
Когда нужно остановить тестирование и нужно ли его останавливать? Полный ли объем информации проработан и все ли учтено? И вообще – есть ли предел совершенству? Эти вопросы актуальны для каждого тестировщика. Так давайте остановимся на минуту и подумаем: в какой момент нужно и можно прервать стремящийся к бесконечности процесс тестирования?
Причина для остановки: «Сроки поджимают! Время – деньги!»
Часто на проекте есть четко определенные сроки, которые заказчик не всегда готов передвинуть. В этом случае команда «заканчиваем тестирование!» зависит именно от установленных сроков, и это важный критерий. Да, такой сценарий нельзя назвать лучшим (так как времени всегда катастрофически не хватает для полной проверки, и часто страдает качество), но он тоже возможен.

Пример из практики. Вспоминается ситуация, когда из-за жестких сроков пострадало качество продукта. Тестировался интернет-магазин хозтоваров, и вместе с новой акционной скидкой только для зарегистрированных клиентов был внедрен баг: невозможность активировать несколько действующих на тот момент акций. Таким образом, релиз превратился в «релиз плюс еще пару напряженных дней баг-фикса». Наверное, гораздо лучше было подвинуть жесткие рамки на день-два и дать возможность дотестировать новый функционал… но в жизни встречаются разные ситуации.
Вывод. Главной задачей тестировщика в условиях ограниченного времени является охват максимально возможного количества критически важных тест-кейсов (тест-кейсы приоритета high и medium), запись всех найденных дефектов (во избежание их потери из-за времени и текучести задач) и формирование сообщения о реальном объеме проделанных работ. В итоге от тестировщика должна поступить полная картина проверенного и список того, что проверить еще не успели (чтобы в дальнейшем определить фронт работ).
Причина для остановки: «Это не конечная, а промежуточная»
Бывает, что в ходе тестирования нужно сделать вынужденную остановку, так как «что-то» критично блокирует оптимальную оценку тестируемого объекта, и из-за этого в дальнейшем может «протухнуть» вся система проверки. В таком случае лучше остановиться и дождаться решения проблемы.
 Пример из практики. Тестировалось довольно крупное медицинское программное обеспечение. На тестовом стенде не было возможности проверить в полном объеме новый функционал (отправку писем клиентам при заполнении формы и данных личного кабинета клиента). Задача была довольно обширной и затрагивала многие аспекты: активацию отдельных разделов при полной загрузке документов, ограничения в доступе к разделам при определенной степени заполнения профиля и другие. На вопрос перед релизом «все ли проверено и можно ли заканчивать тестирование?» однозначный ответ дать было просто невозможно: проверка частично блокировалась из-за невозможности проверить факт получения части писем на тестовой среде. В итоге при релизе на стороне клиента вылезли критические ошибки. Клиенту не поступали нужные уведомительные письма, а потому он не мог получить и полный доступ к своему профилю. Во избежание появления подобных ситуаций было найдено следующее решение: после доработки стали доступны опции отправки и получения писем на тестовом стенде, что позволило в дальнейшем проверять эту часть достаточно важного функционала. Включение этих проверок во все последующие прохождения регресса дало возможность более оптимально оценивать готовность продукта перед выпуском на клиентскую часть.
Пример из практики. Тестировалось довольно крупное медицинское программное обеспечение. На тестовом стенде не было возможности проверить в полном объеме новый функционал (отправку писем клиентам при заполнении формы и данных личного кабинета клиента). Задача была довольно обширной и затрагивала многие аспекты: активацию отдельных разделов при полной загрузке документов, ограничения в доступе к разделам при определенной степени заполнения профиля и другие. На вопрос перед релизом «все ли проверено и можно ли заканчивать тестирование?» однозначный ответ дать было просто невозможно: проверка частично блокировалась из-за невозможности проверить факт получения части писем на тестовой среде. В итоге при релизе на стороне клиента вылезли критические ошибки. Клиенту не поступали нужные уведомительные письма, а потому он не мог получить и полный доступ к своему профилю. Во избежание появления подобных ситуаций было найдено следующее решение: после доработки стали доступны опции отправки и получения писем на тестовом стенде, что позволило в дальнейшем проверять эту часть достаточно важного функционала. Включение этих проверок во все последующие прохождения регресса дало возможность более оптимально оценивать готовность продукта перед выпуском на клиентскую часть.
Вывод. Анализ ошибок позволил сделать верные выводы и устранить все блокирующие моменты. И все-таки, в подобной ситуации работа над оптимизацией средств и инструментов тестирования по итогу уже выявленных ошибок вряд ли может считаться хорошим вариантом. Несомненно, гораздо более уместной и правильной была бы остановка процесса тестирования и доработка изначально неполного функционала тестовой среды для предотвращения появления критических моментов уже на клиентской части.
Причина для остановки: «Стоять нельзя двигаться дальше». Где поставить запятую, и почему возникает неразбериха?»
Правильно ли исправлять баги прямо по ходу проверки, которая при этом не прерывается? Логика подсказывает, что процесс нужно остановить и начать с самого начала после внесения корректировки, так как любое исправление ошибки может повлечь за собой появление еще десятка новых.

Пример из практики. Сразу приходит на память довольно распространенный и известный любому тестировщику случай, когда по ходу тестирования обнаруживаются критические баги, а половина тест-кейсов уже проверена, и результаты по ним проставлены. Иногда разработчики стараются настолько быстро исправить ошибку, что «забывают» известить об этом старательного тестировщика, который вовсю спешит пройти все запланированные тест-кейсы с регресса. В итоге тестирование продолжается после исправления (bug-fix) вместо того, чтобы остановить проверку и начать ее заново; часть ошибок уже не будет обнаружена.
Вывод. В таких ситуациях разработчику важно своевременно сообщить о своих исправлениях тестировщику для того, чтобы тот остановил тестирование и повторно прошел тест-кейсы – все или только самые критичные и высокого приоритета (если времени остается не так уж и много). Это поможет избежать в дальнейшем неразберихи в вопросе: а откуда взялись новые дефекты в продукте, и кто за них отвечает?
Причина для остановки: «Поступил приказ отступать!»
Случается, что заказчик буквально на последнем этапе приостанавливает проверку. На это может быть масса причин: появление более важной задачи или функционала, который требует дальнейшего уточнения, переоценка приоритетов релиза, пересмотр плана на текущий момент. Наша задача при этом – приостановить процесс, но ничего не забыть!

Пример из практики. Случалось, что практически полностью протестированный релиз откладывался. Казалось бы, все готово – тщательно протестированы все блоки, сделаны все задачи, – и можно отдавать готовый продукт на радость пользователю, но заказчик вдруг решает, что лучше все сделать совершенно по-другому, а практически уже готовый релиз временно нужно остановить. Минусом такой ситуации является потраченное время тестировщика, плюсом – написанные тест-кейсы, которые могут быть использованы для проверки функционала другого ПО.
Вывод. Для тестировщика в таком случае важно написать качественные тест-кейсы, с которыми можно будет работать в дальнейшем либо на аналогичных задачах, либо (в случае возобновления работы) по отмененному/отложенному релизу.
Причина для остановки: «Все, устал, хватит!»
Остановка может произойти и просто из-за того, что напряжение достигло своего пика. Желание сделать как можно больше за максимально возможное время иногда негативно сказывается на результатах работы.

Пример из практики. На одном из наших проектов «случился» довольно затяжной релиз; мы тестировали его напряженно и активно. Тестирование в моей голове не прекращалось даже во время сна. И в тот момент, когда ошибка оказалась буквально перед моими глазами, явно «сигнализируя» мне в логах, – я ее просто не увидела. В такие моменты нужно уметь сказать себе: «Стой, передохни, а иначе допустишь ошибку, пропустишь баг, внимательность будет на нуле!» А внимательность – это основное качество тестировщика. Конечно, сам процесс нельзя просто взять и остановить, но выделить личное время на отдых – необходимо!
Вывод. В подобных случаях остановка в тестировании – это обязательный и важный момент для тестировщика. Заканчивая работу, нужно обязательно отдохнуть и отвлечься (заняться другим делом, например), дабы избежать «замыливания глаз».
Причина для остановки: «Есть сомнения? Остановись!»
Перед выходом каждого релиза тестировщик, оценивая проделанную работу и пройденный набор тест-кейсов, подводит итог: а все ли протестировано? Конечно, естественным состоянием будет желание продолжить процесс проверки, которое не всегда соответствует фактору времени. И все-таки обоснованные сомнения нужно по крайней мере озвучить. Даже если баг был «пойман» на последнем этапе, и его исправление задержит весь процесс релиза, – ни в коем случае нельзя оставлять ошибку без внимания, лучше остановить запущенный механизм и дать время на корректировку.

