
Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main()). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Ошибка на единицу
Вы начали циклforс единицы вместо нуля или наоборот. Или, например, подумали, что метод.count()или.length()вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключенияIndex out of range. - Состояние гонки
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использованиеsleep()в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д. - Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в/etc/hosts, которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки наnull, особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значениеNULLпредставлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали=вместо==, особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместоDecimal, илиfloatдля денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые вINSERT, на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строкуxsi:type='xs:string', все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss. Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss, и ошибка исчезла.
Перевод статьи «How to fix bugs, step by step»
Добавлено 30 мая 2021 в 21:14
В уроке «7.14 – Распространенные семантические ошибки при программировании на C++» мы рассмотрели многие типы распространенных семантических ошибок, с которыми сталкиваются начинающие программисты при работе с языком C++. Если ошибка является результатом неправильного использования языковой функции или логической ошибки, исправить ее можно просто.
Но большинство ошибок в программе возникает не в результате непреднамеренного неправильного использования языковых функций – скорее, большинство ошибок возникает из-за ошибочных предположений, сделанных программистом, и/или из-за отсутствия надлежащего обнаружения/обработки ошибок.
Например, в функции, предназначенной для поиска оценки учащегося, вы могли предположить, что:
- просматриваемый студент будет существовать;
- имена всех студентов будут уникальными;
- в предмете используется числовая оценка (вместо «зачет/незачет»).
Что, если какое-либо из этих предположений неверно? Если программист не предвидел этих случаев, программа при возникновении таких случаев, скорее всего, завершится со сбоем (обычно в какой-то момент в будущем, через долгое время после того, как функция была написана).
Есть три ключевых места, где обычно возникают ошибки предположений:
- Когда функция возвращает значение, программист мог предположить, что вызов функции будет успешным, хотя это не так.
- Когда программа получает входные данные (либо от пользователя, либо из файла), программист мог предположить, что ввод будет в правильном формате и семантически корректен, хотя это не так.
- Когда функция была вызвана, программист мог предположить, что параметры будут семантически допустимыми, хотя это не так.
Многие начинающие программисты пишут код, а затем проверяют только счастливый путь: только те случаи, когда ошибок нет. Но вы также должны планировать и проверять печальные пути, на которых что-то может пойти и пойдет не так. В уроке «3.10 – Поиск проблем до того, как они станут проблемами», мы определили защитное программирование как попытку предвидеть все способы неправильного использования программного обеспечения конечными пользователями или разработчиками (либо самим программистом, либо другими). Как только вы ожидаете (или обнаруживаете) какое-то неправильное использование, следующее, что вам нужно сделать, – это обработать его.
В этом уроке мы поговорим о стратегиях обработки ошибок (что делать, если что-то пойдет не так) внутри функции. В следующих уроках мы поговорим о проверке ввода данных пользователем, а затем представим полезный инструмент, помогающий документировать и проверять предположения.
Обработка ошибок в функциях
Функции могут давать сбой по любому количеству причин – вызывающий мог передать аргумент с недопустимым значением, или что-то может дать сбой в теле функции. Например, функция, открывающая файл для чтения, может не работать, если файл не может быть найден.
Когда это произойдет, в вашем распоряжении будет несколько вариантов. Лучшего способа справиться с ошибкой нет – это на самом деле зависит от характера проблемы и от того, можно ли устранить проблему или нет.
Можно использовать 4 основные стратегии:
- обработать ошибку в функции;
- передать ошибку вызывающему, чтобы он разобрался с ней;
- остановить программу;
- выбросить исключение.
Обработка ошибки в функции
Если возможно, наилучшей стратегией является восстановление после ошибки в той же функции, в которой возникла ошибка, так, чтобы ошибку можно было локализовать и исправить, не влияя на какой-либо код вне функции. Здесь есть два варианта: повторять попытки до успешного завершения или отменить выполняемую операцию.
Если ошибка возникла из-за чего-то, не зависящего от программы, программа может повторять попытку, пока не будет достигнут успех. Например, если программе требуется подключение к Интернету, и пользователь потерял соединение, программа может отобразить предупреждение, а затем использовать цикл для периодической повторной проверки подключения к Интернету. В качестве альтернативы, если пользователь ввел недопустимые входные данные, программа может попросить пользователя повторить попытку и выполнять этот цикл до тех пор, пока пользователь не введет корректные входные данные. Мы покажем примеры обработки недопустимого ввода и использования циклов для повторных попыток в следующем уроке (7.16 – std::cin и обработка недопустимого ввода).
Альтернативная стратегия – просто игнорировать ошибку и/или отменить операцию. Например:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
}В приведенном выше примере, если пользователь ввел недопустимое значение для y, мы просто игнорируем запрос на печать результата операции деления. Основная проблема при этом заключается в том, что у вызывающей функции или у пользователя нет возможности определить, что что-то пошло не так. В таком случае может оказаться полезным напечатать сообщение об ошибке:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Однако если вызывающая функция ожидает, что вызываемая функция выдаст возвращаемое значение или какой-либо полезный побочный эффект, тогда просто игнорирование ошибки может быть недопустимым вариантом.
Передача ошибок вызывающей функции
Во многих случаях обработать ошибку с помощью функции, которая ее обнаруживает, невозможно. Например, рассмотрим следующую функцию:
double doDivision(int x, int y)
{
return static_cast<double>(x) / y;
}Если y равно 0, что нам делать? Мы не можем просто пропустить логику программы, потому что функция должна возвращать какое-то значение. Мы не должны просить пользователя ввести новое значение для y, потому что это функция вычисления, и введение в нее процедур ввода может быть или не быть подходящим для программы, вызывающей эту функцию.
В таких случаях лучшим вариантом может быть передача ошибки обратно вызывающей функции в надежде, что вызывающая сторона сможет с ней справиться.
Как мы можем это сделать?
Если функция имеет тип возвращаемого значения void, его можно изменить, чтобы она возвращала логическое значение, указывающее на успех или на неудачу. Например, вместо:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Мы можем сделать так:
bool printDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: could not divide by zeron";
return false;
}
std::cout << static_cast<double>(x) / y;
return true;
}Таким образом, вызывающий может проверить возвращаемое значение, чтобы узнать, не завершилась ли функция по какой-либо причине неудачей.
Если функция возвращает обычное значение, всё немного сложнее. В некоторых случаях полный диапазон возвращаемых значений не используется. В таких случаях, чтобы указать на ошибку, мы можем использовать возвращаемое значение, которое иначе было бы невозможно. Например, рассмотрим следующую функцию:
// Обратное (reciprocal) к x равно 1/x
double reciprocal(double x)
{
return 1.0 / x;
}Обратное к некоторому числу x определяется как 1/x, а число, умноженное на обратное, равно 1.
Однако что произойдет, если пользователь вызовет эту функцию как reciprocal(0.0)? Мы получаем ошибку деления на ноль и сбой программы, поэтому очевидно, что мы должны защититься от этого случая. Но эта функция должна возвращать значение doube, так какое же значение мы должны вернуть? Оказывается, эта функция никогда не выдаст 0.0 как допустимый результат, поэтому мы можем вернуть 0.0, чтобы указать на случай ошибки.
// Обратное (reciprocal) к x равно 1/x; возвращает 0.0, если x=0
double reciprocal(double x)
{
if (x == 0.0)
return 0.0;
return 1.0 / x;
}Однако если требуется полный диапазон возвращаемых значений, то использование возвращаемого значения для указания ошибки будет невозможно (поскольку вызывающий не сможет определить, является ли возвращаемое значение допустимым значением или значением ошибки). В таком случае выходной параметр (рассмотренный в уроке «11.3 – Передача аргументов по ссылке») может быть жизнеспособным вариантом.
Фатальные ошибки
Если ошибка настолько серьезна, что программа не может продолжать работать правильно, она называется неисправимой ошибкой (или фатальной ошибкой). В таких случаях лучше всего завершить программу. Если ваш код находится в main() или в функции, вызываемой непосредственно из main(), лучше всего позволить main() вернуть ненулевой код состояния. Однако если вы погрузились в какую-то глубоко вложенную подфункцию, передать ошибку обратно в main() может быть неудобно или невозможно. В таком случае можно использовать инструкцию остановки (например, std::exit()).
Например:
double doDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: Could not divide by zeron";
std::exit(1);
}
return static_cast<double>(x) / y;
}Исключения
Поскольку возврат ошибки из функции обратно вызывающей функции сложен (и множество различных способов сделать это приводит к несогласованности, а несогласованность ведет к ошибкам), C++ предлагает совершенно отдельный способ передачи ошибок обратно вызывающей стороне: исключения.
