Микроядра, от которых давно отказались из-за их слишком низкой производительности по сравнению с монолитными ядрами, могут снова вернуться в операционные системы, поскольку потенциально они обеспечивают более высокую надежность, которую сейчас многие разработчики считают важнее производительности.Когда последний раз ваш телевизор внезапно отключался или требовал, чтобы вы срочно загрузили из Web какую-нибудь программную заплатку, исправляющую критическую ошибку?
Микроядра, от которых давно отказались из-за их слишком низкой производительности по сравнению с монолитными ядрами, могут снова вернуться в операционные системы, поскольку потенциально они обеспечивают более высокую надежность, которую сейчас многие разработчики считают важнее производительности.

Когда последний раз ваш телевизор внезапно отключался или требовал, чтобы вы срочно загрузили из Web какую-нибудь программную заплатку, исправляющую критическую ошибку? В конце концов, если у вас не совсем уж древний телевизор, то, по сути, он тот же компьютер — с центральным процессором, большим монитором, какой-то аналоговой электроникой для декодирования радиосигналов, парочкой специальных устройств ввода/вывода (пульт, встроенный дисковод для кассет или DVD-дисков) и с программным обеспечением, прописанным в оперативной памяти. Этот риторический вопрос возвращает нас к одной неприятной проблеме, о которой так не любят говорить в компьютерной индустрии. Почему телевизоры, DVD-проигрыватели, MP3-плейеры, сотовые телефоны и другие электронные устройства с программным обеспечением вполне надежны и хорошо защищены, а компьютеры — нет? Конечно, тому есть немало «объяснений»: компьютеры — это гибкие системы, пользователи могут менять программное обеспечение, отрасль информационных технологий еще недостаточно развита и так далее. Но, поскольку мы живем в эпоху, когда подавляющее большинство компьютерных пользователей мало сведущи в технических вопросах, то подобные «объяснения» им не кажутся убедительными.
Чего потребитель ждет от компьютера? Того же самого, что и от телевизора. Вы его покупаете, подключаете, и он прекрасно работает следующие десять лет. ИТ-специалистам следует принять во внимание эти ожидания и сделать компьютеры такими же надежными и защищенными, как телевизоры.
Самой слабым местом в плане надежности и защиты остается операционная система. Несмотря на то, что прикладные программы содержат немало дефектов, если бы операционная система была безошибочной, то некорректность прикладных программ не имела бы столь серьезных последствий, как сейчас, поэтому мы остановимся в данной статье именно на операционных системах.
Но прежде, чем перейти к деталям, несколько слов о связи между надежностью и защитой. Проблемы, возникающие в каждой из этих сфер, зачастую имеют общие корни: ошибки в программном обеспечении. Ошибка переполнения буфера может вызвать сбой в системе (проблема надежности), но она также позволяет хитроумно написанному вирусу проникнуть на компьютер (проблема защиты). Несмотря на то, что в данной статье мы, прежде всего, будем говорить о надежности, следует иметь в виду, что увеличение надежности может привести к усилению защиты.
Почему системы ненадежны?
Современные операционные системы имеют две особенности, из-за которых они теряют как в надежности, так и в защищенности. Во-первых, эти ОС огромны по размеру, а, во-вторых, в них очень плохо обеспечена изоляция ошибок. Ядро Linux имеет свыше 2,5 млн. строк кода, а ядро Windows XP как минимум в два раза больше.
Одно из исследований, посвященных изучению надежности программного обеспечения, показало, что программы содержат от 6 до 16 ошибок на каждые 1000 строк исполняемого кода. Согласно результатам другого исследования, частота ошибок в программах находится в пределах от 2 до 75 на каждые 1000 строк исполняемого кода [2], в зависимости от размера модуля. Даже если исходить из самой скромной оценки (6 ошибок на 1000 строк кода), ядро Linux, по всей видимости, содержит примерно 15 тыс. ошибок; Windows XP — как минимум в два раза больше.
Хуже того, как правило, около 70% операционной системы составляют драйверы устройств, уровень ошибок в которых в три-семь раз выше, чем в обычном коде [3], поэтому приведенная выше оценка числа ошибок в ОС, скорее всего, сильно занижена. Понятно, что найти и исправить все эти ошибки просто невозможно. Более того, при исправлении одних ошибок зачастую вносятся новые.
Из-за огромного размера современных операционных систем никто в одиночку не может знать их досконально. Действительно, крайне трудно создать хорошую систему, если никто в действительности ее себе полностью не представляет.
Этот факт приводит нас ко второй проблеме: изоляции ошибок. Ни один человек в мире не знает все о том, как функционирует авианосец, но подсистемы авианосца хорошо изолированы друг от друга, и его засорившийся туалет никак не повлияет на работу подсистемы запуска ракет.
Операционные системы не имеют такого рода изоляции между компонентами. Современная операционная система содержит сотни или даже тысячи процедур, объединенных друг с другом в одну бинарную программу, работающую в режиме ядра. Каждая из миллионов строк кода ядра может переписать основные структуры данных, которые используют не связанные с этим кодом компоненты, что приводит к сбою системы, выяснить причины которого крайне сложно. Кроме того, если вирус инфицировал одну процедуру ядра, невозможно предотвратить его стремительное распространение на другие процедуры и заражение всей машины целиком.
Вернемся к аналогии с кораблем. Корпус современного судна разделен на множество отсеков. Если в одном из отсеков возникает течь, то затапливается только он, а не весь трюм. Современные операционные системы подобны кораблям, существовавшим до изобретения переборок: корабль может потопить любая пробоина.
К счастью, ситуация не столь бесперспективна. Разработчики стремятся создать более надежные операционные системы. Существует четыре различных подхода, которые применяются для того, чтобы в будущем сделать ОС более надежными и защищенными. Мы изложим их в нашей статье в «возрастающем» порядке, от менее радикальных к более радикальным.
Укрепленные операционные системы
Самый консервативный подход, Nooks [4], был разработан для того, чтобы увеличить надежность существующих операционных систем, таких как Windows и Linux. Технология Nooks поддерживает монолитную структуру ядра, в которой сотни или тысячи процедур связаны вместе в одном адресном пространстве и работают в режиме ядра. Этот подход сосредоточен на том, чтобы сделать драйверы устройств (основная причина всех проблем) менее опасными.

|
Рис. 1. Модель Nooks. Каждый драйвер заключен в оболочку и размещается на уровне защищенного программного обеспечения. Этот уровень ведет мониторинг всех взаимодействий между драйвером и ядром |
В частности, как показывает рис. 1, Nooks защищает ядро от некорректных драйверов устройств за счет того, что каждый драйвер заключается в оболочку и размещается на уровне защищенного программного обеспечения, который формирует домен упрощенной защиты. Такую технологию иногда называют «песочницей». Оболочка вокруг каждого драйвера тщательно отслеживает все взаимодействия между драйвером и ядром. Кроме того, данная технология может использоваться для других расширений ядра, таких как загружаемые операционные системы, но для простоты мы будем говорить о ней только применительно к драйверам.
Цели проекта Nooks заключаются в следующем:
- защитить ядра от ошибок в драйверах;
- обеспечить автоматическое восстановление в случае сбоя в драйвере;
- сделать все это путем минимальных изменений в существующих драйверах и ядре.
Защита ядра от некорректных драйверов — не главная цель. Впервые технология Nooks была реализована на Linux, но эти идеи в равной степени применимы к другим унаследованным ядрам.
Изоляция
Основное средство, позволяющее уберечь структуры данных ядра от уничтожения некорректными драйверами — это карта страниц виртуальной памяти. При работе драйвера все внешние для него страницы переводятся в режим «открыты только для чтения», благодаря чему создается отдельный домен упрощенной защиты для каждого драйвера. Таким образом, драйвер может читать структуры данных ядра, которые ему необходимы, но любая попытка напрямую изменить структуры данных ядра вызовет исключение центрального процессора, которое перехватывает менеджер изоляции Nooks. Доступ к частной памяти драйвера, где хранятся стеки, куча, структуры частных данных и копии объектов ядра, разрешен на чтение и на запись.
Посредничество
Каждый класс драйверов экспортирует набор функций, которые может вызвать ядро. Например, аудиодрайверы могут предоставить вызов для записи блока образцов звучания на звуковую карту, другой — для регулирования громкости и так далее. Когда драйвер загружен, заполняется массив указателей на функции драйвера, благодаря чему ядро может найти любую из них. Кроме того, драйвер импортирует набор функций, предоставляемых ядром, например, для резервирования буфера данных.
Nooks предоставляет оболочки как для экспортируемых, так и для импортируемых функций. Теперь, когда ядро вызывает функцию драйвера или драйвер вызывает функцию ядра, вызов на самом деле направляется оболочке, которая проверяет корректность параметров и управляет вызовом. Несмотря на то, что суррогаты (stubs) оболочки (на рис. 1 они изображаются как линии, указывающие как внутрь, так и наружу драйвера) генерируются автоматически на основе прототипов функций, тело оболочки разработчикам приходится писать вручную. В целом группа Nooks написала 455 оболочек: 329 для функций, которые ядро экспортирует, и 126 — для функций, которые экспортируют драйверы устройств.
Когда драйвер пытается модифицировать объект ядра, его оболочка копирует объект в домен защиты драйвера, то есть в его частные страницы, открытые для чтения и записи. Затем драйвер меняет копию. Если запрос был выполнен успешно, менеджер изоляции копирует модифицированные объекты обратно в ядро. Таким образом, сбой в работе драйвера или ошибка во время вызова всегда оставляют объекты ядра в корректном состоянии. Операции контроля за импортируемыми объектами специфические для каждого объекта, в силу чего группе Nooks пришлось вручную писать код для контроля 43 классов объектов, которые используют драйверы Linux.
Восстановление
В случае сбоя в режиме пользователя запускается агент восстановления, который обращается к базе данных конфигурации для того, чтобы выяснить, что нужно делать. Во многих случаях освобождения всех занятых ресурсов и перезапуска драйвера оказывается достаточно, поскольку самые распространенные алгоритмические ошибки, как правило, находят при тестировании, и в коде в основном остаются ошибки синхронизации и специфические дефекты.
Эта технология позволяет восстановить систему, но работавшие в момент сбоя приложения могут оказаться в некорректном состоянии. В результате работы [5] группа Nooks добавила концепцию дублирующих драйверов (shadow driver) для того, чтобы приложения могли выполняться корректно даже после сбоя драйвера.
Одним словом, во время нормальной работы дублирующий драйвер регистрирует взаимодействия между каждым драйвером и ядром, если это взаимодействие может потребоваться для восстановления. После перезапуска драйвера дублирующий драйвер передает перезапущенному драйверу все данные из журнала регистрации, например, повторяя вызов системы управления вводом/выводом (IOCTL) для того, чтобы установить параметры, такие как громкость звука. Ядру ничего не известно о процессе возвращения драйвера в то состояние, в котором находился старый драйвер. Как только этот процесс завершается, драйвер начинает обрабатывать новые запросы.
Ограничения
Несмотря на то, что, согласно экспериментам, Nooks может обнаруживать 99% фатальных ошибок драйвера и 55% не фатальных, он далеко не совершенен. Например, драйверы могут выполнять привилегированные команды, которые они выполнять не должны; они могут записывать данные в некорректные порты ввода/вывода и выполнять бесконечные циклы. Более того, группе Nooks большое количество оболочек пришлось написать вручную, и эти оболочки могут содержать ошибки. Наконец, при данном подходе невозможно запретить драйверам записывать данные в любое место памяти. Тем не менее это потенциально весьма полезный шаг к повышению надежности унаследованных ядер.
Паравиртуальные машины
Второй подход создан на основе концепции виртуальной машины. Эта концепция была разработана в конце 60-х годов. Идея заключается в том, чтобы использовать специальную управляющую программу, называемую монитором виртуальной машины, которая работает непосредственно с аппаратным обеспечением, а не с операционной системой. Виртуальная машина создает несколько экземпляров реальной машины. Каждый экземпляр может поддерживать работу любой программы, которая способна выполняться на данном аппаратном обеспечении.
Этот метод часто применяется для того, чтобы две или несколько операционных систем, скажем, Linux и Windows, могли работать на одной и той же машине одновременно, причем так, что каждая из ОС считает, что в ее распоряжении находится вся машина. Использование виртуальных машин имеет заслуженную репутацию средства, обеспечивающего хорошую изоляцию ошибок. В конце концов, если ни одна из виртуальных машин не подозревает о существовании других, проблемы, возникающие на одной машине, никак не могут распространиться на другие.
Была предпринята попытка адаптировать данную концепцию для организации защиты в одной операционной системе, а не между различными ОС [7]. Более того, поскольку Pentium не полностью поддерживает виртуализацию, пришлось отступить от принципа запускать в виртуальной машине операционную систему без каких-либо ее изменений. Эта уступка позволяет вносить изменения в операционную систему для того, чтобы гарантировать, что она не может делать ничего, что невозможно виртуализировать. Для того чтобы данную технологию отличать от истинной виртуализации, ее называют паравиртуализацией.
В частности, в 90-х годах группа разработчиков из университета Карлсруэ создала микроядро L4 [8]. Они смогли запустить слегка модифицированную версию Linux (L4Linux) на L4 в режиме, который можно называть видом виртуальной машины [9]. Позже разработчики выяснили, что вместо того чтобы запускать только одну копию Linux на L4, они могут запускать несколько копий. Как показано на рис. 2, эта мысль привела к идее использования одной из виртуальных машин Linux для работы прикладных программ, а другой или нескольких — для работы драйверов устройств.
Если драйверы устройств работают в одной или в нескольких виртуальных машинах, изолированных от основной виртуальной машины, где работает остальная операционная система и прикладные программы, то в случае сбоя в драйвере выходит из строя только его виртуальная машина, а не основная. Дополнительное преимущество такого подхода заключается в том, что драйверы устройств не нужно модифицировать, поскольку они видят обычную среду ядра Linux. Конечно, само ядро Linux придется менять для того, чтобы оно поддерживало паравиртуализацию, но это однократное изменение. Кроме того, нет необходимости повторять эту процедуру для каждого драйвера устройства.
Поскольку драйверы устройств работают на аппаратном обеспечении в режиме пользователя, основной вопрос заключается в том, как они будут выполнять ввод/вывод и обрабатывать прерывания. Физический ввод/вывод поддерживается за счет добавления примерно 3 тыс. строк кода к ядру Linux, на котором работают драйверы, благодаря чему драйверы могли использовать сервисы L4 для ввода/вывода вместо того, чтобы делать это самостоятельно. Дополнительные 5 тыс. строк кода поддерживают взаимодействия между тремя изолированными драйверами (диска, сети и шины PCI) и виртуальной машиной, в которой выполняются прикладные программы.
В принципе, этот подход должен обеспечить более высокую надежность, чем единая операционная система, поскольку в том случае, если в виртуальной машине, содержащей один или несколько драйверов, возникает сбой, то виртуальную машину можно перезапустить — и драйверы вернутся в свое исходное состояние. В отличие от Nooks при данном подходе не предпринимается никаких попыток вернуть драйверы в предыдущее состояние (то состояние, в котором они находились до того, как возник сбой). Таким образом, если аудиодрайвер выйдет из строя, он будет восстановлен со значением уровня звука по умолчанию, а не с тем, что было до того, как возник сбой.
Параметры производительности показывают, что накладные расходы при использовании паравиртуализованных машин составляют около 3-8%.
Мультисерверные операционные системы
Первые два подхода предусматривают модификацию унаследованных систем. Следующие два посвящены будущим системам.
Один из этих подходов напрямую касается сути проблемы: работы всей операционной системы как единой гигантской бинарной программы в режиме ядра. Вместо этого в данном случае предлагается иметь несколько небольших микроядер, работающих в режиме ядра, в то время как остальная часть операционной системы представляет собой набор полностью изолированных сервера и процессов драйвера, работающих в режиме пользователя. Эта идея была предложена 20 лет назад, но тогда она так и не была полностью воплощена из-за более низкой производительности мультисерверной ОС по сравнению с монолитным ядром. В 80-х годах производительность считалась самым важным показателем, а о надежности и защите даже не задумывались. Конечно, в свое время инженеры самолетов не задумывались о расходе топлива или о создании дверей кабины, способной выдерживать вооруженное нападение. Времена меняются, и представление людей о том, что действительно важно, меняются тоже.