Пример из практики. В моем опыте были ситуация, когда ошибка обнаружилась уже на последних шагах (можно даже сказать, на последних минутах) регрессионного тестирования. Был ли это недочет тестировщика (то есть, мой)? Да, и это стало хорошим «пинком» для дальнейшей работы над своими ошибками. Но баг нужно было искоренять. Задачу «выкинули» из релиза для доработки, сам релиз состоялся довольно успешно. Не забывайте: заказчик скорее оценит качество проверки, чем соблюдения сроков без сохранения качества.
Вывод. Каждый этап процесса тестирования важен. Неверная проработка материала или неполное покрытие задачи тест-кейсами может стать причиной того, что тестировщик упустит важный и критический баг. На каком бы этапе тестирования это не обнаружилось – важно понимать, что в таких случаях необходимо остановиться, оценить ситуацию и принять решение о дальнейшем плане работ!
Причина для остановки: «По моему хотению – остановитесь!»
В тестировании важную роль играет понимание специалистом важности выпускаемого продукта. Плохо, если в человеке присутствует безразличие к итоговому продукту. В таком случае тестирование может остановиться просто потому, что сам процесс надоел тестировщику («и так сойдет!»).
 По этому поводу вспоминается старый анекдот:
По этому поводу вспоминается старый анекдот:
«Мужчина сшил в ателье костюм. Пришел домой, надел. Жена в ужасе:
– Ты что сшил? Посмотри: один рукав длиннее, другой – короче. Полы у пиджака разные, штанины. Неси все назад!
Муж пошел назад:
– Что вы мне сшили? Посмотрите! Брюки разной длины!
– А вы одну ногу согните в колене, ведь вы не ходите на прямых ногах. И все будет хорошо.
– Смотрите, рукава разной длины!
– Ну и что? Вы же не по швам руки держите. Согните их в локтях. Вот! Прекрасно!
– А полы? Что с ними делать?
– А вы немного набок наклонитесь. Все отлично!
Мужчина вышел в новом костюме. Люди на остановке:
– Смотри, какой урод! А как костюм хорошо сидит!»
Для тестировщика халатное отношение к процессу просто недопустимо. Все недочеты в итоге становятся явными, что в конечном итоге приводит к плачевным результатам.
Пример из практики. У меня и моих коллег, к счастью, таких ситуаций никогда не возникало: мы любим свою работу и с уважением относимся к конечным пользователям (ведь наши ошибки влияют на их опыт взаимодействия с продуктом). Надеюсь, подобного никогда и не случится. Главное – не забывать, что такое возможно, и избегать подобных случаев.
Вывод. Останавливать тестирование лишь по желанию тестировщика нельзя, каждая остановка должна быть обоснована. Решение об остановке процесса будет закономерным лишь в том случае, если оптимально и позитивно пройденным и тщательно проработанным оказывается целый набор параметров: написан полный объем тест-кейсов по задаче, правильно расставлены приоритеты для оценки времени в случае срочных или быстрых проверок, все задачи полностью проанализированы и сверены с техническими требованиями еще на начальных этапах ознакомления, все учтено на этапе планирования релиза.
И наконец… Барабанная дробь… Последняя, но самая желанная причина для остановки: «Готово, можно забирать!»
При начале планирования нового релиза закладывается определенный план тестирования, приоритеты и объемы. Правильное планирование ведет к положительным и качественным результатам. Когда все результаты тестирования полностью удовлетворяют критериям качества, можно смело сказать себе: «Стоп, здесь мы сделали все, что могли!» Но для этого нужно, чтобы все найденные ошибки были исправлены, все запланированные тест-кейсы пройдены (и не обнаружено ни одного бага выше минорного), все необходимые правки выполнены, а результат приемочного тестирования оказался полностью положительным. И так бывает на самом деле! Заказчик в таком случае доволен, а тестировщик может смело выписывать себе «медаль» за хорошую работу. А уж как это настраивает на дальнейшие «подвиги»!
Пример из практики. К примеру, некоторое время назад тестировали обновление сайта бытовой техники. Сайт пользовался и продолжает пользоваться довольно большой популярностью, ответственность за выпускаемый продукт была достаточно высокой. Итогом проведенного релиза стала положительная динамика и улучшение статистики по количеству пользователей, оформивших заказ через интернет. Это, конечно, огромный плюс для заказчика. Главный же показатель удачного релиза для тестировщиков – это продукт, максимально адаптированный под клиента и содержащий минимальное количество ошибок (а может, их там вообще не осталось?!!!). Остановка тестирования в таком случае вполне закономерна, так как заложена в четко установленных сроках с учетом всех необходимых критериев.
Вывод. Для получения хорошего результата важно учитывать в работе все факторы. Оценка и анализ задачи, написание тест-кейсов для ее покрытия, расчет времени и максимальная внимательность гарантируют положительные результаты в работе.
Финал
Подводя итоги, можно сказать, что последний сценарий – это идеальный вариант остановки тестирования: в нем сочетаются верное планирование, детальное тестирование и итоговая положительная приемочная часть. В остальных случаях остановки происходят из-за ошибок тестировщика, по желанию заказчика, недостаточно продуманного плана тестирования, неверного расчета времени или просто из-за лени (кстати, недопустимого в нашей профессии качества).
Поэтому и остановки в таких случаях не влекут за собой того конечного положительного результата, которого всегда хочется добиться. В данной ситуации важно сделать правильные выводы и вычленить причину основной ошибки. Как правило, это неверное планирование времени, боязнь спросить разработчика о готовности исправлений (то есть, плохо налаженное общение между разработчиком и тестировщиком) и халатное написание тест-кейсов из-за неполного ознакомления со спецификациями и требованиями. Выявив слабые места на проекте или в личных качествах, можно приступить к проработке плана дальнейшей более результативной работы.
Для этого всегда необходимо учитывать основные критерии: условия и пожелания заказчика, установленные временные рамки и степень покрытия тест-кейсами требований, указанных и описанных в задаче. Каждый пункт должен быть четко проработан и обговорен как с заказчиком, так и с разработчиком. Тестировщик должен представлять объем работ: какое тестирование можно успеть осуществить в обозначенные сроки, сколько тест-кейсов потребуется, до какого момента допускаются баг-фиксы, когда начинается код фриз и допускает ли найденное количество багов сам выпуск продукта.
Конечно, каждый проект имеет свои особенности. Невозможно найти единый правильный эталонный метод решения. И все-таки учет указанных выше основных критериев приведет к тому, что выпускаемый продукт будет максимально соответствовать поставленным требованиям, а процесс и остановка тестирования будут понятны и закономерны.

Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.

Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.