Основная идея состоит в том, что при возникновении ошибки «выбрасывается» исключение. Если текущая функция не «улавливает» ошибку, то уловить ошибку есть шанс у вызывающей функции. Если вызывающая функция не обнаруживает ошибку, то обнаружить ошибку есть шанс у функции, вызвавшей вызывающую функцию. Ошибка постепенно перемещается вверх по стеку вызовов до тех пор, пока она не будет обнаружена и обработана (в этот момент выполнение продолжается в обычном режиме), или пока main() не сможет обработать ошибку (в этот момент программа завершится с ошибкой исключения).
Мы рассмотрим обработку исключений в главе 20 этой серии обучающих статей.
Теги
C++ / CppException / ИсключениеLearnCppstd::exit()Для начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование
Содержание
- 1 Методы обработки ошибок
- 2 Исключения
- 3 Классификация исключений
- 3.1 Проверяемые исключения
- 3.2 Error
- 3.3 RuntimeException
- 4 Обработка исключений
- 4.1 try-catch-finally
- 4.2 Обработка исключений, вызвавших завершение потока
- 4.3 Информация об исключениях
- 5 Разработка исключений
- 6 Исключения в Java7
- 7 Примеры исключений
- 8 Гарантии безопасности
- 9 Источники
Методы обработки ошибок
1. Не обрабатывать.
2. Коды возврата. Основная идея — в случае ошибки возвращать специальное значение, которое не может быть корректным. Например, если в методе есть операция деления, то придется проверять делитель на равенство нулю. Также проверим корректность аргументов a и b:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return null;
}
//...
if (Math.abs(b) < EPS) {
return null;
} else {
return a / b;
}
}
При вызове метода необходимо проверить возвращаемое значение:
Double d = f(a, b); if (d != null) { //... } else { //... }
Минусом такого подхода является необходимость проверки возвращаемого значения каждый раз при вызове метода. Кроме того, не всегда возможно определить тип ошибки.
3.Использовать флаг ошибки: при возникновении ошибки устанавливать флаг в соответствующее значение:
boolean error; Double f(Double a, Double b) { if ((a == null) || (b == null)) { error = true; return null; } //... if (Math.abs(b) < EPS) { error = true; return b; } else { return a / b; } }
error = false; Double d = f(a, b); if (error) { //... } else { //... }
Минусы такого подхода аналогичны минусам использования кодов возврата.
4.Можно вызвать метод обработки ошибки и возвращать то, что вернет этот метод.
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return nullPointer();
}
//...
if (Math.abs(b) < EPS) {
return divisionByZero();
} else {
return a / b;
}
}
Но в таком случае не всегда возможно проверить корректность результата вызова основного метода.
5.В случае ошибки просто закрыть программу.
if (Math.abs(b) < EPS) { System.exit(0); return this; }
Это приведет к потере данных, также невозможно понять, в каком месте возникла ошибка.
Исключения
В Java возможна обработка ошибок с помощью исключений:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
throw new IllegalArgumentException("arguments of f() are null");
}
//...
return a / b;
}
Проверять b на равенство нулю уже нет необходимости, так как при делении на ноль метод бросит непроверяемое исключение ArithmeticException.
Исключения позволяют:
- разделить обработку ошибок и сам алгоритм;
- не загромождать код проверками возвращаемых значений;
- обрабатывать ошибки на верхних уровнях, если на текущем уровне не хватает данных для обработки. Например, при написании универсального метода чтения из файла невозможно заранее предусмотреть реакцию на ошибку, так как эта реакция зависит от использующей метод программы;
- классифицировать типы ошибок, обрабатывать похожие исключения одинаково, сопоставлять специфичным исключениям определенные обработчики.
Каждый раз, когда при выполнении программы происходит ошибка, создается объект-исключение, содержащий информацию об ошибке, включая её тип и состояние программы на момент возникновения ошибки.
После создания исключения среда выполнения пытается найти в стеке вызовов метод, который содержит код, обрабатывающий это исключение. Поиск начинается с метода, в котором произошла ошибка, и проходит через стек в обратном порядке вызова методов. Если не было найдено ни одного подходящего обработчика, выполнение программы завершается.
Таким образом, механизм обработки исключений содержит следующие операции:
- Создание объекта-исключения.
- Заполнение stack trace’а этого исключения.
- Stack unwinding (раскрутка стека) в поисках нужного обработчика.
Классификация исключений
Класс Java Throwable описывает все, что может быть брошено как исключение. Наследеники Throwable — Exception и Error — основные типы исключений. Также RuntimeException, унаследованный от Exception, является существенным классом.
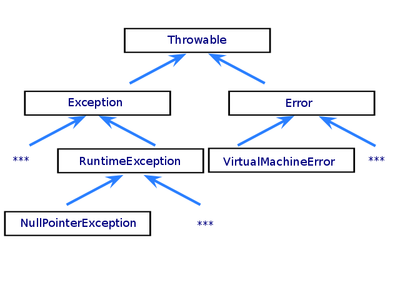
Иерархия стандартных исключений
Проверяемые исключения
Наследники класса Exception (кроме наслеников RuntimeException) являются проверяемыми исключениями(checked exception). Как правило, это ошибки, возникшие по вине внешних обстоятельств или пользователя приложения – неправильно указали имя файла, например. Эти исключения должны обрабатываться в ходе работы программы, поэтому компилятор проверяет наличие обработчика или явного описания тех типов исключений, которые могут быть сгенерированы некоторым методом.
Все исключения, кроме классов Error и RuntimeException и их наследников, являются проверяемыми.
Error
Класс Error и его подклассы предназначены для системных ошибок. Свои собственные классы-наследники для Error писать (за очень редкими исключениями) не нужно. Как правило, это действительно фатальные ошибки, пытаться обработать которые довольно бессмысленно (например OutOfMemoryError).
RuntimeException
Эти исключения обычно возникают в результате ошибок программирования, такие как ошибки разработчика или неверное использование интерфейса приложения. Например, в случае выхода за границы массива метод бросит OutOfBoundsException. Такие ошибки могут быть в любом месте программы, поэтому компилятор не требует указывать runtime исключения в объявлении метода. Теоретически приложение может поймать это исключение, но разумнее исправить ошибку.
Обработка исключений
Чтобы сгенерировать исключение используется ключевое слово throw. Как и любой объект в Java, исключения создаются с помощью new.
if (t == null) { throw new NullPointerException("t = null"); }
Есть два стандартных конструктора для всех исключений: первый — конструктор по умолчанию, второй принимает строковый аргумент, поэтому можно поместить подходящую информацию в исключение.
Возможна ситуация, когда одно исключение становится причиной другого. Для этого существует механизм exception chaining. Практически у каждого класса исключения есть конструктор, принимающий в качестве параметра Throwable – причину исключительной ситуации. Если же такого конструктора нет, то у Throwable есть метод initCause(Throwable), который можно вызвать один раз, и передать ему исключение-причину.
Как и было сказано раньше, определение метода должно содержать список всех проверяемых исключений, которые метод может бросить. Также можно написать более общий класс, среди наследников которого есть эти исключения.
void f() throws InterruptedException, IOException { //...
try-catch-finally
Код, который может бросить исключения оборачивается в try-блок, после которого идут блоки catch и finally (Один из них может быть опущен).
try { // Код, который может сгенерировать исключение }
Сразу после блока проверки следуют обработчики исключений, которые объявляются ключевым словом catch.
try { // Код, который может сгенерировать исключение } catch(Type1 id1) { // Обработка исключения Type1 } catch(Type2 id2) { // Обработка исключения Type2 }
Сatch-блоки обрабатывают исключения, указанные в качестве аргумента. Тип аргумента должен быть классом, унаследованного от Throwable, или самим Throwable. Блок catch выполняется, если тип брошенного исключения является наследником типа аргумента и если это исключение не было обработано предыдущими блоками.
Код из блока finally выполнится в любом случае: при нормальном выходе из try, после обработки исключения или при выходе по команде return.
NB: Если JVM выйдет во время выполнения кода из try или catch, то finally-блок может не выполниться. Также, например, если поток выполняющий try или catch код остановлен, то блок finally может не выполниться, даже если приложение продолжает работать.
Блок finally удобен для закрытия файлов и освобождения любых других ресурсов. Код в блоке finally должен быть максимально простым. Если внутри блока finally будет брошено какое-либо исключение или просто встретится оператор return, брошенное в блоке try исключение (если таковое было брошено) будет забыто.
import java.io.IOException; public class ExceptionTest { public static void main(String[] args) { try { try { throw new Exception("a"); } finally { throw new IOException("b"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println(ex.getMessage()); } } }
После того, как было брошено первое исключение — new Exception("a") — будет выполнен блок finally, в котором будет брошено исключение new IOException("b"), именно оно будет поймано и обработано. Результатом его выполнения будет вывод в консоль b. Исходное исключение теряется.