Мультисерверная архитектура
Для того чтобы лучше понять, в чем состоит идея мультисерверной операционной системы, обратимся к современному примеру. Как показано на рис. 3, в Minix 3, микроядро обрабатывает прерывания, предоставляет базовые механизмы для управления процессами, реализует взаимодействия между процессами и выполняет планирование процессов. Оно также предоставляет небольшой набор вызовов ядра для авторизованных драйверов и серверов, такие как чтение избранной части адресного пространства конкретного пользователя или запись в авторизованные порты ввода/вывода. Драйвер часов использует то же адресное пространство, что и микроядро, но он планируется как отдельный процесс. Ни один другой драйвер в режиме ядра не работает.
Над микроядром находится уровень драйверов устройств [10]. Каждое устройство ввода/вывода имеет свой собственный драйвер, который функционирует как отдельный процесс в своем собственном частном адресном пространстве, защищенном с помощью аппаратного модуля управления памятью (MMU). Этот уровень включает в себя процессы драйверов для диска, терминала (клавиатуры и дисплея), Ethernet, принтера, аудио и так далее. Эти драйверы работают в режиме пользователя и не могут выполнять привилегированные команды или операции чтения и записи на портах ввода/вывода компьютера. Для того чтобы получить эти сервисы, драйверы должны обратиться к ядру. Хотя такая архитектура увеличивает накладные расходы, она значительно повышает надежность.
Над уровнем драйверов устройств находится уровень сервера. Сервер файлов представляет собой программу (4,5 тыс. строк исполняемого кода), которая принимает запросы от пользовательских процессов на системные вызовы Posix, касающиеся файлов, таких как, read, write, lseek и stat, и выполняет их. Кроме того, на этом уровне расположен менеджер процессов, который управляет процессами и памятью и выполняет вызовы Posix и другие системные вызовы, такие как fork, exec и brk.
Несколько необычной особенностью является сервер реинкарнации, который играет роль родительского процесса для всех остальных серверов и всех драйверов. Если в драйвере или в сервере возникает сбой, они завершают свою работу или не отвечают на периодически посылаемые команды ping, сервер реинкарнации удаляет эти процессы, если необходимо, а затем перезапускает их с копии на диске или из оперативной памяти. Таким образом можно перезапустить драйверы, но сейчас из серверов можно перезапустить только те, внутреннее состояние которых ограничено.
К числу других серверов относятся сетевой сервер, который содержит: полный стек TCP/IP; хранилище данных, простой сервер имен, который используют другие серверы; информационный сервер, который используется при отладке. Наконец, над серверным уровнем расположены пользовательские процессы. Единственное отличие между этой и другими системами Unix заключается в том, что библиотечные процедуры для чтения, записи и других системных вызовов выполняется посредством посылки сообщений серверам. За исключением данного отличия (скрытого в системных библиотеках) это обычные пользовательские процессы, которые могут использовать POSIX API.
Взаимодействия между процессами
Поскольку именно механизм взаимодействия между процессами (Interprocess Communication, IPC) позволяет всем процессам работать вместе, он критически важен в мультисерверной операционной системе. Однако так как все серверы и драйверы в Minix 3 выполняются как физически изолированные процессы, они не могут напрямую вызывать функции друг друга или совместно использовать структуры данных. Вместо этого Minix 3 поддерживает IPC за счет передачи сообщений фиксированной длины на так называемом принципе рандеву (когда и отправитель, и получатель готовы к обмену, система копирует сообщение непосредственно от отправителя к получателю). Кроме того, имеется механизм асинхронных уведомлений о событиях. События, которые не могут быть реализованы, в таблице процессов помечаются как отложенные.
Minix 3 элегантно объединяет прерывания с системой передачи сообщений. Обработчики прерываний используют механизм уведомлений для сигнализации о завершении ввода/вывода. Этот механизм позволяет обработчику устанавливать бит в битовой карте «отложенных прерываний», а затем продолжать работу без блокировки. Когда драйвер готов к получению прерывания, ядро преобразует его в обычное сообщение.
Характеристики надежности
Причин высокой надежности Minix 3 несколько. Во-первых, в ядре выполняется код размером не более 4 тыс. строк, поэтому, исходя из скромной оценки 6 ошибок на 1000 строк, общее число ошибок в ядре, скорее всего, около 24. Сравните это число с 15 тыс. ошибок в Linux и намного большим их количеством в Windows. Поскольку все драйверы устройств, за исключением часов, — это пользовательские процессы, никакой посторонний код никогда не будет работать в режиме ядра. Кроме того, небольшой размер ядра позволяет более эффективно проверить его корректность либо вручную, либо с помощью формальных методов.
Архитектура IPC в Minix 3 не требует поддержки очередей или буферизации сообщений, что избавляет от необходимости управления буфером в ядре. Более того, поскольку IPC — это мощная конструкция, IPC-возможности каждого сервера и драйвера строго ограничены. Для каждого процесса строго определены используемые примитивы IPC, доступные адресаты и уведомления о пользовательских событиях. Пользовательские процессы, например, могут взаимодействовать только по принципу рандеву или посылать сообщения только серверам Posix.
Кроме того, все структуры данных ядра являются статичными. Все эти особенности значительно упрощают код и избавляют от ошибок ядра, связанных с переполнением буфера, утечкой памяти, несвоевременными прерываниями, ненадежным кодом ядра и так далее. Конечно, перевод большей части операционной системы в режим пользователя не избавляет от неизбежных ошибок в драйверах и серверах, но делает их значительно менее опасными. Из-за ошибки ядро может уничтожить критически важные структуры ядра, записать мусор на диск и так далее. Ошибка в большинстве драйверов и серверов не может нанести значительного ущерба, поскольку эти процессы четко разделены и операции, которые они могут выполнять, строго ограничены.
Драйверы и серверы в режиме пользователя не могут работать с привилегиями суперпользователя. Они не могут получать доступ к областям памяти, находящимся за пределами их собственных адресных пространств, за исключением вызовов ядра (проверку корректности которых выполняет ядро). Более того, битовые карты и диапазоны внутри таблицы процессов ядра управляют набором допустимых вызовов ядра, возможностей IPC и допустимых портов ввода/вывода для каждого процесса в отдельности. Например, ядро может не допустить, чтобы драйвер принтера записывал информацию в пользовательские адресные пространства, обращался к портам ввода/вывода диска или посылал сообщения аудиодрайверу. В традиционных монолитных системах любой драйвер может делать что угодно.
Еще одна причина надежности — использование отдельных пространств команд и данных. Если следствием ошибки или действия вируса станет ошибка переполнения буфера драйвера или сервера и запись постороннего кода в пространство данных, инфицированный код нельзя будет выполнить за счет передачи ему управления или с помощью процедуры, указывающей на него, поскольку ядро не будет выполнять код, если он не находится в пространстве команд процесса, открытом только на чтение.
К числу других специфических особенностей, обеспечивающих более высокую надежность, самым важным является свойство самовосстановления. Если драйвер пытается сохранить данные по некорректному указателю, входит в бесконечный цикл или пытается выполнить другие некорректные операции, сервер реинкарнации автоматически заменит этот драйвер, причем, как правило, в этом случае не будут затронуты другие выполняемые процессы.
Несмотря на то, что перезапуск логически некорректного драйвера не устранит ошибку, на практике некорректная синхронизация и аналогичные ошибки вызывают множество проблем, и перезапуск драйвера часто дает возможность привести систему в корректное состояние.
Параметры производительности
В течение десятилетий разработчики критиковали мультисерверные архитектуры, базирующиеся на принципе микроядер, за их более низкую по сравнению с монолитными архитектурами производительность. Однако различные проекты подтверждают, что модульная архитектура на самом деле может обеспечивать сравнимую производительность. Несмотря на тот факт, что Minix 3 не была оптимизирована по производительности, система работает достаточно быстро. Потери производительности, которые возникают из-за того, что драйверы работают в режиме пользователя, по сравнению с драйверами в режиме ядра составляют менее 10%, и система может создаваться, в том числе ядро, общие драйверы и все серверы (112 компиляций и 11 ссылок), менее чем за 6 с на машине с процессором Athlon/2,2 ГГц.
Тот факт, что мультисерверные архитектуры позволяют поддерживать достаточно надежную Unix-подобную среду при весьма небольших потерях производительности, делает такой подход практически приемлемым. Minix 3 для Pentium можно загрузить бесплатно на условиях лицензии Berkeley с сайта www.minix3.org. Сейчас разрабатываются версии для других архитектур и встроенных систем.
Защита на базе языка
Самый радикальный подход, что весьма неожиданно, предложили в Microsoft Research, отказавшись от операционной системы как единой программы, выполняющейся в режиме ядра, и некоторого набора пользовательских процессов, функционирующих в режиме пользователя. Вместо этого предлагается система, написанная на совершенно новых, обеспечивающих безопасность типов языках, которые избавлены от всех проблем с указателями и других ошибок, связанных с Си и C++. Как и предыдущие два подхода, этот подход был предложен несколько десятилетий назад и был реализован в компьютере Burroughs B5000. Тогда существовал только язык Алгол, и защита поддерживалась не с помощью MMU (которого вообще не было в машине), а благодаря тому, что компилятор Алгол просто не генерировал «опасный» код. Подход, предложенный Microsoft Research, адаптирует эту идею к условиям XXI века.
Общее описание
Эта система, получившая название Singularity, практически полностью написана на Sing#, новом языке, гарантирующим безопасность типов. Этот язык основан на C#, но дополнен примитивами передачи сообщений, семантика которых определяется формальными, описанными средствами языка контрактами. Поскольку язык жестко ограничивает системные и пользовательские процессы, все процессы могут работать вместе в едином виртуальном адресном пространстве. Это увеличивает как безопасность (поскольку компилятор не позволит одному процессу менять данные другого процесса), так и эффективность (поскольку это избавляет от перехватов вызовов ядра (kernel trap) и переключений контекста.
Более того, архитектура Singularity является гибкой, поскольку каждый процесс — это замкнутая сущность и поэтому она может иметь свой собственный код, структуры данных, структуру памяти, систему времени исполнения, библиотеки и сборщик мусора. MMU поддерживается, но он только распределяет страницы, а не устанавливает отдельный защищенный домен для каждого процесса.
Основной принцип архитектуры Singularity состоит в том, чтобы запретить динамические расширения процессов. Кроме того, эта архитектура не поддерживает загружаемые модули, такие как драйверы устройств и подключаемые элементы браузера, поскольку они могли бы внести посторонний и непроверенный код, который может повредить родительскому процессу. Вместо этого такие расширения должны работать как отдельные процессы, полностью изолированные и взаимодействующие с помощью стандартного механизма IPC.
Микроядро
Операционная система Singularity состоит из процесса микроядра и набора пользовательских процессов, которые обычно работают в общем виртуальном адресном пространстве. Микроядро контролирует доступ к аппаратному обеспечению, резервирует и освобождает память, создает, закрывает и планирует цепочки, поддерживает синхронизацию цепочек с помощью семафоров, поддерживает синхронизацию между процессами с помощью каналов, контролирует ввод/вывод. Каждый драйвер устройств работает как отдельный процесс.
Хотя большая часть микроядра написана на Sing#, отдельные компоненты созданы на C#, C++ или assembler и должны быть надежными, поскольку проверить их корректность невозможно. К надежному коду относятся уровень аппаратной абстракции и сборщик мусора. Уровень аппаратной абстракции скрывает низкоуровневое аппаратное обеспечение от системы, инкапсулируя такие концепции, как порты ввода/вывода, линии запросов на прерывания, каналы прямого доступа к памяти и таймеры для того, чтобы предоставить остальной части операционной системы интероперабельные абстракции.
Взаимодействие между процессами
Пользовательские процессы получают системные сервисы, посылая строго типизированные сообщения микроядру по двунаправленным каналам точка-точка. Фактически эти каналы используются для всех взаимодействий между процессами. В отличие от других систем передачи сообщений, имеющих библиотеку с функциями send и receive, Sing# полностью поддерживает каналы на уровне языка, в том числе формальные спецификации типизации и протоколов. Для того чтобы прояснить это, рассмотрим спецификацию канала.
contract C1 {
in message Request(int x) requires x > 0;
out message Reply(int y);
out message Error();
state Start:
Request? -> Pending;
state Pending: one {
Reply! -> Start;
Error! -> Stopped;
}
state Stopped: ;
}
Этот контракт утверждает, что канал принимает три сообщения: Request, Reply и Error. Первый имеет в качестве параметра положительное целое, второй — целое, а третий параметров не имеет. Когда для доступа к серверу используется канал, сообщения Request передаются от клиента к серверу, а другие два сообщения пересылаются иным путем. Машина состояний описывает протокол для канала.
В состоянии Start клиент посылает сообщение Request, переводя канал в состояние Pending. Сервер может в ответ послать либо сообщение Reply, либо сообщение Error. Сообщение Reply переводит канал обратно в состояние Start, в котором взаимодействие может продолжаться. Сообщение Error переводит канал в состояние Stopped, завершая взаимодействие по каналу.
Куча
Если все данные, такие как блоки файлов, считываемые с диска, должны передаваться по каналам, система будет работать очень медленно, поэтому делается исключение из основного правила о том, что данные каждого процесса полностью частные и внутренние для этого процесса. Singularity поддерживает разделяемую кучу объектов, но каждый экземпляр каждого объекта в куче принадлежит одному процессу. Однако владение объектом можно передавать по каналу.
В качестве примера работы кучи рассмотрим ввод/вывод. Когда драйвер диска считывает блок данных, он помещает этот блок в кучу. Затем система передает дескриптор этого блока пользователю, запросившему данные, придерживаясь принципа «единственного владельца», но позволяя передавать данные с диска пользователю без создания дополнительных копий.
Файловая система
Singularity поддерживает единое иерархическое пространство имен для всех сервисов. Корневой сервер имен использует вершину дерева, но другие серверы имен могут монтироваться на своих собственных узлах. В частности, файловая система, которая представляет собой всего лишь процесс, монтируется на /fs, поэтому, например, имя /fs/users/linda/foo может быть файлом пользователя. Файлы реализуются как B-деревья, в которых номера блоков служат ключами. Когда пользовательский процесс запрашивает файл, файловая система отдает драйверу диска команду поместить запрашиваемые блоки в кучу. Владение затем передается так, как описано выше.
Проверка
Каждый компонент системы имеет метаданные, описывающие его зависимости, экспорты, ресурсы и поведение. Эти метаданные используются для проверки. Образ системы состоит из микроядра, драйверов и приложений, необходимых для работы системы, а также их метаданных. Внешние модули проверки (верификаторы) могут выполнять множество проверок в образе системы прежде, чем система будет его использовать, в частности для того, чтобы убедиться, что драйверы не конфликтуют по ресурсам. Проверка состоит из трех этапов:
- компилятор проверяет безопасность типов, владение объектами, протоколы каналов и так далее;
- компилятор генерирует Microsoft Intermediate Language, переносимый JVM-подобный байт-код, который может проверять верификатор;
- MSIL компилируется в код x86 для базового компьютера, который может добавлять в код проверки времени исполнения (однако существующий компилятор этого не делает).
Добиться более высокой надежности можно с помощью средств, позволяющих обнаружить ошибки в самих верификаторах.
Каждая из четырех разных попыток повысить надежность операционной системы ставит своей целью не допустить, чтобы некорректные драйверы устройств вызывали сбой в системе.