- Содержание статьи
- Средство проверки памяти Windows
- TestMem5
- Prime95
- MemTest86
- Что делать, если обнаружены ошибки памяти?
- Добавить комментарий
Для проверки оперативной памяти (она же RAM или ОЗУ) существуют различные программы, которые могут работать как из под операционной системы, так и без неё. Необходимость проверки памяти может возникнуть по различным причинам — внезапный отказ работы компьютера во время его загрузки, внезапные перезагрузки или появление «синего окна смерти», проверка стабильности разгона, либо еще какие-либо причины.
Если Вы желаете проверить стабильность работы оперативной памяти после разгона, то не ограничивайтесь одним единственным тестом. В идеале, оперативную память следует проверить несколькими тестами (по очереди) — например, TestMem5 и Prime95.
Средство проверки памяти Windows
Начиная с Windows 7, в комплекте с операционными системами этого семейства, в комплекте идет собственное средство для проверки оперативной памяти. Запустить его достаточно легко — достаточно в меню Пуск набрать словосочетание «Средство проверки», и найти среди отображенных вариантов «Средство проверки памяти Windows». Так же запустить данное средство можно выполнив команду mdsched в окне «Выполнить» или Командной строке.
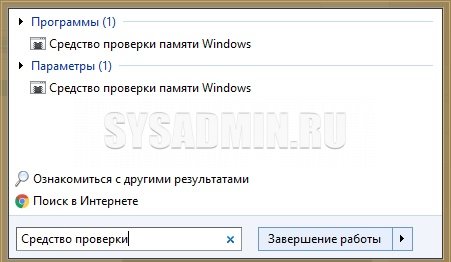
По запуску данная программа спросить о том, когда вы хотите выполнить проверку — прямо сейчас, перезагрузив компьютер, или выполнив позже, при следующей загрузке Windows. Разница собственно в том, что при выборе первого пункта компьютер будет перезагружен сейчас же, а если выбрать второй пункт, то перезагрузить компьютер уже надо будет самому.
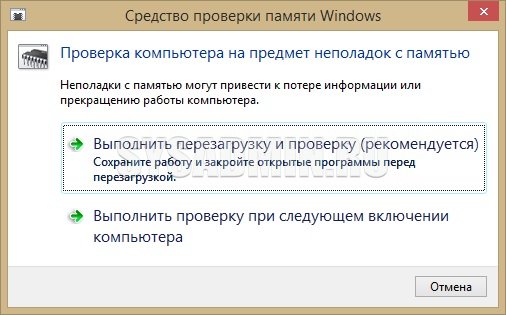
После перезагрузки начнется сам процесс проверки памяти, время прохождение которого будет прямо пропорционально количеству проверяемой памяти — чем больше, тем дольше.
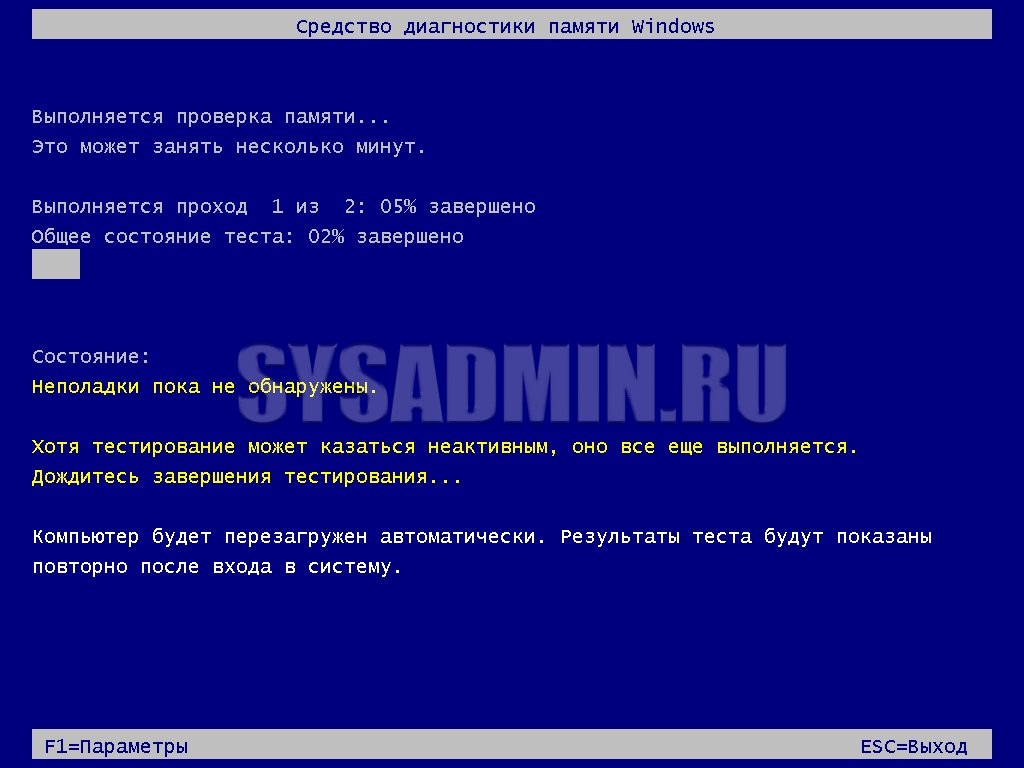
После завершения теста компьютер будет повторно перезагружен, после чего в системном трее Windows будет показан результат проверки. Например, в случае отсутствия ошибок, выглядеть это будет так:
![]()
- Встроен в операционную систему Windows
- Может не справится с поиском сложнонаходимых ошибок
TestMem5
Разработка данной программы началась в 2010 году, программа TestMem5 предлагает качественный подход к тестированию оперативной памяти из под Windows. Благодаря возможности гибкой настройки тестов, есть возможность настроить программу как душе угодно, из-за чего она долго уже не теряет актуальность.
Скачать программу можно на домашней странице автора — TestMem5, или по этой ссылке с нашего сайта.
Пользоваться программой проще простого — достаточно запустить исполняемый файл TM5.exe с правами администратора, и программа автоматически начнет тестирование оперативной памяти.
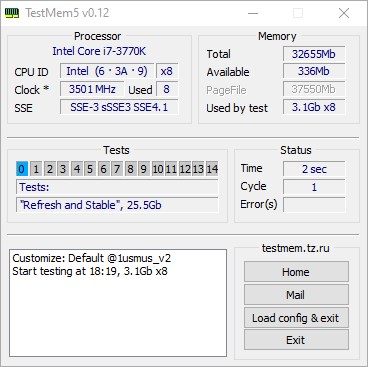
Наблюдать за итогами тестирования можно в окошке Status — где Cycle это количество раз, сколько программа раз «прогнала» оперативную память через свои тесты, ну а Error(s), это количество обнаруженных ошибок.
Для лучшей работы, рекомендуется использовать пользовательские конфиги, которые можно взять по следующим ссылкам:
Конфиг 1usmus_v3 — ссылка для скачивания
Конфиг extreme@anta777 — ссылка для скачивания
В случае обнаружения ошибок с использованием конфига 1usmus_v3, следует обратить внимание на возможные причины, которое перечислены в следующей таблице (на английском).
Нужный файл конфига следует распаковать в любое удобное место, после чего в программе TestMem5 нажать на кнопку «Load config & exit«, и выбрать ранее распакованный файл конфигурации. Программа автоматически закроется, после чего потребуется её запустить вручную.
- Позволяет проводить тестирование из операционной системы Windows
- Хорошо справляется с выявлением ошибок при разгоне
- Для эффективной работы требуются дополнительные действия с загрузкой файлов конфигурации
Prime95
Один из самых лучших вариантов проверки стабильности разгона оперативной памяти. Данная программа бесплатно распространяется на её официальном сайте, работает из под Windows, MacOS X, Linux и FreeBSD.
После скачивания архива, нужно распаковать его содержимое в любое удобное место и запустить исполняемый файл под названием prime95.
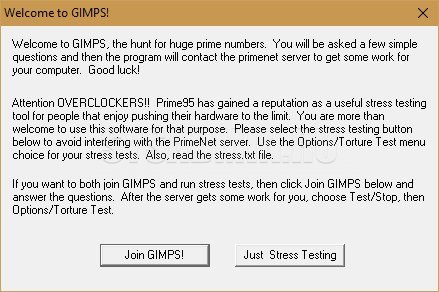
При первом запуске программа предложит присоедениться к проект по поиску простых чисел Мерсенна — но, если вас интересует лишь проверка оперативной памяти, нужно нажать кнопку «Just Stress Testing«. Далее, для лучшего результата проверки оперативной памяти, нужно выполнить небольшую настройку программы:
- В верхнем списке различных режимов тестирования отмечаем пункт «Custom«;
- Ставим в поле «Memory to use (in MB)» 70-80% от имеющейся оперативной памяти — например, если у вас в компьютере установлено 4GB оперативной памяти, то вписать стоит 2800;
- В поле «Time to run each FFT size (in minutes)» ставим минимум 120 минут (2 часа).
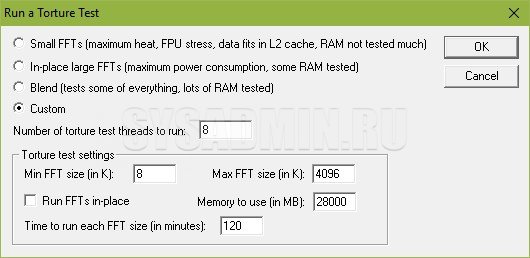
Теперь нажимаем кнопку «ОК», и смотрим, как проходит тестирование вашей оперативной памяти. Если во время теста будут найдены ошибки, то об этом будет сообщено в одном из многочисленных окошек программы.
- Широкие возможности по тестированию стабильности системы — кроме оперативной памяти, так же можно проверить стабильность работы процессора
- Не обнаружено
MemTest86
Одна из самых старых и авторитетных программ — MemTest86. Работает вне операционной системы, обладает достаточно простым интерфейсом. Загрузить её можно на сайте разработчика по этой ссылке.
Если вы планируете записать данный образ на диск, то достаточно скачать «Image for creating bootable CD (ISO format)». Если вы планируете записать программу на USB носитель (флешку), то скачать нужно «Image for creating bootable USB Drive».
Затем, нужно перезагрузить компьютер, и выбрать загрузку с внешнего накопителя. Начнется загрузка программы, после которой будет небольшое загрузочное меню. Если ничего не делать, то загрузка пойдет дальше, после чего программа сразу же начнет тестирование оперативной памяти.
Выглядит окно программы следующим образом:
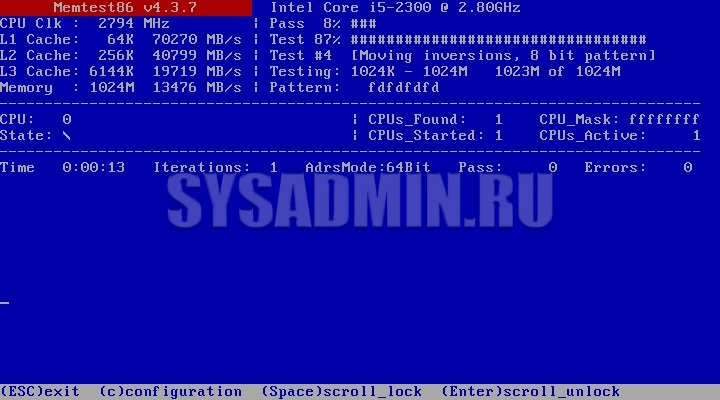
Данная программа по умолчанию не перезагружает компьютер по прохождению теста, а начинает его повторно. Прервать тест можно в любой момент нажав клавишу Esc. Узнать о количестве уже пройденных тестов можно посмотрев на значение «Pass«, рядом с которым так же находится и счетчик ошибок — «Errors». Если оно равно 0, то это значит, что ошибок не обнаружено. Программа проводит очень тщательные тесты, поэтому даже одно полное прохождение всех тестов может занять очень долгое время.
Для проверки стабильности разгона оперативной памяти рекомендуется дать пройти всем тестам не менее 10 раз.
- Не требует наличия установленной операционной системы
- Нет возможности запустить из под операционной системы
- Слабые возможности тестирования памяти при её разгоне
Что делать, если обнаружены ошибки памяти?
Ошибки в оперативной памяти могут возникнуть по разным причинам. Если вы разгоняли свою оперативную память, то вполне может быть, что ошибки возникают именно из-за этого — попробуйте снизить частоту памяти, или повысить её тайминги.
Если же вы ничего такого со своей оперативной памятью не делали, то для полной уверенности не лишним будет проделать следующее:
- Вытащить оперативную память из компьютера, протереть её контактную площадку от пыли, и вернуть её на место.
- Сбросить настройки BIOS (как сбросить настройки BIOS).
- Заново провести тесты памяти.
В случае повторного возникновения ошибок оперативной памяти уже можно будет нести оперативную память в магазин для замены по гарантии, или же принять решение о покупке новой.
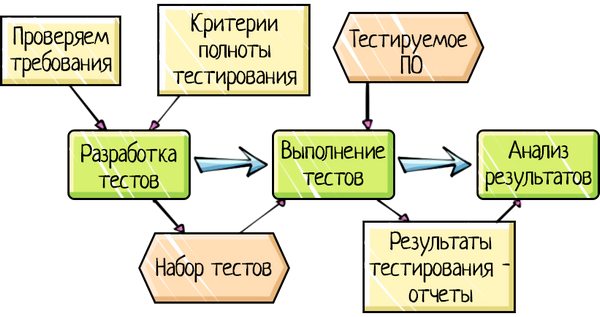
Тестирование программ
Тестирование
– процесс анализа программы или
контролируемого выполнения программы