Обработка исключений, вызвавших завершение потока
При использовании нескольких потоков бывают ситуации, когда поток завершается из-за исключения. Для того, чтобы определить с каким именно, начиная с версии Java 5 существует интерфейс Thread.UncaughtExceptionHandler. Его реализацию можно установить нужному потоку с помощью метода setUncaughtExceptionHandler. Можно также установить обработчик по умолчанию с помощью статического метода Thread.setDefaultUncaughtExceptionHandler.
Интерфейс Thread.UncaughtExceptionHandler имеет единственный метод uncaughtException(Thread t, Throwable e), в который передается экземпляр потока, завершившегося исключением, и экземпляр самого исключения. Когда поток завершается из-за непойманного исключения, JVM запрашивает у потока UncaughtExceptionHandler, используя метод Thread.getUncaughtExceptionHandler(), и вызвает метод обработчика – uncaughtException(Thread t, Throwable e). Все исключения, брошенные этим методом, игнорируются JVM.
Информация об исключениях
-
getMessage(). Этот метод возвращает строку, которая была первым параметром при создании исключения; -
getCause()возвращает исключение, которое стало причиной текущего исключения; -
printStackTrace()печатает stack trace, который содержит информацию, с помощью которой можно определить причину исключения и место, где оно было брошено.
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
Все методы выводятся в обратном порядке вызовов. В примере исключение IllegalStateException было брошено в методе getBookIds, который был вызван в main. «Caused by» означает, что исключение NullPointerException является причиной IllegalStateException.
Разработка исключений
Чтобы определить собственное проверяемое исключение, необходимо создать наследника класса java.lang.Exception. Желательно, чтобы у исключения был конструкор, которому можно передать сообщение:
public class FooException extends Exception { public FooException() { super(); } public FooException(String message) { super(message); } public FooException(String message, Throwable cause) { super(message, cause); } public FooException(Throwable cause) { super(cause); } }
Исключения в Java7
- обработка нескольких типов исключений в одном
catch-блоке:
catch (IOException | SQLException ex) {...}
В таких случаях параметры неявно являются final, поэтому нельзя присвоить им другое значение в блоке catch.
Байт-код, сгенерированный компиляцией такого catch-блока будет короче, чем код нескольких catch-блоков.
-
Tryс ресурсами позволяет прямо вtry-блоке объявлять необходимые ресурсы, которые по завершению блока будут корректно закрыты (с помощью методаclose()). Любой объект реализующийjava.lang.AutoCloseableможет быть использован как ресурс.
static String readFirstLineFromFile(String path) throws IOException { try (BufferedReader br = new BufferedReader(new FileReader(path))) { return br.readLine(); } }
В приведенном примере в качестве ресурса использутся объект класса BufferedReader, который будет закрыт вне зависимосити от того, как выполнится try-блок.
Можно объявлять несколько ресурсов, разделяя их точкой с запятой:
public static void viewTable(Connection con) throws SQLException { String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES"; try (Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query)) { //Work with Statement and ResultSet } catch (SQLException e) { e.printStackTrace; } }
Во время закрытия ресурсов тоже может быть брошено исключение. В try-with-resources добавленна возможность хранения «подавленных» исключений, и брошенное try-блоком исключение имеет больший приоритет, чем исключения получившиеся во время закрытия. Получить последние можно вызовом метода getSuppressed() от исключения брошенного try-блоком.
- Перебрасывание исключений с улучшенной проверкой соответствия типов.
Компилятор Java SE 7 тщательнее анализирует перебрасываемые исключения. Рассмотрим следующий пример:
static class FirstException extends Exception { } static class SecondException extends Exception { } public void rethrowException(String exceptionName) throws Exception { try { if ("First".equals(exceptionName)) { throw new FirstException(); } else { throw new SecondException(); } } catch (Exception ex) { throw e; } }
В примере try-блок может бросить либо FirstException, либо SecondException. В версиях до Java SE 7 невозможно указать эти исключения в декларации метода, потому что catch-блок перебрасывает исключение ex, тип которого — Exception.
В Java SE 7 вы можете указать, что метод rethrowException бросает только FirstException и SecondException. Компилятор определит, что исключение Exception ex могло возникнуть только в try-блоке, в котором может быть брошено FirstException или SecondException. Даже если тип параметра catch — Exception, компилятор определит, что это экземпляр либо FirstException, либо SecondException:
public void rethrowException(String exceptionName) throws FirstException, SecondException { try { // ... } catch (Exception e) { throw e; } }
Если FirstException и SecondException не являются наследниками Exception, то необходимо указать и Exception в объявлении метода.
Примеры исключений
- любая операция может бросить
VirtualMachineError. Как правило это происходит в результате системных сбоев. -
OutOfMemoryError. Приложение может бросить это исключение, если, например, не хватает места в куче, или не хватает памяти для того, чтобы создать стек нового потока. -
IllegalArgumentExceptionиспользуется для того, чтобы избежать передачи некорректных значений аргументов. Например:
public void f(Object a) { if (a == null) { throw new IllegalArgumentException("a must not be null"); } }
IllegalStateExceptionвозникает в результате некорректного состояния объекта. Например, использование объекта перед тем как он будет инициализирован.
Гарантии безопасности
При возникновении исключительной ситуации, состояния объектов и программы могут удовлетворять некоторым условиям, которые определяются различными типами гарантий безопасности:
- Отсутствие гарантий (no exceptional safety). Если было брошено исключение, то не гарантируется, что все ресурсы будут корректно закрыты и что объекты, методы которых бросили исключения, могут в дальнейшем использоваться. Пользователю придется пересоздавать все необходимые объекты и он не может быть уверен в том, что может переиспозовать те же самые ресурсы.
- Отсутствие утечек (no-leak guarantee). Объект, даже если какой-нибудь его метод бросает исключение, освобождает все ресурсы или предоставляет способ сделать это.
- Слабые гарантии (weak exceptional safety). Если объект бросил исключение, то он находится в корректном состоянии, и все инварианты сохранены. Рассмотрим пример:
class Interval { //invariant: left <= right double left; double right; //... }
Если будет брошено исключение в этом классе, то тогда гарантируется, что ивариант «левая граница интервала меньше правой» сохранится, но значения left и right могли измениться.
- Сильные гарантии (strong exceptional safety). Если при выполнении операции возникает исключение, то это не должно оказать какого-либо влияния на состояние приложения. Состояние объектов должно быть таким же как и до вызовов методов.
- Гарантия отсутствия исключений (no throw guarantee). Ни при каких обстоятельствах метод не должен генерировать исключения. В Java это невозможно, например, из-за того, что
VirtualMachineErrorможет произойти в любом месте, и это никак не зависит от кода. Кроме того, эту гарантию практически невозможно обеспечить в общем случае.
Источники
- Обработка ошибок и исключения — Сайт Георгия Корнеева
- Лекция Георгия Корнеева — Лекториум
- The Java Tutorials. Lesson: Exceptions
- Обработка исключений — Википедия
- Throwable (Java Platform SE 7 ) — Oracle Documentation
- try/catch/finally и исключения — www.skipy.ru
Новенький файл, открытый в текстовом редакторе, и ни одной написанной строчки кода…Каждый новый проект видится полным возможностей и перспектив…
Несколькими тысячами строк кода позже, тот же самый проект может оказаться отягощенным ошибками, из-за которых добавление новых функций становится головной болью, и падает энтузиазм программистов. Лучшие разработчики знают, как найти и устранить ошибки, и придерживаются лучших практик в разработке программного обеспечения, чтобы свести к минимуму, в первую очередь, возникновение ошибок.
Ни один программист никогда не напишет абсолютно верный код, но с некоторой практикой и решимостью вполне возможно писать чистый код, сдерживать ошибки и разрабатывать надежные программные системы.

- Ваш набор инструментов для борьбы с ошибками
- Оператор печати
- Отладчик
- Система отслеживания ошибок
- Верификация программ
- Контроль версий
- Модульность
- Автоматизированные тесты
- Метод «Плюшевый мишка» (или отладка «Резиновая уточка»)
- Пишите комментарии к коду
- Пишите документацию
- На пути к мастерству: избавляемся от ошибок
Инструмент номер один для отладки кода – это опробованный и верный способ вставки операторов печати. В качестве равнозначной замены, для случаев, когда операторов печати много, и ими трудно управлять, может быть использована система протоколирования вместо операторов печати. Во многих языках программирования для этого есть в свободном доступе специальные библиотеки, как, например, библиотека logging, встроенная в Python.
