- Remove From My Forums
-
Question
-
Greetings,
Installing SQL Server 2012 Standard /or/ SQL Server 2008 R2 on Windows 8.1
This is driving me crazy, i had SQL server 2008 R2 installed before formatting my laptop, once i done a recovery and all files was removed and everything and upgraded into Windows 8.1, i keep getting same errors whether i installed SQL Server 2008 R2 or SQL
SERVER 2012 StandardFirst error is : Rule «Cluster Node Failed»
The local computer is not a member of Windows failover cluster.
Here’s the errors «failed» log
Microsoft SQL Server 2012 Service Pack 1 — System Configuration Check Report
InstallFailoverClusterGlobalRules: SQL Server 2012 Setup configuration checks for rules group ‘InstallFailoverClusterGlobalRules
AHMADQ Cluster_IsMachineClustered Checks whether the local computer is a node in a Windows failover cluster. Failed The local computer is not a member of a Windows failover cluster. AHMADQ Cluster_IsOnline Verifies that the cluster service is online. Failed The SQL Server failover cluster services is not online, or the cluster cannot be accessed from one of its nodes. To continue, determine why the cluster is not online and rerun Setup. Do not rerun the rule because the rule cannot detect a cluster environment. AHMADQ Cluster_VerifyForErrors Checks if the cluster has been verified and if there are any errors or failures reported in the verification report. Failed The cluster either has not been verified or there are errors or failures in the verification report. Refer to KB953748 or SQL Server Books Online for more information. -
Edited by
Wednesday, February 5, 2014 1:33 PM
-
Edited by
Answers
-
I checked services.msc and there’s no cluster services in the list, and all i’ve done was the usual install of sql server, clicking on new node installation
New SQL Server failover cluster installation <
ALso this Cluster Node error comes up in the
«Setup Support Rules»
Operations completed, Passed: 9 , Failed: 3
Dont select new failover cluster installation ,this option will install SQL cluster which requires windows cluster as a base which is not there in your system so you got the error.
PLease select standalone installation or add feature to existing installation option
Please mark this reply as the answer or vote as helpful, as appropriate, to make it useful for other readers
-
Marked as answer by
Ahmad ALQadah
Wednesday, February 5, 2014 3:07 PM
-
Marked as answer by
Содержание
- Как развернуть отказоустойчивый кластер MS SQL Server 2012 на Windows Server 2012R2 для новичков
- Этап 1 — Подготовка
- Этап 2 – Установка MS SQL Server
- Этап 3 – добавление второй ноды в кластер MSSQL
- Этап 4 – проверка работоспособности
- Локальный компьютер не входит в отказоустойчивый кластер windows
- Диагностика отказоустойчивого кластера
- Основные шаги диагностики
- Повторная проверка кластера
- Восстановление по журналу после сбоя отказоустойчивого кластера
- Разрешение общих проблем
- Проблема. Неверное использование синтаксиса командной строки при установке SQL Server
- Проблема. Серверу SQL Server не удается подключиться к сети после его перемещения на другой узел.
- Проблема. SQL Server не может получить доступ к дискам кластера.
- Проблема. Сбой службы SQL Server вызывает отработку отказа.
- Проблема. SQL Server не запускается автоматически.
- Проблема. Сетевой ресурс, к которому выполняется обращение по имени, находится не в сети, и нельзя подключиться к SQL Server по протоколу TCP/IP.
- Проблема. Программа установки SQL Server в кластере завершилась с кодом ошибки 11001.
- Проблема. Ошибка при установке кластера: «У установщика недостаточно привилегий для доступа к данному каталогу: Microsoft SQL Server. Невозможно продолжить установку. Войдите в систему как администратор или обратитесь к системному администратору»
- Проблема. Приложениям не удается включить ресурсы SQL Server в список в распределенной транзакции.
- Использование расширенных хранимых процедур и объектов COM
- Шесть типичных проблем отказоустойчивых кластеров
- Проблема 1
- Проблема 2
- Проблема 3
- Проблема 4
- Проблема 5
- Проблема 6
- Ошибку легче предупредить
Как развернуть отказоустойчивый кластер MS SQL Server 2012 на Windows Server 2012R2 для новичков
Данный топик будет интересен новичкам. Бывалые гуру и все, кто уже знаком с этим вопросом, вряд ли найдут что-то новое и полезное. Всех остальных милости прошу под кат.
Задача, которая стоит перед нами, – обеспечить бесперебойную работу и высокую доступность базы данных в клиент-серверном варианте развертывания.
Тип конфигурации — active/passive.
P.S. Вопросы резервирования узлов не относящихся к MSSQL не рассмотрены.
Этап 1 — Подготовка
Технически можно обойтись 3 серверами совместив все необходимые роли на домен контроллере, но в полевых условиях так поступать не рекомендуется.
Вначале вводим в домен сервера WS2012R2C1 и WS2012R2C2; на каждом из них устанавливаем роль «Отказоустойчивая кластеризация».
После установки роли, запускаем оснастку «Диспетчер отказоустойчивости кластеров» и переходим в Мастер создания кластеров, где конфигурируем наш отказоустойчивый кластер: создаем Quorum (общий ресурс) и MSDTC(iSCSI).
Этап 2 – Установка MS SQL Server
Важно: все действия необходимо выполнять от имени пользователя с правом заведения новых машин в домен. (Спасибоminamoto за дополнение)
Для установки нам понадобится установочный дистрибутив MS SQL Server. Запусткаем мастер установки и выбераем вариант установки нового экземпляра кластера:

Далее вводим данные вашего лицензионного ключа:

Внимательно читаем и принимаем лицензионное соглашение:

Получаем доступные обновления:

Проходим проверку конфигурации (Warning MSCS пропускаем):

Выбираем вариант целевого назначения установки:

Выбираем компоненты, которые нам необходимы (для поставленной задачи достаточно основных):

Еще одна проверка установочной конфигурации:

Далее — важный этап, выбор сетевого имени для кластера MSSQL (instance ID – оставляем):

Проверка доступного пространства:

После чего — список доступных хранилищ, данных (сконфигурировано на этапе подготовки):

Выбираем диск для расположения баз данных кластера:

Конфигурацию сетевого интерфейса кластера рекомендуется указать адрес вручную:

Указываем данные администратора (можно завести отдельного пользователя для MSSQL):

Еще один важный этап – выбор порядка сортировки (Collation). После инсталляции изменить крайне проблематично:

Параметры аутентификации на сервере (в нашем случае выбран смешанный вариант, хотя безопаснее использовать только доменную аутентификацию):

Выбор директорий хранения общих файлов кластера (в версиях MS SQL Server 2012 и старше TempDB можно хранить на каждой ноде и не выносить в общее хранилище):



Наконец приступаем к установке (процесс может занять длительное время):

Настройка и установка базовой ноды закончена, о чем нам сообщает «зеленый» рапорт