на конечном множестве входных данных
с целью обнаружения ошибок
Статическое
– анализ текста программы
Динамическое
– анализ контролируемого выполнения
Методы
тестирования –
совокупность правил, регламентирующих
последовательность шагов по тестированию
Критерии
тестирования – оценки,
позволяющие судить о достаточности
выполненного тестирования
Результативным считается тест, который
приводит к обнаружению ошибки. Тестирование
– деструктивный процесс.
Тест
– набор входных данных, набор ожидаемых
результатов, набор условий, разработанных
для проверки определенного пути
выполнения программы.
Особенности
1) Частое отсутствие полностью определенного
эталона, которому должны соответствовать
результаты
2) Высокая сложность программ исключает
исчерпывающее тестирование (проверка
всех возможных маршрутов выполнения)
3) Невысокая формализация критериев
завершения тестирования
Основные принципы тестирования
1) Нельзя планировать тестирование в
предположении, что ошибки отсутствуют
2) Следует избегать тестирования программы
ее автором
3) Описание предполагаемых значений
результатов должно быть неотъемлемой
частью теста
4) Тесты для неправильных входных данных
следует разрабатывать также тщательно,
как и для правильных
5) Следует понимать, сто вероятность
наличия необнаруженных ошибок
пропорциональна числу уже обнаруженных
6) Не следует выбрасывать тесты, даже
если программа уже не используется
Объекты тестирования. Категории тестов
1) Спецификации программных модулей,
групп программ и программных комплексов
— полнота и согласованность функций
программных компонент
— согласованность интерфейсов программных
компонент (для групп программ и комплексов)
2) Программные модули
— структура
— преобразование данных, выполняемое
модулем
— полнота функций, выполняемых модулем
3) Группы программ, объединенные для
решения законченной функциональной
задачи
— то же, что и для модулей
— интерфейс между программами
— тестирование потребления ресурсов
4) Программный комплекс, используемый
для решения нескольких функциональных
задач
— полнота решения функциональных задач
— функционирование программ в критических
ситуациях
— тестирование потребления ресурсов
— оценка надежности работы комплекса
— эффективность защиты от искажения
общих данных
5) Программное средство, сдаваемое в
опытную эксплуатацию
— то же, что и для 4)
— удобство инсталляции рабочей версии
программы
— проверка работы при изменении
конфигурации оборудования
— проверка наличия и корректности
документации
— испытание на соответствие техническому
заданию
6) Программное средство на стадии
сопровождения
— удобство модификации, типа расширения
функциональности и повышения эффективности

1 – Спецификации
2 – Модули
3 – Группы программ
4 – Программные комплексы на стадии
отладки
5 – Программные комплексы как продукты
Виды и методы тестирования
Особенности нисходящего тестирования:
Достоинства:
— с самого начала выполняется проверка
главных функций – концептуальная
проверка
Недостатки:
— необходимость разработки заглушек,
часто достаточно интеллектуальных
—
параллельная разработка модулей
различных уровней не всегда обеспечивает
возможность нужной последовательности
тестирования модулей разных уровней
Особенности восходящего тестирования
Достоинства:
— для тестирования используются готовые
модули нижних уровней
Недостатки:
— необходимость разработки тест-драйверов
для управления работой нижних уровней
с верхних
— отложенная проверка основной концепции
функционирования комплекса
1) Модульное тестирование. Включает
проверку:
— корректности структуры модуля
— корректности основных конструктивных
компонент
— полноты и качества реализации функций
обработки данных
Структурная корректность проверяется
структурными методами по принципу
«белого ящика»
2) Интеграционное тестирование. Проверка:
— корректности объединения модулей в
группу или комплекс программ
Проводится на основе 2-х подходов:
— монолитное тестирование, при котором
модули сразу объединяются в единый
комплекс и после этого вместе тестируются
— инкрементальное (пошаговое), модули
подключаются друг к другу последовательно
(снизу вверх или сверху вниз)
Использует структурную проверку
подключаемых модулей и функциональную
проверку полноты и качества реализации
функций. Функциональные проверки
осуществляются по принципу «черного
ящика»
3) Системное тестирование. Обеспечивает
проверку соответствия программного
средства специфицированным требованиям
в заданной среде и режимах функционирования.
Предусматривает следующие виды
тестирования:
— тестирование функциональности
— стрессовое тестирование (тестирование
на повышенных нагрузках по использованным
ресурсам)
— тестирование безопасности (защита от
несанкционированного доступа)
— тестирование восстановления при сбоях
В последнее время стало широко применяться
альфа и бета тестирование – это виды
тестирования, выполняемые с участием
заказчика. Альфа тестирование выполняется
на территории разработчика в условиях
ограниченного времени (не более недели).
Бета тестирование выполняется после
введения программы в опытную эксплуатацию
на территории заказчика, проводится
достаточно долго (норма 1 год).
Статистика ошибок в программных продуктах
по типам.
|
Ошибки спецификации |
8.1 |
|
Структурные ошибки |
25.2 |
|
Ошибки представления |
22.4 |
|
Полнота и корректность |
16.2 |
|
Кодирование |
9.9 |
|
Интеграция |
9.0 |
|
Системные |
3.0 |
|
Прочие |
остальные |
Методы тестирования
Все методы делятся на две неравнозначных
группы:
— статическое (ручное)
— динамическое (машинное)
Основные методы ручного:
— инспекция кода
— сквозной просмотр
Методы динамического:
— структурные
— функциональные
Методы статического тестирования
Общая
черта – они используют визуальный
контроль программы по ее тексту группой
из 3-4 человек, один из которых автор
программы. Целью проверки является
обнаружение ошибок, но не их устранение.
Основная концепция – наличие ошибок
не есть вина автора программы, а
несовершенство средств разработки
программы и сложность программы как
некоторой системы. При нормальном
проведении статические методы тестирования
позволяют обнаруживать 30-70% первоначальных
ошибок в программе. Они, в отличие от
машинных, позволяют обнаруживать типовые
группы ошибок автора.
Инспекция
кода. В группу входит 4 человека:
руководитель проведения инспекции,
автор программы, проектировщик и
тестировщик. За неделю до инспекции
руководитель раздает всем участникам
листинг программ, которые будут
инспектироваться.
2 этапа:
1) автор рассказывает логику работы
программы и отвечает на вопросы,
преследующие цель обнаружения ошибок
2) программа анализируется по типовому
списку часто встречающихся ошибок:
— ошибки обращения к данным
(неинициализирование данных, выход
индексов за границы массивов, ссылки
на пустую память)
— ошибки описания данных, соответствие
заданных типов и значений
— ошибки вычислений
— ошибки передач управления (зацикливание,
корректность завершения программы)
— ошибки интерфейса (ошибки, связанные
с взаимодействием частей друг с другом)
— ошибки ввода/вывода
Результат инспекции кода:
— обнаруженные ошибки
— обучение автора улучшенным методам
кодирования программ
Сквозной просмотр. Начинается так же
как и инспекции кода, но в процессе
заседания группы ознакомление с
программой выполняется путем небольшого
числа сеансов ручного тестирования
программы на простых данных.
Динамическое тестирование
Структурное тестирование программных
модулей
При структурном тестировании проверяется
— прохождение тестов по логике программы,
в качестве элементов которой выступают
вершины, дуги, маршруты, условия и
комбинации условий управляющего графа
программы
— в последнее время проверяется прохождение
потока данных по информационному графу
программы, которое выявляет аномалии
в обработке данных
Тестирование на основе потока управления