Операторы печати – это самый быстрый, простой и непосредственный для программиста способ инспектирования значений данных и типов переменных. Правильно размещенные операторы печати позволяют программисту отслеживать поток данных на участке кода и быстро определять источник ошибки.
Не имеет значения, сколько передовых технологий используется, скромный оператор печати должен быть первым инструментом, к которому обращается программист, когда пытается отладить участок кода.
Отладчики исходного кода доводят метод отладки с помощью операторов печати до его логического завершения. Они позволяют программисту отследить по шагам выполнение кода строка за строкой и инспектировать все, что угодно, начиная от значений переменных и заканчивая состоянием виртуальной машины.
Большинство языков программирования имеют множество доступных отладчиков, которые предлагают различные возможности, включая графические интерфейсы, настройки точек останова для приостановки выполнения программы, и выполнение произвольного кода внутри среды исполнения.
Применение отладчика может быть излишним во многих ситуациях, но при надлежащем использовании, отладчик может стать мощным и эффективным инструментом. Для лучшего понимания возможностей отладчика, познакомьтесь с отладчиком Python pdb.
Использование какой-либо системы отслеживания ошибок является жизненно важным условием для нетривиальных проектов по созданию программного обеспечения. Типичная ситуация, которая складывается, когда не используют систему отслеживания ошибок, такова: программисты вынуждены разбираться в старых е-мейлах или переписке в чате в поисках информации об ошибках, или того хуже — единственным хранилищем информации об ошибках является память программиста.
Когда такое случается, некоторые ошибки неизбежно остаются неисправленными, и что более важно, их труднее обнаружить и устранить другие, связанные с ними ошибки.
Простой текстовый файл может служить начальной системой отслеживания ошибок для проекта. С ростом объема кода количество ошибок выйдет за рамки текстового файла.
Существует большой выбор систем отслеживания ошибок в программном обеспечении, как коммерческих, так и с открытым исходным кодом. Самым важным критерием в выборе такой системы является доступность для сотрудников-непрограммистов, которым нужно работать с файлом ошибок.
В некоторых языках программирования верификатор может проводить статический анализ кода для обнаружения проблемных мест до того, как код будет откомпилирован или выполнен, а в других языках верификатор полезен для проверки синтаксиса и стиля написания.
Исполнение программы верификации внутри редактора во время написания кода или прогон кода через верификатор до компиляции и выполнения помогает программистам находить и исправлять неисправности до того, как они переросли в ошибки в исполняемом программном обеспечении.
Использование верификации позволяет значительно сэкономить время по отслеживанию источника неисправности, вызванных синтаксическими ошибками, опечатками, и некорректными типами данных. Чтобы получить более полное представление о возможностях верификатора, посмотрите Pyflakes, верификатор для Python.
Также как и использование системы отслеживания ошибок, применение системы контроля версии – это самая лучшая практика в разработке программного обеспечения, которая не может быть игнорирована при разработке любого проекта значительного размера.
Системы контроля версии, такие как Git, Mercurial и SVN, позволяют разным версиям базы кода быть разделенными, основываясь на том, над чем работают или кто разрабатывает код. Разные версии могут быть объединены вместе, поэтому несколько программистов могут работать с базой кода в одно то же время, не создавая ошибки, которые могли бы повлиять на ход работы остальных разработчиков.
Системы контроля версий играют ключевую роль еще и потому, что позволяют программистам откатить изменения до более ранней версии кода, просто возвратившись в состояние базы до появления ошибок, не допуская при этом других ошибок, за исправление которых пришлось бы дорого поплатиться.
Плохо спроектированный код – это главный источник трудно исправляемых ошибок. Если код легко понять, и он может быть «выполнен» в уме или на бумаге, есть большая вероятность, что программисты смогут быстро находить и исправлять ошибки.
Самый лучший способ добиться этого – писать функции, выполняющие что-то одно. А вот участок кода с большим количеством функций имеет большую склонность к возникновению ошибок, которые сложно отслеживать.
Проектирование компонентов программного обеспечения, которые осуществляет только одну функцию, часто называется модульным дизайном. Модульность помогает программистам рассматривать системы программного обеспечения в двух измерениях. Во-первых, модульность создает уровень абстракции, позволяющий думать о модуле системы без понимания всех деталей его работы.
Например, программист, разрабатывающий систему электронной коммерции, мог бы, рассматривая модуль обработки кредитной карты, видеть, как он связан с остальным кодом, не вдаваясь в детали самой обработки кредитной карты. С другой стороны, детали модуля (в нашем примере того, который занимается обработкой кредитной карты) могут быть рассмотрены и поняты без обращения к не имеющему отношение к этому модулю коду.
Модульные тесты и другие типы автоматизированных тестов идут рука об руку с модульным программированием.
Автоматизированный код – это участок кода, который выполняет программу с определенными входными параметрами и проверяет, соответствует ли поведение программы ожидаемому.
Модульные тесты проверяют функционирование отдельных функций или методов класса, в то время как функциональные тесты проверяют специфичное поведение всей программы, а интеграционные тесты проверяют большие части системы или всю систему в целом.
Существует много фреймворков для тестирования, которые делают написание тестов легче. Многие из известных фреймворков, используемых сегодня, были получены из библиотеки JUnit, написанной Кентом Бентом (Kent Bent), одним из первых сторонников идеи разработки через тестирование. Стандартная библиотека Python включает свою версию JUnit под именем PyUni или просто unittest.
Если верить легендам программирования Брайану Кернигану и Робу Пайку (Brain Kernighan и Rob Pike), отладка по типу «Резиновая уточка» возникла в университетском компьютерном центре, где студенты должны были садиться напротив плюшевого мишки и объяснять ему их ошибки, прежде чем обращаться за помощью к живому человеку.
Этот метод отладки оказался настолько эффективным, что быстро распространился во всем мире разработки программного обеспечения, и также как простой оператор печати, продолжает существовать по сей день, несмотря на то, что есть, казалось бы, более сложные инструменты. Практически все может заменить плюшевого мишку: резиновые уточки, как терпеливые слушатели, тоже пользуются спросом.
Важной частью этого метода является то, что нужно объяснять код и проблему вслух в простых и понятных терминах. Есть подобная методика, которая также полезна – вести журнал программирования, в который нужно записывать мысли о коде до и после его реализации.
Комментарии должны объяснять цель кода на низком уровне. Должна существовать возможность легко ответить на вопросы о том, что строка кода делает и как она это делает, прочитав сам код. Это достигается путем написания читаемого кода, который разработан настолько просто, насколько это возможно, и использует осмысленные имена для функций и переменных.
Комментарии к коду должны заполнять пробелы информации в максимально возможной степени, отвечая на такие вопросы, как: почему используется конкретная реализация, или как данный участок кода взаимодействует с остальной частью программы.
Написание хороших комментариев – это отличная практика разработки программного обеспечения даже в свободном от ошибок коде, но когда ошибки появляются, комментарии помогут сэкономить массу времени, затрачиваемого на понимание кода, написанного несколько дней, недель или даже месяцев назад.
В то время как комментарии описывают код на низком уровне, с точки зрения программиста, программная документация описывает функционирование всей системы в доступной для пользователей форме. В зависимости от типа разрабатываемого программного обеспечения, документация может описывать интерфейсы программирования, графические интерфейсы или рабочие процессы.
Написание документации демонстрирует понимание программной системы, и часто указывает на те части системы, которые не до конца понятны и являются вероятным источником ошибок.
Программирование – это, прежде всего, искусство. И также как для любого другого вида искусства, путь к мастерству в нем вымощен трудолюбием и стремлением учиться. Работа по изучению программирования никогда не заканчивается. Всегда есть что-то новое для изучения и новые способы по улучшению.
Какими из этих 10 средств отладки вы пользуетесь сейчас? Какими вы могли бы начать пользоваться с сегодняшнего дня? Какие из этих инструментов требуют времени на практику и освоения новых навыков?
Программисты пользуются преимуществом, которым только некоторые другие мастера могут когда-либо воспользоваться: самые лучшие инструменты и знания о программировании свободно и бесплатно доступны для всех, кто заинтересован в этом вопросе. Вы можете стать профи в отладке кода: все, что вы должны сделать для этого – просто взять инструменты по отладке и приступить к работе.
Цель
работы:
получить
начальное представление о возможностях
отладчика VBA.
