выше значение атрибута, тем хуже.
По серьезности баги классифицируют так:
- Blocker — блокирующий баг. Программа запускается, но спустя время баг останавливает ее выполнение. Чтобы снова пользоваться программой, блокирующую ошибку в коде устраняют.
- Critical — критический баг. Нарушает функциональность программы. Появляется в разных частях кода, из-за этого основные функции не выполняются.
- Major — существенный баг. Не нарушает, но затрудняет работу основного функционала программы либо не дает функциям выполняться так, как задумано.
- Minor — незначительный баг. Слабо влияет на функционал программы, но может нарушать работу некоторых дополнительных функций.
- Trivial — тривиальный баг. На работу программы не влияет, но ухудшает общее впечатление. Например, на экране появляются посторонние символы или всё рябит.
🚦 По приоритету. Атрибут показывает, как быстро баг необходимо исправить, пока он не нанес программе приличный ущерб. Бывает таким:
- Top — наивысший. Такой баг — суперсерьезный, потому что может обвалить всю программу. Его устраняют в первую очередь.
- High — высокий. Может затруднить работу программы или ее функций, устраняют как можно скорее.
- Normal — обычный. Баг программу не ломает, просто где-то что-то будет работать не совсем верно. Устраняют в штатном порядке.
- Low — низкий. Баг не влияет на программу. Исправляют, только если у команды есть на это время.
Типы ошибок в программе
🧨 Логические. Приводят к тому, что программа зависает, работает не так, как надо, или выдает неожиданные результаты — например, не записывает файл, а стирает.
Логические ошибки коварны: их трудно обнаружить. Программа выглядит так, будто в ней всё правильно, но при этом работает некорректно. Чтобы победить логические ошибки, специалист должен хорошо ориентироваться в коде программы.
🧨 Синтаксические. Это опечатки в названиях операторов, пропущенные запятые или кавычки. Безобидные ошибки: их обнаруживают и подсвечивают в коде компиляторы, а программисту остается исправить.
🧨 Взаимодействия. Это ошибка в участке кода, который отвечает за взаимодействие с аппаратным или программным окружением. Такая ошибка возникает, например, если неправильно использовать веб-протоколы. Исправляется элементарно: разработчик переписывает нужный кусок кода.
🧨 Компиляционные. Любая программа — это текст. Чтобы он заработал как программа, используют компилятор. Он преобразует программный код в машинный, но одновременно может вызывать ошибки.
Компиляционные баги появляются, если что-то не так с компилятором или в коде есть синтаксические ошибки. Компилятор будто ругается: «Не понимаю, что тут написано. Не знаю, как обработать».
🧨 Ошибки среды выполнения. Возникают, когда программа скомпилирована и уже выглядит как файл — жми и работай. Юзер запускает файл, а программа тормозит и виснет. Причина — нехватка ресурсов, например памяти или буфера.
Такой баг — ошибка разработчика. Он не предвидел реальные условия развертывания программы. Теперь ему надо вернуться в исходный код и поправить фрагмент.
🧨 Арифметические. Бывает, в коде есть числовые переменные и математические формулы. Если где-то проблема — не указаны константы или округление сработало не так, возникает баг. Надо лезть в код и проверять математику.

Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
Что такое исключения в программах
Это механизм, который помогает программе обрабатывать нестандартную ситуацию и при этом не вылетать. Идеально, если программист предусмотрел все возможные ситуации. Но так бывает редко, поэтому лучше использовать специальный обработчик. Он обработает исключения так, что программа продолжит работать.
Как это происходит:
- Когда программист кодит, то продумывает, в какой части программы может вылезти ошибка.
- В этой части пишет специальный фрагмент, который предупредит компьютер, что ошибка — вполне ожидаемое явление и резко обрывать программу не нужно.
- Когда юзер запустит программу и появится ошибка, компьютер увидит заранее подготовленное предупреждение программиста. Продолжит выполнять алгоритм так, словно никакого бага и не было.
Исключения бывают программными и аппаратными:
- Аппаратные создает процессор. К ним относят деление на ноль, выход за границы массива, обращение к невыделенной памяти.
- Программные создает операционка и приложения. Возникают, когда программа их инициирует: аномальная ситуация возникла — программа создала исключение.
Как контролировать баги в программе
🔧 Следите за компилятором. Когда компилятор преобразует текст программы в машинный код, то подсвечивает в нём сомнительные участки, которые способны вызывать баги. Некоторые предупреждения не обозначают баг как таковой, а только говорят: «Тут что-то подозрительное». Всё подозрительное надо изучать и прорабатывать, чтобы не было проблемы в будущем.
🔧 Используйте отладчик. Это программа, которая без участия айтишника проверяет, исправно ли работает алгоритм. В случае чего сообщает об ошибках. Например, отладчик используют для построчного выполнения программы. Вместе с тем проверяют значения переменных: фактические сравнивают с ожидаемыми. Если что-то не сходится, ищут баги и исправляют.
🔧 Проводите юнит-тесты. Это когда разработчик или тестировщик описывает ситуации для каждого компонента и указывает, к какому результату должна привести программа. Потом запускает проверку. Если результат не совпадает с ожидаемым, появляется предупреждение. Дальше программисты находят и устраняют проблему.
Ключевое: что такое ошибки в программировании
- Ошибка в программировании — это дефект кода, баг, который может вызывать в программе сбои и неожиданное поведение.
- По серьезности баги делятся на блокирующие, критические, существенные, незначительные, тривиальные. По приоритету — на наивысший, высокий, обычный, низкий.
- Ошибки в коде могут быть разными, например связанные с логикой программы. Или с математическими вычислениями — логические. Еще бывают синтаксические, ошибки взаимодействия, компиляционные и ошибки среды выполнения.
- Некоторые ошибки помогают ловить обработчики исключений.
- Чтобы находить ошибки в коде, тестировщики используют компиляторы, отладчики и пишут юнит-тесты.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки, ошибки в программировании , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок в программировании
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки кода в програмировании
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки программного кода
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке. Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции в выявлении ошибок в пограммировании
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции использемый при выявлении ошибок
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки программного кода
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация и виды ошибок в программировании
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
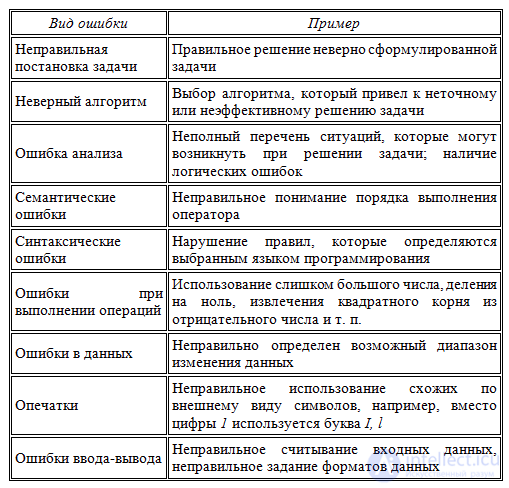
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
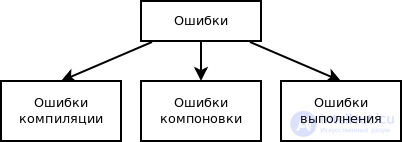
Классификация ошибок по этапу обработки программы
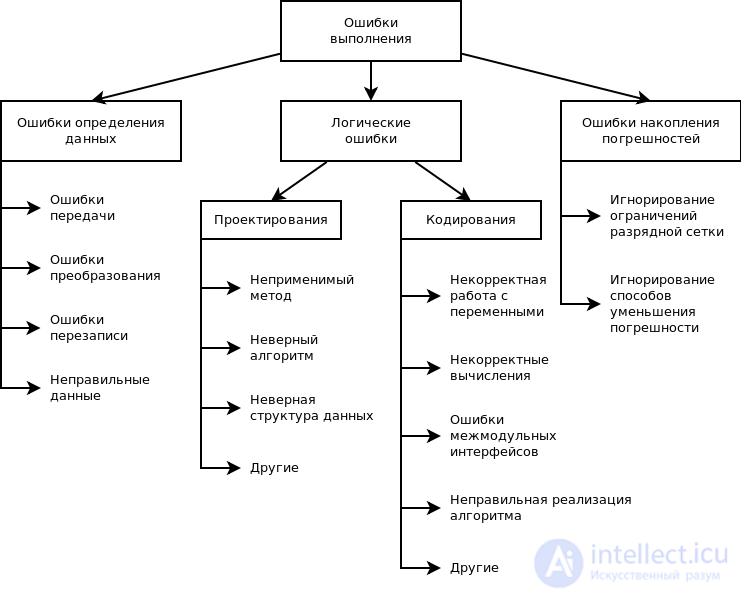
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs ,
- основы qa , тестовые артефакты ,
- метрики по обеспечению качества , метрики тестирования ,
- баг , ошибки в программировании ,
- причины появления ошибок , ошибки ,
- try-catch , исключения ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
Выводы из данной статьи про виды ошибок программного обеспечения указывают на необходимость использования современных методов для оптимизации систем. Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки, ошибки в программировании
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.