Вводят критерии отбора элементов для
тестирования:
1)
покрытие операторов (покрытие вершин
УГП, покрытие строк кода). Необходимо
проверить выполнение каждого оператора
хотя бы один раз. Нужно реализовать путь
a-c-e
(например при тестовом наборе a=2,
b=0, x=3,
результат x=2.5). Не проверяется
прохождение пути a-b-d.
Не проверяются отдельные условия,
например OR вместо &.
Является самым слабым критерием и
используется только при первоначальной
проверке.
2) Покрытие ветвей (решений). Необходимо
проверить каждую дугу выполнения
программы. Этот критерий включает в
себя предыдущий.
1) Покрытьдугиa-c-e, a-b-d
2) Покрытьдугиa-c-d, a-b-e. A=3, B=0, X=3иA=2, B=1,
X=1
Не
выполняет обнаружения всех ошибок,
например, если вместо x>1
будет x<1. Критерий не
является исчерпывающим
3)
Критерий покрытия условий. Каждое
условие, используемое в программе должно
выполняться хотя бы один раз. Используются
следующие условия: A>1,
B=0, A=2, x>1.
Нужно реализовать проверки: A>1,
A<=1, B=0,
B!=0, A=2, A!=2,
x>1, x<=1.
Для проверки этого достаточно следующей
пары тестов: (A=1, B=0,
X=3) идет по пути a-b-e
и (A=2, B=1,
x=1) идет по пути a-b-e.
Оба теста проверяют один и тот же путь.
4) Комбинированный критерий «условий/решений»,
который должен проверять все условия
в программе и хотя бы один раз пройти
по каждой дуге.
Следующие
тестовые наборы: (A=2, B=0,
x=4) a-c-e,
(A=1, B=1, x=1)
a-b-d.
5) Комбинаторное покрытие условий. Должны
быть покрыты следующие комбинации
условий:
(1)
A>1, B=0
(2)
A>1, B!=0
(3)
A<=1, B=0
(4)
A<=1, B!=0
(5)
A=2, x>1
(6)
A=2, x<=1
(7)
A!=2, x>1
(8)
A!=2, x<=1
Тестовые наборы:
(A=2,
B=0, x=4) (1,5)
(A=2,
B=1, x=1) (2, 6)
(A=1,
B=0, x=2) (3, 7)
(A=1,
B=1, x=1) (4,
6) Критерий покрытия вызовов. Обеспечивает
проверку корректности вызова каждой
процедуры или функции в программе.
7)
Критерий покрытия путей. Применяется
в ограниченном варианте, когда при
использовании циклов рассматриваются
только отдельные варианты проверки
цикла: тело цикла не выполняется ни
разу, тело цикла выполняется один раз,
тело цикла выполняется k
раз (k<=n –
максимально возможное число повторений),
тело цикла выполняется n
раз, тело цикла выполняется n+1
раз. Является очень сложным и громоздким,
применяется только при очень тщательном
тестировании.
Структурное тестирование на основе
потока данных
Работа
любой программы представляется как
обработка потока данных, передаваемых
от ее входа на выход. Если имеется
управляющий граф программы вида

Информационный граф программы
представляется пунктирными линиями.
Для
каждой вершины i УГП можно
определить множество def(i)
– данных, определенных в этой вершине
и множество use(i)
– данных, используемых в этой вершине.
Для
тестирования надо выделить DU
цепочки, которые имеют следующий вид
DU=(Data, i,
j), Data – данное, i
– вершина, в которой создается данное,
j – вершина, в которой
используется данное.
Для
нашего примера множество DU
цепочек:
DU={(a,
1, 4), (b, 1, 3), (b,
1, 6), (c, 4, 6)}.
После
формирования набора DU
цепочек выполняется отображение DU
цепочек во фрагменты УГП, соответствующие
путям определения и использования
данной цепочки.
Для
цепочки (a, 1, 4) путь 1-2-3-4.
По информационному графу программы
порождается путь в управляющем графе
программы, который тестируется. Этот
способ называется «стратегия требуемых
пар»
Недостаток:
трудность выбора минимального количества
тестов, обеспечивающих эффективную
проверку всех DU цепочек.
Функциональное тестирование (ФТ)
Структурное тестирование не позволяет
проверить все функции, возлагаемые на
программу, потому что некоторые функции
могут просто отсутствовать в предложенной
реализации.
Функциональное тестирование – это
тестирование, необходимое для проверки
соответствия программного продукта
функциональным требованиям, заданным
в спецификации. При выполнении ФТ логика
работы программы игнорируется и все
внимание фокусируется на выходных
значениях, полученных в результате
обработки заданных входных наборов.
Обычно ФТ обнаруживаются следующие
виды ошибок:
1) некорректные или отсутствующие функции
2) ошибки интерфейса
3) ошибки потребления ресурсов (превышение
занимаемых памяти или времени выполнения)
4) ошибки инициализации или завершения
программы
Для проведения ФТ необходимо иметь:
наборы входных данных, приводящих к
аномалиям выполнения программы, наборы
выходных данных, позволяющих обнаруживать
дефекты в работе программы.
Методы ФТ должны обеспечивать:
1) сокращение необходимого числа тестовых
вариантов (проверки выполняются
динамически)
2) выявлять классы ошибок, а не отдельные
ошибки
Методы ФТ как правило применяются на
более поздних стадиях тестирования,
чем структурные.
Примеры.
Метод разбиения на классы эквивалентности.
Область
входных данных разбивается на классы
эквивалентности (КлЭ), представляющие
собой набор данных с общими свойствами,
обработка которых программой производится
совершенно одинаково. При обработке
используются одни и те же операторы и
одни и те же связи. КлЭ делятся на
правильные (допустимые) и неправильные.
КлЭ определяются по спецификации на
программу, например следующим образом:
20000<=x<=80000, правильный
КлЭ — 20000<=x<=80000, 2
неправильных КлЭ – x<20000,
x>80000. Разработка тестов
состоит из 2 этапов:
1) разбиение на КлЭ
2) построение тестов
Выделение КлЭ по спецификации – процесс
эвристический
Рекомендации
1) если проверяемое входное данное
представлено в виде диапазона значений,
то строится один правильный класс
(внутри диапазона) и два неправильных
2) если конкретное значение, то строится
один правильный и два неправильных КлЭ
3)
если входное условие описывает множество
значений m={a,b,c},
то строится по одному правильному классу
для каждого из значений и один неправильный
класс для значений, не принадлежащих
множеству (m!=a)&(m!=b)&(m!=c)
4) если есть основание считать, что
элементы КлЭ трактуются программой
неодинаково, то этот класс необходимо
разбить на меньшие классы с разнесением
по-разному трактуемых элементов
Построение тестов.
1) Каждому КлЭ присваивается уникальный
номер
2) Строятся тесты для правильных КлЭ,
чтобы каждый тест покрывал как можно
больше этих классов
3) Строятся тесты для неправильных
классов, которые должны быть индивидуальны,
поскольку проверки с ошибочными входами
могут скрывать друг друга.
Анализ граничных условий.
Метод является развитием предыдущего
в том смысле, что под граничными условиями
понимаются ситуации, возникающие на
границах входных и выходных КлЭ.
Отличается от предыдущего
1)
при выборе элементов КлЭ используются
значения на и вблизи границ классов
-1.0<=x<=1.0 x={-1.0,
1.0, -1.01, 1.01}
2) метод должен рассматривать не только
входные, но КлЭ для выходных значений.
Общее правило использования метода:
1) построить тесты для значений, лежащих
на границе области, и тесты с неправильными
данными, немного выходящих за пределы
границ
2) если обрабатывается определенное
количество файлов в заданном диапазоне,
то построить тесты для граничных значений
файлов, на 1 больше и меньше верхней и
нижней границы соответственно
3) применить подходы 1, 2 для каждого из
выходных значений
4) если проверяется упорядоченное
множество значений, то необходимо
выполнить проверки первого и последнего
элементов.
Недостатками рассмотренных методов
является то, что они не позволяют
проверять комбинации условий.
Метод
функциональных диаграмм (метод диаграмм
причинно-следственных связей ДПС)
Метод позволяет формально генерировать
результативные тесты, позволяющие
обнаруживать неоднозначность требований
спецификаций при комбинировании входных
условий
Функциональная диаграмма – это формальный
графо-аналитический язык, позволяющий
описывать спецификации, написанные на
естественном языке.
Методика построения функциональных
диаграмм
1) спецификация разбивается на «рабочие
участки», т.е. такие участки, для которых
диаграмма не будет слишком громоздкой
2)
спецификации выделяются причины и
следствия. Причина – отдельное входное
условие или КлЭ входных условий, следствие
– выходное условие, результат выполнения
программы. Каждой причине и следствию
присваивается уникальный номер
3) анализируется семантика информации,
заданной в спецификации, и строится
булевский граф, связывающий причины и
следствия, который является функциональной
диаграммой. Каждый узел графа может
принимать 2 значения: 1 – присутствует
(выполняется)
Для представления диаграмм используются
следующие базовые символы:

Пример.
Задана спецификация. Файл обновляется,
если символ, считываемый в позиции 1
равен а А или Б, а символ в позиции 2 стоит
цифра. Если первый символ ошибочный, то
сообщение Х1, если второй не цифра, то
сообщение Х2.
Причины
1) символ в позиции 1 равен А
2) символ в позиции 1 равен Б
3) символ в позиции 2 цифра
Следствия
1) файл обновляется
2) выдается сообщение Х1
3) выдается сообщение Х2

В приведенной диаграмме есть проблема:
никак не ограничено применение причин
1 и 2.
Для учета невозможных комбинаций причин
или следствий предусмотрены дополнительные
базовые элементы.