-
Методические указания
Одной
из важнейших проблем, связанных с
программированием, является проблема
своевременного обнаружения и устранения
ошибок, возникающих при создании
программ. Человечество подходит к
разрешению этой проблемы с разных
сторон. Во-первых, создаются методы и
средства автоматизации программирования,
позволяющие уменьшить вероятность
возникновения ошибки как таковой. К их
числу относятся технологии структурного
программирования и само объектно-ориентированное
программирование. Во вторых, совершенствуются
сами программные средства и языки
программирования, создаются
специализированные программы, которые
позволяют относительно легко обнаруживать
ошибки. Наконец, в третьих, ведутся
статистические исследования и выявляются
типовые ошибки, которые делают
программисты. На основании полученной
статистики выдаются рекомендации
разработчикам нового программного
обеспечения. Настоящая лабораторная
работа посвящена изучению методов
обнаружения ошибок, реализованному в
VBA.
Обычно
выделяют три основных вида ошибок,
которые приводят к неправильному
выполнению программы или делают ее
выполнение просто невозможным. Первый
вид ошибок – это ошибки, возникающие
на этапе компиляции. Основной смысл
определяемых на этапе компиляции ошибок
– это некорректная запись операторов
программы с точки зрения правил языка
программирования. Как следствие,
компилятор не может создать код и требует
внести изменения в программу. Компилятор
VBA
высвечивает строку программы, которая
содержит ошибку, красным цветом и выдает
дополнительное диагностическое
сообщение.
Ошибки
этапа компиляции устраняются программистом
с относительно небольшими затратами
труда, поскольку их поиск автоматизирован,
а для уточнения правил языка программист
может легко воспользоваться справочной
литературой или встроенной в компилятор
VBA
системой помощи. Ее вызов осуществляется
при нажатии клавиши F1.
С целью минимизации вероятности
возникновения орфографической ошибки
при записи класса или метода объекта
может быть вызвано специальное контекстное
меню вводом команды Редактирование/Список
свойств и методов.
Аналогичное меню может быть вызвано и
для списка констант. Быстрый вызов меню
можно осуществить и правой клавишей
мыши при наборе текста. Наконец,
распознанные операторы языка выделяются
цветом, что позволяет уменьшить
вероятность ошибки, связанной с
неправильным именем переменной. В любом
случае ошибки компиляции сопровождаются
диагностическим сообщением, из которого,
воспользовавшись при необходимости
системой помощи, можно установить их
причину.
Более
сложный класс ошибок – это ошибки,
возникающие на этапе выполнения
программы. Эти ошибки в том или ином
виде связаны с обрабатываемыми данными
и, как следствие, не могут быть определены
на этапе компиляции, поскольку конкретные
значения данных в этот момент неизвестны.
При возникновении подобных ошибок на
экран выдается диагностическое сообщение
с указанием кода ошибки и его кратким
описанием. Составляя алгоритм, программист
обязан предусмотреть возможность их
появления и принять дополнительные
меры по их локализации и, если это
требуется, перехвату. Список некоторых
ошибок этапа выполнения приведен в
табл. 2.1.
Наиболее
сложным видом ошибок при программировании
являются алгоритмические ошибки. Причина
таких ошибок двояка – с одной стороны
они возникают из-за неправильного
составления алгоритма, с другой из-за
неправильного кодирования (записи
операторов программы не в соответствии
с составленным алгоритмом). К сожалению,
единственным способом обнаружения
алгоритмических ошибок является
тестирование. Под тестированием обычно
понимают испытание программы при условии
подачи на нее заведомо известных данных
(теста) и проверки результатов ее работы
(они должны быть определены совместно
с подготовкой теста). Особенностью
тестирования является то обстоятельство,
что если тест обнаруживает факт
существования алгоритмической ошибки
(программа выполняется неверно), то
ошибка существует и должна быть устранена.
В тоже время, если тест не находит ошибки,
то это обстоятельство не является
доказательством того, что ошибка
отсутствует. Как следствие, созданная
программа должна быть подвергнута
максимально возможному тестированию.
Однако исчерпывающее тестирование
программы, как правило, является
невозможным из-за чрезвычайно большого
числа возможных вариантов данных, в
связи с чем приходится использовать
методы программирования, уменьшающие
вероятность возникновения ошибки, и
рассчитывать на искусство программиста.
Если в процессе тестирования была
обнаружена ошибка, программист должен
начать процесс определения конкретных
операторов программы, вызвавших появление
ошибки, обычно называемый отладкой. Для
автоматизации процесса тестирования
и отладки созданы специальные программы,
которые получили название программ-отладчиков.
Подобная программа есть и в составе
редактора VBA.
Таблица
2.1.
Ошибки
этапа выполнения
|
Код |
Диагностическое |
|
5 |
Приложение |
|
6 |
Переполнение |
|
7 |
Не |
|
9 |
Выход |
|
11 |
Деление |
|
13 |
Несоответствие |
|
18 |
Произошло |
|
52 |
Неправильное |
|
53 |
Файл |
|
54 |
Неправильный |
|
55 |
Файл |
|
56 |
Ошибка |
|
61 |
Переполнение |
|
68 |
Устройство |
|
71 |
Диск |
|
72 |
Повреждена |
|
335 |
Невозможен |
|
368 |
Истек |
|
482 |
Ошибка |

Режим
отладки включается из главного меню
при активном окне редактора при выполнении
команды Отладка/Шаг
с заходом.
Выключение режима обеспечивает выполнение
команды Выполнить/Сброс.
Внешний вид меню показан на рис. 4.
Обратите внимание на то, что основные
команды отладчика вызываются комбинациями
клавиш F8
и F9.
Команда Шаг
с заходом
позволяет оператор за оператором
выполнить тестируемую программу, включая
вызываемые программой функции и
процедуры. Команда Шаг
с обходом исключает
пошаговое выполнение вызываемых модулей.
Команда Шаг
с выходом
завершает пошаговое выполнение вызванного
модуля. Команда Выполнить
до текущей позиции выполняет
программу до оператора, на котором
установлен курсор. Команда Точка
останова
задает и снимает точку останова в тексте
программы, причем конкретный оператор
предварительно выбирается курсором.
Команда Снять
все точки останова удаляет
все установленные в программе точки
останова. Выполнение команд Задать
следующую инструкцию и
Показать следующую инструкцию позволяет
найти следующий выполняемый оператор
в окне редактирования.
Текущие
значения переменных можно наблюдать
задавая их имена в окне контрольных
значений (Отладка/Добавить
контрольные значения, Отладка/Контрольные
значения, Вид/Окно локальных переменных).
При выполнении команды Вид/Проверка
можно
задать дополнительный оператор VBA,
или изменить значение любой переменной
оператором присваивания.
Соседние файлы в папке МУ
- #
- #
- #
- #
- #
Искать ошибки в программах — непростая задача. Здесь нет никаких готовых методик или рецептов успеха. Можно даже сказать, что это — искусство. Тем не менее есть общие советы, которые помогут вам при поиске. В статье описаны основные шаги, которые стоит предпринять, если ваша программа работает некорректно.
Шаг 1: Занесите ошибку в трекер
После выполнения всех описанных ниже шагов может так случиться, что вы будете рвать на себе волосы от безысходности, все еще сидя на работе, когда поймете, что:
- Вы забыли какую-то важную деталь об ошибке, например, в чем она заключалась.
- Вы могли делегировать ее кому-то более опытному.
Трекер поможет вам не потерять нить размышлений и о текущей проблеме, и о той, которую вы временно отложили. А если вы работаете в команде, это поможет делегировать исправление коллеге и держать все обсуждение в одном месте.
Вы должны записать в трекер следующую информацию:
- Что делал пользователь.
- Что он ожидал увидеть.
- Что случилось на самом деле.
Это должно подсказать, как воспроизвести ошибку. Если вы не сможете воспроизвести ее в любое время, ваши шансы исправить ошибку стремятся к нулю.
Шаг 2: Поищите сообщение об ошибке в сети
Если у вас есть сообщение об ошибке, то вам повезло. Или оно будет достаточно информативным, чтобы вы поняли, где и в чем заключается ошибка, или у вас будет готовый запрос для поиска в сети. Не повезло? Тогда переходите к следующему шагу.
Шаг 3: Найдите строку, в которой проявляется ошибка
Если ошибка вызывает падение программы, попробуйте запустить её в IDE под отладчиком и посмотрите, на какой строчке кода она остановится. Совершенно необязательно, что ошибка будет именно в этой строке (см. следующий шаг), но, по крайней мере, это может дать вам информацию о природе бага.