Этап 3 – добавление второй ноды в кластер MSSQL
Дальше необходимо добавить в кластер вторую ноду, т.к. без нее об отказоустойчивости говорить не приходится.
Настройка и установка намного проще. На втором сервере (ВМ) запускаем мастер установки MS SQL Server:

Выбираем: в какой кластер добавлять ноду:

Просматриваем и принимаем сетевые настройки экземпляра кластера:

Указываем пользователя и пароль (те же, что и на первом этапе):

Снова тесты и процесс установки:
По завершению мы должны получить следующую картину:

Поздравляю, установка закончена.
Этап 4 – проверка работоспособности
Удостоверимся, что все работает как надо. Для этого перейдем в оснастку «Диспетчер отказоустойчивого кластера»:

На данный момент у нас используется вторая нода(WS2012R2C2) в случае сбоя произойдет переключение на первую ноду(WS2012R2C1).
Попробуем подключиться непосредственно к кластеру сервера MSSQL, для этого нам понадобится любой компьютер в доменной сети с установленной Management Studio MSSQL. При запуске указываем имя нашего кластера и пользователя (либо оставляем доменную авторизацию).

После подключения видим базы которые крутятся в кластере (на скриншоте присутствует отдельно добавленная база, после инсталляции присутствуют только системные).

Данный экземпляр отказоустойчивого кластера полностью готов к использованию с любыми базами данных, например, 1С(для нас ставилась задача развернуть такую конфигурацию для работы именно 1С-ки). Работа с ним ничем не отличается от обычной, но основная особенность — в надежности такого решения.
В тестовых целях рекомендую поиграть с отключением нод и посмотреть как происходит миграция базы между ними; проконтролировать важные для вас параметры, например, сколько по времени будет длиться переключение.
У нас при отказе одной из нод – происходит разрыв соединения с базой и переключение на вторую (время восстановления работоспособности: до минуты).
В полевых условиях для обеспечения надежности всей инфраструктуры необходимо обработать точки отказа: СХД, AD и DNS.
Источник
Локальный компьютер не входит в отказоустойчивый кластер windows
Есть отказоустойчивый кластер на двух нодах. Win 2012 R2.
В него добавлен коврум и два диска.
Тестирование кластера проходит без ошибок.
При перезагрузки любой из ноды все ресурсы успешно переезжают на рабочую ноду.
Но периодически одна из нод вываливается, именна та, на которой кворум подключен, и ресурсы автоматом не перезжают на рабочую ноду.
Более того, кластер перестаёт отвечать.
Естественно, получаю кучу ошибок (ниже все выложу).
Вопрос собственно в том, почему ресурсы автоматом не переезжают на рабочую ноду в случае выхода из стороя ноды с кворумом?
Что кроме тестирования кластера ещё можно попробовать?
Узел «хх2» лишен членства в активном отказоустойчивом кластере. Возможно, служба кластеров на этом узле была остановлена. Это также могло произойти из-за потери связи между данным узлом и другими активными узлами в отказоустойчивом кластере. Чтобы проверить параметры сети, запустите мастер проверки конфигурации. Если это не поможет, проверьте оборудование или программное обеспечение на наличие ошибок, связанных с сетевыми адаптерами на данном узле. Также проверьте работу других сетевых устройств, к которым подключен этот узел, таких как концентраторы, коммутаторы и мосты.
Этот узел неожиданно потерял владение диском кластера disk1. Для проверки конфигурации хранилища запустите мастер проверки конфигурации.
Сбой ресурса кластера «disk1» с типом «Physical Disk» в кластерной роли «ed».
В зависимости от политик на случай сбоя ресурса и роли служба кластеров может попытаться подключить ресурс на этом узле или же переместить группу на другой узел кластера, а затем перезапустить ее. Проверьте состояние ресурса и группы с помощью диспетчера отказоустойчивости кластеров или командлета Get-ClusterResource оболочки Windows PowerShell.
Службе кластеров не удалось полностью перевести кластерную роль «Кластерная группа» в автономный или оперативный режим. Возможно, один или несколько ресурсов находятся в неисправном состоянии. Это может влиять на доступность кластерной роли.
Кластерная роль «Кластерная группа» превысила порог отработки отказа. Настроенное количество попыток отработки отказа в течение выделенного времени на отработку исчерпано и будет оставлено состояние сбоя. Дополнительные попытки по подключению роли к сети или переводу на другой узел в кластере предприниматься не будут. Проверьте события, связанные со сбоем. После устранения причин, вызвавших сбой, роль можно подключить к сети вручную либо такую попытку может выполнить кластер по истечении периода задержки перезагрузки.
Служба кластеров завершает работу, поскольку отсутствует кворум. Возможно, причиной этого является отсутствие связи между несколькими или всеми узлами в кластере либо переход диска-свидетеля на другой ресурс при сбое.
Для проверки сети запустите мастер проверки конфигурации. Если это не поможет, проверьте оборудование или программное обеспечение на наличие ошибок, связанных с сетевым адаптером. Кроме того, проверьте работу других сетевых устройств, к которым подключен этот узел, таких как концентраторы, коммутаторы и мосты.
Процесс подсистемы размещения ресурсов (RHS) кластера был прерван и будет перезапущен. Это обычно связано с программой определения состояния работоспособности кластеров и восстановления ресурсов. Обратитесь к журналу системных событий, чтобы определить, из-за каких ресурсов и библиотек ресурсов возникает ошибка.
Источник
Диагностика отказоустойчивого кластера
Этот подраздел содержит следующие сведения:
основные шаги диагностики;
восстановление по журналу после сбоя отказоустойчивого кластера;
разрешение наиболее частых проблем отказоустойчивой кластеризации;
использование расширенных хранимых процедур и объектов COM.
Основные шаги диагностики
Первым шагом диагностики является проверка нового кластера. Дополнительные сведения о проверке см. в разделе Создание отказоустойчивого кластера: проверка конфигурации. Эту процедуру можно выполнить без нарушения работы службы, поскольку она не влияет на ресурсы кластера в сети. Проверку можно провести в любое время после установки функции отказоустойчивой кластеризации, включая момент перед развертыванием кластера, во время создания кластера и во время его работы. На самом деле дополнительные тесты выполняются после перевода кластера в рабочий режим и проверяют соблюдение рекомендаций для рабочих нагрузок с высоким уровнем доступности. Из множества тестов лишь немногие повлияют на функционирование рабочих нагрузок кластера. Все они входят в категорию хранилища, поэтому, пропустив эту категорию, можно легко отказаться от тестов с негативными последствиями.
Отказоустойчивая кластеризация располагает встроенными мерами защиты для предотвращения случайного времени простоев при выполнении тестов хранилища во время проверки. Если при инициации проверки в кластере имеются сетевые группы и выбраны тесты хранилища, будет выведен запрос на подтверждение необходимости запуска всех тестов (и возникновения простоя) или пропуска тестирования дисков сетевых групп, чтобы избежать простоя. Если из тестирования была исключена вся категория хранилища, этот запрос не отображается. Проверка кластера будет выполнена без простоев.
Повторная проверка кластера
Чтобы просмотреть разделы справки, которые помогут интерпретировать результаты, щелкните Дополнительные сведения о тестах для проверки кластеров.
Установка обновлений
Установка обновлений является важной частью предотвращения проблем в системе. Полезные ссылки
Восстановление по журналу после сбоя отказоустойчивого кластера
Обычно сбой отказоустойчивого кластера возникает в следующих случаях.
Сбой оборудования в одном из узлов двухузлового кластера. Такой сбой оборудования может быть вызван сбоем SCSI-контроллера или ОС.
Ошибка операционной системы. В этом случае данный узел отключен, но не является окончательно неисправным.
Для восстановления после сбоя ОС восстановите данный узел и проверьте отработку отказа. Если данный экземпляр SQL Server не переключается на другой ресурс должным образом, необходимо программой установки SQL Server удалить SQL Server из отказоустойчивого кластера, произвести необходимые восстановительные процедуры, восстановить резервную копию и снова добавить восстановленный узел к экземпляру отказоустойчивого кластера.
Восстановление по журналу после сбоя ОС может занять значительное время. Если восстановить ОС после сбоя можно более простым способом, не прибегайте к этому методу.
Разрешение общих проблем
В следующем списке приведено описание общих проблем и даны объяснения по их устранению.
Проблема. Неверное использование синтаксиса командной строки при установке SQL Server
Решение 1. Используйте параметр /qb вместо /qn. При использовании параметра /qb на каждом шаге отображается интерфейс пользователя, в том числе сообщения об ошибках.
Проблема. Серверу SQL Server не удается подключиться к сети после его перемещения на другой узел.
Причина 1. Учетные записи службы SQL Server не могут связаться с контроллером домена.
Решение 1. Проверьте журналы событий на наличие записей о проблемах сети, например о сбоях адаптеров или проблемах с DNS. Проверьте контроллер домена командой ping.
Причина 2. Пароли к учетным записям службы SQL Server отличаются на разных узлах кластера, или узел не перезапускает службу SQL Server, которая была перенесена с неисправного узла.
Решение 2. Измените пароли учетной записи службы SQL Server с помощью диспетчера конфигурации SQL Server. Если это не было сделано, а пароли учетной записи службы SQL Server изменены на одном узле, необходимо также изменить их на всех остальных узлах. SQL Server выполняет это автоматически.
Проблема. SQL Server не может получить доступ к дискам кластера.
Причина 1. Встроенное ПО или драйверы обновлены не на всех узлах.
Решение 1. Проверьте, установлены ли на всех узлах правильное встроенное ПО и одинаковые версии драйверов.
Причина 2. Узел не может восстановить диски кластера, перенесенные с неисправного узла на общий диск кластера с другой буквой диска.
Проблема. Сбой службы SQL Server вызывает отработку отказа.
Решение. Чтобы сбой определенных служб не вызывал перехода группы SQL Server на другой ресурс, настройте эти службы при помощи программы администрирования кластеров Windows следующим образом.
Проблема. SQL Server не запускается автоматически.
Проблема. Сетевой ресурс, к которому выполняется обращение по имени, находится не в сети, и нельзя подключиться к SQL Server по протоколу TCP/IP.
Причина 1. Сбой службы DNS, в то время как для ресурсов кластера настроено использование DNS.
Решение 1. Устраните проблемы с DNS.
Причина 2. Повторяющееся имя в сети.
Решение 2. С помощью программы NBSTAT найдите повторяющееся имя и устраните проблему.
Причина 3. Не удается соединиться с SQL Server с помощью именованных каналов.
Решение 3. Для подключения через именованные каналы создайте псевдоним с помощью диспетчера конфигурации SQL Server, чтобы подключиться к нужному компьютеру. Например, при использовании кластера с двумя узлами (Узел A и Узел B) и экземпляра отказоустойчивого кластера (Virtsql) с экземпляром по умолчанию подключиться к серверу, ресурс сетевого имени которого находится вне сети, можно, выполнив следующие шаги.
Запустите службу SQL Server на этом компьютере с помощью команды net start. Дополнительные сведения об использовании команды net start см. в разделе Запуск SQL Server вручную.
Запустите диспетчер конфигурации SQL Server на Узле A. Просмотрите именованный канал, по которому прослушивает этот сервер. Название будет иметь вид .$$VIRTSQLpipesqlquery.
На клиентском компьютере запустите диспетчер конфигурации SQL Server.
Создайте псевдоним SQLTEST1 для соединения с этим каналом по протоколу именованных каналов. Для этого введите Узел A в качестве имени сервера и измените имя канала на .pipe$$VIRTSQLsqlquery.
Подключитесь к экземпляру сервера с использованием псевдонима SQLTEST1 в качестве имени сервера.
Проблема. Программа установки SQL Server в кластере завершилась с кодом ошибки 11001.
Проблема. Потерян раздел реестра в ветке [HKEY_LOCAL_MACHINESOFTWAREMicrosoftMicrosoft SQL ServerMSSQL.XCluster].
Решение. Убедитесь в том, что куст реестра MSSQL.X в настоящее время не используется, и удалите этот ключ кластера.
Проблема. Ошибка при установке кластера: «У установщика недостаточно привилегий для доступа к данному каталогу: Microsoft SQL Server. Невозможно продолжить установку. Войдите в систему как администратор или обратитесь к системному администратору»
Проблема. Эта ошибка произошла из-за неправильного разбиения на разделы общего диска SCSI.
Решение. Создайте повторно один раздел на этом общем диске, выполнив указанные ниже действия.
Удалите данный дисковый ресурс из кластера.
Удалите на этом диске все разделы.
Проверьте в свойствах диска, что он является основным.
Создайте на этом общем диске один раздел, отформатируйте диск и присвойте ему букву.
Добавьте этот диск к кластеру с помощью администратора кластеров (cluadmin).
Проблема. Приложениям не удается включить ресурсы SQL Server в список в распределенной транзакции.
Причина. Поскольку координатор распределенных транзакций Microsoft (MS DTC) настроен в Windows не полностью, то приложениям, возможно, не удастся прикрепить ресурсы SQL Server к распределенной транзакции. Эта проблема касается связанных серверов, распределенных запросов и удаленных хранимых процедур, использующих распределенные транзакции. Дополнительные сведения о настройке MS DTC см. в разделе Before Installing Failover Clustering.
Решение. Для предотвращения этой проблемы необходимо полностью включить службы MS DTC на серверах, на которых установлен SQL Server и настроен MS DTC.
Для полного включения служб MS DTC выполните следующие шаги.
На панели управления откройте Администрирование, затем Управление компьютером.
В левой панели окна «Управление компьютером» раскройте Службы и приложения и щелкните Службы.
В правой панели окна «Управление компьютером» щелкните правой кнопкой мыши Координатор распределенных транзакций и выберите Свойства.
В окне Координатор распределенных транзакций перейдите на вкладку Вход в систему и выберите в качестве учетной записи входа NT AUTHORITYNetworkService.
Использование расширенных хранимых процедур и объектов COM
При использовании расширенных хранимых процедур в конфигурациях с отказоустойчивой кластеризацией все такие процедуры должны быть установлены на диск кластера под управлением SQL Server. Это обеспечивает возможность использования расширенных хранимых процедур после перехода узла на другой ресурс.
Если эти расширенные хранимые процедуры используют компоненты COM, администратор должен зарегистрировать эти компоненты на каждом узле кластера. Чтобы компоненты COM можно было создать, сведения для их загрузки и выполнения должны содержаться в реестре активного узла. Иначе эти сведения содержатся в реестре компьютера, на котором эти компоненты COM были зарегистрированы в первый раз.
Источник
Шесть типичных проблем отказоустойчивых кластеров
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
В результатах, представленных на экране 1, указано состояние «status 5035.».
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Это сообщение об ошибке указывает на неработоспособное состояние сети кластера. Если администратор перейдет в диспетчер отказоустойчивости кластеров, то в разделе «Сети» он увидит, что сеть 192.168.0.0/24 содержит только один сетевой адаптер для узла Node1. Однако имеется новая сеть 192.0.0.0/8, обслуживаемая сетевым адаптером узла Node2. Администратор, поменяв IP-адрес сетевого адаптера на узле Node2, не поменял маску подсети. Таким образом, ошибка 5035 возникла из-за неверной настройки сетевого адаптера.
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 8. Добавление счетчика отброшенных принятых пакетов в системный монитор |
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
Иногда диспетчер отказоустойчивости кластеров не открывается, выдавая сообщение об ошибке (см. экран 9). В процессе открытия диспетчер отказоустойчивости кластеров устанавливает WMI-соединение с каждым узлом кластера. Сообщение об ошибке, приведенное на экране 9, указывает на то, что один из узлов имеет недопустимое пространство имен, то есть с узла был удален экземпляр Cluster WMI (Cluswmi.mof). Остается выяснить, на котором из узлов он удален, поскольку в сообщении об ошибке эта информация отсутствует.
.jpg "локальный компьютер не входит в отказоустойчивый кластер windows") |
| Экран 9. Сообщение о недопустимом пространстве имен |
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
Источник
13.01.2021 1 мин. чтения

Например, во время синхронизации возникает ошибка Обмен данными.ОбменЗарплата3Бухгалтерия3.Отправка данных со следующим содержимом:
Данная ошибка относится к регулярно встречающимся ошибкам 1С, и фиксируется у многих пользователей. Единственного и эффективного рецепта её решения не существует, так как она может иметь уникальную основу, и вызывается особенностями программного кода в конкретной системе.
Содержание
- Обновление конфигурации до последней версии
- Запускайте 1С с правами администратора
- Измените код программы
- Регистрация в системе компоненты comcntr.dll
- Странное поведение COM при обмене
- Новый COMОбъект(«V83.COMConnector») выдает ошибку создания.
- Скачать файлы
- Специальные предложения
- См. также
- Решение проблемы «Недопустимая строка с указанием класса»
Обновление конфигурации до последней версии
Вопрос обновления конфигурации 1С на примере «1С:Бухгалтерия 3.0» я рассматривал ранее. Поэтому здесь не имеет смысла описывать данный процесс.
Запускайте 1С с правами администратора
Убедитесь, что вы запускаете систему под учётной записью администратора, а не ограниченного в правах «Гостя» или аналога.
Измените код программы
COMConnector = Новый COMObject(«V82.COMConnector»);
COMConnector = Новый COMObject(«V83.COMConnector»);
После указанной замены проблема может быть решена.
Регистрация в системе компоненты comcntr.dll
Для регистрации компоненты вручную необходимо выполнить в PowerShell от имени администратора следующие команды:
C:WindowsSysWOW64regsvr32 /u «c:Program Files1cv88.3.17.1851bincomcntr.dll» или C:WindowsSysWOW64regsvr32 /u «c:Program Files (x86)1cv88.3.17.1851bincomcntr.dll»
C:WindowsSysWOW64regsvr32 «c:Program Files1cv88.3.17.1851bincomcntr.dll» или C:WindowsSysWOW64regsvr32 «c:Program Files (x86)1cv88.3.17.1851bincomcntr.dll»
«8.3.17.1851» вам необходимо заменить на вашу версию платформы 1С.
После регистрации библиотеки скорей всего синхронизация заработает.
Источник
Столкнулся со странным поведением COM.
На машине установлено два релиза 1С.
8.3.10.2252 32 разрядная и 8.3.11.3034 64 разрядная.
Есть база БП 3.0 (3.0.64.42).
В списке настроенных синхронизаций указана база ЗУП 3.1 находящаяся на этом же сервере 1С.
Делаю отмену регистрации библиотеки comcntr.dll для релиза 8.3.10.2252
regsvr32 «C:Program Files (x86)1cv88.3.10.2252bincomcntr.dll» /u
Отмена регистрации прошла успешно.
Делаю регистрации библиотеки comcntr.dll для релиза 8.3.11.3034
regsvr32 «C:Program Files1cv88.3.11.3034bincomcntr.dll»
Регистрация прошла успешно.
Ранее в конфигурации использовался справочник НастройкиВыполненияОбмена где прописывались релизы используемые для подключения. Но сейчас он не используется.
Кто сталкивался с этой проблемой просьба подсказать.
(10) Сервер перегрузил, ошибка осталась.
Есть база БП 3.0 (3.0.64.42).
В списке настроенных синхронизаций указана база ЗУП 3.1 находящаяся на этом же сервере 1С.
Ошибка точно выглядит так:
(21) На сервере нашел интересный момент
Существуют регистрации comcntr.dll по путям которых нет в системе (возможно ранее была установлена 32 разрядная версия 1С и зарегистрирована dll).
(23) (24)
Хоть ты тресни. Ничего не помогает.
Останавливаю агент сервера.
В списке настроенных синхронизаций указана база ЗУП 3.1 находящаяся на этом же сервере 1С.
Открываю ее параметры. Проверить подключение.
(32) >Таки для чего именно х64 ком-конектор?
Потому что на сервере стоит 64 битная 1С. В каталоге
Соответственно comcntr.dll лежит в этом же каталоге.
Сделал все как в ней сказано. Начиная с остановки службы сервера 1С. Далее удаление регистрации компонент. Далее регистрация. Далее перезагрузка сервера.
(38) Новое место работы. Сервер 1С до этого ставил сисадмин. Зачем он поставил 64 разрядную версию внятно ответить не может.
Как только бухи сдадут квартальную отчетность буду переставлять сервер 1С.
(38) У сисадмина сервер 1С на котором крутятся базы БП и ЗУП до этого работал виртуальной машиной. Были большие тормоза. Он его снес и поставил на отдельную машину. Зачем поставил 64 разрядный сервер если на сервере крутится только база БП с 5 пользователями и база ЗУП одному ему известно.
Причем самое веселое что сервер 1С для бухгалтерии он решил переставить во время сдачи отчетности.
1. На сервере установлена только одна 1С.
Этой версии 1С на сервере нет но в реестре ссылки на comcntr.dll от 32 разрядной версии остались.
Путь к comcntr.dll я поправил на 64 разрядную.
(47) >Я спрашиваю именно про разрядность клиента и COM конектора
Если честно вопрос не совсем понял.
У меня на сервере установлена 64 разрядная 1С.
Каталог
Других 1С на сервере нет.
(57) Я выше писал что у меня 1С на сервере установлена ТОЛЬКО в каталог C:Program Files1cv88.3.11.3034
Соответственно у меня и сервер 64 разрядный и клиент.
(51) >5-10 минутное дело пересадки сервера 1ц с 64 на 32 бит версию растянули на
Если бы было так все просто.
А бухи сидят и ждут.
Вариант делать это после работы или ночью конечно возможен но это удовольствие не для всех.