Е – не могут быть одновременно
I
– не могут быть одновременно 0
R
– требует (a=1, то и b=1)
M
– запрещает (a=1, то b=0)
С учетом этого:

Генерация таблицы решений
Использование столбцов таблицы решений
в качестве тестов
Генерация таблицы решений:
1) Формируются строки, соответствующие
причинам и следствиям
2) Выбирается некоторое следствие,
которое имеет значение 1
3) Находятся комбинации причин, которые
обеспечивают такое значение следствия
Незаполненные элементы строк причин
могут принимать любые значения
|
1 |
1 |
0 |
0 |
|
|
2 |
0 |
1 |
0 |
|
|
3 |
1 |
1 |
0 |
|
|
4 |
1 |
1 |
||
|
5 |
1 |
|||
|
6 |
1 |
Используемые тесты будут иметь следующий
вид
1)
A 2
2) B
2
3) 1
1
4) A
A
Метод, основанный на предположении об
ошибке (метод отрицательного тестирования)
Сущность основана на опыте тестировщика
и идея заключается в перечислении
некоторого набора возможных ошибок,
для обеспечения которого пишутся тесты.
Метод определяет способы как заставить
программу сделать ошибку или прекратить
выполнение. У проектировщиков выявляются
требования для успешного выполнения
программы и далее разрабатываются
тесты, каждый из которых нарушает одно
из требований. Проверяется устойчивость
программы к исключительным ситуациям.
1) запуск на другой платформе
2) перестановка значений в файле
3) отсутствие данных в БД
4) неверные или отсутствующие значения
параметров конфигурации
Общая стратегия разработки тестов
1) проверить логику программу с помощью
методов структурного тестирования по
критериям покрытия операторов, покрытия
ветвей (условий), покрытие решений
условий, комбинаторное покрытие условий
2) проверка функциональности программы
с помощью методов ФТ. Если есть комбинации
входных условий, то надо начинать с
метода функциональных диаграмм, затем
разбиение на КлЭ, анализ граничных
условий, метод отрицательного тестирования.
Критерии завершения тестирования
Обычно применяется 3 группы
1) критерии, основанные на определенной
методологии тестирования, определяющей
процент покрытия тестами логики и
функциональности программы.
2) критерии, основанные на экспертных
оценках возможного числа ошибок,
имеющихся в программе данного класса
и целевого назначения.
3) критерий, основанный на временной
диаграмме тестирования для каждой фазы
разработки программы

Тестирование — это не поиск ошибок!
Время на прочтение
5 мин
Количество просмотров 147K
Многие считают, что тестирование ПО — это поиск ошибок. Иногда я говорю тестировщикам: «не старайся найти как можно больше ошибок, старайся пропустить как можно меньше!», и меня не понимают: а в чём разница?
А разница огромная! В этой статье я хочу рассказать, в чём она заключается, и какие инструменты необходимо использовать для настоящего полезного тестирования.
Что такое поиск ошибок?
Я тестирую продукт. Моя задача — завести как можно больше багов. Оно и логично! Заводить баги тестировщику всегда приятно, это видимый измеримый результат работы, И чем их больше, тем больше меня ценят как тестировщика.
Какие области я буду тестировать в таком случае? В первую очередь, самые нестабильные. Зачастую они нестабильны потому, что менее приоритетны, но это неважно, значительно важнее количество багов.
Что будет, если я столкнусь со сложновоспроизводимым багом? ROI на его исследование считается в голове очень быстро. Зачем мне с ним возиться, если я за это же время смогу завести 3 менее критичных, зато простых в заведении?
Какие тесты я буду проводить в первую очередь? Конено, самые нестандартные. Ввести в поле логина «Войну и мир», поделить на ноль, вставить в профиль фотографию в формате .exe.
Скажу по секрету — иногда на собеседованиях тестировщики в ответ на просьбу «протеструйте калькулятор» перечисляют интересные и дельные тесты, но в числе первых тридцати нет теста «проверить сложение» и другие базовые операции.
Именно так выглядит поиск ошибок — не имеющий ничего общего с тестированием.
Что такое тестирование?
Я тестирую продукт. Моя задача — пропустить как можно меньше приоритетных для пользователя багов. Чем меньше багов пропущено, чем меньше недовольства клиентом выражено — тем выше я оцениваю эффективность своей работы.
Какие области я буду тестировать в этом случае? Естественно, я начну с самых приоритетных для пользователя. Даже если они стабильно и успешно работают, я всё равно буду проверять основные пользовательские сценарии, чтобы ни в коем случае не пропустить серьёзных проблем.
Что будет, если я столкнусь с трудностями? К примеру, со сложновоспроизводимым дефектом, или непониманием бизнес-процесса пользователя, или нехваткой требований? Если это важный функционал, то я буду выяснять «что не так», «как правильно». На заведение дефекта в итоге может уйти немало времени, и с точки зрения баг/время результат эффективности тестирования будет не очень высок, зато у меня появятся более глубокие знания о продукте, архитектуре, пользователях.
Какие тесты я буду проводить в первую очередь? Конечно, самые-самые стандартные. Выполнение самого основного сценария в самых основных условиях, чтобы убедиться, что самый важный функционал работает. И только после этого я перейду к менее стандартным сценариям.
Результаты тестирования и поиска ошибок
В случае с поиском ошибок, в краткосрочной перспективе результаты выше: багов заводится больше и сразу.
Но в долгосрочной перспективе всё не так радужно:
- из-за отсутствия глубоких знаний о продукте, постепенно начинает расти % пропущенных дефектов
- команда разработки занята исправлением страшных-ужасных-немыслимых багов, полученных путём клика на одну и ту же кнопку 144 раза под IE в полнолуние
- в релиз попадают некоторые ужасно неприятные и очевидные для пользователя баги
- количество находимых ошибок в ДОЛГОСРОЧНОЙ перспективе падает
Как перейти от поиска ошибок к тестированию?
Чтобы тестирование было эффективным и полезным в долгосрочной перспективе, необходимо следовать простым правилам и использовать ключевые инструменты тестирования:
1. Анализ продукта и документирование тестов
Кликая на кнопки, можно завести много багов — но нельзя сказать, что было проверено. Единственное решение — документирование тестов. Подробные тест-кейсы, удручающие тестировщиков и отнимающие уйму времени, бывают нужны очень редко. А вот чек-листы с перечнем «что нужно проверить» — необходимы.
Что они дают:
- Вы анализируете продукт, выписываете основные фичи, действия, их параметры. Таким образом существенно снижается риск что-либо забыть.
- Чек-листы — отличная напоминалка «здесь надо вникнуть глубже». Есть какая-то невнятная фича с недостаточным описанием. Как её тестировать? В тестировании без тестов проще всего сказать «я вернусь к этому позже», и уже никогда не вернуться. А с тестами — у вас будет висеть тест, в котором непонятно как и что проверять, вы будете такие тесты видеть и не забудете необходимость выяснения.
- Чек-листы можно и НУЖНО согласовывать. С разработчиками, аналитиками. Вся команда включается в процесс тестирования, тестировщики узнают много нового о продукте, коллективный разум улучшает качество тестирования. И помимо однократного повышения качества отдельно взятого чек-листа, повышается качество тестирования в целом: тестировщики начинают больше учитывать в тестировании, развиваться, эти знания со временем окупаются в виде более результативного тестирования.
Залог успеха в ведении тестов — создание карты, по которой вы будете идти. Цель — покрыть весь продукт. Только пожалуйста, не надо отмазок об ужасной ресурсоёмкости — я покрывала проекты с миллионами строк кода меньше чем за месяц-полтора. И в процессе написания таких тестов поднимались неожиданные вопросы и всплывали критичные ошибки, которые несмотря на наличие горе-тестеров болтались в продукте годами.
2. Оценка тестирования
Чтобы не быть слепыми котятами, необходимо оценивать эффективность тестирования. Анализировать пропущенные ошибки и причины их пропуска. Покрытие функционала и кода тестами. Уровень удовлетворения пользователей, через анкеты и сбор обратной связи. Качество заведения ошибок, опрашивая разработчиков.
ВСЕГДА есть что улучшать, и отсутствие непрерывного процесса совершенствования — неизбежное болото.
3. Обсуждение целей тестирования с командой
Многие считают, что у тестирования есть какие-то мифические цели. И что они всегда одинаковы.
Как бы не так!
В каждом проекте, компании, команде цели свои собственные. Все ли их понимают одинаково? Проговаривали ли вы их вслух?
Чтобы приносить максимум пользы, надо хорошо понимать, в чём эта самая польза заключается. И не удивляйтесь, если мнение РМов и разработчиков не будет соответствовать вашему. Надо не переубеждать их, а подстраиваться под текущие проектные цели!
4. Понимание пользователей и их бизнес-процессов
Для меня загадка, как это возможно, но тем не менее это факт: зачастую тестировщики проверяют продукт, ничего не зная о пользователе.
- Как этот продукт используется?
- Зачем он вообще нужен, какие проблемы решает?
- Какая средняя квалификация у пользователей?
- В каких условиях работают пользователи? На каких окружениях, оборудовании?
Не надо догадок и додумок про «в среднем про отрасли»! Тестировщики должны ИДЕАЛЬНО знать СВОИХ пользователей. Часто им эту информацию не предоставляют аналитики. Одумайтесь! Не зная пользователя, тестировать продукт по-нормальному невозможно.
5. Техническая квалификация и понимание архитектуры
Для иллюстрации приведу баг, который на меня недавно завели в баг-трекере:
Зайти на сайт тестируемого продукта http://****.ru в браузере Firefox
Ввести логин и пароль
Зайти с того же компьютера в браузере Opera
Просит повторно ввести логин и пароль, автоматически не логинится.
Такие баги не просто бесполезны, они позорят тестировщиков и дискредетируют отрасль в целом! Чтобы заводить дефекты правильно, необходимо понимать платформу, на которой написан тестируемый продукт. Если мы говорим про веб-тестирование, то можно хотя бы указать в баг-репорте возвращаемый сервером код ошибки, посмотреть подробности файрбагом, предоставить подробную информацию и сэкономить разработке массу времени!
Выводы
Очень многие разработчики не любят тестировщиков. И правильно делают!
Зато хороших тестировщиков любят и ценят все. Но тестировщиков, а не кликеров и багозаводильцев!
Учитесь узнавать, что не так, что не нравится другим участникам команды разработки. Обязательно исследуйте пропущенные ошибки и делайте всё для того, чтобы больше их не пропускать. Не гонитесь за заведением багов — вашей мантрой должны быть «счастье пользователя», «качественный продукт» и «успешный проект», а не «завести как можно больше багов» — ОЧЕНЬ часто эти 2 цели оказываются слишком далеки друг от друга.
И да пребудет с вами сила!
Это для опытного специалиста разница очевидна. А для начинающего между этими двумя процессами обычно стоит знак равно. Давайте раз и навсегда закроем вопрос о том, почему тестирование и поиск багов — это разные вещи.
Отдельное спасибо всем, кто принял участие в обсуждении данного вопроса. Дополнил статью вашими интересными рассуждениями.
Ну что, давайте разберемся.
Сначала разберем, что же такое поиск ошибок и как мы будем себя при нем вести.
Поиск багов
Итак, моя задача — найти баги. Что я буду делать? Искать как можно больше багов. Это логично. А чем больше я их найду, тем лучше. Ну и тем моя ценность, как сотрудника, выше.
Так, а где найти как можно больше багов? Конечно в самых нестабильных областях программы. И не важно значимы они или нет. Чем нестабильней, тем привлекательней.
Также не важно насколько абсурдными будут действия. Главное, что они приведут к багу. Никто не будет нажимать 100 раз подряд на эту кнопку? Не важно, зато это приводит к ошибке. Правда пропущу много критических, ведь буду копаться только там, где возможно большая концентрация багов.
А что делать с багами, которые сложно воспроизвести? Давайте подумаем: лучше найти 1 серьезный, но сложно воспроизводимый, баг или 10 обычных. Конечно 10 обычных. Ведь задача просто найти баги. И чем больше, тем лучше.
Что мы имеем в итоге?
- не проверили основные и значимые участки кода,
- пропустили много критических багов,
- в принципе не проверили программу на работоспособность (позитивное тестирование). Ведь нам не нужно убеждаться, что программа работает. Нам просто нужно искать баги.
Тестирование
Теперь к тестированию. Какими наши действия будут тут?
Задача тестирования — не найти ошибки, а проверить корректность работы программы. То есть на выходе мы должны иметь не 100 найденных багов, а работающий продукт.
А что главное для пользователя в продукте? Отсутствие проблем при работе с основными важными функциями. Чтобы при вводе корректных данных мы получили ожидаемый результат.
Получается, что тестировать начнем не с самых нестабильных участков, а самых значимых и с тех, где высока вероятность нахождения критических багов.
Поскольку мы не гонимся за количеством, то уделим внимание сложно воспроизводимым багам. Это позволит не пропустить хоть и сложных, но значимых ошибок.
Если в какой-то момент не хватит информации для тестирования, то пойдем тратить время на поиск этой информации, а не забудем об этом и побежим в другое забагованное место. И в спорных ситуациях «баг или фича», потратим время, чтобы разобраться в этом. Потому что важно, чтобы продукт точно вышел в свет без бага.
Что мы имеем в итоге?
- в первую очередь проверяем значимые участки кода и основные функции продукта,
- пропускаем меньше багов,
- сначала проверяем работоспособность программы при вводе корректных данных. Это как раз то, что ждет пользователь от продукта.
- в перспективе количество пропущенных багов сокращается, так как мы работаем над качеством продукта и стремимся к тому, чтобы в нем в принципе было как можно меньше багов.
Разница
Давайте на примере из жизни. Есть стиральная машина. При поиске ошибок мы будем пробовать нажать на кнопку выключения 50 раз подряд. Потом во время стирки покрутим переключатель программ во все стороны 20 минут без перерыва.
Но мы не проверим, запускается ли она при одинарном нажатии на кнопку пуск или нет. Ведь в этом месте вряд ли найдется ошибка. А если в этом месте она будет, то мне, как пользователю, такая стиральная машинка будет не нужна и я от нее откажусь.
А теперь ближе к тестированию. Возьмем сайт по заказу пиццы. Где искать ошибки? Конечно будем добавлять в корзину невообразимое количество пицц. Еще попробуем уменьшать и увеличивать количество персон 50 раз подряд. Потом в поле отправки заказа будем вводить такое, что просто не вообразить.
А банальную проверку отправки заказа обойдем стороной. И если там был баг, то никто не сможет оформить заказ.
Чувствуете разницу? Она просто колоссальная.
________________________________
В случае с поиском ошибок мы по факту совсем не заботимся о качестве продукта.
________________________________
Именно поэтому поиск ошибок — это путь в никуда, а точнее к забагованному продукту. А тестирование — это возможность выпускать качественный продукт, с которым пользователю будет приятно работать и к которому он будет возвращаться снова и снова.
Как верно отметил Дмитрий Безносов, продукт может быть без единого дефекта (условно), но совершенно непригоден к использованию юзерами как в плане UI/IX, так и в плане функциональности.
А Ольга Журавлёва написала, что как раз на первых порах идет эта гонка за багами, потому что они создают ощущение выполненной работы. А вот уже кто эту зависимость преодолел и понял сакральный смысл тестирования — тот уже не джун, а мидл.
То есть начинающему специалисту трудно, когда он не может измерить результат своей работы, поэтому и начинается гонка за количеством. А это путь в никуда.
***
Кто-то может сказать, что я сильно преувеличиваю. Может в краткосрочной перспективе так и покажется. Но на длинной дистанции однозначно придем к тому, что продукт перестанет соответствовать ожиданиям пользователей и от него попросту отвернутся.
Доброго времени суток, дорогие друзья, знакомые, читатели, почитатели и прочие личности. Сегодня будем тестировать компьютер через OCCT.
Частенько бывает необходимо узнать причину возникновения синих экранов смерти, да и просто любых проблем, начиная от перезагрузок/зависаний и заканчивая перегревами и самовыключениями компьютера.