Шаг 4: Найдите точную строку, в которой появилась ошибка
Как только вы найдете строку, в которой проявляется ошибка, вы можете пройти назад по коду, чтобы найти, где она содержится. Иногда это может быть одна и та же строка. Но чаще всего вы обнаружите, что строка, на которой упала программа, ни при чем, а причина ошибки — в неправильных данных, которые появились ранее.
Если вы отслеживаете выполнение программы в отладчике, то вы можете пройтись назад по стектрейсу, чтобы найти ошибку. Если вы находитесь внутри функции, вызванной внутри другой функции, вызванной внутри другой функции, то стектрейс покажет список функций до самой точки входа в программу (функции main()). Если ошибка случилась где-то в подключаемой библиотеке, предположите, что ошибка все-таки в вашей программе — это случается гораздо чаще. Найдите по стектрейсу, откуда в вашем коде вызывается библиотечная функция, и продолжайте искать.
Шаг 5: Выясните природу ошибки
Ошибки могут проявлять себя по-разному, но большинство из них можно отнести к той или иной категории. Вот наиболее частые.
- Ошибка на единицу
Вы начали циклforс единицы вместо нуля или наоборот. Или, например, подумали, что метод.count()или.length()вернул индекс последнего элемента. Проверьте документацию к языку, чтобы убедиться, что нумерация массивов начинается с нуля или с единицы. Эта ошибка иногда проявляется в виде исключенияIndex out of range. - Состояние гонки
Ваш процесс или поток пытается использовать результат выполнения дочернего до того, как тот завершил свою работу. Ищите использованиеsleep()в коде. Возможно, на мощной машине дочерний поток выполняется за миллисекунду, а на менее производительной системе происходят задержки. Используйте правильные способы синхронизации многопоточного кода: мьютексы, семафоры, события и т. д. - Неправильные настройки или константы
Проверьте ваши конфигурационные файлы и константы. Я однажды потратил ужасные 16 часов, пытаясь понять, почему корзина на сайте с покупками виснет на стадии отправки заказа. Причина оказалась в неправильном значении в/etc/hosts, которое не позволяло приложению найти ip-адрес почтового сервера, что вызывало бесконечный цикл в попытке отправить счет заказчику. - Неожиданный null
Бьюсь об заклад, вы не раз получали ошибку с неинициализированной переменной. Убедитесь, что вы проверяете ссылки наnull, особенно при обращении к свойствам по цепочке. Также проверьте случаи, когда возвращаемое из базы данных значениеNULLпредставлено особым типом. - Некорректные входные данные
Вы проверяете вводимые данные? Вы точно не пытаетесь провести арифметические операции с введенными пользователем строками? - Присваивание вместо сравнения
Убедитесь, что вы не написали=вместо==, особенно в C-подобных языках. - Ошибка округления
Это случается, когда вы используете целое вместоDecimal, илиfloatдля денежных сумм, или слишком короткое целое (например, пытаетесь записать число большее, чем 2147483647, в 32-битное целое). Кроме того, может случиться так, что ошибка округления проявляется не сразу, а накапливается со временем (т. н. Эффект бабочки). - Переполнение буфера и выход за пределы массива
Проблема номер один в компьютерной безопасности. Вы выделяете память меньшего объема, чем записываемые туда данные. Или пытаетесь обратиться к элементу за пределами массива. - Программисты не умеют считать
Вы используете некорректную формулу. Проверьте, что вы не используете целочисленное деление вместо взятия остатка, или знаете, как перевести рациональную дробь в десятичную и т. д. - Конкатенация строки и числа
Вы ожидаете конкатенации двух строк, но одно из значений — число, и компилятор пытается произвести арифметические вычисления. Попробуйте явно приводить каждое значение к строке. - 33 символа в varchar(32)
Проверяйте данные, передаваемые вINSERT, на совпадение типов. Некоторые БД выбрасывают исключения (как и должны делать), некоторые просто обрезают строку (как MySQL). Недавно я столкнулся с такой ошибкой: программист забыл убрать кавычки из строки перед вставкой в базу данных, и длина строки превысила допустимую как раз на два символа. На поиск бага ушло много времени, потому что заметить две маленькие кавычки было сложно. - Некорректное состояние
Вы пытаетесь выполнить запрос при закрытом соединении или пытаетесь вставить запись в таблицу прежде, чем обновили таблицы, от которых она зависит. - Особенности вашей системы, которых нет у пользователя
Например: в тестовой БД между ID заказа и адресом отношение 1:1, и вы программировали, исходя из этого предположения. Но в работе выясняется, что заказы могут отправляться на один и тот же адрес, и, таким образом, у вас отношение 1:многим.
Если ваша ошибка не похожа на описанные выше, или вы не можете найти строку, в которой она появилась, переходите к следующему шагу.
Шаг 6: Метод исключения
Если вы не можете найти строку с ошибкой, попробуйте или отключать (комментировать) блоки кода до тех пор, пока ошибка не пропадет, или, используя фреймворк для юнит-тестов, изолируйте отдельные методы и вызывайте их с теми же параметрами, что и в реальном коде.
Попробуйте отключать компоненты системы один за другим, пока не найдете минимальную конфигурацию, которая будет работать. Затем подключайте их обратно по одному, пока ошибка не вернется. Таким образом вы вернетесь на шаг 3.
Шаг 7: Логгируйте все подряд и анализируйте журнал
Пройдитесь по каждому модулю или компоненту и добавьте больше сообщений. Начинайте постепенно, по одному модулю. Анализируйте лог до тех пор, пока не проявится неисправность. Если этого не случилось, добавьте еще сообщений.
Ваша задача состоит в том, чтобы вернуться к шагу 3, обнаружив, где проявляется ошибка. Также это именно тот случай, когда стоит использовать сторонние библиотеки для более тщательного логгирования.
Шаг 8: Исключите влияние железа или платформы
Замените оперативную память, жесткие диски, поменяйте сервер или рабочую станцию. Установите обновления, удалите обновления. Если ошибка пропадет, то причиной было железо, ОС или среда. Вы можете по желанию попробовать этот шаг раньше, так как неполадки в железе часто маскируют ошибки в ПО.
Если ваша программа работает по сети, проверьте свитч, замените кабель или запустите программу в другой сети.
Ради интереса, переключите кабель питания в другую розетку или к другому ИБП. Безумно? Почему бы не попробовать?
Если у вас возникает одна и та же ошибка вне зависимости от среды, то она в вашем коде.
Шаг 9: Обратите внимание на совпадения
- Ошибка появляется всегда в одно и то же время? Проверьте задачи, выполняющиеся по расписанию.
- Ошибка всегда проявляется вместе с чем-то еще, насколько абсурдной ни была бы эта связь? Обращайте внимание на каждую деталь. На каждую. Например, проявляется ли ошибка, когда включен кондиционер? Возможно, из-за этого падает напряжение в сети, что вызывает странные эффекты в железе.
- Есть ли что-то общее у пользователей программы, даже не связанное с ПО? Например, географическое положение (так был найден легендарный баг с письмом за 500 миль).
- Ошибка проявляется, когда другой процесс забирает достаточно большое количество памяти или ресурсов процессора? (Я однажды нашел в этом причину раздражающей проблемы «no trusted connection» с SQL-сервером).
Шаг 10: Обратитесь в техподдержку
Наконец, пора попросить помощи у того, кто знает больше, чем вы. Для этого у вас должно быть хотя бы примерное понимание того, где находится ошибка — в железе, базе данных, компиляторе. Прежде чем писать письмо разработчикам, попробуйте задать вопрос на профильном форуме.
Ошибки есть в операционных системах, компиляторах, фреймворках и библиотеках, и ваша программа может быть действительно корректна. Но шансы привлечь внимание разработчика к этим ошибкам невелики, если вы не сможете предоставить подробный алгоритм их воспроизведения. Дружелюбный разработчик может помочь вам в этом, но чаще всего, если проблему сложно воспроизвести вас просто проигнорируют. К сожалению, это значит, что нужно приложить больше усилий при составлении багрепорта.
Полезные советы (когда ничего не помогает)
- Позовите кого-нибудь еще.
Попросите коллегу поискать ошибку вместе с вами. Возможно, он заметит что-то, что вы упустили. Это можно сделать на любом этапе. - Внимательно просмотрите код.
Я часто нахожу ошибку, просто спокойно просматривая код с начала и прокручивая его в голове. - Рассмотрите случаи, когда код работает, и сравните их с неработающими.
Недавно я обнаружил ошибку, заключавшуюся в том, что когда вводимые данные в XML-формате содержали строкуxsi:type='xs:string', все ломалось, но если этой строки не было, все работало корректно. Оказалось, что дополнительный атрибут ломал механизм десериализации. - Идите спать.