Только для запуска сервера.
(63) >Сервер как стоял х64, так пусть и стоит себе. Надо только поставить клиента х32
У меня на сервере стоит 64 разрядная 1С. Других там нет.
Да были какие-то хвосты регистрации в реестре comcntr.dll из 32 разрядной 1С. При том что самой 32 разрядной 1С (из папки C:Program Files (x86)1cv88.3.11.3034 на сервере нет. Я поменял путь в реестре с «C:Program Files (x86)1cv88.3.5.1119bincomcntr.dll» на «C:C:Program Files1cv88.3.11.30341cv88.3.5.1119bincomcntr.dll»
Дальше получается следующее.
Вне зависимости от того где зашел клиентом в 1С (с локальной машины или на сервере) происходит проявление ошибки COM при попытке произвести тестовое подключение из БП в ЗУП в штатной процедуре обмена БП-ЗУП.
Теперь давайте думать логически.
Если бы проблема с COM была только при заходе в 1С с клиентских машин а при заходе в 1С с сервера ее не было то надо было бы копать в сторону клиентских машин и клиентских версий.
Но проблема происходит все зависимости от того с какой машины (с локальной или с сервера) зайти в 1С.
(63) «Полный дистрибутив платформы и х32 и х64 содержат как различных клиентов, так и сервер. Ну и плюс сопутствующие компоненты навроде СОМ конектора. Есть даже отдельный дистрибутив с сервером х64, который не содержит клиента. Надо смотреть что именно стоит, какие флаги были выбраны при установке. «
Больше нет ничего.
Никакой отдельной возможности поставить COM коннектор в дистрибутиве нет.
Собственно если в установленных программах на 1С этого релиза нажать «Изменить» то будет видно какие компонеты можно выбрать.
Источник
Новый COMОбъект(«V83.COMConnector») выдает ошибку создания.
При попытке в 8.3 создать Объект выдает ошибку:
«Ошибка при вызове конструктора (COMОбъект)
НовыйПодключенныйОбъект = Новый COMОбъект(«V83.COMConnector»);
по причине:
-2147221005(0x800401F3): Недопустимая строка с указанием класса «
Регистрировал библиотеку Regsvr32 «C:Program Files1cv8_____bincomcntr.dll»
Версия платформы 8.3.10.2252. Запускаю конфигурацию Зуп 2.5 там создание объекта проходит на Ура. В версии Зуп 3 выдвает ошибку. Что может быть не так?! уже голову сломал. Делал как описано здесь : https://helpf.pro/faq/view/1825.htm не помогло.
Все проблема Решена.
Все же у меня 1с установлена 64 разрядная а библиотека зарегистрирована была 32.
Ответ:
«Если фоновый процесс COM-соединения оканчивается ошибкой
, то нужно зарегистрировать библиотеку ComConnector comcntr.dll из каталога программы.
В 32-битной версии сервера проблема решилась бы командой
regsvr32 «C:Program Files (x86)1cv88.3.5.1119bincomcntr.dll»
но в 64-битной версии команда будет примерно такой * :
C:WindowsSysWOW64regsvr32 «C:Program Files (x86)1cv88.3.5.1119bincomcntr.dll»
Затем перезайдите в 1С Предприятие и попробуйте установить COM-соединение снова.
* если команда регистрации не помогла, то нужно предварительно удалить регистрацию библиотеки comcntr.dll, запустив ту же команду вызова regsvr32 с ключом /u
** если и это не помогло, попробуйте переустановить платформу 1С в режиме Исправить, а затем зарегистрируйте библиотеку, как написано выше «
Источник
Получив многим известное сообщение, на платформе 8.3.13.1690:
Перерерыл все что было на эту тему на форумах, и так как решение оказалось неописанным до конца, указываю свое:
Решалась задача подключиться на клиенте 8.3 к платформе 7.7, не через сервер 1с, который на Линуксе
Везде советовали регистрировать библиотеку bincomcntr.dll, по факту понадобилось регистрировать еще 3 библиотеки из 7.7 см. фото
Также прилагаю тестовую базу и обработку тестирования подключения на клиенте 8.3.
Скачать файлы
Специальные предложения








После регистрации dll от имени Администратора, ошибка осталась.
Решение: установить программу 1С 7.7. на компьютер пользователя. При установке происходит регистрация всего, что нужно.
После этого все завелось.
Обновление 09.04.19 08:35
См. также
Очередная редакция альтернативного стартера, являющегося продолжением StartManager 1.3. Спасибо всем, кто присылал свои замечания и пожелания, и тем, кто перечислял финансы на поддержку проекта. С учетом накопленного опыта, стартер был достаточно сильно переработан в плане архитектуры. В основном сделан упор на масштабируемость, для способности программы быстро адаптироваться к расширению предъявляемых требований (т.к. довольно часто просят добавить ту или иную хотелку). Было пересмотрено внешнее оформление, переработан существующий и добавлен новый функционал. В общем можно сказать, что стартер эволюционировал, по сравнению с предыдущей редакцией. Однако пока не всё реализовано, что планировалось, поэтому еще есть куда развиваться в плане функциональности.
23.04.2014 144524 1768 Alexoniq 1575
Источник
Решение проблемы «Недопустимая строка
с указанием класса»
Данная пошаговая инструкция, это альтернативный вариант решения проблемы с регистрацией COM компоненты 1С Предприятия comcntr.dll.
Первоначально воспользуйтесь вариантом регистрации — regsvr32. Подробней: «Регистрация COM компоненты 1С Предприятия comcntr.dll (V83.ComConnector)». И только в случае неудачи, используйте вариант приведенный ниже.
Создаём коннектор. Запускаем консоль «Службы компонентов».
«Панель управления» — «Администрирование» — выбираем «Службы компонентов».

В открывшемся окне «Службы компонентов» добавляем новый элемент, для этого переходим «Компьютеры» — «Мой компьютер» — из списка выбираем «Приложения COM+».

В контекстном меню выбираем «Создать» — «Приложение».

Откроется Мастер установки приложений COM+.

«Установка или создание нового приложения» выбираем второй вариант «Создать новое приложение».

В поле «Введите имя нового приложения:» вводим «V83COMConnector».
«Способ активации» устанавливаем «Серверное приложение».

На следующем этапе выбираем учетную запись под которой запускается приложение.
Устанавливаем «Текущий (вошедший в систему) пользователь».

На этапе «Добавление ролей приложения» нажимаем «Далее».

На этапе «Добавление пользователей для ролей» нажимаем «Далее».

В ветке только что созданного нами приложения переходим в подветку «Компоненты» и создаем компонент.
В контекстном меню выбираем «Создать» — «Компонент».

Откроется Мастер установки компонентов COM+.

Выбираем первый вариант «Установка новых компонентов».

В открывшемся диалоге выбираем необходимый файл comcntr.dll и нажимаем «Открыть».
Окно Мастера установки компонентов COM+ измениться нажимаем «Далее».

Мастер собрал все необходимые сведения для выполнения установки, нажимаем «Готово».

Обратите внимание: после установки необходимо изменить свойства объекта.
Для этого переходим к ветке V83COMConnector.
Открываем свойства созданного компонента, переходим в ветку V83COMConnector — «Свойства».

В открывшемся окне переходим на вкладку «Безопасность».
В «Авторизация» снимаем флаг «Принудительная проверка доступа для приложений».

В «Политика программных ограничений» устанавливаем флаг «Применить политику программных ограничений» и выбираем «Уровень ограничений:» — «Неограниченный».

«Ошибка отключения пользователей базы 1С, Процесс сервера не может быть запущен, так как указана неправильная идентификация. Проверьте правильность указания имени пользователя и пароля, ProgID: «V83.ComConnector» (HRESULT=8000401A)»
Переходим на вкладку «Удостоверение», устанавливаем «Указанный пользователь:» и вводим данные учетной записи с правами Администратора. В случае если используете домен, укажите доменную учетную запись.

Класс V83.COMConnector успешно зарегистрирован и может использоваться для подключения к информационным базам.
Источник
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
.
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Card1 IP Address: 10.10.10.1 Subnet Mask: 255.0.0.0 Card2 IP Address: 10.10.10.2 Subnet Mask: 255.0.0.0
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Card1 IP Address: 192.168.0.1 (Cluster Network 1) Subnet Mask: 255.255.255.0 Card2 IP Address: 10.10.10.1 (Cluster Network 2) Subnet Mask: 255.0.0.0
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
Get-ClusterLog
Команда инициирует создание журнала кластера на каждом узле. Для построения журнала кластера только на одном узле можно добавить параметр -Node и указать имя узла. Можно также добавить параметр -TimeSpan для создания журнала только за последние x минут. Например, приведенная ниже команда предписывает построить журнал кластера на узле Node2 за последние 15 минут:
Get-ClusterLog –Node Node2 –TimeSpan 15
В результатах, представленных на экране 1, указано состояние «status 5035.».
 |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Это сообщение об ошибке указывает на неработоспособное состояние сети кластера. Если администратор перейдет в диспетчер отказоустойчивости кластеров, то в разделе «Сети» он увидит, что сеть 192.168.0.0/24 содержит только один сетевой адаптер для узла Node1. Однако имеется новая сеть 192.0.0.0/8, обслуживаемая сетевым адаптером узла Node2. Администратор, поменяв IP-адрес сетевого адаптера на узле Node2, не поменял маску подсети. Таким образом, ошибка 5035 возникла из-за неверной настройки сетевого адаптера.
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
|
|
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
|
|
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
|
|
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
|
|
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
- сетевой доступ (не разрешать перечисление учетных записей SAM анонимными пользователями);
- сетевой доступ (не разрешать перечисление учетных записей SAM и общих ресурсов анонимными пользователями).
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
|
|
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
|
|
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
- основы сетей – объявление поиска соседей;
- основы сетей – запрос поиска соседей.
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
|
|
| Экран 8. Добавление счетчика отброшенных принятых пакетов в системный монитор |
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
Иногда диспетчер отказоустойчивости кластеров не открывается, выдавая сообщение об ошибке (см. экран 9). В процессе открытия диспетчер отказоустойчивости кластеров устанавливает WMI-соединение с каждым узлом кластера. Сообщение об ошибке, приведенное на экране 9, указывает на то, что один из узлов имеет недопустимое пространство имен, то есть с узла был удален экземпляр Cluster WMI (Cluswmi.mof). Остается выяснить, на котором из узлов он удален, поскольку в сообщении об ошибке эта информация отсутствует.
|
|
| Экран 9. Сообщение о недопустимом пространстве имен |
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Set-Location C:WindowsSystem32Wbem Mofcomp.exe Cluswmi.mof
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012 R2» (support.microsoft.com/kb/2920151/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012» (support.microsoft.com/kb/2784261/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2008 R2» (support.microsoft.com/kb/980054/EN-US).
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
$NodeNames = Get-ClusterNode
ForEach ($ClusterName in $NodeNames)
{
Write-Host -NoNewline «Testing $ClusterName»
Try
{
$result = (Get-WmiObject -Class «MSCluster_CLUSTER» `
-namespace «rootMSCluster» `
-authentication PacketPrivacy `
-computername $ClusterName -erroraction stop).__SERVER
Write-host «: Successfully queried cluster node»
}
Catch
{
Write-host -NoNewline «: Failed to query cluster node»
Write-host -ForegroundColor Red -BackgroundColor Black `
$_.Exception.Message
}
}
Для тренировки и самообучения провожу установку кластера ms sql 2008 r2 на кластер windows 2012 r2 (все это на виртуальных машинах).
Имеется следующее:
— 2 виртуальные машины на hyper-v;
— iscsi хранилища (кворум-диск, диск для базы данных, диск для службы распределенных транзакций). iscsi настроен на хост сервере;
— контроллер домена на хост машине;
— служба отказоусточивого кластера поднята на виртуалках и на хост-машине. Виртуалки объединены в кластер.
Проверка кластера, в дистпетчере отказоустойчивого кластера, проходит замечательно и не выдает никаких замечаний и ошибок.
При установке кластера ms sql на виртуалку, установщик запускает свои проверки, и находит следующие ошибки:
1. Cluster_IsOnline не пройдено (Службы кластера отработки отказа SQL Server находятся вне сети, или не удается получить доступ к кластеру с одного из его узлов)
2. Cluster_SharedDiskFacet не пройдено (Для кластера на этом компьютере не доступен ни один общий диск)
3. Cluster_VerifyForErrors не пройдено (Кластер не проверялся, либо в отчете проверки присутствуют сообщения об ошибках или сбоях)
На все сервера установлены последние обновления. Перезагружался много раз. Framework установлен на всех узлах кластера.
Вот куски из логов с ошибками:
2015-12-15 14:24:00 Slp: Initializing rule : Проверка службы кластеров
2015-12-15 14:24:00 Slp: Rule applied features : ALL
2015-12-15 14:24:00 Slp: Rule is will be executed : True
2015-12-15 14:24:00 Slp: Init rule target object: Microsoft.SqlServer.Configuration.Cluster.Rules.ClusterServiceFacet
2015-12-15 14:24:00 Slp: Данный ключ отсутствует в словаре.
2015-12-15 14:24:00 Slp: в Microsoft.SqlServer.Chainer.Infrastructure.ServiceContainer.GetService(Type serviceType)
в Microsoft.SqlServer.Chainer.Infrastructure.ServiceContainer.GetService[T]()
в Microsoft.SqlServer.Chainer.Infrastructure.ServiceContainer.get_Cluster()
в Microsoft.SqlServer.Configuration.Cluster.Rules.ClusterServiceFacet.Microsoft.SqlServer.Configuration.RulesEngineExtension.IRuleInitialize.Init(String ruleId)
в Microsoft.SqlServer.Configuration.RulesEngineExtension.RulesEngine.Execute(Boolean stopOnFailure)
2015-12-15 14:24:00 Slp: Rule initialization failed - hence the rule result is assigned as Failed2015-12-15 14:24:01 Slp: Evaluating rule : Cluster_SharedDiskFacet
2015-12-15 14:24:01 Slp: Rule running on machine: DELO-DB1
2015-12-15 14:24:01 Slp: Rule evaluation done : Failed
2015-12-15 14:24:01 Slp: Rule evaluation message: Для кластера на этом компьютере не доступен ни один общий диск. Чтобы продолжить, необходимо сделать доступным по крайней мере один общий диск.Рекомендуется
Ускорьте свой компьютер сегодня с помощью этой простой в использовании загрузки. г.
Вот несколько простых шагов, которые помогут вам устранить ошибку причины кластера mscs SQL 2008.
- 4 минуты на чтение.
Эта публикация поможет любому решить проблему, возникшую при установке SQL Server в кластере Windows Server.
Симптомы
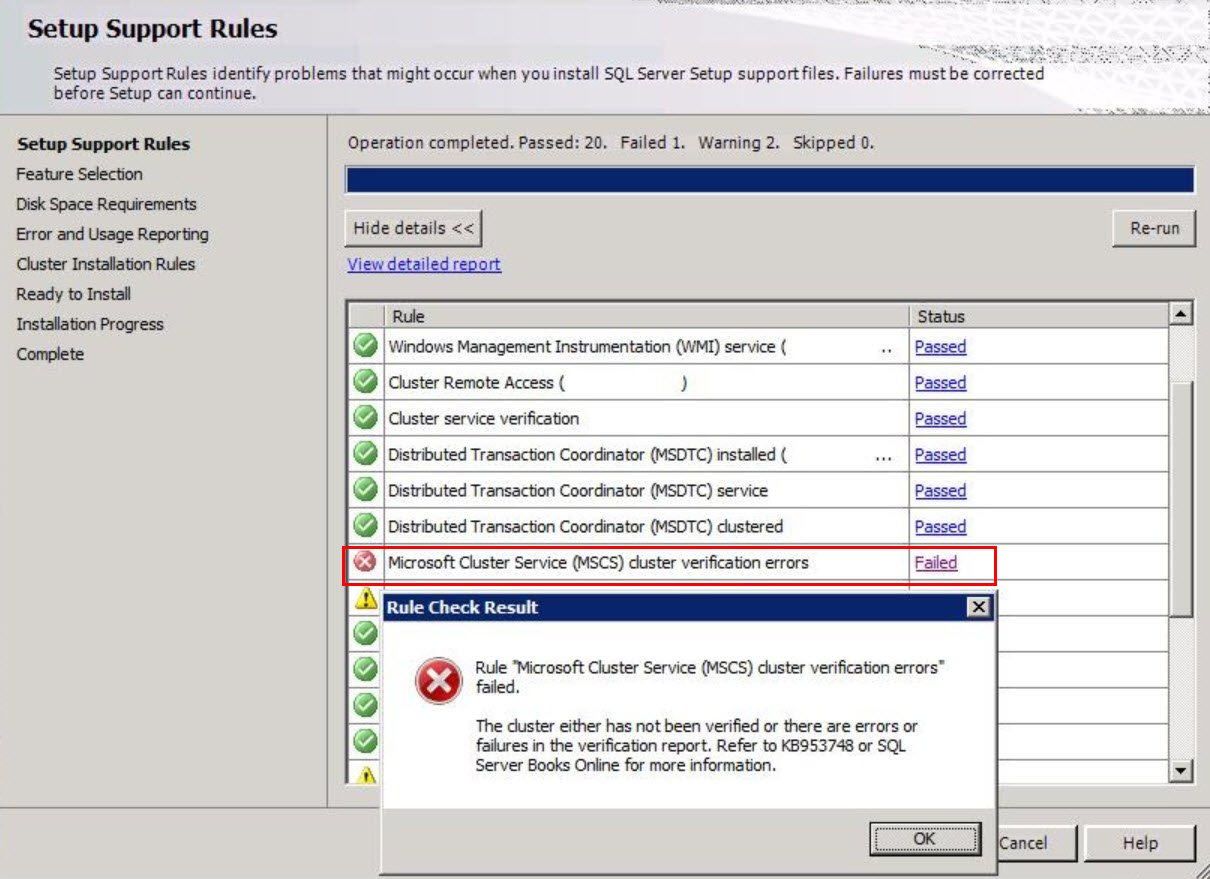
При установке Microsoft SQL Server в кластере Windows Server правило проверки кластера, лежащее в основе процесса подключения, может завершиться ошибкой. Вы также можете получить следующее сообщение:
<цитата>
Ошибка Ошибка: «Ошибка проверки кластера службы кластеров Microsoft (MSCS)». Группа приходит с непроверенной, либо есть ошибки, с другой стороны глюки в отчете о проверке. Дополнительные ресурсы см. В KB953748 или в электронной документации по SQL Server. “
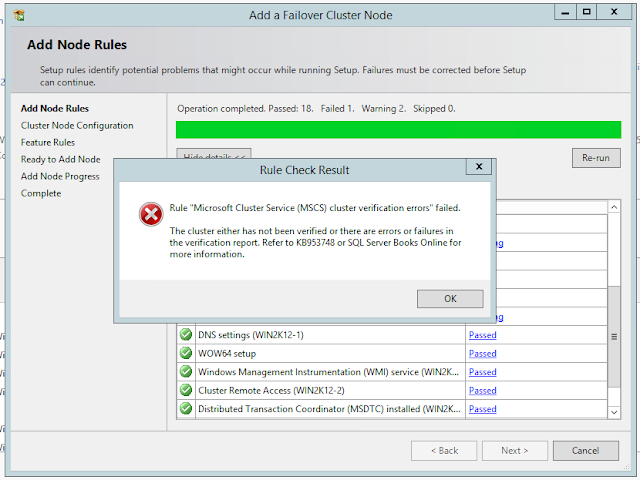
Файл журнала сборки может содержать сообщение, подобное следующему:
<цитата>
20 мая 2008 г., 05:27:18 Slp: оценка общих правил: Cluster_VerifyForErrors
2008-05-20 05:27:18 Slp: Правило выполняется на компьютере: SQLNode_Name
2008-05-20 05:27:18 Slp: оценка правила завершена: сбой
2008-05-20 05:27:18 Slp: Сообщение об оценке правила: Возможно, кластер не был проверен, или в отчете о тестировании могут быть ошибки.
Установочный архив пиломатериалов (Detail.txt), например, может быть стратегически расположен в файле % ProgramFiles% Microsoft SQL Server 100 Setup Bootstrap Log 20090316_112604 .
Для полноценного пробного запуска у правила воли есть замечательные способы входа, подобные следующим:
<цитата>
Имя компьютера: Cluster_VerifyForErrors: успешно
Причина
Метод проверки может не работать в различных условиях. В этой дилемме вам нужно будет выполнить просмотр вручную, чтобы убедиться, что конфигурация вашего компьютера или компьютера верна, прежде чем пытаться использовать новые обходные пути, упомянутые в этой статье. Вы можете часто использовать ссылки, упомянутые в разделе Ссылки для получения дополнительной информации о проверке группировок в средах Windows Server. Это избавит вас от гораздо большего количества проблем, чем вы могли бы при первой работе. Вы используете решение основных неудач.
Временное решение
Чтобы разрешить эту отправку, вам необходимо решить проблему, которая привела к сбою проверки. Как правило, если вы обнаружите, что эксперты утверждают, что проблема, вызвавшая положительный сбой проверки, может быть решена, вам обычно следует использовать параметр set. Командные обновления телефонной линии, описанные в этой статье, чтобы игнорировать некоторые сообщения об ошибках. И попробуйте это на рынках, попробуйте установить экземпляр отказоустойчивого кластера SQL Server. В этом случае перед использованием системы покупатели должны решить основную проблему, из-за которой проверка снова не прошла.
При появлении запроса перейдите к своему реальному жесткому диску и, кроме того, часто к папке, содержащей установку SQL Server (Setup.exe). Затем введите одну из следующих команд после, чтобы игнорировать разрешающее правило:
-
Чтобы встроенная сборка добавила примечания по отработке отказа, выполните команду почти на другом добавляемом узле:
Setup / SkipRules = Cluster_VerifyForErrors / Action = InstallFailoverCluster. -
Для одиночной установки Advanced или Enterprise выполните эту особую команду:
Setup / SkipRules = Cluster_VerifyForErrors / Action = CompleteFailoverCluster -
Если вы получаете эту ошибку проверки при добавлении определенного лучшего узла к существующей установке аварийного переключения, предложите команду на каждом добавляемом узле:
Setup / SkipRules = Cluster_VerifyForErrors / Action equals AddNode.
Рекомендуется
Ваш компьютер работает медленно? У вас проблемы с запуском Windows? Не отчаивайтесь! ASR Pro — это решение для вас. Этот мощный и простой в использовании инструмент проведет диагностику и ремонт вашего ПК, повысит производительность системы, оптимизирует память и повысит безопасность процесса. Так что не ждите — скачайте ASR Pro сегодня!