В «полевых» (т.е в обычных рабочих) условиях это сделать не всегда возможно, ибо некоторые проблемы имеют довольно своеобразный, так сказать, плавающий характер и диагностировать их не так просто. Да и обычно мало просто узнать, что виновато именно железо, а не программная часть, но необходимо еще понять что именно строит козни, а точнее какая конкретно железка глючит. В таких ситуациях нам на помощь приходит специализированный софт для проверки стабильности.
В своё время я уже писал о подобном тесте на основе программы AIDA64. В общем-то, он неплохо справлялся со своими задачами, но, признаться, не был достаточно мощен и удобен в ряде аспектов, которые требуются для столь серьезного дела. Здраво поразмышляв, я решил поделиться с Вами еще одной более мощной программой-тестером стабильности, которая позволит выявить все проблемные места Вашего компьютера.
Интересно? Тогда поехали.
-
Общий обзор возможностей OCCT
-
Почему именно она
-
Загрузка, установка и использование
-
Как вообще тестировать компьютер
-
Тест стабильности процессора и памяти
-
Предпреждение по тестированию
-
Тест стабильности видеокарты OCCT
-
Тест стабильности блока питания OCCT
-
Анализ результатов тестирования OCCT
-
Послесловие
Общий обзор возможностей OCCT
Речь пойдет о утилите OCCT, которая полностью называется этаким советским именем OCCT Perestroпka.
Само собой, что как и многое о чем мы тут пишем, она полностью бесплатна и поддерживает русский язык, что не может не радовать.
OCCT представляет собой мощнейший инструмент для диагностики и тестирования стабильности различных компонентов Вашего компьютера. Она позволяет комплексно или отдельно тестировать процессор (CPU), подсистемы памяти, графическое ядро (GPU) и видеопамять, системы питания, а так же, вдовесок ко всему, снабжена функциями мониторинга температур, вольтажей и всего прочего на основе нескольких типов датчиков.
к содержанию ↑
Почему именно она
Даваемые нагрузки на компоненты системы, а так же мощнейшая система регистрации ошибок, позволяют получать самые полные и точные результаты. Что приятно, — результат каждого теста выводится в виде наглядных графиков, иллюстрирующих необходимые данные.
Кроме того, некоторые тесты имеют специальный 64-х битный режим для лучшей работы на соответственных операционных системах и ПК. В общем, то, что нужно каждому.
Визуально (на момент обновления статьи) выглядит примерно так:
Скриншот кликабелен. Давайте теперь загрузим её, установим и попробуем использовать.
к содержанию ↑
Загрузка, установка и использование
Взять можно с сайта разработчика. Установка как таковая не требуется (если скачивать ZIP-версию, т.е архив, который можно просто распаковать чем-то вроде 7-zip), либо предельно проста (если Вы скачивали установщик, он же Installer), поэтому на этом я останавливаться не буду.
После запуска перед собой мы увидим красненькое СССР-образное окно программы (см.скриншот выше) в котором, по идее, сразу должен быть выставлен русский язык. Перед этим может появиться окно с кнопкой пожертвования, пока его можно закрыть (ну или сразу поддержать разработчика, дело Ваше).
Если это не так, то нажмите в значок шестерёнки справа, после чего задайте нужный параметр. Либо используйте как есть.
к содержанию ↑
Как вообще тестировать компьютер
Программа имеет набор вкладок:
- CPU:OCCT и CPU:LINKPACK, — тестирование стабильности процессора в стрессовых условиях (по нагрузке, питанию, температуре и тп);
- GPU:3D, — тестирование стабильности видеокарты;
- POWER SUPPLY, — тестирование стабильности элементов питания (мат.платы, блока питания, цепей и пр, в общем нагрузочные тесты).
Давайте попробуем каждый из них, т.к каждый имеет свои параметры.
ВНИМАНИЕ! С осторожностью применяйте OCCT на ноутбуках по причине высокой создаваемой нагрузки и прогрева. На ноутбуках со слабой/поврежденной системой охлаждения (и других элементов) это может привести к непредсказуемым последствиям. Вероятно разумно использовать на них AIDA64.
Перед тестом зайдите в вышеупомянутые настройки (где задавали язык) и выставьте ограничитель температуры процессора (чаще всего 85 слишком большое значение) и других (при необходимости) компонентов.
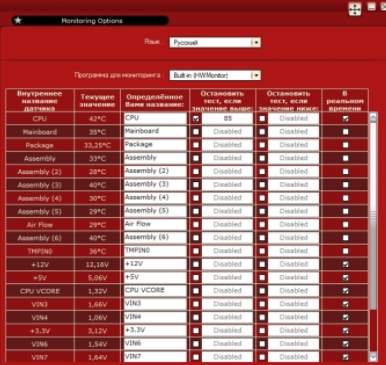
Не забывайте ставить галочки в соответствующих столбцах, чтобы ограничитель работал. Старайтесь не трогать значения питания (V). Если Вы не понимаете, зачем всё это может быть нужно, то либо не делайте этого (ограничения температур), либо прочитайте следующую статью.
Теперь к тестированию.
к содержанию ↑
Тест стабильности процессора и памяти
Самая первая вкладка, а именно CPU: OCCT позволяет запустить тест на проверку либо только центрального процессора, либо центрального процессора и памяти, либо центрального процессора + памяти + чипсета.
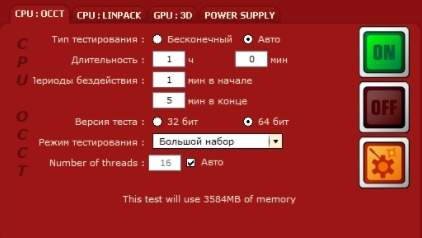
Делается это следующим образом. Выставляем:
- Тип теста: авто;
- Длительность теста: 1 час 0 минут;
- Режим теста: большой набор данных.
Комментарии по пунктам, которые выставили:
- Работает заданное время, т.е час и более (либо до обнаружения ошибки), позволяет не тратить лишнее время на диагностику;
- Время теста, — это время теста;
- Набор данных, — определяет уровень нагрузки и создаваемый нагрев, а так же количество тестируемых элементов. Если набор данных малый, то тестируется только процессор, если средний, то процессор+память, если большой, то процессор+память+чипсет. В большом наборе сильнее прогрев, но можно найти больше ошибок, в малом меньше нагрев, но можно пропустить что-то важное;
Остальные параметры:
- Бездействие вначале и в конце, — оставляем как есть, позволяет снизить нагрузку до/после запуска и считать необходимые данные;
- Версия теста, — выберите ту, которая соответствует установленной версии операционной системы;
- Число потоков, — как правило, достаточно галочки «Авто«, но если оно определятся некорректно (меньше, чем число физических и логических ядер процессора), то можно выставить вручную, сняв галочку.
Дальше остается только нажать на кнопочку ON и подождать часик (или меньше, если будет найдена ошибка, компьютер зависнет, выключится или проявит еще какие-то признаки перегрева и сбоя) пока будет идти сканирование системы. Об анализе результатов сказано в конце статьи.
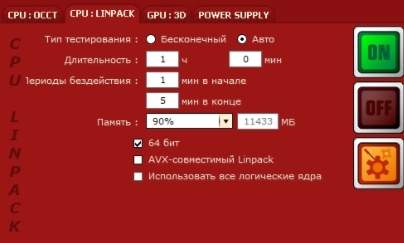
Вторая вкладка, а именно CPU: LINPACK, представляет собой еще один тест, но исключительно процессора, а не многих элементов сразу (см.описание первой вкладки выше).
к содержанию ↑
Предпреждение по тестированию
Стоит с осторожностью относиться к этому тесту, т.к он нагружает и разогревает процессор крайне сильно (в том числе по питанию ядра, если это поддерживается мат.платой) и является крайне экстремальным тестом. Рекомендуется использовать только при наличии мощнейший системы охлаждения и острой необходимости диагностирования оный и процессора. В остальных случаях лучше использовать первый тест.
Для тех кто решился (обычно требуется, если первый тест не выявил проблем, но «визуально» они сохраняются):
- Тип теста: авто;
- Длительность теста: 1 час 0 минут;
- Режим теста: 90% памяти (рекомендую закрыть все возможные программы, антивирусы и тп, либо уменьшить это значение до 70-80%);
- 64 бит: если система и процессор поддерживают;
- AVX-совместимый Linkpack, — есть смысл избегать, если не знаете о чем речь;
- Использовать все логические ядра, — ставить обязательно, если галочка доступна (может быть недоступна, если их нет или нет к ним доступа).
Дальше остается только нажать на кнопочку ON и подождать часик (или меньше, если будет найдена ошибка, компьютер зависнет, выключится или проявит еще какие-то признаки перегрева и сбоя) пока будет идти сканирование системы. Об анализе результатов сказано в конце статьи.
Идем дальше.
к содержанию ↑
Тест стабильности видеокарты OCCT
Следующий тест стабильно, который обитает на третьей вкладке, а именно GPU: OCCT, позволяет протестировать стабильность видеокарты, а именно, как уже говорилось, её графического процессора и памяти.
Поддерживается Crossfire и SLI, проверка и выявление множества ошибок при сильном прогреве в ходе нагрузок, а так же, при помощи специальной системы, определяются артефакты (искажения изображения). Можно делать тестирование при разном количестве шейдеров, FPS и всем остальным.
Здесь, собственно, выставляем следующее:
- Тип теста: авто
- Длительность теста: 1 час 0 минут
- Версия DirectX: если доступна, то 11, если нет, то 9, если нужно специфично протестироваться под какое-то приложение, то выбираем то значение, которое использует приложение;
- Разрешение: текущее, либо, если нужно специфично протестироваться под какое-то приложение, то выбираем то значение, которое использует приложение;
- Тип: полноэкранный (галочка);
- Проверка наличия ошибок: для первого теста обычно ставить нет необходимости, для второго (если проблема визуально сохраняется, но ошибки не найдены) есть смысл поставить галочку;
- Сложность шейдеров: в целом, этот параметр отвечает за количество операций выполняемых видеокартой за один проход (чаще всего выбирается максимально доступное значение, либо , если нужно специфично протестироваться под какое-то приложение, то выбираем то значение, которое использует приложение);
- Ограничитель: 0 (ноль), либо 60 (если используете вертикальную синхронизацию и нужно протестировать работу под неё).
Дальше остается только нажать на кнопочку ON и подождать часик (или меньше, если будет найдена ошибка, компьютер зависнет, выключится или проявит еще какие-то признаки перегрева и сбоя) пока будет идти сканирование системы. Об анализе результатов сказано в конце статьи.