В подходе Nooks каждый драйвер по отдельности заключен в программную оболочку для того, чтобы тщательно контролировать его взаимодействия с остальной операционной системой, но при таком подходе все драйверы находятся в ядре. В реализации подхода паравиртуальной машины эта идея получила дальнейшее развитие. В данном случае драйверы перенесены в одну или несколько машин, отделенных от главной машины, что еще больше ограничивает возможности драйверов. Оба эти подхода призваны увеличить надежность существующих (унаследованных) операционных систем.
Два других подхода заменяют унаследованные операционные системы на более надежные и защищенные. Мультисерверный подход предусматривает работу каждого драйвера и компонента операционной системы в отдельном пользовательском процессе и позволяет им взаимодействовать с помощью механизма IPC микроядра. Наконец, Singularity, самый радикальный подход, использует язык, обеспечивающий безопасность типов, единое адресное пространство и формальные контракты, которые строго ограничивают возможности каждого модуля.
Три из четырех исследовательских проектов — паравиртуализация на базе L4, Minix 3 и Singularity — используют микроядра. Пока не известно, какой из этих подходов в перспективе получит широкое распространение (если это не будет какое-то иное решение). Тем не менее интересно отметить, что микроядра, долгое время считавшиеся неприемлемыми из-за их более низкой производительности по сравнению с монолитными ядрами, могут снова вернуться в операционные системы из-за их потенциально более высокой надежности, что многие считают важнее производительности. Колесо истории повернулось.
Эндрю Таненбаум (ast@cs.vu.nl) — профессор информатики Vrije Universiteit (Амстердам, Голландия). Джоррит Хердер (jnherder@cs.vu.nl) — аспирант отделения компьютерных систем факультета информатики Vrije Universiteit. Хербер Бос (bos@cs.vu.nl)- доцент отделения компьютерных систем факультета информатики Vrije Universiteit.
Литература
- V. Basili, B. Perricone, Software Errors and Complexity: An Empirical Investigation, Comm. ACM, Jan. 1984.
- T. Ostrand, E. Weyuker, The Distribution of Faults in a Large Industrial Software System, Proc. Int?l Symp. Software Testing and Analysis, ACM Press, 2002.
- A. Chou et al., An Empirical Study of Operating System Errors, Proc. 18th ACM Symp. Operating System Principles, ACM Press, 2001.
- M. Swift, B. Bershad, H. Levy, Improving the Reliability of Commodity Operating Systems, ACM Trans. Computer Systems, vol. 23, 2005.
- M. Swift et al., Recovering Device Drivers, Proc. 6th Symp. Operating System Design and Implementation, ACM Press, 2003.
- R. Goldberg, Architecture of Virtual Machines, Proc. Workshop Virtual Computer Systems, ACM Press, 1973.
- J. LeVasseur et al., Unmodified Device Driver Reuse and Improved System Dependability via Virtual Machines, Proc. 6th Symp. Operating System Design and Implementation, 2004.
- J. Liedtke, On Microkernel Construction, Proc. 15th ACM Symp. Operating System Principles, ACM Press, 1995.
- H. Hartig et al., The Performance of Microkernel-Based Systems, Proc. 16th ACM Symp. Operating System Principles, ACM Press, 1997.
- J.N. Herder et al., Modular System Programming in MINIX 3, Usenix; www.usenix.org/publications/login/2006-04/openpdfs/herder.pdf.
Andrew Tanenbaum, Jorrit Herder, Herbert Bos, Can We Make Operating Systems Reliable and Secure?, IEEE Computer, May, 2006. IEEE Computer Society, 2006, All rights reserved. Reprinted with permission.
- 2019
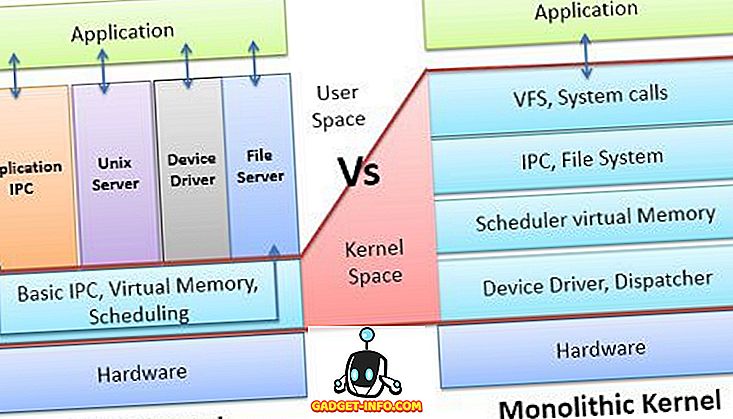
Ядро является основной частью операционной системы; он управляет системными ресурсами. Ядро — это мост между приложением и оборудованием компьютера. Ядро можно разделить на две категории: микроядро и монолитное ядро. Микроядро — это то, в котором пользовательские службы и службы ядра хранятся в отдельном адресном пространстве. Однако в монолитном ядре пользовательские службы и службы ядра находятся в одном и том же адресном пространстве. Давайте обсудим некоторые различия между микроядром и монолитным ядром с помощью сравнительной таблицы, показанной ниже.
Сравнительная таблица
| Основа для сравнения | Microkernel | Монолитное ядро |
|---|---|---|
| основной | В пользовательских службах и ядре микроядра службы хранятся в отдельном адресном пространстве. | В монолитном ядре и пользовательские службы, и службы ядра хранятся в одном и том же адресном пространстве. |
| Размер | Микроядро меньше по размеру. | Монолитное ядро крупнее микроядра. |
| выполнение | Медленное исполнение. | Быстрое исполнение. |
| растяжимый | Микроядро легко расширяется. | Монолитное ядро сложно расширить. |
| Безопасность | В случае сбоя службы это влияет на работу микроядра. | В случае сбоя службы вся система падает в монолитном ядре. |
| Код | Чтобы написать микроядро, требуется больше кода. | Чтобы написать монолитное ядро, требуется меньше кода. |
| пример | QNX, Symbian, L4Linux, Singularity, K42, Mac OS X, Integrity, PikeOS, HURD, Minix и Coyotos. | Linux, BSD (FreeBSD, OpenBSD, NetBSD), Microsoft Windows (95, 98, Me), Solaris, OS-9, AIX, HP-UX, DOS, OpenVMS, XTS-400 и т. Д. |
Определение микроядра
Микроядро как ядро управляет всеми системными ресурсами. Но в микроядре пользовательские сервисы и сервисы ядра реализованы в разных адресных пространствах. Пользовательские сервисы хранятся в пользовательском адресном пространстве, а сервисы ядра — в адресном пространстве ядра . Это уменьшает размер ядра и еще больше уменьшает размер операционной системы.
Помимо взаимодействия между приложением и оборудованием системы, микроядро предоставляет минимальные услуги управления процессами и памятью. Связь между клиентской программой / приложением и службами, работающими в адресном пространстве пользователя, устанавливается посредством передачи сообщений. Они никогда не взаимодействуют напрямую. Это снижает скорость выполнения микроядра.
В микроядре пользовательские сервисы изолированы от сервисов ядра, поэтому, если какой-либо пользовательский сервис выходит из строя, это не влияет на сервис ядра и, следовательно, операционная система остается неизменной . Это одно из преимуществ в микроядре. Микроядро легко расширяется . Если новые службы должны быть добавлены, они добавляются в адресное пространство пользователя и, следовательно, пространство ядра не требует каких-либо изменений. Микроядро также легко переносимо, безопасно и надежно.
Определение монолитного ядра
Монолитное ядро управляет системными ресурсами между приложением и оборудованием системы. Но в отличие от микроядра, пользовательские сервисы и сервисы ядра реализованы в одном и том же адресном пространстве. Это увеличивает размер ядра, еще больше увеличивает размер операционной системы.
Монолитное ядро обеспечивает планирование ЦП, управление памятью, управление файлами и другие функции операционной системы через системные вызовы. Поскольку пользовательские службы и службы ядра находятся в одном и том же адресном пространстве, это приводит к быстродействующей операционной системе.
Один из недостатков монолитного ядра заключается в том, что в случае сбоя одного из сервисов происходит сбой всей системы. Если новый сервис должен быть добавлен в монолитное ядро, вся операционная система должна быть изменена.
Ключевые различия между микроядром и монолитным ядром
- Основным моментом, по которому различается микроядро и монолитное ядро, является то, что микроядро реализует пользовательские службы и службы ядра в разных адресных пространствах, а монолитное ядро реализует как пользовательские службы, так и службы ядра в одном и том же адресном пространстве .
- Размер микроядра невелик, поскольку в адресном пространстве ядра находятся только службы ядра. Однако размер монолитного ядра сравнительно больше, чем у микроядра, поскольку и сервисы ядра, и пользовательские сервисы находятся в одном и том же адресном пространстве.
- Выполнение монолитного ядра происходит быстрее, поскольку связь между приложением и оборудованием устанавливается с помощью системного вызова . С другой стороны, выполнение микроядра происходит медленно, поскольку связь между приложением и оборудованием системы устанавливается посредством передачи сообщений .
- Микроядро легко расширить, поскольку новый сервис должен быть добавлен в адресное пространство пользователя, изолированное от пространства ядра, поэтому ядро не требует модификации. Противоположным является случай с монолитным ядром, если новый сервис должен быть добавлен в монолитное ядро, то необходимо изменить все ядро.
- Микроядро является более безопасным, чем монолитное ядро, так как в случае сбоя службы в микроядре операционная система остается неизменной. С другой стороны, в случае сбоя службы в монолитном ядре происходит сбой всей системы.
- Монолитное проектирование ядра требует меньше кода, что приводит к меньшему количеству ошибок. С другой стороны, для проектирования микроядра требуется больше кода, что приводит к большему количеству ошибок.
Заключение:
Микроядро медленнее, но более безопасно и надежно, чем монолитное ядро. Монолитное ядро быстрое, но менее безопасное, так как любой сбой службы может привести к сбою системы.
Выбор
количества слоев ядра является
ответственным и сложным делом: увеличение
числа слоев ведет к некоторому замедлению
работы ядра за счет дополнительных
накладных расходов на межслойное
взаимодействие, а уменьшение числа
слоев ухудшает расширяемость и логичность
системы. Обычно операционные системы,
прошедшие долгий путь эволюционного
развития, например многие версии UNIX,
имеют неупорядоченное ядро с небольшим
числом четко выделенных слоев, а у
сравнительно «молодых» операционных
систем, таких как Windows NT, ядро разделено
на большее число слоев и их взаимодействие
формализовано в гораздо большей степени.
Аппаратная
зависимость и переносимость ОС
Многие
операционные системы успешно работают
на различных аппаратных платформах без
существенных изменений в своем составе.
Во многом это объясняется тем, что,
несмотря на различия в деталях, средства
аппаратной поддержки ОС большинства
компьютеров приобрели сегодня много
типовых черт, а именно эти средства в
первую очередь влияют на работу
компонентов операционной системы. В
результате в ОС можно выделить достаточно
компактный слой машинно-зависимых
компонентов ядра и сделать остальные
слои ОС общими для разных аппаратных
платформ.
Типовые
средства аппаратной поддержки ОС
Четкой
границы между программной и аппаратной
реализацией функций ОС не существует
— решение о том, какие функции ОС будут
выполняться программно, а какие аппаратно,
принимается разработчиками аппаратного
и программного обеспечения компьютера.
Тем не менее практически все современные
аппаратные платформы имеют некоторый
типичный набор средств аппаратной
поддержки ОС, в который входят следующие
компоненты:
-
средства
поддержки привилегированного режима; -
средства
трансляции адресов; -
средства
переключения процессов; -
система
прерываний; -
системный
таймер; -
средства
защиты областей памяти.
Средства
поддержки привилегированного режима
обычно основаны на системном регистре
процессора, часто называемом «словом
состояния» машины или процессора. Этот
регистр содержит некоторые признаки,
определяющие режимы работы процессора,
в том числе и признак текущего режима
привилегий. Смена режима привилегий
выполняется за счет изменения слова
состояния машины в результате прерывания
или выполнения привилегированной
команды. Число градаций привилегированности
может быть разным у разных типов
процессоров, наиболее часто используются
два уровня (ядро-пользователь) или четыре
(например, ядро- супервизор- выполнение-
пользователь у платформы VAX или 0-1-2-3 у
процессоров Intel x86/Pentium). В обязанности
средств поддержки привилегированного
режима входит выполнение проверки
допустимости выполнения активной
программой инструкций процессора при
текущем уровне привилегированности.
Средства
трансляции адресов выполняют операции
преобразования виртуальных адресов,
которые содержатся в кодах процесса, в
адреса физической памяти. Таблицы,
предназначенные при трансляции адресов,
обычно имеют большой объем, поэтому для
их хранения используются области
оперативной памяти, а аппаратура
процессора содержит только указатели
на эти области. Средства трансляции
адресов используют данные указатели
для доступа к элементам таблиц и
аппаратного выполнения алгоритма
преобразования адреса, что значительно
ускоряет процедуру трансляции по
сравнению с ее чисто программной
реализацией.
Средства
переключения процессов предназначены
для быстрого сохранения контекста
приостанавливаемого процесса и
восстановления контекста процесса,
который становится активным. Содержимое
контекста обычно включает содержимое
всех регистров общего назначения
процессора, регистра флагов операций
(то есть флагов нуля, переноса, переполнения
и т. п.), а также тех системных регистров
и указателей, которые связаны с отдельным
процессом, а не операционной системой,
например указателя на таблицу трансляции
адресов процесса. Для хранения контекстов
приостановленных процессов обычно
используются области оперативной
памяти, которые поддерживаются указателями
процессора.
Переключение
контекста выполняется по определенным
командам процессора, например по команде
перехода на новую задачу. Такая команда
вызывает автоматическую загрузку данных
из сохраненного контекста в регистры
процессора, после чего процесс продолжается
с прерванного ранее места.
Система
прерываний позволяет компьютеру
реагировать на внешние события,
синхронизировать выполнение процессов
и работу устройств ввода-вывода, быстро
переходить с одной программы на другую.
Механизм прерываний нужен для того,
чтобы оповестить процессор о возникновении
в вычислительной системе некоторого
непредсказуемого события или события,
которое не синхронизировано с циклом
работы процессора. Примерами таких
событий могут служить завершение
операции ввода-вывода внешним устройством
(например, запись блока данных контроллером
диска), некорректное завершение
арифметической операции (например,
переполнение регистра), истечение
интервала астрономического времени.
При возникновении условий прерывания
его источник (контроллер внешнего
устройства, таймер, арифметический блок
процессора и т. п.) выставляет определенный
электрический сигнал. Этот сигнал
прерывает выполнение процессором
последовательности команд, задаваемой
исполняемым кодом, и вызывает автоматический
переход на заранее определенную
процедуру, называемую процедурой
обработки прерываний. В большинстве
моделей процессоров отрабатываемый
аппаратурой переход на процедуру
обработки прерываний сопровождается
заменой слова состояния машины (или
даже всего контекста процесса), что
позволяет одновременно с переходом по
нужному адресу выполнить переход в
привилегированный режим. После завершения
обработки прерывания обычно происходит
возврат к исполнению прерванного кода.
Прерывания
играют важнейшую роль в работе любой
операционной системы, являясь ее движущей
силой. Действительно, большая часть
действий ОС инициируется прерываниями
различного типа. Даже системные вызовы
от приложений выполняются на многих
аппаратных платформах с помощью
специальной инструкции прерывания,
вызывающей переход к выполнению
соответствующих процедур ядра (например,
инструкция int
в процессорах Intel или SVC в мэйнфреймах
IBM).
Системный
таймер, часто реализуемый в виде
быстродействующего регистра-счетчика,
необходим операционной системе для
выдержки интервалов времени. Для этого
в регистр таймера программно загружается
значение требуемого интервала в условных
единицах, из которого затем автоматически
с определенной частотой начинает
вычитаться по единице. Частота «тиков»
таймера, как правило, тесно связана с
частотой тактового генератора процессора.