Не бойтесь идти домой до того, как исправите ошибку. Ваши способности обратно пропорциональны вашей усталости. Вы просто потратите время и измотаете себя. - Сделайте творческий перерыв.
Творческий перерыв — это когда вы отвлекаетесь от задачи и переключаете внимание на другие вещи. Вы, возможно, замечали, что лучшие идеи приходят в голову в душе или по пути домой. Смена контекста иногда помогает. Сходите пообедать, посмотрите фильм, полистайте интернет или займитесь другой проблемой. - Закройте глаза на некоторые симптомы и сообщения и попробуйте сначала.
Некоторые баги могут влиять друг на друга. Драйвер для dial-up соединения в Windows 95 мог сообщать, что канал занят, при том что вы могли отчетливо слышать звук соединяющегося модема. Если вам приходится держать в голове слишком много симптомов, попробуйте сконцентрироваться только на одном. Исправьте или найдите его причину и переходите к следующему. - Поиграйте в доктора Хауса (только без Викодина).
Соберите всех коллег, ходите по кабинету с тростью, пишите симптомы на доске и бросайте язвительные комментарии. Раз это работает в сериалах, почему бы не попробовать?
Что вам точно не поможет
- Паника
Не надо сразу палить из пушки по воробьям. Некоторые менеджеры начинают паниковать и сразу откатываться, перезагружать сервера и т. п. в надежде, что что-нибудь из этого исправит проблему. Это никогда не работает. Кроме того, это создает еще больше хаоса и увеличивает время, необходимое для поиска ошибки. Делайте только один шаг за раз. Изучите результат. Обдумайте его, а затем переходите к следующей гипотезе. - «Хелп, плиииз!»
Когда вы обращаетесь на форум за советом, вы как минимум должны уже выполнить шаг 3. Никто не захочет или не сможет вам помочь, если вы не предоставите подробное описание проблемы, включая информацию об ОС, железе и участок проблемного кода. Создавайте тему только тогда, когда можете все подробно описать, и придумайте информативное название для нее. - Переход на личности
Если вы думаете, что в ошибке виноват кто-то другой, постарайтесь по крайней мере говорить с ним вежливо. Оскорбления, крики и паника не помогут человеку решить проблему. Даже если у вас в команде не в почете демократия, крики и применение грубой силы не заставят исправления магическим образом появиться.
Ошибка, которую я недавно исправил
Это была загадочная проблема с дублирующимися именами генерируемых файлов. Дальнейшая проверка показала, что у файлов различное содержание. Это было странно, поскольку имена файлов включали дату и время создания в формате yyMMddhhmmss. Шаг 9, совпадения: первый файл был создан в полпятого утра, дубликат генерировался в полпятого вечера того же дня. Совпадение? Нет, поскольку hh в строке формата — это 12-часовой формат времени. Вот оно что! Поменял формат на yyMMddHHmmss, и ошибка исчезла.
Перевод статьи «How to fix bugs, step by step»
Отладка программы призвана выискивать «вредителей» кода и устранять их. За это отвечают отладчик и журналирование для вывода сведений о программе.
В предыдущей части мы рассмотрели исходный код и его составляющие.
После того, как вы начнете проверять фрагменты кода или попытаетесь решить связанные с ним проблемы, вы очень скоро поймете, что существуют моменты, когда программа крашится, прерывается и прекращает работу.

Это часто вызвано ошибками, известными как дефекты или исключительные ситуации во время выполнения. Акт обнаружения и удаления ошибок из нашего кода – это отладка программы. Вы лучше разберетесь в отладке на практике, используя ее как можно чаще. Мы не только отлаживаем собственный код, но и порой дебажим написанное другими программистами.
Для начала необходимо рассортировать общие ошибки, которые могут возникнуть в исходном коде.

Синтаксические ошибки
Эти эрроры не позволяют скомпилировать исходный код на компилируемых языках программирования. Они обнаруживаются во время компиляции или интерпретации исходного кода. Они также могут быть легко обнаружены статическими анализаторами (линтами). Подробнее о линтах мы узнаем немного позже.
Синтаксические ошибки в основном вызваны нарушением ожидаемой формы или структуры языка, на котором пишется программа. Как пример, это может быть отсутствующая закрывающая скобка в уравнении.
Семантические ошибки
Отладка программы может потребоваться и по причине семантических ошибок, также известных как логические. Они являются наиболее сложными из всех, потому что не могут быть легко обнаружены. Признак того, что существует семантическая ошибка, – это когда программа запускается, отрабатывает, но не дает желаемого результата.
Рассмотрим данный пример:
3 + 5 * 6
По порядку приоритета, называемому старшинством операции, с учетом математических правил мы ожидаем, что сначала будет оценена часть умножения, и окончательный результат будет равен 33. Если программист хотел, чтобы сначала происходило добавление двух чисел, следовало поступить иначе. Для этого используются круглые скобки, которые отвечают за смещение приоритетов в математической формуле. Исправленный пример должен выглядеть так:
(3 + 5) * 6
3 + 5, заключенные в скобки, дадут желаемый результат, а именно 48.
Ошибки в процессе выполнения
Как и семантические, ошибки во время выполнения никогда не обнаруживаются при компиляции. В отличие от семантических ошибок, эти прерывают программу и препятствуют ее дальнейшему выполнению. Они обычно вызваны неожиданным результатом некоторых вычислений в исходном коде.
Вот хороший пример:
input = 25 x = 0.8/(Math.sqrt(input) - 5)
Фрагмент кода выше будет скомпилирован успешно, но input 25 приведет к ZeroDivisionError. Это ошибка во время выполнения. Другим популярным примером является StackOverflowError или IndexOutofBoundError. Важно то, что вы идентифицируете эти ошибки и узнаете, как с ними бороться.
Существуют ошибки, связанные с тем, как ваш исходный код использует память и пространство на платформе или в среде, в которой он запущен. Они также являются ошибками во время выполнения. Такие ошибки, как OutOfMemoryErrorand и HeapError обычно вызваны тем, что ваш исходный код использует слишком много ресурсов. Хорошее знание алгоритмов поможет написать код, который лучше использует ресурсы. В этом и заключается отладка программы.
Процесс перезаписи кода для повышения производительности называется оптимизацией. Менее популярное наименование процесса – рефакторинг. Поскольку вы тратите больше времени на кодинг, то должны иметь это в виду.
Отладка программы
Вот несколько советов о том, как правильно выполнять отладку:
- Использовать Linters. Linters – это инструменты, которые помогают считывать исходный код, чтобы проверить, соответствует ли он ожидаемому стандарту на выбранном языке программирования. Существуют линты для многих языков.
- Превалирование IDE над простыми редакторами. Вы можете выбрать IDE, разработанную для языка, который изучаете. IDE – это интегрированные среды разработки. Они созданы для написания, отладки, компиляции и запуска кода. Jetbrains создают отличные IDE, такие как Webstorm и IntelliJ. Также есть NetBeans, Komodo, Qt, Android Studio, XCode (поставляется с Mac), etc.
- Чтение кода вслух. Это полезно, когда вы ищете семантическую ошибку. Читая свой код вслух, есть большая вероятность, что вы зачитаете и ошибку.
- Чтение логов. Когда компилятор отмечает Error, обязательно посмотрите, где он находится.
Двигаемся дальше
Поздравляем! Слово «ошибка» уже привычно для вас, равно как и «отладка программы». В качестве новичка вы можете изучать кодинг по книгам, онлайн-урокам или видео. И даже чужой код вам теперь не страшен 
В процессе кодинга измените что-нибудь, чтобы понять, как он работает. Но будьте уверены в том, что сами написали.
Викторина
- Какая ошибка допущена в фрагменте кода Python ниже?
items = [0,1,2,3,4,5] print items[8] //комментарий: элементы здесь представляют собой массив с шестью элементами. Например, чтобы получить 4-й элемент, вы будете использовать [3]. Мы начинаем отсчет с 0.
- Какая ошибка допущена в фрагменте кода Python ниже?
input = Hippo' if input == 'Hippo': print 'Hello, Hippo'
Ответы на вопросы
- Ошибка выполнения: ошибка индекса вне диапазона.
2. Синтаксическая ошибка: Отсутствует стартовая кавычка в первой строке.
Добавлено 30 мая 2021 в 21:14
В уроке «7.14 – Распространенные семантические ошибки при программировании на C++» мы рассмотрели многие типы распространенных семантических ошибок, с которыми сталкиваются начинающие программисты при работе с языком C++. Если ошибка является результатом неправильного использования языковой функции или логической ошибки, исправить ее можно просто.