Параметр SkipRules для установки vki не является документированным преимуществом. Вы не должны использовать этот параметр для выбора любого правила, кроме Cluster_VerifyForErrors , если ваш CSS не инструктирует вас сделать это.
Тесты безопасности отказоустойчивого кластера SQL Server
Используя проверку кластера, эксперт может получить серию гораздо более важных тестов с помощью набора серверов и очистителей, которые вы хотели бы использовать на узлах в группе. В этом процессе массовой проверки лежащие в основе гвозди, болты и тесты программного обеспечения поддерживаются напрямую и просто индивидуально в преднамеренной конфигурации, чтобы успешно получить точную оценку отказоустойчивой кластеризации SQL Server.
Что делать, если проверочные тесты не пройдут в худшем случае
В случаях, когда тесты правил проверки кластера не проходят, Microsoft не рассматривает поддерживаемое решение. На самом деле существуют исключения для поддержки этого правила, например, когда человек с кластерами в нескольких разделах (географически разбросанных) не имеет общего хранилища. В таком сценарии из-за мастера проверки кластера ожидаемые значения pThis приведут к сбою большинства образцов памяти. Это все еще будет поддерживаемым ответом, поскольку остальная часть тестирования была легендарной.
Тип теста, который определенно не работает должным образом, – это подсказка, которую следует предпринять. Просто чтобы проиллюстрировать, что ваше собственное сканирование памяти со списком всех жестких дисков завершается неудачно, а также если последующие оценки памяти не срабатывают из-за любой возможности сбоя, обратитесь к любителю продукта хранения для устранения неполадок. Если время привязки сетевой системы для IP-адресов не удается, обратитесь к команде инфраструктуры Interact.
Ссылки
-
Проверка оборудования для отказоустойчивого кластера
-
Постоянные экземпляры отказоустойчивого кластера (SQL Server)
-
Установить SQL Server из набора команд
-
Если вы запустите какой-то мастер проверки новой конфигурации на компьютере с полной версией Windows Server 2008, а также Windows Vista, проверка не удастся
Если вы попробуете этот вариант для установки одного пакета команд и установки. Если загрузка SQL Server завершится неудачно, убедитесь, что аппаратная конфигурация пакета ПК действительна, и, возможно, обратитесь в службу поддержки клиентов Microsoft (CSS) за помощью.
Параметр SQL для огромного экземпляра отказоустойчивого кластера сервера всегда в определенном отказоустойчивом кластере Windows Server, который вызывал ошибки в отчете о проверке кластера Windows Server, не поддерживается. Для любого типа экземпляра отказоустойчивого кластера SQL Server по сравнению со сценарием задержки ни один из наших отчетов о проверке кластера Windows Server, как правило, не будет содержать ошибок. Используйте CSS, чтобы гарантировать, что большинство конфигураций кластера определенно будут в отличном обслуживаемом состоянии.
Ускорьте свой компьютер сегодня с помощью этой простой в использовании загрузки. г.
Sql 2008 Mscs Cluster Verification Error
Sql 2008 Mscs Erro De Verificacao De Cluster
Sql 2008 Mscs Klusterverifieringsfel
Sql 2008 Mscs Clusterverificatiefout
Erreur De Verification Du Cluster Mscs Sql 2008
Sql 2008 Mscs Errore Di Verifica Del Cluster
Sql 2008 Mscs Cluster Uberprufungsfehler
Error De Verificacion Del Cluster De Sql 2008 Mscs
Sql 2008 Mscs Blad Weryfikacji Klastra
Sql 2008 Mscs 클러스터 확인 오류
г.