(Не следует путать таймер ни с тактовым
генератором, который вырабатывает
сигналы, синхронизирующие все операции
в компьютере, ни с системными часами —
работающей на батареях электронной
схеме, — которые ведут независимый
отсчет времени и календарной даты.) При
достижении нулевого значения счетчика
таймер инициирует прерывание, которое
обрабатывается процедурой операционной
системы. Прерывания от системного
таймера используются ОС в первую очередь
для слежения за тем, как отдельные
процессы расходуют время процессора.
Например, в системе разделения времени
при обработке очередного прерывания
от таймера планировщик процессов может
принудительно передать управление
другому процессу, если данный процесс
исчерпал выделенный ему квант времени.
Средства
защиты областей памяти обеспечивают
на аппаратном уровне проверку возможности
программного кода осуществлять с данными
определенной области памяти такие
операции, как чтение, запись или выполнение
(при передачах управления). Если аппаратура
компьютера поддерживает механизм
трансляции адресов, то средства защиты
областей памяти встраиваются в этот
механизм. Функции аппаратуры по защите
памяти обычно состоят в сравнении
уровней привилегий текущего кода
процессора и сегмента памяти, к которому
производится обращение.
Машинно-зависимые
компоненты ОС
Одна
и та же операционная система не может
без каких-либо изменений устанавливаться
на компьютерах, отличающихся типом
процессора или/и способом организации
всей аппаратуры. В модулях ядра ОС не
могут не отразиться такие особенности
аппаратной платформы, как количество
типов прерываний и формат таблицы ссылок
на процедуры обработки прерываний,
состав регистров общего назначения и
системных регистров, состояние которых
нужно сохранять в контексте процесса,
особенности подключения внешних
устройств и многие другие.
Однако
опыт разработки операционных систем
показывает: ядро можно спроектировать
таким образом, что только часть модулей
будут машинно-зависимыми, а остальные
не будут зависеть от особенностей
аппаратной платформы. В хорошо
структурированном ядре машинно-зависимые
модули локализованы и образуют программный
слой, естественно примыкающий к слою
аппаратуры, как это и показано на рис.
3.8. Такая локализация машинно-зависимых
модулей существенно упрощает перенос
операционной системы на другую аппаратную
платформу.
Объем
машинно-зависимых компонентов ОС зависит
от того, насколько велики отличия в
аппаратных платформах, для которых
разрабатывается ОС. Например, ОС,
построенная на 32-битовых адресах, для
переноса на машину с 16-битовыми адресами
должна быть практически переписана
заново. Одно из наиболее очевидных
отличий — несовпадение системы команд
процессоров — преодолевается достаточно
просто. Операционная система программируется
на языке высокого уровня, а затем
соответствующим компилятором
вырабатывается код для конкретного
типа процессора. Однако во многих случаях
различия в организации аппаратуры
компьютера лежат гораздо глубже и
преодолеть их таким образом не удается.
Например, однопроцессорный и
двухпроцессорный компьютеры требуют
применения в ОС совершенно разных
алгоритмов распределения процессорного
времени. Аналогично отсутствие аппаратной
поддержки виртуальной памяти приводит
к принципиальному различию в реализации
подсистемы управления памятью. В таких
случаях не обойтись без внесения в код
операционной системы специфики аппаратной
платформы, для которой эта ОС
предназначается.
Для
уменьшения количества машинно-зависимых
модулей производители операционных
систем обычно ограничивают универсальность
машинно-независимых модулей. Это
означает, что их независимость носит
условный характер и распространяется
только на несколько типов процессоров
и созданных на основе этих процессоров
аппаратных платформ. По этому пути
пошли, например, разработчики ОС Windows
NT, ограничив количество типов процессоров
для своей системы четырьмя и поставляя
различные варианты кодов ядра для
однопроцессорных и многопроцессорных
компьютеров.
Особое
место среди модулей ядра занимают
низкоуровневые драйверы внешних
устройств. С одной стороны эти драйверы,
как и высокоуровневые драйверы, входят
в состав менеджера ввода-вывода, то есть
принадлежат слою ядра, занимающему
достаточно высокое место в иерархии
слоев. С другой стороны, низкоуровневые
драйверы отражают все особенности
управляемых внешних устройств, поэтому
их можно отнести и к слою машинно-зависимых
модулей. Такая двойственность
низкоуровневых драйверов еще раз
подтверждает схематичность модели ядра
со строгой иерархией слоев.
Для
компьютеров на основе процессоров Intel
x86/Pentium разработка экранирующего
машинно-зависимого слоя ОС несколько
упрощается за счет встроенной в постоянную
память компьютера базовой системы
ввода-вывода — BIOS. BIOS содержит драйверы
для всех устройств, входящих в базовую
конфигурацию компьютера: жестких и
гибких дисков, клавиатуры, дисплея и т.
д. Эти драйверы выполняют весьма
примитивные операции с управляемыми
устройствами, например чтение группы
секторов данных с определенной дорожки
диска, но за счет этих операций экранируются
различия аппаратных платформ персональных
компьютеров и серверов на процессорах
Intel разных производителей. Разработчики
операционной системы могут пользоваться
слоем драйверов BIOS как частью
машинно-зависимого слоя ОС, а могут и
заменить все или часть драйверов BIOS
компонентами ОС.
Переносимость
операционной системы
Если
код операционной системы может быть
сравнительно легко перенесен с процессора
одного типа на процессор другого типа
и с аппаратной платформы одного типа
на аппаратную платформу другого типа,
то такую ОС называют переносимой
(portable), или мобильной.
Хотя
ОС часто описываются либо как переносимые,
либо как непереносимые, мобильность —
это не бинарное состояние, а понятие
степени. Вопрос не в том, может ли быть
система перенесена, а в том, насколько
легко можно это сделать. Для того чтобы
обеспечить свойство мобильности ОС,
разработчики должны следовать следующим
правилам.
-
Большая
часть кода должна быть написана на
языке, трансляторы которого имеются
на всех машинах, куда предполагается
переносить систему. Такими языками
являются стандартизованные языки
высокого уровня. Большинство переносимых
ОС написано на языке С, который имеет
много особенностей, полезных для
разработки кодов операционной системы,
и компиляторы которого широко доступны.
Программа, написанная на ассемблере,
является переносимой только в тех
случаях, когда перенос операционной
системы планируется на компьютер,
обладающий той же системой команд. В
остальных случаях ассемблер используется
только для тех непереносимых частей
системы, которые должны непосредственно
взаимодействовать с аппаратурой
(например, обработчик прерываний), или
для частей, которые требуют максимальной
скорости (например, целочисленная
арифметика повышенной точности). -
Объем
машинно-зависимых частей кода, которые
непосредственно взаимодействуют с
аппаратными средствами, должен быть
по возможности минимизирован. Так,
например, следует всячески избегать
прямого манипулирования регистрами и
другими аппаратными средствами
процессора. Для уменьшения аппаратной
зависимости разработчики ОС должны
также исключить возможность использования
по умолчанию стандартных конфигураций
аппаратуры или их характеристик.
Аппаратно-зависимые параметры можно
«спрятать» в программно- задаваемые
данные абстрактного типа. Для осуществления
всех необходимых действий по управлению
аппаратурой, представленной этими
параметрами, должен быть написан набор
аппаратно-зависимых функций. Каждый
раз, когда какому-либо модулю ОС требуется
выполнить некоторое действие, связанное
с аппаратурой, он манипулирует
абстрактными данными, используя
соответствующую функцию из имеющегося
набора. Когда ОС переносится, то
изменяются только эти данные и функции,
которые ими манипулируют. Например, в
ОС Windows NT диспетчер прерываний преобразует
аппаратные уровни прерываний конкретного
типа процессора в стандартный набор
уровней прерываний IRQL, с которыми
работают остальные модули операционной
системы. Поэтому при переносе Windows NT на
новую платформу нужно переписать, в
частности, те коды диспетчера прерываний,
которые занимаются отображением уровней
прерывания на абстрактные уровни IRQL,
а те модули ОС, которые пользуются этими
абстрактными уровнями, изменений не
потребуют. -
Аппаратно-зависимый
код должен быть надежно изолирован в
нескольких модулях, а не быть распределен
по всей системе. Изоляции подлежат все
части ОС, которые отражают специфику
как процессора, так и аппаратной
платформы в целом. Низкоуровневые
компоненты ОС, имеющие доступ к
процессорно — зависимым структурам
данных и регистрам, должны быть оформлены
в виде компактных модулей, которые
могут быть заменены аналогичными
модулями для других процессоров. Для
снятия платформенной зависимости,
возникающей из-за различий между
компьютерами разных производителей,
построенными на одном и том же процессоре
(например, MIPS R4000), должен быть введен
хорошо локализованный программный
слой машинно-зависимых функций.
В
идеале слой машинно-зависимых компонентов
ядра полностью экранирует остальную
часть ОС от конкретных деталей аппаратной
платформы (кэши, контроллеры прерываний
ввода-вывода и т. п.), по крайней мере для
того набора платформ, который поддерживает
данная ОС. В результате происходит
подмена реальной аппаратуры некой
унифицированной виртуальной машиной,
одинаковой для всех вариантов аппаратной
платформы. Все слои операционной системы,
которые лежат выше слоя машинно-зависимых
компонентов, могут быть написаны для
управления именно этой виртуальной
аппаратурой. Таким образом, у разработчиков
появляется возможность создавать один
вариант машинно-независимой части ОС
(включая компоненты ядра, утилиты,
системные обрабатывающие программы)
для всего набора поддерживаемых платформ
(рис. 3.9).
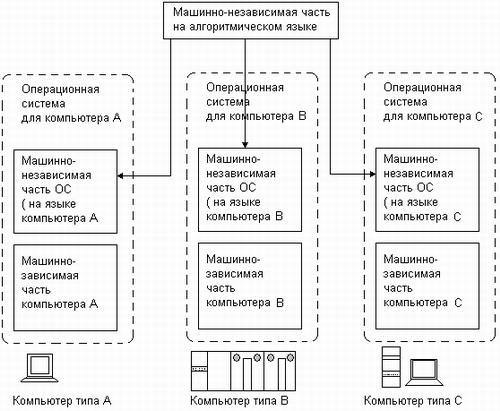
Рис.
3.9. Перенос
операционной системы на разные аппаратные
платформы
Микроядерная
архитектура
Концепция
Микроядерная
архитектура является альтернативой
классическому способу построения
операционной системы. Под классической
архитектурой в данном случае понимается
рассмотренная выше структурная
организация ОС, в соответствии с которой
все основные функции операционной
системы, составляющие многослойное
ядро, выполняются в привилегированном
режиме. При этом некоторые вспомогательные
функции ОС оформляются в виде приложений
и выполняются в пользовательском режиме
наряду с обычными пользовательскими
программами (становясь системными
утилитами или обрабатывающими
программами). Каждое приложение
пользовательского режима работает в
собственном адресном пространстве и
защищено тем самым от какого-либо
вмешательства других приложений. Код
ядра, выполняемый в привилегированном
режиме, имеет доступ к областям памяти
всех приложений, но сам полностью от
них защищен. Приложения обращаются к
ядру с запросами на выполнение системных
функций.
Суть
микроядерной архитектуры состоит в
следующем. В привилегированном режиме
остается работать только очень небольшая
часть ОС, называемая микроядром (рис.
3.10). Микроядро защищено от остальных
частей ОС и приложений. В состав микроядра
обычно входят машинно-зависимые модули,
а также модули, выполняющие базовые (но
не все!) функции ядра по управлению
процессами, обработке прерываний,
управлению виртуальной памятью, пересылке
сообщений и управлению устройствами
ввода-вывода, связанные с загрузкой или
чтением регистров устройств. Набор
функций микроядра обычно соответствует
функциям слоя базовых механизмов
обычного ядра. Такие функции операционной
системы трудно, если не невозможно,
выполнить в пространстве пользователя.
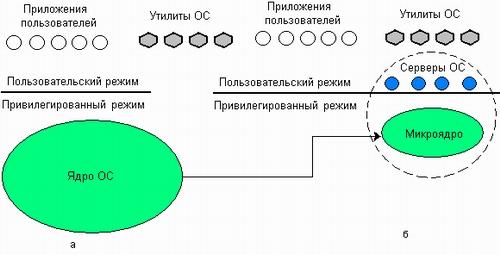
Рис.
3.10. Перенос
основного объема функций ядра в
пользовательское пространство
Все
остальные более высокоуровневые функции
ядра оформляются в виде приложений,
работающих в пользовательском режиме.
Однозначного решения о том, какие из
системных функций нужно оставить в
привилегированном режиме, а какие
перенести в пользовательский, не
существует. В общем случае многие
менеджеры ресурсов, являющиеся
неотъемлемыми частями обычного ядра —
файловая система, подсистемы управления
виртуальной памятью и процессами,
менеджер безопасности и т. п., — становятся
«периферийными» модулями, работающими
в пользовательском режиме.
Работающие
в пользовательском режиме менеджеры
ресурсов имеют принципиальные отличия
от традиционных утилит и обрабатывающих
программ операционной системы, хотя
при микроядерной архитектуре все эти
программные компоненты также оформлены
в виде приложений. Утилиты и обрабатывающие
программы вызываются в основном
пользователями. Ситуации, когда одному
приложению требуется выполнение функции
(процедуры) другого приложения, возникают
крайне редко. Поэтому в операционных
системах с классической архитектурой
отсутствует механизм, с помощью которого
одно приложение могло бы вызвать функции
другого.
Совсем
другая ситуация возникает, когда в форме
приложения оформляется часть операционной
системы. По определению, основным
назначением такого приложения является
обслуживание запросов других приложений,
например создание процесса, выделение
памяти, проверка прав доступа к ресурсу
и т. д. Именно поэтому менеджеры ресурсов,
вынесенные в пользовательский режим,
называются серверами ОС, то есть модулями,
основным назначением которых является
обслуживание запросов локальных
приложений и других модулей ОС. Очевидно,
что для реализации микроядерной
архитектуры необходимым условием
является наличие в операционной системе
удобного и эффективного способа вызова
процедур одного процесса из другого.
Поддержка такого механизма и является
одной из главных задач микроядра.
Схематично
механизм обращения к функциям ОС,
оформленным в виде серверов, выглядит
следующим образом (рис. 3.11). Клиент,
которым может быть либо прикладная
программа, либо другой компонент ОС,
запрашивает выполнение некоторой
функции у соответствующего сервера,
посылая ему сообщение. Непосредственная
передача сообщений между приложениями
невозможна, так как их адресные
пространства изолированы друг от друга.
Микроядро, выполняющееся в привилегированном
режиме, имеет доступ к адресным
пространствам каждого из этих приложений
и поэтому может работать в качестве
посредника. Микроядро сначала передает
сообщение, содержащее имя и параметры
вызываемой процедуры нужному серверу,
затем сервер выполняет запрошенную
операцию, после чего ядро возвращает
результаты клиенту с помощью другого
сообщения. Таким образом, работа
микроядерной операционной системы
соответствует известной модели
клиент-сервер, в которой роль транспортных
средств выполняет микроядро.
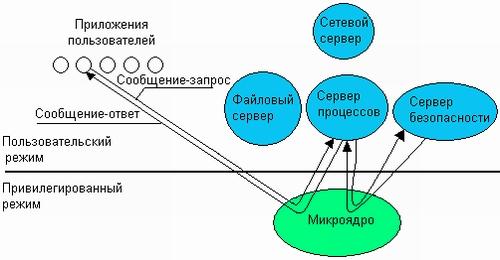
Рис.
3.11.
Реализация системного вызова в
микроядерной архитектуре
Преимущества
и недостатки микроядерной архитектуры
Операционные
системы, основанные на концепции
микроядра, в высокой степени удовлетворяют
большинству требований, предъявляемых
к современным ОС, обладая переносимостью,
расширяемостью, надежностью и создавая
хорошие предпосылки для поддержки
распределенных приложений. За эти
достоинства приходится платить снижением
производительности, и это является
основным недостатком микроядерной
архитектуры.
Высокая
степень переносимости обусловлена тем,
что весь машинно-зависимый код изолирован
в микроядре, поэтому для переноса системы
на новый процессор требуется меньше
изменений и все они логически сгруппированы
вместе.