Но большинство ошибок в программе возникает не в результате непреднамеренного неправильного использования языковых функций – скорее, большинство ошибок возникает из-за ошибочных предположений, сделанных программистом, и/или из-за отсутствия надлежащего обнаружения/обработки ошибок.
Например, в функции, предназначенной для поиска оценки учащегося, вы могли предположить, что:
- просматриваемый студент будет существовать;
- имена всех студентов будут уникальными;
- в предмете используется числовая оценка (вместо «зачет/незачет»).
Что, если какое-либо из этих предположений неверно? Если программист не предвидел этих случаев, программа при возникновении таких случаев, скорее всего, завершится со сбоем (обычно в какой-то момент в будущем, через долгое время после того, как функция была написана).
Есть три ключевых места, где обычно возникают ошибки предположений:
- Когда функция возвращает значение, программист мог предположить, что вызов функции будет успешным, хотя это не так.
- Когда программа получает входные данные (либо от пользователя, либо из файла), программист мог предположить, что ввод будет в правильном формате и семантически корректен, хотя это не так.
- Когда функция была вызвана, программист мог предположить, что параметры будут семантически допустимыми, хотя это не так.
Многие начинающие программисты пишут код, а затем проверяют только счастливый путь: только те случаи, когда ошибок нет. Но вы также должны планировать и проверять печальные пути, на которых что-то может пойти и пойдет не так. В уроке «3.10 – Поиск проблем до того, как они станут проблемами», мы определили защитное программирование как попытку предвидеть все способы неправильного использования программного обеспечения конечными пользователями или разработчиками (либо самим программистом, либо другими). Как только вы ожидаете (или обнаруживаете) какое-то неправильное использование, следующее, что вам нужно сделать, – это обработать его.
В этом уроке мы поговорим о стратегиях обработки ошибок (что делать, если что-то пойдет не так) внутри функции. В следующих уроках мы поговорим о проверке ввода данных пользователем, а затем представим полезный инструмент, помогающий документировать и проверять предположения.
Обработка ошибок в функциях
Функции могут давать сбой по любому количеству причин – вызывающий мог передать аргумент с недопустимым значением, или что-то может дать сбой в теле функции. Например, функция, открывающая файл для чтения, может не работать, если файл не может быть найден.
Когда это произойдет, в вашем распоряжении будет несколько вариантов. Лучшего способа справиться с ошибкой нет – это на самом деле зависит от характера проблемы и от того, можно ли устранить проблему или нет.
Можно использовать 4 основные стратегии:
- обработать ошибку в функции;
- передать ошибку вызывающему, чтобы он разобрался с ней;
- остановить программу;
- выбросить исключение.
Обработка ошибки в функции
Если возможно, наилучшей стратегией является восстановление после ошибки в той же функции, в которой возникла ошибка, так, чтобы ошибку можно было локализовать и исправить, не влияя на какой-либо код вне функции. Здесь есть два варианта: повторять попытки до успешного завершения или отменить выполняемую операцию.
Если ошибка возникла из-за чего-то, не зависящего от программы, программа может повторять попытку, пока не будет достигнут успех. Например, если программе требуется подключение к Интернету, и пользователь потерял соединение, программа может отобразить предупреждение, а затем использовать цикл для периодической повторной проверки подключения к Интернету. В качестве альтернативы, если пользователь ввел недопустимые входные данные, программа может попросить пользователя повторить попытку и выполнять этот цикл до тех пор, пока пользователь не введет корректные входные данные. Мы покажем примеры обработки недопустимого ввода и использования циклов для повторных попыток в следующем уроке (7.16 – std::cin и обработка недопустимого ввода).
Альтернативная стратегия – просто игнорировать ошибку и/или отменить операцию. Например:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
}В приведенном выше примере, если пользователь ввел недопустимое значение для y, мы просто игнорируем запрос на печать результата операции деления. Основная проблема при этом заключается в том, что у вызывающей функции или у пользователя нет возможности определить, что что-то пошло не так. В таком случае может оказаться полезным напечатать сообщение об ошибке:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Однако если вызывающая функция ожидает, что вызываемая функция выдаст возвращаемое значение или какой-либо полезный побочный эффект, тогда просто игнорирование ошибки может быть недопустимым вариантом.
Передача ошибок вызывающей функции
Во многих случаях обработать ошибку с помощью функции, которая ее обнаруживает, невозможно. Например, рассмотрим следующую функцию:
double doDivision(int x, int y)
{
return static_cast<double>(x) / y;
}Если y равно 0, что нам делать? Мы не можем просто пропустить логику программы, потому что функция должна возвращать какое-то значение. Мы не должны просить пользователя ввести новое значение для y, потому что это функция вычисления, и введение в нее процедур ввода может быть или не быть подходящим для программы, вызывающей эту функцию.
В таких случаях лучшим вариантом может быть передача ошибки обратно вызывающей функции в надежде, что вызывающая сторона сможет с ней справиться.
Как мы можем это сделать?
Если функция имеет тип возвращаемого значения void, его можно изменить, чтобы она возвращала логическое значение, указывающее на успех или на неудачу. Например, вместо:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Мы можем сделать так:
bool printDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: could not divide by zeron";
return false;
}
std::cout << static_cast<double>(x) / y;
return true;
}Таким образом, вызывающий может проверить возвращаемое значение, чтобы узнать, не завершилась ли функция по какой-либо причине неудачей.
Если функция возвращает обычное значение, всё немного сложнее. В некоторых случаях полный диапазон возвращаемых значений не используется. В таких случаях, чтобы указать на ошибку, мы можем использовать возвращаемое значение, которое иначе было бы невозможно. Например, рассмотрим следующую функцию:
// Обратное (reciprocal) к x равно 1/x
double reciprocal(double x)
{
return 1.0 / x;
}Обратное к некоторому числу x определяется как 1/x, а число, умноженное на обратное, равно 1.
Однако что произойдет, если пользователь вызовет эту функцию как reciprocal(0.0)? Мы получаем ошибку деления на ноль и сбой программы, поэтому очевидно, что мы должны защититься от этого случая. Но эта функция должна возвращать значение doube, так какое же значение мы должны вернуть? Оказывается, эта функция никогда не выдаст 0.0 как допустимый результат, поэтому мы можем вернуть 0.0, чтобы указать на случай ошибки.
// Обратное (reciprocal) к x равно 1/x; возвращает 0.0, если x=0
double reciprocal(double x)
{
if (x == 0.0)
return 0.0;
return 1.0 / x;
}Однако если требуется полный диапазон возвращаемых значений, то использование возвращаемого значения для указания ошибки будет невозможно (поскольку вызывающий не сможет определить, является ли возвращаемое значение допустимым значением или значением ошибки). В таком случае выходной параметр (рассмотренный в уроке «11.3 – Передача аргументов по ссылке») может быть жизнеспособным вариантом.
Фатальные ошибки
Если ошибка настолько серьезна, что программа не может продолжать работать правильно, она называется неисправимой ошибкой (или фатальной ошибкой). В таких случаях лучше всего завершить программу. Если ваш код находится в main() или в функции, вызываемой непосредственно из main(), лучше всего позволить main() вернуть ненулевой код состояния. Однако если вы погрузились в какую-то глубоко вложенную подфункцию, передать ошибку обратно в main() может быть неудобно или невозможно. В таком случае можно использовать инструкцию остановки (например, std::exit()).
Например:
double doDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: Could not divide by zeron";
std::exit(1);
}
return static_cast<double>(x) / y;
}Исключения
Поскольку возврат ошибки из функции обратно вызывающей функции сложен (и множество различных способов сделать это приводит к несогласованности, а несогласованность ведет к ошибкам), C++ предлагает совершенно отдельный способ передачи ошибок обратно вызывающей стороне: исключения.
Основная идея состоит в том, что при возникновении ошибки «выбрасывается» исключение. Если текущая функция не «улавливает» ошибку, то уловить ошибку есть шанс у вызывающей функции. Если вызывающая функция не обнаруживает ошибку, то обнаружить ошибку есть шанс у функции, вызвавшей вызывающую функцию. Ошибка постепенно перемещается вверх по стеку вызовов до тех пор, пока она не будет обнаружена и обработана (в этот момент выполнение продолжается в обычном режиме), или пока main() не сможет обработать ошибку (в этот момент программа завершится с ошибкой исключения).
Мы рассмотрим обработку исключений в главе 20 этой серии обучающих статей.
Теги
C++ / CppException / ИсключениеLearnCppstd::exit()Для начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование