При проведении регрессионного анализа
основная трудность заключается в том,
что генеральная дисперсия случайной
ошибки является неизвестной величиной,
что вызывает необходимость в расчёте
её несмещённой выборочной оценки.
Несмещённой оценкой дисперсии(или
исправленной дисперсией) случайной
ошибки линейной модели парной регрессии
называется величина, рассчитываемая
по формуле:
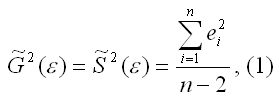
где n
– это объём выборочной совокупности;
еi– остатки регрессионной модели:
![]()
Для линейной модели множественной
регрессии несмещённая оценка дисперсии
случайной ошибки рассчитывается по
формуле:

где k
– число оцениваемых параметров модели
регрессии.
Оценка матрицы ковариаций случайных
ошибок Cov(ε) будет являться оценочная
матрица ковариаций:
![]()
где In
– единичная матрица.
Оценка дисперсии случайной
ошибки модели регрессии распределена
по ε2(хи-квадрат)
закону распределения с (n-k-1)
степенями свободы.
Для доказательства несмещённости оценки
дисперсии случайной ошибки модели
регрессии необходимо доказать
справедливость равенства
![]()
Доказательство. Примем без
доказательства справедливость следующих
равенств:

где G2(ε)
– генеральная дисперсия случайной
ошибки;
S2(ε)– выборочная дисперсия случайной
ошибки;
![]()
– выборочная оценка дисперсии
случайной ошибки.
Тогда:

т. е.
![]()
что и требовалось доказать.
Следовательно, выборочная оценка
дисперсии случайной ошибки
![]()
является несмещённой оценкой
генеральной дисперсии случайной ошибки
модели регрессии G2(ε).
При условии извлечения из
генеральной совокупности нескольких
выборок одинакового объёма n
и при одинаковых значениях объясняющих
переменных х,
наблюдаемые значения зависимой переменной
у будут случайным образом колебаться
за счёт случайного характера случайной
компоненты β.
Отсюда можно сделать вывод, что будут
варьироваться и зависеть от значений
переменной у значения оценок коэффициентов
регрессии и оценка дисперсии случайной
ошибки модели регрессии.
Для иллюстрации данного утверждения
докажем зависимость значения МНК-оценки
![]()
от величины случайной ошибки
ε.
МНК-оценка коэффициента β1 модели
регрессии определяется по формуле:

В связи с тем, что переменная
у зависит от случайной компоненты ε
(yi=β0+β1xi+εi), то ковариация
между зависимой переменной у
и независимой переменной х
может быть представлена следующим
образом:
![]()
Для дальнейших преобразования используются
свойства ковариации:
1) ковариация между переменной
х и
константой С
равна нулю: Cov(x,C)=0,
C=const;
2) ковариация
переменной х
с самой собой равна дисперсии этой
переменной: Cov(x,x)=G2(x).
Исходя из указанных свойств ковариации,
справедливы следующие равенства:
Cov(x,β0)=0
(β0=const);
Cov(x, β1x)=
β1*Cov(x,x)=
β1*G2(x).
Следовательно, ковариация
между зависимой и независимой переменными
Cov(x,y)
может быть записана как:
Cov(x,y)=
β1G2(x)+Cov(x,ε).
В результате МНК-оценка коэффициента
β1 модели регрессии примет вид:
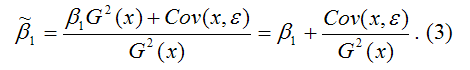
Таким образом, МНК-оценка
![]()
может быть представлена как сумма двух
компонент:
1) константы β1,
т. е. истинного значения коэффициента;
2) случайной ошибки Cov(x,ε),
вызывающей вариацию коэффициента модели
регрессии.
Однако на практике подобное разложение
МНК-оценки невозможно, потому что
истинные значения коэффициентов модели
регрессии и значения случайной ошибки
являются неизвестными. Теоретически
данное разложение можно использовать
при изучении статистических свойств
МНК-оценок.
Аналогично доказывается, что МНК-оценка
![]()
коэффициента модели регрессии и
несмещённая оценка дисперсии случайной
ошибки
![]()
могут быть представлены как сумма
постоянной составляющей (константы) и
случайной компоненты, зависящей от
ошибки модели регрессии ε.
Содержание:
Точечные оценки:
Пусть случайная величина имеет неизвестную характеристику а. Такой характеристикой может быть, например, закон распределения, математическое ожидание, дисперсия, параметр закона распределения, вероятность определенного значения случайной величины и т.д. Пронаблюдаем случайную величину n раз и получим выборку из ее возможных значений 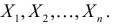
Существует два подхода к решению этой задачи. Можно по результатам наблюдений вычислить приближенное значение характеристики, а можно указать целый интервал ее значений, согласующихся с опытными данными. В первом случае говорят о точечной оценке, во втором – об интервальной.
Определение. Функция результатов наблюдений 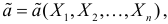
Для одной и той же характеристики можно предложить разные точечные оценки. Необходимо иметь критерии сравнения оценок, для суждения об их качестве. Оценка 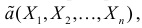 как функция случайных результатов наблюдений
как функция случайных результатов наблюдений 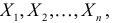 сама является случайной величиной. Значения
сама является случайной величиной. Значения 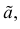 найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики
найденные по разным сериям наблюдений, могут отличаться от истинного значения характеристики 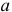 в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
в ту или другую сторону. Естественно потребовать, чтобы оценка систематически не завышала и не занижала оцениваемое значение, а с ростом числа наблюдений становилась более точной. Формализация названных требований приводит к следующим понятиям.
Определение. Оценка называется несмещенной, если ее математическое ожидание равно оцениваемой величине: 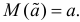 В противном случае оценку называют смещенной.
В противном случае оценку называют смещенной.
Определение. Оценка называется состоятельной, если при увеличении числа наблюдений она сходится по вероятности к оцениваемой величине, т.е. для любого сколь угодно малого 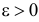
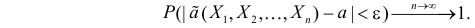
Если известно, что оценка 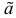 несмещенная, то для ее состоятельности достаточно, чтобы
несмещенная, то для ее состоятельности достаточно, чтобы
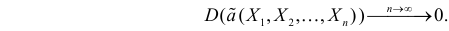
Последнее условие удобно для проверки. В качестве меры разброса значений оценки относительно 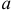 можно рассматривать величину
можно рассматривать величину 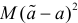 Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по
Из двух оценок предпочтительней та, для которой эта величина меньше. Если оценка имеет наименьшую меру разброса среди всех оценок характеристики, построенных по 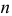 наблюдениям, то оценку называют эффективной.
наблюдениям, то оценку называют эффективной.
Следует отметить, что несмещенность и состоятельность являются желательными свойствами оценок, но не всегда разумно требовать наличия этих свойств у оценки. Например, может оказаться предпочтительней оценка хотя и обладающая небольшим смещением, но имеющая значительно меньший разброс значений, нежели несмещенная оценка. Более того, есть характеристики, для которых нет одновременно несмещенных и состоятельных оценок.
Оценки для математического ожидания и дисперсии
Пусть случайная величина имеет неизвестные математическое ожидание и дисперсию, причем 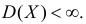 Если
Если 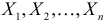 – результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений
– результаты независимых наблюдений случайной величины, то в качестве оценки для математического ожидания можно предложить среднее арифметическое наблюдаемых значений 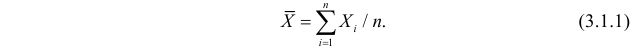
Несмещенность такой оценки следует из равенств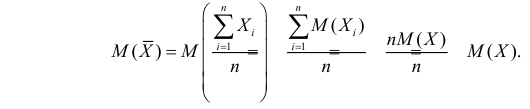
В силу независимости наблюдений 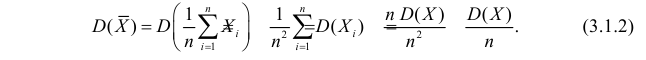
При условии 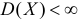 имеем
имеем 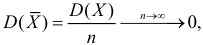 что означает состоятельность оценки
что означает состоятельность оценки 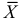 .
.
Доказано, что для математического ожидания нормально распределенной случайной величины оценка 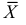 еще и эффективна.
еще и эффективна.
Оценка математического ожидания посредством среднего арифметического наблюдаемых значений наводит на мысль предложить в качестве оценки для дисперсии величину

Преобразуем величину 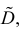 обозначая для краткости
обозначая для краткости 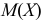 через
через 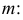
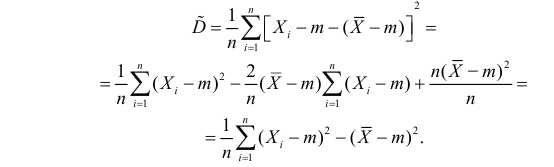
В силу (3.1.2) имеем 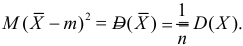 Поэтому
Поэтому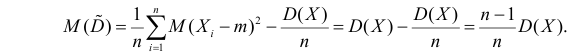
Последняя запись означает, что оценка 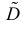 имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя
имеет смещение. Она систематически занижает истинное значение дисперсии. Для получения несмещенной оценки введем поправку в виде множителя 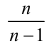 и полученную оценку обозначим через
и полученную оценку обозначим через 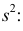
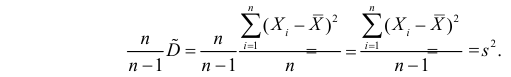
Величина
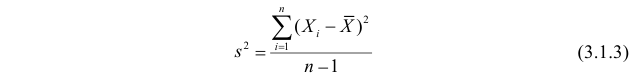
является несмещенной и состоятельной оценкой дисперсии.
Пример:
Оценить математическое ожидание и дисперсию случайной величины Х по результатам ее независимых наблюдений: 7, 3, 4, 8, 4, 6, 3.