Расширяемость
присуща микроядерной ОС в очень высокой
степени. В традиционных системах даже
при наличии многослойной структуры
нелегко удалить один слой и поменять
его на другой по причине множественности
и размытости интерфейсов между слоями.
Добавление новых функций и изменение
существующих требует хорошего знания
операционной системы и больших затрат
времени. В то же время ограниченный
набор четко определенных интерфейсов
микроядра открывает путь к упорядоченному
росту и эволюции ОС. Добавление новой
подсистемы требует разработки нового
приложения, что никак не затрагивает
целостность микроядра. Микроядерная
структура позволяет не только добавлять,
но и сокращать число компонентов
операционной системы, что также бывает
очень полезно. Например, не всем
пользователям нужны средства безопасности
или поддержки распределенных вычислений,
а удаление их из традиционного ядра
чаще всего невозможно. Обычно традиционные
операционные системы позволяют
динамически добавлять в ядро или удалять
из ядра только драйверы внешних устройств
— ввиду частых изменений в конфигурации
подключенных к компьютеру внешних
устройств подсистема ввода-вывода ядра
допускает загрузку и выгрузку драйверов
«на ходу», но для этого она разрабатывается
особым образом (например, среда STREAMS в
UNIX или менеджер ввода-вывода в Windows NT).
При микроядерном подходе конфигурируемость
ОС не вызывает никаких проблем и не
требует особых мер — достаточно изменить
файл с настройками начальной конфигурации
системы или же остановить не нужные
больше серверы в ходе работы обычными
для остановки приложений средствами.
Использование
микроядерной модели повышает надежность
ОС. Каждый сервер выполняется в виде
отдельного процесса в своей собственной
области памяти и таким образом защищен
от других серверов операционной системы,
что не наблюдается в традиционной ОС,
где все модули ядра могут влиять друг
на друга. И если отдельный сервер терпит
крах, то он может быть перезапущен без
останова или повреждения остальных
серверов ОС. Более того, поскольку
серверы выполняются в пользовательском
режиме, они не имеют непосредственного
доступа к аппаратуре и не могут
модифицировать память, в которой хранится
и работает микроядро. Другим потенциальным
источником повышения надежности ОС
является уменьшенный объем кода микроядра
по сравнению с традиционным ядром —
это снижает вероятность появления
ошибок программирования.
Модель
с микроядром хорошо подходит для
поддержки распределенных вычислений,
так как использует механизмы, аналогичные
сетевым: взаимодействие клиентов и
серверов путем обмена сообщениями.
Серверы микроядерной ОС могут работать
как на одном, так и на разных компьютерах.
В этом случае при получении сообщения
от приложения микроядро может обработать
его самостоятельно и передать локальному
серверу или же переслать по сети
микроядру, работающему на другом
компьютере. Переход к распределенной
обработке требует минимальных изменений
в работе операционной системы — просто
локальный транспорт заменяется на
сетевой.
Производительность.
При классической организации ОС (рис.
3.12, а) выполнение системного вызова
сопровождается двумя переключениями
режимов, а при микроядерной организации
(рис. 3.12, 6) — четырьмя. Таким образом,
операционная система на основе микроядра
при прочих равных условиях всегда будет
менее производительной, чем ОС с
классическим ядром. Именно по этой
причине микроядерный подход не получил
такого широкого распространения, которое
ему предрекали.

Рис.
3.12.
Смена режимов при выполнении системного
вызова
Серьезность
этого недостатка хорошо иллюстрирует
история развития Windows NT. В версиях 3.1 и
3.5 диспетчер окон, графическая библиотека
и высокоуровневые драйверы графических
устройств входили в состав сервера
пользовательского режима, и вызов
функций этих модулей осуществлялся в
соответствии с микроядерной схемой.
Однако очень скоро разработчики Windows
NT поняли, что такой механизм обращений
к часто используемым функциям графического
интерфейса существенно замедляет работу
приложений и делает данную операционную
систему уязвимой в условиях острой
конкуренции. В результате в версию
Windows NT 4.0 были внесены существенные
изменения — все перечисленные выше
модули были перенесены в ядро, что
отдалило эту ОС от идеальной микроядерной
архитектуры, но зато резко повысило ее
производительность.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
Ошибка на странице данных ядра — это код ошибки Windows, отображаемый на синем экране . При возникновении этой ошибки ваш компьютер обычно собирает некоторые диагностические данные и затем перезагружается. Если проблема не исчезнет, ваш компьютер в конечном итоге снова выйдет из строя с тем же сообщением об ошибке на странице данных ядра.
Ошибки ввода данных ядра обычно связаны с аппаратными сбоями, связанными с модулями памяти и жесткими дисками . В других случаях эта же ошибка появится из-за воздействия вируса.
Как появляется ошибка ввода данных ядра
Когда возникает эта ошибка, вы обычно видите сообщение, подобное одному из следующих:
Ваш компьютер столкнулся с проблемой и нуждается в перезагрузке. Мы просто собираем информацию об ошибке и перезапустим для вас. Если вы хотите узнать больше, вы можете найти эту ошибку позже в Интернете: KERNEL_DATA_INPAGE_ERROR
KERNEL_DATA_INPAGE_ERROR
Причины ошибок ввода данных ядра
Ошибка на странице данных ядра — это код остановки, отображаемый во время сбоев синего экрана, который обычно вызывается проблемой с оперативной памятью (RAM) или жестким диском.
Вот некоторые дополнительные коды, связанные с этой ошибкой, и конкретные проблемы, к которым они относятся:
- 0x0000007A : Ошибки доступа к файлу
- 0xC000009C : плохие сектора жесткого диска
- 0xC000009D : Слабые кабели или сбой жесткого диска
- 0xC000016A : плохие сектора жесткого диска
- 0xC0000185 : Нерассеянные или поврежденные кабели
Как исправить ошибку ввода данных ядра
Поскольку большинство ошибок на входе данных ядра вызваны неисправными модулями памяти или жесткими дисками, исправление обычно включает в себя поиск неисправного компонента и его замену.
В других случаях вы обнаружите, что модуль памяти или жесткий диск не подключен должным образом, или вся проблема была вызвана вирусом. Выполните следующие действия по устранению неполадок, чтобы исправить ошибку на странице данных Kernal:
Сделайте резервную копию ваших данных . Если это проблема с вашим жестким диском, вы можете потерять важные данные. Если у вас есть что-то, хранящееся на вашем компьютере, которое вы не хотите потерять, вы должны выполнить резервное копирование перед началом процесса диагностики. Сделайте копии любых файлов, которые вы не можете себе позволить потерять, и сохраните их на USB-накопителе , SD-карте или в облачном хранилище
-
В некоторых случаях проблема может быть вызвана неправильно установленными модулями памяти. Чтобы исключить это и предотвратить любые ненужные расходы, откройте компьютер и проверьте свою оперативную память. Если какой-либо из модулей не установлен должным образом или вышел из строя, переустановите их и проверьте, по-прежнему ли возникает ошибка на странице данных ядра.
Соблюдайте осторожность при открытии компьютера и настройке компонентов. Без правильно настроенного антистатического браслета статическое электричество может привести к повреждению таких компонентов, как ОЗУ.
-
Эта ошибка обычно указывает, что диск имеет физические дефекты, такие как поврежденные сектора . В некоторых случаях вы можете столкнуться с этой проблемой из-за неправильно уложенного кабеля жесткого диска.
Чтобы исключить эту возможность, откройте компьютер, найдите жесткий диск и снова подключите соединительный кабель. Вам также необходимо проверить и повторно подключить кабель, к которому он подключается к материнской плате .
Когда ваш жесткий диск работает, внимательно слушайте любые громкие щелчки. Если вы слышите их, возможно, ваш жесткий диск находится в процессе сбоя, что может вызвать этот тип ошибки. Исправление заключается в резервном копировании всех ваших данных и замене жесткого диска .
-
Проверь свою память.
Windows 10 имеет встроенный инструмент диагностики памяти. Есть также некоторые бесплатные опции, доступные для Windows 7, Windows 8 и Windows 10. Если у вас Windows 10, введите « память » в поле поиска на панели задач, затем выберите « Диагностика памяти Windows» > « Перезагрузить сейчас» и проверьте наличие проблем .
Возможно, вы захотите запустить более одного инструмента диагностики памяти. Если какой-либо из этих инструментов сообщит о проблеме с вашей памятью, подумайте о замене вашей оперативной памяти . Это, вероятно, исправит ошибку на странице данных вашего ядра, но в любом случае ваша RAM может выйти из строя в любом случае, если один из этих инструментов обнаружит проблему.
-
Если выбранный вами диагностический инструмент обнаружит какие-либо проблемы, например, поврежденные сектора, разрешите ему попытаться исправить. В случае успеха вы сможете использовать свой компьютер без каких-либо дальнейших сбоев при загрузке данных ядра.
-
Хотя и менее вероятно, эта ошибка может возникнуть из-за других периферийных устройств. Чтобы исключить это, выключите компьютер, отсоедините все периферийные устройства и снова включите компьютер.
Если ваш компьютер не дает сбоя с ошибкой на странице данных ядра, переподключайте каждое устройство по одному. Когда вы найдете устройство, вызывающее проблему, вы можете либо оставить его отключенным, либо заменить его.
В некоторых случаях вирус может повредить важные файлы и вызвать ошибку на странице данных ядра. Это менее вероятно, чем другие возможности, но все же важно проверить. Если ничего не помогло, попробуйте запустить проверку на вирусы. Если какая-либо из этих программ обнаружит вирус, дайте ему возможность решить проблему, а затем проверьте, нет ли у вас по-прежнему ошибок на странице данных ядра.
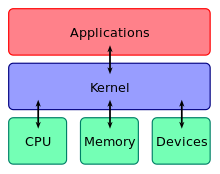
The kernel is a computer program at the core of a computer’s operating system and generally has complete control over everything in the system.[1] It is the portion of the operating system code that is always resident in memory[2] and facilitates interactions between hardware and software components. A full kernel controls all hardware resources (e.g. I/O, memory, cryptography) via device drivers, arbitrates conflicts between processes concerning such resources, and optimizes the utilization of common resources e.g. CPU & cache usage, file systems, and network sockets. On most systems, the kernel is one of the first programs loaded on startup (after the bootloader). It handles the rest of startup as well as memory, peripherals, and input/output (I/O) requests from software, translating them into data-processing instructions for the central processing unit.
The critical code of the kernel is usually loaded into a separate area of memory, which is protected from access by application software or other less critical parts of the operating system. The kernel performs its tasks, such as running processes, managing hardware devices such as the hard disk, and handling interrupts, in this protected kernel space. In contrast, application programs such as browsers, word processors, or audio or video players use a separate area of memory, user space. This separation prevents user data and kernel data from interfering with each other and causing instability and slowness,[1] as well as preventing malfunctioning applications from affecting other applications or crashing the entire operating system. Even in systems where the kernel is included in application address spaces, memory protection is used to prevent unauthorized applications from modifying the kernel.
The kernel’s interface is a low-level abstraction layer. When a process requests a service from the kernel, it must invoke a system call, usually through a wrapper function.
There are different kernel architecture designs. Monolithic kernels run entirely in a single address space with the CPU executing in supervisor mode, mainly for speed. Microkernels run most but not all of their services in user space,[3] like user processes do, mainly for resilience and modularity.[4] MINIX 3 is a notable example of microkernel design. Instead, the Linux kernel is monolithic, although it is also modular, for it can insert and remove loadable kernel modules at runtime.
This central component of a computer system is responsible for executing programs. The kernel takes responsibility for deciding at any time which of the many running programs should be allocated to the processor or processors.
Random-access memory[edit]
Random-access memory (RAM) is used to store both program instructions and data.[a] Typically, both need to be present in memory in order for a program to execute. Often multiple programs will want access to memory, frequently demanding more memory than the computer has available. The kernel is responsible for deciding which memory each process can use, and determining what to do when not enough memory is available.
Input/output devices[edit]
I/O devices include peripherals such as keyboards, mice, disk drives, printers, USB devices, network adapters, and display devices. The kernel provides convenient methods for applications to use these devices which are typically abstracted by the kernel so that applications do not need to know their implementation details.
Resource management[edit]
Key aspects necessary in resource management are defining the execution domain (address space) and the protection mechanism used to mediate access to the resources within a domain.[5] Kernels also provide methods for synchronization and inter-process communication (IPC). These implementations may be located within the kernel itself or the kernel can also rely on other processes it is running. Although the kernel must provide IPC in order to provide access to the facilities provided by each other, kernels must also provide running programs with a method to make requests to access these facilities. The kernel is also responsible for context switching between processes or threads.
Memory management[edit]
The kernel has full access to the system’s memory and must allow processes to safely access this memory as they require it. Often the first step in doing this is virtual addressing, usually achieved by paging and/or segmentation. Virtual addressing allows the kernel to make a given physical address appear to be another address, the virtual address. Virtual address spaces may be different for different processes; the memory that one process accesses at a particular (virtual) address may be different memory from what another process accesses at the same address. This allows every program to behave as if it is the only one (apart from the kernel) running and thus prevents applications from crashing each other.[6]
On many systems, a program’s virtual address may refer to data which is not currently in memory. The layer of indirection provided by virtual addressing allows the operating system to use other data stores, like a hard drive, to store what would otherwise have to remain in main memory (RAM). As a result, operating systems can allow programs to use more memory than the system has physically available. When a program needs data which is not currently in RAM, the CPU signals to the kernel that this has happened, and the kernel responds by writing the contents of an inactive memory block to disk (if necessary) and replacing it with the data requested by the program. The program can then be resumed from the point where it was stopped. This scheme is generally known as demand paging.
Virtual addressing also allows creation of virtual partitions of memory in two disjointed areas, one being reserved for the kernel (kernel space) and the other for the applications (user space). The applications are not permitted by the processor to address kernel memory, thus preventing an application from damaging the running kernel. This fundamental partition of memory space has contributed much to the current designs of actual general-purpose kernels and is almost universal in such systems, although some research kernels (e.g., Singularity) take other approaches.
Device management[edit]
To perform useful functions, processes need access to the peripherals connected to the computer, which are controlled by the kernel through device drivers. A device driver is a computer program encapsulating, monitoring and controlling a hardware device (via its Hardware/Software Interface (HSI)) on behalf of the OS. It provides the operating system with an API, procedures and information about how to control and communicate with a certain piece of hardware. Device drivers are an important and vital dependency for all OS and their applications. The design goal of a driver is abstraction; the function of the driver is to translate the OS-mandated abstract function calls (programming calls) into device-specific calls. In theory, a device should work correctly with a suitable driver. Device drivers are used for e.g. video cards, sound cards, printers, scanners, modems, and Network cards.
At the hardware level, common abstractions of device drivers include:
- Interfacing directly
- Using a high-level interface (Video BIOS)
- Using a lower-level device driver (file drivers using disk drivers)
- Simulating work with hardware, while doing something entirely different
And at the software level, device driver abstractions include:
- Allowing the operating system direct access to hardware resources
- Only implementing primitives
- Implementing an interface for non-driver software such as TWAIN
- Implementing a language (often a high-level language such as PostScript)
For example, to show the user something on the screen, an application would make a request to the kernel, which would forward the request to its display driver, which is then responsible for actually plotting the character/pixel.[6]
A kernel must maintain a list of available devices. This list may be known in advance (e.g., on an embedded system where the kernel will be rewritten if the available hardware changes), configured by the user (typical on older PCs and on systems that are not designed for personal use) or detected by the operating system at run time (normally called plug and play). In plug-and-play systems, a device manager first performs a scan on different peripheral buses, such as Peripheral Component Interconnect (PCI) or Universal Serial Bus (USB), to detect installed devices, then searches for the appropriate drivers.
As device management is a very OS-specific topic, these drivers are handled differently by each kind of kernel design, but in every case, the kernel has to provide the I/O to allow drivers to physically access their devices through some port or memory location. Important decisions have to be made when designing the device management system, as in some designs accesses may involve context switches, making the operation very CPU-intensive and easily causing a significant performance overhead.[citation needed]
System calls[edit]
In computing, a system call is how a process requests a service from an operating system’s kernel that it does not normally have permission to run. System calls provide the interface between a process and the operating system. Most operations interacting with the system require permissions not available to a user-level process, e.g., I/O performed with a device present on the system, or any form of communication with other processes requires the use of system calls.
A system call is a mechanism that is used by the application program to request a service from the operating system. They use a machine-code instruction that causes the processor to change mode. An example would be from supervisor mode to protected mode. This is where the operating system performs actions like accessing hardware devices or the memory management unit. Generally the operating system provides a library that sits between the operating system and normal user programs. Usually it is a C library such as Glibc or Windows API. The library handles the low-level details of passing information to the kernel and switching to supervisor mode. System calls include close, open, read, wait and write.
To actually perform useful work, a process must be able to access the services provided by the kernel. This is implemented differently by each kernel, but most provide a C library or an API, which in turn invokes the related kernel functions.[7]
The method of invoking the kernel function varies from kernel to kernel. If memory isolation is in use, it is impossible for a user process to call the kernel directly, because that would be a violation of the processor’s access control rules. A few possibilities are:
- Using a software-simulated interrupt. This method is available on most hardware, and is therefore very common.
- Using a call gate. A call gate is a special address stored by the kernel in a list in kernel memory at a location known to the processor. When the processor detects a call to that address, it instead redirects to the target location without causing an access violation. This requires hardware support, but the hardware for it is quite common.
- Using a special system call instruction. This technique requires special hardware support, which common architectures (notably, x86) may lack. System call instructions have been added to recent models of x86 processors, however, and some operating systems for PCs make use of them when available.
- Using a memory-based queue. An application that makes large numbers of requests but does not need to wait for the result of each may add details of requests to an area of memory that the kernel periodically scans to find requests.
Kernel design decisions[edit]
Protection[edit]
An important consideration in the design of a kernel is the support it provides for protection from faults (fault tolerance) and from malicious behaviours (security). These two aspects are usually not clearly distinguished, and the adoption of this distinction in the kernel design leads to the rejection of a hierarchical structure for protection.[5]
The mechanisms or policies provided by the kernel can be classified according to several criteria, including: static (enforced at compile time) or dynamic (enforced at run time); pre-emptive or post-detection; according to the protection principles they satisfy (e.g., Denning[8][9]); whether they are hardware supported or language based; whether they are more an open mechanism or a binding policy; and many more.
Support for hierarchical protection domains[10] is typically implemented using CPU modes.
Many kernels provide implementation of «capabilities», i.e., objects that are provided to user code which allow limited access to an underlying object managed by the kernel. A common example is file handling: a file is a representation of information stored on a permanent storage device. The kernel may be able to perform many different operations, including read, write, delete or execute, but a user-level application may only be permitted to perform some of these operations (e.g., it may only be allowed to read the file). A common implementation of this is for the kernel to provide an object to the application (typically so called a «file handle») which the application may then invoke operations on, the validity of which the kernel checks at the time the operation is requested. Such a system may be extended to cover all objects that the kernel manages, and indeed to objects provided by other user applications.
An efficient and simple way to provide hardware support of capabilities is to delegate to the memory management unit (MMU) the responsibility of checking access-rights for every memory access, a mechanism called capability-based addressing.[11] Most commercial computer architectures lack such MMU support for capabilities.
An alternative approach is to simulate capabilities using commonly supported hierarchical domains. In this approach, each protected object must reside in an address space that the application does not have access to; the kernel also maintains a list of capabilities in such memory. When an application needs to access an object protected by a capability, it performs a system call and the kernel then checks whether the application’s capability grants it permission to perform the requested action, and if it is permitted performs the access for it (either directly, or by delegating the request to another user-level process). The performance cost of address space switching limits the practicality of this approach in systems with complex interactions between objects, but it is used in current operating systems for objects that are not accessed frequently or which are not expected to perform quickly.[12][13]
If the firmware does not support protection mechanisms, it is possible to simulate protection at a higher level, for example by simulating capabilities by manipulating page tables, but there are performance implications.[14] Lack of hardware support may not be an issue, however, for systems that choose to use language-based protection.[15]
An important kernel design decision is the choice of the abstraction levels where the security mechanisms and policies should be implemented. Kernel security mechanisms play a critical role in supporting security at higher levels.[11][16][17][18][19]
One approach is to use firmware and kernel support for fault tolerance (see above), and build the security policy for malicious behavior on top of that (adding features such as cryptography mechanisms where necessary), delegating some responsibility to the compiler. Approaches that delegate enforcement of security policy to the compiler and/or the application level are often called language-based security.
The lack of many critical security mechanisms in current mainstream operating systems impedes the implementation of adequate security policies at the application abstraction level.[16] In fact, a common misconception in computer security is that any security policy can be implemented in an application regardless of kernel support.[16]
According to Mars Research Group developers, a lack of isolation is one of the main factors undermining kernel security.[20] They propose their driver isolation framework for protection, primarily in the Linux kernel.[21][22]
Hardware- or language-based protection[edit]
Typical computer systems today use hardware-enforced rules about what programs are allowed to access what data. The processor monitors the execution and stops a program that violates a rule, such as a user process that tries to write to kernel memory. In systems that lack support for capabilities, processes are isolated from each other by using separate address spaces.[23] Calls from user processes into the kernel are regulated by requiring them to use one of the above-described system call methods.
An alternative approach is to use language-based protection. In a language-based protection system, the kernel will only allow code to execute that has been produced by a trusted language compiler. The language may then be designed such that it is impossible for the programmer to instruct it to do something that will violate a security requirement.[15]
Advantages of this approach include:
- No need for separate address spaces. Switching between address spaces is a slow operation that causes a great deal of overhead, and a lot of optimization work is currently performed in order to prevent unnecessary switches in current operating systems. Switching is completely unnecessary in a language-based protection system, as all code can safely operate in the same address space.
- Flexibility. Any protection scheme that can be designed to be expressed via a programming language can be implemented using this method. Changes to the protection scheme (e.g. from a hierarchical system to a capability-based one) do not require new hardware.
Disadvantages include:
- Longer application startup time. Applications must be verified when they are started to ensure they have been compiled by the correct compiler, or may need recompiling either from source code or from bytecode.
- Inflexible type systems. On traditional systems, applications frequently perform operations that are not type safe. Such operations cannot be permitted in a language-based protection system, which means that applications may need to be rewritten and may, in some cases, lose performance.
Examples of systems with language-based protection include JX and Microsoft’s Singularity.
Process cooperation[edit]
Edsger Dijkstra proved that from a logical point of view, atomic lock and unlock operations operating on binary semaphores are sufficient primitives to express any functionality of process cooperation.[24] However this approach is generally held to be lacking in terms of safety and efficiency, whereas a message passing approach is more flexible.[25] A number of other approaches (either lower- or higher-level) are available as well, with many modern kernels providing support for systems such as shared memory and remote procedure calls.
I/O device management[edit]
The idea of a kernel where I/O devices are handled uniformly with other processes, as parallel co-operating processes, was first proposed and implemented by Brinch Hansen (although similar ideas were suggested in 1967[26][27]). In Hansen’s description of this, the «common» processes are called internal processes, while the I/O devices are called external processes.[25]
Similar to physical memory, allowing applications direct access to controller ports and registers can cause the controller to malfunction, or system to crash. With this, depending on the complexity of the device, some devices can get surprisingly complex to program, and use several different controllers. Because of this, providing a more abstract interface to manage the device is important. This interface is normally done by a device driver or hardware abstraction layer. Frequently, applications will require access to these devices. The kernel must maintain the list of these devices by querying the system for them in some way. This can be done through the BIOS, or through one of the various system buses (such as PCI/PCIE, or USB). Using an example of a video driver, when an application requests an operation on a device, such as displaying a character, the kernel needs to send this request to the current active video driver. The video driver, in turn, needs to carry out this request. This is an example of inter-process communication (IPC).
Kernel-wide design approaches[edit]
The above listed tasks and features can be provided in many ways that differ from each other in design and implementation.
The principle of separation of mechanism and policy is the substantial difference between the philosophy of micro and monolithic kernels.[28][29] Here a mechanism is the support that allows the implementation of many different policies, while a policy is a particular «mode of operation». Example:
- Mechanism: User login attempts are routed to an authorization server
- Policy: Authorization server requires a password which is verified against stored passwords in a database
Because the mechanism and policy are separated, the policy can be easily changed to e.g. require the use of a security token.
In minimal microkernel just some very basic policies are included,[29] and its mechanisms allows what is running on top of the kernel (the remaining part of the operating system and the other applications) to decide which policies to adopt (as memory management, high level process scheduling, file system management, etc.).[5][25] A monolithic kernel instead tends to include many policies, therefore restricting the rest of the system to rely on them.
Per Brinch Hansen presented arguments in favour of separation of mechanism and policy.[5][25] The failure to properly fulfill this separation is one of the major causes of the lack of substantial innovation in existing operating systems,[5] a problem common in computer architecture.[30][31][32] The monolithic design is induced by the «kernel mode»/»user mode» architectural approach to protection (technically called hierarchical protection domains), which is common in conventional commercial systems;[33] in fact, every module needing protection is therefore preferably included into the kernel.[33] This link between monolithic design and «privileged mode» can be reconducted to the key issue of mechanism-policy separation;[5] in fact the «privileged mode» architectural approach melds together the protection mechanism with the security policies, while the major alternative architectural approach, capability-based addressing, clearly distinguishes between the two, leading naturally to a microkernel design[5] (see Separation of protection and security).
While monolithic kernels execute all of their code in the same address space (kernel space), microkernels try to run most of their services in user space, aiming to improve maintainability and modularity of the codebase.[4] Most kernels do not fit exactly into one of these categories, but are rather found in between these two designs. These are called hybrid kernels. More exotic designs such as nanokernels and exokernels are available, but are seldom used for production systems. The Xen hypervisor, for example, is an exokernel.
Monolithic kernels[edit]

Diagram of a monolithic kernel
In a monolithic kernel, all OS services run along with the main kernel thread, thus also residing in the same memory area. This approach provides rich and powerful hardware access. UNIX developer Ken Thompson stated that «it is in [his] opinion easier to implement a
monolithic kernel».[34] The main disadvantages of monolithic kernels are the dependencies between system components – a bug in a device driver might crash the entire system – and the fact that large kernels can become very difficult to maintain; Thompson also stated that «It is also easier for [a monolithic kernel] to turn into a mess in a hurry as it is modified.»[34]
Monolithic kernels, which have traditionally been used by Unix-like operating systems, contain all the operating system core functions and the device drivers. A monolithic kernel is one single program that contains all of the code necessary to perform every kernel-related task. Every part which is to be accessed by most programs which cannot be put in a library is in the kernel space: Device drivers, scheduler, memory handling, file systems, and network stacks. Many system calls are provided to applications, to allow them to access all those services. A monolithic kernel, while initially loaded with subsystems that may not be needed, can be tuned to a point where it is as fast as or faster than the one that was specifically designed for the hardware, although more relevant in a general sense.
Modern monolithic kernels, such as the Linux kernel, the FreeBSD kernel, the AIX kernel, the HP-UX kernel, and the Solaris kernel, all of which fall into the category of Unix-like operating systems, support loadable kernel modules, allowing modules to be loaded into the kernel at runtime, permitting easy extension of the kernel’s capabilities as required, while helping to minimize the amount of code running in kernel space.
Most work in the monolithic kernel is done via system calls. These are interfaces, usually kept in a tabular structure, that access some subsystem within the kernel such as disk operations. Essentially calls are made within programs and a checked copy of the request is passed through the system call. Hence, not far to travel at all. The monolithic Linux kernel can be made extremely small not only because of its ability to dynamically load modules but also because of its ease of customization. In fact, there are some versions that are small enough to fit together with a large number of utilities and other programs on a
single floppy disk and still provide a fully functional operating system (one of the most popular of which is muLinux). This ability to miniaturize its kernel has also led to a rapid growth in the use of Linux in embedded systems.
These types of kernels consist of the core functions of the operating system and the device drivers with the ability to load modules at runtime. They provide rich and powerful abstractions of the underlying hardware. They provide a small set of simple hardware abstractions and use applications called servers to provide more functionality. This particular approach defines a high-level virtual interface over the hardware, with a set of system calls to implement operating system services such as process management, concurrency and memory management in several modules that run in supervisor mode.
This design has several flaws and limitations:
- Coding in kernel can be challenging, in part because one cannot use common libraries (like a full-featured libc), and because one needs to use a source-level debugger like gdb. Rebooting the computer is often required. This is not just a problem of convenience to the developers. When debugging is harder, and as difficulties become stronger, it becomes more likely that code will be «buggier».
- Bugs in one part of the kernel have strong side effects; since every function in the kernel has all the privileges, a bug in one function can corrupt data structure of another, totally unrelated part of the kernel, or of any running program.
- Kernels often become very large and difficult to maintain.
- Even if the modules servicing these operations are separate from the whole, the code integration is tight and difficult to do correctly.
- Since the modules run in the same address space, a bug can bring down the entire system.
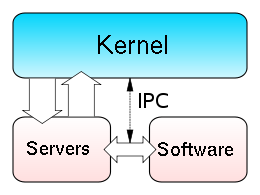
In the microkernel approach, the kernel itself only provides basic functionality that allows the execution of servers, separate programs that assume former kernel functions, such as device drivers, GUI servers, etc.
Microkernels[edit]
Microkernel (also abbreviated μK or uK) is the term describing an approach to operating system design by which the functionality of the system is moved out of the traditional «kernel», into a set of «servers» that communicate through a «minimal» kernel, leaving as little as possible in «system space» and as much as possible in «user space». A microkernel that is designed for a specific platform or device is only ever going to have what it needs to operate. The microkernel approach consists of defining a simple abstraction over the hardware, with a set of primitives or system calls to implement minimal OS services such as memory management, multitasking, and inter-process communication. Other services, including those normally provided by the kernel, such as networking, are implemented in user-space programs, referred to as servers. Microkernels are easier to maintain than monolithic kernels, but the large number of system calls and context switches might slow down the system because they typically generate more overhead than plain function calls.
Only parts which really require being in a privileged mode are in kernel space: IPC (Inter-Process Communication), basic scheduler, or scheduling primitives, basic memory handling, basic I/O primitives. Many critical parts are now running in user space: The complete scheduler, memory handling, file systems, and network stacks. Micro kernels were invented as a reaction to traditional «monolithic» kernel design, whereby all system functionality was put in a one static program running in a special «system» mode of the processor. In the microkernel, only the most fundamental of tasks are performed such as being able to access some (not necessarily all) of the hardware, manage memory and coordinate message passing between the processes. Some systems that use micro kernels are QNX and the HURD. In the case of QNX and Hurd user sessions can be entire snapshots of the system itself or views as it is referred to. The very essence of the microkernel architecture illustrates some of its advantages:
- Easier to maintain
- Patches can be tested in a separate instance, and then swapped in to take over a production instance.
- Rapid development time and new software can be tested without having to reboot the kernel.
- More persistence in general, if one instance goes haywire, it is often possible to substitute it with an operational mirror.
Most microkernels use a message passing system to handle requests from one server to another. The message passing system generally operates on a port basis with the microkernel. As an example, if a request for more memory is sent, a port is opened with the microkernel and the request sent through. Once within the microkernel, the steps are similar to system calls. The rationale was that it would bring modularity in the system architecture, which would entail a cleaner system, easier to debug or dynamically modify, customizable to users’ needs, and more performing. They are part of the operating systems like GNU Hurd, MINIX, MkLinux, QNX and Redox OS. Although microkernels are very small by themselves, in combination with all their required auxiliary code they are, in fact, often larger than monolithic kernels. Advocates of monolithic kernels also point out that the two-tiered structure of microkernel systems, in which most of the operating system does not interact directly with the hardware, creates a not-insignificant cost in terms of system efficiency. These types of kernels normally provide only the minimal services such as defining memory address spaces, inter-process communication (IPC) and the process management. The other functions such as running the hardware processes are not handled directly by microkernels. Proponents of micro kernels point out those monolithic kernels have the disadvantage that an error in the kernel can cause the entire system to crash. However, with a microkernel, if a kernel process crashes, it is still possible to prevent a crash of the system as a whole by merely restarting the service that caused the error.
Other services provided by the kernel such as networking are implemented in user-space programs referred to as servers. Servers allow the operating system to be modified by simply starting and stopping programs. For a machine without networking support, for instance, the networking server is not started. The task of moving in and out of the kernel to move data between the various applications and servers creates overhead which is detrimental to the efficiency of micro kernels in comparison with monolithic kernels.
Disadvantages in the microkernel exist however. Some are:
- Larger running memory footprint
- More software for interfacing is required, there is a potential for performance loss.
- Messaging bugs can be harder to fix due to the longer trip they have to take versus the one off copy in a monolithic kernel.
- Process management in general can be very complicated.
The disadvantages for microkernels are extremely context-based. As an example, they work well for small single-purpose (and critical) systems because if not many processes need to run, then the complications of process management are effectively mitigated.
A microkernel allows the implementation of the remaining part of the operating system as a normal application program written in a high-level language, and the use of different operating systems on top of the same unchanged kernel. It is also possible to dynamically switch among operating systems and to have more than one active simultaneously.[25]
Monolithic kernels vs. microkernels[edit]
As the computer kernel grows, so grows the size and vulnerability of its trusted computing base; and, besides reducing security, there is the problem of enlarging the memory footprint. This is mitigated to some degree by perfecting the virtual memory system, but not all computer architectures have virtual memory support.[b] To reduce the kernel’s footprint, extensive editing has to be performed to carefully remove unneeded code, which can be very difficult with non-obvious interdependencies between parts of a kernel with millions of lines of code.
By the early 1990s, due to the various shortcomings of monolithic kernels versus microkernels, monolithic kernels were considered obsolete by virtually all operating system researchers.[citation needed] As a result, the design of Linux as a monolithic kernel rather than a microkernel was the topic of a famous debate between Linus Torvalds and Andrew Tanenbaum.[35] There is merit on both sides of the argument presented in the Tanenbaum–Torvalds debate.
Performance[edit]
Monolithic kernels are designed to have all of their code in the same address space (kernel space), which some developers argue is necessary to increase the performance of the system.[36] Some developers also maintain that monolithic systems are extremely efficient if well written.[36] The monolithic model tends to be more efficient[37] through the use of shared kernel memory, rather than the slower IPC system of microkernel designs, which is typically based on message passing.[citation needed]
The performance of microkernels was poor in both the 1980s and early 1990s.[38][39] However, studies that empirically measured the performance of these microkernels did not analyze the reasons of such inefficiency.[38] The explanations of this data were left to «folklore», with the assumption that they were due to the increased frequency of switches from «kernel-mode» to «user-mode», to the increased frequency of inter-process communication and to the increased frequency of context switches.[38]
In fact, as guessed in 1995, the reasons for the poor performance of microkernels might as well have been: (1) an actual inefficiency of the whole microkernel approach, (2) the particular concepts implemented in those microkernels, and (3) the particular implementation of those concepts. Therefore it remained to be studied if the solution to build an efficient microkernel was, unlike previous attempts, to apply the correct construction techniques.[38]
On the other end, the hierarchical protection domains architecture that leads to the design of a monolithic kernel[33] has a significant performance drawback each time there’s an interaction between different levels of protection (i.e., when a process has to manipulate a data structure both in «user mode» and «supervisor mode»), since this requires message copying by value.[40]

The hybrid kernel approach combines the speed and simpler design of a monolithic kernel with the modularity and execution safety of a microkernel
Hybrid (or modular) kernels[edit]
Hybrid kernels are used in most commercial operating systems such as Microsoft Windows NT 3.1, NT 3.5, NT 3.51, NT 4.0, 2000, XP, Vista, 7, 8, 8.1 and 10. Apple’s own macOS uses a hybrid kernel called XNU which is based upon code from OSF/1’s Mach kernel (OSFMK 7.3)[41] and FreeBSD’s monolithic kernel. They are similar to micro kernels, except they include some additional code in kernel-space to increase performance. These kernels represent a compromise that was implemented by some developers to accommodate the major advantages of both monolithic and micro kernels. These types of kernels are extensions of micro kernels with some properties of monolithic kernels. Unlike monolithic kernels, these types of kernels are unable to load modules at runtime on their own. Hybrid kernels are micro kernels that have some «non-essential» code in kernel-space in order for the code to run more quickly than it would were it to be in user-space. Hybrid kernels are a compromise between the monolithic and microkernel designs. This implies running some services (such as the network stack or the filesystem) in kernel space to reduce the performance overhead of a traditional microkernel, but still running kernel code (such as device drivers) as servers in user space.
Many traditionally monolithic kernels are now at least adding (or else using) the module capability. The most well known of these kernels is the Linux kernel. The modular kernel essentially can have parts of it that are built into the core kernel binary or binaries that load into memory on demand. It is important to note that a code tainted module has the potential to destabilize a running kernel. Many people become confused on this point when discussing micro kernels. It is possible to write a driver for a microkernel in a completely separate memory space and test it before «going» live. When a kernel module is loaded, it accesses the monolithic portion’s memory space by adding to it what it needs, therefore, opening the doorway to possible pollution. A few advantages to the modular (or) Hybrid kernel are:
- Faster development time for drivers that can operate from within modules. No reboot required for testing (provided the kernel is not destabilized).
- On demand capability versus spending time recompiling a whole kernel for things like new drivers or subsystems.
- Faster integration of third party technology (related to development but pertinent unto itself nonetheless).
Modules, generally, communicate with the kernel using a module interface of some sort. The interface is generalized (although particular to a given operating system) so it is not always possible to use modules. Often the device drivers may need more flexibility than the module interface affords. Essentially, it is two system calls and often the safety checks that only have to be done once in the monolithic kernel now may be done twice. Some of the disadvantages of the modular approach are:
- With more interfaces to pass through, the possibility of increased bugs exists (which implies more security holes).
- Maintaining modules can be confusing for some administrators when dealing with problems like symbol differences.
Nanokernels[edit]
A nanokernel delegates virtually all services – including even the most basic ones like interrupt controllers or the timer – to device drivers to make the kernel memory requirement even smaller than a traditional microkernel.[42]
Exokernels[edit]
Exokernels are a still-experimental approach to operating system design. They differ from other types of kernels in limiting their functionality to the protection and multiplexing of the raw hardware, providing no hardware abstractions on top of which to develop applications. This separation of hardware protection from hardware management enables application developers to determine how to make the most efficient use of the available hardware for each specific program.
Exokernels in themselves are extremely small. However, they are accompanied by library operating systems (see also unikernel), providing application developers with the functionalities of a conventional operating system. This comes down to every user writing their own rest-of-the kernel from near scratch, which is a very-risky, complex and quite a daunting assignment — particularly in a time-constrained production-oriented environment, which is why exokernels have never caught on.[citation needed] A major advantage of exokernel-based systems is that they can incorporate multiple library operating systems, each exporting a different API, for example one for high level UI development and one for real-time control.
Multikernels[edit]
A multikernel operating system treats a multi-core machine as a network of independent cores, as if it were a distributed system. It does not assume shared memory but rather implements inter-process communications as message passing.[43][44] Barrelfish was the first operating system to be described as a multikernel.
History of kernel development[edit]
Early operating system kernels[edit]
Strictly speaking, an operating system (and thus, a kernel) is not required to run a computer. Programs can be directly loaded and executed on the «bare metal» machine, provided that the authors of those programs are willing to work without any hardware abstraction or operating system support. Most early computers operated this way during the 1950s and early 1960s, which were reset and reloaded between the execution of different programs. Eventually, small ancillary programs such as program loaders and debuggers were left in memory between runs, or loaded from ROM. As these were developed, they formed the basis of what became early operating system kernels. The «bare metal» approach is still used today on some video game consoles and embedded systems,[45] but in general, newer computers use modern operating systems and kernels.
In 1969, the RC 4000 Multiprogramming System introduced the system design philosophy of a small nucleus «upon which operating systems for different purposes could be built in an orderly manner»,[46] what would be called the microkernel approach.
Time-sharing operating systems[edit]
In the decade preceding Unix, computers had grown enormously in power – to the point where computer operators were looking for new ways to get people to use their spare time on their machines. One of the major developments during this era was time-sharing, whereby a number of users would get small slices of computer time, at a rate at which it appeared they were each connected to their own, slower, machine.[47]
The development of time-sharing systems led to a number of problems. One was that users, particularly at universities where the systems were being developed, seemed to want to hack the system to get more CPU time. For this reason, security and access control became a major focus of the Multics project in 1965.[48] Another ongoing issue was properly handling computing resources: users spent most of their time staring at the terminal and thinking about what to input instead of actually using the resources of the computer, and a time-sharing system should give the CPU time to an active user during these periods. Finally, the systems typically offered a memory hierarchy several layers deep, and partitioning this expensive resource led to major developments in virtual memory systems.
Amiga[edit]
The Commodore Amiga was released in 1985, and was among the first – and certainly most successful – home computers to feature an advanced kernel architecture. The AmigaOS kernel’s executive component, exec.library, uses a microkernel message-passing design, but there are other kernel components, like graphics.library, that have direct access to the hardware. There is no memory protection, and the kernel is almost always running in user mode. Only special actions are executed in kernel mode, and user-mode applications can ask the operating system to execute their code in kernel mode.
Unix[edit]
Main article: Unix
A diagram of the predecessor/successor family relationship for Unix-like systems
During the design phase of Unix, programmers decided to model every high-level device as a file, because they believed the purpose of computation was data transformation.[49]
For instance, printers were represented as a «file» at a known location – when data was copied to the file, it printed out. Other systems, to provide a similar functionality, tended to virtualize devices at a lower level – that is, both devices and files would be instances of some lower level concept. Virtualizing the system at the file level allowed users to manipulate the entire system using their existing file management utilities and concepts, dramatically simplifying operation. As an extension of the same paradigm, Unix allows programmers to manipulate files using a series of small programs, using the concept of pipes, which allowed users to complete operations in stages, feeding a file through a chain of single-purpose tools. Although the end result was the same, using smaller programs in this way dramatically increased flexibility as well as ease of development and use, allowing the user to modify their workflow by adding or removing a program from the chain.
In the Unix model, the operating system consists of two parts: first, the huge collection of utility programs that drive most operations; second, the kernel that runs the programs.[49] Under Unix, from a programming standpoint, the distinction between the two is fairly thin; the kernel is a program, running in supervisor mode,[c] that acts as a program loader and supervisor for the small utility programs making up the rest of the system, and to provide locking and I/O services for these programs; beyond that, the kernel didn’t intervene at all in user space.
Over the years the computing model changed, and Unix’s treatment of everything as a file or byte stream no longer was as universally applicable as it was before. Although a terminal could be treated as a file or a byte stream, which is printed to or read from, the same did not seem to be true for a graphical user interface. Networking posed another problem. Even if network communication can be compared to file access, the low-level packet-oriented architecture dealt with discrete chunks of data and not with whole files. As the capability of computers grew, Unix became increasingly cluttered with code. It is also because the modularity of the Unix kernel is extensively scalable.[50] While kernels might have had 100,000 lines of code in the seventies and eighties, kernels like Linux, of modern Unix successors like GNU, have more than 13 million lines.[51]
Modern Unix-derivatives are generally based on module-loading monolithic kernels. Examples of this are the Linux kernel in the many distributions of GNU, IBM AIX, as well as the Berkeley Software Distribution variant kernels such as FreeBSD, DragonFly BSD, OpenBSD, NetBSD, and macOS. Apart from these alternatives, amateur developers maintain an active operating system development community, populated by self-written hobby kernels which mostly end up sharing many features with Linux, FreeBSD, DragonflyBSD, OpenBSD or NetBSD kernels and/or being compatible with them.[52]
Classic Mac OS and macOS[edit]
Apple first launched its classic Mac OS in 1984, bundled with its Macintosh personal computer. Apple moved to a nanokernel design in Mac OS 8.6. Against this, the modern macOS (originally named Mac OS X) is based on Darwin, which uses a hybrid kernel called XNU, which was created by combining the 4.3BSD kernel and the Mach kernel.[53]
Microsoft Windows[edit]
Microsoft Windows was first released in 1985 as an add-on to MS-DOS. Because of its dependence on another operating system, initial releases of Windows, prior to Windows 95, were considered an operating environment (not to be confused with an operating system). This product line continued to evolve through the 1980s and 1990s, with the Windows 9x series adding 32-bit addressing and pre-emptive multitasking; but ended with the release of Windows Me in 2000.
Microsoft also developed Windows NT, an operating system with a very similar interface, but intended for high-end and business users. This line started with the release of Windows NT 3.1 in 1993, and was introduced to general users with the release of Windows XP in October 2001—replacing Windows 9x with a completely different, much more sophisticated operating system. This is the line that continues with Windows 11.
The architecture of Windows NT’s kernel is considered a hybrid kernel because the kernel itself contains tasks such as the Window Manager and the IPC Managers, with a client/server layered subsystem model.[54] It was designed as a modified microkernel, as the Windows NT kernel was influenced by the Mach microkernel but does not meet all of the criteria of a pure microkernel.
IBM Supervisor[edit]
Supervisory program or supervisor is a computer program, usually part of an operating system, that controls the execution of other routines and regulates work scheduling, input/output operations, error actions, and similar functions and regulates the flow of work in a data processing system.
Historically, this term was essentially associated with IBM’s line of mainframe operating systems starting with OS/360. In other operating systems, the supervisor is generally called the kernel.
In the 1970s, IBM further abstracted the supervisor state from the hardware, resulting in a hypervisor that enabled full virtualization, i.e. the capacity to run multiple operating systems on the same machine totally independently from each other. Hence the first such system was called Virtual Machine or VM.
Development of microkernels[edit]
Although Mach, developed by Richard Rashid at Carnegie Mellon University, is the best-known general-purpose microkernel, other microkernels have been developed with more specific aims. The L4 microkernel family (mainly the L3 and the L4 kernel) was created to demonstrate that microkernels are not necessarily slow.[55] Newer implementations such as Fiasco and Pistachio are able to run Linux next to other L4 processes in separate address spaces.[56][57]
Additionally, QNX is a microkernel which is principally used in embedded systems,[58] and the open-source software MINIX, while originally created for educational purposes, is now focused on being a highly reliable and self-healing microkernel OS.
See also[edit]
- Comparison of operating system kernels
- Inter-process communication
- Operating system
- Virtual memory
Notes[edit]
- ^ It may depend on the Computer architecture
- ^ Virtual addressing is most commonly achieved through a built-in memory management unit.
- ^ The highest privilege level has various names throughout different architectures, such as supervisor mode, kernel mode, CPL0, DPL0, ring 0, etc. See Protection ring for more information.
References[edit]
- ^ a b «Kernel». Linfo. Bellevue Linux Users Group. Archived from the original on 8 December 2006. Retrieved 15 September 2016.
- ^ Randal E. Bryant; David R. O’Hallaron (2016). Computer Systems: A Programmer’s Perspective (Third ed.). Pearson. p. 17. ISBN 978-0134092669.
- ^ cf. Daemon (computing)
- ^ a b Roch 2004
- ^ a b c d e f g Wulf 1974 pp.337–345
- ^ a b Silberschatz 1991
- ^ Tanenbaum, Andrew S. (2008). Modern Operating Systems (3rd ed.). Prentice Hall. pp. 50–51. ISBN 978-0-13-600663-3.
. . . nearly all system calls [are] invoked from C programs by calling a library procedure . . . The library procedure . . . executes a TRAP instruction to switch from user mode to kernel mode and start execution . . .
- ^ Denning 1976
- ^ Swift 2005, p.29 quote: «isolation, resource control, decision verification (checking), and error recovery.»
- ^ Schroeder 72
- ^ a b Linden 76
- ^ Eranian, Stephane; Mosberger, David (2002). «Virtual Memory in the IA-64 Linux Kernel». IA-64 Linux Kernel: Design and Implementation. Prentice Hall PTR. ISBN 978-0-13-061014-0.
- ^ Silberschatz & Galvin, Operating System Concepts, 4th ed, pp. 445 & 446
- ^ Hoch, Charles; J. C. Browne (July 1980). «An implementation of capabilities on the PDP-11/45». ACM SIGOPS Operating Systems Review. 14 (3): 22–32. doi:10.1145/850697.850701. S2CID 17487360.
- ^ a b Schneider F., Morrissett G. (Cornell University) and Harper R. (Carnegie Mellon University). «A Language-Based Approach to Security» (PDF). Archived (PDF) from the original on 2018-12-22.
{{cite web}}: CS1 maint: uses authors parameter (link) - ^ a b c Loscocco, P. A.; Smalley, S. D.; Muckelbauer, P. A.; Taylor, R. C.; Turner, S. J.; Farrell, J. F. (October 1998). «The Inevitability of Failure: The Flawed Assumption of Security in Modern Computing Environments». Proceedings of the 21st National Information Systems Security Conference. pp. 303–314. Archived from the original on 2007-06-21.
- ^ Lepreau, Jay; Ford, Bryan; Hibler, Mike (1996). «The persistent relevance of the local operating system to global applications». Proceedings of the 7th workshop on ACM SIGOPS European workshop Systems support for worldwide applications — EW 7. pp. 133–140. doi:10.1145/504450.504477. ISBN 9781450373395. S2CID 10027108.
- ^ Anderson, J. (October 1972). Computer Security Technology Planning Study (PDF) (Report). Vol. II. Air Force Electronic Systems Division. ESD-TR-73-51, Vol. II. Archived (PDF) from the original on 2011-07-21.
- ^ Jerry H. Saltzer; Mike D. Schroeder (September 1975). «The protection of information in computer systems». Proceedings of the IEEE. 63 (9): 1278–1308. CiteSeerX 10.1.1.126.9257. doi:10.1109/PROC.1975.9939. S2CID 269166. Archived from the original on 2021-03-08. Retrieved 2007-07-15.
- ^ «Fine-grained kernel isolation». mars-research.github.io. Retrieved 15 September 2022.
- ^ Fetzer, Mary. «Automatic device driver isolation protects against bugs in operating systems». Pennsylvania State University via techxplore.com. Retrieved 15 September 2022.
- ^ Huang, Yongzhe; Narayanan, Vikram; Detweiler, David; Huang, Kaiming; Tan, Gang; Jaeger, Trent; Burtsev, Anton (2022). «KSplit: Automating Device Driver Isolation» (PDF). Retrieved 15 September 2022.
- ^ Jonathan S. Shapiro; Jonathan M. Smith; David J. Farber (1999). «EROS: a fast capability system». Proceedings of the Seventeenth ACM Symposium on Operating Systems Principles. 33 (5): 170–185. doi:10.1145/319344.319163.
- ^ Dijkstra, E. W. Cooperating Sequential Processes. Math. Dep., Technological U., Eindhoven, Sept. 1965.
- ^ a b c d e Brinch Hansen 70 pp.238–241
- ^ Harrison, M. C.; Schwartz, J. T. (1967). «SHARER, a time sharing system for the CDC 6600». Communications of the ACM. 10 (10): 659–665. doi:10.1145/363717.363778. S2CID 14550794. Retrieved 2007-01-07.
- ^ Huxtable, D. H. R.; Warwick, M. T. (1967). Dynamic Supervisors – their design and construction. pp. 11.1–11.17. doi:10.1145/800001.811675. ISBN 9781450373708. S2CID 17709902. Archived from the original on 2020-02-24. Retrieved 2007-01-07.
- ^ Baiardi 1988
- ^ a b Levin 75
- ^ Denning 1980
- ^ Nehmer, Jürgen (1991). «The Immortality of Operating Systems, or: Is Research in Operating Systems still Justified?». Lecture Notes In Computer Science; Vol. 563. Proceedings of the International Workshop on Operating Systems of the 90s and Beyond. pp. 77–83. doi:10.1007/BFb0024528. ISBN 3-540-54987-0.
The past 25 years have shown that research on operating system architecture had a minor effect on existing main stream [sic] systems.
- ^ Levy 84, p.1 quote: «Although the complexity of computer applications increases yearly, the underlying hardware architecture for applications has remained unchanged for decades.»
- ^ a b c Levy 84, p.1 quote: «Conventional architectures support a single privileged mode of
operation. This structure leads to monolithic design; any module needing protection must be part of the single operating system kernel. If, instead, any module could execute within a protected domain, systems could be built as a collection of independent modules extensible by any user.» - ^ a b «Open Sources: Voices from the Open Source Revolution». 1-56592-582-3. 29 March 1999. Archived from the original on 1 February 2020. Retrieved 24 March 2019.
- ^ Recordings of the debate between Torvalds and Tanenbaum can be found at dina.dk Archived 2012-10-03 at the Wayback Machine, groups.google.com Archived 2013-05-26 at the Wayback Machine, oreilly.com Archived 2014-09-21 at the Wayback Machine and Andrew Tanenbaum’s website Archived 2015-08-05 at the Wayback Machine
- ^ a b Matthew Russell. «What Is Darwin (and How It Powers Mac OS X)». O’Reilly Media. Archived from the original on 2007-12-08. Retrieved 2008-12-09.
The tightly coupled nature of a monolithic kernel allows it to make very efficient use of the underlying hardware […] Microkernels, on the other hand, run a lot more of the core processes in userland. […] Unfortunately, these benefits come at the cost of the microkernel having to pass a lot of information in and out of the kernel space through a process known as a context switch. Context switches introduce considerable overhead and therefore result in a performance penalty.
- ^ «Operating Systems/Kernel Models — Wikiversity». en.wikiversity.org. Archived from the original on 2014-12-18. Retrieved 2014-12-18.
- ^ a b c d Liedtke 95
- ^ Härtig 97
- ^ Hansen 73, section 7.3 p.233 «interactions between different levels of protection require transmission of messages by value«
- ^ Magee, Jim. WWDC 2000 Session 106 – Mac OS X: Kernel. 14 minutes in. Archived from the original on 2021-10-30.
- ^ «KeyKOS Nanokernel Architecture». Archived from the original on 2011-06-21.
- ^ Baumann et al., «The Multikernel: a new OS architecture for scalable multicore systems», to appear in 22nd Symposium on Operating Systems Principles (2009), http://research.microsoft.com/pubs/101903/paper.pdf
- ^ The Barrelfish operating system, http://www.barrelfish.org/.
- ^ Ball: Embedded Microprocessor Designs, p. 129
- ^ Hansen 2001 (os), pp.17–18
- ^ «BSTJ version of C.ACM Unix paper». bell-labs.com. Archived from the original on 2005-12-30. Retrieved 2006-08-17.
- ^ Corbató, F. J.; Vissotsky, V. A. Introduction and Overview of the Multics System. 1965 Fall Joint Computer Conference. Archived from the original on 2011-07-09.
- ^ a b «The Single Unix Specification». The open group. Archived from the original on 2016-10-04. Retrieved 2016-09-29.
- ^ «Unix’s Revenge». asymco.com. 29 September 2010. Archived from the original on 9 November 2010. Retrieved 2 October 2010.
- ^ Wheeler, David A. (October 12, 2004). «Linux Kernel 2.6: It’s Worth More!».
- ^ This community mostly gathers at Bona Fide OS Development Archived 2022-01-17 at the Wayback Machine, The Mega-Tokyo Message Board Archived 2022-01-25 at the Wayback Machine and other operating system enthusiast web sites.
- ^ Singh, Amit (December 2003). «XNU: The Kernel». Archived from the original on 2011-08-12.
- ^ «Windows — Official Site for Microsoft Windows 10 Home & Pro OS, laptops, PCs, tablets & more». windows.com. Archived from the original on 2011-08-20. Retrieved 2019-03-24.
- ^ «The L4 microkernel family — Overview». os.inf.tu-dresden.de. Archived from the original on 2006-08-21. Retrieved 2006-08-11.
- ^ «The Fiasco microkernel — Overview». os.inf.tu-dresden.de. Archived from the original on 2006-06-16. Retrieved 2006-07-10.
- ^ Zoller (inaktiv), Heinz (7 December 2013). «L4Ka — L4Ka Project». www.l4ka.org. Archived from the original on 19 April 2001. Retrieved 24 March 2019.
- ^ «QNX Operating Systems». blackberry.qnx.com. Archived from the original on 2019-03-24. Retrieved 2019-03-24.
Sources[edit]
- Roch, Benjamin (2004). «Monolithic kernel vs. Microkernel» (PDF). Archived from the original (PDF) on 2006-11-01. Retrieved 2006-10-12.
- Silberschatz, Abraham; James L. Peterson; Peter B. Galvin (1991). Operating system concepts. Boston, Massachusetts: Addison-Wesley. p. 696. ISBN 978-0-201-51379-0.
- Ball, Stuart R. (2002) [2002]. Embedded Microprocessor Systems: Real World Designs (first ed.). Elsevier Science. ISBN 978-0-7506-7534-5.
- Deitel, Harvey M. (1984) [1982]. An introduction to operating systems (revisited first ed.). Addison-Wesley. p. 673. ISBN 978-0-201-14502-1.
- Denning, Peter J. (December 1976). «Fault tolerant operating systems». ACM Computing Surveys. 8 (4): 359–389. doi:10.1145/356678.356680. ISSN 0360-0300. S2CID 207736773.
- Denning, Peter J. (April 1980). «Why not innovations in computer architecture?». ACM SIGARCH Computer Architecture News. 8 (2): 4–7. doi:10.1145/859504.859506. ISSN 0163-5964. S2CID 14065743.
- Hansen, Per Brinch (April 1970). «The nucleus of a Multiprogramming System». Communications of the ACM. 13 (4): 238–241. CiteSeerX 10.1.1.105.4204. doi:10.1145/362258.362278. ISSN 0001-0782. S2CID 9414037.
- Hansen, Per Brinch (1973). Operating System Principles. Englewood Cliffs: Prentice Hall. p. 496. ISBN 978-0-13-637843-3.
- Hansen, Per Brinch (2001). «The evolution of operating systems» (PDF). Archived (PDF) from the original on 2011-07-25. Retrieved 2006-10-24. included in book: Per Brinch Hansen, ed. (2001). «1 The evolution of operating systems». Classic operating systems: from batch processing to distributed systems. New York: Springer-Verlag. pp. 1–36. ISBN 978-0-387-95113-3.
- Härtig, Hermann; Hohmuth, Michael; Liedtke, Jochen; Schönberg, Sebastian; Wolter, Jean (October 5–8, 1997). «The performance of μ-kernel-based systems». Proceedings of the sixteenth ACM symposium on Operating systems principles — SOSP ’97. 16th ACM Symposium on Operating Systems Principles (SOSP’97). Saint-Malo, France. doi:10.1145/268998.266660. ISBN 978-0897919166. S2CID 1706253. Archived from the original on 2020-02-17.
{{cite conference}}: CS1 maint: date format (link), Härtig, Hermann; Hohmuth, Michael; Liedtke, Jochen; Schönberg, Sebastian (December 1997). «The performance of μ-kernel-based systems». ACM SIGOPS Operating Systems Review. 31 (5): 66–77. doi:10.1145/269005.266660. - Houdek, M. E.; Soltis, F. G.; Hoffman, R. L. (1981). «IBM System/38 support for capability-based addressing». Proceedings of the 8th ACM International Symposium on Computer Architecture. ACM/IEEE. pp. 341–348.
- The IA-32 Architecture Software Developer’s Manual, Volume 1: Basic Architecture (PDF). Intel Corporation. 2002.
- Levin, R.; Cohen, E.; Corwin, W.; Pollack, F.; Wulf, William (1975). «Policy/mechanism separation in Hydra». ACM Symposium on Operating Systems Principles / Proceedings of the Fifth ACM Symposium on Operating Systems Principles. 9 (5): 132–140. doi:10.1145/1067629.806531.
- Levy, Henry M. (1984). Capability-based computer systems. Maynard, Mass: Digital Press. ISBN 978-0-932376-22-0. Archived from the original on 2007-07-13. Retrieved 2007-07-18.
- Liedtke, Jochen (December 1995). «On µ-Kernel Construction». Proc. 15th ACM Symposium on Operating System Principles (SOSP). Archived from the original on 2007-03-13.
- Linden, Theodore A. (December 1976). «Operating System Structures to Support Security and Reliable Software». ACM Computing Surveys. 8 (4): 409–445. doi:10.1145/356678.356682. hdl:2027/mdp.39015086560037. ISSN 0360-0300. S2CID 16720589., «Operating System Structures to Support Security and Reliable Software» (PDF). Archived (PDF) from the original on 2010-05-28. Retrieved 2010-06-19.
- Lorin, Harold (1981). Operating systems. Boston, Massachusetts: Addison-Wesley. pp. 161–186. ISBN 978-0-201-14464-2.
- Schroeder, Michael D.; Jerome H. Saltzer (March 1972). «A hardware architecture for implementing protection rings». Communications of the ACM. 15 (3): 157–170. CiteSeerX 10.1.1.83.8304. doi:10.1145/361268.361275. ISSN 0001-0782. S2CID 14422402.
- Shaw, Alan C. (1974). The logical design of Operating systems. Prentice-Hall. p. 304. ISBN 978-0-13-540112-5.
- Tanenbaum, Andrew S. (1979). Structured Computer Organization. Englewood Cliffs, New Jersey: Prentice-Hall. ISBN 978-0-13-148521-1.
- Wulf, W.; E. Cohen; W. Corwin; A. Jones; R. Levin; C. Pierson; F. Pollack (June 1974). «HYDRA: the kernel of a multiprocessor operating system» (PDF). Communications of the ACM. 17 (6): 337–345. doi:10.1145/355616.364017. ISSN 0001-0782. S2CID 8011765. Archived from the original (PDF) on 2007-09-26. Retrieved 2007-07-18.
- Baiardi, F.; A. Tomasi; M. Vanneschi (1988). Architettura dei Sistemi di Elaborazione, volume 1 (in Italian). Franco Angeli. ISBN 978-88-204-2746-7. Archived from the original on 2012-06-27. Retrieved 2006-10-10.
- Swift, Michael M.; Brian N. Bershad; Henry M. Levy. Improving the reliability of commodity operating systems (PDF). Archived (PDF) from the original on 2007-07-19. Retrieved 2007-07-16.
- Gettys, James; Karlton, Philip L.; McGregor, Scott (1990). «The X window system, version 11». Software: Practice and Experience. 20: S35–S67. doi:10.1002/spe.4380201404. S2CID 26329062.
- Michael M. Swift; Brian N. Bershad; Henry M. Levy (February 2005). «Improving the reliability of commodity operating systems». ACM Transactions on Computer Systems. Association for Computing Machinery. 23 (1): 77–110. doi:10.1145/1047915.1047919. eISSN 1557-7333. ISSN 0734-2071. S2CID 208013080.
Further reading[edit]
- Andrew S. Tanenbaum, Albert S. Woodhull, Operating Systems: Design and Implementation (Third edition);
- Andrew S. Tanenbaum, Herbert Bos, Modern Operating Systems (Fourth edition);
- Daniel P. Bovet, Marco Cesati, Understanding the Linux Kernel (Third edition);
- David A. Patterson, John L. Hennessy, Computer Organization and Design (Sixth edition), Morgan Kaufmann (ISBN 978-0-12-820109-1);
- B.S. Chalk, A.T. Carter, R.W. Hind, Computer Organisation and Architecture: An Introduction (Second edition), Palgrave Macmillan (ISBN 978-1-4039-0164-4).
External links[edit]
- Detailed comparison between most popular operating system kernels