Сам тест выглядит обычно, как на скриншоте выше. Запускается не сразу (см.периоды бездействия), может менять тип картинки (изображения). Существенные визуальные искажения (их сложно с чем-то перепутать) являются артефактами и свидетельствуют о проблемах с видеокартой, её памятью и чем-либо еще.
Идем дальше.
к содержанию ↑
Тест стабильности блока питания OCCT
Данный тест, обитающий на вкладке POWER SUPPLY, предназначен для подачи очень высокой нагрузки на все элементы питания, путем сочетания нескольких тестов. Чаще всего предназначен для тестирования блока питания путем подачи максимальной нагрузки на все компоненты, но может являться свидетельством проблем с питанием на мат.плате как таковой.
ВНИМАНИЕ! Достаточно сложен для анализа, рекомендуется использовать только, если первые тесты не выяснили ничего и никак, но проблемы сохраняются. Опасен и решительно не подходит для дешевых (noname) и некачественных блоков питания. Используйте на свой страх и риск.
Аналогично прошлому тесту тут выставляется следующее:
- Тип теста: авто
- Длительность теста: 1 час 0 минут
- Версия DirectX: если доступна, то 11, если нет, то 9, если нужно специфично протестироваться под какое-то приложение, то выбираем то значение, которое использует приложение;
- Разрешение: текущее, либо, если нужно специфично протестироваться под какое-то приложение, то выбираем то значение, которое использует приложение;
- Тип: полноэкранный режим (галочка);
- 64 бит: если система и процессор поддерживают;
- AVX-совместимый Linkpack, — есть смысл избегать, если не знаете о чем речь;
- Использовать все логические ядра, — ставить обязательно, если галочка доступна (может быть недоступна, если их нет или нет к ним доступа).
Дальше остается только нажать на кнопочку ON и подождать часик (или меньше, если будет найдена ошибка, компьютер зависнет, выключится или проявит еще какие-то признаки перегрева и сбоя) пока будет идти сканирование системы. Об анализе результатов сказано ниже.
к содержанию ↑
Анализ результатов тестирования OCCT
В результате тестов Вы можете получить следующий результат:
- Графики, — чаще всего, при отсутствии сурового физического сбоя (выключение, перезагрузка, зависание и тп), являются результирующей любого теста, содержат температуры, вольтажи и другие данные для анализа;
- Ошибку (в программе), — обычно это ошибка ядра или что-то еще, что останавливает тест (но компьютер работает), чаще всего указан её номер или хотя бы краткое описание (сбой ядра такого-то);
- Синий экран смерти, — что это есть смысл почитать в соответствующей статье;
- Физический сбой (или срабатывание защиты), — выключение, перезагрузка, зависание и тому подобные ужасы жизни.
Как с этим взлетать;
- Для анализа графиков температур прочитайте статью о температурах (уделите особо внимание максимально допустимым значениям), при появлении сомнений см.документацию к перегревающемуся компоненту (бумажную, либо на сайте производителя) для анализа максимально допустимых температур;
- Для анализа графиков, связанных с питанием, стоит понимать, что допустимы незначительные расхождения (на десятые, сотые, и менее, порядки), исключая определенные значения (например, питание процессора может меняться достаточно сильно, в связи с технологиями энергосбережения, регулирования частоты, разгона и тп). Если сложно разобраться, то обращайтесь к нам на форум и/или к документации;
- Для анализа синих экранов читайте соответствующую статью;
- Физические сбои, — часто связаны с перегревом и срабатыванием систем защиты. В базовом виде обычно решаются очисткой пыли с куллеров, не сложной сменой термопасты, добавлением (или изменением положения на вдув/выдув) вентиляторов в корпус, небольшими лайфхаками по доп.охлаждению. Реже, — меняется система охлаждения целиком (как выбрать писали здесь) на более мощную, либо они (сбои) являются следствием полного выхода компонента из строя. Последние диагностируются сложнее всего, чаще всего сразу понятны сбои блока питания (не полное выключение компьютера или включение не сразу) и/или видеокарты (артефакты изображения).
Если возникают сложные проблемы в которых надо разобраться, посмотрев графики и прочее, то обращайтесь, например, к нам на форум.
к содержанию ↑
Послесловие
Повторюсь, что один из мощнейших тестов стабильности, который в принципе можно найти. Он довольно часто используется оверклокерами (теми, кто разгоняет компоненты компьютера) в целях проверки стабильности очередной взятой частоты, что говорит о многом.
Как и всегда, если есть (разумные) мысли, вопросы, благодарности или дополнения, то, традиционно, пишите их в комментариях к этой статье (или на упомянутом выше форуме).
Спасибо, что Вы с нами.
Стабильности Вам!
Когда нужно остановить тестирование и нужно ли его останавливать? Полный ли объем информации проработан и все ли учтено? И вообще – есть ли предел совершенству? Эти вопросы актуальны для каждого тестировщика. Так давайте остановимся на минуту и подумаем: в какой момент нужно и можно прервать стремящийся к бесконечности процесс тестирования?
Причина для остановки: «Сроки поджимают! Время – деньги!»
Часто на проекте есть четко определенные сроки, которые заказчик не всегда готов передвинуть. В этом случае команда «заканчиваем тестирование!» зависит именно от установленных сроков, и это важный критерий. Да, такой сценарий нельзя назвать лучшим (так как времени всегда катастрофически не хватает для полной проверки, и часто страдает качество), но он тоже возможен.
Пример из практики. Вспоминается ситуация, когда из-за жестких сроков пострадало качество продукта. Тестировался интернет-магазин хозтоваров, и вместе с новой акционной скидкой только для зарегистрированных клиентов был внедрен баг: невозможность активировать несколько действующих на тот момент акций. Таким образом, релиз превратился в «релиз плюс еще пару напряженных дней баг-фикса». Наверное, гораздо лучше было подвинуть жесткие рамки на день-два и дать возможность дотестировать новый функционал… но в жизни встречаются разные ситуации.
Вывод. Главной задачей тестировщика в условиях ограниченного времени является охват максимально возможного количества критически важных тест-кейсов (тест-кейсы приоритета high и medium), запись всех найденных дефектов (во избежание их потери из-за времени и текучести задач) и формирование сообщения о реальном объеме проделанных работ. В итоге от тестировщика должна поступить полная картина проверенного и список того, что проверить еще не успели (чтобы в дальнейшем определить фронт работ).
Причина для остановки: «Это не конечная, а промежуточная»
Бывает, что в ходе тестирования нужно сделать вынужденную остановку, так как «что-то» критично блокирует оптимальную оценку тестируемого объекта, и из-за этого в дальнейшем может «протухнуть» вся система проверки. В таком случае лучше остановиться и дождаться решения проблемы.
Пример из практики. Тестировалось довольно крупное медицинское программное обеспечение. На тестовом стенде не было возможности проверить в полном объеме новый функционал (отправку писем клиентам при заполнении формы и данных личного кабинета клиента). Задача была довольно обширной и затрагивала многие аспекты: активацию отдельных разделов при полной загрузке документов, ограничения в доступе к разделам при определенной степени заполнения профиля и другие. На вопрос перед релизом «все ли проверено и можно ли заканчивать тестирование?» однозначный ответ дать было просто невозможно: проверка частично блокировалась из-за невозможности проверить факт получения части писем на тестовой среде. В итоге при релизе на стороне клиента вылезли критические ошибки. Клиенту не поступали нужные уведомительные письма, а потому он не мог получить и полный доступ к своему профилю. Во избежание появления подобных ситуаций было найдено следующее решение: после доработки стали доступны опции отправки и получения писем на тестовом стенде, что позволило в дальнейшем проверять эту часть достаточно важного функционала. Включение этих проверок во все последующие прохождения регресса дало возможность более оптимально оценивать готовность продукта перед выпуском на клиентскую часть.
Вывод. Анализ ошибок позволил сделать верные выводы и устранить все блокирующие моменты. И все-таки, в подобной ситуации работа над оптимизацией средств и инструментов тестирования по итогу уже выявленных ошибок вряд ли может считаться хорошим вариантом. Несомненно, гораздо более уместной и правильной была бы остановка процесса тестирования и доработка изначально неполного функционала тестовой среды для предотвращения появления критических моментов уже на клиентской части.
Причина для остановки: «Стоять нельзя двигаться дальше». Где поставить запятую, и почему возникает неразбериха?»
Правильно ли исправлять баги прямо по ходу проверки, которая при этом не прерывается? Логика подсказывает, что процесс нужно остановить и начать с самого начала после внесения корректировки, так как любое исправление ошибки может повлечь за собой появление еще десятка новых.
Пример из практики. Сразу приходит на память довольно распространенный и известный любому тестировщику случай, когда по ходу тестирования обнаруживаются критические баги, а половина тест-кейсов уже проверена, и результаты по ним проставлены. Иногда разработчики стараются настолько быстро исправить ошибку, что «забывают» известить об этом старательного тестировщика, который вовсю спешит пройти все запланированные тест-кейсы с регресса. В итоге тестирование продолжается после исправления (bug-fix) вместо того, чтобы остановить проверку и начать ее заново; часть ошибок уже не будет обнаружена.
Вывод. В таких ситуациях разработчику важно своевременно сообщить о своих исправлениях тестировщику для того, чтобы тот остановил тестирование и повторно прошел тест-кейсы – все или только самые критичные и высокого приоритета (если времени остается не так уж и много). Это поможет избежать в дальнейшем неразберихи в вопросе: а откуда взялись новые дефекты в продукте, и кто за них отвечает?
Причина для остановки: «Поступил приказ отступать!»
Случается, что заказчик буквально на последнем этапе приостанавливает проверку. На это может быть масса причин: появление более важной задачи или функционала, который требует дальнейшего уточнения, переоценка приоритетов релиза, пересмотр плана на текущий момент. Наша задача при этом – приостановить процесс, но ничего не забыть!
Пример из практики. Случалось, что практически полностью протестированный релиз откладывался. Казалось бы, все готово – тщательно протестированы все блоки, сделаны все задачи, – и можно отдавать готовый продукт на радость пользователю, но заказчик вдруг решает, что лучше все сделать совершенно по-другому, а практически уже готовый релиз временно нужно остановить. Минусом такой ситуации является потраченное время тестировщика, плюсом – написанные тест-кейсы, которые могут быть использованы для проверки функционала другого ПО.
Вывод. Для тестировщика в таком случае важно написать качественные тест-кейсы, с которыми можно будет работать в дальнейшем либо на аналогичных задачах, либо (в случае возобновления работы) по отмененному/отложенному релизу.
Причина для остановки: «Все, устал, хватит!»
Остановка может произойти и просто из-за того, что напряжение достигло своего пика. Желание сделать как можно больше за максимально возможное время иногда негативно сказывается на результатах работы.
Пример из практики. На одном из наших проектов «случился» довольно затяжной релиз; мы тестировали его напряженно и активно. Тестирование в моей голове не прекращалось даже во время сна. И в тот момент, когда ошибка оказалась буквально перед моими глазами, явно «сигнализируя» мне в логах, – я ее просто не увидела. В такие моменты нужно уметь сказать себе: «Стой, передохни, а иначе допустишь ошибку, пропустишь баг, внимательность будет на нуле!» А внимательность – это основное качество тестировщика. Конечно, сам процесс нельзя просто взять и остановить, но выделить личное время на отдых – необходимо!
Вывод. В подобных случаях остановка в тестировании – это обязательный и важный момент для тестировщика. Заканчивая работу, нужно обязательно отдохнуть и отвлечься (заняться другим делом, например), дабы избежать «замыливания глаз».
Причина для остановки: «Есть сомнения? Остановись!»
Перед выходом каждого релиза тестировщик, оценивая проделанную работу и пройденный набор тест-кейсов, подводит итог: а все ли протестировано? Конечно, естественным состоянием будет желание продолжить процесс проверки, которое не всегда соответствует фактору времени. И все-таки обоснованные сомнения нужно по крайней мере озвучить. Даже если баг был «пойман» на последнем этапе, и его исправление задержит весь процесс релиза, – ни в коем случае нельзя оставлять ошибку без внимания, лучше остановить запущенный механизм и дать время на корректировку.
Пример из практики. В моем опыте были ситуация, когда ошибка обнаружилась уже на последних шагах (можно даже сказать, на последних минутах) регрессионного тестирования. Был ли это недочет тестировщика (то есть, мой)? Да, и это стало хорошим «пинком» для дальнейшей работы над своими ошибками. Но баг нужно было искоренять. Задачу «выкинули» из релиза для доработки, сам релиз состоялся довольно успешно. Не забывайте: заказчик скорее оценит качество проверки, чем соблюдения сроков без сохранения качества.
Вывод. Каждый этап процесса тестирования важен. Неверная проработка материала или неполное покрытие задачи тест-кейсами может стать причиной того, что тестировщик упустит важный и критический баг. На каком бы этапе тестирования это не обнаружилось – важно понимать, что в таких случаях необходимо остановиться, оценить ситуацию и принять решение о дальнейшем плане работ!
Причина для остановки: «По моему хотению – остановитесь!»
В тестировании важную роль играет понимание специалистом важности выпускаемого продукта. Плохо, если в человеке присутствует безразличие к итоговому продукту. В таком случае тестирование может остановиться просто потому, что сам процесс надоел тестировщику («и так сойдет!»).
По этому поводу вспоминается старый анекдот:
«Мужчина сшил в ателье костюм. Пришел домой, надел. Жена в ужасе:
– Ты что сшил? Посмотри: один рукав длиннее, другой – короче. Полы у пиджака разные, штанины. Неси все назад!
Муж пошел назад:
– Что вы мне сшили? Посмотрите! Брюки разной длины!
– А вы одну ногу согните в колене, ведь вы не ходите на прямых ногах. И все будет хорошо.
– Смотрите, рукава разной длины!
– Ну и что? Вы же не по швам руки держите. Согните их в локтях. Вот! Прекрасно!
– А полы? Что с ними делать?
– А вы немного набок наклонитесь. Все отлично!
Мужчина вышел в новом костюме. Люди на остановке:
– Смотри, какой урод! А как костюм хорошо сидит!»
Для тестировщика халатное отношение к процессу просто недопустимо. Все недочеты в итоге становятся явными, что в конечном итоге приводит к плачевным результатам.
Пример из практики. У меня и моих коллег, к счастью, таких ситуаций никогда не возникало: мы любим свою работу и с уважением относимся к конечным пользователям (ведь наши ошибки влияют на их опыт взаимодействия с продуктом). Надеюсь, подобного никогда и не случится. Главное – не забывать, что такое возможно, и избегать подобных случаев.
Вывод. Останавливать тестирование лишь по желанию тестировщика нельзя, каждая остановка должна быть обоснована. Решение об остановке процесса будет закономерным лишь в том случае, если оптимально и позитивно пройденным и тщательно проработанным оказывается целый набор параметров: написан полный объем тест-кейсов по задаче, правильно расставлены приоритеты для оценки времени в случае срочных или быстрых проверок, все задачи полностью проанализированы и сверены с техническими требованиями еще на начальных этапах ознакомления, все учтено на этапе планирования релиза.
И наконец… Барабанная дробь… Последняя, но самая желанная причина для остановки: «Готово, можно забирать!»
При начале планирования нового релиза закладывается определенный план тестирования, приоритеты и объемы. Правильное планирование ведет к положительным и качественным результатам. Когда все результаты тестирования полностью удовлетворяют критериям качества, можно смело сказать себе: «Стоп, здесь мы сделали все, что могли!» Но для этого нужно, чтобы все найденные ошибки были исправлены, все запланированные тест-кейсы пройдены (и не обнаружено ни одного бага выше минорного), все необходимые правки выполнены, а результат приемочного тестирования оказался полностью положительным. И так бывает на самом деле! Заказчик в таком случае доволен, а тестировщик может смело выписывать себе «медаль» за хорошую работу. А уж как это настраивает на дальнейшие «подвиги»!
Пример из практики. К примеру, некоторое время назад тестировали обновление сайта бытовой техники. Сайт пользовался и продолжает пользоваться довольно большой популярностью, ответственность за выпускаемый продукт была достаточно высокой. Итогом проведенного релиза стала положительная динамика и улучшение статистики по количеству пользователей, оформивших заказ через интернет. Это, конечно, огромный плюс для заказчика. Главный же показатель удачного релиза для тестировщиков – это продукт, максимально адаптированный под клиента и содержащий минимальное количество ошибок (а может, их там вообще не осталось?!!!). Остановка тестирования в таком случае вполне закономерна, так как заложена в четко установленных сроках с учетом всех необходимых критериев.
Вывод. Для получения хорошего результата важно учитывать в работе все факторы. Оценка и анализ задачи, написание тест-кейсов для ее покрытия, расчет времени и максимальная внимательность гарантируют положительные результаты в работе.
Финал
Подводя итоги, можно сказать, что последний сценарий – это идеальный вариант остановки тестирования: в нем сочетаются верное планирование, детальное тестирование и итоговая положительная приемочная часть. В остальных случаях остановки происходят из-за ошибок тестировщика, по желанию заказчика, недостаточно продуманного плана тестирования, неверного расчета времени или просто из-за лени (кстати, недопустимого в нашей профессии качества).
Поэтому и остановки в таких случаях не влекут за собой того конечного положительного результата, которого всегда хочется добиться. В данной ситуации важно сделать правильные выводы и вычленить причину основной ошибки. Как правило, это неверное планирование времени, боязнь спросить разработчика о готовности исправлений (то есть, плохо налаженное общение между разработчиком и тестировщиком) и халатное написание тест-кейсов из-за неполного ознакомления со спецификациями и требованиями. Выявив слабые места на проекте или в личных качествах, можно приступить к проработке плана дальнейшей более результативной работы.
Для этого всегда необходимо учитывать основные критерии: условия и пожелания заказчика, установленные временные рамки и степень покрытия тест-кейсами требований, указанных и описанных в задаче. Каждый пункт должен быть четко проработан и обговорен как с заказчиком, так и с разработчиком. Тестировщик должен представлять объем работ: какое тестирование можно успеть осуществить в обозначенные сроки, сколько тест-кейсов потребуется, до какого момента допускаются баг-фиксы, когда начинается код фриз и допускает ли найденное количество багов сам выпуск продукта.
Конечно, каждый проект имеет свои особенности. Невозможно найти единый правильный эталонный метод решения. И все-таки учет указанных выше основных критериев приведет к тому, что выпускаемый продукт будет максимально соответствовать поставленным требованиям, а процесс и остановка тестирования будут понятны и закономерны.