Решение. По формулам (3.1.1) и (3.1.3) имеем 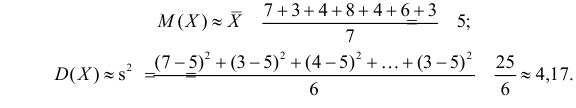
Ответ. 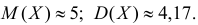
Пример:
Данные 25 независимых наблюдений случайной величины представлены в сгруппированном виде: 
Требуется оценить математическое ожидание и дисперсию этой случайной величины.
Решение. Представителем каждого интервала можно считать его середину. С учетом этого формулы (3.1.1) и (3.1.3) дают следующие оценки: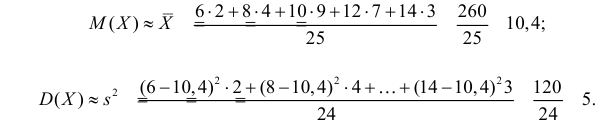
Ответ. 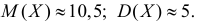
Метод наибольшего правдоподобия для оценки параметров распределений
В теории вероятностей и ее приложениях часто приходится иметь дело с законами распределения, которые определяются некоторыми параметрами. В качестве примера можно назвать нормальный закон распределения 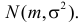 Его параметры
Его параметры 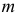 и
и 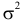 имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью
имеют смысл математического ожидания и дисперсии соответственно. Их можно оценить с помощью 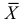 и
и 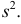 В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
В общем случае параметры законов распределения не всегда напрямую связаны со значениями числовых 179 характеристик. Поэтому практический интерес представляет следующая задача.
Пусть случайная величина Х имеет функцию распределения 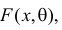 причем тип функции распределения F известен, но неизвестно значение параметра
причем тип функции распределения F известен, но неизвестно значение параметра 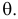 По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
По данным результатов наблюдений нужно оценить значение параметра. Параметр может быть и многомерным.
Продемонстрируем идею метода наибольшего правдоподобия на упрощенном примере. Пусть по результатам наблюдений, отмеченных на рис. 3.1.1 звездочками, нужно отдать предпочтение одной из двух функций плотности вероятности 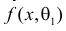 или
или 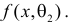
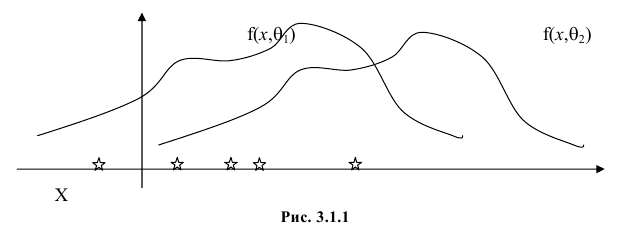
Из рисунка видно, что при значении параметра 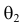 такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же
такие результаты наблюдений маловероятны и вряд ли бы реализовались. При значении же 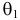 эти результаты наблюдений вполне возможны. Поэтому значение параметра
эти результаты наблюдений вполне возможны. Поэтому значение параметра 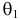 более правдоподобно, чем значение
более правдоподобно, чем значение 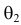 . Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
. Такая аргументация позволяет сформулировать принцип наибольшего правдоподобия: в качестве оценки параметра выбирается то его значение, при котором данные результаты наблюдений наиболее вероятны.
Этот принцип приводит к следующему способу действий. Пусть закон распределения случайной величины Х зависит от неизвестного значения параметра 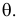 Обозначим через
Обозначим через 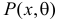 для непрерывной случайной величины плотность вероятности в точке
для непрерывной случайной величины плотность вероятности в точке 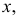 а для дискретной случайной величины – вероятность того, что
а для дискретной случайной величины – вероятность того, что 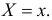 Если в
Если в 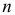 независимых наблюдениях реализовались значения случайной величины
независимых наблюдениях реализовались значения случайной величины 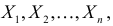 то выражение
то выражение 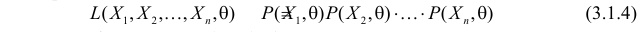
называют функцией правдоподобия. Величина 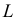 зависит только от параметра
зависит только от параметра 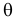 при фиксированных результатах наблюдений
при фиксированных результатах наблюдений 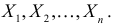 При каждом значении параметра
При каждом значении параметра 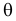 функция
функция 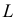 равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства
равна вероятности именно тех значений дискретной случайной величины, которые получены в процессе наблюдений. Для непрерывной случайной величины равна плотности вероятности в точке выборочного пространства 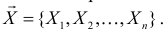
Сформулированный принцип предлагает в качестве оценки значения параметра выбрать такое 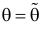 при котором принимает наибольшее значение. Величина
при котором принимает наибольшее значение. Величина 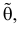 будучи функцией от результатов наблюдений
будучи функцией от результатов наблюдений 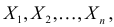 называется оценкой наибольшего правдоподобия.
называется оценкой наибольшего правдоподобия.
Во многих случаях, когда дифференцируема, оценка наибольшего правдоподобия находится как решение уравнения 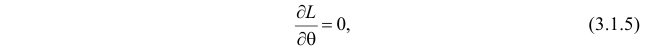
которое следует из необходимого условия экстремума. Поскольку 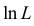 достигает максимума при том же значении
достигает максимума при том же значении 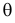 , что и , то можно решать относительно
, что и , то можно решать относительно 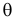 эквивалентное уравнение
эквивалентное уравнение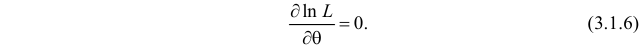
Это уравнение называют уравнением правдоподобия. Им пользоваться удобнее, чем уравнением (3.1.5), так как функция равна произведению, а – сумме, а дифференцировать проще.
Если параметров несколько (многомерный параметр), то следует взять частные производные от функции правдоподобия по всем параметрам, приравнять частные производные нулю и решить полученную систему уравнений.
Оценку, получаемую в результате поиска максимума функции правдоподобия, называют еще оценкой максимального правдоподобия.
Известно, что оценки максимального правдоподобия состоятельны. Кроме того, если для q существует эффективная оценка, то уравнение правдоподобия имеет единственное решение, совпадающее с этой оценкой. Оценка максимального правдоподобия может оказаться смещенной.
Метод моментов
Начальным моментом 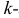 го порядка случайной величины Х называется математическое ожидание
го порядка случайной величины Х называется математическое ожидание 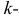 й степени этой величины, т.е.
й степени этой величины, т.е. 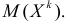 Само математическое ожидание считается начальным моментом первого порядка.
Само математическое ожидание считается начальным моментом первого порядка.
Центральным моментом 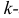 го порядка называется
го порядка называется 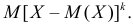 Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Очевидно, что дисперсия – это центральный момент второго порядка. Если закон распределения случайной величины зависит от некоторых параметров, то от этих параметров зависят и моменты случайной величины.
Для оценки параметров распределения по методу моментов находят на основе опытных данных оценки моментов в количестве, равном числу оцениваемых параметров. Эти оценки приравнивают к соответствующим теоретическим моментам, величины которых выражены через параметры. Из полученной системы уравнений можно определить искомые оценки.
Например, если Х имеет плотность распределения 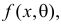 то
то 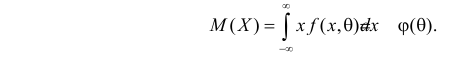
Если воспользоваться величиной  как оценкой для
как оценкой для  на основе опытных данных, то оценкой по методу моментов будет решение уравнения
на основе опытных данных, то оценкой по методу моментов будет решение уравнения 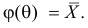
Пример:
Найти оценку параметра показательного закона распределения по методу моментов.
Решение. Плотность вероятности показательного закона распределения имеет вид 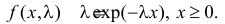 Поэтому
Поэтому 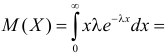
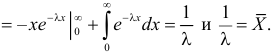 Откуда
Откуда 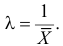
Ответ. 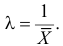
Пример:
Пусть имеется простейший поток событий неизвестной интенсивности 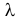 . Для оценки параметра
. Для оценки параметра 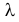 проведено наблюдение потока и зарегистрированы
проведено наблюдение потока и зарегистрированы 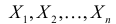 – длительности
– длительности 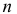 последовательных интервалов времени между моментами наступления событий. Найти оценку для
последовательных интервалов времени между моментами наступления событий. Найти оценку для 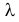 .
.
Решение. В простейшем потоке интервалы времени между последовательными моментами наступления событий потока имеют показательный закон распределения 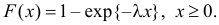 Так как плотность вероятности показательного закона распределения равна
Так как плотность вероятности показательного закона распределения равна 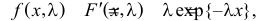 то функция правдоподобия (3.1.4) имеет вид
то функция правдоподобия (3.1.4) имеет вид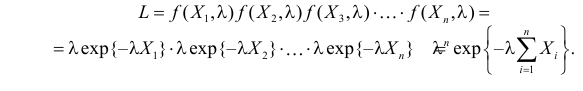
Тогда 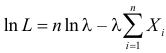 и уравнение правдоподобия
и уравнение правдоподобия 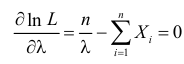 имеет решение
имеет решение 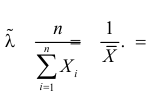
При таком значении 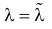 функция правдоподобия действительно достигает наибольшего значения, так как
функция правдоподобия действительно достигает наибольшего значения, так как 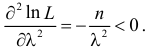
Ответ. 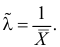
Определение. Пусть 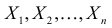 – результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:
– результаты n независимых наблюдений случайной величины X. Если расставить эти результаты в порядке возрастания, то получится последовательность значений, которую называют вариационным рядом и обозначают:

В этой записи 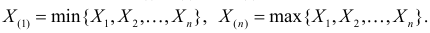
Величины 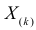 называют порядковыми статистиками.
называют порядковыми статистиками.
Пример:
Случайная величина Х имеет равномерное распределение на отрезке 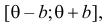 где
где 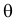 и
и 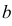 неизвестны. Пусть
неизвестны. Пусть 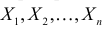 – результаты независимых наблюдений. Найти оценку параметра .
– результаты независимых наблюдений. Найти оценку параметра .
Решение. Функция плотности вероятности величины Х имеет вид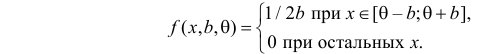
В этом случае функция правдоподобия 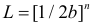 от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в
от явно не зависит. Дифференцировать по такую функцию нельзя и нет возможности записать уравнение правдоподобия. Однако легко видеть, что возрастает при уменьшении . Все результаты наблюдений лежат в 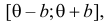 поэтому можно записать:
поэтому можно записать:
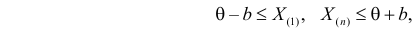
где 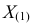 – наименьший, а
– наименьший, а 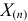 – наибольший из результатов наблюдений. При минимально возможном
– наибольший из результатов наблюдений. При минимально возможном
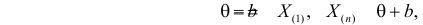
откуда 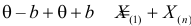 или
или 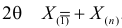
Оценкой наибольшего правдоподобия для параметра будет величина
Ответ. 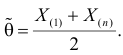
Пример:
Случайная величина X имеет функцию распределения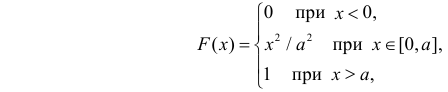
где 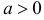 неизвестный параметр.
неизвестный параметр.
Пусть 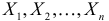 – результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра
– результаты независимых наблюдений случайной величины X. Требуется найти оценку наибольшего правдоподобия для параметра  и найти оценку для M(X).
и найти оценку для M(X).
Решение. Для построения функции правдоподобия найдем сначала функцию плотности вероятности
Тогда функция правдоподобия: 
Логарифмическая функция правдоподобия: 
Уравнение правдоподобия

не имеет решений. Критических точек нет. Наибольшее и наименьшее значения находятся на границе допустимых значений 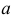 .
.
По виду функции можно заключить, что значение тем больше, чем меньше величина . Но не может быть меньше 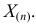 Поэтому наиболее правдоподобное значение
Поэтому наиболее правдоподобное значение 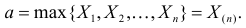
Так как 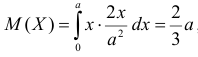 , то оценкой наибольшего правдоподобия для
, то оценкой наибольшего правдоподобия для 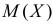 будет величина
будет величина 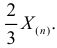
Ответ. 
Пример:
Случайная величина Х имеет нормальный закон распределения  c неизвестными параметрами
c неизвестными параметрами 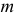 и
и 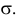 По результатам независимых наблюдений
По результатам независимых наблюдений 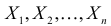 найти наиболее правдоподобные значения этих параметров.
найти наиболее правдоподобные значения этих параметров.
Решение. В соответствии с (3.1.4) функция правдоподобия имеет вид 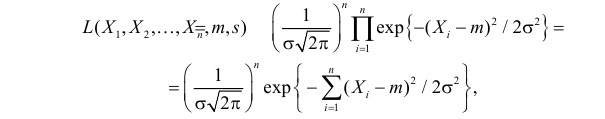
а логарифмическая функция правдоподобия: 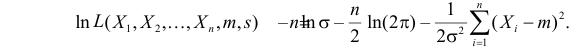
Необходимые условия экстремума дают систему двух уравнений: 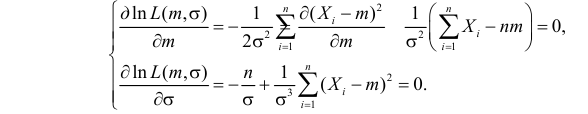
Решения этой системы имеют вид: 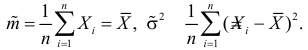
Отметим, что обе оценки являются состоятельными, причем оценка для 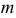 несмещенная, а для
несмещенная, а для 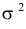 смещенная (сравните с формулой (3.1.3)).
смещенная (сравните с формулой (3.1.3)).
Ответ. 
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. 1) Число экспериментальных данных вычисляется по формуле:
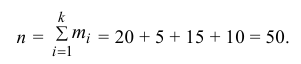
Значит, объем выборки n = 50.
2) Вычислим среднее арифметическое значение эксперимента:
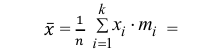
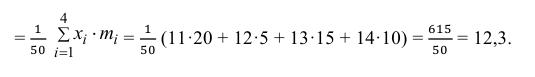
Значит, найдена оценка математического ожидания 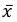 = 12,3.
= 12,3.
3) Вычислим исправленную выборочную дисперсию:
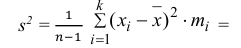
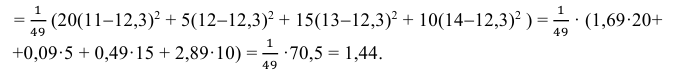
Значит, найдена оценка дисперсии: 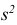 = 1,44.
= 1,44.
5) Вычислим оценку среднего квадратического отклонения:
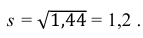
Ответ: 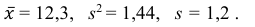
Пример:
По данным эксперимента построен статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения случайной величины X.
Решение. По формуле
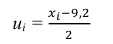
перейдем к условным вариантам:

Для них произведем расчет точечных оценок параметров:
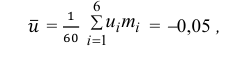
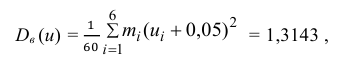
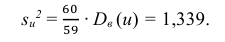
Следовательно, вычисляем искомые точечные оценки:
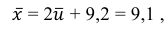
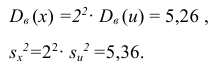
Ответ: 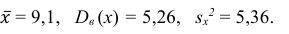
Пример:
По данным эксперимента построен интервальный статистический ряд:

Найти оценки математического ожидания, дисперсии и среднего квадратического отклонения.
Решение. 1) От интервального ряда перейдем к статистическому ряду, заменив интервалы их серединами 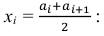

2) Объем выборки вычислим по формуле:
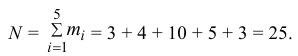
3) Вычислим среднее арифметическое значений эксперимента:
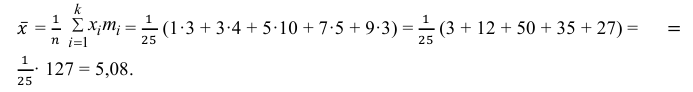
3) Вычислим исправленную выборочную дисперсию:
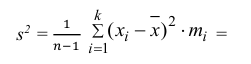
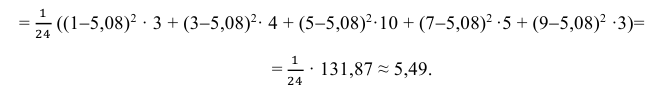
Можно было воспользоваться следующей формулой:
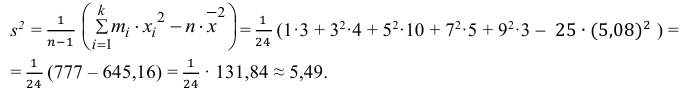
5) Вычислим оценку среднего квадратического отклонения:
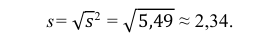
Ответ: 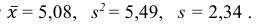
Пример:
Найти доверительный интервал с надежностью 0,95 для оценки математического ожидания M(X) нормально распределенной случайной величины X, если известно среднее квадратическое отклонение σ = 2, оценка математического ожидания 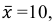 объем выборки n = 25.
объем выборки n = 25.
Решение. Доверительный интервал для истинного математического ожидания с доверительной вероятностью 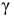 = 0,95 при известной дисперсии σ находится по формуле:
= 0,95 при известной дисперсии σ находится по формуле:
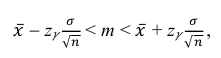
где m = M(X) – истинное математическое ожидание; 𝑥̅ − оценка M(X) по выборке; n – объем выборки; 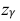 – находится по доверительной вероятности
– находится по доверительной вероятности 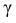 = 0,95 из равенства:
= 0,95 из равенства:
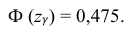
Из табл. П 2.2 приложения 2 находим: 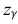 = 1,96. Следовательно, найден доверительный интервал для M(X):
= 1,96. Следовательно, найден доверительный интервал для M(X):
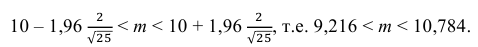
Ответ: (9,216 ; 10,784).
Пример:
По данным эксперимента построен статистический ряд:

Найти доверительный интервал для математического ожидания M (X) с надежностью 0,95.
Решение. Воспользуемся формулой для доверительного интервала математического ожидания при неизвестной дисперсии:
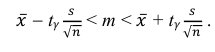
где n – объем выборки; 𝑥̅ оценка M(X); s – оценка среднего квадратического отклонения; 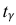 − находится по доверительной вероятности
− находится по доверительной вероятности 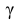 = 0,95.
= 0,95.
По числам 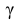 = 0,95 и n = 20 находим:
= 0,95 и n = 20 находим: 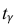 = 2,093.
= 2,093.
Теперь вычисляем оценки для M(X) и D(X):
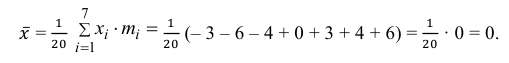
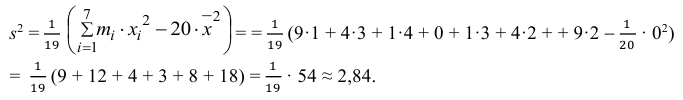
Следовательно, s ≈ 1,685. Поэтому искомый доверительный интервал математического ожидания задается формулой:
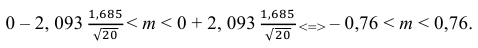
Ответ: (– 0,76; 0,76).
Пример:
По данным десяти независимых измерений найдена оценка квадратического отклонения 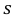 = 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
= 0,5. Найти доверительный интервал точности измерительного прибора с надежностью 99 %.
Решение. Задача сводится к нахождению доверительного интервала для истинного квадратического отклонения, так как точность прибора характеризуется средним квадратическим отклонением случайных ошибок измерений.
Доверительный интервал для среднего квадратического отклонения находим по формуле:
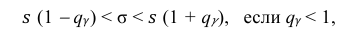
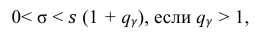
где 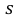 = 0,5 − оценка среднего квадратического отклонения;
= 0,5 − оценка среднего квадратического отклонения; 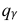 – число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности
– число, определяемое из табл. П 2.4 приложения 2 по заданной доверительной вероятности 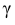 = 0,99 и заданному объему выборки n = 10.
= 0,99 и заданному объему выборки n = 10.
Находим: 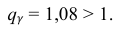
Тогда можно записать:
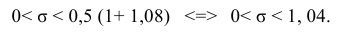
Ответ: (0; 1,04).
- Доверительный интервал для вероятности события
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Системы случайных величин
- Вероятность и риск
- Определения вероятности событий
- Предельные теоремы теории вероятностей
На практике часто удается предсказать или оценить с помощью гистограммы вид распределения наблюдаемой случайной величины ξ с точностью до неизвестного параметра ![]() (или нескольких параметров). Одной из основных задач математической статистики является нахождение оценки (приближенного значения) неизвестного параметра по имеющейся выборке.
(или нескольких параметров). Одной из основных задач математической статистики является нахождение оценки (приближенного значения) неизвестного параметра по имеющейся выборке.
Основные понятия
Пусть наблюдается случайная величина ξ с функцией распределения ![]() и плотностью распределения
и плотностью распределения ![]() . Случайная выборка представлена вектором
. Случайная выборка представлена вектором ![]() с реализацией
с реализацией ![]() . (3.7)
. (3.7)
Параметром распределения ![]() случайной величины
случайной величины ![]() называется любая числовая характеристика этой случайной величины (математическое ожидание, дисперсия и т. п.) или любая константа, явно входящая в выражение для функции или плотности распределения.
называется любая числовая характеристика этой случайной величины (математическое ожидание, дисперсия и т. п.) или любая константа, явно входящая в выражение для функции или плотности распределения.
Если параметр ![]() неизвестен, то его точечной оценкой называется произвольная функция элементов выборки
неизвестен, то его точечной оценкой называется произвольная функция элементов выборки
![]() . (3.8) Реализацию оценки, т. е. значение оценки для наблюдавшейся в эксперименте реализации выборки, принимают за приближенное значение неизвестного параметра
. (3.8) Реализацию оценки, т. е. значение оценки для наблюдавшейся в эксперименте реализации выборки, принимают за приближенное значение неизвестного параметра ![]()
![]()
Из соотношения (3.8) видно, что ![]() как функция случайных величин сама также является случайной величиной. Закон распределения оценки
как функция случайных величин сама также является случайной величиной. Закон распределения оценки ![]() зависит от вида функции
зависит от вида функции ![]() , числа наблюдений и значения оцениваемого параметра.
, числа наблюдений и значения оцениваемого параметра.
Ясно, что существует много разных способов построения точечной оценки, и не всякая зависимость ![]() может давать удовлетворительную оценку неизвестного параметра
может давать удовлетворительную оценку неизвестного параметра ![]() . Рассмотрим некоторые свойства, которыми должна обладать оценка, чтобы ее можно было считать хорошим приближением к неизвестному параметру.
. Рассмотрим некоторые свойства, которыми должна обладать оценка, чтобы ее можно было считать хорошим приближением к неизвестному параметру.
Оценка ![]() параметра
параметра ![]() называется Несмещенной, если ее математическое ожидание равно оцениваемому параметру, то есть
называется Несмещенной, если ее математическое ожидание равно оцениваемому параметру, то есть
![]() . (3.9)
. (3.9)
Если свойство (2.2) не выполняется, то есть
![]() , (3.10)
, (3.10)
То оценку ![]() называют Смещенной, при этом величину
называют Смещенной, при этом величину ![]() называют систематической ошибкой оценки
называют систематической ошибкой оценки ![]() .
.
Требование несмещенности означает, что выборочные значения оценок, полученных в результате повторения выборок, группируются около оцениваемого параметра.
Оценка ![]() параметра
параметра ![]() называется Состоятельной, если при
называется Состоятельной, если при ![]() она сходится по вероятности к оцениваемому параметру
она сходится по вероятности к оцениваемому параметру ![]() , т. е. для любого ε > 0 выполняется равенство
, т. е. для любого ε > 0 выполняется равенство
![]()
![]() . (3.11)
. (3.11)
Следующая теорема устанавливает достаточные условия состоятельности оценки ![]() параметра
параметра ![]() .
.
Теорема. Если при ![]()
![]() и
и ![]() , то оценка
, то оценка ![]() параметра
параметра ![]() является состоятельной.
является состоятельной.
Состоятельность оценки означает, что, при достаточно большом объеме выборки с вероятностью близкой к единице, отклонение оценки от истинного значения параметра меньше ранее заданной величины.
Обычно в качестве Меры точности оценки ![]() используется среднеквадратическая ошибка (среднее значение квадрата ошибки)
используется среднеквадратическая ошибка (среднее значение квадрата ошибки) 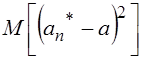 . Очевидно, чем меньше эта ошибка, тем теснее сгруппированы значения оценки около оцениваемого параметра. Поэтому всегда желательно, чтобы ошибка оценки была по возможности малой. Используя свойства математического ожидания, нетрудно получить
. Очевидно, чем меньше эта ошибка, тем теснее сгруппированы значения оценки около оцениваемого параметра. Поэтому всегда желательно, чтобы ошибка оценки была по возможности малой. Используя свойства математического ожидания, нетрудно получить
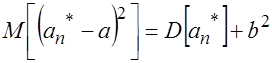 . (3.12)
. (3.12)
Для несмещенных оценок
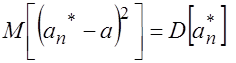 , (3.13)
, (3.13)
То есть их мерой точности является дисперсия.
Несмещенная оценка параметра ![]() называется его Эффективной Оценкой, если ее дисперсия
называется его Эффективной Оценкой, если ее дисперсия ![]() является наименьшей среди дисперсий всех возможных оценок параметра
является наименьшей среди дисперсий всех возможных оценок параметра ![]() , вычисленных по одному и тому же объему выборки.
, вычисленных по одному и тому же объему выборки.
Точечные оценки математического ожидания и дисперсии
Пусть случайная выборка ![]() порождена наблюдаемой случайной величиной ξ, математическое ожидание
порождена наблюдаемой случайной величиной ξ, математическое ожидание ![]() и дисперсия
и дисперсия ![]() которой неизвестны. В качестве оценок для этих характеристик было предложено использовать выборочное среднее
которой неизвестны. В качестве оценок для этих характеристик было предложено использовать выборочное среднее
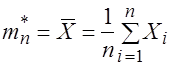
И выборочную дисперсию
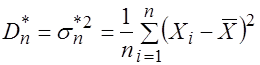 . (3.14)
. (3.14)
Рассмотрим некоторые свойства оценок математического ожидания и дисперсии.
1. Вычислим математическое ожидание выборочного среднего:
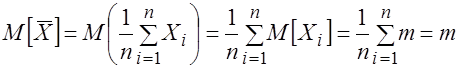 . (3.15)
. (3.15)
Следовательно, выборочное среднее является несмещенной оценкой для ![]() .
.
2. Напомним, что результаты ![]() наблюдений – независимые случайные величины, каждая из которых имеет такой же закон распределения, как и величина
наблюдений – независимые случайные величины, каждая из которых имеет такой же закон распределения, как и величина ![]() , а значит,
, а значит, ![]() ,
, ![]() ,
, ![]() . Будем предполагать, что дисперсия
. Будем предполагать, что дисперсия ![]() конечна. Тогда, согласно теореме Чебышева о законе больших чисел, для любого ε > 0 имеет место равенство
конечна. Тогда, согласно теореме Чебышева о законе больших чисел, для любого ε > 0 имеет место равенство ![]()
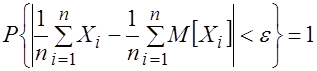 ,
,
Которое можно записать так: 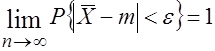 . (3.16) Сравнивая (3.16) с определением свойства состоятельности (3.11), видим, что оценка
. (3.16) Сравнивая (3.16) с определением свойства состоятельности (3.11), видим, что оценка ![]() является состоятельной оценкой математического ожидания
является состоятельной оценкой математического ожидания ![]() .
.
3. Найдем дисперсию выборочного среднего:
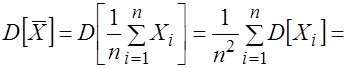
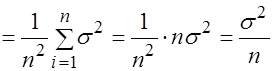 . (3.17)
. (3.17)
Таким образом, дисперсия оценки математического ожидания уменьшается обратно пропорционально объему выборки.
Можно доказать, что если случайная величина ξ распределена нормально, то выборочное среднее ![]() является эффективной оценкой математического ожидания
является эффективной оценкой математического ожидания ![]() , то есть дисперсия
, то есть дисперсия ![]() принимает наименьшее значение по сравнению с любой другой оценкой математического ожидания. Для других законов распределения ξ это может быть и не так.
принимает наименьшее значение по сравнению с любой другой оценкой математического ожидания. Для других законов распределения ξ это может быть и не так.
Выборочная дисперсия ![]() является смещенной оценкой дисперсии
является смещенной оценкой дисперсии ![]() , так как
, так как 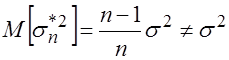 . (3.18)
. (3.18)
Действительно, используя свойства математического ожидания и формулу (3.17), найдем
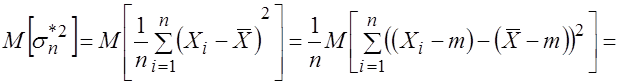
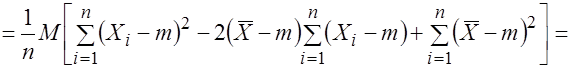
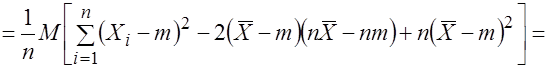
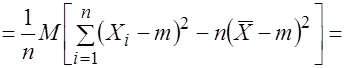
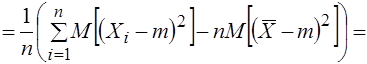
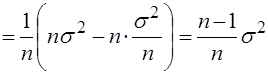 .
.
Чтобы получить несмещенную оценку дисперсии, оценку (3.14) нужно исправить, то есть домножить на ![]() . Тогда получим несмещенную выборочную дисперсию
. Тогда получим несмещенную выборочную дисперсию
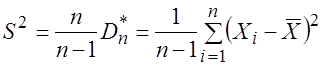 . (3.19)
. (3.19)
Отметим, что формулы (3.14) и (3.19) отличаются лишь знаменателем, и при больших значениях ![]() выборочная и несмещенная дисперсии отличаются мало. Однако при малом объеме выборки
выборочная и несмещенная дисперсии отличаются мало. Однако при малом объеме выборки ![]() следует пользоваться соотношением (3.19).
следует пользоваться соотношением (3.19).
Для оценки среднего квадратического отклонения случайной величины используют так называемое “исправленное” среднее квадратическое отклонение, которое равно квадратному корню из несмещенной дисперсии: ![]() .
.
| < Предыдущая | Следующая > |
|---|
На практике часто удается предсказать или оценить с помощью гистограммы вид распределения наблюдаемой случайной величины ξ с точностью до неизвестного параметра ![]() (или нескольких параметров). Одной из основных задач математической статистики является нахождение оценки (приближенного значения) неизвестного параметра по имеющейся выборке.
(или нескольких параметров). Одной из основных задач математической статистики является нахождение оценки (приближенного значения) неизвестного параметра по имеющейся выборке.
Основные понятия
Пусть наблюдается случайная величина ξ с функцией распределения ![]() и плотностью распределения
и плотностью распределения ![]() . Случайная выборка представлена вектором
. Случайная выборка представлена вектором ![]() с реализацией
с реализацией ![]() . (3.7)
. (3.7)
Параметром распределения ![]() случайной величины
случайной величины ![]() называется любая числовая характеристика этой случайной величины (математическое ожидание, дисперсия и т. п.) или любая константа, явно входящая в выражение для функции или плотности распределения.
называется любая числовая характеристика этой случайной величины (математическое ожидание, дисперсия и т. п.) или любая константа, явно входящая в выражение для функции или плотности распределения.
Если параметр ![]() неизвестен, то его точечной оценкой называется произвольная функция элементов выборки
неизвестен, то его точечной оценкой называется произвольная функция элементов выборки
![]() . (3.8) Реализацию оценки, т. е. значение оценки для наблюдавшейся в эксперименте реализации выборки, принимают за приближенное значение неизвестного параметра
. (3.8) Реализацию оценки, т. е. значение оценки для наблюдавшейся в эксперименте реализации выборки, принимают за приближенное значение неизвестного параметра ![]()
![]()
Из соотношения (3.8) видно, что ![]() как функция случайных величин сама также является случайной величиной. Закон распределения оценки
как функция случайных величин сама также является случайной величиной. Закон распределения оценки ![]() зависит от вида функции
зависит от вида функции ![]() , числа наблюдений и значения оцениваемого параметра.
, числа наблюдений и значения оцениваемого параметра.
Ясно, что существует много разных способов построения точечной оценки, и не всякая зависимость ![]() может давать удовлетворительную оценку неизвестного параметра
может давать удовлетворительную оценку неизвестного параметра ![]() . Рассмотрим некоторые свойства, которыми должна обладать оценка, чтобы ее можно было считать хорошим приближением к неизвестному параметру.
. Рассмотрим некоторые свойства, которыми должна обладать оценка, чтобы ее можно было считать хорошим приближением к неизвестному параметру.
Оценка ![]() параметра
параметра ![]() называется Несмещенной, если ее математическое ожидание равно оцениваемому параметру, то есть
называется Несмещенной, если ее математическое ожидание равно оцениваемому параметру, то есть
![]() . (3.9)
. (3.9)
Если свойство (2.2) не выполняется, то есть
![]() , (3.10)
, (3.10)
То оценку ![]() называют Смещенной, при этом величину
называют Смещенной, при этом величину ![]() называют систематической ошибкой оценки
называют систематической ошибкой оценки ![]() .
.
Требование несмещенности означает, что выборочные значения оценок, полученных в результате повторения выборок, группируются около оцениваемого параметра.
Оценка ![]() параметра
параметра ![]() называется Состоятельной, если при
называется Состоятельной, если при ![]() она сходится по вероятности к оцениваемому параметру
она сходится по вероятности к оцениваемому параметру ![]() , т. е. для любого ε > 0 выполняется равенство
, т. е. для любого ε > 0 выполняется равенство
![]()
![]() . (3.11)
. (3.11)
Следующая теорема устанавливает достаточные условия состоятельности оценки ![]() параметра
параметра ![]() .
.
Теорема. Если при ![]()
![]() и
и ![]() , то оценка
, то оценка ![]() параметра
параметра ![]() является состоятельной.
является состоятельной.
Состоятельность оценки означает, что, при достаточно большом объеме выборки с вероятностью близкой к единице, отклонение оценки от истинного значения параметра меньше ранее заданной величины.
Обычно в качестве Меры точности оценки ![]() используется среднеквадратическая ошибка (среднее значение квадрата ошибки) . Очевидно, чем меньше эта ошибка, тем теснее сгруппированы значения оценки около оцениваемого параметра. Поэтому всегда желательно, чтобы ошибка оценки была по возможности малой. Используя свойства математического ожидания, нетрудно получить
используется среднеквадратическая ошибка (среднее значение квадрата ошибки) . Очевидно, чем меньше эта ошибка, тем теснее сгруппированы значения оценки около оцениваемого параметра. Поэтому всегда желательно, чтобы ошибка оценки была по возможности малой. Используя свойства математического ожидания, нетрудно получить
. (3.12)
Для несмещенных оценок
, (3.13)
То есть их мерой точности является дисперсия.
Несмещенная оценка параметра ![]() называется его Эффективной Оценкой, если ее дисперсия
называется его Эффективной Оценкой, если ее дисперсия ![]() является наименьшей среди дисперсий всех возможных оценок параметра
является наименьшей среди дисперсий всех возможных оценок параметра ![]() , вычисленных по одному и тому же объему выборки.
, вычисленных по одному и тому же объему выборки.
Точечные оценки математического ожидания и дисперсии
Пусть случайная выборка ![]() порождена наблюдаемой случайной величиной ξ, математическое ожидание
порождена наблюдаемой случайной величиной ξ, математическое ожидание ![]() и дисперсия
и дисперсия ![]() которой неизвестны. В качестве оценок для этих характеристик было предложено использовать выборочное среднее
которой неизвестны. В качестве оценок для этих характеристик было предложено использовать выборочное среднее
И выборочную дисперсию
. (3.14)
Рассмотрим некоторые свойства оценок математического ожидания и дисперсии.
1. Вычислим математическое ожидание выборочного среднего:
. (3.15)
Следовательно, выборочное среднее является несмещенной оценкой для ![]() .
.
2. Напомним, что результаты ![]() наблюдений – независимые случайные величины, каждая из которых имеет такой же закон распределения, как и величина
наблюдений – независимые случайные величины, каждая из которых имеет такой же закон распределения, как и величина ![]() , а значит,
, а значит, ![]() ,
, ![]() ,
, ![]() . Будем предполагать, что дисперсия
. Будем предполагать, что дисперсия ![]() конечна. Тогда, согласно теореме Чебышева о законе больших чисел, для любого ε > 0 имеет место равенство
конечна. Тогда, согласно теореме Чебышева о законе больших чисел, для любого ε > 0 имеет место равенство ![]() ,
,
Которое можно записать так: . (3.16) Сравнивая (3.16) с определением свойства состоятельности (3.11), видим, что оценка ![]() является состоятельной оценкой математического ожидания
является состоятельной оценкой математического ожидания ![]() .
.
3. Найдем дисперсию выборочного среднего:
. (3.17)
Таким образом, дисперсия оценки математического ожидания уменьшается обратно пропорционально объему выборки.
Можно доказать, что если случайная величина ξ распределена нормально, то выборочное среднее ![]() является эффективной оценкой математического ожидания
является эффективной оценкой математического ожидания ![]() , то есть дисперсия
, то есть дисперсия ![]() принимает наименьшее значение по сравнению с любой другой оценкой математического ожидания. Для других законов распределения ξ это может быть и не так.
принимает наименьшее значение по сравнению с любой другой оценкой математического ожидания. Для других законов распределения ξ это может быть и не так.
Выборочная дисперсия ![]() является смещенной оценкой дисперсии
является смещенной оценкой дисперсии ![]() , так как . (3.18)
, так как . (3.18)
Действительно, используя свойства математического ожидания и формулу (3.17), найдем
.
Чтобы получить несмещенную оценку дисперсии, оценку (3.14) нужно исправить, то есть домножить на ![]() . Тогда получим несмещенную выборочную дисперсию
. Тогда получим несмещенную выборочную дисперсию
. (3.19)
Отметим, что формулы (3.14) и (3.19) отличаются лишь знаменателем, и при больших значениях ![]() выборочная и несмещенная дисперсии отличаются мало. Однако при малом объеме выборки
выборочная и несмещенная дисперсии отличаются мало. Однако при малом объеме выборки ![]() следует пользоваться соотношением (3.19).
следует пользоваться соотношением (3.19).
Для оценки среднего квадратического отклонения случайной величины используют так называемое “исправленное” среднее квадратическое отклонение, которое равно квадратному корню из несмещенной дисперсии: ![]() .
.
| < Предыдущая | Следующая > |
|---|
Несмещенная оценка выборочной дисперсии
Краткая теория
Пусть из генеральной совокупности в результате
независимых наблюдений над количественным
признаком
извлечена повторная выборка объема
:
При этом
Требуется по данным выборки оценить (приближенно найти) неизвестную
генеральную дисперсию
.
Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то
эта оценка будет приводить в систематическим ошибкам, давая заниженное значение
генеральной дисперсии. Объясняется это тем, что, как можно доказать, выборочная
дисперсия является смещенной оценкой
,
другими словами, математическое ожидание выборочной дисперсии не равно
оцениваемой генеральной дисперсии, а равно:
Легко «исправить» выборочную дисперсию так, чтобы ее математическое
ожидание было равно генеральной дисперсии. Достаточно для этого умножить
на дробь
.
Сделав это, получим исправленную дисперсию, которую обычно обозначают через
:
Исправленная дисперсия является, конечно, несмещенной оценкой
генеральной дисперсии. Действительно:
Итак, в качестве оценки генеральной дисперсии принимают
исправленную дисперсию:
Для оценки среднего квадратического
отклонения генеральной совокупности используют исправленное среднее квадратическое отклонение, которое равно квадратному корню
из исправленной дисперсии:
При достаточно больших значениях
объема выборки выборочная и исправленная
дисперсия отличаются мало. На практике используются исправленной дисперсией,
если примерно
.
Пример решения задачи
Задача
Найти
несмещенную выборочную дисперсию на основании данного распределения выборки.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Выборочная дисперсия является смещенной оценкой генеральной дисперсии, поэтому в статистике применяют также исправленную выборочную дисперсию, которая является несмещенной оценкой генеральной дисперсии.
Сумма
частот:
Вычислим
среднюю:
Средняя квадратов:
Несмещенная
выборочная дисперсия:
Ответ:
Кроме этой задачи на другой странице сайта есть
пример расчета исправленной выборочной дисперсии и среднего квадратического отклонения для интервального вариационного ряда
В предыдущем параграфе мы выяснили, что дисперсия оценки (widehat {beta _2}) равна:
begin{equation*} mathit{var}left(widehat {beta _2}right)=frac{sigma ^2}{Sigma left(x_i-overline xright)^2}. end{equation*}
Это полезная информация, так как дисперсия (widehat {beta _2}) характеризует точность результатов оценивания соответствующего параметра (чем меньше дисперсия, тем точнее наша оценка). Проблема в том, что непосредственно величину (mathit{var}left(widehat {beta _2}right)) мы вычислить не можем: хотя мы наблюдаем значения (x_i,) (i=1,2,{dots},n), но мы не наблюдаем величину (sigma ^2). Этот параметр является неизвестным параметром классической линейной модели подобно величинам (beta _1) и (beta _2). Впрочем, как и в случае с (beta _1) и (beta _2), мы можем получить оценку неизвестного параметра (sigma ^2). Несмещенная оценка дисперсии случайной ошибки (sigma ^2) имеет вид:
begin{equation*} S^2=frac 1{n-2}{ast}sum _{i=1}^ne_i^2 end{equation*}
Чтобы доказать её несмещенность, достаточно осуществить выкладки, аналогичные преобразованиям из предыдущего параграфа, и убедиться, что (Eleft(S^2right)=sigma ^2).
Если в формуле для (mathit{var}left(widehat {beta _2}right)) вместо дисперсии случайной ошибки (sigma ^2) подставить её оценку (S^2), мы получим несмещенную оценку дисперсии МНК-оценки (widehat {beta _2}), которая будет иметь вид:
begin{equation*} widehat {mathit{var}}left(widehat {beta _2}right)=frac{S^2}{Sigma left(x_i-overline xright)^2} end{equation*}
Корень из этой величины называется стандартной ошибкой оценки коэффициента (widehat {beta _2}):
begin{equation*} mathit{se}left(widehat {beta _2}right)=sqrt{widehat {mathit{var}}left(widehat {beta _2}right)}=sqrt{frac{S^2}{Sigma left(x_i-overline xright)^2}} end{equation*}
Аналогичным образом вычисляется стандартная ошибка оценки коэффициента (widehat {beta _1}) (здесь мы опираемся на равенство 2.4, заменяя в нем дисперсию случайной ошибки её оценкой).
begin{equation*} mathit{se}left(widehat {beta _1}right)=sqrt{widehat {mathit{var}}left(widehat {beta _1}right)}=sqrt{frac{frac{S^2} n{ast}sum x_i^2}{sum left(x_i-overline xright)^2}} end{equation*}
Стандартные ошибки оценок коэффициентов пригодятся нам для тестирования гипотез.
Представим, что мы хотим выяснить, влияет ли уровень образования (переменная x) на заработную плату работника в некоторой отрасли (переменная y)? Ответы на такого сорта вопросы, как мы обсудили в первой главе, и есть одна из главных задач эконометрики.
Представим также, что все предпосылки классической линейной модели парной регрессии выполнены. Тогда в терминах нашей модели вопрос «Верно ли, что образование не влияет на заработную плату?» эквивалентен вопросу «Верно ли, что в регрессии (y_i=beta _1+beta _2x_i+varepsilon _i) коэффициент (beta _2) равен нулю?».
Как мы могли бы ответить на этот вопрос?
Естественная идея состоит в том, чтобы посмотреть оценки коэффициентов (widehat {beta _1}) и (widehat {beta _2}) и увидеть, равен ли коэффициент (widehat {beta _2}) нулю. Однако при этом возникает следующая проблема: (widehat {beta _1}) и (widehat {beta _2}) — оценки, полученные при помощи МНК на основе случайной выборки. Следовательно, они сами являются случайными величинами, которые могут принимать значения лишь «приблизительно» равные истинным. Поэтому, даже если истинное значение коэффициента (beta _2) равно нулю, его оценка (widehat {beta _2}), скорее всего, будет отклоняться от нуля.
Следовательно, нужно уметь определять, достаточно ли сильно (widehat {beta _2}) отличается от нуля для того, чтобы можно было с уверенностью утверждать, что и истинное значение коэффициента (beta _2) также не равно нулю. Опишем процедуру, которая позволяет это сделать.
Процедура тестирования незначимости коэффициента:
Формулируем тестируемую гипотезу (H_0:beta _2=0) («переменная x не влияет на переменную y») и альтернативную гипотезу (H_1:beta _2{neq}0) («переменная x влияет на переменную y»)
Находим расчетное значение тестовой статистки по формуле
(frac{widehat {beta _2}}{mathit{se}left(widehat {beta }_2right)}.)
Выбираем уровень значимости (alpha ). Уровнем значимости в математической статистике называется вероятность ошибки первого рода, то есть вероятность отклонить тестируемую гипотезу при условии, что в действительности эта гипотеза верна. Разумеется, нам хотелось бы ошибаться не слишком часто, поэтому данную вероятность обычно выбирают маленькой. Чаще всего в эконометрике используются уровни значимости 1% и 5%.
Из таблиц распределения Стьюдента находим критическое значение тестовой статистки (t_{n-2}^{alpha }) для выбранного уровня значимости и так называемого числа степеней свободы, которое в нашем случае равно (left(n-2right)).
Если (left|frac{widehat {beta _2}}{mathit{se}left(widehat {beta }_2right)}right|>t_{n-2}^{alpha }), то есть (widehat {beta _2}) достаточно велик по абсолютной величине, следует отвергнуть гипотезу (H_0:beta _2=0) и сделать вывод в пользу альтернативной гипотезы, то есть заключить, что переменная x влияет на переменную y. В этом случае переменную x называют статистически значимой при уровне значимости (alpha ). В противном случае, соответственно, гипотеза (H_0) не может быть отвергнута, и переменную x называют статистически незначимой при уровне значимости (alpha ).
Здесь и далее во всех тестах, если явно не указано иное, мы подразумеваем альтернативную гипотезу «(beta _2) не равно c» , а не (beta _2<c) или (beta _2>c). Поэтому под критическими значениями из таблиц распределения Стьюдента по умолчанию подразумеваются критические значения для двусторонних (а не односторонних) тестов. Все стандартные эконометрические пакеты используют такой же подход.}
Замечание 1. В этой процедуре мы опираемся на тот факт, что тестовая статистика имеет t-распределение Стьюдента. Чтобы это было верно, как раз и нужна предпосылка №6 КЛМПР, которую мы до этого никак не использовали.
В соответствии с этой предпосылкой случайные ошибки имеют нормальное распределение. Мы показали (см. равенство (2.2)), что (widehat {beta _2}) — это линейная комбинация случайных ошибок, то есть независимых, одинаково и нормально распределенных случайных величин.
Из математической статистики известно, что отсюда следуют два утверждения:
Во-первых, (widehat {beta _2}) имеет нормальное распределение (так как линейная комбинация нормальных случайных величин является нормальной случайной величиной), дисперсию и математическое ожидание которого мы вычислили в предыдущем параграфе. Иными словами (widehat {beta _2}) имеет вот такое распределение:
begin{equation*} Nleft(beta _2,frac{sigma ^2}{Sigma left(x_i-overline xright)^2}right) end{equation*}
Во-вторых, случайная величина (frac{widehat {beta _2}-beta _2}{mathit{se}left(widehat {beta _2}right)}) имеет t-распределение Стьюдента. В нашем случае это будет распределение с (n-2) степенями свободы: (frac{widehat {beta _2}-beta _2}{mathit{se}left(widehat {beta _2}right)})~(t_{n-2})
В частности, если верна сформулированная нами гипотеза (beta _2=0), то распределение Стьюдента имеет дробь (frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}), которую мы используем в нашей процедуре. В этом случае критическое значение определяется из вот такого условия (его геометрическая интерпретация представлена в примере 2.3):
begin{equation*} Pleft(left|frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}right|<t_{n-2}^{alpha }right)=1-alpha . end{equation*}
Замечание 2. Аналогичным образом можно тестировать гипотезу (H_0:beta _2=c) (против альтернативной гипотезы (H_0:beta _2{neq}c)), где c — это некоторая константа. В этом случае процедура тестирования остается такой же с одним исключением: расчетное значение тестовой статистики будет иметь вид (frac{widehat {beta }_2-c}{mathit{se}left(widehat {beta }_2right)}).
Замечание 3. Раньше для определения величины критического значения (t_{n-2}^{alpha }) было необходимо использовать таблицы распределения Стьюдента. Сейчас этот способ тоже доступен (например, соответствующая таблица представлена в Приложении 3.А в конце третьей главы), однако теперь это значение можно рассчитать непосредственно в эконометрическом пакете или, например, в MS Excel (см. пример ниже).
Альтернативным способом является использование для тестирования гипотезы так называемого p-значения. P-значением называют такой уровень значимости, при котором тестируемая гипотеза находится на грани между отвержением и принятием.
Поэтому использовать p-значение при принятии решения очень просто: если оно меньше заранее выбранного уровня значимости (alpha ), то тестируемая гипотеза отвергается при уровне значимости (alpha ). Например, если при тестировании незначимости коэффициента вы используете пятипроцентный уровень значимости ( (alpha =0,05)), а p-значение оказалось равно 0,0002, следует заключить, что соответствующий коэффициент является значимым. Удобство использования p-значения состоит в том, что эта величина автоматически рассчитывается всеми стандартными эконометрическими пакетами, поэтому для принятия решения о значимости или незначимости того или иного коэффициента (а также для проведения любых других тестов, которые мы обсудим далее) вам не требуется никаких таблиц распределения и никаких дополнительных расчетов.
Рассмотрим для большей наглядности еще один пример.
Пример 2.3. Тестирование незначимости коэффициента и графическая иллюстрация
Представим, что у нас 10 наблюдений ( (n=10)), оценка коэффициента оказалась равна (widehat {beta _2})= 8,0, а ее стандартная ошибка (mathit{se}left(widehat {beta }_2right))= 4,0. Если использовать подход, связанный с критическими значениями, нужно открыть таблицу распределения Стьюдента (см. Приложение 3.А), и найти критическое значение для пятипроцентного уровня значимости и (left(n-2right)=8) степеней свободы2. Это критическое значение (t_{mathit{text{к}text{р}}}=t_8^{0,05}{approx}2,3). Расчетное значение t-статистики здесь тоже посчитать несложно
begin{equation*} t_{mathit{text{р}text{а}text{с}text{ч}}}=frac{widehat {beta }_2}{mathit{se}left(widehat {beta }_2right)}=frac 8 4=2 end{equation*}
Если мы нанесем все указанные значения на картинку, у нас получится рисунок 2.4а. Критическое значение отсекает по 2,5% слева и справа (всего 5%). Следовательно, вероятность попасть между (-t_{mathit{text{к}text{р}}}) и (t_{mathit{text{к}text{р}}}) будет 95%. Нанесем также (-t_{mathit{text{р}text{а}text{с}text{ч}}}) и (t_{mathit{text{р}text{а}text{с}text{ч}}}). Эти значения отсекают по 3% справа и слева, как это показано на рисунке 2.4б.
Обозначим (xi ) — случайную величину, имеющую распредление стьюдента с (left(n-2right)=8) степенями свободы. Тогда формально P-значение в нашем случае — это вот такая вероятность:
p-значение (Pleft(left|xi right|>2right)).
То есть в нашем примере p-значение — это вероятность такого события, что случайная величина, имеющая t-распределение Стьюдента с 8 степенями свободы, по модулю превысит (t_{mathit{text{р}text{а}text{с}text{ч}}}=2). Как видно из рисунка, в нашем случае эта вероятность равна 0,03+0,03=0,06.
Рисунок 2.4а. Расчетное и критическое значения тестовой статистики для примера 2.3.
Рисунок 2.4б. P-значение для примера 2.3.
Как видно из нашего примера, P-значение больше заранее выбранного уровня значимости только тогда, когда (left|t_{mathit{text{р}text{а}text{с}text{ч}}}right|<t_{mathit{text{к}text{р}}}), что подтверждает сформулированное нами правило принятия решения при помощи P-значения: если P-значение больше уровня значимости, то нулевая гипотеза не отвергается. Если P-значение меньше уровня значимости, то нулевая гипотеза отвергается.
***
Решив неравенство (left|frac{widehat {beta }_2-beta _2}{mathit{se}left(widehat {beta }_2right)}right|<t_{n-2}^{alpha }) относительно (beta _2), получим:
begin{equation*} widehat {beta }_2-mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha }<beta _2<widehat {beta }_2+mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha } end{equation*}
Иными словами, с вероятностью (1-alpha ) интервал (left(widehat {beta }_2-mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha },widehat {beta }_2+mathit{se}left(widehat {beta }_2right){ast}t_{n-2}^{alpha }right)) содержит истинное значение оцениваемого параметра. Например, если (alpha =0,05) и, следовательно, (1-alpha =0,95), этот интервал и называют 95-процентным доверительным интервалом для параметра (beta _2).
Возможность построения доверительных интервалов важна с практической точки зрения. Дело в том, что, так как (widehat {beta }_2) является лишь приблизительной оценкой параметра (beta _2), эта точечная оценка сама по себе несет гораздо меньше информации, чем интервал. Ведь без доверительного интервала невозможно понять, насколько она эта оценка на самом деле (не)точная. Например, утверждение « (widehat {beta }_2) равно 23,4» куда менее информативно, чем утверждение «истинное значение оцениваемого параметра с вероятностью 95 процентов содержится в пределах от 23,1 до 23,7».
Завершим раздел еще двумя примерами. В первом из них все расчеты проделаны вручную, чтобы, проследив их, можно было еще раз разобраться во взаимосвязях между введенными нами понятиями. Во втором примере используется эконометрический пакет, что позволяет продемонстрировать, как подобные вычисления осуществляются в реальных прикладных исследованиях.
Пример 2.4. Доходы индивидов и потребление риса
Исследователь анализирует зависимость потребления риса от уровня дохода (кривую Энгеля) для однородной группы из 20 потребителей. Все потребители из этой группы сталкиваются с одинаковыми ценами на рис и другие товары, и только уровни дохода у них различны, поэтому исследователь использует модель парной регрессии.
Обозначим:
(x_i) — ежемесячный располагаемый доход i-го потребителя (в тысячах денежных единиц),
(y_i) — ежемесячное потребление риса i-м потребителем (в килограммах).
Имеются следующие данные о переменных x и y:
begin{equation*} sum _{i=1}^{20}x_i=20,sum _{i=1}^{20}x_i^2=40,sum _{i=1}^{20}y_i=42,sum _{i=1}^{20}y_i^2=108, end{equation*}
begin{equation*} sum _{i=1}^{20}x_i{ast}y_i=60 end{equation*}
(а) Вычислите МНК-оценки коэффициентов в регрессии
begin{equation*} y_i=beta _1+beta _2{ast}x_i+varepsilon _i. end{equation*}
Выпишите полученное уравнение регрессии и коэффициент (R^2).
(б) При уровне значимости 5% проверьте значимость переменной x.
(в) Дайте содержательную интерпретацию коэффициента при переменной x.
(г) Вспомнив соответствующие определения из курса микроэкономики и вычислив необходимую эластичность, определите: является ли рис для этой группы потребителей низкокачественным товаром, товаром первой необходимости или предметом роскоши?
(д) При уровне значимости 5% проверьте гипотезу о том, что коэффициент (beta _2) равен единице.
(е) Постройте 95-процентный доверительный интервал для коэффициента (beta _2).
Решение:
(а) Вычислим средние значения:
begin{equation*} overline x=1,overline{x^2}=2,overline y=2,1,overline{y^2}=5,4,overline{mathit{xy}}=3 end{equation*}
Найдем оценки коэффициентов:
begin{equation*} widehat {beta _2}=frac{overline{mathit{xy}}-overline x{ast}overline y}{overline{x^2}-overline x^2}=frac{3-1{ast}2,1}{2-1}=0,9 end{equation*}
begin{equation*} widehat {beta _1}=overline y-widehat {beta _2}{ast}overline x=2,1-1{ast}0,9=1,2 end{equation*}
Таким образом, (widehat y_i=1,2+0,9{ast}x_i).
Теперь вычислим (R^2). Для этого воспользуемся тем, что по определению он равен отношению объясненной суммы квадратов к общей сумме квадратов:
begin{equation*} R^2=frac{sum _{i=1}^{20}left(widehat y_i-overline yright)^2}{sum _{i=1}^{20}left(y_i-overline yright)^2}. end{equation*}
Вычислим каждую из этих сумм по отдельности. Сначала найдем общую сумму квадратов:
begin{equation*} mathit{TSS}=sum _{i=1}^{20}left(y_i-overline yright)^2=sum _{i=1}^{20}y_i^2-2{ast}sum _{i=1}^{20}y_i{ast}overline y+sum _{i=1}^{20}overline y^2= end{equation*}
begin{equation*} sum _{i=1}^{20}y_i^2-2{ast}overline y{ast}sum _{i=1}^{20}y_i+20{ast}overline y^2=108-2{ast}2,1{ast}42+20{ast}2,1^2=19,8 end{equation*}
Теперь найдем объясненную сумму квадратов:
begin{equation*} sum _{i=1}^{20}left(widehat y_i-overline yright)^2=sum _{i=1}^{20}left(1,2+0,9{ast}x_i-2,1right)^2=sum _{i=1}^{20}left(0,9{ast}x_i-0,9right)^2= end{equation*}
begin{equation*} 0,9^2sum _{i=1}^{20}left(x_i-1right)^2=0,81{ast}left(sum _{i=1}^{20}x_i^2-2{ast}sum _{i=1}^{20}x_i+20right)=16,2 end{equation*}
Теперь можно вычислить коэффициент детерминации:
begin{equation*} R^2=frac{sum _{i=1}^{20}left(widehat y_i-overline yright)^2}{sum _{i=1}^{20}left(y_i-overline yright)^2}=frac{16,2}{19,8}=0,82 end{equation*}
Ответ на пункт (а): (widehat y_i=1,2+0,9{ast}x_i,R^2=0,82)
(б) Тестируемая гипотеза (H_0:beta _2=0). Альтернативная гипотеза (H_1:beta _2{neq}0).
Чтобы проверить значимость, нам понадобится стандартная ошибка оценки коэффициента. Для этого нам придется оценить сумму квадратов остатков. Воспользуемся тем фактом, что для регрессии с константой верно равенство:
begin{equation*} sum _{i=1}^{20}left(y_i-overline yright)^2=sum _{i=1}^{20}left(widehat y_i-overline yright)^2+sum _{i=1}^{20}e_i^2 end{equation*}
В этой формуле мы вычислили все элементы, кроме суммы квадратов остатков:
begin{equation*} 19,8=16,2+sum _{i=1}^{20}e_i^2 end{equation*}
Следовательно, (sum _{i=1}^{20}e_i^2=19,8-16,2=3,6).
Вычислим оценку дисперсии случайной ошибки:
begin{equation*} S^2=frac{sum _{i=1}^{20}e_i^2}{n-2}=frac{3,6}{20-2}=0,2 end{equation*}
Теперь вычислим стандартную ошибку оценки коэффициента:
begin{equation*} mathit{se}left(widehat {beta _2}right)=sqrt{frac{S^2}{sum _{i=1}^{20}left(x_i-overline xright)^2}}=end{equation*}
begin{equation*} =sqrt{frac{0,2}{sum _{i=1}^{20}x_i^2-n{ast}left(overline xright)^2}}=sqrt{frac{0,2}{40-20}}=0,1 end{equation*}
Расчетное значение t-статистики равно (frac{widehat {beta _2}}{mathit{se}left(widehat {beta _2}right)}=frac{0,9}{0,1}=9).
Критическое значение t-статистки из таблицы распределения Стьюдента при уровне значимости 5% и (20–2)=18 степенях свободы составляет 2,101. Расчетное значение больше критического, следовательно, мы отклоняем нулевую гипотезу и делаем вывод о том, что уровень дохода индивида значимо влияет на его спрос на рис.
Ответ на пункт (б): Переменная значима.
Ответ на пункт (в): При увеличении располагаемого дохода потребителя на одну тысячу денежных единиц его спрос на рис увеличивается в среднем на 0,9 кг.
(г) Вычислим эластичность спроса на рис по доходу. По определению эластичность равна:
begin{equation*} frac{frac{dwidehat y}{mathit{dx}}{ast}x}{widehat y}=frac{0,9{ast}x}{1,2+0,9{ast}x} end{equation*}
Легко видеть, что при любых положительных значениях (x) эластичность спроса по доходу лежит между нулем и единицей, следовательно, для рассматриваемой группы потребителей рис является товаром первой необходимости. Что, в общем-то, неудивительно.
Ответ на пункт (г): Товар первой необходимости.
(д) Тестируемая гипотеза (H_0:beta _2=1). Альтернативная гипотеза (H_1:beta _2{neq}1).
Для проверки значимости нам понадобится стандартная ошибка оценки коэффициента.
Расчетное значение t-статистики равно (frac{widehat {beta _2}-1}{mathit{se}left(widehat {beta _2}right)}=frac{0,9-1}{0,1}=-1).
Критическое значение t-статистки из таблицы распределения Стьюдента при уровне значимости 5% и (20–2)=18 степенях свободы составляет 2,101. Расчетное значение по модулю меньше критического, следовательно, мы принимаем (не отклоняем) нулевую гипотезу.
Ответ на пункт (д): Гипотеза не отклоняется.
(е) В рамках предпосылок классической линейной модели парной регрессии доверительный интервал может быть посчитан следующим образом:
begin{equation*} left(widehat {beta _2}-mathit{se}left(widehat {beta _2}right){ast}t_{n-2},widehat {beta _2}+mathit{se}left(widehat {beta _2}right){ast}t_{n-2}right) end{equation*}
begin{equation*} left(0,9-0,1{ast}2,101,0,9+0,1{ast}2,101right) end{equation*}
Таким образом, c вероятностью 95% интервал (left(0,69,1,11right)) содержит истинное значение коэффициента (beta _2).
Ответ на пункт (е): (left(0,69,1,11right)).
***
Пример 2.5. Площадь однокомнатной квартиры и её цена
В этом задании вам предлагается проанализировать взаимосвязь между площадью квартиры и ее ценой. Вам доступны следующие данные о московском рынке недвижимости в 2012 году (файл Price2012):
Price — рыночная цена однокомнатной квартиры в Москве (в тысячах руб.), выкуп которой был осуществлен с 10.01.2012 по 28.09.2012
TotalArea — общая площадь квартиры (кв. м)
(а) Оцените регрессию переменной Price на переменную TotalArea. Запишите оцененное уравнение регрессии, указав коэффициент детерминации и (в скобках под соответствующими коэффициентами) стандартные ошибки. Постройте диаграмму рассеяния с линией регрессии.
(б) Является ли коэффициент при переменной TotalArea статистически значимым при уровне значимости 1%? Дайте содержательную интерпретацию для этого коэффициента.
Решение:
(а) Ниже представлена распечатка результатов оценивания уравнения в эконометрическом пакете Gretl3. (Любой стандартный эконометрический пакет, например R, Stata или Econometric Views, выдаст аналогичную табличку. Пользуйтесь тем из них, который вам больше нравится. Ну или тем, который есть под рукой.)
Модель 1: МНК, использованы наблюдения 1-121
Зависимая переменная: Price
| Коэффициент | Ст. ошибка | t-статистика | P-значение | ||
| const | 786,456 | 583,051 | 1,349 | 0,1799 | |
| TotalArea | 135,317 | 16,5144 | 8,194 | 0,0001 | *** |
| Среднее зав. перемен | 5540,335 | Ст. откл. зав. перемен | 792,7127 | |
| Сумма кв. остатков | 48208118 | Ст. ошибка модели | 636,4827 | |
| R-квадрат | 0,360696 | Испр. R-квадрат | 0,355324 | |
| F(1, 119) | 67,14000 | Р-значение (F) | 3,30e-13 | |
| Лог. правдоподобие | $-$951,8540 | Крит. Акаике | 1907,708 | |
| Крит. Шварца | 1913,300 | Крит. Хеннана-Куинна | 1909,979 |
В столбце «Коэффициент» указаны оценки коэффициентов, а в столбце «Ст. ошибка» — их стандартные ошибки. В нижней части таблицы среди прочих показателей можно найти и коэффициент R-квадрат.
Общепринятый формат записи полученных результатов имеет следующий вид (в скобках под оценками коэффициентов указаны соответствующие стандартные ошибки):
begin{equation*} widehat {mathit{Price}}_i=underset{left(583,051right)}{786,456}+underset{left(16,514right)}{135,317}mathit{TotalArea}_i,R^2=0,36 end{equation*}
Обратите внимание, что в скобках под оценками коэффициентов мы указали их стандартные ошибки. Такой формат является хорошим тоном при записи результатов эконометрического моделирования, так как позволяет читателю оценить точность ваших результатов и прикинуть доверительные интервалы для коэффициентов.
(б) В столбце «P-значение» указано, что P-значение для оценки коэффициента при переменной TotalArea меньше, чем 0,0001 (и тем более меньше, чем 0,01). Следовательно, этот коэффициент является статистически значимым при уровне значимости 1%.
Содержательная интерпретация: при увеличении общей площади квартиры на один квадратный метр ее цена в среднем при прочих равных условиях увеличивается на 135 тысяч рублей.
Отметим, что свободное слагаемое в данном случае отличается от нуля статистически незначимо, так как соответствующее P-значение равно 0,18, что больше любого разумного уровня значимости. Да и если бы даже эта константа была значима, все равно отдельно интерпретировать её смысла не было бы, ведь константа показывает значение зависимой переменной при условии, что регрессор TotalArea равен нулю (то есть при условии, что анализируемая квартира имеет нулевую площадь). Вряд ли кто-то всерьез интересуется ценой квартиры площадью 0 квадратных метров.
- Вместо использования готовых таблиц распределения можно, например, ввести в MS Excel формулу =СТЬЮДЕНТ.ОБР( 1 — 0,05 / 2; 10 — 2) ↵
- Для получения этого результата достаточно запустить Gretl; используя пункт меню «Импорт», импортировать данные из файла MS Excel (или просто мышкой «перетащить» нужный файл в рабочую область эконометрического пакета); выбрать в меню «Модель» пункт «Метод наименьших квадратов» и указать в качестве зависимой переменной переменную Price, а в качестве объясняющей — переменную TotalArea. ↵